[{"content":"开始一个新的项目 初始化 1 git init 添加remote 1 git remote origin add \u0026lt;url\u0026gt; 添加文件 1 git add 提交 1 git commit -m \u0026#34;注释\u0026#34; 同步 远端拉取 1 git push -u origin \u0026lt;branchname\u0026gt; 远端推送 1 git pull origin \u0026lt;branchname\u0026gt; 查看日志和状态 日志 1 git log --oneline 状态 1 git status 删除文件 彻底删除 1 2 git rm filename git rm -r filedir 从git删除而不物理删除 1 2 git rm --cached fielname git rm --cached -r filedir 执行了git add,尚未commit 1 git restore --staged fielname 恢复文件 1 2 3 - 执行了git rm 未commit git reset head git restore \u0026lt;file|dir\u0026gt; 分支 查看分支 1 git branch 后面没有接任何参数,它仅会输出当前在这个项目中有哪些分支。git默认会设置一个名为master的分支,前面的星号(*)表示现在正在这个分支上。\n新增分支 1 git branch \u0026lt;分支名\u0026gt; 改分支名 1 git branch -m 老分支名 新分支名 删除分支 1 git branch -d 要删除的分支名 若被删除的分支还有未被合并的内容,会有提示,无法删除,此时需要使用-d强行删除\n1 git branch -d 要删除的分支名 切换分支 | 切换分支之前,首先得查看当前分支状态,看看有无未更改的提交,若不想提交,则需贮藏修改\n已存在分支切换 1 git checkout 分支名 不存在分支,创建并切换 1 git checkout -b 分支名 恢复已被删除的分支 已合并的分支随意删除\n未合并的分支若被删除\n使用 git reflog 删前的版本号,reflog 保留30天记录 使用 git branch branchname version 老创建新的分支恢复 合并 概念 在a上合并b, a为当前分支,b为被合并分支\nmerge 合并 git merge b master 主分支其余分支,使用快转模式直接合并 子分支合并子分支,会产生一次新的commit来处理 rebase 合并 git rebase b 不会产生一次合并commit 合并冲突 文本冲突\n编辑冲突文件,确认到底保留哪方的内容 然后 add → commit 操作 非文本冲突\n保留当前分支文件 git checkout --ours 文件名 保留被合并分支文件 git checkout --theirs 文件名 然后 add → commit 操作 贮藏 有时,当你在项目的一部分上已经工作一段时间后,所有东西都进入了混乱的状态, 而这时你想要切换到另一个分支做一点别的事情。 问题是,你不想仅仅因为过会儿回到这一点而为做了一半的工作创建一次提交。 针对这个问题的答案是 git stash 命令。\n创建贮藏 前提,被贮藏文件是被 暂存(add)的\n贮藏当前目录全部文件 1 git stash 贮藏某个文件 1 git stash push filename 查看贮藏的东西 1 git stash list 恢复贮藏 不指定贮藏名,默认最近的 1 git stash apply 指定贮藏名 1 git stash apply stash@{2} 删除贮藏 直接删除 1 git stash drop stash@{2} 应用贮藏然后立即从栈上扔掉它 1 git stash pop stash@{2} 其余贮藏相关操作详见 链接\n","date":"2024-08-24","permalink":"https://hobocat.github.io/post/tool/git-use/","summary":"开始一个新的项目 初始化 1 git init 添加remote 1 git remote origin add \u0026lt;url\u0026gt; 添加文件 1 git add 提交 1 git commit -m \u0026#34;注释\u0026#34; 同步 远端拉取 1 git push -u origin \u0026lt;branchName\u0026gt; 远端推送 1 git pull origin \u0026lt;branchName\u0026gt; 查看日志和状","title":"git use"},]
[{"content":"用户分类 git 用户分类 global (全局) local(仓库)级别 优先级 local \u0026gt; global 全局配置 查看配置 1 git config --list 清空全局 user.name email 1 2 git config --global --unset user.name git config --global --unset user.email 设置全局 user.name email 1 2 git config --global user.name \u0026#34;hobocat\u0026#34; git config --global user.email \u0026#34;hobocat@126.com\u0026#34; 本地配置 配置单个仓库的用户信息\n清空 user.name email\n1 2 git config --unset user.name git config --unset user.email 设置 user.name email\n1 2 git config user.name \u0026#34;hobocat\u0026#34; git config user.email \u0026#34;hobocat@126.com\u0026#34; ssh 多用户配置 生成秘钥 生成命令 1 ssh-keygen -t {算法名} -f {文件路劲及文件名} -c \u0026#34;解释信息,一般是邮箱\u0026#34; 生成gitee仓库的ssh 1 ssh-keygen -t rsa -f ~/.ssh/id_rsa.gitee -c \u0026#34;hobocat@126.com\u0026#34; 生成github仓库的ssh 1 ssh-keygen -t rsa -f ~/.ssh/id_rsa.github -c \u0026#34;hobocat@126.com\u0026#34; 生成公司仓库的ssh 1 ssh-keygen -t rsa -f ~/.ssh/id_rsa.company -c \u0026#34;hobocat@126.com\u0026#34; 将 ssh-key 分别添加到 ssh-agent 信任列 1 2 3 4 ssh-agent bash ssh-add ~/.ssh/id_rsa.gitee ssh-add ~/.ssh/id_rsa.github ssh-add ~/.ssh/id_rsa.company 添加公钥到自己的 git 账户中 | 使用命令,copy公钥,到 git 账户中粘贴即可。或者打开文件复制,带 pub 的文件\n1 pbcopy \u0026lt; ~/.ssh/id_rsa.gitee.pub git平台添加ssh gitee方式 配置多平台 | 在生成密钥的.ssh 目录下,新建一个config文件,然后配置不同的仓库,\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #default github user self host github.com hostname github.com user hobocat #默认就是git,可以不写 identityfile ~/.ssh/id_rsa.github # gitee的配置 host gitee.com # 别名,最好别改 hostname gitee.com #要连接的服务器 user hobocat #用户名 #密钥文件的地址,注意是私钥 identityfile ~/.ssh/id_rsa_gitee #add gitlab user host xxxx hostname xxxx user hobocat preferredauthentications publickey identityfile ~/.ssh/id_rsa.company ","date":"2024-08-24","permalink":"https://hobocat.github.io/post/tool/git%E5%A4%9A%E7%94%A8%E6%88%B7%E9%85%8D%E7%BD%AE/","summary":"用户分类 git 用户分类 global (全局) local(仓库)级别 优先级 local \u0026gt; global 全局配置 查看配置 1 git config --list 清空全局 user.name email 1 2 git config --global --unset user.name git config --global --unset user.email 设置全局 user.name email 1 2 git config --global user.name \u0026#34;hobocat\u0026#34; git config --global user.email \u0026#34;hobocat@126.com\u0026#34; 本","title":"git多用户配置"},]
[{"content":"docker宿主机磁盘满了处理方法 清理docker资源 删除未使用的容器 1 docker container prune 删除未使用的镜像 1 docker image prune 删除未使用的卷 1 docker volume prune 删除未使用的网络 1 docker network prune 全量清理 清理所有未使用的资源 1 docker system prune 清理未使用的镜像和卷 1 docker system prune -a --volumes 增加docker主机的存储空间 增加磁盘空间 重新分区,后迁移docker存储目录 迁移docker储存目录 docker存储目录一般存放在 /var/lib/docker 目录\n停止docker服务 1 sudo systemctl stop docker 移动存储目录 1 sudo rsync -ap /var/lib/docker /new/docker/dir 更新docker配置 编辑docker配置文件 /etc/docker/daemon.json, 添加或更新 data-root 选项。 1 2 3 { \u0026#34;data-root\u0026#34;: \u0026#34;/new/docker/dir\u0026#34; } 重启docker服务 1 sudo systemctl start docker ","date":"2024-08-22","permalink":"https://hobocat.github.io/post/docker/docker%E6%80%BB%E7%BB%93/","summary":"Docker宿主机磁盘满了处理方法 清理Docker资源 删除未使用的容器 1 docker container prune 删除未使用的镜像 1 docker image prune 删除未使用的卷 1 docker volume prune 删除未使用的网络 1 docker network prune 全量清理 清理","title":"docker总结"},]
[{"content":"","date":"2024-07-28","permalink":"https://hobocat.github.io/post/mysql/%E4%BA%8B%E5%8A%A1%E7%AF%87/","summary":"","title":"mysql事务"},]
[{"content":"安装 配置 常用命令与sql语句 sql语句的执行 ","date":"2024-07-28","permalink":"https://hobocat.github.io/post/mysql/%E5%9F%BA%E7%A1%80%E7%AF%87/","summary":"安装 配置 常用命令与SQL语句 SQL语句的执行","title":"mysql基础"},]
[{"content":"存储引擎 ","date":"2024-07-28","permalink":"https://hobocat.github.io/post/mysql/%E5%AD%98%E5%82%A8%E7%AF%87/","summary":"存储引擎","title":"mysql存储"},]
[{"content":"","date":"2024-07-28","permalink":"https://hobocat.github.io/post/mysql/%E7%B4%A2%E5%BC%95%E7%AF%87/","summary":"","title":"mysql索引"},]
[{"content":"","date":"2024-07-28","permalink":"https://hobocat.github.io/post/mysql/%E9%94%81%E7%AF%87/","summary":"","title":"mysql锁"},]
[{"content":"写一个工具类 download.js 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 /** * 下载base64格式文件 * @param {base64} data * @param {文件名} filename */ export const downloadfilebybyte = (data, filename) =\u0026gt; { const blob = buildblobbybyte(data) downloadfile(blob, filename) } /** * 将base64格式文件转为 blob * @param {base64格式} data * @returns blob */ export const buildblobbybyte = (data) =\u0026gt; { const raw = window.atob(data) const rawlength = raw.length const uint8array = new uint8array(rawlength) for (let i = 0; i \u0026lt; rawlength; ++i) { uint8array[i] = raw.charcodeat(i) } return new blob([uint8array]) } /** * 下载文件 * @param {blob文件} blob * @param {文件名} filename */ export const downloadfile = (blob, filename) =\u0026gt; { const link = document.createelement(\u0026#39;a\u0026#39;) link.href = window.url.createobjecturl(blob) link.download = filename // 此写法兼容可火狐浏览器 document.body.appendchild(link) const evt = document.createevent(\u0026#39;mouseevents\u0026#39;) evt.initevent(\u0026#39;click\u0026#39;, false, false) link.dispatchevent(evt) document.body.removechild(link) } 调用 1 2 3 4 // 注意文件位置 import { downloadfilebybyte } from \u0026#39;@/utils/download\u0026#39; downloadfilebybyte(base64str, filename) ","date":"2024-07-04","permalink":"https://hobocat.github.io/post/node/node/","summary":"写一个工具类 download.js 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 /** * 下载Base64格式文件 * @param {Base64} data * @param {文件名} fileName */ export const","title":"vue实现转存base64格式的文件下载"},]
[{"content":"常用日志框架 log4j apache log4j 是一个基于 java 的日志记录工具。它是由 ceki gülcü首创的,现在则是 apache 软件基金会的一个项目。 log4j 是几种 java 日志框架之一。 log4j 2 apache log4j 2 是 apache 开发的一款 log4j 的升级产品。 commons logging apache 基金会所属的项目,是一套 java 日志接口,之前叫 jakarta commons logging,后更名为 commons logging。 slf4j 类似于 commons logging,是一套简易 java 日志门面,本身并无日志的实现。(simple logging facade for java,缩写 slf4j)。 logback 一套日志组件的实现(slf4j 阵营)。 jul java util logging,自 java1.4 以来的官方日志实现。 日志结构框架 日志门面 门面设计模式,它只提供一套接口规范,自身不负责日志功能的实现,目的是让使用者不需要关注底层具体是哪个日志库来负责日志打印及具体的使用细节。目前使用广泛的有两种:slf4j 和 common logging\n日志实现 他具体实现了日志的相关功能,主流的三个 log4j、logback 、log-jdk。\n日志适配器 日志适配器分两种场景:桥接模式-即中间桥梁,把两方连接起来 日志门面适配器:\n因为 slf4j 是后提出来的,在此之前的日志库是没有实现 slf4j 接口的,所以额外需要一个适配器解决接口不兼容问题。\n日志库适配器:\n老的工程里,已经使用了别的日志库的 api 打印日志,要将日志库模式改为 slf4j+日志库模式,但是项目中使用老的 api 打印日志的地方太多,无法全改,此时需要一个适配器完成从就日志 api 到 slf4j 的路由,使得在不改动原有代码的情况下,升级为 slf4j 规范统一管理日志。\n为什么要用日志门面? 日志门面提供了统一接口规范,使用者只需使用门面,而不需要关心具体的实现。另一方面,项目中引入别的依赖项目或 jar,而此依赖使用别的日志框架,则会使项目变得难以维护\n常用日志框架的使用及配置 新项目推荐使用 slf4j + logback 组合 slf4j slf4j 用法\nslf4j 与其它日志组件的关系说明\nslf4j 的设计思想比较简洁,使用了 facade 设计模式,slf4j 本身只提供了一个 slf4j-api-version.jar 包,这个 jar 中主要是日志的抽象接口,jar 中本身并没有对抽象出来的接口做实现。 对于不同的日志实现方案(例如 logback,log4j\u0026hellip;),封装出不同的桥接组件(例如 logback-classic-version.jar,slf4j-log4j12-version.jar),这样使用过程中可以灵活的选取自己项目里的日志实现。 slf4j 与其它日志组件调用关系图\n项目集成\n1 2 3 4 5 6 \u0026lt;!--只有slf4j-api依赖--\u0026gt; \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;org.slf4j\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;slf4j-api\u0026lt;/artifactid\u0026gt; \u0026lt;version\u0026gt;${slf4j-api.version}\u0026lt;/version\u0026gt; \u0026lt;/dependency\u0026gt; 1 2 private static final logger log = loggerfactory.getlogger(xxx.class); // log 使用static修饰,代表跟当前类绑定,避免每次都new 一个新对象 另外,使用 slf4j+日志库模式时,一定得注意 jar 或日志库冲突问题,可能导致日志打印失效。 log4j 先于 slf4j 出现的日志实现,若想使用 slf4j 的接口规范,需要中间桥接 slf4j-log4j12\n项目集成\n1 2 3 4 5 6 7 8 9 10 \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;org.slf4j\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;slf4j-log4j12\u0026lt;/artifactid\u0026gt; \u0026lt;version\u0026gt;${slf4j-log4j12.version}\u0026lt;/version\u0026gt; \u0026lt;/dependency\u0026gt; \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;log4j\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;log4j\u0026lt;/artifactid\u0026gt; \u0026lt;version\u0026gt;${log4j.version}\u0026lt;/version\u0026gt; \u0026lt;/dependency\u0026gt; 配置文件 log4j.xml | log4j.properties\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 # [level], [appendernames] eg : debug, stdout,d,e log4j.rootlogger = debug, stdout,d,e # 配置日志信息输出目的地 log4j.appender.stdout = org.apache.log4j.consoleappender # target是输出目的地的目标 log4j.appender.stdout.target = system.out # 指定日志消息的输出最低层次 log4j.appender.stdout.threshold = info # 定义名为stdout的输出端的layout类型 log4j.appender.stdout.layout = org.apache.log4j.patternlayout # 如果使用pattern布局就要指定的打印信息的具体格式conversionpattern log4j.appender.stdout.layout.conversionpattern = [%-5p] %d{yyyy-mm-dd hh:mm:ss} %l%m%n #log4j.logger.com.camore.copy = debug,stdout # 名字为d的对应日志处理 log4j.appender.d = org.apache.log4j.dailyrollingfileappender # file是输出目的地的文件名 log4j.appender.d.file = log//app_debug.log #false:默认值是true,即将消息增加到指定文件中,false指将消息覆盖指定的文件内容 log4j.appender.d.append = true log4j.appender.d.threshold = debug log4j.appender.d.layout = org.apache.log4j.ttcclayout # 名字为e的对应日志处理 log4j.appender.e = org.apache.log4j.dailyrollingfileappender log4j.appender.e.file = log//app_error.log log4j.appender.e.append = true log4j.appender.e.threshold = error log4j.appender.e.layout = org.apache.log4j.patternlayout log4j.appender.e.layout.conversionpattern = %-d{yyyy-mm-dd hh:mm:ss} [ %t:%r ] - [ %p ] %m%n logback 与 log4j 同一作者,是 log4j 的升级,具备比 log4j 更多的优点。后于 slf4j 接口规范开发,所以直接实现了 slf4j 的接口。\nlogback 当前分为 3 个模块 logback-core,logback-classic, logback-access\nlogback-core 是其他模块的基础 logback-classic 是 log4j 的改良,本省实现了 slf4j 的接口 logback-access 访问模块与 servlet 容器集成提供通过 http 来访日志的功能 logback 组件\nlogger:日志的记录器,主要用于存放日志对象,也可以定义日志类型、级别 appender:用于指定日志输出的目的地,可以是 控制台、文件、数据库等 layout:负责把事件转成字符串,格式化的日志信息的输出。在 logback 中 layout 对象被封装成 encoder 中 项目集成\n1 2 3 4 5 6 7 8 9 10 11 \u0026lt;!--logback-classic依赖logback-core,会自动级联引入--\u0026gt; \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;ch.qos.logback\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;logback-classic\u0026lt;/artifactid\u0026gt; \u0026lt;version\u0026gt;${logback-classic.version}\u0026lt;/version\u0026gt; \u0026lt;/dependency\u0026gt; \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;ch.qos.logback\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;logback-core\u0026lt;/artifactid\u0026gt; \u0026lt;version\u0026gt;${logback-core.version}\u0026lt;/version\u0026gt; \u0026lt;/dependency\u0026gt; 配置文件 logback.groovy | logback-test.xml | logback.xml\n加载顺序 logback-test.xml \u0026gt; logback.groovy \u0026gt; logback.xml \u0026gt; basicconfigurator(默认配置)\n配置详情\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 \u0026lt;?xml version=\u0026#34;1.0\u0026#34; encoding=\u0026#34;utf-8\u0026#34;?\u0026gt; \u0026lt;!-- 配置文件修改时重新加载,默认true --\u0026gt; \u0026lt;configuration scan=\u0026#34;true\u0026#34;\u0026gt; \u0026lt;!--定义日志文件的存储地址 勿在 logback 的配置中使用相对路径--\u0026gt; \u0026lt;property name=\u0026#34;catalina_base\u0026#34; value=\u0026#34;**/logs\u0026#34;\u0026gt;\u0026lt;/property\u0026gt; \u0026lt;!-- 控制台输出 --\u0026gt; \u0026lt;appender name=\u0026#34;console\u0026#34; class=\u0026#34;ch.qos.logback.core.consoleappender\u0026#34;\u0026gt; \u0026lt;encoder charset=\u0026#34;utf-8\u0026#34;\u0026gt; \u0026lt;!-- 输出日志记录格式 --\u0026gt; \u0026lt;pattern\u0026gt;%d{yyyy-mm-dd hh:mm:ss.sss} [%thread] %-5level %logger{36} - %msg%n\u0026lt;/pattern\u0026gt; \u0026lt;/encoder\u0026gt; \u0026lt;/appender\u0026gt; \u0026lt;!-- 第一个文件输出,每天产生一个文件 --\u0026gt; \u0026lt;appender name=\u0026#34;file1\u0026#34; class=\u0026#34;ch.qos.logback.core.rolling.rollingfileappender\u0026#34;\u0026gt; \u0026lt;rollingpolicy class=\u0026#34;ch.qos.logback.core.rolling.timebasedrollingpolicy\u0026#34;\u0026gt; \u0026lt;!-- 输出文件路径+文件名 --\u0026gt; \u0026lt;filenamepattern\u0026gt;${catalina_base}/aa.%d{yyyymmdd}.log\u0026lt;/filenamepattern\u0026gt; \u0026lt;!-- 保存30天的日志 --\u0026gt; \u0026lt;maxhistory\u0026gt;30\u0026lt;/maxhistory\u0026gt; \u0026lt;/rollingpolicy\u0026gt; \u0026lt;encoder charset=\u0026#34;utf-8\u0026#34;\u0026gt; \u0026lt;!-- 输出日志记录格式 --\u0026gt; \u0026lt;pattern\u0026gt;%d{yyyy-mm-dd hh:mm:ss.sss} [%thread] %-5level %logger{36} - %msg%n\u0026lt;/pattern\u0026gt; \u0026lt;/encoder\u0026gt; \u0026lt;/appender\u0026gt; \u0026lt;!-- 第二个文件输出,每天产生一个文件 --\u0026gt; \u0026lt;appender name=\u0026#34;file2\u0026#34; class=\u0026#34;ch.qos.logback.core.rolling.rollingfileappender\u0026#34;\u0026gt; \u0026lt;file\u0026gt;${catalina_base}/bb.log\u0026lt;/file\u0026gt; \u0026lt;rollingpolicy class=\u0026#34;ch.qos.logback.core.rolling.timebasedrollingpolicy\u0026#34;\u0026gt; \u0026lt;filenamepattern\u0026gt;${catalina_base}/bb.%d{yyyymmdd}.log\u0026lt;/filenamepattern\u0026gt; \u0026lt;maxhistory\u0026gt;30\u0026lt;/maxhistory\u0026gt; \u0026lt;/rollingpolicy\u0026gt; \u0026lt;encoder charset=\u0026#34;utf-8\u0026#34;\u0026gt; \u0026lt;pattern\u0026gt;%d{yyyy-mm-dd hh:mm:ss.sss} [%thread] %-5level %logger{36} - %msg%n\u0026lt;/pattern\u0026gt; \u0026lt;/encoder\u0026gt; \u0026lt;/appender\u0026gt; \u0026lt;appender name=\u0026#34;custom\u0026#34; class=\u0026#34;ch.qos.logback.core.rolling.rollingfileappender\u0026#34;\u0026gt; \u0026lt;file\u0026gt;${catalina_base}/custom.log\u0026lt;/file\u0026gt; \u0026lt;rollingpolicy class=\u0026#34;ch.qos.logback.core.rolling.timebasedrollingpolicy\u0026#34;\u0026gt; \u0026lt;!-- daily rollover --\u0026gt; \u0026lt;filenamepattern\u0026gt;${catalina_base}/custom.%d{yyyy-mm-dd}.log\u0026lt;/filenamepattern\u0026gt; \u0026lt;!-- keep 30 days\u0026#39; worth of history --\u0026gt; \u0026lt;maxhistory\u0026gt;30\u0026lt;/maxhistory\u0026gt; \u0026lt;/rollingpolicy\u0026gt; \u0026lt;encoder charset=\u0026#34;utf-8\u0026#34;\u0026gt; \u0026lt;pattern\u0026gt;%d{yyyy-mm-dd hh:mm:ss.sss} [%thread] %-5level %logger{36} - %msg%n\u0026lt;/pattern\u0026gt; \u0026lt;/encoder\u0026gt; \u0026lt;/appender\u0026gt; \u0026lt;!-- 设置日志输出级别 --\u0026gt; \u0026lt;root level=\u0026#34;error\u0026#34;\u0026gt; \u0026lt;appender-ref ref=\u0026#34;console\u0026#34; /\u0026gt; \u0026lt;/root\u0026gt; \u0026lt;logger name=\u0026#34;file1\u0026#34; level=\u0026#34;debug\u0026#34;\u0026gt; \u0026lt;appender-ref ref=\u0026#34;file1\u0026#34; /\u0026gt; \u0026lt;/logger\u0026gt; \u0026lt;logger name=\u0026#34;file1\u0026#34; level=\u0026#34;info\u0026#34;\u0026gt; \u0026lt;appender-ref ref=\u0026#34;file2\u0026#34; /\u0026gt; \u0026lt;/logger\u0026gt; \u0026lt;!-- 自定义logger --\u0026gt; \u0026lt;logger name=\u0026#34;custom\u0026#34; level=\u0026#34;info\u0026#34;\u0026gt; \u0026lt;appender-ref ref=\u0026#34;custom\u0026#34; /\u0026gt; \u0026lt;/logger\u0026gt; \u0026lt;/configuration\u0026gt; ","date":"2024-07-03","permalink":"https://hobocat.github.io/post/log/java-log/","summary":"常用日志框架 Log4j Apache Log4j 是一个基于 Java 的日志记录工具。它是由 Ceki Gülcü首创的,现在则是 Apache 软件基金会的一个项目。 Log4j 是几种 Java 日志框架之一。 Log4j 2 Apache Log4j 2 是 apache 开发的一款 Log4j 的升级","title":"java log"},]
[{"content":"学习计划 加油~ 努力找个好工作 复习老的笔记知识 java系列\njava基础 多线程 集合 io | nio jvm、gc及调优 设计模式 srping | spring cloud\nspring | springboot 基础 注解及部分源码分析 spring cloud各组件 mysql\nmysql 基础 索引 事务 mq\nrocketmq kafka nosql\nredis 其他\ndocker nginx mybatis | mybatis plus 学习及总结前端笔记 node 基础 vue3 选项式api | 组合式api 组件 element | ant design 老的笔记差缺补漏 jvm调优 gc详解 算法与数据结构 网络基础 | 通信协议 leetcode刷题 边面试边学习 外语学习 英语 or 日语\n","date":"2024-07-03","permalink":"https://hobocat.github.io/study/","summary":"学习计划 加油~ 努力找个好工作 复习老的笔记知识 Java系列 Java基础 多线程 集合 IO | NIO JVM、GC及调优 设计模式 Srping | Spring Cloud Spring | SpringBoot 基础 注解及部分源码分析 Spring Cloud各","title":"study"},]
[{"content":"java 关键字 编号 名称 功能 其他 1 package 指明包路径 2 import 引入类 3 public 类/方法/属性 修饰符,公有 一种访问控制方式:共用模式,可以应用于类、方法或字段(在类中声明的变量)的访问控制修饰符。 4 private 类/方法/属性 修饰符, 私有 只有本类可以引用 一种访问控制方式:私用模式,访问控制修饰符,可以应用于类、方法或字段(在类中声明的变量) 5 rotected 类/方法/属性 修饰符,保护类型,同一包下可用 一种访问控制方式:保护模式,可以应用于类、方法或字段(在类中声明的变量)的访问控制修饰符 6 interface 接口关键字 7 class 类关键字 声明一个类,用来声明新的 java 类 8 enum 枚举关键字 9 extends 继承 类 表明一个类型是另一个类型的子类型。对于类,可以是另一个类或者抽象类;对于接口,可以是另一个接口 10 implements 实现 接口 表明一个类实现了给定的接口 11 static 类/方法/属性 修饰符,静态代码块 表明具有静态属性。类创建时加载,存在堆区 12 abstract 类/方法/变量 修饰符 表示抽象类/方法 表明类或者成员方法具有抽象属性,用于修改类或方法 13 final 类/方法/属性修饰符 不可被重新赋值 用来说明最终属性,表明一个类不能派生出子类,或者成员方法不能被覆盖,或者成员域的值不能被改变,用来定义常量 14 volitate 类/方法/属性修饰符 表示被修饰属性的内存可见性 多线程下别的线程修改的值对另一线程可见 15 transient 类/方法/属性修饰符 被修饰的属性序列化时忽略 声明不用序列化的成员域 16 native 类/方法/属性修饰符 表示方法是 c/c++实现 用来声明一个方法是由与计算机相关的语言(如 c/c++/fortran 语言)实现的 17 strictfp 类/方法/属性修饰符 用来声明 fp_strict(单精度或双精度浮点数)表达式遵循 ieee 754 算术规范 18 synchronized 类/方法/属性修饰符 同步锁 表明一段代码需要同步执行 19 new 创建新对象关键字 new 对象时分配内存空间 用来创建新实例对象 20 void 方法返回值修饰符 代表无返回值 21 return 返回语句 方法级 跳出方法 22 break 中断语句 跳出循环或当前条件 提前跳出一个块 23 continue 结束本次循环语句 回到一个块的开始处 24 for 循环语句 25 do 循环语句循环体 26 while 循环语句 条件判断 27 assert 断言 调试 28 switch 分支结构 可替换多 if 语句 如 3 个以上 29 case switch 子分支 30 default switch 默认分支 31 if 条件判断语句 32 else if 之外的条件 还可单配 else if 条件判断 33 try 异常捕获语句 try 块 要捕获异常的内容 一个 必执行 34 catch 异常捕获语句 捕获的异常类型 可 0~n 个 无异常发生不执行 35 finally 异常捕获语句 异常最后的处理 必执行 36 throw 方法内抛出一个异常语句 手动 37 throws 抛出多个异常 方法定义上 被动 38 instanceof 判断对象的类型 39 this 对象/类 本身 40 super 调用父类方法 41 null 空值 42 true 布尔值 true 43 false 布尔值 false 44 byte 基本数据类型 字节 1byte 8 位 (-2^7~2^7 -1) 45 short 基本数据类型 短整型 2byte 16 位 46 int 基本数据类型 整型 4byte 32 位(bit) 47 long 基本数据类型 长整型 8byte 64 位 48 float 基本数据类型 浮点型 单精度 4byte 32 位 49 double 基本数据类型 浮点型 双精度 8byte 64 位 50 char 基本数据类型 字符 2byte16 位 0-255 51 boolean 基本数据类型 布尔 1byte 8 位 true 1 false 0 52 const 保留字 53 var 保留字 54 goto 保留字 ","date":"2024-07-02","permalink":"https://hobocat.github.io/post/java/%E5%85%B3%E9%94%AE%E5%AD%97/","summary":"Java 关键字 编号 名称 功能 其他 1 package 指明包路径 2 import 引入类 3 public 类/方法/属性 修饰符,公有 一种访问控制方式:共用模式,可以应用于类、方法或字段(在类中声明的变量)的访问控制","title":"java关键字"},]
[{"content":"线程 几个概念 | 并行 | 并发\n并行(parallel) 多个任务同时操作多个资源,每个任务独立执行,互不影响 并发(concurrent) 多个任务同时操作同一资源,多个线程交替执行 | 进程 | 线程 | 管程\n进程(process) 操作系统上任务执行的最小单元,一个服务就是一个进程。放在java里,启动一个程序就是一个进程。\n线程(thread) 线程是比进程更小的执行单元,一个进程内包含n多个线程\n管程monitor 可以理解为锁\n线程状态 线程分为 用户线程和守护线程(damon=true) 生命周期随进程周期 如 gc 线程\nnew:新建状态,未运行 runnable:可执行状态{运行状态,待运行} blocked:阻塞状态 等待锁,然后执行 waiting:无限期等待 timed_waiting:限时等待 terminated:终止状态 线程的创建 1. 继承 thread 实际上 thread 也是实现了 runnable 接口\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public class mythread extends thread { void run () { // 执行体 } } // 创建并运行 new mythread().start(); // 简易写法 thread a = new thread(r -\u0026gt; { // 执行体 }); // 运行 a.start(); 2. 实现 runnable 无返回值\n1 2 3 4 5 6 7 8 9 public class myrunnable implements runnable { void run(){ // 执行体 } } // 调用 new thread(new myrunnable()).start(); 3. 实现 callable 有返回值 ,获取返回值会阻塞|抛出异常\n1 2 3 4 5 6 7 8 9 10 11 public class mycallable implements callable{ v call(){ // 执行体 return null; } } // 调用 mycallable call = new mycallable (); new thread(call).start(); run() 与 start() 区别 run: 只是方法的执行体 start: 创建一个新的线程,会执行 run() 常用操作 线程停止\n1. 正常停止,即执行完run()方法\r2. 设置一个标志位,暴露public方法停止\ra. `volatile boolean flag`\rb. `atomicboolean flag`\rc. 中断操作 `thread.interrupt()`\r3. 不建议使用jdk提供的`stop()` 或 `destory()` 方法\r中断机制\n概念:停止线程的协商机制 中断标志位: interrupt=true。发起一个协商,而不是立即停止线程 常用方法: 1 2 3 4 5 6 7 8 9 // 将标志位设置为true,线程处于阻塞状态时,会抛出异常,且标志位会置为false void interrupt() // 1. 判断当前线程是否已经中断,并返回中断状态 // 2. 若线程已是中断状态,则清空状态位,并设为false thread.interrupt() // 返回中断状态位,线程正常停止的话返回false boolean isinterrupted() 线程的等待与唤醒\n1 2 3 4 5 6 7 8 9 10 11 12 13 // synchronized wait() nofity() notifyall() // lock unlock 块中 lock.newcondition().await() lock.newcondition().singal() lock.newcondition().singalall() // locksupport locksupport.park(thread thread) locksupport.unpark() 线程安全 原子性 同一个操作不能被中途打断,类似事务,要么全部完成,要么全不完成\n可见性 有一个线程变更了共享变量,主线程或其他线程需要知道变量已经变更\n有序性 指令重排问题, 编译器编译代码的过程中,会对代码执行顺序重排\nfuture 传统的创建线程方式都无法获取到异步执行结果,通过实现callback接口,并用future可以来接收多线程的执行结果。 future表示一个可能还没有完成的异步任务的结果,针对这个结果可以添加callback以便在任务执行成功或失败后作出相应的操作。\nfuture主要方法\nfuturetask\u0026lt;t\u0026gt;\n能用来包装一个callable或runnable对象,因为它实现了runnable接口,而且它能被传递到executor进行执行。为了提供单例类,这个类在创建自定义的工作类时提供了protected构造函数。\n1 2 3 4 5 futuretask\u0026lt;string\u0026gt; task = new futuretask\u0026lt;\u0026gt;(callable\u0026lt;v\u0026gt; callable); futuretask\u0026lt;string\u0026gt; task = new futuretask\u0026lt;\u0026gt;(runnable runnable, v result); // 会阻塞线程 task.get() schedualfuture\n这个接口表示一个延时的行为可以被取消。通常一个安排好的future是定时任务schedualedexecutorservice的结果\ncompletefuture\n一个future类是显示的完成,而且能被用作一个完成等级,通过它的完成触发支持的依赖函数和行为。当两个或多个线程要执行完成或取消操作时,只有一个能够成功。\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 // 1.无返回值 // 1.1 不指定线程池,使用默认线程池 forkjoinpool.commonpool completablefuture.runasync(runnable runnable) // 1.2 自定义线程池 completablefuture.runasync(runnable runnable, excutor excutor) // 2. 有返回值 // 2.1 不指定线程池,使用默认线程池 forkjoinpool.commonpool completablefuture.supplyasync(supplier\u0026lt;u\u0026gt; supplier) // 2.2 自定义线程池 completablefuture.supplyasync(supplier\u0026lt;u\u0026gt; supplier, excutor excutor) // 3结果处理 有返回值 // 3.1 串行。入参分别是上一步的处理结果,一旦发生异常,直接断路 进入异常处理方法 .thenapply(function\u0026lt;? super t,? extends u\u0026gt; fn) // 3.2 handle 是依次执行,串行。入参分别是上一步的处理结果。发生异常,并未发生断路,而是继续执行其余的handle方法和whencomplete方法 .handle(bifunction\u0026lt;? super t, throwable, ? extends u\u0026gt; fn) // 3.3 .whencomplete(biconsumer\u0026lt;? super t, ? super throwable\u0026gt; action) // 3.4 handle发生异常时并未进入该方法执行. whencomplete发生异常会调用执行异常处理 .exceptionally(function\u0026lt;throwable, ? extends t\u0026gt; fn) // 4结果处理 无返回值 /** * 1. 可以看到串行方法上一步若无返回值,则下一个方法入参为null,即结果丢失* * 2. consumer类型方法都无返回值,或许再接其他方法,上面的执行结果会丢失* * 3. consumer类型方法应在supplier类型方法之后执行 个人总结 */ .thenaccept(function\u0026lt;? super t,? extends u\u0026gt; fn) // 5. 执行速度选择 // 5.1有2任务future1和future2 applytoeither对比哪个任务先完成,则执行后续 fn future1.applytoeither(future2, function\u0026lt;? super t, u\u0026gt; fn) future1.applytoeitherasync(future2, function\u0026lt;? super t, u\u0026gt; fn) // 6. 结果合并 // 6.1 有2任务future1和future2 合并方法时,哪个任务先完成,则等待其余任务完成后执行合并任务 fn future1.thencombine(future2, bifunction\u0026lt;? super t,? super u,? extends v\u0026gt; fn) future1.thencombineasync(future2, bifunction\u0026lt;? super t,? super u,? extends v\u0026gt; fn) forkjointask\n基于任务的抽象类,可以通过forkjoinpool来执行。一个forkjointask是类似于线程实体,但是相对于线程实体是轻量级的。大量的任务和子任务会被forkjoinpool池中的真实线程挂起来,以某些使用限制为代价。\njmm java 内存模型 cpu 和内存的桥梁\r概念\njmm 是一种抽象的概念,并不真实存在,描述的是一种规范或约束。通过这个规范定义了程序中多线程下各线程之间变量的读写访问,并决定一个线程对共享变量的写入什么时候对另外的线程可见。\n共享变量\n共享变量是存在主内存中的,多线程下,访问共享变量,新的线程将会创建一个变量的副本,各自独立。若要更新主内存中共享变量的值,主要是将自己副本中的值写会主内存中。\n不同线程之间变量是独立的,不能直接访问,都需要通过主内存。\rhappen-before 约定,本质上可见性\n一个线程内,程序执行得满足约定的顺序,预期的结果。\n关键点\n1. 原子性\r2. 可见性\r3. 有序性\rvolatile关键字\n作用: 保证了有序性和可见性,不保证原子性\n可见性: 某一线程对 volatile 修饰的变量更改,会立马同步到主内存中\n有序性: volatile 修饰的变量的操作,能锁定某些代码的重排\n原子性: 多线程下可能发生写丢失\n常用场景\n线程标志位 多线程下的单例 dcl 单例(double check ) 低消耗的读 同步写 内存屏障\n即线程对资源变更的一种保护机制。java 内存模型的重排规则要求 java 编译器在生成 jvm 指令时插入特定的内存屏障指令,通过这些【屏障指令】,volatile 实现了可见性和有序性。\nvolatile 写之前的操作,都禁止重排序到 volatile 之后 volatile 读之后得操作,都禁止重排序到 volatile 之前 volatile 写之后 volatile 读,禁止重排序 内存屏障之前的所有写操作都要回写到主内存\r内存屏障之后的读操作都能获得内存屏障之前的所有写操作的最新结果\r分类\n粗分 读屏障 load memory barrier :告诉处理器在写屏障之前,将所有存储在缓存 store buffer 中的数据同步到主内存 写屏障 store memory barrier: 细分 load-load load-store store-store store-load cas(compare and swap) 概念\n比较并替换,当且仅当预期值与内存中值相同时,更新为新值;非阻塞的原子操作 硬件保证\ncas(v, a, b) 参数:v 内存地址; a 旧的预期值; b 新值\r非阻塞的原子操作(硬件保证)\n底层使用 unsafe 类,如 compareandswapint 方法,底层使用汇编 atomic::cmpchg 命令,保证了其是原子操作\n自旋\n多线程下,跟获取锁类似,需要先获取到资源,才可执行 +1 操作。若没获取到,则自旋一次,再次尝试,直到成功。\n例 new atomicinteger.getandincrement()\n自旋锁\n详见锁篇章\n缺点\n自旋带来的资源浪费 aba 问题(偷梁换柱):解决方案\u0026mdash;带版本号判断, atomicstamprefrence aba 问题\n产生原因:compare 比较值和替换结果,cas 只检查最终的结果,而不关心中间的过程,中间过程中发生了什么不清楚\n举例\n目的 cas(1, 3) ,中间出现 cas(1, 0) → cas(0, 2) → cas(2, 1)\r解决方案, 加版本号对比\r原子类 java.util.consurrent.atomic 包下类\n工具类 locksupport\n线程阻塞工具类,本身就持有锁,最多一个许可证,不会累计 | 单一开关式\r1 2 3 4 5 6 // 发放许可证 locksupport.unpark(thread); // 获取通行证 locksupport.park(); locksupport.park(thread); semaphore\n计数信号量 维护一组许可证| 坑位抢占式\r1 2 3 4 5 6 7 8 9 10 // 每个人都 acquire 会阻止,直到获得许可证,然后拿走它。 // 每个都 release 增加了一个许可证,可能会释放一个阻止的收购方。 // 但是,没有使用实际的许可对象;只是 semaphore 保留可用数量的计数并采取相应的行动。 private final semaphore available = new semaphore(max_available, true); // 通常用于限制可以访问某些(物理或逻辑)资源的线程数 // 从信号量获取许可,阻塞,直到一个信号量可用或线程 中断。 void acquire() // 释放许可证,将其返回到信号量。 void release() cyclicbarrier\n循环屏障 | 分片处理型\r1 2 3 4 5 6 7 // 等到 各方 都援用这个 await 屏障 int await() // 所有线程都到达await()方法 cyclicbarrier barrier = new cyclicbarrier(7, ()-\u0026gt; { system.out.println(\u0026#34;所有parties都完成了,该结束了\u0026#34;); }); countdownlatch\n一种同步辅助工具,它允许一个或多个线程等待,直到在其他线程中执行的一组操作完成。\r1 2 3 4 5 6 7 8 9 10 11 12 // 阻塞 等待计数器减到0 // 计数器减到0 或 超时 boolean await(long timeout, timeunit unit) // 一直阻塞,直到计数器减为0 // 使当前线程等待,直到闩锁倒计时为零,除非线程中断。 void await() // 递减闩锁的计数,如果计数达到零,则释放所有等待的线程。 // 如果当前计数大于零,则递减。如果新计数为零,则重新启用所有等待线程以进行线程调度。 // 如果当前计数等于零,则不会发生任何反应。 // 计数器减1 void countdown() blockingqueue\n阻塞队列\r1 2 3 4 5 6 7 8 9 10 11 12 // 不阻塞,返回异常 add() 添加元素到队列,若队列已满,则抛出异常 remove() 获取并删除元素,若独立已空,则抛出异常 // 不阻塞 offer() 若添加失败,则返回false poll() 获取头元素,获取失败则返回null // 阻塞 put() 添加时若队列已满,则一直等待 take() 获取时,若队列已空,则一直等待 锁 主要解决问题:串行 并行 数据安全问题\n什么是锁 多线程环境下,存在资源抢占问题,可能出现多个线程同时访问同一资源而导致的数据不一致或异常情况,为了保证共享资源的安全性,就出现了锁。\n锁是用于控制多个线程对共享资源访问的机制。\n锁-锁的是什么 8大锁 锁类模版\n1 2 3 4 5 6 public class a { // 静态方法 使用了 synchronized修饰, 则锁住的的是类模板 public synchronized static void method() { system.out.println(\u0026#34;\u0026#34;); } } 1 2 3 4 5 6 7 8 9 public class a { // 静态方法 public static void method() { // 此处锁的也是类模板 synchronized(this){ system.out.println(\u0026#34;此处锁的也是类模板\u0026#34;); } } } 锁方法的调用对象\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 public class a { // 普通方法 使用了 synchronized修饰, 则锁住的的是方法的调用对象 即类的实例对象 public synchronized void method() { system.out.println(\u0026#34;\u0026#34;); } } a a = new a(); // a调用锁a a.method(); a b = new a(); // b调用锁b b.method(); 锁变量\n1 2 3 4 5 6 7 8 9 10 11 12 public class a { private int index = 0; public void method() { // 此处锁住的是index变量 synchronized(index) { // 代码块中执行对index的操作 system.out.println(\u0026#34;\u0026#34;); } } } 锁对象\n1 2 3 4 5 6 7 8 9 10 11 public class a { public void method() { // 此处锁住的是this对象,即 a的实例 synchronized(this) { // 代码块中执行对index的操作 system.out.println(\u0026#34;\u0026#34;); } .... } } 锁分类及概念 按线程是否阻塞可分为 有锁(悲观锁) 和 无锁(乐观锁)\n按线程是否共享分为 共享锁(读锁) 和 排它锁(写锁)\n按竞争性可分为 公平锁 和 非公平锁\n按锁状态划分为 偏向锁 | 轻量级锁 | 重量级锁\n按递归性 分为 递归锁(可重入锁)\n问题 加锁会影响性能,使并行改为串行。因此在实际的使用中,根据场景的不同,要合理的控制锁的粒度,尽量减少性能的开销,线程的阻塞等。这个过程,也就是锁的优化,jdk7 以上自带锁的膨胀与消除,即在加锁的情况下,编译器会自动根据实际情况进行锁的消除或膨胀,如不会产生竞争的情况加锁了,会自动消除锁,避免性能损耗;\n分布式锁 以上锁均为本地锁,即在同一个 jvm 中有效,而在不同的 jvm 中无效\n在集群环境中,就需要使用分布式锁来保证资源的统一\n分布式锁详见 分布式锁\n此处做简单总结\n目前常用的分布式锁\n基于 redis 的 set nx 的简易分布式锁。 原理:利用 redis 的 set nx(当不存在的时才设置成功,存在则不成功) 特性,实现简易的分布式锁。 缺点: 不可重入: 不可重试:无法重试,加锁失败即刻返回 超时释放问题:业务卡死或者服务器宕机,锁一直无法释放,卡死了 主从一致问题:主节点宕机,从节点转变为主,锁数据还未同步到该从节点,锁丢失 可在获取锁之后在设置超时时间,但不是原子操作了。 redisson 基于 redis 的分布式锁 实现原理也是基于 redis 的原子操作,使用 lua 脚本实现。 它的功能更加完善,主要有以下优点:\n对锁设置了自动过期时间,避免了因为服务器宕机而导致的锁无法释放问题。 采用哨兵机制看门狗超时续约,1 中对锁设置了过期时间,而过期时间的设置又与业务代码的执行时间有关,假若业务代码执行时长大于锁的过期时间,会造成锁的提前释放;使用看门狗模式,就避免了这种情况。看门狗原理:看门狗在每隔一段时间会检测业务代码是否执行完,若没完则续期过期时间,知道业务代码执行完毕。此时也有问题,若业务代码出现异常卡死,则会造成死锁,锁一直无法释放,这时会有一个最大等待时间,过了这个时间,锁同样也会自动释放。 可以设置最大等待时间,过期锁自动释放。即 2 中最后提到的问题。 实现了可重入功能:使用 hash 结构,存储了重入次数及当前线程标识,同一线程每获取一次锁,重入次数加一。释放一次减一。到 0 就是彻底释放了。 实现了可重试功能:利用消息订阅与信号量机制,在约定时间内多次获取锁。 multilock:解决了主从一致问题。同时向多个节点获取锁,所有节点获取成功,才算锁成功。 线程安全的集合 juc下的类\nblockingqueue blockingdeque linkedblockingqueue concurrentlinkedqueue concurrenthashmap copyonwritearraylist copyonwritearrayset 常用线程类 1 2 3 4 5 6 7 8 9 10 futuretask\u0026lt;t\u0026gt; completabledfuture\u0026lt;t\u0026gt; cyclicbarrier countdownlatch locksupport semaphore blockingqueue exchanger 线程池 概念 线程池状态 线程池创建方法 7大参数\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 threadpoolexcutor pool = threadpoolexecutor( int corepoolsize, // 线程池初始化大小 核心线程数 int maximumpoolsize, // 最大线程数 long keepalivetime, // 当线程数大于核心数时,这时多余的空闲线程在终止之前等待新任务的最长时间。 timeunit unit, // keepalivetime 单位 blockingqueue\u0026lt;runnable\u0026gt; workqueue, // 等待队列 threadfactory threadfactory, // 执行程序创建新线程时使用的工厂 rejectedexecutionhandler handler) // 拒绝策略 最大线程数 = 最大线程数 + 等待队列大小 // corepoolsize 线程池初始化大小 核心池大小是保持活动状态(并且不允许超时等)的最小工作线程数 // maximumpoolsize最大线程数 // keepalivetime 等待工作的空闲线程的超时(以纳秒为单位)。当存在超过 corepoolsize 或 allowcorethreadtimeout 时, 线程将使用此超时。否则,他们将永远等待新的工作。 // workqueue 常见线程池 4大方法\n1 2 3 4 5 executors.newfixedthreadpool(5); // 固定线程数 executors.newsinglethreadexecutor(); // 单线程 executors.newcachedthreadpool(); // 缓存线程池 executors.newworkstealingpool(); // executors.newscheduledthreadpool(3); // 定时任务线程池 ","date":"2024-07-02","permalink":"https://hobocat.github.io/post/java/java%E5%A4%9A%E7%BA%BF%E7%A8%8B/","summary":"线程 几个概念 | 并行 | 并发 并行(parallel) 多个任务同时操作多个资源,每个任务独立执行,互不影响 并发(concurrent) 多个任务同时操作同一资源,多个线","title":"java多线程基础篇"},]
[{"content":"种类 list、list\u0026lt;object\u0026gt; 、list\u0026lt;?\u0026gt; 、list\u0026lt;t\u0026gt;、list\u0026lt;? extend t\u0026gt;、list\u0026lt;? super t\u0026gt;\n1. list\u0026lt;object\u0026gt; 与无泛型 list 差不多,都可往里 add 任何对象,但意义不大,只能往里 add,取出遍历往往出现类型错误\n2. list\u0026lt;?\u0026gt; 泛型不确定的集合,一般用来接收不能确定泛型的集合\n**3. 重点区分 list\u0026lt;? extend t\u0026gt;、list\u0026lt;? super t\u0026gt; **\n功能/类型 list\u0026lt;? extend t\u0026gt; list\u0026lt;? super t\u0026gt; 特性 get first put first 实际存储内容 t 及 t 子类对象, null 1. 初始化时接受 t 及 t 子类型的 list。\n2. 不能 add t 及 t 子类对象,t 的父类对象,null 1. 初始化时可接受父类类型的 list。 2. add 操作时只能添加 t 及 t 子类对象 get 功能 获取到的值强转为 t,子类对象丢失泛型\nt t = list.get(0); 获取到对象类型为 object,所有对象丢失类型\nobject o = list.get(0); put 功能 除 null 外,其余对象均不能被 add 可 put 对象:null,t 及 t 子类对象 集合值接收(初始化) t 及 t 子类类型的 list 可赋值给该泛型 list t 及 t 父类类型的 list 可赋值给该泛型 list pecs 常用来做结果接收 producer extend 常用来做参数 consumer super ","date":"2024-07-02","permalink":"https://hobocat.github.io/post/java/java%E6%B3%9B%E5%9E%8B/","summary":"种类 List、List\u0026lt;Object\u0026gt; 、List\u0026lt;?\u0026gt; 、List\u0026lt;T\u0026gt;、List\u0026lt;? extend T\u0026gt;、List\u0026lt;? Super","title":"java泛型"},]
[{"content":"一、集合框架图 二、list 1、 概述 list 是一种有序列表,有明确的第一个元素、最后一个元素、上一个元素和下一个元素。\rlist 的行为和数组几乎一致:list 内部按照放啊如元素的先后顺序存放,每个元素都可以通过索引确定元素的位置,list 的索引和数组一样,从 0 开始。 list 可以添加重复元素、null 等 遍历尽量使用遍历器 iterator 进行遍历,效率高。for each 默认实现了 iterator 迭代器遍历。\n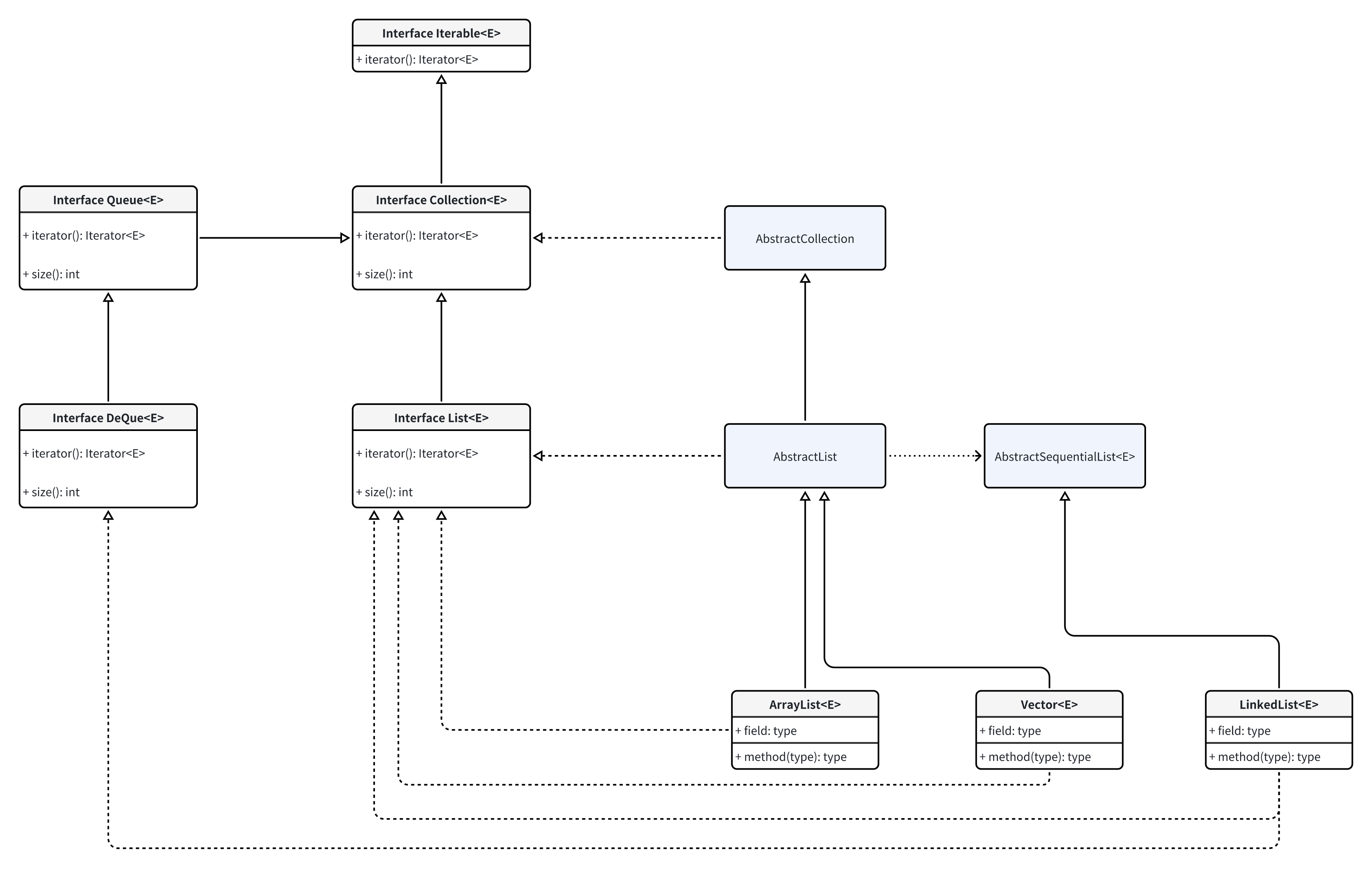\r2、 arraylist 查询快、增删慢;自动扩容(1.5 倍);线程不安全; arraylist 底层使用数组实现,在新添或删除一个元素时,都需要通过数组的移动来完成,如下图 初始化时最好设置初始化值,默认大小 10 。因为结构底层使用数组存储,数组是不可变长度的,当空闲元素填充满了时,需要扩充空间原有容量大小的 1.5 倍,每次扩展容都需创建一个新数组,然后进行数组的拷贝,会消耗性能(时间、空间)\n3、 linkedlist (有序) 线程不安全 增删效率高,检索效率低;空间占用率高;可作为队列、栈来使用\r单向链表存储结构如下 linkedlist 是通过双向链表实现,结构如下 三、 queue 队列\n队列 fifo(first input first output) 先进先出\n队列元素只能添加到末尾;只能从头部去除元素;能添加 null,但是避免添加 null\n队列示意图 队列操作方法对比\n操作 抛异常 返回false或null 添加元素到队尾 add(e e) boolean offer(e e) 取队首元素并删除 e remove() e poll() 取队首元素但不删除 e element() e peek() 栈\n栈 stack filo (first input last output)先进后出 or (last in first out)后进先出\n栈只有入栈 push 和出栈 pop2 种操作 peek()取栈顶而不弹出\n栈示意图 java 种没有 stack 接口,一般将 deque 来模拟 stack 使用。只调用 push() pop() peek() 方法来模拟\n使用实例 中缀表达式计算 1 + 3 * (9 - 2)、进制转换\n四、set 五、map map\u0026lt;k, v\u0026gt; 是一种键值映射表\r1. hashmap 数组+链表实现 不指定初始化大小时 默认 16,加载因子 0.75(即空间再次扩容的判断依据。threshold=table.length * loadfactor),第一次 put 时初始化 table ; size \u0026gt;= threshold(size 为 map 种 entry 的实际个数)时 ,需要扩容,扩容到 table.length 的 2 倍\njdk1.8 之后,若某一节点链表元素超过 8 个,同时 table.length \u0026gt; 64,则将链表转为红黑树。红黑树相关内容详见算法与数据结构树内容。\n2. linkedhashmap 3. treemap 4. concurrenthashmap ","date":"2024-07-02","permalink":"https://hobocat.github.io/post/java/java%E9%9B%86%E5%90%88/","summary":"一、集合框架图 二、List 1、 概述 List 是一种有序列表,有明确的第一个元素、最后一个元素、上一个元素和下一个元素。 list 的行为和数组几乎一致:list 内部按照放啊如元素","title":"java集合"},]
[{"content":"1. jvmjdk\u0026amp;jre\u0026amp;jvm之间的关系 jdk包含jre和jvm,jre包含jvm javac用于编译java代码到字节码文件 使用java命令启动jvm,字节码最终运行在jvm上 内存结构 内存结构图 jvm 内存共分为 5 个区:java 虚拟机栈、本地方法栈、堆、程序计数器、方法区(元空间)\r程序计数器\n 程序计数器是一块比较小的内存空间,可以看作当前线程字节码所执行的行号指示器。属于线程独占区。如果线程执行的是java方法,则计数器的值是正在执行的字节码指令的地址。如果线程执行的是native方法,则计数器的值为undefined。\n本地方法栈\n\t本地方法栈为虚拟机执行native服务,结构和虚拟机栈完全相同。用于管理本地方法的调用,里面并没有我们写的代码逻辑,其由 native 修饰,由 c 语言实现。\n虚拟机栈\n虚拟机栈描述的是java方法执行的动态内存模型\n栈帧:每个方法执行都会创建一个栈帧,栈帧伴随着方法的创建到执行完成,用于存储局部变量表、操作数栈、动态链接、方法出口等(栈里面存的是地址,实际指向的是堆里面的对象) 局部变量表:用于保存方法的参数及局部变量,局部变量表内存空间大小在编译时期固定,在运行过程中不会改变局部变量表的大小 操作数栈:主要保存计算过程的中间结果,同时作为计算过程中变量临时的存储空间 java堆 存放对象的实例、垃圾收集器管理的主要区域。 java 虚拟机中内存最大的一块,是被所有线程共享的,几乎所有的对象实例都在这里分配内存;\n方法区\n\t属于线程共享区,存储了虚拟机加载的类信息【版本、字段、方法、接口】、运行时常量池【字面量和符号引用】、静态变量、即时编译器编译后的代码等数据。在hotspot中方法区是使用永久代实现的,所以永久代等于方法区。这里很少进行垃圾回收。\n从java8开始hotspots使用元空间取代了永久代,永久代物理是是堆的一部分而元空间属于本地内存。元空间存储类的元信息,静态变量和常量池等并入堆中。相当于永久代的数据被分到了堆和元空间中。\n直接内存【并非jvm规范定义的区域,不属于虚拟机运行时内存的一部分】\n\tjdk1.4为了弥补io缺陷引入nio,运行直接在堆外分配内存,不受jvm制约,由操作系统分配。\n线程私有、公有\n线程全局共享的区域:\n堆 方法区 线程私有:每个线程在开辟、运行的过程中会单独创建这样的一份内存,有多少个线程可能有多少个内存java\n虚拟机栈 本地方法栈 程序计数器是线程私有的 栈虽然方法运行完毕了之后被清空了,但是堆上面的还没有被清空,所以引出了 gc(垃圾回收),不能立马删除,因为不知道是否还有其它的也是引用了当前的地址来访问的\n性能调优 2. 类加载机制 一个java对象的创建过程往往包括两个阶段:类初始化阶段 和 类实例化阶段\n\t类的加载:代表jvm将java文件编译成class文件后,以二进制流的方式存放到运行时数据的方法区中,并在java的堆中创建一个java.lang.class对象,用来指向存放在方法堆中的数据结构。且虚拟机加载class文件是懒加载机制。\n类的加载 通过一个类的全限定名来获取定义此类的二进制字节流 文件方式【class文件、jar文件】 网络 程序生成【动态代理】 其它【jsp-会转换为servlet,数据库】 将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构 在内存中生成一个代表这个类的class对象,作为这个类的各种数据的访问入口 类的验证 \t验证是连接的第一步,但是并非是必须的。这一阶段的目的是为了确保class文件的字流中包含的狺息符合当前虚拟机的要求,并且不会危害虚拟机自身的安全包含:\n文件格式验证 是否以魔数0xcaffebabe开头 主次版本号是否在虚拟机处理范围内 常量池中的常量是否有不被支持的常量类型 指向常量的各种索引值是否有指向不存在的常量 元数据验证 这个类是否有父类 这个类的父类是否继承不被允许的类(final修饰的类) 如果这个类不是抽象类,是否实现了接口要求实现的方法 类中的字段,方法是否与父类矛盾(例如出现不符合规则的方法重载) 字节码验证 保证任何时刻操作数栈的数据类型与指令代码序列能配合工作 保证跳转指令不会跳转到方法体以外的字节码指令 保证方法体中类型转换有效,如避免出现将父类对象赋值到子类数据类型上 符号引用验证 符号引用中通过字符串描述的全限定名是否能找到对应的类 在指定类中是否存在符合方法的字段描述符号 符号引用的类,字段,方法的访问性是否可以被当前类访问 类的准备 \t准备阶段正式为类的静态变量分配内存并设置变量的初始值。这些变量使用的内存都将在方法区中进行分配。设置的初始值并非我们指定的值而是这种变量的默认值,但是如果是被final修饰的常量则会被初始为我们指定的值\n类的解析 \t**解析阶段是将常量池中的符号引用替换为直接引用的过程。**在进行解析之前需要对符号引用进行解析,不同虚拟机实现可以根据需要判断到底是在类被加载器加载的时候对常量池的符号引用进行解析(也就是初始化之前),还是等到一个符号引用被使用之前进行解析(也就是在初始化之后)。如果一个符号引用进行多次解析请求,虚拟机中除了invokedynamic指令外,虚拟机可以对第一次解析的结果进行缓存(在运行时常量池中记录引用,并把常量标识为一解析状态),这样就避免了一个符号引用的多次解析。\n类或者接口解析\n要把一个类或者接口的符号引用解析为直接引用,需要以下三个步骤\n如果该符号引用不是一个数组类型,那么虚拟机将会把该符号代表的全限定名称传递给类加载器去加载这个类。这个过程由于涉及验证过程所以可能会触发其他相关类的加载\n如果该符号引用是一个数组类型,并且该数组的元素类型是对象。我们知道符号引用是存在方法区的常量池中的,该符号引用的描述符会类似”[java/lang/integer”的形式,将会按照上面的规则进行加载数组元素类型,如果描述符如前面假设的形式,需要加载的元素类型就是java.lang.integer ,接着由虚拟机将会生成一个代表此数组对象的直接引用\n如果上面的步骤都没有出现异常,那么该符号引用已经在虚拟机中产生了一个直接引用,但是在解析完成之前需要对符号引用进行验证,主要是确认当前调用这个符号引用的类是否具有访问权限,如果没有访问权限将抛出java.lang.illegalaccess异常\n字段解析\n对字段的解析需要首先对其所属的类进行解析,因为字段是属于类的,只有在正确解析得到其类的正确的直接引用才能继续对字段的解析。对字段的解析主要包括以下几个步骤:\n如果该字段符号引用就包含了简单名称和字段描述符都与目标相匹配的字段,则返回这个字段的直接引用,解析结束 否则,如果在该符号的类实现了接口,将会按照继承关系从下往上递归搜索各个接口和它的父接口,如果在接口中包含了简单名称和字段描述符都与目标相匹配的字段,那么久直接返回这个字段的直接引用,解析结束 否则,如果该符号所在的类不是object类的话,将会按照继承关系从下往上递归搜索其父类,如果在父类中包含了简单名称和字段描述符都相匹配的字段,那么直接返回这个字段的直接引用,解析结束 否则,解析失败,抛出java.lang.nosuchfielderror异常 如果最终返回了这个字段的直接引用,就进行权限验证,如果发现不具备对字段的访问权限,将抛出java.lang.illegalaccesserror异常\n类方法解析\n进行类方法的解析仍然需要先解析此类方法的类,在正确解析之后需要进行如下的步骤:\n类方法和接口方法的符号引用是分开的,所以如果在类方法表中发现class_index(类中方法的符号引用)的索引是一个接口,那么会抛出java.lang.incompatibleclasschangeerror的异常 如果class_index的索引确实是一个类,那么在该类中查找是否有简单名称和描述符都与目标字段相匹配的方法,如果有的话就返回这个方法的直接引用,查找结束 否则,在该类的父类中递归查找是否具有简单名称和描述符都与目标字段相匹配的字段,如果有,则直接返回这个字段的直接引用,查找结束 否则,在这个类的接口以及它的父接口中递归查找,如果找到的话就说明这个方法是一个抽象类,查找结束,返回java.lang.abstractmethoderror异常 否则,查找失败,抛出java.lang.nosuchmethoderror异常 如果最终返回了直接引用,还需要对该符号引用进行权限验证,如果没有访问权限,就抛出java.lang.illegalaccesserror异常\n接口方法解析\n同类方法解析一样,也需要先解析出该方法的类或者接口的符号引用,如果解析成功,就进行下面的解析工作:\n如果在接口方法表中发现class_index的索引是一个类而不是一个接口,那么也会抛出java.lang.incompatibleclasschangeerror的异常\n否则,在该接口方法的所属的接口中查找是否具有简单名称和描述符都与目标字段相匹配的方法,如果有的话就直接返回这个方法的直接引用。\n否则,在该接口以及其父接口中查找,直到object类,如果找到则直接返回这个方法的直接引用\n否则,查找失败\n类的初始化 初始化时机 对于初始化阶段,虚拟机规范严格规定了有且只有5种情况必须对类进行初始化(加载、验证、准备自然需在此之前开始):\n①遇到new、getstatic、putstatic、invokestatic这四条字节码指令时,如果类没有进行过初始化,则需要先触发其初始化。生成这四条指令的最常见的java代码场景是:\n使用new关键字实例化对象的时候\n读取或设置一个类的静态字段【被final修饰己在编译器把结果放入常量池的静态字段除外】\n调用一个类的静态方法的时候\n②使用java.lang.reflect包的方法对类进行反射调用的时,如果类没有进行过初始化则需要先触发其初始化\n③当初始化一个类的时候,如果发现其父类还没有进行过初始化,则需要先触发其父类的初始化\n④当虚拟机启动时,用户需要指定一个要执行的主类(包含main()方法的那个类),虚拟机会先初始化这个主类\n⑤当使用jdk7动态语言支持时,如果methodhandle实例最后的解析结果ref_getstatic、ref_putstatic、ref_invokestatic的方法句柄,并且这个方法句柄所对应的类没有进行初始化,则需要先出触发其初始化\n不执行初始化的例子\n调用类常量【public static final】 通过数组定义来引用类【base[] car = new base[5]】 通过子类引用父类的静态字段【base.parentvariable】时,子类不会被初始化 初始化过程 \t类初始化时类加载过程的最后一步,前面的类加载过程中,除了在加载阶段(类加载过程的一个阶段)应用程序可以通过自定义类加载器参与之外,其余动作完全由虚拟机主导和控制。到了初始化阶段,才真正开始执行类中定义的java程序代码。初始化阶段是执行类构造器\u0026lt;clinit\u0026gt;()方法的过程。\n\u0026lt;clinit\u0026gt;()方法执行过程中可能会影响程序运行行为:\n\u0026lt;clinit\u0026gt;()方法是由编译器自动收集类中的所有类变量的赋值动作和静态语句块中的语句合并产生的,编译器收集的顺序是由语句在源文件中出现的顺序所决定的,静态语句块中只能访问到定义在静态语句块之前的变量,定义在它之后的变量,在前面的静态语句块中可以赋值,但不能访问,属于非法向前引用。\n1 2 3 4 5 6 7 8 public class test { static { v = 3; system.out.println(v);\t//编译报错,只能赋值不能访问 } static int v = 1; } // 顺序执行最后v的值为\u0026#34;1\u0026#34; \u0026lt;clinit\u0026gt;()方法与类的构造函数(即类的实例构造器\u0026lt;init\u0026gt;()方法)不同,它不需要显式地调用父类构造器,虚拟机会保证在子类的\u0026lt;clinit\u0026gt;()方法执行之前,父类的\u0026lt;clinit\u0026gt;()方法已经执行完毕。因此在虚拟机中第一个被执行的\u0026lt;clinit\u0026gt;()方法一定是java.lang.object\n\u0026lt;clinit\u0026gt;()方法对于类(抽象类)或接口来说并不是必需的,如果一个类中没有静态语句块,也没有对变量的赋值操作,那么编译器可以不为这个类生成\u0026lt;clinit\u0026gt;()方法\n接口中不能使用静态语句块,但仍然有变量初始化的赋值操作,因此接口与类一样都会生成\u0026lt;clinit\u0026gt;()方法。但接口与类不同的是,执行接口的\u0026lt;clinit\u0026gt;()方法不需要先执行父接口的\u0026lt;clinit\u0026gt;()方法。只有当父接口中定义的变量使用时,父接口才会初始化。另外,接口的实现类在初始化时也一样不会执行接口的\u0026lt;clinit\u0026gt;()方法\n虚拟机会保证一个类的\u0026lt;clinit\u0026gt;()方法在多线程环境中被正确的加锁,同步,如果多个线程同时去初始化一个类,那么只会有一个线程去执行这个类的\u0026lt;clinit\u0026gt;()方法,其他线程都需要阻塞等待,直到活动线程执行\u0026lt;clinit\u0026gt;()方法完毕。在实际应用中这种阻塞引起的问问往往是很隐蔽\n类加载器的种类 启动(bootstrap)类加载器\n\t启动类加载器主要加载的是jvm自身需要的类,这个类加载使用c++语言实现的,是虚拟机自身的一部分,它负责将 /lib路径下的核心类库或-xbootclasspath参数指定的路径下的jar包加载到内存中。它本身是虚拟机的一部分,所以它并不是一个java类,也就是无法在java代码中获取它的引用。即extension classloader的代码中的parent为null\n注意必由于虚拟机是按照文件名识别加载jar包的,如rt.jar,如果文件名不被虚拟机识别,即使把jar包丢到lib目录下也是没有作用的(出于安全考虑,bootstrap启动类加载器只加载包名为java、javax、sun等开头的类)\n扩展(extension)类加载器\n\t扩展类加载器是指sun公司实现的sun.misc.launcher$extclassloader类,由java语言实现的,是launcher的静态内部类,它负责加载/lib/ext目录下或者由系统变量-djava.ext.dir指定位路径中的类库,开发者可以直接使用标准扩展类加载器。\n系统(system)类加载器\n\t也称应用程序加载器是指 sun公司实现的sun.misc.launcher$appclassloader。它负责加载系统类路径java -classpath或-d java.class.path 指定路径下的类库,开发者可以直接使用系统类加载器,一般情况下该类加载是程序中默认的类加载器,通过classloader#getsystemclassloader()方法可以获取到该类加载器。\n自定义(custom)类加载器\n\t自定义类加载器由第三方实现,建议满足双亲委派模式。\n只有被同一个类加载器加载的类才会相等,相同的字节码被不同的类加载器加载的类不相同。\n双亲委派模式 \t双亲委派模式要求除了顶层的启动类加载器外,其余的类加载器都应当有自己的父类加载器【并非继承】采用组合关系来复用父类加载器的相关代码,类加载器间的关系如下:\n3. 对象初始化机制 对象创建过程 对象内存分配方式 指针碰撞\n\t假设java堆中内存是绝对规整的,所有用过的内存都放在一边,空闲的内存放在另一边,中间放着一个指针作为分界点的指示器,那所分配内存就仅仅是把那个指针向空闲空间那边挪动一段与对象大小相等的距离,这种分配方式称为指针碰撞\n空闲列表\n\t如果java堆中的内存并不是规整的,已使用的内存和空闲的内存相互交错,那就没有办法简单地进行指针碰撞了,虚拟机就必须维护一个列表,记录上哪些内存块是可用的,在分配的时候从列表中找到一块足够大的空间划分给对象实例,并更新列表上的记录,这种分配方式称为空闲列表\n具体是使用空闲列表还是指针碰撞需要根据内存状况决定\n多线程内存分配管理 \t不管使用哪种对象内存分配方式,在多线程环境时,如果一个线程正在给a对象分配内存,指针还没有来的及修改,其它为b对象分配内存的线程,而且还是引用这之前的指针指向,这样会带来分配问题。于是有两种处理方式。\n分配时加锁\n\t堆是jvm中所有线程共享的,因此在其上进行对象内存的分配均需要进行加锁,这也导致了new对象的开销是比较大的。\ntlab【线程本地分配缓存区】\n\t为了提升对象内存分配的效率,对于所创建的线程都会分配一块独立的空间tlab(thread local allocation buffer),其大小由jvm根据运行的情况计算而得,在tlab上分配对象时不需要加锁,因此jvm在给线程的对象分配内存时会尽量的在tlab上分配,在这种情况下jvm中分配对象内存的性能和c基本是一样高效的,但如果对象过大的话则仍然是直接使用堆空间分配。\n\tjvm在内存新生代eden space中开辟了一小块线程私有的区域称作tlab。默认设定为占用eden space的1%。\n对象的结构 对象头\n_mark:用于存储对象自身的运行时数据,如哈希码(hashcode)、gc分代年龄、锁状态标志、线程持有的锁、偏向线程id、偏向时间戳等,称之为“markword” _klass:指向类元数据的指针 _length:数组长度(只有数组对象有) 实例数据\n\t存储在程序代码中所定义的各种类型的字段内容\n对齐填充\n\t帮助对象凑满8字节的倍数,不一定存在\n对象访问方式 句柄访问\n 使用句柄访问。java堆中将会划分出一块内存来作为句柄池,reference中存储的是对象的句柄地址,而句柄中包含了对象实例数据和类型数据各自的具体地址信息。\n直接指针访问\n\t使用直接指针访问。reference中存储的就是对象的地址。\nhotspot是用直接指针访问方式进行对象访问的。\n4. 内存分配机制 分配策略 对象优先分配到eden区\n大对象直接分配到老年代\n长期存活对象分配到老年代\n空间分配担保\n存入对象时发现年轻代空间不足,将判断老年代最大可用的连续空间是否大于当前年起代所有对象\n满足,minor gc是安全的,可以进行minor gc 不满足,虚拟机查看handlepromotionfailure参数 true会继续检测[老年代最大可用的连续空间]是否大于[历次晋升到老年代对象的平均大小]。若大于,将尝试进行一次minor gc,若失败,则重新进行一次full gc false则不允许冒险,要进行full gc 栈上分配和逃逸分析 在jdk7(包括)之后完全支持栈上分配和逃逸分析。\n逃逸分析\n\t如果某个方法之内创建的实例只在方法内被使用,方法结束之后没有任何对象引用它【即可被gc回收】,这样的对象叫做未发生逃逸对象。如果某个方法之内创建的实例在方法结束之后有对象引用它【即不可被gc回收】,这样的对象叫做逃逸对象。\n栈上分配\n\t如果一个对象未发生逃逸则这个对象的生命周期只存在一个方法体内,这样的对象可以直接在栈上分配提高效率,也方便回收【方法结束,栈销毁,未发生逃逸也就随着销毁】\n5. gc垃圾处理回收机制 鉴定垃圾对象 引用计数法\n\t在对象中添加一个引用计数器,当有地方释放这个引用时,对象上存储的引用计数减一,但是当出现互相引用时【对象实例3和对象实例5】引用计数依旧不为0,无法对其进行垃圾回收\n可达性分析\n\t该算法的核心算法是从gc roots对象作为起始点,如果对象不可达到gc root则认为此对象是要回收的对象。可作为gc roots的对象\n虚拟机栈的局部变量所引用的对象 本地方法栈的jni所引用的对象 方法区的静态变量和常量所引用的对象 回收策略 标记-清除算法\n\t算法分为标记和清除两个阶段:先标记出所有需要回收的对象,完成后统一回收掉所有被标记的对象。\n\t缺陷:①标记和清除过程的效率不高;②极易造成空间碎片问题\n复制收集算法\n\t复制收集算法将可用内存按容量划分为大小相等的两块,survivor区每次只使用其中的一块。当这一块的内存用完了,就将eden和survivor还存活着的对象复制到另外一块survivor上面,然后再把已使用过的内存空间一次清理掉。 这样内存分配时也就不用考虑内存碎片等复杂情况,实现简单运行高效。长期存活的对象移入oldgen区这里面的对象很少执行垃圾回收。\n标记-整理算法\n\t当预估能回收的对象并不多时(例如老年代)采用复制收集算法就要执行较多的复制操作,效率将会变低且还浪费了大量空间,所以此时进行复制收集算法不明智。采用标记-整理算法较为合适,标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存。且下次在此空间继续分配内存可以使用指针碰撞法提高速度。\n分代收集算法\n\t把java堆分为新生代和老年代,根据各个年代的特点采用最适当的收集算法。新生代每次垃圾收集时都有大量对象需要回收那就选用复制算法。而老年代中因为对象存活率高就使用标记-清理或标记-整理算法进行回收。\ngc分类 minor gc:清理年轻代,不会影响到永久代\nmajor gc :清理老年代,major gc大部分由minor gc触发\nfull gc :清理整个堆空间—包括年轻代、老年代和永久代\n垃圾回收器 针对新生代的垃圾回收器 serial收集器【复制收集算法】\njdk1.3之前回收新生代内存的唯一选择 单线程的垃圾收集器,单cpu环境下效果较好 parnew【复制收集算法】\nserial收集器的多线程版本 parnew收集器是许多运行多cpu模式下的虚拟机中首选的新生代收集器 它是除了serial收集器外,唯一一个能与cms收集器配合工作的 parallel scavenge【复制收集算法】\n达到一个可控制的吞吐量有gc自适应调节策略 针对老年代的垃圾回收器 serial old 收集器【标记-整理算法】\n单线程垃圾收集器 parallel old 收集器【标记-整理算法】\nparallel scavenge的老年版本 cms 收集器【标记-清除算法】\n一种以获取最短回收停顿时间为目标的收集器 [1]初始标记:标记gc roots能直接到的对象。速度很快但是仍存在stop the world问题。\n[2]并发标记:进行gc roots tracing 的过程,找出存活对象且用户线程可并发执行。\n[3]重新标记:为了修正并发标记期间因用户程序继续运行发生改变的对象的记录。仍然存在stop the world。\n[4]并发清除:对标记的对象进行清除回收。\n特殊收集器 g1收集器\n\tg1垃圾收集器并没有将内存按照连续内存地址分为新生代、老年代。而是分成了一个个的区域【region】,采用了分代与分区算法。这些区域大小不固定,根据回收的情况进行评估,到达阀值视为老年代。在进行一次垃圾回收之后,会进行日志收集确定分代划分和是否进行混合清理(新生代和老年代一起清理)。\n并行性:g1回收期间可以多线程同时工作 并发性:g1拥有与应用程序交替执行的能力,部分工作可与应用程序同时执行,在整个gc期间不会完全阻塞应用程序 分代gc:依旧分为新生代和老年代,新生代依然有eden,from和to 空间整理:g1在垃圾回收过程中,不会像cms那样在若干次gc后需要进行碎片整理,g1采用了有效复制对象方式 可预见性:由于分区的原因,g1可以只选取部分区域进行回收,缩小了回收的范围,提高性能 g1的内存结构如下所示:\njdk11之后g1触发full gc时可并行处理,以前只能串行处理\n各代hotspot(server模式下)默认垃圾收集器 jdk1.7 默认垃圾收集器parallel scavenge(新生代)+parallel old(老年代) jdk1.8 默认垃圾收集器parallel scavenge(新生代)+parallel old(老年代) jdk1.9 默认垃圾收集器g1 附录 jit编译(just-in-time compilation) \t在部分商用虚拟机中(如hotspot),java程序最初是通过解释器(interpreter)进行解释执行的,当虚拟机发现某个方法或代码块的运行特别频繁时,就会把这些代码认定为“热点代码”。为了提高热点代码的执行效率,在运行时,虚拟机将会把这些代码编译成与本地平台相关的机器码,并进行各种层次的优化,完成这个任务的编译器称为即时编译器(just in time compile)。\n\t即时编译器并不是虚拟机必须的部分,java虚拟机规范并没有规定java虚拟机内必须要有即时编译器存在,更没有限定或指导即时编译器应该如何去实现。但是,即时编译器编译性能的好坏、代码优化程度的高低却是衡量一款商用虚拟机优秀与否的最关键的指标之一,它也是虚拟机中最核心且最能体现虚拟机技术水平的部分。\n\tjit编译狭义来说是当某段代码即将第一次被执行时进行编译,因而叫“即时编译”。jit编译是动态编译的一种特例。jit编译一词后来被泛化,时常与动态编译等价。\n符号引用\u0026amp;直接引用 符号引用(symbolic references)\n\t符号引用以一组符号来描述所引用的目标,符号可以是任何形式的字面量,只要使用时能够无歧义的定位到目标即可。例如,在class文件中它以constant_class_info、constant_fieldref_info、constant_methodref_info等类型的常量出现。符号引用与虚拟机的内存布局无关,引用的目标并不一定加载到内存中。\n直接引用(direct references)\n(1)直接指向目标的指针【比如指向class对象、类变量、类方法的直接引用可能是指向方法区的指针)\n(2)相对偏移量【比如指向实例变量、实例方法的直接引用都是偏移量】\n(3)一个能间接定位到目标的句柄\n管程 管程可以看做一个软件模块,它是将共享的变量和对于这些共享变量的操作封装起来,形成一个具有一定接口的功能模块,进程可以调用管程来实现进程级别的并发控制。\r进程只能互斥得使用管程,即当一个进程使用管程时,另一个进程必须等待。当一个进程使用完管程后,它必须释放管程并唤醒等待管程的某一个进程。\r在管程入口处的等待队列称为入口等待队列,由于进程会执行唤醒操作,因此可能有多个等待使用管程的队列,这样的队列称为紧急队列,它的优先级高于等待队列。 ","date":"2024-07-02","permalink":"https://hobocat.github.io/post/java/jvm/","summary":"1. JVMJDK\u0026amp;JRE\u0026amp;JVM之间的关系 JDK包含JRE和JVM,JRE包含JVM javac用于编译java代码到字节码文件 使用java命令启动","title":"jvm"},]
[{"content":"一、jdk\u0026amp;jre\u0026amp;jvm之间的关系 jdk包含jre和jvm,jre包含jvm javac用于编译java代码到字节码文件 使用java命令启动jvm,字节码最终运行在jvm上 【少】javafx是一种富客户端技术,用于替换flash和swing程序 【少】java web start第一次运行需要借助浏览器,之后生成快捷方式当web站点更新是程序也更新,效果类似swing 二、jvm虚拟机结构和厂商 sun classic vm\n第一款商用的java虚拟机,伴随着jdk1.0发布,只能使用纯解释器方式来执行java代码,只能外挂jit编译器(just-in-time compilation)进行编译java代码,但是解释器和jit编译器不能同时执行。存在较大性能问题。\nexact vm\nexact vm全称为exact memory management【准确式内存管理】,编译器和解释器可以混合工作以及两级及时编译器。但是只能在solaris平台使用。jdk1.2时发布。\nhotspotvm\n从jdk1.3开始运用至今的hotspot虚拟机(oracle jdk和open jdk)。加入热点代码探测技术。\nkvm\n面对移动设备和嵌入式设备的kilobyte虚拟机,运行速度较慢、简单、轻量、高度可移植。\njrockit\nbea公司(2008年被oracle收购)开发的jrockit虚拟机,被称为当时世界上最快的java虚拟机,专注于服务端应用。jdk7时部分功能被整合到hotspot。不包含解释器实现,只有即时编译器。\nj9\nibm开发类似hotspotvm虚拟机桌面、服务器、嵌入式端都支持。ibm内部使用。\ndalvik\n安卓操作系统所使用的虚拟机,并非是一个java虚拟机,未遵循java规范,基于寄存器架构【其它pc虚拟机基于栈架构】,不能执行.class文件。可以通过.class文件转化为.dex文件运行在dalvik上,开发的语法也为java,也可使用java api。\nmicorsoftvm\n只能在windows平台下运行,最终因为法律问题被sun公司禁止使用。\ntaobaovm\n根据hotspotvm深度定制,在淘宝内部使用,对硬件依赖性高。\nazul vm和 liquid vm\nazul vm和bea liquid vm是一类运行在特定硬件平台的专有虚拟机,是\u0026quot;高性能\u0026quot;虚拟机。\nazul vm是azul systems公司在hotspot基础上进行大量改进,运行于azul systems公司的专有硬件vega系统上的java虚拟机。每个azul vm实例都可以管理至少数十个cpu和数百gb内存的硬件资源,并提供在巨大内存范围内实现可控的gc时间的垃圾收集器、为专有硬件优化的线程调度等优秀特性。\nliquid vm即是现在的jrockit ve(virtual edition),由bea公司开发,可以直接运行在自家hypervisor系统上的jrockit vm的虚拟化版本,liquid vm不需要操作系统的支持,或者说它自己本身实现了一个专用操作系统的必要功能,如文件系统、网络支持等。由虚拟机越过通用操作系统直接控制硬件可以获得更好的性能,如在线程调度时,不需要再进行内核态/用户态的切换等,这样可以最大限度地发挥硬件的能力,提升程序的执行性能。\n三、jvm内存管理 程序计数器\n 程序计数器是一块比较小的内存空间,可以看作当前线程字节码所执行的行号指示器。属于线程独占区。如果线程执行的是java方法,则计数器的值是正在执行的字节码指令的地址。如果线程执行的是native方法,则计数器的值为undefined。\n虚拟机栈\n虚拟机栈描述的是java方法执行的动态内存模型\n栈帧:每个方法执行都会创建一个栈帧,栈帧伴随着方法的创建到执行完成,用于存储局部变量表、操作数栈、动态链接、方法出口等 局部变量表:用于保存方法的参数及局部变量,局部变量表内存空间大小在编译时期固定,在运行过程中不会改变局部变量表的大小 操作数栈:主要保存计算过程的中间结果,同时作为计算过程中变量临时的存储空间 本地方法栈\n\t本地方法栈为虚拟机执行native服务,结构和虚拟机栈完全相同。hotspotvm将虚拟机栈和本地方法栈放在一起管理不做区分。\njava堆\n\t存放对象的实例、垃圾收集器管理的主要区域。\n方法区\n\t属于线程共享区,存储了虚拟机加载的类信息【版本、字段、方法、接口】、运行时常量池【字面量和符号引用】、静态变量、即时编译器编译后的代码等数据。在hotspot中方法区是使用永久代实现的,所以永久代等于方法区。这里很少进行垃圾回收。\n从java8开始hotspots使用元空间取代了永久代,永久代物理是是堆的一部分而元空间属于本地内存。元空间存储类的元信息,静态变量和常量池等并入堆中。相当于永久代的数据被分到了堆和元空间中。\n直接内存【并非jvm规范定义的区域,不属于虚拟机运行时内存的一部分】\n\tjdk1.4为了弥补io缺陷引入nio,运行直接在堆外分配内存,不受jvm制约,由操作系统分配。\n四、java的对象 对象创建过程 对象内存分配方式 指针碰撞\n\t假设java堆中内存是绝对规整的,所有用过的内存都放在一边,空闲的内存放在另一边,中间放着一个指针作为分界点的指示器,那所分配内存就仅仅是把那个指针向空闲空间那边挪动一段与对象大小相等的距离,这种分配方式称为指针碰撞\n空闲列表\n\t如果java堆中的内存并不是规整的,已使用的内存和空闲的内存相互交错,那就没有办法简单地进行指针碰撞了,虚拟机就必须维护一个列表,记录上哪些内存块是可用的,在分配的时候从列表中找到一块足够大的空间划分给对象实例,并更新列表上的记录,这种分配方式称为空闲列表\n具体是使用空闲列表还是指针碰撞需要根据内存状况决定\n多线程内存分配管理 \t不管使用哪种对象内存分配方式,在多线程环境时,如果一个线程正在给a对象分配内存,指针还没有来的及修改,其它为b对象分配内存的线程,而且还是引用这之前的指针指向,这样会带来分配问题。于是有两种处理方式。\n分配时加锁\n\t堆是jvm中所有线程共享的,因此在其上进行对象内存的分配均需要进行加锁,这也导致了new对象的开销是比较大的。\ntlab【线程本地分配缓存区】\n\t为了提升对象内存分配的效率,对于所创建的线程都会分配一块独立的空间tlab(thread local allocation buffer),其大小由jvm根据运行的情况计算而得,在tlab上分配对象时不需要加锁,因此jvm在给线程的对象分配内存时会尽量的在tlab上分配,在这种情况下jvm中分配对象内存的性能和c基本是一样高效的,但如果对象过大的话则仍然是直接使用堆空间分配。\n\tjvm在内存新生代eden space中开辟了一小块线程私有的区域称作tlab。默认设定为占用eden space的1%。\n对象的结构 对象头\n_mark:用于存储对象自身的运行时数据,如哈希码(hashcode)、gc分代年龄、锁状态标志、线程持有的锁、偏向线程id、偏向时间戳等,称之为“markword” _klass:指向类元数据的指针 _length:数组长度(只有数组对象有) 实例数据\n\t存储在程序代码中所定义的各种类型的字段内容\n对齐填充\n\t帮助对象凑满8字节的倍数,不一定存在\n对象访问方式 句柄访问\n 使用句柄访问。java堆中将会划分出一块内存来作为句柄池,reference中存储的是对象的句柄地址,而句柄中包含了对象实例数据和类型数据各自的具体地址信息。\n直接指针访问\n\t使用直接指针访问。reference中存储的就是对象的地址。\nhotspot是用直接指针访问方式进行对象访问的。\n五、垃圾回收 鉴定垃圾对象 引用计数法\n\t在对象中添加一个引用计数器,当有地方释放这个引用时,对象上存储的引用计数减一,但是当出现互相引用时【对象实例3和对象实例5】引用计数依旧不为0,无法对其进行垃圾回收\n可达性分析\n\t该算法的核心算法是从gc roots对象作为起始点,如果对象不可达到gc root则认为此对象是要回收的对象。可作为gc roots的对象\n虚拟机栈的局部变量所引用的对象 本地方法栈的jni所引用的对象 方法区的静态变量和常量所引用的对象 回收策略 标记-清除算法\n\t算法分为标记和清除两个阶段:先标记出所有需要回收的对象,完成后统一回收掉所有被标记的对象。\n\t缺陷:①标记和清除过程的效率不高;②极易造成空间碎片问题\n复制收集算法\n\t复制收集算法将可用内存按容量划分为大小相等的两块,survivor区每次只使用其中的一块。当这一块的内存用完了,就将eden和survivor还存活着的对象复制到另外一块survivor上面,然后再把已使用过的内存空间一次清理掉。 这样内存分配时也就不用考虑内存碎片等复杂情况,实现简单运行高效。长期存活的对象移入oldgen区这里面的对象很少执行垃圾回收。\n标记-整理算法\n\t当预估能回收的对象并不多时(例如老年代)采用复制收集算法就要执行较多的复制操作,效率将会变低且还浪费了大量空间,所以此时进行复制收集算法不明智。采用标记-整理算法较为合适,标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存。且下次在此空间继续分配内存可以使用指针碰撞法提高速度。\n分代收集算法\n\t把java堆分为新生代和老年代,根据各个年代的特点采用最适当的收集算法。新生代每次垃圾收集时都有大量对象需要回收那就选用复制算法。而老年代中因为对象存活率高就使用标记-清理或标记-整理算法进行回收。\ngc分类 minor gc:清理年轻代,不会影响到永久代\nmajor gc :清理老年代,major gc大部分由minor gc触发\nfull gc :清理整个堆空间—包括年轻代、老年代和永久代\n垃圾回收器 针对新生代的垃圾回收器 serial收集器【复制收集算法】\njdk1.3之前回收新生代内存的唯一选择 单线程的垃圾收集器,单cpu环境下效果较好 parnew【复制收集算法】\nserial收集器的多线程版本 parnew收集器是许多运行多cpu模式下的虚拟机中首选的新生代收集器 它是除了serial收集器外,唯一一个能与cms收集器配合工作的 parallel scavenge【复制收集算法】\n达到一个可控制的吞吐量有gc自适应调节策略 针对老年代的垃圾回收器 serial old 收集器【标记-整理算法】\n单线程垃圾收集器 parallel old 收集器【标记-整理算法】\nparallel scavenge的老年版本 cms 收集器【标记-清除算法】\n一种以获取最短回收停顿时间为目标的收集器 [1]初始标记:标记gc roots能直接到的对象。速度很快但是仍存在stop the world问题。\n[2]并发标记:进行gc roots tracing 的过程,找出存活对象且用户线程可并发执行。\n[3]重新标记:为了修正并发标记期间因用户程序继续运行发生改变的对象的记录。仍然存在stop the world。\n[4]并发清除:对标记的对象进行清除回收。\n特殊收集器 g1收集器\n\tg1垃圾收集器并没有将内存按照连续内存地址分为新生代、老年代。而是分成了一个个的区域【region】,采用了分代与分区算法。这些区域大小不固定,根据回收的情况进行评估,到达阀值视为老年代。在进行一次垃圾回收之后,会进行日志收集确定分代划分和是否进行混合清理(新生代和老年代一起清理)。\n并行性:g1回收期间可以多线程同时工作 并发性:g1拥有与应用程序交替执行的能力,部分工作可与应用程序同时执行,在整个gc期间不会完全阻塞应用程序 分代gc:依旧分为新生代和老年代,新生代依然有eden,from和to 空间整理:g1在垃圾回收过程中,不会像cms那样在若干次gc后需要进行碎片整理,g1采用了有效复制对象方式 可预见性:由于分区的原因,g1可以只选取部分区域进行回收,缩小了回收的范围,提高性能 g1的内存结构如下所示:\njdk11之后g1触发full gc时可并行处理,以前只能串行处理\n各代hotspot(server模式下)默认垃圾收集器 jdk1.7 默认垃圾收集器parallel scavenge(新生代)+parallel old(老年代) jdk1.8 默认垃圾收集器parallel scavenge(新生代)+parallel old(老年代) jdk1.9 默认垃圾收集器g1 六、内存分配 分配策略 对象优先分配到eden区\n大对象直接分配到老年代\n长期存活对象分配到老年代\n空间分配担保\n存入对象时发现年轻代空间不足,将判断老年代最大可用的连续空间是否大于当前年起代所有对象\n满足,minor gc是安全的,可以进行minor gc 不满足,虚拟机查看handlepromotionfailure参数 true会继续检测[老年代最大可用的连续空间]是否大于[历次晋升到老年代对象的平均大小]。若大于,将尝试进行一次minor gc,若失败,则重新进行一次full gc false则不允许冒险,要进行full gc 栈上分配和逃逸分析 在jdk7(包括)之后完全支持栈上分配和逃逸分析。\n逃逸分析\n\t如果某个方法之内创建的实例只在方法内被使用,方法结束之后没有任何对象引用它【即可被gc回收】,这样的对象叫做未发生逃逸对象。如果某个方法之内创建的实例在方法结束之后有对象引用它【即不可被gc回收】,这样的对象叫做逃逸对象。\n栈上分配\n\t如果一个对象未发生逃逸则这个对象的生命周期只存在一个方法体内,这样的对象可以直接在栈上分配提高效率,也方便回收【方法结束,栈销毁,未发生逃逸也就随着销毁】\n七、虚拟机工具 jps\n显示当前所有java进程pid相关信息\n参数 解释 -q 只显示pid,不显示class名称,jar文件名和传递给main方法的参数 -l 输出应用程序main class的完整package名或者应用程序的jar文件完整路径名 -m 输出传递给main方法的参数 -v 输出传递给jvm的参数 -v 隐藏输出传递给jvm的参数 jstat\n对java应用程序的资源和性能进行监控,包括了对类的装载、内存、jit编译和垃圾回收状况的监控。\n用法: jstat [option] [pid] [ []]\ninterval - 间隔的时间 count - 统计次数 参数 解释 -t 打印时打印时间戳 -class 显示classload的相关信息 -compiler 显示jit编译的相关信息 -gc 显示和gc相关的堆信息 -gccapacity 显示各个代的容量以及使用情况 -gcmetacapacity 显示metaspace的大小 -gcnew 显示年轻代信息 -gcnewcapacity 显示年轻代大小和使用情况 -gcold 显示老年代和永久代的信息 -gcoldcapacity 显示老年代的大小 -gcutil 显示垃圾收集信息 -gccause 显示垃圾收集信息并显示最后一次垃圾回收的诱因 -printcompilation 输出jit编译的方法信息 jinfo\n用于实时查看和调整虚拟机参数\n用法:jinfo [option] [pid]\n参数 解释 -flag [name] 输出对应名称的参数 -flag [[+/-]name] 开启或者关闭对应名称的参数 -flag [name=value] 设定对应名称的参数 -flags 输出全部的参数 -sysprops 输出系统属性 jmap\n用于生成java程序的dump文件, 以及查看堆内对象的统计信息、classloader的信息以及finalizer队列\n用法:jmap [option] [pid]\n参数 解释 -histo[:live] 显示堆中对象的统计信息 -clstats 打印类加载器信息 -finalizerinfo 显示在f-queue队列等待finalizer线程执行finalizer方法的对象 -dump:live,format=b,file=heap.bin 内存转储dump数据,过程中会暂停应用 jhat\n分析内存dump文件,会占用大量cpu和内存生成报告,默认最后会启动一个web服务端口7000,可访问查看相应指标信息,但是很少使用,不够直观灵活。\njstack\n查看生成线程状态信息\n用法:jstack [option] [pid]\n参数 解释 -l 长列表. 打印关于锁的附加信息 jconsole\n提供了内存、线程、线程死锁检测、类、vm概要等gui查看功能\nvisualvm\njdk8之后被移除默认的jdk安装包,需要单独下载,官方地址\n八、class文件 概述 \tclass文件是一组以8位字节为基础单位的二进制流,在当遇到8位字节以上数据项时,则按照高位在前的方式分割成若干个8位以上字节进行分别存储。各个数据项目按照严格顺序紧凑的排列在class文件之中,中间没有添加任何分隔符,整个class文件中存储的内容几乎全部都是程序运行的必要数据,没有空隙存在。\n\tclass文件中只有两种数据类型,分别是无符号数和表\nclass文件结构 顺序依次为:\n①魔数[4字节]\n②class文件版本[4字节]\n③常量池[长度不固定]\n④访问标志[2字节]\n⑤类索引[2字节]、父类索引[2字节]、接口索引集合[长度不固定]\n⑥字段表集合[长度不固定]\n⑦方法表集合[长度不固定]\n⑧属性表集合[长度不固定]\n长度 含义 数量 u4 magic 1 u2 minor_version 1 u2 major_version 1 u2 constant_pool_count 1 cp_info constant_pool constant_pool_count - 1 u2 access_flags 1 u2 this_class 1 u2 super_class 1 u2 interfaces_count 1 u2 interfaces interfaces_count u2 fields_count 1 field_info fields fields_count u2 methods_count 1 method_info methods methods_count u2 attribute_count 1 attribute_info attributes attributes_count 魔数\n用于区分是否是class文件,占四个字节,十六进制表示值为ca fe ba be\nclass文件版本\n占4字节为字节码版本,为小版本号minor_version[2字节]和主版本号major_version[2字节]的组合\n常量池\n长度不固定,先用两个字节描述长度,真实长度为描述长度减一【0位置代表无引用,它也占一位】\n常量池的组成:\n常量池计数器(constant_pool_count):占用前两个字节,记录着常量池的组成元素个数\n常量池项(cp_info):元素信息,一共constant_pool_count-1个数量\ncp_info结构如下:\n1 2 3 4 cp_info { ul tag; ul info[]; } 常量池数量是从1开始计数的并非从0开始,所有元素真实个数需要减一,将第0项常量空出来是为了满足执向常量池的索引数据在特定情况下表达“不引用任何一个常量池项”的含义\ncp_info的类型:\n常量类型 值 constant_class 7 constant_fieldref 9 constant_methodref 10 constant_interfacemethodref 11 constant_string 8 constant_integer 3 constant_float 4 constant_long 5 constant_double 6 constant_nameandtype 12 constant_utf8 1 constant_methodhandle 15 constant_methodtype 16 constant_invokedynamic 18 可使用javap -verbose [name].class查看常量池内容\n访问标志\naccess_flages占有两个字节,没有使用到的标志为要求一律为0\n标志名称 标志值 含义 acc_public 0x00 01 是否为public类型 acc_final 0x00 10 是否被声明为final,只有类可以设置 acc_super 0x00 20 是否允许使用invoke special字节码指令的新语义 acc_interface 0x02 00 标志这是一个接口 acc_abstract 0x04 00 是否为abstract类型,对于接口或者抽象类来说标志值为真 acc_synthetic 0x10 00 标志这个类并非由用户代码产生 acc_annotation 0x20 00 标志这是一个注解 acc_enum 0x40 00 标志这是一个枚举 可使用javap -verbose [name].class查看访问标志\n类索引、父类索引、接口索引集合\n类索引:占用两个字节,指向常量池中的引用\n父类索引:占用两个字节,指向常量池中的引用\n接口索引集合:统计个数interfaces_count占用两个字节,interfaces占用interfaces_count*2个字节,每个interfaces指向常量池中的引用\n字段表集合\n字段表【field_info】用于描述类中声明的变量,但是不包括在方法内部声明的局部变量\n字段表的结构:\n长度 名称 数量 u2 access_flags 1 u2 name_index 1 u2 descriptor_index 1 u2 attributes_count 1 attribute_info attributes attributes_count access_flags访问标志值:\n标志名称 标志值 含义 acc_public 0x00 01 字段是否为public acc_private 0x00 02 字段是否为private acc_protected 0x00 04 字段是否为protected acc_static 0x00 08 字段是否为static acc_final 0x00 10 字段是否为final acc_volatile 0x00 40 字段是否为volatile acc_transtent 0x00 80 字段是否为transient acc_synchetic 0x10 00 字段是否为由编译器自动产生 acc_enum 0x40 00 字段是否为enum 属性表集合\n在class文件,字段表,方法表都可以携带自己的属性表集合用于描述某些场景专有的信息\n属性名称 使用位置 含义 code 方法表 java代码编译成的字节码指令 constantvalue 字段表 final关键字定义的常量池 deprecated 类,方法表,字段表 被声明为deprecated的方法和字段 exceptions 方法表 方法抛出的异常 enclosingmethod 类文件 仅当一个类为局部类或者匿名类是才能拥有这个属性,这个属性用于标识这个类所在的外围方法 innerclass 类文件 内部类列表 linenumbertable code属性 java源码的行号与字节码指令的对应关系 localvariabletable code属性 方法的局部变量描述 stackmaptable code属性 供新的类型检查检验器检查和处理目标方法的局部变量和操作数有所需要的类是否匹配 signature 类,方法表,字段表 用于支持泛型情况下的方法签名 sourcefile 类文件 记录源文件名称 sourcedebugextension 类文件 用于存储额外的调试信息 synthetic 类,方法表,字段表 标志方法或字段为编译器自动生成的 localvariabletypetable 类 使用特征签名代替描述符,是为了引入泛型语法之后能描述泛型参数化类型而添加 runtimevisibleannotations 类,方法表,字段表 为动态注解提供支持 runtimeinvisibleannotations 表,方法表,字段表 用于指明哪些注解是运行时不可见的 runtimevisibleparameterannotation 方法表 作用与runtimevisibleannotations属性类似,只不过作用对象为方法 runtimeinvisibleparameterannotation 方法表 作用与runtimeinvisibleannotations属性类似,作用对象哪个为方法参数 annotationdefault 方法表 用于记录注解类元素的默认值 bootstrapmethods 类文件 用于保存invokeddynamic指令引用的引导方式限定符 字节码指令 \tjava虚拟机的指令由一个字节长度的、代表着某种特定操作含义的数字(称为操作码,opcode)以及跟随其后的零至多个代表此操作所需参数(称为操作数,operands)而构成。jvm字节码指令是基于栈架构的指令,安卓虚拟机是基于寄存器架构的指令。\n\t部分指令有类型区分:【i:integer】、【l:long】、【f:float】、【d:double】、【a:reference】\n加载与存储指令\n将一个局部变量加载到操作数栈:[i/l/f/d/a]load 将一个数值从操作数栈存储到局部变量表:[i/l/f/d/a]store 将一个常量加载到操作数栈: bipush 将取值为【-128~127】的常量入栈 sipush 将取值为【-32768~32767】的将常量入栈 ldc 将取值为【2147483648~2147483647】的将常量入栈 ldc_w 从由常量池中取出指的索引位的一个字长的值,然后将其压入栈 ldc2_w 从由常量池中取出指的索引位的两个字长的值,然后将其压入栈 aconst_null 将null对象引用压入栈 iconst_m1 将int类型且值为【-1】的压入栈 iconst_value 将int类型且值为【0、1、2、3、4、5】压入栈 lconst_value 将long类型且值为【0、1】压入栈 fconst_value 将float类型且值为【0、1、2】压入栈 dconst_value 将double类型且值为【0、1】压入栈 扩充局部变量表的访问索引指令:wide 运算指令\n加法指令:[i/l/f/d]add 减法指令:[i/l/f/d]sub 乘法指令:[i/l/f/d]mul 除法指令:[i/l/f/d]div 取余指令:[i/l/f/d]rem 取反指令:neg 位移指令:ishl(逻辑左移)、ishr(逻辑右移)、iushr(算术右移)【其余类型不常见】 按位或指令:ior【其余类型不常见】 按位与指令:iand【其余类型不常见】 按位异或指令:ixor【其余类型不常见】 局部变量自增指令:iinc【其余类型执行压栈常量1再进行相加操作】 类型转换指令\n\t类型转换指令可以将两种不同的数值类型进行相互转换,这些转换操作一般用于实现用户代码中的显示类型转换以及用来处理字节码指令集中的数据类型相关指令无法与数据指令一一对应的问题。\n分类:宽化类型处理和窄化类型处理\n宽化类型转换:i2l、i2f,i2d,l2f,l2d,f2d等 窄化类型转换:l2i、f2i,d2i,f2l,d2l,d2f等 对象创建与访问指令\n创建类的指令:new 创建数组的指令:newarray、anewarray 、multianewarray 访问类的字段指令:getfield、putfield、getstatic、putstatic 把数组元素加载到操作数栈:[b/c/s/i/l/f/d/a]aload 将操作数栈的元素存储到数组:[b/c/s/i/l/f/d/a]astore 取数组长度的指令:arraylength 检查实例类型指令:instanceof、checkcast 操作数栈管理指令\n一个元素和两个元素出栈指令:pop、pop2 复制栈顶一个或两个数值并将复制或双份复制值重新压入栈顶:dup、dup2、dup_x1、dup_x2 将栈顶的两个数值替换:swap 控制转移指令\n\t控制转移指令可以让jvm有条件或无条件地从指定的位置执行而不是继续下一条指令执行程序,可以认为控制转移指令就是在有条件或无条件地修改pc寄存器的值。\n条件分支:ifeq、iflt、ifle、ifne、ifgt、ifge、ifnull、ifnonnull、if_icmpeq、 if_icmpne、if_icmplt、if_icmpgt、if_icmple、if_icmpge、if_acmpeq和if_acmpne 复合条件分支:tableswitch、lookupswitch 无条件分支:goto、goto_w、jsr、jsr_w、ret 方法调用指令\n指令 解释 invokevirtual 指令用于调用对象的实例方法即非私有的实例方法,根据对象实际类型进行分派(虚方法分派) invokeinterface 指令用于调用对象的接口方法,会在运行时搜索一个实现了这个接口方法的对象,找出适合的方法进行调用 invokespecial 指令用于调用一些需要特殊处理的实例方法,包括初始化方法、私有方法和父类方法 invokestatic 指令用于调用类的static方法 invokedynamic jdk7之后支持,调用动态方法,在运行时动态解析出调用点限定符所引用的方法之后,调用该方法 方法返回指令\n\t返回指令是根据返回的数据类型进行区分的,有ireturn(返回值是boolean、byte、char、short和int)、lretrun、freturn、dreturn、areturn还有返回voide、实例初始化、类和接口的初始化使用的return\n异常处理指令\n\tathrow用于显示抛出异常时(明确throw new runtimeexception和exception均会),但是对于\u0026quot;i/0“这种未显示表明的抛出是不会使用athrow的。\n同步指令\n\tjava虚拟机可以支持方法级的同步和方法内部一段指令序列的同步,这两种同步结构都是使用管程(monitor)来支持的。\n\t方法级的同步是隐式的,无须通过字节码指令来控制,它实现在方法调用和返回操作之中。虚拟机可以从方法常量池的方法表结构中的acc_synchronized访问标志得知一个方法是否声明为同步方法。当方法调用时,调用指令将会检查方法的acc_synchronized访问标志是否被设置,如果设置了,执行线程就要求先成功持有管程,然后才能执行方法,最后当方法完成(无论是正常完成还是非正常完成)时释放管程。在方法执行期间,执行线程持有了管程,其他任何线程都无法再获取到同一个管程。如果一个同步方法执行期间抛出了异常,并且在方法内部无法处理此异常,那么这个同步方法所持有的管程将在异常抛到同步方法之外时自动释放。\n\t同步一段指令集通常是由java语言中的synchronized语句块来表示的,java虚拟机的指令集中有monitorenter和monitorexit两条指令来支持synchronized关键字的语义,正确实现synchronized关键字需要javac编译器与java虚拟机两者共同协作支持。\n九、类加载机制 \t一个java对象的创建过程往往包括两个阶段:类初始化阶段 和 类实例化阶段\n\t类的加载:代表jvm将java文件编译成class文件后,以二进制流的方式存放到运行时数据的方法区中,并在java的堆中创建一个java.lang.class对象,用来指向存放在方法堆中的数据结构。且虚拟机加载class文件是懒加载机制。\n类的加载 通过一个类的全限定名来获取定义此类的二进制字节流 文件方式【class文件、jar文件】 网络 程序生成【动态代理】 其它【jsp-会转换为servlet,数据库】 将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构 在内存中生成一个代表这个类的class对象,作为这个类的各种数据的访问入口 类的验证 \t验证是连接的第一步,但是并非是必须的。这一阶段的目的是为了确保class文件的字流中包含的狺息符合当前虚拟机的要求,并且不会危害虚拟机自身的安全包含:\n文件格式验证 是否以魔数0xcaffebabe开头 主次版本号是否在虚拟机处理范围内 常量池中的常量是否有不被支持的常量类型 指向常量的各种索引值是否有指向不存在的常量 元数据验证 这个类是否有父类 这个类的父类是否继承不被允许的类(final修饰的类) 如果这个类不是抽象类,是否实现了接口要求实现的方法 类中的字段,方法是否与父类矛盾(例如出现不符合规则的方法重载) 字节码验证 保证任何时刻操作数栈的数据类型与指令代码序列能配合工作 保证跳转指令不会跳转到方法体以外的字节码指令 保证方法体中类型转换有效,如避免出现将父类对象赋值到子类数据类型上 符号引用验证 符号引用中通过字符串描述的全限定名是否能找到对应的类 在指定类中是否存在符合方法的字段描述符号 符号引用的类,字段,方法的访问性是否可以被当前类访问 类的准备 \t准备阶段正式为类的静态变量分配内存并设置变量的初始值。这些变量使用的内存都将在方法区中进行分配。设置的初始值并非我们指定的值而是这种变量的默认值,但是如果是被final修饰的常量则会被初始为我们指定的值\n类的解析 \t**解析阶段是将常量池中的符号引用替换为直接引用的过程。**在进行解析之前需要对符号引用进行解析,不同虚拟机实现可以根据需要判断到底是在类被加载器加载的时候对常量池的符号引用进行解析(也就是初始化之前),还是等到一个符号引用被使用之前进行解析(也就是在初始化之后)。如果一个符号引用进行多次解析请求,虚拟机中除了invokedynamic指令外,虚拟机可以对第一次解析的结果进行缓存(在运行时常量池中记录引用,并把常量标识为一解析状态),这样就避免了一个符号引用的多次解析。\n类或者接口解析\n要把一个类或者接口的符号引用解析为直接引用,需要以下三个步骤\n如果该符号引用不是一个数组类型,那么虚拟机将会把该符号代表的全限定名称传递给类加载器去加载这个类。这个过程由于涉及验证过程所以可能会触发其他相关类的加载\n如果该符号引用是一个数组类型,并且该数组的元素类型是对象。我们知道符号引用是存在方法区的常量池中的,该符号引用的描述符会类似”[java/lang/integer”的形式,将会按照上面的规则进行加载数组元素类型,如果描述符如前面假设的形式,需要加载的元素类型就是java.lang.integer ,接着由虚拟机将会生成一个代表此数组对象的直接引用\n如果上面的步骤都没有出现异常,那么该符号引用已经在虚拟机中产生了一个直接引用,但是在解析完成之前需要对符号引用进行验证,主要是确认当前调用这个符号引用的类是否具有访问权限,如果没有访问权限将抛出java.lang.illegalaccess异常\n字段解析\n对字段的解析需要首先对其所属的类进行解析,因为字段是属于类的,只有在正确解析得到其类的正确的直接引用才能继续对字段的解析。对字段的解析主要包括以下几个步骤:\n如果该字段符号引用就包含了简单名称和字段描述符都与目标相匹配的字段,则返回这个字段的直接引用,解析结束 否则,如果在该符号的类实现了接口,将会按照继承关系从下往上递归搜索各个接口和它的父接口,如果在接口中包含了简单名称和字段描述符都与目标相匹配的字段,那么久直接返回这个字段的直接引用,解析结束 否则,如果该符号所在的类不是object类的话,将会按照继承关系从下往上递归搜索其父类,如果在父类中包含了简单名称和字段描述符都相匹配的字段,那么直接返回这个字段的直接引用,解析结束 否则,解析失败,抛出java.lang.nosuchfielderror异常 如果最终返回了这个字段的直接引用,就进行权限验证,如果发现不具备对字段的访问权限,将抛出java.lang.illegalaccesserror异常\n类方法解析\n进行类方法的解析仍然需要先解析此类方法的类,在正确解析之后需要进行如下的步骤:\n类方法和接口方法的符号引用是分开的,所以如果在类方法表中发现class_index(类中方法的符号引用)的索引是一个接口,那么会抛出java.lang.incompatibleclasschangeerror的异常 如果class_index的索引确实是一个类,那么在该类中查找是否有简单名称和描述符都与目标字段相匹配的方法,如果有的话就返回这个方法的直接引用,查找结束 否则,在该类的父类中递归查找是否具有简单名称和描述符都与目标字段相匹配的字段,如果有,则直接返回这个字段的直接引用,查找结束 否则,在这个类的接口以及它的父接口中递归查找,如果找到的话就说明这个方法是一个抽象类,查找结束,返回java.lang.abstractmethoderror异常 否则,查找失败,抛出java.lang.nosuchmethoderror异常 如果最终返回了直接引用,还需要对该符号引用进行权限验证,如果没有访问权限,就抛出java.lang.illegalaccesserror异常\n接口方法解析\n同类方法解析一样,也需要先解析出该方法的类或者接口的符号引用,如果解析成功,就进行下面的解析工作:\n如果在接口方法表中发现class_index的索引是一个类而不是一个接口,那么也会抛出java.lang.incompatibleclasschangeerror的异常\n否则,在该接口方法的所属的接口中查找是否具有简单名称和描述符都与目标字段相匹配的方法,如果有的话就直接返回这个方法的直接引用。\n否则,在该接口以及其父接口中查找,直到object类,如果找到则直接返回这个方法的直接引用\n否则,查找失败\n类的初始化 初始化时机 对于初始化阶段,虚拟机规范严格规定了有且只有5种情况必须对类进行初始化(加载、验证、准备自然需在此之前开始):\n①遇到new、getstatic、putstatic、invokestatic这四条字节码指令时,如果类没有进行过初始化,则需要先触发其初始化。生成这四条指令的最常见的java代码场景是:\n使用new关键字实例化对象的时候\n读取或设置一个类的静态字段【被final修饰己在编译器把结果放入常量池的静态字段除外】\n调用一个类的静态方法的时候\n②使用java.lang.reflect包的方法对类进行反射调用的时,如果类没有进行过初始化则需要先触发其初始化\n③当初始化一个类的时候,如果发现其父类还没有进行过初始化,则需要先触发其父类的初始化\n④当虚拟机启动时,用户需要指定一个要执行的主类(包含main()方法的那个类),虚拟机会先初始化这个主类\n⑤当使用jdk7动态语言支持时,如果methodhandle实例最后的解析结果ref_getstatic、ref_putstatic、ref_invokestatic的方法句柄,并且这个方法句柄所对应的类没有进行初始化,则需要先出触发其初始化\n不执行初始化的例子\n调用类常量【public static final】 通过数组定义来引用类【base[] car = new base[5]】 通过子类引用父类的静态字段【base.parentvariable】时,子类不会被初始化 初始化过程 \t类初始化时类加载过程的最后一步,前面的类加载过程中,除了在加载阶段(类加载过程的一个阶段)应用程序可以通过自定义类加载器参与之外,其余动作完全由虚拟机主导和控制。到了初始化阶段,才真正开始执行类中定义的java程序代码。初始化阶段是执行类构造器\u0026lt;clinit\u0026gt;()方法的过程。\n\u0026lt;clinit\u0026gt;()方法执行过程中可能会影响程序运行行为:\n\u0026lt;clinit\u0026gt;()方法是由编译器自动收集类中的所有类变量的赋值动作和静态语句块中的语句合并产生的,编译器收集的顺序是由语句在源文件中出现的顺序所决定的,静态语句块中只能访问到定义在静态语句块之前的变量,定义在它之后的变量,在前面的静态语句块中可以赋值,但不能访问,属于非法向前引用。\n1 2 3 4 5 6 7 8 public class test { static { v = 3; system.out.println(v);\t//编译报错,只能赋值不能访问 } static int v = 1; } // 顺序执行最后v的值为\u0026#34;1\u0026#34; \u0026lt;clinit\u0026gt;()方法与类的构造函数(即类的实例构造器\u0026lt;init\u0026gt;()方法)不同,它不需要显式地调用父类构造器,虚拟机会保证在子类的\u0026lt;clinit\u0026gt;()方法执行之前,父类的\u0026lt;clinit\u0026gt;()方法已经执行完毕。因此在虚拟机中第一个被执行的\u0026lt;clinit\u0026gt;()方法一定是java.lang.object\n\u0026lt;clinit\u0026gt;()方法对于类(抽象类)或接口来说并不是必需的,如果一个类中没有静态语句块,也没有对变量的赋值操作,那么编译器可以不为这个类生成\u0026lt;clinit\u0026gt;()方法\n接口中不能使用静态语句块,但仍然有变量初始化的赋值操作,因此接口与类一样都会生成\u0026lt;clinit\u0026gt;()方法。但接口与类不同的是,执行接口的\u0026lt;clinit\u0026gt;()方法不需要先执行父接口的\u0026lt;clinit\u0026gt;()方法。只有当父接口中定义的变量使用时,父接口才会初始化。另外,接口的实现类在初始化时也一样不会执行接口的\u0026lt;clinit\u0026gt;()方法\n虚拟机会保证一个类的\u0026lt;clinit\u0026gt;()方法在多线程环境中被正确的加锁,同步,如果多个线程同时去初始化一个类,那么只会有一个线程去执行这个类的\u0026lt;clinit\u0026gt;()方法,其他线程都需要阻塞等待,直到活动线程执行\u0026lt;clinit\u0026gt;()方法完毕。在实际应用中这种阻塞引起的问问往往是很隐蔽\n十、类加载器 类加载器的种类 启动(bootstrap)类加载器\n\t启动类加载器主要加载的是jvm自身需要的类,这个类加载使用c++语言实现的,是虚拟机自身的一部分,它负责将 /lib路径下的核心类库或-xbootclasspath参数指定的路径下的jar包加载到内存中。它本身是虚拟机的一部分,所以它并不是一个java类,也就是无法在java代码中获取它的引用。即extension classloader的代码中的parent为null\n注意必由于虚拟机是按照文件名识别加载jar包的,如rt.jar,如果文件名不被虚拟机识别,即使把jar包丢到lib目录下也是没有作用的(出于安全考虑,bootstrap启动类加载器只加载包名为java、javax、sun等开头的类)\n扩展(extension)类加载器\n\t扩展类加载器是指sun公司实现的sun.misc.launcher$extclassloader类,由java语言实现的,是launcher的静态内部类,它负责加载/lib/ext目录下或者由系统变量-djava.ext.dir指定位路径中的类库,开发者可以直接使用标准扩展类加载器。\n系统(system)类加载器\n\t也称应用程序加载器是指 sun公司实现的sun.misc.launcher$appclassloader。它负责加载系统类路径java -classpath或-d java.class.path 指定路径下的类库,开发者可以直接使用系统类加载器,一般情况下该类加载是程序中默认的类加载器,通过classloader#getsystemclassloader()方法可以获取到该类加载器。\n自定义(custom)类加载器\n\t自定义类加载器由第三方实现,建议满足双亲委派模式。\n只有被同一个类加载器加载的类才会相等,相同的字节码被不同的类加载器加载的类不相同。\n双亲委派模式 \t双亲委派模式要求除了顶层的启动类加载器外,其余的类加载器都应当有自己的父类加载器【并非继承】采用组合关系来复用父类加载器的相关代码,类加载器间的关系如下:\n十一、虚拟机字节码执行引擎 运行时栈帧结构 栈:线程私有,生命周期跟线程相同,当创建一个线程时,同时会创建一个栈,栈的大小和深度都是固定的。\n栈帧:一个栈中可以有多个栈帧,栈帧是栈的元素,栈帧随着方法的调用而创建,随着方法的结束而消亡。栈帧存储了方法的局部变量表、操作数栈、动态连接和方法返回地址等信息。在活动线程中,只有位于栈顶的栈帧才是有效的,称为当前栈帧,与这个栈帧相关联的方法称为当前方法。\n在编译程序代码的时候,栈帧中需要多大的局部变量表,多深的操作数栈都已经完全确定了。因此一个栈帧需要分配多少内存,不会受到程序运行期变量数据的影响,而仅仅取决于具体的虚拟机实现。\n局部变量表\n\t局部变量表(local variable table) 是一组变量值存储空间,用于存放方法参数和方法内部定义的局部变量。在 java 程序编译为 class 文件时,就在方法的 code 属性的 max_locals 数据项中确定了该方法所需要分配的局部变量表的最大容量。 局部变量表的容量以变量槽(variable slot)为最小单位。\n操作数栈\n\t操作数栈和局部变量表在访问方式上存在着较大差异,操作数栈并非采用访问索引的方式来进行数据访问的,而是通过标准的入栈和出栈操作来完成一次数据访问。每一个操作数栈都会拥有一个明确的栈深度用于存储数值(max_stack)。\n动态连接\n\t在类加载解析时无法确定的符号引用(应该转为直接引用)在运行时进行动态确定转换为直接引用的过程叫做动态连接,包括动态分派、动态语言支持\n方法返回地址\n\t返回调用完成都需要返回到方法被调用的位置,程序才能继续执行,方法返回时可能需要在栈帧中保存一些信息,用来帮助恢复它的上层方法的执行状态。一般来说,方法正常退出时,调用者的pc计数器的值可以作为返回地址,栈帧中很可能会保存这个计数器值。而方法异常退出时,返回地址是要通过异常处理器表来确定的,栈帧中一般不会保存这部分信息。\n附加信息\n虚机规范中允许具的虚拟机实现增加一些规范里没有描述的到栈帧中。这部信息完全取决于虚拟机的实现。 方法调用 方法调用并不等同于方法的执行,方法调用阶段的唯一任务就是确定被调用方法的版本\n解析调用\n\t在类加载的类解析阶段就已经调用方法的版本即在编译期已经确定了调用的方法,这种调用方式称之为解析调用。\n\t在java中被final、private、static修饰的方法以及构造方法都是属于这种类型,在编译期间就可确定,对应编译出的字节码指令为invokestatic【调用静态方法】、invokespecial:调用非静态私有方法和final方法、构造方法(包括super)\n静态分派调用\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public class staticdispatch { static class parent{ } static class child extends parent{ } public static void sayhello(parent p){ system.out.println(\u0026#34;hello,parent\u0026#34;); } public static void sayhello(child c) { system.out.println(\u0026#34;hello,child\u0026#34;); } public static void main(string[] args) { // 静态类型 实际类型 parent parent = new parent(); parent child = new child(); sayhello(parent); //hello,parent sayhello(child); //hello,parent } } \t我们把“parent”称为变量的静态类型,后面的“child”称为变量的实际类型,静态类型和实际类型在程序中都可以发生一些变化,区别是静态类型的变化仅仅在使用时发生,变量本身的静态类型不会被改变,并且最终的静态类型在编译阶段可知依旧是invokespecial调用。而实际类型变化的结果在运行期才确定,编译器在编译期并不知道一个对象的实际类型是什么。\n\t静态分派的典型应用是方法重载。编译器在重载时是通过参数的静态类型而不是实际类型作为判定的依据。并且静态类型在编译期解析阶段可知,因此,javac编译器会根据参数的静态类型决定使用哪个重载版本。\n动态分派调用\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public class dynamicdispatch { static class parent{ public void sayhello(){ system.out.println(\u0026#34;hello,i am parent\u0026#34;); } } static class child extends parent{ @override public void sayhello(){ system.out.println(\u0026#34;hello,i am child\u0026#34;); } } public static void main(string[] args) { parent parent = new parent(); parent child = new child(); parent.sayhello(); // hello,i am parent child.sayhello(); // hello,i am child } } \t因为子类重写父类的方法,在运行阶段才可确定类型在方法调用时候jvm其实是使用了invokevirtual指令。java中采用oop-klass二分模型表示一个对象。klass保存着类的数据,在其中保存着方法表,方法表中保存着从父类继承下来,自己定义的所有方法,如果子类重写父类方法,那么在这个方法表中相同位置上的父类方法则会被覆盖。也就意味着从子类实例来说是无法找到父类该方法的。\n动态类型语言支持 静态类型语言:在非运行阶段,变量的类型是可以确定的,也就是变量是有类型的。\n动态类型语言:在非运行阶段,变量的类型是无法确定的,也就是变量是没类型的。但是值是有类型的,也就是运行期间可以确定变量的值类型。\njdk7新增对动态语言调用的支持invokedynamic,java里没有函数指针无法在运行时动态调用方法。\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 import static java.lang.invoke.methodhandles.lookup; import java.lang.invoke.methodhandle; import java.lang.invoke.methodtype; public class methodhandletest { static class classa { public void println(string s) { system.out.println(s); } } public static void main(string[] args) throws throwable { // 无论obj最终是哪个实现类,下面这句都能正确调用到println方法。 object obj = system.currenttimemillis() % 2 == 0 ? system.out : new classa(); /** * methodtype:代表“一个方法” * 第一个参数 - 方法的返回值 * 第一个参数 - 方法的具体参数 */ methodtype mt = methodtype.methodtype(void.class, string.class); /** * lookup()方法来自于methodhandles.lookup * 作用是在指定类中查找符合给定的方法名称、方法类型,并且符合调用权限的方法句柄。 * bindto()用于绑定本地变量表的第一个元素this */ methodhandle methodhandle = lookup().findvirtual(obj.getclass(), \u0026#34;println\u0026#34;, mt).bindto(obj); // 调用方法 methodhandle.invokeexact(\u0026#34;hello\u0026#34;); } } 附录 jit编译(just-in-time compilation) \t在部分商用虚拟机中(如hotspot),java程序最初是通过解释器(interpreter)进行解释执行的,当虚拟机发现某个方法或代码块的运行特别频繁时,就会把这些代码认定为“热点代码”。为了提高热点代码的执行效率,在运行时,虚拟机将会把这些代码编译成与本地平台相关的机器码,并进行各种层次的优化,完成这个任务的编译器称为即时编译器(just in time compile)。\n\t即时编译器并不是虚拟机必须的部分,java虚拟机规范并没有规定java虚拟机内必须要有即时编译器存在,更没有限定或指导即时编译器应该如何去实现。但是,即时编译器编译性能的好坏、代码优化程度的高低却是衡量一款商用虚拟机优秀与否的最关键的指标之一,它也是虚拟机中最核心且最能体现虚拟机技术水平的部分。\n\tjit编译狭义来说是当某段代码即将第一次被执行时进行编译,因而叫“即时编译”。jit编译是动态编译的一种特例。jit编译一词后来被泛化,时常与动态编译等价。\n符号引用\u0026amp;直接引用 符号引用(symbolic references)\n\t符号引用以一组符号来描述所引用的目标,符号可以是任何形式的字面量,只要使用时能够无歧义的定位到目标即可。例如,在class文件中它以constant_class_info、constant_fieldref_info、constant_methodref_info等类型的常量出现。符号引用与虚拟机的内存布局无关,引用的目标并不一定加载到内存中。\n直接引用(direct references)\n(1)直接指向目标的指针【比如指向class对象、类变量、类方法的直接引用可能是指向方法区的指针)\n(2)相对偏移量【比如指向实例变量、实例方法的直接引用都是偏移量】\n(3)一个能间接定位到目标的句柄\n管程 管程可以看做一个软件模块,它是将共享的变量和对于这些共享变量的操作封装起来,形成一个具有一定接口的功能模块,进程可以调用管程来实现进程级别的并发控制。 进程只能互斥得使用管程,即当一个进程使用管程时,另一个进程必须等待。当一个进程使用完管程后,它必须释放管程并唤醒等待管程的某一个进程。 在管程入口处的等待队列称为入口等待队列,由于进程会执行唤醒操作,因此可能有多个等待使用管程的队列,这样的队列称为紧急队列,它的优先级高于等待队列。 ","date":"2024-05-12","permalink":"https://hobocat.github.io/post/java/2024-05-12jvm/","summary":"一、JDK\u0026amp;JRE\u0026amp;JVM之间的关系 JDK包含JRE和JVM,JRE包含JVM javac用于编译java代码到字节码文件 使用java命令启动JV","title":"jvm详解"},]
[{"content":"一、软件设计七大原则 开闭原则\n定义:一个软件实体如类、模块、函数应该对扩展开放,对修改关闭\n强调:用抽象构建框架,用实现扩展细节\n优点:提高软件系统的可复用性及可维护性\n依赖倒置原则\n定义:高层模块不应该依赖底层模块,二者都应该依赖其抽象\n强调:抽象不应该依赖细节,细节应该依赖抽象;针对接口编程,不要针对实现编程\n优点:可以减少类间的耦合性、提高系统稳定性,提高代码的可读性和可维护性,可降低修改程序所造成的风险\n单一职责原则\n定义:不要存在对于一个导致类变更的原因\n强调:一个类/接口/方法只负责一项职责\n优点:降低类的复杂度、提高类的可读性,提高系统的可维护性、降低变更引起的风险\n接口隔离原则\n定义:用多个专门的接口,而不使用单一的总接口,客户端不应该依赖它不需要的接口\n强调:一个类对一个类的依赖应该建立在最小的接口上。建立单一接口,不要建立庞大臃肿的接口,尽量细化接口,接口中的方法尽量少\n优点:符合高内聚低耦合的设计思想从而使得类具有很好的可读性、可扩展性和可维护性\n迪米特法则(最少知道原则)\n定义:一个对象应该对其他对象保持最少的了解\n强调:强调只和朋友交流,不和陌生人说话\n朋友:出现在成员变量、方法输入、输出参数中的类称为成员朋友类,而出现在方法体内部的类不属于\n优点:降低耦合\n里氏替换原则\n定义:主张用抽象和多态将设计中的静态结构改为动态结构,维持设计的封闭性\n强调:某个对象实例的子类实例应当可以在不影响程序正确性的基础上替换它们\n优点:提高代码抽象层的可维护性,提高实现层代码与抽象层的一致性\n合成/复用原则(组合/复用原则)\n定义:在一个新的对象里面使用一些已有的对象,使之成为新对象的一部分,不依靠继承关系\n强调:要尽量使用合成/聚合,尽量不要使用继承\n优点:减少耦合\n二、创建型设计模式 简单工厂模式【创建型】 适用场景\n工厂类负责创建的对象比较少 客户端只知道传入工厂类的参数对于如何创建对象不关心 优点\u0026amp;缺点\n优点:只需要传入正确的参数,就可以获取所需创建的对象而无需知道其创建的细节\n缺点:工厂类的职责相对过重,增加新的产品需要修改工厂类的逻辑判断,违背开闭原则\n编码示例\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 //抽象基类 public abstract class video { abstract public void produce(); } //实现类 public class javavideo extends video{ @override public void produce() { system.out.println(\u0026#34;java学习视频\u0026#34;); } } public class pythonvideo extends video{ @override public void produce() { system.out.println(\u0026#34;python学习视频\u0026#34;); } } //简单工厂类 public class videofactory { //工厂方法,通过传入的字符串得到video public video getvideo(string type) { if(\u0026#34;javavideo\u0026#34;.equals(type)){ return new javavideo(); } if(\u0026#34;pythonvideo\u0026#34;.equals(type)){ return new pythonvideo(); } return null; } //升级版工厂方法,通过类限定,使得更加方便、安全 public video getvideo(class\u0026lt;? extends video\u0026gt; cls) { video video = null; try { video = (video) class.forname(cls.getname()).newinstance(); } catch (exception e) { e.printstacktrace(); } return null; } } //测试简单工厂方法 public class testsimplefactory { public static void main(string[] args) { videofactory videofactory = new videofactory(); video video = videofactory.getvideo(\u0026#34;javavideo\u0026#34;); video.produce(); } } 工厂方法模式【创建型】 定义\n定义一个创建对象的接口但让实现这个接口的类来决定实例化哪个类,工厂方法让类的实例化推迟到子类中进行\n适用场景\n创建对象需要大量重复的代码 客户端不依赖于产品类实例如何被实现的细节 一个类通过其子类来指定创建哪个对象 优点\n使用者只需要关心所需产品对应的工厂,无需关心实现细节 加入新的产品符合开闭原则,提高可扩展性 缺点\n类的个数容易过多,增加复杂度 增加了系统的抽象性和理解难度 编码示例\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 //抽象基类 public abstract class video { abstract public void produce(); } //实现类 public class javavideo extends video{ @override public void produce() { system.out.println(\u0026#34;java学习视频\u0026#34;); } } public class pythonvideo extends video{ @override public void produce() { system.out.println(\u0026#34;python学习视频\u0026#34;); } } //工厂方法类 public class javavideofactory extends videofactory{ @override public video getvideo() { return new javavideo(); } } public class pythonvideofactory extends videofactory{ @override public video getvideo() { return new pythonvideo(); } } //测试工厂方法 public class testfactorymethod { public static void main(string[] args) { videofactory videofactory = new javavideofactory(); video video = videofactory.getvideo(); video.produce(); } } 抽象工厂模式【创建型】 定义\n抽象工厂模式提供一个创建一系列相关或相互依赖对象的接口且无需指向它们具体的类\n适用场景\n客户端不依赖于产品类示例如何被创建、实现等细节 强调一系列相关的产品对象一起使用创建对象需要大量代码 提供一个产品类库,所有的产品以同样的接口出现,从而使客户端不依赖于具体实现 优点\n具体产品在应用层代码隔离,无须关心创建细节 将一个系列的产品族统一到一起创建 缺点\n规定了所有可能被创建的产品集合,产品族中扩展新的产品困难,需要修改抽象工厂的接口 增加了系统的抽象性和理解难度 编码示例\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 //抽象基类 public abstract class video { abstract public void produce(); } public abstract class article { abstract public void produce(); } //video实现类 public class javavideo extends video{ @override public void produce() { system.out.println(\u0026#34;java学习视频\u0026#34;); } } public class pythonvideo extends video{ @override public void produce() { system.out.println(\u0026#34;python学习视频\u0026#34;); } } //article实现类 public class javaartice extends article { @override public void produce() { system.out.println(\u0026#34;java学习笔记\u0026#34;); } } public class pythonartice extends article { @override public void produce() { system.out.println(\u0026#34;python学习笔记\u0026#34;); } } //工厂方法类 public class javacoursefactory implements coursefactory{ @override public video getvideo() { return new javavideo(); } @override public article getarticle() { return new javaartice(); } } public class pythoncoursefactory implements coursefactory{ @override public video getvideo() { return new pythonvideo(); } @override public article getarticle() { return new pythonartice(); } } //测试抽象工厂方法 public class testabstractfactory { public static void main(string[] args) { coursefactory coursefactory = new javacoursefactory(); coursefactory.getvideo().produce(); coursefactory.getarticle().produce(); } } 建造者模式【创建型】 定义\n将一个复杂对象的构建与它的表示分离,使得同样的构建过程可以创建不同的表示\n特点\n用户只需指定需要建造的类型就可以得到它们,建造过程及细节不需要知道\n适用场景\n一个对象有非常复杂的内部结构(很多属性) 分离复杂的对象创建与使用 优点\n封装性好,创建与使用分离 扩展性好、建造类之间独立、一定程度上解耦 缺点\n产生多余的builder对象 产品内部发生变化,建造者都要修改,成本较大 编码示例\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 //需要构建的目标 public class course { private string coursename; private string courseppt; private string coursevideo; private string coursearticle; private course(coursebuilder coursebuilder) { this.coursename = coursebuilder.coursename; this.courseppt = coursebuilder.courseppt; this.coursevideo = coursebuilder.coursevideo; this.coursearticle = coursebuilder.coursearticle; } public string getcoursename() { return coursename; } public string getcourseppt() { return courseppt; } public string getcoursevideo() { return coursevideo; } public string getcoursearticle() { return coursearticle; } //构建器 public static class coursebuilder { private string coursename; private string courseppt; private string coursevideo; private string coursearticle; public coursebuilder buildcoursename(string coursename) { this.coursename = coursename; return this; } public coursebuilder buildcourseppt(string courseppt) { this.courseppt = courseppt; return this; } public coursebuilder buildcoursevideo(string coursevideo) { this.coursevideo = coursevideo; return this; } public coursebuilder buildcoursearticle(string coursearticle) { this.coursearticle = coursearticle; return this; } //最后一步构建对象 public course build() { return new course(this); } } } //测试构建者模式 public class testcreation { public static void main(string[] args) { coursebuilder coursebuilder = new coursebuilder(); course course = coursebuilder.buildcoursename(\u0026#34;java设计模式\u0026#34;) .buildcourseppt(\u0026#34;java设计模式ppt\u0026#34;) .buildcoursevideo(\u0026#34;java设计模式video\u0026#34;) .buildcoursearticle(\u0026#34;java设计模式article\u0026#34;) .build(); } } 单例模式【创建型】 定义\n保证一个类仅有一个实例,并提供一个全局访问点\n适用场景\n想确保任何情况下都绝对只有一个实例\n优点\n减少内存开销 避免对资源的多重占用 设置全局访问点,严格控制访问 缺点\n没有接口,扩展困难 编码示例\n饿汉式 1 2 3 4 5 6 7 8 9 10 public class singleton { private final static singleton instance = new singleton(); private singleton(){} public static singleton getinstance(){ return instance; } } 懒汉式 1 2 3 4 5 6 7 8 9 10 11 12 13 public class singleton { private static singleton singleton; private singleton() {} public static synchronized singleton getinstance() { if (singleton == null) { singleton = new singleton(); } return singleton; } } 双重检查 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class singleton { private static volatile singleton singleton; private singleton() {} public static singleton getinstance() { if (singleton == null) { synchronized (singleton.class) { if (singleton == null) { singleton = new singleton(); } } } return singleton; } } 静态内部类【推荐用】 1 2 3 4 5 6 7 8 9 10 11 12 public class singleton { private singleton() {} private static class singletoninstance { private static final singleton instance = new singleton(); } public static singleton getinstance() { return singletoninstance.instance; } } 枚举【推荐用】 1 2 3 4 5 6 7 8 9 10 11 12 public enum singleton { instance; private string content; public string getcontent() { return content; } public void setcontent(string content) { this.content = content; } } 原型模式【创建型】 定义\n原型实例指定创建对象的种类,并且通过拷贝这些原型创建新的对象\n特点\n不需要知道任何创建细节,不调用构造函数\n适用场景\n类初始化消耗过多资源 new产生一个对象需要非常繁琐的过程(数据准备、访问权限等) 构造函数比较复杂 循环体中产生大量对象时 优点\n性能相比new一个对象高 简化创建过程 缺点\n必须配备克隆方法 对克隆复杂对象或对克隆出的对象进行复杂改造时容易引入风险 深浅拷贝要运用得当 编码示例\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 //需要被克隆的类要实现cloneable接口 public class mail implements cloneable{ private string usernamesender; private string content; private string subject; private date writedate; @override protected object clone() throws clonenotsupportedexception { mail mail = (mail) super.clone(); //深拷贝,如果外面调用get拿到writedate重新设置时间也不会产生影响 mail.writedate = (date) writedate.clone(); return mail; } //==================getter/setter================== } //测试原型模式 public class testprototype { public static void main(string[] args) throws exception{ mail mail = new mail(); dateformat dateformat = new simpledateformat(\u0026#34;yyyy-mm-dd\u0026#34;); mail.setwritedate(dateformat.parse(\u0026#34;2019-04-20\u0026#34;)); mail.setusernamesender(\u0026#34;kun\u0026#34;); mail.setsubject(\u0026#34;会议\u0026#34;); mail.setcontent(\u0026#34;技术交流\u0026#34;); //创建克隆对象,不会调用构造函数 mail backupmail = (mail)mail.clone(); //mail do something mail.getwritedate().settime(system.currenttimemillis()); //backupmail do something, 此时backupmail的writedate依旧为 } } 三、结构型设计模式 外观模式【结构型】 定义\n提供了一个统一的接口,用来访问子系统中的一群接口\n特点\n定义了一个高层接口,让子系统更容易使用\n适用场景\n子系统越来越复杂,增加外观模式提供简单的接口调用 构建多层系统结构,利用外观对象作为每层的入口,简化层间调用 优点\n简化了调用过程,无需了解深入子系统,防止带来风险 减少系统依赖、松散耦合 更好的划分访问的层次 符合迪米特法则,即最少知道原则 缺点\n增加子系统、扩展子系统行为容易引入风险 不符合开闭原则 编码示例\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 public class pointsgift { private string name; public pointsgift(string name) { this.name = name; } public string getname() { return name; } } //基础服务类 public class pointspaymentservice { public boolean pay(pointsgift pointsgift){ system.out.println(\u0026#34;支付\u0026#34;+pointsgift.getname()+\u0026#34; 积分成功\u0026#34;);//扣减积分 return true; } } public class qualifyservice { public boolean isavailable(pointsgift pointsgift){ system.out.println(\u0026#34;校验\u0026#34;+pointsgift.getname()+\u0026#34; 积分资格通过,库存通过\u0026#34;); return true; } } public class shippingservice { public string shipgift(pointsgift pointsgift){ system.out.println(pointsgift.getname()+\u0026#34;进入物流系统\u0026#34;); string shippingorderno = \u0026#34;666\u0026#34;; return shippingorderno; } } //暴露的门面【facade】,调用此逻辑完成了一整套操作,调用者不用再关心内部细节 public class giftexchangeservice { private qualifyservice qualifyservice = new qualifyservice(); private pointspaymentservice pointspaymentservice = new pointspaymentservice(); private shippingservice shippingservice = new shippingservice(); public void giftexchange(pointsgift pointsgift){ if(qualifyservice.isavailable(pointsgift)){//资格校验通过 if(pointspaymentservice.pay(pointsgift)){//如果支付积分成功 string shippingorderno = shippingservice.shipgift(pointsgift); system.out.println(\u0026#34;物流系统下单成功,订单号是:\u0026#34;+shippingorderno); } } } } //测试外观者模式 public class testfacade { public static void main(string[] args) { giftexchangeservice giftexchangeservice = new giftexchangeservice(); giftexchangeservice.giftexchange(new pointsgift(\u0026#34;方便面\u0026#34;)); } } 装饰者模式【结构型】 定义\n在不改变原有对象的基础之上,将功能附加到对象上\n特点\n提供了比继承更有弹性的替代方案(扩展原有对象功能)\n适用场景\n扩展一个类的功能或给一个类添加附加职责 动态的给一个对象添加功能,这些功能可以再动态的撤销 优点\n继承的有利补充,比继承灵活,不改变原有对象的情况下给一个对象扩展功能 通过使用不同装饰类和装饰类的排列组合,可以实现不同的效果 符合开闭原则 缺点\n会出现更多的代码,更多的类,增加程序复杂性 动态装饰时,多层装饰时会更复杂 编码示例\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 //被包装的基类的抽象 public abstract class abstractbattercake{ protected abstract string getdesc(); protected abstract int cost(); } //需要被包装的基类 public class battercake extends abstractbattercake { @override protected string getdesc() { return \u0026#34;煎饼\u0026#34;; } @override protected int cost() { return 8; } } //抽象包装器,用于子类继承扩展被包装对象的某些功能 public abstract class abstractdecorator extends abstractbattercake { private abstractbattercake battercake; public abstractdecorator(abstractbattercake battercake) { this.battercake = battercake; } @override protected string getdesc() { return this.battercake.getdesc(); } @override protected int cost() { return this.battercake.cost(); } } //包装器 public class eggdecorator extends abstractdecorator { public eggdecorator(abstractbattercake battercake) { super(battercake); } @override protected string getdesc() { return super.getdesc() + \u0026#34; 加一个鸡蛋\u0026#34;; } @override protected int cost() { return super.cost() + 1; } } //测试装饰者模式 public class testdecorator { public static void main(string[] args) { abstractbattercake battercake = new eggdecorator(new battercake()); system.out.println(\u0026#34;需求:\u0026#34; + battercake.getdesc()); system.out.println(\u0026#34;价格:\u0026#34; + battercake.cost()); } } 适配器模式【结构型】 定义\n将一个类的接口转换为客户期望的另一个接口\n特点\n使原本接口不兼容的类可以一起工作\n适用场景\n已经存在的类,它的方法和需求不匹配时(方法结果相同或相似) 不是软件设计阶段考虑的设计模式,是随着软件维护,由于不同产品,不同厂家造成功能类似而接口不相同情况下的解决方案 优点\n能提高类的透明性和复用,现有的类复用但不需要改变 目标类和适配器类解耦,提高程序扩展性 缺点\n适配器编写过程需全面考虑,会增加系统的复杂性 增加系统代码可读的难度 编码示例\n类适配器模式 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 //需要被适配的类 public class adaptee { public void adapteerequest(){ system.out.println(\u0026#34;被适配的方法\u0026#34;); } } //适配器接口 public interface adatperinterface { void adapteerequest(); } //适配器 public class adapter extends adaptee implements adatperinterface{ @override public void adapteerequest() { system.out.println(\u0026#34;do something\u0026#34;); super.adapteerequest(); system.out.println(\u0026#34;do something\u0026#34;); } } //测试适配器模式 public class testclassadapter { public static void main(string[] args) { adatperinterface adatper = new adapter(); adatper.adapteerequest(); } } 对象适配器模式 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 //需要被适配的类 public class adaptee { public void adapteerequest(){ system.out.println(\u0026#34;被适配的方法\u0026#34;); } } //适配器接口 public interface adatperinterface { void adapteerequest(); } //适配器 public class adapter implements adatperinterface{ private adaptee adaptee = new adaptee(); @override public void adapteerequest() { system.out.println(\u0026#34;do something\u0026#34;); adaptee.adapteerequest(); system.out.println(\u0026#34;do something\u0026#34;); } } //测试适配器模式 public class testclassadapter { public static void main(string[] args) { adatperinterface adatper = new adapter(); adatper.adapteerequest(); } } 享元模式【结构型】 定义\n提供了减少对象数量从而改善应用所需的对象结构的方式\n特点\n运用共享技术有效的支持大量细粒度的对象\n适用场景\n常常应用于系统底层的开发,以便解决系统的性能问题\n系统有大量相似对象、需要缓存池的场景\n优点\n减少对象的创建、降低内存中的对象数量,降低系统内存,提高效率【string、integer、数据库连接池】 减少内存之外的其他资源的占用 缺点\n关注内/外状态、关注线程安全问题 使系统、程序的逻辑复杂化 编码示例\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 /** * 享元类 * 内部状态指对象共享出来的信息,存储在享元对象内部并且不会随环境的改变而改变 * 外部状态指对象得以依赖的一个标记,是随环境改变而改变的、不可共享的状态 */ public class flyweight { //内部状态。各个类都相同,在此只是示例,并未进行赋值 public string intrinsic; //外部状态 protected final string extrinsic; //要求享元角色必须接受外部状态 public flyweight(string extrinsic) { this.extrinsic = extrinsic; } //定义业务操作 public void operate(int extrinsic){ system.out.println(\u0026#34;do something \u0026#34; + extrinsic); }; public string getintrinsic() { return intrinsic; } public void setintrinsic(string intrinsic) { this.intrinsic = intrinsic; } } //享元工厂 public class flyweightfactory { //定义一个池容器 private static hashmap\u0026lt;string, flyweight\u0026gt; pool = new hashmap\u0026lt;\u0026gt;(); public static flyweight getflyweight(string extrinsic) { flyweight flyweight = pool.get(extrinsic); if(flyweight != null) { //池中有该对象 system.out.print(\u0026#34;已有 \u0026#34; + extrinsic + \u0026#34; 直接从池中取----\u0026gt;\u0026#34;); } else { //根据外部状态创建享元对象 flyweight = new concreteflyweight(extrinsic); pool.put(extrinsic, flyweight); //放入池中 system.out.print(\u0026#34;创建 \u0026#34; + extrinsic + \u0026#34; 并从池中取出----\u0026gt;\u0026#34;); } return flyweight; } } //测试享元模式 public class testflyweight { public static void main(string[] args) { int extrinsic = 22; flyweight flyweightx = flyweightfactory.getflyweight(\u0026#34;x\u0026#34;); flyweightx.operate(++extrinsic); flyweight flyweighty = flyweightfactory.getflyweight(\u0026#34;y\u0026#34;); flyweighty.operate(++extrinsic); flyweight flyweightrex = flyweightfactory.getflyweight(\u0026#34;x\u0026#34;); flyweightrex.operate(++extrinsic); } } 组合模式【结构型】 定义\n将对象组合成树形结构以表示部分-整体的层次结构\n特点\n组合模式使客户端对单个对象和组合对象保持一致的处理方式\n适用场景\n希望客户端可以忽略组合对象与单个对象的差异时 处理一个树形结构时 优点\n清楚的定义分层次的复杂对象,表示对象的全部或部分层次 让客户端忽略了层次的差异,方便对整个层次结构进行控制 简化客户端代码 符合开闭原则 缺点\n限制类型时会较为复杂 使设计变得更加抽象 编码示例\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 //需要抽象成的基类,基类一般不支持任何操作 public class component { public void add(component component){ throw new unsupportedoperationexception(\u0026#34;不支持添加操作\u0026#34;); } public void remove(component component){ throw new unsupportedoperationexception(\u0026#34;不支持删除操作\u0026#34;); } public string getname(component component){ throw new unsupportedoperationexception(\u0026#34;不支持获取名称操作\u0026#34;); } public double getprice(component component){ throw new unsupportedoperationexception(\u0026#34;不支持获取价格操作\u0026#34;); } public void print(){ throw new unsupportedoperationexception(\u0026#34;不支持打印操作\u0026#34;); } } //一个组件的实现 public class course extends component{ private string name; private double price; public course(string name, double price) { this.name = name; this.price = price; } @override public string getname(component component) { return this.name; } @override public double getprice(component component) { return this.price; } @override public void print() { system.out.println(\u0026#34;course name:\u0026#34;+name+\u0026#34; price:\u0026#34;+price); } } //顶层组件的实现 public class coursecatalog extends component{ private list\u0026lt;component\u0026gt; items = new arraylist\u0026lt;component\u0026gt;(); private string name; public coursecatalog(string name) { this.name = name; } @override public void add(component component) { items.add(component); } @override public string getname(component component) { return this.name; } @override public void remove(component component) { items.remove(component); } @override public void print() { system.out.println(this.name); for(component component : items){ component.print(); } } } //测试组合模式 public class testcomponent { public static void main(string[] args) { component linuxcourse = new course(\u0026#34;linux课程\u0026#34;,11); component windowscourse = new course(\u0026#34;windows课程\u0026#34;,11); component javacoursecatalog = new coursecatalog(\u0026#34;java课程目录\u0026#34;); component mmallcourse1 = new course(\u0026#34;java操作数据库\u0026#34;,55); component designpattern = new course(\u0026#34;java设计模式\u0026#34;,77); javacoursecatalog.add(mmallcourse1); javacoursecatalog.add(mmallcourse2); javacoursecatalog.add(designpattern); component maincoursecatalog = new coursecatalog(\u0026#34;课程主目录\u0026#34;); maincoursecatalog.add(linuxcourse); maincoursecatalog.add(windowscourse); maincoursecatalog.add(javacoursecatalog); maincoursecatalog.print(); } } 桥接模式【结构型】 定义\n将抽象部分与它的具体实现部分分离,使它们都可以独立地变化\n特点\n通过组合的方式建立两个类之间联系,而不是继承\n适用场景\n一个类存在两个(或多个)独立变化的维度,且这两个(或多个)维度都需要独立进行扩展 优点\n分离抽象部分及其和具体实现部分 提高了系统的可扩展性 缺点\n增加系统理解和设计难度 需要正确地识别出系统中两个(多个)独立变化的维度 编码示例\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 //桥接接口类,使得类之前产生关系,相当于桥梁 public interface account { account openaccount(); } public abstract class bank { protected account account; public bank(account account){ this.account = account; } abstract account openaccount(); } //桥接接口实现类 public class abcbank extends bank { public abcbank(account account) { super(account); } @override account openaccount() { system.out.println(\u0026#34;打开中国农业银行账号\u0026#34;); account.openaccount(); return account; } } public class icbcbank extends bank { public icbcbank(account account) { super(account); } @override account openaccount() { system.out.println(\u0026#34;打开中国工商银行账号\u0026#34;); account.openaccount(); return account; } } public class savingaccount implements account { @override public account openaccount() { system.out.println(\u0026#34;打开活期账号\u0026#34;); return new savingaccount(); } } public class depositaccount implements account{ @override public account openaccount() { system.out.println(\u0026#34;打开定期账号\u0026#34;); return new depositaccount(); } } //测试桥接模式 public class testbridge { public static void main(string[] args) { bank icbcbank = new icbcbank(new depositaccount()); account icbcaccount = icbcbank.openaccount(); bank icbcbank2 = new icbcbank(new savingaccount()); account icbcaccount2 = icbcbank2.openaccount(); bank abcbank = new abcbank(new savingaccount()); account abcaccount = abcbank.openaccount(); } } 代理模式【结构型】 定义\n为其它对象提高一种代理,以控制对这个对象的访问\n特点\n代理对象在客户端和目标对象之间起到中介作用\n适用场景\n保护目标对象 增强目标对象 优点\n能将代理对象与真实被调用的目标对象进行分离 一定程度上降低了系统耦合,扩展性好 保护目标对象 缺点\n代理模式会造成系统设计中类数目的增加 会造成请求速度变慢 增加系统复杂度 编码示例\n静态代理 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 //接口 public interface iuserdao { void save(); } //接口实现,目标对象 public class userdao implements iuserdao { @override public void save() { system.out.println(\u0026#34;----保存数据----\u0026#34;); } } //代理对象 public class userdaoproxy implements iuserdao { private iuserdao target; public userdaoproxy(iuserdao userdao){ this.target = userdao; } @override public void save() { system.out.println(\u0026#34;开始事务...\u0026#34;); target.save();//执行目标对象的方法 system.out.println(\u0026#34;提交事务...\u0026#34;); } } //测试静态代理 public class teststaticproxy { public static void main(string[] args) { userdao target = new userdao();//目标对象 userdaoproxy proxy = new userdaoproxy(target);//代理对象,把目标对象传给代理对象,建立代理关系 proxy.save();//执行的是代理的方法 } } 动态代理\njdk动态代理【只能代理实现接口的对象】 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 //接口 public interface iuserdao { void save(); } //接口实现,目标对象 public class userdao implements iuserdao { @override public void save() { system.out.println(\u0026#34;----保存数据----\u0026#34;); } } //生成代理对象工厂 public class proxyfactory { private object target; //维护一个目标对象 public proxyfactory(object target){ this.target=target; } //为目标对象生成代理 public object getproxyinstance() { return proxy.newproxyinstance(target.getclass().getclassloader(), target.getclass().getinterfaces(), new daoinvocationhandler()); } //处理逻辑 class daoinvocationhandler implements invocationhandler{ @override public object invoke(object proxy, method method, object[] args) throws throwable { system.out.println(\u0026#34;开始事务...\u0026#34;); //传入的proxy为当前已包装好的对象,target是原始对象 object result = method.invoke(target, args); system.out.println(\u0026#34;提交事务...\u0026#34;); return result; } } } //测试jdk动态代理 public class testjdkdynamicproxy { public static void main(string[] args) { iuserdao userdao = (iuserdao) new proxyfactory(new userdao()).getproxyinstance(); userdao.save(); } } cglib代理【可以代理没有实现任何接口的对象】 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 //接口 public interface iuserdao { void save(); } //接口实现,目标对象 public class userdao implements iuserdao { @override public void save() { system.out.println(\u0026#34;----保存数据----\u0026#34;); } } //生成代理对象工厂 public class proxyfactory implements methodinterceptor { private object target; //维护一个目标对象 public proxyfactory(object target){ this.target=target; } //给目标对象创建一个代理对象 public object getproxyinstance(){ enhancer en = new enhancer(); //1.工具类 en.setsuperclass(target.getclass()); //2.设置父类 en.setcallback(this); //3.设置回调函数 return en.create(); //4.创建子类(代理对象) } @override public object intercept(object o, method method, object[] args, methodproxy methodproxy) throws throwable { system.out.println(\u0026#34;开始事务...\u0026#34;); object returnvalue = method.invoke(target,args); system.out.println(\u0026#34;提交事务...\u0026#34;); return returnvalue; } } //测试cglib动态代理 public class testcglibporxy { public static void main(string[] args) { userdao target = new userdao();//目标对象 userdao proxy = (userdao)new proxyfactory(target).getproxyinstance();//代理对象 proxy.save();//执行代理对象的方法 } } 注意:代理的类不能为final\n\t目标对象的方法如果为final/static,那么就不会被拦截,即不会执行目标对象额外的业务方法\n四、行为型设计模式 模板方法模式【行为型】 定义\n定义了一个算法的骨架,并允许子类为一个或多个步骤提供实现\n特点\n模板方法使得子类可以在不改变算法结构的情况下,重新定义算法的某些步骤\n适用场景\n一次性实现一个算法的不变部分,并将可变的行为留给子类来实现 各子类中公共的行为被提取出来并集中到一个公共父类中,从而避免代码重复 优点\n提高复用性 提高扩展性 符合开闭原则 缺点\n类数目的增加 增加了系统实现的复杂度 继承关系自身的缺点,如果父类添加新的抽象方法,所有子类都要改一遍 编码示例\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 //模板类,abstract方法 public abstract class game { abstract void initialize(); abstract void startplay(); abstract void endplay(); //模板方法必须定义为final,因为逻辑不应该被子类重写 public final void play(){ initialize(); //初始化游戏 startplay(); //开始游戏 endplay(); //结束游戏 } } //模板子类 public class football extends game { @override void endplay() { system.out.println(\u0026#34;football game finished!\u0026#34;); } @override void initialize() { system.out.println(\u0026#34;football game initialized! start playing.\u0026#34;); } @override void startplay() { system.out.println(\u0026#34;football game started. enjoy the game!\u0026#34;); } } public class cricket extends game { @override void endplay() { system.out.println(\u0026#34;cricket game finished!\u0026#34;); } @override void initialize() { system.out.println(\u0026#34;cricket game initialized! start playing.\u0026#34;); } @override void startplay() { system.out.println(\u0026#34;cricket game started. enjoy the game!\u0026#34;); } } //测试模板模式 public class testtemplate { public static void main(string[] args) { game cricket = new cricket(); cricket.play(); //调用模板方法,按照模板类规定的逻辑调用 game football = new football(); football.play(); //调用模板方法,按照模板类规定的逻辑调用 } } 迭代器模式【行为型】 定义\n提供一种方法,顺序访问集合对象中的各个元素,而又不暴露该对象的内部表示\n适用场景\n访问一个集合对象而无需暴露它的内部表示 为遍历不同的集合结构提供一个统一的接口 优点\n分离了集合对象的遍历行为 缺点\n类的个数成对增加 编码示例\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 /* *容器接口 *iterable 有iterator\u0026lt;t\u0026gt; iterator();\t声明 */ public interface container extends iterable\u0026lt;string\u0026gt;{ void add(string ele); } //容器实现类 public class namerepository implements container { list\u0026lt;string\u0026gt; names = new arraylist\u0026lt;\u0026gt;(); @override public iterator\u0026lt;string\u0026gt; iterator() { return new nameiterator(); } @override public void add(string ele) { names.add(ele); } private class nameiterator implements iterator\u0026lt;string\u0026gt; { private int index; @override public boolean hasnext() { if(index \u0026lt; names.size()){ return true; } return false; } @override public string next() { if(this.hasnext()){ return names.get(index++); } return null; } } } //测试迭代器模式 public class testiterator { public static void main(string[] args) { container container = new namerepository(); container.add(\u0026#34;tom\u0026#34;); container.add(\u0026#34;lili\u0026#34;); container.add(\u0026#34;jack\u0026#34;); iterator\u0026lt;string\u0026gt; iterator = container.iterator(); while (iterator.hasnext()){ string name = iterator.next(); system.out.println(name); } } } 策略模式【行为型】 定义\n定义了算法家族,分别封装起来,让它们之间可以互相替换,此模式让算法的变化不会影响到使用算法的用户\n适用场景\n系统有很多类,而它们的区别仅仅在于他们的行为不同 一个系统需要动态地在几种算法中选择一种 优点\n符合开闭原则 避免使用多重条件转移语句 提高算法的保密性和安全性 缺点\n客户端必须知道所有的策略类,并自行决定使用哪一个策略类 产生很多的策略类 编码示例\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 //策略接口类 public interface promotionstrategy { void dopromotion(integer price); } //满减策略 public class fullrductionstrategy implements promotionstrategy { @override public void dopromotion(integer price) { system.out.println(\u0026#34;满100减少10元,原价:\u0026#34; + price + \u0026#34;,实际应支付:\u0026#34; + (price - price / 100 * 10)); } } //返现策略 public class cashbackstrategy implements promotionstrategy { @override public void dopromotion(integer price) { system.out.println(\u0026#34;满100返现15元,实际支付:\u0026#34; + price + \u0026#34;,返回账户余额+\u0026#34; + price / 100 * 15); } } //使用策略的主体类,根据不同的策略会有不同的结果 public class promotionactivity { private promotionstrategy promotionstrategy; public promotionactivity(promotionstrategy promotionstrategy) { this.promotionstrategy = promotionstrategy; } public void executepromotionstrategy(integer price){ promotionstrategy.dopromotion(price); } } //测试策略模式 public class teststrategy { public static void main(string[] args) { promotionactivity activity618 = new promotionactivity(new fullrductionstrategy()); activity618.executepromotionstrategy(100); promotionactivity activity11d = new promotionactivity(new cashbackstrategy()); activity11d.executepromotionstrategy(100); } } 解释器模式【行为型】 定义\n给定一个语言,定义它的文法的一种表示,并定义一个解释器,这个解释器使用该表示来解释语言中的句子\n特点\n为了解释一种语言,而为语言创建的解释器\n适用场景\n某个特定类型问题发生的频率足够高 优点\n语法有很多类表示,容易改变及扩展此“语言” 缺点\n当语法规则太多时,增加了系统复杂度 编码示例\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 //表达式解释器接口 public interface expression { string interpret(string expression); } //解释器实现 public class loveexpression implements expression { @override public string interpret(string expression) { stringbuilder stringbuilder = new stringbuilder(); string[] splits = expression.split(\u0026#34;\\\\s\u0026#34;); string sec = splits[0]; string min = splits[1]; string day = splits[2]; if(day.equals(\u0026#34;*\u0026#34;)){ stringbuilder.append(\u0026#34;每天\u0026#34;); } if(min.equals(\u0026#34;*\u0026#34;)){ stringbuilder.append(\u0026#34;每分\u0026#34;); } if(sec.equals(\u0026#34;*\u0026#34;)){ stringbuilder.append(\u0026#34;每秒\u0026#34;); } stringbuilder.append(\u0026#34;,都爱你\u0026#34;); return stringbuilder.tostring(); } } //测试解释器模式 public class testinterpret { public static void main(string[] args) { expression expression = new loveexpression(); string result = expression.interpret(\u0026#34;* * *\u0026#34;); system.out.println(result); } } 观察者模式【行为型】 定义\n多个观察者对象同时监听某一个主题对象,当主题对象发生变化时,它的所有观察者都会收到通知并更新\n适用场景\n关联行为场景,建立一套触发机制 优点\n观察者和被观察者之间建立一个抽象的耦合 观察者模式支持广播通信 缺点\n观察者之间有过多的细节依赖 提高时间消耗及程序复杂度 设计要得当,避免循环调用 编码示例\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 //被观察者,根据jdk规范继承observable public class child extends observable { private string name; public child(string name) { this.name = name; } public string getname() { return name; } //通知改变,通知所有观察者 public void notifyevent(string event) { setchanged(); notifyobservers(event); } } //观察者实现observer接口 public class father implements observer { @override public void update(observable o, object arg) { if (o instanceof child){ child child = (child) o; string event = (string) arg; system.out.println(\u0026#34;孩子\u0026#34; + child.getname() + \u0026#34;发生了\u0026#34; + event + \u0026#34;,父亲马上去处理。。。\u0026#34;); } } } public class mother implements observer { @override public void update(observable o, object arg) { if (o instanceof child){ child child = (child) o; string event = (string) arg; system.out.println(\u0026#34;孩子\u0026#34; + child.getname() + \u0026#34;发生了\u0026#34; + event + \u0026#34;,母亲马上去处理。。。\u0026#34;); } } } //测试观察者模式 public class testobserver { public static void main(string[] args) { child child = new child(\u0026#34;tom\u0026#34;); child.addobserver(new mother()); child.addobserver(new father()); child.notifyevent(\u0026#34;肚子疼\u0026#34;); } } 备忘录模式【行为型】 定义\n保存一个对象的某个状态,以便在适当的时候恢复对象\n特点\n“后悔药”\n适用场景\n保存及恢复数据相关业务场景 优点\n为用户提供一种可恢复机制 存档信息的封装 缺点\n资源占用 编码示例\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 //需要被保存部分状态的类 public class player { private string name; private integer price; private list\u0026lt;string\u0026gt; equipmentlist = new arraylist\u0026lt;\u0026gt;(); public player(string name) { this.name = name; } public string getname() { return name; } public integer getprice() { return price; } public void setprice(integer price) { this.price = price; } public list\u0026lt;string\u0026gt; getequipmentlist() { return equipmentlist; } public void setequipmentlist(list\u0026lt;string\u0026gt; equipmentlist) { equipmentlist = equipmentlist; } } //需要被保存的状态 public class mementoshoppingstate { private list\u0026lt;string\u0026gt; equipmentlist; private int playeroldprice; public mementoshoppingstate(list\u0026lt;string\u0026gt; equipmentlist, int playeroldprice) { equipmentlist = new arraylist\u0026lt;\u0026gt;(equipmentlist); this.playeroldprice = playeroldprice; } public int getplayeroldprice() { return playeroldprice; } public void setplayeroldprice(int playeroldprice) { this.playeroldprice = playeroldprice; } public list\u0026lt;string\u0026gt; getequipmentlist() { return equipmentlist; } public void setequipmentlist(list\u0026lt;string\u0026gt; equipmentlist) { equipmentlist = equipmentlist; } } //实际业务 public class store { private static map\u0026lt;string, integer\u0026gt; goods_map = new hashmap\u0026lt;\u0026gt;(); private stack\u0026lt;mementoshoppingstate\u0026gt; mementoshoppingstate = new stack\u0026lt;\u0026gt;(); static { goods_map.put(\u0026#34;黑色切割者\u0026#34;, 2300); goods_map.put(\u0026#34;暴风大剑\u0026#34;, 900); } public void shopping(player player,string goodsname){ //先进行存档用于回退 mementoshoppingstate.add(new mementoshoppingstate(player.getequipmentlist(),player.getprice())); //实际业务执行 int oldprice = player.getprice(); player.setprice(oldprice-goods_map.get(goodsname)); player.getequipmentlist().add(goodsname); system.out.println(\u0026#34;购买:\u0026#34;+goodsname+\u0026#34; 原金币:\u0026#34;+oldprice+\u0026#34; 现金币:\u0026#34;+player.getprice()); } //回滚存档 public void recentfallback(player player){ mementoshoppingstate shoppingstate = mementoshoppingstate.pop(); system.out.println(\u0026#34;回退:\u0026#34;+\u0026#34; 原金币:\u0026#34;+player.getprice()+\u0026#34; 现金币:\u0026#34;+shoppingstate.getplayeroldprice()); player.setprice(shoppingstate.getplayeroldprice()); player.setequipmentlist(shoppingstate.getequipmentlist()); } } //测试备忘录模式 public class testmemento { public static void main(string[] args) { player player = new player(\u0026#34;阿卡丽\u0026#34;); player.setprice(6000); store store = new store(); store.shopping(player,\u0026#34;暴风大剑\u0026#34;); store.shopping(player,\u0026#34;黑色切割者\u0026#34;); system.out.println(\u0026#34;打印现装备\u0026#34;); for (string equipment : player.getequipmentlist()) { system.out.println(equipment); } store.recentfallback(player); system.out.println(\u0026#34;打印现装备\u0026#34;); for (string equipment : player.getequipmentlist()) { system.out.println(equipment); } store.recentfallback(player); system.out.println(\u0026#34;打印现装备\u0026#34;); for (string equipment : player.getequipmentlist()) { system.out.println(equipment); } } } 命令模式【行为型】 定义\n将“请求”封装成对象,以便使用不同的请求\n特点\n解决了应用程序中对象的职责以及它们之间的通讯方式\n适用场景\n请求的调用者和请求的接收者需要解耦,使得调用者和接收者不直接交互 优点\n降低耦合 容易扩展新命令或者一组命令 缺点\n命令的无限扩展会增加类的数量,体高系统实现复杂度 编码示例\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 //普通实体类 public class stock { private string name; private int quantity; public stock(string name, int quantity) { this.name = name; this.quantity = quantity; } public string getname() { return name; } public int getquantity() { return quantity; } public void setquantity(int quantity) { this.quantity = quantity; } } //命令接口 public interface stockcommand { void execute(); } //具体命令 public class depositgoodscommand implements stockcommand { private stock stock; private int buysize; public depositgoodscommand(stock stock, int buysize) { this.stock = stock; this.buysize = buysize; } @override public void execute() { stock.setquantity(stock.getquantity() + buysize); system.out.println(stock.getname() + \u0026#34;存入仓库\u0026#34; + buysize + \u0026#34;,仓库总计\u0026#34; + stock.getquantity()); } } public class takeoutgoodscommand implements stockcommand { private stock stock; private int takesize; public takeoutgoodscommand(stock stock, int takesize) { this.stock = stock; this.takesize = takesize; } @override public void execute() { stock.setquantity(stock.getquantity() - takesize); system.out.println(stock.getname() + \u0026#34;取出仓库\u0026#34; + takesize + \u0026#34;,仓库总计\u0026#34; + stock.getquantity()); } } //命令的执行者 public class broker { private list\u0026lt;stockcommand\u0026gt; stockcommandlist = new arraylist\u0026lt;stockcommand\u0026gt;(); public void receivecommand(stockcommand command){ stockcommandlist.add(command); } public void executecommand(){ for (stockcommand command : stockcommandlist) { command.execute(); } stockcommandlist.clear(); } } //测试命令模式 public class testcommand { public static void main(string[] args) { stock stock = new stock(\u0026#34;空气清新剂\u0026#34;, 10); stockcommand depositgoodscommand = new depositgoodscommand(stock,200); stockcommand takeoutgoodscommand = new takeoutgoodscommand(stock,100); broker broker = new broker(); broker.receivecommand(depositgoodscommand); broker.receivecommand(takeoutgoodscommand); broker.executecommand(); } } 中介者模式【行为型】 定义\n用一个中介对象来封装一系列的对象交互\n特点\n通过使对象明确地相互引用来促进松散耦合,并允许独立地改变它们的交互\n适用场景\n系统中对象之间存在复杂的引用关系,产生的相互依赖关系结构混乱切难以理解 如果需要改变交互的公共行为可以增加中介者类 优点\n将一对多转化成了一对一,降低程序复杂度 类之间解耦 缺点\n中介者过多,导致系统复杂 编码示例\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 //内部调用中介者完成消息发送 public class user { private string name; private studygroup studygroup; public user(string name) { this.name = name; } public string getname() { return name; } public void setname(string name) { this.name = name; } public studygroup getstudygroup() { return studygroup; } public void setstudygroup(studygroup studygroup) { this.studygroup = studygroup; } public void sendmessage(string s) { studygroup.showmessage(this, s);\t//由中介者进行发送 } } //中介者类,用来传递信息 public class studygroup { private string name; public studygroup(string name) { this.name = name; } public void showmessage(user user, string message){ system.out.println(\u0026#34;chat-\u0026#34; + name + \u0026#34; [\u0026#34; + user.getname() +\u0026#34;] : \u0026#34; + message); } } //测试中介者模式 public class testmediator { public static void main(string[] args) { studygroup studygroup = new studygroup(\u0026#34;法语学习小组\u0026#34;); user robert = new user(\u0026#34;robert\u0026#34;); robert.setstudygroup(studygroup); user john = new user(\u0026#34;john\u0026#34;); john.setstudygroup(studygroup); robert.sendmessage(\u0026#34;hi! john!\u0026#34;); john.sendmessage(\u0026#34;hello! robert!\u0026#34;); } } 责任链模式【行为型】 定义\n为请求创建一个接收此次请求对象的链\n适用场景\n一个请求的处理需要多个对象当中的一个或几个协作处理 优点\n请求的发送者和接收者解耦 责任链可以动态组合 缺点\n责任链太长或者处理时间过长会影响性能 责任链可能过多 编码示例\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 //普通实体类 public class course { private string name; public course(string name) { this.name = name; } public string getname() { return name; } } //抽象审批者 public abstract class approver { protected approver nextapprover; abstract boolean doapproval(course course); public void setnextapprover(approver nextapprover) { this.nextapprover = nextapprover; } } //具体的审批方式 public class videoapprover extends approver { @override boolean doapproval(course course) { system.out.println(\u0026#34;审核\u0026#34;+course.getname()+\u0026#34;视频内容通过。。。\u0026#34;); return nextapprover == null ? true : nextapprover.doapproval(course); } } public class articleapprover extends approver { @override boolean doapproval(course course) { system.out.println(\u0026#34;审核\u0026#34;+course.getname()+\u0026#34;手记内容通过。。。\u0026#34;); return nextapprover == null ? true : nextapprover.doapproval(course); } } //测试责任链模式 public class testchain { public static void main(string[] args) { course course = new course(\u0026#34;java设计模式\u0026#34;); videoapprover videoapprover = new videoapprover(); articleapprover articleapprover = new articleapprover(); videoapprover.setnextapprover(articleapprover); videoapprover.doapproval(course); } } 访问者模式【行为型】 定义\n封装作用于某数据结构(如list/set/map等)中的各种元素的操作\n特点\n可以在不改变元素的类前提情况下,定义作用于这些元素的操作\n适用场景\n一个数据结构如(如list/set/map等)包含很多类型对象 数据结构和数据操作分离 优点\n增加新的操作简单,即增加一个新的访问者 缺点\n增加新的数据结构困难 具体元素的变更比较麻烦 编码示例\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 //被访问的抽象类 public interface bill { void accept(accountbookviewer viewer);\t//不同的访问者对单子的重点看的不同 } //被访问的抽象类的实现 public class consumebill implements bill { private double amount; private string item; public consumebill(double amount, string item) { super(); this.amount = amount; this.item = item; } @override public void accept(accountbookviewer viewer) { viewer.view(this); } public double getamount() { return amount; } public string getitem() { return item; } } public class incomebill implements bill{ private double amount; private string item; public incomebill(double amount, string item) { super(); this.amount = amount; this.item = item; } @override public void accept(accountbookviewer viewer) { viewer.view(this); } public double getamount() { return amount; } public string getitem() { return item; } } //访问者抽象类 public interface accountbookviewer { void view(consumebill bill);//查看消费的单子 void view(incomebill bill);//查看收入的单子 } //访问者的实现类 public class boss implements accountbookviewer{ private double totalincome; private double totalconsume; //老板只关注一共花了多少钱以及一共收入多少钱,其余并不关心 public void view(consumebill bill) { totalconsume += bill.getamount(); } public void view(incomebill bill) { totalincome += bill.getamount(); } public double gettotalincome() { system.out.println(\u0026#34;查看一共收入多少,数目是:\u0026#34; + totalincome); return totalincome; } public double gettotalconsume() { system.out.println(\u0026#34;查看一共花费多少,数目是:\u0026#34; + totalconsume); return totalconsume; } } public class cpa implements accountbookviewer{ //注册会计在看账本时,如果是支出,则如果支出是工资,则需要看应该交的税交了没 public void view(consumebill bill) { if (bill.getitem().equals(\u0026#34;工资\u0026#34;)) { system.out.println(\u0026#34;查看工资是否交个人所得税。\u0026#34;); } } //如果是收入,则所有的收入都要交税 public void view(incomebill bill) { system.out.println(\u0026#34;查看收入交税了没。\u0026#34;); } } //一堆被访问者的集合存储类 public class accountbook { //单子列表 private list\u0026lt;bill\u0026gt; billlist = new arraylist\u0026lt;bill\u0026gt;(); //添加单子 public void addbill(bill bill){ billlist.add(bill); } //供账本的查看者查看账本 public void show(accountbookviewer viewer){ for (bill bill : billlist) { bill.accept(viewer); } } } //测试访问者模式 public class testvisitor { public static void main(string[] args) { accountbook accountbook = new accountbook(); //添加两条收入 accountbook.addbill(new incomebill(10000, \u0026#34;卖商品\u0026#34;)); accountbook.addbill(new incomebill(12000, \u0026#34;卖广告位\u0026#34;)); //添加两条支出 accountbook.addbill(new consumebill(1000, \u0026#34;工资\u0026#34;)); accountbook.addbill(new consumebill(2000, \u0026#34;材料费\u0026#34;)); accountbookviewer boss = new boss(); accountbookviewer cpa = new cpa(); //两个访问者分别访问账本 accountbook.show(cpa); accountbook.show(boss); ((boss) boss).gettotalconsume(); ((boss) boss).gettotalincome(); } } 状态模式【行为型】 定义\n允许对象在内部状态发生改变时改变它的行为\n特点\n对象的行为依赖于它的状态(属性),并且可以根据它的状态改变而改变它的相关行为\n适用场景\n一个对象存在多个状态(不同状态下行为不同),且状态可相互转换 优点\n将不同状态隔离 把各种状态的转化逻辑,分布到state的子类中,减少相互依赖 增加新的状态较为简单 缺点\n状态多的业务场景导致类数目增加,系统变复杂 编码示例\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 //状态接口 public interface videostate { void doaction(videoplayer player);\t//处于此状态下要作的动作 } //各种状态 public class playstate implements videostate{ @override public void doaction(videoplayer player) { system.out.println(\u0026#34;开始播放\u0026#34;); } } public class stopstate implements videostate{ @override public void doaction(videoplayer player) { system.out.println(\u0026#34;停止播放\u0026#34;); } } public class pausestate implements videostate{ @override public void doaction(videoplayer player) { system.out.println(\u0026#34;暂停播放\u0026#34;); } } //使用此状态的上下文 public class videoplayer { private videostate state; public static final videostate stopstate = new stopstate(); public static final videostate playstate = new playstate(); public static final videostate pausestate = new pausestate(); public videoplayer(){ } public void changestate(videostate state){ this.state = state; state.doaction(this); } public videostate getstate(){ return state; } } //测试状态模式 public class teststate { public static void main(string[] args) { videoplayer videoplayer = new videoplayer(); videoplayer.changestate(videoplayer.playstate); videoplayer.changestate(videoplayer.pausestate); videoplayer.changestate(videoplayer.stopstate); } } ","date":"2024-04-25","permalink":"https://hobocat.github.io/post/java/2024-04-25-design/","summary":"一、软件设计七大原则 开闭原则 定义:一个软件实体如类、模块、函数应该对扩展开放,对修改关闭 强调:用抽象构建框架,用实现扩展细节 优点:提高软件系统的可复用性及可维护","title":"java设计模式"},]
[{"content":"一、分布式锁起因 分布式锁出现的原因\n\t在传统单体应用单机部署的情况下,可以使用并发处相关的功能(如java并发处理相关的api:reentrantlock或者syncchronized等)进行互斥控制来解决。但随着业务发展,系统架构也会逐步优化升级,原本单体单机部署的系统被演化为分布式集群系统。由于分布式系统多线程,多进程并且分布在多个不同机器上,这将使原来单机部署情况下的并发控制锁策略无法满足,并不能提供分布式锁的能力。为了解决这个问题就需一个跨机器的互斥机制来控制共享资源的访问,这就是分布式锁的解决的难题。\n分布式锁应用的场景\n提升效率:如果不使用分布式锁,会导致业务重复执行一些没有意义的工作 正确性: 使用分布式锁可以防止对数据的并发访问,避免数据不一致,数据损失等 分布式锁需要具备的特性\n特性 说明 排他性 同一时间只会有一个客户端能获取到锁,其它客户端无法同时获取 避免死锁 锁在一段时间内有效,超过这个时间后会被释放(正常释放或异常释放) 高可用 获取或释放锁的机制必须高可用且性能不能过差 二、使用redission实现分布式锁 redis锁自实现及其问题 首先我们可以使用redis实现初步具有锁能力的代码\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 @test public void testdistributedlockredis() { string lock_key = \u0026#34;goods_001\u0026#34;; string lockthreadflag = uuid.randomuuid().tostring(); boolean lockresult = stringredistemplate.opsforvalue().setifabsent(lock_key, lockthreadflag, 30, timeunit.seconds); try { if (boolean.true.equals(lockresult)) { // 执行业务代码 dobusinesscode(); // .... } } finally { if (boolean.true.equals(lockresult) \u0026amp;\u0026amp; lockthreadflag.equals(stringredistemplate.opsforvalue().get(lock_key))) { stringredistemplate.delete(lock_key); } } } 问题:①如果业务代码执行的时间超过锁过期时间那么资源锁被释放了,就会有并发问题。如果时间设置过久,程序宕机没有释放锁,会导致锁时间过长。②重入问题没有考虑\n为解决以上问题,需要获得锁的线程开启一个守护线程,用来给快要过期的锁\u0026quot;续航\u0026quot;。例如每过10s检查,如果业务代码没执行完则重设锁时长为30。由于业务线程和守护线程在同一个进程,业务线程执行完成或者终止,守护线程也会停下。这把锁到了超时的时候,没人给它续命,也就自动释放了。但是编写这些代码在实际生产过程种可能要考虑更多问题,此时我们可以用redisson框架的封装完善的锁。\nredission锁的原理 redission加锁和解锁采用的是lua脚本,需要先研究一下加锁和解锁脚本都做了什么\n加锁脚本\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 -- 若锁不存在:则新增锁,并设置锁重入计数为1、设置锁过期时间 if (redis.call(\u0026#39;exists\u0026#39;, keys[1]) == 0) then redis.call(\u0026#39;hset\u0026#39;, keys[1], argv[2], 1); redis.call(\u0026#39;pexpire\u0026#39;, keys[1], argv[1]); return nil; end; -- 若锁存在,且唯一标识也匹配:则表明当前加锁请求为锁重入请求,故锁重入计数+1,并再次设置锁过期时间 if (redis.call(\u0026#39;hexists\u0026#39;, keys[1], argv[2]) == 1) then redis.call(\u0026#39;hincrby\u0026#39;, keys[1], argv[2], 1); redis.call(\u0026#39;pexpire\u0026#39;, keys[1], argv[1]); return nil; end; -- 若锁存在,但唯一标识不匹配:表明锁是被其他线程占用,当前线程无权解他人的锁,直接返回锁剩余过期时间 return redis.call(\u0026#39;pttl\u0026#39;, keys[1]); 加锁脚本流程解读\n解锁脚本\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 -- 若锁不存在:则直接广播解锁消息,并返回1 if (redis.call(\u0026#39;exists\u0026#39;, keys[1]) == 0) then redis.call(\u0026#39;publish\u0026#39;, keys[2], argv[1]); return 1; end; -- 若锁存在,但唯一标识不匹配:则表明锁被其他线程占用,当前线程不允许解锁其他线程持有的锁 if (redis.call(\u0026#39;hexists\u0026#39;, keys[1], argv[3]) == 0) then return nil; end; -- 若锁存在,且唯一标识匹配:则先将锁重入计数减1 local counter = redis.call(\u0026#39;hincrby\u0026#39;, keys[1], argv[3], -1); if (counter \u0026gt; 0) then -- 锁重入计数减1后还大于0:表明当前线程持有的锁还有重入,不能进行锁删除操作,但可以友好地帮忙设置下过期时期 redis.call(\u0026#39;pexpire\u0026#39;, keys[1], argv[2]); return 0; else -- 锁重入计数已为0:间接表明锁已释放了。直接删除掉锁,并广播解锁消息,去唤醒那些争抢过锁但还处于阻塞中的线程 redis.call(\u0026#39;del\u0026#39;, keys[1]); redis.call(\u0026#39;publish\u0026#39;, keys[2], argv[1]); return 1; end; return nil; 解锁脚本流程解读\n广播解锁消息的作用:通知其它争抢锁阻塞住的线程,从阻塞中解除,并再次去争抢锁\n加锁和解锁总流程图\nredission的使用 普通非公平重入锁 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 /** * 普通非公平重入锁 */ @test public void testredissionlock() { string lock_key = \u0026#34;goods_001\u0026#34;; //获取分布式锁,只要锁的名字一样,就是同一把锁 rlock lock = redissonclient.getlock(lock_key); //加锁(阻塞等待),默认过期时间是30秒,实现的jdk的lock接口,也可使用trylock尝试加锁 lock.lock(); try { //如果业务执行过长,redisson会自动给锁续期 dobusinesscode(); } finally { //解锁,如果业务执行完成,就不会继续续期,即使没有手动释放锁,在30秒过后,也会释放锁 lock.unlock(); } } 公平锁 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 /** * 公平锁 */ @test public void testredissionfairlock() { string lock_key = \u0026#34;goods_001\u0026#34;; //获取分布式锁,只要锁的名字一样,就是同一把锁 rlock lock = redissonclient.getfairlock(lock_key); //加锁(阻塞等待) lock.lock(); try { //如果业务执行过长,redisson会自动给锁续期 dobusinesscode(); } finally { //解锁,如果业务执行完成,就不会继续续期,即使没有手动释放锁,在30秒过后,也会释放锁 lock.unlock(); } } 读写锁 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 /** * 读写锁 */ @test public void testredissionreadwritelock() { string lock_key = \u0026#34;goods_001\u0026#34;; //获取分布式锁,只要锁的名字一样,就是同一把锁 rreadwritelock lock = redissonclient.getreadwritelock(lock_key); //加锁(阻塞等待) rlock readlock = lock.readlock(); try { //如果业务执行过长,redisson会自动给锁续期 dobusinesscode(); } finally { //解锁,如果业务执行完成,就不会继续续期,即使没有手动释放锁,在30秒过后,也会释放锁 readlock.unlock(); } } 批量连锁 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 /** * 批量连锁 */ @test public void testredissionmultilock() { rlock lock1 = redissonclient.getlock(\u0026#34;goods_001\u0026#34;); rlock lock2 = redissonclient.getlock(\u0026#34;goods_002\u0026#34;); rlock lock3 = redissonclient.getlock(\u0026#34;goods_003\u0026#34;); // 同时对几个资源一起加锁 rlock lock = redissonclient.getmultilock(lock1, lock2, lock3); //加锁(阻塞等待) lock.lock(); try { //如果业务执行过长,redisson会自动给锁续期 dobusinesscode(); } finally { //解锁,如果业务执行完成,就不会继续续期,即使没有手动释放锁,在30秒过后,也会释放锁 lock.unlock(); } } countdownlatch,和jdk的countdownlatch用法相同 1 2 3 4 5 6 7 8 9 10 11 /** * countdownlatch */ @test public void testredissioncountdownlatch() { string lock_key = \u0026#34;test_count_down_latch\u0026#34;; // 获取countdownlatch,其它地方有个设置countdown的数量 countdownlatch.trysetcount(10); rcountdownlatch countdownlatch = redissonclient.getcountdownlatch(lock_key); countdownlatch.countdown(); dobusinesscode(); } semaphore,和jdk的semaphore用法相同 1 2 3 4 5 6 7 8 9 10 11 /** * semaphore */ @test public void testredissionsemaphorekey() throws interruptedexception { string semaphore_key = \u0026#34;test_semaphore\u0026#34;; rsemaphore semaphore = redissonclient.getsemaphore(semaphore_key); semaphore.acquire(2); dobusinesscode(); semaphore.release(2); } redlock 因为redis是ap架构,主从之间是异步复制。极端情况下如果master节点挂掉,但是slave节点还未同步到master数据,这时候锁会失效。为了避免这种极端情况可以使用redlock【其实不推荐使用,redlock本身也存在一些问题,达到cp的效果不如直接使用zookeeper或者etcd这种本就是cp的架构】\n算法大概逻辑:部署多台与master节点同等级别的其他节点,这几个redis不参与其他的业务。每一个线程在向master节点请求锁的同时,也向这几个同等级别的节点发送加锁请求,只有当超过一半的节点数加锁成功,此时的分布式锁才算真正的成功。\n缺点:\n增加了部署成本,因为使用redlock需要增加几台与master同等级的节点来实现加锁。这几个节点啥也不干,就只是负责加锁和释放锁逻辑。、 安全争议。让我们假设客户端从大多数redis实例取到了锁。所有的实例都包含同样的key,并且key的有效时间也一样。然而,key肯定是在不同的时间被设置上的,所以key的失效时间也不是精确的相同。如果客户端在获取到大多数redis实例锁,使用的时间接近或者已经大于失效时间,客户端将认为锁是失效的锁,并且将释放掉已经获取到的锁,所以我们只需要在有效时间范围内获取到大部分锁这种情况。 系统活性争议。系统的活性安全基于三个主要特性: 锁的自动释放(因为key失效了):最终锁可以再次被使用。客户端通常会将没有获取到的锁删除,或者锁被取到后,使用完后,客户端会主动(提前)释放锁,而不是等到锁失效另外的客户端才能取到锁。当客户端重试获取锁时,需要等待一段时间,这个时间必须大于从大多数redis实例成功获取锁使用的时间,以最大限度地避免脑裂。然而,当网络出现问题时系统在失效时间(ttl){.highlighter-rouge}内就无法服务,这种情况下我们的程序就会为此付出代价。如果网络持续的有问题,可能就会出现死循环了。这种情况发生在当客户端刚取到一个锁还没有来得及释放锁就被网络隔离。如果网络一直没有恢复,这个算法会导致系统不可用。 三、使用zookeeper实现分布式锁 利用zookeeper实现分布式锁原理 \tzookeeper实现分布式锁的原理就是多个节点同时在一个指定的节点下面创建临时会话顺序节点,谁创建的节点序号最小,谁就获得了锁。并且其他节点就会监听序号比自己小的节点【利用zookeeper的watcher机制】,一旦序号比自己小的节点被删除了,其他节点就会得到相应的事件,然后查看自己是否为序号最小的节点,如果是,则获取锁。\n\tzookeeper实现的分布式锁是cp的,性能没redis的高。但是不用担心redis主从架构,主节点挂掉从节点还没同步数据造成的锁失效。\n可重入是利用jdk线程threadid是否相同判断的\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public class zklock implements lock { //...... final atomicinteger lockcount = new atomicinteger(0); //...... @override public boolean lock() { //可重入,确保同一线程,可以重复加锁 synchronized (this) { if (lockcount.get() == 0) { thread = thread.currentthread(); lockcount.incrementandget(); } else { if (!thread.equals(thread.currentthread())) { return false; } lockcount.incrementandget(); return true; } //...... } } } 使用curator完成zookeeper分布式锁 \tcurator是netflix公司开源的一套zookeeper客户端框架,解决了很多zookeeper客户端非常底层的细节开发工作,包括连接重连、反复注册watcher和分布式锁等。\n使用spring boot初始化curator的前置代码\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 @configuration public class curatorconfig { @bean(destroymethod = \u0026#34;close\u0026#34;, initmethod = \u0026#34;start\u0026#34;) public curatorframework curatorframework() { retrypolicy retrypolicy = new exponentialbackoffretry(1000, 3); return curatorframeworkfactory.builder() .connectstring(\u0026#34;192.168.153.133:2181\u0026#34;) .sessiontimeoutms(5000) .connectiontimeoutms(5000) .namespace(\u0026#34;zookeeper-lock\u0026#34;) .retrypolicy(retrypolicy) .build(); } } 分布式可重入排它锁 1 2 3 4 5 6 7 8 9 10 11 12 @test public void testzkmutex() throws exception { string lock_key = \u0026#34;goods_001\u0026#34;; interprocessmutex zkmutex = new interprocessmutex(curatorframework, \u0026#34;/\u0026#34;+ lock_key); // 阻塞死等 zkmutex.acquire(); try { dobusinesscode(); } finally { zkmutex.release(); } } 分布式读写锁 1 2 3 4 5 6 7 8 9 10 11 12 @test public void testzkreadlock() throws exception { string lock_key = \u0026#34;goods_001\u0026#34;; interprocessreadwritelock readwritelock = new interprocessreadwritelock(curatorframework, \u0026#34;/\u0026#34; + lock_key); // 阻塞死等 interprocessmutex readlock = readwritelock.readlock(); try { dobusinesscode(); } finally { readlock.release(); } } 批量连锁 1 2 3 4 5 6 7 8 9 10 11 12 13 @test public void testzkmultilock() throws exception { final interprocesslock lock1 = new interprocessmutex(curatorframework, \u0026#34;/lock_good01\u0026#34;); final interprocesslock lock2 = new interprocessmutex(curatorframework, \u0026#34;/lock_good02\u0026#34;); interprocessmultilock interprocessmultilock = new interprocessmultilock(arrays.aslist(lock1, lock2)); // 阻塞死等 interprocessmultilock.acquire(); try { dobusinesscode(); } finally { interprocessmultilock.release(); } } semaphore 1 2 3 4 5 6 7 8 9 10 11 @test public void testzksemaphore() throws exception { interprocesssemaphorev2 semaphore = new interprocesssemaphorev2(curatorframework, \u0026#34;/test_semaphore\u0026#34;, 10); // 阻塞死等 collection\u0026lt;lease\u0026gt; acquirelease = semaphore.acquire(8); try { dobusinesscode(); } finally { semaphore.returnall(acquirelease); } } ","date":"2024-03-15","permalink":"https://hobocat.github.io/post/tool/2022-02-15-distributed-lock/","summary":"一、分布式锁起因 分布式锁出现的原因 在传统单体应用单机部署的情况下,可以使用并发处相关的功能(如java并发处理相关的API:ReentrantLock或者sy","title":"分布式锁"},]
[{"content":"一、线程的状态 从操作系统层面划分 从java代码的角度来进行划分 二、jdk创建线程的方式 继承thread类 1 2 3 4 5 6 7 8 9 10 11 12 13 public class threadtest { public static void main(string[] args) { thread thread = new threaddemo(); thread.start(); } } class threaddemo extends thread { @override public void run() { system.out.println(\u0026#34;do something\u0026#34;); } } 实现runnable接口 1 2 3 4 5 6 7 8 9 10 11 12 13 public class threadtest { public static void main(string[] args) { thread thread = new thread(new runnabledemo()); thread.start(); } } class runnabledemo implements runnable { @override public void run() { system.out.println(\u0026#34;do something\u0026#34;); } } 实现callable接口携带返回值 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public class threadtest { public static void main(string[] args) throws exception { futuretask\u0026lt;string\u0026gt; futuretask = new futuretask\u0026lt;\u0026gt;(new callabledemo()); thread thread = new thread(futuretask); thread.start(); //此时callable接口已经被调用 string result = futuretask.get(); system.out.println(result); } } class callabledemo implements callable\u0026lt;string\u0026gt; { @override public string call() throws exception { return \u0026#34;do something\u0026#34;; } } 定时器 1 2 3 4 5 6 7 8 9 10 11 12 13 public class threadtest { public static void main(string[] args) { timer timer = new timer(); timer.schedule(new timertaskdemo(),1000); } } class timertaskdemo extends timertask { @override public void run() { system.out.println(\u0026#34;do something\u0026#34;); } } 线程池 1 2 3 4 5 6 7 8 9 10 11 12 13 14 public class threadtest { public static void main(string[] args) { executorservice executor = executors.newfixedthreadpool(5); executor.execute(new executordemo()); executor.shutdown();\t//线程池销毁,正在执行和在队列等待的线程不会销毁 } } class executordemo implements runnable { @override public void run() { system.out.println(\u0026#34;do something\u0026#34;); } } 三、线程带来的风险 线程安全性问题 出现线程安全性问题的条件\n在多线程的环境下 必须有共享资源 对共享资源进行非原子性操作 解决线程安全性问题的方法\n针对多个线程操作同一共享资源——不共享资源(threadlocal、不共享、操作无状态化、不可变) 针对多个线程进行非原子性操作——将非原子性操作改成原子性操作(使用加锁机制来保证可见性和有序性以及原子性、使用jdk自带的原子性操作的类、juc提供的相应的并发工具类) 活跃性问题 死锁问题\n指两个或两个以上的进程(或线程)在执行过程中,因争夺资源而造成的一种互相等待的现象(至少两个资源),若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程。\n比喻解释:有两根筷子,线程a和线程b都抢到了一个,互不相让\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 public class deadlocktest { public static final object resource1 = new object(); public static final object resource2 = new object(); public static void main(string[] args) { new thread(() -\u0026gt; { synchronized (resource1) { try { thread.sleep(500); } catch (interruptedexception e) { e.printstacktrace(); } system.out.println(thread.currentthread().getname() + \u0026#34;:等待\u0026#34;); synchronized (resource2) { system.out.println(thread.currentthread().getname() + \u0026#34;:可以执行\u0026#34;); } } }, \u0026#34;a\u0026#34;).start(); new thread(() -\u0026gt; { synchronized (resource2) { try { thread.sleep(500); } catch (interruptedexception e) { e.printstacktrace(); } system.out.println(thread.currentthread().getname() + \u0026#34;:等待\u0026#34;); synchronized (resource1) { system.out.println(thread.currentthread().getname() + \u0026#34;:可以执行\u0026#34;); } } }, \u0026#34;b\u0026#34;).start(); } } 活锁问题\n活锁出现在两个线程互相改变对方的结束条件,最后谁也无法结束\n比喻解释:线程a和b再同一个家庭(总共有10w),一个每月攒1w(攒够20w不攒了,出去玩),一个每月花1w(花光去打工)\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 public class livelock { static volatile int count = 10; // 无法解锁,一个想加到20,一个想减到0 public static void main(string[] args) { thread t1 = new thread(() -\u0026gt; { // 期望减到 0 退出循环 while (count \u0026gt; 0) { try { timeunit.milliseconds.sleep(500); } catch (interruptedexception e) { throw new runtimeexception(e); } count--; system.out.println(\u0026#34;t1 count: \u0026#34; + count); } }, \u0026#34;t1\u0026#34;); thread t2 = new thread(() -\u0026gt; { // 期望超过 20 退出循环 while (count \u0026lt; 20) { try { timeunit.milliseconds.sleep(500); } catch (interruptedexception e) { throw new runtimeexception(e); } count++; system.out.println(\u0026#34;t2 count: \u0026#34; + count); } }, \u0026#34;t2\u0026#34;); t1.start(); t2.start(); try { t1.join(); t2.join(); } catch (interruptedexception e) { throw new runtimeexception(e); } system.out.println(\u0026#34;main end\u0026#34;); } } 饥饿问题\n是指如果线程a占用了资源r,线程b又请求封锁r,于是b等待。线程c也请求资源r,当线程a释放了r上的封锁后,系统首先批准了线程c的请求,线程b仍然等待。然后线程d又请求封锁r,当线程c释放了r上的封锁之后,系统又批准了线程d的请求\u0026hellip;\u0026hellip;,线程b可能永远等待。\n比喻解释:餐厅有两个人(厨师兼服务员),来了两波客人,客人都要求贴身服务。这样就没人做饭了,于是客人永远也吃不到饭了\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 public class threadstarvingtest { public static void main(string[] args) { executorservice executorservice = executors.newfixedthreadpool(2); executorservice.submit(() -\u0026gt; { system.out.println(currentthreadname() + \u0026#34;接待客人\u0026#34;); future\u0026lt;string\u0026gt; cook = executorservice.submit(() -\u0026gt; { system.out.println(currentthreadname() + \u0026#34;做回锅肉\u0026#34;); return \u0026#34;回锅肉\u0026#34;; }); try { system.out.println(currentthreadname() + \u0026#34;上\u0026#34; + cook.get()); } catch (interruptedexception e) { e.printstacktrace(); } catch (executionexception e) { e.printstacktrace(); } }); executorservice.submit(() -\u0026gt; { system.out.println(currentthreadname() + \u0026#34;接待客人\u0026#34;); future\u0026lt;string\u0026gt; cook = executorservice.submit(() -\u0026gt; { system.out.println(currentthreadname() + \u0026#34;做鱼香肉丝\u0026#34;); return \u0026#34;鱼香肉丝\u0026#34;; }); try { system.out.println(currentthreadname() + \u0026#34;上\u0026#34; + cook.get()); } catch (interruptedexception e) { e.printstacktrace(); } catch (executionexception e) { e.printstacktrace(); } }); } public static string currentthreadname() { return thread.currentthread().getname(); } } 性能问题 线程的生命周期开销非常高。在线程切换时存在cpu上下文切换开销,内存同步也存在着开销。 消耗过多的cpu资源。如果可运行的线程数量多于可用处理器的数量,那么有线程将会被闲置。大量空闲的线程会占用许多内存,给垃圾回收器带来压力,而且大量的线程在竞争cpu资源时还将产生其他性能的开销。 降低稳定性 四、synchronized的原理和使用 synchronized是一个:非公平、悲观、独享、互斥、可重入锁。自jdk6优化以后,基于jvm可以根据竞争激烈程度,从偏向锁\u0026ndash;\u0026raquo;轻量级锁\u0026ndash;\u0026raquo;重量级锁升级。\nsynchronized的用法 修饰方法\n修饰普通方法,相当于锁当前对象,调用者,即指 this对象 1 2 3 public synchronized void method() { system.out.println(\u0026#34;do something\u0026#34;); } 修饰静态方法,相当于锁当前类对象,也指 classname.class 1 2 3 public static synchronized void method() { system.out.println(\u0026#34;do something\u0026#34;); } 修饰代码块【可以缩小锁的范围,提升性能】\n锁普通对象和锁this 1 2 3 4 5 public void method() { synchronized(this) { system.out.println(\u0026#34;do something\u0026#34;); } } 锁定类对象classname.class 1 2 3 4 5 public void method() { synchronized(synchronizedtest.class) { system.out.println(\u0026#34;do something\u0026#34;); } } synchronized3种级别锁原理 使用了对象的markword\nmarkword总共有四种状态:无锁状态、偏向锁、轻量级锁和重量级锁。 随着锁的竞争:偏向锁\u0026ndash;\u0026gt;轻量级锁\u0026ndash;\u0026gt;重量级锁,只能升级 不同锁状态的markword结构不同 markword 数据一览\n偏向锁的原理 偏向锁状态的消息头结构\n消息头锁标志位01 是否是偏向锁【0或1】 偏向线程id 一个对象创建时\n如果开启了偏向锁(默认开启),那么对象创建后,markword 值为 0x05 即最后 3 位为 101,这时它的,thread、epoch、age 都为 0\n偏向锁是默认是延迟的,不会在程序启动时立即生效,如果想避免延迟,可以加 vm 参数-xx:biasedlockingstartupdelay=0来禁用延迟\n如果没有开启偏向锁,那么对象创建后,markword 值为 0x01 即最后 3 位为 001,这时它的 hashcode、age 都为 0,第一次用到 hashcode 时才会赋值(那么使用hash方法会使偏向锁失效)\n偏向锁衍化过程\n如果3个条件都满足【锁标志位\u0026ndash;01】,【是否是偏向锁\u0026ndash;1】,【偏向线程id\u0026ndash;当前线程】则直接获取到锁,不需要任何cas操作,而且执行完同步代码块后,并不会修改这3个条件 如果一个新的线程尝试获取锁发现【锁标志位\u0026ndash;01】,【是否是偏向锁 \u0026ndash;1】,【偏向线程id\u0026ndash;不是自己】,则会触发一个check判断偏向锁指向的线程id锁是否已经使用完了 如果使用完了,则不存在竞争,cas把偏向线程id指向自己,这个对象锁就归自己所有了 如果还在使用,竞争成立,则挂起当前线程,并达到原偏向线程释放锁之后将对象锁升级为轻量级锁 偏向锁的好处\n老线程重复使用锁,无需任何cas操作 新线程获取偏向锁,但是没有竞争,只需要在满足条件的时候cas偏向线程id即可 完美支持重入功能,而且没有任何cas操作 轻量级【自旋】锁 轻量级锁状态的消息头结构\n①消息头锁标志位00\n②指向栈中锁记录的指针\n轻量级锁衍化过程\n创建锁记录(lock record)对象,每个线程都的栈帧都会包含一个锁记录的结构,内部可以存储锁定对象的mark word 让锁记录中 object reference 指向锁对象,并尝试用 cas 替换 object 的 mark word,将 mark word 的值存入锁记录 如果 cas 失败,有两种情况\n其它线程已经持有了该 object 的轻量级锁,这时表明有竞争,进入锁膨胀过程\n自己执行了 synchronized 锁重入,那么再添加一条 lock record 作为重入的计数,如果退出则计数减一\n轻量级锁衍化过程细节描述\n检查消息头的状态:是否处于无锁状态(偏向锁状态结束,等安全点后释放锁了,就是无锁状态),不是无锁状态挂起当前线程等待锁释放\n所有争夺的线程都会拷贝一份消息头到各自的线程栈的lock record中,叫做displace mark word,并且记录自己的唯一线程标识符\ncas把公有的消息头,变成指向自己线程标识符,这个时候消息头的数据结构发生改变,变成线程引用\ncas成功的线程会执行同步操作,等到需要释放锁时把displace mark word写回到公有消息头里面,释放锁\n重入的时候,无需要任何的操作,只需要在自己的displace mark word中标记一下\ncas争夺锁失败的线程会发生自旋,自旋一定次数后还是失败的话,会修改消息头的状态为重量级锁,并且自身进入阻塞状态,等待拥有锁的线程执行结束。\n轻量级锁的优势\n\t在获取锁的耗时不长的时候(比如锁的执行时间短、或者争抢的线程不多可以很快获得锁),通过一定次数的自旋,避免了重量级锁的线程阻塞和切换,提升了响应速度也兼顾了cpu的性能。\n重量级锁 重量级锁状态的消息头结构\n①消息头锁标志位10\n②指向互斥量(重量级锁)的指针\n重量级锁衍化过程\n所有的竞争线程首先通过cas拼接到contention list这个队列里面\n当锁的所有者释放的时候,会把一些线程推入到entrylist当中,然后entrylist开始cas竞争,竞争成功就拿到锁,其它线程开始阻塞,等待下一次机会\n当有锁线程调用obj.wait方法时,它会释放锁进入waitset,当调用notify方法,会从waitset中随机选一个线程,notifyall就是全部进行操作,让他们进入entrylist\n重量级锁特点\n处于contentionlist、entrylist、waitset中的线程都处于阻塞状态,该阻塞是由操作系统来完成的 synchronized是非公平锁。synchronized在线程进入contentionlist时,等待的线程会先尝试自旋获取锁,如果获取不到就进入contentionlist,这明显对于已经进入队列的线程是不公平的。 五、早期线程通信机制 wait\\notify\\notifyall wait()、notify/notifyall()必须要在synchronized代码块执行,且一定是操作同一个对象【wait\\notify\\notifyall会操作synchronized锁定对象】。由于 wait()、notify/notifyall() 在synchronized 代码块执行,说明当前线程一定是获取了锁的。当线程执行wait()方法时候,会释放当前的锁,然后让出cpu,进入等待状态。只有当notify/notifyall()被执行时候,才会随机唤醒一个或多个正处于等待状态的线程,然后继续往下执行,直到执行完synchronized 代码块的代码或是中途遇到wait() ,再次释放锁。\nnotify/notifyall() 的执行只是唤醒沉睡的线程,而不会立即释放锁。所以尽量在使用了notify/notifyall() 后立即退出临界区,以唤醒其他线程让其获得锁\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 public class notifytest { public static void main(string[] args) throws interruptedexception { notifyrunnable notifyrunnable = new notifyrunnable(); new thread(notifyrunnable).start(); timeunit.seconds.sleep(5); notifyrunnable.setflag(false); synchronized (notifyrunnable) { notifyrunnable.notify(); } } } class notifyrunnable implements runnable { private volatile boolean flag = true; public void setflag(boolean flag) { this.flag = flag; } public synchronized void deal() { try { // synchronized的是当期对象,这里需要while循环,被唤醒之后是继续执行的 while(flag) { wait(); } system.out.println(\u0026#34;唤醒了一个线程\u0026#34;); } catch ( interruptedexception e) { e.printstacktrace(); } } @override public void run() { deal(); } } 当一个线程生命周期结束【线程run完成】,会发送这个线程对象的notifyall()\npark \u0026amp; unpark 每个线程都有自己的一个 parker 对象,由三部分组成 _counter ,_cond和_mutex。打个比喻线程就像一个旅人,parker 就像他随身携带的背包,条件变量就好比背包中的帐篷。_counter 就好比背包中的备用干粮(0 为耗尽,1 为充足)\n(1)调用 park 就是要看需不需要停下来歇息\n如果备用干粮耗尽,那么钻进帐篷歇息 如果备用干粮充足,那么不需停留,继续前进 (2)调用 unpark,就好比令干粮充足\n如果这时线程还在帐篷,就唤醒让他继续前进 如果这时线程还在运行,那么下次他调用 park 时,仅是消耗掉备用干粮,不需停留继续前进(仅会补充一份备用干粮) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 public class paker { public static void main(string[] args) { thread t1 = new thread(() -\u0026gt; { system.out.println(\u0026#34;start...\u0026#34;); try { timeunit.seconds.sleep(1); } catch (interruptedexception e) { throw new runtimeexception(e); } system.out.println(\u0026#34;park...\u0026#34;); locksupport.park(); system.out.println(\u0026#34;resume...\u0026#34;); }); t1.start(); try { timeunit.seconds.sleep(3); } catch (interruptedexception e) { throw new runtimeexception(e); } locksupport.unpark(t1); } } 特点\n与 object 的 wait \u0026amp; notify 相比\nwait,notify 和 notifyall 必须配合 object monitor 一起使用较为重量级 park \u0026amp; unpark 是以线程为单位来【阻塞】和【唤醒】线程,而 notify 只能随机唤醒一个等待线程,notifyall 是唤醒所有等待线程,就不那么【精确】 park \u0026amp; unpark 可以先 unpark,而 wait \u0026amp; notify 不能先 notify interrupt方法 (1)打断 sleep,wait,join 的线程,会清空打断状态\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class interrupttest { public static void main(string[] args) throws interruptedexception { thread t1 = new thread(()-\u0026gt;{ try { timeunit.seconds.sleep(3); } catch (interruptedexception e) { throw new runtimeexception(e); } }, \u0026#34;t1\u0026#34;); t1.start(); timeunit.seconds.sleep(1); t1.interrupt(); // 打印false system.out.println(\u0026#34; 打断状态: \u0026#34; + t1.isinterrupted()); } } (2)打断正常运行的线程,不会清空打断状态\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public class interrupttest { public static void main(string[] args) throws interruptedexception { thread t1 = new thread(()-\u0026gt;{ while(true) { thread current = thread.currentthread(); boolean interrupted = current.isinterrupted(); if(interrupted) { system.out.println(\u0026#34; 打断状态: \u0026#34; + interrupted); break; } } }, \u0026#34;t2\u0026#34;); t1.start(); timeunit.seconds.sleep(1); t1.interrupt(); } } (3)打断 park 线程,不会清空打断状态\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public class interrupttest { public static void main(string[] args) throws interruptedexception { thread t1 = new thread(() -\u0026gt; { system.out.println(\u0026#34;park...\u0026#34;); locksupport.park(); system.out.println(\u0026#34;unpark...\u0026#34;); // 打印 true system.out.println(\u0026#34;打断状态: \u0026#34; + thread.currentthread().isinterrupted()); }, \u0026#34;t1\u0026#34;); t1.start(); timeunit.seconds.sleep(1); t1.interrupt(); } } 线程的join join内部使用的是判断线程是否存活如果存活一直调用wait()。唤醒原理是当调用者的线程死亡时自动发送的notifyall(),此时wait()被唤醒且线程已死亡。join这种机制并不常用。\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public class joindemo { public static void main(string[] args) { thread t1 = new thread(() -\u0026gt; { try { timeunit.seconds.sleep(3); } catch (interruptedexception e) { system.out.println(e); } }); t1.start(); try { t1.join(); } catch (interruptedexception e) { throw new runtimeexception(e); } // 3s 之后才会打印,即t1执行完成打印 system.out.println(\u0026#34;main end\u0026#34;); } } join源码\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 public final void join() throws interruptedexception { join(0); } public final synchronized void join(long millis) throws interruptedexception { long base = system.currenttimemillis(); long now = 0; if (millis \u0026lt; 0) { throw new illegalargumentexception(\u0026#34;timeout value is negative\u0026#34;); } if (millis == 0) { // 如果线程存活一直调用wait(即使被打断也会继续阻塞) while (isalive()) { wait(0); } } else { // 有时间的等待,考虑了打断的影响 while (isalive()) { long delay = millis - now; if (delay \u0026lt;= 0) { break; } wait(delay); now = system.currenttimemillis() - base; } } } 如果threadobj.join()线程对象不是存活状态不会产生阻塞\n如果threadobj.join()线程对象是存活状态直接调用notify()是不会放行的\n六、volatile原理与使用 volatile原子可见性 java内存模型规定在多线程情况下,线程操作主内存(类比内存条)变量,需要通过线程独有的工作内存(类比cpu高速缓存)拷贝主内存变量副本来进行。此处的所谓内存模型要区别于通常所说的虚拟机堆模型\n如果是一个大对象,并不会从主内存完全拷贝一份,而是这个被访问对象引用的对象、对象中的字段可能存在拷贝\n线程独有的工作内存和进程内存(主内存)之间通过8中原子操作来实现,如下所示\nread load\t从主存复制变量到当前工作内存\nuse assign 执行代码,改变共享变量值,可以多次出现\nstore write 用工作内存数据刷新主存相关内容\n这些操作并不是原子性,也就是在read load之后,如果主内存变量发生修改之后,线程工作内存中的值由于已经加载,不会产生对应的变化,所以计算出来的结果会和预期不一样,对于volatile修饰的变量,jvm虚拟机只是保证从主内存加载到线程工作内存的值是最新的。\nvolatile的禁止指令重排序 volatile止指令重排序的实现原理\nvolatile变量的禁止指令重排序是基于内存屏障(memory barrier)实现【synchronized不具有此功能】。内存屏障又称内存栅栏,是一个cpu指令,内存屏障会导致jvm无法优化屏障内的指令集。\n对volatile变量的写指令后会加入写屏障,对共享变量的改动,都同步到主存当中\n对volatile变量的读指令前会加入读屏障,对共享变量的读取,加载的是主存中最新数据\n如果单例模式中的懒汉式变量没有使用volatile仅仅使用synchronized双重检测加锁依旧会因为重排序问题产生线程安全性问题参见。\n七、原子操作类 jdk提供了原子类型操作类,保证原子性,保证线程安全,这些类使用了cas算法进行无锁运算避免阻塞的发生。\n使用原子的方式更新基本类型\natomicboolean\natomicinteger\natomiclong\n使用原子的方式更新数组类型\natomicintegerarray\natomiclongarray\natomicreferencearray\n使用原子的方式更新引用类型\natomicreference\natomicstampedreference【使用时间戳记录引用版本,解决aba问题,但时间戳相同也会产生aba问题】\natomicmarkablereference【使用boolean类型记录引用版本,适用在只需要知道对象是否有被修改的情景】\n使用原子的方式更新字段\natomicintegerfieldupdater\natomiclongfieldupdater\natomicreferencefieldupdater\n高并发环境下更好性能的更新基本类型\ndoubleadder\nlongadder\ndoubleaccumulator\nlongaccumulator\n将基数进行拆分成为数组,这样共享资源变多,每次一个线程抢占更新一个数组的元素,最后进行运算,在线程数量不变的情况下,共享资源变多可增加并发效率。因为操作的是数组,所以以上四个类还解决了伪共享问题\nlongaccumulator相比longadder 可以提供累加器初始非0值和指定累加规则【比如乘法】,后者只能默认为0且只能为相加\n八、lock\u0026amp;aqs\u0026amp;condition lock接口是jdk锁实现的标准 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public interface lock { // 获取锁。如果锁不可用,将禁用当前线程,并且在获得锁之前,该线程将一直处于休眠状态 void lock(); // 获取锁,等待过程中如果当前线程被中断,则抛出异常,此时加锁还未成功不需要释放资源 void lockinterruptibly() throws interruptedexception; // 仅在调用时锁为空闲状态才获取该锁。如果锁可用立即返回值true。如果锁不可用,立即返回值 false boolean trylock(); // 如果锁在给定的等待时间内空闲,并且当前线程未被中断,则获取锁,如果等待期间被中断,则抛出异常 boolean trylock(long time, timeunit unit) throws interruptedexception; // 释放锁。锁必须由当前线程持有。调用condition.await()将在等待前以原子方式释放锁 void unlock(); // 返回绑定到此lock实例的新condition实例 condition newcondition(); } 锁相关类\nreentrantlock 可重入锁 reentrantreadwritelock 可重入读写锁,非公平状态下,可能会发生饥饿问题 stampedlock jdk8对reentrantreadwritelock的升级[详见] aqs抽象类 abstractqueuedsynchronizer是readwritelock、reentrantlock、stampedlock、semaphore、reentrantreadwritelock、synchronousqueue、futuretask等同步类的内部工具帮助类。\naqs支持独占锁(exclusive)和共享锁(share)两种模式\n独占锁:只能被一个线程获取到(reentrantlock) 共享锁:可以被多个线程同时获取(countdownlatch,readwritelock) 无论是独占锁还是共享锁,本质上都是对aqs内部的一个变量state的获取。state是一个原子的int变量,用来表示锁状态、资源数等。\naqs内部实现了两个队列,一个同步队列,一个条件队列\n同步队列的作用是:当线程获取资源失败之后,就进入同步队列的尾部保持自旋等待,不断判断自己是否是链表的头节点,如果是头节点,就不断参试获取资源,获取成功后则退出同步队列。 同步队列的作用是:为lock实现的一个基础同步器,并且一个线程可能会有多个条件队列,只有在使用了condition才会存在条件队列。\naqs的基本属性和方法\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 //头节点 private transient volatile node head; //尾节点 private transient volatile node tail; //共享变量,使用volatile修饰保证线程可见性,用于记录了加锁次数 private volatile int state; // 队列头节点,头结点不储存数据 private transient volatile node head; // 队列尾节点 private transient volatile node tail; 同步队列和条件队列都是由一个个node组成的\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 static final class node { /** 节点为共享模式下等待 */ static final node shared = new node(); /** 节点为独占模式下等待 */ static final node exclusive = null; /** 当前节点由于超时或中断被取消 */ static final int cancelled = 1; /** 表示当前节点的前节点被阻塞 */ static final int signal = -1; /** 当前节点在等待condition */ static final int condition = -2; /** 状态需要向后传播 */ static final int propagate = -3; volatile int waitstatus; volatile node prev; volatile node next; volatile thread thread; node nextwaiter; } 重要方法的源码解析\n1 2 3 4 5 //独占模式下获取资源 public final void acquire(int arg) { if (!tryacquire(arg) \u0026amp;\u0026amp; acquirequeued(addwaiter(node.exclusive), arg)) selfinterrupt(); } acquire(int arg)首先调用tryacquire(arg)尝试直接获取资源具体实现由子类负责。\n如果直接获取到资源,直接return\n如果没有直接获取到资源,将当前线程加入等待队列的尾部,并标记为独占模式,使线程在等待队列中自旋等待获取资源,直到获取资源成功才返回,如果线程在等待的过程中被中断过,就返回true,否则返回false\n返回false就不需要判断中断了,直接return 返回true执行selfinterrupt()方法,而这个方法就是简单的中断当前线程thread.currentthread().interrupt();其作用就是补上在自旋时没有响应的中断 可以看出在整个方法中,最重要的就是acquirequeued(addwaiter(node.exclusive), arg)\n首先看node addwaiter(node mode),这个方法的作用就是添加一个等待者,添加等待者就是将该节点加入等待队列\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 private node addwaiter(node mode) { node node = new node(thread.currentthread(), mode); node pred = tail; //尝试快速入队 if (pred != null) { //队列已经初始化 node.prev = pred; if (compareandsettail(pred, node)) { pred.next = node; return node; //快速入队成功后,就直接返回了 } } //快速入队失败,也就是说队列都还每初始化 enq(node); return node; } //执行入队 private node enq(final node node) { for (;;) { node t = tail; // 如果没有队尾即还没初始化 if (t == null) { //如果队列为空,用一个空节点充当队列头 if (compareandsethead(new node())) //尾部指针也指向队列头 tail = head; } else { //队列已经初始化,入队 node.prev = t; if (compareandsettail(t, node)) { t.next = node; //打断循环 return t; } } } } 然后看acquirequeued(final node node, int arg),等待出队\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 final boolean acquirequeued(final node node, int arg) { boolean failed = true; try { boolean interrupted = false; for (;;) { //拿到node的上一个节点 final node p = node.predecessor(); //前置节点为head,说明可以尝试获取资源。排队成功后,尝试拿锁 if (p == head \u0026amp;\u0026amp; tryacquire(arg)) { //获取成功,更新head节点 sethead(node); p.next = null; // help gc failed = false; return interrupted; } //尝试拿锁失败后,根据条件进行park if (shouldparkafterfailedacquire(p, node) \u0026amp;\u0026amp; parkandcheckinterrupt()) interrupted = true; } } finally { if (failed) cancelacquire(node); } } //获取资源失败后,检测并更新等待状态 private static boolean shouldparkafterfailedacquire(node pred, node node) { int ws = pred.waitstatus; if (ws == node.signal) return true; if (ws \u0026gt; 0) { do { //如果前节点取消了,那就往前找到一个等待状态的接替你,并排在它的后面 node.prev = pred = pred.prev; } while (pred.waitstatus \u0026gt; 0); pred.next = node; } else { compareandsetwaitstatus(pred, ws, node.signal); } return false; } //阻塞当前线程,返回中断状态 private final boolean parkandcheckinterrupt() { locksupport.park(this); return thread.interrupted(); } 具体的boolean tryacquire(int acquires)实现有所不同\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 // 公平锁的实现 protected final boolean tryacquire(int acquires) { final thread current = thread.currentthread(); int c = getstate(); if (c == 0) { if (!hasqueuedpredecessors() \u0026amp;\u0026amp; compareandsetstate(0, acquires)) { setexclusiveownerthread(current); return true; } } else if (current == getexclusiveownerthread()) { int nextc = c + acquires; if (nextc \u0026lt; 0) throw new error(\u0026#34;maximum lock count exceeded\u0026#34;); setstate(nextc); return true; } return false; } // 非公平锁的实现 final boolean nonfairtryacquire(int acquires) { final thread current = thread.currentthread(); int c = getstate(); if (c == 0) { if (compareandsetstate(0, acquires)) { setexclusiveownerthread(current); return true; } } else if (current == getexclusiveownerthread()) { int nextc = c + acquires; if (nextc \u0026lt; 0) // overflow throw new error(\u0026#34;maximum lock count exceeded\u0026#34;); setstate(nextc); return true; } return false; } aqs的设计思想\n(1)获取锁的逻辑\n1 2 3 4 5 6 while(state 状态不允许获取) { if(队列中还没有此线程) { 入队并阻塞 } } 当前线程出队 (2)释放锁的逻辑\n1 2 3 if(state 状态允许了) { 恢复阻塞的线程(s) } condition condition对象是依赖于lock对象的,即condition对象需要通过lock对象进行创建出来(调用lock对象的newcondition()方法),condition是用于替代wait()/notify()/notifyall()的接口标准。condition调用时必须和lock、unlock联用,如果没被独占会被抛出异常(因为存储在node的nextwaiter上)\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public interface condition { // 一直等待可能抛出中断异常 void await() throws interruptedexception; // 一直等待不会被中断异常打扰 void awaituninterruptibly(); // 等待指定纳秒,期间可能抛出中断异常 long awaitnanos(long nanostimeout) throws interruptedexception; // 等待指定时间,期间可能抛出中断异常 boolean await(long time, timeunit unit) throws interruptedexception; // 等待到指定时间,期间可能抛出中断异常 boolean awaituntil(date deadline) throws interruptedexception; // 发送信号,解除任意一个等待 void signal(); // 发送信号,解除所有等待 void signalall(); } conditionobject是condition的实现类是一个aqs的内部类,condition可以实现各种队列【有界队列、阻塞队列等】,conditionobject实现了一个fifo的等待队列await方法在队列后面添加一个元素,signal释放一个元素【有序释放】。\n九、线程工具类 threadlocal threadloal变量,线程局部变量,同一个 threadlocal 所包含的对象,在不同的 thread 中有不同的副本。\n因为每个 thread 内有自己的实例副本,且该副本只能由当前 thread 使用\n每个 thread 有自己的实例副本,且其它 thread 不可访问,那就不存在多线程间共享的问题\nthreadloal正真保存变量数据的是threadloalmap\nthreadlocal类的有个初始化方法是可以被重写的,用于赋初值\n1 2 3 protected t initialvalue() { return null; } threadlocal使用示例\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 public class threadlocaldemo implements runnable { private static threadlocal\u0026lt;integer\u0026gt; threadlocal = new threadlocal\u0026lt;integer\u0026gt;() { @override protected integer initialvalue() { return 0; } }; @override public void run() { threadlocal.set(threadlocal.get()+1); } } threadlocal内存泄露\nthreadlocal本身并不存储值,它依赖于thread类中的threadlocalmap,当调用set(t value)时,threadlocal将自身作为key,值作为value存储到thread类中的threadlocalmap中(存储和获取其实都是操作的thread对象),这就相当于所有线程读写的都是自身的一个私有副本,线程之间的数据是隔离的,互不影响,也就不存在线程安全问题了。\n由于threadlocal对象是弱引用,如果外部没有强引用指向它,它就会被gc回收,导致entry的key为null,如果这时value外部也没有强引用指向它,那么value就永远也访问不到了,按理也应该被gc回收,但是由于entry对象还在强引用value,导致value无法被回收,这时「内存泄漏」就发生了,value成了一个永远也无法被访问,但是又无法被回收的对象。\nentry对象属于threadlocalmap,threadlocalmap属于thread,如果线程本身的生命周期很短,短时间内就会被销毁,那么「内存泄漏」立刻就会得到解决,只要线程被销毁,value也会随之被回收。问题是,线程本身是非常珍贵的计算机资源,很少会去频繁的创建和销毁,一般都是通过线程池来使用,这就将线程的生命周期大大拉长,「内存泄漏」的影响也会越来越大。\ncountdownlatch \tcountdownlatch是一个同步类工具,不涉及锁定,当count的值为零时当前线程继续运行。在不涉及同步,只涉及线程通信的时候,使用它较为合适。\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 // 计算多行数字合 public class countdownlatchdemo { private countdownlatch countdownlatch; private int storenum[]; public countdownlatchdemo(final int numslines) { this.countdownlatch = new countdownlatch(numslines); this.storenum = new int[numslines]; } //计算每行数字合 private void calc(int index, int calcnums[]){ storenum[index] = 0; for (int i = 0; i \u0026lt; calcnums.length; i++) { storenum[index] += calcnums[i]; } countdownlatch.countdown(); } //总计 private int calcsum() throws interruptedexception { countdownlatch.await(); int result = 0; for (int i = 0; i \u0026lt; storenum.length; i++) { result+= storenum[i]; } return result; } public static void main(string[] args) throws interruptedexception { countdownlatchdemo countdownlatchdemo = new countdownlatchdemo(nums.length); for (int i = 0; i \u0026lt; nums.length; i++) { int finali = i; new thread(new runnable() { @override public void run() { countdownlatchdemo.calc(finali, nums[finali]); } }).start(); } int sum = countdownlatchdemo.calcsum(); system.out.println(sum); } } countdownlatch的原理\n构造函数其实是初始化aqs的state 1 2 3 4 5 6 7 8 public countdownlatch(int count) { if (count \u0026lt; 0) throw new illegalargumentexception(\u0026#34;count \u0026lt; 0\u0026#34;); this.sync = new sync(count); } sync(int count) { setstate(count); } await()是自旋等待计数变为0的过程 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 public void await() throws interruptedexception { sync.acquiresharedinterruptibly(1); } public final void acquiresharedinterruptibly(int arg) throws interruptedexception { if (thread.interrupted()) throw new interruptedexception(); // tryacquireshared(arg) ==》return (getstate() == 0) ? 1 : -1; // 即当state不为0时进入,为0直接运行不阻塞 if (tryacquireshared(arg) \u0026lt; 0) doacquiresharedinterruptibly(arg); } private void doacquiresharedinterruptibly(int arg) throws interruptedexception { // 加入一个共享队列元素 final node node = addwaiter(node.shared); boolean failed = true; try { for (;;) { final node p = node.predecessor(); if (p == head) { // tryacquireshared(arg) ==》(getstate() == 0) ? 1 : -1 // 即如果是队列首元素就等待释放 int r = tryacquireshared(arg); if (r \u0026gt;= 0) { setheadandpropagate(node, r); p.next = null; // help gc failed = false; return; } } if (shouldparkafterfailedacquire(p, node) \u0026amp;\u0026amp; parkandcheckinterrupt()) throw new interruptedexception(); } } finally { if (failed) cancelacquire(node); } } } cyclicbarrier \tcyclicbarrier可以使一定数量的线程反复地在栅栏位置处汇集。当线程到达栅栏位置时将调用await方法,这个方法将阻塞直到指定数量的线程到达栅栏位置。如果指定数量的线程到达栅栏位置,那么栅栏将打开,然后栅栏将被重置以便下次使用。\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 public class cyclicbarrierdemo { public void meet(cyclicbarrier cyclicbarrier){ string threadname = thread.currentthread().getname(); system.out.println(threadname + \u0026#34; 到场 \u0026#34;); try { thread.sleep(1000); cyclicbarrier.await(); } catch (interruptedexception e) { // 当前线程被中断 e.printstacktrace(); } catch (brokenbarrierexception e) { // 不是被中断的线程,但是其它相关线程await()时发生中断 e.printstacktrace(); } system.out.println(threadname + \u0026#34; 准备开会发言\u0026#34;); } public static void main(string[] args) { cyclicbarrierdemo cyclicbarrierdemo = new cyclicbarrierdemo(); cyclicbarrier cyclicbarrier = new cyclicbarrier(5); for (int i = 0; i \u0026lt; 5; i++) { new thread(new runnable() { @override public void run() { cyclicbarrierdemo.meet(cyclicbarrier); } }).start(); } } } cyclicbarrier的原理\n\tcyclicbarrier内部使用了reentrantlock和condition完成栅栏操作\nsemaphore \tsemaphore控制了最多同时执行的线程个数,但不控制线程创建的个数,线程创建之后会阻塞不是不创建线程。semaphore可以灵活控制释放和需要解锁资源的个数。\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 public class semaphoredemo { private semaphore semaphore = new semaphore(5); public void dosomething() { try { /** * 在 semaphore.acquire() 和 semaphore.release()之间的代码,同一时刻只允许制定个数的线程进入, * 因为semaphore的构造方法是5,则同一时刻只允许5个线程进入,其他线程只能等待。 **/ semaphore.acquire(); system.out.println(thread.currentthread().getname() + \u0026#34;:dosomething start-\u0026#34; + new date()); thread.sleep(2000); system.out.println(thread.currentthread().getname() + \u0026#34;:dosomething end-\u0026#34; + new date()); semaphore.release(); } catch (interruptedexception e) { e.printstacktrace(); } } public static void main(string[] args) { semaphoredemo service = new semaphoredemo(); for (int i = 0; i \u0026lt; 20; i++) { new thread(new runnable() { @override public void run() { service.dosomething(); } }).start(); } } } semaphore的原理\n\tsemaphore内部使用了aqs来完成等待队列和计数。\nexchanger \t一个线程在完成一定的事务后想与另一个线程交换数据,则第一个先拿出数据的线程会一直等待第二个线程,直到第二个线程拿着数据到来时才能彼此交换对应数据。\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 // 每次计算完成交换结果 public class exchangertest { static class producer extends thread { private exchanger\u0026lt;integer\u0026gt; exchanger; private static int data = 0; producer(exchanger\u0026lt;integer\u0026gt; exchanger) { super(\u0026#34;producer\u0026#34;); this.exchanger = exchanger; } @override public void run() { for (int i=1; i\u0026lt;5; i++) { try { timeunit.seconds.sleep(1); data = i; system.out.println(getname()+\u0026#34; 交换前:\u0026#34; + data); data = exchanger.exchange(data); system.out.println(getname()+\u0026#34; 交换后:\u0026#34; + data); } catch (interruptedexception e) { e.printstacktrace(); } } } } static class consumer extends thread { private exchanger\u0026lt;integer\u0026gt; exchanger; private static int data = 0; consumer(exchanger\u0026lt;integer\u0026gt; exchanger) { super(\u0026#34;consumer\u0026#34;); this.exchanger = exchanger; } @override public void run() { while (true) { data = 0; system.out.println(getname()+\u0026#34; 交换前:\u0026#34; + data); try { timeunit.seconds.sleep(1); data = exchanger.exchange(data); } catch (interruptedexception e) { e.printstacktrace(); } system.out.println(getname()+\u0026#34; 交换后:\u0026#34; + data); } } } public static void main(string[] args) throws interruptedexception { exchanger\u0026lt;integer\u0026gt; exchanger = new exchanger\u0026lt;integer\u0026gt;(); new producer(exchanger).start(); new consumer(exchanger).start(); } } 十、future模式 \t从jdk5开始提供了callable和future,通过它们可以在任务执行完毕之后得到任务执行结果。future模式的核心思想是能够让执行线程在原来需要同步等待的这段时间用来做其他的事情。(因为可以异步获得执行结果,所以不用一直同步等待去获得执行结果)\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 public class futuredemo { private static class product implements callable\u0026lt;product\u0026gt; { @override public product call() throws exception { system.out.println(\u0026#34;生成产品中...\u0026#34;); thread.sleep(5000); system.out.println(\u0026#34;生成产品结束...\u0026#34;); return new product(); } } public static void main(string[] args) { futuretask\u0026lt;product\u0026gt; futuretask = new futuretask\u0026lt;\u0026gt;(new product()); // 使用futuretask创建一个thread,futuretask实现了runnable接口 thread thread = new thread(futuretask); // 启动线程任务 thread.start(); // 此时futuretask任务在其它线程中执行,主线程不受影响 system.out.println(\u0026#34;干点其他事...\u0026#34;); try { // 此时需要futuretask任务执行的结果,会在此一直等候 product product = futuretask.get(); } catch (interruptedexception e) { system.out.println(\u0026#34;发生中断\u0026#34;); } catch (executionexception e) { system.out.println(\u0026#34;执行过程中发生异常 \u0026#34; + e.getmessage()); } } } futuretask实现了runnable接口,其实callable接口会在futuretask的run方法被调用时执行call()方法,在调用get()方法是等待call()方法执行完成,获取执行结果。\ncompletefuture future获得异步执行结果 有两种方法:调用get()或者轮询isdone()是否为true,这两种方法都不是太好,因为主线程也会被迫等待。为了减少这种等待 jdk8引入了这个completefuture对future做了改进,可以传入回调对象\n异步执行,无返回结果,但是返回了future对象\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 public static void main(string[] args) { runnable runnable = () -\u0026gt; { system.out.println(\u0026#34;执行无返回结果的异步任务-开始\u0026#34;); try { timeunit.seconds.sleep(5); } catch (interruptedexception e) { e.printstacktrace(); } system.out.println(\u0026#34;执行无返回结果的异步任务-结束\u0026#34;); }; completablefuture\u0026lt;void\u0026gt; futurevoid = completablefuture.runasync(runnable); futurevoid.join(); } 异步执行阻塞获取结果\n1 2 3 4 5 6 7 8 9 10 11 12 13 public static void main(string[] args) { completablefuture\u0026lt;string\u0026gt; future = completablefuture.supplyasync(() -\u0026gt; { system.out.println(\u0026#34;执行有返回值的异步任务\u0026#34;); try { timeunit.seconds.sleep(5); } catch (interruptedexception e) { e.printstacktrace(); } return \u0026#34;hello world\u0026#34;; }); string result = future.get(); system.out.println(result); } 异步执行,阻塞获取结果后对结果进行运算处理,不改变最终结果\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 public static void main(string[] args) { completablefuture\u0026lt;string\u0026gt; future = completablefuture.supplyasync(() -\u0026gt; { system.out.println(\u0026#34;执行有返回值的异步任务\u0026#34;); try { timeunit.seconds.sleep(5); } catch (interruptedexception e) { e.printstacktrace(); } return \u0026#34;hello world\u0026#34;; }); string result2 = future.whencomplete(new biconsumer\u0026lt;string, throwable\u0026gt;() { @override public void accept(string t, throwable action) { t = t + 1; system.out.println(\u0026#34;任务执行后结果处理\u0026#34;); } }).exceptionally(new function\u0026lt;throwable, string\u0026gt;() { @override public string apply(throwable t) { system.out.println(\u0026#34;任务执行后结果额外处理-如果有异常进入此处\u0026#34;); return \u0026#34;异常结果\u0026#34;; } }).get(); string result = future.get(); system.out.println(result); system.out.println(\u0026#34;最终结果 \u0026#34; + result2); } thencombine会将两个任务的执行结果作为所提供函数的参数,且该方法有返回值\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public static void main(string[] args) { completablefuture\u0026lt;integer\u0026gt; cf1 = completablefuture.supplyasync(() -\u0026gt; { system.out.println(thread.currentthread() + \u0026#34; cf1 do something....\u0026#34;); return 1; }); completablefuture\u0026lt;integer\u0026gt; cf2 = completablefuture.supplyasync(() -\u0026gt; { system.out.println(thread.currentthread() + \u0026#34; cf2 do something....\u0026#34;); return 2; }); completablefuture\u0026lt;integer\u0026gt; cf3 = cf1.thencombine(cf2, (a, b) -\u0026gt; { system.out.println(thread.currentthread() + \u0026#34; cf3 do something....\u0026#34;); return a + b; }); system.out.println(\u0026#34;cf3结果-\u0026gt;\u0026#34; + cf3.get()); } thenacceptboth同样将两个任务的执行结果作为方法入参,但是无返回值\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public static void main(string[] args) { completablefuture\u0026lt;integer\u0026gt; cf4 = completablefuture.supplyasync(() -\u0026gt; { system.out.println(thread.currentthread() + \u0026#34; cf4 do something....\u0026#34;); return 1; }); completablefuture\u0026lt;integer\u0026gt; cf5 = completablefuture.supplyasync(() -\u0026gt; { system.out.println(thread.currentthread() + \u0026#34; cf5 do something....\u0026#34;); return 2; }); completablefuture\u0026lt;void\u0026gt; cf6 = cf4.thenacceptboth(cf5, (a, b) -\u0026gt; { system.out.println(thread.currentthread() + \u0026#34; cf6 do something....\u0026#34;); system.out.println(\u0026#34;处理结果不返回:\u0026#34;+(a + b)); }); } allof多个任务都执行完成后才会执行,只有有一个任务执行异常,则返回的completablefuture执行get方法时会抛出异常,如果都是正常执行,则get返回null;anyof多个任务只要有一个任务执行完成,则返回的completablefuture执行get方法时会抛出异常,如果都是正常执行,则get返回执行完成任务的结果\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 public static void main(string[] args) { completablefuture\u0026lt;string\u0026gt; cf7 = completablefuture.supplyasync(() -\u0026gt; { try { system.out.println(thread.currentthread() + \u0026#34; cf7 do something....\u0026#34;); thread.sleep(2000); } catch (interruptedexception e) { e.printstacktrace(); } system.out.println(\u0026#34;cf7 任务完成\u0026#34;); return \u0026#34;cf7 任务完成\u0026#34;; }); completablefuture\u0026lt;string\u0026gt; cf8 = completablefuture.supplyasync(() -\u0026gt; { try { system.out.println(thread.currentthread() + \u0026#34; cf8 do something....\u0026#34;); thread.sleep(5000); } catch (interruptedexception e) { e.printstacktrace(); } system.out.println(\u0026#34;cf8 任务完成\u0026#34;); return \u0026#34;cf8 任务完成\u0026#34;; }); completablefuture\u0026lt;string\u0026gt; cf9 = completablefuture.supplyasync(() -\u0026gt; { try { system.out.println(thread.currentthread() + \u0026#34; cf9 do something....\u0026#34;); thread.sleep(3000); } catch (interruptedexception e) { e.printstacktrace(); } system.out.println(\u0026#34;cf9 任务完成\u0026#34;); return \u0026#34;cf9 任务完成\u0026#34;; }); completablefuture\u0026lt;void\u0026gt; cfall = completablefuture.allof(cf7, cf8, cf9); system.out.println(\u0026#34;cfall结果-\u0026gt;\u0026#34; + cfall.get()); completablefuture\u0026lt;object\u0026gt; cfany = completablefuture.anyof(cf7, cf8, cf9); system.out.println(\u0026#34;cfany结果-\u0026gt;\u0026#34; + cfany.get()); } 十一、fork/join框架 \tfork/join 框架:就是在必要的情况下,将一个大任务,进行拆分(fork)成若干个小任务(拆到不可再拆时),再将一个个的小任务运算的结果进行join 汇总。详细参见fork/join框架\n十二、并发容器 copyonwrite容器 【copyonwritearraylist、copyonwritearrayset】\n\tcopyonwrite容器即写时复制的容器。通俗的理解是当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行copy,复制出一个新的容器,然后新的容器添加元素,再将原容器的引用指向新的容器。这样做的好处是可以并发读,不需要加锁。\n\t在进行同时进行add()操作时依旧会加锁,此时不影响任何读操作。\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 public boolean add(e e) { final reentrantlock lock = this.lock; lock.lock(); try { object[] elements = getarray(); int len = elements.length; object[] newelements = arrays.copyof(elements, len + 1); newelements[len] = e; setarray(newelements); return true; } finally { lock.unlock(); } } 并发map 【concurrenthashmap、concurrentskiplistmap(支持排序)】\n\tconcurrenthashmap内部使用段(segment)来表示这些不同的部分,每个段其实就是一个小的hashtable,它们有自己的锁。只要多个修改操作发生在不同的段上,它们就可以并发进行。把一个整体分成了16个段。也就是说最高支持16个线程的并发修改操作。而且大量使用volatile关键字,第一时间获取修改的内容。\n非阻塞queue 【concurrentlinkedqueue、concurrentlinkeddeque】\n\t是一个适用于高并发场景下的队列,通过cas无锁的方式,实现了高并发状态下的高性能。它是一个基于链接节点的无界线程安全队列。该队列不允许null元素。\nadd()和offer()都是加入元素,无区别\npoll()和peek()都是取头元素节点,前者会删除元素,后者不会\n阻塞queue 【arrayblockingqueue、linkedblockingqueue、linkedblockingdeque、priorityblockingqueue】\narrayblockingqueue:基于数组的有界阻塞队列实现,在arrayblockingqueue内部,维护了一个定长数组,以便从缓存队列中的数据对象,其实内部没实现读写分离,也就意味着生产者和消费者不能完全并行,长度需要定义,可以指定先进先出或者先进后出,在很多场合非常适合使用。 linkedblockingqueue:基于链表的阻塞队列,同arrayblockingqueue类似,其内部也维持着一个数据缓存队列。linkedblockingqueue内部采用分离锁(读写分离两个锁),从而实现生产者和消费者操作的完全并行运行。他是一个无界队列(如果初始化指定长度则为有界队列)。 priorityblockingqueue:基于优先级的阻塞队列(队列中的对象必须实现comparable接口),内部控制线程同步的锁采用公平锁,也是无界队列。 特殊queue delayqueue:带有延迟时间的queue,其中的元素只有当其指定的延迟时间到了,才能够从队列中获取到该元素。delayqueue中的元素必须实现delayed接口,delayqueue是一个没有大小限制的队列。delayqueue支持阻塞和非阻塞两种模式。\nsynchronousqueue:一种没有缓冲的队列,生存者生产的数据直接会被消费者获取并消费。每个put操作必须等待一个take,反之亦然。同步队列没有任何内部容量,甚至连一个队列的容量都没有。\n十三、线程池 线程池的优势 降低资源消耗。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。 提高响应速度。当任务到达时,任务可以不需要的等到线程创建就能立即执行。 提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。 使用原始api创建线程池 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 /** * corepoolsize:线程池的核心大小,当提交一个任务到线程池时,线程池会创建一个线程来执行任务 * 即使其他空闲的基本线程能够执行新任务也会创建线程,如需要执行的任务数大于线 * 程池基本大小时就不再创建。如果调用了线程池的prestartallcorethreads()方法 * 线程池会提前创建并启动所有基本线程。 * maximumpoolsize:线程池最大大小,线程池允许创建的最大线程数。如果队列满了,并且已创建的线程数 * 小于最大线程数大于等于核心线程数,则线程池会再创建新的线程执行任务。如果使用 * 了无界的任务队列这个参数就没什么效果。 * keepalivetime:救急线程活动保持时间,线程池的工作线程空闲后,保持存活的时间。所以如果任务很多 * 并且每个任务执行的时间比较短,可以调大这个时间,提高线程的利用率。 * timeunit:救急线程活动保持时间的单位,可选的单位有天(days),小时(hours),分钟(minutes), * 毫秒(milliseconds),微秒(microseconds, 千分之一毫秒)和毫微秒(nanoseconds, * 千分之一微秒) * workqueue:任务对列,用于保存等待执行的任务的阻塞队列 * - arrayblockingqueue:基于数组结构的有界阻塞队列 * - linkedblockingqueue:基于链表的阻塞队列,如果没构造函数没传入队列大小则为无界队列 * executors.newfixedthreadpool()使用了这个队列 * - synchronousqueue:一个不存储元素的阻塞队列。每个插入操作必须等到另一个线程调用 * 移除操作,否则插入操作一直处于阻塞状态 * executors.newcachedthreadpool使用了这个队列 * - priorityblockingqueue:个具有优先级得无限阻塞队列 * threadfactory:用于设置创建线程的工厂,可以通过线程工厂给每个创建出来的线程设置更有意义的名字, * debug和定位问题时非常有帮助。 * handler:当队列和线程池都满了,必须采取一种策略处理提交的新任务。 * - abortpolicy:默认策略,无法处理新任务时抛出异常 * - callerrunspolicy:使用调用者所在线程来运行任务 * - discardoldestpolicy:丢弃队列里最近的一个任务,并执行当前任务 * - discardpolicy:不处理,丢弃掉 */ public threadpoolexecutor(int corepoolsize, int maximumpoolsize, long keepalivetime, timeunit unit, blockingqueue\u0026lt;runnable\u0026gt; workqueue, threadfactory threadfactory, rejectedexecutionhandler handler); 线程池源代码概览 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 public class threadpoolexecutor extends abstractexecutorservice { public void execute(runnable command) { if (command == null) throw new nullpointerexception(); // 获取线程池控制状态 int c = ctl.get(); if (workercountof(c) \u0026lt; corepoolsize) { // worker数量小于corepoolsize if (addworker(command, true)) // 添加worker return; // 不成功则再次获取线程池控制状态 c = ctl.get(); } // 线程池处于running状态,将用户自定义的runnable对象添加进workqueue队列 if (isrunning(c) \u0026amp;\u0026amp; workqueue.offer(command)) { // 再次检查,获取线程池控制状态 int recheck = ctl.get(); // 线程池不处于running状态,将自定义任务从workqueue队列中移除 if (! isrunning(recheck) \u0026amp;\u0026amp; remove(command)) // 拒绝执行命令 reject(command); else if (workercountof(recheck) == 0) // worker数量等于0 // 添加worker addworker(null, false); } else if (!addworker(command, false)) // 添加worker失败 // 拒绝执行命令 reject(command); } } private boolean addworker(runnable firsttask, boolean core) { //... if (workeradded) { // worker被添加 // 开始执行worker的run方法,调用线程start启动线程 t.start(); // 设置worker已开始标识 workerstarted = true; } //... return workerstarted; } private final class worker extends abstractqueuedsynchronizer implements runnable{ public void run() { runworker(this); } final void runworker(worker w) { thread wt = thread.currentthread(); runnable task = w.firsttask; w.firsttask = null; w.unlock(); // allow interrupts boolean completedabruptly = true; try { while (task != null || (task = gettask()) != null) { w.lock(); if ((runstateatleast(ctl.get(), stop) || (thread.interrupted() \u0026amp;\u0026amp; runstateatleast(ctl.get(), stop))) \u0026amp;\u0026amp; !wt.isinterrupted()) wt.interrupt(); try { beforeexecute(wt, task); throwable thrown = null; try { // 执行run方法 task.run(); } catch (runtimeexception x) { thrown = x; throw x; } catch (error x) { thrown = x; throw x; } catch (throwable x) { thrown = x; throw new error(x); } finally { afterexecute(task, thrown); } } finally { task = null; w.completedtasks++; w.unlock(); } } completedabruptly = false; } finally { processworkerexit(w, completedabruptly); } } } executors创建线程池 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 public class executors { // 创建一个立即执行无缓冲的线程池 public static executorservice newcachedthreadpool() { return new threadpoolexecutor(0, integer.max_value,60l, timeunit.seconds,new synchronousqueue\u0026lt;runnable\u0026gt;()); } // 创建一个固定大小的线程池,corepoolsize和maximumpoolsize相等即不会在队列满了创建线程 // linkedblockingqueue默认构造器为无界队列,队列不可能满 public static executorservice newfixedthreadpool(int nthreads) { return new threadpoolexecutor(nthreads, nthreads, 0l, timeunit.milliseconds, new linkedblockingqueue\u0026lt;runnable\u0026gt;()); } // 创建一个单一线程运行的线程池,corepoolsize和maximumpoolsize相等即不会在队列满了创建线程 // linkedblockingqueue默认构造器为无界队列,队列不可能满 public static executorservice newsinglethreadexecutor() { return new finalizabledelegatedexecutorservice(new threadpoolexecutor(1, 1, 0l, timeunit.milliseconds,new linkedblockingqueue\u0026lt;runnable\u0026gt;())); } // 创建一个可以线程可以定时调度的线程池 public static scheduledexecutorservice newscheduledthreadpool(int corepoolsize) { return new scheduledthreadpoolexecutor(corepoolsize); } public class scheduledthreadpoolexecutor extends threadpoolexecutor implements scheduledexecutorservice public scheduledthreadpoolexecutor(int corepoolsize) { super(corepoolsize, integer.max_value, 0, nanoseconds, new delayedworkqueue()); } } // 创建一个可执行fork/join任务的线程池 public static executorservice newworkstealingpool(int parallelism) { return new forkjoinpool(parallelism, forkjoinpool.defaultforkjoinworkerthreadfactory,null, true); } } 关闭线程池 关闭线程池源码\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 /* 线程池状态变为 shutdown - 不会接收新任务 - 但已提交任务会执行完 - 此方法不会阻塞调用线程的执行 */ public void shutdown() { final reentrantlock mainlock = this.mainlock; mainlock.lock(); try { checkshutdownaccess(); // 修改线程池状态 advancerunstate(shutdown); // 仅会打断空闲线程 interruptidleworkers(); onshutdown(); // 扩展点 scheduledthreadpoolexecutor } finally { mainlock.unlock(); } // 尝试终结(没有运行的线程可以立刻终结,如果还有运行的线程也不会等) tryterminate(); } 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 /* 线程池状态变为 stop - 不会接收新任务 - 会将队列中的任务返回 - 并用 interrupt 的方式中断正在执行的任务 */ public list\u0026lt;runnable\u0026gt; shutdownnow() { list\u0026lt;runnable\u0026gt; tasks; final reentrantlock mainlock = this.mainlock; mainlock.lock(); try { checkshutdownaccess(); // 修改线程池状态 advancerunstate(stop); // 打断所有线程 interruptworkers(); // 获取队列中剩余任务 tasks = drainqueue(); } finally { mainlock.unlock(); } // 尝试终结 tryterminate(); return tasks; } 附录 查看进程线程的方法 linux\n1 2 3 ps -ef # 查看所有进程 ps -ft -p \u0026lt;pid\u0026gt; # 查看某个进程(pid)的所有线程 top -h -p \u0026lt;pid\u0026gt; # 查看某个进程(pid)的所有线程 java\n1 2 3 jps # 命令查看所有 java 进程 jstack \u0026lt;pid\u0026gt; # 查看某个java进程(pid)的所有线程状态 jconsole # 来查看某个java进程中线程的运行情况(图形界面) 线程常见方法 start()\n启动一个新线程,在新的线程运行 run 方法中的代码。start 方法只是让线程进入就绪,里面代码不一定立刻运行(cpu 的时间片还没分给它)。每个线程对象的start方法只能调用一次,如果调用了多次会出现illegalthreadstateexception\nrun()\n新线程启动后会调用的方法。如果在构造 thread 对象时传递了 runnable 参数,则线程启动后会调用 runnable 中的 run 方法,否则默认不执行任何操作。但可以创建 thread 的子类对象,来覆盖默认行为\njoin() / join(long n)\n等待线程运行结束\ngetid()\n获取线程长整型的唯一 id\ngetname() / setname(string)\n获取/修改 线程名\ngetpriority() / setpriority(int)\n获取/修改 线程优先级。java中规定线程优先级是1~10 的整数,较大的优先级能提高该线程被 cpu 调度的机率\ngetstate()\n获取线程状态,new、runnable、blocked、waiting、timed_waiting、terminated\nisinterrupted()\n判断是否被打断, 不会清除打断标记\nisalive()\n线程是否存活(还没有运行完毕)\ninterrupt()\n打断线程,如果被打断线程正在 sleep,wait,join 会导致被打断的线程抛出 interruptedexception,并清除打断标记;如果打断的正在运行的线程,则会设置打断标记 ;park 的线程被打断,也会设置打断标记\n${interrupted()}^{static}$\n判断当前线程是否被打断 ,会清除打断标记\n${currentthread()}^{static}$\n获取当前正在执行的线程\n${sleep(long n)}^{static}$\n让当前执行的线程休眠n毫秒,休眠时让出 cpu 的时间片给其它线程\n${yield()}^{static}$\n提示线程调度器让出当前线程对cpu的使用,主要是为了测试和调试\n线程中断 \tinterrupted()是java提供的一种中断机制,thread.stop, thread.suspend, thread.resume都已经被废弃了,所以在java中没有办法立即停止一条线程。因此,java提供了一种用于停止线程的机制中断。\n中断只是一种协作机制,java没有给中断增加任何语法,中断的过程完全需要程序员自己实现。若要中断一个线程,需要手动调用该线程的interrupted方法,该方法也仅仅是将线程对象的中断标识设成true;接着需要自己写代码不断地检测当前线程的标识位;如果为true,表示别的线程要求这条线程中断,此时究竟该做什么需要自己写代码实现。 每个线程对象中都有一个标识,用于表示线程是否被中断;该标识位为true表示中断,为false表示未中断 中断的相关方法\n1 2 3 4 5 6 7 8 // 本地方法,返回线程中断状态,并且根据参数判断是否需要清除标识位 private native boolean isinterrupted(boolean clearinterrupted); // 返回线程中断状态,不清空标识 public boolean isinterrupted() {return isinterrupted(false);} // 静态方法,返回当前线程中断状态,清空标识 public static boolean interrupted() { return currentthread().isinterrupted(true);} 使用中断举例\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 public class interrupttest{ private static reentrantlock reentrantlock = new reentrantlock(); private static class interruptrunnable implements runnable { @override public void run() { string currentthreadname = thread.currentthread().getname(); reentrantlock.lock(); while (!thread.interrupted()) { system.out.println(currentthreadname + \u0026#34; do business logic\u0026#34;); for (int i = 0; i \u0026lt; 2000000000; i++) { } system.out.println(currentthreadname + \u0026#34; do business logic over\u0026#34;); } // 线程发生中断 system.out.println(currentthreadname + \u0026#34; happen interrupt do something\u0026#34;); // 必须释放资源否则“t-2”线程一直阻塞 reentrantlock.unlock(); // 释放资源 system.out.println(currentthreadname + \u0026#34; release resources\u0026#34;); } } public static void main(string[] args) throws interruptedexception { thread thread = new thread(new interruptrunnable(),\u0026#34;t-1\u0026#34;); thread.start(); timeunit.seconds.sleep(1); thread thread2 = new thread(new interruptrunnable(), \u0026#34;t-2\u0026#34;); thread2.start(); thread.interrupt(); // 如果调用的是thread.stop()可以释放synchronized资源但是不会释放lock实现类的资源 } } \tjava类库中提供的一些可能会发生阻塞的方法都会抛interruptedexception异常,当在某一条线程中调用这些方法时,这个方法可能会被阻塞很长时间,就可以在别的线程中调用当前线程对象的interrupt方法触发这些函数抛出interruptedexception异常,这时候需要自己处理中断了。\ncas算法 \tcas算法【compare-and-swap】是硬件对于并发操作共享数据的支持。cas是一种无锁算法,cas有3个操作数①内存值v;②旧的预期值a;③要修改为的新值b;\n\t更新规则当且仅当预期值a和内存值v相同时,将内存值v修改为b,否则什么都不做。其实就是拿副本中的预期值与主存中的值作比较,如果相等就继续替换新值,如果不相等就说明主存中的值已经被别的线程修改,就继续重试。\ncas 的底层是 lock cmpxchg 指令(x86 架构),在单核 cpu 和多核 cpu 下都能够保证【比较-交换】的原子性。在多核状态下,某个核执行到带 lock 的指令时,cpu 会让总线锁住,当这个核把此指令执行完毕,再开启总线。这个过程中不会被线程的调度机制所打断,保证了多个线程对内存操作的准确性,是原子的。\naba问题\n\t线程a从内存中获取到预期值a之后开始进行逻辑运算,会有一个时间差。在这个时间差之间有某些线程对这个内存值v进行了一系列操作,但是最终又恢复了和线程a拿到预期值v时候一样的内存值。线程a进行cas算法发现内存值v等于预期值a(实际v被改变过只是比较时还是原值)。此时线程a仍然能cas成功,但是中间多出的那些过程仍然可能引发问题。\n根据实际情况,判断是否处理aba问题。如果aba问题并不会影响我们的业务结果,可以不处理。\n\t可以通过加一个标记位来解决这个问题。即:如果在用到该引用时,都对该引用标记位进行推进,进行比较时除了要对比内存值外,还要对比标记位的值是否一样,这样就解决了aba问题。\n指令重排序 \tjava编译器为了优化程序的性能,会重新对字节码指令排序,虽然会重排序,但是指令重排序运行的结果一定是正常的。在程序运行过程中(多核cpu环境下)也可能处理器会对执行的指令进行重排序。\n\t在单线程中对我们程序的帮助一定是正向的,它能够很好的优化我们程序的性能。但是在多线程环境下,如果由于出现指令重排序情况导致线程安全性问题,这种情况下比较少见(出现概率小,难复现)很隐蔽。例如:双检查锁单例模式\n指令重排序需要满足一定条件才能进行的,能够进行指令重排序的地方,需要看这个段代码是否具有数据依赖性\n有数据依赖性的情况 名称 代码示例 说明 写后读 a = 1;b = a; 写一个变量之后,再读这个位置 写后写 a = 1;a = 2; 写一个变量之后,再写这个变量 读后写 a = b;b = 1; 读一个变量之后,再写这个变量 在单线程环境下编译器、runtime和处理器都遵循as-if-serial语义【不管怎么重排序,执行结果不变】\nfinal变量的指令重排序\n1 2 3 4 5 6 7 8 /** * 步骤1:为new出来的对象开辟内存空间 * 步骤2:初始化,执行构造器方法的逻辑代码片段 * 步骤3:完成obj引用的赋值操作,将其指向刚刚开辟的内存地址 * 这三个步骤可能进行指令重排序变为:步骤1、步骤3、步骤2 * 如果发生重排序可能obj不为null但是未初始化完成 */ objectvarilabe obj = new objectvarilabe() 在构造函数内对一个final变量的写入,与随后把这个被构造对象的引用赋值给一个引用变量,这个两个操作不能被重排序,即需要先初始化final变量才可以给构造的对象地址赋给引用【普通域可能在地址赋给引用之后才初始化】\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public class finalexample { int i = 0; final int f; static finalexample obj; public finalexample() { // 构造函数 i = 1; // 写普通域 f = 2; // 写final域 } public static void writer() { /** * 此代码执行之时,另一线程读取obj不为null那么obj.f一定初始化完成 * 另一线程读取obj不为null,但是i不一定初始化完成 */ obj = new finalexample();\t} } 初次读一个包含final的对象的引用,与随后初次读这个final域,这两个操作之间不能重排序\n1 2 3 4 5 6 // ①一定发生在③之前,但是①不一定发生在②之前 public static void reader() { finalexample example = obj; // ①读对象引用 system.out.println(example.i); // ②读普通域 system.out.println(example.f); // ③读final域 } happen-before \tjmm(java memory model)可以通过happens-before关系向提供跨线程的内存可见性保证(如果a线程的写操作a与b线程的读操作b之间存在happens-before关系,尽管a操作和b操作在不同的线程中执行,但jmm向程序员保证a操作将对b操作可见)happen-before是可见性保证,不是发生性保证\n定义\n1)如果一个操作happens-before另一个操作,那么第一个操作的执行结果将对第二个操作可见,而且第一个操作的执行顺序排在第二个操作之前。\n2)两个操作之间存在happens-before关系,并不意味着java平台的具体实现必须要按照happens-before关系指定的顺序来执行。如果重排序之后的执行结果,与按happens-before关系来执行的结果一致,那么这种重排序合法。\n具体规则\n程序顺序规则:一个线程中的每个操作,happens-before于该线程中的任意后续操作 监视器锁规则:对一个锁的解锁,happens-before于随后对这个锁的加锁 volatile变量规则:对一个volatile变量,happens-before于任意后续对这个volatile域的读 传递性:如果a happens-before b,且b happens-before c,那么a happens-before c start()规则:如果线程a执行操作threadb.start(),那么a线程的threadb.start()操作happens-before于线程b中的任意操作。 join()规则:如果线程a执行操作threadb.join()并成功返回,那么线程b中的任意操作happens-before于线程a从threadb.join()操作成功返回。 程序中断规则:对线程interrupted()方法的调用先行于被中断线程的代码检测到中断时间的发生。 对象finalize规则:一个对象的初始化完成(构造函数执行结束)先行于发生它的finalize()方法的开始 伪共享 缓存行\n\tcpu的存取最小单位是缓存行。一般一行缓存行有64字节。所以使用缓存时,并不是一个一个字节使用,而是一行缓存行、一行缓存行这样使用。\n\t在64位系统下,java数组对象头固定占16字节,而long类型占8个字节。所以16+8*6=64字节,刚好等于一条缓存行的长度,即一个缓存行可以装填6个long类型的数组数据。\n伪共享\n\t伪共享的非标准定义为:缓存系统中是以缓存行(cache line)为单位存储的,当多线程修改互相独立的变量时,如果这些变量位于同一个缓存行,只要这个缓存行里有一个变量失效则此缓存行所有数据全部失效。\n\t在jdk8以前,我们一般是在属性间填充长整型变量来分隔每一组属性。jdk8之后加入@contended注解方式【jvm需要添加参数-xx:-restrictcontended才能开启此功能 】\n懒汉式指令重排序问题 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public class singleton { private static volatile singleton instance; private singleton() { } public static singleton getinstance() { if(instance==null){ synchronized (singleton.class){ if(instance==null){ instance=new singleton(); } } } return instance; } } instance=new singleton()这个语句不是一个原子操作,编译后会多条字节码指令:\n步骤1:为new出来的对象开辟内存空间 步骤2:初始化,执行构造器方法的逻辑代码片段 步骤3:完成instance引用的赋值操作,将其指向刚刚开辟的内存地址 这三个步骤可能进行指令重排序变为:步骤1、步骤3、步骤2\n在发生重排序时其它线程如果进入getinstance()方法会在第一次判断是否为null时通过,导致拿到一个还未完全初始化完成的地址空间,此时如果进行操作很可能发生线程安全性问题\nstampedlock stampedlock是java 8新增的一个读写锁,它是对reentrantreadwritelock的改进。\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 public class demo { private int balance; private stampedlock lock = new stampedlock(); //===================================读写锁转化==================================== public void conditionreadwrite (int value) { // 首先加独占读锁判断balance的值是否符合更新的条件 long stamp = lock.readlock(); try{ while (balance \u0026gt; 0) { // 下面需要进行写操作,所以转化为写锁 // reentrantreadwritelock是直接加写锁,锁升级 long writestamp = lock.tryconverttowritelock(stamp); if(writestamp != 0) { // 成功转换成为写锁 stamp = writestamp; balance += value; break; } else { // 没有转换成写锁,这里需要首先释放读锁,然后再拿到写锁 lock.unlockread(stamp); //。。。 // 获取写锁 stamp = lock.writelock(); } } }finally{ lock.unlock(stamp); } } //====================================乐观读操作=================================== public void optimisticread() { // 获取乐观读锁 long stamp = lock.tryoptimisticread(); int c = balance; // 这里其它可能会出现了写操作,因此要进行判断读锁获取的是否有问题 if(!lock.validate(stamp)) { // 要从新读取 long readstamp = lock.readlock(); c = balance; stamp = readstamp; } lock.unlockread(stamp); } //==============以下read/write操作和reentrantreadwritelock效果完全一样============== public void read () { long stamp = lock.readlock(); lock.tryoptimisticread(); int c = balance; // ... lock.unlockread(stamp); } public void write(int value) { long stamp = lock.writelock(); balance += value; lock.unlockwrite(stamp); } } ","date":"2024-03-08","permalink":"https://hobocat.github.io/post/java/2020-01-01-concurrent/","summary":"一、线程的状态 从操作系统层面划分 从java代码的角度来进行划分 二、JDK创建线程的方式 继承Thread类 1 2 3 4 5 6 7 8 9 10 11 12 13 public class ThreadTest { public static void main(String[] args) { Thread thread = new ThreadDemo();","title":"java多线程并发编程"},]
[{"content":"1、mysql部署前准备 关闭numa\nnuma(non-uniform memory access,非一致性内存访问)服务器的基本特征是 linux 将系统的硬件资源划分为多个软件抽象,称为节点。每个节点上有单独的 cpu、内存和 i/o 槽口等。cpu 访问自身 node 内存的速度将远远高于访问远地内存(系统内其它节点的内存)的速度,这也是非一致内存访问 numa 的由来。\n简单来比方就是如果是8g内存,4核cpu,那么一个核心分得2g内存,减少共享内存带来的资源争夺。但是mysql分配了6g内存。某些线程超出节点本地内存部分会被 swap 到磁盘上,而不是使用其他节点的物理内存,引发性能问题。\nbios级别关闭【推荐】 在bios层面numa关闭时,无论os层面的numa是否打开,都不会影响性能。一般在bios的advanced下 使用如下命令可以查看numactl是否被关闭 numactl --hardware available: 1 nodes (0) #如果是2或多个nodes就说明numa没关掉 ============================================================================ os级别关闭 注意:在os层numa关闭时,bios层是打开的话会影响性能,qps会下降15-30%; vi /boot/grub2/grub.cfg 找到并安装如下设置numa=off kernel /boot/vmlinuz-2.6.18-128.1.16.0.1.el5 root=label=dbsys ro bootarea=dbsys rhgb quiet console=ttys0,115200n8 console=tty1 crashkernel=128m@16m numa=off initrd /boot/initrd-2.6.18-128.1.16.0.1.el5.img ============================================================================ 数据库级别关闭 mysql\u0026gt; show variables like \u0026#39;%numa%\u0026#39;; +------------------------+-------+ | variable_name | value | +------------------------+-------+ | innodb_numa_interleave | off | +------------------------+-------+ 或者修改etc/init.d/mysqld 将$bindir/mysqld_safe --datadir=\u0026#34;$datadir\u0026#34;这一行修改为: /usr/bin/numactl --interleave all $bindir/mysqld_safe --datadir=\u0026#34;$datadir\u0026#34; --pid-file=\u0026#34;$mysqld_pid_file_path\u0026#34; $other_args \u0026gt;/dev/null \u0026amp; wait_for_pid created \u0026#34;$!\u0026#34; \u0026#34;$mysqld_pid_file_path\u0026#34;; return_value=$? 开启cpu高性能模式\nbios设置operator mode设置为maximum performance\n阵列卡raid配置\n建议配置为raid10\n关闭thp\nthp(transparent_hugepage)即分配大页内存,mysql有自己的内存分配机制。\nchomd +x /etc/rc.d/rc.local 修改 /etc/rc.local 在文件末尾添加如下指令 if test -f /sys/kernel/mm/transparent_hugepage/enabled; then echo never \u0026gt; /sys/kernel/mm/transparent_hugepage/enabled fi if test -f /sys/kernel/mm/transparent_hugepage/defrag; then echo never \u0026gt; /sys/kernel/mm/transparent_hugepage/defrag fi # 查看transparent hugepage是否关闭 cat /sys/kernel/mm/transparent_hugepage/enabled # 显示这样为关闭 always madvise [never] 网卡绑定\nbonding技术,业务数据库服务器都要配置bonding继续。建议是主备模式。交换机一定要堆叠。 系统层面参数优化\n更改文件句柄和进程数 修改 /etc/sysctl.conf vm.swappiness = 5 # 交换分区(也可以设置为0)的攻击性。较高的值会更激进 vm.dirty_ratio = 20 # 文件系统缓存脏页数量达到系统内存百分之多少时,系统阻塞处理缓存脏页 vm.dirty_background_ratio = 10 # 文件系统缓存脏页数量达到系统内存百分之多少时,系统异步处理缓存脏页 net.ipv4.tcp_max_syn_backlog = 819200 # 半连接队列大小 net.core.netdev_max_backlog = 400000 # 内核从网卡收到数据包后,交由协议栈(如ip、tcp)处理之前的缓冲队列 net.core.somaxconn = 4096 # 指服务端所能accept即处理数据的最大客户端数量,即完成连接上限 net.ipv4.tcp_tw_reuse=1 # 表示开启重用。允许将time-wait sockets重新用于新的tcp连接,默认为0,表示关闭 net.ipv4.tcp_tw_recycle=0 # 表示开启tcp连接中time-wait sockets的快速回收,默认为0,表示关闭 ===================================================================== 防火墙 禁用selinux /etc/sysconfig/selinux 更改selinux=disabled. iptables如果不使用可以关闭。如果需要打开mysql需要的端口号 ===================================================================== 文件系统优化 推荐使用xfs文件系统 mysql数据分区独立 ,例如挂载点为: /data fdisk /dev/sdb 依次安装提示键入 p n l w 修改 /etc/fstab 加入 /dev/sdb /data xfs defaults,noatime,nodiratime,nobarrier - defaults 默认值包括rw、suid、dev、exec、auto、nouser和async,文件挂载配置的很多情况下都使用默认值 - noatime 不更新文件访问时间 - nodiratime 不更新目录访问时间 - nobarrier 不开启barrier ===================================================================== 不使用lvm ===================================================================== io调度 sas: deadline ssd\u0026amp;pci-e: noop - deadline 对读写请求进行了分类管理,并且在调度处理的过程中读请求具有较高优先级。这主要是因为读请求往往是同步操作,对延迟时间比较敏感,而写操作往往是异步操作,可以尽可能的将相邻访问地址的请求进行合并,但是,合并的效率越高,延迟时间会越长。 - noop电梯式调度器,实现了一个简单的fifo队列,它像电梯的工作方式一样对i/o请求进行组织。它是基于先入先出(fifo)队列概念的 linux 内核里最简单的i/o 调度器。此调度程序最适合于固态硬盘。 centos 7 默认是deadline,使用如下命令查看 cat /sys/block/sda/queue/scheduler 修改调度算法 grubby --update-kernel=all --args=\u0026#34;elevator=noop\u0026#34; 预装mysql前硬件烤机压测\nyum install -y epel-release yum install -y stress # 烤机cpu stress -c 4 # 烤机 mem stress -m 3 --vm-bytes 300m # 烤机多参数 stress -c 4 -m 2 -d 1 # 重要参数解读 -c # forks 产生多个处理sqrt()函数的cpu进程 -m # 产生多个处理malloc()内存分配 --vm-bytes bytes # 指定内存的byte数,默认值是1 -d # 写进程,写入固定大小,通过mkstemp()函数写入当前目录 --hdd-bytes bytes # 指定写的字节数,默认1g 2、mysql8.0二进制安装过程 ①、创建用户,用户组\n1 2 3 4 5 6 7 # 创建用户组 groupadd mysql # 创建用户加入用户组,且不允许登录 useradd -r -g mysql -s /bin/false mysql # 安装基础库 yum install libaio yum install library ②、解压\n1 2 3 tar -xvf mysql-8.0.30-linux-glibc2.12-x86_64.tar.xz -c /opt/module/ mv /opt/module/文件夹 /opt/module/mysql80 ln -s /opt/module/mysql80 /usr/local/mysql ③、加入path\n1 2 3 4 5 6 7 8 # 修改 /etc/profile,加入 path=/usr/local/mysql/bin:$path # 更新环境变量 source /etc/profile # 测试环境变量 mysql -v ④、挂载硬盘\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 # 查看未挂载的硬盘 fdisk -l # 依次安装提示键入 # p n l w fdisk /dev/未挂载的硬盘 # 格式化文件系统 mkfs.xfs 未挂载硬盘 # 挂载 mount /dev/未挂载硬盘 /data # 开机挂载,修改/etc/fstab,加入 /dev/未挂载硬盘 /data defaults,noatime,nodiratime,nobarrier # 查看挂载 df -ht /dev/未挂载的硬盘 ⑤、修改目录权限\n1 2 mkdir -p /data/mysql80 chown -r mysql:mysql /data ⑥、创建/etc/my.cnf\n[mysqld] user=mysql # 管理用户 datadir=/data/mysql80 # 数据路径 basedir=/usr/local/mysql # 软件路径 socket=/tmp/mysql.sock # socket文件位置 server_id=51 # 服务器id,主从时标识不同主机 default_authentication_plugin=mysql_native_password #使用旧版本密码插件 log_bin=/data/mysql80/binlog # 二进制日志 binlog_format=row # 二进制日志行格式 gtid-mode=on # 开启gtid模式,会记录gtid的标识符 enforce-gtid-consistency=on # 强制gtid一致性,保证事务的安全 log-slave-updates=on # mysql5.7之前必须配置 port=3306 # 端口 log_error=/data/mysql80/log/mysql-err.log # 错误日志路径 log_bin=/data/mysql80/log/mysql-bin # binlog日志路径 slow_query_log=on # 开启慢查询日志 slow_query_log_file=/data/mysql80/log/mysql-slow.log # 慢查询日志位置 long_query_time=0.5 # 记录执行时间(real time)超过该值以上的sql,默认值为10秒 log_queries_not_using_indexes=1 # 未使用索引的查询是否写入慢日志 log_throttle_queries_not_using_indexes=1000 # 限制每分钟所记录的slow log数量 innodb_log_file_size=2048m # redo log大小,建议大小 512m-4g innodb_log_files_in_group=4 # redo log组数,建议 2-4组 innodb_temp_data_file_path=ibtmp1:512m;ibtmp2:512m:autoextend:max:512m # 临时表空间,一般2-3个,大小512m-1g innodb_undo_tablespaces=4 #undo文件个数,建议3-5个 [mysql] [client] [server] [mysqld_safe] [mysqldump] ⑦、初始化\u0026amp;启动\u0026amp;登录\n初始化\n1 2 # 不设置密码,root密码为空 mysqld --initialize-insecure 启动方式\nsystemd【系统管理】 -\u0026gt; /etc/init.d/mysqld 【系统管理】 -\u0026gt;mysql.server 【系统管理】-\u0026gt; mysqld_safe【安全启动,crash会重启服务】-\u0026gt;mysqld\n1 2 3 4 5 mysqld_safe --defaults-file=/etc/my.cnf \u0026amp; 可加参数 --skip-grant-tables :跳过授权表 --skip-networking :不启动网络 关闭命令shutdown\n3、mysql体系总览 架构介绍 客户端连接器 【connectors】\n提供编程语言层级和mysql交互的api接口,以及本地mysql客户端程序和mysql服务端连接交互\n本地连接socket方式:mysql -u用户名 -p密码 -s socket文件路径\ntcp/ip远程连接:mysql -u用户名 -p密码 -h地址 -p端口\n服务层【mysql server】 服务层是mysql server的核心,主要包含系统管理和控制工具、连接池、sql接口、解析器、查询优化器和缓存六个部分\n组件 功能 连接池(connection pool) 负责存储和管理客户端与数据库的连接,一个线程负责管理一个连接 系统管理和控制工具(management services \u0026amp; utilities) 例如备份恢复、安全管理、集群管理等 sql接口(sql interface) 用于接受客户端发送的各种sql命令,并返回结果。比如dml、ddl、存储过程、视图、触发器等 解析器(parser) 负责将请求的sql解析生成一个\u0026quot;解析树\u0026quot;。然后根据一些mysql规则进一步检查解析树是否合法 查询优化器(optimizer) 当“解析树”通过解析器语法检查后,将交由优化器将其转化成执行计划,然后与存储引擎交互 缓存(cache\u0026amp;buffer) 缓存机制是由一系列小缓存组成的。比如表缓存,记录缓存,权限缓存,引擎缓存等。如果查询缓存有命中的查询结果,查询语句就可以直接去查询缓存中取数据 存储引擎层(pluggable storage engines) 储引擎负责mysql中数据的存储与提取,与底层系统文件进行交互。mysql存储引擎是插件式的,服务器中的查询执行引擎通过接口与存储引擎进行通信,接口屏蔽了不同存储引擎之间的差异 。现在有很多种存储引擎,各有各的特点,最常见的是myisam和innodb 线程介绍 \nmaster thread\n核心线程,负责缓冲池的数据异步入盘,包括脏页刷新、合并插入缓冲、undo页回收等\n控制刷新脏页到磁盘(ckpt) 控制日志缓冲刷新到磁盘(log buffer \u0026ndash;\u0026gt; redo) undo页回收 合并插入缓冲(change buffer) 控制io刷新数量 参数说明:\ninnodb_io_capacity:表示每秒刷新脏页的数量,默认为200。\ninnodb_max_dirty_pages_pct:设置刷盘的脏页百分比,即当脏页占到缓冲区数据达到这个百分比时,就会刷新innodb_io_capacity个脏页到磁盘\ninnodb_adaptive_flushing:自适应刷新mysql根据当前运行信息绝对何时刷新,默认开启。回合innodb_max_dirty_pages_pct配合管理\nio thread\n在innodb存储引擎中大量使用async io来处理写io请求,io thread的工作主要是负责这些io请求的回调处理。写线程和读线程分别由innodb_write_threads和innodb_read_threads参数控制,默认都为4,使用show variables like '%innodb_%io_thread%';查看\npurge thread\n回收事务提交后不再需要的undo log,可以在配置文件中添加innodb_purge_threads=threadnum来开启独立的purge thread,等号后边控制该线程数量,默认为4个,通过show variables like '%innodb_purge_threads%'; 查看\npage clear thread\n脏页的刷新操作,从master thread分离出来,减轻master thread的工作,提高性能\nmysql 8.0 innodb结构 innodb buffer pool\n查看mysql的innodb_buffer_pool大小select @@innodb_buffer_pool_size/1024/1024; --单位m\nbuffer pool中存在三个双向链表。分别是freelist、lrulist以及flushlist\nfreelist存放了空闲的缓存页的描述信息,即哪些区域是空闲状态,用于管理分配内存\nlrulist冷热数据分离优化,5/8的区域是热数据区域,3/8的区域算是冷数据区域。新加载的数据页会被放在冷数据区的靠前的位置上。如果该数据页读取出来加载进缓存页中后,间隔没到1s,就使用该缓存页。那么是不会将这个描述信息移动到5/8的热数据区域的。但是当超过1s后,你又去读这个数据页。那这个数据页的描述信息就会被放到热数据区域。\nflushlist中的节点存放的是被修改了脏数据页的描述信息块。随着mysql被使用的时间越来越长,bufferpool的大小就越来越小。等它不够用的时候,就会将部分lru中的数据页描述信息移除出去,这时如果发现被移除出来的数据页在flushlist中,就会触发fsync的操作,触发随机写磁盘。如果该数据页是干净的,那移除出去就好,不需要其它操作\nchange buffer\nmysql写的性能提升提升主要依赖change buffer,以前 change buffer称为insert buffer,因为以前只做了insert操作的性能优化,之后版本更新之后,也能对于修改和删除做缓存处理,所以改名为change buffer\n例如:update xx set name = \u0026ldquo;赐我100w\u0026rdquo; where id = 5;【name是个非唯一的二级索引】\n执行时不仅要更新聚簇索引,还要加载name这个辅助索引进行更新,如果现在name这个非唯一二级索引没有在内存中,将会进行io操作,浪费性能。所以mysql进行了改进:当这些二级索引页不在内存中时,对它们的操作会被缓存在change buffer中(目的是省去这次随机的磁盘io)。等之后mysql空闲了、或者是mysql关闭前、或者是有读取操作时再将这部分缓存操作merge到b+tree中\n要求二级索引不能唯一。这个很好理解。如果name列是唯一的。那我每次dml之前都必须去看下有没有已经存在的相同值的索引。这也就意味着这个dml操作必须加载无法缓存\nadaptive hash index\n自适应哈希索引,innodb存储引擎会监控对表上索引的查找,如果观察到建立哈希索引可以带来速度的提升,则建立自适应哈希索引,实现本质上就是一个哈希表:从某个检索条件到某个数据页的哈希表\nlog buffer\nlog buffer的作用是缓存redo log的写入操作,考虑到一个大事务,在事务期间可能会有很多次数据库操作,不需要在事务中的每一次操作都写入redo log,可以缓存一定量的redo log,在合适的时间进行写盘。\n合适的时间取决于mysql的配置(innodb_flush_log_at_trx_commit),值有0、1、2,默认是1\n如果设置为0,每隔一秒把log buffer刷到文件系统中(os buffer)去,并且调用文件系统的“flush”操作将缓存刷新到磁盘上去。也就是说一秒之前的日志都保存在日志缓冲区,如果机器宕掉,可能丢失1秒的事务数据 如果设置为1,在每次事务提交的时候会把log buffer刷到文件系统中(os buffer)去,并且调用文件系统的“flush”操作将缓存刷新到磁盘上去。保证acid 如果设置为2,在每次事务提交的时候会把log buffer刷到文件系统中去,但并不会立即刷写到磁盘 存储结构 文件存储结构(宏观)\n表的存储结构(微观)\n表抽象为表空间,表空间由segment、extend、page组成\nsegment (段)\n常见的segment有数据段、索引段、回滚段等, 数据段为b+树的叶子节点(leaf node segment)、索引段为b+树的非叶子节点(non-leaf node segment)\nextent(区、簇)\n每个区大小固定为1mb,为保证区中page的连续性通常innodb会一次从磁盘中申请4-5个区。在默认page的大小为16kb的情况下,一个区则由64个连续的page组成\npage(数据页)\n默认16kb。innodb最小的io单元。mysql有预读机制,就是当从磁盘上加载一个数据页的时候,可能会把这个它相邻的其他数据页也进行加载\n系统库表介绍 mysql 的数据字典 - information_schema\ninformation_schema数据库保存着其他数据库的元信息\n控制和管理信息库 - mysql\nmysql库是mysql 服务器的核心数据库,主要负责存储数据库的用户、权限、关键字等等\n表名 介绍 user 用户信息、用户密码、针对所有库的权限 db 用户对某个数据库的操作权限信息 tables_priv 单个表进行权限设置时使用 columns_priv 单个数据列进行权限设置时使用 procs_priv 存储过程和存储函数进行权限设置 slave_master_info 主从信息存储的地方 slave_relay_log_info salve的中继日志信息 slave_worker_info slave的工作信息 slow_log 慢查询日志 服务器性能指标 - performance_schema\nperformance_schema是运行在较低级别的用于监控mysql server运行过程中的资源消耗、资源等待等情况\n表名 介绍 processlist 当前连接信息 threads events_statements_current 当前语句事件表 events_statements_history 历史语句事件表 events_statements_history_long 长语句历史事件表 summary 类表 聚合后的摘要表 dba 的好帮手 - sys\nsys库对information_schema和performance_schema统计的各种信息进行记录并生成新的视图表,通过 sys,我们可以快速的查询出:哪些语句使用了临时表、哪个线程占用了最多的内存、哪些索引是冗余的等等,sys库的功能需要单独配置开启\n4、mysql的日常管理 用户管理 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 -- 创建用户,mysql8.0的密码插件有更改,兼容不行(特别是主从),建议还是使用mysql_native_password create user [用户名]@\u0026#39;[ip描述]\u0026#39; identified with mysql_native_password by \u0026#39;[密码]\u0026#39;; -- 查询用户 select user, host, plugin from mysql.user; -- 删除用户 drop user [用户名]@\u0026#39;[ip描述]\u0026#39;; -- 修改用户密码 alter user [用户名]@\u0026#39;[ip描述]\u0026#39; identified with mysql_native_password by \u0026#39;[密码]\u0026#39;; -- 密码过期设置 select @@default_password_lifetime; -- 查看过期时间 alter user [用户名]@\u0026#39;[ip描述]\u0026#39; password expire interval [天数] day; alter user [用户名]@\u0026#39;[ip描述]\u0026#39; password expire never; -- 锁定用户 alter user [用户名]@\u0026#39;[ip描述]\u0026#39; account lock; 权限管理 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 -- 显示所有权限 show privileges; -- 授予权限 grant 权限 on 权限级别 to 用户; grant all on *.* to [用户名]@\u0026#39;[ip描述]\u0026#39;; -- 授予用户所有权限 grant select, update, delete, insert on 数据库名称.* to [用户名]@\u0026#39;[ip描述]\u0026#39;; -- 授予用户dml给指定数据库 -- 查看用户权限 show grants for [用户名]@\u0026#39;[ip描述]\u0026#39; ; -- 回收权限 revoke 权限 on *.* from [用户名]@\u0026#39;[ip描述]\u0026#39;; -- 角色创建及授权 create role [角色名]@\u0026#39;[ip描述]\u0026#39;; grant 权限 on *.* to [角色名]@\u0026#39;[ip描述]\u0026#39;; grant 角色名 to [用户名]@\u0026#39;[ip描述]\u0026#39;; -- 查看角色和用户的映射关系 select * from mysql.role_edges; -- 查看用户和角色的权限 select * from information_schema.user_privileges; 生产环境的权限分配\n管理员:all 开发:create, create routine, create temporary tables, create view, show view, delete, event, execute, insert, references, select, trigger, update 监控:select, replication slave, replication client, super 备份:select, show databases, process, lock tables, reload 主从:replication slave, replication client 业务:insert, update, delete, select 5、mysql系统的日志 日志类型 建议日志都设置到单独的文件夹,不要和数据目录混着\n错误日志\n默认位置:log_error=$datddir/hostname.err,默认是开启的,看错误日志时主要关注 [error],deadlock\nlog_error=/data/mysql80/log/mysql-err.log #错误日志路径 二进制日志(binlog)\n记录了mysql 发生过的修改的操作的日志。mysql8.0 默认开启 binlog,默认在 datadir 文件夹内\n①备份恢复必须依赖二进制日志;②复制环境必须依赖二进制日志\nlog_bin=/data/mysql80/log/mysql-bin #binlog日志路径 慢日志(slow_log)\n记录mysql工作中,运行较慢的语句。用来定位sql语句性能问题,默认关闭,建议开启\nslow_query_log=on # 开启慢查询日志 slow_query_log_file=/data/mysql80/log/mysql-slow.log # 慢查询日志位置 long_query_time=0.5 # 记录执行时间(real time)超过该值以上的sql,默认值为10秒 log_queries_not_using_indexes=1 # 未使用索引的查询是否写入慢日志 log_throttle_queries_not_using_indexes=1000 # 限制每分钟所记录的slow log数量 也可用 set global 进行修改 普通日志(general_log)\n普通日志,会记录所有数据库发生的事件及语句,文件信息较大,生成、测试都不建议打开,默认关闭\n日志参数查询设置 1 show variables like \u0026#39;log_output\u0026#39;; -- 看看日志输出类型 table或file 6、sql知识相关 sql_mode 查看sql_modelselect @@sql_mode;\nsql_mode comments only_full_group_by 对于group by聚合操作,如果在select中的列、having或者order by子句的列,没有在group by中出现,或者不在函数中聚合,那么这个sql是不合法的 strict_trans_tables 严格模式,进行数据的严格校验,错误数据不能插入,报error错误。如果不能将给定的值插入到事务表中,则放弃该语句。对于非事务表,如果值出现在单行语句或多行语句的第1行,则放弃该语句 no_zero_in_date 在严格模式,不接受月或日部分为0的日期 no_zero_date 在严格模式,不要将 \u0026lsquo;0000-00-00\u0026rsquo;做为合法日期 error_for_division_by_zero 在严格模式,在insert或update过程中,如果被零除(或mod(x,0)),则产生错误(否则为警告) no_engine_substitution 如果需要的存储引擎被禁用或未编译,那么抛出错误 列的数据类型 数字类型-整型\n类型 占用字节 无符号范围 有符号范围 数据长度 tinyint 1 0-255 -128-127 3 smallint 2 0-65535 -32768~32767 5 mediumint 3 0~16777215 -8388608~8388607 8 int 4 0~2^32 -2^31~ 2^32-1 10 bigint 5 0~2^64 -2^63~ 2^63-1 20 解惑:int(11) 啥意思?不是长度已经一定了吗?\n11 代表的并不是长度,而是字符的显示宽度,在无符号且填充零(unsigned zerofill)下才有作用,例如:b int(11) unsigned zerofill not null\n+-------------+ | b | +-------------+ | 00000000001 | | 01234567890 | +-------------+ 数字类型-浮点型与定点数\n建议:使用整形类型存储小数\nfloat float:表示不指定小数位的浮点数\n float(m,d):表示一共存储m个有效数字,其中小数部分占d位\n float(10,2):整数部分为8位,小数部分为2位\ndouble double又称之为双精度:系统用8个字节来存储数据,表示的范围更大,10^308次方,但是精度也只有15位左右\ndecimal decimal系统自动根据存储的数据来分配存储空间,每大概9个数就会分配四个字节来进行存储,同时小数和整数部分是分开的。\n 定点数:能够保证数据精确的小数(小数部分可能不精确,超出长度会四舍五入),整数部分一定精确\n decimal(m,d):m表示总长度,最大值不能超过65,d代表小数部分长度,最长不能超过30\n字符串类型\nchar(l)\n系统一定会分配指定的空间用于存储数据,l取值范围0到255\nvarchar(l)\n变长字符:指定长度之后,系统会根据实际存储的数据长度和数据,所以每个varchar数据产生后,系统都会在数据后面增加1-2个字节的额外开销。如果数据本身小于255个字符:额外开销一个字节;如果大于255个,就开销两个字节\n基本语法:varchar(l),l的长度理论值位0到65535\n 如果数据长度超过255个字符,不论是否固定长度,都会使用text,不再使用char和varchar\n长文本类型\ntext:允许存放65535字节内的文字字符串字段类型\nmediumtext:允许存放16777215字节内的文字字符串字段类型\nlongtext:允许存放2147483647字节内的文字字符串字段类型\n时间类型\n类型 占用字节 范围 格式 用途 date 3 1000-01-01/9999-12-31 yyyy-mm-dd 日期 time 3 \u0026lsquo;-838:59:59\u0026rsquo;/\u0026lsquo;838:59:59\u0026rsquo; hh:mm:ss 时间值或持续时间 year 1 1901/2155 yyyy 年份 datetime 8 1000-01-01 00:00:00/\n9999-12-31 23:59:59 yyyy-mm-dd hh:mm:ss 混合日期和时间 timestamp 4 1970-01-01 00:00:00/\n2038-1-19 11:14:07 yyyymmdd 时间戳 常用函数 字符函数\n函数名 作用 示例 length 获取字节量,收到字符集影响 length(\u0026lsquo;abc\u0026rsquo;) concat 拼接字符串 concat(\u0026rsquo;%\u0026rsquo;, \u0026lsquo;abc\u0026rsquo;, \u0026lsquo;%\u0026rsquo;) upper\u0026amp;lower 转换大小写 upper(\u0026lsquo;abc\u0026rsquo;) substr 截取字符串 substr(字符串,pos,[len]) trim 掐头去尾 trim(\u0026rsquo; s \u0026lsquo;) lpad\u0026amp;rpad 左/右填充 lpad(\u0026lsquo;1\u0026rsquo;,2, 0) replace 替换 replace(uuid(), \u0026lsquo;-\u0026rsquo;, \u0026lsquo;\u0026rsquo;) 数学函数\n函数名 作用 示例 round 四舍五入 round(3.1415, 2) ceil 向上取整 ceil(3.14) floor 向下取整 floor(9.99) truncate 小数点保留截断 truncate(3.15, 1) mod 取模 mod(10, 3) rand 生成(-∞, 0]范围内的随机整数 rand()*10 日期函数\n函数名 作用 示例 now 返回当前时间,类型datetime now() curdate 返回日期,类型date curdate() curtime 返回时间值,类型time curtime() current_timestamp 返回时间戳,类型timestamp current_timestamp() month\nday\nhour\nminute\nsecond\nyear 截取时间信息 year(now()) str_to_date 以指定格式识别日期 str_to_date(\u0026lsquo;2023-01-07 14:57:00\u0026rsquo;,\u0026rsquo;%y-%m-%d %h:%i:%s\u0026rsquo;) date_format 以指定字符串格式输出日期 date_format(now(),\u0026rsquo;%y-%m-%d %h:%i:%s\u0026rsquo;) 分组统计\n函数名 作用 sum 数值型数据统计 avg 数值型数据平均值 max 任何类型数据最大值 min 任何类型数据最小值 count 非空值个数 group_concat 同一个分组中的值 流程控制函数\nif函数,示例:\n1 if(2\u0026gt;1, \u0026#39;yes\u0026#39;, \u0026#39;no\u0026#39;) case函数,示例:\n1 2 3 4 5 6 7 select case 110 when 110 then \u0026#39;警察\u0026#39; when 119 then\u0026#39;消防队\u0026#39; else \u0026#39;其它号码\u0026#39; end 7、索引\u0026amp;执行计划 sql的执行流程 主要分为四个阶段:预处理、解析、优化、执行语句\n预处理:判断语句中的语法、语义、权限处理等\n解析 :校验ok,就生成“解析树”,把语句拆分成多个块,生成一种树形结构来表示执行顺序。解析出来的树叫抽像语法树ast\n优化 :分为逻辑优化和物理优化。预估每条执行方式的成本,选择成本最小的执行方式,最终转化为执行计划explain\n逻辑优化:将 sql 语法树中的谓词转化为逻辑代数操作符,对条件表达式进行等价谓词重写、条件简化,对视图进行重写,对子查询进行优化,对连接语义进行了外连接消除、嵌套连接消除等 物理优化:统计信息(表的状态信息,比如表名、数据行、数据分布、索引状态信息)、选择索引和算法 执行 :根据执行计划去执行语句\n索引 btree 查找算法演变\nb-树有如下特点:\n所有键值分布在整颗树中(索引值和具体data都在每个节点里) 任何一个关键字出现且只出现在一个结点中 搜索有可能在非叶子结点结束(最好情况o(1)就能找到数据) 在关键字全集内做一次查找,性能逼近二分查找 b+树有如下特点:\n所有关键字存储在叶子节点出现,内部节点(非叶子节点并不存储真正的 data) 为所有叶子结点增加了一个链指针 聚簇索引\ninnodb表中一定是有聚簇索引的,聚簇索引的建立规则如下\n1、 如果表中设置了主键(例如id列),自动根据id列生成聚簇索引\n2、 如果没有设置主键,自动选择第一个非空唯一键的列作为聚簇索引\n3、 自动生成隐藏(6字节row_id)的聚簇索引\n辅助索引\n需要人为创建辅助索引,将经常作为查询条件的列创建辅助索引,起到加速查询的效果。叶子节点存储的是主键id。使用辅助索引查出对应的主键id,可能会用这些主键id查询聚簇索引,这个过程叫做回表\n执行计划 获取语句的执行计划工具,只针对索引应用和优化器算法应用部分信息,不会执行语句。\n使用方式\n1 explain/desc [formrt=\u0026#39;json\u0026#39;/\u0026#39;tree\u0026#39;] sql语句 执行计划信息介绍\nid:查询的顺序,表示执行的顺序,id越大越先执行,id一样的从上往下执行\n使用formrt=\u0026lsquo;tree\u0026rsquo;可更加直观看出执行顺序。从右到左,从上到下阅读\nselect_type:表示查询类型\n值 描述 simple 表示不需要union操作或者不包含子查询的简单查询 primary 表示最外层查询 union union操作中第二个及之后的查询 dependent union union操作中第二个及之后的查询,并且该查询依赖于外部查询 subquery 子查询中的第一个查询 dependent subquery 子查询中的第一个查询,并且该查询依赖于外部查询 derived 派生表查询,既from字句中的子查询 materialized 物化查询 uncacheable subquery 无法被缓存的子查询,对外部查询的每一行都需要重新进行查询 uncacheable union union操作中第二个及之后的查询,并且该查询属于uncacheable subquery table:此次查询访问的表\npartitions:分区信息,非分区表为null\ntype:查询时使用索引的类型\n值 描述 all 没有使用到索引 index 全索引扫描,如果时聚簇索引列相当于全表扫描 range 索引范围扫描 ref 辅助索引等值查询 eq_ref 多表连接查询中,非驱动表的连接条件是主键或唯一键时 const / system 主键或唯一键等值查询 null 无需访问表或者索引 possible_keys:可能会应用的索引\nkey:最终选择的索引\nkey_len:用来判断联合索引应用的部分。值是真实字节数,如果不是非空约束列,记得要加1\nformat=json在used_key_parts字段上可以直观的看出\nref:表示连接查询的连接条件\nrows:需要扫描的行数\nfiltered:某个表经过搜索条件过滤后剩余记录条数的百分比\nextra:额外信息,常见如下值\n信息描述 解释 no tables used 当查询语句的没有 from 子句时将会提示该额外信息 impossible where 查询语句的 where 子句永远为 false 时将会提示该额外信息 using index 索引覆盖的情况 using index condition 有些搜索条件中虽然出现了索引列,但却不能使用到索引 using where 全表扫描来执行对某个表的查询,并且该语句的 where 子句中有针对该表的搜索条件时 using filesort 用到了索引做排序 using temporary 使用了临时表 优化器针对索引的算法 优化器算法及开启状态查询\n1 select @@optimizer_switch; 索引下推(index_condition_pushdown,icp)\n作用:根据表数据分析,联合索引尽可能的多过滤数据,减少回表\n原理:下推到引擎层过滤\n例如:联合索引(a, b, c),执行查询条件 \u0026quot; where a = and b \u0026gt; and c = \u0026quot;\nsql层做完过滤后,联合索引(a, b, c)只能用(a, b)部分,索引下推可将c列条件的过滤下推到engine层,进行再次过滤,排除无用的数据页,最终去磁盘上拿数据页\n索引多范围查找(multi range read,mrr)\n作用:减少对磁盘的随机访问,进而对基表执行更多的顺序扫描\n原理:由于mysql 辅助索引的存储顺序并非与主键的顺序一致,所以根据辅助索引获取的主键来访问表中的数据会导致随机的io。mrr将多个需要回表的二级索引根据主键进行排序,然后一起回表,将原来的回表时进行的随机io,转变成顺序io\n表连接算法 普通嵌套循环连接(simple nested-loops join,snlj)\n优化器自动选择结果集小的表作为驱动表。对于两表连接,驱动表只会被访问一遍,被驱动表具体访问几遍取决于对驱动表执行单表查询后的结果集中的记录条数。这种驱动表只访问一次,但被驱动表却可能被多次访问的连接执行方式称之为嵌套循环连接。\n可以用left join强制驱动表\n索引嵌套循环连接(index nested loops join, inlj)\n有一方在连接字段上有索引,优化器会考虑选择有索引的一方作为被驱动表,双方都有索引则选择索引高度低的,索引高度一样则选择记录数多的作为被驱动表,对于驱动表的每一条记录,在被驱动表中使用索引查询,大大减少了比较次数,提高了查询效率\n基于块的嵌套循环连接(block nested-loop join,bnl)\n被驱动表要被访问好多次,如果被驱动表中的数据特别多而且不能使用索引访问的话,那就相当于从磁盘上读好多次这个表,这个io代价就非常大,所以应该尽量减少访问被驱动表的次数。\n在嵌套循环连接中,驱动表查询结果集中有多少条记录,就需要驱动表数据被加载多少次来进行匹配,那可不可以把被驱动表的记录加载到内存的时候,一次性和多条驱动表中的记录做匹配,这样就可以大大减少重复从磁盘上加载被驱动表的代价了。\n所以提出可join buffer的概念,join buffer就是执行连接查询前申请的一块固定大小的内存,先把若干条驱动表结果集中的记录装在这个join buffer中,然后扫描被驱动表,每一条被驱动表的记录一次性和join buffer中的多条驱动表记录进行匹配,因为匹配的过程是在内存中完成的,所以这样可以减少被驱动表的io代价。\n批量键访问联接(batched key access join,bka)\n当被驱动表的链接字段有非主键索引时,通过范围扫描读取一部分记录放入内存中,然后按照主键排序,这样匹配到数据后需要按对应的主键索引去查询被驱动表的真实数据时,可以按照排好序的主键进行顺序访问。相当于(bnl + mrr)\n哈希连接(hash join)\nhash join被应用的条件是那些不走索引,或者索引应用不好的时候。\nhash join 包含两个部分:build构建阶段和probe探测阶段\n1 select persons.name, countries.country_name from persons join countries on persons.country_id = countries.country_id; build 阶段 遍历驱动表,以join条件为key(countries.country_id),查询需要的列作为value(countries.country_id,countries.country_name)创建hash表。\n案例中对 countries.country_id 进行 hash 计算:hash(countries.country_id) 然后将值放入内存中 hash table 的相应位置。countries 表中的所有 country_id 都放入内存的哈希表中\nprobe 探测阶段\nbuild阶段完成后,mysql逐行遍历被驱动表,然后计算 join条件的hash值,并在hash表中查找,如果匹配,则输出给客户端,否则跳过。所有内表记录遍历完,则整个过程就结束了。\n如图所示 ,mysql 对 persons 表中每行中的 join 字段的值进行 hash 计算;hash(persons.country_id),拿着计算结果到内存 hash table 中进行查找匹配\n如果驱动表的数据记录在内存中存不下时就会利用磁盘文件。此时mysql 要构建临时文件做hash join。此时的过程如下:\nbuild阶段会首先利用hash算将外表进行分区,并产生临时分片写到磁盘上\n然后在probe阶段,对于内表使用同样的hash算法进行分区\n由于使用分片hash函数相同,那么key相同(join条件相同)必然在同一个分片编号中。接下来,再对外表和内表中相同分片编号的数据进行内存hash join的过程,所有分片的内存hash join做完,整个join过程就结束了\n可以调整join_buffer_size和open_files_limit参数提高性能\n8、innodb 存储引擎 核心特性总览 mvcc: 多版本并发控制 聚簇索引 : 用来组织存储数据和优化查询 支持事务 : 数据最终一致提供保证 支持行级锁 : 并发控制 外键 : 多表之间的数据一致一致性 多缓冲区支持 自适应hash索引: ahi 复制中支持高级特性 备份恢复: 支持热备 自动故障恢复:cr crash recovery 双写机制 : dwb double write buffer 存储引擎的管理 查看碎片情况\n1 2 -- 查看某个数据库下的碎片情况 select table_name,data_free,engine from information_schema.tables where table_schema=\u0026#39;[数据库名称]\u0026#39;; 整理碎片\n1 2 3 4 5 6 -- 以下两个操作相当于重新生成表,并更新统计信息 alter table 表名 engine=innodb; analyze table 表名; -- 对数据表优化 optimize table 表名; 查询线程信息\n1 2 3 4 5 6 7 8 9 10 11 12 -- 前台线程查询(连接层) show processlist ; show full processlist; select * from information_schema.processlist; -- 后台线程(server\\engine) select * from performance_schema.threads; -- 查询连接线程和sql线程关系 select * from information_schema.processlist ; ---\u0026gt; id=10 select * from performance_schema.threads where processlist_id=10; select * from performance_schema.events_statements_history where thread_id=? 表空间 表空间的分类\nsystem tablespace(系统表空间/共享表空间) file-per-table tablespace(独立表空间) undo tablespace(undo 表空间) temp tablespace(临时表空间) system tablespace(系统表空间/共享表空间)\n查询共享表空间信息\nselect @@innodb_data_file_path;默认(ibdata1:12m:autoextend)\nselect @@innodb_autoextend_increment;默认64m\n即ibdata1文件,默认初始大小12m,不够用会自动扩展,默认每次扩展64m。不建议使用默认大小,并发太小\n# 如果已经初始化,第一个大小必须和硬盘中的第一个文件实际大小一致,否则会报错 innodb_data_file_path=ibdata1:1024m;ibdata2:1024m:autoextend 5.7 中建议:设置共享表空间2-3个,大小建议512m或者1g,最后一个定制为自动扩展。\n8.0 中建议:设置1-2个就ok,大小建议512m或者1g\nfile-per-table tablespace(独立表空间)\n每个表的表空间包含单个 innodb表的数据和索引,并存储在文件系统上的单个数据文件中。mysql每创建一个表,就会生成一个独立表空间以 table_name.idb 命名的。\nundo tablespace(undo 表空间)\n用作撤销日志,回滚日志\n5.7版本,默认存储在共享表空间中(ibdatan);8.0版本以后默认就是独立的(undo_001-undo_002)\n1 2 3 4 select @@innodb_undo_tablespaces; -- 打开独立undo模式,并设置undo的个数,建议3-5个 select @@innodb_max_undo_log_size; -- undo日志的大小,默认1g。 select @@innodb_undo_log_truncate; -- 开启undo自动回收的机制(undo_purge)。 select @@innodb_purge_rseg_truncate_frequency; -- 触发自动回收的条件,单位是检测次数。 temp tablespace(临时表空间)\n把临时表的数据从系统表空间中抽离出来,形成独立的表空间参数innodb_temp_data_file_path,独立表空间文件名为 ibtmp1,默认大小 12mb。建议进行修改。\n# 建议数据初始化之前设定好,一般2-3个,大小512m-1g innodb_temp_data_file_path=ibtmp1:512m;ibtmp2:512m:autoextend:max:512m 行格式 1 2 3 4 5 6 7 8 9 10 create table record_format_demo ( c1 varchar (10), c2 varchar (10) not null, c3 char(10), c4 varchar(10)) charset=ascii row_format = compact; -- 记录1 insert into record_format_demo(c1, c2, c3, c4) values(\u0026#39;aaaa\u0026#39;, \u0026#39;bbb\u0026#39;, \u0026#39;cc\u0026#39;, \u0026#39;d\u0026#39;); -- 记录2 insert into record_format_demo(c1, c2, c3, c4) values(\u0026#39;eeee\u0026#39;, \u0026#39;fff\u0026#39;, null, null); compact行格式\n一条完整的记录其实可以被分为记录的额外信息和记录的真实数据两大部分\n记录的额外信息:为了描述这条记录而不得不额外添加的一些信息,这些额外信息分为3类,分别是变长字段长度列表、null值列表和记录头信息\n变长字段长度列表\n所有变长字段的真实数据占用的字节长度都存放在记录的开头部位,从而形成一个变长字段长度列表,各变长字段数据占用的字节数按照列的顺序逆序存放,变长字段长度列表中只存储值为 非null 的列内容占用的长度,值为 null 的列的长度是不储存的\nnull值列表\n表中如果没有允许存储 null 的列,则 null值列表也不存在了。否则将每个允许存储null的列对应一个标记【1-null,0-not null】,标记位按照列的顺序逆序排列。null值列表必须用整数个字节的位表示,如果使用的二进制位个数不是整数个字节,则在字节的高位补0\n记录头信息\n由固定的5个字节组成。5个字节也就是40个二进制位,不同的位代表不同的意思\n名称 大小(bit) 描述 预留位1 1 没有使用 预留位2 1 没有使用 delete_mask 1 标记该记录是否被删除 min_rec_mask 1 b+树的每层叶子节点中的最小记录都会添加该记标记 n_owned 4 表示当前记录拥有的记录数 heap_no 13 表示当前记录在记录堆的位置信息 record_type 3 表示当前记录的类型,0表示普通记录,1表示b+树非叶子节点记录,2表示最小记录,3表示最大记录 next_record 16 表示下一条记录的相对位置 记录的真实数据:除了报错了自己定义列的存储数据以外,mysq还l会为每个记录默认的添加一些列(也称为隐藏列),具体的列如下\n列名 是否必须 占用空间(单位:b) 描述 db_row_id 否 6 行id,唯一标识一条记录 db_trx_id 是 6 事务id db_roll_ptr 是 7 回滚指针 dynamic和compressed行格式\n默认存储格式是dynamic,这俩行格式和compact行格式挺像,只不过在处理行溢出数据时有点儿分歧,它们不会在记录的真实数据处存储字段真实数据的前768个字节,而是把所有的字节都存储到其他页面中,只在记录的真实数据处存储其他页面的地址**。**compressed行格式和dynamic不同的一点是,compressed行格式会采用压缩算法对页面进行压缩,以节省空间。\n页结构 页中使用/未使用空间(user records / free space)\n开始生成页的时候,其实并没有user records这个部分,每当我们插入一条记录,都会从free space部分,也就是尚未使用的存储空间中申请一个记录大小的空间划分到user records部分,当free space部分的空间全部被user records部分替代掉之后,也就意味着这个页使用完了,如果还有新的记录插入的话,就需要去申请新的页了\n最小记录和最大记录(infimum+supremum)\ninfimum和supremum本质上就是两条数据行,只不过是虚拟的。infimum记录(也就是最小记录) 的next_record记录就是本页中主键值最小的用户记录,而本页中主键值最大的用户记录的next_record记录就是supremum记录(也就是最大记录)\ninnodb会维护一条记录的单链表,链表中的各个节点是按照主键值由小到大的顺序连接起来的\n当数据页中存在多条被删除掉的记录时,这些记录的next_record属性将会把这些被删除掉的记录组成一个垃圾链表,以备之后重用这部分存储空间。上面删除了一行记录,又将记录原封不动插回来的情况,原来的存储空间是会被重用的。\n还有一种情况是不会被重用的:删除原记录后,新插入的记录真实数据所占存储空间大于原先记录存储空间的时候,这时原空间不会被重用且被加入垃圾链表,新插入的记录会从free space申请新的空间,和已有的记录组合成新的链表。\n页目录(page directory)\n做出页目录结构,用于在页内快速定位数据\n将所有正常的记录(包括最大和最小记录,不包括标记为已删除的记录)划分为几个组,有点类似与跳表思想 每个组的最后一条记录(也就是组内最大的那条记录)的头信息中的n_owned属性表示该记录拥有多少条记录,也就是该组内共有几条记录 将每个组的最后一条记录的地址偏移量单独提取出来按顺序存储到靠近页的尾部的地方,这个地方就是所谓的page directory,也就是页目录。页面目录中的这些地址偏移量被称为槽(slot),所以这个页面目录就是由槽组成的 页面头部(page header)\ninnodb为了能得到一个数据页中存储的记录的状态信息,比如本页中已经存储了多少条记录,第一条记录的地址是什么,页目录中存储了多少个槽等等,特意在页中定义了一个叫page header的部分\n名称 大小(byte) 描述 page_n_dir_slots 2 页目录的插槽数 page_heap_top 2 还未使用的空间最小地址,也就是说从该地址之后就是free space page_n_heap 2 本页中的记录的数量(包括最小和最大记录以及标记为删除的记录) page_free 2 第一个已经标记为删除的记录地址(各个已删除的记录通过next_record也会组成一个单链表,这个单链表中的记录可以被重新利用) page_garbage 2 已删除记录占用的字节数 page_last_insert 2 最后插入记录的位置 page_direction 2 记录插入的方向 page_n_direction 2 一个方向连续插入的记录数量 page_n_recs 2 页中记录的数量(不包括最小和最大记录以及被标记为删除的记录) page_max_trx_id 8 修改当前页的最大事务id,该值仅在二级索引中定义 page_level 2 当前页在b+树中所处的层级 page_index_id 8 索引id,表示当前页属于哪个索引 page_btr_seg_leaf 10 b+树叶子段的头部信息,仅在b+树的root页定义 page_btr_seg_top 10 b+树非叶子段的头部信息,仅在b+树的root页定义 文件头部(file header)\nfile header是针对各种类型的页都通用数据部分,也就是说不同类型的页都会以file header作为第一个组成部分,它描述了一些针对各种页都通用的一些信息,比方说这个页的编号是多少,它的上一个页、下一个页是谁等信息,这个部分占用固定的38个字节,是由下边这些内容组成的\n名称 大小(byte) 描述 fil_page_space_or_chksum 4 页的校验和(checksum值) fil_page_offset 4 页号 fil_page_prev 4 上一个页的页号 fil_page_next 4 下一个页的页号 fil_page_lsn 8 页面被最后修改时对应的日志序列位置 fil_page_type 2 该页的类型 fil_page_file_flush_lsn 8 仅在系统表空间的一个页中定义,代表文件至少被刷新到了对应的lsn值 fil_page_arch_log_no_or_space_id 4 页属于哪个表空间 文件尾部(file trailer)\n前4个字节代表页的校验和,和file header的遥相呼应,刷盘时先写file header的校验和,再写file trailer的,如果不一致证明页面出现损坏 后4个字节代表页面被最后修改时对应的日志序列位置(lsn) 日志与数据刷新 dwb(double write bufffffer)\nmysql的一页的大小是16k,文件系统一页的大小是4k,即mysql将buffer中一页数据刷入磁盘,要写4个文件系统里的页\n这个操作并非原子,如果执行到一半断电,会不会出现问题呢?会,这就是所谓的“页数据损坏”\nredo无法修复这类\u0026quot;页数据损坏\u0026quot;的异常,修复的前提是\u0026quot;页数据正确\u0026quot;并且redo日志正常\n于是就有了解决方案double write buffer,但它与传统的buffer不同,它分为内存和磁盘的两层架构。即传统的buffer,大部分是内存存储,而dwb里的数据,是需要落地的\n第一步:页数据内存的数据先拷贝到dwb的内存里\n第二步:dwb的内存刷到dwb的磁盘上\n第三步:dwb的内存刷到数据磁盘存储上\n假设步第二步出现问题,磁盘里依然是1+2+3+4的完整数据,只要有页数据完整,就还能通过redo还原数据\n假设步第三步出现问题,dwb里存储着完整的数据,可通过dwb的数据恢复磁盘数据\nredo日志\n在页面修改完成之后,在脏页刷出磁盘之前,要先写入redo日志,防止异常情况导致数据错误,而且redo日志一定是先行的(聚簇索引、二级索引、undo页面修改,均需要记录redo日志)\n存储位置:数据路径下,进行轮序覆盖记录日志(名称ib_logfilen)\n查询redo log文件配置:show variables like '%innodb_log_file%';\n生产建议:512m-4g 2-4组\n从mysql 8.0.30开始,innodb的重做日志架构发生了重大变化,重做日志文件被固定为32个,并存放在一个专门的目录(#innodb_redo)下面,用户可以使用系统变量innodb_redo_log_capacity(默认100m)在线修改重做日志容量,原来的innodb_log_files_in_group和innodb_log_file_size两个系统变量已经废弃。\nundo 日志\n当事务执行过程中突然中止,为了保证事务的原子性,需要回滚回原来的样子,每当要对一条记录进行改动时,都需要记录下一些信息,为了回滚而记录的东西称为撤销日志,即undo日志。二级索引记录的修改,不记录undo日志。\nlsn(日志序列号)\nlsn(log sequence number)日志序列号,占用8字节,lsn主要用于发生宕机时对数据进行恢复,lsn是一个一直递增的整型数字,表示事务写入到日志的字节总量。lsn不仅只存在于重做日志中,在每个数据页头部也会有对应的lsn号,该lsn记录当前页最后一次修改的lsn号,用于在恢复时对比重做日志lsn号决定是否对该页进行恢复数据。checkpoint也是有lsn号记录的,lsn号串联起一个事务开始到恢复的过程\n1 2 3 4 5 6 7 8 -- 查看lsn信息 show engine innodb status\\g; -- 返回信息说明: -- log sequence number: 当前系统最大的lsn号 -- log flushed up to:当前已经写入redo日志文件的lsn -- pages flushed up to:已经将更改写入脏页的lsn号 -- last checkpoint at就是系统最后一次刷新buffer pool脏中页数据到磁盘的checkpoint -- 以上4个lsn是递减的: lsn1\u0026gt;=lsn2\u0026gt;=lsn3\u0026gt;=lsn4 checkpoint(检查点)\n按照类型分类\nsharp checkpoint:完全检查点,数据库正常干净关闭时,会触发把所有的脏页都写入到磁盘上(这时候logfile的日志就没用了,脏页已经写到磁盘上了) fuzzy checkpoint:模糊检查点,部分页写入磁盘。 按照触发源头分类\nmaster thread checkpoint:差不多以每秒或每十秒的速度从缓冲池的脏页列表中刷新一定比例的页回磁盘,这个过程是异步的,不会阻塞用户查询\n1 2 3 4 -- pci-e建议 2000-3000 4000-6000 -- flash建议 5000-8000 10000-16000 select @@innodb_io_capacity; -- 默认200 select @@innodb_io_capacity_max; -- 默认2000 flush_lru_list checkpoint:控制lru列表中可用页的数量,默认是1024\n1 select @@innodb_lru_scan_depth; async/sync flush checkpoint:log file快满了,会批量的触发数据页回写,这个事件触发的时候又分为异步和同步\nredo log 占 log file 的比值大于75%是异步;大于90%是同步\ndirty page too much checkpoint:脏页太多检查点,为了保证buffer pool的空间可用性的一个检查点\n1 2 3 4 5 6 -- innodb_buffer_pool_pages_dirty/innodb_buffer_pool_pages_total:表示脏页在buffer的占比 select @@innodb_buffer_pool_pages_dirty; select @@innodb_buffer_pool_pages_total; -- 如果\u0026gt;0,说明出现性能负载,buffer pool中没有干净可用块 show global status like \u0026#39;%innodb_buffer_pool_wait_free\u0026#39;; innodb 事务详解 事务的acid\natomicity:原子性,一个事务生命周期中的dml语句,要么全成功要么全失败,不可以出现中间状态\n实现机制:undo保证的\nconsistency:一致性,事务发生前,中,后,数据都最终保持一致\n实现机制:cr + dwb\nisolation:隔离性,事务操作数据行的时候,不会受到其他事务的影响\n实现机制:mvcc、锁\ndurability:持久性,一但事务提交,永久生效(落盘)\n实现机制:redo、ckpt\n隔离级别\nread-uncommitted(ru):读未提交,可以读取到事务未提交的数据。隔离性差,会出现脏读(当前内存读),不可重复读,幻读问题\nread-committed(rc):读已提交(生成一般使用)。可以读取到事务已提交的数据。隔离性一般,不会出现脏读问题,但是会出现不可重复读,幻读问题\nrepeatable-read(rr ):可重复读(默认)。防止脏读(当前内存读),不可重复读,幻读问题。需要配合锁机制来避免幻读\nserializable(se):可串行化\ninnodb 锁机制 latch\nlatch,闩(shuān)锁,直译过来就是锁,但latch的作用是用于控制内存中的数据结构并发访问的(通俗来讲,就是保护内存中数据结构完整性的)。与数据库的锁(lock)不同,数据库中的锁对象不是内存结构,锁住的是一行一行的记录,而latch锁住的是并发资源的对象,也称作临界区。并且二者持续的时间不一样,lock是贯穿整个事务,事务提交了,lock才会释放。其实任何系统中都有latch,无处不在。就像java中的lock\n在innodb存储引擎中,latch又可以分为mutex(互斥量)和rwlock(读写锁)。其目的是用来保证并发线程操作临界资源的正确性,并且通常没有死锁检测机制\ninnodb的s锁、x锁\n共享锁(s)和排他锁(x)都属于行级别(row-level)的锁,且都比较好理解,s锁与x锁互相冲突,x锁与x锁也是互相冲突,s锁与s锁不会冲突\n当读取一行记录时,为了防止别人修改,需要添加s锁。 当修改一行记录时,为了防止别人同时进行修改,需要添加x锁 通常情况下,普通的查询属于非锁定读,不会添加任何锁(即一致性读,利用mvcc)。还有一种是锁定读(即当前读),那么以下两种当前读情况会触发锁:\nselect ... lock in share mode; 这个语法会添加s锁,对于其他事务可以读但不可以修改 select ... for update; 这个语法会添加x锁,其他事务修改或者执行select ... for update操作都会被阻塞 使用set global innodb_status_output_locks='on'; show engine innodb status ;可以查看当前锁是什么\ninnodb的is锁和ix锁\ns锁和x锁都是行级别,是加在索引(记录)上的。innodb存储引擎是支持多粒度锁定的,这种锁定允许事务在行级别上和表级别上同时存在。为了支持在不同粒度上进行加锁操作,innodb存储引擎支持一种额外的锁方式,称之为意向锁(intention lock)。意向锁是将锁定的对象分为多个层次,意味着事务希望在更细粒度上进行加锁。\n如果需要对行记录r加x锁,那么分别需要对数据库、表、页上先加 ix 或者 is锁,最后对记录r上加x锁。\ninnodb存储引擎层的加锁顺序是:库 → 表 → 页 → 记录\ninnodb存储引擎设计意向锁的主要目的就是:为了在一个事务中揭示下一层将被请求的锁类型。即意向锁表示的是下一层级要加什么锁,对于当前这个层级,大家都是互相兼容的(大家加的都是锁的意向【有想法,但还未落实,落实的事情交给下一层手下的人去做】),所以锁兼容矩阵中 → 意向锁之间都是互相兼容的\n也可手动给表级别加s/x锁,非常特殊情况才会使用\nlock tables t read:\nlock tables t write:对表t加x锁\ninnodb engine级别锁\nrc隔离级别下,只有record lock(记录锁),没有gap lock(间隙锁)和next-key lock(临键锁)\n使用非聚集索引列进行数据更新时,mysql会使用非聚集索引进行查找,对于查找到满足过滤条件的每一行索引记录\n在查找到的非聚集索引记录上加锁 根据非聚集索引记录上包含的聚集索引键值进行回表查找 在查找到的聚集索引记录上加锁 循环1、2、3步处理下一条满足过滤条件的数据 record lock (记录锁):单个索引记录上的锁。锁定的是一条记录\ngap (间隙锁):锁定一个范围,但不包含记录本身(x, y)。间隙锁存在于rr(可重复读)隔离级别下,为防止幻读发生设计出来的一种手段,因rc(读已提交)隔离级别可能发生幻读,故rc隔离级别下没有间隙锁。\nnext-key lock(临键锁):gap lock + record lock,锁定一个范围,并且锁定记录本身(x, y]。间隙锁存在于rr(可重复读)隔离级别下,为防止幻读发生设计出来的一种手段,因rc(读已提交)隔离级别可能发生幻读,故rc隔离级别下没有间隙锁。\nperformance_schema.data_locks表能看到加了哪些锁\n在rr级别下的加锁细节\n原则 1:加锁的基本单位是 next-key lock。并且next-key lock 是前开后闭区间。(5,10]\n原则 2:查找过程中访问到的索引才会加锁\n原则 3:索引上的等值查询,给唯一索引加锁的时候,next-key lock 退化为行锁\n常见场景:\nupdate ... where id=?,rc\\rr模式下都是record lock\nupdate ... where id in (?,?,?),rc\\rr模式下都是record lock\nupdate ... where id \u0026lt; ?,rc模式下record lock,rr模式下gap\nupdate ... where id \u0026lt;= ?,rc模式下record lock,rr模式id存在是next-key lock,否则是gap\n不同情况下的锁处理示例 组合一:id主键+rc\n给定sql:delete from t1 where id = 10; 只需要将主键上,id = 10的记录加上x锁即可。如下图所示\n组合二:id唯一索引+rc\n这个组合,id不是主键,而是一个unique的二级索引键值。那么在rc隔离级别下,delete from t1 where id = 10;\n此时,加锁的情况由于组合一有所不同。由于id是unique索引,因此delete语句会选择走id列的索引进行where条件的过滤,在找到id=10的记录后,首先会将unique索引上的id=10索引记录加上x锁,同时,会根据读取到的name列,回主键索引(聚簇索引),然后将聚簇索引上的name = ‘d’ 对应的主键索引项加x锁。\n组合三:id非唯一索引+rc\n首先,id列索引上,满足id = 10查询条件的记录,均已加锁。同时,这些记录对应的主键索引上的记录也都加上了锁。与组合二唯一的区别在于,组合二最多只有一个满足等值查询的记录,而组合三会将所有满足查询条件的记录都加锁、\n组合四:id无索引+rc\n由于id列上没有索引,因此只能走聚簇索引,进行全部扫描。从图中可以看到,满足删除条件的记录有两条,但是,聚簇索引上所有的记录,都被加上了x锁。无论记录是否满足条件,全部被加上x锁。既不是加表锁,也不是在满足条件的记录上加行锁。\n为什么不是只在满足条件的记录上加锁呢?这是由于mysql的实现决定的。如果一个条件无法通过索引快速过滤,那么存储引擎层面就会将所有记录加锁后返回,然后由mysql server层进行过滤。因此也就把所有的记录,都锁上了。在实际的实现中,mysql有一些改进,在mysql server过滤条件,发现不满足后,会调用unlock_row方法,把不满足条件的记录放锁 (违背了2pl的约束)。这样做,保证了最后只会持有满足条件记录上的锁,但是每条记录的加锁操作还是不能省略的。\n组合五:id主键+rr\n组合一:[id主键,read committed]一致\n组合六:id唯一索引+rr\n与组合二[id唯一索引,read committed]一致。两个x锁,id唯一索引满足条件的记录上一个,对应的聚簇索引上的记录一个\n组合七:id非唯一索引+rr\nkey(id) 锁定了(【6, c】, 【10, b】) + 【10, b】; (【10, b】, 【10, d】) + 【10, d】; + (【10, d】, 【11, f】)\nprimary key 锁定了【b】,【d】\nrr隔离级别下,id列上有一个非唯一索引,对应sql:delete from t1 where id = 10; 首先,通过id索引定位到第一条满足查询条件的记录,加记录上的x锁,加gap上的gap锁,然后加主键聚簇索引上的记录x锁,然后返回;然后读取下一条,重复进行。直至进行到第一条不满足条件的记录[11,f],此时,不需要加记录x锁,但是仍旧需要加gap锁,最后返回结束\n组合八:id无索引+rr\n这是一个很恐怖的现象。首先,聚簇索引上的所有记录,都被加上了x锁。其次,聚簇索引每条记录间的间隙(gap),也同时被加上了gap锁。这个示例表,只有6条记录,一共需要6个记录锁,7个gap锁。试想,如果表上有1000万条记录呢!\nmvcc 多版本并发控制 在innodb中的每一条记录实际都会存在三个隐藏列:\ndb_trx_id:事务 id,是根据事务产生时间顺序自动递增的,是独一无二的。如果某个事务执行过程中对该记录执行了增、删、改操作,那么innodb存储引擎就会记录下该条事务的 id db_roll_ptr:回滚指针,本质上就是一个指向记录对应的undo log的一个指针,innodb 通过这个指针找到之前版本的数据 db_row_id:主键,如果有自定义主键,那么该值就是主键;如果没有主键,那么就会使用定义的第一个唯一索引;如果没有唯一索引,那么就会默认生成一个隐藏列作为主键 read view\nread view是innodb在实现mvcc时用到的一致性读视图,用于支持读提交和可重复读隔离级别的实现,作用是执行期间判断版本链中的哪个版本是当前事务可见的。本质上是innodb为每个事务构造了一个数组,用来保存当前正在活跃(启动了但还没提交)的所有事务id。\n数组里面事务id的最小值记为低水位,当前系统里面已经创建过的事务id的最大值加1记为高水位;这个视图数组和高水位,就组成了当前事务的一致性视图(read-view)。\nmvcc与隔离级别\nmvcc 只在 **read commited(读已提交) 和 repeatable read(可重读读) **两种隔离级别下工作。\n在rc隔离级别下,是每个快照读都会生成并获取最新的read view,这就是我们在rc级别下的事务中可以看到别的事务提交的更新的原因 在rr隔离级别下,则是同一个事务中的第一个快照读才会创建read view, 之后的快照读获取的都是同一个read view,从而做到可重复读 rr级别下当前读的幻读问题 时刻 事务1 事务2 t1 select * from user where id\u0026gt;100; t2 # 输出n条记录 insert into user values(103, ‘wangwu’, 20); t3 commit; t4 update user set age=21 where id\u0026gt;100; t5 select * from user where id\u0026gt;100; t6 # 输出n+1条记录 产生幻读的原因:\n在t4时刻,由于update语句采用的是当前读,会对事务2新增的记录进行加锁、修改age字段值、修改db_trx_id隐藏字段值。\n在t5时刻使用快照读时,根据可见性算法,这条新增记录的db_trx_id是当前事务,所以是可见的,所以输出了n+1条记录\n解决方案:select的时候加for update;或者lock in share mode;\n9、备份恢复与迁移 binlog 日志的格式 statement(statement-based replication,sbr):每一条会修改数据的 sql语句 都会记录在 binlog 中,如果使用uuid()等函数会出现问题\nrow(row-based replication,rbr):不记录 sql 语句上下文信息,仅保存哪条记录被修改\nmixed(mixed-based replication,mbr):statement 和 row 的混合体,系统会自动判断执行语句该用 statement (优先使用)还是 row\ngtid 在传统的mysql基于二进制日志的模式复制中,从库需要告知主库要从哪个二进制日志文件中的那个偏移量进行增量同步,如果指定错误会造成数据的遗漏,从而造成数据的不一致。借助gtid,在发生主备切换的情况下,mysql的其它从库可以自动在新主库上找到正确的复制位置,这大大简化了复杂复制拓扑下集群的维护,也减少了人为设置复制位置发生误操作的风险。另外,基于gtid的复制可以忽略已经执行过的事务,减少了数据发生不一致的风险。所以说,相比mysql传统的主从复制模式,gtid模式的复制对于 dba/开发人员/运维 等相关技术人员更加友好。\nbinlog操作 基本操作\n1 2 3 4 5 6 7 8 9 10 11 -- 查看二进制文件列表 show binary logs; -- 查看正在使用的二进制文件,包含了偏移量和gtid信息 show master status; -- 查看二进制文件存储的内容 show binlog events in \u0026#39;二进制日志文件\u0026#39;\\g; # 使用工具查看 mysqlbinlog --read-from-remote-server -h地址 -p端口 -u用户名 -p密码 -d 数据库 二进制文件 自动清理日志\n1 2 3 4 5 -- 查看日志自动清理时间 -- 8.0之前expire_logs_days -- 8.0之后expire_logs_days -- 企业建议,至少保留两个全备周期+1的binlog show variables like \u0026#39;%expire%\u0026#39;; my2sql 应用\n1 2 3 4 5 6 7 8 # 安装配置 wget https://github.com/liuhr/my2sql/blob/master/releases/centos_release_7.x/my2sql # 解析日志事件sql ./my2sql -user 用户名 -password 密码 -host 地址 -port 端口 -mode repl -work-type 2sql -start-file 二进制文件 -start-datetime 开始时间 -output-dir ./tmpdir #生成指定事件回滚语句 ./my2sql -user 用户名 -password 密码 -host 地址 -port 端口 -mode repl -work-type rollback -start-file 二进制文件 -start-pos 开始位置 -stop-file 二进制文件 -stop-pos 结束位置 -output-dir ./tmpdir slow log的查看 1 2 3 # -s c 安装执行个数排序 # -t top mysqldumpslow -s c -t 10 慢查询文件路径 物理备份 链接\nclone plugin mysql 8.0推出了clone plugin插件有两种模式\n本地克隆:启动克隆操作的mysql服务器实例中的数据,克隆到同服务器或同节点上的一个目录里\n远程克隆:默认情况下,远程克隆操作会删除接受者(recipient)数据目录中的数据,并将其替换为捐赠者(donor)的\n克隆数据。您也可以将数据克隆到接受者的其他目录,以避免删除现有数据。(可选)\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 -- 加载插件 -- 或者配置my.cnf -- plugin-load-add=mysql_clone.so -- clone=force_plus_permanent install plugin clone soname \u0026#39;mysql_clone.so\u0026#39;; -- 查看插件信息 select plugin_name, plugin_status from information_schema.plugins where plugin_name like \u0026#39;clone\u0026#39;; -- 创建克隆专用用户 create user clone_user@\u0026#39;%\u0026#39; identified with mysql_native_password by \u0026#39;password\u0026#39;; grant backup_admin on *.* to \u0026#39;clone_user\u0026#39;; -- 本地克隆 mkdir -p /data/backup/ chown -r mysql.mysql /data/ mysql -uclone_user -ppassword -e\u0026#34;clone local data directory = \u0026#39;/data/backup/clonedir\u0026#39;\u0026#34;; -- 观察状态 select stage, state, end_time from performance_schema.clone_progress; -- 日志观测 set global log_error_verbosity=3; tail -f 错误日志 -- 克隆远程数据 -- 创建远程clone用户 -- 捐赠者授权(源端) create user clone_s@\u0026#39;%\u0026#39; identified by \u0026#39;源端密码\u0026#39;; grant backup_admin on *.* to clone_s@\u0026#39;%\u0026#39;; -- 接受者授权(目标端) create user clone_t@\u0026#39;%\u0026#39; identified by \u0026#39;目标端密码\u0026#39;; grant clone_admin on *.* to clone_t@\u0026#39;%\u0026#39;; -- 目标端开始克隆 set global clone_valid_donor_list=\u0026#39;源端ip:源端口\u0026#39;; mysql -uclone_t -p123 -h目标端ip -p目标端端口 -e \u0026#34;clone instance from clone_s@\u0026#39;源端ip\u0026#39;:端口 identified by \u0026#39;源端密码\u0026#39;;\u0026#34; 10、各种架构体系 无故障时间 故障时间 方案 99.9% 0.1% = 525.6 min ka+双主 :人为干预 99.99% 0.01% = 52.56 min mha 99.999% 0.001% = 5.256 min pxc、 mgr 99.9999% 0.5256 min 自动化、云化、平台化、分布式 附录 8.0版本相对于5.7版本的变化 支持事务性ddl,崩溃可以回滚,保证一致\n保留一份数据字典信息,取消frm数据字典。\n数据字典存放至innodb表中\n采用套锁机制,管理数据字典的并发访问(mdl)\n全新的plugin支持,8.0.17+ 加入clone plugin,更好的支持mgr,innodb cluster的节点管理\n安全加密方式改变,改变加密方式为caching_sha2_password\n改变授权管理方式\n加入role角色管理\n取消query cache\n各版本innodb表文件结构的变化 8.0 以前 innodb表:\nibd : 数据和索引 frm : 存私有的数据字典信息 8.0 之后 innodb表:\nibd:数据和索引\n公共sdi(冗余的私有数据字典信息)\nmysql5.7升级到8.0 升级前一定要先做冷备,方便失败回退。\n下载安装mysql-shell工具,8.0以后可以调用这个命令,升级之前的预检查。\n创建连接用户\n1 grant all on *.* to root@\u0026#39;%\u0026#39; identified by \u0026#39;密码\u0026#39;; 预检查\n1 mysqlsh root:密码@\u0026#39;%\u0026#39;:端口 -e \u0026#34;util.checkforserverupgrade()\u0026#34; \u0026gt;/tmp/up.log 停原库\n1 2 3 # 0代表当mysql关闭时,innodb需要完成所有full purge和merge insert buffer操作。如果做升级,通常需要将这个参数调为0,然后在关闭数据库 set global innodb_fast_shutdown=0; mysqladmin -s socket文件路径 shutdown 使用高版本软件挂低版本数据启动\n1 2 3 4 5 6 # 让数据库升级 /usr/local/mysql/bin/mysqld_safe --defaults file=5.7库配置文件路径 --skip-grant-tables --skip-networking \u0026amp; # 关闭数据库,并重新启动数据库 /usr/local/mysql/bin/mysqld_safe --defaults file=5.7库配置文件路径 \u0026amp; # 设置回默认值 set global innodb_fast_shutdown=1; innodb undo、redo在增删改操作时的工作 insert\nundo\n将插入记录的主键值,写入undo;\nredo\n将完整数据行信息写入redo;\ndelete\nundo\ndelete,在innodb内部为delete mark操作,将记录上标识delete_bit,而不删除记录 将当前记录的系统列写入undo 将当前记录的主键列写入 将当前记录的所有索引列写入undo 将undo page的修改,写入redo redo\n将完整数据行信息写入redo\nupdate\n情况一:update(未修改聚簇索引键值,属性列长度未变化)\nundo(聚簇索引) 将当前记录的系统列写入undo 将当前记录的主键列写入undo 将当前update列的前镜像写入undo 若update列中包含二级索引列,则将二级索引其他未修改列写入undo 将undo页面的修改,写入redo redo 进行in place update,记录update redo日志(聚簇索引) 若更新列包含二级索引列,二级索引肯定不能进行in place update,记录delete mark + insert 日志 情况二: update(未修改聚簇索引键值,属性列长度发生变化)\nundo(聚簇索引) 将当前记录的系统列写入 将当前记录的主键列写入 将当前update列的前镜像写入 若update列中包含二级索引列,则将二级索引其他未修改列写入undo 将undo页面的修改,写入redo redo 不可进行in place update,记录delete + insert redo日志(聚簇索引) 若更新列包含二级索引列,二级索引肯定不能进行in place update,记录delete mark + insert redo日志 情况三:update(修改聚簇索引键值)\nundo (聚簇索引)\n不可进行in place update。update = delete mark + insert 对原有记录进行delete mark操作,写入delete mark操作undo 将新纪录插入聚簇索引,写入insert操作undo 将undo页面的修改,写入redo redo\n不可进行in place update,记录delete mark + insert redo日志(聚簇索引) 若更新列包含二级索引列,二级索引肯定不能进行in place update,记录delete mark + insert 日志 ","date":"2023-01-10","permalink":"https://hobocat.github.io/post/database/2023-01-10-mysql_dba_%E8%A7%86%E8%A7%92/","summary":"1、MySQL部署前准备 关闭NUMA NUMA(Non-Uniform Memory Access,非一致性内存访问)服务器的基本特征是 Linux 将系统的硬件资源划分为多个软件抽象,称","title":"mysql dba视角"},]
[{"content":"一、前置知识\u0026amp;总览 对象结构全貌 redis的每种对象其实都由对象结构(redisobject) 与 对应编码的数据结构组合而成,每种对象类型对应若干种编码方式,不同的编码方式所对应不同的底层数据结构\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 /* * redis 对象 */ typedef struct redisobject { unsigned type:4; // 类型 unsigned encoding:4; // 编码方式 unsigned lru:24; // 记录最后一次访问时间(相对于lru_clock); 或者lfu(最少使用的数据:8位频率,16位访问时间) int refcount; // 引用计数 void *ptr; // 指向底层数据结构实例 } robj; 对应如下结构\ntype记录了对象所保存的值的类型 1 2 3 4 5 6 7 8 /* * 对象类型 */ #define obj_string 0 // 字符串 #define obj_list 1 // 列表 #define obj_set 2 // 集合 #define obj_zset 3 // 有序集 #define obj_hash 4 // 哈希表 encoding记录了对象所保存的值的编码 1 2 3 4 5 6 7 8 9 10 11 12 /* * 对象编码 */ #define obj_encoding_raw 0 /* raw representation */ #define obj_encoding_int 1 /* encoded as integer */ #define obj_encoding_ht 2 /* encoded as hash table */ #define obj_encoding_ziplist 5 /* encoded as ziplist */ #define obj_encoding_intset 6 /* encoded as intset */ #define obj_encoding_skiplist 7 /* encoded as skiplist */ #define obj_encoding_embstr 8 /* embedded sds string encoding */ #define obj_encoding_quicklist 9 /* encoded as linked list of ziplists */ #define obj_encoding_stream 10 /* encoded as a radix tree of listpacks */ ptr是一个指针,指向实际保存值的数据结构 lru属性记录了对象最后一次被命令程序访问的时间 基本数据类型对应的底层数据结构 基本数据类型 底层数据结构 string 简单动态字符串(sds - simple dynamic string) hash 压缩列表(ziplist),哈希表(dict) list 双向链表(quicklist),压缩列表(ziplist) set 整数数组(intset),哈希表(dict) zset 压缩列表(ziplist), 跳表(zskiplist) redis所有编码方式以及底层数据结构之间的关系 数据类型 编码类型 底层数据结构 string obj_encoding_raw simpledynamicstring obj_encoding_embstr obj_encoding_int 直接存储在redisobject的ptr list obj_encoding_quicklist quicklist obj_encoding_ziplist ziplist hash obj_encoding_ziplist ziplist obj_encoding_ht dict set obj_encoding_intset intset obj_encoding_ht dict zset obj_encoding_ziplist ziplist obj_encoding_skiplist zskiplist 命令的类型检查和多态行为 当执行一个处理数据类型命令的时候,redis执行以下步骤\n根据给定的key,在数据库字典中查找和他相对应的redisobject,如果没找到,就返回null 检查redisobject的type属性和执行命令所需的类型是否相符,如果不相符,返回类型错误 根据redisobject的encoding属性所指定的编码,选择合适的操作函数来处理底层的数据结构 返回数据结构的操作结果作为命令的返回值 object encoding [key] 命令可以查看底层对象编码\n二、simpledynamicstring 结构介绍 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 struct __attribute__ ((__packed__)) sdshdr8 { uint8_t len; uint8_t alloc; unsigned char flags; char buf[]; }; struct __attribute__ ((__packed__)) sdshdr16 { uint16_t len; uint16_t alloc; unsigned char flags; char buf[]; }; struct __attribute__ ((__packed__)) sdshdr32 { uint32_t len; uint32_t alloc; unsigned char flags; char buf[]; }; struct __attribute__ ((__packed__)) sdshdr64 { uint64_t len; uint64_t alloc; unsigned char flags; char buf[]; }; len 保存字符串的长度\nbuf[] 数组用来保存字符串的每个元素\nalloc分别以8位, 16位, 32位, 64位表示整个sds,不包含header(sds是指向buf的char*,所以结构体中buf都是放在最后。header就是len、alloc、flags)和结束字符\\0\nflags 以低三位标示着用着那种类型的sds\n1 2 3 4 5 6 #define sds_type_8 1 #define sds_type_16 2 #define sds_type_32 3 #define sds_type_64 4 #define sds_type_mask 7 #define sds_type_bits 3 分配细节 空间预分配\n空间预分配是用于优化 sds 字符串增长操作的,简单来说就是当字节数组空间不足触发重分配的时候,总是会预留一部分空闲空间。这样的话,就能减少连续执行字符串增长操作时的内存重分配次数。\n有两种预分配的策略:\nlen 小于 1mb 时:每次重分配时会多分配同样大小的空闲空间; len 大于等于 1mb 时:每次重分配时会多分配 1mb 大小的空闲空间。 惰性空间释放\n惰性空间释放是用于优化 sds 字符串缩短操作的。简单来说就是当字符串缩短时,并不立即使用内存重分配来回收多出来的字节,而是用 free 属性记录,等待将来使用。sds 也提供直接释放未使用空间的 api,在需要的时候,也能真正的释放掉多余的空间。\n实现细节技巧与优点 实现的技巧\nsds结构体取消了字节对齐,然后又将指针直接指向了结构体的尾部的buf对象。指针指向的位置完全兼容了c的字符串操作,如果需要得到其它信息则使用了flags = s[-1]的下标访问操作得到类型之后再做计算。\n优点\n常数复杂度获取字符串长度\n由于 len 属性的存在,我们获取 sds 字符串的长度只需要读取 len 属性,时间复杂度为 o(1)。而对于 c 语言,获取字符串的长度通常是经过遍历计数来实现的,时间复杂度为 o(n)\n杜绝缓冲区溢出\nc语言中使用 strcat 函数来进行两个字符串的拼接,一旦没有分配足够长度的内存空间,就会造成缓冲区溢出。而对于 sds 数据类型,在进行字符修改的时候,会首先根据记录的len属性检查内存空间是否满足需求,如果不满足,会进行相应的空间扩展,然后在进行修改操作,所以不会出现缓冲区溢出\n减少修改字符串的内存重新分配次数\nc语言由于不记录字符串的长度,所以如果要修改字符串,必须要重新分配内存。而对于sds,由于len属性和alloc属性的存在,对于修改字符串sds实现了空间预分配和惰性空间释放两种策略\n二进制安全\n因为c字符串以空字符作为字符串结束的标识,而对于一些二进制文件(如图片等),内容可能包括空字符串,因此c字符串无法正确存取。而所有sds的api都是以处理二进制的方式来处理 buf 里面的元素,并且 sds 不是以空字符串来判断是否结束,而是以len属性表示的长度来判断字符串是否结束\n兼容c字符串函数\n三、intset 1 2 3 4 5 typedef struct intset { uint32_t encoding; uint32_t length; int8_t contents[]; } intset; encoding表示编码方式,取值有三个:intset_enc_int16, intset_enc_int32, intset_enc_int64\nlength代表其中存储的整数的个数\ncontents实际存储数值数组,数组元素从小到大有序排序,且数组中不包含任何重复项。\n虽然intset结构将contents属性声明为int8_t类型的数组,但实际上contents数组并不保存任何int8_t类型的值,contents数组的真正类型取决于encoding属性的值\n整数集合的升级\n当在一个int16类型的整数集合中插入一个int32类型的值,整个集合的所有元素都会转换成32类型。 整个过程有三步:\n根据新元素的类型(比如int32),扩展整数集合底层数组的空间大小,并为新元素分配空间 将底层数组现有的所有元素都转换成与新元素相同的类型, 并将类型转换后的元素放置到正确的位上, 而且在放置元素的过程中, 需要继续维持底层数组的有序性质不变 最后改变encoding的值,length+1 集合不支持降级\n四、dict 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 /* * 哈希表 */ typedef struct dictht { dictentry **table; // 哈希表数组 unsigned long size; // 哈希表大小 unsigned long sizemask; // 哈希表大小掩码,用于计算索引值 unsigned long used; // 哈希表数组的长度 } dictht; /* * 哈希表节点 */ typedef struct dictentry { void *key; // 键 union { // 值 void *val; uint64_t u64; int64_t s64; double d; } v; struct dictentry *next; // 链的后继节点 } dictentry; /* * 字典 * 每个字典使用两个哈希表,用于实现渐进式 rehash */ typedef struct dict { dicttype *type; // 特定于类型的处理函数 void *privdata; // 类型处理函数的私有数据 dictht ht[2]; // 哈希表(2 个) long rehashidx; // 记录rehash进度的标志,值为-1表示rehash未进行 int16_t pauserehash; // 如果大于0则代表rehash暂停 } dict; 扩容和收缩\n当哈希表保存的键值对太多或者太少时,就要通过rerehash(重新散列)来对哈希表进行相应的扩展或者收缩。\n如果执行扩展操作,会基于原哈希表创建一个大小等于 ht[0].used*2n 的哈希表(也就是每次扩展都是根据原哈希表已使用的空间扩大一倍创建另一个哈希表)。相反如果执行的是收缩操作,每次收缩是根据已使用空间缩小一倍创建一个新的哈希表 重新利用上面的哈希算法,计算索引值,然后将键值对放到新的哈希表位置上 所有键值对都迁徙完毕后,释放原哈希表的内存空间 渐近式 rehash\n渐进式rehash是指扩容和收缩操作不是一次性、集中式完成的,而是分多次、渐进式完成的。如果保存在redis中的键值对只有几个几十个,那么 rehash 操作可以瞬间完成,但是如果键值对有几百万,几千万甚至几亿,那么要一次性的进行rehash,势必会造成redis一段时间内不能进行别的操作。所以redis采用渐进式rehash,在进行渐进式rehash期间,字典的删除查找更新等操作可能会在两个哈希表上进行,第一个哈希表没有找到,就会去第二个哈希表上进行查找。但是进行增加操作,一定是在新的哈希表上进行的。\n五、zskiplist 跳跃表结构在redis中的运用场景只有一个,那就是作为有序列表zset的使用。跳跃表的性能可以保证在查找,删除,添加等操作的时候在对数期望时间内完成,这个性能是可以和平衡树来相比较的,而且在实现方面比平衡树要优雅,这就是跳跃表的长处。跳跃表的缺点就是需要的存储空间比较大,属于利用空间来换取时间的数据结构。\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 typedef struct zskiplistnode { sds ele; // 数据 double score; // 分数 struct zskiplistnode *backward; // 后退指针 struct zskiplistlevel { struct zskiplistnode *forward; // 前进指针 unsigned int span; // 跨度 } level[]; } zskiplistnode; typedef struct zskiplist { struct zskiplistnode *header, *tail; // 表头节点和表尾节点 unsigned long length; // 表中节点的数量 int level; // 表中层数最大的节点的层数 } zskiplist zskiplist结构\nheader/tail指向跳跃表的表头/尾节点 level记录目前跳跃表内,层数最大的那个节点层数(表头节点的层数不计算在内,头节点一直32个level) length记录跳跃表的长度,也就是跳跃表目前包含节点的数量(表头节点不计算在内,即真实数据量) zskiplistnode结构\nele存储的元素\nscore元素分数,从小到大排列\nbackward指向结点的前一个紧邻结点\nlevel字段,用以记录所有结点(除过头节点外)每个结点中最多持有32个zskiplistlevel结构. 实际数量在结点创建时,按幂次定律随机生成,每加一层概率为1/4\nforward字段指向比自己得分高的下个节点 span字段代表forward字段指向的结点, 距离当前结点的距离. 紧邻的两个结点之间的距离定义为1 六、ziplist ziplist是一个经过特殊编码达到双向链表效果的结构,它的设计目标就是为了提高存储和访问效率。它能以o(1)的时间复杂度在表的两端提供push和pop操作。又因为ziplist是一个内存连续的集合,所以ziplist遍历只要通过当前节点的指针加上当前节点的长度或减去上一节点的长度 ,即可得到下一个节点的数据或上一个节点的数据,这样就省去的指针从而节省了存储空间,又因为内存连续所以在数据读取上的效率也远高于普通的链表\nziplist结构\nzlbytes存储的是整个ziplist所占用的内存的字节数(包含他自己) zltail指的是ziplist中最后一个entry的偏移量. 用于快速定位最后一个entry, 以快速完成pop等操作 zllen 记录entry的数量(redis作了特殊的处理:当实体数超过2^16,该值被固定为2^16-1所以这种时候要知道所有实体的数量就必须要遍历整个结构了,效率会降低) entry真正存数据的结构。 zlend固定为 255 (0xff),作为ziplist的结束标识 entry结构\nprevlen前一个entry的大小\n如果前一个元素长度小于254(255用于zlend)的时候,prevlen长度为1个字节,值即为前一个entry的长度 如果前一个元素长度大于等于254的时候,prevlen用5个字节表示,第一字节设置为254,后面4个字节存储一个无符号整型,表示前一个entry的长度,例如长度300则表示为 0xfe 00 00 00 12c encoding不同的情况下值不同,用于表示当前entry的类型和长度,如果存储时数字则可能不需要使用entry-data存储信息,而是直接受用encoding存储数据\nentry-data存储entry表示的数据\nziplist缺点\nziplist不适合保存很多的元素,因为插入、删除、更新操作需要重新分配地址并且复制原来的元素,所以在保存数据量较少的数据时,ziplist才有优势。而且可能设计的结构会引发连锁更新问题,ziplist在v7.0被listpack替代\n连锁更新\n假设有这样的一个ziplist,每个节点都是等于253字节的。新增了一个大于等于254字节的新节点,由于之前的节点prevlen长度是1个字节。为了要记录新增节点的长度所以需要对节点1进行扩展,由于节点1本身就是253字节,再加上扩展为5字节的pervlen则长度超过了 254字节,这时候下一个节点又要进行扩展了。噩梦就开始了。 七、quicklist quicklist实际上就是ziplist和linkedlist的混合体,它将linkedlist按段切分,每一段使用ziplist来紧凑存储,多个ziplist之间使用双向指针串接起来。避免了过多的内存碎片。\nquicklist结构\nfill的值影响着每个链表结点中, ziplist的长度\n-1 不超过 4kb\n-2 不超过 8kb\n-3 不超过 16kb\n-4 不超过 32kb\n-5 不超过 64kb\n当数值为正数时, 代表以entry数目限制单个ziplist的长度\ncount所有ziplist中entry数量\nlen所有quicklistnodes节点数量\ncompress的值影响着ziplist指针指向的是原生的ziplist,还是经过压缩包装后的\nhead和tail代表着头尾指针\nquicklistnode结构\nprev和next代表前/后一节点指针 ziplist是指向ziplist的指针 sz统计指向的ziplist实际占用内存大小。(如果ziplist被压缩了,那么这个sz的值仍然是压缩前的ziplist大小) count统计ziplist里面包含的数据项个数 encoding 表示是否压缩 container 指存储类型,目前使用固定值2表示使用ziplist存储 recompress现在数据是否被解压了 attempted_compress节点不能被压缩因为太小了 extra 占位没用上 八、基本数据类型底层编码场景 string obj_encoding_int\n当字符串键值的内容可以用一个 64位有符号整形 来表示时,redis会将键值转化为long型来进行存储,此时即对应 obj_encoding_int 编码类型,而且 redis 启动时会预先建立10000个分别存储0~9999的 redisobject变量作为共享对象,这就意味着如果set字符串的键值在0~10000之间的话,则可以直接指向共享对象而不需要再建立新对象,此时键值不占空间\nobj_encoding_embstr\n对于长度小于44的字符串,redis键值采用obj_encoding_embstr方式,表示嵌入式的string。从内存结构上来讲即字符串sds结构体与其对应的redisobject对象分配在同一块连续的内存空间,这就仿佛字符串sds嵌入在redisobject对象之中一样\nobj_encoding_raw\n当字符串长度大于44的时,redis则会将键值的内部编码方式改为obj_encoding_raw 格式,这与上面的obj_encoding_embstr编码方式的不同之处在于此时动态字符串sds的内存与其依赖的redisobject的内存不再连续了,且当在原有字符串上进行追加时创建的新字符串的编码时raw\nlist 满足如下条件list会用ziplist作为实现,否则使用quicklist\n(1)列表对象保存的所有字符串元素的长度都小于64字节\nlist-max-ziplist-value 64 #保存的所有字符串元素的长度都小于64字节。 (2)列表对象保存的元素数量小于512个\nlist-max-ziplist-entries 512 #保存的元素数量小于512个。 hash hash的底层存储可以使用ziplist和dict。当hash对象可以同时满足一下两个条件时,哈希对象使用ziplist编码(一个元素存key,下一个元素存value)\n(1)哈希对象保存的所有键值对的键和值的字符串长度都小于64字节\nhash-max-ziplist-value 64 (2)哈希对象保存的键值对数量小于512个\nhash-max-ziplist-entries 512 set 元素都是整数类型,就用intset存储,否则使用dict存储\nzset 发送如下事情,zset底层实现会从ziplist变为zskiplist\n(1)当sorted set中的元素个数,即(数据, score)对的数目超过128的时\nzset-max-ziplist-entries 128 (2)当sorted set中插入的任意一个数据的长度超过了64的时\nzset-max-ziplist-value 64 ","date":"2022-09-05","permalink":"https://hobocat.github.io/post/nosql/2022-09-05-redisstruct/","summary":"一、前置知识\u0026amp;总览 对象结构全貌 Redis的每种对象其实都由对象结构(redisObject) 与 对应编码的数据结构组合而成,每种对象类型对应若干种编码方式","title":"redis底层数据结构"},]
[{"content":"一、nio基础 bio blocking io: 同步阻塞的编程方式。\njdk1.4版本提供了bio编程方式。编程实现过程为:首先在服务端启动一个serversocket来监听网络请求,客户端启动socket发起网络请求,默认情况下serversocket回建立一个线程来处理此请求,如果服务端没有线程可用,客户端则会阻塞等待或遭到拒绝。通讯过程中,是同步的。在并发处理效率上比较低。\n同步并阻塞,服务器实现模式为一个连接一个线程,即客户端有连接请求时服务器端就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销,当然可以通过线程池机制改善。bio方式适用于连接数目比较小且固定的架构,这种方式对服务器资源要求比较高,并发局限于应用中,jdk1.4以前的唯一选择,但程序直观简单易理解。\nnio unblocking io(new io): 同步非阻塞的编程方式。\nnio本身是基于事件驱动思想来完成的,其主要想解决的是bio的大并发问题,nio基于reactor,当socket有流可读或可写入socket时,操作系统会相应的通知引用程序进行处理,应用再将流读取到缓冲区或写入操作系统。也就是说,这个时候,已经不是一个连接就要对应一个处理线程了,而是有效的请求,对应一个线程,当连接没有数据时,是没有工作线程来处理的。\nnio - 三大组件 channel \u0026amp; buffer\nchannel有一点类似于stream,它就是读写数据的双向通道,可以从channel将数据读入buffer,也可以将buffer的数据写入channel,而之前的stream要么是输入,要么是输出,channel比stream更为底层\n常见的channel:filechannel【file】、datagramchannel【udp】、socketchannel【tcp】、serversocketchannel【tcp】\nbuffer用来缓冲读写数据,常见的buffer:mappedbytebuffer【内存映射文件】、directbytebuffer【直接内存分配】、heapbytebuffer【堆内存】\nselector\nselector的作用就是配合一个线程来管理多个channel,获取这些channel上发生的事件。这些channel工作在非阻塞模式下,适合连接数特别多,但流量低的场景。调用selector的select()会阻塞直到channel发生了读写就绪事件,当事件发生select方法就会返回这些事件交给thread来处理\nnio - bytebuffer bytebuffer 正确使用姿势\n向buffer写入数据,例如调用channel.read(buffer) 调用flip()切换至读模式 从 buffer 读取数据,例如调用 buffer.get() 调用 clear() 或 compact() 切换至写模式 重复 1~4 步骤 用buytebuffer读取文件数据示例\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 @test public void testbytebuffer() throws exception { randomaccessfile file = new randomaccessfile(\u0026#34;data.txt\u0026#34;, \u0026#34;rw\u0026#34;); filechannel channel = file.getchannel(); bytebuffer buffer = bytebuffer.allocate(10); int readlen = 0; do { // 向 buffer 写入 readlen = channel.read(buffer); log.info(\u0026#34;读取到字节 {}\u0026#34;,readlen); // 切换 buffer 读模式 buffer.flip(); while (buffer.hasremaining()) { log.info(\u0026#34;{}\u0026#34;, (char) buffer.get()); } // 切换 buffer 写模式 buffer.clear(); } while (readlen != -1); } bytebuffer结构\nbytebuffer的重要属性:capacity【容量】、position【读写位置】、limit【读写限制位置】\n初始时\n写模式下,position是写入位置,limit等于容量(含义是可写入的最大限制)\nflip动作发生后,position切换为读取位置,limit切换为读取限制\nclear动作发生后,会将position置为0,limit置为capacity位置,但是数据块不会重置\ncompact方法,是把未读完的部分向前压缩,然后切换至写模式\n调试工具类\nnio - bytebuffer 常见方法 分配空间 1 2 3 4 // heap 内存 bytebuffer buf = bytebuffer.allocate(16); // 直接内存 bytebuffer directbuf = bytebuffer.allocatedirect(16); 向buffer写入数据 1 2 3 int readbytes = channel.read(buf); //返回从channel读取的长度 buf.put((byte)127); //手动放入数据 从buffer读取数据 1 2 3 4 int writebytes = channel.write(buf); // 返回写入到channle的自己数量 byte b = buf.get(); // 手动读取数据,会移动position指针 byte b = buf.get(i); // 手动读取数据,不移动position指针 重置读取位置 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 buf.rewind(); // 重置position为0 /** * mark \u0026amp; reset * mark在读取时,做一个标记。即使position改变,只要调用reset就能回到mark的位置 */ @test public void markandresttest() { bytebuffer buffer = bytebuffer.allocate(10); buffer.put(\u0026#34;123456\u0026#34;.getbytes()); buffer.flip(); byte b1 = buffer.get(); // \u0026#39;1\u0026#39; buffer.mark(); byte b2 = buffer.get(); // \u0026#39;2\u0026#39; byte b3 = buffer.get(); // \u0026#39;3\u0026#39; buffer.reset(); byte hasb2 = buffer.get(); //\u0026#39;2\u0026#39; assert hasb2 == b2; } 字符串与bytebuffer互转 1 2 3 4 5 6 7 // 字符串转bytebuffer bytebuffer buffer1 = standardcharsets.utf_8.encode(\u0026#34;你好\u0026#34;); debug(buffer1); // bytebuffer转字符串 charbuffer buffer2 = standardcharsets.utf_8.decode(buffer1); system.out.println(buffer2.tostring()); scattering reads 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 // 分散读取,有一个文本文件 3parts.txt 内容 onetwothree @test public void partsreadtest() { try (randomaccessfile file = new randomaccessfile(\u0026#34;3parts.txt\u0026#34;, \u0026#34;rw\u0026#34;)) { filechannel channel = file.getchannel(); bytebuffer a = bytebuffer.allocate(3); bytebuffer b = bytebuffer.allocate(3); bytebuffer c = bytebuffer.allocate(5); channel.read(new bytebuffer[]{a, b, c}); a.flip(); b.flip(); c.flip(); bytebufferutil.debugall(a);\t//one bytebufferutil.debugall(b); //two bytebufferutil.debugall(c); //three } catch (ioexception e) { e.printstacktrace(); } } gathering writes 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 // 将多个buffer的数据合并写入到一个channel @test public void gatheringwritestest() { try (randomaccessfile file = new randomaccessfile(\u0026#34;2parts.txt\u0026#34;, \u0026#34;rw\u0026#34;)) { filechannel channel = file.getchannel(); bytebuffer d = bytebuffer.allocate(4); bytebuffer e = bytebuffer.allocate(4); d.put(new byte[]{\u0026#39;f\u0026#39;, \u0026#39;o\u0026#39;, \u0026#39;u\u0026#39;, \u0026#39;r\u0026#39;}); e.put(new byte[]{\u0026#39;f\u0026#39;, \u0026#39;i\u0026#39;, \u0026#39;v\u0026#39;, \u0026#39;e\u0026#39;}); d.flip(); e.flip(); channel.write(new bytebuffer[]{d, e}); } catch (ioexception e) { e.printstacktrace(); } } 注意:buffer是非线程安全\nnio - 文件编程 nio中使用filechannel建立与文件的链接通道,filechannel只能工作在阻塞模式下。\n获取\n可以通过filechannel.open获取filechannel,也可通过fileinputstream、fileoutputstream或者randomaccessfile来获取,它们都有getchannel方法\n通过fileinputstream获取的channel只能读 通过fileoutputstream获取的channel只能写 通过randomaccessfile是否能读写根据构造randomaccessfile时的读写模式决定 读取\n1 2 // 会从channel读取数据填充bytebuffer,返回值表示读到了多少字节,-1表示到达了文件的末尾 int readbytes = channel.read(buffer); 写入\n1 2 3 4 // 正确的写入姿势,如果buffer较大,一次会写不完 while(buffer.hasremaining()) { channel.write(buffer); } 关闭\nchannel必须关闭,不过调用了fileinputstream、fileoutputstream或者randomaccessfile的close方法会间接地调用channel的close方法\n位置\n1 2 3 4 5 6 7 8 9 10 // 获取当前位置 long pos = channel.position(); /** * 设置当前位置 * 设置当前位置时,如果设置为文件的末尾 * - 这时读取会返回 -1 * - 这时写入,会追加内容,但要注意如果position超过了文件末尾,再写入时在新内容和原末尾之间会有空洞(00) */ channel.position(newpos); 大小\n1 channel.size(); //获取文件大小 强制写入\n操作系统出于性能的考虑,会将数据缓存,不是立刻写入磁盘。可以调用force(true) 方法将文件内容和元数据(文件的权限等信息)立刻写入磁盘\n两个 channel 传输数据\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public void filechanneltransfertotest() { try ( filechannel from = new fileinputstream(\u0026#34;data.txt\u0026#34;).getchannel(); filechannel to = new fileoutputstream(\u0026#34;to.txt\u0026#34;).getchannel(); ) { // 效率高,底层会利用操作系统的零拷贝进行优化 long size = from.size(); // left 变量代表还剩余多少字节 for (long left = size; left \u0026gt; 0; ) { system.out.println(\u0026#34;position:\u0026#34; + (size - left) + \u0026#34; left:\u0026#34; + left); left -= from.transferto((size - left), left, to); } } catch (ioexception e) { e.printstacktrace(); } } path\njdk7 引入了path和paths类\npath用来表示文件路径 paths是工具类,用来获取path实例 1 2 3 4 5 6 7 8 path source = paths.get(\u0026#34;1.txt\u0026#34;); // 相对路径使用user.dir环境变量来定位1.txt path source = paths.get(\u0026#34;d:\\\\1.txt\u0026#34;); // 绝对路径代表了d:\\1.txt path projects = paths.get(\u0026#34;d:\\\\data\u0026#34;, \u0026#34;projects\u0026#34;); // 代表了d:\\data\\projects path path = paths.get(\u0026#34;d:\\\\data\\\\projects\\\\a\\\\..\\\\b\u0026#34;); path.normalize() // 计算为d:\\data\\projects\\b files\n检查文件是否存在 1 2 path path = paths.get(\u0026#34;data.txt\u0026#34;); system.out.println(files.exists(path)); 创建一级目录 1 2 path path = paths.get(\u0026#34;d1\u0026#34;); files.createdirectory(path); 创建多级目录用 1 2 path path = paths.get(\u0026#34;d1/d2/d3\u0026#34;); files.createdirectories(path); 拷贝文件 1 2 3 4 5 path source = paths.get(\u0026#34;data.txt\u0026#34;); path target = paths.get(\u0026#34;target.txt\u0026#34;); // 如果文件已存在,会抛异常filealreadyexistsexception // 可以使用files.copy(source, target, standardcopyoption.replace_existing); files.copy(source, target); 移动文件 1 2 3 4 5 path source = paths.get(\u0026#34;data.txt\u0026#34;); path target = paths.get(\u0026#34;data.txt\u0026#34;); // standardcopyoption.atomic_move 保证文件移动的原子性 files.move(source, target, standardcopyoption.atomic_move); 删除文件 1 2 path target = paths.get(\u0026#34;target.txt\u0026#34;); files.delete(target); // 如果文件不存在,会抛异常 nosuchfileexception 删除目录 1 2 path target = paths.get(\u0026#34;d1\u0026#34;); files.delete(target); // 如果目录还有内容,会抛异常 directorynotemptyexception 遍历目录文件 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 @test public void loopdirtest() throws exception { path path = paths.get(\u0026#34;c:\\\\program files\\\\java\\\\jdk1.8.0_181\u0026#34;); files.walkfiletree(path, new simplefilevisitor\u0026lt;path\u0026gt;(){ @override public filevisitresult previsitdirectory(path dir, basicfileattributes attrs) throws ioexception { log.info(\u0026#34;previsitdirectory dir={}\u0026#34;, dir.getfilename()); return super.previsitdirectory(dir, attrs); } @override public filevisitresult visitfile(path file, basicfileattributes attrs) throws ioexception { log.info(\u0026#34;visitfile file={}\u0026#34;, file.getfilename()); return super.visitfile(file, attrs); } @override public filevisitresult visitfilefailed(path file, ioexception exc) throws ioexception { log.info(\u0026#34;visitfilefailed file={} exc={}\u0026#34;, file.getfilename(), exc.getmessage()); return super.visitfilefailed(file, exc); } @override public filevisitresult postvisitdirectory(path dir, ioexception exc) throws ioexception { log.info(\u0026#34;postvisitdirectory dir={}\u0026#34;, dir.getfilename()); return super.postvisitdirectory(dir, exc); } }); } nio - 网络编程 非阻塞vs阻塞 阻塞\n阻塞模式下,相关方法都会导致线程暂停\nserversocketchannel.accept会在没有连接建立时让线程暂停 socketchannel.read会在没有数据可读时让线程暂停 阻塞的表现其实就是线程暂停了,暂停期间不会占用cpu,但线程相当于闲置 单线程下,阻塞方法之间相互影响,几乎不能正常工作,需要多线程支持\n多线程下,有新的问题,体现在以下方面\n32 位jvm一个线程320k,64位jvm一个线程1024k,如果连接数过多,必然导致oom,并且线程太多,反而会因为频繁上下文切换导致性能降低 可以采用线程池技术来减少线程数和线程上下文切换,但治标不治本,如果有很多连接建立,但长时间inactive,会阻塞线程池中所有线程,因此不适合长连接,只适合短连接 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 @test public void blockiotest() throws ioexception { // 使用 nio 来理解阻塞模式, 单线程 // 0. bytebuffer bytebuffer buffer = bytebuffer.allocate(16); // 1. 创建了服务器 serversocketchannel ssc = serversocketchannel.open(); // 2. 绑定监听端口 ssc.bind(new inetsocketaddress(8080)); // 3. 连接集合 list\u0026lt;socketchannel\u0026gt; channels = new arraylist\u0026lt;\u0026gt;(); while (true) { // 4. accept 建立与客户端连接, socketchannel 用来与客户端之间通信 log.debug(\u0026#34;connecting...\u0026#34;); socketchannel sc = ssc.accept(); // 阻塞方法,线程停止运行 log.debug(\u0026#34;connected... {}\u0026#34;, sc); channels.add(sc); for (socketchannel channel : channels) { // 5. 接收客户端发送的数据 log.debug(\u0026#34;before read... {}\u0026#34;, channel); channel.read(buffer); // 阻塞方法,线程停止运行 buffer.flip(); bytebufferutil.debugread(buffer); buffer.clear(); log.debug(\u0026#34;after read...{}\u0026#34;, channel); } } } 非阻塞\n非阻塞模式下,相关方法都会不会让线程暂停 在serversocketchannel.accept 在没有连接建立时,会返回 null,继续运行 socketchannel.read在没有数据可读时,会返回0,但线程不必阻塞,可以去执行其它socketchannel的read或是去执行serversocketchannel.accept 写数据时,线程只是等待数据写入channel即可,无需等channel通过网络把数据发送出去 但非阻塞模式下,即使没有连接建立,和可读数据,线程仍然在不断运行,白白浪费了cpu 数据复制过程中,线程实际还是阻塞的(aio 改进的地方) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 @test public void nonblockiotest() throws ioexception { // 使用 nio 来理解非阻塞模式, 单线程 // 0. bytebuffer bytebuffer buffer = bytebuffer.allocate(16); // 1. 创建了服务器 serversocketchannel ssc = serversocketchannel.open(); // 非阻塞模式 ssc.configureblocking(false); // 2. 绑定监听端口 ssc.bind(new inetsocketaddress(8080)); // 3. 连接集合 list\u0026lt;socketchannel\u0026gt; channels = new arraylist\u0026lt;\u0026gt;(); while (true) { // 4. accept 建立与客户端连接, socketchannel 用来与客户端之间通信 socketchannel sc = ssc.accept(); // 非阻塞,线程还会继续运行,如果没有连接建立,但sc是null if (sc != null) { log.debug(\u0026#34;connected... {}\u0026#34;, sc); sc.configureblocking(false); // 非阻塞模式 channels.add(sc); } for (socketchannel channel : channels) { // 5. 接收客户端发送的数据 int read = channel.read(buffer);// 非阻塞,线程仍然会继续运行,如果没有读到数据,read 返回 0 if (read \u0026gt; 0) { buffer.flip(); bytebufferutil.debugread(buffer); buffer.clear(); log.debug(\u0026#34;after read...{}\u0026#34;, channel); } } } } selector 单线程可以配合selector完成对多个channel可读写事件的监控,这称之为多路复用\n多路复用仅针对网络io、普通文件io没法利用多路复用 如果不用selector的非阻塞模式,线程大部分时间都在做无用功,而selector能够保证 有可连接事件时才去连接 有可读事件才去读取 有可写事件才去写入【限于网络传输能力,channel未必时时可写,一旦channel可写,会触发selector的可写事件】 graph td subgraph selector 版 thread --\u0026gt; selector selector --\u0026gt; c1(channel) selector --\u0026gt; c2(channel) selector --\u0026gt; c3(channel) end 创建 1 selector selector = selector.open(); 绑定 channel 事件 1 2 3 4 5 6 7 8 9 10 /** * channel 必须工作在非阻塞模式 * 绑定的事件类型可以有 * - connect - 客户端连接成功时触发 * - accept - 服务器端成功接受连接时触发 * - read - 数据可读入时触发,有因为接收能力弱,数据暂不能读入的情况 * - write - 数据可写出时触发,有因为发送能力弱,数据暂不能写出的情况 */ channel.configureblocking(false); selectionkey key = channel.register(selector, selectionkey.op_accept); 监听 channel 事件 1 2 3 4 5 6 7 8 // 阻塞直到绑定事件发生 int count = selector.select(); // 阻塞直到绑定事件发生,或是超时(时间单位为 ms) int count = selector.select(1000l); // 不会阻塞,也就是不管有没有事件,立刻返回,自己根据返回值检查是否有事件 int count = selector.selectnow(); select不阻塞的情况:①事件发生时;②调用selector.wakeup();③调用selector.close();④selector所在线程interrupt\n处理 accept 事件 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 @test public void acceptortest() { try (serversocketchannel channel = serversocketchannel.open()) { channel.bind(new inetsocketaddress(8080)); system.out.println(channel); selector selector = selector.open(); channel.configureblocking(false); channel.register(selector, selectionkey.op_accept); while (true) { int count = selector.select(); log.debug(\u0026#34;select count: {}\u0026#34;, count); // 获取所有事件 set\u0026lt;selectionkey\u0026gt; keys = selector.selectedkeys(); // 遍历所有事件,逐一处理 iterator\u0026lt;selectionkey\u0026gt; iter = keys.iterator(); while (iter.hasnext()) { selectionkey key = iter.next(); // 判断事件类型 if (key.isacceptable()) { serversocketchannel c = (serversocketchannel) key.channel(); // 必须处理 socketchannel sc = c.accept(); log.debug(\u0026#34;{}\u0026#34;, sc); } // 处理完毕,必须将事件移除 iter.remove(); } } } catch (ioexception e) { e.printstacktrace(); } } 处理 read 事件 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 @test public void readeventtest() { try (serversocketchannel channel = serversocketchannel.open()) { channel.bind(new inetsocketaddress(8080)); system.out.println(channel); selector selector = selector.open(); channel.configureblocking(false); channel.register(selector, selectionkey.op_accept); while (true) { int count = selector.select(); log.debug(\u0026#34;select count: {}\u0026#34;, count); // 获取所有事件 set\u0026lt;selectionkey\u0026gt; keys = selector.selectedkeys(); // 遍历所有事件,逐一处理 iterator\u0026lt;selectionkey\u0026gt; iter = keys.iterator(); while (iter.hasnext()) { selectionkey key = iter.next(); // 判断事件类型 if (key.isacceptable()) { serversocketchannel c = (serversocketchannel) key.channel(); // 必须处理 socketchannel sc = c.accept(); sc.configureblocking(false); sc.register(selector, selectionkey.op_read); log.debug(\u0026#34;连接已建立: {}\u0026#34;, sc); } else if (key.isreadable()) { socketchannel sc = (socketchannel) key.channel(); bytebuffer buffer = bytebuffer.allocate(128); int read = sc.read(buffer); if (read == -1) { // cancel会取消注册在selector上的channel,并从keys集合中删除key后续不会再监听事件 key.cancel(); sc.close(); } else { buffer.flip(); bytebufferutil.debugread(buffer); } } // 处理完毕,必须将事件移除 iter.remove(); } } } catch (ioexception e) { e.printstacktrace(); } } 处理消息的边界\n①一种思路是固定消息长度,数据包大小一样,服务器按预定长度读取,缺点是浪费带宽\n②另一种思路是按分隔符拆分,缺点是效率低\n③tlv格式,即type类型、length长度、value数据,类型和长度已知的情况下,就可以方便获取消息大小,分配合适的buffer,缺点是buffer需要提前分配,如果内容过大,则影响server吞吐量,http1.1是tlv格式、http2.0是ltv格式\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 private static void split(bytebuffer source) { source.flip(); for (int i = 0; i \u0026lt; source.limit(); i++) { // 找到一条完整消息 if (source.get(i) == \u0026#39;\\n\u0026#39;) { int length = i + 1 - source.position(); // 把这条完整消息存入新的 bytebuffer bytebuffer target = bytebuffer.allocate(length); // 从 source 读,向 target 写 for (int j = 0; j \u0026lt; length; j++) { target.put(source.get()); } bytebufferutil.debugall(target); } } source.compact(); } // 使用 \\n 区分消息段 if (key.isreadable()) { try { socketchannel channel = (socketchannel) key.channel(); // 拿到触发事件的channel // 获取selectionkey上关联的附件,在accept时设置上的 bytebuffer buffer = (bytebuffer) key.attachment(); int read = channel.read(buffer); // 如果是正常断开,read的方法的返回值是-1 if(read == -1) { key.cancel(); } else { split(buffer); // 需要扩容 if (buffer.position() == buffer.limit()) { bytebuffer newbuffer = bytebuffer.allocate(buffer.capacity() * 2); buffer.flip(); newbuffer.put(buffer); key.attach(newbuffer); } } } catch (ioexception e) { e.printstacktrace(); key.cancel(); // 因为客户端断开了,因此需要将 key 取消 } } bytebuffer 大小分配 每个channel都需要记录可能被切分的消息,因为bytebuffer不能被多个channel共同使用,因此需要为每个channel维护一个独立的bytebuffer,bytebuffer不能太大,比如一个bytebuffer1mb的话,要支持百万连接就要1tb内存,因此需要设计大小可变的bytebuffer\n①一种思路是首先分配一个较小的buffer,例如4k如果发现数据不够,再分配8k的。将4k buffer内容拷贝至8k的,优点是消息连续容易处理,缺点是数据拷贝耗费性能\n②另一种思路是用多个数组组成buffer,一个数组不够,把多出来的内容写入新的数组,与前面的区别是消息存储不连续解析复杂,优点是避免了拷贝引起的性能损耗\n处理 write 事件 非阻塞模式下,无法保证把buffer中所有数据都写入channel【网卡能力也是有限的】,因此需要追踪write方法的返回值(代表实际写入字节数)\n用selector监听所有channel的可写事件,每个channe 都需要一个key来跟踪buffer,但这样又会导致占用内存过多,就有两阶段策略\n①当消息处理器第一次写入消息时,才将channel注册到selector上\n②selector 检查channel上的可写事件,如果所有的数据写完了,就取消channel的注册\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 if (key.isacceptable()) { socketchannel sc = ssc.accept(); sc.configureblocking(false); selectionkey sckey = sc.register(selector, selectionkey.op_read); // 1. 向客户端发送内容 stringbuilder sb = new stringbuilder(); for (int i = 0; i \u0026lt; 3000000; i++) { sb.append(\u0026#34;a\u0026#34;); } bytebuffer buffer = charset.defaultcharset().encode(sb.tostring()); int write = sc.write(buffer); // 3. write 表示实际写了多少字节 system.out.println(\u0026#34;实际写入字节:\u0026#34; + write); // 4. 如果有剩余未读字节,才需要关注写事件 if (buffer.hasremaining()) { // read 1 write 4 // 在原有关注事件的基础上,多关注 写事件 sckey.interestops(sckey.interestops() + selectionkey.op_write); // 把 buffer 作为附件加入 sckey sckey.attach(buffer); } } else if (key.iswritable()) { bytebuffer buffer = (bytebuffer) key.attachment(); socketchannel sc = (socketchannel) key.channel(); int write = sc.write(buffer); system.out.println(\u0026#34;实际写入字节:\u0026#34; + write); if (!buffer.hasremaining()) { // 写完了 key.interestops(key.interestops() - selectionkey.op_write); // 如果不取消,会每次可写均会触发write事件 key.attach(null); } } 事件发生后,要么处理,要么取消(cancel),不能什么都不做,否则下次该事件仍会触发,这是因为nio底层使用的是水平触发\nselect在事件发生后,就会将相关的key放入selectedkeys集合,但不会在处理完后从selectedkeys集合中移除,需要我们自己编码删除。例如\n第一次触发了ssckey上的accept事件,没有移除ssckey 第二次触发了sckey上的read事件,但这时selectedkeys中还有上次的ssckey,在处理时因为没有真正的serversocket连上了,就会导致空指针异常 零拷贝 传统io 传输数据问题\njava本身并不具备io读写能力,因此read方法调用后,要从java程序的用户态切换至内核态,去调用操作系统(kernel)的读能力,将数据读入内核缓冲区。这期间用户线程阻塞,操作系统使用dma(direct memory access)来实现文件读,其间也不会使用cpu\ndma可以理解为硬件单元,用来解放cpu完成文件io\n从内核态切换回用户态,将数据从内核缓冲区读入用户缓冲区(即 byte[] buf),这期间cpu会参与拷贝,无法利用dma\n调用write方法,这时将数据从用户缓冲区(byte[] buf)写入socket 缓冲区,cpu会参与拷贝\n接下来要向网卡写数据,这项能力java又不具备,因此又得从用户态切换至内核态,调用操作系统的写能力,使用dma将socket 缓冲区的数据写入网卡,不会使用cpu\n可以看到中间环节较多,java 的 io 实际不是物理设备级别的读写,而是缓存的复制,底层的真正读写是操作系统来完成的\n用户态与内核态的切换发生了 3 次,这个操作比较重量级 数据拷贝了共 4 次 nio 优化\n通过bytebuffer.allocatedirect(capacity) 创建directbytebuffer使用的是操作系统内存。directbytebuf将堆外内存映射到jvm内存中来直接访问使用,\n这块内存不受 jvm 垃圾回收的影响,因此内存地址固定,有助于 io 读写 java 中的 directbytebuf 对象仅维护了此内存的虚引用,内存回收分成两步 directbytebuf 对象被垃圾回收,将虚引用加入引用队列 通过专门线程访问引用队列,根据虚引用释放堆外内存 减少了一次数据拷贝,用户态与内核态的切换次数没有减少 进一步优化(底层采用了linux 2.1后提供的sendfile方法),java 中对应着两channel调用transferto/transferfrom方法拷贝数据\njava调用transferto方法后,要从java程序的用户态切换至内核态,使用 dma将数据读入内核缓冲区,不会使用 cpu 数据从内核缓冲区传输到socket 缓冲区,cpu会参与拷贝 最后使用dma将socket 缓冲区的数据写入网卡,不会使用 cpu 只发生了一次用户态与内核态的切换,数据拷贝了 3 次\n进一步优化(linux 2.4)\njava调用transferto方法后,要从java程序的用户态切换至内核态,使用dma将数据读入内核缓冲区,不会使用 cpu 只会将一些offset和length信息拷入socket 缓冲区,几乎无消耗 使用dma将内核缓冲区的数据写入网卡,不会使用 cpu 整个过程仅只发生了一次用户态与内核态的切换,数据拷贝了 2 次。\n所谓的【零拷贝】,并不是真正无拷贝,而是在不会拷贝重复数据到 jvm 内存中\nnio vs bio stream vs channel\nstream不会自动缓冲数据,channel会利用系统提供的发送缓冲区、接收缓冲区(更为底层) stream仅支持阻塞api,channel同时支持阻塞、非阻塞api,网络channel可配合selector实现多路复用 二者均为全双工,即读写可以同时进行 io 模型\n同步阻塞、同步非阻塞、同步多路复用、异步阻塞(没有此情况)、异步非阻塞\n同步:线程自己去获取结果(一个线程) 异步:线程自己不去获取结果,而是由其它线程送结果(至少两个线程) 二、netty的基本使用 简介 netty是一个异步的、基于事件驱动的网络应用框架,用于快速开发可维护、高性能的网络服务器和客户端。\nnetty vs nio的优势\nnio,工作量大,bug 多 nio需要自己构建协议 netty解决tcp传输问题,如粘包、半包 nio的epoll空轮询导致cpu100% 对api进行增强,使之更易用 最基础的netty示例 服务器端 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 @test public void simpleservertest() throws ioexception { new serverbootstrap() // 创建 nioeventloopgroup,可以简单理解为 线程池 + selector .group(new nioeventloopgroup()) // 选择服务socket实现类,其中nioserversocketchannel表示基于nio的服务器端实现 .channel(nioserversocketchannel.class) // childhandler添加的处理器都是给socketchannel用的,而不是给serversocketchannel // channelinitializer处理器(仅执行一次),它的作用是待客户端socketchannel建立连接后,执行initchannel以便添加更多的处理器 .childhandler(new channelinitializer\u0026lt;niosocketchannel\u0026gt;() { protected void initchannel(niosocketchannel ch) { // socketchannel 的处理器,解码 bytebuf =\u0026gt; string ch.pipeline().addlast(new stringdecoder()); // socketchannel 的业务处理器,使用上一个处理器的处理结果 ch.pipeline().addlast(new simplechannelinboundhandler\u0026lt;string\u0026gt;() { @override protected void channelread0(channelhandlercontext ctx, string msg) { system.out.println(msg); } }); } }) // 绑定的监听端口 .bind(8080); system.in.read(); } 客户端 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 @test public void simpleclienttest() throws ioexception, interruptedexception { channelfuture client = new bootstrap() // 创建 nioeventloopgroup,可以简单理解为 线程池 + selector .group(new nioeventloopgroup()) // 选择服务socket实现类,其中niosocketchannel表示基于nio的客户器端实现 .channel(niosocketchannel.class) // channelinitializer处理器(仅执行一次),它的作用是待客户端socketchannel建立连接后,执行initchannel以便添加更多的处理器 .handler(new channelinitializer\u0026lt;niosocketchannel\u0026gt;() { protected void initchannel(niosocketchannel ch) { // socketchannel 的处理器,编码 bytebuf =\u0026gt; string ch.pipeline().addlast(new stringencoder()); } // 连接服务器 }).connect(new inetsocketaddress(8080)); // future是异步的,要等待连接上服务器 client.sync(); // 发送数据 client.channel().writeandflush(\u0026#34;hello world\u0026#34;); system.in.read(); } 相关概念 需要树立正确的理解观念\n把 channel 理解为数据的通道 把 msg 理解为流动的数据,最开始输入是 bytebuf,但经过 pipeline 的加工,会变成其它类型对象,最后输出又变成 bytebuf 把 handler 理解为数据的处理工序 工序有多道,合在一起就是pipeline,pipeline负责发布事件(读、读取完成\u0026hellip;)传播给每个handler, handler对自己感兴趣的事件进行处理(重写了相应事件处理方法) handler分inbound和outbound两类 把 eventloop 理解为处理数据的工人 工人可以管理多个channel的io操作,并且一旦工人负责了某个 channel,就要负责到底(绑定) 工人既可以执行io操作,也可以进行任务处理,每位工人有任务队列,队列里可以堆放多个channel的待处理任务,任务分为普通任务、定时任务 工人按照pipeline顺序,依次按照handler的规划(代码)处理数据,可以为每道工序指定不同的工人 eventloop组件 eventloop【时间循环对象】\n本质是一个单线程执行器(同时维护了一个selector),里面有run方法处理channel上源源不断的io事件\neventloopgroup【事件循环组】\neventloopgroup是一组eventloop,channel一般会调用eventloopgroup的register方法来绑定其中一个eventloop,后续这个channel上的io事件都由此 eventloop来处理(保证了io事件处理时的线程安全),有next方法获取集合中下一个eventloop\n1 2 3 4 5 6 7 8 9 10 11 // 简单的示例 defaulteventloopgroup group = new defaulteventloopgroup(2); system.out.println(group.next()); //io.netty.channel.defaulteventloop@60f82f98 system.out.println(group.next()); //io.netty.channel.defaulteventloop@35f983a6 system.out.println(group.next()); //io.netty.channel.defaulteventloop@60f82f98 // 也可以是有for循环 defaulteventloopgroup group = new defaulteventloopgroup(2); for (eventexecutor eventloop : group) { system.out.println(eventloop); } 优雅关闭\n优雅关闭 shutdowngracefully 方法。该方法会首先切换 eventloopgroup 到关闭状态从而拒绝新的任务的加入,然后在任务队列的任务都处理完成后,停止线程的运行。从而确保整体应用是在正常有序的状态下退出。\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 @test public void simpleclienttest() throws ioexception, interruptedexception { nioeventloopgroup eventloopgroup = new nioeventloopgroup(); channelfuture client = new bootstrap() .group(eventloopgroup) .channel(niosocketchannel.class) .handler(new channelinitializer\u0026lt;niosocketchannel\u0026gt;() { protected void initchannel(niosocketchannel ch) { ch.pipeline().addlast(new stringencoder()); } }).connect(new inetsocketaddress(8080)); client.sync(); client.channel().writeandflush(\u0026#34;hello world\u0026#34;); // 优雅关闭 eventloopgroup.shutdowngracefully().sync(); } eventloop和channel强绑定\n关键代码 io.netty.channel.abstractchannelhandlercontext#invokechannelread()\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 static void invokechannelread(final abstractchannelhandlercontext next, object msg) { final object m = next.pipeline.touch(objectutil.checknotnull(msg, \u0026#34;msg\u0026#34;), next); // 下一个 handler 的事件循环是否与当前的事件循环是同一个线程 eventexecutor executor = next.executor(); // 是,直接调用 if (executor.ineventloop()) { next.invokechannelread(m); } // 不是,将要执行的代码作为任务提交给下一个事件循环处理(换人) else { executor.execute(new runnable() { @override public void run() { next.invokechannelread(m); } }); } } channel组件 channel的主要作用\nclose() 可以用来关闭channel closefuture() 用来处理channel的关闭 sync方法作用是同步等待channel关闭 而addlistener方法是异步等待channel关闭 pipeline() 方法添加处理器 write() 方法将数据写入 writeandflush() 方法将数据写入并刷出 channelfuture\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 public void simpleclienttest() throws ioexception, interruptedexception { nioeventloopgroup eventloopgroup = new nioeventloopgroup(); channelfuture client = new bootstrap() .group(eventloopgroup) .channel(niosocketchannel.class) .handler(new channelinitializer\u0026lt;niosocketchannel\u0026gt;() { protected void initchannel(niosocketchannel ch) { ch.pipeline().addlast(new stringencoder()); } }).connect(new inetsocketaddress(8080)); // connect方法是异步的,意味着不等连接建立,方法执行就返回了。 // 因此channelfuture对象中不能【立刻】获得到正确的channel对象 client.sync(); // 返回的是channelfuture对象,它的作用是利用channel()方法来获取channel对象 client.channel().writeandflush(\u0026#34;hello world\u0026#34;); channelfuture channelfuture = client.channel().closefuture(); // 可执行channel关闭后的扫尾操作 channelfuture.addlistener(new genericfuturelistener\u0026lt;future\u0026lt;? super void\u0026gt;\u0026gt;() { @override public void operationcomplete(future\u0026lt;? super void\u0026gt; future) throws exception { system.out.println(\u0026#34;关闭后扫尾操作\u0026#34;); } }); eventloopgroup.shutdowngracefully().sync(); } 异步的好处\n举个例子,如果4个医生同步处理看病的全流程,则会是如下,假设挂号、取药10min,看病、缴费20min,则60min能走完4个病人看病流程\n如果改为异步,则60min,可以处理6个挂号,6个取药,3个看病,3个缴费。这样挂号数量上升会使吞吐量上升。单实际看完的病人数量会下降。\n单线程没法异步提高效率,必须配合多线程、多核 cpu 才能发挥异步的优势 异步并没有缩短响应时间,反而有所增加,提高的是吞吐量 合理进行任务拆分,也是利用异步的关键 future \u0026amp; promise 在异步处理时,经常用到这两个接口\n首先要说明netty中的future与jdk中的future同名,但是是两个接口,netty的future继承自jdk的future,而promise又对netty future进行了扩展\njdk future只能同步等待任务结束(或成功、或失败)才能得到结果 netty future可以同步等待任务结束得到结果,也可以异步方式得到结果,但都是要等任务结束 netty promise不仅有netty future的功能,而且脱离了任务独立存在,只作为两个线程间传递结果的容器 功能/名称 jdk future netty future promise cancel 取消任务 - - iscanceled 任务是否取消 - - isdone 任务是否完成,不能区分成功失败 - - get 获取任务结果,阻塞等待 - - getnow - 获取任务结果,非阻塞,还未产生结果时返回 null - await - 等待任务结束,如果任务失败,不会抛异常,而是通过issuccess判断 - sync - 等待任务结束,如果任务失败,抛出异常 - issuccess - 判断任务是否成功 - cause - 获取失败信息,非阻塞,如果没有失败,返回null - addlinstener - 添加回调,异步接收结果 - setsuccess - - 设置成功结果 setfailure - - 设置失败结果 示例\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 // ==================================== 同步处理任务成功 ==================================== public void syncsuccesstest() throws executionexception, interruptedexception { defaulteventloop eventexecutors = new defaulteventloop(); defaultpromise\u0026lt;integer\u0026gt; promise = new defaultpromise\u0026lt;\u0026gt;(eventexecutors); eventexecutors.execute(()-\u0026gt;{ try { thread.sleep(1000); } catch (interruptedexception e) { e.printstacktrace(); } log.info(\u0026#34;set success, {}\u0026#34;,10); promise.setsuccess(10); }); log.info(\u0026#34;start...\u0026#34;); log.info(\u0026#34;getnow = {}\u0026#34;,promise.getnow()); // 还没有结果 log.info(\u0026#34;get = {}\u0026#34;,promise.get()); } // ==================================== 异步处理任务成功 ==================================== public void asyncsuccesstest() throws executionexception, interruptedexception { defaulteventloop eventexecutors = new defaulteventloop(); defaultpromise\u0026lt;integer\u0026gt; promise = new defaultpromise\u0026lt;\u0026gt;(eventexecutors); // 设置回调,异步接收结果 promise.addlistener(future -\u0026gt; { log.info(\u0026#34;getnow = {}\u0026#34;, future.getnow()); }); // 等待 1000 后设置成功结果 eventexecutors.execute(() -\u0026gt; { try { thread.sleep(1000); } catch (interruptedexception e) { e.printstacktrace(); } log.info(\u0026#34;set success, {}\u0026#34;, 10); promise.setsuccess(10); }); log.info(\u0026#34;start...\u0026#34;); promise.await(); } handler \u0026amp; pipeline channelhandler用来处理channel上的各种事件,分为入站、出站两种。所有channelhandler被连成一串,就是pipeline\n入站处理器通常是channelinboundhandleradapter的子类,主要用来读取客户端数据,写回结果 出站处理器通常是channeloutboundhandleradapter的子类,主要对写回结果进行加工 channelinboundhandleradapter是按照addlast的顺序执行的,而channeloutboundhandleradapter是按照addlast的逆序执行的。channelpipeline的实现是一个channelhandlercontext(包装了 channelhandler)组成的双向链表\n读取消息执行顺序:head -\u0026gt; in_1 -\u0026gt; in_2 -\u0026gt; out_1(不处理)-\u0026gt; out_2(不处理)-\u0026gt; tail\n发送消息执行顺序:tail -\u0026gt; out_2 -\u0026gt; out_1 -\u0026gt; in_2 (不处理)-\u0026gt; in_1 (不处理)-\u0026gt; head\nchx.writeandflush是从当前位置向head返回发送数据\nch.writeandflush是从tail向head返回发送数据,如果是在channeloutboundhandleradapte进行会是死循环\nbytebuf 是对字节数据的封装,提供了比nio bytebuffer更好的使用体验\n调试准备\n1 2 3 4 5 6 7 8 9 10 11 12 private static void log(bytebuf buffer) { int length = buffer.readablebytes(); int rows = length / 16 + (length % 15 == 0 ? 0 : 1) + 4; stringbuilder buf = new stringbuilder(rows * 80 * 2) .append(\u0026#34;read index:\u0026#34;).append(buffer.readerindex()) .append(\u0026#34; write index:\u0026#34;).append(buffer.writerindex()) .append(\u0026#34; capacity:\u0026#34;).append(buffer.capacity()) .append(\u0026#34; class:\u0026#34;).append(buffer.getclass()) .append(newline); bytebufutil.appendprettyhexdump(buf, buffer); system.out.println(buf.tostring()); } 1)创建\n1 2 3 4 5 6 7 @test public void bytebuftest() { // 默认创建的是池化的直接内存 bytebuf buffer = bytebufallocator.default.buffer(10); // read index:0 write index:0 capacity:10 class:class io.netty.buffer.pooledunsafedirectbytebuf log(buffer); } 2)直接内存 vs 堆内存\n可以使用下面的代码来创建池化基于堆的 bytebuf\n1 bytebuf buffer = bytebufallocator.default.heapbuffer(10); 也可以使用下面的代码来创建池化基于直接内存的 bytebuf\n1 bytebuf buffer = bytebufallocator.default.directbuffer(10); 直接内存创建和销毁的代价昂贵,但读写性能高(少一次内存复制),适合配合池化功能一起用 直接内存对 gc 压力小,因为这部分内存不受 jvm 垃圾回收的管理,但也要注意及时主动释放 3)池化 vs 非池化\n池化的最大意义在于可以重用 bytebuf,优点有\n没有池化,则每次都得创建新的 bytebuf 实例,这个操作对直接内存代价昂贵,就算是堆内存,也会增加 gc 压力 有了池化,则可以重用池中 bytebuf 实例,并且采用了与 jemalloc 类似的内存分配算法提升分配效率 高并发时,池化功能更节约内存,减少内存溢出的可能 池化功能是否开启,可以通过系统环境变量来设置-dio.netty.allocator.type={unpooled|pooled}\n4.1 以后,非 android 平台默认启用池化实现,android 平台启用非池化实现 4.1 之前,池化功能还不成熟,默认是非池化实现 4)组成\n5)写入\n方法签名 含义 备注 writeboolean(boolean value) 写入 boolean 值 用一字节 01|00 代表 true|false writebyte(int value) 写入 byte 值 writeshort(int value) 写入 short 值 writeint(int value) 写入 int 值 big endian,即 0x250,写入后 00 00 02 50 writeintle(int value) 写入 int 值 little endian,即 0x250,写入后 50 02 00 00 writelong(long value) 写入 long 值 writechar(int value) 写入 char 值 writefloat(float value) 写入 float 值 writedouble(double value) 写入 double 值 writebytes(bytebuf src) 写入 netty 的 bytebuf writebytes(byte[] src) 写入 byte[] writebytes(bytebuffer src) 写入 nio 的 bytebuffer int writecharsequence(charsequence sequence, charset charset) 写入字符串 6)扩容\nbytebuf具有自动扩容能力,规则是\n如何写入后数据大小未超过 512,则选择下一个16的整数倍,例如写入后大小为12 ,则扩容后capacity是16 如果写入后数据大小超过512,则选择下一个 2^n,例如写入后大小为513,则扩容后 capacity是2^10=1024(2^9=512 已经不够了) 扩容不能超过max capacity否则报错 7)读取\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 @test public void bytebufreadtest() { bytebuf buffer = bytebufallocator.default.buffer(10); buffer.writebytes(\u0026#34;abcdefg\u0026#34;.getbytes()); // 读取,影响读指针 system.out.println((char)buffer.readbyte()); // a system.out.println((char)buffer.readbyte()); // b system.out.println((char)buffer.readbyte()); // c system.out.println((char)buffer.readbyte()); // d // mark标记读指针 buffer.markreaderindex(); system.out.println((char)buffer.readbyte()); // e system.out.println((char)buffer.readbyte()); // f // 读指针复位 buffer.resetreaderindex(); system.out.println((char)buffer.readbyte()); // e // get方法不影响指针 system.out.println((char)buffer.getbyte(0)); // a } 8)retain \u0026amp; release\n由于netty中有堆外内存的bytebuf实现,堆外内存最好是手动来释放,而不是等gc垃圾回收\nunpooledheapbytebuf 使用的是 jvm 内存,只需等 gc 回收内存即可 unpooleddirectbytebuf 使用的就是直接内存了,需要特殊的方法来回收内存 pooledbytebuf 和它的子类使用了池化机制,需要更复杂的规则来回收内存 netty 这里采用了引用计数法来控制回收内存,每个 bytebuf 都实现了 referencecounted 接口\n每个bytebuf对象的初始计数为 1 调用release方法计数减 1,如果计数为0,bytebuf内存被回收 调用retain方法计数加 1,表示调用者没用完之前,其它handler即使调用了release也不会造成回收 当计数为0时,底层内存会被回收,这时即使bytebuf对象还在,其各个方法均无法正常使用 因为pipeline的存在,一般需要将bytebuf传递给下一个channelhandler,所以基本规则是,谁是最后使用者,谁负责 release,即tailcontext负责释放\n9)slice\n【零拷贝】的体现之一,对原始bytebuf进行切片成多个bytebuf,还是使用原始bytebuf的内存,切片后的bytebuf维护独立的read,write指针\n10)duplicate\n【零拷贝】的体现之一,截取了原始bytebuf所有内容,并且没有max capacity的限制,也是与原始bytebuf使用同一块底层内存,只是读写指针是独立的\n11)copy\n会将底层内存数据进行深拷贝,因此无论读写,都与原始 bytebuf 无关\n12)compositebytebuf\n【零拷贝】的体现之一,将多个bytebuf合并为一个逻辑上的bytebuf,避免拷贝。compositebytebuf是一个组合的bytebuf,它内部维护了一个component数组,每个component管理一个bytebuf,记录了这个bytebuf 相对于整体偏移量等信息,代表着整体中某一段的数据。\n13)unpooled\nunpooled 是一个工具类,类如其名,提供了非池化的 bytebuf 创建、组合、复制等操作\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 @test public void bytebufunpooledtest() { bytebuf buffer1 = unpooled.buffer(10); buffer1.release(); bytebuf buffer2 = unpooled.buffer(10); buffer2.release(); // false system.out.println(buffer1 == buffer2); bytebuf buffer3 = bytebufallocator.default.buffer(10); buffer3.release(); bytebuf buffer4 = bytebufallocator.default.buffer(10); buffer4.release(); // true system.out.println(buffer3 == buffer4); } bytebuf 优势\n池化 - 可以重用池中 bytebuf 实例,更节约内存,减少内存溢出的可能 读写指针分离,不需要像 bytebuffer 一样切换读写模式 可以自动扩容 支持链式调用,使用更流畅 很多地方体现零拷贝,例如 slice、duplicate、compositebytebuf 三、netty高级用法 粘包与半包 粘包和半包的现象是消息边界的另一种说法\n粘包\n现象:发送 abc def,接收 abcdef 原因 应用层:接收方bytebuf设置太大(netty默认1024) 滑动窗口:假设发送方256bytes表示一个完整报文,但由于接收方处理不及时且窗口大小足够大,这256bytes 字节就会缓冲在接收方的滑动窗口中,当滑动窗口中缓冲了多个报文就会粘包 nagle算法:会造成粘包 半包\n现象:发送 abcdef,接收 abc def 原因 应用层:接收方bytebuf小于实际发送数据量 滑动窗口:假设接收方的窗口只剩了128bytes,发送方的报文大小是256bytes,这时放不下了,只能先发送前128bytes,等待ack后才能发送剩余部分,这就造成了半包 mss限制:当发送的数据超过mss限制后,会将数据切分发送,就会造成半包 nagle 算法\n即使发送一个字节,也需要加入tcp头和ip头,也就是总字节数会使用41bytes,非常不经济。因此为了提高网络利用率,tcp希望尽可能发送足够大的数据,这就是 nagle 算法产生的缘由,该算法是指发送端即使还有应该发送的数据,但如果这部分数据很少的话,则进行延迟发送\nmss限制\nmss的值在三次握手时通知对方自己mss的值【网卡的传输能力】,然后在两者之间选择一个小值作为mss\nnetty解决的途径\n固定长度\n让所有数据包长度固定\n1 ch.pipeline().addlast(new fixedlengthframedecoder(8)); 缺点:\n长度定的太大,浪费 长度定的太小,对某些数据包又显得不够 固定分隔符\n服务端加入,默认以\\n或\\r\\n作为分隔符,如果超出指定长度仍未出现分隔符,则抛出异常\n1 ch.pipeline().addlast(new linebasedframedecoder(1024)); 缺点:处理字符数据比较合适,但如果内容本身包含了分隔符(字节数据常常会有此情况),那么就会解析错误\n预设长度\n1 2 // 最大长度,长度偏移,长度占用字节,长度调整,剥离字节数 ch.pipeline().addlast(new lengthfieldbasedframedecoder(1024, 0, 1, 0, 1)); 心跳机制 可以使用idlestatehandler发送心跳,也可以自定义发送心跳\n1 2 3 4 5 6 7 /** * readeridletime 读空闲时间 * writeridletime 写空闲时间 * allidletime 所有空闲时间 * unit 时间单位 */ pipeline.addlast(new idlestatehandler(0, 5, 0, timeunit.seconds)); 编码 netty编解码技术(就是指序列化传递对象),我们可以使用java进行对象序列化,netty去传输,但是java序列化没法跨语言,存在序列化后的码流太大,序列化性能太低等。\n主流的编解码框架\njboss的marshalling google的protobuf 基于protobuf的kyro messagepack框架 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 //======================================= 集成marshalling ======================================= public class marshallingcodefactory { public static marshallingdecoder bulidmarshallingdecoder(){ //首先通过marshalling工具类获取marshalling实例对象,参数serial标识创建的是java序列化工厂对象 marshallerfactory marshallerfactory = marshalling.getprovidedmarshallerfactory(\u0026#34;serial\u0026#34;); //创建了marshallingconfiguration对象,配置版本号为5 marshallingconfiguration configuration = new marshallingconfiguration(); configuration.setversion(5); //根据marshallerfactory好configuration创建provider unmarshallerprovider provider = new defaultunmarshallerprovider(marshallerfactory, configuration); //构建netty的marshallingdecoder对象,俩个参数分别为provider和单个消息序列化后的最大长度 marshallingdecoder decoder = new marshallingdecoder(provider, 1024*1024); return decoder; } public static marshallingencoder bulidmarshallingencoder(){ marshallerfactory marshallerfactory = marshalling.getprovidedmarshallerfactory(\u0026#34;serial\u0026#34;); marshallingconfiguration configuration = new marshallingconfiguration(); configuration.setversion(5); marshallerprovider provider = new defaultmarshallerprovider(marshallerfactory, configuration); marshallingencoder encoder = new marshallingencoder(provider); return encoder; } } /** * 客户端和服务器都加上marshalling编解码器 */ protected void initchannel(socketchannel ch) throws exception { //注意顺序 ch.pipeline().addlast(marshallingcodefactory.bulidmarshallingdecoder()); ch.pipeline().addlast(marshallingcodefactory.bulidmarshallingencoder()); //... } netty提供的主要tcp参数 参数 解释 so_timeout 控制读取操作将阻塞多少毫秒。如果返回值为0,计时器就被禁止了,该线程将无限期阻塞 so_sndbuf 套接字使用的发送缓冲区大小 so_rcvbuf 套接字使用的接收缓冲区大小 connecttimeoutmillis 客户端连接超时时间,由于nio原生的客户端并不提供设置连接超时的接口。\n因此,netty采用的是自定义连接超时定时器负责检测和超时控制 tcpnodelay 激活或禁止tcpnodelay套接字选项,它决定是否使用nagle算法。如果是时延敏感型的应用,建议关闭nagle算法 ","date":"2022-03-09","permalink":"https://hobocat.github.io/post/network/2022-03-09-netty/","summary":"一、NIO基础 BIO Blocking IO: 同步阻塞的编程方式。 JDK1.4版本提供了BIO编程方式。编程实现过程为:首先在服务端启动一个ServerSocket来监听网络请求,客","title":"netty的基本使用"},]
[{"content":"一、简介 \t在一个成熟的工程中,尤其是现在的分布式系统中,应用与应用之间,还有单独的应用细分模块之后,对象需要经过转换包装才能对外提供服务(比如使用vo返回与http相关的出入参,dto提供与rpc服务相关的出入参)。而对象之间的相互转化成了一个必不可少的工作,这使就需要有一个专门用来解决转换问题的工具,毕竟每一个字段都\u0026quot;get/set\u0026quot;会很麻烦。mapstruct就提供了专业的对象之间的转化方式。\njava中数据传输对象的分类 po(persistant object)\n用于表示数据库中的一条记录映射成的 java 对象。po仅仅用于表示数据,没有任何数据操作。通常遵守java bean的规范。\nvo(value object)\n主要体现在视图的对象,对于一个web页面将整个页面的属性封装成一个对象。然后用一个vo对象在控制层与视图层进行传输交换。\ndto(data transfer object)\n用于表示一个数据传输对象。dto通常用于不同服务或服务不同分层之间的数据传输。dto与vo概念相似,并且通常情况下字段也基本一致。但dto与vo又有一些不同,这个不同主要是设计理念上的,比如api服务需要使用的dto就可能与vo存在差异。\nbo(business object)\n用于表示一个业务对象。bo 包括了业务逻辑,常常封装了对dao、rpc等的调用,可以进行po与vo/dto之间的转换。bo通常位于业务层,在设计上属于被服务层业务流程调用的对象,一个业务流程可能需要调用多个bo来完成。\n二、使用示例 前置条件:引入依赖\n1 2 3 4 5 6 7 8 9 10 11 12 \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;org.mapstruct\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;mapstruct\u0026lt;/artifactid\u0026gt; \u0026lt;version\u0026gt;1.4.2.final\u0026lt;/version\u0026gt; \u0026lt;version\u0026gt;[version]\u0026lt;/version\u0026gt; \u0026lt;/dependency\u0026gt; \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;org.mapstruct\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;mapstruct-processor\u0026lt;/artifactid\u0026gt; \u0026lt;version\u0026gt;[version]\u0026lt;/version\u0026gt; \u0026lt;scope\u0026gt;compile\u0026lt;/scope\u0026gt; \u0026lt;/dependency\u0026gt; 准备演示基本类\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 //=====================================数据库对象===================================== /** * 用户信息entity:数据库对应的映射对象 */ /** * 用户信息entity:数据库对应的映射对象 */ @data public class userinfo { /** * 用户id */ private long id; /** * 用户名称 */ private string name; /** * 用户出生日期 */ private date birthdate; /** * @ */ private integer sex; /** * 账户余额 */ private bigdecimal price; } /** * 用户地址信息entity:数据库对应的映射对象 */ @data public class useraddressinfo { /** * 地址id */ private long id; /** * 用户id */ private long uid; /** * 省id */ private long provinceid; /** * 省名 */ private string provincename; /** * 市id */ private long cityid; /** * 市名 */ private string cityname; /** * 区id */ private long countid; /** * 区名 */ private string countyname; } //=====================================数据库操作===================================== /** * 模拟数据库操作 */ @component public class userinfodao { private static simpledateformat data_format = new simpledateformat(\u0026#34;yyyy-mm-dd hh:mm:ss\u0026#34;); @sneakythrows public userinfo getuser(long uid) { userinfo userinfo = new userinfo(); userinfo.setid(1l); userinfo.setname(\u0026#34;jack\u0026#34;); userinfo.setsex(1); userinfo.setprice(new bigdecimal(\u0026#34;100.123\u0026#34;)); userinfo.setbirthdate(data_format.parse(\u0026#34;1999-09-19 19:19:19\u0026#34;)); return userinfo; } @sneakythrows public list\u0026lt;useraddressinfo\u0026gt; getaddressinfo(long uid) { useraddressinfo addressinfo = new useraddressinfo(); addressinfo.setid(100l); addressinfo.setuid(1l); addressinfo.setprovinceid(1l); addressinfo.setprovincename(\u0026#34;北京\u0026#34;); addressinfo.setcityid(1001l); addressinfo.setcityname(\u0026#34;北京市\u0026#34;); addressinfo.setcountid(1001003l); addressinfo.setcountyname(\u0026#34;海淀区\u0026#34;); return collections.singletonlist(addressinfo); } } //=====================================返回前端vo===================================== /** * 用户基本信息vo */ @data @noargsconstructor public class basicuserinfovo { /** * 用户id */ private long userid; /** * 用户名称 */ private string name; /** * 用户出生日期 */ private string birthdate; /** * 性别 */ private integer sex; /** * 余额 */ private string price; /** * 是否需要账户不足提醒 */ private boolean underaccountreminder; public basicuserinfovo(basicuserinfovo basicuserinfovo) { this.userid = basicuserinfovo.userid; this.name = basicuserinfovo.name; this.birthdate = basicuserinfovo.birthdate; this.sex = basicuserinfovo.sex; this.price = basicuserinfovo.price; this.underaccountreminder = basicuserinfovo.underaccountreminder; } } /** * 地址信息vo */ @data public class useraddressinfovo { /** * 地址id */ private long addressid; /** * 用户id */ private long uid; /** * 省id */ private long provinceid; /** * 省名 */ private string provincename; /** * 市id */ private long cityid; /** * 市名 */ private string cityname; /** * 区id */ private long countid; /** * 区名 */ private string countyname; } /** * 用户全量信息vo */ @data @noargsconstructor public class userinfovo extends basicuserinfovo{ public userinfovo(basicuserinfovo basicuserinfovo, list\u0026lt;useraddressinfovo\u0026gt; useraddressinfo) { super(basicuserinfovo); this.useraddressinfo = useraddressinfo; } /** * 用户地址信息 */ private list\u0026lt;useraddressinfovo\u0026gt; useraddressinfo; } 传统方式 1 2 3 4 5 6 7 8 9 10 11 12 13 /** * 传统方式:手动设置 */ @test public void traditionalwaytest() { userinfo user = userinfodao.getuser(1l); basicuserinfovo basicuserinfovo = new basicuserinfovo(); basicuserinfovo.setname(user.getname()); basicuserinfovo.setuserid(user.getid()); basicuserinfovo.setbirthdate(data_format.format(user.getbirthdate())); log.info(\u0026#34;userinfo={}\u0026#34;, json.tojsonstring(user)); log.info(\u0026#34;basicuserinfovo={}\u0026#34;, json.tojsonstring(basicuserinfovo)); } 传统方式手动设置每个对象的属性,在属性很多时会耗费太多无用的精力。仔细用心的写,输出结果是正确的\nbeanutils方式 1 2 3 4 5 6 7 8 9 10 11 /** * beanutils方式 */ @test public void beanutilswaytest() { userinfo user = userinfodao.getuser(1l); basicuserinfovo basicuserinfovo = new basicuserinfovo(); beanutils.copyproperties(user, basicuserinfovo); log.info(\u0026#34;userinfo={}\u0026#34;, json.tojsonstring(user)); log.info(\u0026#34;basicuserinfovo={}\u0026#34;, json.tojsonstring(basicuserinfovo)); } 输出结果\nuserinfo={\u0026#34;birthdate\u0026#34;:937739959000,\u0026#34;id\u0026#34;:1,\u0026#34;name\u0026#34;:\u0026#34;jack\u0026#34;} basicuserinfovo={\u0026#34;name\u0026#34;:\u0026#34;jack\u0026#34;} beanutils当属性名称不一致时,结果是有问题的。且如果转换的是不同包的对象,即使属性名一样,也是无法转换的\n使用mapstruct 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 @mapper public abstract class userconvert { public static userconvert instance = mappers.getmapper(userconvert.class); @mappings( value = { @mapping(source = \u0026#34;id\u0026#34;, target = \u0026#34;userid\u0026#34;), @mapping(source = \u0026#34;name\u0026#34;, target = \u0026#34;name\u0026#34;), @mapping(source = \u0026#34;birthdate\u0026#34;, target = \u0026#34;birthdate\u0026#34;, dateformat = \u0026#34;yyyy-mm-dd hh:mm:ss\u0026#34;) } ) public abstract basicuserinfovo entity2basicuserinfovo(userinfo userinfo); } @test public void mapstructtest() { userinfo user = userinfodao.getuser(1l); basicuserinfovo basicuserinfovo = userconvert.instance.entity2basicuserinfovo(user); log.info(\u0026#34;userinfo={}\u0026#34;, json.tojsonstring(user)); log.info(\u0026#34;basicuserinfovo={}\u0026#34;, json.tojsonstring(basicuserinfovo)); } 输出结果\nuserinfo={\u0026#34;birthdate\u0026#34;:937739959000,\u0026#34;id\u0026#34;:1,\u0026#34;name\u0026#34;:\u0026#34;jack\u0026#34;} basicuserinfovo={\u0026#34;birthdate\u0026#34;:\u0026#34;1999-09-19 19:19:19\u0026#34;,\u0026#34;name\u0026#34;:\u0026#34;jack\u0026#34;,\u0026#34;userid\u0026#34;:1} mapstruct转换结果完全正确,符合预期\n三、mapstruct的具体用法 类型转换分类 自动转换\n以下的类型之间是mapstruct自动进行类型转换的\n基本类型及其他们对应的包装类型,此时mapstruct会自动进行拆装箱,不需要人为的处理 基本类型的包装类型和string类型之间 例如:integer -\u0026gt; int / int -\u0026gt; integer / int -\u0026gt; string / integer -\u0026gt; string\n格式化类型转换\n@mapping(source = \u0026ldquo;birthdate\u0026rdquo;, target = \u0026ldquo;birthdate\u0026rdquo;, dateformat = \u0026ldquo;yyyy-mm-dd hh:mm:ss\u0026rdquo;)\n@mapping(source = \u0026ldquo;price\u0026rdquo;, target = \u0026ldquo;price\u0026rdquo;, numberformat= #.00\u0026quot;)\n自定义类型转换\n自定义属性的转换方式,很多时候需要自定义属性转换能力\n@mapping(target = \u0026ldquo;price\u0026rdquo;, expression = \u0026ldquo;java(com.kun.utils.numberutils.toroundup(userinfo.getprice(), 2, \u0026quot;#0.00\u0026quot;))\u0026rdquo;)\n1 2 3 4 5 6 7 8 public class numberutils { public static string toroundup(bigdecimal bigdecimal, int newscale, string format) { bigdecimal resultdecimal = bigdecimal.setscale(newscale, bigdecimal.round_up); decimalformat df = new decimalformat(format); return df.format(resultdecimal); } } 常量\u0026amp;默认值\u0026amp;忽略 设置常类量\n@mapping(target = \u0026ldquo;name\u0026rdquo;, constant = \u0026ldquo;匿名用户\u0026rdquo;)\n设置属性值为常量,不需要映射\n忽略\n@mapping(target = \u0026ldquo;price\u0026rdquo;, ignore = true)\n忽略属性,不设置\n设置默认值\n@mapping(source = \u0026ldquo;name\u0026rdquo;, target = \u0026ldquo;name\u0026rdquo;, defaultvalue = \u0026ldquo;匿名用户\u0026rdquo;)\n如果值不存在,使用默认值\n多对象转一对象 以下代码仅仅是演示,如何从两个对象的参数标识取哪些属性进行组合\n1 2 3 4 5 6 7 @mappings( value = { @mapping(source = \u0026#34;userinfo1.id\u0026#34;, target = \u0026#34;userid\u0026#34;), @mapping(source = \u0026#34;userinfo2.name\u0026#34;, target = \u0026#34;name\u0026#34;, constant = \u0026#34;匿名用户\u0026#34;), } ) public abstract basicuserinfovo entity2basicuserinfovo(userinfo userinfo1, userinfo userinfo2); 转换之后/之前自定义操作 进行基本的转换之后,有些属性可能需要进行一些自定义操作才能设置正确值\n1 2 3 4 5 6 7 8 @aftermapping public void underaccountreminderjudge(userinfo userinfo, @mappingtarget basicuserinfovo basicuserinfovo) { if (userinfo.getprice() != null \u0026amp;\u0026amp; userinfo.getprice().compareto(new bigdecimal(\u0026#34;500.00\u0026#34;)) \u0026gt;= 0 ) { basicuserinfovo.setunderaccountreminder(false); } else { basicuserinfovo.setunderaccountreminder(true); } } @beforemapping和@aftermapping对立,为在映射之前操作\nlist转换 将入参是list的参数批量转换为出参是list的出餐\n当转换类里面有且只有一个入参和出参均和批量参数类型一致的时候会自动循环调用单个出参的方法进行映射 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 @mappings( value = { @mapping(source = \u0026#34;id\u0026#34;, target = \u0026#34;userid\u0026#34;), @mapping(source = \u0026#34;name\u0026#34;, target = \u0026#34;name\u0026#34;), @mapping(source = \u0026#34;birthdate\u0026#34;, target = \u0026#34;birthdate\u0026#34;, dateformat = \u0026#34;yyyy-mm-dd hh:mm:ss\u0026#34;), @mapping(target = \u0026#34;price\u0026#34;, expression = \u0026#34;java(com.kun.utils.numberutils.toroundup(userinfo.getprice(), 2, \\\u0026#34;#0.00\\\u0026#34;))\u0026#34;) } ) public abstract basicuserinfovo entity2basicuserinfovo(userinfo userinfo); /** * 会自动定位到上面的方法进行循环调用 */ public abstract list\u0026lt;basicuserinfovo\u0026gt; entity2basicuserinfovos(list\u0026lt;userinfo\u0026gt; userinfo); 当转换类里面有多个入参和出参均和批量参数类型一致的时候,之间写批量方法会有二义性异常,此项明确指定调用方法名即可 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 @mappings( value = { @mapping(source = \u0026#34;id\u0026#34;, target = \u0026#34;userid\u0026#34;), @mapping(source = \u0026#34;name\u0026#34;, target = \u0026#34;name\u0026#34;), @mapping(source = \u0026#34;birthdate\u0026#34;, target = \u0026#34;birthdate\u0026#34;, dateformat = \u0026#34;yyyy-mm-dd hh:mm:ss\u0026#34;), @mapping(target = \u0026#34;price\u0026#34;, expression = \u0026#34;java(com.kun.utils.numberutils.toroundup(userinfo.getprice(), 2, \\\u0026#34;#0.00\\\u0026#34;))\u0026#34;) } ) @named(\u0026#34;entity2basicuserinfovo\u0026#34;) // 指定名称 public abstract basicuserinfovo entity2basicuserinfovo(userinfo userinfo); /** * 会自动定位到上面的方法进行循环调用 */ @iterablemapping(qualifiedbyname = \u0026#34;entity2basicuserinfovo\u0026#34;) public abstract list\u0026lt;basicuserinfovo\u0026gt; entity2basicuserinfovos(list\u0026lt;userinfo\u0026gt; userinfo); 深拷贝 @mapping、@mapper注解下,都有一个mappingcontrol属性,里面有个deepclone.class是深拷贝\n多对象带list转一对象 很多时候,对象带有别的类的引用,此时我们可以自己书写代码,组合一下使用\n1 2 3 4 5 6 7 8 public userinfovo entity2userinfovo(userinfo userinfo, list\u0026lt;useraddressinfo\u0026gt; useraddressinfo) { // 先转换userinfo basicuserinfovo basicuserinfovo = instance.entity2basicuserinfovo(userinfo); // 再转换useraddressinfo list\u0026lt;useraddressinfovo\u0026gt; useraddressinfovos = instance.entity2useraddressinfovos(useraddressinfo); // 塞入返回结果 return new userinfovo(basicuserinfovo, useraddressinfovos); } 继承 继承已有的映射规则,减少冗余代码\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 @mappings( value = { @mapping(source = \u0026#34;id\u0026#34;, target = \u0026#34;userid\u0026#34;), @mapping(source = \u0026#34;name\u0026#34;, target = \u0026#34;name\u0026#34;), @mapping(source = \u0026#34;birthdate\u0026#34;, target = \u0026#34;birthdate\u0026#34;, dateformat = \u0026#34;yyyy-mm-dd hh:mm:ss\u0026#34;), @mapping(target = \u0026#34;price\u0026#34;, expression = \u0026#34;java(com.kun.utils.numberutils.toroundup(userinfo.getprice(), 2, \\\u0026#34;#0.00\\\u0026#34;))\u0026#34;) } ) @named(\u0026#34;entity2basicuserinfovo\u0026#34;) public abstract basicuserinfovo entity2basicuserinfovo(userinfo userinfo); /** * 更新basicuserinfovo的属性 */ @inheritconfiguration(name = \u0026#34;entity2basicuserinfovo\u0026#34;) public abstract basicuserinfovo updatebasicuserinfovo(userinfo userinfo, @mappingtarget basicuserinfovo basicuserinfovo); 集成spring 只需要处理以下@mapper注解,就可以用@autowire进行注入\n1 2 3 4 5 6 7 @mapper(componentmodel=\u0026#34;spring\u0026#34;) public abstract class userconvert { // 可以删除了 // public static userconvert instance = mappers.getmapper(userconvert.class); //....... } ","date":"2022-02-27","permalink":"https://hobocat.github.io/post/tool/2022-02-27-mapstruct/","summary":"一、简介 在一个成熟的工程中,尤其是现在的分布式系统中,应用与应用之间,还有单独的应用细分模块之后,对象需要经过转换包装才能对外提供服务(比如使用VO返回与HT","title":"mapstruct的使用"},]
[{"content":"一、canal简介 canal是用java开发的基于数据库增量日志解析,提供增量数据订阅\u0026amp;消费的中间件。canal(canal deployer)主要支持了mysql的binlog解析,解析完成后利用canal client、canal adapter来处理获得的相关数据。\ncanal就是一个同步增量数据的一个工具。\n利用canal可以同步mysql数据到redis、es、mq等中间件。可自己使用canal client编写代码同步数据,也可以使用canal adapter配置数据同步到第三方中间件。\n二、canal的工作原理 canal把自己伪装成 slave,假装从master复制数据。然后解析binlog日志读取变化数据\ncanal工作的前提是mysql要开启binlog日志,且为row模式\nbinlog可以说是mysql最重要的日志了,它记录了所有的 ddl和dml(除了数据查询语句)语句。以事件形式记录,还包含语句所执行的消耗的时间,mysql的二进制日志是事务安全型的\nbinlog 的分类\nstatement:语句级,binlog 会记录每次一执行写操作的语句。相对row模式节省空间,但是可能产生不一致性,比如\u0026quot;update tt set create_date=now()\u0026quot;,如果用binlog日志进行恢复,由于执行时间不同可能产生的数据就不同 row:行级,会记录每次操作后每行记录的变化,保持数据的绝对一致性。缺点:占用较大空间 mixed:statement的升级版,一定程度上解决了因为一些情况而造成的 statement模式数据不一致问题,当执行结果可能发生变化的函数时会按照row的方式进行处理 三、canal的搭建 canal集群的ha其实包含了服务端ha和客户端的ha。两者的实现原理差不多,都是通过zookeeper实例标识某个特定路径下抢占ephemeral(临时)节点的方式进行控制。抢占成功的一者会作为运行节点(状态为running),而抢占失败的一方会作为备用节点(状态是standby)\n下载canal.adapter、canal.admin、canal.deployer\nip 角色 192.168.22.161 canal-admin 192.168.22.162 canal.deployer 192.168.22.163 canal.deployer 部署canal admin 第一步:解压\n1 2 mkdir /opt/module/canal-admin tar -zxvf canal.admin-$version.tar.gz -c /opt/module/canal-admin 第二步:修改conf/application.yml\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 server: port: 8089 spring: jackson: date-format: yyyy-mm-dd hh:mm:ss time-zone: gmt+8 spring.datasource: address: 127.0.0.1:3306 # 修改为自己的mysql地址,用于存储canal admin的配置 database: canal_manager # 可不修改(需要建立并初始化数据库,官方脚本默认为canal_manager) username: canal # 修改为自己的数据库用户名 password: canal # 修改为自己的数据库密码 driver-class-name: com.mysql.jdbc.driver url: jdbc:mysql://${spring.datasource.address}/${spring.datasource.database}?useunicode=true\u0026amp;characterencoding=utf-8\u0026amp;usessl=false hikari: maximum-pool-size: 30 minimum-idle: 1 # canal的adminpasswd并不是登陆admin的密码,登陆admin的密码是设置在对应的数据库中的,默认为123456 canal: adminuser: admin # canal-admin用户名,可以修改server注册使用 adminpasswd: admin # canal-admin密码,可以修改server注册使用 第三步:执行初始化数据库脚本conf/canal_manager.sql\n第四步:启动canal admin\n1 2 3 sh /opt/module/canal-admin/bin/startup.sh # 查看启动日志 cat /opt/module/canal-admin/logs/admin.log 第五步:访问canal admin,浏览器输入http://adminip:8089\n第六步:创建集群\n第七步:修改主配置\n主要修改\n1 2 3 4 5 6 7 8 9 10 11 12 13 # canal admin config # 这里的密码就是前面在application.yml最后的参数提到的admin/admin # 不过这里需要使用mysql加密后的密码,可以在mysql内通过命令 select password(\u0026#39;yourpassword\u0026#39;) 获取加密串(去掉星号) canal.admin.manager = 192.168.22.161:8089 canal.admin.port = 11110 canal.admin.user = admin canal.admin.passwd = 4acfe3202a5ff5cf467898fc58aab1d615029441 canal.zkservers = 192.168.22.161:2181,192.168.22.162:2181,192.168.22.163:2181 canal.instance.global.spring.xml = classpath:spring/default-instance.xml #监控到的binlog输出到tcp canal.servermode = tcp 部署canal-deployer 第一步:需要先开启mysql的binlog写入功能,配置binlog-format为row模式\n1 2 3 4 5 6 7 8 9 [mysqld] # 开启 binlog log-bin=mysql-bin # 选择 row 模式 binlog-format=row # 配置mysql replaction需要定义,不要和canal的slaveid重复 server_id=1 # 根据自己的情况进行修改,指定具体要同步的数据库,如果不配置则表示所有数据库均开启 binlog # binlog-do-db=canal-test 第二步:创建mysql账号,用于作为mysql slave的角色\n1 2 3 create user canal identified by \u0026#39;canal\u0026#39;; grant select, replication slave, replication client on *.* to \u0026#39;canal\u0026#39;@\u0026#39;%\u0026#39;; flush privileges; 第三步:解压\n1 2 mkdir /opt/module/canal-deployer tar -zxvf canal.deployer-$version.tar.gz -c /opt/module/canal-deployer 第四步:配置每台canal server的conf/canal_local.properties\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 # register ip canal.register.ip = 192.168.22.162 # canal admin config canal.admin.manager = 192.168.22.161:8089 canal.admin.port = 11110 canal.admin.user = admin canal.admin.passwd = 4acfe3202a5ff5cf467898fc58aab1d615029441 # admin auto register canal.admin.register.auto = true # 刚在admin创建的集群名称 canal.admin.register.cluster = canal-test-cluster # 自己显示的服务机器名称,如果不填回显的是ip canal.admin.register.name = centos162 第五步:启动\n1 /opt/module/canal-deployer/bin/startup.sh local 第六步:查看deployer是否启动成功\n第七步:创建任务实例,选择刚创建的集群,创建属于它的实例任务\n主要修改\n1 2 3 4 5 6 7 8 9 10 11 # 需要读取的mysql数据的服务器地址 canal.instance.master.address=192.168.22.120:3306 # username/password # 这里的用户必须是刚才授权该库的binlog权限的用户 canal.instance.dbusername=canal canal.instance.dbpassword=canal_pwd # table regex # 配置监控test_csdn库下的所有表,这里的正则可以定制匹配规则,具体可参考官方文档:https://github.com/alibaba/canal/wiki/adminguide canal.instance.filter.regex=canal-monitor\\\\..* 第八步:启动实例\n四、canal client同步数据 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 @test public void testreadupdatedata() throws exception { //1.获取 canal 连接对象, destination:刚创建的实例名称 canalconnector canalconnector = canalconnectors.newclusterconnector( \u0026#34;192.168.22.161:2181,192.168.22.162:2181,192.168.22.163:2181\u0026#34;, \u0026#34;test-canal-tcp\u0026#34;, \u0026#34;\u0026#34;, \u0026#34;\u0026#34;); //2、连接 canalconnector.connect(); //3、订阅数据库 canalconnector.subscribe(\u0026#34;canal-monitor.*\u0026#34;); while (true) { // 每次获取1000条增量数据 message message = canalconnector.getwithoutack(1000); // 获取entry集合 list\u0026lt;canalentry.entry\u0026gt; entries = message.getentries(); // 判断集合是否为空,如果为空,则等待一会继续拉取数据 if (entries.size() \u0026lt;= 0) { system.out.println(\u0026#34;当次抓取没有数据,休息一会。。。。。。\u0026#34;); thread.sleep(1000); } else { // 遍历entries,单条解析 for (canalentry.entry entry : entries) { //1.获取表名 string tablename = entry.getheader().gettablename(); //2.获取类型 canalentry.entrytype entrytype = entry.getentrytype(); //3.获取序列化后的数据 bytestring storevalue = entry.getstorevalue(); //4.判断当前entrytype类型是否为rowdata if (canalentry.entrytype.rowdata.equals(entrytype)) { //5.反序列化数据 canalentry.rowchange rowchange = canalentry.rowchange.parsefrom(storevalue); //6.获取当前事件的操作类型 canalentry.eventtype eventtype = rowchange.geteventtype(); //7.获取数据集 list\u0026lt;canalentry.rowdata\u0026gt; rowdatalist = rowchange.getrowdataslist(); //8.遍历rowdatalist,并打印数据集 for (canalentry.rowdata rowdata : rowdatalist) { jsonobject beforedata = new jsonobject(); list\u0026lt;canalentry.column\u0026gt; beforecolumnslist = rowdata.getbeforecolumnslist(); for (canalentry.column column : beforecolumnslist) { beforedata.put(column.getname(), column.getvalue()); } jsonobject afterdata = new jsonobject(); list\u0026lt;canalentry.column\u0026gt; aftercolumnslist = rowdata.getaftercolumnslist(); for (canalentry.column column : aftercolumnslist) { afterdata.put(column.getname(), column.getvalue()); } //数据打印 system.out.println(\u0026#34;table:\u0026#34; + tablename + \u0026#34;,eventtype:\u0026#34; + eventtype + \u0026#34;,before:\u0026#34; + beforedata + \u0026#34;,after:\u0026#34; + afterdata); } } else { system.out.println(\u0026#34;当前操作类型为:\u0026#34; + entrytype); } } } } } 五、canal adapter同步数据 同步数据到es参考https://github.com/alibaba/canal/tree/master/client-adapter,实际当中可能tcp模式的还要简单可控一点\n同步数据到mq较为简单,不需要用canal adapter。配置canal admin的模板即可\nserver主配置 1 2 # tcp, kafka, rocketmq, rabbitmq canal.servermode = rocketmq instance实例配置 1 2 3 4 5 6 # 都发送到指定名称的topic canal.mq.topic=canal_test_topic # 针对库名或者表名发送动态topic,规则查看https://github.com/alibaba/canal/wiki/canal-kafka-rocketmq-quickstart # canal.mq.dynamictopic=.*\\\\..* # 过滤dml语句 canal.instance.filter.query.dml=true ","date":"2022-02-15","permalink":"https://hobocat.github.io/post/tool/2022-02-15-canal/","summary":"一、Canal简介 Canal是用Java开发的基于数据库增量日志解析,提供增量数据订阅\u0026amp;消费的中间件。Canal(Canal Deployer)主要支持了","title":"canal的使用"},]
[{"content":"一、rocketmq介绍 mq作用 mq是一种\u0026quot;\u0026ldquo;先进先出\u0026quot;的数据结构,主要包含以下三个作用\n应用解耦 \t系统的耦合性越高,容错性就越低。例如下订单如果rpc调用仓储系统,如果仓储系统出库模块异常将导致订单无法创建,这基本是我们无法容忍的。所以可以采用mq的方式,接收创建订单成功的消息调用仓储出库。\n流量削峰 \t应用系统如果遇到系统请求流量的瞬间猛增,有可能会将系统压垮。有了消息队列可以将大量请求缓存起来,分散到很长一段时间处理,这样可以大大提到系统的稳定性和用户体验。\n异步执行 \t通过消息队列可以让数据在多个系统更加之间进行流通。数据的产生方不需要关心谁来使用数据,只需要将数据发送到消息队列,数据使用方直接在消息队列中直接获取数据即可。\n各种mq产品的比较 特性 activemq rabbitmq rocketmq kafka 开发语言 java erlang java scala 单机吞吐量 万级 万级 10万级 10万级 时效性 ms级 us级 ms级 ms级以内 可用性 高(主从架构) 高(主从架构) 非常高(分布式架构) 非常高(分布式架构) 功能特性 成熟的产品,在很多公司得到应用;有较多的文档;各种协议支持较好 基于erlang开发,所以并发能力很强,性能极其好,延时很低;管理界面较丰富 mq功能比较完备,扩展性佳 只支持主要的mq功能,像一些消息查询,消息回溯等功能没有提供,毕竟是为大数据准备的,在大数据领域应用广 rocketmq各角色介绍 角色 含义 producer 消息的发送者 consumer 消息接收者 broker 暂存和传输消息 nameserver 管理broker,发送者和消费者从nameserver找到对应的broker topic 消息主题 message queue 相当于是topic的分区 二、rocketmq集群搭建 前置条件:jdk1.8\nrocketmq下载地址、rocketmq-externals(gui管理界面)下载地址\n各角色之间的关系 nameserver是一个几乎无状态节点。可集群部署,节点之间无任何信息同步。\nbroker部署相对复杂,broker分为master与slave,一个master可以对应多个slave,但是一个slave只能对应一个master,master与slave的对应关系通过指定相同的brokername,不同的brokerid来定义,brokerid为0表示master,非0表示slave。master也可以部署多个。每个broker与nameserver集群中的所有节点建立长连接,定时注册topic信息到所有nameserver。\nproducer与nameserver集群中的其中一个节点(随机选择)建立长连接,定期从nameserver取topic路由信息,并向提供topic服务的master建立长连接,且定时向master发送心跳。producer完全无状态,可集群部署。\nconsumer与nameserver集群中的其中一个节点(随机选择)建立长连接,定期从nameserver取topic路由信息,并向提供topic服务的master、slave建立长连接,且定时向master、slave发送心跳。consumer既可以从master订阅消息,也可以从slave订阅消息,订阅规则由broker配置决定。\n2master-2slave的rocketmq服务搭建 角色介绍\nip 角色 架构模式 192.168.22.162 nameserver、brokerserver master1、slave2、nameserver 192.168.22.163 nameserver、brokerserver master2、slave1、nameserver 第一步:两台机器都解压\n1 2 3 unzip rocketmq-all-[version]-bin-release.zip mv rocketmq-[version] /opt/module mv /opt/module/rocketmq-[version] /opt/module/rocketmq 第二步:两台机器都创建消息存储目录\n1 2 3 4 5 6 7 # 192.168.22.162 mkdir -p /opt/module/rocketmq/store/broker-a mkdir -p /opt/module/rocketmq/store/broker-b-s # 192.168.22.163 mkdir -p /opt/module/rocketmq/store/broker-b mkdir -p /opt/module/rocketmq/store/broker-a-s 第三步:\n配置192.168.22.162的master1,编辑/opt/module/rocketmq/conf/2m-2s-sync/broker-a.properties (可重命名),删除 broker-a-s.properties 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 # 所属集群名字 brokerclustername=rocketmq-cluster # broker名字,注意此处不同的配置文件填写的不一样 brokername=broker-a # 0表示master,1表示slave brokerid=0 # nameserver地址,分号分割 namesrvaddr=192.168.22.162:9876;192.168.22.163:9876 # 在发送消息时,自动创建服务器不存在的topic,默认创建的队列数 defaulttopicqueuenums=4 # 是否允许broker自动创建topic,建议线下开启,线上关闭 autocreatetopicenable=true # 是否允许broker自动创建订阅组,建议线下开启,线上关闭 autocreatesubscriptiongroup=true # broker对外服务的监听端口,不可重复 listenport=10911 # 删除文件时间点,默认凌晨4点 deletewhen=04 # 文件保留时间,默认48小时 filereservedtime=120 # commitlog每个文件的大小默认1g mapedfilesizecommitlog=1073741824 # consumequeue每个文件默认存30w条,根据业务情况调整 mapedfilesizeconsumequeue=300000 #destroymapedfileintervalforcibly=120000 #redeletehangedfileinterval=120000 # 检测物理文件磁盘空间 diskmaxusedspaceratio=88 # 存储路径 storepathrootdir=/opt/module/rocketmq/store/broker-a # 限制的消息大小 maxmessagesize=65536 #flushcommitlogleastpages=4 #flushconsumequeueleastpages=2 #flushcommitlogthoroughinterval=10000 #flushconsumequeuethoroughinterval=60000 # broker 的角色 # - async_master 异步复制master # - sync_master 同步双写master # - slave brokerrole=sync_master # 刷盘方式 # - async_flush 异步刷盘 # - sync_flush 同步刷盘 flushdisktype=sync_flush #checktransactionmessageenable=false # 发消息线程池数量 #sendmessagethreadpoolnums=128 # 拉消息线程池数量 #pullmessagethreadpoolnums=128 配置192.168.22.162的slave2,编辑/opt/module/rocketmq/conf/2m-2s-sync/broker-b-s.properties (可重命名),删除 broker-b.properties 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 # 所属集群名字 brokerclustername=rocketmq-cluster # broker名字,注意此处不同的配置文件填写的不一样 brokername=broker-b # 0表示master,1表示slave brokerid=1 # nameserver地址,分号分割 namesrvaddr=192.168.22.162:9876;192.168.22.163:9876 # 在发送消息时,自动创建服务器不存在的topic,默认创建的队列数 defaulttopicqueuenums=4 # 是否允许broker自动创建topic,建议线下开启,线上关闭 autocreatetopicenable=true # 是否允许broker自动创建订阅组,建议线下开启,线上关闭 autocreatesubscriptiongroup=true # broker 对外服务的监听端口 listenport=11011 # 删除文件时间点,默认凌晨 4点 deletewhen=04 # 文件保留时间,默认 48 小时 filereservedtime=120 # commitlog每个文件的大小默认1g mapedfilesizecommitlog=1073741824 # consumequeue每个文件默认存30w条,根据业务情况调整 mapedfilesizeconsumequeue=300000 #destroymapedfileintervalforcibly=120000 #redeletehangedfileinterval=120000 # 检测物理文件磁盘空间 diskmaxusedspaceratio=88 # 存储路径 storepathrootdir=/opt/module/rocketmq/store/broker-b-s # 限制的消息大小 maxmessagesize=65536 #flushcommitlogleastpages=4 #flushconsumequeueleastpages=2 #flushcommitlogthoroughinterval=10000 #flushconsumequeuethoroughinterval=60000 # broker 的角色 # - async_master 异步复制master # - sync_master 同步双写master # - slave brokerrole=slave # 刷盘方式 # - async_flush 异步刷盘 # - sync_flush 同步刷盘 flushdisktype=async_flush #checktransactionmessageenable=false # 发消息线程池数量 #sendmessagethreadpoolnums=128 # 拉消息线程池数量 #pullmessagethreadpoolnums=128 配置192.168.22.163的master2,编辑/opt/module/rocketmq/conf/2m-2s-sync/broker-b.properties (可重命名),删除 broker-b-s.properties 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 # 所属集群名字 brokerclustername=rocketmq-cluster # broker名字,注意此处不同的配置文件填写的不一样 brokername=broker-b # 0表示master,1表示slave brokerid=0 # nameserver地址,分号分割 namesrvaddr=192.168.22.162:9876;192.168.22.163:9876 # 在发送消息时,自动创建服务器不存在的topic,默认创建的队列数 defaulttopicqueuenums=4 # 是否允许broker自动创建topic,建议线下开启,线上关闭 autocreatetopicenable=true # 是否允许broker自动创建订阅组,建议线下开启,线上关闭 autocreatesubscriptiongroup=true # broker对外服务的监听端口,不可重复 listenport=10911 # 删除文件时间点,默认凌晨4点 deletewhen=04 # 文件保留时间,默认48小时 filereservedtime=120 # commitlog每个文件的大小默认1g mapedfilesizecommitlog=1073741824 # consumequeue每个文件默认存30w条,根据业务情况调整 mapedfilesizeconsumequeue=300000 #destroymapedfileintervalforcibly=120000 #redeletehangedfileinterval=120000 # 检测物理文件磁盘空间 diskmaxusedspaceratio=88 # 存储路径 storepathrootdir=/opt/module/rocketmq/store/broker-b # 限制的消息大小 maxmessagesize=65536 #flushcommitlogleastpages=4 #flushconsumequeueleastpages=2 #flushcommitlogthoroughinterval=10000 #flushconsumequeuethoroughinterval=60000 # broker 的角色 # - async_master 异步复制master # - sync_master 同步双写master # - slave brokerrole=sync_master # 刷盘方式 # - async_flush 异步刷盘 # - sync_flush 同步刷盘 flushdisktype=sync_flush #checktransactionmessageenable=false # 发消息线程池数量 #sendmessagethreadpoolnums=128 # 拉消息线程池数量 #pullmessagethreadpoolnums=128 配置192.168.22.163的slave1,编辑/opt/module/rocketmq/conf/2m-2s-sync/broker-a-s.properties (可重命名),删除 broker-a.properties 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 # 所属集群名字 brokerclustername=rocketmq-cluster # broker名字,注意此处不同的配置文件填写的不一样 brokername=broker-a # 0表示master,1表示slave brokerid=1 # nameserver地址,分号分割 namesrvaddr=192.168.22.162:9876;192.168.22.163:9876 # 在发送消息时,自动创建服务器不存在的topic,默认创建的队列数 defaulttopicqueuenums=4 # 是否允许broker自动创建topic,建议线下开启,线上关闭 autocreatetopicenable=true # 是否允许broker自动创建订阅组,建议线下开启,线上关闭 autocreatesubscriptiongroup=true # broker 对外服务的监听端口 listenport=11011 # 删除文件时间点,默认凌晨 4点 deletewhen=04 # 文件保留时间,默认 48 小时 filereservedtime=120 # commitlog每个文件的大小默认1g mapedfilesizecommitlog=1073741824 # consumequeue每个文件默认存30w条,根据业务情况调整 mapedfilesizeconsumequeue=300000 #destroymapedfileintervalforcibly=120000 #redeletehangedfileinterval=120000 # 检测物理文件磁盘空间 diskmaxusedspaceratio=88 # 存储路径 storepathrootdir=/opt/module/rocketmq/store/broker-a-s # 限制的消息大小 maxmessagesize=65536 #flushcommitlogleastpages=4 #flushconsumequeueleastpages=2 #flushcommitlogthoroughinterval=10000 #flushconsumequeuethoroughinterval=60000 # broker 的角色 # - async_master 异步复制master # - sync_master 同步双写master # - slave brokerrole=slave # 刷盘方式 # - async_flush 异步刷盘 # - sync_flush 同步刷盘 flushdisktype=async_flush #checktransactionmessageenable=false # 发消息线程池数量 #sendmessagethreadpoolnums=128 # 拉消息线程池数量 #pullmessagethreadpoolnums=128 第四步:修改启动脚本文件\n修改/opt/module/rocketmq/bin/runbroker.sh\n1 2 3 #=================================================== # 开发环境配置 jvm configuration java_opt=\u0026#34;${java_opt} -server -xms256m -xmx256m -xmn128m\u0026#34; 修改/opt/module/rocketmq/bin/runserver.sh\n1 2 3 #=================================================== # 开发环境配置 jvm configuration java_opt=\u0026#34;${java_opt} -server -xms256m -xmx256m -xmn128m -xx:metaspacesize=128m -xx:maxmetaspacesize=320m\u0026#34; 第五步:启动nameserve集群,分别在两台机器都启动nameserver\n1 2 3 4 # 1.启动nameserver nohup sh mqnamesrv \u0026gt; mqnamesrv.log 2\u0026gt;\u0026amp;1 \u0026amp; # 查看进程 jps 第六步:在192.168.22.162上启动master1和slave2\n1 2 3 nohup sh mqbroker -c /opt/module/rocketmq/conf/2m-2s-sync/broker-a.properties \u0026gt; broker-a.log 2\u0026gt;\u0026amp;1 \u0026amp; nohup sh mqbroker -c /opt/module/rocketmq/conf/2m-2s-sync/broker-b-s.properties \u0026gt; broker-b-s.log 2\u0026gt;\u0026amp;1 \u0026amp; jps 第七步:在192.168.22.163上启动master2和slave1\n1 2 3 nohup sh mqbroker -c /opt/module/rocketmq/conf/2m-2s-sync/broker-b.properties \u0026gt; broker-b.log 2\u0026gt;\u0026amp;1 \u0026amp; nohup sh mqbroker -c /opt/module/rocketmq/conf/2m-2s-sync/broker-a-s.properties \u0026gt; broker-a-s.log 2\u0026gt;\u0026amp;1 \u0026amp; jps 关闭broker命令:sh mqshutdown broker\n集群监控平台搭建 下载源码包,修改application.properties文件\n1 rocketmq.config.namesrvaddr=192.168.22.162:9876;192.168.22.163:9876 打包编译运行即可\n1 2 mvn clean package -dmaven.test.skip=true java -jar target/rocketmq-dashboard-[version].jar 三、rocketmq基本使用 发送同步消息 可靠性的同步反馈发送结果\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 @test public void syncsendmessagetest() throws exception { // 实例化消息生产者producer defaultmqproducer producer = new defaultmqproducer(\u0026#34;rocketmq-cluster\u0026#34;, \u0026#34;sync_send_message_producer_group\u0026#34;); // 设置nameserver的地址 producer.setnamesrvaddr(\u0026#34;192.168.22.162:9876;192.168.22.163:9876\u0026#34;); // 启动producer producer.start(); for (int i = 0; i \u0026lt; 10; i++) { // 创建消息,并指定topic,tag和消息体 message message = new message(\u0026#34;sync_product\u0026#34;, json.tojsonbytes(\u0026#34;hello rocketmq sync send message \u0026#34; + i)); // 发送消息 sendresult sendresult = producer.send(message); system.out.println(\u0026#34;sendresult = \u0026#34; + json.tojsonstring(sendresult)); } timeunit.seconds.sleep(5); // 如果不再发送消息,关闭producer实例。 producer.shutdown(); } 发送异步消息 异步接收发送的结果,不阻塞,快速响应\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 @test public void asyncsendmessagetest() throws exception { // 实例化消息生产者producer defaultmqproducer producer = new defaultmqproducer(\u0026#34;rocketmq-cluster\u0026#34;, \u0026#34;async_send_message_producer_group\u0026#34;); // 设置nameserver的地址 producer.setnamesrvaddr(\u0026#34;192.168.22.162:9876;192.168.22.163:9876\u0026#34;); // 启动producer producer.start(); for (int i = 0; i \u0026lt; 10; i++) { // 创建消息,并指定topic,tag和消息体 message message = new message(\u0026#34;async_product\u0026#34;, json.tojsonbytes(\u0026#34;hello rocketmq async send message \u0026#34; + i)); // 发送消息 producer.send(message, new sendcallback() { // 成功处理 @override public void onsuccess(sendresult sendresult) { system.out.println(\u0026#34;act=onsuccess sendresult = \u0026#34; + json.tojsonstring(sendresult)); } // 异常处理 @override public void onexception(throwable throwable) { system.out.println(\u0026#34;act=onexception throwable = \u0026#34; + json.tojsonstring(throwable)); } }); } timeunit.seconds.sleep(5); // 如果不再发送消息,关闭producer实例。 producer.shutdown(); } 单向发送消息 发送消息,对发送结果不关心\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 @test public void onewaysendmessagetest() throws exception { // 实例化消息生产者producer defaultmqproducer producer = new defaultmqproducer(\u0026#34;rocketmq-cluster\u0026#34;, \u0026#34;oneway_send_message_producer_group\u0026#34;); // 设置nameserver的地址 producer.setnamesrvaddr(\u0026#34;192.168.22.162:9876;192.168.22.163:9876\u0026#34;); // 启动producer producer.start(); for (int i = 0; i \u0026lt; 10; i++) { // 创建消息,并指定topic,tag和消息体 message message = new message(\u0026#34;oneway_product\u0026#34;, json.tojsonbytes(\u0026#34;hello rocketmq oneway send message \u0026#34; + i)); // 发送消息, 不关心发送结果直接返回 producer.sendoneway(message); } timeunit.seconds.sleep(5); // 如果不再发送消息,关闭producer实例。 producer.shutdown(); } 批量发送消息 批量发送消息,消息一次不能超过4m\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 @test public void batchsendmessagetest() throws exception { // 实例化消息生产者producer defaultmqproducer producer = new defaultmqproducer(\u0026#34;rocketmq-cluster\u0026#34;, \u0026#34;batch_send_message_producer_group\u0026#34;); // 设置nameserver的地址 producer.setnamesrvaddr(\u0026#34;192.168.22.162:9876;192.168.22.163:9876\u0026#34;); // 启动producer producer.start(); // 构建消息 list\u0026lt;message\u0026gt; messages = new arraylist\u0026lt;\u0026gt;(); messages.add(new message(\u0026#34;batch_topic\u0026#34;, json.tojsonbytes(\u0026#34;batch message 0\u0026#34;))); messages.add(new message(\u0026#34;batch_topic\u0026#34;, json.tojsonbytes(\u0026#34;batch message 1\u0026#34;))); messages.add(new message(\u0026#34;batch_topic\u0026#34;, json.tojsonbytes(\u0026#34;batch message 2\u0026#34;))); // 发送消息, 不关心发送结果直接返回 sendresult sendresult = producer.send(messages); system.out.println(\u0026#34;sendresult = \u0026#34; + json.tojsonstring(sendresult)); timeunit.seconds.sleep(5); // 如果不再发送消息,关闭producer实例。 producer.shutdown(); } 如果消息超过了4m,可以用如下工具类切分\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 public class listsplitter implements iterator\u0026lt;list\u0026lt;message\u0026gt;\u0026gt; { private final int size_limit = 1024 * 1024 * 4; private final list\u0026lt;message\u0026gt; messages; private int currindex; public listsplitter(list\u0026lt;message\u0026gt; messages) { this.messages = messages; } @override public boolean hasnext() { return currindex \u0026lt; messages.size(); } @override public list\u0026lt;message\u0026gt; next() { int nextindex = currindex; int totalsize = 0; for (; nextindex \u0026lt; messages.size(); nextindex++) { message message = messages.get(nextindex); int tmpsize = message.gettopic().length() + message.getbody().length; map\u0026lt;string, string\u0026gt; properties = message.getproperties(); for (map.entry\u0026lt;string, string\u0026gt; entry : properties.entryset()) { tmpsize += entry.getkey().length() + entry.getvalue().length(); } tmpsize = tmpsize + 20; // 增加日志的开销20字节 if (tmpsize \u0026gt; size_limit) { // 单个消息超过了最大的限制 // 忽略,否则会阻塞分裂的进程 if (nextindex - currindex == 0) { // 假如下一个子列表没有元素,则添加这个子列表然后退出循环,否则只是退出循环 nextindex++; } break; } if (tmpsize + totalsize \u0026gt; size_limit) { break; } else { totalsize += tmpsize; } } list\u0026lt;message\u0026gt; sublist = messages.sublist(currindex, nextindex); currindex = nextindex; return sublist; } } 集群模式消费消息 消费者采用集群方式消费消息,同一个组多个消费者共同消费队列消息(即发送10个消息,两个不同组,每组都部署了n台,每组都消费10个消息),这是最常用的消费模式\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 @test public void clusterconsumertest() throws exception { // 实例化消息生产者,指定组名 defaultmqpushconsumer consumer = new defaultmqpushconsumer(\u0026#34;rocketmq-cluster\u0026#34;,\u0026#34;clusterconsumergroup\u0026#34;); // 设置nameserver的地址 consumer.setnamesrvaddr(\u0026#34;192.168.22.162:9876;192.168.22.163:9876\u0026#34;); // 订阅topic consumer.subscribe(\u0026#34;sync_product\u0026#34;, \u0026#34;*\u0026#34;); // 集群模式消费 consumer.setmessagemodel(messagemodel.clustering); // 从队列尾部消费 consumer.setconsumefromwhere(consumefromwhere.consume_from_last_offset); // 注册回调函数,处理消息 consumer.registermessagelistener(new messagelistenerconcurrently() { @override public consumeconcurrentlystatus consumemessage(list\u0026lt;messageext\u0026gt; msgs, consumeconcurrentlycontext context) { for (messageext msg : msgs) { system.out.printf(\u0026#34;topic=%s tag=%s msgid=%s msgkey=%s msgbody=%s \\n\u0026#34;, msg.gettopic(), msg.gettags(), msg.getmsgid(), msg.getkeys(), json.parseobject(msg.getbody(), string.class)); } return consumeconcurrentlystatus.consume_success; } }); //启动消息者 consumer.start(); timeunit.seconds.sleep(1000); } 广播模式消费消息 消费者采用广播方式消费消息,每个部署实例都消费队列的消息(即只要有实例都消费,每个实例会消费到相同的消息)\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 @test public void broadcastconsumertest() throws exception { // 实例化消息生产者,指定组名 defaultmqpushconsumer consumer = new defaultmqpushconsumer(\u0026#34;rocketmq-cluster\u0026#34;,\u0026#34;broadcastconsumergroup\u0026#34;); // 设置nameserver的地址 consumer.setnamesrvaddr(\u0026#34;192.168.22.162:9876;192.168.22.163:9876\u0026#34;); // 订阅topic consumer.subscribe(\u0026#34;sync_product\u0026#34;, \u0026#34;*\u0026#34;); // 广播模式消费 consumer.setmessagemodel(messagemodel.broadcasting); // 从队列尾部消费 consumer.setconsumefromwhere(consumefromwhere.consume_from_last_offset); // 注册回调函数,处理消息 consumer.registermessagelistener(new messagelistenerconcurrently() { @override public consumeconcurrentlystatus consumemessage(list\u0026lt;messageext\u0026gt; msgs, consumeconcurrentlycontext context) { for (messageext msg : msgs) { system.out.printf(\u0026#34;topic=%s tag=%s msgid=%s msgkey=%s msgbody=%s \\n\u0026#34;, msg.gettopic(), msg.gettags(), msg.getmsgid(), msg.getkeys(), json.parseobject(msg.getbody(), string.class)); } return consumeconcurrentlystatus.consume_success; } }); //启动消息者 consumer.start(); timeunit.seconds.sleep(1000); } 顺序消息 消息有序指的是可以按照消息的发送顺序来消费(fifo)。rocketmq可以严格的保证消息有序,可以分为分区有序或者全局有序。\n在默认的情况下消息发送会采取round robin轮询方式把消息发送到不同的queue(分区队列),而消费消息的时候从多个queue上拉取消息,这种情况发送和消费是不能保证顺序。但是如果控制发送的顺序消息只依次发送到同一个queue中,消费的时候只从这个queue上依次拉取,则就保证了顺序。当发送和消费参与的queue只有一个,则是全局有序;如果多个queue参与,则为分区有序,即相对每个queue,消息都是有序的。\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 @test public void sendordermessagetest() throws exception { // 实例化消息生产者producer defaultmqproducer producer = new defaultmqproducer(\u0026#34;rocketmq-cluster\u0026#34;, \u0026#34;order_message_producer_group\u0026#34;); // 设置nameserver的地址 producer.setnamesrvaddr(\u0026#34;192.168.22.162:9876;192.168.22.163:9876\u0026#34;); // 启动producer producer.start(); for (int i = 0; i \u0026lt; 10; i++) { // 创建消息,并指定topic,tag和消息体 message message = new message(\u0026#34;order_product\u0026#34;, json.tojsonbytes(\u0026#34;order message \u0026#34; + i)); // 发送消息 sendresult sendresult = producer.send(message,new messagequeueselector() { @override public messagequeue select(list\u0026lt;messagequeue\u0026gt; mqs, message msg, object arg) { integer argint = (integer) arg; return mqs.get(argint % mqs.size()); } }, 101); system.out.println(\u0026#34;sendresult = \u0026#34; + json.tojsonstring(sendresult)); } timeunit.seconds.sleep(10); // 如果不再发送消息,关闭producer实例。 producer.shutdown(); } @test public void orderconsumertest3() throws exception { // 实例化消息生产者,指定组名 defaultmqpushconsumer consumer = new defaultmqpushconsumer(\u0026#34;rocketmq-cluster\u0026#34;, \u0026#34;orderconsumergroup\u0026#34;); // 设置nameserver的地址 consumer.setnamesrvaddr(\u0026#34;192.168.22.162:9876;192.168.22.163:9876\u0026#34;); // 订阅topic consumer.subscribe(\u0026#34;order_product\u0026#34;, \u0026#34;*\u0026#34;); // 集群模式消费 consumer.setmessagemodel(messagemodel.clustering); // 从队列尾部消费 consumer.setconsumefromwhere(consumefromwhere.consume_from_last_offset); // 注册回调函数,处理消息 consumer.registermessagelistener(new messagelistenerorderly() { @override public consumeorderlystatus consumemessage(list\u0026lt;messageext\u0026gt; msgs, consumeorderlycontext context) { for (messageext msg : msgs) { system.out.printf(\u0026#34;topic=%s tag=%s msgid=%s msgkey=%s msgbody=%s \\n\u0026#34;, msg.gettopic(), msg.gettags(), msg.getmsgid(), msg.getkeys(), json.parseobject(msg.getbody(), string.class)); } return consumeorderlystatus.success; } }); //启动消息者 consumer.start(); timeunit.seconds.sleep(1000); } 延时消息 延迟消息可见,rocketmq支持如下时间点的延迟1s 5s 10s 30s 1m 2m 3m 4m 5m 6m 7m 8m 9m 10m 20m 30m 1h 2h, 等级从左到右从1开始\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 @test public void testdelaymessage() throws exception { // 实例化消息生产者producer defaultmqproducer producer = new defaultmqproducer(\u0026#34;rocketmq-cluster\u0026#34;, \u0026#34;delay_message_producer_group\u0026#34;); // 设置nameserver的地址 producer.setnamesrvaddr(\u0026#34;192.168.22.162:9876;192.168.22.163:9876\u0026#34;); // 启动producer producer.start(); for (int i = 0; i \u0026lt; 10; i++) { // 创建消息,并指定topic,tag和消息体 message message = new message(\u0026#34;delay_product\u0026#34;, json.tojsonbytes(\u0026#34;hello rocketmq delay send message \u0026#34; + i)); // 设置消息延迟等级 message.setdelaytimelevel(4); // 发送消息 sendresult sendresult = producer.send(message); system.out.println(\u0026#34;sendresult = \u0026#34; + json.tojsonstring(sendresult)); } timeunit.seconds.sleep(10); // 如果不再发送消息,关闭producer实例。 producer.shutdown(); } apache没有定时消息的概念,阿里云有定时消息的概念:指定时间转成时间戳,表示定时消息\n过滤消息消费 tag过滤 1 2 // 利用tag进行过滤,接收所有tag消息为 * consumer.subscribe(\u0026#34;topic\u0026#34;, \u0026#34;taga || tagb || tagc\u0026#34;); sql过滤消息消费 1 2 // a取自消息的属性,即message.putuserproperty(\u0026#34;a\u0026#34;, string.valueof(num)) consumer.subscribe(\u0026#34;topictest\u0026#34;, messageselector.bysql(\u0026#34;a between 0 and 3\u0026#34;); 事务消息 事务消息只保证发送端的事务,不保证消费端的事务,消费失败时发送并不会任务补偿回滚\n1)事务消息发送及提交\n发送消息(half消息,不可见) 服务端响应消息写入结果 根据发送结果执行本地事务(如果写入失败,此时half消息对业务不可见,本地逻辑不执行) 根据本地事务状态执行commit或者rollback(commit操作生成消息索引,消息对消费者可见) 2)事务补偿\n对没有commit/rollback的事务消息(pending状态的消息),从服务端发起一次“回查” producer收到回查消息,检查回查消息对应的本地事务的状态 根据本地事务状态,重新commit或者rollback 3)事务消息状态\ntransactionstatus.committransaction: 提交事务,它允许消费者消费此消息 transactionstatus.rollbacktransaction: 回滚事务,它代表该消息将被删除,不允许被消费 transactionstatus.unknown: 中间状态,它代表需要检查消息队列来确定状态 发送事务消息\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 @test public void sendtransactionmessagetest() throws exception { // 实例化消息生产者producer transactionmqproducer producer = new transactionmqproducer(\u0026#34;rocketmq-cluster\u0026#34;, \u0026#34;transaction_message_producer_group\u0026#34;); // 设置nameserver的地址 producer.setnamesrvaddr(\u0026#34;192.168.22.162:9876;192.168.22.163:9876\u0026#34;); producer.settransactionlistener(new ordertransactionlistenerimpl()); // 启动producer producer.start(); for (int i = 0; i \u0026lt; 10; i++) { // 创建消息,并指定topic,tag和消息体 message message = new message(\u0026#34;transaction_product\u0026#34;, json.tojsonbytes(\u0026#34;order transaction message\u0026#34;)); // 发送消息 sendresult sendresult = producer.sendmessageintransaction(message, null); system.out.println(\u0026#34;sendresult = \u0026#34; + json.tojsonstring(sendresult)); } timeunit.seconds.sleep(1000); // 如果不再发送消息,关闭producer实例。 producer.shutdown(); } 事务消息的listener\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 public class ordertransactionlistenerimpl implements transactionlistener { // 这里不应该是本地缓存,应该使用redis等 private static concurrenthashmap\u0026lt;string, integer\u0026gt; countchecknummap = new concurrenthashmap\u0026lt;\u0026gt;(); // 最大检查次数 private static final int max_check = 5; @override public localtransactionstate executelocaltransaction(message msg, object arg) { try { system.out.println(\u0026#34;transactionid = \u0026#34; + msg.gettransactionid()); //执行本地事务 system.out.println(\u0026#34;执行本地事务并保存transactionid到一张表中\u0026#34;); // 模拟执行过程中发送异常 boolean exeexception = randomutil.randomboolean(); if (exeexception) { system.out.println(\u0026#34;transactionid = \u0026#34; + msg.gettransactionid() + \u0026#34; 执行过程中遇到了异常\u0026#34;); throw new runtimeexception(\u0026#34;执行过程中遇到了异常\u0026#34;); } // 模拟执行过程宕机,回滚 boolean unknowexception = randomutil.randomboolean(); if (unknowexception) { system.out.println(\u0026#34;transactionid = \u0026#34; + msg.gettransactionid() + \u0026#34; 执行过程中遇到了中断执行\u0026#34;); return localtransactionstate.unknow; } } catch (throwable e) { return localtransactionstate.rollback_message; } system.out.println(\u0026#34;transactionid = \u0026#34; + msg.gettransactionid() + \u0026#34; 提交\u0026#34;); return localtransactionstate.commit_message; } @override public localtransactionstate checklocaltransaction(messageext msg) { system.out.println(\u0026#34;checklocaltransaction transactionid = \u0026#34; + msg.gettransactionid()); // 从数据库中查找是否有此transactionid,有返回commit,没有返回unknow,示例代码用随机了 boolean findtransaction = randomutil.randomboolean(); if (findtransaction) { system.out.println(\u0026#34;提交 transactionid = \u0026#34; + msg.gettransactionid()); return localtransactionstate.commit_message; } return rollbackorunknow(msg.gettransactionid()); } private localtransactionstate rollbackorunknow(string transactionid) { integer countchecknum = countchecknummap.get(transactionid); if (countchecknum != null \u0026amp;\u0026amp; countchecknum \u0026gt; max_check) { system.out.println(\u0026#34;回滚 transactionid = \u0026#34; + transactionid); return localtransactionstate.rollback_message; } if (countchecknum == null) { countchecknummap.put(transactionid, 1); } system.out.println(\u0026#34;未知 transactionid = \u0026#34; + transactionid); return localtransactionstate.unknow; } } 事务消息注意点\n事务消息不支持延时消息和批量消息。\n为了避免单个消息被检查太多次而导致半队列消息累积,默认单个消息的检查次数限制为15次,可以修改broker配置文件的 transactioncheckmax参数来修改此限制。如果已经检查某条消息超过 n 次的话(n =transactioncheckmax ) 则broker将丢弃此消息,并在默认情况下同时打印错误日志。可以重写abstracttransactionchecklistener修改这个行为\n事务消息将在broker配置文件中的参数transactionmsgtimeout这样的特定时间长度之后被检查。当发送事务消息时,用户还可以通过设置用户属性 check_immunity_time_in_seconds来改变这个限制,默认为1分钟\n事务性消息可能不止一次被检查或消费\n事务消息的生产者id不能与其他类型消息的生产者id共享。事务消息允许反向查询、mq服务器能通过它们的生产者id查询到消费者\n四、springboot集成rocketmq 前置条件pom引入依赖\n1 2 3 4 5 \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;org.apache.rocketmq\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;rocketmq-spring-boot-starter\u0026lt;/artifactid\u0026gt; \u0026lt;version\u0026gt;[version]\u0026lt;/version\u0026gt; \u0026lt;/dependency\u0026gt; 配置application.properties文件\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 # nameserver服务器地址 rocketmq.name-server=192.168.22.162:9876;192.168.22.163:9876 # 发送者组名称 rocketmq.producer.group=myapp-producer-group # 发送消息的超时时间 rocketmq.producer.send-message-timeout=3000 # 压缩消息发送的阈值,单位字节 rocketmq.producer.compress-message-body-threshold=4096 # 消息体允许的最大大小 rocketmq.producer.max-message-size=4194304 # 异步发送消息失败的重试次数。默认2次 rocketmq.producer.retry-times-when-send-async-failed=0 # 发送消息给broker时,如果发送失败,是否重试另外一台broker,默认为false rocketmq.producer.retry-next-server=false # 同步发送消息失败的重试次数,默认2次 rocketmq.producer.retry-times-when-send-failed=2 # 是否开启消息轨迹功能,默认为false关闭 rocketmq.producer.enable-msg-trace=true # 是否开启消息轨迹功能,默认为false关闭 rocketmq.consumer.enable-msg-trace=true # 自定义消息轨迹的topic,默认为 rmq_sys_trace_topic rocketmq.producer.customized-trace-topic=rmq_sys_trace_topic 发送消息 同步发送消息\n1 2 3 4 // 第一种方式 rocketmqtemplate.convertandsend(\u0026#34;usertopic:taga\u0026#34;, user); // 第二种方式 rocketmqtemplate.send(\u0026#34;usertopic:tagb\u0026#34;, messagebuilder.withpayload(user).build()); 异步发送消息\n1 2 3 4 5 6 7 8 9 10 11 rocketmqtemplate.asyncsend(\u0026#34;usertopic:tagc\u0026#34;, user, new sendcallback() { @override public void onsuccess(sendresult sendresult) { system.out.println(\u0026#34;async onsuccess sendresult=\u0026#34; + json.tojsonstring(sendresult)); } @override public void onexception(throwable throwable) { system.out.println(\u0026#34;async onexception throwable=\u0026#34; + json.tojsonstring(throwable)); } }); 发送顺序消息\n1 2 // 第三个参数为以哪个字段作为hashkey发送到对应队列 rocketmqtemplate.syncsendorderly(\u0026#34;orderly_user_topic\u0026#34;, user, \u0026#34;name\u0026#34;); 发送事务消息[以下采用分离rockettemplate方式]\n创建新的专属的rockettemplate 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 @configuration @autoconfigureafter({ rocketmqautoconfiguration.class}) @autoconfigurebefore({ rocketmqtransactionconfiguration.class}) public class mqtransactionconfigure implements applicationcontextaware { public static final string producer_bean_name = \u0026#34;defaultmqproducer\u0026#34;; public static final string consumer_bean_name = \u0026#34;defaultlitepullconsumer\u0026#34;; private applicationcontext applicationcontext; @override public void setapplicationcontext(applicationcontext applicationcontext) throws beansexception { this.applicationcontext = applicationcontext; } @bean(name = \u0026#34;usertransactionrocketmqtemplate\u0026#34;, destroymethod = \u0026#34;destroy\u0026#34;) public rocketmqtemplate usertransactionrocketmqtemplate(rocketmqmessageconverter rocketmqmessageconverter) { rocketmqtemplate usertransactionrocketmqtemplate = new rocketmqtemplate(){ @override public void afterpropertiesset() throws exception { return; } }; if (applicationcontext.containsbean(producer_bean_name)) { usertransactionrocketmqtemplate.setproducer((defaultmqproducer) applicationcontext.getbean(producer_bean_name)); } if (applicationcontext.containsbean(consumer_bean_name)) { usertransactionrocketmqtemplate.setconsumer((defaultlitepullconsumer) applicationcontext.getbean(consumer_bean_name)); } usertransactionrocketmqtemplate.setmessageconverter(rocketmqmessageconverter.getmessageconverter()); return usertransactionrocketmqtemplate; } } 事务执行listener 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 @service @rocketmqtransactionlistener(corepoolsize=5, maximumpoolsize = 20, rocketmqtemplatebeanname=\u0026#34;usertransactionrocketmqtemplate\u0026#34;) public class usertransactionlistener implements rocketmqlocaltransactionlistener { @override public rocketmqlocaltransactionstate executelocaltransaction(message msg, object arg) { system.out.println(\u0026#34;executelocaltransaction\u0026#34;); return rocketmqlocaltransactionstate.commit; } @override public rocketmqlocaltransactionstate checklocaltransaction(message msg) { system.out.println(\u0026#34;checklocaltransaction\u0026#34;); return rocketmqlocaltransactionstate.commit; } } 发送事务消息 1 2 transactionsendresult sendresult = usertransactionrocketmqtemplate.sendmessageintransaction( \u0026#34;test_transaction\u0026#34;, messagebuilder.withpayload(user).build(), null); 消费消息 只需要消息的有效负载\n1 2 3 4 5 6 7 8 9 10 11 12 13 @service @rocketmqmessagelistener( consumergroup = \u0026#34;myapp-usertopic-consumer\u0026#34;, topic = \u0026#34;usertopic\u0026#34;, selectorexpression = \u0026#34;*\u0026#34;, messagemodel = messagemodel.clustering) public class userconsumer implements rocketmqlistener\u0026lt;user\u0026gt; { @override public void onmessage(user user) { system.out.println(\u0026#34;user = \u0026#34; + json.tojsonstring(user)); } } 需要消息本身的属性\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 @service @rocketmqmessagelistener( topic = \u0026#34;usertopic\u0026#34;, selectorexpression = \u0026#34;tagb||tagc\u0026#34;, consumergroup = \u0026#34;myapp-usertopic-ext-consumer\u0026#34;) public class usermessageextconsumer implements rocketmqlistener\u0026lt;messageext\u0026gt; { @override public void onmessage(messageext message) { system.out.println(\u0026#34;topic=\u0026#34; + message.gettopic()); system.out.println(\u0026#34;tags=\u0026#34; + message.gettags()); system.out.println(\u0026#34;msgid=\u0026#34; + message.getmsgid()); system.out.println(\u0026#34;msgkey=\u0026#34; + message.getkeys()); system.out.println(\u0026#34;body=\u0026#34; + json.parseobject(message.getbody(), user.class)); system.out.println(\u0026#34;重试次数=\u0026#34; + message.getreconsumetimes()); } } 消费顺序消息\n1 2 3 4 5 6 7 8 9 10 11 12 13 @service @rocketmqmessagelistener( consumergroup = \u0026#34;myapp-usertopic-orderly-consumer\u0026#34;, topic = \u0026#34;orderly_user_topic\u0026#34;, selectorexpression = \u0026#34;*\u0026#34;, consumemode = consumemode.orderly) public class orderlyuserconsumer implements rocketmqlistener\u0026lt;user\u0026gt; { @override public void onmessage(user user) { system.out.println(\u0026#34;orderly user = \u0026#34; + json.tojsonstring(user)); } } 五、高级功能 消息存储 rocketmq使用文件顺序存储和零拷贝的方法存储数据,目前的高性能磁盘,顺序写速度可以达到600mb/s,而随机写的速度只有大概100kb/s。\nrocketmq消息的存储是由consumequeue和commitlog配合完成 的,消息真正的物理存储文件是commitlog,consumequeue是消息的逻辑队列,类似数据库的索引文件,存储的是指向物理存储的地址。每个topic下的每个message queue都有一个对应的consumequeue文件。\n消息在通过producer写入rocketmq的时候,有两种写磁盘方式,分别是同步刷盘和异步刷盘\n同步刷盘\n在返回写成功状态时,消息已经被写入磁盘。具体流程是,消息写入内存的pagecache后,立刻通知刷盘线程刷盘, 然后等待刷盘完成,刷盘线程执行完成后唤醒等待的线程,返回消息写 成功的状态。\n异步刷盘\n在返回写成功状态时,消息可能只是被写入了内存的pagecache。当内存里的消息量积累到一定程度时,统一触发写磁盘动作,快速写入。\n同步刷盘还是异步刷盘,都是通过broker配置文件里的flushdisktype参数设置的,这个参数被配置成sync_flush、async_flush中的 一个\n高可用性机制 消息消费高可用\n在consumer的配置文件中,并不需要设置是从master读还是从slave读。当master不可用或者繁忙的时候,consumer会被自动切换到从slave读。有了自动切换consumer这种机制,当一个master角色的机器出现故障后,consumer仍然可以从slave读取消息,不影响consumer程序。这就达到了消费端的高可用性。\n消息发送高可用\n在创建topic的时候,把topic的多个message queue创建在多个broker组上(相同broker名称,不同brokerid的机器组成一个broker组),这样当一个broker组的master不可用后,其他组的master仍然可用,producer仍然可以发送消息。目前还不支持slave自动转成master,如果机器资源不足需要把slave转成master,则要手动停止slave角色的broker,更改配置文件,用新的配置文件启动broker。\n消息主从复制\n如果一个broker组有master和slave,消息需要从master复制到slave 上,有同步和异步两种复制方式。\n同步复制\n同步复制方式是等master和slave均写成功后才反馈给客户端写成功状态在同步复制方式下,如果master出故障, slave上有全部的备份数据,容易恢复,但是同步复制会增大数据写入延迟,降低系统吞吐量\n异步复制\n异步复制方式是只要master写成功即可反馈给客户端写成功状态。在异步复制方式下,系统拥有较低的延迟和较高的吞吐量,但是如果master出了故障,有些数据因为没有被写入slave,有可能会丢失\n配置:同步复制和异步复制是通过broker配置文件里的brokerrole参数进行设置的,这个参数可以被设置成async_master、 sync_master、slave中的一个\n实际应用中要结合业务场景,合理设置刷盘方式和主从复制方式, 尤其是sync_flush方式,由于频繁地触发磁盘写动作,会明显降低性能。通常情况下,应该把master的save配置成async_flush的刷盘方式,主从之间配置成sync_master的复制方式,这样即使有一台机器出故障,仍然能保证数据不丢,是个不错的选择。\n负载均衡 producer负载均衡\nproducer端,每个实例在发消息的时候,默认会轮询所有的message queue发送,以达到让消息平均落在不同的queue上。而由于queue可以散落在不同的broker,所以消息就发送到不同的broker下\nconsumer负载均衡\n集群模式\n在集群消费模式下,每条消息只需要投递到订阅这个topic的consumer group下的一个实例即可。rocketmq采用主动拉取的方式拉取并消费消息,在拉取的时候需要明确指定拉取哪一条message queue。而每当实例的数量有变更,都会触发一次所有实例的负载均衡,这时候会按照queue的数量和实例的数量平均\n分配queue给每个实例。有如下分配策略\n策略名称 策略 平均分配策略(默认) allocatemessagequeueaveragely 环形分配策略 allocatemessagequeueaveragelybycircle 手动配置分配策略 allocatemessagequeuebyconfig 机房分配策略 allocatemessagequeuebymachineroom 一致性哈希分配策略 allocatemessagequeueconsistenthash 广播模式\n由于广播模式下要求一条消息需要投递到一个消费组下面所有的消费者实例,所以也就没有消息被分摊消费的说法。\n消息重试 顺序消息的重试\n对于顺序消息,当消费者消费消息失败后,会自动不断进行消息重试(每次间隔时间为1秒),这时应用会出现消息消费被阻塞的情况。因此在使用顺序消息时,务必保证应用能够及时监控并处理消费失败的情况,避免阻塞现象的发生。\n无序消息的重试\n对于无序消息(普通、定时、延时、事务消息),当消费者消费消息失败时,可以通过设置返回状态达到消息重试的结果\n消息队列 rocketmq 默认允许每条消息最多重试 16 次,每次重试的间隔时间如下\n第几次重试 与上次重试的间隔时间 第几次重试 与上次重试的间隔时间 1 10 秒 9 7 分钟 2 30 秒 10 8 分钟 3 1 分钟 11 9 分钟 4 2 分钟 12 10 分钟 5 3 分钟 13 20 分钟 6 4 分钟 14 30 分钟 7 5 分钟 15 1 小时 8 6 分钟 16 2 小时 如果消息重试16次后仍然失败,消息将不再投递。如果严格按照上述重试时间间隔计算,某条消息在一直消费失败的前提下,将会在接下来的4小时46分钟之内进行16次重试,超过这个时间范围消息将不再重试投递。可通过message.getreconsumetimes()获取当前重试次数。\n注意: 一条消息无论重试多少次,这些重试消息的 message id不会改变。\n广播方式不提供失败重试特性,即消费失败后,失败消息不再重试,继续消费新的消息\n死信队列 当一条消息初次消费失败,rocketmq会自动进行消息重试。达到最大重试次数后,若消费依然失败,则表明消费者在正常情况下无法正确地消费该消息。此时不会立刻将消息丢弃,而是将其发送到该消费者对应的特殊队列中。\n在rocketmq中,这种正常情况下无法被消费的消息称为死信消息(dead-letter message),存储死信消息的特殊队列称为死信队列(dead-letter queue)\n死信队列的特点\n不会再被消费者正常消费。\n有效期与正常消息相同,均为 3 天,3 天后会被自动删除。因此,请在死信消息产生后的 3 天内及时处理。\n一个死信队列对应一个group id,而不是对应单个消费者实例。\n如果一个group id未产生死信消息,不会为其创建相应的死信队列。\n一个死信队列包含了对应group id产生的所有死信消息,不论该消息属于哪个topic。\n消费幂等 在网络不稳定的情况下,消息有可能会出现重复投递,或者消费失败会进行重新消费。一般情况下应用都是允许消息重复投递和消费的,所以要在消费端做幂等。\n因为message id有可能出现冲突(重复),所以真正安全的幂等处理,不建议以message id作为处理依据。 最好的方式是以业务唯一标识作为幂等处理的关键依据,而业务的唯一标识可以通过消息message key进行设置。message key做幂等可以使用redis、或者etcd的方式存储\n","date":"2022-02-13","permalink":"https://hobocat.github.io/post/mq/2022-02-13-rocketmq/","summary":"一、RocketMQ介绍 MQ作用 MQ是一种\u0026quot;\u0026ldquo;先进先出\u0026quot;的数据结构,主要包含以下三个作用 应用解耦 系统的耦合性越高,容错性就越低","title":"rocketmq的使用"},]
[{"content":"一、prometheus简介 prometheus是一个开源监控和警报系统。prometheus将其指标收集并存储在时序数据库中,用于灵活展示当前监控应用的状态。\nprometheus其对传统监控系统的测试和告警模型进行了彻底的颠覆,形成了基于中央化的规则计算、统一分析和告警的新模型。 相比于传统监控系统,prometheus具有以下优点\n易于管理\nprometheus核心部分只有一个单独的二进制文件,不存在任何的第三方依赖(数据库,缓存等)。因此不会有潜在级联故障的风险\nprometheus基于pull模型的架构方式,可以在任何地方(本地电脑,开发环境,测试环境)搭建我们的监控系统\n对于一些复杂的情况,还可以使用prometheus服务发现(service discovery)的能力动态管理监控目标\n监控服务的内部运行状态\n\tprometheus有丰富的client库,可以轻松的在应用中添加对prometheus的支持,从而可以获取服务和应用内部真正的运行状态\n强大的数据模型 \t所有采集的监控数据均以指标和标签的形式保存在内置的时序数据库(tsdb)当中。\n强大的查询语言promql\nprometheus内置了一个强大的数据查询语言promql。通过 promql可以实现对监控数据的查询、聚合\n高效\nprometheus可以高效地处理收集的数据,对于单一实例而言它可以处理数以百万的监控指标和每秒处理数十万的数据\n可扩展性\n去中心化设计,便于扩展部署,任务量过大时可以对其进行扩展\n二、prometheus的架构 采集层\n组件 作用 pushgateway 当prometheus与监控服务不在同一网段,或者监控的是任务类型的数据(可能只运行一会)使用将数据推送到网关的方式 exporters 主要用来采集数据,并通过http服务的形式暴露给prometheus server,prometheus server通过访问该exporter提供的接口,即可获取到需要采集的监控数据 存储计算层\n组件 作用 prometheus server 面包含了存储引擎和计算引擎 retrieval 组件为取数组件,它会主动从pushgateway或者exporter拉取指标数据 service discovery 可以动态发现要监控的目标 tsdb 数据核心存储与查询 http server 对外提供http服务 应用层\n组件 作用 alertmanager 报警设置,可以设置email、webhook等等告警通知 数据可视化 可于各种数据可视化组件集成例如grafana,达到专业的展示效果 三、prometheus及其组件的安装 prometheus server的安装 1、从[官网地址][https://prometheus.io/]下载安装包\n1 wget https://github.com/prometheus/prometheus/releases/download/[version]/prometheus-[version].linux-amd64.tar.gz 2、解压\n1 2 tar -zxvf prometheus-[version].linux-amd64.tar.gz -c /opt/module/ mv /opt/module/prometheus-[version].linux-amd64 /opt/module/prometheus 3、修改配置文件prometheus.yml\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 # 全局设置 global: scrape_interval: 15s # 配置拉取数据的时间间隔,默认为1分钟。 evaluation_interval: 15s # 规则验证(生成alert)的时间间隔,默认为1分钟。 # scrape_timeout is set to the global default (10s). # 报警配置,没有可视化界面,也可使用grafana的报警机制 alerting: alertmanagers: - static_configs: - targets: # - alertmanager:9093 # 报警规则 rule_files: # - \u0026#34;first_rules.yml\u0026#34; # - \u0026#34;second_rules.yml\u0026#34; # 修改如下配置,此台服务器作为prometheus server scrape_configs: - job_name: \u0026#34;prometheus\u0026#34; # 监控作业的名称 static_configs: # 表示静态目标配置,就是固定从某个target拉取数据 - targets: [\u0026#34;hostname:9090\u0026#34;] # 会从[http://hostname:9090/metrics]上拉取数据 4、添加系统服务,或者直接启动\n添加系统服务 1 vim /etc/systemd/system/prometheus.service 1 2 3 4 5 6 7 8 9 10 11 [unit] description=prometheus monitoring system documentation=prometheus monitoring system [service] execstart=/opt/module/prometheus/prometheus \\ --config.file=/opt/module/prometheus/prometheus.yml \\ --web.listen-address=:9090 [install] wantedby=multi-user.target 启动 1 2 3 4 systemctl daemon-reload systemctl enable prometheus systemctl start prometheus systemctl status prometheus 访问【http://hostname:9090/】能打开web界面即可 安装exporter(选择性安装) 在prometheus的架构设计中,prometheus server主要负责数据的收集,存储并且对外提供数据查询支持,而实际的监控样本数据的收集则是由exporter直接上报,或者pushgateway收集上报完成。因此为了能够监控到某些东西,如主机cpu使用率,需要使用exporter。prometheus周期性的从exporter暴露的http服务地址(通常是/metrics)拉取监控样本数据。exporter可以是一个相对开放的概念,有很多实现的exporter如mysqld_exporter。其可以是一个独立运行的程序独立于监控目标以外,也可以是直接内置在监控目标中。只要能够向prometheus提供标准格式的监控样本数据即可。\n安装node_exporter 能够采集到主机的运行指标如cpu, 内存,磁盘等信息。我们可以使用node exporter。node exporter同样采用golang编写,并且不存在任何的第三方依赖,只需要下载,解压即可运行。\n1、从[官网地址][https://prometheus.io/]下载安装包到需要监控的主机\n1 wget https://github.com/prometheus/node_exporter/releases/download/[version]/node_exporter-[version].linux-amd64.tar.gz 2、解压\n1 2 tar -zxvf node_exporter-[version].linux-amd64.tar.gz -c /opt/module/ mv /opt/module/node_exporter-[version].linux-amd64 /opt/module/node_exporter 3、添加系统服务,或者直接启动\n添加系统服务 1 vim /etc/systemd/system/node_exporter.service 1 2 3 4 5 6 7 8 9 10 11 12 [unit] description=node_exporter after=network.target [service] user=root group=root execstart=/opt/module/node_exporter/node_exporter\\ --web.listen-address=:9100 [install] wantedby=multi-user.target 启动服务 1 2 3 4 systemctl daemon-reload systemctl enable node_exporter systemctl start node_exporter systemctl status node_exporter 4、配置prometheus server,修改prometheus.yml\n1 2 3 4 5 6 # 添加如下信息 scrape_configs: - job_name: \u0026#34;node_exporter\u0026#34; static_configs: - targets: - \u0026#34;targethostname:9100\u0026#34; 5、重启prometheus server,查看http://prometheus_server:9090,下status/targets\n安装mysqld_exporter 1、从[官网地址][https://prometheus.io/]下载安装包到需要监控的主机\n1 wget https://github.com/prometheus/mysqld_exporter/releases/download/[version]/mysqld_exporter-[version].linux-amd64.tar.gz 2、解压\n1 2 tar -zxvf mysqld_exporter-[version].linux-amd64.tar.gz -c /opt/module/ mv /opt/module/mysqld_exporter-[version].linux-amd64 /opt/module/mysqld_exporter 3、配置,创建my.conf配置文件\n1 2 3 4 5 [client] host=[hostname] port=[port] user=[monitoruser] password=[monitorpassword] 4、添加系统服务,或者直接启动\n1 nohup /opt/module/mysqld_exporter/mysqld_exporter --web.listen-address=\u0026#34;:9104\u0026#34; --config.my-cnf=/opt/module/mysqld_exporter/my.conf \u0026amp; 5、配置prometheus server,修改prometheus.yml\n1 2 3 4 5 6 # 添加如下信息 scrape_configs: - job_name: \u0026#34;mysqld_exporter\u0026#34; static_configs: - targets: - \u0026#34;targethostname:9104\u0026#34; 6、重启prometheus server,查看http://prometheus_server:9090,下status/targets\n安装 pushgateway(选择性安装) prometheus在正常情况下是采用拉模式从exporter(比如专门监控主机的nodeexporter)拉取监控数据,但当遇到定时性任务,或者网络不在同一网段上时需要采用pushgateway。将需要监控的数据上传到pushgateway,之后再由prometheus server拉取数据。\n1、从[官网地址][https://prometheus.io/]下载安装包到需要监控的主机\n1 wget https://github.com/prometheus/pushgateway/releases/download/[version]/pushgateway-[version].linux-amd64.tar.gz 2、解压\n1 2 tar -zxvf pushgateway-[version].linux-amd64.tar.gz -c /opt/module/ mv /opt/module/pushgateway-[version].linux-amd64 /opt/module/pushgateway 3、添加系统服务,或者直接启动\n添加系统服务 1 vim /etc/systemd/system/pushgateway.service 1 2 3 4 5 6 7 8 9 10 11 12 [unit] description=pushgateway after=network.target [service] user=root group=root execstart=/opt/module/pushgateway/pushgateway\\ --web.listen-address=:9091 [install] wantedby=multi-user.target 启动服务 1 2 3 4 systemctl daemon-reload systemctl enable pushgateway systemctl start pushgateway systemctl status pushgateway 4、配置prometheus server,修改prometheus.yml\n1 2 3 4 5 6 7 # 添加如下信息 scrape_configs: - job_name: \u0026#39;pushgateway\u0026#39; honor_labels: true #加上此配置exporter节点上传数据中的一些标签将不会被pushgateway节点的相同标签覆盖 static_configs: - targets: - \u0026#34;hostname:9091\u0026#34; 5、重启prometheus server,查看http://prometheus_server:9090,下status/targets\nalertmanager模块 安装十分简单,但是没有可视化界面提供实时编辑,灵活读较低,编写较为麻烦,可使用grafana的报警\n四、promql使用 prometheus通过指标名称(metrics name)以及对应的一组标签(label set)唯一定义一条时间序列。指标名称反映了监控样本的基本标识,而label则在这个基本特征上为采集到的数据提供了多种特征维度。用户可以基于这些特征维度过滤,聚合,统计从而产生新的计算后的一条时间序列。promql是prometheus内置的数据查询语言,其提供对时间序列数据丰富的查询,聚合以及逻辑运算能力的支持。并且被广泛应用在prometheus的日常应用当中,包括对数据查询、可视化、告警处理当中。\n基本用法 查询时间序列[每个时间序列包含单个样本,它们共享相同的时间戳。即返回值只会包含该时间序列中的最新的一个样本值] 1 2 3 # 查询mysql链接超时时长,此指标只需要查询当前状态,时间段内的是没有意义的 mysql_global_variables_connect_timeout mysql_global_variables_connect_timeout{} 过滤标签的匹配模式 1 2 3 4 5 6 # 等值查询 mysql_global_variables_connect_timeout{instance=\u0026#34;centos161:9104\u0026#34;} # 不等值查询 mysql_global_variables_connect_timeout{instance!=\u0026#34;centos161:9104\u0026#34;} # 正则表达式查询 mysql_global_variables_connect_timeout{instance=~\u0026#34;.*:9104\u0026#34;} 范围查询,一段时间序列的集合 1 2 # 查询5min内的所有io设备的取样 node_disk_io_now[5m] 时间位移操作 1 2 # 例如当前是12点,此查询查询的是11:50-11:55的数据 node_disk_io_now[5m] offset 5m 聚合操作 支持sum(求和)、min(最小值)、max(最大值)、avg(平均值)、stddev(标准差)、stdvar(标准差异)、count(计数)、count_values(对value进行计数)、bottomk(后n条时序)、topk(前n条时序)、quantile(分布统计)\n1 2 3 4 5 # 查询系统所有 http 请求的总量 sum(prometheus_http_requests_total) # 按照 mode 计算主机 cpu 的平均使用时间 avg(node_cpu_seconds_total) by (mode) 操作符 promql支持的所有数学运算符:+(加法)、-(减法)、*(乘法)、/(除法)、%(求余)、^(幂运算)\npromql支持的所有布尔运算符:=(相等)、!=(不相等)、\u0026gt;(大于)、\u0026lt;(小于)、\u0026gt;=(大于等于)、\u0026lt;=(小于等于)\npromql支持的集合运算符:and(并且)、or(或者)、unless(排除)\n五、自定义上传监控指标 export/metrice方式 可使用micrometer和prometheus java simpleclient上传监控指标,spring boot集成了micrometer\nmicrometer可对接多种监控系统,如果不再使用prometheus也可直接切换未别的监控系统,是通用型组件 prometheus java simpleclient是prometheus的java客户端,用于上传数据 如下以spring micrometer为例\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 @springboottest(webenvironment = springboottest.webenvironment.defined_port) public class prometheusmetricapplicationtests { @autowired private meterregistry registry; /** * 用于统计次数,例如mq消费失败次数 * counter接口允许以固定的数值递增,该数值必须为正数 */ @test public void counterstest() throws exception { // 写入实例名称 tag instancetag = tag.of(\u0026#34;instance\u0026#34;, inetaddress.getlocalhost().gethostname()); // 消费者组名称 tag groupnametag = tag.of(\u0026#34;groupname\u0026#34;, \u0026#34;publishgoodsstatechange\u0026#34;); // 错误信息 tag errormsgtag = tag.of(\u0026#34;errormsg\u0026#34;, \u0026#34;error: error msg is long long text\u0026#34;); // description 相当于 help信息 counter.builder(\u0026#34;c2c_consume_exception\u0026#34;) .description(\u0026#34;统计失败个数。。。\u0026#34;) .tags(lists.list(instancetag, groupnametag, errormsgtag)) .register(registry) .increment(); thread.sleep(10 * 1000l); } /** * gauge是获取当前值的句柄。典型的例子是,获取集合、map、或运行中的线程数等 */ @test public void gaugestest() throws exception { list\u0026lt;integer\u0026gt; monitorcollect = new arraylist\u0026lt;\u0026gt;(); monitorcollect.add(1); monitorcollect.add(2); monitorcollect.add(3); monitorcollect.add(4); gauge.builder(\u0026#34;monitor_collect_size\u0026#34;, monitorcollect, list::size) .description(\u0026#34;监控某线程、集合的大小\u0026#34;) .register(registry); thread.sleep(10 * 1000l); monitorcollect.add(5); thread.sleep(10 * 1000l); } /** * timers(计时器) * timer用于测量短时间延迟和此类事件的频率。所有timer实现至少将总时间和事件次数报告为单独的时间序列。 */ @test public void timerstest() throws interruptedexception { // 记录执行开始时间 instant startinstant = instant.now(); // 切面,执行程序 thread.sleep(5 * 1000l); // 执行结束时间 instant endinstant = instant.now(); timer.builder(\u0026#34;c2c_publish_goods_task\u0026#34;) .description(\u0026#34;记录执行时间\u0026#34;) .register(registry) .record(duration.between(startinstant, endinstant)); thread.sleep(100 * 1000l); } /** * 任务计时器用于跟踪所有正在运行的长时间运行任务的总持续时间和此类任务的数量。 */ @test public void longtasktimers() throws interruptedexception { // 记录执行开始时间 longtasktimer.builder(\u0026#34;b2c_publish_goods_task\u0026#34;) .description(\u0026#34;记录执行时间\u0026#34;) .register(registry) .record(() -\u0026gt; { try { thread.sleep(5000l); } catch (interruptedexception e) { e.printstacktrace(); } }); thread.sleep(100 * 1000l); } /** * distribution summaries(分布汇总) * 用于跟踪分布式的事件。它在结构上类似于计时器,但是记录的值不代表时间单位。例如,记录http服务器上的请求的响应大小。 * 可以用百分比直方图、客户端百分比 */ @test public void distributionsummariestest() throws interruptedexception { distributionsummary uploadfilesize = distributionsummary.builder(\u0026#34;upload_file_size\u0026#34;) .distributionstatisticexpiry(duration.of(10, chronounit.seconds)) .register(registry); uploadfilesize.record(30); uploadfilesize.record(30); uploadfilesize.record(40); thread.sleep(100 * 1000l); } } application.properties配置\n1 2 3 4 spring.application.name=kun_application management.endpoints.web.exposure.include=* management.metrics.tags.application=${spring.application.name} management.metrics.export.prometheus.enabled=true 额外补充:histograms and percentiles(直方图和百分比)\ntimers 和 distribution summaries 支持收集数据来观察它们的百分比。查看百分比有两种主要方法:\npercentile histograms(百分比直方图): micrometer将值累积到底层直方图,并将一组预先确定的buckets发送到监控系统。监控系统的查询语言负责从这个直方图中计算百分比。目前,只有prometheus , atlas , wavefront支持基于直方图的百分位数近似值,并且通过histogram_quantile , :percentile , hs()依次表示。\nclient-side percentiles(客户端百分比):micrometer为每个meter id(一组name和tag)计算百分位数近似值,并将百分位数值发送到监控系统。\n配置prometheus与spring boot程序对接,需要配置prometheus server,修改prometheus.yml\n1 2 3 4 5 6 7 # 添加如下信息 scrape_configs: - job_name: \u0026#39;jobname-application\u0026#39; metrics_path: \u0026#39;/actuator/prometheus\u0026#39; static_configs: - targets: - \u0026#34;targethostaname:prot\u0026#34; 也可以使用服务发现能力集成\npushgateway方式 只需要改变application.properties配置和引入依赖\n1 2 3 4 5 6 7 8 9 spring.application.name=kun_application management.endpoints.web.exposure.include=* management.metrics.tags.application=${spring.application.name} management.metrics.export.prometheus.enabled=true management.metrics.export.prometheus.pushgateway.enabled=true management.metrics.export.prometheus.pushgateway.base-url=192.168.22.161:9091 management.metrics.export.prometheus.pushgateway.job=${spring.application.name}-job management.metrics.export.prometheus.pushgateway.push-rate=15s management.metrics.export.prometheus.pushgateway.base-url=http://pushgatewayhost:prot 1 2 3 4 5 \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;io.prometheus\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;simpleclient_pushgateway\u0026lt;/artifactid\u0026gt; \u0026lt;version\u0026gt;[version]\u0026lt;/version\u0026gt; \u0026lt;/dependency\u0026gt; 六、grafana安装与集成prometheus grafana是一款采用go语言编写的开源应用,主要用于大规模指标数据的可视化展现,是网络架构和应用分析中最流行的时序数据展示工具,目前已经支持绝大部分常用的时序数据库。\n下载、安装、启动 下载、安装 1 2 wget https://dl.grafana.com/oss/release/grafana-[version]-1.x86_64.rpm sudo yum install grafana-[version]-1.x86_64.rpm 查看安装目录 1 2 rpm -qa | grep -i grafana rpm -ql grafana-[version]-1.x86_64 启动 1 2 systemctl start grafana-server systemctl status grafana-server 查看,访问http://[hostname]:3000默认用户名admin、密码admin 集成 点击setting \u0026raquo; configuration \u0026raquo; data sources \u0026raquo; add data source【选择prometheus,并填写相关信息】\ngrafana的使用 自定义panel\n添加promql即可\nrow是panel的集合,即由多个pannel组成一个界面\n拉取公共dashboard\n访问grafana-dashboards,下载json或copy id文件,使用create \u0026raquo; import【上传json文件或粘贴id】\n七、grafana自定义报警 使用webhook模式可以自定义任何报警,当然也可以使用最基础的邮件报警机制\n点击alert \u0026raquo; contact points \u0026raquo; new contact point \u0026raquo; 添加一个webhook\n编写webhook代码,也可以使用更简便的第三方云平台\n1 2 3 4 5 6 7 8 @restcontroller public class prometheuswebhook { @postmapping(\u0026#34;/prometheus/webhook\u0026#34;) public void doalert(@requestbody string body) { system.out.println(body); } } 到此webhook设置完成,然后对需要设置的监控指标,设置报警阈值即可\n","date":"2022-01-29","permalink":"https://hobocat.github.io/post/tool/2022-01-29-prometheus-grafana/","summary":"一、Prometheus简介 Prometheus是一个开源监控和警报系统。Prometheus将其指标收集并存储在时序数据库中,用于灵活展示当前监控应用的状态。","title":"prometheus\u0026grafana的使用"},]
[{"content":"一、介绍 \tguava工程包含了若干被google的java项目广泛依赖的核心库,例如:集合、缓存、原生类型支持、并发库、通用注解、字符串处理、i/o等等\n二、工具类 校验参数合法性-preconditions 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 /** * 判断参数是否为空,并给出异常信息 */ @test public void testchecknotnull() { integer paramflag = null; try { preconditions.checknotnull(null, \u0026#34;this param [%s] must be not null.\u0026#34;, \u0026#34;paramflag\u0026#34;); } catch (exception e) { assertthat(e, is(instanceof(nullpointerexception.class))); assertthat(e.getmessage(), equalto(\u0026#34;this param [paramflag] must be not null.\u0026#34;)); } } /** * 参数校验 */ @test public void testcheckarguments() { boolean flag = false; try { preconditions.checkargument(flag == true, \u0026#34;flag must be not true.\u0026#34;); } catch (exception e) { assertthat(e, is(instanceof(illegalargumentexception.class))); assertthat(e.getmessage(), equalto(\u0026#34;flag must be not true.\u0026#34;)); } } /** * 状态校验 */ @test public void testcheckstate() { string flag = \u0026#34;fail\u0026#34;; try { preconditions.checkstate(\u0026#34;success\u0026#34;.equals(flag), \u0026#34;flag state is %s, not success.\u0026#34;, flag); } catch (exception e) { assertthat(e, is(instanceof(illegalstateexception.class))); assertthat(e.getmessage(), equalto(\u0026#34;flag state is fail, not success.\u0026#34;)); } } /** * 越界检测 */ @test public void testcheckindex() { try { list\u0026lt;string\u0026gt; list = immutablelist.of(); preconditions.checkelementindex(3, list.size()); } catch (exception e) { assertthat(e, is(instanceof(indexoutofboundsexception.class))); } } /** * jdk的objects也可做null检测 */ @test(expected = nullpointerexception.class) public void testbyobjects() { objects.requirenonnull(null); } 计算程序块时间-stopwatch 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 /** * 得到程序执行的耗时,自动根据耗时设置单位 */ @test public void teststopwatch() throws interruptedexception { stopwatch stopwatch = stopwatch.createstarted(); timeunit.nanoseconds.sleep(500l); log.info(\u0026#34;the process successful and elapsed [{}]\u0026#34;, stopwatch.stop().elapsed()); } /** * 得到程序执行的耗时,根据指定的单位获得 */ @test public void teststopwatchwithutil() throws interruptedexception { stopwatch stopwatch = stopwatch.createstarted(); timeunit.nanoseconds.sleep(500l); log.info(\u0026#34;the process successful and elapsed [{}]\u0026#34;, stopwatch.stop().elapsed(timeunit.seconds)); } base编码-baseencoding 1 2 3 4 5 6 7 8 9 10 11 @test public void testbase64encode() { string encoderesult = baseencoding.base64().encode(\u0026#34;hello\u0026#34;.getbytes()); assertthat(encoderesult, equalto(\u0026#34;sgvsbg8=\u0026#34;)); } @test public void testbase64decode() { byte[] decoderesult = baseencoding.base64().decode(\u0026#34;sgvsbg8=\u0026#34;); assertthat(new string(decoderesult), equalto(\u0026#34;hello\u0026#34;)); } 统一资源关闭类-closer 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 @test public void testcloser() throws ioexception { string target_file = \u0026#34;f:\\\\ideaworkerspace\\\\练习\\\\guava-lean\\\\target.txt\u0026#34;; string content = \u0026#34;give me the strength lightly to bear my joys and sorrows.\u0026#34; + \u0026#34;\\n\u0026#34; + \u0026#34;give me the strength to make my love fruitful in service\u0026#34; + \u0026#34;\\n\u0026#34; + \u0026#34;give me the strength never to disown the poor or bend my knees before insolent might.\u0026#34; + \u0026#34;\\n\u0026#34; + \u0026#34;give me the strength to raise my mind high above daily trifles.\u0026#34; + \u0026#34;\\n\u0026#34; + \u0026#34;and give me the strength to surrender my strength to thy will with love.\u0026#34;; closer closer = closer.create(); try { file file = new file(target_file); fileoutputstream outputstream = new fileoutputstream(file); // 注册入closer closer.register(outputstream); } catch (ioexception e) { // 重新包装异常进行抛出,目的是如果finally抛出异常,try里面的异常将被替换掉 throw closer.rethrow(e); } finally { // 执行关闭close closer.close(); } } 限流器 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 public class ratelimitertest { // 从速率限流,令牌产生速率是每秒两个许可 private final static ratelimiter limiter = ratelimiter.create(2); // 同时只能工作线程数,来自jdk5,限制同时处理的线程个数来限流 private final static semaphore semaphore = new semaphore(3); @test public void testlimiter() { while (true) { // 每次消耗4个令牌,即当前为2秒执行一次 system.out.println(currentthread() + \u0026#34; waiting \u0026#34; + limiter.acquire(4)); } } @test public void testsemaphore() throws interruptedexception { executorservice service = executors.newfixedthreadpool(10); for (int i = 0; i \u0026lt; 10; i++) { service.submit(() -\u0026gt; { while (true) { try { semaphore.acquire(); system.out.println(currentthread().getname() + \u0026#34; is doing work...\u0026#34;); timeunit.milliseconds.sleep(threadlocalrandom.current().nextint(10)); } catch (interruptedexception e) { e.printstacktrace(); }finally { semaphore.release(); system.out.println(currentthread().getname() + \u0026#34; release the semaphore\u0026#34;); } } }); } timeunit.seconds.sleep(100); } } 三、字符串处理 连接器-joiner 把其它集合的数据处理,拼接成为字符串\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 public class joinertest { private final list\u0026lt;string\u0026gt; stringlist = arrays.aslist(\u0026#34;google\u0026#34;, \u0026#34;guava\u0026#34;, \u0026#34;java\u0026#34;, \u0026#34;scala\u0026#34;, \u0026#34;kafka\u0026#34;); private final list\u0026lt;string\u0026gt; stringlistwithnull = arrays.aslist(\u0026#34;google\u0026#34;, \u0026#34;guava\u0026#34;, \u0026#34;java\u0026#34;, \u0026#34;scala\u0026#34;, null); /** * 使用指定符合连接数组或list形成字符串 */ @test public void testjoineron() { string result = joiner.on(\u0026#34;#\u0026#34;).join(stringlist); assertthat(result, equalto(\u0026#34;google#guava#java#scala#kafka\u0026#34;)); } /** * 连接数组或list(包含null)会抛出nullpointerexception异常 */ @test(expected = nullpointerexception.class) public void testjoineroncontainsnull() { joiner.on(\u0026#34;#\u0026#34;).join(stringlistwithnull); } /** * 连接数组或list(包含null),设置跳过null */ @test public void testjoinoncontainsnullbutskip() { string result = joiner.on(\u0026#34;#\u0026#34;).skipnulls().join(stringlistwithnull); assertthat(result, equalto(\u0026#34;google#guava#java#scala\u0026#34;)); } /** * 连接数组或list(包含null),使用默认值替换null */ @test public void testjoinoncontainsnullusedefaultvalue() { string result = joiner.on(\u0026#34;#\u0026#34;).usefornull(\u0026#34;dv\u0026#34;).join(stringlistwithnull); assertthat(result, equalto(\u0026#34;google#guava#java#scala#dv\u0026#34;)); } /** * 连接数组或list,将结果追加到stringbuilder中 */ @test public void testjoinonappendtostringbuilder() { stringbuilder sb = new stringbuilder(\u0026#34;mysql#\u0026#34;); stringbuilder result = joiner.on(\u0026#34;#\u0026#34;).appendto(sb, stringlist); assertthat(result, sameinstance(sb)); assertthat(result.tostring(), equalto(\u0026#34;mysql#google#guava#java#scala#kafka\u0026#34;)); } /** * 连接数组或list,将结果追加到writer中 */ @test public void testjoinonappendtowriter() throws ioexception { writer writer = new filewriter(\u0026#34;f:\\\\ideaworkerspace\\\\练习\\\\guava-lean\\\\writer.txt\u0026#34;); joiner.on(\u0026#34;#\u0026#34;).appendto(writer, stringlist); writer.close(); byte[] bytes = files.readallbytes(paths.get(\u0026#34;f:\\\\ideaworkerspace\\\\练习\\\\guava-lean\\\\writer.txt\u0026#34;)); string content = new string(bytes); assertthat(content, equalto(\u0026#34;google#guava#java#scala#kafka\u0026#34;)); file file = new file(\u0026#34;f:\\\\ideaworkerspace\\\\练习\\\\guava-lean\\\\writer.txt\u0026#34;); file.deleteonexit(); } /** * 使用java8实现join效果,还可使用filter进行过滤,map实现值处理等 */ @test public void testjoiningstream() { string result = stringlist.stream().map(str -\u0026gt; \u0026#34;*\u0026#34; + str + \u0026#34;*\u0026#34;).collect(collectors.joining(\u0026#34;#\u0026#34;)); assertthat(result, equalto(\u0026#34;*google*#*guava*#*java*#*scala*#*kafka*\u0026#34;)); } /** * 拼接map数据成为字符串 */ @test public void testjoinonwithmap() { map\u0026lt;string, string\u0026gt; params = immutablemap.of(\u0026#34;name\u0026#34;, \u0026#34;kun\u0026#34;, \u0026#34;age\u0026#34;, \u0026#34;18\u0026#34;); string result = joiner.on(\u0026#34;,\u0026#34;).withkeyvalueseparator(\u0026#34;=\u0026#34;).join(params); assertthat(result, equalto(\u0026#34;name=kun,age=18\u0026#34;)); } } 拆分器-splitter 使用各种方式将字符串拆分为不同的集合\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 /** * 使用指字符串拆分字符串为list */ @test public void testspliton() { list\u0026lt;string\u0026gt; result = splitter.on(\u0026#34;#\u0026#34;).splittolist(\u0026#34;java#mysql#guava\u0026#34;); assertthat(result, notnullvalue()); assertthat(result.size(), equalto(3)); assertthat(result.get(0), equalto(\u0026#34;java\u0026#34;)); assertthat(result.get(1), equalto(\u0026#34;mysql\u0026#34;)); assertthat(result.get(2), equalto(\u0026#34;guava\u0026#34;)); } /** * 使用指字符串拆分字符串为list,忽略字符串切分出的空值 */ @test public void testsplitomitempty() { list\u0026lt;string\u0026gt; result = splitter.on(\u0026#34;#\u0026#34;).splittolist(\u0026#34;java##\u0026#34;); assertthat(result, notnullvalue()); assertthat(result.size(), equalto(3)); assertthat(result.get(0), equalto(\u0026#34;java\u0026#34;)); assertthat(result.get(1), equalto(\u0026#34;\u0026#34;)); assertthat(result.get(2), equalto(\u0026#34;\u0026#34;)); result = splitter.on(\u0026#34;#\u0026#34;).omitemptystrings().splittolist(\u0026#34;java##\u0026#34;); assertthat(result, notnullvalue()); assertthat(result.size(), equalto(1)); assertthat(result.get(0), equalto(\u0026#34;java\u0026#34;)); } /** * 使用指字符串拆分字符串为list,对切分出的list每个元素进行trim操作 */ @test public void testsplittrimresult() { list\u0026lt;string\u0026gt; result = splitter.on(\u0026#34;#\u0026#34;).trimresults().splittolist(\u0026#34; java # mysql # guava\u0026#34;); assertthat(result, notnullvalue()); assertthat(result.size(), equalto(3)); assertthat(result.get(0), equalto(\u0026#34;java\u0026#34;)); assertthat(result.get(1), equalto(\u0026#34;mysql\u0026#34;)); assertthat(result.get(2), equalto(\u0026#34;guava\u0026#34;)); } /** * 已指定长度拆分字符串为list */ @test public void testsplitfixlength() { list\u0026lt;string\u0026gt; result = splitter.fixedlength(4).splittolist(\u0026#34;aaaabbbbcccc\u0026#34;); assertthat(result, notnullvalue()); assertthat(result.size(), equalto(3)); assertthat(result.get(0), equalto(\u0026#34;aaaa\u0026#34;)); assertthat(result.get(1), equalto(\u0026#34;bbbb\u0026#34;)); assertthat(result.get(2), equalto(\u0026#34;cccc\u0026#34;)); } /** * 使用指字符串拆分字符串为list,且只切分出指定个数的元素 */ @test public void testsplitlimit() { list\u0026lt;string\u0026gt; result = splitter.on(\u0026#34;#\u0026#34;).limit(2).splittolist(\u0026#34;java#mysql#guava\u0026#34;); assertthat(result, notnullvalue()); assertthat(result.size(), equalto(2)); assertthat(result.get(0), equalto(\u0026#34;java\u0026#34;)); assertthat(result.get(1), equalto(\u0026#34;mysql#guava\u0026#34;)); } /** * 使用正则表达切分字符串 */ @test public void testsplitpattern() { list\u0026lt;string\u0026gt; result = splitter.onpattern(\u0026#34;\\\\d+\\\\.\u0026#34;) .omitemptystrings() .trimresults() .splittolist(\u0026#34;1.java 2.mysql 3.guava\u0026#34;); assertthat(result, notnullvalue()); assertthat(result.size(), equalto(3)); assertthat(result.get(0), equalto(\u0026#34;java\u0026#34;)); assertthat(result.get(1), equalto(\u0026#34;mysql\u0026#34;)); assertthat(result.get(2), equalto(\u0026#34;guava\u0026#34;)); result = splitter.on(pattern.compile(\u0026#34;\\\\d+\\\\.\u0026#34;)) .omitemptystrings() .trimresults() .splittolist(\u0026#34;1.java 2.mysql 3.guava\u0026#34;); assertthat(result, notnullvalue()); assertthat(result.size(), equalto(3)); assertthat(result.get(0), equalto(\u0026#34;java\u0026#34;)); assertthat(result.get(1), equalto(\u0026#34;mysql\u0026#34;)); assertthat(result.get(2), equalto(\u0026#34;guava\u0026#34;)); } /** * 使用指定字符串为字符串切分符,使用指定分隔符为key-value,生成map */ @test public void testsplittomap() { map\u0026lt;string, string\u0026gt; result = splitter.on(\u0026#34;,\u0026#34;).withkeyvalueseparator(\u0026#34;=\u0026#34;).split(\u0026#34;name=kun,age=18\u0026#34;); assertthat(result, notnullvalue()); assertthat(result.get(\u0026#34;name\u0026#34;), equalto(\u0026#34;kun\u0026#34;)); assertthat(result.get(\u0026#34;age\u0026#34;), equalto(\u0026#34;18\u0026#34;)); } 字符匹配器-charmatcher 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 /** * 把每组连续的空白字符替换为特定字符 */ @test public void testcharmatcherreplacewhitespace() { string result = charmatcher.whitespace().collapsefrom(\u0026#34;1 2 3 4\u0026#34;, \u0026#39;-\u0026#39;); assertthat(result, equalto(\u0026#34;1-2-3-4\u0026#34;)); } /** * 把字符串的匹配字符移除 */ @test public void testcharmatcheranyoperator() { string result = charmatcher.anyof(\u0026#34;a\u0026#34;).removefrom(\u0026#34;ahia\u0026#34;); assertthat(result, equalto(\u0026#34;hi\u0026#34;)); } /** * 查看字符串是不是每个字符都在指定范围内 */ @test public void testcharmatcherany() { boolean result = charmatcher.inrange(\u0026#39;a\u0026#39;, \u0026#39;z\u0026#39;).matchesallof(\u0026#34;abc\u0026#34;); assertthat(result, equalto(true)); } 字符串简单处理-strings 用于字符串的判空,填充,判断相同前后缀等操作\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 @test public void teststringsmethod() { // 如果字符串是空串\u0026#34;\u0026#34;,则转换为null assertthat(strings.emptytonull(\u0026#34;\u0026#34;), nullvalue()); // 如果字符串是null,则转化为空串\u0026#34;\u0026#34; assertthat(strings.nulltoempty(null), equalto(\u0026#34;\u0026#34;)); // 判断字符串是否为\u0026#34;\u0026#34;或者null assertthat(strings.isnullorempty(\u0026#34;\u0026#34;), equalto(true)); assertthat(strings.isnullorempty(null), equalto(true)); // 得到两个字符串的相同前缀 assertthat(strings.commonprefix(\u0026#34;hello\u0026#34;, \u0026#34;her\u0026#34;), equalto(\u0026#34;he\u0026#34;)); // 得到两个字符串的相同后缀 assertthat(strings.commonsuffix(\u0026#34;goods\u0026#34;, \u0026#34;books\u0026#34;), equalto(\u0026#34;s\u0026#34;)); // 得到字符串重复三次的结果 assertthat(strings.repeat(\u0026#34;book\u0026#34;, 3), equalto(\u0026#34;bookbookbook\u0026#34;)); // 填充 assertthat(strings.padstart(\u0026#34;kun\u0026#34;, 5, \u0026#39;*\u0026#39;), equalto(\u0026#34;**kun\u0026#34;)); assertthat(strings.padend(\u0026#34;kun\u0026#34;, 5, \u0026#39;*\u0026#39;), equalto(\u0026#34;kun**\u0026#34;)); } 大小写格式-caseformat 1 2 3 4 5 6 7 8 9 10 11 12 13 /** * 格式\t范例 * lower_camel\tlowercamel * lower_hyphen\tlower-hyphen * lower_underscore\tlower_underscore * upper_camel\tuppercamel * upper_underscore\tupper_underscore */ @test public void testcaseformat() { string result = caseformat.lower_camel.to(caseformat.upper_underscore, \u0026#34;lowercamel\u0026#34;); assertthat(result,equalto(\u0026#34;lower_camel\u0026#34;)); } 字符集-charsets 直接创建了字符集对象,比jdk的charset.forname更加便捷\n1 2 3 4 5 6 7 8 /** * 比jdk的charset.forname更加便捷 */ @test public void testcharsets() { charset charset = charset.forname(\u0026#34;utf-8\u0026#34;); assertthat(charsets.utf_8, equalto(charset)); } 四、文件操作 向文件写入数据 1 2 3 4 5 6 7 8 9 10 11 12 13 14 @test public void testfilewrite() throws ioexception { string content = \u0026#34;give me the strength lightly to bear my joys and sorrows.\u0026#34; + \u0026#34;\\n\u0026#34; + \u0026#34;give me the strength to make my love fruitful in service\u0026#34; + \u0026#34;\\n\u0026#34; + \u0026#34;give me the strength never to disown the poor or bend my knees before insolent might.\u0026#34; + \u0026#34;\\n\u0026#34; + \u0026#34;give me the strength to raise my mind high above daily trifles.\u0026#34; + \u0026#34;\\n\u0026#34; + \u0026#34;and give me the strength to surrender my strength to thy will with love.\u0026#34;; file file = new file(target_file); file.deleteonexit(); files.ascharsink(file, charsets.utf_8).write(content); string actually = files.ascharsource(file, charsets.utf_8).read(); assertthat(actually, equalto(content)); } 向文件追加数据 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 @test public void testfileappend() throws ioexception { string contentfirst = \u0026#34;give me the strength lightly to bear my joys and sorrows.\u0026#34; + \u0026#34;\\n\u0026#34; + \u0026#34;give me the strength to make my love fruitful in service\u0026#34; + \u0026#34;\\n\u0026#34;; + \u0026#34;give me the strength never to disown the poor or bend my knees before insolent might.\u0026#34; + \u0026#34;\\n\u0026#34;; string contentsecond = \u0026#34;give me the strength to raise my mind high above daily trifles.\u0026#34; + \u0026#34;\\n\u0026#34; + \u0026#34;and give me the strength to surrender my strength to thy will with love.\u0026#34;; file file = new file(target_file); file.deleteonexit(); files.ascharsink(file, charsets.utf_8, filewritemode.append).write(contentfirst); files.ascharsink(file, charsets.utf_8, filewritemode.append).write(contentsecond); string actually = files.ascharsource(file, charsets.utf_8).read(); assertthat(actually, equalto(contentfirst + contentsecond)); } 创建空文件 1 2 3 4 5 6 7 @test public void testtouchfile() throws ioexception { file file = new file(target_file); file.deleteonexit(); files.touch(file); assertthat(file.exists(), equalto(true)); } 使用guava拷贝文件 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 @test public void testcopyfilewithguava() throws ioexception { string content = \u0026#34;give me the strength lightly to bear my joys and sorrows.\u0026#34; + \u0026#34;\\n\u0026#34; + \u0026#34;give me the strength to make my love fruitful in service\u0026#34; + \u0026#34;\\n\u0026#34; + \u0026#34;give me the strength never to disown the poor or bend my knees before insolent might.\u0026#34; + \u0026#34;\\n\u0026#34; + \u0026#34;give me the strength to raise my mind high above daily trifles.\u0026#34; + \u0026#34;\\n\u0026#34; + \u0026#34;and give me the strength to surrender my strength to thy will with love.\u0026#34;; file sourcefile = new file(source_file); sourcefile.deleteonexit(); files.ascharsink(sourcefile, charsets.utf_8).write(content); file targetfile = new file(target_file); targetfile.deleteonexit(); files.copy(sourcefile, targetfile); hashcode sourcehash = files.asbytesource(sourcefile).hash(hashing.sha256()); hashcode targethash = files.asbytesource(targetfile).hash(hashing.sha256()); assertthat(targethash.tostring(), equalto(sourcehash.tostring())); } 使用nio拷贝文件 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 @test public void testcopyfilewithjdknio() throws ioexception { string content = \u0026#34;give me the strength lightly to bear my joys and sorrows.\u0026#34; + \u0026#34;\\n\u0026#34; + \u0026#34;give me the strength to make my love fruitful in service\u0026#34; + \u0026#34;\\n\u0026#34; + \u0026#34;give me the strength never to disown the poor or bend my knees before insolent might.\u0026#34; + \u0026#34;\\n\u0026#34; + \u0026#34;give me the strength to raise my mind high above daily trifles.\u0026#34; + \u0026#34;\\n\u0026#34; + \u0026#34;and give me the strength to surrender my strength to thy will with love.\u0026#34;; file sourcefile = new file(source_file); sourcefile.deleteonexit(); files.ascharsink(sourcefile, charsets.utf_8).write(content); file targetfile = new file(target_file); targetfile.deleteonexit(); java.nio.file.files.copy(paths.get(source_file), new fileoutputstream(targetfile)); hashcode sourcehash = files.asbytesource(sourcefile).hash(hashing.sha256()); hashcode targethash = files.asbytesource(targetfile).hash(hashing.sha256()); assertthat(targethash.tostring(), equalto(sourcehash.tostring())); } 剪切文件 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 @test public void testmovefile() throws ioexception { string content = \u0026#34;give me the strength lightly to bear my joys and sorrows.\u0026#34; + \u0026#34;\\n\u0026#34; + \u0026#34;give me the strength to make my love fruitful in service\u0026#34; + \u0026#34;\\n\u0026#34; + \u0026#34;give me the strength never to disown the poor or bend my knees before insolent might.\u0026#34; + \u0026#34;\\n\u0026#34; + \u0026#34;give me the strength to raise my mind high above daily trifles.\u0026#34; + \u0026#34;\\n\u0026#34; + \u0026#34;and give me the strength to surrender my strength to thy will with love.\u0026#34;; file sourcefile = new file(source_file); files.ascharsink(sourcefile, charsets.utf_8).write(content); file targetfile = new file(target_file); targetfile.deleteonexit(); files.move(sourcefile, targetfile); string actually = files.ascharsource(targetfile, charsets.utf_8).read(); assertthat(actually, equalto(content)); } 读取文件 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 @test public void testread() throws ioexception { string content = \u0026#34;give me the strength lightly to bear my joys and sorrows.\u0026#34; + \u0026#34;\\n\u0026#34; + \u0026#34;give me the strength to make my love fruitful in service\u0026#34; + \u0026#34;\\n\u0026#34; + \u0026#34;give me the strength never to disown the poor or bend my knees before insolent might.\u0026#34; + \u0026#34;\\n\u0026#34; + \u0026#34;give me the strength to raise my mind high above daily trifles.\u0026#34; + \u0026#34;\\n\u0026#34; + \u0026#34;and give me the strength to surrender my strength to thy will with love.\u0026#34;; file sourcefile = new file(source_file); files.ascharsink(sourcefile, charsets.utf_8).write(content); sourcefile.deleteonexit(); // 读取所有文件内容 string actuallyallcontent = files.ascharsource(sourcefile, charsets.utf_8).read(); assertthat(actuallyallcontent, equalto(content)); // 按行读取文件内容 immutablelist\u0026lt;string\u0026gt; lines = files.ascharsource(sourcefile, charsets.utf_8).readlines(); assertthat(lines, notnullvalue()); assertthat(lines.size(), equalto(5)); } 递归获取文件列表 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 /** * 递归获取文件列表(包含文件夹),可将结果使用lists.newarraylist(breadthfirstfiles).stream()来进行处理 * breadthfirst 横向有限,先读取第一层目录,再读取第二层,广度优先 * depthfirstpreorder 第一次访问到节点的顺序 * depthfirstpostorder 先访问到最后一层,然后回退访问节点的顺序 */ @test public void testrecursive() { file file = new file(\u0026#34;f:\\\\ideaworkerspace\\\\练习\\\\guava-lean\u0026#34;); iterable\u0026lt;file\u0026gt; breadthfirstfiles = files.filetraverser().breadthfirst(file); breadthfirstfiles.foreach(system.out::println); iterable\u0026lt;file\u0026gt; depthfirstpostorderfiles = files.filetraverser().depthfirstpostorder(file); depthfirstpostorderfiles.foreach(system.out::println); iterable\u0026lt;file\u0026gt; depthfirstpreorderfiles = files.filetraverser().depthfirstpreorder(file); depthfirstpreorderfiles.foreach(system.out::println); } 五、集合 lists工具集 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 /** * 两个集合做笛卡尔积 * cartesian 笛卡尔积 */ @test public void testcartesianproduct() { // [[a, c], [a, d], [b, c], [b, d]] list\u0026lt;list\u0026lt;string\u0026gt;\u0026gt; cartesianproduct = lists.cartesianproduct( lists.newarraylist(\u0026#34;a\u0026#34;, \u0026#34;b\u0026#34;), lists.newarraylist(\u0026#34;c\u0026#34;, \u0026#34;d\u0026#34;)); assertthat(cartesianproduct.size(), equalto(4)); } /** * 处理加工原有的list产生新的list */ @test public void testtransform() { arraylist\u0026lt;string\u0026gt; sourcelist = lists.newarraylist(\u0026#34;scala\u0026#34;, \u0026#34;guava\u0026#34;, \u0026#34;lists\u0026#34;); list\u0026lt;string\u0026gt; result = lists.transform(sourcelist, string::touppercase); assertthat(result.size(), equalto(3)); assertthat(result.get(0), equalto(\u0026#34;scala\u0026#34;)); assertthat(result.get(1), equalto(\u0026#34;guava\u0026#34;)); assertthat(result.get(2), equalto(\u0026#34;lists\u0026#34;)); } /** * 将list内元素反转返回新的list */ @test public void testreverse() { arraylist\u0026lt;string\u0026gt; sourcelist = lists.newarraylist(\u0026#34;scala\u0026#34;, \u0026#34;guava\u0026#34;, \u0026#34;lists\u0026#34;); list\u0026lt;string\u0026gt; result = lists.reverse(sourcelist); assertthat(result.size(), equalto(3)); assertthat(result.get(0), equalto(\u0026#34;lists\u0026#34;)); assertthat(result.get(1), equalto(\u0026#34;guava\u0026#34;)); assertthat(result.get(2), equalto(\u0026#34;scala\u0026#34;)); } /** * 将list内数据进行分区 */ @test public void testpartition(){ // [[scala, guava], [lists]] arraylist\u0026lt;string\u0026gt; sourcelist = lists.newarraylist(\u0026#34;scala\u0026#34;, \u0026#34;guava\u0026#34;, \u0026#34;lists\u0026#34;); list\u0026lt;list\u0026lt;string\u0026gt;\u0026gt; result = lists.partition(sourcelist, 2); } sets工具集 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 /** * 创建set */ @test public void testcreate() { hashset\u0026lt;string\u0026gt; sourceset = sets.newhashset(\u0026#34;a\u0026#34;, \u0026#34;b\u0026#34;, \u0026#34;c\u0026#34;, \u0026#34;a\u0026#34;); assertthat(sourceset.size(), equalto(3)); } /** * 生成笛卡尔积 */ @test public void testcartesianproduct() { hashset\u0026lt;string\u0026gt; sourcesetfirst = sets.newhashset(\u0026#34;a\u0026#34;, \u0026#34;b\u0026#34;, \u0026#34;c\u0026#34;); hashset\u0026lt;string\u0026gt; sourcesetsecond = sets.newhashset(\u0026#34;a\u0026#34;, \u0026#34;d\u0026#34;, \u0026#34;e\u0026#34;); // [[a, a], [a, d], [a, e], [b, a], [b, d], [b, e], [c, a], [c, d], [c, e]] set\u0026lt;list\u0026lt;string\u0026gt;\u0026gt; result = sets.cartesianproduct(sourcesetfirst, sourcesetsecond); system.out.println(result); } /** * 产生所有规定个数的子集 */ @test public void testcombinations() { hashset\u0026lt;string\u0026gt; sourceset = sets.newhashset(\u0026#34;a\u0026#34;, \u0026#34;b\u0026#34;, \u0026#34;c\u0026#34;); set\u0026lt;set\u0026lt;string\u0026gt;\u0026gt; result = sets.combinations(sourceset, 2); result.foreach(system.out::println); } /** * 取差集 */ @test public void testdiff() { hashset\u0026lt;string\u0026gt; sourcesetfirst = sets.newhashset(\u0026#34;a\u0026#34;, \u0026#34;b\u0026#34;, \u0026#34;c\u0026#34;, \u0026#34;f\u0026#34;); hashset\u0026lt;string\u0026gt; sourcesetsecond = sets.newhashset(\u0026#34;a\u0026#34;, \u0026#34;d\u0026#34;, \u0026#34;e\u0026#34;); sets.setview\u0026lt;string\u0026gt; diffview = sets.difference(sourcesetfirst, sourcesetsecond); //[b, c, f] system.out.println(diffview); } /** * 取交集 */ @test public void testintersection() { hashset\u0026lt;string\u0026gt; sourcesetfirst = sets.newhashset(\u0026#34;a\u0026#34;, \u0026#34;b\u0026#34;, \u0026#34;c\u0026#34;, \u0026#34;f\u0026#34;); hashset\u0026lt;string\u0026gt; sourcesetsecond = sets.newhashset(\u0026#34;a\u0026#34;, \u0026#34;d\u0026#34;, \u0026#34;e\u0026#34;); sets.setview\u0026lt;string\u0026gt; interview = sets.intersection(sourcesetfirst, sourcesetsecond); //[a] system.out.println(interview); } /** * 取并集 */ @test public void testunionsection() { hashset\u0026lt;string\u0026gt; sourcesetfirst = sets.newhashset(\u0026#34;a\u0026#34;, \u0026#34;b\u0026#34;, \u0026#34;c\u0026#34;); hashset\u0026lt;string\u0026gt; sourcesetsecond = sets.newhashset(\u0026#34;a\u0026#34;, \u0026#34;d\u0026#34;, \u0026#34;e\u0026#34;); sets.setview\u0026lt;string\u0026gt; unionview = sets.union(sourcesetfirst, sourcesetsecond); // [a, b, c, d, e] system.out.println(unionview); } maps工具集 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 /** * 将一个map进行处理生成另一个map */ @test public void testmaptransform() { hashmap\u0026lt;integer, string\u0026gt; sourcemap = maps.newhashmap(); sourcemap.put(1, \u0026#34;java\u0026#34;); sourcemap.put(2, \u0026#34;guava\u0026#34;); map\u0026lt;integer, string\u0026gt; newmap = maps.transformentries(sourcemap, (key, value) -\u0026gt; { return \u0026#34;#\u0026#34; + value + \u0026#34;#\u0026#34;; }); assertthat(newmap.get(1), equalto(\u0026#34;#java#\u0026#34;)); assertthat(newmap.get(2), equalto(\u0026#34;#guava#\u0026#34;)); } /** * 过滤map生成另一个map */ @test public void testmapfilter() { hashmap\u0026lt;integer, string\u0026gt; sourcemap = maps.newhashmap(); sourcemap.put(1, \u0026#34;java\u0026#34;); sourcemap.put(2, \u0026#34;guava\u0026#34;); map\u0026lt;integer, string\u0026gt; filtermap = maps.filterentries(sourcemap, entry -\u0026gt; entry.getkey() != 1); assertthat(filtermap.get(1), nullvalue()); assertthat(filtermap.get(2), equalto(\u0026#34;guava\u0026#34;)); } /** * 可以用一个key对应多个value的map */ @test public void testmultimapbasic() { linkedlistmultimap\u0026lt;integer, string\u0026gt; multimap = linkedlistmultimap.create(); multimap.put(1, \u0026#34;java\u0026#34;); multimap.put(1, \u0026#34;guava\u0026#34;); assertthat(multimap.size(), equalto(2)); assertthat(multimap.get(1).get(0), equalto(\u0026#34;java\u0026#34;)); assertthat(multimap.get(1).get(1), equalto(\u0026#34;guava\u0026#34;)); } /** * value不能重复的map */ @test public void testbimapcreate() { hashbimap\u0026lt;integer, string\u0026gt; bimap = hashbimap.create(); bimap.put(1, \u0026#34;java\u0026#34;); bimap.put(1, \u0026#34;guava\u0026#34;); assertthat(bimap.containskey(1), equalto(true)); assertthat(bimap.size(), equalto(1)); assertthat(bimap.get(1), equalto(\u0026#34;guava\u0026#34;)); try { bimap.put(2, \u0026#34;guava\u0026#34;); fail(); } catch (exception e) { assertthat(e, is(instanceof(illegalargumentexception.class))); } } /** * bimap的key-value进行反转 */ @test public void testbimapinverse() { hashbimap\u0026lt;integer, string\u0026gt; bimap = hashbimap.create(); bimap.put(1, \u0026#34;java\u0026#34;); bimap.put(2, \u0026#34;guava\u0026#34;); bimap.put(3, \u0026#34;mysql\u0026#34;); bimap\u0026lt;string, integer\u0026gt; inverseresult = bimap.inverse(); assertthat(inverseresult.size(), equalto(3)); assertthat(inverseresult.get(\u0026#34;java\u0026#34;), equalto(1)); assertthat(inverseresult.get(\u0026#34;guava\u0026#34;), equalto(2)); assertthat(inverseresult.get(\u0026#34;mysql\u0026#34;), equalto(3)); } /** * bimap强制放入数据,会删除原有value相同的key */ @test public void testbiforceput() { hashbimap\u0026lt;integer, string\u0026gt; bimap = hashbimap.create(); bimap.put(1, \u0026#34;java\u0026#34;); bimap.forceput(2, \u0026#34;java\u0026#34;); assertthat(bimap.size(), equalto(1)); assertthat(bimap.get(1), nullvalue()); assertthat(bimap.get(2), equalto(\u0026#34;java\u0026#34;)); } table工具 生成类似excel的内存表格,实现有:arraytable、treebasetable、hashbasetable、immutabletable\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 @test public void testtable() { table\u0026lt;string, string, string\u0026gt; table = hashbasedtable.create(); table.put(\u0026#34;language\u0026#34;, \u0026#34;java\u0026#34;, \u0026#34;1.8\u0026#34;); table.put(\u0026#34;language\u0026#34;, \u0026#34;scala\u0026#34;, \u0026#34;2.3\u0026#34;); table.put(\u0026#34;database\u0026#34;, \u0026#34;oracle\u0026#34;, \u0026#34;12c\u0026#34;); table.put(\u0026#34;database\u0026#34;, \u0026#34;mysql\u0026#34;, \u0026#34;8.0\u0026#34;); map\u0026lt;string, string\u0026gt; language = table.row(\u0026#34;language\u0026#34;); assertthat(language.containskey(\u0026#34;java\u0026#34;), is(true)); assertthat(language.get(\u0026#34;java\u0026#34;), equalto(\u0026#34;1.8\u0026#34;)); assertthat(language.get(\u0026#34;scala\u0026#34;), equalto(\u0026#34;2.3\u0026#34;)); // [(language,java)=1.8, (language,scala)=2.3, (database,oracle)=12c, (database,mysql)=8.0] set\u0026lt;table.cell\u0026lt;string, string, string\u0026gt;\u0026gt; cells = table.cellset(); system.out.println(cells); } 创建不可变集合 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 public class immutablecollectionstest { @test(expected = unsupportedoperationexception.class) public void testimmutableof() { immutablelist\u0026lt;string\u0026gt; list = immutablelist.of(\u0026#34;a\u0026#34;, \u0026#34;b\u0026#34;, \u0026#34;c\u0026#34;, \u0026#34;d\u0026#34;); assertthat(list, notnullvalue()); list.add(\u0026#34;e\u0026#34;); } @test(expected = unsupportedoperationexception.class) public void testimmutablecopy() { integer[] array = {1, 2, 3, 4, 5}; immutablelist\u0026lt;integer\u0026gt; list = immutablelist.copyof(array); list.add(6); } @test(expected = unsupportedoperationexception.class) public void testimmutablebuild() { immutablelist\u0026lt;integer\u0026gt; list = immutablelist.\u0026lt;integer\u0026gt;builder().add(1).add(2).add(3).build(); list.add(4); } @test(expected = unsupportedoperationexception.class) public void testimmutablemap() { immutablemap\u0026lt;integer, string\u0026gt; map = immutablemap.\u0026lt;integer, string\u0026gt;builder() .put(1, \u0026#34;java\u0026#34;).put(2, \u0026#34;guava\u0026#34;).build(); map.put(3, \u0026#34;mysql\u0026#34;); } } 六、缓存 创建基本缓存对象 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 @test public void testbasic() { cache\u0026lt;integer, string\u0026gt; cache = cachebuilder.newbuilder().maximumsize(3).build(); cache.put(1, \u0026#34;java\u0026#34;); cache.put(2, \u0026#34;mysql\u0026#34;); cache.put(3, \u0026#34;guava\u0026#34;); string cachevalue = cache.getifpresent(1); assertthat(cachevalue, equalto(\u0026#34;java\u0026#34;)); cache.put(4, \u0026#34;redis\u0026#34;); cachevalue = cache.getifpresent(2); assertthat(cachevalue, nullvalue()); } 通过cacheloader创建缓存对象 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 @test public void testcacheloader() { cacheloader\u0026lt;integer, string\u0026gt; cacheloader = new cacheloader\u0026lt;integer, string\u0026gt;() { @override public string load(integer key) throws exception { return \u0026#34;#\u0026#34; + key + \u0026#34;#\u0026#34;; } }; loadingcache\u0026lt;integer, string\u0026gt; cache = cachebuilder.newbuilder().maximumsize(3).build(cacheloader); string cachevalue = cache.getunchecked(1); assertthat(cachevalue, equalto(\u0026#34;#1#\u0026#34;)); cachevalue = cache.getunchecked(2); assertthat(cachevalue, equalto(\u0026#34;#2#\u0026#34;)); cachevalue = cache.getunchecked(3); assertthat(cachevalue, equalto(\u0026#34;#3#\u0026#34;)); cachevalue = cache.getunchecked(4); assertthat(cachevalue, equalto(\u0026#34;#4#\u0026#34;)); assertthat(cache.getifpresent(1), nullvalue()); assertthat(cache.getifpresent(4), notnullvalue()); } 通过weigher权重设置数量 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 @test public void testcacheweight() { cacheloader\u0026lt;integer, string\u0026gt; cacheloader = new cacheloader\u0026lt;integer, string\u0026gt;() { @override public string load(integer key) throws exception { return \u0026#34;#\u0026#34; + key + \u0026#34;#\u0026#34;; } }; weigher\u0026lt;integer, string\u0026gt; weigher = (key, value) -\u0026gt; key; loadingcache\u0026lt;integer, string\u0026gt; cache = cachebuilder.newbuilder() .maximumweight(10).weigher(weigher).build(cacheloader); cache.getunchecked(1); cache.getunchecked(2); cache.getunchecked(3); cache.getunchecked(4); cache.getunchecked(5); assertthat(cache.getifpresent(1), nullvalue()); assertthat(cache.getifpresent(2), nullvalue()); assertthat(cache.getifpresent(3), nullvalue()); assertthat(cache.getifpresent(4), equalto(\u0026#34;#4#\u0026#34;)); assertthat(cache.getifpresent(5), equalto(\u0026#34;#5#\u0026#34;)); } 设置存活时间 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 /** * 创建一个缓存对象,通过以访问的最后时间为锚点,设置存活时间 */ @test public void testaccessttl() throws interruptedexception { cache\u0026lt;integer, string\u0026gt; cache = cachebuilder.newbuilder() .expireafteraccess(1, timeunit.seconds).build(); cache.put(1, \u0026#34;java\u0026#34;); string cachevalue = cache.getifpresent(1); assertthat(cachevalue, equalto(\u0026#34;java\u0026#34;)); timeunit.milliseconds.sleep(700l); cachevalue = cache.getifpresent(1); assertthat(cachevalue, equalto(\u0026#34;java\u0026#34;)); timeunit.milliseconds.sleep(700l); cachevalue = cache.getifpresent(1); assertthat(cachevalue, equalto(\u0026#34;java\u0026#34;)); timeunit.milliseconds.sleep(1200l); cachevalue = cache.getifpresent(1); assertthat(cachevalue, nullvalue()); } /** * 创建一个缓存对象,通过以写入时间为锚点,设置存活时间 */ @test public void testwritettl() throws interruptedexception { cache\u0026lt;integer, string\u0026gt; cache = cachebuilder.newbuilder() .expireafterwrite(1, timeunit.seconds).build(); cache.put(1, \u0026#34;java\u0026#34;); string cachevalue = cache.getifpresent(1); assertthat(cachevalue, equalto(\u0026#34;java\u0026#34;)); timeunit.seconds.sleep(2l); cachevalue = cache.getifpresent(1); assertthat(cachevalue, nullvalue()); } 弱、虚、幻引用 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 /** * jvm argument: -xms64m -xmx64m -xx:+printgcdetails * 设置强引用(默认)、软引用(safe)、弱引用(weak)、虚引用(phantom) * 软引用:当jvm内存紧缺时gc开始回收 * 弱引用:当执行gc时开始回收 * 虚引用:主要用来跟踪对象被垃圾回收器回收的活动,虚引用必须和引用队列 (referencequeue)联合使用。 * 当gc准备回收一个对象时,如果发现它还有虚引用,就会在回收对象的内存之前,把这个虚引用加入到与之关联的引用队列 */ @test public void testreftype() throws interruptedexception { cache\u0026lt;integer, byte[]\u0026gt; cache = cachebuilder.newbuilder().softvalues().build(); int i = 0; while (true) { cache.put(++i, new byte[1024 * 1024]); system.out.println(\u0026#34;the [\u0026#34; + i + \u0026#34;] element is store into cache.\u0026#34;); timeunit.milliseconds.sleep(500); } } /** * 虚引用使用示例 */ @test public void testphantomreference() throws exception { byte[] values = new byte[1024 * 1024 * 6]; referencequeue\u0026lt;byte[]\u0026gt; referencequeue = new referencequeue\u0026lt;\u0026gt;(); phantomreference\u0026lt;byte[]\u0026gt; phantomreference = new phantomreference\u0026lt;\u0026gt;(values, referencequeue); // 第一次未执行时,referencequeue为空 reference\u0026lt;? extends byte[]\u0026gt; ref = referencequeue.remove(100l); assertthat(ref, nullvalue()); values = null; system.gc(); // 执行完gc时,values被释放,加入到referencequeue timeunit.seconds.sleep(1l); ref = referencequeue.remove(100l); field referentfield = reference.class.getdeclaredfield(\u0026#34;referent\u0026#34;); referentfield.setaccessible(true); values = (byte[]) referentfield.get(ref); assertthat(values, notnullvalue()); } 获取value为null处理 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 /** * 直接通过缓存的key获取对象为null时会抛出invalidcacheloadexception异常 */ @test public void testloadnullwithexception() { cacheloader\u0026lt;integer, string\u0026gt; cacheloader = new cacheloader\u0026lt;integer, string\u0026gt;() { @override public string load(integer key) throws exception { return null; } }; loadingcache\u0026lt;integer, string\u0026gt; cache = cachebuilder.newbuilder().build(cacheloader); try { cache.getunchecked(1); fail(); } catch (exception e) { assertthat(e, is(instanceof(cacheloader.invalidcacheloadexception.class))); } } /** * 直接通过缓存的key获取对象为optional时可根据情况获取null值 */ @test public void testloadnullwihoptional() { cacheloader\u0026lt;integer, optional\u0026lt;string\u0026gt;\u0026gt; cacheloader = new cacheloader\u0026lt;integer, optional\u0026lt;string\u0026gt;\u0026gt;() { @override public optional\u0026lt;string\u0026gt; load(integer key) throws exception { return optional.ofnullable(null); } }; loadingcache\u0026lt;integer, optional\u0026lt;string\u0026gt;\u0026gt; cache = cachebuilder.newbuilder().build(cacheloader); optional\u0026lt;string\u0026gt; value = cache.getunchecked(1); assertthat(value.ispresent(), equalto(false)); } 设置缓存初始化值 1 2 3 4 5 6 7 8 9 10 11 @test public void testcachepreload() { cacheloader\u0026lt;string, string\u0026gt; loader = cacheloader.from(string::touppercase); loadingcache\u0026lt;string, string\u0026gt; cache = cachebuilder.newbuilder().build(loader); map\u0026lt;string, string\u0026gt; predata = immutablemap.of(\u0026#34;kun\u0026#34;, \u0026#34;kun\u0026#34;, \u0026#34;tbb\u0026#34;, \u0026#34;tbb\u0026#34;); cache.putall(predata); assertthat(cache.getunchecked(\u0026#34;kun\u0026#34;), equalto(\u0026#34;kun\u0026#34;)); assertthat(cache.getunchecked(\u0026#34;tbb\u0026#34;), equalto(\u0026#34;tbb\u0026#34;)); assertthat(cache.getunchecked(\u0026#34;jack\u0026#34;), equalto(\u0026#34;jack\u0026#34;)); } 刷新缓存 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 @test public void testcacherefresh() throws interruptedexception { atomicinteger count = new atomicinteger(0); cacheloader\u0026lt;string, integer\u0026gt; loader = cacheloader.from(key -\u0026gt; count.getandincrement()); loadingcache\u0026lt;string, integer\u0026gt; cache = cachebuilder.newbuilder() .refreshafterwrite(1, timeunit.seconds).build(loader); integer key = cache.getunchecked(\u0026#34;key\u0026#34;); assertthat(key, equalto(0)); key = cache.getunchecked(\u0026#34;key\u0026#34;); assertthat(key, equalto(0)); timeunit.seconds.sleep(1l); key = cache.getunchecked(\u0026#34;key\u0026#34;); assertthat(key, equalto(1)); } 缓存移除通知 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 @test public void testcacheremovednotification() { removallistener\u0026lt;string, string\u0026gt; listener = notification -\u0026gt; { // 状态时被移除 if (notification.wasevicted()) { removalcause cause = notification.getcause(); /** * 被移除的原因 * removalcause.explicit 显示的使缓存失效,invalidate,invalidateall * removalcause.replaced 值被另一个值替代 * removalcause.collected 软引用、弱引用被垃圾回收器回收 * removalcause.expired 超过ttl时间 * removalcause.size 超过缓存大小 */ assertthat(cause, is(removalcause.size)); assertthat(notification.getkey(), equalto(\u0026#34;tom\u0026#34;)); } }; cacheloader\u0026lt;string, string\u0026gt; loader = cacheloader.from(string::touppercase); loadingcache\u0026lt;string, string\u0026gt; cache = cachebuilder.newbuilder() .maximumsize(3).removallistener(listener).build(loader); cache.getunchecked(\u0026#34;tom\u0026#34;); cache.getunchecked(\u0026#34;jack\u0026#34;); cache.getunchecked(\u0026#34;jane\u0026#34;); cache.getunchecked(\u0026#34;rose\u0026#34;); } 获取缓存状态 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 @test public void testcachestatinfo() { cacheloader\u0026lt;string, string\u0026gt; loader = cacheloader.from(string::touppercase); loadingcache\u0026lt;string, string\u0026gt; cache = cachebuilder.newbuilder() .maximumsize(3).recordstats().build(loader); assertthat(cache.getunchecked(\u0026#34;kun\u0026#34;), equalto(\u0026#34;kun\u0026#34;)); cachestats stats = cache.stats(); assertthat(stats.hitcount(), equalto(0l)); assertthat(stats.misscount(), equalto(1l)); assertthat(cache.getunchecked(\u0026#34;kun\u0026#34;), equalto(\u0026#34;kun\u0026#34;)); stats = cache.stats(); assertthat(stats.hitcount(), equalto(1l)); assertthat(stats.misscount(), equalto(1l)); assertthat(bigdecimal.valueof(stats.missrate()), equalto(bigdecimal.valueof(0.5))); assertthat(bigdecimal.valueof(stats.hitrate()), equalto(bigdecimal.valueof(0.5))); } ","date":"2021-02-07","permalink":"https://hobocat.github.io/post/tool/2021-02-07-guava/","summary":"一、介绍 Guava工程包含了若干被Google的Java项目广泛依赖的核心库,例如:集合、缓存、原生类型支持、并发库、通用注解、字符串处理、I/O等等 二、工具","title":"guava的使用"},]
[{"content":"一、naocs简介 \tnacos是阿里巴巴开源的一款支持服务注册与发现,配置管理以及微服务管理的组件。用来取代以前常用的注册中心(zookeeper , eureka等等),以及配置中心(spring cloud config等等)。nacos是集成了注册中心和配置中心的功能,做到了二合一。\nnacos 的关键特性包括\n服务发现和服务健康监测 动态配置服务 动态dns服务 服务及其元数据管理 二、naocs安装部署 单机部署 第一步:运行conf/nacos-mysql.sql文件【默认nacos用嵌入式数据库derby,需切换为mysql】\n第二步:修改conf/application.properties文件\n1 2 3 4 5 6 spring.datasource.platform=mysql db.num=1 db.url.0=jdbc:mysql://11.162.196.16:3306/nacos_devtest?characterencoding=utf8\u0026amp;connecttimeout=1000\u0026amp;sockettimeout=3000\u0026amp;autoreconnect=true\u0026amp;servertimezone=asia/shanghai db.user=nacos_devtest db.password=youdontknow 第三步:修改conf/cluster.conf,配置成ip:port格式\n# ip:port 200.8.9.16:8848 200.8.9.17:8848 200.8.9.18:8848 集群部署 因为每个nacos都是读取的mysql的信息,所有数据是一样的,只需要前面挂上nginx实现负载均衡即可实现集群模式\n三、naocs作为服务注册中心 第一步:添加依赖\n1 2 3 4 \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;com.alibaba.cloud\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;spring-cloud-starter-alibaba-nacos-discovery\u0026lt;/artifactid\u0026gt; \u0026lt;/dependency\u0026gt; 第二步:配置yaml\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 spring: application: name: cloud-order-service cloud: nacos: # nacos地址 server-addr: localhost:8848 discovery: # namespace的区分 namespace: dev # 所属组 group: wyk_group # 注册的服务名称,默认即为${spring.application.name} service: ${spring.application.name} # 服务集群名称,默认default cluster-name: wykcluster 第三步:主启动类\n1 2 3 4 5 6 7 8 @springbootapplication @enablediscoveryclient public class paymentapplication8005 { public static void main(string[] args) { springapplication.run(paymentapplication8005.class); } } 第四步:配置路由,nacos使用的是ribbon【如果使用open feign可以跳过】\n1 2 3 4 5 6 7 8 9 @configuration public class resttemplateconfig { @bean @loadbalanced public resttemplate resttemplate() { return new resttemplate(); } } 四、naocs作为配置中心 第一步:添加依赖\n1 2 3 4 \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;com.alibaba.cloud\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;spring-cloud-starter-alibaba-nacos-config\u0026lt;/artifactid\u0026gt; \u0026lt;/dependency\u0026gt; 第二步:配置yaml【bootstrap文件】\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 spring: cloud: nacos: # nacos地址 server-addr: localhost:8848 config: # 文件后缀 file-extension: yaml # namespace的区分 namespace: dev # 所属组 group: wyk_group # 服务集群名称,默认default cluster-name: wykcluster # data id name: payment-dev 还可以使用spring.cloud.config.prefix+-+spring.profiles.active+.+spring.cloud.config.file-extension的组合\nspring.cloud.config.prefix默认值为applicationname\n五、几种注册中心的比较 nacos eureka consul zookeeper 一致性协议 ap / cp ap cp cp 健康检查 tcp/http/mysql/client beat client beat tcp/http/grpc/cmd keep alive 雪崩保护 支持 支持 不支持 不支持 自动注销实例 支持 支持 不支持 支持 访问协议 http/dns/udp http http/dns tcp 监听支持 支持 支持 支持 支持 多数据中心 支持 支持 支持 不支持 跨注册中心 支持 不支持 支持 不支持 k8s集成 支持 不支持 不支持 支持 一般来说,如果不需要存储服务级别的信息且服务实例是通过nacos-client注册,并能够保持心跳上报,那么就可以选择ap模式。当前主流的服务如springcloud和dubbo服务,都适用与ap模式,ap模式为了服务的可能性而减弱了一致性,因此ap模式下只支持注册临时实例。如果需要在服务级别编辑或存储配置信息,那么cp是必须,k8s服务和dns服务则适用于cp模式。cp模式下则支持注册持久化实例,此时则是以raft协议为集群运行模式,该模式下注册实例之前必须先注册服务,如果服务不出存在,则会返回错误。\n","date":"2021-02-02","permalink":"https://hobocat.github.io/post/spring-cloud/2021-02-02-spring-cloud-alibaba-nacos/","summary":"一、Naocs简介 Nacos是阿里巴巴开源的一款支持服务注册与发现,配置管理以及微服务管理的组件。用来取代以前常用的注册中心(zookeeper , eureka","title":"spring cloud alibaba naocs使用详解"},]
[{"content":"一、sentinel简介 \tsentinel是面向分布式服务框架的轻量级流量控制框架,主要以流量为切入点,从流量控制,熔断降级,系统负载保护等多个维度来维护系统的稳定性。\nsentinel 基本概念 资源\n资源是 sentinel 的关键概念。它可以是 java 应用程序中的任何内容,例如,由应用程序提供的服务,或由应用程序调用的其它应用提供的服务,甚至可以是一段代码。只要通过 sentinel api 定义的代码,就是资源,能够被 sentinel 保护起来。大部分情况下,可以使用方法签名,url,甚至服务名称作为资源名来标示资源。\n规则\n围绕资源的实时状态设定的规则,可以包括流量控制规则、熔断降级规则以及系统保护规则。所有规则可以动态实时调整。\n二、sentinel 流量控制 针对来源\nsentinel可以针对调用者进行限流,填写微服务名,指定对哪个微服务进行限流 ,默认default(不区分来源,全部限制)\n阈值类型\nqps:设置每秒能承受的请求数量 线程数:设置最多支持的线程数量【并非一个请求对应一个线程】 流控模式\n直接:到达阈值时对当前资源进行限流操作 关联:当关联的资源接收到的请求达到了阈值上线,则对当前资源进行限流操作【例如支付模块压力大时对订单模块进行限流】 链路:以调用链路为单位做限流,整个链路的总体流量只按照入口资源的请求量来计算【feign.sentinel.enabled: true需要打开】 使用簇点链路时可能需要展开链路关系,基本不用\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 /** * 在spring-cloud-alibaba v2.1.1.release及前,sentinel1.7.0及后,关闭url path聚合需要通过该方式 * 在spring-cloud-alibaba v2.1.1.release后,可以配置关闭:spring.cloud.sentinel.web-context-unify=false * 手动注入sentinel的过滤器,关闭sentinel注入commonfilter实例, * 修改配置文件中的 spring.cloud.sentinel.filter.enabled=false */ @bean public filterregistrationbean sentinelfilterregistration() { filterregistrationbean registration = new filterregistrationbean(); registration.setfilter(new commonfilter()); registration.addurlpatterns(\u0026#34;/*\u0026#34;); // 入口资源关闭聚合 registration.addinitparameter(commonfilter.web_context_unify, \u0026#34;false\u0026#34;); registration.setname(\u0026#34;sentinelfilter\u0026#34;); registration.setorder(1); return registration; } 链路必须使用@sentinelresource实现监控\n流控效果\n快速失败:直接抛出限流异常 预热模式:避免低水位服务器突然接收到大量请求宕机采用逐渐放宽限流策略,例如qps=x,预热时长=y,冷加载因子默认为3,就是要让该资源在第y秒的时候每秒能够承受x次并发请求数量,第一次进行限流的时间点大概在x/3次请求时发生【可通过spring.cloud.sentinel.flow.coldfactor设置冷加载因子】 排队等待:匀速器模式,所有请求堆积在入口处等待,以qps为准每秒放行响应的请求进行处理,请求间隔为(1/阈值s),可设置超时时间来过滤掉部分等待中的请求,超时时间需要小于请求的间隔才能生效 三、热点参数降流 \t热点参数限流会统计传入参数中的热点参数,并根据配置的限流阈值与模式,对包含热点参数的资源调用进行限流,热点参数限流可以看做是一种特殊的流量控制,仅对包含热点参数的资源调用生效\n四、sentinel 熔断降级 降级策略\n慢调用比例: 平均响应时间,当1s内持续进入n个请求,对应时刻的平均响应时间(秒级)均超过阈值,那么在接下的时间窗口之内,对这个方法的调用都会自动地熔断),注意sentinel默认统计的rt上限是4900ms,超出此阈值的都会算作4900ms,若需要变更此上限可以通过启动配置项-dcsp.sentinel.statistic.max.rt=4900来配置 异常比例:是指当资源的每秒异常总数占通过量的比值超过阈值之后,资源进入降级状态,即在接下的时间窗口之内,对这个方法的调用都会自动地返回,异常比率的阈值范围是[0.0, 1.0],代表0% - 100% 异常数:是指当资源近1分钟的异常数目超过阈值之后会进行熔断,注意由于统计时间窗口是分钟级别的,若时间窗口小于 60s,则结束熔断状态后仍可能再进入熔断状态 五、sentinel 系统自适应 \tsentinel系统自适应保护从整体维度对应用入口流量进行控制,结合应用的load、总体平均rt、入口qps和线程数等几个维度的监控指标,让系统的入口流量和系统的负载达到一个平衡,让系统尽可能跑在最大吞吐量的同时保证系统整体的稳定性。\nload:仅对linux/unix-like机器生效,系统的load1【uptime命令】作为启发指标,进行自适应系统保护,当系统load1超过设定的启发值,且系统当前的并发线程数超过估算的系统容量时才会触发系统保护,系统容量由系统的maxqps * minrt估算得出,设定参考值一般是cpu cores * 2.5\n平均rt:当单台机器上所有入口流量的平均rt达到阈值即触发系统保护,单位是毫秒\n**并发线程数:**当单台机器上所有入口流量的并发线程数达到阈值即触发系统保护\n**入口 qps:**当单台机器上所有入口流量的 qps 达到阈值即触发系统保护\ncpu使用率:当系统 cpu 使用率超过阈值即触发系统保护(取值范围 0.0-1.0),比较灵敏\n六、授权规则 \t当我们需要根据调用来源来判断该次请求是否允许放行,这时候可以就使用sentinel的来源访问控制的功能,对应的操作就是加上相应的授权规则\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 /** * 解析流控应用表示 */ @component public class customrequestoriginparser implements requestoriginparser { // 获取调用方标识信息并返回 @override public string parseorigin(httpservletrequest request) { string servicename = request.getparameter(\u0026#34;servicename\u0026#34;); stringbuffer url = request.getrequesturl(); if (url.tostring().endswith(\u0026#34;favicon.ico\u0026#34;)) { // 浏览器会向后台请求favicon.ico图标 return servicename; } if (stringutils.isempty(servicename)) { throw new illegalargumentexception(\u0026#34;servicename must not be null\u0026#34;); } return servicename; } } 七、配置持久化 在sentinel dashboard操作并将规则写入文件 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 /** * 拉模式规则持久化\t*/ public class filedatasourceinit implements initfunc { @override\tpublic void init() throws exception {\t// 存放路径 string ruledir = system.getproperty(\u0026#34;user.home\u0026#34;) + \u0026#34;/sentinel/rules\u0026#34;;\tstring flowrulepath = ruledir + \u0026#34;/flow-rule.json\u0026#34;;\tstring degraderulepath = ruledir + \u0026#34;/degrade-rule.json\u0026#34;;\tstring systemrulepath = ruledir + \u0026#34;/system-rule.json\u0026#34;;\tstring authorityrulepath = ruledir + \u0026#34;/authority-rule.json\u0026#34;;\tstring paramflowrulepath = ruledir + \u0026#34;/param-flow-rule.json\u0026#34;;\tthis.mkdirifnotexits(ruledir);\tthis.createfileifnotexits(flowrulepath);\tthis.createfileifnotexits(degraderulepath);\tthis.createfileifnotexits(systemrulepath);\tthis.createfileifnotexits(authorityrulepath);\tthis.createfileifnotexits(paramflowrulepath);\t// 流控规则\treadabledatasource\u0026lt;string, list\u0026lt;flowrule\u0026gt;\u0026gt; flowrulerds = new filerefreshabledatasource\u0026lt;\u0026gt;( flowrulepath,\tflowrulelistparser\t);\t// 将可读数据源注册至flowrulemanager\t// 这样当规则文件发生变化时,就会更新规则到内存\tflowrulemanager.register2property(flowrulerds.getproperty()); writabledatasource\u0026lt;list\u0026lt;flowrule\u0026gt;\u0026gt; flowrulewds = new filewritabledatasource\u0026lt;\u0026gt;( flowrulepath,\tthis::encodejson\t);\t// 将可写数据源注册至transport模块的writabledatasourceregistry中\t// 这样收到控制台推送的规则时,sentinel会先更新到内存,然后将规则写入到文件中\twritabledatasourceregistry.registerflowdatasource(flowrulewds); // 降级规则\treadabledatasource\u0026lt;string, list\u0026lt;degraderule\u0026gt;\u0026gt; degraderulerds = new filerefreshabledatasource\u0026lt;\u0026gt;( degraderulepath,\tdegraderulelistparser\t);\tdegraderulemanager.register2property(degraderulerds.getproperty()); writabledatasource\u0026lt;list\u0026lt;degraderule\u0026gt;\u0026gt; degraderulewds = new filewritabledatasource\u0026lt;\u0026gt;(\tdegraderulepath,\tthis::encodejson\t);\twritabledatasourceregistry.registerdegradedatasource(degraderulewds);\t// 系统规则\treadabledatasource\u0026lt;string, list\u0026lt;systemrule\u0026gt;\u0026gt; systemrulerds = new filerefreshabledatasource\u0026lt;\u0026gt;( systemrulepath,\tsystemrulelistparser\t);\tsystemrulemanager.register2property(systemrulerds.getproperty()); writabledatasource\u0026lt;list\u0026lt;systemrule\u0026gt;\u0026gt; systemrulewds = new filewritabledatasource\u0026lt;\u0026gt;(\tsystemrulepath,\tthis::encodejson\t);\twritabledatasourceregistry.registersystemdatasource(systemrulewds);\t// 授权规则\treadabledatasource\u0026lt;string, list\u0026lt;authorityrule\u0026gt;\u0026gt; authorityrulerds = new filerefreshabledatasource\u0026lt;\u0026gt;( flowrulepath,\tauthorityrulelistparser\t);\tauthorityrulemanager.register2property(authorityrulerds.getproperty()); writabledatasource\u0026lt;list\u0026lt;authorityrule\u0026gt;\u0026gt; authorityrulewds = new filewritabledatasource\u0026lt;\u0026gt;(\tauthorityrulepath,\tthis::encodejson\t);\twritabledatasourceregistry.registerauthoritydatasource(authorityrulewds);\t// 热点参数规则\treadabledatasource\u0026lt;string, list\u0026lt;paramflowrule\u0026gt;\u0026gt; paramflowrulerds = new filerefreshabledatasource\u0026lt;\u0026gt;( paramflowrulepath,\tparamflowrulelistparser\t);\tparamflowrulemanager.register2property(paramflowrulerds.getproperty()); writabledatasource\u0026lt;list\u0026lt;paramflowrule\u0026gt;\u0026gt; paramflowrulewds = new filewritabledatasource\u0026lt;\u0026gt;(\tparamflowrulepath,\tthis::encodejson\t);\tmodifyparamflowrulescommandhandler.setwritabledatasource(paramflowrulewds); }\tprivate converter\u0026lt;string, list\u0026lt;flowrule\u0026gt;\u0026gt; flowrulelistparser = source -\u0026gt; json.parseobject( source,\tnew typereference\u0026lt;list\u0026lt;flowrule\u0026gt;\u0026gt;() { }\t);\tprivate converter\u0026lt;string, list\u0026lt;degraderule\u0026gt;\u0026gt; degraderulelistparser = source -\u0026gt; json.parseobject(\tsource,\tnew typereference\u0026lt;list\u0026lt;degraderule\u0026gt;\u0026gt;() { }\t);\tprivate converter\u0026lt;string, list\u0026lt;systemrule\u0026gt;\u0026gt; systemrulelistparser = source -\u0026gt; json.parseobject(\tsource,\tnew typereference\u0026lt;list\u0026lt;systemrule\u0026gt;\u0026gt;() {\t}\t);\tprivate converter\u0026lt;string, list\u0026lt;authorityrule\u0026gt;\u0026gt; authorityrulelistparser = source -\u0026gt; json.parseobject(\tsource,\tnew typereference\u0026lt;list\u0026lt;authorityrule\u0026gt;\u0026gt;() {\t}\t);\tprivate converter\u0026lt;string, list\u0026lt;paramflowrule\u0026gt;\u0026gt; paramflowrulelistparser = source -\u0026gt; json.parseobject(\tsource,\tnew typereference\u0026lt;list\u0026lt;paramflowrule\u0026gt;\u0026gt;() {\t}\t);\tprivate void mkdirifnotexits(string filepath) { file file = new file(filepath); if (!file.exists()) {\tfile.mkdirs();\t}\t}\tprivate void createfileifnotexits(string filepath) throws ioexception {\tfile file = new file(filepath);\tif (!file.exists()) {\tfile.createnewfile(); }\t}\tprivate \u0026lt;t\u0026gt; string encodejson(t t) {\treturn json.tojsonstring(t);\t}\t} 在resources下创建配置目录meta-inf/services,然后添加文件com.alibaba.csp.sentinel.init.initfunc\n在文件中添加配置类全类名\n从nacos读取配置 引入依赖\n1 2 3 4 \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;com.alibaba.csp\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;sentinel-datasource-nacos\u0026lt;/artifactid\u0026gt; \u0026lt;/dependency\u0026gt; 配置yaml\n1 2 3 4 5 6 7 8 9 10 11 12 spring: cloud: sentinel: datasource: ds: nacos: serveraddr: localhost:8848 groupid: wyk_group namespace: dev dataid: ${spring.application.name}-sentinel datatype: \u0026#39;json\u0026#39; ruletype: flow 创建配置文件${spring.application.name}-sentinel\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 [ { \u0026#34;clusterconfig\u0026#34;: { \u0026#34;fallbacktolocalwhenfail\u0026#34;: true, \u0026#34;samplecount\u0026#34;: 10, \u0026#34;strategy\u0026#34;: 0, \u0026#34;thresholdtype\u0026#34;: 0, \u0026#34;windowintervalms\u0026#34;: 1000 }, \u0026#34;clustermode\u0026#34;: false, \u0026#34;controlbehavior\u0026#34;: 0, \u0026#34;count\u0026#34;: 10.0, \u0026#34;grade\u0026#34;: 1, \u0026#34;limitapp\u0026#34;: \u0026#34;default\u0026#34;, \u0026#34;maxqueueingtimems\u0026#34;: 500, \u0026#34;resource\u0026#34;: \u0026#34;/payment/{id}\u0026#34;, \u0026#34;strategy\u0026#34;: 0, \u0026#34;warmupperiodsec\u0026#34;: 10 } ] 八、自定义错误提示 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 /** * 自定义sentinel报错信息 */ @component public class customblockexceptionhandler implements blockexceptionhandler { private objectmapper objectmapper = new objectmapper(); @override public void handle(httpservletrequest request, httpservletresponse response, blockexception e) throws exception { response.setcontenttype(mediatype.application_json_value); response.setcharacterencoding(charencoding.utf_8); printwriter writer = response.getwriter(); // 触发限流 if(e instanceof flowexception) { response.setstatus(2001); writer.print(objectmapper.writevalueasstring(commentresult.failed(\u0026#34;触发限流\u0026#34;))); } // 授权规则不通过 else if(e instanceof authorityexception) { response.setstatus(2002); writer.print(objectmapper.writevalueasstring(commentresult.failed(\u0026#34;授权规则不通过\u0026#34;))); } // 服务降级 else if(e instanceof degradeexception) { response.setstatus(2003); writer.print(objectmapper.writevalueasstring(commentresult.failed(\u0026#34;服务降级\u0026#34;))); } // 热点参数限流 else if(e instanceof paramflowexception) { response.setstatus(2004); writer.print(objectmapper.writevalueasstring(commentresult.failed(\u0026#34;触发热点限流\u0026#34;))); } // 系统保护 else if(e instanceof systemblockexception) { response.setstatus(2005); writer.print(objectmapper.writevalueasstring(commentresult.failed(\u0026#34;触发系统保护规则\u0026#34;))); } // 兜底 else { response.setstatus(httpstatus.internal_server_error.value()); writer.print(objectmapper.writevalueasstring(commentresult.failed(\u0026#34;发生未知错误\u0026#34;))); } writer.flush(); writer.close(); } } 九、其它 @sentinelresource注解还有blockhandler、blockhandlerclass、fallback、fallbackclass用于限流和服务降级使用方法类似hystrixcommand注解\nopenfeign也可以和sentinel配合使用@feignclient中fallback来实现降级\n","date":"2021-02-02","permalink":"https://hobocat.github.io/post/spring-cloud/2021-02-02-spring-cloud-alibaba-sentinel/","summary":"一、Sentinel简介 sentinel是面向分布式服务框架的轻量级流量控制框架,主要以流量为切入点,从流量控制,熔断降级,系统负载保护等多个维度来维护系统的","title":"spring cloud alibaba sentinel使用详解"},]
[{"content":"一、spring cloud config简介 \tspring cloud config项目是一个解决分布式系统的配置管理方案。它包含了client和server两个部分,server提供配置文件的存储以接口的形式将配置文件的内容提供出去,client通过接口获取数据并依据此数据初始化自己的应用。目前springcloud config的server主要是通过git方式做一个配置中心,然后每个服务从server获取自身配置所需的参数。\n二、spring cloud config server配置 第一步:引入依赖\n1 2 3 4 5 \u0026lt;!-- server 配置 --\u0026gt; \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;org.springframework.cloud\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;spring-cloud-config-server\u0026lt;/artifactid\u0026gt; \u0026lt;/dependency\u0026gt; 第二步:配置yaml\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 server: port: 3000 spring: application: name: cloud-config-center cloud: config: server: git: # git工程下的https地址 uri: https://github.com/mynamelancelot/spring-cloud-config.git # 工程名 search-paths: spring-cloud-config # 默认拉取的分支,客户端可以手动设置 default-label: master # 本地文件被污染时强制拉取 force-pull: true # 需要在本地配置ssh的公钥,如果不配置需要忽略公钥检查 strict-host-key-checking: false management: endpoints: web: exposure: # 暴露消息总线刷新地址,用于bus刷新 include: bus-refresh 第三步:主启动类\n1 2 3 4 5 6 7 8 @springbootapplication @enableconfigserver public class configcenter3000 { public static void main(string[] args) { springapplication.run(configcenter3000.class); } } 三、spring cloud config client配置 第一步:引入依赖\n1 2 3 4 \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;org.springframework.cloud\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;spring-cloud-starter-config\u0026lt;/artifactid\u0026gt; \u0026lt;/dependency\u0026gt; 第二步:配置yaml[bootstrap.yaml]\n1 2 3 4 5 6 7 8 9 10 11 spring: cloud: config: # 使用的分支,覆盖server的默认分支 label: master # 配置文件名称 name: app # 配置文件环境 profile: dev # server地址 uri: http://localhost:3000 访问的git文件为{label}分支下的{name}-{profile}.yaml或{name}-{profile}.properties\n注意:使用@refreshscope的spring管理下的类才能实现自动刷新\n四、spring cloud bus简介 \t如果只使用spring cloud config则需要自己手动一个个刷新,所以需要bus进行总线消息通知,用于全局刷新和单节点刷新。springcloud bus目前支持rabbitmq和kafka。\n五、spring cloud bus配置 第一步:引入依赖\n1 2 3 4 \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;org.springframework.cloud\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;spring-cloud-starter-bus-amqp\u0026lt;/artifactid\u0026gt; \u0026lt;/dependency\u0026gt; 第二步:配置yaml【配置rabbitmq或者kafaka均可】\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 spring: cloud: bus: trace: # 总线事件跟踪,访问/trace可获得更新信息 enabled: true rabbitmq: host: 192.168.2.189 port: 5672 password: guest username: guest virtual-host: / management: endpoints: web: exposure: include: bus-refresh 六、spring cloud bus说明 注意配置时必须要暴露management.endpoints.web.exposure.include=bus-refresh\n全局刷新即刷新所有客户端\n1 curl -x post http:/[config-server-ip]:[port]/actuator/bus-refresh 指定刷新\n1 curl -x post http:/[config-client-ip]:[port]/actuator/bus-refresh ","date":"2021-02-02","permalink":"https://hobocat.github.io/post/spring-cloud/2021-02-02-spring-cloud-config/","summary":"一、Spring Cloud Config简介 Spring Cloud Config项目是一个解决分布式系统的配置管理方案。它包含了Client和Server两个部分,Server提供配置文件","title":"spring cloud config使用详解"},]
[{"content":"一、简介 \tspring cloud封装了netflix公司开发的eureka模块来实现服务注册和发现,eureka采用了c-s的设计架构。eureka server 作为服务注册功能的服务器,它是服务注册中心。而系统中的其他微服务,作为eureka 的客户端连接到eureka server并定时发送心跳。这样就可以通过eureka server来监控系统中各个微服务是否正常运行。spring cloud的一些其他模块就可以通过eureka server 来发现系统中的其他微服务。\n二、eureka server搭建 单机版搭建 一、导入依赖\n1 2 3 4 5 6 \u0026lt;dependencies\u0026gt; \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;org.springframework.cloud\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;spring-cloud-starter-netflix-eureka-server\u0026lt;/artifactid\u0026gt; \u0026lt;/dependency\u0026gt; \u0026lt;/dependencies\u0026gt; 二、配置yaml\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 server: port: 7001 spring: application: name: cloud-eureka-server eureka: instance: # eureka服务端的名称 hostname: localhost client: # 服务端不需要向注册中心注册自己 register-with-eureka: false # 服务端不需要检索服务 fetch-registry: false service-url: # 设置与eureka server交互的查询服务和注册服务的地址 defaultzone: http://${eureka.instance.hostname}:${server.port}/eureka/ 三、主启动类\n1 2 3 4 5 6 7 8 @springbootapplication @enableeurekaserver public class eurekaapplication7001 { public static void main(string[] args) { springapplication.run(eurekaapplication7001.class); } } 集群版搭建 eureka server在启动时默认会注册自己,成为一个服务。所以eureka server也是一个客户端。也就是说们可以配置多个eureka server让他们之间相互注册。当服务提供者向其中一个eureka注册服务时,这个服务就会被共享到其他eureka上,这样所有的eureka都会有相同的服务\n相对与单机版,集群版只需修改单机版的yaml\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 server: port: 7002 spring: application: name: cloud-eureka-server eureka: instance: # eureka服务端的名称 hostname: eureka7002.com client: # 服务端不需要向注册中心注册自己 register-with-eureka: false # 服务端不需要检索服务 fetch-registry: false service-url: # 与其它eureka server交互的查询服务和注册服务的地址,不用包含自己 defaultzone: http://eureka7003.com:7003/eureka/,http://eureka7004.com:7004/eureka/ 三、服务注册进eureka 第一步:主启动类\n1 2 3 4 5 6 7 8 @springbootapplication @enableeurekaclient public class paymentapplication8001 { public static void main(string[] args) { springapplication.run(paymentapplication8001.class); } } 第二步:配置yaml\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 spring: application: name: cloud-payment-service eureka: client: # 需要向注册中心注册自己,默认true register-with-eureka: true # 需要检索服务,默认true fetch-registry: true service-url: # 设置与eureka server交互的查询服务和注册服务的地址 defaultzone: http://eureka7002:7002/eureka/,http://eureka7003.com:7003/eureka/ instance: # eureka面板上的实例名称 instance-id: payment8001 # 访问路径显示ip地址 prefer-ip-address: true 四、消费者调用服务\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 @restcontroller @requiredargsconstructor @slf4j public class ordercontroller { // 调用服务,直接使用服务名称即可 private static final string provider_url = \u0026#34;http://cloud-payment-service\u0026#34;; private final resttemplate resttemplate; @getmapping(\u0026#34;/order/{id}\u0026#34;) public commentresult getorder(@pathvariable(\u0026#34;id\u0026#34;) long id) { log.info(\u0026#34;查询订单{}\u0026#34;, id); commentresult commentresult = resttemplate.getforobject(provider_url + \u0026#34;/payment/\u0026#34; + id, commentresult.class); return commentresult; } } @configuration public class resttemplateconfig { @bean @loadbalanced //必须加此注解开启负载均衡才能成功调用, public resttemplate resttemplate() { return new resttemplate(); } } 四、主动获取eureka注册的服务 第一步:主启动类\n1 2 3 4 5 6 7 8 @springbootapplication @enablediscoveryclient public class paymentapplication8001 { public static void main(string[] args) { springapplication.run(paymentapplication8001.class); } } 第二步:主动读取信息\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public class paymentcontroller { private final discoveryclient discoveryclient; @getmapping(\u0026#34;/discoveryclientinfo\u0026#34;) public discoveryclient getdiscoveryclientinfo() { list\u0026lt;string\u0026gt; services = discoveryclient.getservices(); for (string service : services) { log.info(\u0026#34;service: {}\u0026#34;, service); list\u0026lt;serviceinstance\u0026gt; instances = discoveryclient.getinstances(service); for (serviceinstance instance : instances) { log.info(\u0026#34;instanceid={} instancehost={} instanceport={}\u0026#34;, instance.getinstanceid(),instance.gethost(), instance.getport()); } } return discoveryclient; } } 五、eureka的自我保护机制 \teureka server在运行期间会去统计心跳失败比例在15分钟之内是否低于85%,如果低于85%,eureka server会将这些实例保护起来,让这些实例不会过期,但是在保护期内如果服务刚好这个服务提供者非正常下线了,此时服务消费者就会拿到一个无效的服务实例,此时会调用失败,对于这个问题需要服务消费者端要有一些容错机制,如重试,断路器等。\n自我保护模式被激活的条件是:在 1 分钟后,renews (last min) \u0026lt; renews threshold。\nrenews threshold:eureka server 期望每分钟收到客户端实例续约的总数。\nrenews (last min):eureka server最后1分钟收到客户端实例续约的总数。\n解决方式有三种:\n关闭自我保护模式(eureka.server.enable-self-preservation设为false),不推荐。 降低renewalpercentthreshold的比例(eureka.server.renewal-percent-threshold设置为0.5以下),不推荐。 部署多个eureka server并开启其客户端行为(eureka.client.register-with-eureka不要设为false,默认为true),推荐。 ","date":"2021-02-02","permalink":"https://hobocat.github.io/post/spring-cloud/2021-02-02-spring-cloud-eureka/","summary":"一、简介 Spring Cloud封装了Netflix公司开发的Eureka模块来实现服务注册和发现,Eureka采用了C-S的设计架构。Eureka Server 作为服务注册功能的服","title":"spring cloud eureka使用详解"},]
[{"content":"一、gateway概述 微服务网关简介 在微服务架构中,不同的微服务可以有不同的网络地址,各个微服务之间通过互相调用完成用户请求。这样会带来几个问题:\n客户端多次请求不同的微服务,增加客户端的复杂性 认证复杂,每个服务都要进行认证 存在跨域请求,比较复杂 于是微服务网关就是在客户端和服务端之间增加一个api网关,所有的外部请求先通过这个微服务网关,它只需跟网关进行交互,而由网关进行各个微服务的调用。这样前端只需请求一个ip地址,也解决的权鉴问题。\n总结一下,服务网关大概就是四个功能:统一接入、流量管控、协议适配、安全维护\ngateway简介 spring cloud gateway是spring cloud推出的第二代网关框架,取代zuul网关。提供了路由转发、权限校验、限流控制等作用。spring cloud gateway 使用非阻塞 api,支持 websockets。\n相关概念:\nroute(路由):网关的基本构建块。由一个 id,一个目标 uri,一组断言和一组过滤器定义。如果断言为真,则路由匹配。 predicate(断言):这是一个predicate。输入类型是一个serverwebexchange。可以使用它来匹配来自 http 请求的任何内容,例如headers或参数。 filter(过滤器):这是gatewayfilter或globalfilter的实例,可以使用它修改请求和响应。 客户端向spring cloud gateway发出请求。如果gateway handler mapping中找到与请求相匹配的路由,将其发送到gateway web handler。handler再通过指定的过滤器链来将请求发送到实际的服务执行业务逻辑,然后返回。\n二、集成gateway 第一步:添加依赖\n1 2 3 4 5 \u0026lt;!-- 不可以引入spring-boot-starter-web会有冲突 --\u0026gt; \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;org.springframework.cloud\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;spring-cloud-starter-gateway\u0026lt;/artifactid\u0026gt; \u0026lt;/dependency\u0026gt; 第二步:配置好注册中心[按照eureka、zookeeper、nacos客户端配置即可]\n第三步:编写yaml\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 spring: cloud: gateway: discovery: locator: # 是否从注册中心读取服务 enabled: true routes: # 服务的id,唯一即可一般与微服务的service name一致 - id: cloud-order-service # lb表示负载均衡 uri: lb://cloud-order-service predicates: # 路径匹配,所有order的请求都转发到cloud-order-service - path=/order/** 三、gateway的设置 gateway的断言设置 断言设置可以用户延迟发布和信息校验等\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 spring: cloud: gateway: discovery: locator: enabled: true routes: - id: cloud-order-service uri: lb://cloud-order-service predicates: - path=/order/** # 日期类断言 - after=2020-12-11t10:58:41.659+08:00[asia/shanghai] - before=2020-06-20t22:46:41.659+08:00[asia/shanghai] - between=2020-06-20t22:46:41.659+08:00[asia/shanghai] # 参数校验,后跟正则表达式 - cookie=username,^\\w+$ - header=username,^\\w+$ - query=username, \\d+ - query=password, \\d+ # 请求方式校验 - method=get gateway的过滤器设置 spring cloud gateway的filter从作用范围可分为另外两种gatewayfilter与globalfilter。filter可用于权鉴、流控、日志等\nglobalfilter应用到所有的路由上\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 @component public class loginfilter implements globalfilter, ordered { /** * 执行过滤器中的业务逻辑 */ @override public mono\u0026lt;void\u0026gt; filter(serverwebexchange exchange, gatewayfilterchain chain) { system.out.println(\u0026#34;执行了自定义的全局过滤器\u0026#34;); //1.获取请求参数access-token string token = exchange.getrequest().getqueryparams().getfirst(\u0026#34;access-token\u0026#34;); //2.判断是否存在 if(token == null) { //3.如果不存在 : 认证失败 system.out.println(\u0026#34;没有登录\u0026#34;); exchange.getresponse().setstatuscode(httpstatus.unauthorized); return exchange.getresponse().setcomplete(); //请求结束 } //4.如果存在,继续执行 return chain.filter(exchange); //继续向下执行 } /** * 指定过滤器的执行顺序 , 返回值越小执行优先级越高 */ @override public int getorder() { return ordered.highest_precedence; } } gatewayfilter一般使用系统提供的\n例如:gateway以及微服务上都设置了cors(解决跨域),如果不做任何配置[请求 -\u0026gt; 网关 -\u0026gt; 微服务]将会有重复的请求头,使用gatewayfilter过滤器可以过滤重复请求头\n1 2 3 4 5 6 7 8 9 10 11 12 spring: cloud: gateway: discovery: locator: enabled: true routes: - id: cloud-order-service uri: lb://cloud-order-service filters: # 表示采用第一个为准 - deduperesponseheader=access-control-allow-credentials access-control-allow-origin origin, retain_first gateway的自定义错误页面 gateway是采用webflux开发,所以不能使用spring-webmvc那套@controlleradvice自定义错误处理\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 /** * 实际业务处理 */ public class jsonerrorwebexceptionhandler extends defaulterrorwebexceptionhandler { public jsonerrorwebexceptionhandler(errorattributes errorattributes, resourceproperties resourceproperties, errorproperties errorproperties, applicationcontext applicationcontext) { super(errorattributes, resourceproperties, errorproperties, applicationcontext); } @override protected map\u0026lt;string, object\u0026gt; geterrorattributes(serverrequest request, boolean includestacktrace) { // 这里可以根据异常类型进行定制化逻辑 throwable error = super.geterror(request); map\u0026lt;string, object\u0026gt; errorattributes = new hashmap\u0026lt;\u0026gt;(8); errorattributes.put(\u0026#34;message\u0026#34;, error.getmessage()); errorattributes.put(\u0026#34;code\u0026#34;, httpstatus.internal_server_error.value()); errorattributes.put(\u0026#34;method\u0026#34;, request.methodname()); errorattributes.put(\u0026#34;path\u0026#34;, request.path()); if(error instanceof responsestatusexception){ responsestatusexception statusexception = (responsestatusexception) error; errorattributes.put(\u0026#34;code\u0026#34;, statusexception.getstatus().value()); } return errorattributes; } @override protected routerfunction\u0026lt;serverresponse\u0026gt; getroutingfunction(errorattributes errorattributes) { return routerfunctions.route(requestpredicates.all(), this::rendererrorresponse); } @override protected int gethttpstatus(map\u0026lt;string, object\u0026gt; errorattributes) { // 这里其实可以根据errorattributes里面的属性定制http响应码 return (int)errorattributes.get(\u0026#34;code\u0026#34;); } } /** * 自定义异常处理 */ @configuration @enableconfigurationproperties({ serverproperties.class, resourceproperties.class }) public class exceptionhandlerconfiguration { private final serverproperties serverproperties; private final applicationcontext applicationcontext; private final resourceproperties resourceproperties; private final list\u0026lt;viewresolver\u0026gt; viewresolvers; private final servercodecconfigurer servercodecconfigurer; public exceptionhandlerconfiguration(serverproperties serverproperties, resourceproperties resourceproperties, objectprovider\u0026lt;list\u0026lt;viewresolver\u0026gt;\u0026gt; viewresolversprovider, servercodecconfigurer servercodecconfigurer, applicationcontext applicationcontext) { this.serverproperties = serverproperties; this.applicationcontext = applicationcontext; this.resourceproperties = resourceproperties; this.viewresolvers = viewresolversprovider.getifavailable(collections::emptylist); this.servercodecconfigurer = servercodecconfigurer; } // 实例化逻辑错误处理类 @bean @order(ordered.highest_precedence) public errorwebexceptionhandler errorwebexceptionhandler(errorattributes errorattributes) { jsonerrorwebexceptionhandler exceptionhandler = new jsonerrorwebexceptionhandler(errorattributes, this.resourceproperties, this.serverproperties.geterror(), this.applicationcontext); exceptionhandler.setviewresolvers(this.viewresolvers); exceptionhandler.setmessagewriters(this.servercodecconfigurer.getwriters()); exceptionhandler.setmessagereaders(this.servercodecconfigurer.getreaders()); return exceptionhandler; } } gateway设置跨域请求 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 @configuration public class gwcorsfilter { @bean public corswebfilter corsfilter() { corsconfiguration config = new corsconfiguration(); config.setallowcredentials(true); // 允许cookies跨域 config.addallowedorigin(\u0026#34;*\u0026#34;); // #允许向该服务器提交请求的uri,*表示全部允许 config.addallowedheader(\u0026#34;*\u0026#34;); // #允许访问的头信息,*表示全部 config.addallowedmethod(\u0026#34;*\u0026#34;); // 允许提交请求的方法类型,*表示全部允许 config.setmaxage(18000l); // 预检请求的缓存时间(秒),即在这个时间段里,对于相同的跨域请求不会再预检了 urlbasedcorsconfigurationsource source = new urlbasedcorsconfigurationsource(new pathpatternparser()); source.registercorsconfiguration(\u0026#34;/**\u0026#34;, config); return new corswebfilter(source); } } ","date":"2021-02-02","permalink":"https://hobocat.github.io/post/spring-cloud/2021-02-02-spring-cloud-gateway/","summary":"一、Gateway概述 微服务网关简介 在微服务架构中,不同的微服务可以有不同的网络地址,各个微服务之间通过互相调用完成用户请求。这样会带来几个问题: 客户端多次请求","title":"spring cloud gateway使用详解"},]
[{"content":"一、hystrix简介 \thystrix是netflix开源的一款容错框架,包含常用的容错方法:线程池隔离、信号量隔离、熔断、降级回退。在高并发访问下,系统所依赖的服务的稳定性对系统的影响非常大,依赖有很多不可控的因素,比如网络连接变慢,资源突然繁忙,暂时不可用,服务脱机等。我们要构建稳定、可靠的分布式系统,就必须要有这样一套容错方法。\nhystrix的主要功能 服务降级\n服务降级是指当服务器压力剧增的情况下,根据实际业务情况及流量对一些服务和页面有策略的不处理或换种简单的方式处理,从而释放服务器资源以保证核心业务正常运作或高效运作。\n触发场景:程序运行异常、超时、服务熔断触发服务降级、线程池/信号量满\n服务熔断\n依赖的下游服务多次在一定时间类故障达到了熔断阈值,为避免引发系统崩溃系统进行熔断(不再调用下游故障服务),熔断一定时间会自动尝试恢复\n触发场景:n分钟内下游出现了m次故障\n服务限流\n当集群处于高并发场景下为保证服务的可靠而进行限流操作\n二、hystrix使用 第一步:引入依赖\n1 2 3 4 \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;org.springframework.cloud\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;spring-cloud-starter-netflix-hystrix\u0026lt;/artifactid\u0026gt; \u0026lt;/dependency\u0026gt; 第二步:主启动类\n1 2 3 4 5 6 7 8 @springbootapplication @enablehystrix public class paymentapplication8007 { public static void main(string[] args) { springapplication.run(paymentapplication8007.class); } } 第三步:如果服务消费端使用需要配置yaml\n1 2 3 feign: hystrix: enabled: true hystrix服务降级 单个方法定制服务降价\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 /** * fallbackmethod 发生服务降级的处理方法 */ @override @hystrixcommand( fallbackmethod = \u0026#34;getpaymenttimeoutbyid_handler\u0026#34;, commandproperties = { @hystrixproperty( name = hystrixpropertiesmanager.execution_isolation_thread_timeout_in_milliseconds, value = \u0026#34;1000\u0026#34;) }) public payment getpaymenttimeoutbyid(long id) { int i = 10 / 0; threadutil.sleep(id, timeunit.seconds); payment payment = new payment(); payment.setid(id); payment.setserial(uuid.randomuuid().tostring(true)); return payment; } public payment getpaymenttimeoutbyid_handler(long id) { log.info(\u0026#34;发生服务降级 id = {}\u0026#34;, id); return null; } 如果是服务提供端可以将服务降级的方法放在service实现类上,如果是消费端需要将注解标签放在controller类上【service是interface的open feign】\n定制某个类级别全局默认降级服务\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 @restcontroller @requiredargsconstructor @slf4j // 配置这个类的默认降级服务方法 @defaultproperties(defaultfallback = \u0026#34;globdefaultfallback\u0026#34;) public class ordercontroller { private final paymentservice paymentservice; @getmapping(\u0026#34;/order/timeout/{id}\u0026#34;) @hystrixcommand\t//这个注解不可省略 public commentresult getordertimeout(@pathvariable(\u0026#34;id\u0026#34;) long id) { log.info(\u0026#34;查询订单{}\u0026#34;, id); return paymentservice.getpaymentbyidtimeout(id); } // 降级服务方法,方法不需要参数,但是方法的返回值包括泛型类型要和被调用方法一致,否则保存 private commentresult globdefaultfallback() { log.error(\u0026#34;======paymentdefaultfallback======\u0026#34;); return commentresult.failed(); } } openfeign为服务每个方法配置降级服务\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 /** * 处理服务降级的具体类 */ @slf4j @component public class paymentservicefallbackimpl implements paymentservice { @override public commentresult\u0026lt;payment\u0026gt; getpaymentbyid(long id) { log.error(\u0026#34;发生服务降级\u0026#34;); return commentresult.failed(); } @override public commentresult\u0026lt;payment\u0026gt; getpaymentbyidtimeout(long id) { log.error(\u0026#34;发生服务降级\u0026#34;); return commentresult.failed(); } } /** * 如果需要定制方法级别限制,需配置yaml[超时时间等也要考虑feign设置的因素] * hystrix: * command: * paymentservice#getpaymentbyidtimeout(long): * execution: * isolation: * thread: * timeoutinmilliseconds: 2000 */ // 指定服务降级的处理类 @feignclient(name = \u0026#34;cloud-payment-service\u0026#34;, fallback = paymentservicefallbackimpl.class) public interface paymentservice { @getmapping(\u0026#34;/payment/{id}\u0026#34;) commentresult\u0026lt;payment\u0026gt; getpaymentbyid(@pathvariable(\u0026#34;id\u0026#34;) long id); @getmapping(\u0026#34;/payment/timeout/{id}\u0026#34;) commentresult\u0026lt;payment\u0026gt; getpaymentbyidtimeout(@pathvariable(\u0026#34;id\u0026#34;) long id); } hystrix服务熔断 熔断打开:请求不再调用当前服务,内部设置时钟一般为mtr(平均故障处理时间),当打开时长达到所设时钟则进入半熔断状态\n熔断关闭:熔断关闭不会对服务进行熔断\n熔断半开:部分请求根据规则调用当前服务,如果请求成功且符合规则则认为当前服务恢复正常,关闭熔断\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 @override @hystrixcommand(fallbackmethod = \u0026#34;getpaymenttimeoutbyid_handler\u0026#34;, commandproperties = { // 开启服务熔断 @hystrixproperty(name = hystrixpropertiesmanager.circuit_breaker_enabled, value = \u0026#34;true\u0026#34;), // 触发熔断的最小请求量,默认20 @hystrixproperty(name = hystrixpropertiesmanager.circuit_breaker_request_volume_threshold, value = \u0026#34;20\u0026#34;), // 时间窗口大小,默认5s @hystrixproperty(name = hystrixpropertiesmanager.circuit_breaker_sleep_window_in_milliseconds, value = \u0026#34;10000\u0026#34;), // 触发熔断的错误百分比,默认百分之50 @hystrixproperty(name = hystrixpropertiesmanager.circuit_breaker_error_threshold_percentage, value = \u0026#34;50\u0026#34;) }) public payment getpaymenttimeoutbyid(long id) { long i = 10 / id; payment payment = new payment(); payment.setid(id); payment.setserial(uuid.randomuuid().tostring(true)); return payment; } hystrix参数参考 服务降级\nhystrixpropertiesmanager.execution_isolation_strategy\n可选值 thread, semaphore,默认thread\nhystrixpropertiesmanager.execution_isolation_semaphore_max_concurrent_requests\n信号池策略下信号池的大小,默认10\nhystrixpropertiesmanager.execution_isolation_thread_timeout_in_milliseconds\n线程池策略下线程的超时时间,默认1s\nhystrixpropertiesmanager.execution_timeout_enabled\n是否启动超时检查,默认true\nhystrixpropertiesmanager.execution_isolation_thread_interrupt_on_timeout\n执行超时时是否中断,默认true\nhystrixpropertiesmanager.execution_isolation_semaphore_max_concurrent_requests\n允许回调方法执行的最大并发数,默认10\nhystrixpropertiesmanager.fallback_enabled\n服务降级是否启用,默认true\n服务熔断\nhystrixpropertiesmanager.circuit_breaker_request_volume_threshold\n触发熔断的最小请求量,默认20\nhystrixpropertiesmanager.circuit_breaker_error_threshold_percentage\n触发熔断的错误百分比,默认百分之50\nhystrixpropertiesmanager.circuit_breaker_sleep_window_in_milliseconds\n时间窗口大小,默认5s\nhystrixpropertiesmanager.circuit_breaker_force_open\n断路器强制打开\nhystrixpropertiesmanager.circuit_breaker_force_closed\n断路器强制关闭\n收集信息\nhystrixpropertiesmanager.metrics_rolling_stats_time_in_milliseconds\n滚动窗口的时间,即判断健康度持续收集的时间,默认10s\nhystrixpropertiesmanager.metrics_rolling_stats_num_buckets\n滚动时间窗桶的数量,桶内累计各指标,必须能被滚动窗口整除,默认10\nhystrixpropertiesmanager.metrics_rolling_percentile_enabled\n对命令执行的延迟是否使用百分位跟踪计算,如果为false,则返回-1\nhystrixpropertiesmanager.metrics_rolling_percentile_time_in_milliseconds\n百分位滚动窗口持续时间,默认60s\nhystrixpropertiesmanager.metrics_rolling_percentile_num_buckets\n百分位统计的桶数量,默认6\nhystrixpropertiesmanager.metrics_rolling_percentile_bucket_size\n百分位统计的每个桶大小,默认100\nhystrixpropertiesmanager.metrics_health_snapshot_interval_in_milliseconds\n默认0.5s\n其它\nhystrixpropertiesmanager.request_cache_enabled\n是否开启请求缓存,默认true\nhystrixpropertiesmanager.request_log_enabled\n请求日志是否打印,默认true\n线程相关threadpoolproperties属性\nhystrixpropertiesmanager.core_size\n核心线程数,默认10\nhystrixpropertiesmanager.max_queue_size\n线程池阻塞队列大小,默认-1,采用synchronousqueue,否则使用linkedblockingqueue\nhystrixpropertiesmanager.queue_size_rejection_threshold\n设置拒绝队列阀值,通过此参数即使队列没达到最大请求也能拒绝,默认5\n三、hystrix 监控搭建 单节点监控 第一步:引入依赖\n1 2 3 4 \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;org.springframework.cloud\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;spring-cloud-starter-netflix-hystrix-dashboard\u0026lt;/artifactid\u0026gt; \u0026lt;/dependency\u0026gt; 第二步:主启动类添加@enablehystrixdashboard\n第三步:配置yaml\n1 2 3 hystrix: dashboard: proxy-stream-allow-list: \u0026#34;localhost\u0026#34; 第四步:访问dashboard端的地址ip:port/hystrix,填入http://服务端ip/port/actuator/hystrix.stream[服务端actuator中的hystrix.stream需要开放]\nterbine集群监控 第一步:引入依赖\n1 2 3 4 \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;org.springframework.cloud\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;spring-cloud-netflix-turbine\u0026lt;/artifactid\u0026gt; \u0026lt;/dependency\u0026gt; 第二步:主启动类添加@enableturbine\n第三步:配置yaml\n1 2 3 4 5 6 7 8 9 turbine: # 需要收集信息的服务名,即注册中心服务名称 appconfig: cloud-payment-service aggregator: cluster-config: default # 指定集群名称 cluster-name-expression: new string(\u0026#34;default\u0026#34;) # 同一主机上的服务通过主机名和端口号的组合来进行区分,默认以host来区分 combine-host-port: true 第四步:访问dashboard端的地址ip:port/hystrix,填入http://[terbine-ip]:[port]/turbine.stream\n","date":"2021-02-02","permalink":"https://hobocat.github.io/post/spring-cloud/2021-02-02-spring-cloud-hystrix/","summary":"一、Hystrix简介 Hystrix是Netflix开源的一款容错框架,包含常用的容错方法:线程池隔离、信号量隔离、熔断、降级回退。在高并发访问下,系统所依赖","title":"spring cloud hystrix使用详解"},]
[{"content":"一、简介 \topen feign为微服务架构下服务之间的调用提供了解决方案。首先利用了openfeign的声明式方式定义web服务客户端,其次还更进一步通过集成ribbon实现负载均衡的http客户端,而且还可以和服务降级、熔断、限流框架集成提供了发生熔断,错误情况下的处理。\n二、open feign的使用 第一步:引入依赖\n1 2 3 4 \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;org.springframework.cloud\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;spring-cloud-starter-openfeign\u0026lt;/artifactid\u0026gt; \u0026lt;/dependency\u0026gt; 第二步:主启动类配置\n1 2 3 4 5 6 7 8 @springbootapplication @enablefeignclients public class feignorderapplication80 { public static void main(string[] args) { springapplication.run(feignorderapplication80.class); } } 第三步:创建service\n1 2 3 4 5 6 7 8 // 指定服务的名称 @feignclient(name = \u0026#34;cloud-payment-service\u0026#34;) public interface paymentservice { // 书写http请求 @getmapping(\u0026#34;/payment/{id}\u0026#34;) commentresult\u0026lt;payment\u0026gt; getpaymentbyid(@pathvariable(\u0026#34;id\u0026#34;) long id); } open feign的yaml配置\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 feign: compression: request: # 开启请求压缩 enabled: true # 希望返回的类型,默认也是以下列表 mime-types: text/xml,application/xml,application/json # 请求超过此大小才进行压缩 min-request-size: 2048 response: # 是否可解压响应 enabled: true # 可使用gzip解压缩 usegzipdecoder: true client: config: # 全局设置 default: # 发生请求读取结果的超时时间 read-timeout: 10000 # 连接超时时间 connection-timeout: 2000 # 不同服务的超时时间设置 cloud-payment-service: read-timeout: 10000 三、open feign的额外配置 open feign的日志配置 yaml配置需要开启日志的包和日志等级\n1 2 3 4 5 6 7 8 9 10 11 12 13 feign: client: config: default: # none: 不开启日志(默认) # basic:记录请求方法、url、响应状态、执行时间 # headers: 在basic基础上 加载请求/响应头 # full: 在headers基础上 增加body和请求元数据 logger-level: full logging: level: com.kun.springcloud.service: debug open feign重试机制 默认open feign不进行任何重试,使用feign.retryer.never_retry\n第一种,直接注入相当于修改了全局配置\n1 2 3 4 5 @bean public retryer feignretryer() { // fegin提供的默认实现,最大请求次数为5,初始间隔时间为100ms,下次间隔时间1.5倍递增,重试间最大间隔时间为1s, return new retryer.default(); // =\u0026gt;this(100, seconds.tomillis(1), 5); } 第二种,创建类可精确配置在不同地方\n1 2 3 4 5 6 7 8 feign: client: config: default: retryer: com.kun.springcloud.config.simpleretryer cloud-payment-service: read-timeout: 1000 retryer: com.kun.springcloud.config.simpleretryer ","date":"2021-02-02","permalink":"https://hobocat.github.io/post/spring-cloud/2021-02-02-spring-cloud-open-feign/","summary":"一、简介 Open Feign为微服务架构下服务之间的调用提供了解决方案。首先利用了OpenFeign的声明式方式定义Web服务客户端,其次还更进一步通过集成Ribbo","title":"spring cloud open feign使用详解"},]
[{"content":"一、ribbon概述 ribbon简介 \tspring cloud ribbon 是基于netflix ribbon实现的一套客户端负载均衡的工具。主要功能是提供客户端的软件负载均衡算法和服务调用。ribbon客户端组件提供一系列完善的配置项如连接超时、重试等。简单的说就是在配置文件中列出load balancer后面所有的机器,ribbon会自动的帮助你基于某种规则(如简单轮询,随机连接等)去连接这些机器。现在项目处于维护状态中,但依旧还在大范围使用\nlb负载均衡(load balance) 将用户的请求平摊到多个服务上,从而达到系统的高可用(ha)。常见的负载均衡软件有nginx、lvs等。 ribbon本地负载均衡与nginx服务端负载均衡的区别 nginx是服务器负载均衡,客户端所有请求都会交给nginx,然后由nginx实现转发请求。即负载均衡由服务端实现。 ribbon本地负载均衡在调用服务接口的时候,会在注册中心上获取注册信息服务列表之后缓存到jvm本地,从而在本地实现rpc远程服务调用技术。ribbon属于进程内负载均衡(将lb逻辑集成到消费方,消费方从服务注册中心获知有那些地址可用,然后自己再从这些地址中选出一个合适的服务器) 二、集成ribbon 如果项目中使用了eureka client、zookeeper、consul、nacos则已经自动依赖了ribbon, 然后结合resttemplate使用即可【@loadbalanced】\n1 2 3 4 \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;org.springframework.cloud\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;spring-cloud-starter-netflix-ribbon\u0026lt;/artifactid\u0026gt; \u0026lt;/dependency\u0026gt; 使用ribbon提供的负载均衡算法 算法 解释 roundrobinrule 轮询,默认算法 randomrule 随机 retryrule 先按照roudrobinrule的策略获取服务,如果获取服务失败则在指定时间内会进行重试,获取可用的服务 weightedresponsetimerule 对roudrobinrule的扩展,响应速度越快的实例选择权重越大,越容易被选择 bestavailablerule 会优过滤掉由于多次访问故障而处于断路器跳闸状态的服务,然后选择一个并发量最小的服务 availabilityfilteringrule 先过滤掉故障实例,再选择并发较小的实例 zoneavoidancerule 复合判断server所在区域的性能和server的可用性选择服务器 主启动类加入注解@ribbonclients\n1 2 3 @ribbonclients( @ribbonclient(name = \u0026#34;cloud-payment-service\u0026#34;, configuration = randomrule.class) ) 三、自定义负载规则 自定义某服务的规则不能被spring boot扫描到,否则定义的配置类就会被所有的ribbon客户端使用【全局使用】,起不到特殊化定制的效果。\n自定义类实现abstractloadbalancerrule或者irue即可\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public class myrule extends abstractloadbalancerrule { public server choose(iloadbalancer lb, object key) { //...自定义规则... } protected int chooserandomint(int servercount) { return threadlocalrandom.current().nextint(servercount); } @override public server choose(object key) { return choose(getloadbalancer(), key); } @override public void initwithniwsconfig(iclientconfig clientconfig) { } } 主启动类加入注解@ribbonclients\n1 2 3 @ribbonclients( @ribbonclient(name = \u0026#34;cloud-payment-service\u0026#34;, configuration = myrule.class) ) ","date":"2021-02-02","permalink":"https://hobocat.github.io/post/spring-cloud/2021-02-02-spring-cloud-ribbon/","summary":"一、Ribbon概述 Ribbon简介 Spring Cloud Ribbon 是基于Netflix Ribbon实现的一套客户端负载均衡的工具。主要功能是提供客户端的软件负载均衡算法和服务调用。R","title":"spring cloud ribbon使用详解"},]
[{"content":"一、sleuth简介 \t微服务跟踪(sleuth)其实是一个工具,它在整个分布式系统中能跟踪一个用户请求的过程(包括数据采集,数据传输,数据存储,数据分析,数据可视化),捕获这些跟踪数据,就能构建微服务的整个调用链的视图,这是调试和监控微服务的关键工具。\n特点 说明 提供链路追踪 通过sleuth可以很清楚的看出一个请求经过了哪些服务,可以方便的理清服务局的调用关系 性能分析 通过sleuth可以很方便的看出每个采集请求的耗时,分析出哪些服务调用比较耗时,当服务调用的耗时随着请求量的增大而增大时,也可以对服务的扩容提供一定的提醒作用 数据分析 优化链路 对于频繁地调用一个服务,或者并行地调用等,可以针对业务做一些优化措施 可视化 对于程序未捕获的异常,可以在zipkpin界面上看到 术语 trace\n从客户发起请求(request)抵达被追踪系统的边界开始,到被追踪系统向客户返回响应(response)为止的整个过程\nspan\n每个trace中会调用若干个服务,为了记录调用了哪些服务,以及每次调用的消耗时间等信息,在每次调用服务时,埋入一个调用记录\n二、sleuth配置 zipkin下载地址,可以使用源文件编译,也可以使用脚本启动,默认访问端口9411\n第一步:引入依赖\n1 2 3 4 \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;org.springframework.cloud\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;spring-cloud-sleuth-zipkin\u0026lt;/artifactid\u0026gt; \u0026lt;/dependency\u0026gt; 第二步:配置yaml\n1 2 3 4 5 6 7 spring: zipkin: # zipkin地址 base-url: http://localhost:9411/ sleuth: # 采样率0-1 sampler: 1 ","date":"2021-02-02","permalink":"https://hobocat.github.io/post/spring-cloud/2021-02-02-spring-cloud-sleuth/","summary":"一、sleuth简介 微服务跟踪(sleuth)其实是一个工具,它在整个分布式系统中能跟踪一个用户请求的过程(包括数据采集,数据传输,数据存储,数据分析,数据可","title":"spring cloud sleuth使用详解"},]
[{"content":"一、简介 \tzookeeper作为知名的分布式调度系统,我们也可以利用其作为配置中心。其wacth 主动通知机制, 可以将node节点数据变更信息及时通知到client端。【注册的服务节点为zookeeper的临时节点,即客户端退出节点删除】\n二、服务注册进zookeeper 服务注册 配置依赖\n1 2 3 4 \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;org.springframework.cloud\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;spring-cloud-starter-zookeeper-discovery\u0026lt;/artifactid\u0026gt; \u0026lt;/dependency\u0026gt; 第一步:配置主启动类\n1 2 3 4 5 6 7 8 @springbootapplication @enablediscoveryclient public class paymentapplication8003 { public static void main(string[] args) { springapplication.run(paymentapplication8003.class); } } 第二步:配置yaml\n1 2 3 4 5 6 spring: application: name: cloud-payment-service cloud: zookeeper: connect-string: 192.168.22.160:2181 服务消费 第一步:配置主启动类\n1 2 3 4 5 6 7 8 @springbootapplication @enablediscoveryclient public class orderapplication80 { public static void main(string[] args) { springapplication.run(orderapplication80.class); } } 第二步:配置yaml\n1 2 3 4 5 6 spring: application: name: cloud-order-service cloud: zookeeper: connect-string: 192.168.22.160:2181 第三步:配置resttemplate\n1 2 3 4 5 6 7 8 9 @configuration public class resttemplateconfig { @bean @loadbalanced public resttemplate resttemplate() { return new resttemplate(); } } 第四步:调用服务\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 @restcontroller @requiredargsconstructor @slf4j public class ordercontroller { // 注意eureka是大写,这个是小写 private static final string provider_url = \u0026#34;http://cloud-payment-service\u0026#34;; private final resttemplate resttemplate; @getmapping(\u0026#34;/order/{id}\u0026#34;) public commentresult getorder(@pathvariable(\u0026#34;id\u0026#34;) long id) { log.info(\u0026#34;查询订单{}\u0026#34;, id); commentresult commentresult = resttemplate.getforobject(provider_url + \u0026#34;/payment/\u0026#34; + id, commentresult.class); return commentresult; } } 三、主动获取eureka注册的服务 1 2 3 4 5 6 7 8 9 10 11 12 @getmapping(\u0026#34;/discoveryclientinfo\u0026#34;) public discoveryclient getdiscoveryclientinfo() { list\u0026lt;string\u0026gt; services = discoveryclient.getservices(); for (string service : services) { log.info(\u0026#34;service: {}\u0026#34;, service); list\u0026lt;serviceinstance\u0026gt; instances = discoveryclient.getinstances(service); for (serviceinstance instance : instances) { log.info(\u0026#34;instanceid={} instancehost={} instanceport={}\u0026#34;,instance.getinstanceid(),instance.gethost(), instance.getport()); } } return discoveryclient; } ","date":"2021-02-02","permalink":"https://hobocat.github.io/post/spring-cloud/2021-02-02-spring-cloud-zookeeper/","summary":"一、简介 Zookeeper作为知名的分布式调度系统,我们也可以利用其作为配置中心。其wacth 主动通知机制, 可以将node节点数据变更信息及时通知到clien","title":"spring cloud zookeeper使用详解"},]
[{"content":"一、微服务概念 \t微服务架构风格是一种将单一应用程序开发成一组小型服务的方法,每个服务运行在自己的进程中,服务间通信采用轻量级通信机制【通常用http资源api】。这些服务围绕业务能力构建并且可通过自动部署机制独立部署。这些服务共用一个最小型的集中式的管理,服务可用不同的语言开发,使用不同的数据存储技术。\n微服务架构应该具备的特性 每个微服务可独立运行在自己的进程里 一系列独立运行的微服务共同构建起整个系统 每个服务为独立的业务开发,一个微服务只关注某个特定的功能 微服务之间通过一些轻量的通信机制进行通信,例如通过restful api进行调用 可以使用不同的语言与数据存储技术 全自动的部署机制 微服务架构的优点 易于开发和维护\n一个微服务只会关注一个特定的业务功能,所以它业务清晰、代码量较少。开发和维护单个微服务相对简单。而整个应用是由若干个微服务构建而成的,所以整个应用也会被维持在一个可控状态。\n单个微服务启动较快\n单个微服务代码量较少,所以启动会比较快。\n局部修改容易部署\n单体应用只要有修改,就得重新部署整个应用,微服务解决了这样的问题。一般来说,对某个微服务进行修改,只需要重新部署这个服务即可。\n技术栈不受限\n在微服务架构中,可以结合项目业务及团队特点,使用不同的语言和技术。\n按需伸缩\n可根据需求,实现细粒度的扩展。例如,系统中的某个微服务遇到了瓶颈,可以结合这个微服务的业务特点,增加内存、升级cpu或者是增加节点。\n二、微服务和soa区别 微服务架构强调的第一个重点就是业务系统需要彻底的组件化和服务化,原有的单个业务系统会拆分为多个可以独立开发,设计,运行和运维的小应用。这些小应用之间通过服务完成交互和集成。每个小应用从前端web ui,到控制层,逻辑层,数据库访问,数据库都完全是独立的一套。在这里我们不用组件而用小应用这个词更加合适,每个小应用除了完成自身本身的业务功能外,重点就是还需要消费外部其它应用暴露的服务,同时自身也将自身的能力朝外部发布为服务。\n如果一句话来谈soa和微服务的区别,即微服务不再强调传统soa架构里面比较重的esb企业服务总线,同时soa的思想进入到单个业务系统内部实现真正的组件化。\n三、spring cloud现在的生态 四、spring cloud和spring boot的版本选择 通过spring官网暴露的actuator的接口可以查看spring cloud、spring cloud alibaba所需的spring boot版本,项目初始化时应选择好对应版本避免冲突\nspring cloud每版本的参考文档也有建议的spring boot版本可以查看\n","date":"2021-02-02","permalink":"https://hobocat.github.io/post/spring-cloud/2021-02-02-spring-cloud-preorder/","summary":"一、微服务概念 微服务架构风格是一种将单一应用程序开发成一组小型服务的方法,每个服务运行在自己的进程中,服务间通信采用轻量级通信机制【通常用HTTP资源API】","title":"微服务介绍"},]
[{"content":"一、seata简介 \tseata 是一款开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务。seata 将为用户提供了 at、tcc、saga 和 xa 事务模式。\n在seata中,一个at分布式事务的生命周期如下:\ntm请求tc开启一个全局事务,tc会生成一个xid作为该全局事务的编号,xid会在微服务的调用链路中传播,保证将多个微服务的子事务关联在一起 rm请求tc将本地事务注册为全局事务的分支事务,通过全局事务的xid进行关联 tm请求tc告诉xid对应的全局事务是进行提交还是回滚 tc驱动rm将xid对应的自己的本地事务进行提交还是回滚 二、seata at事务 使用前提:需要分布式事务的系统必须是自己可掌控的【因为需要添加数据表】\nat事务时基于两阶段提交xa协议的演变【并没使用xa协议,参考xa协议自定义了一种业务层的规则】\n一阶段:业务数据和回滚日志记录在同一个本地事务中提交,释放本地锁和连接资源\n二阶段:异步化提交,非常快速地完成。发生错误时回滚通过一阶段的回滚日志进行反向补偿\n写隔离机制 一阶段本地事务提交前,需要确保先拿到全局锁 。 拿不到全局锁,不能提交本地事务。 拿全局锁的尝试被限制在一定范围内,超出范围将放弃,并回滚本地事务,释放本地锁。 举例说明\n两个全局事务tx1和tx2,分别对a表的m字段进行更新操作,m的初始值1000\n①、tx1先开始,开启本地事务,拿到本地锁,更新操作m = 1000 - 100 = 900。本地事务提交前,先拿到该记录的全局锁,本地提交释放本地锁。\n②、tx2后开始,开启本地事务,拿到本地锁,更新操作m = 900 - 100 = 800。本地事务提交前,尝试拿该记录的全局锁 ,tx1全局提交前,该记录的全局锁被tx1持有,tx2需要重试等待全局锁\n③、tx1二阶段全局提交释放全局锁 。tx2拿到全局锁提交本地事务。\n如果tx1的二阶段全局回滚,则tx1需要重新获取该数据的本地锁,进行反向补偿的更新操作实现分支的回滚。此时,如果tx2仍在等待该数据的全局锁,同时持有本地锁,则tx1的分支回滚会失败。分支的回滚会一直重试,直到 tx2 的全局锁等锁超时,放弃全局锁并回滚本地事务释放本地锁,tx1的分支回滚最终成功。\n因为整个过程全局锁在tx1结束前一直是被tx1持有的,所以不会发生脏写的问题\n读隔离机制 在数据库本地事务隔离级别读已提交(read committed)或以上的基础上,seata(at 模式)的默认全局隔离级别是读未提交(read uncommitted)\n如果应用在特定场景下,必需要求全局的读已提交,目前seata的方式是通过\u0026quot;select for update\u0026quot;语句的代理\nselect for update 语句的执行前会申请全局锁,如果全局锁被其他事务持有,则释放本地锁(回滚 select for update语句的本地执行)并重试。这个过程中,查询是被 block 住的直到全局锁拿到,即读取的相关数据是已提交的,才返回。\n出于总体性能上的考虑,seata目前的方案并没有对所有select语句都进行代理,仅针对for update的select语句\n工作机制 一阶段:在一阶段,seata 会拦截业务sql,首先解析sql语义找到业务sql要更新的业务数据,在业务数据被更新前,将其保成\u0026quot;before image\u0026quot;,然后执行业务sql更新业务数据,在业务数据更新之后再将其保存成\u0026quot;after image\u0026quot;,最后生成行锁。以上操作全部在一个数据库事务内完成,这样保证了一阶段操作的原子性。\n二阶段提交: 二阶段如果是提交的话,因为业务 sql在一阶段已经提交至数据库, 所以seata框架只需将一阶段保存的快照数据和行锁删掉,完成数据清理即可。\n二阶段回滚:二阶段如果是回滚的话,seata就需要回滚一阶段已经执行的业务sql,还原业务数据。回滚方式便是用\u0026quot;before image\u0026quot;还原业务数据;但在还原前要首先要校验脏写,对比数据库当前业务数据和\u0026quot;after image\u0026quot;,如果两份数据完全一致就说明没有脏写,可以还原业务数据,如果不一致就说明有脏写,出现脏写就需要转人工处理。\n代码示例 前置步骤:选择script\\client\\at\\db的对应数据库脚本执行生成undo_log表\n订单服务\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 @override @globaltransactional //seata全局事务注解 public string createorder(integer userid, integer productid) { integer amount = 1; // 购买数量,暂时设为 1 log.info(\u0026#34;[createorder] 当前 xid: {}\u0026#34;, rootcontext.getxid()); // 减库存 (feign的调用) http远程调用 store store = feignproductservice.reducestock(productid, amount); // 减余额 feignaccountservice.reducebalance(userid, store.getprice().toplainstring()); // 下订单 order order = new order(); order.setuserid(userid); order.setproductid(productid); order.setpayamount(store.getprice().multiply(new bigdecimal(amount))); ordermapper.insertselective(order); log.info(\u0026#34;[createorder] 下订单: {}\u0026#34;, order.getid()); //int a = 10 / 0; // 返回订单编号 return string.valueof(order.getid()); } 仓储服务\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 @slf4j @service @requiredargsconstructor public class storeserviceimpl implements storeservice { private final storemapper storemapper; @override public store reducestock(integer productid, integer amount) { log.info(\u0026#34;[reducestock] 当前 xid: {}\u0026#34;, rootcontext.getxid()); // 检查库存 store store = storemapper.selectbyprimarykey(productid); if (store.getstock() \u0026lt; amount) { throw new runtimeexception(\u0026#34;库存不足\u0026#34;); } // 减库存 int updatecount = storemapper.reducestock(productid, amount); // 减库存失败 if (updatecount == 0) { throw new runtimeexception(\u0026#34;库存不足\u0026#34;); } // 减库存成功 log.info(\u0026#34;减库存 {} 库存成功\u0026#34;, productid); return store; } } 账户服务\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 @service @requiredargsconstructor @slf4j public class accountserviceimpl implements accountservice { private final accountmapper accountmapper; @override public void reducebalance(integer userid, bigdecimal money) { log.info(\u0026#34;[reducebalance] 当前 xid: {}\u0026#34;, rootcontext.getxid()); // 检查余额 account account = accountmapper.selectaccountbyuserid(userid); if (account.getbalance().compareto(money) \u0026lt; 0) { throw new runtimeexception(\u0026#34;余额不足\u0026#34;); } // 扣除余额 int updatecount = accountmapper.reducebalance(userid, money); // 扣除成功 if (updatecount == 0) { throw new runtimeexception(\u0026#34;余额不足\u0026#34;); } log.info(\u0026#34;[reducebalance] 扣除用户 {} 余额成功\u0026#34;, userid); } } 上述所有服务的yaml配置\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 seata: # seata应用编号,默认为${spring.application.name} application-id: ${spring.application.name} enabled: true # 注册中心 registry: type: nacos nacos: cluster: seata server-addr: localhost namespace: dev # seata事务组编号,用于tc集群名 tx-service-group: ${spring.application.name}-group # 虚拟组和分组的映射 service: vgroup-mapping: # 此配置需要和seata中register文件的cluster一致 seata-at-order-service-group: \u0026#39;seata\u0026#39; feign: client: config: default: logger-level: full read-timeout: 5000 connection-timeout: 5000 在可能出现并发问题但不是分布式事务的服务,比如上述例子有修改库存的服务,可能会导致数据脏写需要加@globallock注解\n三、seata tcc事务 at模式基本上能满足我们使用分布式事务大部分需求,但涉及非关系型数据库与中间件的操作、跨公司服务的调用、跨语言的应用调用就需要结合tcc模式\n1、一阶段 prepare 行为:调用自定义的 prepare 逻辑;(比如插入订单,锁定库存,冻结部分余额)\n2、二阶段 commit 行为: 调用自定义的 commit 逻辑;(减少库存、扣款)\n3、二阶段 rollback 行为:调用自定义的 rollback 逻辑;(回滚订单、释放库存、解冻部分余额)\n订单服务\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 //服务入口不需要try、commit、cancel,因为发生异常已立即回滚 @override @globaltransactional //seata全局事务注解 public string createorder(integer userid, integer productid) { integer amount = 1; // 购买数量,暂时设为 1 log.info(\u0026#34;[createorder] 当前 xid: {}\u0026#34;, rootcontext.getxid()); // 减库存 (feign的调用) http远程调用 store store = feignproductservice.reducestock(productid, amount); // 减余额 feignaccountservice.reducebalance(userid, store.getprice().toplainstring()); // 下订单 order order = new order(); order.setuserid(userid); order.setproductid(productid); order.setpayamount(store.getprice().multiply(new bigdecimal(amount))); ordermapper.insertselective(order); log.info(\u0026#34;[createorder] 下订单: {}\u0026#34;, order.getid()); // 返回订单编号 return string.valueof(order.getid()); } 仓储服务\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 // tcc事务注解 @localtcc public interface storeservice { /** * 锁定库存,try操作 */ @twophasebusinessaction( name = \u0026#34;reducestock\u0026#34;, commitmethod = \u0026#34;committcc\u0026#34;, rollbackmethod = \u0026#34;canceltcc\u0026#34;) store reducestock(@businessactioncontextparameter(paramname = \u0026#34;productid\u0026#34;) integer productid, @businessactioncontextparameter(paramname = \u0026#34;amount\u0026#34;) integer amount); /** * 提交操作 */ boolean committcc(businessactioncontext context); /** * 取消操作 */ boolean canceltcc(businessactioncontext context); } /* ################################################################################################# */ @slf4j @service @requiredargsconstructor public class storeserviceimpl implements storeservice { private final storetccmapper storemapper; private final tccstatusmapper tccstatusmapper; @override @transactional public store reducestock(integer productid, integer amount) { log.info(\u0026#34;[reducebalance] 当前 xid: {}\u0026#34;, rootcontext.getxid()); // 幂等,如果xid重复 主键冲突 // 防悬挂控制(cancel 比 try先执行),cancel已经插入记录,主键冲突 tccstatus tccstatus = new tccstatus(); tccstatus.settrystatus(true); tccstatus.setxid(rootcontext.getxid()); tccstatusmapper.insertselective(tccstatus); // 检查余额 store store = storemapper.selectbyprimarykey(productid); if (store.getstock().compareto(amount) \u0026lt; 0) { throw new runtimeexception(\u0026#34;库存不足\u0026#34;); } // 执行冻结操作 int updatecount = storemapper.lockstore(productid, amount); if (updatecount == 0) { throw new runtimeexception(\u0026#34;库存不足\u0026#34;); } log.info(\u0026#34;[reducebalance] 锁定库存 {} 成功\u0026#34;, productid); return store; } @override @transactional public boolean committcc(businessactioncontext context) { log.info(\u0026#34;confirm阶段,accountserviceimpl, committcc --\u0026gt; xid = {}\u0026#34;, context.getxid() + \u0026#34;, committcc提交成功\u0026#34;); tccstatus tccstatusrecord = tccstatusmapper.selectbyprimarykey(context.getxid()); // 解决幂等 if (tccstatusrecord == null || tccstatusrecord.getcommitstatus()) { return true; } integer productid = (integer) context.getactioncontext(\u0026#34;productid\u0026#34;); integer amount = (integer) context.getactioncontext(\u0026#34;amount\u0026#34;); int updatecount = storemapper.reducestock(productid, amount); tccstatusrecord.setcommitstatus(true); tccstatusmapper.updatebyprimarykeyselective(tccstatusrecord); return updatecount != 0; } @override @transactional public boolean canceltcc(businessactioncontext context) { log.info(\u0026#34;cancel阶段,accountserviceimpl, canceltcc --\u0026gt; xid = \u0026#34; + context.getxid() + \u0026#34;, canceltcc提交失败\u0026#34;); tccstatus tccstatusrecord = tccstatusmapper.selectbyprimarykey(context.getxid()); // 空回滚 if (tccstatusrecord == null ) { tccstatus tccstatus = new tccstatus(); tccstatus.setxid(context.getxid()); tccstatus.setcancelstatus(true); return true; } // 解决幂等 if (tccstatusrecord.getcancelstatus()) { return true; } //进行数据库回滚处理 integer productid = (integer) context.getactioncontext(\u0026#34;productid\u0026#34;); integer amount = (integer) context.getactioncontext(\u0026#34;amount\u0026#34;); //把余额再加回去 storemapper.increasestock(productid, amount); tccstatusrecord.setcancelstatus(true); int updatecount = tccstatusmapper.updatebyprimarykeyselective(tccstatusrecord); log.info(\u0026#34;cancel阶段,accountserviceimpl, canceltcc this data: productid= {}, amount = {}\u0026#34;, productid, amount); return updatecount != 0; } } 账户服务\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 @localtcc public interface accountservice { /** * 扣除余额总方法,当前相当于try,为锁定部分余额 * 定义两阶段提交 * name = reducestock为一阶段try方法 * commitmethod = committcc 为二阶段确认方法 * rollbackmethod = cancel 为二阶段取消方法 * businessactioncontextparameter注解 可传递参数到二阶段方法 * * @param userid 用户id * @param money 扣减金额 * @throws exception 失败时抛出异常 */ @twophasebusinessaction( name = \u0026#34;reducebalance\u0026#34;, commitmethod = \u0026#34;committcc\u0026#34;, rollbackmethod = \u0026#34;canceltcc\u0026#34;) void reducebalance(@businessactioncontextparameter(paramname = \u0026#34;userid\u0026#34;) integer userid, @businessactioncontextparameter(paramname = \u0026#34;money\u0026#34;) bigdecimal money); /** * 确认方法、可以另命名,但要保证与commitmethod一致 * context可以传递try方法的参数 * * @param context 上下文 * @return boolean */ boolean committcc(businessactioncontext context); /** * 二阶段取消方法 * * @param context 上下文 * @return boolean */ boolean canceltcc(businessactioncontext context); } /* ################################################################################################# */ @service @requiredargsconstructor @slf4j public class accountserviceimpl implements accountservice { private final accounttccmapper accountmapper; private final tccstatusmapper tccstatusmapper; @override @transactional public void reducebalance(integer userid, bigdecimal money) { log.info(\u0026#34;[reducebalance] 当前 xid: {}\u0026#34;, rootcontext.getxid()); // 幂等,如果xid重复 主键冲突 // 防悬挂控制(cancel 比 try先执行),cancel已经插入记录,主键冲突 tccstatus tccstatus = new tccstatus(); tccstatus.settrystatus(true); tccstatus.setxid(rootcontext.getxid()); tccstatusmapper.insertselective(tccstatus); // 检查余额 account account = accountmapper.selectaccountbyuserid(userid); if (account.getbalance().compareto(money) \u0026lt; 0) { throw new runtimeexception(\u0026#34;余额不足\u0026#34;); } // 执行冻结操作 int updatecount = accountmapper.lockbalance(userid, money); if (updatecount == 0) { throw new runtimeexception(\u0026#34;余额不足\u0026#34;); } log.info(\u0026#34;[reducebalance] 锁定用户 {} 余额成功\u0026#34;, userid); } /** * tcc服务(confirm)方法 * 可以空确认 */ @override @transactional public boolean committcc(businessactioncontext context) { log.info(\u0026#34;confirm阶段,accountserviceimpl, committcc --\u0026gt; xid = {}\u0026#34;, context.getxid() + \u0026#34;, committcc提交成功\u0026#34;); tccstatus tccstatusrecord = tccstatusmapper.selectbyprimarykey(context.getxid()); // 解决幂等 if (tccstatusrecord == null || tccstatusrecord.getcommitstatus()) { return true; } integer userid = (integer) context.getactioncontext(\u0026#34;userid\u0026#34;); bigdecimal money = (bigdecimal) context.getactioncontext(\u0026#34;money\u0026#34;); int updatecount = accountmapper.reducebalance(userid, money); tccstatusrecord.setcommitstatus(true); tccstatusmapper.updatebyprimarykeyselective(tccstatusrecord); return updatecount != 0; } /** * tcc服务(cancel)方法 * * @param context 上下文 * @return boolean */ @override @transactional public boolean canceltcc(businessactioncontext context) { log.info(\u0026#34;cancel阶段,accountserviceimpl, canceltcc --\u0026gt; xid = \u0026#34; + context.getxid() + \u0026#34;, canceltcc提交失败\u0026#34;); tccstatus tccstatusrecord = tccstatusmapper.selectbyprimarykey(context.getxid()); // 空回滚 if (tccstatusrecord == null ) { tccstatus tccstatus = new tccstatus(); tccstatus.setxid(context.getxid()); tccstatus.setcancelstatus(true); return true; } // 解决幂等 if (tccstatusrecord.getcancelstatus()) { return true; } //进行数据库回滚处理 integer userid = (integer) context.getactioncontext(\u0026#34;userid\u0026#34;); bigdecimal money = (bigdecimal) context.getactioncontext(\u0026#34;money\u0026#34;); //把余额再加回去 accountmapper.increasebalance(userid, money); tccstatusrecord.setcancelstatus(true); int updatecount = tccstatusmapper.updatebyprimarykeyselective(tccstatusrecord); log.info(\u0026#34;cancel阶段,accountserviceimpl, canceltcc this data: userid= {}, money = {}\u0026#34;, userid, money); return updatecount != 0; } } 四、seata集群部署 \t在生产环境下,需要部署集群seata tc server实现高可用,在集群时多个seata tc server通过数据库或者redis实现全局事务会话信息的共享。每个seata tc server注册自己到注册中心上,应用从注册中心获得seata tc server实例,这就是seata tc server的集群\n搭建步骤:\n第一步:在源码目录下seata/script/server/db/mysql.sql有需要执行的脚本\n第二步:修改seata/conf/file.conf配置文件,修改使用数据库,实现seata tc server的全局事务会话信息的共享\nstore { mode = \u0026#34;db\u0026#34; db { datasource = \u0026#34;druid\u0026#34;. dbtype = \u0026#34;mysql\u0026#34; driverclassname = \u0026#34;com.mysql.cj.jdbc.driver\u0026#34; url = \u0026#34;jdbc:mysql://192.168.22.1/seata?useunicode=true\u0026amp;characterencoding=utf8\u0026amp;autoreconnect=true\u0026amp;servertimezone=asia/shanghai\u0026#34; user = \u0026#34;root\u0026#34; password = \u0026#34;123456\u0026#34; minconn = 5 maxconn = 100 globaltable = \u0026#34;global_table\u0026#34; branchtable = \u0026#34;branch_table\u0026#34; locktable = \u0026#34;lock_table\u0026#34; querylimit = 100 } 第三步:修改seata/conf/registry.conf配置文件,设置使用nacos注册中心\nregistry { type = \u0026#34;nacos\u0026#34; loadbalance = \u0026#34;randomloadbalance\u0026#34; loadbalancevirtualnodes = 10 nacos { # 为nacos注册的服务名,1.4版本和spring cloud对接时发现servicename被写死了为serveraddr,所以必须为此值 application = \u0026#34;serveraddr\u0026#34; serveraddr = \u0026#34;192.168.22.1:8848\u0026#34; # 为nacos注册的组名,1.4版本和spring cloud对接时发现group被写死了为default_group,所以必须为此值 group = \u0026#34;default_group\u0026#34; namespace = \u0026#34;dev\u0026#34; # 为nacos注册的集群名,与spring cloud配置的虚拟组和分组的映射有关 cluster = \u0026#34;seata\u0026#34; # 不需要用户名和密码 username = \u0026#34;\u0026#34; password = \u0026#34;\u0026#34; } # 如果配置文件在nacos需要将type = \u0026#34;nacos\u0026#34;,一般情况使用的是file.conf则为file config { type = \u0026#34;nacos\u0026#34; nacos { serveraddr = \u0026#34;192.168.22.1:8848\u0026#34; namespace = \u0026#34;dev\u0026#34; group = \u0026#34;default_group\u0026#34; username = \u0026#34;\u0026#34; password = \u0026#34;\u0026#34; } } } 第三步:启动seata tc server,可能需要修改启动脚本中jvm参数【默认2g】\n代码中的yaml修改:\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 seata: # seata应用编号,默认为${spring.application.name} application-id: seata-at-store-service enabled: true # 注册中心 registry: type: nacos nacos: cluster: seata server-addr: localhost namespace: dev # seata事务组编号,用于tc集群名,一般用${spring.application.name}-group tx-service-group: \u0026#39;seata-at-store-service-group\u0026#39; # 虚拟组和分组的映射 service: vgroup-mapping: # 此配置需要和seata中register文件的cluster一致 seata-at-store-service-group: \u0026#39;seata\u0026#39; ","date":"2021-02-02","permalink":"https://hobocat.github.io/post/database/2021-02-02-alibaba-seata/","summary":"一、Seata简介 Seata 是一款开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务。Seata 将为用户提供了 AT、TCC、SAGA 和 XA 事务模式。 在","title":"seata实现分布式事务"},]
[{"content":"一、分布式事务基础 事务 指的就是一个操作单元,在这个操作单元中的所有操作最终要保持一致的行为,要么所有操作都成功,要么所有的操作都被撤销。\n事务的4个特性\n原子性(atomicity):操作这些指令时,要么全部执行成功,要么全部不执行。只要其中一个指令执行失败,所有的指令都执行失败,数据进行回滚,回到执行指令前的数据状态。\n一致性(consistency):事务的执行使数据从一个状态转换为另一个状态,数据库的完整性约束没有被破坏。\n隔离性(isolation):隔离性是当多个用户并发访问数据库时,比如操作同一张表时,数据库为每一个用户开启的事务,不能被其他事务的操作所干扰,多个并发事务之间要相互隔离。\n持久性(durability):当事务正确完成后,它对于数据的改变是永久性的\n分布式事务 ①、跨jvm进程产生分布式事务。典型的场景就是微服务之间通过远程调用完成事务操作。 比如:订单微服务和库存微服务,下单的同时订单微服务请求库存微服务减库存。\n②、跨数据库实例。一个服务或者单体系统访问多个数据库实例时就会产生分布式事务。比如:用户信息和订单信息分别在两个mysql实例存储,用户管理系统删除用户信息,需要分别删除用户信息及用户的订单信息,由于数据分布在不同的数据实例,需要通过不同的数据库链接去操作数据,此时产生分布式事务。\ncap原则 cap原则又叫cap定理,同时又被称作布鲁尔定理(brewer\u0026rsquo;s theorem),指的是在一个分布式系统中,不可能同时满足以下三点\n一致性(consistency)\n指强一致性,在写操作完成后开始的任何读操作都必须返回该值,或者后续写操作的结果\n可用性(availability)\n可用性是指,每次向未崩溃的节点发送请求,总能保证收到响应数据(允许不是最新数据)\n分区容忍性(partition tolerance)\n分布式系统在遇到任何网络分区故障的时候,仍然能够对外提供满足一致性和可用性的服务,也就是说,服务器a和b发送给对方的任何消息都是可以放弃的,也就是说a和b可能因为各种意外情况,导致无法成功进行同步,分布式系统要能容忍这种情况。除非整个网络环境都发生了故障\n组合 分析 ca 满足原子和可用,放弃分区容错。即就是一个整体的应用 cp 满足原子和分区容错,即要放弃高可用。当系统被分区,为了保证原子性,必须放弃可用性,让服务停用 ap 满足可用性和分区容错,当出现分区,同时为了保证可用性,必须让节点继续对外服务,这样必然导致失去原子性 舍弃p(选择c/a):单点的传统关系型数据库dbms(mysql/oracle),如果采用集群就必须考虑p了 舍弃a(选择c/p):分布式系统要保证p,且保证一致性,如zookeeper / redis / mongodb / hbase; . 舍弃c(选择a/p):分布式系统要保证p,而且保证可用性,如coachdb / cassandra / dynamodb。 base理论 ba: basic available基本可用 整个系统在某些不可抗力的情况下,仍然能够保证\u0026quot;可用性\u0026quot;,即定时间内仍然能够返回一个明确的结果。”基本可用”和”可用”的区别是:\n一定时间可以适当延长当,例如双十一响应时间可以适当延长 给部分用户直接返回一个降级页面,从而缓解服务器压力。但要注意, 返回降级页面仍然是返回明确结果。 s: soft state柔性状态\n是指允许系统中的数据存在中间状态,并认为该中间状态的存在不会影响系统的整体可用性,即允许系统不同节点的数据副本之间进行数据同步的过程存在延时。\ne: eventual consisstency最终一致性\n同一数据的不同副本的状态,可以不需要实时一致,但要保证经过一定时间后是一致的。\nbase理论是对cap中的一致性和可用性进行一个权衡的结果,理论的核心思想就是:我们无法做到强一致,但每个应用都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性( eventual consistency )\n二、2pc协议 2pc即两阶段提交协议,是将整个事务流程分为两个阶段,准备阶段(prepare phase)、提交阶段(commit phase),2是指两个阶段,p是指准备阶段,c是指提交阶段。\n在计算机中部分关系数据库如oracle、mysql支持两阶段提交协议:\n①、准备阶段(prepare phase):事务管理器【tm】给每个参与者【rm】发送prepare消息,每个数据库参与者在本地执行事务,并写本地的undo/redo日志,此时事务没有提交。【undo日志是记录修改前的数据,用于数据库回滚,redo日志是记录修改后的数据,用于提交事务后写入数据文件】。如参与者执行成功,给协调者反馈同意,否则反馈中止。\n②、提交阶段(commit phase):如果事务管理器收到了参与者的执行失败或者等待超时,直接给每个参与者发送回滚(rollback)消息;否则,发送提交(commit)消息;参与者根据事务管理器的指令执行提交或者回滚操作,并释放事务处理过程中使用的锁资源。\n不管最后结果如何,第二阶段都会结束当前事务\n二阶段提交有以下缺点:\n同步阻塞问题。执行过程中所有参与节点都是事务阻塞型的。当参与者占有公共资源时其他第三方节点访问公共资源不得不处于阻塞状 单点故障。由于协调者的重要性,一旦协调者发生故障,参与者会一直阻塞下去。尤其在第二阶段, 协调者发生故障,那么所有的参与者还都处于锁定事务资源的状态中,无法继续完成事务操作。(如果是协调者挂掉,可以重新选举一个协调者,但是无法解决因为协调者宕机导致的参与处于阻塞状态的问题) 数据不一致。在二阶段提交的阶段二中,当协调者向参与者发送commit请求之后,发生了局部网络异常或者在发送commit请求过程中协调发生了故障,这会导致只有一部分参与者接受到了commit请求。而在这部分参与者接到commit请求之后就会执行commit操作。但是其他部分未接到commit请求的机器则无法执行事务提交。于整个分布式系统便出现了数据不致性的现象。 二阶段无法解决的问题。协调者再发出commit消息之后宕机,而唯一接收到这条消息的参与者同时也宕机了。那么即使协调者通过选举协议产生了新的协调者,这条事务的状态也是不确定的,没人知道事务是否被已经提交。 三、xa方案 \t2pc的传统方案是在数据库层面实现的,如oracle、mysql都支持2pc协议,但是接口不一样。为了统一标准减少行业内不必要的对接成本,需要制定标准化的处理模型及接口标准,国际开放标准组织open group定义了分布式事务处理模型dtp(distributed transaction processing reference model)。2pc的缺陷也是xa方案的缺陷。\ndtp模型定义如下角色:\nap(application program)\n即应用程序,可以理解为使用dtp分布式事务的程序\nrm(resource manager)\n即资源管理器,可以理解为事务的参与者。一般情况下是指一个数据库实例\ntm(transaction manager)\n事务管理器,负责协调和管理事务,事务管理器控制着全局事务,管理事务生命周期,并协调各个rm。全局事务是指分布式事务处理环境中,需要操作多个数据库共同完成一个工作,这个工作即是一个全局事务\n执行流程如下:\n1、应用程序(ap)分别向俩rm提出执行sql,rm此时并未提交事务\n2、tm收到rm的执行回复有失败超时,分别向其他rm发起回滚事务,回滚完毕,资源锁释放\n3、tm收到rm执行回复全部成功,此时向所有rm发起提交事务,提交完毕,资源锁释放\ndtp模型定义tm和rm之间通讯的接口规范叫xa,可简单理解为数据库提供的2pc接口协议,基于数据库的xa协议来实现2pc又称为xa方案。\n以上三个角色之间的交互方式如下:\n1、tm向ap提供 应用程序编程接口,ap通过tm提交及回滚事务。\n2、tm交易中间件通过xa接口来通知rm数据库事务的开始、结束以及提交、回滚等。\n四、tcc模式 \ttcc编程模式本质上也是一种二阶段协议,不同在于tcc编程模式需要与具体业务耦合。tcc是try、confirm、cancel三个词语的缩写,tcc要求每个分支事务实现三个操作:预处理try、确认confirm、撤销cancel。try操作做业务检查及资源预留,confirm做业务确认操作,cancel实现一个与try相反的操作即回滚操作。tm首先发起所有的分支事务的try操作,任何一个分支事务的try操作执行失败,tm将会发起所有分支事务的cancel操作,若try操作全部成功,tm将会发起所有分支事务的confirm操作,其中confirm/cancel操作若执行失败,tm会进行重试。tcc模式一般用于和第三方自己无法掌控的系统进行对接操作。\n分支事务成功情况\n分支事务失败情况\ntry 阶段是做业务检查(一致性)及资源预留(隔离),此阶段仅是一个初步操作,它和后续的confirm一起才能真正构成一个完整的业务逻辑。 confirm阶段是做确认提交,try阶段所有分支事务执行成功后开始执行confirm。通常情况下,采用tcc则认为confirm阶段是不会出错的。即:只要try成功,confirm一定成功。若confirm阶段真的出错了,需引入重试机制或人工处理。 cancel阶段是在业务执行错误需要回滚的状态下执行分支事务的业务取消,预留资源释放。通常情况下,采用tcc则认为cancel阶段也是一定成功的。若cancel阶段真的出错了,需引入重试机制或人工处理。 tm事务管理器可以实现为独立的服务,也可以让全局事务发起方充当tm的角色,tm独立出来是为了成为公用组件,是为了考虑系统结构和软件复用。tm在发起全局事务时生成全局事务记录,全局事务id贯穿整个分布式事务调用链条,用来记录事务上下文,追踪和记录状态,由于confirm和cancel失败需进行重试,因此需要实现为幂等,幂等性是指同一个操作无论请求多少次,其结果都相同。 tcc事务要考虑允许空回滚、防悬挂控制、幂等控制\ncancel接口设计时需要允许空回滚。在try接口因为丢包时没有收到,事务管理器会触发回滚。这时会触发cancel接口,这时cancel执行时发现没有对应的事务xid或主键时,需要返回回滚成功。让事务服务管理器认为己回滚,否则会不断重试,而cancel又没有对应的业务数据可以进行回滚。\n悬挂的意思是:cancel比try接口先执行,出现的原因是try由于网络拥堵而超时,事务管理器生成回滚,触发cancel接口,而最终又收到了try接口调用,但是cancel比try先到。按照前面允许空回滚的逻辑,回滚会返回成功,事务管理器认为事务已回滚成功,则此时的try接口不应该执行,则会产生数据不一致,所以我们在cancel空回滚返回成功之前先记录该条事务xid或业务主键,标识这条记录已经回滚过,try 接口先检查这条事务xid或业务主键如果已经标记为为滚成功过,则不执行try的业务操作。\n幂等性的意思是:因为网络抖动或拥堵可能会超时,事务管理器会对资源进行重试操作,所以很可能一个业务操作会被重复调用,为了不因为重复调用而多次占用资源,需要对服务设计时进行幂等控制,通常我们可以用事务xid或业务主键判重来控制。\n五、3pc协议 \t三阶段提交又称3pc,其在两阶段提交的基础上增加了cancommit阶段,并引入了超时机制。一旦事务参与者迟迟没有收到协调者的commit请求,就会自动进行本地commit,这样相对有效地解决了协调者单点故障的问题。但是性能问题和不一致问题仍然没有根本解决。\n第一阶段:cancommit阶段\n\t这个阶段类似于2pc中的第二个阶段中的ready阶段,是一种事务询问操作,事务的协调者向所有参与者询问\u0026quot;是否可以完成本次事务?\u0026quot;,如果参与者节点认为自身可以完成事务就返回\u0026quot;yes\u0026quot;,否则\u0026quot;no\u0026quot;。而在实际的场景中参与者节点会对自身逻辑进行事务尝试,其实说白了就是检查下自身状态的健康性,看有没有能力进行事务操作。\n第二阶段:precommit阶段\n在阶段一中,如果所有的参与者都返回yes的话,那么就会进入precommit阶段进行事务预提交。此时分布式事务协调者会向所有的参与者节点发送precommit请求,参与者收到后开始执行事务操作,并将undo和redo信息记录到事务日志中。参与者执行完事务操作后(此时属于未提交事务的状态),就会向协调者反馈\u0026quot;ack\u0026quot;表示我已经准备好提交了,并等待协调者的下一步指令。\n否则,如果阶段一中有任何一个参与者节点返回的结果是no响应,或者协调者在等待参与者节点反馈的过程中超时(2pc中只有协调者可以超时,参与者没有超时机制)。整个分布式事务就会中断,协调者就会向所有的参与者发送**\u0026ldquo;abort\u0026rdquo;**请求。\n第三阶段:docommit阶段\n在阶段二中如果所有的参与者节点都可以进行precommit提交,那么协调者就会从预提交状态-\u0026gt;提交状态。然后向所有的参与者节点发送**\u0026ldquo;docommit\u0026rdquo;请求,参与者节点在收到提交请求后就会各自执行事务提交操作,并向协调者节点反馈\u0026ldquo;ack\u0026rdquo;**消息,协调者收到所有参与者的ack消息后完成事务。相反,如果有一个参与者节点未完成precommit的反馈或者反馈超时,那么协调者都会向所有的参与者节点发送abort请求,从而中断事务。\n相比较2pc而言,3pc对于协调者(coordinator)和参与者(partcipant)都设置了超时时间,而2pc只有协调者才拥有超时机制。这个优化点,主要是避免了参与者在长时间无法与协调者节点通讯(协调者挂掉了)的情况下,无法释放资源的问题,因为参与者自身拥有超时机制会在超时后,自动进行本地commit从而进行释放资源。而这种机制也侧面降低了整个事务的阻塞时间和范围。\n六、消息最终一致性 利用消息中间件的ack机制来实现\n服务a必须确保消息发送到mq 服务b消费完成必须要签收消息 服务b的消息可能会被重复收到,所以服务b必须做幂等性保证 七、最大努力通知 最大努力通知也是一种解决分布式事务的方案,以下是一个是充值的例\n有一定的消息重复通知机制:因为接收通知方可能没有接收到通知,此时要有一定的机制对消息重复通知 有消息校对机制:如果尽最大努力也没有通知到接收方,或者接收方消费消息后要再次消费,此时可由接收方主动向通知方查询消息 信息来满足需求 最大努力通知与可靠消息一致性区别 1)解决方案思想不同\n\t可靠消息一致性,发起通知方需要保证将消息发出去,并且将消息发到接收通知方,消息的可靠性关键由发起通知方来保证。最大努力通知,发起通知方尽最大的努力将业务处理结果通知为接收通知方,但是可能消息接收不到,此时需要接收通知方主动调用发起通知方的接口查询业务处理结果,通知的可靠性关键在接收通知方。\n2)两者的业务应用场景不同\n可靠消息一致性关注的是过程的事务一致,以异步的方式完成事务\n最大努力通知关注的是结果后的通知事务,即将结果可靠的通知出去\n3)技术解决方向不同\n可靠消息一致性要解决消息从发出到接收的一致性,即消息发出并且被接收到\n最大努力通知无法保证消息从发出到接收的一致性,只提供消息接收的可靠性机制。可靠机制是,最大努力的将消息通知给接收方,当消息无法被接收方接收时,由接收方主动查询消息(业务处理结果)\n最大努力通知的设计方案 方案一 ①、发起通知方将通知发给mq,使用普通消息机制将通知发给mq(不用保证消息一定到达)\n②、接收通知方监听 mq\n③、接收通知方接收消息,业务处理完成回应ack\n④、接收通知方若没有回应ack则mq会重复通知(通知时间间隔会变大)\n⑤、长时间没收到通知,接收通知方可通过消息校对接口来校对消息的一致性(弥补第①步)\n方案二 ①、发起通知方将通知发给mq。使用可靠消息一致方案中的事务消息保证本地事务与消息的原子性,最终确保将通知先发给mq\n②、通知程序监听 mq,接收mq的消息\n③、通知程序通过互联网接口协议(如http、webservice)调用接收通知方案接口,完成通知。通知程序调用接收通知方案接口成功就表示通知成功,即消费mq消息成功,发起通知发将不再向通知程序投递通知消息\n④、接收通知方可通过消息校对接口来校对消息的一致性\n方案一和方案二的区别 方案1中接收通知方与mq接口,即接收通知方案监听 mq,此方案主要应用与内部应用之间的通知 方案2中由通知程序与mq接口,通知程序监听mq,收到mq的消息后由通知程序通过互联网接口协议调用接收通知方。此方案主要应用于外部应用之间的通知,例如支付宝、微信的支付结果通知 八、汇总 分布式事务模式 介绍 at 模式 无侵入的分布式事务解决方案,适用于不希望对业务进行改造的场景,几乎0学习成本(sql都由框架托管统一执行,会存在脏写问题) tcc 模式 高性能分布式事务解决方案,适用于核心系统等对性能有很高要求的场景(第一阶段会产生行锁,事务执行太久会锁行很久) saga 模式 长事务解决方案,适用于业务流程长且需要保证事务最终一致性的业务系统(第一阶段就操作db,会存在脏读问题) xa模式 分布式强一致性的解决方案,但性能低而使用较少。 消息最终一致性 利用mq的ack机制实现,有侵入性,适合内部系统的数据流动 最大努力通知 需要消息接收方对消息处理进行保障,一般用于作为接入者对接第三方系统 ","date":"2021-02-02","permalink":"https://hobocat.github.io/post/database/2021-02-02-%E5%88%86%E5%B8%83%E5%BC%8F%E4%BA%8B%E5%8A%A1/","summary":"一、分布式事务基础 事务 指的就是一个操作单元,在这个操作单元中的所有操作最终要保持一致的行为,要么所有操作都成功,要么所有的操作都被撤销。 事务的4个特性 原子性(A","title":"分布式事务理论"},]
[{"content":"一、mongodb简介\u0026amp;安装 简介 \tmongodb是nosql数据库中的文档型数据库,文档型数据库与关系型最为接近。它支持的数据结构非常松散,是类似json的bson格式,因此可以存储比较复杂的数据类型。mongodb具有便捷和丰富的查询手段,高可用(主备)的特性,横向扩展(sharding)的能力,并支持多个存储引擎(wiredtiger、mmap)等优秀特性。\n单节点安装 第一步:安装依赖\n1 2 3 yum install -y make yum install -y gcc-c++ yum install -y openssl 第二步:tar包解压缩\n1 2 tar -zxvf mongodb-linux-x86_64-rhel[version].tgz -c /opt/module/ mv /opt/module/mongodb-linux-x86_64-rhel[version] /opt/module/mongodb 第三步:目录\n1 2 3 4 5 # 创建数据存储目录 mkdir -p /opt/module/mongodb/data # 创建日志存储目录 mkdir -p /opt/module/mongodb/logs touch /opt/module/mongodb/logs/mongodb.log 第四步:单节点启动\n1 2 3 4 5 6 7 8 9 10 11 12 # 方式一:后台启动方式 --fork,否则是个前台进程 ./mongod --dbpath=/opt/module/mongodb/data --logpath=/opt/module/mongodb/logs/mongodb.log --bind_ip_all --fork [--logappend] # 方式二:配置文件启动 mkdir -p /opt/module/mongodb/conf vim /opt/module/mongodb/conf/mongodb.conf # logpath=/opt/module/mongodb/logs/mongodb.log # dbpath=/opt/module/mongodb/data # bind_ip_all=true # fork=true # logappend=true ./mongod -f /opt/module/mongodb/conf/mongodb.conf 第四步:关闭\n1 2 3 4 5 6 7 8 9 10 11 # 方式一:kill进程 ps -aux | grep mongod kill -9 [processid] # 方式二:命令关闭,关闭时必须指定数据存放位置 ./mongod --shutdown -dbpath=/opt/module/mongodb/data # 方式三:进入mongo客户端,使用函数关闭 ./mongo use admin db.shutdownserver() 二、基本概念 无模式数据库 \t很多nosql数据库有无模式的共同点。若要在关系型数据库中存储数据,首先必须定义模式,也就是用一种预定义结构向数据库说明要有哪些表格,表中有哪些列,每一列都存放何种类型的数据。必须先定义好模式,然后才能存放数据。\n\t相比之下,nosql数据库的数据存储就比较随意。键值数据库可以把任何数据存放在一个键的名下。文档数据库实际上也如此,因为它对所存储的文档结构没有限制。在列族数据库中,任意列里面都可以随意存放数据。你可以在图数据库中新增边,也可以随意向节点和边中添加属性。\nmongodb三要素 mongodb三要素与传统关系型数据库概念类比\n传统数据库 mongdb 解释说明 database database 数据库 table collection 数据库表/集合 row document 数据记录行/文档 column field 数据字段/域 index index 索引 table joins 表连接,mongodb不支持 primary key primary key 主键,mongodb自动将_id字段设置为主键 传统数据库的row与mongodb的document对比\nrow:每一行都是一样的字段,不可添加不可减少,也就说fields的个数在定义table的时候就已经声明完成的\ndocument: 它的每一个document都是独立的,同时也不是在创建collection的时候经声明完成的\nmongodb的数据类型 数据类型 描述 string 字符串,仅utf-8编码合法 integer 整型数值,根据服务器不同,可分为32位或64位 boolean 布尔值 double 双精度浮点数 array 用于将数组或列表或多个值存储为一个键 timestamp 时间戳 object 用于内嵌文档 null 用于创建空文档 symbol 符号。该数据类型基本上等同于字符串类型,但不同的是,它一般用于使用了特殊符号类型的语言 date 日期时间。用unix时间格式来存储日期 三、用户权限 \tmongodb作为时下最为热门的数据库,那么其安全验证也是必不可少的,否则一个没有验证的数据库暴露出去,任何人可随意操作,这将是非常危险的。我们可以通过使用为mongodb创建用户的方式来降低风险。\n权限名 描述 read 允许用户读取指定数据库 readwrite 允许用户读写指定数据库 dbadmin 允许用户在指定数据库中执行管理函数,如索引创建、删除,查看统计或访问system.profile useradmin 允许用户向system.users集合写入,可以在指定数据库里创建、删除和管理用户 clusteradmin 只在admin数据库中可用,赋予用户所有分片和复制集相关函数的管理权限 readanydatabase 只在admin数据库中可用,赋予用户所有数据库的读权限,除系统库的集合 readwriteanydatabase 只在admin数据库中可用,赋予用户所有数据库的读写权限,除系统库的集合 useradminanydatabase 只在admin数据库中可用,赋予用户所有数据库的useradmin权限,除系统库的集合 dbadminanydatabase 只在admin数据库中可用,赋予用户所有数据库的dbadmin权限,除系统库的集合 root 只在admin数据库中可用。超级账号,超级权限 创建用户 前置条件:在admin库下操作。如果配置auth=true启动参数则需要有权限的用户操作,否则先不配置此参数,创建完用户之后开启此参数,并重启服务。\n语法: db.createuser({ user: \u0026#34;\u0026lt;name\u0026gt;\u0026#34;, pwd: \u0026#34;\u0026lt;cleartext password\u0026gt;\u0026#34;, customdata: { \u0026lt;any object data\u0026gt; }, roles: [ { role: \u0026#34;\u0026lt;role\u0026gt;\u0026#34;, db: \u0026#34;\u0026lt;database\u0026gt;\u0026#34; }, ... ] }); user:新建用户名\npwd:新建用户密码\ncustomdata:存放一些用户相关的自定义数据,该属性也可忽略\nroles:数组类型,配置用户的权限\n示例: db.createuser({user:\u0026#39;root\u0026#39;,pwd:\u0026#39;root\u0026#39;,roles:[{role:\u0026#39;root\u0026#39;,db:\u0026#39;admin\u0026#39;}]}) 创建用户完成之后,配置auth=true启动参数\n登陆用户 前置条件:在admin库下操作\n语法: db.auth(\u0026#39;\u0026lt;username\u0026gt;\u0026#39;, \u0026#39;\u0026lt;password\u0026gt;\u0026#39;); 示例: db.auth(\u0026#39;root\u0026#39;,\u0026#39;root\u0026#39;); 查看用户信息 前置条件:在admin库下操作\nshow users db.system.users.find() 更新用户 前置条件:在admin库下操作\n语法: db.updateuser(\u0026#39;\u0026lt;username\u0026gt;\u0026#39;, {\u0026lt;新的用户数据对象\u0026gt;}); 示例: db.updateuser(\u0026#39;root\u0026#39;, {\u0026#39;pwd\u0026#39;:\u0026#39;123456\u0026#39;, \u0026#39;roles\u0026#39;:[{\u0026#39;role\u0026#39;:\u0026#39;root\u0026#39;, \u0026#39;db\u0026#39;:\u0026#39;admin\u0026#39;}]}); 修改用户密码函数 虽然更新用户函数也可以修改用户密码,mongodb也提供了独立修改密码的函数\n前置条件:在admin库下操作\n语法: db.changeuserpassword(\u0026#34;\u0026lt;newusername\u0026gt;\u0026#34;,\u0026#34;\u0026lt;newpassword\u0026gt;\u0026#34;) 示例: db.changeuserpassword(\u0026#39;root\u0026#39;, \u0026#39;123456\u0026#39;); 删除用户 前置条件:在admin库下操作\n语法: db.dropuser(\u0026#39;\u0026lt;username\u0026gt;\u0026#39;) 示例: db.dropuser(\u0026#39;root\u0026#39;); 四、database操作 创建数据库\n在mongodb中创建数据库的命令使用的是use命令。该命令有两层含义:\n切换到指定数据库 如果切换的数据库不存在,则创建该数据库 如果只创建数据库未在数据库中创建集合,则此创建为逻辑创建,在内存中,但并未在生成对应目录。使用查看数据库命令是扫描磁盘目录,所以无法看到\n查看数据库\nshow dbs show databases 删除数据库\n在mongodb中使用db.dropdatabase()函数来删除数据库。在删除数据库之前,需要切换到需要删除的数据库,执行即可\n示例: use test; db.dropdatabase(); 五、collection操作 mongodb中的集合是一组文档的集,相当于关系型数据库中的表\n创建集合\n在mongodb中,我们也可以不用创建集合,当我们插入一些数据时,会自动创建集合\n语法格式:db.createcollection(\u0026lt;collectionname\u0026gt;, \u0026lt;options\u0026gt;)\noptions可以是如下参数\n字段 类型 描述 capped 布尔 (可选),如果为 true,则创建固定集合,且必须指定 size 参数固定集合是指当达到最大值时,它会自动覆盖最早的文档 size 数值 (可选)为固定集合指定一个最大值(以字节计)。 如果 capped 为 true,也需要指定该字段。 max 数值 (可选)指定固定集合中包含文档的最大数量。 示例: db.createcollection(\u0026#39;testcollection\u0026#39;); db.createcollection(\u0026#39;testcollection\u0026#39;, {\u0026#39;capped\u0026#39;:true, \u0026#39;size\u0026#39;:2000000, \u0026#39;max\u0026#39;:1000}); 查看集合\n如果要查看已有集合,可以使用show collections或show tables命令\nshow collections; show tables; 查看集合详情\n如果要查看已有集合的详情,可以使用db.\u0026lt;collectionname\u0026gt;.stats()命令\n示例: db.testcollection.stats(); 删除集合\n需要先切换到需要删除集合所在的数据库,使用db.\u0026lt;collectionname\u0026gt;.drop()函数删除集合即可\n示例: db.testcollection.drop(); 六、document 操作 在mongodb中文档是指多个键及其关联的值有序地放置在一起就是文档,其实指的就是数据。mongodb中的文档的数据结构和json基本一样。所有存储在集合中的数据都是bson格式。bson是一种类似json的二进制形式的存储格式,是binary json的简称。\n新增文档 新增单一文档\ninsert函数\n语法:db.\u0026lt;collectionname\u0026gt;.insert(document)\n示例: db.user.insert({name: \u0026#39;张三\u0026#39;, nickname: \u0026#39;tom\u0026#39;, \u0026#39;age\u0026#39;: 18, course: [\u0026#39;java\u0026#39;, \u0026#39;spring\u0026#39;]}); save函数\n语法:db.\u0026lt;collectionname\u0026gt;.save(document)\n示例: db.user.save({name: \u0026#39;李四\u0026#39;, nickname: \u0026#39;jack\u0026#39;, \u0026#39;age\u0026#39;: 18, course: [\u0026#39;html\u0026#39;, \u0026#39;js\u0026#39;]}); insertone函数\n语法:db.\u0026lt;collectionname\u0026gt;.insertone(document)\n示例: db.user.insertone({name: \u0026#39;王五\u0026#39;, nickname: \u0026#39;king\u0026#39;, \u0026#39;age\u0026#39;: 20, course: [\u0026#39;java\u0026#39;, \u0026#39;js\u0026#39;]}); 批量新增文档\ninsert函数\n语法:db.\u0026lt;collectionname\u0026gt;.insert(documents)\n示例: db.user.insert([ {name: \u0026#39;张三\u0026#39;, nickname: \u0026#39;tom\u0026#39;, \u0026#39;age\u0026#39;: 18, course: [\u0026#39;java\u0026#39;, \u0026#39;spring\u0026#39;]}, {name: \u0026#39;李四\u0026#39;, nickname: \u0026#39;jack\u0026#39;, \u0026#39;age\u0026#39;: 18, course: [\u0026#39;html\u0026#39;, \u0026#39;js\u0026#39;]}, {name: \u0026#39;王五\u0026#39;, nickname: \u0026#39;king\u0026#39;, \u0026#39;age\u0026#39;: 20, course: [\u0026#39;java\u0026#39;, \u0026#39;js\u0026#39;]} ]); save函数\n语法:db.\u0026lt;collectionname\u0026gt;.save(documents)\n示例: db.user.save([ {name: \u0026#39;张三\u0026#39;, nickname: \u0026#39;tom\u0026#39;, \u0026#39;age\u0026#39;: 18, course: [\u0026#39;java\u0026#39;, \u0026#39;spring\u0026#39;]}, {name: \u0026#39;李四\u0026#39;, nickname: \u0026#39;jack\u0026#39;, \u0026#39;age\u0026#39;: 18, course: [\u0026#39;html\u0026#39;, \u0026#39;js\u0026#39;]}, {name: \u0026#39;王五\u0026#39;, nickname: \u0026#39;king\u0026#39;, \u0026#39;age\u0026#39;: 20, course: [\u0026#39;java\u0026#39;, \u0026#39;js\u0026#39;]} ]); insertmany函数\n语法:db.\u0026lt;collectionname\u0026gt;.save(documents)\n示例: db.user.insertmany([ {name: \u0026#39;张三\u0026#39;, nickname: \u0026#39;tom\u0026#39;, \u0026#39;age\u0026#39;: 18, course: [\u0026#39;java\u0026#39;, \u0026#39;spring\u0026#39;]}, {name: \u0026#39;李四\u0026#39;, nickname: \u0026#39;jack\u0026#39;, \u0026#39;age\u0026#39;: 18, course: [\u0026#39;html\u0026#39;, \u0026#39;js\u0026#39;]}, {name: \u0026#39;王五\u0026#39;, nickname: \u0026#39;king\u0026#39;, \u0026#39;age\u0026#39;: 20, course: [\u0026#39;java\u0026#39;, \u0026#39;js\u0026#39;]} ]); 查询文档 基础应用 findone函数用于查询集合中的一个文档\n语法:db.\u0026lt;collectionname\u0026gt;.findone({\u0026lt;query\u0026gt;}, {\u0026lt;projection\u0026gt;});\nquery:可选,代表查询条件。 projection:可选,代表查询结果的投影字段名。即查询结果需要返回哪些字段或不需要返回哪些字段。 示例: db.user.findone(); db.user.findone({name: \u0026#39;张三\u0026#39;}); db.user.findone({name: \u0026#39;张三\u0026#39;}, {name: 1, age: 1, _id: 0}); 投影时\n_id为1的时候,其他字段必须是1\n_id是0的时候,其他字段可以是0\n如果没有_id字段约束,多个其他字段必须同为0或同为1\nfind函数用于查询集合中的若干文档\n语法:db.\u0026lt;collectionname\u0026gt;.find({\u0026lt;query\u0026gt;}, {\u0026lt;projection\u0026gt;});\n示例: db.user.find(); db.user.find({name: \u0026#39;张三\u0026#39;}); db.user.find({name: \u0026#39;张三\u0026#39;}, {name: 1, age: 1, _id: 0}); 单条件逻辑运算符 操作 格式 范例 类似dbm语句 等于 {\u0026lt;key\u0026gt;:\u0026lt;value\u0026gt;}或\n{\u0026lt;key\u0026gt;:{$eq:\u0026lt;value\u0026gt;}} db.col.find({name: \u0026ldquo;张三\u0026rdquo;}) where name = \u0026lsquo;张三\u0026rsquo; 小于 {\u0026lt;key\u0026gt;:{$lt:\u0026lt;value\u0026gt;}} db.col.find({age: {$lt: 20}}) where age \u0026lt; 20 小于等于 {\u0026lt;key\u0026gt;:{$lte:\u0026lt;value\u0026gt;}} db.col.find({age: {$lte: 20}}) where age \u0026lt;= 20 大于 {\u0026lt;key\u0026gt;:{$gt:\u0026lt;value\u0026gt;}} db.col.find({age: {$gt: 10}}) where age \u0026gt; 10 大于等于 {\u0026lt;key\u0026gt;:{$gte:\u0026lt;value\u0026gt;}} db.col.find({age: {$gte: 10}}) where age \u0026gt;= 10 不等于 {\u0026lt;key\u0026gt;:{$ne:\u0026lt;value\u0026gt;}} db.col.find({age: {$ne: 20}}) where age != 20 多条件逻辑运算符 and条件\nmongodb的find()和findone()函数可以传入多个键(key),每个键(key)以逗号隔开,即常规sql的and条件\n示例: db.user.find({name: \u0026#39;张三\u0026#39;, age :18}); or条件\nmongodb的or条件语句使用了关键字$or,语法格式如下\n示例: db.user.find({$or: [{name: \u0026#39;张三\u0026#39;}, {age :18}]}); $type查询 在mongodb中根据字段的数量类型来查询数据使用$type操作符来实现\n语法:db.\u0026lt;collectionname\u0026gt;.find({\u0026lt;attr\u0026gt;:{$type:\u0026lt;typenum/typealias\u0026gt;}})\ntype number alias double 1 “double” string 2 “string” object 3 “object” array 4 “array” binary data 5 “bindata” objectid 7 “objectid” boolean 8 “bool” date 9 “date” null 10 “null” regular expression 11 “regex” javascript 13 “javascript” javascript (with scope) 15 “javascriptwithscope” 32-bit integer 16 “int” timestamp 17 “timestamp” 64-bit integer 18 “long” 示例: db.user.find({name: {$type: \u0026#39;string\u0026#39;}}); db.user.find({name: {$type: 2}}); 正则查询 mongodb中查询条件也可以使用正则表达式作为匹配约束\n语法:db.\u0026lt;collectionname\u0026gt;.find({\u0026lt;filedname\u0026gt;:\u0026lt;reg\u0026gt;/\u0026lt;option\u0026gt;})\noption的选项有\ni :不区分大小写以匹配大小写的情况 m:对于包含锚点的模式,将\\n视作每行,每行都进行匹配 x:设置x选项后,正则表达式中的非转义的空白字符将被忽略 s:允许点字符(.)匹配包括换行符在内的所有字符 示例: db.user.find({name: /^张/}); db.user.find({name: /三$/}); db.user.find({nickname: /t/i}); 分页查询 在mongodb中读取指定数量的数据记录,可以使用的limit方法,limit(\u0026lt;num\u0026gt;)方法接受一个数字参数,该参数指定读取的记录条数\n在mongodb中使用skip方法来跳过指定数量的文档,skip(\u0026lt;num\u0026gt;)方法同样接受一个数字参数作为跳过的文档条数\n示例: db.user.find().skip(5).limit(5); 排序 在 mongodb中使用sort方法对数据进行排序,sort(\u0026lt;param\u0026gt;) 可以通过参数指定排序的字段,并使用1和-1来指定排序的方式,其中1为升序排列,而 -1是用于降序排列。\n示例: db.user.find().sort({age:\u0026#39;asc\u0026#39;}) 更新文档 save更新文档 save()函数的作用是保存文档,如果文档存在则覆盖,如果文档不存在则新增。save()函数对文档是否存在的唯一判断标准是_id系统唯一字段是否匹配。所以使用save()函数实现更新操作,则必须提供_id字段数据\n示例: db.user.save({name:\u0026#34;赵六\u0026#34;}); -- 新增 db.user.save({\u0026#34;_id\u0026#34; : objectid(\u0026#34;6010c798fc86950278e5caac\u0026#34;),name:\u0026#34;赵六\u0026#34;, age: 22}); --更新 update更新文档 update()函数用于更新已存在的文档\n语法: db.\u0026lt;collectionname\u0026gt;.update( \u0026lt;query\u0026gt;, \u0026lt;update\u0026gt;, \u0026lt;upsert:boolean\u0026gt;, \u0026lt;multi:boolean\u0026gt; ) query:update的查询条件,类似sql的update更新语法内where后面的内容 update:update的对象和一些更新的操作符等,也可以理解为sql update查询内set后面的 upsert:可选,这个参数的意思是,如果不存在update的记录,是否插入这个document,true为插入,默认是false,不插入 multi:可选,mongodb 默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新。只有在表达式更新语法中才可使用。 在mongodb中的update是有两种更新方式,一种是覆盖更新,一种是表达式更新。\n覆盖更新:顾名思义,就是通过某条件,将新文档覆盖原有文档 表达式更新:这种更新方式是通过表达式来实现复杂更新操作,如:字段更新、数值计算、数组操作、字段名修改等 覆盖更新 示例: db.user.update({name: \u0026#39;张三\u0026#39;},{name: \u0026#39;张\u0026#39;}); 将会给第一条符合添加的数据覆盖,因为multi选项默认为false\n表达式更新 $inc\n作用:对一个数字字段的某个field增加value\n示例: db.user.update({name: \u0026#39;张三\u0026#39;},{$inc: {age: 1}}); $set\n作用:把文档中某个字段field的值设为value,如果field不存在,则增加新的字段并赋值为value\n示例: db.user.update({name: \u0026#39;张三\u0026#39;},{$set: {age: 20}}); $unset\n作用:删除某个字段field\n示例: db.user.update({name: \u0026#39;张三\u0026#39;},{$unset: {age: null}}); unset指定的字段后可以跟任何值,只是起占位作用\n$push\n作用:把value追加到field里。注:field只能是数组类型,如果field不存在,会自动插入一个数组类型\n示例: db.user.update({name: \u0026#39;张三\u0026#39;},{$push: {course: \u0026#39;vue\u0026#39;}}); $addtoset\n作用:加一个值到数组内,而且只有当这个值在数组中不存在时才增加\n示例: db.user.update({name: \u0026#39;张三\u0026#39;},{$addtoset: {course: \u0026#39;vue\u0026#39;}}); $pop\n删除数组内第一个值{$pop:{\u0026lt;field\u0026gt;:-1}}、删除数组内最后一个值{$pop:{\u0026lt;field\u0026gt;:1}}\n示例: db.user.update({name: \u0026#39;张三\u0026#39;},{$pop: {course: -1}}); $pull\n从数组field内删除所有等于指定值的值\n示例: db.user.update({name: \u0026#39;张三\u0026#39;},{$pull: {course: \u0026#39;vue\u0026#39;}}); $pullall\n用法同$pull一样,可以一次性删除数组内的多个值\n示例: db.user.update({name: \u0026#39;张三\u0026#39;},{$pullall: {course: [\u0026#39;vue\u0026#39;, \u0026#39;java\u0026#39;, \u0026#39;spring\u0026#39;]}}); $rename\n作用:对字段进行重命名。底层实现是先删除old_field字段,再创建new_field字段\n示例: db.user.update({name: \u0026#39;张三\u0026#39;},{$rename: {nickname: \u0026#39;nick\u0026#39;}}); 删除文档 deleteone函数\n作用:删除一个满足添加的数据\n语法:db.\u0026lt;collectionname\u0026gt;.deleteone({\u0026lt;query\u0026gt;})\ndb.user.deleteone({\u0026#39;name\u0026#39;:\u0026#39;张三\u0026#39;}); deletemany函数\n作用:删除所有满足添加的数据\n语法:db.\u0026lt;collectionname\u0026gt;.deletemany({\u0026lt;query\u0026gt;})\ndb.user.deletemany({\u0026#39;name\u0026#39;:\u0026#39;张三\u0026#39;}); 删除文档还有一个remove函数,但已过时,官方推荐用deleteone()和deletemany()函数来实现删除操作。且在4.0版本中,remove函数并不会真正的释放存储空间,需要使用db.repairdatabase()函数来释放存储空间。\n七、内置函数 aggregate函数 mongodb中聚合的方法使用aggregate\n语法:db.\u0026lt;collectionname\u0026gt;.aggregate(\u0026lt;agg_options\u0026gt;)\nagg_options:数组类型参数,传入具体的聚合表达式,此参数代表聚合规则,如计算总和、平均值、最大最小值等。\n求和$sum 语法:db.collectionname.aggregate([{\u0026quot;$group\u0026quot;:{\u0026quot;_id\u0026quot;:\u0026lt;field/null\u0026gt;, \u0026quot;\u0026lt;aggename\u0026gt;\u0026quot;:{\u0026quot;$sum\u0026quot;:\u0026quot;$\u0026lt;field\u0026gt;\u0026quot;}}}])\n$group:分组,代表聚合的分组条件 _id:分组的字段。相当于sql分组语法group by column中的column部分。如果根据某字段的值分组,则定义为_id:'$field'。如果不需要分组则为_id:null $sum:求和表达式。相当于sql中的sum函数 $\u0026lt;filed\u0026gt;:代表文档中的需要求和字段 示例: db.user.aggregate([{$group:{_id: null, sum_age: {$sum: \u0026#39;$age\u0026#39;}}}]); --不分组求和 db.user.aggregate([{$group:{_id: \u0026#39;$name\u0026#39;, sum_age: {$sum: \u0026#39;$age\u0026#39;}}}]); --以name分组之后求和 统计$sum 示例: db.user.aggregate([{$group:{_id: null, count: {\u0026#39;$sum\u0026#39;: 1}}}]); --不分组统计总数 db.user.aggregate([{$group:{_id: \u0026#39;$name\u0026#39;, count: {\u0026#39;$sum\u0026#39;: 1}}}]); --以name分组之后统计总数 最大值$max 示例: db.user.aggregate([{$group:{_id: null, count: {\u0026#39;$max\u0026#39;: \u0026#39;$age\u0026#39;}}}]); --不分组统计最大值 db.user.aggregate([{$group:{_id: \u0026#39;$name\u0026#39;, count: {\u0026#39;$max\u0026#39;: \u0026#39;$age\u0026#39;}}}]); --以name分组之后统计最大值 最小值$min 示例: db.user.aggregate([{$group:{_id: null, count: {\u0026#39;$min\u0026#39;: \u0026#39;$age\u0026#39;}}}]); --不分组统计最小值 db.user.aggregate([{$group:{_id: \u0026#39;$name\u0026#39;, count: {\u0026#39;$min\u0026#39;: \u0026#39;$age\u0026#39;}}}]); --以name分组之后统计最小值 平均值$avg 示例: db.user.aggregate([{$group:{_id: null, age_avg: {\u0026#39;$avg\u0026#39;: \u0026#39;$age\u0026#39;}}}]); --不分组统计平均值 db.user.aggregate([{$group:{_id: \u0026#39;$name\u0026#39;, age_avg: {\u0026#39;$min\u0026#39;: \u0026#39;$age\u0026#39;}}}]); --以name分组之后统计平均值 字符串拼接 语法:db.collection.aggregate([{\u0026quot;$project\u0026quot;:{\u0026quot;\u0026lt;result_name\u0026gt;\u0026quot;:{\u0026quot;$concat\u0026quot;:[\u0026quot;$\u0026lt;field\u0026gt;\u0026quot;,...]}}}])\n连接字段必须是字符串,否则报错\n$project:管道,进行字符串拼接处理,日期处理等操作的函数\n示例: db.user.aggregate([{$project: {\u0026#39;name-age\u0026#39;:{$concat:[\u0026#39;$name\u0026#39;, \u0026#39;-\u0026#39;, \u0026#39;$nickname\u0026#39;]}}}]); 字符串转大写 示例: db.user.aggregate([{$project: {nameupper:{$toupper:\u0026#39;$nickname\u0026#39;}}}]); 字符串转小写 示例: db.user.aggregate([{$project: {nameupper:{$tolower:\u0026#39;$nickname\u0026#39;}}}]); 截取字符串 示例: db.user.aggregate([{$project: {namesub:{$substr:[\u0026#39;$nickname\u0026#39;, 0, 3]}}}]); 日期格式化 示例: db.user.insert({\u0026#34;birthdate\u0026#34;:isodate(\u0026#39;2020-01-01t10:10:10.000z\u0026#39;)}) db.user.aggregate([{$project: {birth: {$datetostring: {format: \u0026#39;%y年%m月%d日 %h:%m:%s\u0026#39;, date: \u0026#39;$birthdate\u0026#39;}}}}]); 条件过滤 $match:匹配条件,放在前面,相当于sql中的where子句,代表聚合之前进行条件筛选。放在后面,相当于sql中的having子句。代表聚合之后进行条件筛选,只能筛选聚合结果,不能筛选聚合条件。\n示例: db.user.aggregate([{$match: {age: {$lt: 20}}},{$group:{_id: null, count: {$sum: 1}}}]); 八、运算符 在mongodb中,数学类型(int/long/double)和日期类型(date)可以做数学运行。日期只能做加减。\n加法\ndb.user.aggregate([{$project:{name: 1, new_age: {$add: [\u0026#39;$age\u0026#39;, 1]}}}]); 减法\ndb.user.aggregate([{$project:{name: 1, new_age: {$subtract: [\u0026#39;$age\u0026#39;, 1]}}}]); 乘法\ndb.user.aggregate([{$project:{name: 1, new_age: {$multiply: [\u0026#39;$age\u0026#39;, 1]}}}]); 除法\ndb.user.aggregate([{$project:{name: 1, new_age: {$divide: [\u0026#39;$age\u0026#39;, 1]}}}]); 取模\ndb.user.aggregate([{$project:{name: 1, new_age: {$mod: [\u0026#39;$age\u0026#39;, 2]}}}]); 九、索引 在mongodb3版本后,创建集合时默认为系统主键字段_id创建索引。且在关闭_id索引创建时会有警告提示。因为_id字段不创建索引,会导致secondary在同步数据时负载变高。\n创建索引 语法:db.\u0026lt;collectionname\u0026gt;.ensureindex(\u0026lt;keys\u0026gt;, \u0026lt;options\u0026gt;)\nkeys:用于创建索引的列及索引数据的排序规则。如:并升序索引db.\u0026lt;collectionname\u0026gt;.ensureindex({\u0026lt;keyname\u0026gt;:1})、降序索引db.\u0026lt;collectionname\u0026gt;.ensureindex({\u0026lt;keyname\u0026gt;:-1})\noptions:创建索引时可定义的索引参数。可选参数如下\n参数 类型 描述 background boolean 默认false。建索引过程会阻塞其它数据库操作,background可指定以后台方式创建索引 unique boolean 默认false。建立的索引是否唯一,指定为true创建唯一索引 name string 索引的名称。如果未指定默认生成\u0026lt;key\u0026gt;_\u0026lt;1/-1\u0026gt;的名称 sparse boolean 默认false,对文档中不存在的字段数据不启用索引 expireafterseconds integer 指定一个以秒为单位的数值,完成 ttl设定,设定索引的生存时间 如:db.\u0026lt;collectionname\u0026gt;.ensureindex({\u0026lt;key\u0026gt;:1}, {'background':true})\n查看索引 查看集合的索引信息\n语法:db.\u0026lt;collectionname\u0026gt;.getindexes()\n查看索引键\n语法:db.\u0026lt;collectionname\u0026gt;.getindexkeys()\n查看索引详情\n语法:db.\u0026lt;collectionname\u0026gt;.getindexspecs();\n查看索引占用空间\n语法:db.\u0026lt;collectionname\u0026gt;.totalindexsize([is_detail])\nis_detail为false则只显示索引的总大小,为true显示该集合中每个索引的大小及总大小\n删除指定索引\n语法:db.\u0026lt;collectionname\u0026gt;.dropindex('\u0026lt;indexname\u0026gt;')\n删除集合的所有自建索引\n语法:db.\u0026lt;collectionname\u0026gt;.dropindexes()\n此函数只删除自建索引,不会删除mongodb创建的_id索引\n重建索引\n在mongodb中使用reindex函数重建索引。重建索引可以减少索引存储空间,减少索引碎片,优化索引查询效率。一般在数据大量变化后,会使用重建索引来提升索引性能。\n语法:db.\u0026lt;collectionname\u0026gt;.reindex()\n索引类型 mongodb支持多种类型的索引,包括单字段索引、复合索引、多key索引、文本索引等,每种类型的索引有不同的使用场合\n单字段索引 db.\u0026lt;collectionname\u0026gt;.ensureindex({\u0026lt;field\u0026gt;:1});\n上述语句针对field创建了单字段索引,其能加速对此字段的各种查询请求,是最常见的索引形式。mongodb默认创建的id索引也是这种类型。\n交叉索引 为一个集合的多个字段分别建立索引,在查询的时候通过多个字段作为查询条件,这种情况称为交叉索引。\ndb.\u0026lt;collectionname\u0026gt;.ensureindex({\u0026lt;field_1\u0026gt;:1});\ndb.\u0026lt;collectionname\u0026gt;.ensureindex({\u0026lt;field_2\u0026gt;:1});\n交叉索引的查询效率较低,例如db.\u0026lt;collectionname\u0026gt;.find({\u0026lt;field_1\u0026gt;:\u0026lt;value_1\u0026gt;, \u0026lt;field_2\u0026gt;: \u0026lt;value_2\u0026gt;})。在使用时,当查询使用到多个字段的时候,尽量使用复合索引,而不是交叉索引\n复合|组合|聚合索引 针对多个字段联合创建索引,先按第一个字段排序,第一个字段相同的文档按第二个字段排序\ndb.\u0026lt;collectionname\u0026gt;.ensureindex({\u0026lt;field_1\u0026gt;:1, \u0026lt;field_2\u0026gt;:1})\n使用复合索引是需要注意最左前缀原则\n多key索引 当索引的字段为数组时,创建出的索引称为多key索引,多key索引会为数组的每个元素建立一条索引\n语法和建立一般索引一致db.\u0026lt;collectionname\u0026gt;.ensureindex( {\u0026lt;arrayfiled\u0026gt;: 1} )\n唯一索引 保证索引对应的字段不会出现相同的值,比如_id索引就是唯一索引。如果唯一索引所在字段有重复数据写入时,抛出异常\ndb.\u0026lt;collectionname\u0026gt;.ensureindex({\u0026lt;field_1\u0026gt;: 1}, {unique: true})\n部分索引 只针对符合某个特定条件的文档建立索引。部分索引就是带有过滤条件的索引,即索引只存在与某些文档之上\n如:db.\u0026lt;collectionname\u0026gt;.ensureindex({\u0026lt;field_1\u0026gt;: 1},{partialfilterexpression: {field_1: {$gt: \u0026lt;filtervalue\u0026gt;}}})\n只有当字段field_1大于指定的filtervalue才建立索引,且field_1查询值比filtervalue大时才生效\n部分索引只为集合中那些满足指定的筛选条件的文档创建索引。如果你指定的partialfilterexpression和唯一约束、那么唯一性约束只适用于满足筛选条件的文档。具有唯一约束的部分索引不会阻止不符合唯一约束且不符合过滤条件的文档的插入。\n查询计划 语法:db.\u0026lt;collectionname\u0026gt;.find(\u0026lt;findcontent\u0026gt;).explain()\nwinningplain.stage为collscan则为全表扫描,ixscan时使用了索引\n十、集群 复制集(replication set) mongodb的复制至少需要两个节点。其中一个是主节点,负责处理客户端请求,其余的都是从节点,负责复制主节点上的数据。建议提供仲裁节点,此节点不存储数据,作用是当主节点出现故障时,选举出某个备用节点成为主节点,保证mongodb的正常服务。客户端只需要访问主节点或从节点,不需要访问仲裁节点。\n主节点记录在其上的所有操作oplog(操作日志),从节点定期轮询主节点获取这些操作,然后对自己的数据副本执行这些操作,从而保证从节点的数据与主节点一致。\nmongodb各个节点常见的搭配方式为:一主一从一仲裁、一主多从一仲裁。\n环境准备 在一台主机上模拟使用单主机多端口的方式搭建复制集,1主2备1仲裁\n①、创建数据目录\n1 2 3 4 mkdir -p /opt/module/mongodb-replication-set/data/db-primary 主节点 mkdir -p /opt/module/mongodb-replication-set/data/db-s0 从节点 mkdir -p /opt/module/mongodb-replication-set/data/db-s1 从节点 mkdir -p /opt/module/mongodb-replication-set/data/db-arbiter 仲裁节点 ②、创建配置目录\n1 2 3 mkdir /opt/module/mongodb-replication-set/etc 创建配置目录 mkdir /opt/module/mongodb-replication-set/log 创建日志目录 mkdir /opt/module/mongodb-replication-set/pids 创建进程文件目录 ③、配置文件\n# primary配置 vim /opt/module/mongodb-replication-set/etc/mongo-primary.conf # 配置如下: dbpath=/opt/module/mongodb-replication-set/data/db-primary 数据库目录 logpath=/opt/module/mongodb-replication-set/log/primary.log 日志文件 pidfilepath=/opt/module/mongodb-replication-set/pids/primary.pid 进程描述文件 bind_ip_all=true directoryperdb=true 为数据库自动提供重定向 logappend=true 日志追加写入 replset=rs 复制集名称,一个复制集中的多个节点命名一致 port=37010 端口 oplogsize=10000 操作日志容量 fork=true 后台启动 # secondary-0配置 vim /opt/module/mongodb-replication-set/etc/mongo-s0.conf # 配置如下: dbpath=/opt/module/mongodb-replication-set/data/db-s0 logpath=/opt/module/mongodb-replication-set/log/secondary-0.log pidfilepath=/opt/module/mongodb-replication-set/pids/secondary-0.pid bind_ip_all=true directoryperdb=true logappend=true replset=rs port=37011 oplogsize=10000 fork=true # secondary-1配置 vim /opt/module/mongodb-replication-set/etc/mongo-s1.conf # 配置如下: dbpath=/opt/module/mongodb-replication-set/data/db-s1 logpath=/opt/module/mongodb-replication-set/log/secondary-1.log pidfilepath=/opt/module/mongodb-replication-set/pids/secondary-1.pid bind_ip_all=true directoryperdb=true logappend=true replset=rs port=37012 oplogsize=10000 fork=true # arbiter配置 vim /opt/module/mongodb-replication-set/etc/mongo-arbiter.conf # 配置如下: dbpath=/opt/module/mongodb-replication-set/data/db-arbiter logpath=/opt/module/mongodb-replication-set/log/db-arbiter.log pidfilepath=/opt/module/mongodb-replication-set/pids/db-arbiter.pid bind_ip_all=true directoryperdb=true logappend=true replset=rs port=37013 oplogsize=10000 fork=true 启动各节点 ①、启动\n1 2 3 4 bin/mongod --config /opt/module/mongodb-replication-set/etc/mongo-primary.conf bin/mongod --config /opt/module/mongodb-replication-set/etc/mongo-s0.conf bin/mongod --config /opt/module/mongodb-replication-set/etc/mongo-s1.conf bin/mongod --config /opt/module/mongodb-replication-set/etc/mongo-arbiter.conf ②、访问主节点\n1 bin/mongo --port 37010 ③、初始化复制集\nrs.initiate({ # 复制集命名,与配置文件对应 _id:\u0026#34;rs\u0026#34;, members:[ # _id:唯一标记,host:主机地址,priority:权重(数字越大优先级越高),arbiteronly:是否是仲裁节点 {_id:0,host:\u0026#34;127.0.0.1:37010\u0026#34;,priority:3}, {_id:1,host:\u0026#34;127.0.0.1:37011\u0026#34;,priority:1}, {_id:2,host:\u0026#34;127.0.0.1:37012\u0026#34;,priority:1}, {_id:3,host:\u0026#34;127.0.0.1:37013\u0026#34;,arbiteronly:true} ] }); ④、查看状态\nrs.status(); ④、查看当前连接节点是否是primary节点\nrs.ismaster(); 总结 当主节点宕机时,仲裁节点会根据配置信息中的权重值优先选举权重高的节点作为主节点继续提供服务。当宕机的主节点恢复后,复制集会恢复原主节点状态,临时主节点重新成为从节点。默认情况下直接连接从节点是无法查询数据的。因为从节点是不可读的。如果需要在从节点上读取数据,则需要在从节点控制台输入命令rs.slaveok([true|false])来设置。rs.slaveok()或rs.slaveok(true)代表可以在从节点上做读操作;rs.slaveok(false)代表不可在从节点上做读操作。\n分片集群(shard cluster) 在mongodb里面存在另一种集群,就是分片技术,可以满足mongodb数据量大量增长的需求。当mongodb存储海量的数据时,一台机器可能不足以存储数据,也可能不足以提供可接受的读写吞吐量。这时,我们就可以通过在多台机器上分割数据,使得数据库系统能存储和处理更多的数据。\nsharding方案将整个数据集拆分成多个更小的chunk,并分布在集群中多个mongod节点上,最终达到存储和负载能力扩容、压力分流的作用。在sharding架构中,每个负责存储一部分数据的mongod节点称为shard(分片),shard上分布的数据块称为chunk,collections可以根据shard key(称为分片键)将数据集拆分为多个chunks,并相对均衡的分布在多个shards上。\n各术语解释 shard\n用于存储实际的数据块,实际生产环境中一个shard server角色可由几台机器组个一个replica set承担,防止主机单点故障\nconfig server\nmongod实例,存储了整个clustermetadata,其中包括chunk信息。\nrouters\n前端路由,客户端由此接入,且让整个集群看上去像单一数据库,前端应用可以透明使用。\nshard key\n数据的分区根据shard key,对于每个需要sharding的collection,都需要指定shard key(分片键);分片键必须是索引字段或者为组合索引的左前缀;mongodb根据分片键将数据分成多个chunks,并将它们均匀分布在多个shards节点上。目前,mongodb支持两种分区算法:区间分区(range)和哈希(hash)分区。\nrange分区\n首先shard key必须是数字类型或字符串类型(字符串类型根据索引排序作为分裂依据),整个区间的上下边界分别为正无穷大、负无穷大,每个chunk覆盖一段子区间,即整体而言,任何shard key均会被某个特定的chunk所覆盖。区间均为左闭右开。每个区间均不会有重叠覆盖,且互相临近。当然chunk并不是预先创建的,而是随着chunk数据的增大而不断split。\nhash分区\n计算shard key的hash值(64位数字),并以此作为range来分区。hash值具有很强的散列能力,通常不同的shard key具有不同的hash值(冲突是有限的),这种分区方式可以将document更加随机的分散在不同的chunks上。\n搭建分片集群 在一台主机上模拟使用单主机多端口的方式搭建集群,两个复制集(1主1备1仲裁),三个配置服务器(1主2备),一个路由节点\n环境准备 # 分片0的3个节点的数据目录,rs复制集,1主1备1仲裁 mkdir -p /opt/module/mongodb-cluster/data/rs0/primary mkdir -p /opt/module/mongodb-cluster/data/rs0/slave mkdir -p /opt/module/mongodb-cluster/data/rs0/arbiter # 分片1的3个节点的数据目录,rs复制集,1主1备1仲裁 mkdir -p /opt/module/mongodb-cluster/data/rs1/primary mkdir -p /opt/module/mongodb-cluster/data/rs1/slave mkdir -p /opt/module/mongodb-cluster/data/rs1/arbiter # 配置服务器的3个节点的数据目录,rs复制集,1主2备 mkdir -p /opt/module/mongodb-cluster/data/cf/primary mkdir -p /opt/module/mongodb-cluster/data/cf/s0 mkdir -p /opt/module/mongodb-cluster/data/cf/s1 # 创建配置目录 mkdir -p /opt/module/mongodb-cluster/etc mkdir -p /opt/module/mongodb-cluster/log mkdir -p /opt/module/mongodb-cluster/pids 搭建shard # rs0的primary配置 vim /opt/module/mongodb-cluster/etc/rs0-primary.conf # 配置如下: shardsvr=true 代表当前节点是一个shard节点。 dbpath=/opt/module/mongodb-cluster/data/rs0/primary logpath=/opt/module/mongodb-cluster/log/rs0-primary.log pidfilepath=/opt/module/mongodb-cluster/pids/rs0-primary.pid bind_ip_all=true logappend=true replset=rs0 port=27010 oplogsize=10000 fork=true # rs0的secondary配置 vim /opt/module/mongodb-cluster/etc/rs0-slave.conf # 配置如下: dbpath=/opt/module/mongodb-cluster/data/rs0/slave logpath=/opt/module/mongodb-cluster/log/rs0-slave.log pidfilepath=/opt/module/mongodb-cluster/pids/rs0-slave.pid bind_ip_all=true shardsvr=true logappend=true replset=rs0 port=27011 oplogsize=10000 fork=true # rs0的arbiter配置 vim /opt/module/mongodb-cluster/etc/rs0-arbiter.conf # 配置如下: dbpath=/opt/module/mongodb-cluster/data/rs0/arbiter logpath=/opt/module/mongodb-cluster/log/rs0-arbiter.log pidfilepath=/opt/module/mongodb-cluster/pids/rs0-arbiter.pid bind_ip_all=true shardsvr=true logappend=true replset=rs0 port=27012 oplogsize=10000 fork=true # rs1的primary配置 vim /opt/module/mongodb-cluster/etc/rs1-primary.conf # 配置如下: shardsvr=true dbpath=/opt/module/mongodb-cluster/data/rs1/primary logpath=/opt/module/mongodb-cluster/log/rs1-primary.log pidfilepath=/opt/module/mongodb-cluster/pids/rs1-primary.pid bind_ip_all=true logappend=true replset=rs1 port=27020 oplogsize=10000 fork=true # rs1的secondary配置 vim /opt/module/mongodb-cluster/etc/rs1-slave.conf # 配置如下: dbpath=/opt/module/mongodb-cluster/data/rs1/slave logpath=/opt/module/mongodb-cluster/log/rs1-slave.log pidfilepath=/opt/module/mongodb-cluster/pids/rs1-slave.pid bind_ip_all=true shardsvr=true logappend=true replset=rs1 port=27021 oplogsize=10000 fork=true # rs1的arbiter配置 vim /opt/module/mongodb-cluster/etc/rs1-arbiter.conf # 配置如下: dbpath=/opt/module/mongodb-cluster/data/rs1/arbiter logpath=/opt/module/mongodb-cluster/log/rs1-arbiter.log pidfilepath=/opt/module/mongodb-cluster/pids/rs1-arbiter.pid bind_ip_all=true shardsvr=true logappend=true replset=rs1 port=27022 oplogsize=10000 fork=true 启动shard 1 2 3 4 5 6 bin/mongod --config etc/rs0-primary.conf bin/mongod --config etc/rs0-slave.conf bin/mongod --config etc/rs0-arbiter.conf bin/mongod --config etc/rs1-primary.conf bin/mongod --config etc/rs1-slave.conf bin/mongod --config etc/rs1-arbiter.conf 配置shard bin/mongo --port 27010 rs.initiate({ _id:\u0026#34;rs0\u0026#34;, members:[ {_id:0,host:\u0026#34;127.0.0.1:27010\u0026#34;,priority:2}, {_id:1,host:\u0026#34;127.0.0.1:27011\u0026#34;,priority:1}, {_id:3,host:\u0026#34;127.0.0.1:27012\u0026#34;,arbiteronly:true} ] }); bin/mongo --port 27020 rs.initiate({ _id:\u0026#34;rs1\u0026#34;, members:[ {_id:0,host:\u0026#34;127.0.0.1:27020\u0026#34;,priority:2}, {_id:1,host:\u0026#34;127.0.0.1:27021\u0026#34;,priority:1}, {_id:3,host:\u0026#34;127.0.0.1:27022\u0026#34;,arbiteronly:true} ] }); 搭建config server config server的复制集中不允许有单仲裁节点。复制集初始化命令中,不允许设置arbiteronly:true参数\n# config server的primary配置 vim /opt/module/mongodb-cluster/etc/cf-primary.conf # 配置如下: dbpath=/opt/module/mongodb-cluster/data/cf/primary logpath=/opt/module/mongodb-cluster/log/cf-primary.log pidfilepath=/opt/module/mongodb-cluster/pids/cf-primary.pid bind_ip_all=true logappend=true replset=cf port=27030 oplogsize=10000 fork=true configsvr=true 代表当前节点是一个配置服务节点 # config server的s0配置 vim /opt/module/mongodb-cluster/etc/cf-s0.conf # 配置如下: dbpath=/opt/module/mongodb-cluster/data/cf/s0 logpath=/opt/module/mongodb-cluster/log/cf-s0.log pidfilepath=/opt/module/mongodb-cluster/pids/cf-s0.pid bind_ip_all=true logappend=true replset=cf port=27031 oplogsize=10000 fork=true configsvr=true # config server的s1配置 vim /opt/module/mongodb-cluster/etc/cf-s1.conf # 配置如下: dbpath=/opt/module/mongodb-cluster/data/cf/s1 logpath=/opt/module/mongodb-cluster/log/cf-s1.log pidfilepath=/opt/module/mongodb-cluster/pids/cf-s1.pid bind_ip_all=true logappend=true replset=cf port=27032 oplogsize=10000 fork=true configsvr=true 启动config server bin/mongod --config etc/cf-primary.conf bin/mongod --config etc/cf-s0.conf bin/mongod --config etc/cf-s1.conf 配置config server bin/mongo --port 27030 rs.initiate({ _id:\u0026#34;cf\u0026#34;, members:[ {_id:0,host:\u0026#34;127.0.0.1:27030\u0026#34;,priority:2}, {_id:1,host:\u0026#34;127.0.0.1:27031\u0026#34;,priority:1}, {_id:3,host:\u0026#34;127.0.0.1:27032\u0026#34;,priority:1} ] }); 搭建router 生成环境中通常提供多个,使用keepalive和haproxy实现高可用。router不需要数据库目录,不需要配置dbpath。\nvim /opt/module/mongodb-cluster/etc/rt.conf # 配置如下: configdb=cf/127.0.0.1:27030,127.0.0.1:27031,127.0.0.1:27032 logpath=/opt/module/mongodb-cluster/log/rt.log pidfilepath=/opt/module/mongodb-cluster/pids/rt.pid port=27040 fork=true bind_ip_all=true 启动router 注意使用的是mongos命令\n1 bin/mongos --config etc/rt.conf 配置router # 连接 bin/mongo --port 27040 # 进入admin库 use admin # 加入分片信息 db.runcommand({\u0026#39;addshard\u0026#39;:\u0026#39;rs0/127.0.0.1:27010,127.0.0.1:27011,127.0.0.1:27012\u0026#39;}); db.runcommand({\u0026#39;addshard\u0026#39;:\u0026#39;rs1/127.0.0.1:27020,127.0.0.1:27021,127.0.0.1:27022\u0026#39;}); 开启shard 首先需要将database开启sharding,否则数据仍然无法在集群中分布。即数据库、collection默认为non-sharding。对于non-sharding的database或者collection均会保存在primary shard上,直到开启sharding才会在集群中分布。\n# 创建测试库 use test # 开启shard,开启分片命令必须在admin库下运行。 use admin db.runcommand({ enablesharding: \u0026#39;test\u0026#39;}) # collection开启sharding,在此之前需要先指定shard key和建立\u0026#34;shard key索引\u0026#34; use test db.users.ensureindex({\u0026#39;_id\u0026#39;:\u0026#39;hashed\u0026#39;}); db.runcommand({ shardcollection: \u0026#39;test.users\u0026#39;, key: {\u0026#39;_id\u0026#39;: \u0026#39;hashed\u0026#39;}}) # users集合将使用\u0026#34;_id\u0026#34;作为第一维shard key,采用hashed分区模式,可以通过sh.status()查看每个chunk的分裂区间 sh.status() 在gridfs开启shard\ndb.runcommand( { shardcollection : \u0026#34;test.fs.chunks\u0026#34; , key : { files_id : 1 } } ) # 在gridfs中,对chunks集合进行分片时,只有两个片键可以选择,{ files_id : 1 , n : 1 } 与 { files_id : 1 } 十一、spring data mongodb 第一步:引入依赖\n1 2 3 4 \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;org.springframework.boot\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;spring-boot-starter-data-mongodb\u0026lt;/artifactid\u0026gt; \u0026lt;/dependency\u0026gt; 第二步:配置yaml\n1 2 3 4 5 6 7 8 9 10 spring: data: mongodb: database: test host: 192.168.22.161 port: 27017 # 如果需要认证需要下面三行 authentication-database: admin password: root username: root 第三步:建立实体类\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 @document @data // 如果是集群模式需要指定shard @sharded(shardkey = {\u0026#34;_id\u0026#34;}, shardingstrategy = shardingstrategy.hash) public class student { // 指定id,如果是string或者objectid可自动生成id // 注意string使用自动生成时更新操作无法进行 @mongoid private objectid id; // 如果字段名和数据库名称不一致需要指定 @field(name = \u0026#34;name\u0026#34;) private string name; private integer age; private boolean isman; private list\u0026lt;string\u0026gt; course; } 创建文档 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 // 添加文档 public void adddocument(){ student student = new student(); student.setname(\u0026#34;kun\u0026#34;); student.setage(18); student.setisman(true); student res = mongotemplate.insert(student); // id不存在时save可用于新增文档 // student res = mongotemplate.save(student); system.out.println(res); } // 批量添加文档 public void adddocuments(){ list\u0026lt;student\u0026gt; students = new arraylist\u0026lt;\u0026gt;(); student student = new student(); student.setname(\u0026#34;kun\u0026#34;); student.setage(18); student.setisman(true); student.setcourse(arrays.aslist(\u0026#34;spring\u0026#34;, \u0026#34;java\u0026#34;, \u0026#34;mysql\u0026#34;)); students.add(student); student = new student(); student.setname(\u0026#34;jack\u0026#34;); student.setage(18); student.setisman(true); student.setcourse(arrays.aslist(\u0026#34;php\u0026#34;, \u0026#34;mysql\u0026#34;)); students.add(student); student = new student(); student.setname(\u0026#34;lily\u0026#34;); student.setage(16); student.setisman(false); student.setcourse(arrays.aslist(\u0026#34;vue\u0026#34;, \u0026#34;php\u0026#34;)); students.add(student); student = new student(); student.setname(\u0026#34;jane\u0026#34;); student.setage(18); student.setisman(false); student.setcourse(arrays.aslist(\u0026#34;html\u0026#34;, \u0026#34;js\u0026#34;)); students.add(student); mongotemplate.insertall(students); } 更新文档 使用save修改(覆盖更新)\n1 2 3 4 5 6 7 8 9 public void saveupdatedocument(){ student student = new student(); student.setid(new objectid(\u0026#34;601253d33f108b62de913d54\u0026#34;)); student.setname(\u0026#34;kun\u0026#34;); student.setage(20); // id存在时save可用于更新文档 student res = mongotemplate.save(student); system.out.println(res); } 使用运算符实现(表达式更新)\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 public void expressupdatedocument(){ // 查询对象 query query = new query(); criteria criteria = criteria.where(\u0026#34;name\u0026#34;).is(\u0026#34;kun\u0026#34;); query.addcriteria(criteria); // 更新字段 update update = new update(); update.inc(\u0026#34;age\u0026#34;, 1); // updatefirst为更新第一个匹配文档 updateresult updateresult = mongotemplate.updatemulti(query, update, student.class); system.out.println(updateresult.getmodifiedcount()); } 删除文档 根据主键删除\n1 2 3 4 5 6 public void deletedocument(){ student student = new student(); student.setid(new objectid(\u0026#34;601253d33f108b62de913d54\u0026#34;)); deleteresult deleteresult = mongotemplate.remove(student); system.out.println(deleteresult.getdeletedcount()); } 根据条件进行删除\n1 2 3 4 5 public void deletedocumentbycondition(){ criteria criteria = criteria.where(\u0026#34;name\u0026#34;).is(\u0026#34;kun\u0026#34;); deleteresult deleteresult = mongotemplate.remove(query.query(criteria), student.class); system.out.println(deleteresult.getdeletedcount()); } 查询文档 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 // 查询全部文档 public void findall(){ list\u0026lt;student\u0026gt; students = mongotemplate.findall(student.class); } // 查询单个对象,如果有多个结果只返回第一个 public void findone(){ criteria criteria = criteria.where(\u0026#34;name\u0026#34;).is(\u0026#34;kun\u0026#34;); student student = mongotemplate.findone(query.query(criteria),student.class); } // 带有条件的查询多个 public void findbycondition(){ query query = new query(criteria.where(\u0026#34;age\u0026#34;).gte(3)); list\u0026lt;student\u0026gt; students = mongotemplate.find(query, student.class); } // 根据主键进行查询 public void findbyid(){ student student = mongotemplate.findbyid(new objectid(\u0026#34;601266467bb99058c4fc58d6\u0026#34;), student.class); } // 根据字段是否为空进行查询 public void findbyisnull(){ query query = new query(criteria.where(\u0026#34;course\u0026#34;).exists(true)); list\u0026lt;student\u0026gt; students = mongotemplate.find(query, student.class); } // 根据正则查询 public void findbyreg(){ criteria criteria = criteria.where(\u0026#34;name\u0026#34;).regex(\u0026#34;.*n$\u0026#34;); list\u0026lt;student\u0026gt; students = mongotemplate.find(query.query(criteria), student.class); } // 多条件查询 public void findbymultiandcondition(){ criteria criteria = new criteria(); criteria agecriteria = criteria.where(\u0026#34;age\u0026#34;).lt(20); criteria ismancriteria = criteria.where(\u0026#34;isman\u0026#34;).is(false); criteria.andoperator(agecriteria, ismancriteria); list\u0026lt;student\u0026gt; students = mongotemplate.find(query.query(criteria), student.class); } public void findbymultiorcondition(){ criteria criteria = new criteria(); criteria agecriteria = criteria.where(\u0026#34;age\u0026#34;).lt(20); criteria ismancriteria = criteria.where(\u0026#34;isman\u0026#34;).is(true); criteria.oroperator(agecriteria, ismancriteria); list\u0026lt;student\u0026gt; students = mongotemplate.find(query.query(criteria), student.class); students.stream().foreach(system.out::println); } // 查询去重复结果 public void finddistinct(){ // 第一个参数: 查询条件query // 第二个参数: 根据哪个属性去重复 // 第三个参数: 属性所在实体类 // 第四个参数: 属性的类型,此类型作为结果中list集合的泛型 list\u0026lt;integer\u0026gt; ages = mongotemplate.finddistinct(new query(), \u0026#34;age\u0026#34;, student.class, integer.class); } // 结果排序 public void findsort(){ query query = new query(); query.with(sort.by(sort.direction.desc, \u0026#34;age\u0026#34;)); list\u0026lt;student\u0026gt; students = mongotemplate.find(query, student.class); } // 结果分页 public void findpage(){ query query = new query(); // 第一个参数page,从0开始 // 第二个参数size query.with(pagerequest.of(1, 2)); list\u0026lt;student\u0026gt; students = mongotemplate.find(query, student.class); } 聚合操作 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 // 统计总数 public void aggcount(){ typedaggregation\u0026lt;student\u0026gt; aggregation = typedaggregation.newaggregation( student.class, aggregation.group().count().as(\u0026#34;count\u0026#34;)); aggregationresults\u0026lt;map\u0026gt; results = mongotemplate.aggregate(aggregation, map.class); system.out.println(results.getuniquemappedresult()); system.out.println(results.getuniquemappedresult().get(\u0026#34;count\u0026#34;)); } // 分组统计总数 public void aggcountbygroup() { typedaggregation\u0026lt;student\u0026gt; aggregation = typedaggregation.newaggregation( student.class, aggregation.group(\u0026#34;name\u0026#34;).count().as(\u0026#34;count\u0026#34;)); aggregationresults\u0026lt;map\u0026gt; results = mongotemplate.aggregate(aggregation, map.class); // 返回的_id 代表分组字段,如果字段有多个则_id为map(key为字段名,value为值) for (map mappedresult : results.getmappedresults()) { system.out.println(mappedresult.get(\u0026#34;_id\u0026#34;) + \u0026#34; - \u0026#34; + mappedresult.get(\u0026#34;count\u0026#34;)); } } // 具有条件的分组 public void aggcount() { typedaggregation\u0026lt;student\u0026gt; aggregation = typedaggregation.newaggregation( student.class, aggregation.match(criteria.where(\u0026#34;age\u0026#34;).gt(16)), aggregation.group().count().as(\u0026#34;count\u0026#34;)); aggregationresults\u0026lt;map\u0026gt; results = mongotemplate.aggregate(aggregation, map.class); system.out.println(results.getuniquemappedresult().get(\u0026#34;count\u0026#34;)); } gridfs操作 girdfs是mongodb提供的用于持久化存储文件的模块。在gridfs存储文件是将文件分块存储,文件会按照256kb的大小分割成多个块进行存储,gridfs使用两个集合(collection)存储文件,从gridfs中读取文件要对文件的各各块进行组装、合并。\n一个集合是chunks,用于存储文件的二进制数据 一个集合是files,用于存储文件的元数 据信息(文件名称、块大小、上传时间等信息) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 // 上传文件 public void gridfsupload() throws filenotfoundexception { //选择要存储的文件 file file = new file(\u0026#34;c:\\\\users\\\\kun\\\\desktop\\\\tim截图.png\u0026#34;); inputstream inputstream = new fileinputstream(file); //存储文件并起名称 objectid objectid = gridfstemplate.store(inputstream, \u0026#34;tim截图.png\u0026#34;); string id = objectid.tostring(); //获取到文件的id,可以从数据库中查找 system.out.println(id); } // 查询下载文件 public void queryfile() throws ioexception { // 根据id查找文件 // gridfsfile gridfsfile = gridfstemplate.findone( // new query(criteria.where(\u0026#34;_id\u0026#34;).is(\u0026#34;60136de452d6203936d1b035\u0026#34;))); gridfsfile gridfsfile = gridfstemplate.findone( new query(criteria.where(\u0026#34;filename\u0026#34;).is(\u0026#34;tim截图.png\u0026#34;))); //打开下载流对象 gridfsdownloadstream gridfs = gridfsbucket.opendownloadstream(gridfsfile.getobjectid()); //创建gridfssource,用于获取流对象 gridfsresource gridfsresource = new gridfsresource(gridfsfile,gridfs); file file = new file(\u0026#34;d:\\\\\u0026#34; + gridfsresource.getfilename()); ioutil.copy( gridfsresource.getinputstream(), new fileoutputstream(file)); } //删除文件 @test public void delfile() throws ioexception { //根据文件id删除fs.files和fs.chunks中的记录 gridfstemplate.delete(query.query(criteria.where(\u0026#34;_id\u0026#34;).is(\u0026#34;6013678f7d212159fe3a0a64\u0026#34;))); } ","date":"2021-01-29","permalink":"https://hobocat.github.io/post/nosql/2021-01-29-mongodb/","summary":"一、MongoDB简介\u0026amp;安装 简介 MongoDB是NoSQL数据库中的文档型数据库,文档型数据库与关系型最为接近。它支持的数据结构非常松散,是类似jso","title":"mongodb使用详解"},]
[{"content":"一、kubernetes 概述 基本介绍 kubernetes简称k8s,是用8代替\u0026quot;ubernete\u0026quot;而成的缩写。是一个开源的用于管理云平台中多个主机上的容器化的应用。kubernetes的目标是让部署容器化的应用简单并且高效(powerful),kubernetes 提供了应用部署,规划,更新,维护的一种机制。\n功能 自动装箱:基于容器对应用运行环境的资源配置要求自动部署应用容器 自我修复:当容器终止运行时会对容器进行重启。当node节点有问题时会对容器进行重新部署和重新调度 水平扩展:通过简单的命令、用户ui界面或基于cpu等资源使用情况,对应用容器进行规模扩大或规模剪裁 服务发现:用户不需使用额外的服务发现机制,就能够基于kubernetes自身能力实现服务发现和负载均衡 滚动更新:可以根据应用的变化,对应用容器运行的应用,进行一次性或批量式更新 版本回退:可以根据应用部署情况,对应用容器运行的应用,进行历史版本即时回退 密钥和配置管理:在不需要重新构建镜像的情况下,可以部署和更新密钥和应用配置,类似热部署 存储编排:自动实现存储系统挂载及应用,特别对有状态应用实现数据持久化非常重要存储系统可以来自于本地目录、网络存储(nfs、gluster、ceph 等)、公共云存储服务 批处理:提供一次性任务,定时任务调度 架构 master node:k8s 集群控制节点对集群进行调度管理,接受集群外用户的集群操作请求。master node由api server、scheduler、clusterstate store(etcd 数据库)和controller mangerserver所组成 worker node:集群工作节点,运行用户业务应用容器。worker node包含kubelet、kube proxy和containerruntime;\n二、kubernetes 搭建 一般采用kubeadm方式,二进制安装无法纳入容器管理,不能自愈\n第一步:系统初始化\n关闭防火墙\n1 2 3 4 # 临时关闭 systemctl stop firewalld # 永久关闭 systemctl disable firewalld 关闭selinux\n1 2 3 4 # 临时关闭 setenforce 0 # 永久关闭 sed -i \u0026#39;s/enforcing/disabled/\u0026#39; /etc/selinux/config 关闭swap\n1 2 3 4 # 临时关闭 swapoff -a # 永久关闭 sed -ri \u0026#39;s/.*swap.*/#\u0026amp;/\u0026#39; /etc/fstab 设置主机名\n1 hostnamectl set-hostname \u0026lt;hostname\u0026gt; 节点添加主机映射\n1 2 3 4 5 cat \u0026gt;\u0026gt; /etc/hosts \u0026lt;\u0026lt; eof 192.168.22.165 centos165 192.168.22.166 centos166 192.168.22.167 centos167 eof 将桥接的ipv4流量传递到iptables的链\n1 2 3 4 5 6 7 cat \u0026gt; /etc/sysctl.d/k8s.conf \u0026lt;\u0026lt; eof net.bridge.bridge-nf-call-ip6tables = 1 net.bridge.bridge-nf-call-iptables = 1 eof # 生效 sysctl --system 时间同步\n1 2 yum install ntpdate -y ntpdate time.windows.com 开启ipvs\n1 2 3 4 5 6 7 8 9 10 11 12 13 yum install -y ipvsadm modprobe br_netfilter cat \u0026gt; /etc/sysconfig/modules/ipvs.modules \u0026lt;\u0026lt;eof #!/bin/bash modprobe -- ip_vs modprobe -- ip_vs_rr modprobe -- ip_vs_wrr modprobe -- ip_vs_sh modprobe -- nf_conntrack_ipv4 eof chmod 755 /etc/sysconfig/modules/ipvs.modules \u0026amp;\u0026amp; bash /etc/sysconfig/modules/ipvs.modules \u0026amp;\u0026amp; lsmod | grep -e ip_vs -e nf_conntrack_ipv4 设置rsyslogd和systemd journald\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 #docker容器日志可以再 /var/log/containers查看 mkdir /var/log/journal #持久化保存日志的目录 mkdir /etc/systemd/journald.conf.d cat \u0026gt; /etc/systemd/journald.conf.d/99-prophet.conf \u0026lt;\u0026lt;eof [journal] #持久化保存到磁盘 storage=persistent #压缩历史日志 compress=yes syncintervalsec=5m ratelimitinterval=30s ratelimitburst=1000 #最大占用空间10g systemmaxuse=10g #单日志文件最大200m systemmaxfilesize=200m #日志保存时间2周 maxretentionsec=2week #不将日志转发到syslog forwardtosyslog=no eof systemctl restart systemd-journald 第二步:软件安装\n安装docker\n1 2 3 4 5 6 7 8 wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -o /etc/yum.repos.d/docker-ce.repo # 查看可安装的docker版本 yum list docker-ce --showduplicates | sort -r yum -y install docker-ce-[version] systemctl enable docker \u0026amp;\u0026amp; systemctl start docker 为docker添加阿里云镜像加速\n1 2 3 4 5 6 7 8 sudo mkdir -p /etc/docker sudo tee /etc/docker/daemon.json \u0026lt;\u0026lt;-\u0026#39;eof\u0026#39; { \u0026#34;registry-mirrors\u0026#34;: [\u0026#34;https://do6wervs.mirror.aliyuncs.com\u0026#34;] } eof sudo systemctl daemon-reload sudo systemctl restart docker 添加yum源\n1 2 3 4 5 6 7 8 9 10 cat \u0026gt; /etc/yum.repos.d/kubernetes.repo \u0026lt;\u0026lt; eof [kubernetes] name=kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64 enabled=1 gpgcheck=0 repo_gpgcheck=0 gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg eof 安装kubeadm,kubelet 和kubectl\n1 2 yum install -y kubelet kubeadm kubectl systemctl enable kubelet 第三步:部署kubernetes master\n初始化kubeadm\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 # pod-network-cidr必须为10.244.0.0/16,因为flannel使用此网段 kubeadm init \\ --apiserver-advertise-address=[masterip] \\ --image-repository registry.aliyuncs.com/google_containers \\ --kubernetes-version v1.20.1 \\ --service-cidr=10.96.0.0/12 \\ --pod-network-cidr=10.244.0.0/16 # 执行完成之后会有让执行的命令 # master节点执行的命令 # to start using your cluster, you need to run the following as a regular user: # mkdir -p $home/.kube # sudo cp -i /etc/kubernetes/admin.conf $home/.kube/config # sudo chown $(id -u):$(id -g) $home/.kube/config # then you can join any number of worker nodes by running the following on each as root: # worker节点执行的命令 # kubeadm join 192.168.22.165:6443 --token glkg5s.ae3ofk7bh1x2ot0e \\ # --discovery-token-ca-cert-hash # sha256:0cc790ef2d73484c78f4a10081da322b97f72b9d3a91999e3f76b0fd84d4c75c 执行完成之后让执行的命令\n1 2 3 4 5 mkdir -p $home/.kube sudo cp -i /etc/kubernetes/admin.conf $home/.kube/config sudo chown $(id -u):$(id -g) $home/.kube/config kubectl get nodes 第四步:安装pod 网络插件(cni)\n安装flannel【在master节点执行】,flannel作用\n1 kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/documentation/kube-flannel.yml 加入kubernetes node【在work节点执行】\n1 2 3 # 向集群添加新节点,执行在kubeadm init 输出的kubeadm join命令 kubeadm join 192.168.22.165:6443 --token glkg5s.ae3ofk7bh1x2ot0e \\ --discovery-token-ca-cert-hash sha256:0cc790ef2d73484c78f4a10081da322b97f72b9d3a91999e3f76b0fd84d4c75c 第五步:测试kubernetes 集群\n1 2 3 4 5 kubectl create deployment nginx --image=nginx kubectl expose deployment nginx --port=80 --type=nodeport kubectl get pod,svc # 访问地址:http://nodeip:port 三、kubernetes 组件介绍 pod 概念\n\tpod是k8s中可以创建和管理的最小单元,其他的资源对象都是用来支撑或者扩展pod对象功能的,比如controller对象是用来管控pod对象的,service或者ingress资源对象是用来暴露pod引用对象的,persistentvolume资源对象是用来为pod提供存储等等。k8s不会直接处理docker容器,而是操作pod。一个pod是由一个或多个docker容器组成。\n\t每一个pod都有一个特殊的被称为\u0026quot;根容器\u0026quot;的pause容器,其他容器则为业务容器。业务容器共享pause的网络栈和volume挂载卷\n特性\n1)资源共享\n一个pod里的多个容器可以共享存储和网络,可以看作一个逻辑的主机。共享的如namespace,cgroups或者其他的隔离资源\n2)生命周期短暂\npod属于生命周期比较短暂的组件,比如当pod所在节点发生故障,那么该节点上的pod会被调度到其他节点,但被重新调度的pod是一个全新的pod,跟之前的pod没有关系\n3)平坦的网络\nk8s集群中的所有pod都在同一个共享网络地址空间中,也就是说每个pod都可以通过其他pod的ip地址来实现访问\n分类\n1)普通pod\n普通pod一旦被创建,就会被放入到etcd中存储,随后会被kubernetes master调度到某个具体的node上并进行绑定,随后该pod对应的node上的kubelet进程实例化成一组相关的docker 容器并启动起来。\n2)静态pod\n静态pod是由kubelet进行管理的仅存在于特定node上的pod,它们不能通过api server进行管理,用户不能管理。\n创建pod的流程图\ncontroller replicationcontroller \u0026amp; replicaset \u0026amp; deployment\nreplicationcontroller用来确保容器应用的副本数始终保持在用户定义的副本数,即如果有容器异常退出,会自动创建新的pod来替代。而如果异常多出来的容器也会自动回收。在新版本中建议使用replicaset来取代replicationcontroller replicaset跟replicationcontroller没有本质的不同只是名字不一样,只是replicaset支持集合式的selector 虽然replicaset可以独立使用,但一般还是使用deployment来管理replicaset(比如replicaset不支持滚动升级)。deployment经典的应用场景: 定义deployment来创建pod和replicaset 滚动升级和回滚应用 扩容和缩容 暂停和继续deployment 水平自动伸缩仅适用于deployment和replicaset ,根据pod的metric扩缩容\nstatefulset\nstatefulset是为了解决有状态服务的问题(对应deployments 和replicasets是为无状态服务而设计),其应用场景包括:\n稳定的持久化存储。即pod重新调度后还是能访问到相同的持久化数据(基于pvc来实现) 稳定的网络标志。即pod重新调度后其podname和hostname不变,基于headless service(即没有cluster ip的service)实现 有序部署,有序扩展。即pod是有顺序的,在部署或者扩展的时候要依据定义的顺序依次依次进行(即从0 到 n-1,在下一个pod运行之前所有之前的pod必须都是running 和ready状态) 有序收缩,有序删除(即从n-1到 0) daemonset\ndaemonset确保全部或者一些node上运行一个pod的副本。当有node 加入集群时,也会为他们新增一个pod。当有node从集群移除时,这些pod也会被回收。删除daemonset 将会删除它创建的所有pod使用daemonset 的一些典型用法:\n运行集群存储daemon, 例如在每个node上运行glusterd、 ceph 在每个node上运行日志收集daemon, 例如fluentd、 logstash 在每个node上运行监控daemon, 例如prometheus node exporter job \u0026amp; cron job\njob负责批处理任务,即仅执行一次的任务,它保证批处理任务的一个或多个pod成功结束\ncron job管理基于时间的job,即在给定时间点只运行一次或周期性地在给定时间点运行\n容器网络通讯 flannel是coreos团队针对kubernetes设计的一个网络规划服务,简单来说它的功能是让集群中的不同节点主机创建的docker容器都具有全集群唯一的虚拟ip地址。而且它还能在这些ip地址之间建立一个覆盖网络(overlay network) ,通过这个覆盖网络,将数据包原封不动地传递到目标容器内\netcd之flannel作用说明:①存储管理flannel可分配的ip地址段资源;②建立维护pod节点路由表\n同一个pod内部通讯:同一个pod共享同一个网络命名空间,共享同一个linux协议栈\npod1与pod2不在同一台主机:pod的地址是与docker0在同一个网段的,但docker0网段与宿主机网卡是两个完全不同的ip网段,并且不同node之间的通信只能通过宿主机的物理网卡进行。将pod的ip和所在node的ip关联起来,通过这个关联让pod可以互相访问\npod1与pod2在同一台机器:由docker0 网桥直接转发请求至pod2,不需要经过flannel\npod至service的网络:目前基于性能考虑,全部为iptables 维护和转发\npod到外网:pod向外网发送请求,查找路由表,转发数据包到宿主机的网卡,宿主网卡完成路由选择后,iptables执行masquerade,把源ip更改为宿主网卡的ip, 然后向外网服务器发送请求\n**外网访问pod:**service\n四、命令 **kubectl create/apply **\n例:kubectl create deployment nginx-deployment \u0026ndash;image=nginx \u0026ndash;replicas=1\n kubectl apply -f nginx-deployment .yaml\n解释:使用nginx镜像创建一个pod,副本数为1,replicas默认为1\n**kubectl get node **\n例:kubectl get node -o wide\n解释:查看node节点信息\nkubectl get pod\n例:kubectl get pod -o wide \u0026ndash;namespace=default -w\n解释:查看default名称空间下pod详细信息\nkubectl get [all/deployment/rs/daemonset/job/cronjob/svc/pv/pvc/namespace]\n例:kubectl get deployment \u0026ndash;namespace=default\n解释:查看deployment控制器信息\nkubectl delete pods\n例:kubectl delete pods nginx-deployment\n解释:删除指定pod\nkubectl scale\n例:kubectl scale \u0026ndash;replicas=3 deployment/nginx-deployment\n解释:伸缩pod\nkubectl expose\n例:kubectl expose deployment nginx-deployment \u0026ndash;port=8888 \u0026ndash;target-port=80\n解释:创建一个service端口是8888代理容器端口80,并实现了负载均衡\nkubectl edit\n例:kubectl edit svc nginx-deployment\n解释:可修改pod的svc\nkubectl explain 【pod/jobs/persistentvolumes/\u0026hellip;】\n例:kubectl explain pod\n解释:查看资源清单可配置项目,可使用kubectl api-resource查看列出各项\nkubectl describe\n例:kubectl describe pod my-pod\n解释:查看指定pod的状态详情\nkubectl logs\n例:kubectl logs -f \u0026ndash;tail=20 my-pod -c init-myservice\n解释:查看指定pod的指定容器的日志\nkubectl exec\n例:kubectl exec readness-http-pod -c readness-http-pod -i -t \u0026ndash; bash\n解释:查看进入指定pod的指定容器\n五、资源清单 资源分类 名称空间级别\n工作负载型:pod、replicaset、deployment、statefulset、deamonset、job、cronjob\n服务发现及负载均衡资源:service、ingress\n配置与存储资源:volumn、csi【容器存储接口,用于扩展第三方存储】\n特殊类型的存储卷:configmap、secret、downwardapi\n集群级资源\nnamespace、node、role、clusterrole、rolebinding、clusterrolebinding\n元数据级别\nhpa、podtemplate、limitrange\n常用字段 必须存在的属性\n参数名 字段类型 说明 version string k8s api 的版本,目前基本是v1,可以用 kubectl api-version命令查询 kind string 这里指的是 yaml 文件定义的资源类型和角色, 比如: pod metadata object 元数据对象,固定值写 metadata metadata.name string 元数据对象的名字,这里由我们编写,比如命名pod的名字 metadata.namespace string 元数据对象的命名空间,由我们自身定义 spec object 详细定义对象,固定值写spec spec.container[] list 这里是spec对象的容器列表定义,是个列表 spec.container[].name string 这里定义容器的名字 spec.container[].image string 这里定义要用到的镜像名称 spec主要对象\n参数名 字段类型 说明 spec.containers[].name string 定义容器的名字 spec.containers[].image string 定义要用到的镜像的名称 spec.containers[].imagepullpolicy string 定义镜像拉取策略,有 always,never,ifnotpresent 三个值课选(1)always:默认值,意思是每次尝试重新拉取镜像(2)never:表示仅使用本地镜像 (3)ifnotpresent:如果本地有镜像就是用本地镜像,没有就拉取在 spec.containers[].command[] list 指定容器启动命令,因为是数组可以指定多个,不指定则使用镜像打包时使用的启动命令 spec.containers[].args[] list 指定容器启动命令参数,因为是数组可以指定多个 spec.containers[].workingdir string 指定容器的工作目录 spec.containers[].volumemounts[] list 指定容器内部的存储卷配置 spec.containers[].volumemounts[].name string 指定可以被容器挂载的存储卷的名称 spec.containers[].volumemounts[].mountpath string 指定可以被容器挂载的容器卷的路径 spec.containers[].volumemounts[].readonly string 设置存储卷路径的读写模式,true 或者 false,默认为读写模式 spec.containers[].ports[] list 指定容器需要用到的端口列表 spec.containers[].ports[].name string 指定端口名称 spec.containers[].ports[].containerport string 指定容器需要监听的端口号 spec.containers[].ports.hostport string 指定容器所在主机需要监听的端口号,默认跟上面 containerport 相同,注意设置了 hostport 同一台主机无法启动该容器的相同副本(因为主机的端口号不能相同,这样会冲突) spec.containers[].ports[].protocol string 指定端口协议,支持tcp和udp,默认值为tcp spec.containers[].env[] list 指定容器运行千需设置的环境变量列表 spec.containers[].env[].name string 指定环境变量名称 spec.containers[].env[].value string 指定环境变量值 spec.containers[].resources object 指定资源限制和资源请求的值(这里开始就是设置容器的资源上限) spec.containers[].resources.limits object 指定设置容器运行时资源的运行上限 spec.containers[].resources.limits.cpu string 指定cpu的限制,单位为 core 数,将用于 docker run \u0026ndash;cpu-shares 参数 spec.containers[].resources.limits.memory string 指定 mem 内存的限制,单位为 mib,gib spec.containers[].resources.requests object 指定容器启动和调度室的限制设置 spec.containers[].resources.requests.cpu string cpu请求,单位为 core 数,容器启动时初始化可用数量 spec.containers[].resources.requests.memory string 内存请求,单位为 mib,gib 容器启动的初始化可用数量 额外的参数项\n参数名 字段类型 说明 spec.restartpolicy string 定义pod重启策略,可以选择值为always、onfailure(1)always:默认,pod终止运行将被重启(2)onfailure:只有pod以非零退出码终止时,kubelet 才会重启该容器(3)never:pod终止后,kubelet将退出码报告给master,不会重启该pod spec.nodeselector object 定义node的label过滤标签,以key:value格式指定 spec.imagepullsecrets object 定义pull镜像是使用secret名称,以name:secretkey格式指定 spec.hostnetwork boolean 定义是否使用主机网络模式,默认值为false。设置true表示使用宿主机网络,不使用docker网桥,同时设置了true将无法在同一台宿主机上启动第二个副本 pod的生命周期 经历过程:①容器初始化环境;②运行容器的pause基础容器;③init c容器(init c可以有多个,串行运行);④main c启动主容器(启动之初允许执行一个执行命令或一个脚本,在结束的时候允许执行一个命令);⑤readless监控;⑥liveness监控\ninit c pod能够具有多个容器,应用运行在容器里面,但是它也可能有一个或多个先于应用容器启动的init容器\ninit容器与普通的容器非常像,除了如下两点:\ninit容器总是运行到成功完成为止 每个init容器都必须在下一个init容器启动之前成功完成,如果pod的init容器失败,kubernetes会不断地重启该pod,直到init容器成功为止。如果pod对应的restartpolicy 为never, 它不会重新启动 init c使用示例\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 apiversion: v1 kind: pod metadata: name: my-pod labels: app: my spec: containers: - name: my-container image: busybox:1.33.0 command: [\u0026#39;sh\u0026#39;, \u0026#39;-c\u0026#39;, \u0026#39;echo the app is running! \u0026amp;\u0026amp; sleep 3600\u0026#39;] initcontainers: - name: init-myservice image: busybox:1.33.0 # 寻找myservice域名解析,如果失败休息2s command: [\u0026#39;sh\u0026#39;, \u0026#39;-c\u0026#39;, \u0026#39;until nslookup myservice; do echo waiting for myservice; sleep 2; done;\u0026#39;] - name: init-mydb image: busybox:1.33.0 # 寻找mydb域名解析,如果失败休息2s command: [\u0026#39;sh\u0026#39;, \u0026#39;-c\u0026#39;, \u0026#39;until nslookup mydb; do echo waiting for mydb; sleep 2; done;\u0026#39;] --- apiversion: v1 kind: service metadata: name: myservice spec: ports: - protocol: tcp port: 80 targetport: 9376 --- apiversion: v1 kind: service metadata: name: mydb spec: ports: - protocol: tcp port: 80 targetport: 9366 在pod启动过程中,init容器会按顺序在网络和数据卷初始化【即pause容器】之后启动。每个容器必须在下一个容器启动之前成功退出,如果由于运行时或失败退出,将导致容器启动失败,它会根据pod的restartpolicy指定的策略进行重试\n在所有的init容器没有成功之前,pod将不会变成ready状态。init容器的端口将不会在service中进行聚集。正在初始化中的pod处于pending状态,但应该会将initializing 状态设置为true\n如果pod重启,所有init 容器必须重新执行\n对init容器spec 的修改被限制在容器image字段,修改其他字段都不会生效。更改image字段,等价于重启该pod\ninit容器具有应用容器的所有字段。除了readinessprobe,因为init容器无法定义不同于完成(completion)的就绪(readiness) 之外的其他状态。这会在验证过程中强制执行在pod中的每个app和init容器的名称必须唯一\n容器探针 探针是由kubelet对容器执行的定期诊断。kubelet调用由容器实现的handler即节点自动调用。\n类型\nexecaction: 在容器内执行指定命令,如果命令退出返回码为0则认为成功 tcpsocketaction:对指定端口上的容器的ip地址做tcp检查,如果端口打开则被认为成功 httpgetaction: 对指定端口和路径上的容器ip指定http get请求,如状态码大于等于200且小于400则被认为成功 方式\nlivenessprobe: 容器是否正在运行。如果存活探测失败,则kubelet会杀死容器并根据restarpolicy策略执行相应操作。如果容器不提供存活探针,默认状态为success readnessprobe: 容器是否准备好服务请求,如果失败,端点控制器从与pod匹配的所有service的端点中删除该pod的ip地址,初始延迟之前就绪状态为failure。如果容器不提供就绪探针,默认状态为success 探针使用示例\nreadnessprobe-httpgetaction联合使用\n如果nginx下存在readiness.html则就绪检测完成\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 apiversion: v1 kind: pod metadata: name: readness-http-pod spec: containers: - name: readness-http-pod image: nginx:1.19 imagepullpolicy: ifnotpresent readinessprobe: httpget: port: 80 path: /readiness.html initialdelayseconds: 1 periodseconds: 3 容器一直处于ready未就绪状态,当使用echo \u0026quot;page\u0026quot; \u0026gt;\u0026gt; readiness.html创建文件之后即可变为就绪状态\nlivenessprobe-execaction联合使用\n创建文件60秒之后删除,动态检测这个文件,如果文件不存则重启pod\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 apiversion: v1 kind: pod metadata: name: liveness-exec-pod namespace: default spec: containers: - name: liveness-exec-container image: nginx:1.19 imagepullpolicy: ifnotpresent command: [\u0026#34;/bin/sh\u0026#34;, \u0026#34;-c\u0026#34;, \u0026#34;touch /tmp/live; sleep 60; rm -f /tmp/live;sleep 3600\u0026#34;] livenessprobe: exec: command: [\u0026#34;test\u0026#34;, \u0026#34;-e\u0026#34;, \u0026#34;/tmp/live\u0026#34;] initialdelayseconds: 1 periodseconds: 3 livenessprobe-httpgetaction联合使用\n启动容器如果index.html无法访问则重启\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 apiversion: v1 kind: pod metadata: name: liveness-httpget-pod namespace: default spec: containers: - name: liveness-httpget-container image: nginx:1.19 imagepullpolicy: ifnotpresent livenessprobe: httpget: port: 80 path: /index.html initialdelayseconds: 1 periodseconds: 3 timeoutseconds: 10 livenessprobe-tcpsocketaction联合使用\n检测容器80端口是否打开,\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 apiversion: v1 kind: pod metadata: name: liveness-tcp-pod namespace: default spec: containers: - name: liveness-tcp-container image: nginx:1.19 imagepullpolicy: ifnotpresent restartpolicy: always livenessprobe: tcpsocket: port: 80 initialdelayseconds: 1 periodseconds: 3 timeoutseconds: 10 启动和退出动作 在容器启动前后可执行操作\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 apiversion: v1 kind: pod metadata: name: lifecycle spec: containers: - name: lifecycle-container image: nginx:1.19 lifecycle: # 启动后运行 poststart: exec: command: [\u0026#34;/bin/sh\u0026#34;,\u0026#34;-c\u0026#34;,\u0026#34;echo hello from the poststart handler\u0026gt; /usr/share/message\u0026#34;] # 退出前运行 prestop: exec: command: [\u0026#34;/bin/sh\u0026#34;,\u0026#34;-c\u0026#34;,\u0026#34;echo hello from the poststop handler\u0026gt; /usr/share/message\u0026#34;] 六、控制器 kubernetes中内建了很多controller (控制器),这些控制器相当于一个状态机,用来控制pod的具体状态和行为\nreplicationcontroller replicationcontroller (rc)用来确保容器应用的副本数始终保持在用户定义的副本数。即如果有容器异常退出,会自动创建新的pod来替代,而如果异常多出来的容器也会自动回收。\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 apiversion: apps/v1 kind: replicaset metadata: name: nginx-rs spec: replicas: 3 selector: matchlabels: tier: nginx-rs template: metadata: labels: tier: nginx-rs spec: containers: - name: nginx-container image: nginx:1.19 deployment deployment为pod和replicaset提供了一个声明式定义(declarative)方法,用来替代以前的replicationcontroller来方便的管理应用。\n定义deployment来创建pod和replicaset\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 apiversion: apps/v1 kind: deployment metadata: name: nginx-deployment spec: replicas: 3 # 保存回滚历史数,默认为10 revisionhistorylimit: 10 selector: matchlabels: tier: nginx-deployment template: metadata: labels: tier: nginx-deployment spec: containers: - name: nginx-container image: nginx:1.19 滚动升级和回滚应用\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 # 更改镜像版本,也可以使用kubectl edit deployment/nginx-deployment修改版本 kubectl set image deployment/nginx-deployment nginx-container=nginx:1.18 # 查看可回滚的版本,如果rs已经不存在,则历史版本也不存在 kubectl rollout history deployment/nginx-deployment # 回滚 kubectl rollout undo deployment/nginx-deployment [--to-revision=1] # 查看回滚状态 kubectl rollout status deployment/nginx-deployment # 查看当前deployments详细信息,内有rollingupdatestrategy更新策略,默认每次25% kubectl describe deployments 扩容和缩容\n1 kubectl scale deployment nginx-deployment --replicas=5 暂停和继续deployment\n1 2 3 4 5 # 暂停更新 kubectl rollout pause deployment/nginx-deployment # 继续更新 kubectl rollout resume deployment/nginx-deployment daemonset daemonset确保全部(或者一些)node上运行一个pod的副本。当有node加入集群时,也会为他们新增一个pod。当有node从集群移除时,这些pod也会被回收。删除daemonset将会删除它创建的所有pod使用daemonset的一些典型用法\n运行集群存储daemon,例如在每个node上运行glusterd、ceph 在每个node上运行日志收集daemon,例如fluentd、logstash 在每个node上运行监控daemon,例如prometheus node exporter、 collectd、 datadog代理、new relic代理,或ganglia gmond statefulset statefulset作为controller为pod提供唯一的标识。它可以保证部署和scale的顺序\nstatefulset是为了解决有状态服务的问题(对应deployments和replicasets是为无状态服务而设计) ,其应用场景包括:\n稳定的持久化存储,即pod重新调度后还是能访问到相同的持久化数据,基于pvc来实现 稳定的网络标志,即pod重新调度后其podname和hostname不变,基于headless service (即没有cluster ip的service)来实现 有序部署,有序扩展,即pod是有顺序的,在部或者扩展的时候要依据定义的顺序依次依次进行(即从到n-1,在下一个pod运行之前所有之前的pod必须都是running和ready状态),基于init containers来实现 有序收缩,有序删除(即从n-1到0) statefulset一半与pv/pvc联用,详细案例\njob/cronjob job负责批处理任务,即仅执行一次的任务, 它保证批处理任务的一个或多个pod成功结束。\njob.spec.template.spec.restartpolicy仅支持never或onfailure job.spec.completions标志job结束需要成功运行的pod个数,默认为1 job.spec.parallelism标志并运行的pod个数,默认为1 job.spec.activedeadlineseconds标志失败pod的重试最大时间,超过不继续重试 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 apiversion: batch/v1 kind: job metadata: name: pi-job spec: completions: 1 activedeadlineseconds: 3600 parallelism: 1 template: metadata: name: pi spec: restartpolicy: never containers: - name: pi-container image: perl:5.32.0 command: [\u0026#34;perl\u0026#34;, \u0026#34;-mbignum=bpi\u0026#34;, \u0026#34;-wle\u0026#34;, \u0026#34;print bpi(2000)\u0026#34;] cron job管理基于时间的job,原理是根据cron表达式调度job,可以在给定时间点只运行一次,也可以周期性地在给定时间点运行\ncronjob.spec.startingdeadlineseconds:启动job的期限(秒级别),该字段是可选的。如果因为任何原因而错过了被调度的时间,那么错过执行时间的job将被认为是失败的。如果没有指定,则没有期限。\ncronjob.spec.suspend:挂起,该字段是可选的。如果设置为true,后续所有执行都会被挂起。它对已经开始执行的job不起作用。默认值为false.\ncronjob.spec.concurrencypolicy:并发策略,该字段是可选的。它指定了如何处理被cron job创建的job的并发执行。\nallow(默认):允许并发运行job forbid:禁止井发运行,如果前一个还没有完成,则直接跳过下一个 replace:取消当前正在运行的job,用一个新的来替换 cronjob.spec.successfuljobshistorylimit和cronjob.spec.failedjobshistorylimit:历史限制,是可选的字段。它们指定了可以保留多少完成和失败的job。默认情况下,它们分别设置为3和1\n典型的用法如下所示:\n在给定的时间点调度job运行 创建周期性运行的job,例如:数据库备份、发送邮件 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 apiversion: batch/v1beta1 kind: cronjob metadata: name: hello-corn spec: concurrencypolicy: allow schedule: \u0026#34;*/1 * * * *\u0026#34; jobtemplate: spec: template: spec: containers: - name: hello-container image: busybox:1.33.0 args: - \u0026#34;/bin/sh\u0026#34; - \u0026#34;-c\u0026#34; - \u0026#34;date;echo hello from kubernetes cluster\u0026#34; restartpolicy: onfailure horizontal pod autoscaling 应用的资源使用率通常都有高峰和低谷的时候,如何削峰填谷,提高集群的整体资源利用率,让service中的pod个数自动调整呢?这就有赖于horizontal pod autoscaling了,顾名思义,使pod水平自动缩放。\n使用此功能需要先部署metrics-server 实现指标监控,部署方式详见\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 ########################### horizontalpodautoscaler/v1 扩容【仅限cpu指标】 ########################### apiversion: autoscaling/v1 kind: horizontalpodautoscaler metadata: name: nginx-autoscaling namespace: default spec: scaletargetref: apiversion: apps/v1 kind: deployment name: nginx-deployment minreplicas: 1 maxreplicas: 3 # cpu利用率超过50%扩容,基于pod设置的cpu request值进行计算,例如该值为200m,那么系统将维持pod的实际cpu使用值为100m。 targetcpuutilizationpercentage: 50 ########################### horizontalpodautoscaler/v2beta1 扩容 ########################### apiversion: autoscaling/v2beta1 kind: horizontalpodautoscaler metadata: name: nginx-autoscaling namespace: default spec: scaletargetref: apiversion: apps/v1 kind: deployment # 基于deployment进行扩缩 name: nginx-deployment # deployment名 minreplicas: 1 # 最小实例数 maxreplicas: 2 # 最大实例数 metrics: - type: resource resource: name: cpu targetaverageutilization: 50 # cpu阈值设定50% - type: resource resource: name: memory targetaveragevalue: 200mi # 内存设定200m - type: object object: metricname: requests-per-second target: apiversion: extensions/v1beta1 kind: ingress name: main-route targetvalue: 10k # 每秒请求量 --- # 若需要指标生效,需要一定注明该pod的request cpu和memory apiversion: apps/v1 kind: deployment metadata: name: nginx-deployment spec: replicas: 1 selector: matchlabels: tier: nginx-deployment template: metadata: labels: tier: nginx-deployment spec: containers: - name: nginx-container image: nginx:1.19 resources: # 软限制 requests: memory: 50mi cpu: 1500m #1000m为一个cpu # 硬限制 limits: memory: 100mi cpu: 2000m 七、service service的概念 service是一种抽象,它定义了一组pods的逻辑集合和一个用于访问它们的策略。\nservice的类型 clusterip,默认类型,自动分配一个仅cluster内部可以访问的虚拟ip\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 apiversion: apps/v1 kind: deployment metadata: name: nginx-deploy namespace: default spec: replicas: 3 selector: matchlabels: app: nginx-app template: metadata: labels: app: nginx-app spec: containers: - name: nginx-container image: nginx:1.19 imagepullpolicy: ifnotpresent --- apiversion: v1 kind: service metadata: name: nginx-service namespace: default spec: type: clusterip selector: app: nginx-app ports: - name: http # 自己想暴露出的端口 port: 30001 # 对应容器暴露的端口 targetport: 80 使用kubectl get svc可查看生成的随机ip,使用生产的随机ip加上指定的3001端口在集群内可访问 curl 随机ip:30001\nheadless service,有时不需要负载均衡,以及单独的service ip。这时可以通过指定spec.clusterlp的值为\u0026quot;none\u0026quot;来创建headless service。这类service并不会分配cluster ip,kube-proxy不会处理它们,而且平台也不会为它们进行负载均衡和路由\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 apiversion: apps/v1 kind: deployment metadata: name: nginx-deploy namespace: default spec: replicas: 3 selector: matchlabels: app: nginx-app template: metadata: labels: app: nginx-app spec: containers: - name: nginx-container image: nginx:1.19 imagepullpolicy: ifnotpresent --- apiversion: v1 kind: service metadata: name: nginx-service namespace: default spec: clusterip: none selector: app: nginx-app ports: - name: http # 自己想暴露出的端口 port: 30001 # 对应容器暴露的端口 nodeport,在clusterlp基础上为service在每台机器上绑定一个随机端口,这样就可以通过nodeport来访问该服务\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 apiversion: apps/v1 kind: deployment metadata: name: nginx-deploy namespace: default spec: replicas: 3 selector: matchlabels: app: nginx-app template: metadata: labels: app: nginx-app spec: containers: - name: nginx-container image: nginx:1.19 imagepullpolicy: ifnotpresent --- apiversion: v1 kind: service metadata: name: nginx-service namespace: default spec: type: nodeport selector: app: nginx-app ports: - name: http # 自己想暴露出的端口 port: 30001 # 对应容器暴露的端口 targetport: 80 会生成一个随机端口再次映射到指定端口,这是可以用\u0026quot;[集群任意主机ip]:随机端口\u0026quot;访问服务\nloadbalancer,loadbalancer和nodeport其实是同一种方式。区别在于loadbalancer比nodeport多了一步,就是可以调用云服务厂商去创建lb向节点导流,但是需要付费\nendpoint,是k8s集群中的一个资源对象,存储在etcd中,用来记录一个service对应的所有pod的访问地址\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 apiversion: v1 kind: endpoints apiversion: v1 metadata: #此名字需与service文件中的metadata.name的值一致 name: remote-mysql-endpoint namespace: default subsets: - addresses: # 真实的ip - ip: 192.168.22.1 # 随便写的公网ip - ip: 220.181.38.148 ports: - port: 3306 --- apiversion: v1 kind: service metadata: #此名字需与endpoints文件中的metadata.name的值一致 name: remote-mysql-endpoint namespace: default spec: ports: - port: 3306 以后可用随便写的那个公网ip代替真实ip进行访问,如果真实ip发生变化不影响程序。此种方式只适合ip访问,对于像阿里云等数据库的。需要用域名。则需要用externalname方式不而不是endpoints方式。\nexternalname,把集群外部的服务引入到集群内部中,适用于集群内部容器访问外部资源,没有任何类型代理被创建。\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 # 在集群任意的pod中使用external-name-service均会被解析为www.baidu.com # 即相当于创建了svc_name.namespace.svc.cluster.local到指定域名、ip的dns解析 kind: service apiversion: v1 metadata: name: external-name-service namespace: default spec: type: externalname externalname: www.baidu.com ports: - port: 80 protocol: tcp targetport: 80 使用external-name-service代替百度域名,可用于云数据库\ningress 管理对集群中的服务(通常是http)的外部访问的api对象。ingress可以提供负载平衡、ssl终端和基于名称的虚拟主机。\n安装\n1 2 3 4 5 6 7 8 9 10 11 12 13 # 安装nginx-controller # 复制 https://github.com/kubernetes/ingress-nginx/blob/nginx-0.30.0/deploy/static/mandatory.yaml kubectl apply -f mandatory.yaml # 复制https://github.com/kubernetes/ingress-nginx/blob/nginx-0.30.0/deploy/static/provider/baremetal/service-nodeport.yaml # 使用nodeport的方式暴露nginx-controller kubectl apply -f service-nodeport.yaml # 查看是否安装成功 kubectl get pods --all-namespaces -l app.kubernetes.io/name=ingress-nginx --watch # 查看nginx ingress controller暴露的端口 kubectl get svc -n ingress-nginx nginx-ingress原理图\nhttp代理访问\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 apiversion: apps/v1 kind: deployment metadata: name: nginx-deploy namespace: default spec: replicas: 3 selector: matchlabels: app: nginx-app template: metadata: labels: app: nginx-app spec: containers: - name: nginx-container image: nginx:1.19 imagepullpolicy: ifnotpresent --- # 最好创建的是无头svc apiversion: v1 kind: service metadata: name: nginx-service namespace: default spec: type: clusterip selector: app: nginx-app ports: - name: http port: 80 --- # 访问www.kun.com:[ingress映射端口]即可实现负载均衡的访问效果,可以匹配多个主机和多个service # 必须通过域名访问不能通过ip访问 apiversion: networking.k8s.io/v1 kind: ingress metadata: name: nginx-ingress spec: rules: - host: www.kun.com http: paths: - path: / pathtype: exact backend: service: name: nginx-service port: number: 80 https代理访问\n①、创建证书\n1 2 openssl req -x509 -sha256 -nodes -days 365 -newkey rsa:2048 -keyout tls.key -out tls.crt -subj \u0026#34;/cn=nginxsvc/0=nginxsvc\u0026#34; ②、创建secret\n1 kubectl create secret tls tls-secret --key tls.key --cert tls.crt ③、使用ingress\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 apiversion: apps/v1 kind: deployment metadata: name: nginx-deploy namespace: default spec: replicas: 3 selector: matchlabels: app: nginx-app template: metadata: labels: app: nginx-app spec: containers: - name: nginx-container image: nginx:1.19 imagepullpolicy: ifnotpresent --- # 最好创建的是无头svc apiversion: v1 kind: service metadata: name: nginx-service namespace: default spec: type: clusterip selector: app: nginx-app ports: - name: http port: 80 --- # 访问www.kun.com:[ingress映射端口]即可实现负载均衡的访问效果,可以匹配多个主机和多个service # 必须通过域名访问不能通过ip访问 apiversion: networking.k8s.io/v1 kind: ingress metadata: name: nginx-ingress spec: tls: # 要和下面的域名匹配 - hosts: - www.kun.com secretname: tls-secret rules: - host: www.kun.com http: paths: - path: / pathtype: exact backend: service: name: nginx-service port: number: 80 auth认证\n①、创建认证\n1 2 3 yum -y install httpd htpasswd -c auth [username] kubectl create secret generic basic-auth --from-file=auth ②、创建ingress\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 apiversion: apps/v1 kind: deployment metadata: name: nginx-deploy namespace: default spec: replicas: 3 selector: matchlabels: app: nginx-app template: metadata: labels: app: nginx-app spec: containers: - name: nginx-container image: nginx:1.19 imagepullpolicy: ifnotpresent --- # 最好创建的是无头svc apiversion: v1 kind: service metadata: name: nginx-service namespace: default spec: type: clusterip selector: app: nginx-app ports: - name: http port: 80 --- # 访问www.kun.com:[ingress映射端口]即可实现负载均衡的访问效果,可以匹配多个主机和多个service # 必须通过域名访问不能通过ip访问 apiversion: networking.k8s.io/v1 kind: ingress metadata: name: nginx-ingress annotations: nginx.ingress.kubernetes.io/auth-type: basic nginx.ingress.kubernetes.io/auth-secret: basic-auth nginx.ingress.kubernetes.io/auth-realm: \u0026#39;authentication required - kun\u0026#39; spec: rules: - host: www.kun.com http: paths: - path: / pathtype: exact backend: service: name: nginx-service port: number: 80\t八、存储 configmap 许多应用程序会从配置文件、命令行参数或环境变量中读取配置信息。configmap给提供了向容器中注入配置信息的机制的功能,可以被用来保存单个属性,也可以用来保存整个配置文件或者json二进制大对象\n准备工作\n1 2 3 4 5 6 7 8 9 10 文件:doc/user.properties username=tbb age=19 文件:doc/game.properties name=lol age=18+ 文件:doc/conf/file.conf appconfigmap 创建-使用目录\n1 kubectl create configmap file-config --from-file=doc/conf 创建-使用文件\n1 2 kubectl create configmap user-config --from-file=doc/user.properties kubectl create configmap game-config --from-file=doc/game.properties 创建-使用字面值\nkubectl create configmap special-config --from-literal=special.city=bj --from-literal=special.province=bj 创建-使用yaml\n1 2 3 4 5 6 7 8 apiversion: v1 kind: configmap metadata: name: yaml-config data: special.how: lili special.doing: working # 执行 kubectl create -f config.yaml 使用-代替环境变量,启动参数\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 apiversion: v1 kind: pod metadata: name: confgmap-pod namespace: default spec: containers: - name: confgmap-pod-container image: busybox:1.33.0 command: [\u0026#39;sh\u0026#39;, \u0026#39;-c\u0026#39;, \u0026#39;echo $(special_level_key) $(special_type_key);sleep 3600\u0026#39;] env: - name: special_level_key valuefrom: configmapkeyref: name: yaml-config key: special.how - name: special_doing valuefrom: configmapkeyref: name: yaml-config key: special.doing envfrom: - configmapref: name: file-config # 使用env命令查看环境变量 # special_level_key=lili # special_doing=working # file.conf=appconfigmap secret secret解决了密码、token、密钥等敏感数据的配置问题,不需要把这些数据暴露到镜像或者pod.spec中。secret可以以volume或者环境变量的方式使用\nsecret有三种类型\nservice account:来访问kubernetes api,由kubernetes自动创建并且会自动挂载到pod的/run/secrets/kubernetes.io/ serviceaccount目录中,用户不使用【内部组件用于访问kubernetes时使用】。 opaque:base64编码格式的secret,用来存储密码、密钥等 kubernetes.io/dockerconfigison:来存储私有docker registry的认证信息 opaque secret 创建\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 # echo -n \u0026#34;admin\u0026#34; | base64 # ywrtaw4= # echo -n \u0026#34;123456\u0026#34; | base64 # mtizndu2 apiversion: v1 kind: secret metadata: name: mysecret type: opaque data: username: ywrtaw4= password: mtizndu2 # 创建命令 kubectl create -f my-secret.yaml 在环境变量中使用\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 apiversion: v1 kind: pod metadata: name: secret-env-pod spec: containers: - name: secret-env-container image: nginx:1.19 env: - name: secret_username valuefrom: secretkeyref: name: mysecret key: username - name: secret_password valuefrom: secretkeyref: name: mysecret key: password # env | grep secret # secret_username=admin # secret_password=123456 挂在到volume中使用\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 apiversion: v1 kind: pod metadata: name: secret-volume-pod spec: containers: - name: secret-volume-pod-container image: nginx:1.19 volumemounts: - name: secrets mountpath: \u0026#34;/secret\u0026#34; readonly: true volumes: - name: secrets secret: secretname: mysecret # 会用key生成文件名,value变为内容 # ls /secret # password username kubernetes.io/dockerconfigison 使用kuberctl创建docker registry认证的secret\n1 2 3 4 5 kubectl create secret docker-registry docker-wyk-reg \\ --docker-server=[docker_registry_server] \\ --docker-username=[docker_user] \\ --docker-password=[docker_ password] \\ --docker-email=[docker_email] 在创建pod的时候,通过imagepullsecrets来引用\n1 2 3 4 5 6 7 8 9 10 apiversion: v1 kind: pod metadata : name: secret-image spec: containers: - name: nginx image: wangyukun/nginx:v1 imagepullsecrets : - name: docker-wyk-reg volume 容器磁盘上的文件的生命周期是短暂的,这就使得在容器中运行重要应用时会出现一些问题。 首先,当容器崩溃时kubelet会重启它,但是容器中的文件将丢失【容器以干净的状态(镜像最初的状态)重新启动】。其次,在pod中同时运行多个容器时,这些容器之间通常需要共享文件。kubernetes中的volume抽象就很好的解决了这些问题。\nkubernetes中的volume寿命与封装它的pod相同。当pod不再存在时,卷也将不复存在。\nemptydir 当pod分派到某个node上时,emptydir卷在node上会被创建,并且在pod在该节点上运行期间,卷最初是空的,卷一直存在。尽管pod中的容器挂载emptydir卷的路径可能相同也可能不同,这些容器都可以读写emptydir卷中相同的文件。当pod 因为某些原因被从节点上删除时,emptydir卷中的数据也会被永久删除。一般用于存储缓存数据\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 apiversion: apps/v1 kind: deployment metadata: name: nginx-deployment spec: replicas: 5 revisionhistorylimit: 10 selector: matchlabels: tier: nginx-deployment template: metadata: labels: tier: nginx-deployment spec: containers: - name: nginx-container image: nginx:1.19 volumemounts: - mountpath: /cache name: cache-volume volumes: - name: cache-volume emptydir: {} hostpath hostpath能将主机节点文件系统上的文件或目录挂载到pod中。除了必需的path属性之外,用户可以选择性地为hostpath卷指定 type\n值 行为 空字符串(默认) 用于向后兼容,这意味着在安装hostpath卷之前不会执行任何检查 directoryorcreate 如果在给定路径上什么都不存在则创建空目录,权限设置为 0755,具有与 kubelet 相同的组和属主信息 directory 在给定路径上必须存在的目录 fileorcreate 如果在给定路径上什么都不存在,则创建空文件,权限设置为 0644,具有与 kubelet 相同的组和所有权 file 在给定路径上必须存在的文件 socket 在给定路径上必须存在的 unix 套接字 chardevice 在给定路径上必须存在的字符设备 blockdevice 在给定路径上必须存在的块设备 注意事项:由于每个节点上的文件都不同,具有相同配置的pod在不同节点上的行为可能不同\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 apiversion: apps/v1 kind: deployment metadata: name: nginx-deployment spec: replicas: 5 revisionhistorylimit: 10 selector: matchlabels: tier: nginx-deployment template: metadata: labels: tier: nginx-deployment spec: containers: - name: nginx-container image: nginx:1.19 volumemounts: - mountpath: /cache name: cache-volume volumes: - name: cache-volume hostpath: path: /data type: directory node可以使用nfs挂在目录,这样所有pod的数据均一样\npersistent volume volume主要是为了存储一些有必要保存的数据,而persistent volume主要是为了管理集群的存储,persistent volume对具体的存储进行配置和分配,而pods等则可以使用persistent volume抽象出来的存储资源,不需要知道集群的存储细节。\npersistent volume和persistent volume claim类似pods和nodes的关系,persistent volume claim提出需要的存储标准,然后从现有存储资源中匹配或者动态建立新的资源,最后将两者进行绑定。\npods使用的是persistentvolumeclaim而非persistentvolume\npv访问模式\npersistentvolume可以以资源提供者支持的任何方式挂载到主机上。每个pv都有一套自己的用来描述特定功能的访问模式\nreadwriteonce:该卷可以被单个节点以读/写模式挂载,缩写为rwo readonlymany:该卷 可以被多个节点以只读模式挂载,缩写为rox readwritemany:该卷 可以被多个节点以读/写模式挂载,缩写为rwx 回收策略\nretain(保留):手动回收 recycle(回收,已废弃):基本擦除( rm -rf /thevolume/* ) delete(删除):关联的存储资产(例如aws ebs、 gce pd、azure disk和openstack cinder卷)将被删除 当前,只有nfs和hostpath支持recycle策略。aws ebs、gce pd、azure disk和cinder卷支持delete策略\npv状态\navailable(可用):空闲资源还没有被任何声明绑定 bound(已绑定):卷已经被声明绑定 released(已释放):声明被删除,但是资源还未被集群重新声明 failed(失败):该卷的自动回收失败 pv的分类\n静态\n集群管理员创建一些pv。它们带有可供群集用户使用的实际存储的细节。它们存在于kubernetes api中,可用于消费。\n动态 当管理员创建的静态pv都不匹配用户的pvc时,集群会尝试动态地为pvc创建卷。此配置基于storageclasses来对接存储,并且管理员必须创建并配置该类才能进行动态创建。声明该类为\u0026quot;\u0026ldquo;可以有效地禁用其动态配置,要启用基于存储级别的动态存储配置,集群管理员需要启用api server上的defaultstorageclass准入控制器\n案例:搭建nfs,抽象出各种存储对象(pv),创建pod使用pvc绑定pv\n①、搭建nfs\n1 2 3 4 5 6 7 8 9 10 11 12 13 yum install -y nfs-common nfs-utils rpcbind mkdir /nfsdata chmod 666 /nfsdata chown nfsnobody /nfsdata vim /etc/exports /nfsdata *(rw,no_root_squash,no_all_squash,sync) systemctl start rpcbind systemctl start nfs # 测试 showmount -e centos165 ②、创建pv\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 apiversion: v1 kind: persistentvolume metadata: name: pv001nfs spec: storageclassname: manualspeed persistentvolumereclaimpolicy: retain capacity: storage: 1gi accessmodes: - readwritemany nfs: server: centos165 path: \u0026#34;/nfsdata\u0026#34; --- apiversion: v1 kind: persistentvolume metadata: name: pv002nfs spec: storageclassname: manualspeed persistentvolumereclaimpolicy: retain capacity: storage: 5gi accessmodes: - readwritemany nfs: server: centos165 path: \u0026#34;/nfsdata\u0026#34; --- apiversion: v1 kind: persistentvolume metadata: name: pv003nfs spec: storageclassname: slowspeed persistentvolumereclaimpolicy: retain capacity: storage: 1gi accessmodes: - readwritemany nfs: server: centos165 path: \u0026#34;/nfsdata\u0026#34; ③、创建服务并绑定pvc\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 # 创建无头service apiversion: v1 kind: service metadata: name: nginx-service namespace: default spec: clusterip: none selector: app: nginx-app ports: - name: http # 自己想暴露出的端口 port: 80 # 对应容器暴露的端口 --- # 访问www.kun.com:[ingress映射端口]即可实现负载均衡的访问效果,可以匹配多个主机和多个service # 必须通过域名访问不能通过ip访问 apiversion: networking.k8s.io/v1 kind: ingress metadata: name: nginx-ingress spec: rules: - host: www.kun.com http: paths: - path: / pathtype: exact backend: service: name: nginx-service port: number: 80 --- apiversion: apps/v1 kind: statefulset metadata: name: web spec: selector: matchlabels: app: nginx servicename: nginx-service replicas: 1 template: metadata: labels: app: nginx spec: terminationgraceperiodseconds: 3 containers: - name: nginx image: nginx:1.19 ports: - containerport: 80 name: web volumemounts: - name: www mountpath: /usr/share/nginx/html volumeclaimtemplates: - metadata: name: www spec: accessmodes: [ \u0026#34;readwritemany\u0026#34; ] storageclassname: \u0026#34;manualspeed\u0026#34; resources: requests: storage: 5gi 九、集群调度 调度分为几个部分:首先是过滤掉不满足条件的节点,这个过程称为predicate然后对通过的节点按照优先级排序,这个是priority最后从中选择优先级最高的节点。如果在predicate过程中没有合适的节点,pod会一直在pending状态,不断重试调度直到有节点满足条件。经过这个步骤,如果有多个节点满足条件,就继续prioritiy过程,按照优先级大小对节点排序\npredicate有一系列的算法可以使用:\npodfitsresources:节点上剩余的资源是否大于pod请求的资源\npodfitshost:如果pod指定了nodename,检查节点名称是否和nodename匹配\npodfitshostports:节点上已经使用的port是否和pod申请的port冲突\npodselectormatches:过滤掉和pod指定的label不匹配的节点\nnodiskconflict:已经mount的volume和pod指定的volume不冲突,除非它们都是只读\nprioritiy由一系列键值对组成,键是该优先级项的名称,值是它的权重(该项的重要性)。这些优先级选项包括:\nleastrequestedpriority:通过计算cpu和memory的使用率来决定权重,使用率越低权重越高 balancedresourceallocation:点上cpu和memory使用率越接近,权重越高 imagelocalitypriority:倾向于已经有要使用镜像的节点,镜像总大小值越大,权重越高 节点亲和性 查看\u0026amp;设置节点标签\n1 2 3 4 # 设置标签 kubectl label node centos166 ssd=true city=bj # 查看标签 kubectl get nodes --show-labels pod.spec.affinity.nodeaffinity【节点亲和性设置】\npreferredduringschedulingignoredduringexecution【软策略,策略是偏向于,更想(不)落在某个节点上,但如果实在没有,落在其他节点也可以】\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 # pod最优部署在节点标签ssd=\u0026#34;true\u0026#34;节点 apiversion: v1 kind: pod metadata: name: affinity-preferred spec: containers: - name: nginx-container image: nginx:1.19 imagepullpolicy: ifnotpresent affinity: nodeaffinity: preferredduringschedulingignoredduringexecution: - weight: 10 preference: matchexpressions: - key: ssd # in、exists、notin、doesnotexist、gt(字符串比较)、lt(字符串比较) operator: in values: - \u0026#34;true\u0026#34; requiredduringschedulingignoredduringexecution【硬策略,硬策略是必须(不)落在指定的节点上,如果不符合条件,则一直处于pending状态】\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 # pod不会部署在centos166节点 apiversion: v1 kind: pod metadata: name: affinity-required spec: containers: - name: nginx-container image: nginx:1.19 imagepullpolicy: ifnotpresent affinity: nodeaffinity: requiredduringschedulingignoredduringexecution: nodeselectorterms: - matchexpressions: - key: kubernetes.io/hostname operator: notin values: - centos166 pod亲和性 查看pod标签\n1 kubectl get pod --show-labels pod.spec.affinity.podaffinity(pod亲和性)/pod.spec.affinity.podantiaffinity(pod反亲和性)\nrequiredduringschedulingignoredduringexecution硬策略 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 apiversion: v1 kind: pod metadata: name: pod-affinity-required spec: affinity: podaffinity: requiredduringschedulingignoredduringexecution: - labelselector: matchexpressions: - key: app operator: in values: - \u0026#34;demo\u0026#34; # 表示使用主机匹配 topologykey: kubernetes.io/hostname containers: - name: pod-affinity image: nginx:1.19 imagepullpolicy: ifnotpresent preferredduringschedulingignoredduringexecution软策略 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 apiversion: v1 kind: pod metadata: name: pod-affinity-preferred spec: affinity: podaffinity: preferredduringschedulingignoredduringexecution: - weight: 10 podaffinityterm: labelselector: matchexpressions: - key: app operator: notin values: - \u0026#34;demo\u0026#34; # 表示使用主机匹配 topologykey: kubernetes.io/hostname containers: - name: pod-affinity image: nginx:1.19 imagepullpolicy: ifnotpresent 污点 taint使节点能够排斥一类特定的pod\n污点(taint)的组成\n使用kubectl taint命令可以给某个node节点设置污点,node被设置上污点之后就和pod之间存在了一种相斥的关系,可以让node拒绝pod的调度执行,甚至将node已经存在的pod驱逐出去。\n每个污点的组成为key=value:effect,每个污点有一个key和value作为污点的标签,value可以为空,effect描述污点的作用。effect支持以下三个选项:\nnoschedule:表示k8s将不会将pod调度到具有该污点的node上 prefernoschedule:表示k8s将尽量避免将pod调度到具有该污点的node上 noexecute:表示k8s将不会将pod调度到具有该污点的node上,同时会将node上已经存在的pod驱逐出去 1 2 3 4 5 6 7 8 #设置污点 kubectl taint nodes [nodename] [key]=[value]:[effect] #节点说明中,查找taints字段 kubectl describe node [podname] #去除污点 kubectl taint nodes [nodename] [key]=[value]:[effect]- 有多个master存在时,防止资源浪费,可以设置 kubectl taint nodes [nodename] node-role.kubernetes.io/master:prefernoschedule\n容忍 设置了污点的node将和pod发生互斥。pod将在一定程度上不会被调度到node上,但我们可以在pod上设置容忍(toleration),设置了容忍的pod将可以容忍污点的存在,可以被调度到存在污点的node上。\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 apiversion: apps/v1 kind: deployment metadata: name: nginx-deployment spec: replicas: 5 revisionhistorylimit: 10 selector: matchlabels: tier: nginx-deployment template: metadata: labels: tier: nginx-deployment spec: tolerations: # 当不指定key值时,表示容忍所有的污点key - key: \u0026#34;disk\u0026#34; # operator的值为exists将会忽略value值 operator: \u0026#34;equal\u0026#34; value: \u0026#34;error\u0026#34; # 当不指定effect值时,表示容忍所有的污点作用 effect: \u0026#34;noexecute\u0026#34; # 如果被别的条件触发驱逐,保留的运行时间 tolerationseconds: 3600 containers: - name: nginx-container image: nginx:1.19 固定节点 pod.spec.nodename将pod直接调度到指定的node节点上,会跳过scheduler的调度策略,该匹配规则是强制匹配\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 apiversion: apps/v1 kind: deployment metadata: name: nginx-deployment spec: replicas: 3 revisionhistorylimit: 10 selector: matchlabels: tier: nginx-deployment template: metadata: labels: tier: nginx-deployment spec: nodename: centos166 containers: - name: nginx-container image: nginx:1.19 pod.spec.nodeselector 由调度器调度策略匹配label,而后调度pod到目标节点,该四配规则属于强制约束\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 apiversion: apps/v1 kind: deployment metadata: name: nginx-deployment spec: replicas: 3 revisionhistorylimit: 10 selector: matchlabels: tier: nginx-deployment template: metadata: labels: tier: nginx-deployment spec: nodeselector: ssd: \u0026#34;true\u0026#34; containers: - name: nginx-container image: nginx:1.19 十、安全 机制说明 kubernetes作为一个分布式集群的管理工具,保证集群的安全性是其一个重要的任务。 api server是集群内部各个组件通信的中介,也是外部控制的入口。所以kubernetes的安全机制基本就是围绕保护api server来设计的。kubernetes使用了认证(authentication)、鉴权(authorization)、准入控制(admissioncontrol)三步来保证api server的安全。\n认证 集群和节点之间是通过双向https证书认证的,在kubernetes中需要认证的节点分为两种\nkubenetes组件对api server的访问:kubectl、controller manager、scheduler、kubelet、kube-proxy kubernetes管理的pod对容器的访问: pod 安全性说明\ncontroller manage、scheduler与api server在同一台机器,所以直接使用api server的非安全端口访问 kubectl、kubelet、kube-proxy问api server就都需要证书进行https双向认证 证书颁发\n手动签发:通过k8s集群的跟ca进行签发https证书 自动签发:kubelet首次访问api server时,使用token做认证,通过后controller manager会为kubelet生成一个证书,以后的访问都是用证书做认证了 kubeconfig\nkubeconfig文件包含集群参数(ca证书、api server地址)客户端参数(上面生成的证书和私钥),集群context信息(集群名称、用户名)。kubenetes 组件通过启动时指定不同的kubeconfig文件可以切换到不同的集群。\nserviceaccount\npod中的容器访问api server。因为pod的创建、销毁是动态的,所以要为它手动生成证书就不可行了。kubenetes使用了service account解决pod问api server的认证问题\nsecret 与sa的关系\nkubernetes设计了一种资源对象叫做secret,分为两类一种是用于serviceaccount的service-account-token,另一种是用于保存用户自定义保密信息的opaque。serviceaccount 中用到包含三个部分: token、ca.crt、namespace\ntoken是使用 api server私钥签名的jwt。于访问api server时,server端认证\nca.crt, 根证书。于client端验证api server发送的证书\nnamespace, 标识这个service-account-token的作用域名空间\n1 2 kubectl get secret --all-namespaces kubectl describe secret default-token-5gm9r --namespace-kube-system 默认情况下,每个namespace都会有一个serviceaccount,如果pod在创建时没有指定serviceaccount,就会使用pod所属的namespace的serviceaccount\n鉴权 rbac(role-based access control)基于角色的访问控制,在kubernetes 1.5中引入,现行版本成为默认标准\nrbac的api资源对象说明\nrole:表示一组规则权限,权限只会增加(累加权限)\n1 2 3 4 5 6 7 8 9 10 kind: role apiversion: rbac.authorization.k8s.io/v1 metadata : # 只有在指定的命名空间有效 namespace: default name: pod-reader-role rules: - apigroups: [\u0026#34;\u0026#34;] # 空字符串\u0026#34;\u0026#34;表明使用 core api group,就是每个ymal声明得apiversion的“/”前面得组 resources: [\u0026#34;pods\u0026#34;] verbs: [\u0026#34;get\u0026#34;, \u0026#34;watch\u0026#34;, \u0026#34;list\u0026#34;] clusterrole:可以授予与role对象相同的权限,但由于它们属于集群范围对象,也可以使用它们授予对以下几种资源的访问权限\n集群级别的资源控制(例如node访问权限) 非资源型endpoints(例如/healthz访问) 所有命名空间资源控制(例如pods) 1 2 3 4 5 6 7 8 9 ind: clusterrole apiversion: rbac.authorization.k8s.io/v1 metadata: # clusterrole 是集群范围对象,没有 \u0026#34;namespace\u0026#34; 区分 name: secrets-cluster-role rules: - apigroups: [\u0026#34;\u0026#34;] resources: [\u0026#34;secrets\u0026#34;] verbs: [\u0026#34;get\u0026#34;, \u0026#34;watch\u0026#34;, \u0026#34;list\u0026#34;, \u0026#34;create\u0026#34;, \u0026#34;delete\u0026#34;] rolobinding:把role或clusterrole中定义的各种权限映射到user,service account或者group,从而让这些用户继承角色在 namespace中的权限。rolobinding也能绑定clusterrole,但是只能在指定名称空间下。\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 # 以下角色绑定定义将允许用户 \u0026#34;jane\u0026#34; 从 \u0026#34;default\u0026#34; 命名空间中读取pod kind: rolebinding apiversion: rbac.authorization.k8s.io/v1 metadata: name: read-pods-binding # 只有在指定的命名空间有效 namespace: default subjects: - kind: user name: jane apigroup: rbac.authorization.k8s.io roleref: kind: role name: pod-reader-role apigroup: rbac.authorization.k8s.io --- # 以下角色绑定允许用户\u0026#34;dave\u0026#34;读取\u0026#34;development\u0026#34;命名空间中的secret。 kind: rolebinding apiversion: rbac.authorization.k8s.io/v1 metadata: name: read-secrets-binding # 这里表明仅授权读取\u0026#34;development\u0026#34;命名空间中的资源。 namespace: development subjects: - kind: user name: dave apigroup: rbac.authorization.k8s.io roleref: kind: clusterrole name: secrets-cluster-role apigroup: rbac.authorization.k8s.io clusterrolebinding:和rolobinding功能类似,让用户继承clusterrole在整个集群中的权限\n1 2 3 4 5 6 7 8 9 10 11 12 13 # 以下`clusterrolebinding`对象允许在linux用户组\u0026#34;manager\u0026#34;中的任何用户都可以读取集群中任何命名空间中的secret。 kind: clusterrolebinding apiversion: rbac.authorization.k8s.io/v1 metadata: name: read-secrets-global-binding subjects: - kind: group name: manager apigroup: rbac.authorization.k8s.io roleref: kind: clusterrole name: secrets-cluster-role apigroup: rbac.authorization.k8s.io 对资源的引用\n大多数资源由代表其名字的字符串表示,例如\u0026quot;pods\u0026rdquo;。就像它们出现在相关api endpoint的url中一样。然而,有一些kubernetes api还 包含了\u0026quot;子资源\u0026quot;,比如 pod 的 logs。在kubernetes中,pod logs endpoint的url格式为:\nget /api/v1/namespaces/{namespace}/pods/{name}/log 在这种情况下,\u0026ldquo;pods\u0026quot;是命名空间资源,而\u0026quot;log\u0026quot;是pods的子资源。可以使用resource实现更加细粒度的控制。\n1 2 3 4 5 6 7 8 9 10 # 拥有这个角色的用户或者用户组,可以使用kubectl get pods 和 kubectl get pods [podname] log kind: role apiversion: rbac.authorization.k8s.io/v1 metadata: namespace: default name: pod-and-pod-logs-reader rules: - apigroups: [\u0026#34;\u0026#34;] resources: [\u0026#34;pods\u0026#34;, \u0026#34;pods/log\u0026#34;] verbs: [\u0026#34;get\u0026#34;, \u0026#34;list\u0026#34;] 示例:创建一个用户只能管理指定名称空间\n①、创建json配置\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 { # 用户名 \u0026#34;cn\u0026#34;: \u0026#34;devuser\u0026#34;, \u0026#34;hosts\u0026#34;: [], \u0026#34;key\u0026#34;: { \u0026#34;algo\u0026#34;: \u0026#34;rsa\u0026#34;, \u0026#34;size\u0026#34;: 2048 }, \u0026#34;names\u0026#34;: [{ \u0026#34;c\u0026#34;: \u0026#34;cn\u0026#34;, \u0026#34;st\u0026#34;: \u0026#34;beijing\u0026#34;, \u0026#34;l\u0026#34;: \u0026#34;beijing\u0026#34;, # 用户组名 \u0026#34;o\u0026#34;: \u0026#34;k8s\u0026#34;, \u0026#34;ou\u0026#34;: \u0026#34;system\u0026#34; }] } ②、下载证书生成工具\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 wget https://pkg.cfssl.org/r1.2/cfssl_linux-amd64 mv cfssl_linux-amd64 /usr/local/bin/cfssl wget https://pkg.cfssl.org/r1.2/cfssljson_linux-amd64 mv cfssljson_linux-amd64 /usr/local/bin/cfssljson wget https://pkg.cfssl.org/r1.2/cfssl-certinfo_linux-amd64 mv cfssl-certinfo_linux-amd64 /usr/local/bin/cfssl-certinfo chmod 755 /usr/local/bin/cfssl* #生成证书 cd /etc/kubernetes/pki cfssl gencert -ca=ca.crt -ca-key=ca.key -profile=kubernetes [jsonpath] | cfssljson -bare devuser ③、设置各种参数\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 # 设置集群参数 kubectl config set-cluster kubernetes \\ --certificate-authority=/etc/kubernetes/pki/ca.crt \\ --embed-certs=true \\ --server=\u0026#34;https://192.168.22.200:16443\u0026#34; \\ --kubeconfig=[username].kubeconfig # 设置客户端认证参数 kubectl config set-credentials [username] \\ --client-certificate=/etc/kubernetes/pki/[username].pem \\ --embed-certs=true \\ --client-key=/etc/kubernetes/pki/[username]-key.pem \\ --kubeconfig=[username].kubeconfig # 设置上下文参数 kubectl config set-context kubernetes \\ --cluster=kubernetes\\ --user=[username]\\ --namespace=[namespace] \\ --kubeconfig=[username].kubeconfig # 创建命名空间 kubectl create namespace [namespace] # 新建用户 useradd devuser passwd devuser mkdir /home/devuser/.kube mv ./devuser.kubeconfig /home/devuser/.kube/config chown -r devuser:devuser /home/devuser/.kube kubectl create rolebinding devuser-admin-binding --clusterrole=admin --user=[username] --namespace=[namespace] # 切换到devuser设置默认上下文 cd ~/.kube kubectl config use-context kubernetes --kubeconfig=config 准入控制 准入控制是api server的插件集合,通过添加不同的插件,实现额外的准入控制规则。甚至于api server的一些主要的功能都需要通过admission controllers实现,比如serviceaccount。\n官方文档上有针对不同版本的准入控制器推荐列表[每个版本不一样]\n列举插件功能\nnamespacelifecycle:防止在不存在的 namespace上创建对象,防止删除系统预置namespace,删除namespace时,连带删除它的所有资源对象 limitranger:确保请求的资源不会超过资源所在namespace的limitrange的限制 serviceaccount:实现了自动化添加serviceaccount resourcequota:确保请求的资源不会超过资源的resourcequota限制 十一、helm 概念 在没使用helm之前,向kubernetes部署应用,我们要依次部署deployment、svc等步骤较繁琐。况且随着很多项目微服务化,复杂的应用在容器中部署以及管理显得较为复杂。helm通过打包的方式类似包管理工具,支持发布的版本管理和控制,很大程度上简化kubernetes应用的部署和管理。\nchart\nchart是创建一个应用的信息集合,包括各种kubernetes对象的配置模板、参数定义、依赖关系、文档说明等。chart是应用部署的自包含逻辑单元。可以将chart想象成yum中的软件安装包\nrelease\nrelease是chart的运行实例,代表了一个正在运行的应用。当chart被安装到kubernetes集群就生成一个release。chart能够多次安装到同一个集群,每次安装都是一个release\nhelm和k8s交互原理\n部署 ①、下载helm\n②、解压\u0026amp;copy\n1 2 tar -zxvf helm-[version]-linux-amd64.tar.gz mv linux-amd64/helm /usr/bin/ ③、添加仓库源\n1 2 3 4 5 6 7 8 9 10 11 12 # 添加存储库 helm repo add azure http://mirror.azure.cn/kubernetes/charts helm repo add aliyun https://kubernetes.oss-cn-hangzhou.aliyuncs.com/charts # 更新仓库 helm repo update # 查看配置的存储库 helm repo list helm search repo azure # 删除存储库 helm repo remove azure ④、命令补全\n1 2 3 yum install -y bash-completion source /usr/share/bash-completion/bash_completion source \u0026lt;(helm completion bash) 常用命令 命令 描述 helm list 查看当前安装的charts helm pull [repo/charname] [\u0026ndash;version xxx] 将chart包下载到本地,缺省下载的是最新的chart版本,并且是tgz包,可指定版本 helm inspect chart [repo/charname] 查看package详细信息 helm install [charname] 安装本地的helm helm uninstall [charname] \u0026ndash;keep-history 卸载,\u0026ndash;keep-history是可选参数,如果有代表保存,以后可以恢复否则是删除 helm delete [charname] 删除,不可恢复 helm repo add [reponame] [url]helm repo add \u0026ndash;username [admin]\u0026ndash;password [password] [reponame] [url] 增加repo helm repo update 更新repo仓库资源 helm repo list 查看加到本地的仓库列表 helm repo remove [] 删除存储库 helm search hub [helmname]helm search repo [helmname] search hub,从hub中查找chart,这些chart来自于注册到helm hub中的各个仓库search repo,从所有加到本地的仓库中查找应用,这些仓库加到本地时chart清单文件已被存放到kubernetes中,所以查找应用时无需联网 helm编写示例 ①、创建文件夹\n1 2 mkdir hello-helm cd hello-helm ②、创建chart.yaml文件\n1 2 3 4 # 必须存在chart.yaml文件,且文件内必须要有name、version定义 # vim chart.yaml name: hello-helm version: 1.0.0 ③、创建values.yaml文件\n1 2 3 4 # vim values.yaml image: repo: nginx tag: 1.19 ④、创建模板文件,用于生成kubernetes资源清单(manifests)\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 # mkdir templates # cd templates # vim deployment.yaml apiversion: apps/v1 kind: deployment metadata: name: nginx-deploy namespace: default spec: replicas: 3 selector: matchlabels: app: nginx-app template: metadata: labels: app: nginx-app spec: containers: - name: nginx-container image: {{ .values.image.repo }}:{{ .values.image.tag }} imagepullpolicy: ifnotpresent # vim service.yaml apiversion: v1 kind: service metadata: name: nginx-service namespace: default spec: type: nodeport selector: app: nginx-app ports: - name: http # 自己想暴露出的端口 port: 30001 # 对应容器暴露的端口 targetport: 80 ⑤、安装运行\n1 2 3 4 # 不指定helm名称随机生成 helm install . --generate-name # 指定helm的名称 helm install hello-helm 部署应用 prometheus【监控集群的工具】 ①、下载chart\n1 2 3 4 5 helm repo add prometheus-community https://prometheus-community.github.io/helm-charts helm repo add stable https://charts.helm.sh/stable helm repo update helm pull prometheus-community/kube-prometheus-stack ②、解压下载好的文件\n③、修改values.yaml文件,里面有grafana的密码,和svc配置\n十二、高可用kubernetes 集群搭建 kubernetes master节点组件在集群中的状态\napiservice:官方没有给出解决方案,但是它只是一个restful风格的web服务,很好处理 etcd:会自动和所有master节点组成etcd集群,不用关心 controller-manager:只会启动一个,不用关心 scheduler:只会启动一个,不用关心 kubelet:只在当前节点工作,不用关心 proxy:只在当前节点工作,不用关心 第一步:环境准备,与kubernetes搭建第一步相同\n第二步:所有master节点部署keepalived\n①、安装相关包\n1 2 yum install -y conntrack-tools libseccomp libtool-ltdl yum install -y keepalived ②、配置master节点\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 cat \u0026gt; /etc/keepalived/keepalived.conf \u0026lt;\u0026lt;eof ! configuration file for keepalived global_defs { router_id k8s } vrrp_script check_haproxy { script \u0026#34;killall -0 haproxy\u0026#34; interval 3 weight -2 fall 10 rise 2 } vrrp_instance vi_1 { # 其它从机为backup state master interface enp0s3 virtual_router_id 51 priority 250 advert_int 1 # 验证形象 authentication { auth_type pass auth_pass 123456 } virtual_ipaddress { 192.168.22.200 } track_script { check_haproxy } } eof ③、启动和检查\n1 2 3 4 5 6 # 启动keepalived systemctl start keepalived.service # 设置开机启动 systemctl enable keepalived.service # 查看启动状态 systemctl status keepalived.service ④、检查网卡信息\n1 ip a s enp0s3 第三步:所有master节点部署haproxy\n①、安装\n1 yum install -y haproxy ②、配置\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 cat \u0026gt; /etc/haproxy/haproxy.cfg \u0026lt;\u0026lt; eof #--------------------------------------------------------------------- # global settings #--------------------------------------------------------------------- global # to have these messages end up in /var/log/haproxy.log you will # need to: # 1) configure syslog to accept network log events. this is done # by adding the \u0026#39;-r\u0026#39; option to the syslogd_options in # /etc/sysconfig/syslog # 2) configure local2 events to go to the /var/log/haproxy.log # file. a line like the following can be added to # /etc/sysconfig/syslog # # local2.* /var/log/haproxy.log # log 127.0.0.1 local2 chroot /var/lib/haproxy pidfile /var/run/haproxy.pid maxconn 4000 user haproxy group haproxy daemon # turn on stats unix socket stats socket /var/lib/haproxy/stats #--------------------------------------------------------------------- # common defaults that all the \u0026#39;listen\u0026#39; and \u0026#39;backend\u0026#39; sections will # use if not designated in their block #--------------------------------------------------------------------- defaults mode http log global option httplog option dontlognull option http-server-close option forwardfor except 127.0.0.0/8 option redispatch retries 3 timeout http-request 10s timeout queue 1m timeout connect 10s timeout client 1m timeout server 1m timeout http-keep-alive 10s timeout check 10s maxconn 3000 #--------------------------------------------------------------------- # kubernetes apiserver frontend which proxys to the backends #--------------------------------------------------------------------- frontend kubernetes-apiserver mode tcp bind *:16443 option tcplog default_backend kubernetes-apiserver #--------------------------------------------------------------------- # round robin balancing between the various backends #--------------------------------------------------------------------- backend kubernetes-apiserver mode tcp balance roundrobin server centos165 192.168.22.165:6443 check server centos168 192.168.22.168:6443 check #--------------------------------------------------------------------- # collection haproxy statistics message #--------------------------------------------------------------------- listen stats bind *:1080 stats auth admin:awesomepassword stats refresh 5s stats realm haproxy\\ statistics stats uri /admin?stats eof ③、启动和检查\n1 2 3 4 5 6 7 8 9 # 设置开机启动 systemctl enable haproxy # 开启haproxy systemctl start haproxy # 查看启动状态 systemctl status haproxy # 检查端口 netstat -lntup|grep haproxy 第四步:所有节点安装docker/kubeadm/kubelet,与kubernetes搭建第二步相同\n第五步:配置master节点的kubeadm【在具有vip的master节点操作】\n①、创建kubeadm配置文件\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 mkdir /usr/local/kubernetes/manifests -p cd /usr/local/kubernetes/manifests/ vim kubeadm-config.yaml apiserver: certsans: - centos165 - centos168 - k8smaster - 192.168.22.165 - 192.168.22.168 - 192.168.22.200 - 127.0.0.1 extraargs: authorization-mode: node,rbac timeoutforcontrolplane: 4m0s apiversion: kubeadm.k8s.io/v1beta1 certificatesdir: /etc/kubernetes/pki clustername: kubernetes # haproxy的代理端口 controlplaneendpoint: \u0026#34;192.168.22.200:16443\u0026#34; controllermanager: {} dns: type: coredns etcd: local: datadir: /var/lib/etcd imagerepository: registry.aliyuncs.com/google_containers kind: clusterconfiguration kubernetesversion: v1.20.1 networking: dnsdomain: cluster.local podsubnet: 10.244.0.0/16 servicesubnet: 10.1.0.0/16 scheduler: {} ②、执行\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 kubeadm init --config kubeadm-config.yaml # to start using your cluster, you need to run the following as a regular user: # # mkdir -p $home/.kube # sudo cp -i /etc/kubernetes/admin.conf $home/.kube/config # sudo chown $(id -u):$(id -g) $home/.kube/config # you can now join any number of control-plane nodes by copying certificate authorities # and service account keys on each node and then running the following as root: # # kubeadm join 192.168.22.200:16443 --token zhaun4.3esnwfuw7zr9xf3n \\ # --discovery-token-ca-cert-hash sha256:bc6177c8e33375671eb17e47c8336795d9eea071bb965d7004cac8e246ee730e \\ # --control-plane # then you can join any number of worker nodes by running the following on each as root: #kubeadm join 192.168.22.200:16443 --token zhaun4.3esnwfuw7zr9xf3n \\ # --discovery-token-ca-cert-hash #sha256:bc6177c8e33375671eb17e47c8336795d9eea071bb965d7004cac8e246ee730e ③、按照提示配置环境变量,使用kubectl工具:\n1 2 3 4 5 6 mkdir -p $home/.kube sudo cp -i /etc/kubernetes/admin.conf $home/.kube/config sudo chown $(id -u):$(id -g) $home/.kube/config # 检查 kubectl get nodes 第六步:安装集群网络,与kubernetes搭建的第四步:安装pod 网络插件(cni)相同\n第七步:其它master加入\n1 2 3 4 5 6 7 8 9 10 # 把处理好的vip的master节点密钥和相关文件复制到其它master节点 ssh root@192.168.22.168 mkdir -p /etc/kubernetes/pki/etcd scp /etc/kubernetes/admin.conf root@192.168.22.168:/etc/kubernetes scp /etc/kubernetes/pki/{ca.*,sa.*,front-proxy-ca.*} root@192.168.22.168:/etc/kubernetes/pki scp /etc/kubernetes/pki/etcd/ca.* root@192.168.22.168:/etc/kubernetes/pki/etcd # 执行第五步要求执行的命令 kubeadm join 192.168.22.200:16443 --token zhaun4.3esnwfuw7zr9xf3n \\ --discovery-token-ca-cert-hash sha256:bc6177c8e33375671eb17e47c8336795d9eea071bb965d7004cac8e246ee730e \\ --control-plane 第八步:node节点加入\n1 2 3 4 5 6 7 8 9 10 11 12 13 # 执行第五步要求执行的命令 kubeadm join 192.168.22.200:16443 --token zhaun4.3esnwfuw7zr9xf3n \\ --discovery-token-ca-cert-hash sha256:bc6177c8e33375671eb17e47c8336795d9eea071bb965d7004cac8e246ee730e # 查看集群状态 kubectl get nodes kubectl get cs # 如果发现scheduler 和 controller-manager健康检查失败可开放他俩的非安全端口检查 # vim /etc/kubernetes/manifests/kube-scheduler.yaml # vim /etc/kubernetes/manifests/kube-controller-manager.yaml # 将port=0去掉 # systemctl restart kubelet 当一共有 3 个 master 节点时,至少需要 2 个节点可用,api-server 才可以正常工作\n","date":"2021-01-18","permalink":"https://hobocat.github.io/post/docker/2021-01-18-kubernetes%E7%9A%84%E4%BD%BF%E7%94%A8/","summary":"一、kubernetes 概述 基本介绍 kubernetes简称K8s,是用8代替\u0026quot;ubernete\u0026quot;而成的缩写。是一个开源的用于管理云平台中多","title":"kubernetes的使用"},]
[{"content":"一、简介\u0026amp;安装 简介 hbase是一种分布式、可扩展、支持海量数据存储的nosql数据库。\n逻辑上,hbase的数据模型同关系型数据库很类似,数据存储在一张表中,有行有列。 但从hbase的底层物理存储结构(k-v)来看,hbase更像是一个多维度的map\n术语 1)namespace\n命名空间,类似于关系型数据库的database概念,每个命名空间下有多个表。hbase有两个自带的命名空间分别是hbase和default。hbase中存放的是hbase内置的表, default表是用户默认使用的命名空间。\n2)region\n按照数据量切分的行组成的切片称为region。\n3)row\nhbase表中的每行数据都由一个rowkey和多个column(列)组成,数据是按照rowkey的字典顺序存储的,并且查询数据时只能根据 rowkey 进行检索,所以rowkey的设计十分重要。\n4)column\nhbase中的每个列都由column family(列族)和column qualifier(列限定符)进行限定。建表时只需指明列族,而列限定符无需预先定义。\n5)timestamp\n用于标识数据的不同版本(version),每条数据写入时,如果不指定时间戳,系统会自动为其加上该字段,其值为写入hbase的时间。\n6)cell\n由{rowkey, column family:column qualifier, timestamp}唯一确定的单元。cell中的数据是没有类型的,全部是字节码形式存储。\n安装 前提条件:已安装zookeeper,hadoop\n第一步:解压\n1 tar -zxvf hbase-2.3.2-bin.tar.gz -c /opt/module 第二步:配置hbase-env.sh\n1 2 3 4 # java_home配置 export java_home=/opt/module/jdk8 # 不使用内置的zk export hbase_manages_zk=false 第三步:修改hbase-site.xml\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 \u0026lt;!-- 每个regionserver的共享目录,用来持久化hbase,默认情况下在/tmp/hbase下面 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;hbase.rootdir\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;/hbase\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;!-- hbase集群模式,false表示hbase的单机,true表示是分布式模式 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;hbase.cluster.distributed\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;true\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;!-- hbase master节点的端口 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;hbase.master.port\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;16000\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;!-- hbase master的web ui页面的端口 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;hbase.master.info.port\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;16010\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;!-- hbase master的web ui页面绑定的地址 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;hbase.master.info.bindaddress\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;0.0.0.0\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;!-- hbase依赖的zk地址 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;hbase.zookeeper.quorum\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;centos161,centos162,centos163\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;!-- zookeeper的工作目录 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;hbase.zookeeper.property.datadir\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;/opt/module/zookeeper/data\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;!-- 一个region进行major compaction合并的周期,在这个点的时候,这个region下的所有hfile会进行合并,默认是7天。major compaction非常耗资源,建议生产关闭(设置为0),在应用空闲时间手动触发【compact 表名】 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;hbase.hregion.majorcompaction\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;604800000\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;!-- 一个抖动比例,意思是说上一个参数设置是7天进行一次合并,也可以有50%的抖动比例,生产环境majorcompaction应该被关闭,此参数就不重要了 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;hbase.hregion.majorcompaction.jitter\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;0.50\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;!-- 一个store里面允许存的hfile的个数,超过这个个数会被写到新的一个hfile里面 也即是每个region的每个列族对应的memstore在fulsh为hfile的时候,默认情况下当达到3个hfile的时候就会对这些文件进行合并重写为一个新文件,设置个数越大可以减少触发合并的时间,但是每次合并的时间就会越长 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;hbase.hstore.compactionthreshold\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;3\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;!-- #######################################以下是非必须配置参数####################################### --\u0026gt; \u0026lt;!-- regionserver的全局memstore的大小,超过该大小会触发flush到磁盘的操作,默认是堆大小的40%,而且regionserver级别的flush会阻塞客户端读写 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;hbase.regionserver.global.memstore.size\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;!-- 可以理解为一个安全的设置,有时候集群的“写负载”非常高,写入量一直超过flush的量,这时我们就希望memstore不要超过一定的安全设置。在这种情况下,写操作就要被阻塞一直到memstore恢复到一个“可管理”的大小,这个大小就是默认值是堆大小*0.4*0.95,也就是当regionserver级别的flush操作发送后,会阻塞客户端写,一直阻塞到整个regionserver级别的memstore的大小为堆大小*0.4*0.95为止 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;hbase.regionserver.global.memstore.size.lower.limit\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;!-- 内存中的文件在自动刷新之前能够存活的最长时间,默认是1h --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;hbase.regionserver.optionalcacheflushinterval\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;3600000\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;!-- 单个region里memstore的缓存大小,超过那么整个hregion就会flush,默认128m --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;hbase.hregion.memstore.flush.size\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;134217728\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; 第四步:修改regionservers\n1 2 3 centos161 centos162 centos163 第五步:软连接hadoop配置文件到hbase\n1 2 ln -s /opt/module/hadoop/etc/hadoop/core-site.xml /opt/module/hbase/conf/core-site.xml ln -s /opt/module/hadoop/etc/hadoop/hdfs-site.xml /opt/module/hbase/conf/hdfs-site.xml 第六步:配置/etc/profile,加入hbase_home和path路径\n第七步:hbase远程发送到其他集群机器\n第八步:启动\n1 2 3 bin/start-hbase.sh # 进入命令行模式 bin/hbase shell 二、命令行操作 创建命名空间\ncreate_namespace \u0026#39;bigdata\u0026#39; 删除命名空间,需要命名空间下的没有表\ndrop_namespace \u0026#39;bigdata\u0026#39; 创建表\n# 创建一张person表,列族为base_info和addr create \u0026#39;bigdata:person\u0026#39;,\u0026#39;base_info\u0026#39;,\u0026#39;addr\u0026#39; 插入数据到表\nput \u0026#39;bigdata:person\u0026#39;,\u0026#39;1001\u0026#39;,\u0026#39;base_info:name\u0026#39;,\u0026#39;jack\u0026#39; put \u0026#39;bigdata:person\u0026#39;,\u0026#39;1001\u0026#39;,\u0026#39;base_info:age\u0026#39;,\u0026#39;18\u0026#39; put \u0026#39;bigdata:person\u0026#39;,\u0026#39;1001\u0026#39;,\u0026#39;addr:city\u0026#39;,\u0026#39;beijing\u0026#39; put \u0026#39;bigdata:person\u0026#39;,\u0026#39;1002\u0026#39;,\u0026#39;base_info:name\u0026#39;,\u0026#39;tom\u0026#39; put \u0026#39;bigdata:person\u0026#39;,\u0026#39;1003\u0026#39;,\u0026#39;base_info:name\u0026#39;,\u0026#39;rose\u0026#39; put \u0026#39;bigdata:person\u0026#39;,\u0026#39;1003\u0026#39;,\u0026#39;base_info:name\u0026#39;,\u0026#39;rose\u0026#39; # 插入数据并指定时间戳 put \u0026#39;bigdata:person\u0026#39;,\u0026#39;1001\u0026#39;,\u0026#39;addr:city\u0026#39;,\u0026#39;shanghai\u0026#39;,1603437570384 扫描表数据\n# 全表扫描 scan \u0026#39;bigdata:person\u0026#39; # 左闭右开扫描 scan \u0026#39;bigdata:person\u0026#39;,{startrow =\u0026gt; \u0026#39;1001\u0026#39;, endrow =\u0026gt; \u0026#39;1003\u0026#39;} # 从指定startrow开始扫描 scan \u0026#39;bigdata:person\u0026#39;,{startrow =\u0026gt; \u0026#39;1001\u0026#39;} # 从指定startrow开始扫描指定个数 scan \u0026#39;bigdata:person\u0026#39;,{startrow =\u0026gt; \u0026#39;1001\u0026#39;, limit =\u0026gt; 10} 查看表结构信息\ndescribe \u0026#39;bigdata:person\u0026#39; 更新指定字段的数据\nput \u0026#39;bigdata:person\u0026#39;,\u0026#39;1001\u0026#39;,\u0026#39;base_info:name\u0026#39;,\u0026#39;jane\u0026#39; 查看指定行或指定行的指定列数据\n# 查看指定行内容 get \u0026#39;bigdata:person\u0026#39;,\u0026#39;1001\u0026#39; # 查看指定行的指定列祖数据 get \u0026#39;bigdata:person\u0026#39;,\u0026#39;1001\u0026#39;,\u0026#39;base_info\u0026#39; # 查看指定行的指定列数据 get \u0026#39;bigdata:person\u0026#39;,\u0026#39;1001\u0026#39;,\u0026#39;base_info:name\u0026#39; # 获得指定列族下的版本数据 get \u0026#39;bigdata:person\u0026#39;,\u0026#39;1001\u0026#39;,{column=\u0026gt;\u0026#39;base_info\u0026#39;,versions=\u0026gt;3} # 获得指定列族下的指定列版本数据 get \u0026#39;bigdata:person\u0026#39;,\u0026#39;1001\u0026#39;,{column=\u0026gt;\u0026#39;base_info:name\u0026#39;,versions=\u0026gt;3} 统计表指定行数\ncount \u0026#39;bigdata:person\u0026#39; 删除数据\n# 删除某rowkey的全部数据 deleteall \u0026#39;bigdata:person\u0026#39;,\u0026#39;1003\u0026#39; # 删除某rowkey的某一列数据 delete \u0026#39;bigdata:person\u0026#39;,\u0026#39;1001\u0026#39;,\u0026#39;base_info:age\u0026#39; # 清空表数据 truncate \u0026#39;bigdata:person\u0026#39; 删除表\n# 首先先将表变成不可用状态 disable \u0026#39;bigdata:person\u0026#39; # drop表 drop \u0026#39;bigdata:person\u0026#39; 变更表信息\nalter \u0026#39;bigdata:person\u0026#39;,{name=\u0026gt;\u0026#39;base_info\u0026#39;,versions=\u0026gt;3} 三、hbase架构及其原理 storefile\n保存实际数据的物理文件,storefile以hfile的形式存储在hdfs上。每个store会有一个或多个storefile,数据在每个storefile中都是有序的\nmemstore\n写缓存,由于hfile中的数据要求是有序的,所以数据是先存储在memstore中,排好序后等到达刷写时机才会刷写到hfile,每次刷写都会形成一个新的hfile\nhlog【wal】\n由于数据要经memstore排序后才能刷写到hfile,但把数据保存在内存中会导致数据丢失,为了解决这个问题数据会先写在一个叫做write-ahead logfile的文件中,然后再写入memstore中。所以在系统出现故障的时候,数据可以通过这个日志文件重建\n写数据流程 1)client先访问zookeeper,获取hbase:meta表位于哪个regionserver,mate表存储了每个region的信息\n2)访问对应的regionserver,获取hbase:meta表,根据读请求的namespace:table/rowkey, 查询出目标数据位于哪个regionserver中的region中。并将该table的region信息以及meta表的位置信息缓存在客户端的meta cache,方便下次访问\n3)与目标regionserver进行通讯\n4)将数据顺序写入(追加)到wal\n5)将数据写入对应的memstore,数据会在memstore进行排序\n6)向客户端发送ack\n7)等达到memstore的刷写时机后,将数据刷写到hfile\n实际操作是先写入wal内存,再写入memstore,之后wal内存数据刷盘到hdfs,如果过程中出现异常进行回滚操作\nmemstore刷写为hfile时机 当某个memstroe的大小达到了hbase.hregion.memstore.flush.size(默认值128m),其所在region的所有memstore都会刷写。当memstore的大小达到了hbase.hregion.memstore.flush.size*hbase.hregion.memstore.block.multiplier(默认值4)时,会阻止继续往该memstore写数据。\n当regionserver中memstore的总大小达到java_heapsize*hbase.regionserver.global.memstore.size(默认值0.4)\n*hbase.regionserver.global.memstore.size.lower.limit(默认值 0.95)会按照其所有memstore的大小顺序(由大到小)依次进行刷写。直到regionserver中所有memstore的总大小减小到上述值以下。 当regionserver中memstore的总大小达到\njava_heapsize*hbase.regionserver.global.memstore.size时,会阻止继续往所有的 memstore 写数据。\n到达自动刷写的时间。自动刷新的时间间隔由该属性进行配置 hbase.regionserver.optionalcacheflushinterval(默认1小时)。\n当wal文件的数量超过hbase.regionserver.max.logs会按照时间顺序依次进行刷写,直到 wal 文件数量减小到其值以下(该属性名已经废弃, 现无需手动设置,最大值为 32)。\n读数据流程 1)client先访问zookeeper,获取hbase:meta表的regionserver\n2)访问对应的regionserver,获取hbase:meta表,根据读请求的namespace:table/rowkey, 查询出目标数据的regionserver中的region。并将该table的region信息以及meta表的位置信息缓存在客户端的metacache,方便下次访问\n3)与目标regionserver进行通讯\n4)分别在blockcache(读缓存),memstore和storefile(hfile)中查询目标数据,并将查到的所有数据进行合并。此处所有数据是指同一条数据的不同版本(timestamp)或者不同的类型(put/delete)\n5)将从文件中查询到的数据块(block,hfile数据存储单元,默认大小为64kb)缓存到blockcache\n6)将合并后的最终结果返回给客户端\nblockcahce会记录rowkey和落盘文件及对应数据,如果落盘文件已被缓存那么已被缓存的文件不需要再次读取\n文件合并 \t由于memstore每次刷写都会生成一个新的hfile,且同一个字段的不同版本(timestamp)和不同类型(put/delete)有可能会分布在不同的hfile中,因此查询时需要遍历所有的hfile。为了减少hfile的个数,以及清理过期和删除的数据,会进行storefile compaction。 compaction分为两种,分别是minor compaction和major compaction。minor compaction会将临近的若干个较小的hfile合并成一个较大的 hfile,但不会清理过期和删除的数据。major compaction会将一个store下的所有的hfile合并成一个大hfile,并且会清理掉过期和删除的数据。\n可使用scan tablename,{raw=\u0026gt;true,versions=\u0026gt;10}查看先保存的所有数据\nregion split \t默认情况下,每个table起初只有一个region,随着数据的不断写入,region会自动进行拆分。刚拆分时,两个子region都位于当前的regionserver,但处于负载均衡的考虑, hmaster有可能会将某个region转移给其他的regionserver。\n当1个region中的某个store下所有storefile的总大小超过以下公式触发,其中r为当前regionserver中属于该table的个数\nmin(r^2 * hbase.hregion.memstore.flush.size, hbase.hregion.max.filesize)\nhbase.hregion.max.filesize默认10g hbase.hregion.memstore.flush.size默认128m 默认情况下,当我们通过创建一张表时,只有一个region正处于混沌时期,start-end key无边界可谓海纳百川。所有的rowkey都写入到这个region里,然后数据越来越多,region的size越来越大时,大到一定的阀值hbase就会将region一分为二,成为2个region,这个过程称为分裂(region-split)。\n如果我们就这样默认建表,表里不断的put数据,更严重的是我们的rowkey还是顺序增大的,是比较可怕的。存在的缺点比较明显:\n首先是热点写,我们总是向最大的start key所在的region写数据,因为我们的rowkey总是会比之前的大,并且hbase的是按升序方式排序的。所以写操作总是被定位到无上界的那个region中 其次,由于热点,我们总是往最大的start key的region写记录,之前分裂出来的region不会被写数据,有点打入冷宫的感觉,他们都处于半满状态,这样的分布也是不利的 四、hbase api 创建命名空间 1 2 3 4 5 6 7 8 9 10 11 @test public void createnamespace() throws ioexception { configuration configuration = new configuration(); configuration.set(hconstants.zookeeper_quorum, \u0026#34;centos161,centos162,centos163\u0026#34;); connection connection = connectionfactory.createconnection(configuration); admin admin = connection.getadmin(); namespacedescriptor namespacedescriptor = namespacedescriptor.create(\u0026#34;bigdata\u0026#34;).build(); admin.createnamespace(namespacedescriptor); admin.close(); connection.close(); } 判断表是否存在 1 2 3 4 5 6 7 8 9 10 11 @test public void tableexists() throws ioexception { configuration configuration = new configuration(); configuration.set(hconstants.zookeeper_quorum, \u0026#34;centos161,centos162,centos163\u0026#34;); connection connection = connectionfactory.createconnection(configuration); admin admin = connection.getadmin(); boolean result = admin.tableexists(tablename.valueof(\u0026#34;bigdata:person\u0026#34;)); system.out.println(\u0026#34;table exists \u0026#34; + result); admin.close(); connection.close(); } 创建表 1 2 3 4 5 6 7 8 9 10 11 12 13 14 @test public void createtable() throws ioexception { configuration configuration = new configuration(); configuration.set(hconstants.zookeeper_quorum, \u0026#34;centos161,centos162,centos163\u0026#34;); connection connection = connectionfactory.createconnection(configuration); admin admin = connection.getadmin(); tabledescriptorbuilder tabledescriptorbuilder = tabledescriptorbuilder.newbuilder(tablename.valueof(\u0026#34;bigdata\u0026#34;, \u0026#34;student\u0026#34;)); columnfamilydescriptorbuilder familydescriptorbuilder = columnfamilydescriptorbuilder.newbuilder(bytes.tobytes(\u0026#34;info\u0026#34;)); familydescriptorbuilder.setmaxversions(3); tabledescriptorbuilder.setcolumnfamily(familydescriptorbuilder.build()); admin.createtable(tabledescriptorbuilder.build()); admin.close(); connection.close(); } 删除表 1 2 3 4 5 6 7 8 9 10 11 @test public void droptable() throws ioexception { configuration configuration = new configuration(); configuration.set(hconstants.zookeeper_quorum, \u0026#34;centos161,centos162,centos163\u0026#34;); connection connection = connectionfactory.createconnection(configuration); admin admin = connection.getadmin(); admin.disabletable(tablename.valueof(\u0026#34;bigdata\u0026#34;, \u0026#34;student\u0026#34;)); admin.deletetable(tablename.valueof(\u0026#34;bigdata\u0026#34;, \u0026#34;student\u0026#34;)); admin.close(); connection.close(); } 向表中插入数据 1 2 3 4 5 6 7 8 9 10 11 12 @test public void adddata() throws ioexception { configuration configuration = new configuration(); configuration.set(hconstants.zookeeper_quorum, \u0026#34;centos161,centos162,centos163\u0026#34;); connection connection = connectionfactory.createconnection(configuration); table stutable = connection.gettable(tablename.valueof(\u0026#34;bigdata\u0026#34;, \u0026#34;student\u0026#34;)); put put = new put(bytes.tobytes(\u0026#34;1001\u0026#34;)); put.addcolumn(bytes.tobytes(\u0026#34;info\u0026#34;), bytes.tobytes(\u0026#34;name\u0026#34;), bytes.tobytes(\u0026#34;zhangsan\u0026#34;)); stutable.put(put); stutable.close(); connection.close(); } 删除数据 1 2 3 4 5 6 7 8 9 10 11 @test public void deldata() throws ioexception { configuration configuration = new configuration(); configuration.set(hconstants.zookeeper_quorum, \u0026#34;centos161,centos162,centos163\u0026#34;); connection connection = connectionfactory.createconnection(configuration); table stutable = connection.gettable(tablename.valueof(\u0026#34;bigdata\u0026#34;, \u0026#34;student\u0026#34;)); delete delete = new delete(bytes.tobytes(\u0026#34;1001\u0026#34;)); stutable.delete(delete); stutable.close(); connection.close(); } 扫描数据 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 @test public void scandata() throws ioexception { configuration configuration = new configuration(); configuration.set(hconstants.zookeeper_quorum, \u0026#34;centos161,centos162,centos163\u0026#34;); connection connection = connectionfactory.createconnection(configuration); table stutable = connection.gettable(tablename.valueof(\u0026#34;bigdata\u0026#34;, \u0026#34;student\u0026#34;)); scan scan = new scan(); resultscanner scanner = stutable.getscanner(scan); for (result result : scanner) { cell[] cells = result.rawcells(); for (cell cell : cells) { system.out.println(\u0026#34;行键:\u0026#34; + bytes.tostring(cellutil.clonerow(cell))); system.out.println(\u0026#34;列族:\u0026#34; + bytes.tostring(cellutil.clonefamily(cell))); system.out.println(\u0026#34;列:\u0026#34; + bytes.tostring(cellutil.clonequalifier(cell))); system.out.println(\u0026#34;值:\u0026#34; + bytes.tostring(cellutil.clonevalue(cell))); } } stutable.close(); connection.close(); } 获取某一行数据 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 @test public void getrow() throws ioexception { configuration configuration = new configuration(); configuration.set(hconstants.zookeeper_quorum, \u0026#34;centos161,centos162,centos163\u0026#34;); connection connection = connectionfactory.createconnection(configuration); table stutable = connection.gettable(tablename.valueof(\u0026#34;bigdata\u0026#34;, \u0026#34;student\u0026#34;)); get get = new get(bytes.tobytes(\u0026#34;1001\u0026#34;)); //设置读取所有版本 //get.readallversions(); //设置时间戳 //get.settimestamp() result result = stutable.get(get); for (cell cell : result.rawcells()) { system.out.println(\u0026#34;行键:\u0026#34; + bytes.tostring(result.getrow())); system.out.println(\u0026#34;列族:\u0026#34; + bytes.tostring(cellutil.clonefamily(cell))); system.out.println(\u0026#34;列:\u0026#34; + bytes.tostring(cellutil.clonequalifier(cell))); system.out.println(\u0026#34;值:\u0026#34; + bytes.tostring(cellutil.clonevalue(cell))); system.out.println(\u0026#34;时间戳:\u0026#34; + cell.gettimestamp()); } stutable.close(); connection.close(); } 获取某一行指定\u0026quot;列族:列\u0026quot;的数据 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 @test public void getrowqualifier() throws ioexception { configuration configuration = new configuration(); configuration.set(hconstants.zookeeper_quorum, \u0026#34;centos161,centos162,centos163\u0026#34;); connection connection = connectionfactory.createconnection(configuration); table stutable = connection.gettable(tablename.valueof(\u0026#34;bigdata\u0026#34;, \u0026#34;student\u0026#34;)); get get = new get(bytes.tobytes(\u0026#34;1001\u0026#34;)); get.addcolumn(bytes.tobytes(\u0026#34;info\u0026#34;), bytes.tobytes(\u0026#34;name\u0026#34;)); result result = stutable.get(get); for (cell cell : result.rawcells()) { system.out.println(\u0026#34;行键:\u0026#34; + bytes.tostring(result.getrow())); system.out.println(\u0026#34;列族:\u0026#34; + bytes.tostring(cellutil.clonefamily(cell))); system.out.println(\u0026#34;列:\u0026#34; + bytes.tostring(cellutil.clonequalifier(cell))); system.out.println(\u0026#34;值:\u0026#34; + bytes.tostring(cellutil.clonevalue(cell))); system.out.println(\u0026#34;时间戳:\u0026#34; + cell.gettimestamp()); } stutable.close(); connection.close(); } 五、扩展优化 hbase api与mr交互 通过hbase的相关javaapi,我们可以实现伴随hbase操作mapreduce过程,比如使用mapreduce将数据从本地文件系统导入到hbase 的表中,比如我们从hbase中读取一些原始数据后使用mapreduce做数据分析。\n配置环境变量\u0026amp;运行官方案例 临时配置\n1 2 3 export hbase_home=/opt/module/hbase export hadoop_home=/opt/module/hadoop export hadoop_classpath=`${hbase_home}/bin/hbase mapredcp` 永久配置\n配置/etc/profile\n1 2 export hbase_home=/opt/module/hbase export hadoop_home=/opt/module/hadoop 配置hadoop-env.sh(注意:在 for 循环之后配)\n1 export hadoop_classpath=$hadoop_classpath:/opt/module/hbase/lib/* 运行官方案例 测试运行官方的mapreduce任务统计行数\n1 yarn jar lib/hbase-mapreduce-[version].jar rowcounter \u0026#34;bigdata:person\u0026#34; 使用 mapreduce将本地数据导入到hbase\n# 在本地创建一个 tsv 格式的文件:fruit.tsv # 1001\tapple\tred # 1002\tpear\tyellow # 1003\tpineapple yellow # hbase shell执行 create \u0026#39;fruit\u0026#39;,\u0026#39;info\u0026#39; hdfs dfs -mkdir /input_fruit hdfs dfs -put fruit.tsv /input_fruit yarn jar lib/hbase-mapreduce-[version].jar importtsv \\ -dimporttsv.columns=hbase_row_key,info:name,info:color fruit hdfs://centos161:9000/input_fruit scan \u0026#39;fruit\u0026#39; 自定义 实现从hdfs读取数据送入hbase\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 public class fruitmapper extends mapper\u0026lt;longwritable, text, longwritable, text\u0026gt; { @override protected void map(longwritable key, text value, context context) throws ioexception, interruptedexception { context.write(key, value); } } public class fruitreducer extends tablereducer\u0026lt;longwritable, text, nullwritable\u0026gt; { private string inputcolumnfamilycolumnnamesarg; private list\u0026lt;columnfamilycolumnname\u0026gt; columnfamilycolumnnames = new arraylist\u0026lt;\u0026gt;(); @override protected void setup(context context) throws ioexception, interruptedexception { configuration configuration = context.getconfiguration(); this.inputcolumnfamilycolumnnamesarg = configuration.get(\u0026#34;columnfamily-columnname\u0026#34;); string[] inputcolumnfamilycolumnnamesargarray = inputcolumnfamilycolumnnamesarg.split(\u0026#34;,\u0026#34;); for (string item : inputcolumnfamilycolumnnamesargarray) { string[] columnfamilycolumnname = item.split(\u0026#34;:\u0026#34;); columnfamilycolumnnames.add(new columnfamilycolumnname(columnfamilycolumnname[0], columnfamilycolumnname[1])); } for (columnfamilycolumnname columnfamilycolumnname : columnfamilycolumnnames) { system.out.println(\u0026#34;family: \u0026#34; + columnfamilycolumnname.getfamily()); system.out.println(\u0026#34;column: \u0026#34; + columnfamilycolumnname.getcolumnname()); } } @override protected void reduce(longwritable key, iterable\u0026lt;text\u0026gt; values, context context) throws ioexception, interruptedexception { for (text value : values) { string[] fields = value.tostring().split(\u0026#34;\\t\u0026#34;); system.out.println(\u0026#34;length :\u0026#34; + fields.length); put put = new put(bytes.tobytes(fields[0])); int fieldindex = 1; for (columnfamilycolumnname columnfamilycolumnname : columnfamilycolumnnames) { if (fieldindex \u0026lt; fields.length \u0026amp;\u0026amp; fieldindex \u0026lt;= columnfamilycolumnnames.size()) { system.out.println(fields[fieldindex]); put.addcolumn( bytes.tobytes(columnfamilycolumnname.getfamily()), bytes.tobytes(columnfamilycolumnname.getcolumnname()), bytes.tobytes(fields[fieldindex])); } fieldindex++; } context.write(nullwritable.get(), put); } } @data @allargsconstructor private static class columnfamilycolumnname { private string family; private string columnname; } } public class fruitdriver implements tool { private configuration configuration; @override public int run(string[] args) throws exception { // 1.获取job对象 job job = job.getinstance(configuration); // 2.获取驱动类路径 job.setjarbyclass(fruitdriver.class); // 3.设置mapper\u0026amp;mapper输出类型 job.setmapperclass(fruitmapper.class); job.setmapoutputkeyclass(longwritable.class); job.setmapoutputvalueclass(text.class); // 4.设置reducer tablemapreduceutil.inittablereducerjob(\u0026#34;bigdata:student\u0026#34;, fruitreducer.class, job); // 5.设置输入路径 fileinputformat.setinputpaths(job, new path(\u0026#34;hdfs://192.168.22.161:9000/data\u0026#34;)); // 6.提交任务 job.submit(); return job.waitforcompletion(true) ? 0 : -1; } @override public void setconf(configuration conf) { configuration = conf; } @override public configuration getconf() { return this.configuration; } public static void main(string[] args) throws exception { configuration configuration = new configuration(); configuration.set(\u0026#34;fs.defaultfs\u0026#34;, \u0026#34;hdfs://192.168.22.161:9000\u0026#34;); configuration.set(\u0026#34;columnfamily-columnname\u0026#34;, \u0026#34;info:name,info:sex\u0026#34;); configuration.set(hconstants.zookeeper_quorum, \u0026#34;centos161,centos162,centos163\u0026#34;); int res = toolrunner.run(configuration, new fruitdriver(), args); system.exit(res); } } hbase api与hive对接 hive的lib下的hive-hbase-handler-[version].jar可能不兼容,如果有问题需要重新编译\n环境准备 首先配置好hbase_home,hive_home,然后建立软链接\n1 2 3 4 5 6 7 ln -s $hbase_home/lib/hbase-common-[version].jar $hive_home/lib/hbase-common-[version].jar ln -s $hbase_home/lib/hbase-server-[version].jar $hive_home/lib/hbase- server-[version].jar ln -s $hbase_home/lib/hbase-client-[version].jar $hive_home/lib/hbase-client-[version].jar ln -s $hbase_home/lib/hbase-protocol-[version].jar $hive_home/lib/hbase-protocol-[version].jar ln -s $hbase_home/lib/hbase-it-[version].jar $hive_home/lib/hbase-it-[version].jar ln -s $hbase_home/lib/hbase-hadoop2-compat-[version].jar $hive_home/lib/hbase-hadoop2-compat-[version].jar ln -s $hbase_home/lib/hbase-hadoop-compat-[version].jar $hive_home/lib/hbase-hadoop-compat-[version].jar 配置hive-site.xml 1 2 3 4 5 6 7 8 \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;hive.zookeeper.quorum\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;centos161,centos162,centos163\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;hive.zookeeper.client.port\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;2181\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; 案例 建立hive表并关联hbase表,插入数据到hive表的同时能够影响hbase表\n①、创建关联表\n1 2 3 4 5 6 7 8 create table hive_hbase_emp_table( empno int, ename string, job string, mgr int, hiredate string, sal double, comm double, deptno int) stored by \u0026#39;org.apache.hadoop.hive.hbase.hbasestoragehandler\u0026#39; with serdeproperties (\u0026#34;hbase.columns.mapping\u0026#34;=\u0026#34;:key,info:ename,info:job,info:mgr,info:hiredate,info:sal,info:comm,info:deptno\u0026#34;) tblproperties (\u0026#34;hbase.table.name\u0026#34; = \u0026#34;hbase_emp_table\u0026#34;); 完成之后,可以分别进入 hive 和 hbase 查看,都生成了对应的表\n②、在hive中创建临时中间表,用于load文件中的数据\n1 2 3 4 5 6 7 8 9 create table emp( empno int, ename string, job string, mgr int, hiredate string, sal double, comm double, deptno int ) row format delimited fields terminated by \u0026#39;\\t\u0026#39;; ③、向hive中间表中load数据\nload data local inpath \u0026#39;/opt/module/hive/input/emp.txt\u0026#39; into table emp; ④、通过insert命令将中间表中的数据导入到hive关联hbase的那张表中\n1 insert into table hive_hbase_emp_table select * from emp; ⑤、查看hive以及关联的hbase表中是否已经成功的同步插入了数据\n1 2 hive: select * from hive_hbase_emp_table; hbase: scan \u0026#39;hbase_emp_table\u0026#39; hive使用外部表,直接关联hbase\n①、创建关联表\n1 2 3 4 5 6 7 8 create external table relevance_hbase_emp( empno int, ename string, job string, mgr int, hiredate string, sal double, comm double, deptno int) stored by \u0026#39;org.apache.hadoop.hive.hbase.hbasestoragehandler\u0026#39; with serdeproperties (\u0026#34;hbase.columns.mapping\u0026#34; = \u0026#34;:key,info:ename,info:job,info:mgr,info:hiredate,info:sal,info:co mm,info:deptno\u0026#34;) tblproperties (\u0026#34;hbase.table.name\u0026#34; = \u0026#34;hbase_emp_table\u0026#34;); ②、 关联后就可以使用hive函数进行一些分析操作了\n1 select count(*) from relevance_hbase_emp; hbase优化 master高可用 关闭hbase集群(如果没有开启则跳过此步)\n在conf目录下创建backup-masters\n1 touch conf/backup-masters 在backup-masters文件中配置高可用hmaster节点\n1 2 echo centos161 \u0026gt;\u0026gt; conf/backup-masters echo centos162 \u0026gt;\u0026gt; conf/backup-masters 将整个conf目录scp到其他节点\n打开页面测试查看http://192.168.22.161:16010\n预分区 \t每一个region维护着startrow与endrow,如果加入的数据符合某个region维护的rowkey 范围,则该数据交给这个region维护。那么依照这个原则,我们可以将数据所要投放的分区提前大致的规划好,以提高hbase性能。\n预分区设置完成以后自动切分规则依然有效,最好预估每个regionserver上放2~3个region来保证性能\n方式一:手动设置预分区\ncreate\t\u0026#39;staff\u0026#39;,\u0026#39;info\u0026#39;,\u0026#39;partition\u0026#39;,splits\t=\u0026gt; [\u0026#39;1000\u0026#39;,\u0026#39;2000\u0026#39;,\u0026#39;3000\u0026#39;,\u0026#39;4000\u0026#39;] 方式二:生成 16 进制序列预分区\ncreate \u0026#39;staff\u0026#39;,\u0026#39;info\u0026#39;,\u0026#39;partition\u0026#39;,{numregions =\u0026gt; 15, splitalgo =\u0026gt; \u0026#39;hexstringsplit\u0026#39;} 方式三:按照文件中设置的规则预分区\n# 创建 splits.txt 文件内容如下: # aaaa # bbbb # cccc # dddd create \u0026#39;staff\u0026#39;,\u0026#39;partition\u0026#39;,splits_file =\u0026gt; \u0026#39;splits.txt\u0026#39; 方式四:使用javaapi创建预分区\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 /** * 预分区 */ @test public void presplit() throws ioexception { configuration configuration = new configuration(); configuration.set(hconstants.zookeeper_quorum, \u0026#34;centos161,centos162,centos163\u0026#34;); connection connection = connectionfactory.createconnection(configuration); admin admin = connection.getadmin(); byte[][] splitkeys = new byte[][]{bytes.tobytes(\u0026#34;30000\u0026#34;), bytes.tobytes(\u0026#34;60000\u0026#34;)}; tabledescriptorbuilder tabledescriptorbuilder = tabledescriptorbuilder.newbuilder( tablename.valueof(namespacedescriptor.default_namespace_name_str, \u0026#34;staff\u0026#34;)); columnfamilydescriptorbuilder familydescriptorbuilder = columnfamilydescriptorbuilder.newbuilder(bytes.tobytes(\u0026#34;info\u0026#34;)); tabledescriptorbuilder.setcolumnfamily(familydescriptorbuilder.build()); admin.createtable(tabledescriptorbuilder.build(), splitkeys); admin.close(); connection.close(); } rowkey设计原则 rowkey要具有唯一性,散列性,长度原则【尽量长】\n举例场景:\n数据:主叫手机-\u0026gt;被叫手机 时间 时长\n业务:用手机号查询月份详情\n1 2 3 4 5 6 7 8 9 10 11 12 13 数据: 15712904478-\u0026gt;13269081322 2020-10-28 11:24:10 500 rowkey设计,如果数据量3000g数据预计划分300个区 rowkye第一部分:手机号%300 rowkye第二部分:手机号 rowkye第三部分:时间 001_15712904478_2020-10-28 11:24:10 查询2月份账单 rowstart: 001_15712904478_2020-02 rowend: 001_15712904478_2020-03 内存优化\u0026amp;基础优化 内存优化\n\thbase操作过程中需要大量的内存开销,毕竟table是可以缓存在内存中的,一般会分配整个可用内存的70%给hbase的java 堆。但是不建议分配非常大的堆内存,因为gc过程持续太久会导致regionserver处于长期不可用状态,一般16~48g内存就可以了,如果因为框架占用内存过高导致系统内存不足,框架一样会被系统服务拖死。\n优化datanode允许的最大文件打开数\n配置hdfs-site.xml\n1 2 3 4 5 \u0026lt;!-- hbase一般都会同一时间操作大量的文件,根据集群的数量和规模以及数据动作设置为4096或者更高。默认值:4096 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;dfs.datanode.max.transfer.threads\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;4096\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; 优化延迟高的数据操作的等待时间\n配置hdfs-site.xml\n1 2 3 4 5 \u0026lt;!-- 如果对于某一次数据操作来讲,延迟非常高,socket 需要等待更长的时间,建议把该值设置为更大的值(默认 60000 毫秒) --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;dfs.image.transfer.timeout\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;60000\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; 优化数据的写入效率\n配置mapred-site.xml\n1 2 3 4 5 6 7 8 9 10 11 \u0026lt;!-- 如果对于某一次数据操作来讲,延迟非常高,socket 需要等待更长的时间,建议把该值设置为更大的值(默认 60000 毫秒) --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;mapreduce.map.output.compress\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;false\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;!-- 可设置压缩方式为 org.apache.hadoop.io.compress.gzipcodec,默认 defaultcodec--\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;mapreduce.map.output.compress.codec\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;org.apache.hadoop.io.compress.defaultcodec\t\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; 设置rpc监听数量\n配置hbase-site.xml\n1 2 3 4 5 \u0026lt;!-- regionserver端默认开启的rpc监控实例数,也即regionserver能够处理的io请求线程数,默认30 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;hbase.regionserver.handler.count\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;30\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; 优化hstore文件大小\n配置hbase-site.xml\n1 2 3 4 5 \u0026lt;!--hstorefile最大的大小,当某个region的某个列族超过这个大小会进行region拆分,默认10g --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;hbase.hregion.max.filesize\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;10737418240\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; 优化 hbase 客户端缓存\n配置hbase-site.xml\n1 2 3 4 5 \u0026lt;!-- hbase客户端每次写缓冲的大小(也就是客户端批量提交到server端),这块大小会同时占用客户端和服务端,缓冲区更大可以减少rpc次数,但是更大意味着内存占用更多,默认2m --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;hbase.client.write.buffer\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;2097152\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; 指定scan.next 扫描hbase所获取的行数\n配置hbase-site.xml\n1 2 3 4 5 \u0026lt;!-- 在执行hbase scan操作的时候,客户端缓存的行数,设置小意味着更多的rpc次数,设置大比较吃内存 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;hbase.client.scanner.caching\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;2147483647\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; flush、compact、split 机制\n配置hbase-site.xml\n1 2 3 4 5 6 7 8 9 10 11 \u0026lt;!-- regionserver的全局memstore的大小,超过该大小会触发flush到磁盘的操作,默认是堆大小的40%,而且regionserver级别的flush会阻塞客户端读写 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;hbase.regionserver.global.memstore.size\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;!-- 可以理解为一个安全的设置,有时候集群的“写负载”非常高,写入量一直超过flush的量,这时我们就希望memstore不要超过一定的安全设置。在这种情况下,写操作就要被阻塞一直到memstore恢复到一个“可管理”的大小,这个大小就是默认值是堆大小*0.4*0.95,也就是当regionserver级别的flush操作发送后,会阻塞客户端写,一直阻塞到整个regionserver级别的memstore的大小为堆大小*0.4*0.95为止 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;hbase.regionserver.global.memstore.size.lower.limit\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; ","date":"2020-10-29","permalink":"https://hobocat.github.io/post/hbase/2020-10-29-hbase/","summary":"一、简介\u0026amp;安装 简介 HBase是一种分布式、可扩展、支持海量数据存储的NoSQL数据库。 逻辑上,HBase的数据模型同关系型数据库很类似,数据存储在一张表","title":"hbase使用"},]
[{"content":"一、概述\u0026amp;安装 概述 kafka是一个大数据流处理平台\nkafka是一个分布式的基于发布/订阅模式的消息队列(message queue),主要应用于大数据实时处理领域。\nproducer\n消息生产者\nconsumer\n消息消费者\nconsumer group (cg):\n消费者组,由多个consumer组成。消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费。消费者组之间互不影响,所有的消费者都属于某个消费者组\nbroker\n一台kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic\ntopic\n可以理解为一个队列,生产者和消费者面向的都是一个topic\npartition\n一个topic可以分为多个partition,每个partition是一个有序的队列\nreplica\n副本,为保证集群中的某个节点发生故障时,该节点上的partition数据不丢失,且kafka仍然能够继续工作,提供了副本机制,一个topic的每个分区都有若干个副本,一个leader和若干个follower\nleader\n每个分区多个副本的\u0026quot;主\u0026quot;,生产者发送数据的对象,以及消费者消费数据的对象都是leader\nfollower\n每个分区多个副本中的\u0026quot;从\u0026quot;,实时从leader中同步数据,保持和leader数据的同步。leader发生故障时,某个follower会成为新的follower,follower不提供面向消费者和生产者的服务\n安装启动 配置server.properties文件\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 # *broker全局唯一编号,不能重复 broker.id=0 # *主题是否可删除 delete.topic.enable=true # 插入一个不存在的topic时,kafka是否自动创建此topic auto.create.topics.enable=false # 处理网络请求的线程数 num.network.threads=3 # 处理磁盘io的线程数 num.io.threads=8 # 发生套接字缓冲区大小 socket.send.buffer.bytes=102400 # 接收套接字缓冲区大小 socket.receive.buffer.bytes=102400 # 请求套接字缓冲区大小 socket.request.max.bytes=104857600 # 数据存储目录 log.dirs=/opt/module/kafka/config/data # 默认分区数 num.partitions=1 # 用来恢复和清除data下数据的线程数 num.recovery.threads.per.data.dir=1 # topic的offset的备份份数。建议设置更高的数字保证更高的可用性建议以下设置为3 offsets.topic.replication.factor=1 transaction.state.log.replication.factor=1 transaction.state.log.min.isr=1 # 数据文件设置 log.retention.hours=168 log.segment.bytes=1073741824 log.retention.check.interval.ms=300000 # *zk连接配置 zookeeper.connect=centos161:2181,centos162:2181,centos163:2181 zookeeper.connection.timeout.ms=18000 # 消费者组内消费者负载均衡延迟时间 group.initial.rebalance.delay.ms=0 常用命令\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 # 启动节点 kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties # 停止运行 kafka-server-stop.sh # 查看主题列表 kafka-topics.sh --zookeeper centos161:2181 --list # 创建topic # replication-factor:follower + leader数目 # partitions:分区数 kafka-topics.sh --zookeeper [ip:port] --create --replication-factor [num] --partitions [num] --topic [topicname] # 删除主题 kafka-topics.sh --zookeeper [ip:port] --delete --topic [topicname] # 查看某个topic详情 kafka-topics.sh --zookeeper [ip:port] --describe --topic [topicname] # 修改分区数,只能增加 kafka-topics.sh --zookeeper [ip:port] --alter --topic [topicname] --partitions [num] # 模拟生成 kafka-console-producer.sh --topic first2 --broker-list centos161:9092 # 模拟消费 kafka-console-consumer.sh --bootstrap-server centos161:9092, centos162:9092, centos163:9092 [--from-beginning] --topic [topicname] 群起脚本\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 #!/bin/bash host_name_arr=(\u0026#39;centos161\u0026#39; \u0026#39;centos162\u0026#39; \u0026#39;centos163\u0026#39;) for host_name in ${host_name_arr[*]} do echo \u0026#39;========================\u0026#39;$host_name\u0026#39;====================\u0026#39; if [ \u0026#34;$1\u0026#34; == \u0026#34;start\u0026#34; ] ; then ssh $host_name \u0026#34;/opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties\u0026#34; fi if [ \u0026#34;$1\u0026#34; == \u0026#34;stop\u0026#34; ] ; then ssh $host_name \u0026#34;/opt/module/zookeeper/bin/kafka-server-stop.sh /opt/module/kafka/config/server.properties\u0026#34; fi echo -e \u0026#39;\\n\u0026#39; done 二、kafka架构 工作流程及文件存储机制 kafka中消息是以topic进行分类的,生产者生产消息,消费者消费消息,都是面向topic的。topic是逻辑上的概念,而partition是物理上的概念,每个partition对应于一个log文件,该log文件中存储的就是producer生产的数据。producer生产的数据会被不断追加到该log文件末端,且每条数据都有自己的offset。 消费者组中的每个消费者,都会实时记录自己消费到了哪个offset,以便出错恢复时,从上次的位置继续消费。\n由于生产者生产的消息会不断追加到log文件末尾,为防止log文件过大导致数据定位效率低下,kafka采取了分片和索引机制,将每个patition分为多个segment。每个segment对应.index文件【存储索引】和*.1og文件【存储数据】。这些文件位于一个文件夹下,该文件夹的命名规则为topic名称+分区序号。\n生产者数据可靠性保证 为保证producer发送的数据能可靠的发送到指定的topic,topic的每个partition收到producer发送的数据后,都需要向producer发送ack。如果producer收到ack,就会进行下一轮的发送,否则重新发送数据。\nkafka使用了等待全部isr节点同步才发送返回的ack的信息【并非全部follower节点】\nisr:leader维护了一个动态的in-sync replica set (isr),意为和leader保持同步的follower集合。当isr中的follower完成数据的同步之后,leader就会给follower发送ack。如果follower长时间未向leader同步数据,则该follower将被踢出isr,该时间阈值由replica.lag.time.max.ms参数设定。leader发生故障之后,就会从isr中选举新的leader。\nkafka为用户提供了三种可靠性级别,ack参数设置如下\n值 描述 0 producer不等待broker的ack,这一操作提供了一个最低的延迟,broker接收到还没有写入磁盘就已经返回,当broker故障时有可能丢失数据; 1 producer等待broker的ack,partition的leader落盘成功后返回ack,如果在follower同步成功之前leader故障,那么将会丢失数据; -1(all) producer等待broker的ack,partition的leader和follower全部落盘成功后才返回ack。但是如果在follower同步完成后,broker发送ack之前,leader 发生故障,那么会造成数据重复。 offsets.commit.required.acks默认为-1\nleader宕机且isr只有leader节点\nkafka在broker端提供了一个配置参数unclean.leader.election这个参数有两个值:\ntrue(默认)允许不同步副本成为leader,由于不同步副本的消息较为滞后,此时成为leader,可能会出现消息不一致的情况。 false不允许不同步副本成为leader,此时如果发生isr列表为空,会一直等待旧leader恢复,降低了可用性。 生产者数据一致性问题【可见性】 leo【log end offset】:指每个副本的最大的offset\nhw【high watermark】:高水位,指消费者能看见的最大的offset\n当follower故障时\nfollower发生故障后会被临时踢出isr,待该follower恢复后,follower会读取本地磁盘记录的上次的hw,并将log文件高于hw的部分截取掉,从hw开始向leader 进行同步。等该follower的leo大于等于该partition的hw,即follower追上leader之后,就可以重新加入isr。\n当leader故障时\nleader发生故障之后,会从isr中选出一个新的leader,之后为保证多个副本之间的数据一致性,其余的follower会先将各自的log文件高于hw的部分截掉,然后从新的leader同步数据。\n注意:这只能保证副本之间的数据一致性,并不能保证数据不丢失或者不重复。\nexactly once语义 at least once【最少一次】、at most once【最多一次】、exactly once【精准一次】\n0.11版本的kafka,引入了幂等性。所谓的幂等性就是指producer不论向server发送多少次重复数据,server 端都只会持久化一条。幂等性结合at least once语义,就构成了kafka的exactly once语义。即: at least once + 幂等性 = exactly once\n要启用幂等性,需要将producer的参数中enable.idompotence设置为true,此时ack已经为-1。kafka的幂等性实现其实就是将原来下游需要做的去重放在了数据上游。开启幂等性的producer在初始化的时候会被分配一个pid,发往同一partition的消息会附带sequence number。而broker端会对\u0026lt;pid, partition, seqnumber\u0026gt;做缓存,当具有相同主键的消息提交时,broker只会持久化一条。\n但是pid重启就会变化,同时不同的partition也具有不同主键,所以幂等性无法保证跨分区跨会话的exactly once。\n消费者消费方式 consumer采用pull(拉)模式从broker中读取数据。\npush(推)模式很难适应消费速率不同的消费者,因为消息发送速率是由broker决定的。它的目标是尽可能以最快速度传递消息,但是这样很容易造成consumer来不及处理消息,典型的表现就是拒绝服务以及网络拥塞。而pull模式则可以根据consumer的消费能力以适当的速率消费消息。\npull模式不足之处是,如果kafka没有数据,消费者可能会陷入循环中,一直返回空数据。针对这一点,kafka的消费者在消费数据时会传入一个时长参数timeout,如果当前没有数据可供消费,consumer会等待一段时间之后再返回,这段时长即为timeout。\n消费者分区分配策略 kafka记录offset是以consumer group + topic + partition 记录\n一个consumer group中有多个consumer,一个topic有多个partition, 所以必然会涉及到partition的分配问题,即确定那个partition由哪个consumer来消费。kafka有两种分配策略round robin和range。\nrange策略\nrange策略是对每个主题而言的,首先对同一个主题里面的分区按照序号进行排序,并对消费者按照字母顺序进行排序。如果是4个分区3个消费者,排完序的分区将会是0,1,2,3;消费者排完序将会是c1,c2,c3。然后将partitions的个数除于消费者的总数来决定每个消费者消费几个分区。如果除不尽,那么前面几个消费者线程将会多消费一个分区。即c1消费0,3;c2消费1;c3消费2\nround robin策略\n使用roundrobin策略有两个前提条件必须满足:\n同一个consumer group里面的所有消费者的num.streams必须相等 每个消费者订阅的主题必须相同 round robin策略的工作原理:将消费者组按字典排序然后轮询分配。假设现在有cg1订阅t0[p0],cg2订阅t1[p0,p1],cg3订阅t0,t1。则分配为cg1:t0p0;cg2:t1p0;cg3:t1p1;\noffset的维护 默认将offset保存在kafka一个内置的topic中,该topic为_consumer_offsets ,默认有50个分区。记录的key是消费者组id、topic、partition的组合。\n事务 为了实现跨分区跨会话的事务,需要引入一个全局唯一的transaction id,并将producer获得的pid和transaction id绑定。这样当producer重启后就可以通过正在进行的transaction id获得原来的pid。为了管理transaction,kafka 引入了一个新的组件transaction coordinator。producer就是通过和transaction coordinator交互获得transaction id对应的任务状态。transaction coordinator还负责将事务所有写入kafka的一个内部topic,这样即使整个服务重启,由于事务状态得到保存,进行中的事务状态可以得到恢复,从而继续进行。\nzookeeper在kafka中的作用 kafka集群中有一个broker会被选举为controller,负责管理集群broker的上下线,所有topic的分区副本分配和leader选举等工作。 controller的管理工作都是依赖于zookeeper的。\n三、spring boot kafka adminclient api 创建topic\n1 2 3 4 5 6 // 如果要修改分区数,只需修改配置值重启项目即可。修改分区数并不会导致数据的丢失,但是分区数只能增大不能减小 // 删除topic机会少,可使用命令行工具或者gui工具操作 @bean public newtopic initialtopic() { return new newtopic(\u0026#34;test-topic\u0026#34;, 8, short.parseshort(\u0026#34;2\u0026#34;)); } producers api producer并不是一条一条发送消息的,而是批量发送。producer最主要会启动两个线程,第一个是启动守护进程用于轮询队列元素是否满足发送条件,第二个是调用send方法是会创建一个线程用于向队列插入元素。\nspring boot生产者配置\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 spring.kafka.bootstrap-servers=192.168.22.161:9092,192.168.22.162:9092,192.168.22.163:9092 #######################################【初始化生产者配置】####################################### # 重试次数 spring.kafka.producer.retries=1 # 应答级别:多少个分区副本备份完成时向生产者发送ack确认(可选0、1、all/-1) spring.kafka.producer.acks=-1 # broker用来识别消息是来自哪个客户端的。在broker进行打印日志、衡量指标或者配额限制时会用到 spring.kafka.admin.client-id=kun-117 # 批量发送大小 spring.kafka.producer.batch-size=16384 # 提交延时 # 当生产端积累的消息达到batch-size或接收到消息linger.ms后,生产者就会将消息提交给kafka # linger.ms为0表示每接收到一条消息就提交给kafka,这时候batch-size其实就没用了 spring.kafka.producer.properties.linger.ms=0 # 生产端缓冲区大小 spring.kafka.producer.buffer-memory=33554432 # kafka提供的序列化和反序列化类 spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.stringserializer spring.kafka.producer.value-serializer=org.springframework.kafka.support.serializer.jsonserializer # 自定义分区器 # spring.kafka.producer.properties.partitioner.class=com.kun.kafka.producer.customizepartitioner # 消息的压缩发送,可选择snappy、gzip或者lz4,默认不压缩 # spring.kafka.producer.compression-type=snappy # 事务前缀,配置即开启事务 # spring.kafka.producer.transaction-id-prefix=${spring.kafka.admin.client-id} 发送消息\n1 2 3 4 5 6 7 8 // 发送消息 kafkatemplate.send(\u0026#34;test-topic\u0026#34;, new userbean(\u0026#34;kun\u0026#34;, 18)); // 发送消息,取key的hashcode发送到指定的partition kafkatemplate.send(\u0026#34;test-topic\u0026#34;, \u0026#34;key-1\u0026#34;, new userbean(\u0026#34;jack\u0026#34;, 20)); // 发送消息,根据传入的partition发送到指定的partition kafkatemplate.send(\u0026#34;test-topic\u0026#34;, 0, \u0026#34;\u0026#34;, new userbean(\u0026#34;jane\u0026#34;, 21)); // 发送消息,根据传入的partition发送到指定的partition,并添加当前时间戳作为消息头 kafkatemplate.send(\u0026#34;test-topic\u0026#34;, 0, dateutil.currentseconds(), \u0026#34;\u0026#34;, new userbean(\u0026#34;lot\u0026#34;, 33)); 发送消息添加回调功能\n1 2 3 4 5 6 userbean user = new userbean(\u0026#34;kun\u0026#34;, 18); listenablefuture\u0026lt;sendresult\u0026lt;string, object\u0026gt;\u0026gt; future = kafkatemplate.send(\u0026#34;test-topic\u0026#34;, user); future.addcallback(sendresult -\u0026gt; { log.info(\u0026#34;{}\u0026#34;, sendresult.getrecordmetadata()); log.info(\u0026#34;{}\u0026#34;, sendresult.getproducerrecord()); }, throwable -\u0026gt; log.info(\u0026#34;{}\u0026#34;, throwable)); 发送消息的事务功能\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 // 需要设置spring.kafka.producer.transaction-id-prefix kafkatemplate.setallownontransactional(true); kafkatemplate.send(\u0026#34;test-topic-1\u0026#34;, \u0026#34;key-1\u0026#34;, new userbean(\u0026#34;jack\u0026#34;, 20)); kafkatemplate.send(\u0026#34;test-topic-1\u0026#34;, 0, \u0026#34;\u0026#34;, new userbean(\u0026#34;jane\u0026#34;, 21)); kafkatemplate.setallownontransactional(false); // 发送事务消息 kafkatemplate.executeintransaction(kafkaoperations -\u0026gt; { kafkatemplate.send(\u0026#34;test-topic-1\u0026#34;, new userbean(\u0026#34;transaction-1\u0026#34;, 18)); kafkatemplate.send(\u0026#34;test-topic-1\u0026#34;, new userbean(\u0026#34;transaction-2\u0026#34;, 18)); if(true){ throw new runtimeexception(\u0026#34;模拟异常\u0026#34;); } kafkatemplate.send(\u0026#34;test-topic-1\u0026#34;, new userbean(\u0026#34;transaction-3\u0026#34;, 18)); return true; }); 监听发送消息\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 // spring boot本身自带的日志打印 @bean public producerlistener\u0026lt;object, object\u0026gt; kafkaproducerlogginglistener() { return new loggingproducerlistener\u0026lt;\u0026gt;(); } // 自定义功能 @bean public producerlistener\u0026lt;object, object\u0026gt; kafkaproducerlistener() { producerlistener\u0026lt;object, object\u0026gt; listener = new producerlistener\u0026lt;object, object\u0026gt;(){ private int errorcounter = 0; private int successcounter = 0; @override public void onsuccess(producerrecord\u0026lt;object, object\u0026gt; producerrecord, recordmetadata recordmetadata) { successcounter++; system.out.println(\u0026#34;成功个数\u0026#34; + successcounter); } @override public void onerror(producerrecord\u0026lt;object, object\u0026gt; producerrecord, exception exception) { errorcounter++; system.out.println(\u0026#34;失败个数\u0026#34; + errorcounter); } }; return listener; } consumer api consumer并不是一条一条拉取消息的,而是批量拉取,逐一消费,consumer不是线程安全的\nspring boot 消费者配置\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 spring.kafka.bootstrap-servers=192.168.22.161:9092,192.168.22.162:9092,192.168.22.163:9092 #######################################【初始化消费者配置】####################################### # 默认的消费组id spring.kafka.consumer.properties.group.id=kun-117-consumergroup # 是否自动提交offset spring.kafka.consumer.enable-auto-commit=true # 最大拉取条数据需要在session.timeout.ms这个时间内处理完,默认:500 spring.kafka.consumer.max-poll-records=500 # 消费超时时间,大小不能超过session.timeout.ms,默认:3000 spring.kafka.consumer.heartbeat-interval=3000 # 提交offset延时(接收到消息后多久提交offset),默认:5000 spring.kafka.consumer.auto-commit-interval=5000 # 当kafka中没有初始offset或offset超出范围时将自动重置offset # earliest:重置为分区中最小的offset; # latest:重置为分区中最新的offset(消费分区中新产生的数据); # none:只要有一个分区不存在已提交的offset,就抛出异常; spring.kafka.consumer.auto-offset-reset=latest # 消费会话超时时间(超过这个时间consumer没有发送心跳,就会触发rebalance操作) spring.kafka.consumer.properties.session.timeout.ms=120000 # 消费请求超时时间 spring.kafka.consumer.properties.request.timeout.ms=180000 # kafka提供的序列化和反序列化类 spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.stringdeserializer spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.stringdeserializer # 消费端监听的topic不存在时,项目启动是否会报错 spring.kafka.listener.missing-topics-fatal=true # 每次fetch请求时,server应该返回的最小字节数。如果没有足够的数据返回,请求会等待,直到足够的数据才会返回。默认:1 spring.kafka.consumer.fetch-min-size=1 # fetch请求发给broker后,在broker中可能会被阻塞的(当topic中records的总size小于fetch.min.bytes时),此时这个fetch请求耗时就会比较长。这个配置就是来配置consumer最多等待response多久。 spring.kafka.consumer.fetch-max-wait=500 # 设置批量消费 # spring.kafka.listener.type=batch 单条消费消息并处理异常\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 @kafkalistener(topics = {\u0026#34;test-topic\u0026#34;}, groupid = \u0026#34;consumer-kun-app\u0026#34;, containergroup = \u0026#34;consumer-kun-app\u0026#34;, errorhandler = \u0026#34;kafkalistenererrorhandler\u0026#34;) public void onmessage(consumerrecord\u0026lt;string, userbean\u0026gt; record, @header(kafkaheaders.received_message_key) string key) throws exception { system.out.println(\u0026#34;简单消费:\u0026#34;+record.topic()+\u0026#34;-\u0026#34;+record.partition() + \u0026#34;-\u0026#34; +record.value()); throw new exception(\u0026#34;模拟异常\u0026#34;); } // 当不需要将失败的消息发送到其它队列时返回null即可 @bean public kafkalistenererrorhandler kafkalistenererrorhandler() { // 一下业务逻辑是重置offset,重新消费出现异常的消息, consumerawarelistenererrorhandler kafkalistenererrorhandler = (message, exception, consumer) -\u0026gt; { messageheaders headers = message.getheaders(); string topicname = headers.get(kafkaheaders.received_topic, string.class) integer partitionid = headers.get(kafkaheaders.received_partition_id, integer.class) long offset = headers.get(kafkaheaders.offset, long.class); consumer.seek(new topicpartition(topicname, partitionid), offset); return null; }; return kafkalistenererrorhandler; } 批量消费消息并处理异常,需设置spring.kafka.listener.type=batch\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 @kafkalistener( topics = {\u0026#34;test-topic\u0026#34;}, groupid = \u0026#34;consumer-kun-app\u0026#34;, containergroup = \u0026#34;consumer-kun-app\u0026#34;, errorhandler = \u0026#34;kafkalistenererrorhandler\u0026#34;) public void onmessage(list\u0026lt;consumerrecord\u0026lt;string, userbean\u0026gt;\u0026gt; records) throws exception { for (consumerrecord\u0026lt;string, userbean\u0026gt; record : records) { system.out.println(\u0026#34;简单消费:\u0026#34;+record.topic()+\u0026#34;-\u0026#34;+record.partition() + \u0026#34;-\u0026#34; +record.value()); } throw new exception(\u0026#34;模拟异常\u0026#34;); } // 将批次中的所有位移都重置为批次中最小的offset @bean public kafkalistenererrorhandler kafkalistenererrorhandler() { consumerawarelistenererrorhandler kafkalistenererrorhandler = (message, exception, consumer) -\u0026gt; { messageheaders headers = message.getheaders(); list\u0026lt;string\u0026gt; topics = headers.get(kafkaheaders.received_topic, list.class); list\u0026lt;integer\u0026gt; partitions = headers.get(kafkaheaders.received_partition_id, list.class); list\u0026lt;long\u0026gt; offsets = headers.get(kafkaheaders.offset, list.class); map\u0026lt;topicpartition, long\u0026gt; offsetstoreset = new hashmap\u0026lt;\u0026gt;(); for (int i = 0; i \u0026lt; topics.size(); i++) { int index = i; offsetstoreset.compute(new topicpartition(topics.get(i), partitions.get(i)), (k, v) -\u0026gt; v == null ? offsets.get(index) : math.min(v,offsets.get(index))); } offsetstoreset.foreach((k, v) -\u0026gt; consumer.seek(k, v)); return null; }; return kafkalistenererrorhandler; } 直接使用json反序列化消息\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 /** * jsondeserializer限制了可序列化的包名称,需要继承开放权限 * spring.kafka.consumer.value-deserializer=com.kun.kafka.appjsondeserializer * * 也可配置 * spring.kafka.consumer.value-deserializer=org.springframework.kafka.support.serializer.jsondeserializer * spring.kafka.consumer.properties.spring.json.trusted.packages=* */ public class appjsondeserializer extends jsondeserializer { @override public void configure(map configs, boolean iskey) { super.configure(configs, iskey); gettypemapper().addtrustedpackages(\u0026#34;com.kun.kafka.bean\u0026#34;); } } @kafkalistener( topics = {\u0026#34;test-topic\u0026#34;}, groupid = \u0026#34;consumer-kun-app\u0026#34;, containergroup = \u0026#34;consumer-kun-app\u0026#34;) public void onmessage(@payload userbean record, @header(kafkaheaders.received_topic) string topicname) { system.out.println(\u0026#34;topicname: \u0026#34; + topicname); system.out.println(\u0026#34;record: \u0026#34; + record); } 消费失败将消息转发到另一队列,此功能是spring提供,并非死信队列\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 @kafkalistener( topics = {\u0026#34;test-topic\u0026#34;}, groupid = \u0026#34;consumer-kun-app\u0026#34;, containergroup = \u0026#34;consumer-kun-app\u0026#34;, errorhandler = \u0026#34;kafkalistenererrorhandler\u0026#34;) @sendto(\u0026#34;test-error-topic\u0026#34;) public void onmessage(@payload userbean record, @header(kafkaheaders.received_topic) string topicname, @header(kafkaheaders.received_timestamp) long time) throws exception { system.out.println(\u0026#34;topicname: \u0026#34; + topicname); system.out.println(\u0026#34;record: \u0026#34; + record); system.out.println(\u0026#34;time: \u0026#34; + time); throw new exception(\u0026#34;模拟异常\u0026#34;); } @bean public kafkalistenererrorhandler kafkalistenererrorhandler() { consumerawarelistenererrorhandler handler = (message, exception, consumer) -\u0026gt; message.getpayload(); return handler; } streams api kafka stream是提供了对存储于kafka内的数据进行流式处理和分析的功能,是一个程序库\n名称解释\n流处理器【处理流数据的业务处理器】 流【业务处理器之间的流向】 流处理拓扑【流处理器和流组合形成的拓扑关系】 source处理器【数据的来源处理器】 slink处理器【数据的结果处理器】 配置 spring boot\n1 2 3 4 5 6 spring.kafka.streams.bootstrap-servers=192.168.22.161:9092,192.168.22.162:9092,192.168.22.163:9092 spring.kafka.streams.application-id=stream-kun-117 spring.kafka.streams.properties.default.key.serde=org.apache.kafka.common.serialization.serdes$stringserde spring.kafka.streams.properties.default.value.serde=org.apache.kafka.common.serialization.serdes$stringserde # 缓存文件的目录,目录即使被删除数据依然累计,只是为了加快速度,数据存储在kafka主题中 spring.kafka.streams.state-dir=f:\\\\dir 统计value重复个数\n1 2 3 4 5 6 7 8 9 10 @bean public kstream\u0026lt;string, string\u0026gt; kstream(streamsbuilder streamsbuilder){ kstream\u0026lt;string, string\u0026gt; stream = streamsbuilder.stream(\u0026#34;word-topic\u0026#34;); stream.flatmapvalues((values) -\u0026gt; arrays.aslist(values.split(\u0026#34; \u0026#34;))). groupby((k, v)-\u0026gt; v). count(). tostream(). to(\u0026#34;result-topic\u0026#34;, produced.with(serdes.string(), serdes.long())); return stream; } connector api 第三方开源connector组件使用\n四、kafka特性 kafka高效读写数据 1、顺序写磁盘:kafka的producer生产数据,要写入到log文件中,写的过程是一直追加到文件末端,为顺序写。\n2、零复制技术:采用零拷贝\nkafka的吞吐量大原因 均是批量发送接收消息,且有压缩功能\n有partition机制\n日志的顺序读写和快速检索\nkafka自有特点 kafka可以消费以前的数据\nkafka限制 kafka只能保证partition内有序,无法保证topic消息是有序的\n消费者\u0026amp;消费者组 消费者组是kafka的消费单位 单个partition只能由消费者组中的某个消费者消费 消费者组中的单个消费者可以消费多个partition kafka如何保证顺序性 第一种:使用单partition【生产环境不会用】\n第二种:使用kafka的 key + offset 可以做到业务有序,即顺序业务key需要相同\nkafka的topic删除 kafka删除topic的过程\nkafka的broker在被选举成controller后,会执行下面几步 注册deletetopicslistener,监听zookeeper节点/admin/delete_topics下子节点的变化,delete命令实 际上就是要在该节点下创建一个节点,名字是待删除topic名,标记该topic是待删除的 创建一个单独的线程deletetopicsthread,来执行topic删除的操作 deletetopicsthread线程启动时会先在awaittopicdeletionnotification处阻塞并等待删除事件的通知,即有新的topic被添加 当我们使用了delete命令在zookeeper上的节点/admin/delete_topics下创建子节点\u0026lt; topic_name \u0026gt; deletetopicslistener会收到childchange事件会依次判断如下逻辑: 查询topic是否存在,若已经不存在了,则直接删除/admin/delete_topics/\u0026lt; topic_name \u0026gt;节点 查询topic是否为当前正在执行preferred副本选举或分区重分配,若果是,则标记为暂时不适合被删除 将该topic添加到queue中,让删除线程继续往下执行 删除线程执行删除操作的真正逻辑是:\n它首先会向各broker更新原信息,使得他们不再向外提供数据服务,准备开始删除数据。 开始删除这个topic的所有分区 给所有broker发请求,告诉它们这些分区要被删除。broker收到后就不再接受任何在这些分区上的客户端请求了 把每个分区下的所有副本都置于offlinereplica状态,这样isr就不断缩小,当leader副本最后也被置于offlinereplica状态时信息将被更新为-1 将所有副本置于replicadeletionstarted状态 副本状态机捕获状态变更,然后发起stopreplicarequest给broker,broker接到请求后停止所有fetcher线程、移除缓存,然后删除底层log文件 关闭所有空闲的fetcher线程 删除zookeeper上节点/brokers/topics/\u0026lt; topic_name \u0026gt; 删除zookeeper上节点/config/topics/\u0026lt; topic_name \u0026gt; 删除zookeeper上节点/admin/delete_topics/\u0026lt; topic_name \u0026gt; 并删除内存中的topic相关信息 五、kafka manager cmak下载地址,编译需要jdk11\n第一步:安装sbt\n1 2 3 curl https://bintray.com/sbt/rpm/rpm \u0026gt; bintray-sbt-rpm.repo mv bintray-sbt-rpm.repo /etc/yum.repos.d/ yum install -y sbt 第二步:编译\n1 ./sbt clean dist 第三步:提取编译完成文件在target/universal/cmak-[version]\n第四步:配置config/application.conf中zk地址\n第五步:启动\n1 nohup bin/cmak -java-home /opt/module/cmak/jdk11 -dhttp.port=8222 \u0026gt;\u0026gt; output.log 2\u0026gt;\u0026amp;1 \u0026amp; ","date":"2020-10-16","permalink":"https://hobocat.github.io/post/mq/2020-10-16-kafka/","summary":"一、概述\u0026amp;安装 概述 Kafka是一个大数据流处理平台 Kafka是一个分布式的基于发布/订阅模式的消息队列(Message Queue),主要应用于大数据实时","title":"kafka的使用"},]
[{"content":"一、hive的概念 hive由facebook开源基于hadoop的一个数据仓库工具,用于解决海量结构化日志的数据统计,hive可以将结构化的数据文件映射为一张表,并提供类sql 查询功能【本质是将hql转化成mapreduce程序】\nhive的执行原理\n1)hive处理的数据存储在hdfs\n2)hive分析数据底层的默认实现是mapreduce\n3)执行程序运行在yarn上\nhive的优点:\n1)操作接口采用类sql语法,提供快速开发的能力(简单、容易上手)\n2)避免了去写mapreduce,减少开发人员的学习成本\n3)hive 优势在于处理大数据,对于处理小数据没有优势,因为hive 的执行延迟比较高\n4)hive 支持用户自定义函数,用户可以根据自己的需求来实现自己的函数\nhive的缺点:\n1)hive 的执行延迟比较高,因此hive 常用于数据分析,对实时性要求不高的场合\n2)hive 自动生成的mapreduce 作业,通常情况下不够智能化,调优比较困难,粒度较粗\n3)迭代式算法无法表达,数据挖掘方面不擅长\nhive的架构原理\nhive的数据类型\ntinyint/samlint/int/bigint/float/double boolean string timestamp binary struct map array hive的交互方式\n①hive登陆;②hivejdbc;③hive -e \u0026quot;cmd\u0026quot;直接得到结果;④执行sql文件bin/hive -f hive_file.sql\n二、安装部署\u0026amp;hivejdbc 安装部署 下载hive解压,配置\n第一步:拷贝conf/hive-env.sh.template 为conf/hive-env.sh并配置\n1 2 hadoop_home=/opt/module/hadoop export hive_conf_dir=/opt/module/hive/conf 第二步:拷贝mysql驱动到hive的lib文件夹下\n第三步:创建conf/hive-site.xml文件配置mysql\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 \u0026lt;?xml version=\u0026#34;1.0\u0026#34; encoding=\u0026#34;utf-8\u0026#34; standalone=\u0026#34;no\u0026#34;?\u0026gt; \u0026lt;?xml-stylesheet type=\u0026#34;text/xsl\u0026#34; href=\u0026#34;configuration.xsl\u0026#34;?\u0026gt; \u0026lt;configuration\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;javax.jdo.option.connectionurl\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;jdbc:mysql://192.168.22.1:3306/hive?createdatabaseifnotexist=true\u0026amp;amp;useunicode=true\u0026amp;amp;characterencoding=utf-8\u0026amp;amp;allowmultiqueries=true\u0026amp;amp;rewritebatchedstatements=true\u0026amp;amp;servertimezone=asia/shanghai\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;javax.jdo.option.connectiondrivername\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;com.mysql.cj.jdbc.driver\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;!-- hive连接账户密码 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;javax.jdo.option.connectionusername\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;root\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;javax.jdo.option.connectionpassword\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;123456\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;!-- 数据存储在hdfs的目录 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;hive.metastore.warehouse.dir\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;/user/hive/warehouse\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;!-- 返回表头 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;hive.cli.print.header\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;true\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;!-- 返回当前的库 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;hive.cli.print.current.db\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;true\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;/configuration\u0026gt; 第四步:配置日志\n拷贝 conf/hive-log4j2.properties.template到conf/hive-log4j2.properties\n1 2 # log目录 property.hive.log.dir = /opt/module/hive/log 第五步:初始化元数据\n1 schematool -dbtype mysql -initschema hivejdbc 开启hivejdbc服务\n1 nohup bin/hiveserver2 \u0026gt; hiveserver2.log 2\u0026gt;\u0026amp;1 \u0026amp; beeline连接\n1 2 3 bin/beeline # 进入之后连接 # !connect jdbc:hive2://centos162:10000 三、ddl语句 操作数据库语句 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 -- ########################################## 建库语句 ########################################## create database db_emp; create database if not exists db_emp; create database db_emp location \u0026#39;/hive/resposistion/db_emp\u0026#39;; -- ########################################## 查询库语句 ########################################## show databases; desc database extended db_emp; -- ####################################### 修改属性【添加自定义属性】######################################## alter database db_emp set dbproperties(\u0026#39;createown\u0026#39;=\u0026#39;kun\u0026#39;); -- ########################################## 删库语句 ########################################## -- 删除语句【删除空数据库】 drop database db_emp; -- 强制删除 drop database db_emp cascade; -- ########################################## 切库语句 ########################################## use db_emp; 操作表 管理表【内部表】:删除时元数据和hdfs存储数据一起删除\n外部表:删除时只删除元数据\n操作一般表 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 -- ########################################## 查询表结构 ########################################## show create table student; desc student; desc extended student; desc formatted student; -- ########################################## 创建表 ########################################## -- 直接创建表 create external table if not exists student(id int, name string); -- 使用别的表的查询数据创建表,不允许使用外部表方式 create table if not exists student_new as select id, name from student; -- 使用别的表结构创建表 create external table if not exists student_like like student; -- 创建表使用各种分割 -- 数据格式 -- kangkang,lili_xiangxiang,lili:18_xiangxiang:19,fengtai_beijing -- yueyue,lili_sisi,lili:18_sisi:19,daxiao_beijing create table persion_info( name string, friends array\u0026lt;string\u0026gt;, children map\u0026lt;string,int\u0026gt;, address struct\u0026lt;stree:string, city:string\u0026gt; ) row format delimited fields terminated by \u0026#39;,\u0026#39; collection items terminated by \u0026#39;_\u0026#39; map keys terminated by \u0026#39;:\u0026#39; lines terminated by \u0026#39;\\n\u0026#39;; -- ########################################## 修改表 ########################################## -- 表类型转换 alter table student set tblproperties(\u0026#39;external\u0026#39;=\u0026#39;true\u0026#39;); alter table student set tblproperties(\u0026#39;external\u0026#39;=\u0026#39;false\u0026#39;); -- 重命名 alter table student_partition_old rename to student_partition_new; -- 修改列 alter table student_partition change column id stu_id string;-- 增加列 -- 增加列 alter table student_partition add columns(sex int, age int); -- 替换列【全量】 alter table student_partition replace columns(id string, name string, sex int); -- 删除表 drop table student_partition; 操作分区表 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 -- ########################################## 创建分区表 ########################################## -- 创建分区表 create table if not exists student_partition(id int, name string) partitioned by (year string) row format delimited fields terminated by \u0026#39;\\t\u0026#39;; -- 创建二级分区表 create table if not exists student_partition(id int, name string) partitioned by (month string, year string) row format delimited fields terminated by \u0026#39;\\t\u0026#39;; -- ########################################## 插入数据表 ########################################## -- 插入分区表数据 load data local inpath \u0026#39;/opt/module/hive/input/student.txt\u0026#39; into table student_partition partition(year=\u0026#34;2019\u0026#34;); -- 插入二级分区表数据 load data local inpath \u0026#39;/opt/module/hive/input/student.txt\u0026#39; into table student_partition_day partition(month=\u0026#34;2019-01\u0026#34;, day=\u0026#34;01\u0026#34;); -- ########################################## 创建\u0026amp;删除\u0026amp;查询分区 ########################################## -- 创建分区 alter table student_partition add partition(year=\u0026#34;2020\u0026#34;) partition(year=\u0026#34;2018\u0026#34;); -- 删除分区 alter table student_partition drop partition(year=\u0026#34;2020\u0026#34;) , partition(year=\u0026#34;2018\u0026#34;); -- 查看表分区 show partitions student_partition; -- ########################################## 修复分区数据 ########################################## -- 上传数据,完成之后因为没有元数据信息所有无法查询 hadoop fs -mkdir /user/hive/warehouse/student_partition/year=2018 hadoop fs -put input/student.txt /user/hive/warehouse/student_partition/year=2018 -- 方式一:自动修复 msck repair table student_partition; -- 方式二:手动添加分区 alter table student_partition add partition(year=\u0026#34;2017\u0026#34;); -- ########################################## 创建动态分区 ########################################## -- 开启动态分区功能(默认true) set hive.exec.dynamic.partition=true -- 设置为非严格模式(动态分区的模式,默认strict,表示必须指定至少一个分区为静态分区) set hive.exec.dynamic.partition.mode=nonstrict; -- 在所有执行mr的节点上,最大一共可以创建多少个动态分区,默认1000。 set hive.exec.max.dynamic.partitions=1000; -- 在每个执行mr的节点上,最大可以创建多少个动态分区,默认100。 set hive.exec.max.dynamic.partitions.pernode=100; -- 整个mr job中,最大可以创建多少个hdfs文件,默认100000。 set hive.exec.max.created.files=100000 -- 当有空分区生成时,是否抛出异常。一般不需要设置。 hive.error.on.empty.partition=false -- 创建表 create table employee_partition( empno int, ename string, job string, mgr string, hiredate string, sal int, comm int) partitioned by (deptno int) row format delimited fields terminated by \u0026#39;\\t\u0026#39; ; -- 插入数据,此时不用指定partition的字段值,动态获取 insert into employee_partition partition(deptno) select empno, ename, job, mgr, hiredate, sal, comm, deptno from employee; 四、dml语句 插入数据 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 -- ########################################## load装载数据 ########################################## -- 数据在本地文件是上传到hdfs,数据在hdfs上是剪切 -- 追加 load data [local] inpath \u0026#39;/opt/module/hive/input/student.txt\u0026#39; into table student; -- 清空,覆盖 load data [local] inpath \u0026#39;/opt/module/hive/input/student.txt\u0026#39; overwrite into table student; -- ########################################## insert插入数据 ########################################## -- 插入数据 insert into table student_partition partition(year=\u0026#34;2000\u0026#34;) values(\u0026#34;2\u0026#34;, \u0026#34;tom\u0026#34;, null); -- 使用插入数据覆盖, 注意字段顺序 insert overwrite table student_partition partition(year=\u0026#34;2000\u0026#34;) select id, name, sex from student_bak; -- ########################################## 查询并创建数据 ########################################## create table student_new as select id, name from student; -- ######################################## 创建表并指定数据文件夹######################################### -- 创建表并指定存放数据的hdfs文件夹位置,然后上传文件到文件夹即可 create table studeng_new(id int, name string) row format delimited fields terminated by \u0026#39;\\t\u0026#39; location \u0026#39;/user/hive/warehouse/student_new\u0026#39; 数据导出\u0026amp;数据导入 1 2 3 4 5 6 7 8 9 10 -- ########################################## insert导出 ########################################### insert overwrite [local] directory \u0026#39;/opt/module/hive/input/student.data\u0026#39; row format delimited fields terminated by \u0026#39;\\t\u0026#39; select * from student; -- ######################################## export导出import导入 ######################################## -- export导出到hdfs上 export table student to \u0026#39;/hive/export/student\u0026#39;; import table student from \u0026#39;/hive/export/student\u0026#39;; 清除表数据 1 2 -- 必须是管理表才能截断数据 truncate table student; 五、dql语句 sql语句应该避免产生笛卡尔积,产生笛卡尔积的条件\n省略连接条件 连接条件无效 所有表中所有行互相连接 oracle、hive支持满外连接(full join),mysql不支持满外连接可使用左连接union右连接\n排序 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 -- order by[全局排序,只有一个reduce] select * from employee order by sal; -- sort by[局部排序,多个reduce,分区字段随机]\tset mapreduce.job.reduces=2; -- 分为两个区,每个区内有序 select deptno,sal from employee sort by sal; -- distribute by[分区排序],先按照给定字段分区之后再排序 select * from employee distribute by deptno sort by sal; set mapreduce.job.reduces=3; select deptno,sal from employee distribute by deptno sort by sal; --cluster by[当distribute by field sort by field asc相同时可替代] select deptno from employee cluster by deptno; 分桶查询 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 -- 创建分桶表 create table employee_buck(empno int, ename string, deptno int) clustered by(deptno) into 3 buckets row format delimited fields terminated by \u0026#39;\\t\u0026#39;; -- 导入数据 set hive.enforce.bucketmapjoin = true; set mapreduce.job.reduces = -1; insert into table employee_buck select empno, ename, deptno from employee; -- 查询分桶数据 select * from employee_buck where deptno=10; -- 分桶抽样查询 select * from employee_buck tablesample(bucket 1 out of 6 on deptno); -- x out of y -- x: 开始的桶号,基数为1 -- y: 桶数的因子或倍数,如果为因子则为抽取buckets/y个,如果是倍数则为(buckets/y) * buckets个 常用函数 空字段赋值函数 如果第一个参数是null则使用第二个参数值,参数个数为固定两个\n1 select nvl(null, 100); 时间类函数 date_format时间格式只认-\n1 2 3 4 5 6 7 8 9 10 11 -- 字符串转时间 select date_format(\u0026#39;2020-09-22\u0026#39;, \u0026#39;yyyy-mm-dd\u0026#39;); -- 时间增加,数值可为负数为减 select date_add(\u0026#39;2020-09-22\u0026#39;, -1); -- 时间减少,数值可为负数为增 select date_sub(\u0026#39;2020-09-22\u0026#39;, -1); -- 两时间相减 select datediff(\u0026#39;2020-09-22\u0026#39;,\u0026#39;2020-09-21\u0026#39;); 判断函数 1 2 3 4 5 6 7 8 9 -- case when select classno, sum(case sex when \u0026#34;男\u0026#34; then 1 else 0 end) as male, sum(case sex when \u0026#34;女\u0026#34; then 1 else 0 end) as female from emp_sex group by classno; -- if select if(mgr = \u0026#34;\u0026#34;, \u0026#34;领导\u0026#34;, \u0026#34;员工\u0026#34;) from employee; 字符串拼接 1 2 3 4 5 -- 拼接 select concat(\u0026#34;hello\u0026#34;, \u0026#34;_\u0026#34;, \u0026#34;world\u0026#34;); -- 拼接指定分隔符 select concat_ws(\u0026#34;_\u0026#34;, \u0026#34;hello\u0026#34;, \u0026#34;world\u0026#34;); 字段数据汇总 1 2 -- collect_set返回一个array select deptno, collect_set(ename) from employee group by deptno; explode explode:将hive一列中复杂的array或者map结构拆分成多行\nlateral view:用于和split,explode形成侧写,它将一列数据拆成多行数据\n1 select deptno, ename from emp_dept lateral view explode(enames) table_tmp as ename; over over():指定分析函数工作的据窗口大小,这个可能会随着行的变化而变化\nover内可加参数\n参数 说明 current row 当前行 n preceding 往前n行数据 n following 往后n行数据 unbounded 起点 unbounded preceding 表示从前面的起点 unbounded following 表示到后面的终点 over左侧函数\n参数 说明 lag(col,n) 往前第n行数据 lead(col,n) 往后第n行数据 ntile(n) 把有序分区中的行发到指定数据组,各个编号从1开始 rank() 存在并列排序,1、1、3、4 dense_rank() 存在并列排序,1、1、2、3 row_number() 顺序计算,1、2、3、4 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 /* * 数据 * name sale_date price * jack\t2020-01-01\t10 * jack\t2020-01-02\t20 * jack\t2020-01-03\t30 * jack\t2020-01-05\t5 * jane\t2020-01-01\t8 * jane\t2020-01-02\t12 * jane\t2020-01-08\t1 * roes\t2020-01-08\t100 */ -- 按照名称统计,消费时间排序,计算累加消费 select name, sale_date, sum(price) over(distribute by name sort by sale_date) from business; select name, sale_date, sum(price) over(partition by name order by sale_date) from business; /** * 结果如下 * name sale_date sum_window_0 * jack 2020-01-01 10 * jack 2020-01-02 30 * jack 2020-01-03 60 * jack 2020-01-05 65 * jane 2020-01-01 8 * jane 2020-01-02 20 * jane 2020-01-08 21 * roes 2020-01-08 100 */ -- 查询上次消费和本次消费的总计 select name, sale_date, sum(price) over(distribute by name sort by sale_date rows between 1 preceding and current row) from business; /** * 结果如下 * jack 2020-01-01 10 * jack 2020-01-02 30 * jack 2020-01-03 50 * jack 2020-01-05 35 * jane 2020-01-01 8 * jane 2020-01-02 20 * jane 2020-01-08 13 * roes 2020-01-08 100 */ -- 查询顾客上次购买时间 select name, sale_date, lag(sale_data, 1) over(distribute by name sort by sale_date) from business; /** * 结果如下 * jack 2020-01-01 null * jack 2020-01-02 2020-01-01 * jack 2020-01-03 2020-01-02 * jack 2020-01-05 2020-01-03 * jane 2020-01-01 null * jane 2020-01-02 2020-01-01 * jane 2020-01-08 2020-01-02 * roes 2020-01-08 null */ -- 查询消费日期25%为一组的数据 select name, sale_date, ntile(4) over(sort by sale_data) as percent from business order by percent; /** * 结果如下 * jack 2020-01-01 1 * jane 2020-01-01 1 * jack 2020-01-02 2 * jane 2020-01-02 2 * jack 2020-01-05 3 * jack 2020-01-03 3 * jane 2020-01-08 4 * roes 2020-01-08 4 */ -- 消费者自身消费金额排序 select name, price, sale_date, rank() over(distribute by name sort by price desc) from business; /** * 结果如下 * jack 30 2020-01-03 1 * jack 20 2020-01-02 2 * jack 10 2020-01-01 3 * jack 5 2020-01-05 4 * jane 12 2020-01-02 1 * jane 8 2020-01-01 2 * jane 1 2020-01-08 3 * roes 100 2020-01-08 1 */ 六、函数 查看系统内置函数 1 2 3 4 5 6 -- 查看系统自带的函数 show functions; -- 显示自带的函数的用法 desc function [funcname]; desc function extended [funcname]; 自定义函数 当hive提供的内置函数无法满足你的业务处理需要时,此时可以考虑使用用户自定义函数(udf:user-defined function)\n根据用户自定义函数分为以下三类:\nudf(user-defined function):一进一出 udaf(user-defined aggregation function):多进一出 udtf(user-defined table-generating functions):一进多出 自定义函数步骤 第一步:上传jar到hive服务器\n第二步:add jar /opt/module/hive/lib/xxx.jar;\n第三步:添加类create temporary function [funcname]as [classname];\nudf函数定义 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 @description(name = \u0026#34;lower_concat\u0026#34;, value = \u0026#34;_func_(param_1,param_2) - returns concat lower string \u0026#34;, extended = \u0026#34;param can be one of:\\n\u0026#34; + \u0026#34;1. primitive\\n\u0026#34; + \u0026#34;2. null\\n\u0026#34; + \u0026#34;example:\\n \u0026#34; + \u0026#34; \u0026gt; select _func_(\u0026#39;aaa\u0026#39;, \u0026#39;bbb\u0026#39;)\u0026#34;) public class lowerconcat extends genericudf { private transient objectinspectorconverters.converter[] converters; /** * 这个方法只调用一次,并且在evaluate()方法之前调用。该方法接受的参数是一个objectinspectors数组。 * 该方法检查接受正确的参数类型和参数个数。 */ @override public objectinspector initialize(objectinspector[] arguments) throws udfargumentexception { // 长度校验 if (arguments.length != 2) { throw new udfargumentexception(\u0026#34;the function lower_concat accepts 2 arguments.\u0026#34;); } converters = new objectinspectorconverters.converter[arguments.length]; // 参数类型校验 if (!(arguments[0].getcategory().equals(objectinspector.category.primitive))) { throw new udfargumenttypeexception(0, \u0026#34;\\\u0026#34;primitive\\\u0026#34; expected at function lower_concat, but \\\u0026#34;\u0026#34; + arguments[0].gettypename() + \u0026#34;\\\u0026#34; \u0026#34; + \u0026#34;is found\u0026#34;); } converters[0] = objectinspectorconverters.getconverter(arguments[0], primitiveobjectinspectorfactory.writablestringobjectinspector); if (!(arguments[1].getcategory().equals(objectinspector.category.primitive))) { throw new udfargumenttypeexception(0, \u0026#34;\\\u0026#34;primitive\\\u0026#34; expected at function lower_concat, but \\\u0026#34;\u0026#34; + arguments[1].gettypename() + \u0026#34;\\\u0026#34; \u0026#34; + \u0026#34;is found\u0026#34;); } converters[1] = objectinspectorconverters.getconverter(arguments[1], primitiveobjectinspectorfactory.writablestringobjectinspector); return primitiveobjectinspectorfactory.writablestringobjectinspector; } /** * 处理 */ @override public object evaluate(deferredobject[] arguments) throws hiveexception { text firsttext = (text) converters[0].convert(arguments[0].get()); text secondtext = (text) converters[1].convert(arguments[1].get()); string firststr = (firsttext == null ? \u0026#34;\u0026#34; : firsttext.tostring()); string secondstr = (secondtext == null ? \u0026#34;\u0026#34; : secondtext.tostring()); return new text(firststr.tolowercase() + secondstr.tolowercase()); } @override public string getdisplaystring(string[] children) { return getstandarddisplaystring(getfuncname(), children); } } udtf函数定义 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 @description(name = \u0026#34;multi\u0026#34;, value = \u0026#34;_func_(params...) - returns concat lower string \u0026#34;, extended = \u0026#34;param can be number\\n\u0026#34; + \u0026#34;example:\\n \u0026#34; + \u0026#34; \u0026gt; select _func_(1,2,3)\u0026#34;) public class multi extends genericudtf { @override public structobjectinspector initialize(structobjectinspector argois) throws udfargumentexception { // 1.定义输出数据的列名和类型 list\u0026lt;string\u0026gt; fieldnames = new arraylist\u0026lt;\u0026gt;(); list\u0026lt;objectinspector\u0026gt; fieldois = new arraylist\u0026lt;\u0026gt;(); //2.添加输出数据和列名和类型 fieldnames.add(\u0026#34;multi\u0026#34;); fieldois.add(primitiveobjectinspectorfactory.javalongobjectinspector); return objectinspectorfactory.getstandardstructobjectinspector(fieldnames, fieldois); } @override public void process(object[] args) throws hiveexception { list\u0026lt;integer\u0026gt; inputarg = new arraylist\u0026lt;\u0026gt;(); for (object arg : args) { inputarg.add(((intwritable)arg).get()); } long result = 1l; for (integer aint : inputarg) { result = result * aint; } forward(result); } @override public void close() throws hiveexception { } } 七、snappy压缩\u0026amp;文件格式 snappy压缩 前提条件:hadoop先编译安装好支持snappy\n开启map输出阶段压缩 1 2 3 4 5 6 -- 开启hive传输数据压缩功能 set hive.exec.compress.intermediate=true; -- 开启map-reduce中map输出压缩功能 set mapreduce.map.output.compress=true; -- 设置map-reduce中map输出数据的压缩方式 set mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.snappycodec; 开启reduce输出阶段压缩 1 2 3 4 5 6 7 8 9 10 -- 开启hive最终输出数据压缩功能 set hive.exec.compress.output=true; -- 开启map-reduce最终输出数据压缩 set mapreduce.output.fileoutputformat.compress=true; -- 设置map-reduce中map输出数据的压缩方式 set mapreduce.output.fileoutputformat.compress.codec = org.apache.hadoop.io.compress.snappycodec; -- 设置map-reduce最终数据输出压缩为块压缩 set mapreduce.output.fileoutputformat.compress.type=block; -- 测试一下输出结果是否压缩文件 insert overwrite local directory \u0026#39;/opt/module/hive/input/employee\u0026#39; select deptno, sal from employee distribute by deptno sort by sal; 文件格式 hive可使用的文件格式\nsequencefile:生产中绝对不会用,k-v格式,比源文本格式占用磁盘更多 textfile:生产中用的多,行式存储,也是默认的文件格式 orc:生产中最常用,列式存储 parquet:生产中最常用,列式存储 创建不同文件格式的表\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 -- ######################################## textfile ######################################## create table employee_textfile( empno int, ename string ) row format delimited fields terminated by \u0026#39;\\t\u0026#39; stored as textfile; -- ######################################## orc ######################################## create table employee_orc( empno int, ename string ) row format delimited fields terminated by \u0026#39;\\t\u0026#39; stored as orc tblproperties (\u0026#34;orc.compress\u0026#34;=\u0026#34;snappy\u0026#34;); -- 默认压缩为zlib insert into employee_orc select empno, ename from employee_textfile; -- ######################################## parquet ######################################## create table employee_parquet( empno int, ename string ) row format delimited fields terminated by \u0026#39;\\t\u0026#39; stored as parquet; insert into employee_parquet select empno, ename from employee_textfile; 八、优化 fetch抓取 fetch抓取是指,hive中对某些情况的查询可以不必使用mapreduce计算。例如:select * from employee;在这种情况下,hive可以简单地读取employee对应的存储目录下的文件,然后输出查询结果到控制台。\n修改hive-site.xml\n1 2 3 4 5 6 7 8 9 \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;hive.fetch.task.conversion\u0026lt;/name\u0026gt; \u0026lt;!-- none : 全部走mr minimal : select * ,limit,filter在一个表所属的分区表上操作不走mr more : select,filter,limit,都是运行数据的fetch,不跑mr[默认值] --\u0026gt; \u0026lt;value\u0026gt;more\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; 本地模式 大多数的hadoop job是需要hadoop提供的完整的可扩展性来处理大数据集的。不过,有时hive的输入数据量是非常小的。在这种情况下,为查询触发执行任务消耗的时间可能会比实际job的执行时间要多的多。对于大多数这种情况,hive可以通过本地模式在单台机器上处理所有的任务。对于小数据集,执行时间可以明显被缩短。\n1 2 3 4 5 6 -- 开启本地模式默认为false set hive.exec.mode.local.auto=true; -- 数据量必须小于指定参数才使用本地模式,默认128m set hive.exec.mode.local.auto.inputbytes.max=50000000; -- job的map数必须小于参数才使用本地模式,默认4 set hive.exec.mode.local.auto.tasks.max=10; 表查询优化 小表join大表 查询时应该将数据量小的表放在join的左边,这样可以有效减少内存溢出错误发生的几率。实际新版的hive已经对小表join大表和大表join小表进行了优化。小表放在左边和右边已经没有明显区别。\n1 2 -- 关闭mapjoin功能(默认是打开的) set hive.auto.convert.join = false; 大表join大表-空key过滤 如果大表的空key太多,而且空key不参与join,则应该在join之前进行子查询过滤掉空key\n1 select * from (select * from bignullkeytable where bigtable_id is not null) t left join bigtable on bigtable.id = t.bigtable_id; 大表join大表-空key转换 如果大表的空key太多,但是空key参与join,则可以随机生成join用的key避免数据倾斜\n1 select * from bignullkeytable left join bigtable on if(bignullkeytable.bigtable_id is null, concat(\u0026#39;temp_join_key\u0026#39;, rand()) ,bignullkeytable.bigtable_id ) = bigtable.id; mapjoin 如果不指定mapjoin或者不符合mapjoin的条件,那么hive解析器会将在reduce阶段完成join,容易发生数据倾斜。可以用mapjoin把小 表全部加载到内存在map端进行join,避免reduce处理。\n1 2 3 4 -- 设置自动选择mapjoin,默认为true set hive.auto.convert.join = true; -- 大表小表的阈值设置(默认25m下认为是小表) set hive.mapjoin.smalltable.filesize=25000000; group by group by同样的key会分发给一个reduce,如果group by的字段数据倾斜较大(一样的集中在几个值上)压力会集中在个别reduce上。并不是所有的聚合操作都需要在reduce端完成,很多聚合操作都可以先在map端进行部分聚合,最后在reduce端得出最终结果。\n1 2 3 4 5 6 7 8 -- 是否在map端进行聚合,默认为true set hive.map.aggr = true; -- 在map端进行聚合操作的条目数目,默认100000 set hive.groupby.mapaggr.checkinterval = 100000; -- 有数据倾斜的时候进行负载均衡(默认是false) set hive.groupby.skewindata = true; 当选项设定为true, 生成的查询计划会有两个mr job。第一个mr job中,map的输出结果会随机分布到reduce中,每个reduce做部分聚合操作,并输出结果,这样处理的结果是相同的group by key有可能被分发到不同的reduce中,从而达到负载均衡的目的;第二个mr job再根据预处理的数据结果按照group by key分布到reduce中(这个过程可以保证相同的group by key被分布到同一个reduce中),最后完成最终的聚合操作。\n去重统计 数据量小的时候无所谓,数据量大的情况下,由于count distinct操作需要用一个reduce task来完成,这一个reduce需要处理的数据量太大,就会导致整个job很难完成,一般count distinct使用先group by再count的方式替换:\n1 2 3 4 select count(distinct mgr) from employee; set mapreduce.job.reduces=10; select count(mgr) from (select mgr from employee group by mgr) t; 笛卡尔积 默认情况下笛卡尔积校验时关闭的,可以配置hive-site.xml开启\n1 2 3 4 \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;hive.strict.checks.cartesian.product\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;true\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; 当需要使用时可在当前会话开启使用开启笛卡尔积\n1 2 -- 开启可使用笛卡尔积 set hive.strict.checks.cartesian.product=false; 行列过滤 列处理:在select中,只拿需要的列,少使用select *\n行处理:如果能过滤出很多列可先将表执行子查询再join\n1 select ename,deptno from (select * from employee where mgr is not null) emp join department on emp.deptno=department.id; mr优化 合理设置map数\n1 2 -- 决定每个map处理的最大的文件大小,单位为b,默认256m mapreduce.input.fileinputformat.split.maxsize=256000000; 合理设置reduce数量\n1 2 3 4 5 6 -- 每个reduce处理的数据量默认是256mb set hive.exec.reducers.bytes.per.reducer=256000000; -- 每个任务最大的reduce数,默认为1009 set hive.exec.reducers.max=1009; -- reduce个数设置 set mapreduce.job.reduces=2; 小文件进行合并\n1 2 -- 默认已合并 set hive.input.format=org.apache.hadoop.hive.q1.io.combinehive.inputformat; 并行执行 hive会将一个查询转化成-一个或者多个阶段。这样的阶段可以是mapreduce阶段、抽样阶段、合并阶段、limit 阶段。或者hive执行过程中可能需要的其他阶段。默认情况下,hive一次只会执行一个阶段。不过,某个特定的job可能包含众多的阶段,而这些阶段可能并非完全互相依赖的,也就是说有些阶段是可以并行执行的,这样可能使得整个job的执行时间缩短。如果有更多的阶段可以并行执行,那么job可能就越快完成。系统资源比较空闲的时候才有优势\n1 2 3 4 -- 打开任务并行执行,默认false set hive.exec.parallel=true; -- 同一个sq1允许最大并行度,默认8 set hive.exec.plarallel.thread.number=16; 严格模式 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 \u0026lt;!-- hive.mapred.mode被废弃,已被 hive.strict.checks.* 设置替代 --\u0026gt; \u0026lt;!-- ordey by 必须和limit连用,默认false --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;hive.strict.checks.orderby.no.limit\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;false\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;!-- 分区表查询必须含有分区字段过滤,默认false --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;hive.strict.checks.no.partition.filter\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;false\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;!-- 笛卡尔积检测,默认false --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;hive.strict.checks.cartesian.product\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;false\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; hadoop开启jvm重用\u0026amp;推测执行 hive自身也开启了推测执行hive.mapred.reduce.tasks.speculative.execution,默认true\n执行计划 使用extend分析执行计划,查看mr如何运行\n1 2 explain select * from employee_partition where deptno=20; explain extended select * from employee_partition where deptno=20; ","date":"2020-09-25","permalink":"https://hobocat.github.io/post/hive/2020-09-25-hive/","summary":"一、Hive的概念 Hive由Facebook开源基于Hadoop的一个数据仓库工具,用于解决海量结构化日志的数据统计,Hive可以将结构化的数据文件映射为一张表","title":"hive使用"},]
[{"content":"一、hadoop和大数据简介 大数据 \t大数据(bigdata) :指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。大数据含有特点:volumn(大量)、velocity(高速)、variety(多样)、value(低价值密度)\nhadoop \thadoop是一个由apache基金会开发的分布式系统的基础架构,主要解决,海量数据的存储和海量数据的分析计算问题。广义上来说。hadoop通常是指一个更广泛的概念即hadoop生态圈。\nhadoop主要版本:apache版本【最基础版本】、cloudera版本-cdh【大型互联网中应用较多】、hortonworks版本【文档较好】 hadoop主要优势:高可靠【数据有副本】、高扩展【方便扩展节点】、高效性【速度快】、高容错【能自动重新分配失败任务】 hadoop的组成部分:mapreduce(计算)、hdfs(存储)、yarn(资源调度)、common(辅助工具) hadoop的目录和主要文件结构\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 ├── bin【最基本的管理脚本和使用脚本所在的目录,这些脚本是sbin目录下管理脚本的基础实现】 │ ├── container-executor │ ├── hadoop │ ├── hdfs │ ├── mapred │ ├── rcc │ ├── test-container-executor │ └── yarn ├── etc 【配置文件】 │ └── hadoop │ ├── capacity-scheduler.xml │ ├── configuration.xsl │ ├── container-executor.cfg │ ├── core-site.xml 【全局配置文件如namenode的地址、存储目录】 │ ├── hadoop-env.sh 【环境变量配置文件】 │ ├── hadoop-metrics2.properties │ ├── hadoop-metrics.properties │ ├── hadoop-policy.xml │ ├── hdfs-site.xml 【hdfs的核心配置文件如副本数】 │ ├── httpfs-env.sh │ ├── httpfs-log4j.properties │ ├── httpfs-signature.secret │ ├── httpfs-site.xml │ ├── kms-acls.xml │ ├── kms-env.sh │ ├── kms-log4j.properties │ ├── kms-site.xml │ ├── log4j.properties │ ├── mapred-env.sh │ ├── mapred-queues.xml.template │ ├── mapred-site.xml.template 【mapreduce的核心配置文件】 │ ├── slaves 【用于设置所有的slave的名称或ip,每行存放一个】 │ ├── ssl-client.xml.example │ ├── ssl-server.xml.example │ ├── yarn-env.sh │ └── yarn-site.xml 【yarn的核心配置文件】 ├── sbin【管理脚本所在目录,主要包含hdfs和yarn中各类服务启动/关闭的脚本】 │ ├── hadoop-daemon.sh 【启动本机namenode、datanode以及secondarynamenode】 │ ├── hadoop-daemons.sh │ ├── hdfs-config.sh │ ├── refresh-namenodes.sh │ ├── slaves.sh │ ├── start-balancer.sh │ ├── start-dfs.sh 【启动namenode、datanode以及secondarynamenode】 │ ├── start-secure-dns.sh │ ├── start-yarn.sh 【启动resourcemanager以及nodemanager】 │ ├── stop-balancer.sh │ ├── stop-dfs.sh 【停止namenode、datanode以及secondarynamenode】 │ ├── stop-secure-dns.sh │ ├── stop-yarn.sh 【停止resourcemanager以及nodemanager】 │ ├── yarn-daemon.sh 【启动本机】 │ └── yarn-daemons.sh ├── lib【包含了hadoop对外提供的编程动态库和静态库,与include目录中的头文件结合使用】 ├── libexec【各个服务对应的shell配置文件所在的目录,可用于配置日志输出目录、启动参数(比如jvm参数)等基本信息。】 └── share【各个模块编译后的jar包所在目录,这个目录中也包含了hadoop文档】 二、hadoop安装 前置条件:jdk已安装\n编译安装 前置准备:已安装jdk、maven、ant\n安装依赖:yum install -y glibc-headers gcc-c++ make cmake openssl-devel ncurses-devel\n第一步:安装protobuf\n1 2 3 ./configure make \u0026amp;\u0026amp; make install protoc --version 第二步:源码编译\n1 2 tar -zxvf hadoop-[version]-src.tar.gz mvn package -pdist,native -dskiptests -dmaven.javadoc.skip=true -dtar 单节点安装 第一步 安装配置\n已安装openssl ,openssl-devel,gcc,gcc-c++\nhadoop已解压并创建hadoop_home和加入path变量,并将解压的目录权限移交给指定用户\n第二步 测试\n1 2 3 cp etc/hadoop/*.xml input hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-[version].jar grep input output \u0026#39;dfs[a-z.]+\u0026#39; cat output/* 伪装分布式安装 配置hdfs 第一步 安装配置\nhadoop已解压并创建hadoop_home和加入path变量\n第二步 配置集群\n①配置core-site.xml\n1 2 3 4 5 6 7 8 9 10 11 \u0026lt;!-- 指定hdfs中namenode的地址 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;fs.defaultfs\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;hdfs://centos160:9000\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;!-- 指定hadoop运行时产生文件的存储目录 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;hadoop.tmp.dir\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;/opt/module/hadoop/data/tmp\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; ②配置hdfs-site.xml\n1 2 3 4 5 \u0026lt;!-- 指定hdfs副本的数量 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;dfs.replication\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;1\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; 第三步 启动集群:\n①格式化namenode【会产生新的集群id如果和datanode的集群id不同则找不到以往数据】\n1 hdfs namenode -format ②启动namenode和datanode\n1 2 sbin/hadoop-daemon.sh start namenode sbin/hadoop-daemon.sh start datanode ③查看是否启动成功\n1 jps ④访问http://ip:50070查看集群状态\n⑤测试上传文件和删除文件\n1 2 3 4 5 6 7 8 9 10 11 12 # 创建目录 hadoop fs -mkdir -p /user/kun/input # 上传文件 hadoop fs -put input/* /user/kun/input # 查看文件 hadoop fs -ls -r /user # 执行测试 hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-[version].jar wordcount /user/kun/input /user/kun/output # 查看结果 hadoop fs -tail -f /user/kun/output/part-r-00000 # 删除目录 hadoop fs -rm -r /user 配置yarn 第一步 配置集群\n①配置yarn-site.xml\n1 2 3 4 5 6 7 8 9 10 11 \u0026lt;!-- reducer获取数据的方式 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;yarn.nodemanager.aux-services\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;mapreduce_shuffle\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;!-- 指定yarn的resourcemanager的地址 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;yarn.resourcemanager.hostname\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;centos160\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; ②配置mapred-site.xml\n1 2 3 4 5 \u0026lt;!-- 指定mr运行在yarn上 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;mapreduce.framework.name\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;yarn\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; 第二步 启动集群\n①启动resourcemanager和nodemanager\n1 2 3 sbin/yarn-daemon.sh start resourcemanager sbin/yarn-daemon.sh start nodemanager jps ②访问http://ip:8088查看集群状态\n③执行测试\n1 2 # 执行测试 hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-[version].jar wordcount /user/kun/input /user/kun/output 配置历史服务器 ①配置mapred-site.xml\n1 2 3 4 5 6 7 8 9 10 \u0026lt;!-- 历史服务器端地址 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;mapreduce.jobhistory.address\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;centos160:10020\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;!-- 历史服务器web端地址 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;mapreduce.jobhistory.webapp.address\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;centos160:19888\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; ②启动历史服务器\n1 sbin/mr-jobhistory-daemon.sh start historyserver ③访问http://ip:19888/jobhistory历史服务器\n配置日志聚集 ①关闭nodemanager 、resourcemanager和historymanager\n1 2 3 sbin/yarn-daemon.sh stop resourcemanager sbin/yarn-daemon.sh stop nodemanager sbin/mr-jobhistory-daemon.sh stop historyserver ②配置yarn-site.xml\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;yarn.log-aggregation-enable\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;true\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;!-- 日志保留时间设置7天 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;yarn.log-aggregation.retain-seconds\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;604800\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;yarn.nodemanager.aux-services\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;mapreduce_shuffle\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; ③启动nodemanager 、resourcemanager和historymanager\n1 2 3 sbin/yarn-daemon.sh start resourcemanager sbin/yarn-daemon.sh start nodemanager sbin/mr-jobhistory-daemon.sh start historyserver 注:以后执行的任务才能查看聚集日志\n分布式安装 部署规划\nhadoop161 hadoop162 hadoop163 hdfs namenode/datanode datanode datanode/secondarynamenode yarn nodemanager resourcemanager/nodemanager nodemanager 第一步:系统配置\n①配置/etc/hosts\n::1 localhost 127.0.0.1 localhost 192.168.1.161 centos161 192.168.1.162 centos162 192.168.1.163 centos163 分发rsync -rvl /etc/hosts root@192.168.1.162:/etc/hosts\n分发rsync -rvl /etc/hosts root@192.168.1.163:/etc/hosts\n②配置namenode节点ssh登陆【注意切换用户为hadoop的使用用户】\n1 2 3 4 5 6 7 # 生成密钥 ssh-keygen -t rsa # 全部都需要,包括本机 ssh-copy-id centos161 ssh-copy-id centos162 ssh-copy-id centos163 ③配置resourcemanager节点ssh登陆【注意切换用户为hadoop的使用用户】\n第二步:hadoop配置\n①配置core-site.xml\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 \u0026lt;!-- 指定hdfs中namenode的地址 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;fs.defaultfs\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;hdfs://centos161:9000\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;!-- 指定hadoop运行时产生文件的存储目录 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;hadoop.tmp.dir\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;/opt/module/hadoop/data/tmp\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;!-- 有访问权限的代理用户 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;hadoop.proxyuser.kun.hosts\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;*\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;hadoop.proxyuser.kun.groups\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;*\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;!-- 默认用户 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;hadoop.http.staticuser.user\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;kun\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; ②配置hdfs-site.xml 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;dfs.replication\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;3\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;!-- 指定hadoop辅助名称节点主机配置 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;dfs.namenode.secondary.http-address\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;centos163:50090\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;!-- 块存储大小默认128m,hdfs块的大小设置主要取决于磁盘传输速率 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;dfs.blocksize\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;134217728\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; ③配置yarn-site.xml\n1 2 3 4 5 6 7 8 9 10 11 \u0026lt;!-- reducer获取数据的方式 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;yarn.nodemanager.aux-services\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;mapreduce_shuffle\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;!-- 指定yarn的resourcemanager的地址 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;yarn.resourcemanager.hostname\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;centos162\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; ④配置slaves\n1 2 3 centos161 centos162 centos163 ⑤分发配置文件\n1 2 rsync -rvl /opt/module/hadoop/etc/hadoop/* root@192.168.1.162:/opt/module/hadoop/etc/hadoop/ rsync -rvl /opt/module/hadoop/etc/hadoop/* root@192.168.1.163:/opt/module/hadoop/etc/hadoop/ 第三步 启动集群:\n①namenode节点格式化\n1 hdfs namenode -format ②启动hdfs\n1 sbin/start-dfs.sh ③用jps查看每个节点状态\n④访问http://snnip:50090/status.html查看secondarynamenode\n⑤在resourcemanger节点启动yarn\n1 sbin/start-yarn.sh 第四步 集群测试\n1 2 3 hadoop fs -mkdir -p /user/kun/input hadoop fs -put etc/hadoop/*.xml /user/kun/input hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.10.0.jar wordcount /user/kun/input /user/kun/output 集群时间同步 第一步 配置一台机器为时间服务器\n1 yum install ntp 第二步 配置/etc/ntp.conf\n# 授权192.168.1.0-192.168.1.255网段上的所有机器可以从这台机器上查询和同步时间 restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap # 集群在局域网中,不使用其他互联网上的时间,使用自己的时钟 #server 0.centos.pool.ntp.org iburst #server 1.centos.pool.ntp.org iburst #server 2.centos.pool.ntp.org iburst #server 3.centos.pool.ntp.org iburst # 当该节点丢失网络连接,依然可以采用本地时间作为时间服务器为集群中的其他节点提供时间同步 server 127.127.1.0 # 时间精准等级 fudge 127.127.1.0 stratum 10 第三步 配置/etc/sysconfig/ntpd\nsync_hwclock=yes 第四步 重新启动ntpd服务\n1 2 systemctl restart ntpd chkconfig ntpd on 第五步 配置其它机器同步时间服务器\n1 2 crontab -e # */10 * * * * /usr/sbin/ntpdate centos161 第六步 修改任意机器时间查看机器是否与时间服务器同步\n1 2 3 4 date -s \u0026#34;2017-9-11 11:11:11\u0026#34; # 等待同步 date 三、hdf的概述 hdfs (hadoop distributed file system)是个分布式的文件系统,用于存储文件,通过目录树来定位文件。\nhdfs的使用场景:适合一次写入,多次读出的场景,且不支持文件的修改。适合做数据分析,不适合用来做网盘应用,实时性差。\nhdfs的优点\n高容错性 适合大数据处理 可构建在廉价机器上 hdfs的缺点\n不适合低延时数据访问,比如毫秒级的存储数据 无法高效的对大量小文件进行存储 存储大量小文件的话,它会占用narmenode大量的内存来存储文件 小文件存储的寻址时间会超过读取时间,它违反了hdfs的设计目标 不支持并发写入、文件随机修改 不允许多个线程同时写 仅支持数据追加,不支持文件的随机修改 hdfs架构\nnamenode:①管理hdfs名称空间;②配置副本策略;③管理数据块映射信息;④处理客户端读写请求;\ndatanode:①存储实际的数据块;②执行数据块的读/写请求;\nclient:①文件切分,文件上传时切分为一块块block;②namenode交互获取文件位置信息;③datanode交互读写文件;\nsecondarynamenode:①辅助namenode,分担定期工作如fsimage、edits;②紧急情况下辅助恢复namenode;\n四、hdfs的操作 shell操作 ①查看文件列表hadoop fs -ls /path,可选参数-r【递归展示相当于tree】\n②创建目录hadoop fs -mkdir /path/dir,可选参数-p【创建多级目录】\n③剪切本地文件到服务器hadoop fs -movefromlocal file /path\n④追加本地文件到服务器hadoop fs -appendtofile file /path\n⑤查看文件 hadoop fs -cat /path/file\n⑥复制本地文件到服务器hadoop fs -copyfromlocal file /path或hadoop fs -put file /path\n⑦从服务器拷贝到本地hadoop fs -copytolocal /path file或hadoop fs -get /path file\n⑧服务器文件拷贝hadoop fs -cp /path /path\n⑨服务器文件剪切hadoop fs -mv /path /path\n⑩合并多个文件进行下载hadoop fs -getmerge /path/* file\n⑪查看文件后几行hadoop fs -tail /path\n⑫删除文件或文件夹hadoop fs -rm -f /path\n⑬统计文件夹的大小信息hadoop fs -du -h /\n⑭文件副本数量hadoop fs -setrep 10 /path\n⑮修改文件权限chown chgrp chmod\nhdfs的api操作 创建目录 1 2 3 4 5 6 7 8 9 @test public void mkdirtest() throws exception { configuration configuration = new configuration(); configuration.set(\u0026#34;dfs.replication\u0026#34;, \u0026#34;2\u0026#34;); filesystem filesystem = filesystem.get(new uri(\u0026#34;hdfs://192.168.1.161:9000\u0026#34;), configuration, \u0026#34;kun\u0026#34;); boolean success = filesystem.mkdirs(new path(\u0026#34;/java/api/input\u0026#34;)); log.info(\u0026#34;执行结果{}\u0026#34;, success); filesystem.close(); } 上传操作 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 @test public void copytest() throws exception { configuration configuration = new configuration(); filesystem filesystem = filesystem.get(new uri(\u0026#34;hdfs://192.168.1.161:9000\u0026#34;), configuration, \u0026#34;kun\u0026#34;); filesystem.copytolocalfile(false, new path(\u0026#34;/input/sanguo\u0026#34;), new path(\u0026#34;f:\\\\input\u0026#34;)); filesystem.close(); } @test public void ioinputtest() throws exception { configuration configuration = new configuration(); filesystem filesystem = filesystem.get(new uri(\u0026#34;hdfs://192.168.1.161:9000\u0026#34;), configuration, \u0026#34;kun\u0026#34;); inputstream inputstream = new fileinputstream(new file(\u0026#34;f:\\\\input\\\\sanguo\\\\wuguo.txt\u0026#34;)); outputstream outputstream = filesystem.create(new path(\u0026#34;/wuguo.txt\u0026#34;)); ioutils.copybytes(inputstream, outputstream, configuration); filesystem.close(); } 下载操作 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 @test public void copytest() throws exception { configuration configuration = new configuration(); filesystem filesystem = filesystem.get(new uri(\u0026#34;hdfs://192.168.1.161:9000\u0026#34;), configuration, \u0026#34;kun\u0026#34;); filesystem.copytolocalfile(false, new path(\u0026#34;/input/sanguo\u0026#34;), new path(\u0026#34;f:\\\\input\u0026#34;)); filesystem.close(); } @test public void iodowntest() throws exception { configuration configuration = new configuration(); filesystem filesystem = filesystem.get(new uri(\u0026#34;hdfs://192.168.1.161:9000\u0026#34;), configuration, \u0026#34;kun\u0026#34;); outputstream outputstream = new fileoutputstream(new file(\u0026#34;f:\\\\input\\\\sanguo\\\\wuguo.txt\u0026#34;)); inputstream inputstream = filesystem.open(new path(\u0026#34;/wuguo.txt\u0026#34;)); ioutils.copybytes(inputstream, outputstream, configuration); filesystem.close(); } 删除操作 1 2 3 4 5 6 7 8 @test public void rmtest() throws exception { configuration configuration = new configuration(); filesystem filesystem = filesystem.get(new uri(\u0026#34;hdfs://192.168.1.161:9000\u0026#34;), configuration, \u0026#34;kun\u0026#34;); boolean success = filesystem.delete(new path(\u0026#34;/input/sanguo\u0026#34;), false); log.info(\u0026#34;执行结果{}\u0026#34;, success); filesystem.close(); } 重命名操作 1 2 3 4 5 6 7 8 @test public void renametest() throws exception { configuration configuration = new configuration(); filesystem filesystem = filesystem.get(new uri(\u0026#34;hdfs://192.168.1.161:9000\u0026#34;), configuration, \u0026#34;kun\u0026#34;); boolean success = filesystem.rename(new path(\u0026#34;/input/sanguo\u0026#34;), new path(\u0026#34;/input/threeking\u0026#34;)); log.info(\u0026#34;执行结果{}\u0026#34;, success); filesystem.close(); } 文件详情获取 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 @test public void filedetailtest() throws exception { configuration configuration = new configuration(); filesystem filesystem = filesystem.get(new uri(\u0026#34;hdfs://192.168.1.161:9000\u0026#34;), configuration, \u0026#34;kun\u0026#34;); /** * listfiles:只能列出文件,可控制是否递归 * listlocatedstatus: 只能获取当前目录下的目录和文件 * liststatusiterator: 和listlocatedstatus相似,但返回的是文件块状态信息少 */ remoteiterator\u0026lt;locatedfilestatus\u0026gt; listfiles = filesystem.listlocatedstatus(new path(\u0026#34;/input/threeking\u0026#34;)); while (listfiles.hasnext()) { locatedfilestatus filestatus = listfiles.next(); log.info(\u0026#34;文件名:{}\u0026#34;, filestatus.getpath().getname()); log.info(\u0026#34;长度:{}\u0026#34;, filestatus.getlen()); log.info(\u0026#34;权限:{}\u0026#34;, filestatus.getpermission()); log.info(\u0026#34;是文件:{}\u0026#34;, filestatus.isfile()); log.info(\u0026#34;是目录:{}\u0026#34;, filestatus.isdirectory()); // 块信息 blocklocation[] blocklocations = filestatus.getblocklocations(); for (blocklocation blocklocation : blocklocations) { string[] hosts = blocklocation.gethosts(); for (string host : hosts) { log.info(\u0026#34;存储节点:{}\u0026#34;, host); } } } filesystem.close(); } 五、hdfs的工作机制 hdfs写数据流程 跟namenode通信请求上传文件,namenode检查目标文件是否已经存在,父目录是否已经存在 namenode返回是否可以上传 client先对文件进行切分,请求第一个block该传输到哪些datanode服务器上 namenode返回3个datanode服务器datanode 1,datanode 2,datanode 3 client请求3台中的一台datanode 1(网络拓扑上的就近原则)上传数据,datanode 1收到请求会继续调用datanode 2,然后datanode 2调用datanode 3,将整个pipeline建立完成,然后逐级返回客户端 client开始往datanode 1上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以pocket为单位。写入的时候datanode会进行数据校验,它并不是通过一个packet进行一次校验而是以chunk为单位进行校验(512byte)。datanode 1收到一个packet就会传给datanode 2,datanode 2传给datanode 3,datanode 1每传一个pocket会放入一个应答队列等待应答 一个block传输完成之后,client再次请求namenode上传第二个block的服务器. 传输完成client通知namenode hdfs的读数据流程 与namenode通信查询元数据,找到文件块所在的datanode服务器 挑选一台datanode(网络拓扑上的就近原则)服务器,请求建立socket流 datanode开始发送数据,以packet(64kb)为单位来做校验 客户端以packet为单位接收,先在本地缓存,然后写入目标文件 读完一个block继续串行读取下个block namenode和secondarynamenode工作机制 fsimage:namenode内存中元数据序列化后形成的文件;edits:记录客户端更新元数据信息的每一步操作\n第一阶段:namenode启动\n第一次启动格式化后的namenode时,创建fsimage和edits文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存 客户端对元数据进行增删改的请求 namenode记录操作日志,更新滚动日志 namenode在内存中对数据进行增删改 第二阶段:secondary namenode工作\nsecondary namenode询问namenode是否需要checkpoint secondary namenode请求执行checkpoint namenode滚动正在写的edits日志 将滚动前的编辑日志和镜像文件拷贝到secondary namenode secondary namenode加载编辑日志和镜像文件到内存,并合并 生成新的镜像文件fsimage.chkpoint 拷贝fsimage.chkpoint到namenode namenode将fsimage.chkpoint重新命名成fsimage checkpoint的判断 ①默认情况下,secondarynamenode每隔一小时执行一次\n1 2 3 4 \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;dfs.namenode.checkpoint.period\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;3600\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; ②一分钟检查一次操作次数,3当操作次数达到1百万时,secondarynamenode执行一次\n1 2 3 4 5 6 7 8 9 10 11 \u0026lt;!-- 操作次数的阈值 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;dfs.namenode.checkpoint.txns\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;1000000\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;!-- 检查是否到达操作阈值的时间 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;dfs.namenode.checkpoint.check.period\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;60\u0026lt;/value\u0026gt; \u0026lt;/property \u0026gt; namenode故障处理 方式一:将secondarynamenode中数据拷贝到namenode存储数据的目录\n方式二:将检查点时间改小【之后需要改回去】,之后给secondarynamenode存储数据的目录拷贝到namenode存储数据的平级目录,并删除in_use.lock文件。导入检查点数据bin/hdfs namenode -importcheckpoint,等待一会之后退出\n集群安全模式 namenode启动\n\tnamenode启动时,首先将镜像文件(fsimage)载入内存,并执行编辑日志(edits) 中的各项操作。一旦在内存中成功建立文件系统元数据的映像,则创建一个新的fsimage文件和一个空的编辑日志。此时,namenode开始监听datanode请求。这个过程期间namenode一直运行在安全模式,即namenode的文件系统对于客户端来说是只读的。\ndatanode启动\n\t系统中的数据块的位置并不是由namenode维护的,而是以块列表的形式存储在datanode中。在系统的正常操作期间,namenode 会在内存中保留所有块位置的映射信息。在安全模式下,各个datanode会向namenode发送最新的块列表信息,namenode了解到足够多的块位置信息之后,即可高效运行文件系统。\n安全模式退出判断\n\t如果满足\u0026quot;最小副本条件\u0026quot;,namenode会在30秒钟之后就退出安全模式。所谓的最小副本条件指的是在整个文件系统中99.9%的块满足最小副本级别(默认值: dfs.replication.min=1)。在启动一个刚刚格式化的hdfs集群时,因为系统中还没有任何块,所以namenode不会进入安全模式。\n安全模式操作命令\nhdfs dfsadmin -safemode get【查看安全模式状态】 hdfs dfsadmin -safemode enter【进入安全模式状态】 hdfs dfsadmin -safemode leave【离开安全模式状态】 hdfs dfsadmin -safemode wait【等待安全模式结束】 namenode多目录配置 namenode的本地目录可以配置成多个,每个目录存放内容相同,增加了可靠性\n第一步:配置hdfs-site.xml\n1 2 3 4 \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;dfs.namenode.name.dir\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;file:///${hadoop.tmp.dir}/dfs/name1,file:///${hadoop.tmp.dir}/dfs/name2\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; 第二步:重新格式化namenode\ndatanode工作机制 一个数据块在datanode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳 datanode启动后向namenode注册,通过后,周期性(1小时)的向namenode上报所有的块信息 每3秒进行一次心跳检测,心跳返回结果带有namenode给该datanode的命令【如复制块数据到另一台机器或删除某个数据块】如果超过10分钟没有收到某个datanode的心跳,则认为该节点不可用。 掉线时限参数设置 当datanode进程死亡或者网络故障导致无法与namenode进行通讯时,namenode不会立即将此datanode移除,而是要经过一段时间(默认时长为10m30s)\n计算公式为:2 * dfs.namenode.heartbeat.recheck-interval + 10 * dfs.heartbeat.interval\n可在hdfs-site.xml配置\n1 2 3 4 5 6 7 8 9 10 11 \u0026lt;!-- 单位毫秒 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;dfs.namenode.heartbeat.recheck-interval\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;300000\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;!-- 单位秒 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;dfs.heartbeat.interval\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;3\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; 添加节点 第一步:确保新加入的节点的logs和data文件为空\n第二步:配置/etc/hosts,拷贝hadoop的etc目录下的文件\n第三步:启动sbin/hadoop-daemon.sh start datanode和sbin/yarn-daemon.sh start nodemanager\n如果出现数据不均衡的情况,应使用sbin/start-balancer.sh均衡数据\n白名单【应在集群创建时规划】 第一步:创建etc/hadoop/dfs.hosts文件\n1 2 3 4 centos161 centos162 centos163 centos164 第二步:配置hdfs-site.xml\n1 2 3 4 \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;dfs.hosts\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;/opt/module/hadoop/etc/hadoop/dfs.hosts\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; 第三步:分发hdfs-site.xml\n第四步:刷新节点\n1 2 hdfs dfsadmin -refreshnodes yarn rmadmin -refreshnodes 注意:存在与白名单外的已有数据节点,数据不会变化\n黑名单【应在退役节点时使用】 第一步:创建etc/hadoop/dfs.hosts.exclude文件\n1 centos164 第二步:配置hdfs-site.xml\n1 2 3 4 \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;dfs.hosts.exclude\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;/opt/module/hadoop/etc/hadoop/dfs.hosts.exclude\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; 第三步:分发hdfs-site.xml\n1 2 hdfs dfsadmin -refreshnodes yarn rmadmin -refreshnodes 第四步:刷新节点\n注意:同一个主机不能同时存在再黑白名单中。存在与黑名单内的已有数据节点,数据会分配给其它节点\n多目录配置 datanode也可以配置成多个目录,每个目录存储的数据不一样【数据不是副本】\n配置hdfs-site.xml\n1 2 3 4 \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;dfs.datanode.data.dir\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;file:///${hadoop.tmp.dir}/dfs/data1,file:///${hadoop.tmp.dir}/dfs/data2\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; 六、hdfs其它 小文件存档 归档文件\n1 hadoop archive -archivename input.har -p /src *.xml /dest -p:指定父目录,后面的源文件可以使用相对路径\n查看归档文件\n1 hadoop fs -ls -r har:///dest/input.har 解归档文件\n1 hadoop fs -cp har:///dest/input.har/* /noarchive 快照管理 快照相当于是对目录做一个备份,并未对数据做备份,只是记录了文件的变化。\n启用目录快照功能:hdfs dfsadmin -allowsnapshot /dir\n禁用目录快照功能:hdfs dfsadmin -disallowsnapshot /dir\n对目录创建快照:hdfs dfs -createsnapshot /dir snapshotname\n重命名快照:hdfs dfs -renamesnapshot snapshotname newsnapshotname\n列出当前用户所有可快照目录:hdfs lssnapshottabledir\n比较两个快照目录的不同之处:hdfs snapshotdiff\n七、mapreduce概述 \tmapreduce是一个基于hadoop的数据分析应用的分布式运算程序的编程框架。mapreduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个hadoop集群上。\nmapreduce的优点:\n①易于编程,只需简单的实现一些接口\n②良好的扩展性,当计算资源不能满足时可以通过简单增加机器来提升\n③高容错性,如果机器宕机故障会自动将上面的计算任务转移到另一节点运行\n④pb级文件以上海量数据的离线处理\nmapreduce的缺点:\n①不能实时计算\n②不擅长流式计算,即输入数据不是动态的\n③不擅长有向图计算,多个程序之间存在依赖,后一个程序的输入是前一个程序的输出,这种情况下会造成大量io\nmap之后reduce之前称之为shuffle\n八、mapreduce编程 wordcount入门案例 案例说明:计算单词出现的次数\n自定义mapper 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 @slf4j public class wordcountmapper extends mapper\u0026lt;longwritable, text, text, intwritable\u0026gt; { private text outkey = new text(); private intwritable outvalue = new intwritable(); // 任务开始时会被调用一次 @override protected void setup(context context) throws ioexception, interruptedexception { log.info(\u0026#34;=================wordcountmapper setup=================\u0026#34;); } @override protected void map(longwritable key, text value, context context) throws ioexception, interruptedexception { string text = value.tostring(); string[] words = text.split(\u0026#34; \u0026#34;); for (string word : words) { outkey.set(word); outvalue.set(1); context.write(outkey, outvalue); } } // 任务结束会被调用一次 @override protected void cleanup(context context) throws ioexception, interruptedexception { log.info(\u0026#34;=================wordcountmapper cleanup=================\u0026#34;); } } 自定义reducer 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 @slf4j public class wordcountreducer extends reducer\u0026lt;text, intwritable, text, intwritable\u0026gt; { private intwritable outvalue = new intwritable(); @override protected void setup(context context) throws ioexception, interruptedexception { log.info(\u0026#34;=================wordcountreduce setup=================\u0026#34;); } @override protected void reduce(text key, iterable\u0026lt;intwritable\u0026gt; values, context context) throws ioexception, interruptedexception { int count = 0; for (intwritable value : values) { count += value.get(); } outvalue.set(count); context.write(key, outvalue); } @override protected void cleanup(context context) throws ioexception, interruptedexception { log.info(\u0026#34;=================wordcountreduce cleanup=================\u0026#34;); } } 自定义driver 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 public class wordcountdriver { public static void main(string[] args) throws exception { // 获取job configuration configuration = new configuration(); configuration.set(\u0026#34;fs.defaultfs\u0026#34;, \u0026#34;hdfs://192.168.1.161:9000\u0026#34;); job job = job.getinstance(configuration); // 设置jar位置 job.setjarbyclass(wordcountdriver.class); // 关联mapper和reducer job.setmapperclass(wordcountmapper.class); job.setreducerclass(wordcountreducer.class); // 设置mapper阶段输出的kv类型 job.setmapoutputkeyclass(text.class); job.setmapoutputvalueclass(intwritable.class); // 设置最后输出的kv类型 job.setoutputkeyclass(text.class); job.setoutputvalueclass(intwritable.class); // 设置程序输出的输入路径和输出路径 fileinputformat.setinputpaths(job, new path(\u0026#34;hdfs://192.168.1.161:9000/input\u0026#34;)); fileoutputformat.setoutputpath(job, new path(\u0026#34;hdfs://192.168.1.161:9000/output\u0026#34;)); // 提交job job.submit(); job.waitforcompletion(true); } } 自定义序列化 案例说明:统计手机的上下行流量\n自定义序列化bean 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 /** * 必须提供无参构造函数 * 实现writable接口,write和readfields字段顺序必须完全一致 * 重新tostring提供输出到文件的格式 * 如果需要将自定义的bean放在key中传输还要实现comparable接口 * 必须有值,否则序列化报错 */ @data @noargsconstructor public class flowerbean implements writable { private string name; private long upflow; private long downflow; private long sumflow; @override public void write(dataoutput out) throws ioexception { out.writeutf(name); out.writelong(upflow); out.writelong(downflow); out.writelong(sumflow); } @override public void readfields(datainput in) throws ioexception { this.name = in.readutf(); this.upflow = in.readlong(); this.downflow = in.readlong(); this.sumflow = in.readlong(); } @override public string tostring() { return name + \u0026#39;\\t\u0026#39; + upflow + \u0026#39;\\t\u0026#39; + downflow + \u0026#39;\\t\u0026#39; + sumflow; } } 定义mapper 1 2 3 4 5 6 7 8 9 10 11 12 13 public class flowermapper extends mapper\u0026lt;longwritable, text, text, flowerbean\u0026gt; { @override protected void map(longwritable key, text value, context context) throws ioexception, interruptedexception { string linetext = value.tostring(); string[] values = linetext.split(\u0026#34;\\t\u0026#34;); flowerbean flowerbean = new flowerbean(); flowerbean.setname(values[1]); flowerbean.setupflow(long.parselong(values[values.length-3])); flowerbean.setdownflow(long.parselong(values[values.length-2])); context.write(new text(values[1]), flowerbean); } } 定义reducer 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public class flowerreducer extends reducer\u0026lt;text, flowerbean, text, flowerbean\u0026gt; { @override protected void reduce(text key, iterable\u0026lt;flowerbean\u0026gt; values, context context) throws ioexception, interruptedexception { flowerbean flowerbean = new flowerbean(); long downflow = 0; long upflow = 0; for (flowerbean value : values) { downflow += value.getdownflow(); upflow += value.getupflow(); } long sumflow = upflow + downflow; flowerbean.setupflow(upflow); flowerbean.setdownflow(downflow); flowerbean.setsumflow(sumflow); flowerbean.setname(key.tostring()); context.write(key, flowerbean); } } 定义driver 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public class flowerdriver { public static void main(string[] args) throws exception { // 获取job configuration configuration = new configuration(); configuration.set(\u0026#34;fs.defaultfs\u0026#34;, \u0026#34;hdfs://192.168.1.161:9000\u0026#34;); job job = job.getinstance(configuration); // 关联mapper和reducer job.setmapperclass(flowermapper.class); job.setreducerclass(flowerreducer.class); // 设置mapper阶段输出的kv类型 job.setmapoutputkeyclass(text.class); job.setmapoutputvalueclass(flowerbean.class); // 设置最后输出的kv类型 job.setoutputkeyclass(text.class); job.setoutputvalueclass(flowerbean.class); // 设置程序输出的输入路径和输出路径 fileinputformat.setinputpaths(job, new path(\u0026#34;/input/flower\u0026#34;)); fileoutputformat.setoutputpath(job, new path(\u0026#34;/output\u0026#34;)); // 提交job job.submit(); job.waitforcompletion(true); } } inputformat数据输入 textfileinputformat(默认) ①简单的按照文件的内容长度进行切片\n②切片大小,默认等于block大小\n③切片是不考虑数据集整体,而是逐个针对每个文件单独切片\n④key为每行首单词再全文本的偏移量,value为行内容\n切片案例:\n1 2 3 file_1.txt 350m -\u0026gt; file_1.txt.split1 128m;file_1.txt.split2 128m;file_3.txt.split1 94m file_2.txt 10m -\u0026gt; file_2.txt.split1 10m file_3.txt 129m -\u0026gt; file_3.txt.split1 129m 注:物理存储是128m一块,切片是最后一片大小可以是存储的1.1倍\ncombinetextinputformat \t框架默认的textinputformat切片机制是对任务按文件规划切片,不管文件多小,都会是一个单独的切片,都会交给一个maptask,这样如果有大量小文件,就会产生大量的maptask,处理效率极其低下。combinetextinputformat将多个小文件规划成一个大切片。\n①提高小文件处理效率\n②key为每行首单词再全文本的偏移量,value为行内容\n切片案例:\n1 2 3 4 5 6 7 8 9 ①如果最大切片大小设置为4m,文件剩余大小大于4m但小于8m则将最后两端进行平均切分 file_1.txt 10m -\u0026gt; file_1.txt.split1 4m;file_1.txt.split2 3m;file_1.txt.split3 3m file_2.txt 2m -\u0026gt; file_2.txt.split1 2m file_3.txt 6m -\u0026gt; file_3.txt.split1 3m;file_3.txt.split2 3m ②进行组合,两个切片相加小于4m继续加,如果大于等于4m则停止且为一个切片 切片1:file_1.txt.split1 4m; 切片2:file_1.txt.split2 3m;file_3.txt.split1 3m; 切片3:file_2.txt.split1 2m;file_3.txt.split1 3m; 切片4:file_3.txt.split2 3m 代码设置:\n1 2 job.setinputformatclass(combinetextinputformat.class); combinetextinputformat.setmaxinputsplitsize(job, 128 * 1024 * 1024);// 128m keyvaluetextinputformat ①以每行首单词(自定义切分规则)作为key,行除去key的内容作为value\n②切片大小,默认等于block大小\n1 2 3 4 // 设置切割符,必须再得到job实例之前 configuration.set(keyvaluelinerecordreader.key_value_seperator, \u0026#34; \u0026#34;); job job = job.getinstance(configuration); job.setinputformatclass(keyvaluetextinputformat.class); nlineinputformat ①按照行切分,切片数为行数/n有余数加一\n②key为行号,value为行内容\n1 2 nlineinputformat.setnumlinespersplit(job, 3); job.setinputformatclass(nlineinputformat.class); 自定义inputformat 定义format\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public class customarchiveinputformat extends fileinputformat\u0026lt;text, byteswritable\u0026gt; { @override public recordreader\u0026lt;text, byteswritable\u0026gt; createrecordreader(inputsplit split, taskattemptcontext context) throws ioexception, interruptedexception { customarchiverecordreader customarchiverecordreader = new customarchiverecordreader(); customarchiverecordreader.initialize(split, context); return customarchiverecordreader; } /* 文件是否可以在逻辑上进行切分 */ @override protected boolean issplitable(jobcontext context, path filename) { return false; } /* 调用父方法,返回的列表包含文件夹,再将父方法返回的数据再次过滤 */ @override protected list\u0026lt;filestatus\u0026gt; liststatus(jobcontext job) throws ioexception { list\u0026lt;filestatus\u0026gt; statuslist = super.liststatus(job); return statuslist.stream().filter(filestatus::isfile).collect(collectors.tolist()); } } 定义recordreader\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 @slf4j public class customarchiverecordreader extends recordreader\u0026lt;text, byteswritable\u0026gt; { private filesplit split; private taskattemptcontext context; private byteswritable currentvalue = new byteswritable(); private text currentkey = new text(); // 每次mapper都会创建一个新的,所以初始化都为true private boolean isbegin = true; @override public void initialize(inputsplit split, taskattemptcontext context) throws ioexception, interruptedexception { this.split = (filesplit) split; this.context = context; } @override public boolean nextkeyvalue() throws ioexception, interruptedexception { log.info(\u0026#34;file【{}】开始处理\u0026#34;, split.getpath().getname()); if (isbegin) { byte[] contents = new byte[(int)split.getlength()]; path path = split.getpath(); filesystem filesystem = path.getfilesystem(context.getconfiguration()); fsdatainputstream inputstream = filesystem.open(path); currentkey.set(path.getname()); ioutils.readfully(inputstream, contents, 0, contents.length); currentvalue.set(contents, 0, contents.length); isbegin = false; return true; } return false; } @override public text getcurrentkey() throws ioexception, interruptedexception { return currentkey; } @override public byteswritable getcurrentvalue() throws ioexception, interruptedexception { return currentvalue; } @override public float getprogress() throws ioexception, interruptedexception { return 0; } @override public void close() throws ioexception { log.info(\u0026#34;file【{}】已完成\u0026#34;, split.getpath().getname()); } } 定义mapper和reducer\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 @slf4j public class customarchivemapper extends mapper\u0026lt;text, byteswritable, text, byteswritable\u0026gt; { @override protected void map(text key, byteswritable value, context context) throws ioexception, interruptedexception { context.write(key, value); } } @slf4j public class customarchivereducer extends reducer\u0026lt;text, byteswritable, text, byteswritable\u0026gt; { @override protected void reduce(text key, iterable\u0026lt;byteswritable\u0026gt; values, context context) throws ioexception, interruptedexception { context.write(key, values.iterator().next()); } } 定义driver\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 public class customarchivedriver { public static void main(string[] args) throws exception { // 获取job configuration configuration = new configuration(); configuration.set(\u0026#34;fs.defaultfs\u0026#34;, \u0026#34;hdfs://192.168.1.161:9000\u0026#34;); job job = job.getinstance(configuration); // 设置jar位置 job.setjarbyclass(customarchivedriver.class); // 关联mapper和reducer job.setmapperclass(customarchivemapper.class); job.setreducerclass(customarchivereducer.class); job.setinputformatclass(customarchiveinputformat.class); // 设置mapper阶段输出的kv类型 job.setmapoutputkeyclass(text.class); job.setmapoutputvalueclass(byteswritable.class); // 设置最后输出的kv类型 job.setoutputkeyclass(text.class); job.setoutputvalueclass(byteswritable.class); // 设置程序输出的输入路径和输出路径 fileinputformat.setinputpaths(job, new path(\u0026#34;hdfs://192.168.1.161:9000/input\u0026#34;)); fileoutputformat.setoutputpath(job, new path(\u0026#34;hdfs://192.168.1.161:9000/output\u0026#34;)); // 提交job job.submit(); job.waitforcompletion(true); } } 分区 maper通过collector输出到环形缓冲区的使用默认分区是hashpartition分区,是根据key的hashcode对reducertask个数取模得到的,用户无法控制输出到哪个分区。可以通过自定义partition进行控制。\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 /** * 一下代码没用取模的方式,所以如果tasknum设置小于5,返回值会大于numpartitions * 分区号必须从0开始,逐一累加 */ public class custompartition extends partitioner\u0026lt;text, flowerbean\u0026gt; { @override public int getpartition(text text, flowerbean flowerbean, int numpartitions) { string phone = text.tostring(); if(phone.startswith(\u0026#34;139\u0026#34;)) { return 0; } if(phone.startswith(\u0026#34;183\u0026#34;)) { return 1; } if(phone.startswith(\u0026#34;135\u0026#34;)) { return 2; } if(phone.startswith(\u0026#34;137\u0026#34;)) { return 3; } return 4; } } public class flowerdriver { public static void main(string[] args) throws exception { // 。。。 job.setpartitionerclass(custompartition.class); job.setnumreducetasks(5); // 。。。 } } 如果[ reducetask的数量 \u0026gt; partition的数量 ],则会产生几个空的输出文件\n如果[ 1 \u0026lt; reducetask的数量 \u0026lt; partition的数量 ],则部分数据因为找不到输出文件报错\n如果[ reducetask的数量 = 1 ],则不管maptask端输出,最终都输出到一个文件\n排序 maptask和reducetask均会对数据按照key进行排序。该操作属于hadoop的默认行为。任何程序数据均会被排序,而不管逻辑上是否需要。默认是使用快速排序按照字典顺序排序。\nmaptask过程中每次溢写磁盘需要进行快速排序,合并溢写文件要进行归并排序。 reducetask进行分区汇总时,如果发生溢写操作也会进行快速排序,最后合并溢写文件 自定义排序\nbean对象要实现writablecomparable接口重写compareto方法\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 /** * 现象:reducer并未将价格加和 * 原理:进入顺序 * \u0026lt;0000001,33.8\u0026gt; * \u0026lt;0000001,222.8\u0026gt; * \u0026lt;0000002,122.4\u0026gt; * ...... * * 实际数据 reducer结果 * 0000001 222.8 ==\u0026gt; 0000001 33.8 * 0000002 722.4 0000001 222.8 * 0000001 33.8 0000002 122.4 * 0000003 232.8 0000002 522.8 * 0000003 33.8 0000002 722.4 * 0000002 522.8 0000003 33.8 * 0000002 122.4 0000003 232.8 */ @data public class orderbean implements writablecomparable\u0026lt;orderbean\u0026gt; { private int orderid; // 订单id号 private double price; // 价格 @override public int compareto(orderbean o) { int orderidcompare = integer.compare(this.getorderid(), o.getorderid()); return orderidcompare == 0 ? double.compare(this.getprice(), o.getprice()) : orderidcompare; } @override public void write(dataoutput out) throws ioexception { out.writeint(orderid); out.writedouble(price); } @override public void readfields(datainput in) throws ioexception { orderid = in.readint(); price = in.readdouble(); } } public class orderreducer extends reducer\u0026lt;orderbean, nullwritable, orderbean, nullwritable\u0026gt; { @override protected void reduce(orderbean key, iterable\u0026lt;nullwritable\u0026gt; values, context context) throws ioexception, interruptedexception { orderbean currentkey = new orderbean(); for (nullwritable value : values) { currentkey.setorderid(key.getorderid()); currentkey.setprice(currentkey.getprice() + key.getprice()); currentkey.setdate(key.getdate()); } context.write(currentkey, nullwritable.get()); } } 分组排序 指对reduce阶段的数据根据某一个或几个字段进行分组, reducertask会按照key进行分组,判断下一个key是否相同,将同组的key传给reduce()执行\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 /** * 现象:reducer并将价格加和了 * 原理:进入顺序 * \u0026lt;0000001,33.8,2020-09-14\u0026gt; \u0026lt;0000001,222,2020-09-14\u0026gt; * \u0026lt;0000002,122.4,2020-09-10\u0026gt; * \u0026lt;0000002,522.8,2020-09-14\u0026gt; * \u0026lt;0000002,722.4,2020-09-12\u0026gt; * \u0026lt;0000003,33.8,2020-09-11\u0026gt; \u0026lt;0000003,232.8,2020-09-11\u0026gt; * ...... * * 实际数据 reducer结果 * 0000001 222 2020-09-14 ==\u0026gt; 0000001 255.8 2020-09-14 * 0000002 722.4 2020-09-12 0000002 122.4 2020-09-10 * 0000001 33.8 2020-09-14 0000002 522.8 2020-09-14 * 0000003 232.8 2020-09-11 0000002 722.4 2020-09-12 * 0000003 33.8 2020-09-11 0000003 266.6 2020-09-11 * 0000002 522.8 2020-09-14 * 0000002 122.4 2020-09-10 */ @data public class orderbean implements writablecomparable\u0026lt;orderbean\u0026gt; { private int orderid; private double price; private string date; @override public int compareto(orderbean o) { int orderidcompare = integer.compare(this.getorderid(), o.getorderid()); return orderidcompare == 0 ? double.compare(this.getprice(), o.getprice()) : orderidcompare; } @override public void write(dataoutput out) throws ioexception { out.writeint(orderid); out.writedouble(price); out.writeutf(date); } @override public void readfields(datainput in) throws ioexception { orderid = in.readint(); price = in.readdouble(); date = in.readutf(); } } public class ordergroupingcomparator extends writablecomparator { public ordergroupingcomparator() { super(orderbean.class,true); } @override public int compare(writablecomparable a, writablecomparable b) { orderbean abean = (orderbean) a; orderbean bbean = (orderbean) b; return abean.getdate().compareto(bbean.getdate()); } } // 获得数据按照orderid分组price排序 public class orderreducer extends reducer\u0026lt;orderbean, nullwritable, orderbean, nullwritable\u0026gt; { @override protected void reduce(orderbean key, iterable\u0026lt;nullwritable\u0026gt; values, context context) throws ioexception, interruptedexception { orderbean currentkey = new orderbean(); for (nullwritable value : values) { currentkey.setorderid(key.getorderid()); currentkey.setprice(currentkey.getprice() + key.getprice()); } context.write(currentkey, nullwritable.get()); } } combiner合并 combiner在每个maptask节点运行溢写排序和合并分区的过程中工作。combiner的存在意义是对每个maptask的结果进行局部汇总,以减少网络传输量。combiner能够使用的前提是不影响最终结果【平均值之类的操作一定不能用combiner】\ncombiner的使用方为两种:①自定义combiner类实现reducer方法;②直接设置combiner为reducer的实现类方法\noutputformat数据输出 默认的输出格式是textoutputformat,它把每条记录写为文本行。它的键和值可以是任格式,因为它的格式紧凑,很容易被压缩。\n可根据需求自定义outputformat\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 public class logoutputformat extends fileoutputformat\u0026lt;text, nullwritable\u0026gt; { @override public recordwriter\u0026lt;text, nullwritable\u0026gt; getrecordwriter(taskattemptcontext job) throws ioexception, interruptedexception { return new logrecordwriter(job); } } /** * 将数据根据行首字母分类 */ public class logrecordwriter extends recordwriter\u0026lt;text, nullwritable\u0026gt; { private fsdataoutputstream outa_q; private fsdataoutputstream outr_z; public logrecordwriter(taskattemptcontext job) { try { configuration configuration = job.getconfiguration(); filesystem filesystem = filesystem.get(configuration); string dir = configuration.get(fileoutputformat.outdir); outa_q = filesystem.create(new path(dir + \u0026#34;/\u0026#34; + \u0026#34;a-q.text\u0026#34;)); outr_z = filesystem.create(new path(dir + \u0026#34;/\u0026#34; + \u0026#34;r-z.text\u0026#34;)); } catch (ioexception e) { e.printstacktrace(); } } @override public void write(text key, nullwritable value) throws ioexception, interruptedexception { string keystr = key.tostring(); if(stringutils.isnotblank(keystr)) { char firstchar = keystr.tolowercase().charat(0); if (\u0026#39;a\u0026#39; \u0026lt;= firstchar \u0026amp;\u0026amp; firstchar \u0026lt;= \u0026#39;q\u0026#39;) { outa_q.writeutf(keystr + \u0026#34;\\n\u0026#34;); } else { outr_z.writebytes(keystr + \u0026#34;\\n\u0026#34;); } } } @override public void close(taskattemptcontext context) throws ioexception, interruptedexception { outa_q.close(); outr_z.close(); } } join的应用 join时map端的主要工作:为来自不同表或文件的key/value对,打标签以区别不同来源的记录。然后用连接字段作为key,其余部分和新加的标志作为value,最后进行输出。\njoin时reduce端的主要工作:在reduce端以连接字段作为key的分组已经完成,我们只需要在每一个分组当中将那些来源于不同文件的记录(在map阶段已经打标志)分开,最后进行合并。\nreduce join 在reduce过程中进行join操作\n缺点:这种方式中,合并的操作是在reduce阶段完成,reduce端的处理压力太大,map节点的运算负载则很低,资源利用率不高, 且在reduce阶段极易产生数据倾斜。\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 @data public class tablebean implements writable { private string orderid; private string productid; private string name; private int count; private string flag; // 表的标记 @override public void write(dataoutput out) throws ioexception { out.writeutf(orderid); out.writeutf(productid); out.writeutf(name); out.writeint(count); out.writeutf(flag); } @override public void readfields(datainput in) throws ioexception { orderid = in.readutf(); productid = in.readutf(); name = in.readutf(); count = in.readint(); flag = in.readutf(); } @override public string tostring() { return orderid + \u0026#39;\\t\u0026#39; + name + \u0026#39;\\t\u0026#39; + count + \u0026#39;\\t\u0026#39;; } } // 分类 public class tablemapper extends mapper\u0026lt;longwritable, text, text, tablebean\u0026gt; { private string filename; private tablebean tablebean = new tablebean(); private text pid = new text(); @override protected void setup(context context) throws ioexception, interruptedexception { filesplit inputsplit = (filesplit)context.getinputsplit(); filename = inputsplit.getpath().getname(); } @override protected void map(longwritable key, text value, context context) throws ioexception, interruptedexception { string[] data = value.tostring().split(\u0026#34;\\t\u0026#34;); if(filename.startswith(\u0026#34;order\u0026#34;)) { tablebean.setorderid(data[0]); tablebean.setproductid(data[1]); pid.set(data[1]); tablebean.setcount(integer.parseint(data[2])); tablebean.setname(\u0026#34;\u0026#34;); tablebean.setflag(\u0026#34;order\u0026#34;); context.write(pid, tablebean); } if(filename.startswith(\u0026#34;product\u0026#34;)) { tablebean.setorderid(\u0026#34;\u0026#34;); tablebean.setcount(0); tablebean.setproductid(data[0]); tablebean.setname(data[1]); pid.set(data[0]); tablebean.setflag(\u0026#34;product\u0026#34;); context.write(pid, tablebean); } } } public class tablereducer extends reducer\u0026lt;text, tablebean, tablebean, nullwritable\u0026gt; { @override protected void reduce(text key, iterable\u0026lt;tablebean\u0026gt; values, context context) throws ioexception, interruptedexception { list\u0026lt;tablebean\u0026gt; orderbeans = new arraylist\u0026lt;\u0026gt;(); tablebean productbean = new tablebean(); // 必须重新copy对象,不然iterator时使用自己填充,会将记录后移 for (tablebean value : values) { if(value.getflag().equals(\u0026#34;order\u0026#34;)) { tablebean bean = new tablebean(); beanutil.copyproperties(value, bean); orderbeans.add(bean); } else { beanutil.copyproperties(value, productbean); } } for (tablebean orderbean : orderbeans) { tablebean record = new tablebean(); beanutil.copyproperties(orderbean, record); record.setname(productbean.getname()); context.write(record, nullwritable.get()); } } } map join map join适用于一张表十分小、一张表很大的场景。在map端缓存多张表,提前处理业务逻辑,这样增加map端业务,减少reduce端数据的压力,尽可能的减少数据倾斜。\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 public class tablemapper extends mapper\u0026lt;longwritable, text, text, nullwritable\u0026gt; { private map\u0026lt;string, string\u0026gt; productmap = new hashmap\u0026lt;\u0026gt;(); private text k = new text(); @override protected void setup(context context) throws ioexception, interruptedexception { // 1 获取缓存的文件 uri[] cachefiles = context.getcachefiles(); string path = cachefiles[0].getpath(); configuration configuration = context.getconfiguration(); filesystem filesystem = filesystem.get(configuration); fsdatainputstream filestream = filesystem.open(new path(path)); bufferedreader reader = new bufferedreader(new inputstreamreader(filestream)); string line; while(stringutils.isnotempty(line = reader.readline())){ // 2 切割 string[] fields = line.split(\u0026#34;\\t\u0026#34;); // 3 缓存数据到集合 productmap.put(fields[0], fields[1]); } // 4 关流 reader.close(); } @override protected void map(longwritable key, text value, context context) throws ioexception, interruptedexception { // 1 获取一行 string line = value.tostring(); // 2 截取 string[] fields = line.split(\u0026#34;\\t\u0026#34;); // 3 获取产品id string pid = fields[1]; // 4 获取商品名称 string pdname = productmap.get(pid); // 5 拼接 k.set(line + \u0026#34;\\t\u0026#34;+ pdname); // 6 写出 context.write(k, nullwritable.get()); } } public class distributedcachedriver { public static void main(string[] args) throws exception { configuration configuration = new configuration(); configuration.set(\u0026#34;fs.defaultfs\u0026#34;, \u0026#34;hdfs://192.168.1.161:9000\u0026#34;); job job = job.getinstance(configuration); // 设置缓存文件 job.addcachefile(new uri(\u0026#34;hdfs://192.168.1.161:9000/join/product.txt\u0026#34;)); job.setmapoutputkeyclass(text.class); job.setmapoutputvalueclass(nullwritable.class); job.setmapperclass(tablemapper.class); job.setjarbyclass(distributedcachedriver.class); fileinputformat.setinputpaths(job, new path(\u0026#34;hdfs://192.168.1.161:9000/join\u0026#34;)); fileoutputformat.setoutputpath(job, new path(\u0026#34;hdfs://192.168.1.161:9000/output\u0026#34;)); job.submit(); job.waitforcompletion(true); } } 计数器应用 hadoop为每个作业维护若干内置计数器,以描述多项指标。例如,某些计数器记录已处理的字节数和记录数,使用户可监控已处理的输入数据量和已产生的输出数据量。\n1 2 3 4 5 6 7 /* 可使用字符串区分 */ context.getcounter(\u0026#34;status\u0026#34;, \u0026#34;success\u0026#34;).increment(1); context.getcounter(\u0026#34;status\u0026#34;, \u0026#34;fail\u0026#34;).increment(1); /* 可使用枚举 */ context.getcounter(httpstatus.success).increment(1); context.getcounter(httpstatus.fail).increment(1); 九、数据压缩 压缩算法 鉴于磁盘i/o和网络带宽是hadoop的宝贵资源,数据压缩对于节省资源、最小化磁盘i/o和网络传输非常有帮助。可以在任意mapreduce阶段启用压缩。 不过,尽管压缩与解压操作的cpu开销不高,其性能的提升和资源的节省并非没有代价。\nhadoop支持的压缩编码\n压缩格式 hadoop自带 算法 文件扩展名 是否可切分 换压缩格式后原程序是否需要修改 deflate 是 deflate .deflate 否 和文本处理一样,不需要修改 gzip 是 deflate .gz 否 和文本处理一样,不需要修改 bzip2 是 bzip2 .bz2 是 和文本处理一样,不需要修改 lzo 否 lzo .lzo 是 需要建索引,还需要指定输入格式 snappy 否 snappy .snappy 否 和文本处理一样,不需要修改 gzip压缩 优点:压缩率比较高,而且压缩解压速度也比较快;hadoop本身支持,在应用中处理gzip格式的文件就和直接处理文本一样;大部分linux系统都自带gzip命令,使用方便。 缺点:不支持split。 应用场景:当每个文件压缩之后在130m以内的(1个块大小内),都可以考虑用gzip压缩格式。 bzip2压缩 优点:支持split;具有很高的压缩率,比gzip压缩率高; hadoop本身自带,使用方便。 缺点:压缩解压速度慢。 应用场景:适合对速度要求不高,但需要较高的压缩率的时候,或者输出之后的数据比较大,处理之后的数据需要压缩存档减少磁盘空间并且以后数据用得比较少的情况,或者对单个很大的文本文件想压缩减少存储空间,同时又需要支持split,而且兼容之前的应用程序的情况。 lzo压缩 优点:压缩解压速度也比较快,合理的压缩率;支持split,可以在linux系统下安装lzop命令,使用方便。 缺点:压缩率比gzip要低一些,hadoop本身不支持,需要安装;在应用中对lzo格式的文件需要做一-些特殊处理(为了支持split需要建索引,还需要指定inputformat为lzo格式)。 应用场景:一个很大的文本文件,压缩之后还大于200m以上的可以考虑,而且单个文件越大,lzo优点越越明显。 snappy压缩 优点:高速压缩速度和合理的压缩率。 缺点:不支持split,压缩率比gzip要低,hadoop本身不支持, 需要安装。 应用场景:当mapreduce作业的map输出的数据比较大的时候,作为map到reduce的中间数据的压缩格式,或者作为一个mapreduce作业的输出和另外一个mapreduce作业的输入。 压缩位置选择 压缩参数配置 编码器 压缩格式 编码器 deflate org.apache.hadoop.io.compress.defaultcodec gzip org.apache.hadoop.io.compress.gzipcodec bzip2 org.apache.hadoop.io.compress.bzip2codec lzo com.hadoop.compression.lzo.lzopcodec snappy org.apache.hadoop.io.compress.snappycodec 配置文件参数 core-site.xml配置\n1 2 3 4 5 \u0026lt;!-- 输入压缩,hadoop使用文件扩展名判断是否支持某种编解码器,默认以下值 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;io.compression.codecs\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;org.apache.hadoop.io.compress.defaultcodec,org.apache.hadoop.io.compress.gzipcodec,org.apache.hadoop.io.compress.bzip2codec\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; mapred-site.xml配置\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 \u0026lt;!-- 这个参数设为true启用mapper输出压缩 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;mapreduce.map.output.compress\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;false\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;!-- mapper输出压缩格式,企业多使用lzo或snappy编解码器在此阶段压缩数据 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;mapreduce.map.output.compress.codec\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;org.apache.hadoop.io.compress.defaultcodec\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;!-- reducer输出是否压缩 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;mapreduce.output.fileoutputformat.compress\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;false\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;!-- reducer输出压缩格式 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;mapreduce.output.fileoutputformat.compress.codec\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;org.apache.hadoop.io.compress.defaultcodec\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;!-- 压缩类型行压缩(record)、块压缩(block)、无压缩(none),建议块压缩 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;mapreduce.output.fileoutputformat.compress.type\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;record\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; 代码设置 1 2 3 4 5 6 7 8 9 // 开启map端输出压缩 configuration.setboolean(\u0026#34;mapreduce.map.output.compress\u0026#34;, true); // 设置map端输出压缩方式 configuration.setclass(\u0026#34;mapreduce.map.output.compress.codec\u0026#34;, bzip2codec.class, compressioncodec.class); // 设置reduce端输出压缩开启 fileoutputformat.setcompressoutput(job, true); // 设置压缩的方式 fileoutputformat.setoutputcompressorclass(job, bzip2codec.class); lzo安装 下载lzo | 下载lzop | 下载hadoop-lzo-master\n第一步:编译安装lzo与lzop【每台机器都需要】 1 2 3 4 5 6 7 8 9 10 11 12 # lzo tar -xvzf lzo-[version].tar.gz ./configure --enable-shared make -j 10 make install cp /usr/local/lib/*lzo* /usr/lib # lzop tar -xvzf lzop-[version].tar.gz ./configure make -j 10 make install 第二步:安装、编译hadoop-lzo-master 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 unzip master.zip # 编辑pom.xml修改hadoop的版本号与集群中hadoop版本一致 # \u0026lt;hadoop.current.version\u0026gt;2.10.0\u0026lt;/hadoop.current.version\u0026gt; # 安装配置好maven # 导入安装需要的变量 export cflags=-m64 export cxxflags=-m64 export c_include_path=/opt/module/hadoop/lzo/include export library_path=/opt/module/hadoop/lzo/lib # maveb编译 mvn clean package -dmaven.test.skip=true # copy编译后的文件 cd target/native/linux-amd64-64/ mkdir ~/hadoop-lzo-files tar -cbf - -c lib . | tar -xbvf - -c ~/hadoop-lzo-files 第三步:拷贝编译后的文件【每台机器都需要】 1 2 cp ~/hadoop-lzo-files/libgplcompression* $hadoop_home/lib/native/ cp target/hadoop-lzo-0.4.21-snapshot.jar $hadoop_home/share/hadoop/common/ 第四步:配置hadoop配置文件【每台机器都需要】 配置core-site.xml\n1 2 3 4 5 6 7 8 9 10 11 12 13 \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;io.compression.codecs\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;org.apache.hadoop.io.compress.gzipcodec, org.apache.hadoop.io.compress.defaultcodec, com.hadoop.compression.lzo.lzocodec, com.hadoop.compression.lzo.lzopcodec, org.apache.hadoop.io.compress.bzip2codec \u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;io.compression.codec.lzo.class\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;com.hadoop.compression.lzo.lzocodec\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; 配置mapred-site.xml\n1 2 3 4 5 6 7 8 \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;mapred.compress.map.output\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;true\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;mapred.map.output.compression.codec\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;com.hadoop.compression.lzo.lzocodec\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; snappy安装 snappy下载地址\n第一步:安装snappy 1 2 3 ./configure make make install 第二步:和hadoop一起编译 1 mvn package -pdist,native -dskiptests -dmaven.javadoc.skip=true -dtar -dsnappy.lib=/usr/local/lib -dbundle.snappy 编译的hadoop下的lib/native已经存在\nlibsnappy.la libsnappy.so.1 libsnappy.so libsnappy.so.1.3.1 libsnappy.a 第三步:拷贝所有snappy的lib到集群所有hadoop机器的lib/native下 第四步:查看是否成功 1 hadoop checknative 十、yarn资源调度器 yarn基本架构 yarn主要由resourcemanager、nodemanager、applicationmaster和container等组件构成\nresource manager\n①处理客户端请求;②监控nodemanager;③启动或监控app master;④资源分配和调度\nnode manager\n①管理单个节点上的资源;②处理来自reourcemanager的命令;③处理来自app master的命令\napp master\n①负责数据的切分;②为应用程序申请资源并分配内部任务;③任务的监控与容错\ncontainer\n封装节点上多维度资源,例如:cpu、内存、磁盘、网络等\nyarn工作机制 【1】作业提交\n前置步骤:client调用job.waitforcompletion方法,向整个集群提交mapreduce作业\n第1步:client向rm申请一个作业id\n第2步:resourcemanager给client返回该job资源的提交路径和作业id\n第3步:client提交jar包、切片信息和配置文件到指定的资源提交路径\n第4步:client提交完资源后,向rm申请运行appmaster\n【2】作业初始化\n第5步:当rm收到client的请求后,将该job添加到容量调度器中\n第6步:某一个空闲的nm领取到该job\n第7步:该nodemananger创建container,并产生appmaster\n第8步:下载client提交的资源到本地\n【3】任务分配\n第9步:appmaster向resourcemanager申请运行多个maptask任务资源\n第10步:resourcemanager将运行maptask任务分配给nodemanager,nodemanager分别领取任务并创建容器\n【4】任务运行\n第11步:resourcemanager向接收到任务的nodemanager发送程序启动脚本,这些nodemanager分别启动maptask,maptask对数据分区排序\n第12步:appmaster等待所有maptask运行完毕后,向resourcemanager申请容器,运行reducetask\n第13步:reducetask向maptask获取相应分区的数据进行运算\n第14步:程序运行完毕后,mr会向rm申请注销自己\n进度和状态更新 yarn中的任务将其进度和状态包括counter返回给应用管理器, 客户端每秒【通过mapreduce.client.progressmonitor.pollinterval设置】向应用管理器请求进度更新, 展示给用户\n作业完成 除了向应用管理器请求作业进度外,客户端每5秒都会通过调用waitforcompletion()来检查作业是否完成【时间间隔可以通过mapreduce.client.completion.pollinterval设置】。作业完成之后,应用管理器和container会清理工作状态。作业的信息会被作业历史服务器存储以备之后用户核查\n资源调度器 hadoop作业调度器主要有三种:fifo、capacity scheduler【默认】和fair scheduler,在``\n1 2 3 4 \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;yarn.resourcemanager.scheduler.class\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.capacityscheduler\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; fifo scheduler\nfifo scheduler把应用按提交的顺序排成一个队列,这是一个先进先出队列,在进行资源分配的时候,先给队列中最头上的应用进行分配资源,待最头上的应用需求满足后再给下一个分配,以此类推。\nfifo scheduler是最简单也是最容易理解的调度器,也不需要任何配置,但它并不适用于共享集群。大的应用可能会占用所有集群资源,这就导致其它应用被阻塞,比如有个大任务在执行,占用了全部的资源,再提交一个小任务,则此小任务会一直被阻塞。\ncapacity scheduler\n对于capacity调度器,有一个专门的队列用来运行小任务,但是为小任务专门设置一个队列会预先占用一定的集群资源,这就导致大任务的执行时间会落后于使用fifo调度器时的时间。\nfair scheduler\n在fair调度器中,我们不需要预先占用一定的系统资源,fair调度器会为所有运行的job动态的调整系统资源。\n比如:当第一个大job提交时,只有这一个job在运行,此时它获得了所有集群资源;当第二个小任务提交后,fair调度器会分配一半资源给这个小任务,让这两个任务公平的共享集群资源。\n需要注意的是,在fair调度器中,从第二个任务提交到获得资源会有一定的延迟,因为它需要等待第一个任务释放占用的container。小任务执行完成之后也会释放自己占用的资源,大任务又获得了全部的系统资源。最终的效果就是fair调度器即得到了高的资源利用率又能保证小任务及时完成。\n任务的推测执行 因为作业完成时间取决于最慢的任务完成时间,所以当有某些节点因为自身问题拖慢任务结束时间,可使用推测执行进行优化。\n推测执行机制\n发现拖后腿的任务,比如某个任务运行速度远慢于任务平均速度。为拖后腿任务启动一个备份任务,同时运行。谁先运行完,则采用谁的结果。\n执行推测任务的前提条件\n执行推测任务的前提条件 当前job已完成的task必须不小于0.05(5%) 开启推测执行参数设置。mapred-site.xml文件中默认是打开的 1 2 3 4 \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;mapreduce.map.speculative\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;true\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; 不能启用推测执行机制情况\n任务间存在严重的负载倾斜 特殊任务,比如任务向数据库中写数据 算法原理\n推测运行时间 = (当前时刻 - 任务启动时刻) / 任务比例\n推测完成时间 = 推测运行时间 + 任务启动时刻\n备份任务推测完成时间 = 当前时刻 + 运行完成任务的平均时间\nmesourcemanager总是选择推测完成时间 - 备份任务推测完成时间 差值最大的任务,为止启动备份任务 为了防止大量任务同时启动备份任务造成的资源浪费,mesourcemanager为每个作业设置了同时启动的备份任务数目上限 十一、hadoop优化 数据输入 合并小文件在执行mr任务前将小文件进行合并,大量的小文件会产生大量的map任务,增大map任务装载次数,而任务的装载比较耗时,从而导致mr运行较慢\n采用combinetextinpntformat来作为输入, 解决输入端大量小文件场景\nmap阶段 减少溢写(spill) 次数:过调整io.sort.mb及sort.spill.percent参数值,增大触发spill的内存上限,减少spill次数,从而减少磁盘lo 减少合并(merge) 次数:通过调整io.sort.factor参数,增大merge的文件数目,减少merge的次数,从而缩短mr处理时间 在map之后,不影响业务逻辑前提下,先进行combine处理,减少i/o reduce阶段 合理设置map和reduce数:两个都不能设置太少,也不能设置太多。太少会导致task等待,延长处理时间;太多会导致map、reduce任务间竞争资源,造成处理超时等错误\n设置map、reduce共存:调整slowstart.completedmaps参数,使map运行到一定程度后,reduce也开始运行,减少reduce的等待时间。\n规避使用reduce:因为reduce在用于连接数据集的时候将会产生大量的网络消耗。\n合理设置reduce端的buffer:默认情况下,数据达到一个阈值的时候,buffer中的数据就会写入磁盘,然后reduce会从磁盘中获得所有的数据。也就是说,buffer和reduce是没有直接关联的,中间多次写磁盘~\u0026gt;读磁盘的过程,既然 有这个弊端,那么就可以通过参数来配置,使得buffer中的一部分数据可以直接输送到reduce,从而减少io开销:mapreduce reduce .input. buffer percent默认为0.0。当值大于0的时候,会保留指定比例的内存读buffer中的数据直接拿给reduce使用。这样一来, 设置buffer 需要内存,读取数据需要内存,reduce计算也要内存,所以要根据作业的运行情况进行调整。\ni/o传输 采用数据压编的方式,减少网路i/o的时间。安装snappy和lzo编码器\n数据倾斜 抽样和范围分区:可以通过对原始数据进行抽样得到的结果集来预设分区边界值。 自定义分区:基于输出键的背景知识进行自定义分区。 采用combine:使用combine可以大量地减小数据倾斜。在可能的情况下,combine的目的就是聚合并精简数据。 采用map join,尽量避免reduce join。\n常用的调优参数 配置mapred-site.xml文件\n配置参数 参数说明 mapreduce.map.memory.mb 一个maptask可使用的资源上限(单位:mb),默认为1024。如果maptask实际使用的资源量超过该值,则会被强制杀死。 mapreduce.reduce.memory.mb 一个reducetask可使用的资源上限(单位:mb),默认为1024。如果reducetask实际使用的资源量超过该值,则会被强制杀死。 mapreduce.map.cpu.vcores 每个maptask可使用的最多cpu core数目,默认值: 1 mapreduce.reduce.cpu.vcores 每个reducetask可使用的最多cpu core数目,默认值: 1 mapreduce.reduce.shuffle.parallelcopies 每个reduce去map中取数据的并行数。默认值是5 mapreduce.reduce.shuffle.merge.percent buffer中的数据达到多少比例开始写入磁盘。默认值0.66 mapreduce.reduce.shuffle.input.buffer.percent buffer大小占reduce可用内存的比例。默认值0.7 mapreduce.reduce.input.buffer.percent 指定多少比例的内存用来存放buffer中的数据,默认值是0.0 mapreduce.task.io.sort.mb shuffle的环形缓冲区大小,默认100m mapreduce.map.sort.spill.percent 环形缓冲区溢出的阈值,默认80% mapreduce.map.maxattempts 每个map task最大重试次数,一旦重试参数超过该值,则认为map task运行失败,默认值:4 mapreduce.reduce.maxattempts 每个reduce task最大重试次数,一旦重试参数超过该值,则认为map task运行失败,默认值:4 mapreduce.task.timeout task超时时间,默认600000毫秒 配置yarn-site.xml文件\n配置参数 参数说明 yarn.scheduler.minimum-allocation-mb 给应用程序container分配的最小内存,默认值:1024 yarn.scheduler.maximum-allocation-mb 给应用程序container分配的最大内存,默认值:8192 yarn.scheduler.minimum-allocation-vcores 每个container申请的最小cpu核数,默认值:1 yarn.scheduler.maximum-allocation-vcores 每个container申请的最大cpu核数,默认值:32 yarn.nodemanager.resource.memory-mb 给containers分配的最大物理内存,默认值:8192 hdfs小文件优化方法 hadoop archive:是一个高效地将小文件放入hdfs块中的文件存档工具,它能够将多个小文件打包成一个har文件, 这样就减少了namename的内存使用。 combinefileinputformat:用于将多个文件合并成一个单独的split 开启jvm重用mapred-site.xml配置mapreduce.job.jvm.num.tasks,默认为1 十二、hadoop高可用 前提条件:已经搭建zookeeper集群,yum install psmisc\n第一步:配置core-site.xml 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 \u0026lt;!-- zk集群 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;ha.zookeeper.quorum\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;centos161:2181,centos162:2181,centos163:2181\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;!-- 指定hdfs中namenode的地址,配置为集群的 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;fs.defaultfs\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;hdfs://hacluster\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;!-- 指定hadoop运行时产生文件的存储目录 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;hadoop.tmp.dir\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;/opt/module/ha/hadoop/data/tmp\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; 第二步:配置hdfs-site.xml 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 \u0026lt;!-- 集群名称 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;dfs.nameservices\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;hacluster\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;!-- 自动故障转移 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;dfs.ha.automatic-failover.enabled\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;true\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;!-- 配置namenode --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;dfs.ha.namenodes.hacluster\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;nn1,nn2\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;dfs.namenode.rpc-address.hacluster.nn1\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;centos161:8020\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;dfs.namenode.rpc-address.hacluster.nn2\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;centos162:8020\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;dfs.namenode.http-address.hacluster.nn1\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;centos161:50070\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;dfs.namenode.http-address.hacluster.nn2\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;centos162:50070\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;!-- 配置journalnode --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;dfs.namenode.shared.edits.dir\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;qjournal://centos161:8485;centos162:8485;centos163:8485/hacluster\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;dfs.client.failover.proxy.provider.mycluster\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;org.apache.hadoop.hdfs.server.namenode.ha.configuredfailoverproxyprovider\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;dfs.journalnode.edits.dir\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;/opt/module/ha/hadoop/data/tmp/dfs/jn\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;!-- ssh登陆配置 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;dfs.ha.fencing.methods\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;sshfence\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;dfs.ha.fencing.ssh.private-key-files\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;/home/kun/.ssh/id_rsa\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;dfs.replication\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;3\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;dfs.namenode.name.dir\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;file:///${hadoop.tmp.dir}/dfs/name\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;dfs.datanode.data.dir\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;file:///${hadoop.tmp.dir}/dfs/data\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; 第三步:配置yarn-site.xml 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;yarn.nodemanager.aux-services\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;mapreduce_shuffle\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;!-- 启用resourcemanager ha --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;yarn.resourcemanager.ha.enabled\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;true\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;!-- 声明两台resourcemanager的地址 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;yarn.resourcemanager.cluster-id\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;ha-yarn-cluster\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;yarn.resourcemanager.ha.rm-ids\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;rm1,rm2\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;yarn.resourcemanager.hostname.rm1\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;centos162\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;yarn.resourcemanager.hostname.rm2\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;centos163\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;!-- 指定zookeeper集群的地址 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;yarn.resourcemanager.zk-address\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;centos161:2181,centos162:2181,centos163:2181\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;!-- 启用自动恢复 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;yarn.resourcemanager.recovery.enabled\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;true\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;!-- 指定resourcemanager的状态信息存储在zookeeper集群 --\u0026gt; \u0026lt;property\u0026gt; \u0026lt;name\u0026gt;yarn.resourcemanager.store.class\u0026lt;/name\u0026gt; \u0026lt;value\u0026gt;org.apache.hadoop.yarn.server.resourcemanager.recovery.zkrmstatestore\u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; 集群群起 ①启动所有jn节点启动journalnode服务[奇数个]\n1 sbin/hadoop-daemon.sh start journalnode ②格式化\n1 2 3 4 5 6 7 8 9 10 # namenode 1 上格式化 bin/hdfs namenode -format sbin/hadoop-daemon.sh start namenode # namenode 2 同步元数据 bin/hdfs namenode -bootstrapstandby sbin/hadoop-daemon.sh start namenode # 停止服务 sbin/stop-dfs.sh ③初始化ha在zookeeper中状态\n1 bin/hdfs zkfc -formatzk ④群起hdfs\n1 2 3 4 sbin/start-dfs.sh # 查看namenode节点zkfc服务启动状态,低版本没启动使用下面命令启动 sbin/hadoop-daemin.sh start zkfc ⑤启动yarn\n1 2 3 4 5 6 7 8 # 在resourcemanager节点启动 sbin/start-yarn.sh # 查看resourcemanager节点启动状态,低版本没启动使用下面命令启动 sbin/yarn-daemon.sh start resourcemanager # 查看状态 bin/yarn rmadmin -getservicestate rm1 附录 zk节点脚本\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 #!/bin/bash host_name_arr=(\u0026#39;centos161\u0026#39; \u0026#39;centos162\u0026#39; \u0026#39;centos163\u0026#39;) for host_name in ${host_name_arr[*]} do echo \u0026#39;========================\u0026#39;$host_name\u0026#39;========================\u0026#39; if [ \u0026#34;$1\u0026#34; == \u0026#34;start\u0026#34; ] ; then ssh $host_name \u0026#34;/opt/module/zookeeper/bin/zkserver.sh start\u0026#34; fi if [ \u0026#34;$1\u0026#34; == \u0026#34;status\u0026#34; ] ; then ssh $host_name \u0026#34;/opt/module/zookeeper/bin/zkserver.sh status\u0026#34; fi echo -e \u0026#39;\\n\u0026#39; done 自定义driver官方格式\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 public class flowerdriver implements tool { private configuration configuration; public static void main(string[] args) throws exception { int res = toolrunner.run(new flowerdriver(), args); system.exit(res); } @override public int run(string[] args) throws exception { // 获取job job job = job.getinstance(this.configuration); // 关联mapper和reducer job.setmapperclass(flowermapper.class); job.setreducerclass(flowerreducer.class); // 设置mapper阶段输出的kv类型 job.setmapoutputkeyclass(text.class); job.setmapoutputvalueclass(flowerbean.class); // 设置最后输出的kv类型 job.setoutputkeyclass(text.class); job.setoutputvalueclass(flowerbean.class); // 设置程序输出的输入路径和输出路径 fileinputformat.setinputpaths(job, new path(args[0])); fileoutputformat.setoutputpath(job, new path(args[1])); // 提交job job.submit(); return job.waitforcompletion(true) ? 0 : -1; } @override public void setconf(configuration conf) { this.configuration = conf; } @override public configuration getconf() { return configuration; } } 执行方法:hadoop jar xxx.jar qualifiedclassname -dmapred.map.tasks=nums -dmapred.reduce.tasks=nums input output\n","date":"2020-09-24","permalink":"https://hobocat.github.io/post/hadoop/2020-09-24-hadoop/","summary":"一、Hadoop和大数据简介 大数据 大数据(BigData) :指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的","title":"hadoop基础"},]
[{"content":"一、集成spring boot 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;com.baomidou\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;mybatis-plus-boot-starter\u0026lt;/artifactid\u0026gt; \u0026lt;version\u0026gt;[version]\u0026lt;/version\u0026gt; \u0026lt;/dependency\u0026gt; \u0026lt;!-- 用于生成逆向工程 --\u0026gt; \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;com.baomidou\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;mybatis-plus-generator\u0026lt;/artifactid\u0026gt; \u0026lt;version\u0026gt;[version]\u0026lt;/version\u0026gt; \u0026lt;scope\u0026gt;test\u0026lt;/scope\u0026gt; \u0026lt;/dependency\u0026gt; \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;org.freemarker\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;freemarker\u0026lt;/artifactid\u0026gt; \u0026lt;version\u0026gt;[version]\u0026lt;/version\u0026gt; \u0026lt;scope\u0026gt;test\u0026lt;/scope\u0026gt; \u0026lt;/dependency\u0026gt; 二、逆向工程配置 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 public class codegenerator { private static final string project_path = system.getproperty(\u0026#34;user.dir\u0026#34;); // 表名 private static final string table_name = \u0026#34;user\u0026#34;; // 逻辑删除字段 private static final string logic_delete_field_name = \u0026#34;is_delete\u0026#34;; // 是否覆盖 private static final boolean file_override = true; // 模块名称 private static final string module_name = \u0026#34;user\u0026#34;; // 数据库配置 private static final string database_url = \u0026#34;jdbc:mysql://localhost:3306/book?useunicode=true\u0026amp;characterencoding=utf-8\u0026amp;servertimezone=asia/shanghai\u0026#34;; private static final string database_driver = \u0026#34;com.mysql.cj.jdbc.driver\u0026#34;; private static final string database_user_name = \u0026#34;root\u0026#34;; private static final string database_password = \u0026#34;123456\u0026#34;; @test public void generator() { // 代码生成器 autogenerator autogenerator = new autogenerator(); // 全局配置 autogenerator.setglobalconfig(getglobalconfig()); // 数据源配置 autogenerator.setdatasource(getdatasourceconfig()); // 包配置 autogenerator.setpackageinfo(getpackageconfig()); // 自定义配置 autogenerator.setcfg(getinjectionconfig()); // 如需配置自定义输出模板,可以对以下对象进行扩展 templateconfig templateconfig = new templateconfig(); // 自定义路径,不需要默认的xml路径再次生成 templateconfig.setxml(null); autogenerator.settemplate(templateconfig); // 策略配置,除基本设置以为还具有以下功能: // 可以配置各层的父类,和实体类公用的字段【公用字段在子类不在生成】 // 可以设置表前缀 // 可以设置controller的请求路径驼峰转连字符 autogenerator.setstrategy(getstrategyconfig()); // 设置模板引擎 autogenerator.settemplateengine(new freemarkertemplateengine()); autogenerator.execute(); } private injectionconfig getinjectionconfig() { // 如要自定义模板,可添加模板里面的变量 injectionconfig injectionconfig = new injectionconfig() { @override public void initmap() { } }; // 如果模板引擎是 freemarker string templatepath = \u0026#34;/templates/mapper.xml.ftl\u0026#34;; // 自定义输出配置 list\u0026lt;fileoutconfig\u0026gt; fileoutconfigs = new arraylist\u0026lt;\u0026gt;(); // 自定义配置会被优先输出,默认xml生成在对应mapper下,一般需要更改 fileoutconfigs.add(new fileoutconfig(templatepath) { @override public string outputfile(tableinfo tableinfo) { // 自定义输出文件名 , 如果你 entity 设置了前后缀、此处注意 xml 的名称会跟着发生变化!! return project_path + \u0026#34;/src/main/resources/mapper/\u0026#34; + (stringutils.isblank(module_name) ? \u0026#34;\u0026#34; : module_name + \u0026#34;/\u0026#34;) + tableinfo.getentityname() + \u0026#34;mapper\u0026#34; + stringpool.dot_xml; } }); injectionconfig.setfileoutconfiglist(fileoutconfigs); return injectionconfig; } private strategyconfig getstrategyconfig() { strategyconfig strategy = new strategyconfig(); // 字段与属性命名策略 strategy.setnaming(namingstrategy.underline_to_camel); strategy.setcolumnnaming(namingstrategy.underline_to_camel); // 是否使用lombok插件 strategy.setentitylombokmodel(true); // 是否使用restcontroller注解 strategy.setrestcontrollerstyle(true); // 实体类是否实现jdk序列化接口 strategy.setentityserialversionuid(false); // 实体类是否标上字段注解 strategy.setentitytablefieldannotationenable(true); // 设置逻辑删除字段 if(stringutils.isnotblank(logic_delete_field_name)) { strategy.setlogicdeletefieldname(logic_delete_field_name); } strategy.setinclude(table_name); return strategy; } private packageconfig getpackageconfig() { packageconfig pc = new packageconfig(); pc.setmodulename(module_name); // 设置各个层包名 pc.setparent(\u0026#34;com.kun.mybatisplus\u0026#34;); pc.setcontroller(\u0026#34;controller\u0026#34;); pc.setentity(\u0026#34;domain\u0026#34;); pc.setmapper(\u0026#34;mapper\u0026#34;); pc.setservice(\u0026#34;service\u0026#34;); return pc; } private datasourceconfig getdatasourceconfig() { datasourceconfig datasourceconfig = new datasourceconfig(); datasourceconfig.seturl(database_url); datasourceconfig.setdrivername(database_driver); datasourceconfig.setusername(database_user_name); datasourceconfig.setpassword(database_password); // 各种数据库配置 datasourceconfig.setdbtype(dbtype.mysql); datasourceconfig.setkeywordshandler(new mysqlkeywordshandler()); datasourceconfig.settypeconvert(new mysqltypeconvert()); return datasourceconfig; } private globalconfig getglobalconfig() { globalconfig globalconfig = new globalconfig(); globalconfig.setoutputdir(project_path + \u0026#34;/src/main/java\u0026#34;); globalconfig.setauthor(\u0026#34;wangyukun\u0026#34;); globalconfig.setopen(false); // 实体属性 swagger2 注解 globalconfig.setswagger2(true); // 生成的service名称,默认i%sservice globalconfig.setservicename(\u0026#34;%sservice\u0026#34;); // 是否覆盖 globalconfig.setfileoverride(file_override); // xml是否生成基本列 globalconfig.setbasecolumnlist(true); // xml是否生成基本映射 globalconfig.setbaseresultmap(true); // 是否启用缓存 globalconfig.setenablecache(false); // 主键策略 globalconfig.setidtype(idtype.auto); return globalconfig; } } 三、基础mapper的使用 插入方法的使用 1 2 3 4 5 6 7 8 9 public void testinsert() { user user = new user(); user.setname(\u0026#34;rose\u0026#34;); user.setage(18); user.setsex(sexenum.female); user.setemail(\u0026#34;123@qq.com\u0026#34;); // 只有存在的值属性对应得字段才会插入 usermapper.insert(user); } 设置性别使用了枚举的形式,请查看枚举用法\n更新方法的使用 1 2 3 4 5 6 7 8 public void testupdate() { user user = new user(); user.setid(6l); user.setname(\u0026#34;jmi\u0026#34;); user.setversion(1); usermapper.updatebyid(user); usermapper.update(user, wrappers.\u0026lt;user\u0026gt;lambdaquery().eq(user::getname, \u0026#34;jack\u0026#34;)); } 更新使用了乐观锁机制,请查看乐观锁插件\n删除方法的使用 1 2 3 4 public void testdelete() { usermapper.deletebyid(6l); usermapper.delete(wrappers.\u0026lt;user\u0026gt;lambdaquery().eq(user::getname, \u0026#34;jmi\u0026#34;)); } 删除使用逻辑删除,请查看逻辑删除设置\n查询方法的使用 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 public void testselect() { user userbyid = usermapper.selectbyid(1); log.info(\u0026#34;用户{}\u0026#34;, userbyid); // selectbatchids list\u0026lt;user\u0026gt; userslistbyids = usermapper.selectbatchids(arrays.aslist(\u0026#34;1\u0026#34;, \u0026#34;2\u0026#34;)); log.info(\u0026#34;用户列表{}\u0026#34;, userslistbyids); // querywrapper与selectone组合使用 querywrapper\u0026lt;user\u0026gt; querywrapper = new querywrapper\u0026lt;\u0026gt;(); querywrapper.select(user.class, (col) -\u0026gt; !col.isversion()); querywrapper.eq(\u0026#34;id\u0026#34;, 1); user userbywrapper = usermapper.selectone(querywrapper); log.info(\u0026#34;用户{}\u0026#34;, userbywrapper); // lambdaquerywrapper与selectlist组合使用 lambdaquerywrapper\u0026lt;user\u0026gt; userlambdaquerywrapper = new lambdaquerywrapper\u0026lt;\u0026gt;(); userlambdaquerywrapper.gt(true, user::getage, 18); list\u0026lt;user\u0026gt; usersbylambdawrapper = usermapper.selectlist(userlambdaquerywrapper); log.info(\u0026#34;用户列表{}\u0026#34;, usersbylambdawrapper); // selectbymap,注意必须使用数据库列名 map\u0026lt;string, object\u0026gt; params = new hashmap\u0026lt;\u0026gt;(); params.put(\u0026#34;name\u0026#34;, \u0026#34;jone\u0026#34;); list\u0026lt;user\u0026gt; usersbymap = usermapper.selectbymap(params); log.info(\u0026#34;用户列表{}\u0026#34;, usersbymap); // selectcount integer count = usermapper.selectcount(wrappers.\u0026lt;user\u0026gt;lambdaquery().gt(user::getage, 20)); log.info(\u0026#34;20岁以上总计{}人\u0026#34;, count); // 分页 page\u0026lt;user\u0026gt; page = new page\u0026lt;\u0026gt;(2, 2); // 排序字段放入wrapper是不会返回排序字段的,放入page对象会使用它作为查询排序条件饼返回排序字段 page.addorder(orderitem.asc(\u0026#34;id\u0026#34;)); page\u0026lt;user\u0026gt; userpage = usermapper.selectpage(page, null); log.info(\u0026#34;userpage信息 current={}\u0026#34;, userpage.getcurrent()); log.info(\u0026#34;userpage信息 size={}\u0026#34;, userpage.getsize()); log.info(\u0026#34;userpage信息 pages={}\u0026#34;, userpage.getpages()); log.info(\u0026#34;userpage信息 total={}\u0026#34;, userpage.gettotal()); log.info(\u0026#34;userpage信息 orders={}\u0026#34;, userpage.getorders()); log.info(\u0026#34;userpage信息 records={}\u0026#34;, userpage.getrecords()); } 如果不使用分页插件则分页为逻辑分页,可使用分页插件达到物理分页\n四、基础service的使用 插入方法的使用 1 2 3 4 5 6 // 插入一条记录(选择字段,策略插入) boolean save(t entity); // 插入(批量) boolean savebatch(collection\u0026lt;t\u0026gt; entitylist); // 插入(批量) boolean savebatch(collection\u0026lt;t\u0026gt; entitylist, int batchsize); 更新方法的使用 1 2 3 4 5 6 7 8 9 10 // 根据 updatewrapper 条件,更新记录 需要设置sqlset boolean update(wrapper\u0026lt;t\u0026gt; updatewrapper); // 根据 whereentity 条件,更新记录 boolean update(t entity, wrapper\u0026lt;t\u0026gt; updatewrapper); // 根据 id 选择修改 boolean updatebyid(t entity); // 根据id 批量更新 boolean updatebatchbyid(collection\u0026lt;t\u0026gt; entitylist); // 根据id 批量更新 boolean updatebatchbyid(collection\u0026lt;t\u0026gt; entitylist, int batchsize); 插入\u0026amp;更新的使用 1 2 3 4 5 6 7 8 // tableid 注解存在更新记录,否插入一条记录 boolean saveorupdate(t entity); // 根据updatewrapper尝试更新,否继续执行saveorupdate(t)方法 boolean saveorupdate(t entity, wrapper\u0026lt;t\u0026gt; updatewrapper); // 批量修改插入 boolean saveorupdatebatch(collection\u0026lt;t\u0026gt; entitylist); // 批量修改插入 boolean saveorupdatebatch(collection\u0026lt;t\u0026gt; entitylist, int batchsize); 删除方法的使用 1 2 3 4 5 6 7 8 // 根据 entity 条件,删除记录 boolean remove(wrapper\u0026lt;t\u0026gt; querywrapper); // 根据 id 删除 boolean removebyid(serializable id); // 根据 columnmap 条件,删除记录 boolean removebymap(map\u0026lt;string, object\u0026gt; columnmap); // 删除(根据id 批量删除) boolean removebyids(collection\u0026lt;? extends serializable\u0026gt; idlist); 查询单个方法的使用 1 2 3 4 5 6 7 8 9 10 // 根据 id 查询 t getbyid(serializable id); // 根据 wrapper,查询一条记录。结果集,如果是多个会抛出异常,随机取一条加上限制条件 wrapper.last(\u0026#34;limit 1\u0026#34;) t getone(wrapper\u0026lt;t\u0026gt; querywrapper); // 根据 wrapper,查询一条记录 t getone(wrapper\u0026lt;t\u0026gt; querywrapper, boolean throwex); // 根据 wrapper,查询一条记录 map\u0026lt;string, object\u0026gt; getmap(wrapper\u0026lt;t\u0026gt; querywrapper); // 根据 wrapper,查询一条记录 \u0026lt;v\u0026gt; v getobj(wrapper\u0026lt;t\u0026gt; querywrapper, function\u0026lt;? super object, v\u0026gt; mapper); 查询列表方法的使用 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 // 查询所有 list\u0026lt;t\u0026gt; list(); // 查询列表 list\u0026lt;t\u0026gt; list(wrapper\u0026lt;t\u0026gt; querywrapper); // 查询(根据id 批量查询) collection\u0026lt;t\u0026gt; listbyids(collection\u0026lt;? extends serializable\u0026gt; idlist); // 查询(根据 columnmap 条件) collection\u0026lt;t\u0026gt; listbymap(map\u0026lt;string, object\u0026gt; columnmap); // 查询所有列表 list\u0026lt;map\u0026lt;string, object\u0026gt;\u0026gt; listmaps(); // 查询列表 list\u0026lt;map\u0026lt;string, object\u0026gt;\u0026gt; listmaps(wrapper\u0026lt;t\u0026gt; querywrapper); // 查询全部记录 list\u0026lt;object\u0026gt; listobjs(); // 查询全部记录 \u0026lt;v\u0026gt; list\u0026lt;v\u0026gt; listobjs(function\u0026lt;? super object, v\u0026gt; mapper); // 根据 wrapper 条件,查询全部记录 list\u0026lt;object\u0026gt; listobjs(wrapper\u0026lt;t\u0026gt; querywrapper); // 根据 wrapper 条件,查询全部记录 \u0026lt;v\u0026gt; list\u0026lt;v\u0026gt; listobjs(wrapper\u0026lt;t\u0026gt; querywrapper, function\u0026lt;? super object, v\u0026gt; mapper); 分页查询方法的使用 1 2 3 4 5 6 7 8 // 无条件分页查询 ipage\u0026lt;t\u0026gt; page(ipage\u0026lt;t\u0026gt; page); // 条件分页查询 ipage\u0026lt;t\u0026gt; page(ipage\u0026lt;t\u0026gt; page, wrapper\u0026lt;t\u0026gt; querywrapper); // 无条件分页查询 ipage\u0026lt;map\u0026lt;string, object\u0026gt;\u0026gt; pagemaps(ipage\u0026lt;t\u0026gt; page); // 条件分页查询 ipage\u0026lt;map\u0026lt;string, object\u0026gt;\u0026gt; pagemaps(ipage\u0026lt;t\u0026gt; page, wrapper\u0026lt;t\u0026gt; querywrapper); 五、插件的使用 枚举用法 第一步:实现枚举类\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 //================================== 方式一 ================================== public enum sexenum { male(\u0026#34;m\u0026#34;, \u0026#34;男\u0026#34;), female(\u0026#34;f\u0026#34;, \u0026#34;女\u0026#34;); sexenum(string code, string desc) { this.code = code; this.desc = desc; } //标记数据库存的值是code,支持integer、string @enumvalue private final string code; private final string desc; } //================================== 方式二 ================================== public enum sexenum implements ienum\u0026lt;string\u0026gt; { male(\u0026#34;m\u0026#34;, \u0026#34;男\u0026#34;), female(\u0026#34;f\u0026#34;, \u0026#34;女\u0026#34;); private final string code; private final string desc; sexenum(string code, string desc) { this.code = code; this.desc = desc; } // 返回数据库要存储值 @override public string getvalue() { return this.code; } } 第二步:配置要扫描的枚举包\n1 mybatis-plus.type-enums-package=com.kun.mybatisplus.domain.enums 乐观锁 第一步:配置乐观锁插件\n1 2 3 4 @bean public optimisticlockerinterceptor optimisticlockerinterceptor() { return new optimisticlockerinterceptor(); } 第二步:使用@version对实体类标注乐观锁字段\n1 2 3 4 5 6 7 8 public class user { // ...... @tablefield(\u0026#34;version\u0026#34;) @version private integer version; } 乐观锁仅支持 updatebyid(id) 与 update(entity, wrapper) 方法\n逻辑删除 在逆向工程中配置逻辑表删除字段,可以自动生成注解。\n1 2 3 4 5 6 7 8 public class user { // ...... @tablefield(\u0026#34;is_delete\u0026#34;) @tablelogic private boolean isdelete; } 物理分页 第一步:物理分页插件设置\n1 2 3 4 5 6 7 8 9 10 11 @bean public paginationinterceptor paginationinterceptor() { paginationinterceptor paginationinterceptor = new paginationinterceptor(); // 设置请求的页面大于最大页后操作, true调回到首页,false 继续请求 默认false // paginationinterceptor.setoverflow(false); // 设置最大单页限制数量,默认 500 条,-1 不受限制 // paginationinterceptor.setlimit(500); // 开启 count 的 join 优化,只针对部分 left join paginationinterceptor.setcountsqlparser(new jsqlparsercountoptimize(true)); return paginationinterceptor; } 第二步:使用分页查询\n1 2 3 4 5 6 7 8 9 10 11 12 13 public void testselect() { // 分页 page\u0026lt;user\u0026gt; page = new page\u0026lt;\u0026gt;(2, 2); // 排序字段放入wrapper是不会返回排序字段的,放入page对象会使用它作为查询排序条件饼返回排序字段 page.addorder(orderitem.asc(\u0026#34;id\u0026#34;)); page\u0026lt;user\u0026gt; userpage = usermapper.selectpage(page, null); log.info(\u0026#34;userpage信息 current={}\u0026#34;, userpage.getcurrent()); log.info(\u0026#34;userpage信息 size={}\u0026#34;, userpage.getsize()); log.info(\u0026#34;userpage信息 pages={}\u0026#34;, userpage.getpages()); log.info(\u0026#34;userpage信息 total={}\u0026#34;, userpage.gettotal()); log.info(\u0026#34;userpage信息 orders={}\u0026#34;, userpage.getorders()); log.info(\u0026#34;userpage信息 records={}\u0026#34;, userpage.getrecords()); } 注意:做sql映射时进行分页\n1 2 3 4 5 6 7 8 9 10 11 /** * \u0026lt;select id=\u0026#34;selectpagevo\u0026#34; resultmapping=\u0026#34;baseresultmap\u0026#34;\u0026gt; * select id,name from user where state=#{state} * \u0026lt;/select\u0026gt; */ public interface usermapper extends basemapper\u0026lt;user\u0026gt; { /** * @param page 分页对象,xml中可以从里面进行取值,传递参数 page 即自动分页,必须放在第一位(你可以继承page实现自己的分 */ ipage\u0026lt;user\u0026gt; selectpagevo(page\u0026lt;?\u0026gt; page, integer state); } 动态表名 第一步:配置表名和变量存储类\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 /** * 存放查询是需要的变量 */ public class dynamictablecondition { public static threadlocal\u0026lt;string\u0026gt; conditionyear = new threadlocal\u0026lt;\u0026gt;(); } /** * 添加动态表名插件 */ @bean public mybatisplusinterceptor paginationinterceptor() { mybatisplusinterceptor mybatisplusinterceptor = new mybatisplusinterceptor(); dynamictablenameinnerinterceptor dynamictablenameinnerinterceptor = new dynamictablenameinnerinterceptor(); map\u0026lt;string, tablenamehandler\u0026gt; map = new hashmap\u0026lt;\u0026gt;(); // 需要进行动态表名支持的表配置 map.put(\u0026#34;user\u0026#34;, (sql, tablename) -\u0026gt; tablename + \u0026#34;_\u0026#34; + dynamictablecondition.conditionyear.get()); dynamictablenameinnerinterceptor.settablenamehandlermap(map); mybatisplusinterceptor.addinnerinterceptor(dynamictablenameinnerinterceptor); return mybatisplusinterceptor; } 第二步:使用动态表名查询\n1 2 3 4 5 6 7 8 9 10 public void testdynamictablename() { for (int i = 0; i \u0026lt; 6; i++) { if (i / 2 == 1) { dynamictablecondition.conditionyear.set(\u0026#34;2018\u0026#34;); } else { dynamictablecondition.conditionyear.set(\u0026#34;2019\u0026#34;); } user user = usermapper.selectbyid(1); } } 多数据源 第一步:yaml配置\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 mybatis-plus: mapper-locations: classpath*:/mapper/*.xml spring: datasource: dynamic: druid: initial-size: 1 max-active: 20 min-idle: 3 max-wait: 60000 time-between-eviction-runs-millis: 60000 strict: true primary: source201 datasource: # 名称可以随意 source1: username: username password: password driver-class-name: com.mysql.jdbc.driver url: url source2: username: username password: password driver-class-name: com.mysql.jdbc.driver url: url 第二步:service的实现类加入注解@ds\n1 2 3 4 5 6 7 public interface xxxservice extends iservice\u0026lt;categorymap\u0026gt; { } @service @ds(\u0026#34;source1\u0026#34;) public class xxxserviceimpl extends serviceimpl\u0026lt;xxxmapper, xxx\u0026gt; implements xxxservice { } ","date":"2020-08-16","permalink":"https://hobocat.github.io/post/mybatis/2020-08-16-mybatis-plus/","summary":"一、集成Spring boot 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 \u0026lt;dependency\u0026gt; \u0026lt;groupId\u0026gt;com.baomidou\u0026lt;/groupId\u0026gt; \u0026lt;artifactId\u0026gt;mybatis-plus-boot-starter\u0026lt;/artifactId\u0026gt; \u0026lt;version\u0026gt;[version]\u0026lt;/version\u0026gt; \u0026lt;/dependency\u0026gt; \u0026lt;!-- 用于生成逆向工程 --\u0026gt; \u0026lt;dependency\u0026gt; \u0026lt;groupId\u0026gt;com.baomidou\u0026lt;/groupId\u0026gt; \u0026lt;artifactId\u0026gt;mybatis-plus-generator\u0026lt;/artifactId\u0026gt; \u0026lt;version\u0026gt;[version]\u0026lt;/version\u0026gt; \u0026lt;scope\u0026gt;test\u0026lt;/scope\u0026gt; \u0026lt;/dependency\u0026gt; \u0026lt;dependency\u0026gt; \u0026lt;groupId\u0026gt;org.freemarker\u0026lt;/groupId\u0026gt; \u0026lt;artifactId\u0026gt;freemarker\u0026lt;/artifactId\u0026gt; \u0026lt;version\u0026gt;[version]\u0026lt;/version\u0026gt; \u0026lt;scope\u0026gt;test\u0026lt;/scope\u0026gt; \u0026lt;/dependency\u0026gt; 二、逆向工程配置 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15","title":"mybatis plus使用指南"},]
[{"content":"一、logstash架构简介 简介 logstash是一个数据收集处理引擎,可是视之为一个etl工具。\n架构 input 用于从数据源获取数据,常见的插件如file, syslog, redis, beats 等 codec 在输入和输出等插件中用于数据转换的模块,用于对数据进行编码处理,常见的插件如json,multiline queue 数据回经过queue进行分发,有in memory和persistent queue in disk两种 batcher 批量的从queue中取数据,向后传递数据。默认50ms或者待处理文档数大于125时向后传递 filter 用于处理数据如格式转换,数据派生等,常见的插件如grok,mutate, drop, clone, geoip等 output 用于数据输出,常见的如elastcisearch,file, graphite, statsd等 pipeline和logstash event pipline由【input】-【filter】-【output】3个阶段处理流程组成,包含了队列管理和插件生命周期管理\nlogstash event是内部流转的数据的表现形式。原数据在input转换为event,在output event时被转换为目标数据格式,在配置文件中可以对event中的属性进行判断和增删改查\nqueue的分类 in memory\n是一个内存的queue,无法通过参数设置。无法处理进程崩溃、机器宕机等情况,会导致数据丢失\npersistent queue in disk\n可保证在出现意外的情况下保证数据不丢失,而且能保证数据至少被消费一次\npersistent queue in disk对性能影响估计是在5%以内,如果没有特殊需求一般建议打开\n参数 解释 queue.type 队列类型可选值:persisted、memory【默认】 queue.max_bytes 队列存储的最大容量,默认1gb path.queue persistent queue in disk存到磁盘的哪个位置 queue.page_capacity 控制消息队列每一个文件的大小,默认64mb queue.checkpoint.writes 提升容灾能力,如果是1 表示每写一个数据都去做盘,默认1024 pipeline.workers filter_output的线程数,默认cpu核心数 pipeline.batch.size 批处理延迟文档数,默认125 pipeline.batch.delay 批处理延迟,默认50ms logstash配置文件 在conf文件夹中被称之为setting files\nlogstash.yml中是logstash相关配置比如node.name,path.data,pipline.workers、queue.type等,这些配置可以被命令行参数替代 参数 描述 node.name 节点名,便于识别 path.data 持久化存储数据文件夹,默认logstash下的data目录,多实例不能相同 path.config 设定pipeline的路径,如果是目录则扫描目录下的所有.conf文件 path.log pipeline日志文件的目录 pipeline.workers 设定pipeline的线程数 pipeline.batch.size/delay 批处理延迟 queue.type 队列类型可选值:persisted、memory queue.max_bytes 队列存储的最大容量,默认1gb 命令行参数 描述 \u0026ndash;node.name 同node.name -f 同path.config \u0026ndash;path.settings logstash文件夹目录主要包含logstash.yml,启动多实例时会用 -e 指明pipeline文件内容,多用于测试 -w 同pipeline.workers -b 同pipeline.batch.size \u0026ndash;path.data 同path.data \u0026ndash;debug 打开调试日志 -t 检测pipeline文件语法是否正确 jvm.options是修改jvm的相关参数 pipeline文件\n定义数据处理流程的文件,默认以.conf结尾,结构如下\n1 2 3 4 5 input {} filter {} output {} pipeline配置语法 数据类型\n布尔类型 isfailed =\u0026gt; true\n数值类型 num =\u0026gt; 23\n字符串类型 name =\u0026gt; \u0026ldquo;hello\u0026rdquo;\n数组类型 user =\u0026gt; [ { \u0026ldquo;id\u0026rdquo; =\u0026gt;1, \u0026ldquo;name\u0026rdquo; =\u0026gt; \u0026ldquo;bob\u0026rdquo; }, { \u0026ldquo;id\u0026rdquo; =\u0026gt; 2, \u0026ldquo;name\u0026rdquo; =\u0026gt; \u0026ldquo;tom\u0026rdquo; } ] | name =\u0026gt; [ \u0026ldquo;bob\u0026rdquo; , \u0026ldquo;tom\u0026rdquo; ]\n哈希类型\n1 2 3 4 match =\u0026gt; { \u0026#34;k1\u0026#34; =\u0026gt; \u0026#34;v1\u0026#34; \u0026#34;k2\u0026#34; =\u0026gt; \u0026#34;v2\u0026#34; } 注释\n井号开头# this is a comment\n取属性\n直接引用字段 使用[]取出,嵌套使用多层[]即可 字符串使用引用值 使用引用sprintf语法%{} 判断值\n可以if、else if、else语法 判断的表达式 比较 ==,!=,\u0026lt;,\u0026gt;,\u0026lt;=,\u0026gt;= 正则是否匹配 =~,!~ 包含 in,not in 布尔操作符 and,or,nand,xor,! 二、input插件 input插件指定了数据输入源,一个pipeline可以有多个input插件。\nstdin插件 最简单的输入类型,从标准输入流读入数据,通用配置为\ncodec,类型为codec type,类型为string,自定义该事件的类型,可用于后续判断 tags,类型为array,自定义该事件的tag,可用于后续判断 add_field,类型为hash,为该事件添加字段 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 input { stdin { codec =\u0026gt; \u0026#34;plain\u0026#34; type =\u0026gt; \u0026#34;std\u0026#34; tags =\u0026gt; [\u0026#34;info log\u0026#34;] add_field =\u0026gt; { \u0026#34;info\u0026#34; =\u0026gt; \u0026#34;this is info message\u0026#34; } } } output { stdout { codec =\u0026gt; \u0026#34;rubydebug\u0026#34; } } file插件 file插件会定时检查文件是否更新和文件夹下是否有新文件生成,为了不重复读取内容,使用了sincedb记录了文件读取的行号。文件记录的的底层的nodeid所以当文件发生归档时也不会发生错误。其配置为\npath,类型为数组,指明读取文件的路径,基于glob语法 exclude,类型为数组,排除不想监听的文件规则,基于glob语法 sincedb_path,类型为字符串,记录sincedb文件路径 start_position,类型为字符串,beginning or end,是否从头读取文件 stat_interval,类型为数值,单位秒,定时检查文件是否有更新,默认为1s discover_interval,类型为数值,单位秒,定时检查是否有新文件待读取,默认15s ignore_older,类型为数值,单位秒,扫描文件列表时,如果该文件上次更改时间超过设定时长,则不做处理,但依然会监控是否有新的内容,默认关闭 close_older,类型为数值,单位秒,如果监听的文件在超过的时间范围内没有更新则关闭文件句柄,释放资源。但是依然会继续监控,默认时间3600秒 start_postion有两个参数可选,默认是end,表示运行logstash运行之后只会读取从logstash运行之后新进来的数据。如果想让logstash从头读取要设置为beginning。注意只有在第一次读取的时候这个beginning才生效,一旦读取过这个文件在sincedb中有记录了,logstash之后再去跑发现在sincedb中有记录了,就不会生效了也就是不会再从头读取了。这个的坏处就是我们做一些调试的时候比较麻烦只能把sincedb文件给删掉。我们可以把sincedb_path设置为/dev/null 这是个特殊的文件,所有写入到这个文件的内容都不会存储,那么这样再把start_postion设置为beginning这样每一次运行logstash的时候都是从头读取的。\n1 2 3 4 5 6 7 8 9 10 11 12 input { file { path =\u0026gt; \u0026#34;/var/log/*.log\u0026#34; sincedb_path =\u0026gt; \u0026#34;/dev/null\u0026#34; start_position =\u0026gt; \u0026#34;beginning\u0026#34; discover_interval =\u0026gt; 15 } } output { stdout {codec =\u0026gt; rubydebug {}} } kafka插件 kafka是最流行的消息队列,在elastic stack架构中常用,使用相对简单\n1 2 3 4 5 6 7 8 9 10 11 12 input { kafka { zk_connect =\u0026gt; \u0026#34;kafka:2181\u0026#34; group_id =\u0026gt; \u0026#34;logstash\u0026#34; topic_id =\u0026gt; \u0026#34;apache_logs\u0026#34; consumer_threads =\u0026gt; 16 } } output { stdout {codec =\u0026gt; rubydebug {}} } http插件 常和启动参数-r连用,用于热调试\n1 2 3 4 5 6 7 8 9 input { http { port =\u0026gt; \u0026#34;5555\u0026#34; } } output { stdout {codec =\u0026gt; rubydebug {}} } 三、codec插件 codec插件作用于input插件和output插件,负责将数据在原始于logstash event之间转换,常见的codec有\nplain 读取原始内容 dots 将内容简化为点进行输出 rubydebug 将logstash event按照ruby格式输出,便于调试 line 处理带有换行符的内容 json 处理json内容 multiline 处理多行数据的内容 plain\u0026amp;dots\u0026amp;rubydebug 1 2 3 bin/logstash -e \u0026#34;input{stdin{codec=\u0026gt;\\\u0026#34;plain\\\u0026#34;}} output{stdout{codec=\u0026gt;\\\u0026#34;rubydebug\\\u0026#34;}}\u0026#34; bin/logstash -e \u0026#34;input{stdin{codec=\u0026gt;\\\u0026#34;plain\\\u0026#34;}} output{stdout{codec=\u0026gt;\\\u0026#34;dots\\\u0026#34;}}\u0026#34; line\u0026amp;json 1 2 3 bin/logstash -e \u0026#34;input{stdin{codec=\u0026gt;\\\u0026#34;line\\\u0026#34;}} output{stdout{codec=\u0026gt;\\\u0026#34;rubydebug\\\u0026#34;}}\u0026#34; bin/logstash -e \u0026#34;input{stdin{codec=\u0026gt;\\\u0026#34;json\\\u0026#34;}} output{stdout{codec=\u0026gt;\\\u0026#34;rubydebug\\\u0026#34;}}\u0026#34; multiline 当一个event的message由多行组成时需要使用mutiline codec,常见的情况时处理java堆栈异常。主要参数如下\npattern 设置行匹配的正则表达式,可以使用grok语法 what previous | next 如果匹配成功,那么匹配行是属于上一个时间还剩下一个事件 negate true | false 是否对pattern匹配结果取反,默认false 1 2 3 4 5 6 7 8 9 10 11 12 13 14 ##################################以下可以用于简单读取java堆栈跟踪日志################################## input { stdin { codec =\u0026gt; multiline { what =\u0026gt; \u0026#34;next\u0026#34; negate =\u0026gt; false } } } output { stdout { codec =\u0026gt; \u0026#34;rubydebug\u0026#34; } } 四、filter插件 filter是logstash功能强大的主要原因,它可以对logstash event进行丰富的处理,比如数据解析、删除字段、类型转换等等。常见如下:\ndate 日期解析 grok 正则匹配解析 dissect 分割符解析 mutate 对字段处理,比如重命名、删除、替换等 json 按照json解析字段内容到指定字段中 geoip 增加地理位置数据 ruby 利用ruby代码来修改logstash event date filter 将日期字符串解析为日期类型\nmatch 类型为数组,用于指定日期匹配格式,可以一次指定多种日期格式 target 类型为字符串,用于指定赋值的字段名,默认为@timestamp timezone 类型为字符串,用于指定时区 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 input { stdin { codec =\u0026gt; json } } filter { date { # 匹配的字段 match =\u0026gt; [\u0026#34;log_date\u0026#34;, \u0026#34;yyyy-mm-dd hh:mm:ss\u0026#34;] # 赋值目标字段,如果不设置则会覆盖@timestamp,如果设置时区而且覆盖本字段,时区无效 target =\u0026gt; \u0026#34;log_data\u0026#34; # 时区设置 timezone =\u0026gt; \u0026#34;asia/shanghai\u0026#34; } } output{ stdout { codec =\u0026gt; rubydebug } } grok filter 使用定义好的或者自定义的正则表达式进行匹配,已定义的常用正则查看参考\ngrok语法为%{syntax:semantic},syntax为grok pattern的名称,semantic为赋值字段名称。%{number:duration}可以用于匹配数值类型,可以在后跟int或float来进行强制类型转换,例如%{number:duration:int}。如果匹配失败将会有一个_grokparsefailure字段产生,可用于后续判断\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 ##################################使用系统定义的pattern################################## filter { grok { match =\u0026gt; { \u0026#34;message\u0026#34;=\u0026gt;\u0026#34;%{ip:ip} %{greedydata:data}\u0026#34;} } } ##################################使用自定义的pattern################################## filter { grok { match =\u0026gt; { \u0026#34;message\u0026#34;=\u0026gt;\u0026#34;%{ip:ip} %{service_name:service_name} %{greedydata:data}\u0026#34;} pattern_definitions =\u0026gt; { \u0026#34;service_name\u0026#34; =\u0026gt; \u0026#34;[a-za-z]{5}\u0026#34; } } } ###################################overwrite的使用################################### filter { grok { match =\u0026gt; { \u0026#34;message\u0026#34;=\u0026gt;\u0026#34;%{ip:ip} %{greedydata:message}\u0026#34;} overwrite =\u0026gt; [\u0026#34;message\u0026#34;] #将上述匹配的message信息覆盖到message,如果没有overwrite将不执行覆盖操作 } } dissect filter 基于分隔符的原理进行解析数据,数据比grok快,但是使用具有局限性\n+具有拼接效果 /num代表拼接的顺序 ?代表创建一个属性名,\u0026amp;代表给?的属性名赋值 convert_datatype可以进行类型转换 1 2 3 4 5 6 7 8 9 10 11 filter { dissect { mapping =\u0026gt; { \u0026#34;message\u0026#34; =\u0026gt; \u0026#34;%{+ts/2} %{+ts/1}\u0026#34; \u0026#34;urlparams\u0026#34; =\u0026gt; \u0026#34;%{?username}=%{\u0026amp;username}\u0026#34; } convert_datatype =\u0026gt; { \u0026#34;age\u0026#34; =\u0026gt; \u0026#34;int\u0026#34; } } } mutate filter 可以对各种字段进行各种操作,比如重命名、删除、替换、更新等。主要操作如下:\nconvert 类型转换 gsub 字符串替换 split/join/merge 字符串切割、数组合并为字符串、数组合并为数组 rename 字段重命名 update/rename 字段重命名 remove_field 删除字段 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 ############################################################################ #convert 实现字段类型转换,类型为hash,支持转换为integer、float、string和boolean # ############################################################################ filter { mutate { convert =\u0026gt; { \u0026#34;age\u0026#34; =\u0026gt; \u0026#34;integer\u0026#34; \u0026#34;islived\u0026#34; =\u0026gt; \u0026#34;boolean\u0026#34; } } } ############################################################################ #gsub 对字段内容进行替换,类型为数组,每三项为一个替换配置 # ############################################################################ filter { mutate { gsub =\u0026gt; [ \u0026#34;path\u0026#34;,\u0026#34;[\\\\]\u0026#34;,\u0026#34;/\u0026#34;, \u0026#34;urlparams\u0026#34;,\u0026#34;[\\\\?#-]\u0026#34;,\u0026#34;.\u0026#34; ] } } ############################################################################ #split/join/merge 字符串切割、数组合并为字符串、数组合并为数组 # ############################################################################ filter { mutate { split =\u0026gt; {\u0026#34;jobs\u0026#34; =\u0026gt; \u0026#34;,\u0026#34;} join =\u0026gt; {\u0026#34;hobby\u0026#34; =\u0026gt; \u0026#34;,\u0026#34;} merge =\u0026gt; {\u0026#34;dest_arr\u0026#34; =\u0026gt; \u0026#34;source_arr\u0026#34;} } } ############################################################################ #rename 将字段重命名 # ############################################################################ filter { mutate { rename =\u0026gt; { \u0026#34;message\u0026#34; =\u0026gt; \u0026#34;source\u0026#34; \u0026#34;@timestamp\u0026#34; =\u0026gt; \u0026#34;create_time\u0026#34; } } } ############################################################################ #update 只在字段存在时生效 # #replace 如果字段不存在会执行新增操作 # ############################################################################ filter { mutate { replace =\u0026gt; {\u0026#34;source\u0026#34; =\u0026gt; \u0026#34;source: %{message}\u0026#34;} update =\u0026gt; {\u0026#34;age\u0026#34; =\u0026gt; \u0026#34;this is %{age}\u0026#34;} } } ############################################################################ #remove_field 删除字段 # ############################################################################ filter { mutate { remove_field =\u0026gt; [\u0026#34;@timestamp\u0026#34;] } } json filter 将字段内容为json格式的数据进行解析\n1 2 3 4 5 6 7 8 # 注意不能在http的post的entity为json的状态下测试 filter { json { source =\u0026gt; \u0026#34;message\u0026#34; # 如果没有target它将会被放在root级别,如果有target将会放在target下 target =\u0026gt; \u0026#34;msg_json\u0026#34; } } geoip filter 提供了根据ip地址对应的经纬度、城市名等数据的查询,方便进行地理位置的分析\n1 2 3 4 5 filter { geoip { source =\u0026gt; \u0026#34;ip\u0026#34; } } ruby filter 最灵活的插件,可以通过ruby代码来修改logstash event\n1 2 3 4 5 6 filter { ruby { codec =\u0026gt; \u0026#39;size = event.get(\u0026#34;message\u0026#34;).size; event.set(\u0026#34;message_size\u0026#34;, size)\u0026#39; } } 五、output插件 stdout插件 输出到标准输出流,一般用于调试\n1 2 3 4 5 output { stdout { codec =\u0026gt; rubydebug } } file插件 输出到文件,一般用于将多地分散日志统一的需求\n1 2 3 4 5 6 7 # 默认以json格式进行输出,下面改为了行输出,输出event中的format字段 output { file { path =\u0026gt; \u0026#34;/opt/web.log\u0026#34; codec =\u0026gt; line{ format =\u0026gt; \u0026#34;%{message}\u0026#34;} } } elasticsearch插件 1 2 3 4 5 6 7 output { elasticsearch { hosts =\u0026gt; [\u0026#34;127.0.0.1:9200\u0026#34;] index =\u0026gt; \u0026#34;nginx-%{+yyyy.mm.dd}\u0026#34; document_id =\u0026gt; \u0026#34;%{id}\u0026#34; #作为id的字段 } } 六、调试技巧 特殊字段 存在一个@metadata的字段,其内容不会输出在output中,此字段适合用于做条件判断,临时存储等。相比remove_field性能好。\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 input { http { port =\u0026gt; 5555 } } filter { mutate { add_field =\u0026gt; { \u0026#34;[@metadata][debug]\u0026#34;=\u0026gt; true } } } output { if([@metadata][debug]) { stdout { codec =\u0026gt; rubydebug } }else { elasticsearch { hosts =\u0026gt; [\u0026#34;127.0.0.1:9200\u0026#34;] index =\u0026gt; \u0026#34;nginx-%{+yyyy.mm.dd}\u0026#34; } } } 监控 在logstash.yml下打开xpack监控配置,即可在elasticsearch中查看logstash状态\n1 xpack.monitoring.elasticsearch.hosts: [\u0026#34;http://192.168.1.155:9200\u0026#34;] #注意http 七、从mysql导入数据到es 第一步:环境准备\n数据库如果做增量数据导入,必须提高一个可控边界。可控边界一般使用自增主键或者时间戳\nlogstash不能创建elasticsearch中的索引,所以需要手工创建索引或使用索引模板\n导入mysql驱动jar包。最佳保存在$logstash_home/config目录中\n第二步:定义logstash-mysql增量导入配置文件\n$logstash_home/config创建文件logstash-mysql-es.conf\ninput { jdbc { # mysql相关jdbc配置 jdbc_connection_string =\u0026gt; \u0026#34;jdbc:mysql://192.168.1.117:3306/logstash?useunicode=true\u0026amp;characterencoding=utf-8\u0026amp;usessl=false\u0026#34; jdbc_user =\u0026gt; \u0026#34;root\u0026#34; jdbc_password =\u0026gt; \u0026#34;123456\u0026#34; # jdbc连接mysql驱动的文件目录 jdbc_driver_library =\u0026gt; \u0026#34;./config/mysql-connector-java-5.1.5.jar\u0026#34; jdbc_driver_class =\u0026gt; \u0026#34;com.mysql.jdbc.driver\u0026#34; jdbc_paging_enabled =\u0026gt; true jdbc_page_size =\u0026gt; \u0026#34;50000\u0026#34; jdbc_default_timezone =\u0026gt;\u0026#34;asia/shanghai\u0026#34; # 可以直接写sql语句在此处,使用大于等于避免丢失数据。如下: statement =\u0026gt; \u0026#34;select * from test_logstash where update_time \u0026gt;= :sql_last_value\u0026#34; # 也可以将sql定义在文件中,如下: #statement_filepath =\u0026gt; \u0026#34;./config/jdbc.sql\u0026#34; # 这里类似crontab,可以定制定时操作,比如每分钟执行一次同步(分 时 天 月 年) schedule =\u0026gt; \u0026#34;* * * * *\u0026#34; # 在es6.x版本中,不需要定义type。即使定义,logstash也是自动创建索引type为doc #type =\u0026gt; \u0026#34;doc\u0026#34; # 是否记录上次执行结果, 如果为真,将会把上次执行到的tracking_column字段的值记录下来,保存到last_run_metadata_path指定的文件中,对磁盘的存储压力太大 #record_last_run =\u0026gt; true # 是否需要记录某个column的值,如果record_last_run为真,可以自定义我们需要track的column名称,此时该参数就要为true。否则默认track的是timestamp的值 use_column_value =\u0026gt; true # 如果use_column_value为真,需配置此参数.track的数据库column名,该column必须是递增的. 一般是mysql主键 tracking_column =\u0026gt; \u0026#34;update_time\u0026#34; tracking_column_type =\u0026gt; \u0026#34;timestamp\u0026#34; last_run_metadata_path =\u0026gt; \u0026#34;./logstash_capital_bill_last_id\u0026#34; # 是否清除last_run_metadata_path的记录,如果为真那么每次都相当于从头开始查询所有的数据库记录 clean_run =\u0026gt; false #是否将字段(column)名称转小写 lowercase_column_names =\u0026gt; false } } output { elasticsearch { hosts =\u0026gt; \u0026#34;localhost:9200\u0026#34; #如果是多个es,使用逗号分隔多个ip和端口 index =\u0026gt; \u0026#34;mysql_datas\u0026#34; #索引名称 document_id =\u0026gt; \u0026#34;%{id}\u0026#34; #数据库中数据与es中document数据关联的字段,此处代表数据库中的id字段和es中的document的id关联 template_overwrite =\u0026gt; true #是否使用模板,开启效率更高 } # 这里输出调试,正式运行时可以注释掉 stdout { codec =\u0026gt; json_lines } } 第三步:启动\n1 bin/logstash -f config/logstash-mysql-es.conf 八、从csv中导出数据到es 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 input { file { path =\u0026gt; \u0026#34;/opt/elasticsearch/logstash/instance2/earthquakes.csv\u0026#34; sincedb_path =\u0026gt; \u0026#34;/dev/null\u0026#34; start_position =\u0026gt; \u0026#34;beginning\u0026#34; } } filter { csv { columns =\u0026gt; [\u0026#34;datetime\u0026#34;,\u0026#34;latitude\u0026#34;,\u0026#34;longitude\u0026#34;,\u0026#34;depth\u0026#34;,\u0026#34;magnitude\u0026#34;,\u0026#34;magtype\u0026#34;, \u0026#34;nbstations\u0026#34;,\u0026#34;gap\u0026#34;,\u0026#34;distance\u0026#34;,\u0026#34;rms\u0026#34;,\u0026#34;source\u0026#34;,\u0026#34;eventid\u0026#34;] convert =\u0026gt; { \u0026#34;latitude\u0026#34; =\u0026gt; \u0026#34;float\u0026#34; \u0026#34;longitude\u0026#34; =\u0026gt; \u0026#34;float\u0026#34; \u0026#34;depth\u0026#34; =\u0026gt; \u0026#34;float\u0026#34; \u0026#34;rms\u0026#34; =\u0026gt; \u0026#34;float\u0026#34; \u0026#34;gap\u0026#34; =\u0026gt; \u0026#34;float\u0026#34; } } date { match =\u0026gt; [\u0026#34;datetime\u0026#34;, \u0026#34;yyyy/mm/dd hh:mm:ss.ss\u0026#34;] timezone =\u0026gt; \u0026#34;asia/shanghai\u0026#34; } mutate { add_field =\u0026gt; { \u0026#34;[@metadata][debug]\u0026#34;=\u0026gt; true } } } output { if([@metadata][debug]) { stdout { codec =\u0026gt; rubydebug } }else { elasticsearch { hosts =\u0026gt; [\u0026#34;127.0.0.1:9200\u0026#34;] index =\u0026gt; \u0026#34;csv_datas\u0026#34; } } } ","date":"2020-08-09","permalink":"https://hobocat.github.io/post/searchengine/2020-08-09-logstash/","summary":"一、Logstash架构简介 简介 logstash是一个数据收集处理引擎,可是视之为一个ETL工具。 架构 Input 用于从数据源获取数据,常见的插件如file, syslog","title":"logstash的使用"},]
[{"content":"一、简介 一个轻量级的基于golang开发的数据传输者,用于收集数据常用的beat有下:\nfilebeat 日志文件 metricbeat 收集操作系统和常用软件数据 packetbeat 收集网络数据 heartbeat 健康检查 数据扭转可能的示例如下\nbeats【收集数据】 =》 elasticsearch【存储,ingest node处理】=》kibana【可视化分析】\nbeats【收集数据】 =》 logstash【数据处理过滤】=》elasticsearch【存储,ingest node处理】=》kibana【可视化分析】\n二、ingest node ingest node是elasticsearch的一种节点类型【选举节点、协调节点、数据节点】。可以在数据存储到es之前对数据进行处理。\n默认情况下所有节点都已启用此功能,也可通过node.ingest:false关闭\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 ####################################### 创建pipeline ####################################### put _ingest/pipeline/test { \u0026#34;description\u0026#34;: \u0026#34;this is a test pipeline\u0026#34;, \u0026#34;processors\u0026#34;: [ { \u0026#34;set\u0026#34;: { \u0026#34;field\u0026#34;: \u0026#34;custom_field\u0026#34;, \u0026#34;value\u0026#34;: \u0026#34;custom_value\u0026#34; } }, { \u0026#34;convert\u0026#34;: { \u0026#34;field\u0026#34;: \u0026#34;age\u0026#34;, \u0026#34;type\u0026#34;: \u0026#34;integer\u0026#34; } } ], \u0026#34;version\u0026#34;: 1 } ##################################### 删除、查询pipeline ##################################### delete _ingest/pipeline/test get _ingest/pipeline/test ##################################### 模拟测试pipeline ##################################### post _ingest/pipeline/_simulate { \u0026#34;pipeline\u0026#34;: { \u0026#34;description\u0026#34;: \u0026#34;this is a test pipeline\u0026#34;, \u0026#34;processors\u0026#34;: [ { \u0026#34;set\u0026#34;: { \u0026#34;field\u0026#34;: \u0026#34;custom_field\u0026#34;, \u0026#34;value\u0026#34;: \u0026#34;custom_value\u0026#34; }, \u0026#34;geoip\u0026#34;:{ \u0026#34;field\u0026#34;: \u0026#34;ip\u0026#34;, \u0026#34;target_field\u0026#34;: \u0026#34;ip_info\u0026#34; }, \u0026#34;user_agent\u0026#34;: { \u0026#34;field\u0026#34;: \u0026#34;agent\u0026#34;, \u0026#34;target_field\u0026#34;: \u0026#34;user_ua\u0026#34; }, \u0026#34;convert\u0026#34;: { \u0026#34;field\u0026#34;: \u0026#34;age\u0026#34;, \u0026#34;type\u0026#34;: \u0026#34;integer\u0026#34;, \u0026#34;on_failure\u0026#34;: [ { \u0026#34;set\u0026#34;: { \u0026#34;field\u0026#34;: \u0026#34;age_conver_error\u0026#34;, \u0026#34;value\u0026#34;: \u0026#34;{{_ingest.on_failure_message}}\u0026#34; } } ] } } ], \u0026#34;version\u0026#34;: 1 }, \u0026#34;docs\u0026#34;: [ { \u0026#34;_source\u0026#34;: { \u0026#34;message\u0026#34;: \u0026#34;m m m m m \u0026#34;, \u0026#34;age\u0026#34;: \u0026#34;xxx18\u0026#34;, \u0026#34;ip\u0026#34;:\u0026#34;124.207.37.189\u0026#34;, \u0026#34;agent\u0026#34;: \u0026#34;mozilla/5.0 (windows nt 10.0; win64; x64) applewebkit/537.36 (khtml, like gecko) chrome/81.0.4044.129 safari/537.36\u0026#34; } } ] } post _ingest/pipeline/test/_simulate { \u0026#34;docs\u0026#34;: [ { \u0026#34;_source\u0026#34;: { \u0026#34;message\u0026#34;: \u0026#34;m m m m m \u0026#34; } } ] } pipeline的processors基本上和logstash的filter一一对应\nconvert grok data gsub join json geoip user_agent remove script =》 ruby 三、filebeat filebeat是用于转发和集中日志数据的轻量级传送程序,特性有下\n读取日志,但是不做数据的解析处理 保证数据至少被读取一次,即数据不会丢失 可以处理多行数据,可以解析json格式数据,拥有简单的过滤能力 配置filebeat 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 filebeat.inputs: - type: log #type的类型有:log、stdin、redis、udp、docker、tcp、syslog、netflow paths: #文件的位置 - \u0026#34;/var/log/nginx/*\u0026#34; encoding: utf-8 #文件编目 tags: [\u0026#34;txt\u0026#34;,\u0026#34;web\u0026#34;] #添加的自定义标签 fields: #添加的自定义字段 apache: true fields_under_root: true #解析出来的字段是否放在根下,否则在field下 output.elasticsearch: #输出到的es地址,output只能有一个,调试可以启动时用用 -d \u0026#34;publish\u0026#34; 打印 hosts: [\u0026#34;localhost:9200\u0026#34;] setup.kibana: #kibana地址,用于导入dashboard host: \u0026#34;localhost:5601\u0026#34; 配置index template 如果仅使用一次不建议在filebeat中创建,可直接在elasticsearch中创建\n1 2 3 4 5 6 7 8 9 10 #是否启用template setup.template.enable: false #是否每次beats启动就要覆盖以前的template定义 setup.template.overwrite: true #要向elasticsearch中的创建的template名称 setup.template.name: \u0026#34;nginx\u0026#34; #要向elasticsearch中的创建的template的pattern setup.template.pattern: \u0026#34;nginx-*\u0026#34; #要向elasticsearch中的创建的template的mapping信息 setup.template.fields: \u0026#34;nginx_filed.yml\u0026#34; 配置kibana dashboard 可以通过配置打开dashboard也可以通过命令导入./filebeat setup --dashboards,都是一次性全部导入\n1 2 3 4 #向kibana创建的dashboard的index名称 setup.dashboards.index: \u0026#34;nginx-*\u0026#34; #是否启用dashboard,默认false setup.dashboards.enabled: true 查看配置 1 2 3 ./filebeat export config #查看当前配置文件的详细定义 ./filebeat export template #查看当前配置文件使用的template的详细定义 ./filebeat export template -e setup.template.fields=nginx_field.yml #查看指定的template的详细定义 可以通过./filebeat -e -c filebeat.yml -d \u0026quot;publish\u0026quot;执行时看到详细信息\n-e:输出到stderr,默认输出到logs/filebeat文件\n-d \u0026ldquo;publish\u0026rdquo;:输出\u0026quot;publish\u0026quot;的相关日志信息\nmodules的使用 查看模块列表./filebeat modules list 开启模块./filebeat modules enable nginx 关闭模块./filebeat modules disable nginx 修改modules文件夹下对应开启的模块的yml文件【主要时配置文件路径,注意文件权限】 执行nohup ./filebeat -e -c filebeat.yml -d \u0026quot;publish\u0026quot; \u0026amp; 四、metricbeat 简介 metricbeat用于定期收集操作系统、软件服务的指标数据。存入elasticsearch用于记录度量和聚合数据,具有计划性\nmodules的使用 查看模块列表./metricbeat modules list 开启模块./metricbeat modules enable system 关闭模块./metricbeat modules disable system 修改metricbeat.yml配置output和dashboard 导入dashboard配置./metricbeat setup --dashboards 修改对应模块的配置,开启需要的metricsets和调整收集时间间隔 执行nohup ./metricbeat -e -c metricbeat.yml -d \u0026quot;publish\u0026quot; \u0026amp; 五、packetbeat 简介 用于抓取网络包数据,可以自动解析网络包协议例如icmp dns、http、mysql/pgsql/mongodb、memcache、thrift、tls等\npacketbeat抓包配置有两种\n使用 修改packetbeat.yml配置output和dashboard 配置packetbeat.yml各个模块的参数信息 导入dashboard配置./packetbeat setup --dashboards 执行nohup ./packetbeat -e -c packetbeat.yml -d \u0026quot;publish\u0026quot; \u0026amp;【注意网卡权限,不行需要用root用户执行】 六、heartbeat 简介 做心跳检测,判断对方是否存活\n使用 修改heartbeat.yml配置output和dashboard 配置heartbeat.yml各个程序需要的协议 导入dashboard配置./heartbeat setup --dashboards 执行nohup ./heartbeat -e -c heartbeat.yml -d \u0026quot;publish\u0026quot; \u0026amp; 更多社区beat查看链接\n","date":"2020-08-09","permalink":"https://hobocat.github.io/post/searchengine/2020-08-09-beats/","summary":"一、简介 一个轻量级的基于golang开发的数据传输者,用于收集数据常用的beat有下: Filebeat 日志文件 Metricbeat 收集操作系统和常用软件数据 Packetbeat 收集网络数据 Heartbeat 健康检查 数据扭转可能","title":"beats的使用"},]
[{"content":"一、var“关键字” 1 2 3 4 5 // 编译器能根据右边的表达式自动推断类型 // var的好处是在使用lambda表达式时给参数加上注解 var str = \u0026#34;abc\u0026#34;; system.out.println(str.getclass()); //class java.lang.string consumer\u0026lt;integer\u0026gt; consumer = (@deprecated var x) -\u0026gt; system.out.println(x); var“关键字”并非正在的关键字,变量依旧可以用var命名,var“关键字”只是一个语法糖\n二、增加字符串处理方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 // 判断字符串是否为空白 \u0026#34;\\t \u0026#34;.isblank(); // ture // 去除首尾空白 \u0026#34;\\t [content] \u0026#34;.strip(); // [content] // 去除首部空格 \u0026#34;\\t [content] \u0026#34;.stripleading(); // [content]空格空格 // 去除尾部空格 \u0026#34;\\t [content] \u0026#34;.striptrailing(); // 空格空格[content] // 复制字符串 \u0026#34;java \u0026#34;.repeat(3); // java java java // 行数统计 \u0026#34;a\\nb\\nc\u0026#34;.lines().count(); // 3 strip与trim的区别时trim不能去除非英文的空格,strip可以去除所有字符集的空格\n三、标准java异步http客户端 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public class httpclienttest { public static void main(string[] args) throws exception { // 创建httpclient httpclient httpclient = httpclient.newhttpclient(); // 创建request httprequest request = httprequest.newbuilder(uri.create(\u0026#34;http://www.baidu.com\u0026#34;)).build(); // send同步发送数据,并指定resopnse的body如何处理 httpresponse\u0026lt;string\u0026gt; response = httpclient.send(request, httpresponse.bodyhandlers.ofstring()); // 打印headers和body system.out.println(response.headers()); system.out.println(response.body()); // sendasync异步发送 httpclient.sendasync(request, httpresponse.bodyhandlers.ofstring()) .thenapply(httpresponse::body) .thenaccept(system.out::println); } } 四、java flight recorder flight recorder源自飞机的黑盒子,以前是商业版的特性现oracle将其开源用于监视jvm。jfr的可监视生产环境且性能开销最大不超过1%\n采集jfr信息 1 2 3 4 5 6 7 8 # 开启jfr,会显示记录id jcmd \u0026lt;pid\u0026gt; jfr.start # 指定生成文件,和开启时显示的记录id jcmd \u0026lt;pid\u0026gt; jfr.dump filename=recording.jfr name=num # 关闭jfr,需指定记录id jcmd \u0026lt;pid\u0026gt; jfr.stop name=num 解析jfr信息 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 # 打印jfr所有信息 jfr print recording.jfr # 打印指定事件信息 jfr print --events cpuload,garbagecollection recording.jfr # 打印指定时间信息用json格式 jfr print --json --events cpuload recording.jfr # 打印指定分类信息信息 jfr print --categories \u0026#34;gc,jvm,java*\u0026#34; recording.jfr # 打印jdk事件并指定栈深度 jfr print --events \u0026#34;jdk.*\u0026#34; --stack-depth 64 recording.jfr # 打印统计信息 jfr summary recording.jfr # 打印元信息 jfr metadata recording.jfr ","date":"2020-05-29","permalink":"https://hobocat.github.io/post/java/2020-05-29-java11/","summary":"一、var“关键字” 1 2 3 4 5 // 编译器能根据右边的表达式自动推断类型 // var的好处是在使用lambda表达式时给参数加上注解 var str = \u0026#34;abc\u0026#34;; System.out.println(str.getClass()); //class java.lang.String Consumer\u0026lt;Integer\u0026gt; consumer = (@Deprecated var x) -\u0026gt; System.out.println(x); var","title":"java11新特性"},]
[{"content":"一、jdk目录结构 目录名称 说明 bin 包含所有命令和运行时动态链接库 conf 包含用户可编辑的配置文件,例如以前位于jre\\lib目录中的.properties和.policy文件 include 包含编译本地代码时使用的c/c++头文件 jmods 包含jmod格式的平台模块, 创建自定义运行时映像时需要它 legal 包含法律声明 lib 其它平台上的动态链接本地库, 其子目录和文件不应由开发人员直接编辑或使用 二、模块化系统 java运行环境的膨胀和臃肿的主要原因是jvm需要加载rt.jar【runtime环境】。不管其中的类是否被classloader加载,第一步整个jar都会被jvm加载到内存当中去,一般需要30~60mb内存(而模块化可以根据模块的需要加载程序运行需要的class)\n 每一个公共类都可以被类路径之下任何其它的公共类所访问到,这样就会导致无意中使用了并不想被公开访问的 api。模块化限制了类的访问\n使用模块化的前提条件是java文件夹下必须有module-info.java\nexports\u0026amp;requires 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 //========================================= 工程java9.modular ======================================== package com.kun.modular.export.bean; public class person { // filed and method } /* * module-info配置 */ module java9.modular { // exports [包名...] 暴露当前模块的包,所有其它模块均可访问 exports com.kun.modular.export.bean; // exports [包名...] to [包名...] 暴露当前模块的包,只有指定的其它包可访问 // exports com.kun.modular.export.bean to com.kun.test.modular; } //============================================ 工程java9 =========================================== package com.kun.test.modular; public class modulartest { public static void main(string[] args) throws exception { person person = new person(); } } /* * module-info配置 */ module java9 { // 引入模块 requires java9.modular; } opens\u0026amp;requires 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 //========================================= 工程java9.modular ======================================== package com.kun.modular.export.bean; public class person { // filed and method } /* * module-info配置 */ module java9.modular { // 指定包可以通过java反射访问 opens com.kun.modular.export.bean; } //============================================ 工程java9 =========================================== package com.kun.test; public class modulartest { public static void main(string[] args) throws exception { class\u0026lt;?\u0026gt; aclass = class.forname(\u0026#34;com.kun.modular.bean.person\u0026#34;); constructor\u0026lt;?\u0026gt; constructor = aclass.getconstructor(); object o = constructor.newinstance(); } } /* * module-info配置 */ module java9 { // 通过反射也需要显示引入模块 requires java9.modular; } provides [class-qualified] with [class-qualified-impl] \u0026amp; use 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 //========================================= 工程java9.modular ======================================== package com.kun.modular.export.provides; public interface personservice { person getperson(); } public class personserviceimpl implements personservice{ @override public person getperson() { return new person(); } } /* * module-info配置 */ module java9.modular { // 指定服务类和其实现类 provides com.kun.modular.export.provides.personservice with com.kun.modular.export.provides.personserviceimpl; } //============================================ 工程java9 =========================================== package com.kun.test; public class modulartest { public static void main(string[] args) throws exception { // 加载服务 personservice personservice = serviceloader.load(personservice.class).findfirst().get(); personservice.getperson(); } } /* * module-info配置 */ module java9 { requires java9.modular; // 指定使用什么服务,上方的requires也必须使用 uses com.kun.modular.export.provides.personservice; } requires requires static [包名]表示依赖的模块是编译时是必需的,但运行时是可选的,比如一些检查注解,运行时并不需要\nrequires transitive [包名]表示假如模块a依赖模块 b,外界的模块不仅想使用 a 模块还想使用b模块,那么可以使用该指令获取到b 的访问权限,这种对外暴露传递依赖的模块也称为隐式读取(implied read)\n三、接口的私有方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 public interface newinterface { // jdk 7及之前版本只能创建public abstract 方法 和 public static final常量 void methodjdk7(); public static final string constant_data = \u0026#34;常量\u0026#34;; // jdk8允许创建default方法访问修饰符是public, 还允许创建静态方法修饰符是public default void methodjdk8() { system.out.println(\u0026#34;jdk8允许创建default方法\u0026#34;); } static void methodstaticjdk8() { system.out.println(\u0026#34;jdk8允允许创建静态方法\u0026#34;); } // jdk9允许创建private方法,供default方法调用[多个default抽取公共方法] private void methodjdk9() { system.out.println(\u0026#34;jdk9允许创建private方法,供default方法调用[多个default抽取公共方法]\u0026#34;); } default void methoddefault(){ methodjdk9(); } } 四、钻石操作符的使用升级 1 2 3 4 5 6 7 8 9 10 11 12 13 public class diamondoperatortest { public static void main(string[] args) { // jdk8也可以使用但是new hashmap\u0026lt;\u0026gt;不能进行泛型推到必须使用new hashmap\u0026lt;integer, string\u0026gt; map\u0026lt;integer, string\u0026gt; map = new hashmap\u0026lt;\u0026gt;(){ { put(1, \u0026#34;a\u0026#34;); put(2, \u0026#34;b\u0026#34;); put(3, \u0026#34;c\u0026#34;); } }; } } 五、try语句改进 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 //======================================== jdk 7 处理方式 ======================================== inputstream inputstream = null; try { inputstream = new fileinputstream(\u0026#34;index.html\u0026#34;); } catch (filenotfoundexception e) { system.out.println(\u0026#34;异常处理\u0026#34;); } finally { if (inputstream != null) { try { inputstream.close(); } catch (ioexception e) { system.out.println(\u0026#34;异常处理\u0026#34;); } } } //======================================== jdk 8 处理方式 ======================================== // 流会自动关闭但是 inputstream inputstream = new fileinputstream(\u0026#34;index.html\u0026#34;) 必须写在括号内 try(inputstream inputstream = new fileinputstream(\u0026#34;index.html\u0026#34;)) { // do something } catch (filenotfoundexception e) { system.out.println(\u0026#34;异常处理\u0026#34;); } catch (ioexception e) { system.out.println(\u0026#34;异常处理\u0026#34;); } //======================================== jdk 9 处理方式 ======================================== // 流会自动关闭,但是文件找不到这种异常还是会向上抛出 inputstream inputstream = new fileinputstream(\u0026#34;index.html\u0026#34;); try(inputstream) { // do something } catch (ioexception e) { system.out.println(\u0026#34;异常处理\u0026#34;); } 六、string存储结构变更 背景:jdk8的字符串存储在char类型的数组里面,在大多数情况下字符只需要一个字节就能表示出来了[英文字母和数字],所以使用char[一个char占两个字节]存储势必会浪费空间\njdk9改用byte[]表示\n当string中只包含一个字节能表示的字符时,使coder=latin1=0,采用一个byte存储一个字符的策略 当string中包含非一个字节能表示的字符时,使coder=utf-16=1,采用两个byte存储一个字符的策略 计算长度时【byte[].length \u0026laquo; coder】位 string底层存储改变引起的连锁反应:stringbuffer和stringbuilder底层也使用byte[]存储,当调用append时会判断需要连接的俩字符串是否是同coder,是同coder直接连接。不是同coder则需要变为coder=utf-16格式\n七、创建只读集合 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 //========================================= jdk 8 创建只读容器 ========================================= list\u0026lt;string\u0026gt; stringlist = new arraylist\u0026lt;\u0026gt;(); stringlist.add(\u0026#34;1\u0026#34;); stringlist.add(\u0026#34;2\u0026#34;); stringlist.add(\u0026#34;3\u0026#34;); stringlist = collections.unmodifiablelist(stringlist); stringlist.add(\u0026#34;2\u0026#34;); //========================================= jdk 9 创建只读容器 ========================================= list\u0026lt;string\u0026gt; stringlist = list.of(\u0026#34;1\u0026#34;, \u0026#34;2\u0026#34;, \u0026#34;3\u0026#34;, \u0026#34;4\u0026#34;, \u0026#34;5\u0026#34;); set\u0026lt;string\u0026gt; stringset = set.of(\u0026#34;1\u0026#34;, \u0026#34;2\u0026#34;, \u0026#34;3\u0026#34;, \u0026#34;4\u0026#34;, \u0026#34;5\u0026#34;); map\u0026lt;integer, string\u0026gt; map = map.of(1, \u0026#34;v1\u0026#34;, 2, \u0026#34;v2\u0026#34;, 3, \u0026#34;v3\u0026#34;); map\u0026lt;integer, string\u0026gt; mapentry = map.ofentries( map.entry(1, \u0026#34;v1\u0026#34;), map.entry(2, \u0026#34;v2\u0026#34;), map.entry(3, \u0026#34;v3\u0026#34;)); 八、增强的stream api 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 list\u0026lt;integer\u0026gt; list = arrays.aslist(45, 43, 76, 87, 42, 77, 90, 73, 67, 88); // 在流中得到尽可能多的符合条件的数据,即从左往右查找 list.stream().takewhile(x -\u0026gt; x \u0026lt; 80).foreach(system.out::println); // takewhile的补集 list.stream().dropwhile(x -\u0026gt; x \u0026lt; 80).foreach(system.out::println); /* * public static\u0026lt;t\u0026gt; stream\u0026lt;t\u0026gt; of(t... values) 可以元素全部为null,count时null不计入 * public static\u0026lt;t\u0026gt; stream\u0026lt;t\u0026gt; of(t t) 元素不能为null会抛出异常 * public static\u0026lt;t\u0026gt; stream\u0026lt;t\u0026gt; ofnullable(t t) 元素可以为null,count时null计入 */ stream.of(\u0026#34;1\u0026#34;, \u0026#34;2\u0026#34;, null); //count为2 stream.ofnullable(null); //count为1 // iterator()重载的使用,创建一个1~10的integer类型的stream stream.iterate(1, i -\u0026gt; i + 1).limit(10) // 比使用limit更加灵活 stream.iterate(1, i -\u0026gt; i \u0026lt;= 10,i -\u0026gt; i + 1).foreach(system.out::println); // optional类中stream()的使用 optional\u0026lt;list\u0026lt;string\u0026gt;\u0026gt; optional = optional.of(arrays.aslist(\u0026#34;1\u0026#34;, \u0026#34;2\u0026#34;, \u0026#34;3\u0026#34;, \u0026#34;4\u0026#34;)); // optional.stream() 得到的是stream\u0026lt;list\u0026lt;string\u0026gt;\u0026gt; optional.stream().flatmap(x -\u0026gt; x.stream()).foreach(system.out::println); 创建stream的方法:\n通过集合的stream() 通过数组工具类arrays stream中静态方法of() iterator() 九、inputstream增强 inputstream添加了transferto放法,可以用来将数据直接传输到outputstream,这是在处理原始数据流时非常常见的一种用法\n1 2 3 4 5 6 7 8 public class inputstreamtest { public static void main(string[] args) throws ioexception { inputstream inputstream = new fileinputstream(\u0026#34;src/1.txt\u0026#34;); outputstream outputstream = new fileoutputstream(\u0026#34;1_bak.txt\u0026#34;); inputstream.transferto(outputstream); } } ","date":"2020-05-28","permalink":"https://hobocat.github.io/post/java/2020-05-28-java9/","summary":"一、JDK目录结构 目录名称 说明 bin 包含所有命令和运行时动态链接库 conf 包含用户可编辑的配置文件,例如以前位于jre\\lib目录中的.properties和.polic","title":"java9新特性"},]
[{"content":"一、虚拟化概念 \t虚拟化,是指通过虚拟化技术将一台计算机虚拟为多台逻辑计算机。在一台计算机上同时运行多个逻辑计算机,每个逻辑计算机可运行不同的操作系统,并且应用程序都可以在相互独立的空间内运行而互不影响,从而显著提高计算机的工作效率。\n虚拟化前\n每台主机一个操作系统 软件硬件紧密地结合 在同一主机上运行多个应用程序通常会遭遇冲突 系统的资源利用率低 硬件成本高昂而且不够灵活 虚拟化后\n打破了操作系统和硬件的互相依赖 通过封装到到虚拟机的技术,管理操作系统和应用程序为单一的个体 强大的安全和故障隔离 虚拟机是独立于硬件的,它们能在任何硬件上运行 二、虚拟化技术的分类 全虚拟化技术 \t完全虚拟化技术又叫硬件辅助虚拟化技术,最初所使用的虚拟化技术就是全虚拟化【full virtualization】技术,它在虚拟机(vm)和硬件之间加了一个软件层一hypervisor【虚拟机监控器(vmm)】\nhypervisor如果直接运行在物理硬件之上叫做kvm hypervisor如果运行在另一个操作系统中叫做qemu或wine 半虚拟化技术/准虚拟化技术 \t半虚拟化技术,也叫做准虚拟化技术。它就是在全虚拟化的基础上,把客户操作系统进行了修改,增加了一个 专门的api,这个api可以将客户操作系统发出的指令进行最优化,即不需要hypervisor耗费一定的资源进行翻译操作,因此hypervisor的工作负担变得非常的小,因此整体的性能也有很大的提高。但是修改操作系统十分复杂耗费资源,所以一般没人使用。\n三、架构的类型分类 寄居架构 寄居架构是在操作系统之上安装和运行虚拟化程序,依赖于宿主操作系统对设备的支持和物理资源的管理\n优点:简单,便于实现\n缺点:宿主机本身就占据了很多资源而且宿主机的稳定之间影响了虚拟化的稳定\n举例:vmware workstation,virtual box\n裸金属架构 裸金属架构是直接在硬件上而安装虚拟化软件,再在其上安装操作系统和应用,依赖虚拟层内核和服务器控制台进行管理。(虚拟层本身就是一个简易linux内核的系统)\n优点:虚拟机不依赖于操作系统,消耗资源少\n缺点:虚拟层内核开发难度较大(使用者感觉不到)\n举例:vmware esxi server\n","date":"2019-12-09","permalink":"https://hobocat.github.io/post/docker/2019-12-09-%E8%99%9A%E6%8B%9F%E5%8C%96%E7%9A%84%E6%A6%82%E5%BF%B5/","summary":"一、虚拟化概念 虚拟化,是指通过虚拟化技术将一台计算机虚拟为多台逻辑计算机。在一台计算机上同时运行多个逻辑计算机,每个逻辑计算机可运行不同的操作系统,并且应用程","title":"虚拟化概念"},]
[{"content":"一、spring boot与缓存 jsr107中jcache简介 jcache定义了5个核心接口,分别是cachingprovider, cachemanager, cache, entry 和 expiry\ncachingprovider定义了创建、配置、获取、管理和控制多个cachemanager。一个应用可以在运行期访问多个cachingprovider\ncachemanager定义了创建、配置、获取、管理和控制多个唯一命名的cache,这些cache存在于cachemanager的上下文中。一个cachemanager仅被一个cachingprovider所拥有\ncache是一个类似map的数据结构并临时存储以key为索引的值。一个cache仅被一个cachemanager所拥有\nentry是一个存储在cache中的key-value对\nexpiry 每一个存储在cache中的条目有一个定义的有效期。一旦超过这个时间,条目为过期的状态。一旦过期,条目将不可访问、更新和删除。缓存有效期可以通过expirypolicy设置\nspring缓存抽象 spring定义了org.springframework.cache.cache和org.springframework.cache.cachemanager接口来统一不同的缓存技术,并支持使用jcache(jsr-107)注解简化我们开发,但并没有按照jcache实现缓存管理\ncache接口为缓存的组件规范定义,包含缓存的各种操作集合 cachemanager接口实现类用于管理各种cache spring缓存类及注解说明\n类\u0026amp;注解 说明 cache 缓存接口,定义缓存操作 cachemanager 缓存管理器,管理各种缓存(cache)组件 @cacheable 主要针对方法配置,能够根据方法的请求参数对其结果进行缓存 @cacheevict 清空缓存 @cacheput 调用方法并更新缓存 @enablecaching 开启基于注解的缓存 keygenerator 缓存数据时key生成策略 serialize 缓存数据时value序列化策略 cache实现有:rediscache、ehcachecache、concurrentmapcache等\nspring boot缓存使用 前置条件:引入spring-boot-starter-cache并在配置类上加入@enablecaching\n@cacheable的使用【结果存入缓存,下次现在缓存中查找】 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 /** * @cacheable属性介绍 * * cachenames/value 指定cache的名称,cachemanager根据此名称查找对应的cache * * key 如何生成缓存数据的key,可使用spel表达式指定,默认使用方法参数的值作为key *\t例如:#id、#a0、#p0、#root.args[0]【均是使用参数id作为key】 * * keygenerator key的生成器,可以自己指定规则生成id。key/keygenerator二选一 * * condition\t指定条件的情况下才缓存 * * unless 否定缓存;当unless指定的条件为true,方法的返回值就不会被缓存 * * sync 是否使用异步模式,默认否 * * cachemanager/cacheresolver 指定缓存管理器 */ @cacheable(cachenames=\u0026#34;employee\u0026#34;) public employee getemp(integer id) { return employeemapper.getempbyid(id); } @cacheevict的使用【清除缓存】 1 2 3 4 5 6 7 8 /** * beforeinvocation\t是否在调用方法之前情况,默认false【如果方法执行出现异常不会删除缓存信息】 * allentries\t是否删除cachenames域下的所有缓存信息,默认false */ @cacheevict(cachenames=\u0026#34;employee\u0026#34;, key=\u0026#34;#id\u0026#34;) public void deleteemp(integer id) { employeemapper.deleteempbyid(id); } @cacheput的使用【更新缓存,存入缓存的是其返回值】 1 2 3 4 5 6 7 8 /** * 返回值必须是要存入缓存的对象,不可返回void */ @cacheput(cachenames=\u0026#34;employee\u0026#34;, key=\u0026#34;#employee.id\u0026#34;) public employee updateemp(employee employee) { employeemapper.updateemp(employee); return employee; } @caching的使用【caching是cacheable、cacheput和cacheevict的组合用于应对复杂情况】 1 2 3 4 5 public @interface caching { cacheable[] cacheable() default {}; cacheput[] put() default {}; cacheevict[] evict() default {}; } @cacheconfig的使用【用于抽取公共配置,简化方法上的注解】 1 2 3 4 @cacheconfig(cachenames=\u0026#34;employee\u0026#34;) public class employeeservice { //...... } 附:cache spel\n名字 描述 示例 methodname 当前被调用的方法名 #root.methodname method 当前被调用的方法 #root.method.name target 当前被调用的目标对象 #root.target targetclass 当前被调用的目标对象类 #root.targetclass args 当前被调用的方法的参数列表 #root.args[0] caches 当前方法调用使用的缓存列表(如@cacheable(value={\u0026ldquo;cache1\u0026rdquo;, \u0026ldquo;cache2\u0026rdquo;})),则有两个cache #root.caches[0].name argument name 方法参数的名字. 可以直接 #参数名 ,也可以使用#p0或#a0 的形式,0代表参数的索引 #参数名 、 #a0 、 #p0 result 方法执行后的返回值(仅当方法执行之后的判断有效,如‘unless’,’cache put’的表达式 ’cache evict’的表达式beforeinvocation=false) #result spring boot缓存整合原理 spring boot初始化时会通过spring-boot-autoconfigure.jar的meta-inf下的spring.factories导入cacheautoconfiguration\ncacheautoconfiguration通过内部内cacheconfigurationimportselector注册了如下类信息\n1 2 3 4 5 6 7 8 9 10 org.springframework.boot.autoconfigure.cache.genericcacheconfiguration org.springframework.boot.autoconfigure.cache.jcachecacheconfiguration org.springframework.boot.autoconfigure.cache.ehcachecacheconfiguration org.springframework.boot.autoconfigure.cache.hazelcastcacheconfiguration org.springframework.boot.autoconfigure.cache.infinispancacheconfiguration org.springframework.boot.autoconfigure.cache.couchbasecacheconfiguration org.springframework.boot.autoconfigure.cache.rediscacheconfiguration org.springframework.boot.autoconfigure.cache.caffeinecacheconfiguration org.springframework.boot.autoconfigure.cache.simplecacheconfiguration org.springframework.boot.autoconfigure.cache.noopcacheconfiguratio spring boot会根据当前环境上下文使用对应的cacheconfiguration默认使用simplecacheconfiguration\nsimplecacheconfiguration导入了concurrentmapcachemanager作为cachemanager的实现\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 @configuration @conditionalonmissingbean(cachemanager.class) @conditional(cachecondition.class) class simplecacheconfiguration { //提供了cachemanager @bean public concurrentmapcachemanager cachemanager() { concurrentmapcachemanager cachemanager = new concurrentmapcachemanager(); list\u0026lt;string\u0026gt; cachenames = this.cacheproperties.getcachenames(); if (!cachenames.isempty()) { cachemanager.setcachenames(cachenames); } return this.customizerinvoker.customize(cachemanager); } } concurrentmapcachemanager使用concurrentmapcache作为cache的实现\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 public class concurrentmapcachemanager implements cachemanager, beanclassloaderaware { //根据key获得cache的方法 public cache getcache(string name) { cache cache = this.cachemap.get(name); if (cache == null \u0026amp;\u0026amp; this.dynamic) { synchronized (this.cachemap) { cache = this.cachemap.get(name); if (cache == null) { cache = createconcurrentmapcache(name); this.cachemap.put(name, cache); } } } return cache; } //创建cache protected cache createconcurrentmapcache(string name) { serializationdelegate actualserialization = (isstorebyvalue() ? this.serialization : null); return new concurrentmapcache(name, new concurrenthashmap\u0026lt;\u0026gt;(256), isallownullvalues(), actualserialization); } } @enablecaching导入了cachingconfigurationselector,cachingconfigurationselector使用动态代理切入使用cache相关注解的方法\nspring boot与redis整合 前置条件:引入spring-boot-starter-data-redis\n配置连接 1 2 3 4 5 6 7 8 9 10 11 spring: redis: cluster: max-redirects: 5 nodes: - 192.168.1.158:7000 - 192.168.1.158:7001 - 192.168.1.158:7002 - 192.168.1.158:7003 - 192.168.1.158:7004 - 192.168.1.158:7005 spring boot 1.x版本\n配置redistemplate\u0026lt;object, object\u0026gt;用于存储value转换位json的数据【默认使用jdk序列化机制】\nredistemplate\u0026lt;object, object\u0026gt;替换了全局redisautoconfiguration注入的转化\n1 2 3 4 5 6 7 8 9 10 11 @bean public redistemplate\u0026lt;object, object\u0026gt; redistemplate(redisconnectionfactory redisconnectionfactory) { jackson2jsonredisserializer\u0026lt;object\u0026gt; jackson2jsonredisserializer = new jackson2jsonredisserializer\u0026lt;object\u0026gt;(object.class); redistemplate\u0026lt;object, object\u0026gt; template = new redistemplate\u0026lt;object, object\u0026gt;(); template.setconnectionfactory(redisconnectionfactory); template.setkeyserializer(jackson2jsonredisserializer); template.setvalueserializer(jackson2jsonredisserializer); template.sethashkeyserializer(jackson2jsonredisserializer); template.sethashvalueserializer(jackson2jsonredisserializer); return template; } spring boot 2.x版本\nrediscachemanager可以设置缓存过期时间、也可以针对每个缓存空间设置不同的策略\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 @bean public rediscachemanager cachemanager(redisconnectionfactory connectionfactory) { rediscacheconfiguration config = rediscacheconfiguration.defaultcacheconfig() .entryttl(duration.zero)\t//设置缓存过期时间 .serializekeyswith(redisserializationcontext.serializationpair.fromserializer(keyserializer())) .serializevalueswith(redisserializationcontext.serializationpair.fromserializer(valueserializer())) .disablecachingnullvalues(); rediscachemanager rediscachemanager = rediscachemanager.builder(connectionfactory) .cachedefaults(config) .transactionaware() .build(); return rediscachemanager; } private redisserializer\u0026lt;string\u0026gt; keyserializer() { return new stringredisserializer(); } private redisserializer\u0026lt;object\u0026gt; valueserializer() { return new genericjackson2jsonredisserializer(); } 取出cachemanager对象 cachemanager.getcachenames()只能拿到曾经访问过的cachename,没访问过的无法得到\n1 2 3 4 5 6 public class employeeservice { public void printcache(){ collection\u0026lt;string\u0026gt; cachenames = cachemanager.getcachenames(); system.out.println(cachenames); } } 二、spring boot与消息 引入消息中间件解决:模块耦合、异步问题、流量削峰。\n参见spring boot整合\n三、spring boot与检索 导入依赖\n1 2 3 4 5 6 7 8 9 10 \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;org.springframework.boot\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;spring-boot-starter-data-elasticsearch\u0026lt;/artifactid\u0026gt; \u0026lt;/dependency\u0026gt; \u0026lt;!-- 使用jest时导入 --\u0026gt; \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;io.searchbox\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;jest\u0026lt;/artifactid\u0026gt; \u0026lt;/dependency\u0026gt; 使用jest整合elasticsearch 配置链接\n1 2 3 4 5 spring: elasticsearch: jest: uris: - \u0026#34;http://192.168.1.155:9300\u0026#34; 使用示例\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 //实体类 public class book { @jestid private string id; private date postdate; private string title; private string content; private long authorid; //==============getter/setter============== } //创建数据 @test public void testcreate() throws ioexception { book book = new book(); book.setid(\u0026#34;100\u0026#34;); book.setauthorid(1001l); book.setcontent(\u0026#34;好看的书\u0026#34;); book.setpostdate(new date()); book.settitle(\u0026#34;jest系列\u0026#34;); index.builder builder = new index.builder(book); index index = builder.index(\u0026#34;book\u0026#34;).type(\u0026#34;book_type\u0026#34;).build(); documentresult documentresult = jestclient.execute(index); system.out.println(documentresult.getjsonstring()); } //查询数据 @test public void testquery() throws ioexception { xcontentbuilder querybuilder = xcontentfactory.jsonbuilder() .startobject() .startobject(\u0026#34;query\u0026#34;) .startobject(\u0026#34;match_all\u0026#34;) .endobject() .endobject() .endobject(); search search= new search.builder( strings.tostring(querybuilder)) .addindex(\u0026#34;book\u0026#34;).addtype(\u0026#34;book_type\u0026#34;).build(); searchresult documentresult = jestclient.execute(search); system.out.println(documentresult.getsourceasstring()); } 使用spring data整合elasticsearch 注意\nspring data与elasticsearch版本对应有限制,先查看spring-boot-starter-data-elasticsearch引用的spring data elasticsearch版本,如果冲突使用对应版本的elasticsearch或者使用对应的spring data elasticsearch版本【记得剔除spring-boot-starter-data-elasticsearch中的引用】\nspring data elasticsearch elasticsearch 3.2.x 6.5.0 3.1.x 6.2.2 3.0.x 5.5.0 2.1.x 2.4.0 2.0.x 2.2.0 1.3.x 1.5.2 配置信息\n1 2 3 4 5 6 spring: data: elasticsearch: cluster-name: docker-cluster #注意端口默认位9300并非http通讯端口 clusternodes: 192.168.1.155:9300 使用示例\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 //创建数据 @test public void testcreate() throws ioexception { book book = new book(); book.setid(\u0026#34;100\u0026#34;); book.setauthorid(1001l); book.setcontent(\u0026#34;好看的书\u0026#34;); book.setpostdate(new date()); book.settitle(\u0026#34;jest系列\u0026#34;); indexquery indexquery = new indexquery(); indexquery.setobject(book); indexquery.setindexname(\u0026#34;book\u0026#34;); indexquery.settype(\u0026#34;book_type\u0026#34;); template.index(indexquery); } //查询数据 @test public void testquery() throws ioexception { nativesearchquerybuilder nativesearchquery = new nativesearchquerybuilder().withquery(new matchallquerybuilder()); list\u0026lt;book\u0026gt; books = template.queryforlist(nativesearchquery.build(), book.class); system.out.println(books); } 四、spring boot与任务 异步任务 在主配置类上使用@enableasync开启异步注解功能 在需要异步支持的方法上标注@async 1 2 3 4 @async public void asyncmethod() throws interruptedexception{ //do something.... } 定时任务 spring提供了异步执行任务调度的方式,提供taskexecutor 、taskscheduler用户可自扩展\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 /** * fixeddelay\t一次执行完毕时间点之后多长时间再执行 * fixeddelaystring\t与fixeddelay意思相同,只是使用字符串的形式。唯一不同的是支持占位符 * fixedrate\t上一次开始执行时间点之后多长时间再执行 * fixedratestring\t与fixedrate意思相同,只是使用字符串的形式。唯一不同的是支持占位符 * initialdelay\t第一次延迟多长时间后再执行 * initialdelaystring 与initialdelay意思相同,只是使用字符串的形式。唯一不同的是支持占位符 * zone 时区,默认取当前计算器时区 * cron\t使用cron表达式进行设置 */ @scheduled(cron=\u0026#34;0 */1 * * * ?\u0026#34;) public void scheduled() { system.out.println(\u0026#34;---------------------------\u0026#34;); } 附cron表达式\n字段 允许值 允许的特殊字符 秒 0-59 , - * / 分 0-59 , - * / 小时 0-23 , - * / 日期 1-31 , - * ? / l w c 月份 1-12 , - * / 星期 0-7或sun-sat 0,7是sun , - * ? / l c # 特殊字符 代表含义 , 枚举 - 区间 * 任意 / 步长 ? 日/星期冲突匹配 l 最后 w 工作日 c 和calendar联系后计算过的值 # 星期,4#2,第2个星期四 邮件任务 引入依赖 1 2 3 4 \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;org.springframework.boot\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;spring-boot-starter-mail\u0026lt;/artifactid\u0026gt; \u0026lt;/dependency\u0026gt; 配置邮件发送所需的smtp服务器等信息 1 2 3 4 5 spring: mail: host: smtp.qq.com username: source@qq.com password: lvhotbvqbezejfbb #授权码是独立的需要去生成 发送邮件\n发送简单类型邮件 1 2 3 4 5 6 7 8 public void sendsimpleemail() { simplemailmessage simplemessage = new simplemailmessage(); simplemessage.setfrom(\u0026#34;source@qq.com\u0026#34;); simplemessage.setto(\u0026#34;target@qq.com\u0026#34;); simplemessage.setsubject(\u0026#34;测试邮件\u0026#34;); simplemessage.settext(\u0026#34;测试邮件内容\u0026#34;); mailsender.send(simplemessage); } 发送复杂html类型邮件 1 2 3 4 5 6 7 8 9 10 11 12 13 14 public void sendmimeemail() throws messagingexception { mimemessage mimemessage = mailsender.createmimemessage(); /** * mimemessagehelper(mimemessage mimemessage, boolean multipart) * 发生附件邮件是multipart要设置为true */ mimemessagehelper helper = new mimemessagehelper(mimemessage,true); helper.setfrom(\u0026#34;source@qq.com\u0026#34;); helper.setto(\u0026#34;target@qq.com\u0026#34;); helper.setsubject(\u0026#34;测试邮件\u0026#34;); helper.settext(\u0026#34;\u0026lt;html\u0026gt;\u0026lt;body\u0026gt;\u0026lt;div style=\u0026#39;color:red\u0026#39;\u0026gt;测试内容\u0026lt;/div\u0026gt;\u0026lt;/body\u0026gt;\u0026lt;/html\u0026gt;\u0026#34;,true); helper.addattachment(\u0026#34;attach.png\u0026#34;, new classpathresource(\u0026#34;attach.png\u0026#34;)); mailsender.send(helper.getmimemessage()); } 五、spring boot与安全 参见spring security使用指南\n六、spring boot与热部署 引入spring boot官方提供的热部署工具即可拥有热部署能力\n1 2 3 4 5 \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;org.springframework.boot\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;spring-boot-devtools\u0026lt;/artifactid\u0026gt; \u0026lt;optional\u0026gt;true\u0026lt;/optional\u0026gt; \u0026lt;/dependency\u0026gt; 七、spring boot与监管 \tspring boot提供了将应用程序推送到生产环境时监视和管理应用功能,可以使用http端点或jmx来管理和监视应用程序\n第一步:引入spring-boot-actuator模块\n1 2 3 4 5 \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;org.springframework.boot\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;spring-boot-starter-actuator\u0026lt;/artifactid\u0026gt; \u0026lt;optional\u0026gt;true\u0026lt;/optional\u0026gt; \u0026lt;/dependency\u0026gt; 第二步:yml中调整启用的监控模块\n1 2 3 4 5 6 # 启用某个模块,替换模块名shutdown即可 management.endpoint.shutdown.enabled=true # 将所有模块的默认开启全部置为false,并单独开启某个模块 management.endpoints.enabled-by-default=false management.endpoint.info.enabled=true 附:端点的默认启用情况\nid 描述 默认情况下启用 auditevents 公开当前应用程序的审核事件信息。 是 beans 显示应用程序中所有spring bean的完整列表。 是 caches 暴露可用的缓存。 是 conditions 显示在配置和自动配置类上评估的条件以及它们匹配或不匹配的原因。 是 configprops 显示所有的整理列表@configurationproperties。 是 env 露出spring的属性configurableenvironment。 是 health 显示应用健康信息。 是 httptrace 显示http跟踪信息(默认情况下,最后100个http请求 - 响应交换)。 是 info 显示任意应用信息。 是 integrationgraph 显示spring integration图。 是 loggers 显示和修改应用程序中记录器的配置。 是 metrics 显示当前应用程序的“指标”信息。 是 mappings 显示所有@requestmapping路径的整理列表。 是 scheduledtasks 显示应用程序中的计划任务。 是 sessions 允许从spring session支持的会话存储中检索和删除用户会话。使用spring session对响应式web应用程序的支持时不可用。 是 shutdown 允许应用程序正常关闭。 没有 threaddump 执行线程转储。 是 第三步:暴露端点\n1 2 3 4 5 6 7 8 9 10 11 management: endpoints: jmx: exposure: include: health,info web: exposure: include: \u0026#34;*\u0026#34; exposure: exclude: env,beans 附录:默认端点的暴露情况\n属性 默认 management.endpoints.jmx.exposure.exclude management.endpoints.jmx.exposure.include *【代表全部暴露】 management.endpoints.web.exposure.exclude management.endpoints.web.exposure.include info, health 注:访问路径默认以/actuator开头\n","date":"2019-12-09","permalink":"https://hobocat.github.io/post/spring/2019-12-09-spring-boot-%E9%AB%98%E7%BA%A7%E7%AF%87/","summary":"一、Spring Boot与缓存 JSR107中JCache简介 JCache定义了5个核心接口,分别是CachingProvider, CacheManager, Cache, Entry 和 Expiry CachingPro","title":"spring boot高级篇"},]
[{"content":"一、主流消息中间件介绍 activemq \tactivemq是apache出品的能力强劲的开源消息总线,并且它完全支持jms规范的消息中间件。具有丰富的api、多种集群构建模式。中小型公司应用广泛,但服务性能不是特别好。\nkafka \tkafa是linkedln开源的分布式发布系统-订阅消息系统,目前归属于apache顶级项目。kafka主要特点是基于拉取(pull)模式处理信息消费,追求高吞吐量,对消息的重复、丢失、错误没有严格要求,适合生产大量数据的互联网服务的数据收集业务。\nrocketmq \trocketmq是阿里开源的消息中间件,目前归属于apache顶级项目。纯java开发,具有高吞吐量、高可用性、适合大规模分布式系统应用的特点。可用于交易、充值、流计算、消息推送、日志流式处理等场景。\nrabbitmq \trabbitmq是用erlang语言开发的开源消息队列系统,基于amqp协议实现。amqp协议更多是用在企业系统内,对数据一致性、稳定性和可靠性要求高的场景,对性能和吞吐量的要求在次位。\n二、amqp协议 \tamqp【advanced message queuing protocol】一个提供统一消息服务的应用层标准高级消息队列协议,是一个二进制协议,是应用层协议的一个开放标准,为面向消息的中间件设计。基于此协议的客户端与消息中间件可传递消息,并不受客户端中间件不同产品,不同的开发语言等条件的限制。\namqp 中包含的主要元素 生产者【producer】:向exchange发布消息的应用。 消费者【consumer】:从消息队列中消费消息的应用。 消息队列【message queue】:服务器组件,用于保存消息,直到发送给消费者。 消息【message】:传输的内容。 由properties和body组成。 交换器【exchange】:路由组件,接收producer发送的消息,并将消息路由转发给消息队列。 虚拟主机【virtual host】: 一批交换器,消息队列和相关对象。虚拟主机是共享相同身份认证和加密环境的独立服务器域,实现逻辑上的隔离。 broker :amqp的服务端称为broker。 连接【connection】:一个网络连接,比如tcp/ip套接字连接。 信道【channel】:多路复用连接中的一条独立的双向数据流通道,为会话提供物理传输介质。 绑定器【binding】:消息队列和交换器之间的虚拟连接,binding中包含routing key。 路由键【routing key】:一个路由规则,虚拟机用它确定如何进行消息路由。 amqp协议模型 三、rabbit安装\u0026amp;基本命令 安装erlang 第一步:添加一些标准存储库中不存在的包\n1 yum install https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm 第二步:下载rabbitmq对应的erlang包\n1 yum localinstall erlang-[version].x86_64.rpm 安装rabbitmq 第一步:从官网找到下载rabbitmq的rpm安装包\n1 wget https://github.com/rabbitmq/rabbitmq-server/releases/download/[version]/rabbitmq-server-[version].el7.noarch.rpm 第二步:安装rabbitmq\n1 yum localinstall rabbitmq-server-[version]-1.el7.noarch.rpm 第三步:修改/usr/lib/rabbitmq/lib/rabbitmq_server-版本号/ebin/rabbit.app\n1 {loopback_users, [\u0026#34;guest\u0026#34;]} 第四步:启动服务,默认端口5672\n1 2 systemctl start rabbitmq-server rabbitmqctl start_app 安装web管理界面 1 2 # 默认端口15672 rabbitmq-plugins enable rabbitmq_management 基本命令 开启应用:rabbitmqctl start_app 关闭应用:rabbitmqctl stop_app 节点状态:rabbitmqctl status 移除所有数据:rabbitmqctl reset 四、java client的简单使用 消费者 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 public static void main(string[] args) throws exception { //1.创建连接工厂 connectionfactory connectionfactory = new connectionfactory(); connectionfactory.sethost(\u0026#34;192.168.1.155\u0026#34;); connectionfactory.setport(5672); //2.创建连接 connection connection = connectionfactory.newconnection(); //3.通过连接得到channel channel channel = connection.createchannel(); /** * 4.声明queue【创建queue】 * queue - queue名称 * durable - 是否持久化,durable是否持久化,如果不持久化,重启之后不会自动建立 * exclusive - 是否是模式独占,只有创建这个队列的消费者端才允许连接到该队列 * autodelete - 是否自动删除,当没有关联exchange时删除 * arguments - 额外参数 */ channel.queuedeclare(\u0026#34;routingkey-001\u0026#34;, true, false, false, null); /** * 5.创建消费者 pull 模型主动拉取消息,不阻塞 * queue - queue名称 */ getresponse response = channel.basicget(\u0026#34;routingkey-001\u0026#34;, true); if(response != null) { amqp.basicproperties props = response.getprops(); byte[] body = response.getbody(); system.out.println(\u0026#34;routingkey: \u0026#34;+ response.getenvelope().getroutingkey()); system.out.println(\u0026#34;body:\u0026#34;+ new string(body)); } thread.sleep(1000000l); //5.关闭相关连接 channel.close(); connection.close(); } 生产者 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 public static void main(string[] args) throws exception{ //1.创建连接工厂 connectionfactory connectionfactory = new connectionfactory(); connectionfactory.sethost(\u0026#34;192.168.1.155\u0026#34;); connectionfactory.setport(5672); //2.创建连接 connection connection = connectionfactory.newconnection(); //3.通过连接得到channel channel channel = connection.createchannel(); //4.通过channel发生数据 for (int i = 0; i \u0026lt; 5; i++) { string msg = \u0026#34;message \u0026#34; + i; /** * 5.发送消息 * exchange - 交换机名称 * routingkey - 路由键 * props - 属性 * body - 消息内容 */ channel.basicpublish(\u0026#34;\u0026#34;, \u0026#34;routingkey-001\u0026#34;, null, msg.getbytes()); } //6.关闭相关连接 channel.close(); connection.close(); } 五、exchange交换机 exchange:接收消息,并根据路由键转发消息所绑定的队列。通俗是将消息分配给消息队列\namqp【0-9-1】的exchange 有如下四种\n名称 默认预先声明的名字 direct exchange (empty string) and amq.direct topic exchange amq.topic fanout exchange amq.fanout headers exchange amq.match (and amq.headers in rabbitmq) 交换机的属性\ndurability :是否持久化 auto-delete:当最后一个exchange绑定的队列删除时也删除交换机 internal:当前exchange是否用于rabbitmq内部使用,默认为false direct exchange 所有发送到direct exchange中的消息被转发到绑定对应routingkey的queue中,也可以用于多播路由【一个routingkey能绑定多个queue】\n消费者【需要声明exchange并将exchange和queue绑定】\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 public static void main(string[] args) throws ioexception, timeoutexception { //1.创建连接工厂 connectionfactory connectionfactory = new connectionfactory(); connectionfactory.sethost(\u0026#34;192.168.1.155\u0026#34;); connectionfactory.setport(5672); connectionfactory.setvirtualhost(\u0026#34;/\u0026#34;); //设置虚拟主机 connectionfactory.setautomaticrecoveryenabled(true); //设置自动重连 connectionfactory.setconnectiontimeout(5000); //设置超时时间 //2.创建connect connection connection = connectionfactory.newconnection(); //3.创建channel channel channel = connection.createchannel(); /** * 4.声明exchange * exchange -交换机名称 * type -交换机类型 * durable -是否持久化,不持久化重启会消失 * autodelete -当交换机绑定的最后一个queue删除时是否删除 * internal -此交换机是否内部使用 * arguments -额外参数 */ channel.exchangedeclare(\u0026#34;app_exchange_direct\u0026#34;, \u0026#34;direct\u0026#34;, true, false, false, null); /** * 5.声明queue * queue - queue名称 * durable - 是否持久化 * exclusive - 是否独占 * autodelete - 是否自动删除 * arguments - 额外参数 */ channel.queuedeclare(\u0026#34;app_queue_direct\u0026#34;,true,false,false,null); //6.建立绑定关系 channel.queuebind(\u0026#34;app_queue_direct\u0026#34;, \u0026#34;app_exchange_direct\u0026#34;,\u0026#34;direct_routingkey\u0026#34;); //7.读取消息 getresponse response = channel.basicget(\u0026#34;app_queue_direct\u0026#34;, true); if(response != null) { amqp.basicproperties props = response.getprops(); byte[] body = response.getbody(); system.out.println(\u0026#34;routingkey: \u0026#34;+ response.getenvelope().getroutingkey()); system.out.println(\u0026#34;body:\u0026#34;+ new string(body)); } //8.关闭资源 channel.close(); connection.close(); } 生产者\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 public static void main(string[] args) throws exception{ //1.创建连接工厂 connectionfactory connectionfactory = new connectionfactory(); connectionfactory.sethost(\u0026#34;192.168.1.155\u0026#34;); connectionfactory.setport(5672); connectionfactory.setvirtualhost(\u0026#34;/\u0026#34;); //2.创建连接 connection connection = connectionfactory.newconnection(); //3.通过连接得到channel channel channel = connection.createchannel(); /** * 4.通过channel发生数据 * exchange - 交换机名称 * routingkey - 路由键 * props - 属性 * body - 消息内容 */ string msg = \u0026#34;message direct\u0026#34;; channel.basicpublish(\u0026#34;app_exchange_direct\u0026#34;, \u0026#34;direct_routingkey\u0026#34;, null, msg.getbytes()); //5.关闭相关连接 channel.close(); connection.close(); } topic exchange 所有发送到topic exchange的消息被转发到所有关心的routekey的queue上\nexchange将routekey和topic进行模糊匹配\n#:匹配一个或多个词 *:匹配一个词 topic exchange通常用于消息的多播路由\n消费者【需要声明exchange并将exchange和queue绑定】\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 public static void main(string[] args) throws exception { //1.创建连接工厂 connectionfactory connectionfactory = new connectionfactory(); connectionfactory.sethost(\u0026#34;192.168.1.155\u0026#34;); connectionfactory.setport(5672); connectionfactory.setvirtualhost(\u0026#34;/\u0026#34;); //设置虚拟主机 connectionfactory.setautomaticrecoveryenabled(true); //设置自动重连 connectionfactory.setconnectiontimeout(5000); //设置超时时间 //2.创建connect connection connection = connectionfactory.newconnection(); //3.创建channel channel channel = connection.createchannel(); /** * 4.声明exchange * exchange -交换机名称 * type -交换机类型 * durable -是否持久化 * autodelete -当交换机绑定的最后一个queue删除时是否删除 * internal -此交换机是否内部使用 * arguments -额外参数 */ channel.exchangedeclare(\u0026#34;app_exchange_topic\u0026#34;, \u0026#34;topic\u0026#34;, true, false, false, null); /** * 5.声明queue * queue - queue名称 * durable - 是否持久化 * exclusive - 是否独占 * autodelete - 是否自动删除 * arguments - 额外参数 */ channel.queuedeclare(\u0026#34;app_queue_topic\u0026#34;, true, false, false, null); //6.建立绑定关系 channel.queuebind(\u0026#34;app_queue_topic\u0026#34;, \u0026#34;app_exchange_topic\u0026#34;, \u0026#34;broadcast.*\u0026#34;); //7.读取消息 getresponse response = channel.basicget(\u0026#34;app_queue_topic\u0026#34;, true); if(response != null) { amqp.basicproperties props = response.getprops(); byte[] body = response.getbody(); system.out.println(\u0026#34;routingkey: \u0026#34;+ response.getenvelope().getroutingkey()); system.out.println(\u0026#34;body:\u0026#34;+ new string(body)); } //8.关闭资源 channel.close(); connection.close(); } 生产者\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public static void main(string[] args) throws exception { //1.创建连接工厂 connectionfactory connectionfactory = new connectionfactory(); connectionfactory.sethost(\u0026#34;192.168.1.155\u0026#34;); connectionfactory.setport(5672); connectionfactory.setvirtualhost(\u0026#34;/\u0026#34;); //2.创建连接 connection connection = connectionfactory.newconnection(); //3.通过连接得到channel channel channel = connection.createchannel(); /** * 4.通过channel发生数据 * exchange - 交换机名称 * routingkey - 路由键 * props - 属性 * body - 消息内容 */ channel.basicpublish(\u0026#34;app_exchange_topic\u0026#34;, \u0026#34;broadcast.user\u0026#34;, null, \u0026#34;broadcast user\u0026#34;.getbytes()); channel.basicpublish(\u0026#34;app_exchange_topic\u0026#34;, \u0026#34;broadcast.news\u0026#34;, null, \u0026#34;broadcast news\u0026#34;.getbytes()); //5.关闭相关连接 channel.close(); connection.close(); } fanout exchange 不需要routingkey,不处理routingkey 可以理解为路由表的模式 需要提前将exchange与queue进行绑定 一个exchange可以绑定多个queue 一个queue可以同多个exchange进行绑定 如果接受到消息的exchange没有与任何queue绑定,则消息会被抛弃 fanout交换机转发消息是最快的 消费者【需要声明exchange并将exchange和queue绑定但不需要路由键】\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 public static void main(string[] args) throws exception { //1.创建连接工厂 connectionfactory connectionfactory = new connectionfactory(); connectionfactory.sethost(\u0026#34;192.168.1.155\u0026#34;); connectionfactory.setport(5672); connectionfactory.setvirtualhost(\u0026#34;/\u0026#34;); //设置虚拟主机 connectionfactory.setautomaticrecoveryenabled(true); //设置自动重连 connectionfactory.setconnectiontimeout(5000); //设置超时时间 //2.创建connect connection connection = connectionfactory.newconnection(); //3.创建channel channel channel = connection.createchannel(); /** * 4.声明exchange * exchange -交换机名称 * type -交换机类型 * durable -是否持久化 * autodelete -当交换机绑定的最后一个queue删除时是否删除 * internal -此交换机是否内部使用 * arguments -额外参数 */ channel.exchangedeclare(\u0026#34;app_exchange_fanout\u0026#34;, \u0026#34;fanout\u0026#34;, true, false, false, null); /** * 5.声明queue * queue - queue名称 * durable - 是否持久化 * exclusive - 是否独占 * autodelete - 是否自动删除 * arguments - 额外参数 */ channel.queuedeclare(\u0026#34;app_queue_fanout\u0026#34;, true, false, false, null); //6.建立绑定关系[routingkey不能为null] channel.queuebind(\u0026#34;app_queue_fanout\u0026#34;, \u0026#34;app_exchange_fanout\u0026#34;, \u0026#34;\u0026#34;); //7.读取消息 getresponse response = channel.basicget(\u0026#34;app_queue_fanout\u0026#34;, true); if(response != null) { amqp.basicproperties props = response.getprops(); byte[] body = response.getbody(); system.out.println(\u0026#34;routingkey: \u0026#34;+ response.getenvelope().getroutingkey()); system.out.println(\u0026#34;body:\u0026#34;+ new string(body)); } //8.关闭资源 channel.close(); connection.close(); } 生产者\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 public static void main(string[] args) throws exception { //1.创建连接工厂 connectionfactory connectionfactory = new connectionfactory(); connectionfactory.sethost(\u0026#34;192.168.1.155\u0026#34;); connectionfactory.setport(5672); connectionfactory.setvirtualhost(\u0026#34;/\u0026#34;); //2.创建连接 connection connection = connectionfactory.newconnection(); //3.通过连接得到channel channel channel = connection.createchannel(); /** * 4.通过channel发生数据 * exchange - 交换机名称 * routingkey - 路由键,不能为null * props - 属性 * body - 消息内容 */ string msg = \u0026#34;message fanout\u0026#34;; channel.basicpublish(\u0026#34;app_exchange_fanout\u0026#34;, \u0026#34;\u0026#34;, null, msg.getbytes()); //5.关闭相关连接 channel.close(); connection.close(); } headers exchange header exchange与topic exchange有点相似,但是topic exchange的路由是基于路由键,而header exchange的路由值基于消息的header数据 topic exchange路由键只有是字符串,而头交换机可以是整型和哈希值 消息header数据里有一个特殊值”x-match”,它有两个值 all【默认值】: message中header的键值对和交换机的header键值对全部匹配,才可以路由到对应队列 any:message中header键值对和交换机的header键值对任意一个匹配,就可以路由到对应队列 消费者【需要声明exchange并将exchange和queue绑定需要定义头信息】\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 { //1.创建连接工厂 connectionfactory connectionfactory = new connectionfactory(); connectionfactory.sethost(\u0026#34;192.168.1.155\u0026#34;); connectionfactory.setport(5672); connectionfactory.setvirtualhost(\u0026#34;/\u0026#34;); //设置虚拟主机 //2.创建connect connection connection = connectionfactory.newconnection(); //3.创建channel channel channel = connection.createchannel(); /** * 4.声明exchange * exchange -交换机名称 * type -交换机类型 * durable -是否持久化 * autodelete -当交换机绑定的最后一个queue删除时是否删除 * internal -此交换机是否内部使用 * arguments -额外参数 */ channel.exchangedeclare(\u0026#34;app_exchange_header\u0026#34;, builtinexchangetype.headers, true, false, null); /** * 5.声明queue * queue - queue名称 * durable - 是否持久化 * exclusive - 是否独占 * autodelete - 是否自动删除 * arguments - 额外参数 */ channel.queuedeclare(\u0026#34;app_queue_header\u0026#34;, true, false, false, null); //6.定义头信息 map\u0026lt;string,object\u0026gt; headermap = new hashmap\u0026lt;\u0026gt;(); headermap.put(\u0026#34;x-match\u0026#34;, \u0026#34;any\u0026#34;); headermap.put(\u0026#34;student\u0026#34;, true); headermap.put(\u0026#34;teacher\u0026#34;, true); //7.建立绑定关系[routingkey不能为null] channel.queuebind(\u0026#34;app_queue_header\u0026#34;, \u0026#34;app_exchange_header\u0026#34;, \u0026#34;\u0026#34;, headermap); //8.读取消息 getresponse response = channel.basicget(\u0026#34;app_queue_header\u0026#34;, true); if (response != null) { amqp.basicproperties props = response.getprops(); byte[] body = response.getbody(); system.out.println(\u0026#34;routingkey: \u0026#34; + response.getenvelope().getroutingkey()); system.out.println(\u0026#34;body:\u0026#34; + new string(body)); } //9.关闭资源 channel.close(); connection.close(); } 生产者\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 public class producer { public static void main(string[] args) throws exception { //1.创建连接工厂 connectionfactory connectionfactory = new connectionfactory(); connectionfactory.sethost(\u0026#34;192.168.1.155\u0026#34;); connectionfactory.setport(5672); connectionfactory.setvirtualhost(\u0026#34;/\u0026#34;); //设置虚拟主机 //2.创建connect connection connection = connectionfactory.newconnection(); //3.创建channel channel channel = connection.createchannel(); //4.定义头信息 map\u0026lt;string,object\u0026gt; headermap = new hashmap\u0026lt;\u0026gt;(); headermap.put(\u0026#34;student\u0026#34;, true); amqp.basicproperties props = new amqp.basicproperties .builder() .headers(headermap) .build(); //5.发布信息 channel.basicpublish(\u0026#34;app_exchange_header\u0026#34;, \u0026#34;\u0026#34;, props, \u0026#34;i am a student\u0026#34;.getbytes()); //6.关闭相关连接 channel.close(); connection.close(); } } 六、message message信息 服务器与应用程序之间传递的数据\n本质上是一段数据,由properties和payload(body)组成\nproperties具有很多属性\n名称 含义 delivery_mode 消息是否持久化【2持久化,1非持久化】 headers 可自定义属性 content_type 消息的类型 content_encoding 消息的编码或者压缩方式 priority 优先级,0~9之间,0最低 correlation_id 关联业务id或先前消息的id,并没有明确指定行为 replay_to 通常用于命名回调队列,并没有明确指定行为 expiration 消息的失效时间 message_id 消息id,消息的唯一标识,并没有明确指定行为 timestamp 发送消息的时间戳 type 类型,例如content_type为流类型,type为protobuf app_id 应用程序id,差错和定位时使用,并没有明确指定行为 user_id 用户id,rabbitmq会验证当前连接的用户,若不匹配则丢弃消息,不建议使用 cluster_id 集群id,废弃 消息使用示例\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 /** * 发送消息 * exchange - 交换机名称 * routingkey - 路由键 * props - 属性 * body - 消息内容 */ map\u0026lt;string,object\u0026gt; headers = new hashmap\u0026lt;\u0026gt;(); headers.put(\u0026#34;username\u0026#34;,\u0026#34;kun\u0026#34;); amqp.basicproperties properties = new amqp.basicproperties.builder() .deliverymode(2) //2代表持久化投递,1代表非持久化投递 .contentencoding(\u0026#34;utf-8\u0026#34;) //设置字符集 .contenttype(\u0026#34;text/plain\u0026#34;)//设置消息类型 .expiration(\u0026#34;10000\u0026#34;) //设置10s后过期 .headers(headers) //放置headers .build(); string msg = \u0026#34;message\u0026#34;; channel.basicpublish(\u0026#34;\u0026#34;, \u0026#34;routingkey-001\u0026#34;, properties, msg.getbytes()); 消息确认机制 \t消息的确认机制是指生产者投递消息后,如果broker收到消息【集群模式下所有的borker接收到才触发】,则会给生产者一个应答【和消费者无关】,但并不能保证消息一定会被投递到目标queue里【比如路由key没有对应的queue】。生产者进行接收应答,用来确定这条消息是否正常发送到broker,这种投递方式也是消息可靠性投递的核心保障。非正常接收的原因有:磁盘容量满、队列到达最大容量等。\nconfirm确认消息实现步骤\n第一步:在channel上开启确认模式:channel.confirmselect();\n第二步:在channel添加监听:addconfirmlistener\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 public static void main(string[] args) throws exception { //1.创建连接工厂 connectionfactory connectionfactory = new connectionfactory(); connectionfactory.setport(5672); connectionfactory.sethost(\u0026#34;192.168.1.155\u0026#34;); connectionfactory.setvirtualhost(\u0026#34;/\u0026#34;); //2.创建连接 connection connection = connectionfactory.newconnection(); //3.通过连接得到channel channel channel = connection.createchannel(); //4.开启消息确认机制 channel.confirmselect(); //5.准备消息 string exchange = \u0026#34;confirm_exchange_direct\u0026#34;; string routingkey = \u0026#34;confirm_key\u0026#34;; amqp.basicproperties properties = null; string message = \u0026#34;confirm_message\u0026#34;; //6.消息入库 system.out.println(\u0026#34;消息存入数据库 \u0026#34; + exchange + \u0026#34;-\u0026#34; + routingkey + \u0026#34;-\u0026#34; + message); //7.添加监听 channel.addconfirmlistener(new confirmlistener() { @override public void handleack(long deliverytag, boolean multiple) throws ioexception { system.out.println(\u0026#34;此消息被broker接收到\u0026#34;); system.out.println(\u0026#34;deliverytag \u0026#34;+ deliverytag); system.out.println(\u0026#34;multiple \u0026#34; + multiple); system.out.println(\u0026#34;消息存入数据库,改为状态被接收\u0026#34;); system.out.println(exchange + \u0026#34;-\u0026#34; + routingkey + \u0026#34;-\u0026#34; + message); } @override public void handlenack(long deliverytag, boolean multiple) throws ioexception { system.out.println(\u0026#34;此消息没有被broker接收到\u0026#34;); system.out.println(deliverytag +\u0026#34; deliverytag\u0026#34;); system.out.println(\u0026#34;multiple\u0026#34; + multiple); system.out.println(\u0026#34;消息存入数据库,改为状态未被接收\u0026#34;); system.out.println(exchange + \u0026#34;-\u0026#34; + routingkey + \u0026#34;-\u0026#34; + message); } }); //8.发送消息 channel.basicpublish(exchange, routingkey, properties, message.getbytes()); thread.sleep(10000); //9.关闭资源 channel.close(); connection.close(); } 消息返回机制 \t消息返回机制是用于处理无法路由的消息。在某些情况下,发送的exchange[存在]但是找不到匹配的路由规则,这个时候如果需要监听这种不可达消息,需要使用消息返回机制return listener。如果exchange不存在会一直不终止线程。\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 public static void main(string[] args) throws exception { //1.创建连接工厂 connectionfactory connectionfactory = new connectionfactory(); connectionfactory.setport(5672); connectionfactory.sethost(\u0026#34;192.168.1.155\u0026#34;); connectionfactory.setvirtualhost(\u0026#34;/\u0026#34;); //2.创建连接 connection connection = connectionfactory.newconnection(); //3.通过连接得到channel channel channel = connection.createchannel(); //4.消息返回监听 channel.addreturnlistener(new returnlistener() { @override public void handlereturn(int replycode, string replytext, string exchange, string routingkey, amqp.basicproperties properties, byte[] body) throws ioexception { system.out.println(\u0026#34;消息返回,没用对应的路由规则\u0026#34;); system.out.println(replycode); //返回状态码 system.out.println(replytext); //返回状态说明 system.out.println(exchange); //消息的exchange system.out.println(routingkey); //消息的routingkey system.out.println(properties); //消息的properties system.out.println(body); //消息的body } }); /** * 5.发送消息 * exchange - 交换机名称 * routingkey - 路由键 * mandatory - true:监听器接收到路由不可达消息会进行后续处理 * - false:broker自动删除不可达消息 * props - 属性 * body - 消息内容 */ channel.basicpublish(\u0026#34;return_exchange_direct\u0026#34;, \u0026#34;return_key\u0026#34;, true, null, \u0026#34;return_message\u0026#34;.getbytes()); thread.sleep(20000); //6.关闭资源 channel.close(); connection.close(); } 使用消息确认机制mandatory必须设置为true\nttl消息 ttl是time to live的缩写,即生存时间。\nrabbitmq支持消息的过期时间,在消费发送时可以进行指定。 rabbitmq支持队列的过期时间,在消息入队列开始计算,只要超过了队列设置的超时时间配置就会自动清除 消息设置过期时间\n1 2 3 4 5 6 7 8 9 10 11 /** * 发送消息 * exchange - 交换机名称 * routingkey - 路由键 * props - 属性 * body - 消息内容 */ amqp.basicproperties properties = new amqp.basicproperties.builder() .expiration(\u0026#34;10000\u0026#34;) //设置10s后过期 .build(); channel.basicpublish(\u0026#34;ttl_exchange\u0026#34;, \u0026#34;ttl_key\u0026#34;, properties, \u0026#34;ttl msg\u0026#34;.getbytes()); 队列设置过期时间\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 /** * 声明queue【创建queue】 * queue - queue名称 * durable - 是否持久化 * exclusive - 是否独占 * autodelete - 是否自动删除 * arguments - 额外参数 * x-message-ttl 设置队列中的所有消息的生存周期 * x-expires 当队列在指定的时间没有被访问就会被删除 * x-max-length 限定队列的消息的最大值长度,超出行为参见x-overflow * x-max-length-bytes 限定队列最大占用的空间大小,超出行为参见x-overflow * x-overflow 设置队列溢出行为drop-head【删除头部】或reject-publish【拒绝加入】 * x-dead-letter-exchange 产生死信时路由的交换机 * x-dead-letter-routing-key 产生死信时路由的键 * x-max-priority 优先级队列,声明队列时先定义最大优先级,0-9数字越大优先级越高 * x-queue-mode 【lazy】将消息保存到磁盘上不放内存中,消费时加载到内存发送 */ map\u0026lt;string, object\u0026gt; arguments = new hashmap\u0026lt;\u0026gt;(); arguments.put(\u0026#34;x-message-ttl\u0026#34;, 1000); channel.queuedeclare(\u0026#34;ttl_queue\u0026#34;, true, false, false, arguments); 七、消费端 消费端的自定义监听 更加优雅的处理消息的方式,不用使用循环等手段读取消息,而是使用消息机制推送消息。\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 public static void main(string[] args) throws exception { //1.创建连接工厂 connectionfactory connectionfactory = new connectionfactory(); connectionfactory.sethost(\u0026#34;192.168.1.155\u0026#34;); connectionfactory.setport(5672); //2.创建连接 connection connection = connectionfactory.newconnection(); //3.通过连接得到channel channel channel = connection.createchannel(); //4.定义queue channel.queuedeclare(\u0026#34;custom_consumer_queue\u0026#34;, true, false, false, null); //5.定义exchange channel.exchangedeclare(\u0026#34;custom_consumer_exchange\u0026#34;, \u0026#34;direct\u0026#34;, true, false, null); //6.绑定queue channel.queuebind(\u0026#34;custom_consumer_queue\u0026#34;, \u0026#34;custom_consumer_exchange\u0026#34;, \u0026#34;custom_key\u0026#34;); //7.自定消费者 channel.basicconsume(\u0026#34;custom_consumer_queue\u0026#34;, false, new myconsumer(channel)); //8.关闭相关连接 thread.sleep(10000); channel.close(); connection.close(); } //自定义消费者 class myconsumer extends defaultconsumer{ public myconsumer(channel channel) { super(channel); } @override public void handledelivery(string consumertag, envelope envelope, amqp.basicproperties properties, byte[] body) throws ioexception { system.out.println(\u0026#34;consumertag \u0026#34; + consumertag); system.out.println(\u0026#34;envelope \u0026#34; + envelope); system.out.println(\u0026#34;properties \u0026#34; + properties); system.out.println(\u0026#34;body \u0026#34; + body); super.getchannel().basicack(envelope.getdeliverytag(), false); } } 消费端的限流策略 \t假设一个场景,由于我们的消费端突然全部不可用了,导致rabbitmq服务器上有上万条未处理的消息,这时候如果没做任何现在,随便开启一个消费端客户端,就会导致巨量的消息瞬间全部推送过来,但是我们单个客户端无法同时处理这么多的数据,就会导致消费端变得巨卡,有可能直接崩溃不可用。\n\trabbitmq提供了一种qos(服务质量保证)功能,即在非自动确认消息的前提下,如果一定数目的消息未被确认不进行消费新的消息。\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 public static void main(string[] args) throws exception { //1.创建连接工厂 connectionfactory connectionfactory = new connectionfactory(); connectionfactory.sethost(\u0026#34;192.168.1.155\u0026#34;); connectionfactory.setport(5672); //2.创建连接 connection connection = connectionfactory.newconnection(); //3.通过连接得到channel channel channel = connection.createchannel(); //4.声明exchange channel.exchangedeclare(\u0026#34;qos-exchange\u0026#34;, \u0026#34;direct\u0026#34;, true, false, null); //5.声明queue channel.queuedeclare(\u0026#34;qos-queue\u0026#34;, true, false, false, null); //6.绑定 channel.queuebind(\u0026#34;qos-queue\u0026#34;, \u0026#34;qos-exchange\u0026#34;, \u0026#34;qos-key\u0026#34;); /** * 7.设置qos * prefetchsize - 限制抓取消息的大小,一般为0不做限制 * prefetchcount - 每次最多抓取多少个 * global - 一般设置为false,在channel新能并不好 * - true:运用在channel * - false:运用在consumer */ channel.basicqos(0, 1, false); //8.创建消费者,使用qos时autoack必须设置为false getresponse response = channel.basicget(\u0026#34;qos-queue\u0026#34;, false); if(response != null) { amqp.basicproperties props = response.getprops(); byte[] body = response.getbody(); system.out.println(\u0026#34;routingkey: \u0026#34;+ response.getenvelope().getroutingkey()); system.out.println(\u0026#34;body:\u0026#34;+ new string(body)); channel.basicack(response.getenvelope().getdeliverytag(), false); } thread.sleep(1000000l); //9.关闭相关连接 channel.close(); connection.close(); } 消费端ack与重回队列机制 消费端的手工ack和nack\n消息通过ack确认是否被正确接收,每个message都要被确认,可以手动去ack或自动ack 自动确认会在消息发送给消费者后立即确认,但存在丢失消息的可能,如果消费端消费逻辑抛出异常,也就是消费端没有处理成功这条消息,那么就相当于丢失了消息 如果手动确认则当消费者调用ack、nack、reject进行确认,如果消息未被 ack 则会发送到下一个消费者 消费端的重回队列\n消息重回队列是为了对没有处理成功的消息,把消息再次退回broker 一般情况下关闭重回队列 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 public static void main(string[] args) throws exception { //1.创建连接工厂 connectionfactory connectionfactory = new connectionfactory(); connectionfactory.sethost(\u0026#34;192.168.1.155\u0026#34;); connectionfactory.setport(5672); //2.创建连接 connection connection = connectionfactory.newconnection(); //3.通过连接得到channel channel channel = connection.createchannel(); //4.声明queue【创建queue】 channel.queuedeclare(\u0026#34;ack_queue\u0026#34;, true, false, false, null); //5.声明exchange channel.exchangedeclare(\u0026#34;ack_exchange\u0026#34;, \u0026#34;direct\u0026#34;, true); //6.绑定queue channel.queuebind(\u0026#34;ack_queue\u0026#34;, \u0026#34;ack_exchange\u0026#34;, \u0026#34;ack_key\u0026#34;); /** * 7.接收消息 * queue - queue名称 * autoack - 自动签收 * consumer - 自定义消费者 */ channel.basicconsume(\u0026#34;ack_queue\u0026#34;, false, new myconsumer(channel)); //8.关闭资源 thread.sleep(10000); channel.close(); connection.close(); } //自定义消费者 class myconsumer extends defaultconsumer { public myconsumer(channel channel) { super(channel); } private int i = 1; @override public void handledelivery(string consumertag, envelope envelope, amqp.basicproperties properties, byte[] body) throws ioexception { system.out.println(\u0026#34;consumertag \u0026#34; + consumertag); system.out.println(\u0026#34;envelope \u0026#34; + envelope); system.out.println(\u0026#34;properties \u0026#34; + properties); system.out.println(\u0026#34;body \u0026#34; + body); if (i % 3 == 0) { /** * nack签收 * deliverytag - 消息tag * multiple - 是否批量签收 * requeue - 是否重回broker队列尾部,如果false不再重回 * * 与 void basicreject(long deliverytag, boolean requeue) 区别 * basicreject 一次只能拒绝接收一个消息 * basicnack 方法可以支持一次一个或多个消息的拒收 */ super.getchannel().basicnack(envelope.getdeliverytag(), false,false); }else { /** * nack签收 * deliverytag - 消息tag * multiple - 是否批量签收 * requeue - 是否重回队列 */ super.getchannel().basicack(envelope.getdeliverytag(), false); } i++; } } 死信队列【dlx - dead-letter-exchange】 当消息在一个队列中变成死信(dead message)后,它能够被重新publish到另一个exchange,这个exchange就是dlx。\ndlx也是一个正常的和其它exchange没任何区别的交换机,它能在任何队列上被指定。\n消息变成死信的情况:\n消息被拒绝(basic.reject / basic.nack)并且requeue=false 消息ttl过期 队列到达最大长度 死信队列的应用\n\t实现延迟队列:数据进入正常的queue中且没有消费者(根据业务设置相应的失效时间【延迟时间】)进入死信队列,消费者消费死信队列中的数据\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 public static void main(string[] args) throws exception { //1.创建连接工厂 connectionfactory connectionfactory = new connectionfactory(); connectionfactory.sethost(\u0026#34;192.168.1.155\u0026#34;); connectionfactory.setport(5672); //2.创建连接 connection connection = connectionfactory.newconnection(); //3.通过连接得到channel channel channel = connection.createchannel(); //4.创建死信队列 channel.queuedeclare(\u0026#34;dlx_queue\u0026#34;, true, false, false, null); channel.exchangedeclare(\u0026#34;dlx_exchange\u0026#34;, \u0026#34;topic\u0026#34;, true); channel.queuebind(\u0026#34;dlx_queue\u0026#34;, \u0026#34;dlx_exchange\u0026#34;, \u0026#34;#\u0026#34;); /** * 5.声明queue【创建queue】 * x-dead-letter-exchange - 死信队列的交换机 * x-dead-letter-routing-key - 死信队列的路由键 */ map\u0026lt;string, object\u0026gt; arguments = new hashmap\u0026lt;\u0026gt;(); arguments.put(\u0026#34;x-dead-letter-exchange\u0026#34;,\u0026#34;dlx_exchange\u0026#34;); arguments.put(\u0026#34;x-dead-letter-routing-key\u0026#34;,\u0026#34;dlx_key\u0026#34;); channel.queuedeclare(\u0026#34;dlx_test_queue\u0026#34;, true, false, false, arguments); //6.声明exchange channel.exchangedeclare(\u0026#34;dlx_test_exchange\u0026#34;, \u0026#34;direct\u0026#34;, true); //7.绑定queue channel.queuebind(\u0026#34;dlx_test_queue\u0026#34;, \u0026#34;dlx_test_exchange\u0026#34;, \u0026#34;dlx_test_key\u0026#34;); /** * 8.接收消息 * queue - queue名称 * autoack - 自动签收 * consumer - 自定义消费者 */ channel.basicconsume(\u0026#34;dlx_test_queue\u0026#34;, false, new myconsumer(channel)); //9.关闭资源 thread.sleep(10000); channel.close(); connection.close(); } 延迟队列 参见【spring amqp使用-延迟队列】\n八、消息可靠性保障 保障100%投递成功 方案一:消息落库,对消息进行打标\n方案二:消息的延迟投递,做二次确认,回调检查\n幂等性保障 唯一id + 指纹码机制\n原理就是利用数据库主键去重,业务完成后插入主键标识\n1 2 3 -- 唯一id指的是业务的id,例如订单id,商品id,uuid -- 指纹码指每次正常操作的码,例如时间戳+业务编号方式 select count(*) from t_check where id = 唯一id + 指纹码 好处:实现简单\n坏处:高并发下数据库瓶颈\n解决方案:根据id进行分库分表进行算法路由\n利用redis的原子性实现\n原理利用redis的原子性,将标示消息的唯一id【业务生成的】放入redis,在消费消息前判断是否存在此消息\n好处:效率高\n坏处:如果数据需要立即落库,那么数据库和redis要保持“事务一致性”\n 如果数据不需要立即落库由别的服务进行落库,那么如何要保持同步\n九、集群搭建 主备模式 \t实现rabbit高可用,一般用于并发和流量不高的情况,从节点不可读写。主备模式也称为warren模式。当主节点出现故障时备用节点切换为主节点。\n远程模式 \t远程模式可以实现多活,简称shovel模式。远距离通讯和复制,即将消息进行不同中心的复制工作,可以跨地域的让俩mq集群互联。将源节点的消息发布到目标节点,这个过程中shovel就是一个客户端,它负责连接源节点,读取某个队列的消息,然后将消息写入到目标节点的exchange中。不建议使用此模式,已经被federation多活取代。\n镜像模式 \t镜像(mirror)模式保证了100%数据不丢失,一般常用镜像模式搭建rabbitmq集群。\n\t镜像(mirror)队列的目的是为了保证数据的高可靠性解决方案,主要是为了实现数据同步,一般来讲是2-3个节点实现同步。\n搭建高可用镜像模式步骤\n集群搭建\n第一步:修改集群用户与连接心跳检测\n1 2 # /usr/lib/rabbitmq/lib/rabbitmq_server-3.6.5/ebin/rabbit.app {heartbeat, 1} #将60改为1 第二步:安装管理插件\n1 2 # 也是web管理插件 lsof -i:15672 或者 netstat -tnlp|grep 15672 查看是否启动成功 rabbitmq-plugins enable rabbitmq_management 第三步:选取主节点,同步cookie。选取一个做为主节点,将/var/lib/rabbitmq/.erlang.cookie复制到其它节点,注意权限。\n第四步:停止所有节点服务\n1 rabbitmqctl stop 第五步:启动集群\n1 rabbitmq-server -detached 第六步:主机名检查,必须要有主机名【/etc/hostname】,注意设置完成之后重启\n第七步:网络检查,测试各节点之间是否可以用hostname连通,如果不可以需要修改【/etc/hosts】\n第八步:普通node节点执行\n1 2 3 rabbitmqctl stop_app rabbitmqctl join_cluster rabbit@[masterhostname] rabbitmqctl start_app 第九步:任意节点执行rabbitmqctl set_policy ha-all \u0026quot;^\u0026quot; '{\u0026quot;ha-mode\u0026quot;:\u0026quot;all\u0026quot;}' 查看集群状态:rabbitmqctl cluster_status 修改集群名称:rabbitmqctl set_cluster_name [cluster_name] 移除节点:rabbitmqctl forget_cluster_node rabbit@hostname haproxy配置\nglobal ...... defaults ...... # rabbitmq集群节点配置 listen rabbitmq_cluster bind 0.0.0.0:5672 # 配置tcp模式 mode tcp # 简单的轮询 balance roundrobin # inter每隔五秒对mq集群做健康检查,2次正确证明服务器可用,3次失败证明服务器不可用 server rabbit155 192.168.1.155:5672 check inter 5000 rise 2 fall 3 server rabbit149 192.168.1.149:5672 check inter 5000 rise 2 fall 3 server rabbit151 192.168.1.151:5672 check inter 5000 rise 2 fall 3 #配置haproxy web监控,查看统计信息 listen stats bind 0.0.0.0:8100 mode http option httplog stats enable # 设置haproxy监控地址为http://localhost:8100/rabbitmq-stats stats uri /rabbitmq-stats stats refresh 5s keepalived配置\n! configuration file for keepalived global_defs { router_id rabbit149 # 标识节点的字符串,通常为hostname } vrrp_script chk_haproxy { # 执行脚本位置,需要执行权限 script \u0026#34;/etc/keepalived/haproxy_check.sh\u0026#34; # 检测时间间隔 interval 2 # 如果条件成立则权重减20 weight -20 } vrrp_instance vi_1 { state master # 主节点为master,备份节点为backup interface enp0s3 # 绑定虚拟ip的网络接口(网卡) virtual_router_id 60 # 虚拟路由id号(主备节点一定要相同) mcast_src_ip 192.168.1.149 # 本机ip地址 priority 100 #优先级配置(0-254的值),备机要比master低 nopreempt advert_int 1 # 组播信息发送间隔,俩个节点必须配置一致,默认1s authentication { # 认证匹配 auth_type pass auth_pass 1111 } track_script { chk_haproxy } virtual_ipaddress { 192.168.1.60 # 虚拟ip,可以指定多个 } } 检查脚本【chk_haproxy】\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #!/bin/bash a=`ps -c haproxy --no-header |wc -l` if [ $a -eq 0 ];then echo \u0026#34;`date` haproxy is dead\u0026#34; \u0026gt;\u0026gt; /tmp/lvs.log haproxy -f /etc/haproxy/haproxy.cfg sleep 2 fi if [ `ps -c haproxy --no-header |wc -l` -eq 0 ];then echo \u0026#34;`date` haproxy cannot start,stop keepalived\u0026#34; \u0026gt;\u0026gt; /tmp/lvs.log # 杀死keepalived ps -c keepalived --no-header | awk \u0026#39;{print $1}\u0026#39;|xargs kill -9 exit 0 else echo \u0026#34;`date` haproxy restart\u0026#34; \u0026gt;\u0026gt; /tmp/lvs.log exit 1 fi 集群关键配置 配置文件位置:/usr/lib/rabbitmq/lib/rabbitmq_server-[version]/ebin/rabbit.app\ntcp_listerners:设置rabbimq的监听端口,默认为[5672]\ndisk_free_limit【disk模式下有效】:磁盘低水位线,若磁盘容量低于指定值则停止接收数据,默认值为**{mem_relative, 1.0}**,即与内存相关联1:1\nvm_memory_high_watermark【ram模式下有效】:设置内存低水位线,若低于该水位线,则开启流控机制,默认值是0.4,即内存总量的40%\nhipe_compile:将部分rabbimq代码用high performance erlang compiler编译,可提升性能,该参数是实验性,若出现erlang vm segfaults,需要关掉\nforce_fine_statistics:该参数属于rabbimq_management,若为true则进行精细化的统计,但会影响性能\n集群恢复与故障转移 场景一:a先停止,b(master)后停止\n处理方法:改场景下先启动b,再启动a。或者先启动a,隔30s内启动b即可\n场景二:a、b同时停机(同时断点)\n处理方法:30s内同时启动a、b即可\n场景三:a先停止,b(master)后停止,且a无法恢复\n处理方法:b启动之后调用rabbitmqctl forget_cluster_node rabbit@nodea解除与a的cluster关系,再加入新的节点即可\n场景四:a先停止,b(master)后停止,且b无法恢复\n处理方法:在a节点上调用rabbitmqctl forget_cluster_node --offline rabbit@nodeb,之后启动a节点作为master,再加入新的slave节点即可\n多活模式 \tfederation模式是异地数据复制的主流模式,因为shovel模式配置复杂,federation配置简单。可以实现broker和cluster之间的消息传输,连接双方可以使用不同的users和vritual hosts,使用的是amqp协议所以双方也可以使用不同版本的erlang和rabbitmq。\nfederation exchanges,可以看成downstream从upstream主动拉取消息,但并不是拉取所有消息,之须是在downstream上已经明确定义bindings关系的exchange,也就是有实际的物理queue来接收消,才会upstream拉取消息到downstream。downstream会将绑定关系组合在一起,绑定/解除绑定命令将发送到upstream交换机。因此federationexchange只接收具有订阅的消息。\n十、延迟插件的使用 方式一:使用死信队列,参见此链接\n方式二:使用rabbitmq_delayed_message_exchange插件【更加简单优秀】\n官网下载插件,解压到指定位置【usr/lib/rabbitmq/lib/rabbitmq_server-[version]/plugins/ 】 安装插件rabbitmq-plugins enable rabbitmq_delayed_message_exchange 使用spring amqp设置x-delay消息头参数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 // 定义交换机和队列 @configuration public class delayexchangeconfigure { @bean public queue delayqueue() { return new queue(delay_queue_name, true); } // 定义一个延迟交换机 @bean public customexchange delayexchange() { map\u0026lt;string, object\u0026gt; args = new hashmap\u0026lt;string, object\u0026gt;(); // 定义交换机类型 args.put(\u0026#34;x-delayed-type\u0026#34;, \u0026#34;direct\u0026#34;); return new customexchange(delay_exchange_name, \u0026#34;x-delayed-message\u0026#34;, true, false, args); } // 绑定队列到这个延迟交换机上 @bean public binding delaybinding(queue delayqueue, customexchange delayexchange) { return bindingbuilder.bind(delayqueue).to(delayexchange).with(delay_routing_key).noargs(); } } // 生产者 @controller @requiredargsconstructor public class delayexchangecontroller { private final rabbittemplate rabbittemplate; @getmapping(\u0026#34;/delay/send\u0026#34;) public void delayexchangesend() { rabbittemplate.convertandsend( rabbitconstant.delay_exchange_name, rabbitconstant.delay_exchange_routing_key, \u0026#34;delay_test_message\u0026#34; , message -\u0026gt; { // spring amqp已经在方法上已经支持了x-delay这个属性 message.getmessageproperties().setdelay(5000); return message; }); } } // 消费者 @component public class delayconsumer { @rabbitlistener(queues = rabbitconstant.delay_exchange_queue_name) public void process(string data) { system.out.println(data); } } ","date":"2019-11-28","permalink":"https://hobocat.github.io/post/mq/2019-11-28-rabbitmq/","summary":"一、主流消息中间件介绍 ActiveMQ ActiveMQ是Apache出品的能力强劲的开源消息总线,并且它完全支持JMS规范的消息中间件。具有丰富的API、多种集群构建模式。","title":"rabbitmq的使用"},]
[{"content":"一、percona概览 percona server简介 percona server由领先的mysql咨询公司percona发布。percona server是一款独立的数据库产品,其可以完全与mysql兼容,可以在不更改代码的情况了下将存储引擎更换成xtradb。 \tpercona团队的最终声明是“percona server是由oracle发布的最接近官方mysql enterprise发行版的版本”,因此与其他更改了大量基本核心mysql代码的分支有所区别。percona server的一个缺点是他们自己管理代码,不接受外部开发人员的贡献,以这种方式确保他们对产品中所包含功能的控制。\n\tpercona提供了高性能xtradb引擎,还提供pxc高可用解决方案,并且附带了perconatoolkit等dba管理工具。\n\txtradb可以看作是innodb存储引擎的增强版本,它在innodb上进行了大量的修改和patched,它完全兼容innodb,且提供了很多innodb不具备的有用的功能。\npxc集群 \tpxc【percona xtradb cluster】是基于galera的面向oltp的多主同步复制插件,即galera替代了replication技术完成主从复制工作,是实现主从复制的插件。\n\tpxc集群特点:\n同步复制【事务在所有节点要么同时提交,要么不提交】 多主复制【可以在任意节点写入】 同步的强一致性 集群同步速度取决于配置最低的节点 pxc集群并不是节点越多越好【同步操作是要等待所有节点写入,即越多工作量越大】 mysql各类衍生品的比较 二、安装percona 安装percona server 第一步:安装前置依赖【percona server依赖jemalloc】\n1 2 3 4 # 安装epel源方便直接安装jemalloc yum install https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm # 安装jemalloc yum install jemalloc 第二步:解压完tar包直接安装所有rpm\n1 yum localinstall *.rpm 第三步:配置percona server【/etc/my.cnf】\n1 2 3 4 5 #################################添加以下配置################################# character-set-server=utf8 bind-address=0.0.0.0 # 跳过dns解析 skip-name-resolve 第四步:启动和禁止开机自启动\n1 2 3 4 # 启动percona systemctl start mysqld # 禁止开机自启动,如果pxc一个宕机节点宕机时间较长,那么集群会阻塞操作等待这一台机器同步完成 chkconfig mysqld off 第五步:获取\u0026amp;修改root密码\n1 2 3 4 # 根据日志寻找初始密码 cat /var/log/mysqld.log | grep password # 使用以下命令根据提示修改root密码 mysql_secure_installation 第六步:创建用户,开放远程登陆权限\n1 2 create user \u0026#39;[username]\u0026#39;@\u0026#39;%\u0026#39; identified by \u0026#39;password\u0026#39; grant all privileges on *.* to \u0026#39;[username]\u0026#39;@\u0026#39;%\u0026#39; identified by \u0026#39;[password]\u0026#39; with grant option; 忘记root密码解决方案\n修改 my.cnf 加入 skip-grant-tables 然后重启mysql服务,之后直接使用mysql命令进入不需要用户名和密码\n执行 update user set password=password(\u0026rsquo;new-password\u0026rsquo;) where user = \u0026lsquo;root\u0026rsquo;;flush privileges;\n删除 my.cnf 加入的 skip-grant-tables 然后重启mysql服务\n安装pxc集群 第一步:移除mariadb\n1 yum -y remove mari* 第二步:yum仓库源安装pxc\n1 2 3 # 安装源解决依赖问题 yum install https://repo.percona.com/yum/percona-release-latest.noarch.rpm yum install percona-xtradb-cluster-57 第三步:修改配置文件【 /etc/percona-xtradb-cluster.conf.d/mysqld.cnf 】\n1 2 3 4 5 #################################添加以下配置################################# character-set-server=utf8 bind-address=0.0.0.0 # 跳过dns解析 skip-name-resolve 第四步:禁止自启动和修改密码\n参考安装percona server第四、五、六步\n第五步:修改配置文件【/etc/percona-xtradb-cluster.conf.d/wsrep.cnf】\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 #################################修改或添加以下配置################################# # pxc集群中mysql实例的唯一id,不能重复,必须是数字 server-id=1 wsrep_provider=wsrep_provider=/usr/lib64/galera3/libgalera_smm.so # pxc集群名称 wsrep_cluster_name=pxc-cluster # pxc集群中每一个节点的地址 wsrep_cluster_address==gcomm://ip1,ip2,ip3... # 当前节点的名称 wsrep_node_name=pxc-cluster-node-1 # 当前节点的ip wsrep_node_address=ip # 同步方法(mysqldump、rsync、xtrabackup) wsrep_sst_method=xtrabackup-v2 # 同步使用的账户 wsrep_sst_auth=\u0026#34;[username]:[password]\u0026#34; # 同步严厉模式 pxc_strict_mode=enforcing # 基于row复制,pxc不支持mixed binlog_format=row # 默认引擎 default_storage_engine=innodb # 主键自增长不锁表 innodb_autoinc_lock_mode=2 第六步:启动pxc集群\n1 2 3 4 # 第一个节点使用 systemctl start mysql@bootstrap.service # 其余几点 systemctl start mysqld 第七步:查看集群规模\n1 show status like \u0026#39;%wsrep_cluster%\u0026#39; 注:服务器环境下需要开放以下端口\n端口 描述 3306 mysql服务端口 4444 请求全量同步(sst)端口 4567 数据库节点之间通信端口 4568 请求增量同步端口 firewall-cmd \u0026ndash;zone=public \u0026ndash;add-port=[port]/tcp \u0026ndash;permanent\n关闭节点\n\t手动关闭使用什么命令启动,就使用什么命令关闭,如果主节点直接使用systemctl stop mysql则不会关闭,命令无效。非最后一个节点退出 /var/lib/mysql/grastate.dat下safe_to_bootstrap:0,下次按照非主节点启动。最后一个正常退出的节点safe_to_bootstrap:1,下次按照主节点启动。\npxc节点退出情况\npxc节点都是安全推出的,需要先启动最后一个退出的节点作为主节点启动。\npxc所有节点都是意外退出的,但是和最后节点意外退出时间间隔较长,最后节点意外退出还是会将safe_to_bootstrap置为1,依旧先启动最后一个退出的节点作为主节点启动。\npxc所有节点同时异常退出,需要挑选出一个节点将safe_to_bootstrap改为1,在启动。、\n如果还有集群还在服务,可以直接启动mysql服务\n三、pxc集群相关信息 数据复制相关信息 参数名称 含义 wsrep_replicated 发送给节点同步消息次数 wsrep_received 接收的节点同步消息次数 wsrep_last_applied 同步应用次数 wsrep_last_committed 事务提交的次数 队列相关信息 参数名称 含义 wsrep_local_send_queue 发送队列的目前长度 wsrep_local_send_queue_max 发送队列的最大长度 wsrep_local_send_queue_min 发送队列的最小长度 wsrep_local_send_queue_avg 发送队列的平均长度 wsrep_local_recv_queue 接收队列的目前长度 wsrep_local_recv_queue_max 接收队列的最大长度 wsrep_local_recv_queue_min 接收队列的最小长度 wsrep_local_recv_queue_avg 接收队列的平均长度 流量控制相关信息 参数名称 含义 wsrep_flow_control_paused_ns 流控暂停状态下花费的总时间(秒) wsrep_flow_control_paused 流量控制的暂停时间的占比(0~1) wsrep_flow_control_sent 发送的流控暂停事件的数量 wsrep_flow_control_recv 接收的流控暂停事件的数量 wsrep_flow_control_interval 流控的上限和下限。上限是队列中允许的最大请求数,如果队列达到上限,则拒绝新的请求。当处理现有请求时,队列数量会减少,达到下限将再次允许新的请求 wsrep_flow_control_status 流量控制状态 执行同步的线程数一般可设置为cpu核心线程的1~1.5倍\nwsrep_slave_threads=num\n节点状态 参数名称 含义 wsrep_local_state_comment 节点状态 wsrep_connected 节点是否连接到集群 集群状态 参数名称 含义 wsrep_cluster_status 集群状态 wsrep_ready 集群是否正常工作 wsrep_cluster_size 节点数量 wsrep_desync_count 延迟节点数量 wsrep_incoming_addresses 集群节点的ip地址 事务相关信息 参数名称 含义 wsrep_cert_deps_distance 事务执行并发数 wsrep_apply_oooe 接收队列中的事务占比 wsrep_apply_oool 接收队列中事务乱序执行的频率 wsrep_apply_window 接收队列中事务的平均数量 wsrep_commit_oooe 发送队列中的事务占比 wsrep_commit_oool 无任何意义,不存在本地乱序提交 wsrep_commit_window 发送队列中事务的平均数量 四、pxc集群原理 \tpxc集群执行事务是基于gtid的复制进行的,gtid是由server_uuid和transaction_id组成的,pxc集群执行事务server_uuid取得是集群的uuid并非节点的uuid,即每个节点接收的gtid中的server_uuid均相同。\n当本地节点接收有gtid任务时变为joined状态【不提供服务】,之后变为synced【提供服务】\n五、导入大量数据 \t在命令行使用source path/filename.sql导入大量数据速度较慢,需要逐句执行语法分析、优化。\n\t大量数据导入应该用load data命令导入数据(文本文档数据库),速度快不需要语法分析、优化。load data执行的是单线程导入,可以讲数据文件切分做并发导入。\n前置条件:如果数据再另一台mysql服务器上可使用\nselect * from [table]into outfile '[filename]' fields terminated by ',' enclosed by '\u0026quot;' lines terminated by '\\n' ;\n第一步:切分数据文件,并将数据上传到mycat节点服务器\n1 2 3 # -l 按照行拆分 # -d 文件名称 split -l 1000000 -d filename.txt 第二步:每个pxc分片只开启一个节点并修改pxc节点文件,然后重启pxc服务\n1 2 3 4 5 6 # 每秒将日志数据写入硬盘,不论事务是否提交,提升写入速度 innodb_flush_log_at_trx_commit=0 # 不使用操作系统缓冲区,直接将数据写入硬盘 innodb_flush_method=o_direct # 设置mysql日志缓存大小,越大越好 innodb_buffer_pool_size=200m 第三步:在mycat服务器上执行java程序,多线程导入数据\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 @springbootapplication public class dataimport implements applicationlistener\u0026lt;applicationreadyevent\u0026gt;, commandlinerunner { @autowired private jdbctemplate jdbctemplate; @autowired private configurableapplicationcontext applicationcontext; static private logger logger = loggerfactory.getlogger(dataimport.class); // 数据文件目录 private static file datadir; // 表名 private static string tablename; public static void main(string[] args) { springapplication.run(dataimport.class, args); } @override public void run(string... args) throws exception { if( args == null || args.length != 2 ) { logger.error(\u0026#34;请输入数据文件目录路径和表名\u0026#34;); applicationcontext.close(); return; } file file = new file(args[0]); if( !file.isdirectory() ) { logger.error(\u0026#34;第一个参数为目录路径\u0026#34;); applicationcontext.close(); } dataimport.datadir = file; dataimport.tablename=args[1]; } @override public void onapplicationevent(applicationreadyevent event) { executorservice executorservice = executors.newfixedthreadpool(10); for (int i = 0; i \u0026lt; datadir.listfiles().length; i++) { file[] files = datadir.listfiles(); executorservice.execute(new dataimporttask(files[i].getabsolutepath() , tablename, jdbctemplate)); } } } class dataimporttask implements runnable{ private jdbctemplate jdbctemplate; private string filefullpath; private string tablename; public dataimporttask(string filefullpath, string tablename, jdbctemplate jdbctemplate) { this.filefullpath = filefullpath; this.tablename = tablename; this.jdbctemplate = jdbctemplate; } @override public void run() { string sql = \u0026#34;load data infile \u0026#39;\u0026#34;+ filefullpath + \u0026#34;\u0026#39; ignore into table \u0026#34; + tablename +\u0026#34; character set \u0026#39;utf8\u0026#39; \u0026#34; + \u0026#34;fields terminated by \u0026#39;,\u0026#39; \u0026#34; + // 分割符 \u0026#34;optionally enclosed by \u0026#39;\\\u0026#34;\u0026#39; \u0026#34; + \u0026#34;lines terminated by \u0026#39;\\\\n\u0026#39;\u0026#34; + // 行结束符 \u0026#34;(id,data_source,data_source_id,isbn,title,img,brief,publish_name,author,publish_time,price,book_clc_code,currency,create_time,update_time,has_marc,mis_no)\u0026#34;; //字段定义 jdbctemplate.execute(sql); } } 第四步:调回第三步设置参数\n第五步:拷贝数据到其它节点\n六、大数据归档 归档数据使用的存储引擎 tokudb现属于percona公司旗下的mysql存储引擎,它拥有高压缩比,默认使用zlib进行压缩,尤其是对字符串(varchar,text等)类型有非常高的压缩比,比较适合存储日志、原始数据等。 且在线添加索引,不影响读写操作 ,支持完整的acid特性和事务机制。 安装\n第一步:确认安装jemalloc 1 yum install -y jemalloc 第二步:修改my.cnf,并重启服务 1 2 [mysqld_safe] malloc-lib=/usr/lib64/libjemalloc.so.1 第三步:开启linux大页内存 1 2 3 4 # 大页内存管理可以动态分配内存 echo never \u0026gt; /sys/kernel/mm/transparent_hugepage/enabled # 开启内存的碎片整理 echo never \u0026gt; /sys/kernel/mm/transparent_hugepage/defrag 安装tokudb 1 2 3 4 yum install -y percona-server-tokudb-57.x86_64 ps-admin --enable -uroot -p service mysql restart ps-admin --enable -uroot -p 查看安装结果 1 show engines; 归档数据搭建replication集群和高可用 参考博客\n创建和pxc集群表结构一样的归档表,只需将存储引擎改为tokudb\n使用pt-archiver归档数据 安装\n最新安装包地址\n1 2 wget https://www.percona.com/downloads/percona-toolkit/....rpm yum localinstall -y percona-toolkit....rpm 执行归档\n1 2 pt-archiver --source h=[sourceip],p=[sourceport],u=[user],p=[password],d=[database],t=[table] \\ --dest h=[destip],p=[destport],u=[user],p=[password],,d=[database],t=[table] --no-check-charset --where \u0026#39;[where后的条件]\u0026#39; --progress 5000 --bulk-delete --bulk-insert --limit=10000 --statistics 如果字符集乱码需要配置\n1 2 [client] default-character-set=utf8 七、数据库的冷热备份 \tdump是将数据导出成为sql文件,导出的sql文件不能作为mysql的数据文件,需要先导入mysql。\nmysql文件 文件名 描述 auto.cnf 文件,记录了服务器的uuid值,数据还原的时候需要注意,如果没有auto.cnf文件mysql启动会自动创建 grastate.dat 文件里保存的是pxc的同步信息 gvwstate.dat 文件里保存的是pxc集群节点信息 err 错误日志文件 pid 进程id文件 ib_buffer_pool innodb缓存文件 ib_logfile innodb事务日志 ibdata innodb共享表空间文件 logbin 日志文件 index 日志索引文件 ibtmp 临时表空间文件 文件碎片\n\t向数据表写入数据,数据文件的体积会增大,但是删除数据的时候数据文件的体积并不会减小,数据被删除后留下的空白被称作碎片。向再次数据表插入数据会优先使用碎片空间。\n碎片整理\n1 alter table tablename engine=innodb; 冷备份介绍 被备份的数据库必须停机 备份非常占用空间(全量备份),不支持增量备份 冷备份的是所有数据文件和日志文件,所以无法按照逻辑库和数据表备份数据 联机冷备份 第一步:pxc节点退出集群\n关闭服务 注释掉pxc节点配置 第二步:使用java作数据库的表碎片整理\n注意:在做此操作前必须禁止二进制日志记录,否则重新上线节点会引发pxc集群做碎片整理,导致锁表。\n1 2 3 # /etc/my.cnf注释掉一下行,不进行日志记录 # log-bin # log-slave-update 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 @springbootapplication public class optimizetables implements applicationlistener\u0026lt;applicationreadyevent\u0026gt;{ static private logger logger = loggerfactory.getlogger(optimizetables.class); @autowired private jdbctemplate jdbctemplate; @autowired private configurableapplicationcontext applicationcontext; public static void main(string[] args) { springapplication.run(optimizetables.class, args); } @override public void onapplicationevent(applicationreadyevent event) { list\u0026lt;string\u0026gt; tablenames = jdbctemplate.queryforlist(\u0026#34;show tables\u0026#34;, string.class); for (string tablename : tablenames) { jdbctemplate.execute(\u0026#34;alter table \u0026#34; + tablename + \u0026#34; engine = innodb\u0026#34;); logger.info(\u0026#34;表【{}】碎片整理完成\u0026#34;, tablename); } logger.info(\u0026#34;碎片整理全部完成。。。准备关闭容器\u0026#34;); } } 第三步:备份文件\n1 2 # 如果有表分区,也要备份表分区数据 tar -cvf mysql.tar /var/lib/mysql 第四步:节点重新上线\n恢复配置文件 根据节点情况启动 还原节点,只需要覆盖mysql的数据目录\n热备份介绍 数据库在不停机的状况下备份\n备份数据时会加读锁,数据在此期间只能读不能写\n支持(首次)全量备份和增量备份\nxtrabackup联机热备份 xtrabackup是一种物理备份工具,通过协议连接到mysql服务端,然后读取并复制底层的文件,完成物理备份。\nxtrabackup备份过程中innodb不加锁,myisam加读锁,数据可读不可写 xtrabackup备份过程不会打断正在执行的事务 xtrabackup能够基于压缩等功能节约硬盘的空间 xtrabackup支持对innodb引擎做全量和增量备份 xtrabackup只能对myisam做全量备份 xtrabackup命令种类\n命令 解释 xbcrypt 用于加密或解密备份的数据 xbstream 用于压缩或者解压xbstream文件 xtrabackup 备份innodb数据表 innobackupex 上述三种命令的脚本封装 xtrabackup命令处理流程\nxtrabackup全量热备份 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 # 不压缩、不加密,备份出来是一个文件夹 innobackupex --default-file=/etc/my.cnf \\ --host=[ip] \\ --user=[user] \\ --password=[password] \\ --port=[port] \\ [dir] # 压缩、加密,备份出是个文件,需要解密才可使用 # 可使用--include正则表达式或者表名逗号分割标识要备份的库 innobackupex --default-file=/etc/my.cnf \\ --host=[ip] \\ --user=[user] \\ --password=[password] \\ --port=[port] \\ --stream=xbstream \\ --no-timestamp \\ --encrypt=[aes256,aes128] \\ --encrypt-threads=8 \\ --encrypt-key=[24位密码] \\ --compress \\ --compress-thread=8 \\ --galera-info -\u0026gt; [path/file.xbstream] 可使用crontab定时进行全量热备份\nxtrabackup全量冷还原 第一步:关闭mysql服务,清空数据目录(包括表分区目录)\n第二步:创建临时解压目录\n第三步:解压\u0026amp;解密\n1 2 xbstream -x \u0026lt;[xbstreamfilename] -c [dir] innobackupex --decompress --decrypt=[aes256,aes128] --encrypt-key=[key] [dir] 第四步:回滚备份文件未提交的事务,同步备份文件已提交的事务到数据文件\n1 innobackupex --apply-log [/path/dirname] 第四步:执行还原操作\n1 innobackupex --default-file=/etc/my.cnf --copy-back [/path/dirname] 第五步:修改还原的文件所属信息\n1 chown -r mysql:mysql /var/lib/mysql 第六步:已主节点身份启动\n第七步:重启其它节点\nxtrabackup增量热备份 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 # 不压缩、不加密,备份出来是一个文件夹 innobackupex --default-file=/etc/my.cnf \\ --host=[ip] \\ --user=[user] \\ --password=[password] \\ --port=[port] \\ --incremental-basedir=[上次全量备份或增量备份目录,压缩的全量备份需要解压] \\ --incremental [incrementdir] # 压缩、加密,备份出是个文件,需要解密才可使用 innobackupex --default-file=/etc/my.cnf \\ --host=[ip] \\ --user=[user] \\ --password=[password] \\ --port=[port] \\ --incremental-basedir=[上次全量备份或增量备份目录,压缩的全量备份需要解压] \\ --incremental [incrementdir] \\ --compress \\ --compress-thread=8 \\ --encrypt=[aes256,aes128] \\ --encrypt-key=[24位密码] \\ --stream=xbstream ./ \u0026gt; [path/file.xbstream] java定时增量热备份\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 @springbootapplication @enablescheduling public class incrementbackup implements commandlinerunner { static private logger logger = loggerfactory.getlogger(incrementbackup.class); private string configpath; @autowired private configurableapplicationcontext applicationcontext; public static void main(string[] args) { springapplication.run(incrementbackup.class, args); } @override public void run(string... args) throws exception { if(args == null || args.length == 0) { logger.error(\u0026#34;请指定配置文件位置\u0026#34;); applicationcontext.close(); } else { configpath = args[0]; logger.info(\u0026#34;加载配置文件[{}]\u0026#34;, configpath); } } // 这个需要调整时间 @scheduled(cron = \u0026#34;0 */2 * * * ?\u0026#34;) public void incrementscheduling() throws ioexception { yaml yaml = new yaml(); inputstream configinputstream=new fileinputstream(configpath); //读入文件 map\u0026lt;string,string\u0026gt; content= (map) yaml.load(configinputstream); configinputstream.close(); string host = content.get(\u0026#34;host\u0026#34;); string user = content.get(\u0026#34;user\u0026#34;); string password = content.get(\u0026#34;password\u0026#34;); string port = content.get(\u0026#34;port\u0026#34;); string basedir = content.get(\u0026#34;basedir\u0026#34;); string incrementdir = content.get(\u0026#34;incrementdir\u0026#34;); string foldername = localdate.now().format(datetimeformatter.ofpattern(\u0026#34;yyyymmdd\u0026#34;)); string shellcmd = \u0026#34;innobackupex --default-file=/etc/my.cnf \u0026#34; + \u0026#34;--host={0} \u0026#34; + \u0026#34;--user={1} \u0026#34; + \u0026#34;--password={2} \u0026#34; + \u0026#34;--port={3} \u0026#34; + \u0026#34;--incremental-basedir={4} \u0026#34; + \u0026#34;--no-timestamp \u0026#34; +\t//不再在生成一个时间文件夹包裹备份文件 \u0026#34;--incremental {5}\u0026#34;; shellcmd = messageformat.format(shellcmd, host, user, password, port, basedir, incrementdir + file.separator + foldername); logger.info(\u0026#34;shellcmd : {}\u0026#34;, shellcmd); runtime.getruntime().exec(shellcmd); content.put(\u0026#34;basedir\u0026#34;, incrementdir + file.separator + foldername); writer writer = new filewriter(configpath); yaml.dump(content, writer); writer.close(); } } 1 2 3 4 5 6 host: \u0026#39;[ip]\u0026#39; user: \u0026#39;[user]\u0026#39; password: \u0026#39;[password]\u0026#39; port: \u0026#39;[port]\u0026#39; basedir: \u0026#39;[beforebackupdir]\u0026#39; incrementdir: \u0026#39;[backupdir]\u0026#39; xtrabackup增量热备份冷还原 1 2 3 4 5 6 7 8 9 10 11 12 # 全量备份处理 innobackupex --apply-log --redo-only [全量备份目录] # 第一次到n-1次增量备份 innobackupex --apply-log --redo-only [全量备份目录] --incremental-dir=[增量备份目录] # 第n次增量备份 innobackupex --apply-log [全量备份目录] --incremental-dir=[最后一次增量备份目录] # 还原 innobackupex --default-file=/etc/my.cnf --copy-back [全量备份目录] chown -r mysql:mysql /var/lib/mysql ","date":"2019-11-20","permalink":"https://hobocat.github.io/post/database/2019-11-20-pxc/","summary":"一、Percona概览 Percona Server简介 Percona Server由领先的MySQL咨询公司Percona发布。Percona Server是一款独立的数据库产品,其可以完全","title":"pxc集群使用"},]
[{"content":"一、mycat概览 mycat简介 \t支持对mysql等数据库进行垂直切分,水平切分并实现了读写分离和负载均衡的数据库中间件\nmycat的基本元素 逻辑库 对于应用来说相当于mysql的数据库\n逻辑库可对应后端的多个物理数据库\n逻辑库并不保存数据\n逻辑表 对于应用来说相当于mysql的数据表 逻辑表可对应后端的多个物理数据表 逻辑表并不保存数据 逻辑表的类别\n按照是否被水平分片划分为:分片表于非分片表 全局表:在所有分片数据库都存在的表 er关系表:按照er关系进行分片的表(子表和夫表存在于同一数据库示例) 安装mycat 前置条件:jdk7以上\n第一步:建立mycat运行的系统账号\n1 2 adduser mycat groupadd mycat 第二步:解压mycat并将目录所属者\n1 2 tar -zxvf mycat-server-x.y-release-linux.tar.gz chgrp -r mycat mycat 第三步:配置环境变量(/etc/profile)\npath=$path:/opt/mycat/bin export mycat_home=/opt/mycat 第四步:启动mycat\n1 mycat start 如果测试环境内存有限需要修改mycat下bin/wrapper.conf当中的内存限制\n二、mycat核心配置 核心配置文件总览\nserver.xml:配置系统参数、用户访问权限、sql防火墙以及sql拦截\nlog4j2.xml:日志配置\nschema.xml - 逻辑库、逻辑表、物理库定义\nrule.xml - 逻辑表水平切分规则\nserver.xml相关配置 系统参数配置\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 \u0026lt;system\u0026gt; \u0026lt;!-- 1为开启实时统计、0为关闭 --\u0026gt; \u0026lt;property name=\u0026#34;usesqlstat\u0026#34;\u0026gt;0\u0026lt;/property\u0026gt; \u0026lt;!-- 1为开启全局一致性检测、0为关闭 --\u0026gt; \u0026lt;property name=\u0026#34;useglobletablecheck\u0026#34;\u0026gt;0\u0026lt;/property\u0026gt; \u0026lt;!-- 指定使用 mycat 全局序列的类型 0 为本地文件方式 1 为数据库方式 2 为时间戳序列方式 3 为分布式 zk id 生成器 4 为 zk 递增 id 生成。 --\u0026gt; \u0026lt;property name=\u0026#34;sequncehandlertype\u0026#34;\u0026gt;2\u0026lt;/property\u0026gt; \u0026lt;!-- 1为开启mysql压缩协议 --\u0026gt; \u0026lt;!-- \u0026lt;property name=\u0026#34;usecompression\u0026#34;\u0026gt;1\u0026lt;/property\u0026gt; --\u0026gt; \u0026lt;!-- 设置模拟的mysql版本号 --\u0026gt; \u0026lt;!-- \u0026lt;property name=\u0026#34;fakemysqlversion\u0026#34;\u0026gt;5.6.20\u0026lt;/property\u0026gt; --\u0026gt; \u0026lt;!-- 这个属性指定每次分配 socket direct buffer 的大小 --\u0026gt; \u0026lt;!-- \u0026lt;property name=\u0026#34;processorbufferchunk\u0026#34;\u0026gt;40960\u0026lt;/property\u0026gt; --\u0026gt; \u0026lt;!-- 处理器缓冲池类型 0: directbytebufferpool 1 bytebufferarena --\u0026gt; \u0026lt;property name=\u0026#34;processorbufferpooltype\u0026#34;\u0026gt;0\u0026lt;/property\u0026gt; \u0026lt;!-- 默认是65535 64k 用于sql解析时最大文本长度 --\u0026gt; \u0026lt;!-- \u0026lt;property name=\u0026#34;maxstringliterallength\u0026#34;\u0026gt;65535\u0026lt;/property\u0026gt; --\u0026gt; \u0026lt;!-- 后台任务socket非延迟 --\u0026gt; \u0026lt;!-- \u0026lt;property name=\u0026#34;backsocketnodelay\u0026#34;\u0026gt;1\u0026lt;/property\u0026gt; --\u0026gt; \u0026lt;!-- 前台任务socket非延迟 --\u0026gt; \u0026lt;!-- \u0026lt;property name=\u0026#34;frontsocketnodelay\u0026#34;\u0026gt;1\u0026lt;/property\u0026gt; --\u0026gt; \u0026lt;!-- nio线程池大小用于处理异步任务,需求小,建议设置为较小值 --\u0026gt; \u0026lt;!-- \u0026lt;property name=\u0026#34;processorexecutor\u0026#34;\u0026gt;16\u0026lt;/property\u0026gt; --\u0026gt; \u0026lt;!-- mycat服务连接端口 --\u0026gt; \u0026lt;!-- \u0026lt;property name=\u0026#34;serverport\u0026#34;\u0026gt;8066\u0026lt;/property\u0026gt; --\u0026gt; \u0026lt;!-- mycat管理连接端口 --\u0026gt; \u0026lt;!-- \u0026lt;property name=\u0026#34;managerport\u0026#34;\u0026gt;9066\u0026lt;/property\u0026gt; --\u0026gt; \u0026lt;!-- 连接最长闲置时间,超过时间mycat主动断开连接,单位毫秒 --\u0026gt; \u0026lt;!-- \u0026lt;property name=\u0026#34;idletimeout\u0026#34;\u0026gt;300000\u0026lt;/property\u0026gt; --\u0026gt; \u0026lt;!-- 监听网卡 --\u0026gt; \u0026lt;!-- \u0026lt;property name=\u0026#34;bindip\u0026#34;\u0026gt;0.0.0.0\u0026lt;/property\u0026gt; --\u0026gt; \u0026lt;!-- 前端写队列大小 --\u0026gt; \u0026lt;!-- \u0026lt;property name=\u0026#34;frontwritequeuesize\u0026#34;\u0026gt;4096\u0026lt;/property\u0026gt; --\u0026gt; \u0026lt;!-- 进程数量,默认和cpu核数,建议最大值为cpu的3倍 --\u0026gt; \u0026lt;!-- \u0026lt;property name=\u0026#34;processors\u0026#34;\u0026gt;32\u0026lt;/property\u0026gt; --\u0026gt; \u0026lt;!--分布式事务开关 0为不过滤分布式事务 1为过滤分布式事务(如果分布式事务内只涉及全局表,则不过滤) 2为不过滤分布式事务,但是记录分布式事务日志 --\u0026gt; \u0026lt;property name=\u0026#34;handledistributedtransactions\u0026#34;\u0026gt;0\u0026lt;/property\u0026gt; \u0026lt;!-- 是否启用非堆内存处理跨分片结果集:1开启、0关闭 --\u0026gt; \u0026lt;property name=\u0026#34;useoffheapformerge\u0026#34;\u0026gt;1\u0026lt;/property\u0026gt; \u0026lt;!-- 内存也大小,单位为m --\u0026gt; \u0026lt;property name=\u0026#34;memorypagesize\u0026#34;\u0026gt;1m\u0026lt;/property\u0026gt; \u0026lt;!-- 溢出文件缓冲区大小,单位为k --\u0026gt; \u0026lt;property name=\u0026#34;spillsfilebuffersize\u0026#34;\u0026gt;1k\u0026lt;/property\u0026gt; \u0026lt;!-- 使用流输出,0代表否 --\u0026gt; \u0026lt;property name=\u0026#34;usestreamoutput\u0026#34;\u0026gt;0\u0026lt;/property\u0026gt; \u0026lt;!-- 系统保留内存大小,单位为m --\u0026gt; \u0026lt;property name=\u0026#34;systemreservememorysize\u0026#34;\u0026gt;384m\u0026lt;/property\u0026gt; \u0026lt;!--是否采用zookeeper协调切换 --\u0026gt; \u0026lt;property name=\u0026#34;usezkswitch\u0026#34;\u0026gt;true\u0026lt;/property\u0026gt; \u0026lt;!-- 以下参数默认配置未出现 --\u0026gt; \u0026lt;!-- 默认字符集 --\u0026gt; \u0026lt;!-- \u0026lt;property name=\u0026#34;charset\u0026#34;\u0026gt;utf8\u0026lt;/property\u0026gt; --\u0026gt; \u0026lt;!-- sql执行超时时间,单位秒 --\u0026gt; \u0026lt;!-- \u0026lt;property name=\u0026#34;sqlexecutetimeout\u0026#34;\u0026gt;300\u0026lt;/property\u0026gt; --\u0026gt; \u0026lt;!-- 返回数据集默认大小 --\u0026gt; \u0026lt;!-- \u0026lt;property name=\u0026#34;defaultmaxlimit\u0026#34;\u0026gt;100\u0026lt;/property\u0026gt; --\u0026gt; \u0026lt;!-- 允许的最大包大小 --\u0026gt; \u0026lt;!-- \u0026lt;property name=\u0026#34;maxpacketsize\u0026#34;\u0026gt;104857600\u0026lt;/property\u0026gt; --\u0026gt; \u0026lt;/system\u0026gt; 配置用户及用户访问权限\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 \u0026lt;!-- 用户名 --\u0026gt; \u0026lt;user name=\u0026#34;root\u0026#34;\u0026gt; \u0026lt;!-- 密码 --\u0026gt; \u0026lt;property name=\u0026#34;password\u0026#34;\u0026gt;123456\u0026lt;/property\u0026gt; \u0026lt;!-- 所能访问到的逻辑库,可分配多个数据库 --\u0026gt; \u0026lt;!-- \u0026lt;property name=\u0026#34;schemas\u0026#34;\u0026gt;b1,db2,db3...\u0026lt;/property\u0026gt; --\u0026gt; \u0026lt;property name=\u0026#34;schemas\u0026#34;\u0026gt;testdb\u0026lt;/property\u0026gt; \u0026lt;!-- 使用加密密码登陆 --\u0026gt; \u0026lt;!-- \u0026lt;property name=\u0026#34;usingdecrypt\u0026#34;\u0026gt;1\u0026lt;/property\u0026gt; --\u0026gt; \u0026lt;!-- 对表级dml权限设置 --\u0026gt; \u0026lt;!-- check:是否启用这个权限 dml顺序:insert、update、select、delete(table上的表示为所有库下的默认权限)\t\u0026lt;privileges check=\u0026#34;false\u0026#34;\u0026gt; \u0026lt;schema name=\u0026#34;testdb\u0026#34; dml=\u0026#34;0110\u0026#34; \u0026gt; \u0026lt;table name=\u0026#34;tb01\u0026#34; dml=\u0026#34;0000\u0026#34;\u0026gt;\u0026lt;/table\u0026gt; \u0026lt;table name=\u0026#34;tb02\u0026#34; dml=\u0026#34;1111\u0026#34;\u0026gt;\u0026lt;/table\u0026gt; \u0026lt;/schema\u0026gt; \u0026lt;/privileges\u0026gt;\t--\u0026gt; \u0026lt;/user\u0026gt; \u0026lt;user name=\u0026#34;user\u0026#34;\u0026gt; \u0026lt;property name=\u0026#34;password\u0026#34;\u0026gt;user\u0026lt;/property\u0026gt; \u0026lt;property name=\u0026#34;schemas\u0026#34;\u0026gt;testdb\u0026lt;/property\u0026gt; \u0026lt;!-- 用户是否时只读用户只能查询数据库 --\u0026gt; \u0026lt;property name=\u0026#34;readonly\u0026#34;\u0026gt;true\u0026lt;/property\u0026gt; \u0026lt;/user\u0026gt; 密码可加密配置:mycat的lib文件下执行java -cp mycat-server-x.y.z.jar io.mycat.util.decryptutil 0:[user]:[password]加密密码\nsql防火墙以及sql拦截\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 \u0026lt;!-- 全局sql防火墙设置 whitehost 允许访问的名单 blacklist-\u0026gt;check 是否启用黑名单 --\u0026gt; \u0026lt;firewall\u0026gt; \u0026lt;whitehost\u0026gt; \u0026lt;host host=\u0026#34;127.0.0.1\u0026#34; user=\u0026#34;mycat\u0026#34;/\u0026gt; \u0026lt;host host=\u0026#34;127.0.0.2\u0026#34; user=\u0026#34;mycat\u0026#34;/\u0026gt; \u0026lt;/whitehost\u0026gt; \u0026lt;blacklist check=\u0026#34;true\u0026#34;\u0026gt; \u0026lt;!-- 开启检查delete语句后面where是否为空 --\u0026gt; \u0026lt;property name=\u0026#34;deletewherenonecheck\u0026#34;\u0026gt;true\u0026lt;/property\u0026gt; \u0026lt;!-- 开启检查非基本语句的其他语句(ddl) --\u0026gt; \u0026lt;property name=\u0026#34;nonebasestatementallow\u0026#34;\u0026gt;true\u0026lt;/property\u0026gt; \u0026lt;/blacklist\u0026gt; \u0026lt;/firewall\u0026gt; rule.xml相关配置 rule.xml的规则示例\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 \u0026lt;!-- tablerule代表表的分片规则,name为唯一标识符号 columns:水平切分依据的列 algorithm:代表使用的具体算法 --\u0026gt; \u0026lt;tablerule name=\u0026#34;mod-long\u0026#34;\u0026gt; \u0026lt;rule\u0026gt; \u0026lt;columns\u0026gt;id\u0026lt;/columns\u0026gt; \u0026lt;algorithm\u0026gt;mod-long\u0026lt;/algorithm\u0026gt; \u0026lt;/rule\u0026gt; \u0026lt;/tablerule\u0026gt; \u0026lt;!-- function代表水平切分的算法,name为唯一标识符号,class为实现类 property标签:javabean规范注入的属性 --\u0026gt; \u0026lt;function name=\u0026#34;mod-long\u0026#34; class=\u0026#34;io.mycat.route.function.partitionbymod\u0026#34;\u0026gt; \u0026lt;property name=\u0026#34;count\u0026#34;\u0026gt;3\u0026lt;/property\u0026gt; \u0026lt;/function\u0026gt; 常用的切分算法\n简单取模分片 1 2 3 4 5 6 7 8 9 \u0026lt;tablerule name=\u0026#34;mod-long\u0026#34;\u0026gt; \u0026lt;rule\u0026gt; \u0026lt;columns\u0026gt;user_id\u0026lt;/columns\u0026gt; \u0026lt;algorithm\u0026gt;mod-long\u0026lt;/algorithm\u0026gt; \u0026lt;/rule\u0026gt; \u0026lt;/tablerule\u0026gt; \u0026lt;function name=\u0026#34;mod-long\u0026#34; class=\u0026#34;io.mycat.route.function.partitionbymod\u0026#34;\u0026gt; \u0026lt;property name=\u0026#34;count\u0026#34;\u0026gt;3\u0026lt;/property\u0026gt; \u0026lt;/function\u0026gt; 对columns列进行十进制取模运算进行,所以columns列必须为整数,count为分片数量\nhash取模分片 1 2 3 4 5 6 7 8 9 \u0026lt;tablerule name=\u0026#34;user_login\u0026#34;\u0026gt; \u0026lt;rule\u0026gt; \u0026lt;columns\u0026gt;user_name\u0026lt;/columns\u0026gt; \u0026lt;algorithm\u0026gt;mod-hash\u0026lt;/algorithm\u0026gt; \u0026lt;/rule\u0026gt; \u0026lt;/tablerule\u0026gt; \u0026lt;function name=\u0026#34;mod-hash\u0026#34; class=\u0026#34;io.mycat.route.function.partitionbyhashmod\u0026#34;\u0026gt; \u0026lt;property name=\u0026#34;count\u0026#34;\u0026gt;3\u0026lt;/property\u0026gt; \u0026lt;/function\u0026gt; 可以对字符串、数字类型的列做hash运算之后再取模进行分片,count为分片数量\n枚举分片 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 \u0026lt;tablerule name=\u0026#34;sharding-by-intfile\u0026#34;\u0026gt; \u0026lt;rule\u0026gt; \u0026lt;columns\u0026gt;area_id\u0026lt;/columns\u0026gt; \u0026lt;algorithm\u0026gt;area-map-file\u0026lt;/algorithm\u0026gt; \u0026lt;/rule\u0026gt; \u0026lt;/tablerule\u0026gt; \u0026lt;function name=\u0026#34;area-map-file\u0026#34; class=\u0026#34;io.mycat.route.function.partitionbyfilemap\u0026#34;\u0026gt; \u0026lt;property name=\u0026#34;mapfile\u0026#34;\u0026gt;area-map-file.txt\u0026lt;/property\u0026gt; \u0026lt;property name=\u0026#34;type\u0026#34;\u0026gt;0\u0026lt;/property\u0026gt; \u0026lt;property name=\u0026#34;defaultnode\u0026#34;\u0026gt;0\u0026lt;/property\u0026gt; \u0026lt;/function\u0026gt; \u0026lt;!-- area-map-filet.txt 配置: 10000=0 10010=1 default_node=1 --\u0026gt; type默认值为0,0表示key为integer,非0表示key为 string, 所有的节点配置都是从0开始,及0代表节点1\ndefaultnode默认节点:小于0表示不设置默认节点,大于等于0表示设置默认节点【如果不配置默认节点碰到不识别的枚举值就会报错】\n字符串范围取模分片 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 \u0026lt;tablerule name=\u0026#34;mod-string-rang-prefix\u0026#34;\u0026gt; \u0026lt;rule\u0026gt; \u0026lt;columns\u0026gt;user_id\u0026lt;/columns\u0026gt; \u0026lt;algorithm\u0026gt;sharding-by-prefixpattern\u0026lt;/algorithm\u0026gt; \u0026lt;/rule\u0026gt; \u0026lt;/tablerule\u0026gt; \u0026lt;function name=\u0026#34;mod-string-rang-prefix\u0026#34; class=\u0026#34;io.mycat.route.function.partitionbyprefixpattern\u0026#34;\u0026gt; \u0026lt;property name=\u0026#34;patternvalue\u0026#34;\u0026gt;256\u0026lt;/property\u0026gt; \u0026lt;property name=\u0026#34;prefixlength\u0026#34;\u0026gt;5\u0026lt;/property\u0026gt; \u0026lt;property name=\u0026#34;mapfile\u0026#34;\u0026gt;partition-pattern.txt\u0026lt;/property\u0026gt; \u0026lt;/function\u0026gt; \u0026lt;!-- partition-pattern.txt 0-127=0 128-255=1 --\u0026gt; \t字符串范围取模分片是将字符串前缀ascii码指定前缀相加然后进行取模运算。prefixlength:需要截取的字符串长度,patternvalue:取模的模数。如果mapfile文件有些取模之后值未包含,插入取模后未包含的值会报错。\n范围分片 此分片适用于,提前规划好分片字段某个范围属于哪个分片【start \u0026lt;= range \u0026lt;= end 】\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 \u0026lt;tablerule name=\u0026#34;file-rang-partition\u0026#34;\u0026gt; \u0026lt;rule\u0026gt; \u0026lt;columns\u0026gt;user_id\u0026lt;/columns\u0026gt; \u0026lt;algorithm\u0026gt;\u0026gt;rang-long\u0026lt;/algorithm\u0026gt; \u0026lt;/rule\u0026gt; \u0026lt;/tablerule\u0026gt; \u0026lt;function name=\u0026#34;rang-long\u0026#34; class=\u0026#34;io.mycat.route.function.autopartitionbylong\u0026#34;\u0026gt; \u0026lt;property name=\u0026#34;mapfile\u0026#34;\u0026gt;file-rang-partition.txt\u0026lt;/property\u0026gt; \u0026lt;property name=\u0026#34;defaultnode\u0026#34;\u0026gt;0\u0026lt;/property\u0026gt; \u0026lt;/function\u0026gt; \u0026lt;!-- file-rang-partition.txt 0-10000000=0 10000001-20000000=1 --\u0026gt; 自然月分片 1 2 3 4 5 6 7 8 9 10 \u0026lt;tablerule name=\u0026#34;sharding-by-month\u0026#34;\u0026gt; \u0026lt;rule\u0026gt; \u0026lt;columns\u0026gt;create_time\u0026lt;/columns\u0026gt; \u0026lt;algorithm\u0026gt;sharding-by-month\u0026lt;/algorithm\u0026gt; \u0026lt;/rule\u0026gt; \u0026lt;/tablerule\u0026gt; \u0026lt;function name=\u0026#34;sharding-by-month\u0026#34; class=\u0026#34;io.mycat.route.function.partitionbymonth\u0026#34;\u0026gt; \u0026lt;property name=\u0026#34;dateformat\u0026#34;\u0026gt;yyyy-mm-dd\u0026lt;/property\u0026gt; \u0026lt;property name=\u0026#34;sbegindate\u0026#34;\u0026gt;2014-01-01\u0026lt;/property\u0026gt; \u0026lt;/function\u0026gt; mycat还提供了类似redis的crc32slot分片,需要建立槽映射表\nschema.xml相关配置 schema标签定义mycat实例中的逻辑库\n1 2 3 4 5 6 7 8 9 10 \u0026lt;!-- name:逻辑库的名称,全局唯一 checksqlschema true: 如果sql中制定了了db名称则会呗mycat自动删除后执行 false:不检查 sqlmaxlimit:返回结果集数量的最大值,如果schema标签有配置,则不会取server文件的配置 --\u0026gt; \u0026lt;schema name=\u0026#34;testdb\u0026#34; checksqlschema=\u0026#34;false\u0026#34; sqlmaxlimit=\u0026#34;100\u0026#34;\u0026gt; \u0026lt;!-- table标签。。。 --\u0026gt; \u0026lt;/schema\u0026gt; table标签定义了mycat中的逻辑表\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 \u0026lt;!-- name:逻辑表的名称也是物理表名称,每个schema下唯一 datanode:所属的 datanode需要和datanode标签中name属性的值相互对应,顺序与分片规则枚举有对应关系 rule:用于指定逻辑表要使用的规则(rule.xml中定义)必须与tablerule标签中name属性属性值一一对应 primarykey:该逻辑表对应真实表的主键,如果分片键不是主键则会缓存主键和分片键的映射关系 如果命中缓存,则使用非主键进行查询的时候就不会进行广播式的查询,就会直接发送语句给具体的datanode type:如果是全局表需要指定global autoincrement:如果使用自增id需要配置 needaddlimit:sql查询不包含limit时mycat自动添加limit默认true,limit值为配置的最大返回结果集 --\u0026gt; \u0026lt;!-- datanode=\u0026#34;dn1,dn2,dn3\u0026#34; ==\u0026gt; datanode=\u0026#34;dn$1-3\u0026#34; --\u0026gt; \u0026lt;table name=\u0026#34;travelrecord\u0026#34; datanode=\u0026#34;dn1,dn2,dn3\u0026#34; rule=\u0026#34;auto-sharding-long\u0026#34; primarykey=\u0026#34;id\u0026#34; \u0026gt; \u0026lt;!--可能存在childtable --\u0026gt; \u0026lt;/table\u0026gt; datanode标签定义了mycat中的数据节点\n1 2 3 4 5 6 \u0026lt;!-- name:全局唯一标识 datahost:对应的datahost标签,用于指定具体数据库示例 database:真实的物理库名称 --\u0026gt; \u0026lt;datanode name=\u0026#34;dn1\u0026#34; datahost=\u0026#34;dh100\u0026#34; database=\u0026#34;db1\u0026#34; \u0026gt;\u0026lt;/datanode\u0026gt; datahost标签定义了数据库实例、读写分离配置和心跳语句\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 \u0026lt;!-- name:唯一标识datahost标签全局唯一 balance 0:不开启读写分离机制,所有读操作都发送到当前可用的writehost上 1:全部的readhost与stand by writehost参与select语句的负载均衡 简单的说,当双主主备模式,正常情况下,m2,s1,s2 都参与 select 语句的负载均衡。 2:所有读操作都随机的在writehost、readhost上分发 3:所有读请求随机的分发到wiriterhost对应的readhost执行,适合一主多从模式 dbtype:后端数据库类型 writetype 0:所有写操作发送到配置的第一个writehost,第一个挂了切到还生存的第二个writehost 重新启动后已切换后的为准,切换记录在配置文件中:dnindex.properties 1:所有写操作都随机的发送到配置的 writehost,1.5 以后废弃不推荐 switchtype: -1:表示不自动切换,如果后台已经使用mmm或mha这种高可用管理工具,则需要关闭 1:默认值,自动切换。当第一个writehost宕机自动切换为第二个writehost 2:基于mysql主从同步的状态决定是否切换,心跳语句为 show slave status maxcon:数据库连接池最大连接数 mincon:数据库连接池最小连接数 dbdriver:native为mysql原身协议,如果dbtype不是mysql则需要设置为具体的driver类名 --\u0026gt; \u0026lt;datahost name=\u0026#34;dh100\u0026#34; maxcon=\u0026#34;1000\u0026#34; mincon=\u0026#34;10\u0026#34; balance=\u0026#34;0\u0026#34; switchtype=\u0026#34;-1\u0026#34; writetype=\u0026#34;0\u0026#34; dbtype=\u0026#34;mysql\u0026#34; dbdriver=\u0026#34;native\u0026#34; \u0026gt; \u0026lt;!-- heartbeat:心跳测试语句 --\u0026gt; \u0026lt;heartbeat\u0026gt;select user()\u0026lt;/heartbeat\u0026gt; \u0026lt;writehost host=\u0026#34;hostm1\u0026#34; url=\u0026#34;localhost:3306\u0026#34; user=\u0026#34;root\u0026#34; password=\u0026#34;123456\u0026#34;\u0026gt; \u0026lt;!-- \u0026lt;readhost host=\u0026#34;hosts1\u0026#34; url=\u0026#34;localhost:3306\u0026#34; user=\u0026#34;root\u0026#34; password=\u0026#34;123456\u0026#34;/\u0026gt; --\u0026gt; \u0026lt;/writehost\u0026gt; \u0026lt;!-- \u0026lt;writehost host=\u0026#34;hostm2\u0026#34; url=\u0026#34;localhost:3316\u0026#34; user=\u0026#34;root\u0026#34; password=\u0026#34;123456\u0026#34;/\u0026gt; --\u0026gt; \u0026lt;/datahost\u0026gt; 三、数据库的垂直切分 \t项目初期可能只是一个单一的数据库,随着业务的增长而出现了性能瓶颈。当无法通过优化来解决性能瓶颈时应该首先通过分库的方式进行解决。引入mycat进行分库的好处是有连接池的管理和尽量少的修改后台的代码。\n进行垂直切分的步骤\n①、收集分析业务模块之间的关系\n②、复制全量数据到其它实例(建立主从关系,在配置好mycat之前保持数据都为线上全量数据)\n③、配置mycat垂直分库\n④、通过mycat访问db\n⑤、删除原库中已迁移的表\n主从关系建立时从库上的db名字可能发生了改变,需要使用以下命令修改备份到从数据库的名称\nchange replication filter replicate_rewrite_db(([masterdbname],[slavedbname]))\n垂直切分配置示例 配置mycat垂直分库\nschema.xml 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 \u0026lt;?xml version=\u0026#34;1.0\u0026#34;?\u0026gt; \u0026lt;!doctype mycat:schema system \u0026#34;schema.dtd\u0026#34;\u0026gt; \u0026lt;mycat:schema xmlns:mycat=\u0026#34;http://io.mycat/\u0026#34;\u0026gt; \u0026lt;schema name=\u0026#34;app_db\u0026#34; checksqlschema=\u0026#34;false\u0026#34; sqlmaxlimit=\u0026#34;100\u0026#34;\u0026gt; \u0026lt;!-- 订单模块 --\u0026gt; \u0026lt;table name=\u0026#34;order_cart\u0026#34; primarykey=\u0026#34;cart_id\u0026#34; datanode=\u0026#34;dn152\u0026#34; /\u0026gt; \u0026lt;table name=\u0026#34;order_customer_addr\u0026#34; primarykey=\u0026#34;customer_addr_id\u0026#34; datanode=\u0026#34;dn152\u0026#34; /\u0026gt; \u0026lt;table name=\u0026#34;order_master\u0026#34; primarykey=\u0026#34;order_id\u0026#34; datanode=\u0026#34;dn152\u0026#34; /\u0026gt; \u0026lt;table name=\u0026#34;order_detail\u0026#34; primarykey=\u0026#34;order_detail_id\u0026#34; datanode=\u0026#34;dn152\u0026#34; /\u0026gt; \u0026lt;!-- 仓配模块 --\u0026gt; \u0026lt;table name=\u0026#34;shipping_info\u0026#34; primarykey=\u0026#34;ship_id\u0026#34; datanode=\u0026#34;dn152\u0026#34; /\u0026gt; \u0026lt;table name=\u0026#34;warehouse_info\u0026#34; primarykey=\u0026#34;w_id\u0026#34; datanode=\u0026#34;dn152\u0026#34; /\u0026gt; \u0026lt;table name=\u0026#34;warehouse_proudct\u0026#34; primarykey=\u0026#34;wp_id\u0026#34; datanode=\u0026#34;dn152\u0026#34; /\u0026gt; \u0026lt;!-- 商品模块 --\u0026gt; \u0026lt;table name=\u0026#34;product_brand_info\u0026#34; primarykey=\u0026#34;brand_id\u0026#34; datanode=\u0026#34;dn151\u0026#34; /\u0026gt; \u0026lt;table name=\u0026#34;product_category\u0026#34; primarykey=\u0026#34;category_id\u0026#34; datanode=\u0026#34;dn151\u0026#34; /\u0026gt; \u0026lt;table name=\u0026#34;product_comment\u0026#34; primarykey=\u0026#34;comment_id\u0026#34; datanode=\u0026#34;dn151\u0026#34; /\u0026gt; \u0026lt;table name=\u0026#34;product_info\u0026#34; primarykey=\u0026#34;product_id\u0026#34; datanode=\u0026#34;dn151\u0026#34; /\u0026gt; \u0026lt;table name=\u0026#34;product_pic_info\u0026#34; primarykey=\u0026#34;product_pic_id\u0026#34; datanode=\u0026#34;dn151\u0026#34; /\u0026gt; \u0026lt;table name=\u0026#34;product_supplier_info\u0026#34; primarykey=\u0026#34;supplier_id\u0026#34; datanode=\u0026#34;dn151\u0026#34; /\u0026gt; \u0026lt;!-- 用户模块 --\u0026gt; \u0026lt;table name=\u0026#34;customer_balance_log\u0026#34; primarykey=\u0026#34;balance_id\u0026#34; datanode=\u0026#34;dn149\u0026#34; /\u0026gt; \u0026lt;table name=\u0026#34;customer_inf\u0026#34; primarykey=\u0026#34;customer_inf_id\u0026#34; datanode=\u0026#34;dn149\u0026#34; /\u0026gt; \u0026lt;table name=\u0026#34;customer_level_inf\u0026#34; primarykey=\u0026#34;customer_level\u0026#34; datanode=\u0026#34;dn149\u0026#34; /\u0026gt; \u0026lt;table name=\u0026#34;customer_login\u0026#34; primarykey=\u0026#34;customer_id\u0026#34; datanode=\u0026#34;dn149\u0026#34; /\u0026gt; \u0026lt;table name=\u0026#34;customer_login_log\u0026#34; primarykey=\u0026#34;login_id\u0026#34; datanode=\u0026#34;dn149\u0026#34; /\u0026gt; \u0026lt;table name=\u0026#34;customer_point_log\u0026#34; primarykey=\u0026#34;point_id\u0026#34; datanode=\u0026#34;dn149\u0026#34; /\u0026gt; \u0026lt;!-- 地区信息,全局表 --\u0026gt; \u0026lt;table name=\u0026#34;region_info\u0026#34; primarykey=\u0026#34;region_id\u0026#34; datanode=\u0026#34;dn149,dn151,dn152\u0026#34; type=\u0026#34;global\u0026#34;/\u0026gt; \u0026lt;/schema\u0026gt; \u0026lt;datanode name=\u0026#34;dn152\u0026#34; datahost=\u0026#34;dh152\u0026#34; database=\u0026#34;order_db\u0026#34; /\u0026gt; \u0026lt;datanode name=\u0026#34;dn151\u0026#34; datahost=\u0026#34;dh151\u0026#34; database=\u0026#34;product_db\u0026#34; /\u0026gt; \u0026lt;datanode name=\u0026#34;dn149\u0026#34; datahost=\u0026#34;dh149\u0026#34; database=\u0026#34;consumers_db\u0026#34; /\u0026gt; \u0026lt;datahost name=\u0026#34;dh152\u0026#34; maxcon=\u0026#34;1000\u0026#34; mincon=\u0026#34;10\u0026#34; balance=\u0026#34;2\u0026#34; writetype=\u0026#34;0\u0026#34; dbtype=\u0026#34;mysql\u0026#34; dbdriver=\u0026#34;native\u0026#34; switchtype=\u0026#34;1\u0026#34; slavethreshold=\u0026#34;100\u0026#34;\u0026gt; \u0026lt;heartbeat\u0026gt;select user()\u0026lt;/heartbeat\u0026gt; \u0026lt;writehost host=\u0026#34;192.168.1.152\u0026#34; url=\u0026#34;192.168.1.152:3306\u0026#34; user=\u0026#34;root\u0026#34; password=\u0026#34;123456\u0026#34; /\u0026gt; \u0026lt;/datahost\u0026gt; \u0026lt;datahost name=\u0026#34;dh151\u0026#34; maxcon=\u0026#34;1000\u0026#34; mincon=\u0026#34;10\u0026#34; balance=\u0026#34;2\u0026#34; writetype=\u0026#34;0\u0026#34; dbtype=\u0026#34;mysql\u0026#34; dbdriver=\u0026#34;native\u0026#34; switchtype=\u0026#34;1\u0026#34; slavethreshold=\u0026#34;100\u0026#34;\u0026gt; \u0026lt;heartbeat\u0026gt;select user()\u0026lt;/heartbeat\u0026gt; \u0026lt;writehost host=\u0026#34;192.168.1.151\u0026#34; url=\u0026#34;192.168.1.151:3306\u0026#34; user=\u0026#34;root\u0026#34; password=\u0026#34;123456\u0026#34; /\u0026gt; \u0026lt;/datahost\u0026gt; \u0026lt;datahost name=\u0026#34;dh149\u0026#34; maxcon=\u0026#34;1000\u0026#34; mincon=\u0026#34;10\u0026#34; balance=\u0026#34;2\u0026#34; writetype=\u0026#34;0\u0026#34; dbtype=\u0026#34;mysql\u0026#34; dbdriver=\u0026#34;native\u0026#34; switchtype=\u0026#34;1\u0026#34; slavethreshold=\u0026#34;100\u0026#34;\u0026gt; \u0026lt;heartbeat\u0026gt;select user()\u0026lt;/heartbeat\u0026gt; \u0026lt;writehost host=\u0026#34;192.168.1.149\u0026#34; url=\u0026#34;192.168.1.149:3306\u0026#34; user=\u0026#34;root\u0026#34; password=\u0026#34;123456\u0026#34;\u0026gt; \u0026lt;/writehost\u0026gt; \u0026lt;/datahost\u0026gt; \u0026lt;/mycat:schema\u0026gt; server.xml 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 \u0026lt;?xml version=\u0026#34;1.0\u0026#34; encoding=\u0026#34;utf-8\u0026#34;?\u0026gt; \u0026lt;!doctype mycat:server system \u0026#34;server.dtd\u0026#34;\u0026gt; \u0026lt;mycat:server xmlns:mycat=\u0026#34;http://io.mycat/\u0026#34;\u0026gt; \u0026lt;system\u0026gt; \u0026lt;property name=\u0026#34;useglobletablecheck\u0026#34;\u0026gt;0\u0026lt;/property\u0026gt; \u0026lt;property name=\u0026#34;sequncehandlertype\u0026#34;\u0026gt;2\u0026lt;/property\u0026gt; \u0026lt;property name=\u0026#34;processorbufferpooltype\u0026#34;\u0026gt;0\u0026lt;/property\u0026gt; \u0026lt;property name=\u0026#34;serverport\u0026#34;\u0026gt;8066\u0026lt;/property\u0026gt; \u0026lt;property name=\u0026#34;managerport\u0026#34;\u0026gt;9066\u0026lt;/property\u0026gt; \u0026lt;property name=\u0026#34;idletimeout\u0026#34;\u0026gt;300000\u0026lt;/property\u0026gt; \u0026lt;property name=\u0026#34;bindip\u0026#34;\u0026gt;0.0.0.0\u0026lt;/property\u0026gt; \u0026lt;property name=\u0026#34;frontwritequeuesize\u0026#34;\u0026gt;4096\u0026lt;/property\u0026gt; \u0026lt;property name=\u0026#34;processors\u0026#34;\u0026gt;4\u0026lt;/property\u0026gt; \u0026lt;property name=\u0026#34;handledistributedtransactions\u0026#34;\u0026gt;0\u0026lt;/property\u0026gt; \u0026lt;property name=\u0026#34;useoffheapformerge\u0026#34;\u0026gt;1\u0026lt;/property\u0026gt; \u0026lt;property name=\u0026#34;memorypagesize\u0026#34;\u0026gt;1m\u0026lt;/property\u0026gt; \u0026lt;property name=\u0026#34;spillsfilebuffersize\u0026#34;\u0026gt;1k\u0026lt;/property\u0026gt; \u0026lt;property name=\u0026#34;usestreamoutput\u0026#34;\u0026gt;0\u0026lt;/property\u0026gt; \u0026lt;property name=\u0026#34;systemreservememorysize\u0026#34;\u0026gt;100m\u0026lt;/property\u0026gt; \u0026lt;property name=\u0026#34;usezkswitch\u0026#34;\u0026gt;false\u0026lt;/property\u0026gt; \u0026lt;/system\u0026gt; \u0026lt;user name=\u0026#34;root\u0026#34;\u0026gt; \u0026lt;property name=\u0026#34;password\u0026#34;\u0026gt;123456\u0026lt;/property\u0026gt; \u0026lt;property name=\u0026#34;schemas\u0026#34;\u0026gt;app_db\u0026lt;/property\u0026gt; \u0026lt;/user\u0026gt; \u0026lt;/mycat:server\u0026gt; 跨分片查询解决方法\n\t①、使用mycat全局表\n\t②、冗余部分关键数据\n\t③、使用api的方式获取数据\n垂直切分的优缺点 优点\n拆分简单明了,拆分规则明确 应用程序模块清晰明确,整合容易 数据维护方便,容易定位 缺点\n部分表关联无法在数据库级别完成,需要在程序中完成 对于访问极其频繁且数据量超大的表依旧会有性能瓶颈 四、数据库的水平切分 \t一般情况下水平切分是在垂直切分依旧不能满足性能要求的时候进行的,应该按照性能需求和业务规则进行水平切分,即可以不水平切分的表不要水平切分。\n分片后的查询处理 1、mycat查找查询sql中的表对应的分片信息\n2、判断查询中是否包含分片键\n如果查询中包含分片键,则根据分片键的分片规则进行计算查找到后台真实物理db并发送sql\n如果不包含分片键则对后台所有配有此table的物理节点发送sql\n分片键的选择 如果没有分片键可选那就选择主键 如果有多个分片键选择 分片键可以尽可能的将数据均匀分布到各个节点上 该业务字段是最频繁的或最重要的查询条件 水平切分配置示例 schema.xml配置\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 \u0026lt;?xml version=\u0026#34;1.0\u0026#34;?\u0026gt; \u0026lt;!doctype mycat:schema system \u0026#34;schema.dtd\u0026#34;\u0026gt; \u0026lt;mycat:schema xmlns:mycat=\u0026#34;http://io.mycat/\u0026#34;\u0026gt; \u0026lt;schema name=\u0026#34;app_db\u0026#34; checksqlschema=\u0026#34;false\u0026#34; sqlmaxlimit=\u0026#34;100\u0026#34;\u0026gt; \u0026lt;!-- 订单模块 --\u0026gt; \u0026lt;table name=\u0026#34;order_cart\u0026#34; primarykey=\u0026#34;cart_id\u0026#34; datanode=\u0026#34;dn152_order\u0026#34; /\u0026gt; \u0026lt;table name=\u0026#34;order_customer_addr\u0026#34; primarykey=\u0026#34;customer_addr_id\u0026#34; datanode=\u0026#34;dn152_order\u0026#34; /\u0026gt; \u0026lt;!-- 订单表单独水平切分 --\u0026gt; \u0026lt;table name=\u0026#34;order_master\u0026#34; primarykey=\u0026#34;order_id\u0026#34; rule=\u0026#34;order_master_mod_long\u0026#34; datanode=\u0026#34;dn152_order01,dn151_order02,dn149_order03\u0026#34;\u0026gt; \u0026lt;!-- er分片,根据joinkey来进行分片 --\u0026gt; \u0026lt;childtable name=\u0026#34;order_detail\u0026#34; primarykey=\u0026#34;order_detail_id\u0026#34; joinkey=\u0026#34;order_id\u0026#34; parentkey=\u0026#34;order_id\u0026#34; /\u0026gt; \u0026lt;/table\u0026gt; \u0026lt;!-- 仓配模块 --\u0026gt; \u0026lt;table name=\u0026#34;shipping_info\u0026#34; primarykey=\u0026#34;ship_id\u0026#34; datanode=\u0026#34;dn152_order\u0026#34; /\u0026gt; \u0026lt;table name=\u0026#34;warehouse_info\u0026#34; primarykey=\u0026#34;w_id\u0026#34; datanode=\u0026#34;dn152_order\u0026#34; /\u0026gt; \u0026lt;table name=\u0026#34;warehouse_proudct\u0026#34; primarykey=\u0026#34;wp_id\u0026#34; datanode=\u0026#34;dn152_order\u0026#34; /\u0026gt; \u0026lt;!-- 商品模块 --\u0026gt; \u0026lt;table name=\u0026#34;product_brand_info\u0026#34; primarykey=\u0026#34;brand_id\u0026#34; datanode=\u0026#34;dn151_product\u0026#34; /\u0026gt; \u0026lt;table name=\u0026#34;product_category\u0026#34; primarykey=\u0026#34;category_id\u0026#34; datanode=\u0026#34;dn151_product\u0026#34; /\u0026gt; \u0026lt;table name=\u0026#34;product_comment\u0026#34; primarykey=\u0026#34;comment_id\u0026#34; datanode=\u0026#34;dn151_product\u0026#34; /\u0026gt; \u0026lt;table name=\u0026#34;product_info\u0026#34; primarykey=\u0026#34;product_id\u0026#34; datanode=\u0026#34;dn151_product\u0026#34; /\u0026gt; \u0026lt;table name=\u0026#34;product_pic_info\u0026#34; primarykey=\u0026#34;product_pic_id\u0026#34; datanode=\u0026#34;dn151_product\u0026#34; /\u0026gt; \u0026lt;table name=\u0026#34;product_supplier_info\u0026#34; primarykey=\u0026#34;supplier_id\u0026#34; datanode=\u0026#34;dn151_product\u0026#34; /\u0026gt; \u0026lt;!-- 用户模块 --\u0026gt; \u0026lt;table name=\u0026#34;customer_balance_log\u0026#34; primarykey=\u0026#34;balance_id\u0026#34; datanode=\u0026#34;dn149_consumers\u0026#34; /\u0026gt; \u0026lt;table name=\u0026#34;customer_inf\u0026#34; primarykey=\u0026#34;customer_inf_id\u0026#34; datanode=\u0026#34;dn149_consumers\u0026#34; /\u0026gt; \u0026lt;table name=\u0026#34;customer_level_inf\u0026#34; primarykey=\u0026#34;customer_level\u0026#34; datanode=\u0026#34;dn149_consumers\u0026#34; /\u0026gt; \u0026lt;table name=\u0026#34;customer_login\u0026#34; primarykey=\u0026#34;customer_id\u0026#34; datanode=\u0026#34;dn149_consumers\u0026#34; /\u0026gt; \u0026lt;table name=\u0026#34;customer_login_log\u0026#34; primarykey=\u0026#34;login_id\u0026#34; datanode=\u0026#34;dn149_consumers\u0026#34; /\u0026gt; \u0026lt;table name=\u0026#34;customer_point_log\u0026#34; primarykey=\u0026#34;point_id\u0026#34; datanode=\u0026#34;dn149_consumers\u0026#34; /\u0026gt; \u0026lt;!-- 地区信息,全局表 --\u0026gt; \u0026lt;table name=\u0026#34;region_info\u0026#34; primarykey=\u0026#34;region_id\u0026#34; datanode=\u0026#34;dn149_consumers,dn151_product,dn152_order\u0026#34; type=\u0026#34;global\u0026#34;/\u0026gt; \u0026lt;/schema\u0026gt; \u0026lt;datanode name=\u0026#34;dn152_order01\u0026#34; datahost=\u0026#34;dh152\u0026#34; database=\u0026#34;order_db01\u0026#34; /\u0026gt; \u0026lt;datanode name=\u0026#34;dn151_order02\u0026#34; datahost=\u0026#34;dh151\u0026#34; database=\u0026#34;order_db02\u0026#34; /\u0026gt; \u0026lt;datanode name=\u0026#34;dn149_order03\u0026#34; datahost=\u0026#34;dh149\u0026#34; database=\u0026#34;order_db03\u0026#34; /\u0026gt; \u0026lt;datanode name=\u0026#34;dn152_order\u0026#34; datahost=\u0026#34;dh152\u0026#34; database=\u0026#34;order_db\u0026#34; /\u0026gt; \u0026lt;datanode name=\u0026#34;dn151_product\u0026#34; datahost=\u0026#34;dh151\u0026#34; database=\u0026#34;product_db\u0026#34; /\u0026gt; \u0026lt;datanode name=\u0026#34;dn149_consumers\u0026#34; datahost=\u0026#34;dh149\u0026#34; database=\u0026#34;consumers_db\u0026#34; /\u0026gt; \u0026lt;datahost name=\u0026#34;dh152\u0026#34; maxcon=\u0026#34;1000\u0026#34; mincon=\u0026#34;10\u0026#34; balance=\u0026#34;2\u0026#34; writetype=\u0026#34;0\u0026#34; dbtype=\u0026#34;mysql\u0026#34; dbdriver=\u0026#34;native\u0026#34; switchtype=\u0026#34;1\u0026#34; slavethreshold=\u0026#34;100\u0026#34;\u0026gt; \u0026lt;heartbeat\u0026gt;select user()\u0026lt;/heartbeat\u0026gt; \u0026lt;writehost host=\u0026#34;192.168.1.152\u0026#34; url=\u0026#34;192.168.1.152:3306\u0026#34; user=\u0026#34;root\u0026#34; password=\u0026#34;123456\u0026#34; /\u0026gt; \u0026lt;/datahost\u0026gt; \u0026lt;datahost name=\u0026#34;dh151\u0026#34; maxcon=\u0026#34;1000\u0026#34; mincon=\u0026#34;10\u0026#34; balance=\u0026#34;2\u0026#34; writetype=\u0026#34;0\u0026#34; dbtype=\u0026#34;mysql\u0026#34; dbdriver=\u0026#34;native\u0026#34; switchtype=\u0026#34;1\u0026#34; slavethreshold=\u0026#34;100\u0026#34;\u0026gt; \u0026lt;heartbeat\u0026gt;select user()\u0026lt;/heartbeat\u0026gt; \u0026lt;writehost host=\u0026#34;192.168.1.151\u0026#34; url=\u0026#34;192.168.1.151:3306\u0026#34; user=\u0026#34;root\u0026#34; password=\u0026#34;123456\u0026#34; /\u0026gt; \u0026lt;/datahost\u0026gt; \u0026lt;datahost name=\u0026#34;dh149\u0026#34; maxcon=\u0026#34;1000\u0026#34; mincon=\u0026#34;10\u0026#34; balance=\u0026#34;2\u0026#34; writetype=\u0026#34;0\u0026#34; dbtype=\u0026#34;mysql\u0026#34; dbdriver=\u0026#34;native\u0026#34; switchtype=\u0026#34;1\u0026#34; slavethreshold=\u0026#34;100\u0026#34;\u0026gt; \u0026lt;heartbeat\u0026gt;select user()\u0026lt;/heartbeat\u0026gt; \u0026lt;writehost host=\u0026#34;192.168.1.149\u0026#34; url=\u0026#34;192.168.1.149:3306\u0026#34; user=\u0026#34;root\u0026#34; password=\u0026#34;123456\u0026#34;\u0026gt; \u0026lt;/writehost\u0026gt; \u0026lt;/datahost\u0026gt; \u0026lt;/mycat:schema\u0026gt; rule.xml配置\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 \u0026lt;?xml version=\u0026#34;1.0\u0026#34; encoding=\u0026#34;utf-8\u0026#34;?\u0026gt; \u0026lt;!doctype mycat:rule system \u0026#34;rule.dtd\u0026#34;\u0026gt; \u0026lt;mycat:rule xmlns:mycat=\u0026#34;http://io.mycat/\u0026#34;\u0026gt; \u0026lt;tablerule name=\u0026#34;order_master_mod_long\u0026#34;\u0026gt; \u0026lt;rule\u0026gt; \u0026lt;columns\u0026gt;customer_id\u0026lt;/columns\u0026gt; \u0026lt;algorithm\u0026gt;mod-long\u0026lt;/algorithm\u0026gt; \u0026lt;/rule\u0026gt; \u0026lt;/tablerule\u0026gt; \u0026lt;function name=\u0026#34;mod-long\u0026#34; class=\u0026#34;io.mycat.route.function.partitionbymod\u0026#34;\u0026gt; \u0026lt;property name=\u0026#34;count\u0026#34;\u0026gt;3\u0026lt;/property\u0026gt; \u0026lt;/function\u0026gt; \u0026lt;/mycat:rule\u0026gt; 水平切分引发主键问题 \t水平切分带来了主键自增问题,可以使用本地文件方式、数据库方式 、本地时间戳方式 、zk id 生成器和程序使用redis生成自增id的方式\nzk 递增方式\n前提条件mycat是集群模式,已加入zookeeper建立连接\n配置server.xml加入以下部分 1 2 3 \u0026lt;system\u0026gt; \u0026lt;property name=\u0026#34;sequncehandlertype\u0026#34;\u0026gt;4\u0026lt;/property\u0026gt; \u0026lt;/system\u0026gt; 配置sequence_conf.properties 1 2 3 4 5 6 7 8 9 10 11 # 全局 global.hisids= global.minid=10001 global.maxid=20000 global.curid=10000 # 自定义数据 order.hisids= order.minid=1001 order.maxid=2000 order.curid=1000 插入sql改造 1 2 3 4 -- 使用全局配置 insert into order(id, ...) values(next value for mycatseq_global, ...); -- 使用单独表配置 insert into order(id, ...) values(next value for mycatseq_order, ...); 五、mycat高可用搭建 mycat集群搭建 前期准备:搭建好zookeeper集群\n第一步:拷贝修改和增加的配置文件到$mycat/conf/zkconf下\n1 2 # 需将所有修改的配置全部覆盖 cp rule.xml schema.xml server.xml zkconf/ 第二步:配置$mycat/conf/myid.properties\n1 2 3 4 5 6 7 8 9 10 loadzk=true zkurl=192.168.1.158:2181,192.168.1.158:2182,192.168.1.158:2183 # 集群id,规划为同一个集群的clusterid要相同 clusterid=mycat-cluster # 每个节点的id,不能重复 myid=mycat_fz_01 # 每个节点的名称,需要全部写这里 clusternodes=mycat_fz_01,mycat_fz_02 type=server boosterdatahosts=datahost1 第三步:上传文件内容到zk集群\n1 2 # 这个命令需要在$mycat/bin目录下执行否则目录位置会出现问题 init_zk_data.sh 第四步:重启mycat\n此时可以查看集群中所有mycat配置是否一致\nmycat自身高可用 搭建haproxy实现mycat后台负载均衡 第一步:安装haproxy\n1 yum install haproxy 第二步:修改/etc/haproxy/haproxy.cfg的配置\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 global chroot /var/lib/haproxy pidfile /var/run/haproxy.pid maxconn 4000 user haproxy group haproxy daemon stats socket /var/lib/haproxy/stats defaults mode http log global option httplog option dontlognull option http-server-close # 使用tcp时注释掉要不会有警告 # option forwardfor except 127.0.0.0/8 option redispatch retries 3 timeout http-request 10s timeout queue 1m timeout connect 10s timeout client 1m timeout server 1m timeout http-keep-alive 10s timeout check 10s maxconn 3000 # haproxy管理员登陆界面 listen admin_stats bind 0.0.0.0:4001 mode http stats uri /stats stats realm haproxy\\ statistics stats auth admin:admin stats admin if true # mycat服务负载 listen allmycat_service bind 0.0.0.0:8069 mode tcp option tcplog balance roundrobin server mycat1 192.168.1.158:8066 check inter 5s rise 2 fall 3 server mycat2 192.168.1.149:8066 check inter 5s rise 2 fall 3 option tcpka #keepalived死链检测 # mycat监控端口负载 listen allmycat_admin bind 0.0.0.0:9069 mode tcp option tcplog balance roundrobin server mycat1 192.168.1.158:9066 check inter 5s rise 2 fall 3 server mycat2 192.168.1.149:9066 check inter 5s rise 2 fall 3 option tcpka #keepalived死链检测 第三步:检查启动\n1 2 3 4 # 检查配置文件是否正确 haproxy -c -f /etc/haproxy/haproxy.cfg # 启动 haproxy -f /etc/haproxy/haproxy.cfg 搭建keepalived作用于haproxy实现高可用 第一步:安装keepalived\n1 yum install keepalived 第二步:修改/etc/keepalived/keepalived.conf的配置\n! configuration file for keepalived global_defs { # 每个节点不一样 router_id 152 } # 检查脚本配置。必须在使用脚本之前配置好 vrrp_script check_haproxy { script \u0026#34;/etc/keepalived/check_haproxy.sh\u0026#34; interval 2 #检测时间间隔 weight -20 #如果条件成立则权重减20 } vrrp_instance vi_1 { # 分为master和backup state master # 网卡 interface enp0s3 # 同一组keepalive此值一样用于区分组 virtual_router_id 101 # 优先级别 priority 100 # 非抢占模式,master有用 nopreempt # 广播优先级间隔时间 advert_int 1 authentication { auth_type pass auth_pass 1111 } virtual_ipaddress { 192.168.1.101 } # 要放在vip后面 track_script { check_haproxy } } 第三步:配置检查脚本【必须要有执行权限】\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #!/bin/bash a=`ps -c haproxy --no-header |wc -l` if [ $a -eq 0 ];then echo \u0026#34;`date` haproxy is dead\u0026#34; \u0026gt;\u0026gt; /tmp/lvs.log haproxy -f /etc/haproxy/haproxy.cfg sleep 2 fi if [ `ps -c haproxy --no-header |wc -l` -eq 0 ];then echo \u0026#34;`date` haproxy cannot start,stop keepalived\u0026#34; \u0026gt;\u0026gt; /tmp/lvs.log # 杀死keepalived ps -c keepalived --no-header | awk \u0026#39;{print $1}\u0026#39;|xargs kill -9 exit 0 else echo \u0026#34;`date` haproxy restart\u0026#34; \u0026gt;\u0026gt; /tmp/lvs.log exit 1 fi 第四步:启动keepalived和查看日志\n1 2 keepalived -f /etc/keepalived/keepalived.conf tail -f -n 50 /var/log/messages 六、mycat监控 使用mycat生成执行sql记录 在server.xml的system标签下配置拦截\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 \u0026lt;system\u0026gt; \u0026lt;!-- 配置拦截器 --\u0026gt; \u0026lt;property name=\u0026#34;sqlinterceptor\u0026#34;\u0026gt; io.mycat.server.interceptor.impl.statisticssqlinterceptor \u0026lt;/property\u0026gt; \u0026lt;!-- 配置拦截sql类型 --\u0026gt; \u0026lt;property name=\u0026#34;sqlinterceptortype\u0026#34;\u0026gt; select,update,insert,delete \u0026lt;/property\u0026gt; \u0026lt;!-- 配置sql生成文件位置 --\u0026gt; \u0026lt;property name=\u0026#34;sqlinterceptorfile\u0026#34;\u0026gt; /opt/mycat/interceptorfile/sql.txt \u0026lt;/property\u0026gt; \u0026lt;/system\u0026gt; mycat命令行管理工具 使用名 mysql -u[username] -p -p[管理端口,默认9066] -h[ip]连接mycat命令行管理端\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 -- 帮助命令 show @@help \\g; -- 重新加载配置 reload @@config; reload @@config_all; -- 显示物理服务器信息 show @@databases \\g; -- 显示datanode节点 show @@datanode \\g; -- 显示所有连接信息 show @@connection \\g; -- 杀死连接 kill @@connection id1,id2,... -- 展示后台链接详细信息 show @@backend \\g; -- 显示当前缓存信息(er分片信息、主键缓存、路由缓存) show @@cache \\g; -- 显示配置的物理服务器信息 show @@datasource \\g; mycat的gui管理工具 使用mycat-web可以更加直观的看到mycat集群状态,下载地址,配置时注意修改mycat-web/web-inf/classes/mycat.properties,默认访问地址http://ip:8082/mycat\n1 2 # 只需修改zookeeper这行 zookeeper=localhost:2181 七、mycat的限制 mycat不支持的sql语句 ddl语句【如:create table like xxx / create table select xxx / create table】 跨库多表关联,子查询 select for update/select lock in share mode【这俩语句只会随机发送到后端一个节点导致数据库出现问题】 多表update或update分片键 跨分片的带有limit的update/delete 对事务的支持有限(xa 事务) 第一步:像后台数据库发送begin\n第二步:发送执行的sql,等待所有节点都返回成功才执行下面步骤,如果有任何一个返回失败,全部rollback\n第三步:执行commit等待所有节点返回,等待结果返回给客户端,如果有任何一个返回失败,返回事务处理失败\n如果有commit过程中任意一个节点报错,数据一致性将无法保证(可能性很小)\n","date":"2019-11-12","permalink":"https://hobocat.github.io/post/database/2019-11-12-mycat/","summary":"一、MyCat概览 MyCat简介 支持对MySQL等数据库进行垂直切分,水平切分并实现了读写分离和负载均衡的数据库中间件 MyCat的基本元素 逻辑库 对于应用来说相","title":"mycat的使用"},]
[{"content":"一、安装mysql yum源下载方式 预备工作\n1 yum -y install yum-utils\t#安装yum-utils 第一步:下载yum源\n在官网选择downloads\u0026ndash;\u0026raquo;community (gpl) downloads \u0026ndash;\u0026raquo;mysql yum repository最新yum源\n第二步:安装yum源\n1 2 3 4 5 yum localinstall mysqlxx-community-release-版本号.rpm #安装yum信息 yum repolist all | grep mysql #查看默认安装信息 yum-config-manager --disable mysql80-community #禁用mysql80 yum-config-manager --enable mysql57-community #启用mysql57 yum repolist enabled | grep mysql #查看是否正确 第三步:安装mysql\n1 yum install -y mysql-community-server 第四步:启动mysql服务\n1 systemctl start mysqld 第五步:登陆mysql\nmysql初始化root密码在log文件中,使用more /etc/my.cnf查看日志文件位置(默认/var/log/mysqld.log)\n第六步:修改root密码\n1 alter user \u0026#39;root\u0026#39;@\u0026#39;localhost\u0026#39; identified by \u0026#39;root\u0026#39;; -- 没有修改密码策略会提示密码复杂度不够 第七步:开放root远程登陆权限\n1 2 grant all privileges on *.* to \u0026#39;root\u0026#39;@\u0026#39;%\u0026#39; identified by \u0026#39;[newpwd]\u0026#39; with grant option; flush privileges; 注:测试环境下可以修改密码策略\n1 2 3 set global validate_password_policy=0; -- 设置检查策略为最低0和low一样 set global validate_password_length=1; -- 设置密码长度最少为1(实际上mysql会设置为4) show variables like \u0026#39;%password%\u0026#39;; -- 查看密码相关信息 二、操作系统性能优化 内核相关参数设置(/etc/sysctl.conf) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 ############################################################# # 以下参数使用 sudo cat /proc/sys/x/y/z格式可以查看系统当前值 # # 如:sudo cat /proc/sys/net/core/somaxconn # ############################################################# # 默认值是128(系统中每个端口最大监听队列长度),对于负载大的服务远不够。一般会将它修改为2048或者更大 net.core.somaxconn = 2048\t# 每个网络接口接收数据包的速率比内核处理这些包的速率快时,缓冲队列的数据包的最大数目,默认值为1000 net.core.netdev_max_backlog = 2000 # 尚未收到客户端确认信息的连接请求的最大值(排队握手值,默认128) net.ipv4.tcp_max_syn_backlog = 2048 # tcp连接默认的timeout时长,默认60 net.ipv4.tcp_fin_timeout = 10 # 更快的回收套接字,默认0 net.ipv4.tcp_tw_recycle = 1 # 允许将time-wait sockets重新用于新的tcp连接,默认为0 net.ipv4.tcp_tw_reuse = 1 # 默认tcp数据发送窗口大小,默认229376(字节) net.core.wmem_default = 256960 # 最大tcp数据发送窗口大小,默认229376(字节) net.core.wmem_max = 16777216 # 默认tcp数据接收窗口大小,默认229376 net.core.rmem_default = 256960 # 最大tcp数据接收窗口大小,默认229376(字节) net.core.rmem_max = 16777216 # tcp发送keepalive消息的时间间隔,默认7200 net.ipv4.tcp_keepalive_time = 120 # 探测消息未获得响应时,重发该消息的时间间隔,默认75 net.ipv4.tcp_keepalive_intvl = 30 # 认定tcp连接失败失效之前,最多发送多少keepalive消息,默认9 net.ipv4.tcp_keepalive_probes = 3 # 单个共享内存段的最大值。这个值应该设置足够大,便于一个共享内存段可以容纳整个innodb缓冲池大小 # 建议设置为物理内存一半 kernel.shmmax = 17179869184 # swappiness的值越大,表示越积极使用swap分区,为0表示除非内存满了才使用。默认值swappiness=60 vm.swappiness = 0 使用 sysctl -p使之生效\n资源文件设置(/etc/security/limits.conf) #\u0026lt;domain\u0026gt; \u0026lt;type\u0026gt; \u0026lt;item\u0026gt; \u0026lt;value\u0026gt; mysql hard nofile 65535\t#设置mysql可打开文件数 mysql soft nofile 65535 需重启生效\n磁盘调度策略 cfq:完全公平调度策略,桌面级系统较为合适 noop: 电梯式调度程序 ,fifo队列,它像电梯的工作主法一样对i/o请求进行组织,当有一个新的请求到来时,它将请求合并到最近的请求之后,以此来保证请求同一介质 deadline:截至时间调度策略,这个截止时间是可调整的,而默认读期限短于写期限.这样就防止了写操作因为不能被读取而饿死的现象[适合mysql] echo deadline \u0026gt; /sys/block/[devname]/queue/scheduler修改调度策略\n文件系统选择 linux提供的ext3、ext4、xfs文件系统均具有日志功能,可保证数据安全。其中属xfs性能最高。 df -t查看文件系统格式\n如果是ext3/ext4可进行以下优化(/etc/fastab)\n# noatime 禁止记录访问时间 # nodirname 禁止记录目录时间 # data # wirteback 仅写入元数据–innodb最好 # ordered 写元数据和数据 # journal 先计入日志 /dev/[devname]/ext4 noatime,nodirname,data=wirteback 1 1 三、mysql存储引擎的选择 myisam存储引擎 \tmyisam是mysql5.5之前版本所使用的默认存储引擎,也是现在系统表、临时表(排序、分组操作中当数量超过一定大小,由查询优化器建立的临时表)所使用的存储引擎。\n数据文件:myisam表的存储文件有特有的两种,分别是.myd[存储数据]、.myi[存储索引] myisam特性\n表级锁(共享读锁,互斥写锁)\n不支持事务\n支持全文索引,以及text、blob前500字节建立索引。在5.7之前innodb不支持\n支持数据压缩【单行压缩,不用整表解压】, 表变为只读,不能进行写操作\nmyisampack -f [tablename].myi 表支持数据恢复操作\nmysql终端使用check table [tablename] 检查表是否损坏 mysql终端使用repair table [tablename] 修复表 系统终端使用myisamchk -im /path/[tablename].myi 检查表是否损坏 系统终端使用myisamchk -ibfqr /path/[tablename].myi 快速修复表(必须停止mysql服务 ) 系统终端使用myisamchk -ibfqo /path/[tablename].myi 能修复r不能修复的情况(必须停止mysql服务 ) myisam应用场景\n非事务型应用(报表类切不涉及财务要求读取性能高) 只读 空间类应用(在5.7之前只有myisam支持空间函数等) innodb存储引擎 \tinnodb是mysql5.5之后版本所使用的默认存储引擎,支持事务、适用于小而多的事务场景。\n数据文件:innodb表只有一种特有格式ibd[索引、数据]\ninnodb表空间进行数据存储的选择\n1 2 3 [mysqld] innodb_file_per_table=1 #开启独立表空间,存储文件为[tablename].idb innodb_file_per_table=0 #关闭独立表空间,使用系统表空间,存储文件为ibdate[num] 独立表空间\u0026amp;系统表空间\nmysql5.6之前默认使用系统表空间,5.6及其之后默认使用独立表空间\n系统表空间无法简单的收缩文件大小,大量并发还会产生io瓶颈\n独立表空间可以通过optimize table [tablename]命令(会锁表)重新利用未使用的空间,并整理数据文件的碎片\n独立表空间可以同时向多个文件刷新数据,支撑大量io并发\ninnodb引擎特性\n完全支持事务的acid特性 具有redo log日志[记录已提交的事务],undo log日志[记录未提交的事务,需要随机读写] 支持行级锁【间隙锁】,可以支持并发操作 可使用show engine innodb status【间隔采样,最少使用2次】采集相关引擎运行状态信息 适用场景\n需要事务 需要大量并发写入、读取 csv存储引擎 \tcsv存储引擎将数据以文本的方式存储在文件中,可以直接打开文件进行查看。\n数据文件:csv表的存储文件有特有的两种,分别是.csv[存储数据]、.csm[存储元数据如表的状态和数据量]\ncsv引擎特点\n以csv格式进行数据存储\n所有列的都不能为null\n不支持索引【不适合大表,不适合在线处理】\n支持对数据文件直接编辑【编辑之后用flush tables刷新表才可见编辑变化】\n定义数据表是必须显示指出列不为空否则会报出以下异常\n1 the storage engine for the table doesn\u0026#39;t support nullable columns 适用场景\n适合作为数据交换的中间表【可随时拷入、拷贝文件】 archive存储引擎 数据文件:csv表的存储文件有特有的一种.arz[存储数据]\narchive存储引擎特点\n以zlib对表数据进行压缩,磁盘io更少 只支持insert和select操作【支持行级锁和特定缓冲区但不支持事务,可大并发插入】 只允许在自增id上建立索引 适用场景\n日志和数据采集类应用 memory存储引擎 \tmemory存储引擎是mysql在创建临时表(排序、分组操作中时由查询优化器建立的临时表,memory不满足条件时使用myisam作为临时表引擎)所使用的存储引擎。\nmemory存储引擎特点\n所有数据都存在于内存中,重启mysql数据丢失,表定义不丢失(.frm文件是在系统文件中) 支持hash和btree索引 所有字段都是固定长度(varchar(10) = char(10)) 不支持blog和text大字段 使用表级锁【影响并发】 适用场景\n用于查找或者映射表(支持hash索引) 用于保存数据分析中产生的中间表 用于缓存周期性聚合数据的结果表 federated存储引擎 \tfederated存储引擎提供了访问远程mysql 服务器上表的方法,且在本地并不存储数据,数据全部在远程服务器上,但是本地需要保存表结构信息和远程服务器信息(.frm文件依旧存在)。federated引擎效率并不高,默认禁止。\n开启federated存储引擎\n\t在mysql配置文件[mysqld]中加入federated = 1\n使用方法\n1)远程服务器创建用户并授权\n1 2 create user \u0026#39;[username]\u0026#39;@\u0026#39;[host]\u0026#39; identified by \u0026#39;[password]\u0026#39;; grant privileges on delete,update,insert,select [database].[tablename] to \u0026#39;[username]\u0026#39;@\u0026#39;[host]\u0026#39; 2 )本地服务器创建表结构要与远程服务器表结构一致,且加入\n1 2 3 create table [tablename] ( ... ) engine =federated connection=\u0026#39;mysql://username:password@host:port/database/table\u0026#39;; 适用场景\n偶尔的统计分析及手工查询 四、mysql服务参数配置 \t可以使用mysqld --help --verbose | grep -a 1 'default options'查看mysql读取配置文件的顺序,后读取的配置信息会覆盖前配置的信息。\n配置参数的作用域设置\n全局参数 set global 参数名 = 参数值; set @@global.参数名 := 参数值; 会话参数 set [session] 参数名 = 参数值; set @@session.参数名 := 参数值; 内存相关参数 线程级别\nsort_buffer_size:每个线程进行排序操作时创建,每次创建这个数值的全部内存,默认1m,不建议改动\njoin_buffer_size:每个查询语句进行一次join分配一个,多次分配多个。大量join操作可以适当调大\nread_bufer_size:myisam进行全表扫描时创建这个数值的全部内存,如果修改应该为4k倍数\nread_rnd_buffer_size:myisam索引使用,按需分配不是一次使用全部数值内存\n进程级别\ninnodb_buffer_pool_size:innodb所用缓冲池大小包含innodb数据页、索引数据、缓冲数据、 内存中修改尚未刷新(写入)到磁盘的数据 以及 如自适应哈希索引,行锁等。 默认大小为128m,如果只使用innodb引擎建议设置为系统物理内存70% key_buffer_size:myisam所用缓冲池大小只包含索引数据, 如果很少使用myisam表,也要保留16-32mb 的 key_buffer_size 以适应给予磁盘的临时表索引所需 i/o相关参数 redo log相关\ninnodb_log_file_size\ninnodb_log_files_in_group\nredo日志先写到缓冲区再写到日志文件每秒刷盘,所以日志文件不需要太大。innodb_log_files_in_group决定了日志文件个数,日志时先满一个才使用下一个并非并行使用,所以此值不重要。\ninnodb_flush_log_at_trx_commit:刷新事务日志的频繁程度\n0:每秒进行一次log写入操作系统cache,并立即flush log到磁盘,宕机或mysql崩溃可能丢失1s事务数据。\n1【默认】:每次事务提交时执行log写入cache,并立即flush log 到磁盘,不会丢失任何事务数据。\n2:每次事务提交时执行log写入cache,并每秒执行flush log 到磁盘 ,mysql进程奔溃不会丢失,服务器宕可能会事务数据。如果有需要可以开启此选项。\ninnodb_flush_method:建议设置为o_direct,不缓存,不预读,避免操作系统和mysql双缓存\ninnodb_file_per_table:建议设置为1,独立表空间,使用系统表空间【5.6及其以后默认为1】\ninnodb_doublewrite:建议设置为1,避免页没写完整导致数据损坏,增加数据安全。默认为1\ndelay_key_write:类似innodb_flush_log_at_trx_commit\noff:关闭延迟写入,直接刷盘到磁盘 on:只对建表时使用的了delay_key_write选项的表进行延迟写入 对所有myisam表都使用延迟写入 安全相关参数 expire_log_days:指定自动清理binlog的天数,至少两次全备时间,如果每天全备也应该保存7天以上\nmax_allowed_packet:控制可以接收最大的包的大小和用户定义变量的最大容量(主从模式下应该一样),建议32m\nskip_name_resolve:禁用dns查找,如果需要通过主机名连接,建议配置在host文件中\n当有一个新的客户端连接进来时,mysql server会为这个ip在host cache中建立一个新的记录,包括ip,主机名和client lookup validation flag,分别对应host_cache表中的ip,host和host_validated这三列。第一次建立连接因为只有ip,没有主机名,所以host将设置为null,host_validated将设置为false。\nmysql server检测host_validated的值,如果为false,它会试图进行dns解析,如果解析成功,它将更新host的值为主机名,并将host_validated值设为true。如果没有解析成功,判断失败的原因是永久的还是临时的,如果是永久的,则host的值依旧为null,且将host_validated的值设置为true,后续连接不再进行解析,如果该原因是临时的,则host_validated依旧为false,后续连接会再次进行dns解析。\n解析成功的标志并不只是通过ip,获取到主机名即可,这只是其中一步,还有一步是通过解析后的主机名来反向解析为ip,判断该ip是否与原ip相同,如果相同,才判断为解析成功,才能更新host cache中的信息。\nsysdata_is_now:设置为1,确保sysdate()返回确定性日期。 如果主从使用了binlog的statement模式,sysdata的结果会不一样,最后导致数据不一致\nread_only:禁止非super权限用户的写权限,主从模式下建议从机开启\nskip_slave_start:禁用slave自动恢复,当从机恢复工作时,先不启动从属模式,检查完成后,手动启动较好\nsql_model:mysql所使用的sql模式,默认为宽松模式\nstrict_trans_tables: 严格模式,非法数据值被拒绝 no_engine_subtitution: 严格模式下建表的时候指定不可用存储引擎会报错 no_zero_data: 严格模式不接受'0000-00-00\u0026rsquo;作为合法日期 no_zero_in_data: 严格模式不接受月或日部分为0的日期 only_full_group_by: 严格模式下检验group by语句的合法性 其它相关参数 sync_binlog:控制mysql如何向磁盘刷新binlog\n0默认, 事务提交由操作系统决定刷盘时间,这时候的性能是最好的,但是风险也是最大的 大于0, 事务提交两次刷盘的间隔多少次写操作,主服务最好应该是1(最多可能丢失1个事务的数据) tmp_table_size和max_heap_table_size:控制内存临时表大小(memeory引擎创建),超过变为文件临时表(myisam引擎创建)\nmax_connections:控制允许的最大连接数,默认100,建议2000+\n五、mysql基准测试 基准测试的定义 \t基准测试是一种测量和评估软件性能指标的活动用于建立某个时刻的性能基准,以便当系统发生软硬件变化时重新进行基准测试以便评估变化对系统性能的影响\n常见测试指标 单位时间内所处理的事务数(tps)\n单位时间内所处理的查询数(qps)\n响应时间( rt )\n系统同时能处理的请求数量(并发数)\n单位时间内系统能处理的请求数量 (吞吐量 )\nsysbench做基准测试 \tsysbench是一个模块化的、跨平台、多线程基准测试工具,主要用于评估测试各种不同系统参数下的数据库负载情况 。具有以下功能:\n\t1、cpu性能测试\n\t2、磁盘io性能测试\n\t3、调度程序性能测试\n\t4、内存分配及传输速度测试\n\t5、posix线程性能测试\n\t6、数据库性能(oltp基准测试)\n安装sysbench\n标准目录安装 1 2 ./configure \u0026amp;\u0026amp; make \u0026amp;\u0026amp; make install strip /usr/local/bin/sysbench 非标准目录安装 1 2 # 需要先yum install mysql-devel ./configure --with-mysql-includes=/usr/include/mysql --with-mysql-libs=/usr/lib64/mysql \u0026amp;\u0026amp; make \u0026amp;\u0026amp; make install 开始测试\n0)查看各项测试帮助\n1 2 3 # 使用 sysbench --test=\u0026lt;name\u0026gt; help # testname:fileio、cpu、memory、threads、mutex、oltp # 如:sysbench --test=fileio help 1)cpu性能测试\n1 2 # 主要是进行素数的加法运算 sysbench --test=cpu --cpu-max-prime=20000 run 2)线程测试\n1 sysbench --test=threads --num-threads=64 --thread-yields=100 --thread-locks=2 run 3)磁盘io性能测试\n1 2 3 4 5 6 # 会生成测试文件,准备测试 sysbench --test=fileio --file-total-size=3g --file-test-mode=rndrw prepare # 开始测试 sysbench --test=fileio --num-threads=16 --file-test-mode=rndrw run # 删除测试文件 sysbench --test=fileio cleanup 4)内存测试\n1 2 # 内存中传输200m的数据量,每个block大小为8k,单位注意大写 sysbench --test=memory --memory-block-size=8k --memory-total-size=200m run 5)oltp测试\n1 2 3 4 5 6 7 8 # 准备测试,更多参数运行帮助命令 sysbench --test=oltp --mysql-table-engine=innodb --thread=8 --oltp-table-size=10 --oltp-table-size=1000000 --mysql-user=root --mysql-password=123456 --mysql-db=ttt --mysql-host=localhost prepare # 运行测试,更多参数运行帮助命令 sysbench --test=oltp --mysql-table-engine=innodb --thread=8 --oltp-table-size=10 --oltp-table-size=1000000 --mysql-user=root --mysql-password=123456 --mysql-db=ttt --mysql-host=localhost run # 清理测试数据 sysbench --test=oltp --mysql-table-engine=innodb --thread=8 --oltp-table-size=10 --oltp-table-size=1000000 --mysql-user=root --mysql-password=123456 --mysql-db=ttt --mysql-host=localhost cleanup 六、mysql压力测试 \ttpcc-mysql是percona基于tpcc规范衍生的产品,专用于mysql的压力测试,对sql的执行时间有严格要求。\n安装tpcc-mysql\n前置条件:安装mysql-devel\n第一步:下载\n下载地址\n第二步:编译\n1 cd src; make 第三步:取出$tpcc-mysql目录下的sql[create_table.sql、add_fkey_idx.sql]文件\n第四步:创建一个空数据库,并执行create_table.sql、add_fkey_idx.sql\n第五步:执行创建数据操作\n1 $tpcc-mysql/tpcc_load -h [ip] -d [databasename] -u [user] -p [password] -w [num] -w 指的是数据模型中仓库的数量\n第六步:执行压力测试\n1 $tpcc-mysql/tpcc_start -h [ip] -d [databasename] -u [user] -p [password] -w [num] -c [num] -r [num] -l [num] \u0026gt; result.log -c 指的是并发线程数\n-r 数据库预热时间\n-l 测试时间\n例如:/tpcc_start -h 192.168.1.152 -d tpcc -u root -p 123456 -w 1 -c 5 -r 300 -l 600 \u0026gt; result.log\npxc集群使用tpcc-mysql进行压力测试需要更改配置文件pxc_strict_mode=disabled\n七、数据库结构设计 数据库设计范式 数据库设计第一范式\n数据库表中的所有字段都只具有单一属性\n单一属性的列是由基本的数据类型所构成的\n设计出来的表都是简单的二维表\n数据库第二范式\n要求表中只具有一个业务主键,也就是说符合第二范式的表不能存在非主键列只对部分主键的依赖关系 数据库第三范式\n每一个非主属性既不部分依赖也不传递依赖于业务主键 数据库物理设计 表中的列选择数据类型\n\t当一个列可以选择多种数据类型时,应该首先考虑数字类型,其次是日期或二进制类型,最后是字符串类型。对于相同级别的数据类型,应该优先选择占用空间小的数据类型。\n整数类型 列类型 存储空间 范围 tinyint 1字节 -127 ~ 128 smallint 2字节 -32768 ~ 32767 mediunmit 3字节 -8388608 ~ 8388607 int 4字节 -2147483648 ~ 2147483647 bigint 8字节 -9223372036854775808 ~ 9223372036854775807 实数类型 列类型 存储空间 是否精确 float 4字节 否 double 8字节 否 decimal 每4个字节存9个数字,小数点占一个字节 是 注: column_name decimal (p,d);\n1)p是表示有效数字数的精度。 p范围为1〜65\n2)d是表示小数点后的位数。 d的范围是0~30。mysql要求d小于或等于(\u0026lt;=)p\n如amount decimal(6,2); amount列最多可以存储6位数字,小数位数为2位; 因此,amount列的范围是从-9999.99到9999.99\nvarchar和char类型【单位是字符】\nvarchar的存储 varchar用于存储变长字符串,只占用必要的存储空间 列的最大长度小于255则只占用一个额外字节用于记录字符串的长度 列的最大长度大于255则只占用两个额外字节用于记录字符串的长度 varchar的适用场景 最大长度比平均长度大的多的字符串列 很少被更新的字符串列 使用了多字节字符集存储的字符串 char的存储 定长存储 字符串存储再char类型的列中会自动删除末尾的空格 最大宽度255 char的适用场景 存储长度近似的字符串 长度较短的字符串 经常被更新的字符串列 日期类型\ndatetime类型\n\t以yyyy-mm-dd hh:mm:ss[.fraction]格式存储日期时间\ndatetime= yyyy-mm-dd hh:mm:ss\ndatetime(6) = yyyy-mm-dd hh:mm:ss[.fraction]\ndatetime类型与时区无关,占用8个字节的存储空间\ntimestamp类型\n\t存储了由格林尼治时间1970年1月1日到当前时间的秒数,以yyyy-mm-dd hh:mm:ss[.fraction]显示\n类型显示依赖所指定的时区,占用4个字节 行数据修改时可自动修改timestamp列的值 date类型和time类型\ndate类型只占用3个字节、并且可以使用日期函数进行计算 time类型用于存储时间类型,格式为hh:mm:ss 不要使用字符串类型来存储日期时间数据\n分区表的使用 \t分区是将一个表的数据按照某种方式,比如按照时间上的月份,分成多个较小的,更容易管理的部分,但是逻辑上仍是一个表(物理已经被拆分)。\n分区表的限制因素\n一个表最多只能有1024个分区\n如果分区字段中有主键或者唯一索引的列,那么主键列和唯一索引列都必须包含它。即:分区字段要么不包含主键或者唯一索引列,要么包含全部主键和唯一索引列\n分区表中无法使用外键约束\n分区表物理是分区的,但逻辑上是一个表。如果分区表没有主键和唯一索引,则不需要判断键重复。如果分区表存在主键或者唯一索引而分区字段不是它,则需要判断别的分区是否存在键冲突,mysql不支持。\n分区类型\n(1)range分区:基于属于一个给定连续区间的列值,把多行分配给分区。\n(2)list分区:类似于按range分区,区别在于list分区是基于列值匹配一个离散值集合中的某个值来进行选择。\n(3)hash分区:基于用户定义的表达式的返回值来进行选择的分区,该表达式使用将要插入到表中的这些行的列值进行计算。这个函数可以包含mysql 中有效的、产生非负整数值的任何表达式。\n(4)key分区:类似于按hash分区,区别在于key分区只支持计算一列或多列,且mysql服务器提供其自身的哈希函数。必须有一列或多列包含整数值。\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 -- 数字范围分区 create table employees( id int primary key, fname varchar(30), lname varchar(30), hired date not null, entrydate date not null ) engine=innodb charset=utf8 partition by range(id)(\t-- 分区字段为主键没问题 partition p0 values less than (1000), partition p1 values less than (2000), partition p2 values less than (3000), partition p3 values less than (4000), partition p4 values less than maxvalue ); -- list分区 create table employees( id int not null,\t-- 如果id为主键则存在问题 fname varchar(30), lname varchar(30), hired date not null, entry_date date not null, status smallint not null ) engine=innodb charset=utf8 partition by list (status)( partition pnotjob values in (1), -- 1:离职 partition pwilljob values in (2,3),\t-- 2:面试中,3:面试通过待入职 partition ponjob values in (4,5), -- 4:合同工,5:临时工 partition phelpjob values in (6)\t-- 6:兼职 ); -- hash分区 create table employees( id int not null, fname varchar(30), lname varchar(30), hired date not null, entry_date date not null, status smallint not null ) engine=innodb charset=utf8 partition by hash(year(entry_date)) partitions 4; -- key分区不能在使用year等函数,会报错 create table employees( id int not null, fname varchar(30), lname varchar(30), hired date not null, entry_date date not null, status smallint not null ) engine=innodb charset=utf8 partition by key(entry_date) partitions 4; 八、主从模式 mysql二进制日志 \t记录了所有mysql数据库的修改成功的事件(包括增删改事件和对表结构的修改时间)\n开启二进制日志\n1 2 3 [mysqld] server-id=1\t#每台机器server-id均要不同 log-bin=mysql-bin\t#二进制日志的名称前缀 查看二进制日志\n1 2 3 4 # 查看段格式复制 mysqlbinlog -vv mysql-bin.000001 # 查看行格式复制 mysqlbinlog mysql-bin.000001 二级制日志格式\n基于段的格式binlog_format=statement【5.7之前默认使用】就是记录增删改的sql语句\n优点:日志记录量相对较小,节约磁盘/网络io【如果是只对一条记录修改或插入row格式的日志量更小】\n缺点:对uuid()类似不确定结果的函数从服务器在执行时会造成主从数据不一致\n基于行的格式binlog_format=row【5.7之后默认使用】记录了每一行的数据修改\n优点:\n ①更加安全的主从复制,不用再次执行sql减少不确定性。\n ②每行复制更快。\n ③误操作而修改数据时可通过二级制日志分析逆向还原\n缺点:大规模修改产生的日志量大,磁盘和网络负载大\n可调节参数\nbinlog_row_image full 全量记录每条数据修改【默认】 minimal 只记录修改的列【建议】 noblob 类似全量记录,但是如果text或者blob字段列未修改则不记录这些字段 混合的格式binlog_format=mixed\n特点:根据情况使用statement和row格式,row在statement不能记录的情况下记录\n二进制日志对复制的影响\n基于sql语句的复制(sbr)【二进制日志使用的是statement格式,5.1.4之前只有中】 优点\n生成日志量少,节约磁盘/网络io 并不强制要求主从数据库的表定义完全相同【列顺序不同,或者字段类型兼容】 比基于行的复制方式更为灵活 缺点\n非确定性事件无法保证主从数据复制的一致【例如uuid()】数据不一致导致主从复制中断\n对于存储过程,触发器,自定义函数进行修改也可能造成主从数据不一致\n基于行的复制(rbr)【二进制日志使用的是row格式】\n优点\n可以应用任何sql的复制包括非确定函数,存储过程等 可以减少从服务器上锁的使用 缺点\n要求主从数据库的表结构完全相同,否则可能会中断主从复制【从末尾加列没问题】 无法在从服务器上单独执行触发器 混合模式【根据实际内容在以上两者之间转换】\nmysql的复制工作方式 复制工作原理 (1) master将改变记录到二进制日志(binary log)\n(2) slave将master的binary log拷贝到它的中继日志(relay log)\n\t从读取中继日志的位置不同又分为:基于日志的复制、基于gtid的复制\n(3) slave重做中继日志中的事件,将改变反映它自己的数据\n\t基于段的日志是在从库上重新执行记录的sql\n\t基于行的日志是在从库上直接应用对数据库的修改\n当主从复制配置完成后,各复制线程启动顺序\n① 从库上启动复制,在从库上创建i/o线程,i/o线程连接到主库\n② 主库创建binlog dump线程读取数据库事件并发送给io线程\n③ 从库上的i/o线程接收到事件数据,将事件数据更新到中继日志(relay log)中\n④ 从库上sql线程读取中继日志中更新的事件数据并应用到从库上。\nmysql主从搭建 基于日志点复制 主机创建授权账号 1 2 3 # 在主服务器上执行,创建复制账号,并授予权限 create user \u0026#39;[username]\u0026#39;@\u0026#39;[ip]\u0026#39; identified by \u0026#39;[password]\u0026#39; grant replication slave on *.* to \u0026#39;[username]\u0026#39;@\u0026#39;[ip]\u0026#39; 主机服务器配置 1 2 3 4 # 每台mysql要求不同 server-id=1 # 二进制日志开启,如果有条件的话建议单独指定存放在另一个磁盘下,不和数据文件存放一起 log-bin=mysql-bin 从机配置 1 2 3 4 5 6 7 8 9 10 11 12 13 # 每台mysql要求不同 server-id=101 # 二进制日志开启,如果有条件的话建议单独指定存放在另一个磁盘下,不和数据文件存放一起 log-bin=mysql-bin # 中继日志开启,避免默认条件下使用主机名命名,如果修改主机名可能会产生错误 relay-log=mysql-relay-bin # 可选配置,是否将中继日志的内容重新记录到从机二进制日志中 # 当这台从机做另一个从机的主机形成链路复制时,此选项必须打开 log-slave-updates=on # 可选配置,除了supper用户以外没有用户有写权限,建议从服务启用 read-only=on 初始化从数据库数据 1 2 3 4 5 6 7 8 9 10 11 12 13 14 #################################mysqldump备份######################################## # 备份myisam的存储引擎需要加入【--lock-all-tables】 # mysqldump备份会进行锁表操作 # --triggers备份触发器、--routines备份存储过程 # --master-data: # 1[默认]:将dump起始(change master to)binlog点和pos值写到结果中 # 2:是将change master to写到结果中并注释 mysqldump --single-transaction --master-data=2 --triggers --routines --all-databases -u[user] -p \u0026gt;all.sql; # 将备份sql导入未初始化的从服务器 mysql -uroot -p\u0026lt;all.sql #################################xtrabackup备份####################################### # 参见pxc集群部分 启动复制链路 1 2 3 4 5 6 7 8 9 # 修改master信息 # 在备份文件中有[mysql-bin-file]和[log_offset] change master to master_host=\u0026#39;[ip]\u0026#39;, master_user=\u0026#39;[user]\u0026#39;, master_password=\u0026#39;[password]\u0026#39;, master_log_file=\u0026#39;[mysql-bin-file]\u0026#39;, master_log_pos=[log_offset]; # 查看从机slave状态是否有误 show slave status # 启动从机复制 start slave 基于日志点复制的优点\nmysql最早支持的复制技术,bug较少 对sql查询没有任何限制【row格式下所有sql无限制】 故障处理容易 基于日志点复制的缺点\n故障转移时重新获取新主的日志点信息比较难 基于gtid的复制 \tgtid是从mysql5.6版本才引入,使用基于日志点的复制要指定从二进制日志哪个位置进行增量同步,如果指定错误将会造成数据遗漏或者数据重复。基于gtid的复制会记录从库执行的事务gtid值,自动执行从库未执行的gtid值的事务,保证了同一个事务只会在从库中执行一次。【gtid:全局事务id,保证每一个提交的事务在复制集群中可以产生一个唯一的id】\n\tgtid=source_id:transaction_id【source_id:auto.cnf中,transaction_id从一自增】\n主机创建授权账号 1 2 3 # 在主服务器上执行,创建复制账号,并授予权限 create user \u0026#39;[username]\u0026#39;@\u0026#39;[ip]\u0026#39; identified by \u0026#39;[password]\u0026#39; grant replication slave on *.* to \u0026#39;[username]\u0026#39;@\u0026#39;[ip]\u0026#39; 主机服务器配置 1 2 3 4 5 6 7 8 9 10 11 12 13 # 每台mysql要求不同 server-id=1 # 二进制日志开启,如果有条件的话建议单独指定存放在另一个磁盘下,不和数据文件存放一起 log-bin=mysql-bin # 开启gtid模式,会记录gtid的标识符 gtid-mode=on # 强制gtid一致性,保证事务的安全 # 不能使用: # 1.create table 。。select # 2.在事务中使用create temporary table 建立临时表,使用关联更新事务表和非事务表。 enforce-gtid-consistency=on # mysql5.7之前必须配置 log-slave-updates=on 从机配置 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 # 每台mysql要求不同 server-id=101 # 二进制日志开启,如果有条件的话建议单独指定存放在另一个磁盘下,不和数据文件存放一起 log-bin=mysql-bin # 中继日志开启,避免默认条件下使用主机名命名,如果修改主机名可能会产生错误 relay-log=mysql-relay-bin # 开启gtid模式,会记录gtid的标识符 gtid-mode=on # 强制gtid一致性,保证事务的安全 # 不能使用: # 1.create table 。。select # 2.在事务中使用create temporary table 建立临时表,使用关联更新事务表和非事务表。 enforce-gtid-consistency=on # 可选配置,是否将中继日志的内容重新记录到从机二进制日志中 # 当这台从机做另一个从机的主机形成链路复制时,此选项必须打开 # mysql5.7之前必须配置 log-slave-updates=on # 可选配置,除了supper用户以外没有用户有写权限,建议从服务启用 read-only=on # 主服务的相关信息,默认存储在文件中,建议开启,开启存储在salve_master_info表[innodb]中 master-info-repository=table # 中继日志的相关信息,默认存储在文件中,建议开启,开启存储在salve_relay_info表[innodb]中 relay-log-info-repository=table 初始化从数据库数据 1 2 3 4 5 6 7 8 9 10 11 12 13 14 #################################mysqldump备份######################################## # 备份myisam的存储引擎需要加入【--lock-all-tables】 # mysqldump备份会进行锁表操作 # --triggers备份触发器、--routines备份存储过程 # --master-data: # 1[默认]:将dump起始(change master to)binlog点和pos值写到结果中 # 2:是将change master to写到结果中并注释 mysqldump --single-transaction --master-data=2 --triggers --routines --all-databases -u[user] -p \u0026gt;all.sql; # 将备份sql导入未初始化的从服务器 mysql -uroot -p\u0026lt;all.sql #################################xtrabackup备份####################################### # 参见pxc集群部分 启动复制链路 1 2 3 4 5 6 7 8 9 # 修改master信息 # master_auto_position=1表示开启基于gtid的复制协议 change master to master_host=\u0026#39;[ip]\u0026#39;, master_user=\u0026#39;[user]\u0026#39;, master_password=\u0026#39;[password]\u0026#39;, master_auto_position=1; # 查看从机slave状态是否有误 show slave status\\g; # 启动从机复制 start slave; 基于gtid复制的优点\n故障转移方便,根据gtid值即可判断 从库不会丢失主库上的任何更改 基于日志点复制的缺点\n故障处理复杂\n对sql查询有限制\n选择复制模式是需要考虑所使用的mysql的版本以及复制架构及主从切换方式和高可用管理组件是否支持\nmysql的复制拓扑 mysql5.7之前一个从库只能有一个主库\n一主多从\u0026amp;一主一从\n这种架构下配置简单,可以用多个从库分担主库读负载\n双主复制\n如果只有一个主对外提供服务成为主备复制模式:在同一时间只有一台服务器提供服务,另一台为read_only。当提供服务的mysql需要下线,可将从机切换为提供服务的机器。\n如果两个主都对外提供服务成为主主复制模式:不是很好的结构,容易产生冲突。用于两个地区需要保存同样数据。建议两个主不要操作相同的数据库,而且需要设置auto_increment = 2和auto_increment_offset = 1 | 2\n拥有备库的主主复制\n增加从库分担主库的读负载,当一台主库下线时需要将其以它为master的从库下线\n级联复制\n复制性能优化 主库执行事务的时间【从库也需要较长时间执行,导致延迟】\n建议拆分大事务\n二进制日志传输时间【异地机房网络延迟】\n建议使用混合日志格式(mixed)或设置binlog_row_image=minimal\n默认情况下从库只有一个sql线程,变成了串行执行\n建议开启多线程复制(mysql5.6中性能并不会,5.7中引入了逻辑时钟来控制线程效果较好)\n1 2 3 4 5 6 7 8 # 以下配置最好写入my.conf stop slave; set global slave_parallel_type=\u0026#39;logical_clock\u0026#39;; set global slave_parallel_workers=4; start slave; ####################################写入配置文件##################################### slave-parallel-type=logical_clock slave-parallel-workers=4 半同步复制 \tmysql 5.5版本之前,一直采用的是这种异步复制的方式。主库的事务执行不会管备库的同步进度,如果备库落后,主库不幸宕机,那么就会导致数据丢失。于是在mysql在5.5中就引入了半同步复制( after_commit ),主库在应答客户端提交的事务前需要保证至少一个从库接收并写到relay log中。 mysql5.7对半同步复制进行改进支持无损复制( after_sync )。\n半同步复制\n\t半同步复制介于异步复制和全同步复制之间,主库在执行完客户端提交的事务后不是立刻返回给客户端,而是等待至少一个从库接收到并写到relay log中才返回给客户端。 由于master是在三段提交的最后commit阶段完成后才等待,所以master的其他session是可以看到这个提交事务的,所以这时候master上的数据和slave不一致,master宕机后,slave数据丢失。\n无损复制(增强版的半同步复制)\n\t在半同步复制中,master写数据到binlog且sync,然后一直等待ack。当至少一个slave request bilog后写入到relay‐log并flush disk,从机返回ack,主库提交事务。会阻塞master session, 由于是在三段提交的第二阶段sync binlog 完成后才等待, 所以master的其他session是看不见这个提交事务的,所以这时候master上的数据和slave 一致,master宕机后,slave没有丢失数据。\n开启半同步复制\n主库从库都需要进行一下配置\n①mysql会话中执行install plugin rpl_semi_sync_master soname 'semisync_master.so'; 安装半同步复制组件\n② 看一下半同步相关状态信息show global variables like '%semi%'\n1 2 3 4 # 开启半同步 rpl_semi_sync_master_enabled = 1 # 控制等待来自从服务器的确认提交并恢复到异步复制的时间(毫秒),超时之后,就从半同步复制,返回到异步复制 rpl_semi_sync_master_timeout = 1000 ③ mysql5.5~5.6只支持after_commit,mysql5.7默认开启的半同步策略是after_sync\n延迟复制 \t建立主从之后或者关闭salve之后,再设置chang master to master_delay = [秒]语句,之后启动slave节点即可,延迟同步主要用于数据库数据恢复。\n恢复步骤\n第一步:从节点数据准备\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 # 主节点执行 show master logs; # 查找执行误删除的sql,logfilename为上条sql查询到的日志,在结果中查找事务gtid show binlog events in \u0026#34;logfilename\u0026#34;; # 从节点执行 stop slave; set gtid_next=\u0026#39;查找到的事务gtid\u0026#39;; # 这个gtid事务什么都不执行 begin;commit; # 其余自动执行 set gtid_next=\u0026#39;automatic\u0026#39;; # 不在延迟。立即同步主节点所有数据 change master to master_delay=0; # 启动slave start slave; 第二步:停掉数据库业务操作,不允许再读写数据\n第三步:导出从数据库节点数据,在主节点上创建临时数据库,导入数据到临时库\n第四步:将主节点上的业务数据表重命名,然后把临时业务库的数据表迁移到业务库\n九、高可用架构 mmm(multi-master replication manager) \t监控和管理mysql的基于日志点的主主复制拓扑,并在当前的主服务器失效时,进行主备服务器之间的主从切换和故障转移,当主库出现宕机时进行故障转义并自动配置其它从库对新主的复制。可参考官网\n部署mmm所需资源\n资源名称 数量 说明 主db服务器 2 用于主主复制配置 从db服务器 0-n 配置从服务器用于分担读操作 监控服务器 1 用于监控mysql的复制 监控用户 1 用于监控mysql的状态的mysql用户(replication client) 代理用户 1 用于mmm代理的mysql用户(super,replication client,process) 复制用户 1 用于配置mysql复制的mysql用户(replication slave) 第一步:mmm工具安装\n安装epel 1 2 # centos 7 安装perl yum install https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm 监控节点安装监控 1 yum install -y mysql-mmm-monitor.noarch 主服务器和从服务器均安装代理 1 yum install -y mysql-mmm-agent.noarch 第二步:mysql主主搭建\n配置 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 ###############################两台主服务器配置############################### # 每台mysql要求不同 server-id=1 # 二进制日志开启,如果有条件的话建议单独指定存放在另一个磁盘下,不和数据文件存放一起 log-bin=mysql-bin # 中继日志开启,避免默认条件下使用主机名命名,如果修改主机名可能会产生错误 relay-log=mysql-relay-bin # 当这台从机做另一个从机的主机形成链路复制时,此选项必须打开 log-slave-updates=on ###############################从机服务器配置############################### # 每台mysql要求不同 server-id=101 # 二进制日志开启,如果有条件的话建议单独指定存放在另一个磁盘下,不和数据文件存放一起 log-bin=mysql-bin # 中继日志开启,避免默认条件下使用主机名命名,如果修改主机名可能会产生错误 relay-log=mysql-relay-bin # 可选配置,是否将中继日志的内容重新记录到从机二进制日志中 # 当这台从机做另一个从机的主机形成链路复制时,此选项必须打开 log-slave-updates=on # 可选配置,除了supper用户以外没有用户有写权限,建议从服务启用 read-only=on 备份具有数据的主机服务器,并导入到其它机器\n建立主从关系\n第三步:配置mmm\n建立账号 1 2 3 4 5 6 7 ##########################只需在一个主节点执行,因为集群已经搭建完成########################## # 监控用户用于用于监控节点 grant replication client on *.* to \u0026#39;mmm_monitor\u0026#39;@\u0026#39;192.168.1.%\u0026#39; identified by \u0026#39;123456\u0026#39;; # 代理用户用于故障转义和主从切换 grant super, replication client, process on *.* to \u0026#39;mmm_agent\u0026#39;@\u0026#39;192.168.1.%\u0026#39; identified by \u0026#39;123456\u0026#39;; # 复制用户,在搭建集群时以及建立不需再执行 # create user \u0026#39;[username]\u0026#39;@\u0026#39;[ip]\u0026#39; identified by \u0026#39;[password]\u0026#39; grant replication slave on *.* to \u0026#39;[username]\u0026#39;@\u0026#39;[ip]\u0026#39; 配置mmm_common【每台机器都一样】 active_master_role writer \u0026lt;host default\u0026gt; cluster_interface eth0 #使用ifconfig或者ip addr查看网卡替换掉 pid_path /run/mysql-mmm-agent.pid bin_path /usr/libexec/mysql-mmm/ replication_user replicant #复制用户的账号\treplication_password slave #复制用户的密码 agent_user mmm_agent #代理用户的账号 agent_password repagent #代理用户的密码 \u0026lt;/host\u0026gt; \u0026lt;host db1\u0026gt; #第一个主节点的信息 ip 192.168.100.49 mode master peer db2 #标识和它为主主架构的另一台主机 \u0026lt;/host\u0026gt; \u0026lt;host db2\u0026gt; ip 192.168.100.50 #第二个主节点的信息 mode master peer db1 #标识和它为主主架构的另一台主机 \u0026lt;/host\u0026gt; #\u0026lt;host db3\u0026gt; #从节点的信息,有从节点需要配置 # ip 192.168.100.51 # mode slave #\u0026lt;/host\u0026gt; \u0026lt;role writer\u0026gt;\t#能进行写操作的节点(主节点),虚ip一个就够 hosts db1, db2 ips 192.168.100.250 mode exclusive \u0026lt;/role\u0026gt; \u0026lt;role reader\u0026gt; #能进行读操作的节点,虚ip等于或者少于读节点个数 hosts db1, db2 ips 192.168.100.251, 192.168.100.252 mode balanced \u0026lt;/role\u0026gt; 配置mmm_agent【每台机器不一样】 include mmm_common.conf # the \u0026#39;this\u0026#39; variable refers to this server. proper operation requires # that \u0026#39;this\u0026#39; server (db1 by default), as well as all other servers, have the # proper ip addresses set in mmm_common.conf. this db1\t#改成mmm_common所对应的db 配置监控节点的mmm_common.conf include mmm_common.conf \u0026lt;monitor\u0026gt; ip 127.0.0.1 #监控服务器的ip地址 pid_path /run/mysql-mmm-monitor.pid bin_path /usr/libexec/mysql-mmm status_path /var/lib/mysql-mmm/mmm_mond.status ping_ips 192.168.100.50 #所有服务器的ip都配上,最好网关也配上,预防脑裂的发生\tauto_set_online 60 # the kill_host_bin does not exist by default, though the monitor will # throw a warning about it missing. see the section 5.10 \u0026#34;kill host # functionality\u0026#34; in the pdf documentation. # 如果mysql服务器出现问题需要关机可以执行脚本 # kill_host_bin /usr/libexec/mysql-mmm/monitor/kill_host # \u0026lt;/monitor\u0026gt; \u0026lt;host default\u0026gt; #监控账户的账号密码 monitor_user mmm_monitor monitor_password repmonitor \u0026lt;/host\u0026gt; debug 0 第四步:启动mmm\n每个mysql节点执行 mmm_agentd start\n监控节点执行mmm_mond start\n第五步:查看状态\n监控节点执行mmm_control show\nmmm架构的优点\n使用perl脚本语言开发并且完全开源 提供了读写虚拟ip,使服务器角色的变更对前端应用更加透明 提供了延迟监控,在从服务器出现延迟或终端情况下可以把虚拟ip漂移到其它正常的服务器上 主数据库故障转移后服务器对新主的重新同步功能 发生故障的主服务器很容易重新上线 mmm架构的缺点\n发布时间早不支持mysql的gtid复制 mysql5.6之后的多线程复制不支持 提供了延迟监控,但多线程复制不支持,在写并发大的情况下可能发生所有读vip都偏移到主服务器上 在进行主从切换,容易造成数据丢失(直接将主主服务器中的备机提升,但备机存在延迟不一定时最新的数据,从数据库也切换此机器为主机,容易事务多次执行) mmm监控服务存在单点故障 没有提供多个从服务器的读负载均衡功能 mha(master high availability) \t现项目地址在github上是由perl脚本开发,更关注mysql主从架构下的主db【只监控主db】,当主db不可用时,从多个从服务器中选举出数据最新的从数据库作为主服务器,并提供了主从切换的故障转移。并且mha支持gtid复制模式\n第一步:mysql主主搭建\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 #####################################主服务器配置##################################### # 每台mysql要求不同 server-id=1 # 二进制日志开启,如果有条件的话建议单独指定存放在另一个磁盘下,不和数据文件存放一起 log-bin=mysql-bin # 开启gtid模式,会记录gtid的标识符 gtid-mode=on # 强制gtid一致性,保证事务的安全 # 不能使用: # 1.create table 。。select # 2.在事务中使用create temporary table 建立临时表,使用关联更新事务表和非事务表。 enforce-gtid-consistency=on log-slave-updates=on relay-log=mysql-relay-bin #####################################从服务器配置##################################### # 每台从mysql要求不同 server-id=101 # 二进制日志开启,如果有条件的话建议单独指定存放在另一个磁盘下,不和数据文件存放一起 log-bin=mysql-bin # 中继日志开启,避免默认条件下使用主机名命名,如果修改主机名可能会产生错误 relay-log=mysql-relay-bin # 开启gtid模式,会记录gtid的标识符 gtid-mode=on # 强制gtid一致性,保证事务的安全 # 不能使用: # 1.create table 。。select # 2.在事务中使用create temporary table 建立临时表,使用关联更新事务表和非事务表。 enforce-gtid-consistency=on # 从服务器多线程执行sql slave-parallel-type=logical_clock slave-parallel-workers=4 log-slave-updates=on read-only=on # 主服务的相关信息,默认存储在文件中,建议开启,开启存储在salve_master_info表[innodb]中 master-info-repository=table # 中继日志的相关信息,默认存储在文件中,建议开启,开启存储在salve_relay_info表[innodb]中 relay-log-info-repository=table 备份具有数据的主机服务器,并导入到其它机器 建立主从关系 第二步:安装epel\n1 2 # centos 7 安装perl yum install https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm 第三步:配置集群内所有主机相互ssh免认证登陆【用于保存原主服务器的二进制日志,虚拟ip】\n1 2 3 4 5 6 # 一直回车就行 ssh-keygen # 拷贝ssh证书 ssh-copy-id -i /root/.ssh/id_rsa 用户名@ip地址 # 测试是否成功 ssh 用户名@ip地址 第四步:安装mha【centos安装el6包】\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 #################################所有mysql服务节点################################# # 安装依赖 yum install perl-dbd-mysql # 安装node节点 rpm -ivh mha4mysql-node-x.y-n.noarch.rpm #####################################监控节点##################################### yum install perl-dbd-mysql yum install perl-config-tiny yum install perl-log-dispatch yum install perl-parallel-forkmanager # 监控节点也需要安装node rpm -ivh mha4mysql-node-x.y-n.noarch.rpm # 安装监控 rpm -ivh mha4mysql-manager-x.y-n.noarch.rpm 第五步:配置mha\n创建mha的监控节点配置文件【/etc/masterha_default.cnf】,配置官网有示例。监控节点不能和mysql节点放一起 [server default] # 具有所有权限的用户,最好是建立一个mha专用用户对专属网段开放 user=用户名 password=密码 # manager【监控】节点的工作目录 manager_workdir=/home/mysql_mha # manager【监控】节点的日志路径 manager_log=/home/mysql_mha/manager.log # 远程node节点的工作目录,需要在所有node节点手动创建 remote_workdir=/home/mysql_mha # 配置的ssh用户,manager需要用此用户启动 ssh_user=用户名 # 主服务器具有复制权限用户 repl_user=用户名 repl_password=密码 # master主机ping的检查时间 ping_interval=1 # master主机的二进制目录【所有从节点的也应该一样】 master_binlog_dir=/var/lib/mysql # master节点宕机进行虚拟ip漂移的脚本【mha本身不具有虚拟ip漂移功能,脚本可以githhub找到示例】 master_ip_failover_script=/script/masterha/master_ip_failover # master宕机的处理脚本,脚本可以githhub找到示例 # shutdown_script= /script/masterha/power_manager # 主从切换的通知管理员脚本,脚本可以githhub找到示例 # report_script= /script/masterha/send_master_failover_mail # 用于检查master是否可以ping通,避免manager节点自己ping不同,但从节点可以而造成master不可用假象 secondary_check_script=masterha_secondary_check -s remote_host1 -s remote_host2 # 服务器配置,主从关系mha会自动识别,不需要指明 # candidate_master=1 代表可以作为master的候选机器 # no_master=1 代表不作为master的候选机器 [server1] hostname=host1 candidate_master=1 [server2] hostname=host2 candidate_master=1 [server3] hostname=host3 no_master=1 master_ip_failover脚本 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 #!/usr/bin/env perl # copyright (c) 2011 dena co.,ltd. # you should have received a copy of the gnu general public license # along with this program; if not, write to the free software # foundation, inc., # 51 franklin street, fifth floor, boston, ma 02110-1301 usa ## note: this is a sample script and is not complete. modify the script based on your environment. use strict; use warnings fatal =\u0026gt; \u0026#39;all\u0026#39;; use getopt::long; use mha::dbhelper; my ( $command, $ssh_user, $orig_master_host, $orig_master_ip, $orig_master_port, $new_master_host, $new_master_ip, $new_master_port, $new_master_user, $new_master_password ); # 配置虚拟vip my $vip = \u0026#39;192.168.152.159/24\u0026#39;; # vip的网卡key my $key = \u0026#39;1\u0026#39;; # 注意修改网卡为本机使用的网卡 my $ssh_start_vip = \u0026#34;/sbin/ifconfig ens33:$key $vip\u0026#34;; # 注意修改网卡为本机使用的网卡 my $ssh_stop_vip = \u0026#34;/sbin/ifconfig ens33:$key down\u0026#34;; getoptions( \u0026#39;command=s\u0026#39; =\u0026gt; \\$command, \u0026#39;ssh_user=s\u0026#39; =\u0026gt; \\$ssh_user, \u0026#39;orig_master_host=s\u0026#39; =\u0026gt; \\$orig_master_host, \u0026#39;orig_master_ip=s\u0026#39; =\u0026gt; \\$orig_master_ip, \u0026#39;orig_master_port=i\u0026#39; =\u0026gt; \\$orig_master_port, \u0026#39;new_master_host=s\u0026#39; =\u0026gt; \\$new_master_host, \u0026#39;new_master_ip=s\u0026#39; =\u0026gt; \\$new_master_ip, \u0026#39;new_master_port=i\u0026#39; =\u0026gt; \\$new_master_port, \u0026#39;new_master_user=s\u0026#39; =\u0026gt; \\$new_master_user, \u0026#39;new_master_password=s\u0026#39; =\u0026gt; \\$new_master_password, ); exit \u0026amp;main(); sub main { print \u0026#34;\\n\\nin script test====$ssh_stop_vip==$ssh_start_vip===\\n\\n\u0026#34;; if ( $command eq \u0026#34;stop\u0026#34; || $command eq \u0026#34;stopssh\u0026#34; ) { my $exit_code = 1; eval { print \u0026#34;disabling the vip on old master: $orig_master_host \\n\u0026#34;; \u0026amp;stop_vip(); $exit_code = 0; }; if ($@) { warn \u0026#34;got error: $@\\n\u0026#34;; exit $exit_code; } exit $exit_code; } elsif ( $command eq \u0026#34;start\u0026#34; ) { my $exit_code = 10; eval { print \u0026#34;enabling the vip - $vip on the new master - $new_master_host \\n\u0026#34;; \u0026amp;start_vip(); $exit_code = 0; }; if ($@) { warn $@; exit $exit_code; } exit $exit_code; } elsif ( $command eq \u0026#34;status\u0026#34; ) { print \u0026#34;checking the status of the script.. ok \\n\u0026#34;; exit 0; } else { \u0026amp;usage(); exit 1; } } sub start_vip() { `ssh $ssh_user\\@$new_master_host \\\u0026#34; $ssh_start_vip \\\u0026#34;`; } sub stop_vip() { return 0 unless ($ssh_user); `ssh $ssh_user\\@$orig_master_host \\\u0026#34; $ssh_stop_vip \\\u0026#34;`; } sub usage { print \u0026#34;usage: master_ip_failover --command=start|stop|stopssh|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port\\n\u0026#34;; } 检查配置是否正确 1 2 3 4 # 检查ssh配置,如果node和manager是同一台服务器则需要将自己的server注释掉否则报错 masterha_check_ssh --conf=/etc/masterha_default.cnf # 检测主从复制结构 masterha_check_repl --conf=/etc/masterha_default.cnf 启动 1 2 # 启动manager nohup masterha_manager --conf=/etc/masterha_default.cnf \u0026amp; 配置虚拟ip 1 2 # mha并不会主动配置虚拟ip,虚拟ip漂移脚本只在master节点挂掉时启用 ifconfig 网卡名:key 虚拟ip/子网掩码数 mmm架构的优点\n使用perl脚本语言开发并且完全开源,提供了各种脚本可以进行嵌入 支持gtid的复制 mha在进行故障转移时更不易产生数据丢失,可配合mysql半同步最大程度减少数据丢失 同一个监控节点可以监控多个集群 mmm架构的缺点\nmha必须编写脚本或利用第三方工具实现vip配置 mha只对master服务器监控 基于ssh免认证登陆,存在一定隐患 没有提供多个从服务器的读负载均衡功能 使用中间件读写分离和负载均衡 \t写操作只能在master上进行,而slave可以分担读负载所以要进行读写分离、负载均衡。使用中间件完成读写分离负载均衡比程序员实现简单,但是性能损耗较为严重。\nmysql proxy\nmysql官方提供但是一直没有正式版,现在已经改为mysql router,一直存在性能、稳定性缺陷。\nmysql router\n官方维护,mysql proxy的替代方案\nmaxscale\nmariadb开发的插件式,定制灵活,自动检测\nmaxscale的介绍\nauthentication为认证插件提供了数据库用户登陆认证功能,maxscale会读取mysql.user表信息并缓存 protocol为协议模块提供了客户端到maxscale和maxscale到后端的协议 routing为路由模块控制请求发送给后端那个数据库 monitor为监控模块目的是监控后端,使请求发送给后台服务正常的数据库 filter\u0026amp;logging为日志和过滤模块提供了数据库防火墙能改写一部分简单sql和sql容错以及日志记录 maxscale的安装\n1 yum localinstall maxscale-x.y.z.centos.r.x86_64.rpm maxscale的mysql使用账号配置\n1 2 3 4 -- 创建maxscale用于监控主从状态的账号 grant replication slave, replication client on *.* to \u0026#39;maxscale_monitor\u0026#39;@\u0026#39;%\u0026#39; identified by \u0026#39;[passowrd]\u0026#39; with grant option; -- 创建maxscale用于路由模块的账号,需要读取mysql的账号信息 grant all on *.* to \u0026#39;maxscale\u0026#39;@\u0026#39;%\u0026#39; identified by \u0026#39;[passowrd]\u0026#39; with grant option; 配置maxscale\n[maxscale] threads=auto [server1] type=server address=ip地址 port=3306 protocol=mariadbbackend [server2] type=server address=ip地址 port=3306 protocol=mariadbbackend [server3] type=server address=ip地址 port=3306 protocol=mariadbbackend [mariadb-monitor] type=monitor module=mariadbmon servers=server1 user=myuser password=mypwd monitor_interval=2000 # 如果只是负载读均衡则配置此模块,否则注释掉此模块 [read-only-service] type=service router=readconnroute servers=server1 user=myuser password=mypwd router_options=slave # 读写分离模块 [read-write-service] type=service router=readwritesplit servers=server1 user=myuser password=mypwd # 如果只是负载读均衡则配置此模块,否则注释掉此模块 [read-only-listener] type=listener service=read-only-service protocol=mariadbclient port=4008 # 读写分离使用的登陆端口 [read-write-listener] type=listener service=read-write-service protocol=mariadbclient port=4006 #监控模块默认示例文件中没有 [maxadmin-service] type=service router=cli # 监控模块使用的端口,默认示例文件中没有 [maxadmin-listener] type=listener service=maxadmin-service protocol=maxscaled port=6603 检查\u0026amp;启动\n1 2 3 4 5 6 7 8 9 10 # 创建maxscale用户用于启动 useradd maxscale # 查看maxscale配置文件是否语法正确,会打印各个文件位置默认(日志、pid等) maxscale --config-check=/etc/maxscale.cnf -u maxscale # 启动maxscale,查看日志文件是否启动成功,日志文件在 maxscale --config=/etc/maxscale.cnf -u maxscale # 进入命令台管理 maxadmin --user=admin --password=mariadb # 以下命令在进入管理台之后使用 # list servers -- 查看服务器状态,已经主从关系 十、索引优化 \tmysql的索引是由存储引擎实现的,即不同的存储引擎实现的同一种索引的方式也是存在差异的。mysql存储引擎一般支持btree索引和hash索引。\n\tmyisam和innodb存储引擎:只支持btree索引, 也就是说默认使用btree,不能够主动更换(innodb引擎可根据情况自动转换)\n\tmemory存储引擎:支持btree索引和hash索引\nmyisam中索引叶子节点记录的是存储在数据磁盘上的位置数据\ninnodb中索引(主键)叶子节点记录的是存储在数据,其它索引记录的是直向的主键索引\nbtree索引 最左前缀原则\n\t查询条件精确匹配索引的左边连续一个或几个列时,部分索引信息所以可以被用到,但是只能用到一部分,即条件所组成的最左前缀。造成的原因是btree的结构导致。\n匹配列前缀原则\n\t使用like 'value%'方法使用列前缀匹配\n精确匹配左前列并范围匹配令一列\n\t使用a = 1 and b= 2 and c\u0026gt;10 and d = 5,建立了索引(a,b,c,d),只会用到a、b、c三列\n前缀索引建立\n\t在字符串上建立前缀索引create index index_name on table(col_name(n));\nbtree的限制\n如果不是按照索引最左边列开始查找,则无法使用索引\n使用索引时不能跳过索引中的列\n查询条件中含有函数或表达式\n如select ... from product where to_day(out_day) - to_day(current_data) \u0026lt;= 30用不上索引\n改为select ... from product where out_day \u0026lt;= data_add(current_day, interval 30 day)\n覆盖索引\n\t覆盖索引是select的数据列只用从索引中就能够取得,不必读取数据行,换句话说查询列要被所建的索引覆盖\n\t①优化缓存、减少磁盘io操作\n\t②减少随机io,变随机io操作为顺序io操作\n\t③san避免innodb索引列查找主键列的io消耗\n\t④避免myisam表进行系统调用\n使用索引优化排序的限制\n\t①索引的列顺序和order by子句的顺序完全一致\n\t②索引中所有列的方向(升序、降序)和order by子句完全一致\n\t③order by中的字段全部在关联表中的第一张表中\nhash索引 hash索引的限制\nhash索引必须进行二次查找\nhash索引无法用于排序\nhash索引不支持部分索引查找也不支持范围查找\nhash索引中hash码计算可能存在hash冲突\n使用索引的优点 大大减少了存储引擎需要扫描的数据量 帮助进行排序以避免使用临时表 进行事务操作时,避免全表扫描锁定全表(间隙锁) 查找冲突不必要的索引 安装percona-toolkit\n使用pt-duplicate-key-checker --host='[host ]'--user='[user]' --password='[password]' --databases='[database]'查看重复定义的索引\n查看从未使用的索引 1 2 3 4 5 6 7 8 9 select object_schema, object_name, index_name from performance_schema.table_io_waits_summary_by_index_usage where index_name is not null and count_star = 0 and object_schema \u0026lt;\u0026gt; \u0026#39;mysql\u0026#39; order by object_schema,object_name; 更新索引统计信息\u0026amp;减少索引碎片化 1 2 3 4 5 6 #myisam会将统计信息记录在磁盘中,会全表扫描 #innodb不在磁盘存储,更具随机访问存储在内存中,统计结果并非十分准确 analyze table tablename;\t#更新索引统计信息 #不论什么存储引擎均会锁表 optimize table tablename;\t#优化索引,维护索引 十一、sql优化 获取存在性能问题的sql 慢查询日志 \tmysql的慢查询日志是一种开销比较低的获取存在性能问题的sql的一种方法,开销主要在磁盘io和存储日志文件所需要的磁盘空间。建议日志文件(包括二进制日志文件等)和数据文件目录分开,最好分盘存放。慢查询日志记录了所有符合条件的语句包含查询语句、数据修改语句、已回滚的sql\n1 2 3 4 5 6 7 8 # 在运行的系统中可以使用 set global slow-query-log=on slow-query-log=on # 指定慢查询日志的文件名/存储路径 slow-query-log-file=mysql-slow.log # 设置慢查询日志记录的阙值,单位秒,0.02代表20毫秒。默认10 long-query-time=0.02 # 记录未使用索引的sql,不管这个查询是否超过阙值 log-queries-not-using-indexes=on 慢查询日志原始文件示例,慢查询文件内容一般较多,直接查看无法查看出具体信息,无法归类。\n使用mysql自带的慢查询日志查看工具mysqldumpslow查看慢查询日志\n常用mysqldumpslow -s r -t 10 mysql-slow.log查看查询结果\n-s order代表排序方式r代表时间 -t topnum代表取出前topnum条数据 使用更加强大的pt-query-digest分析慢查询日志\n常用pt-query-digest --explain h=[host], u=[user], p=[password] mysql-slow.log查看查询结果\n实时获取性能问题 利有infomation_schema数据库中的processlist表查询当前执行的sql状态信息\n1 select id, `user`, `host`, db, command, `time`, state, info from information_schema.processlist where time \u0026gt;= [time] 预处理及生成执行计划 查询缓存\n根据mysql处理sql请求的大致流程解析可以知道查询缓存对sql性能是有影响的,查询缓存是对查询语句做hash算法然后存储的,所以想命中缓存的第一个必要条件是语句必须一样。\n查询命中不容易 如果缓存数据的设计的原始表发生改变这个缓存也需要刷新 检查是否命中时会对缓存加锁 对于一个读写频繁的系统很可能会降低查询处理的效率,所以建议关闭查询缓存\n1 2 3 4 5 6 7 8 # 0时表示关闭,1时表示打开,2表示只要select 中明确指定sql_cache才缓存 query-cache-type=0 # 用于查询缓存的内存大小,单位字节必须是1024的整数倍 query-cache-size=[size] # 表示单个结果集所被允许缓存的最大值 query-cache-limit=[size] # 每个被缓存的结果集要占用的最小内存 query_cache_min_res_unit=[size] 执行计划生成\n执行计划生成阶段包含了解析sql、预处理、优化执行计划\n解析sql:通过关键字对语法进行解析,并生成一颗对应的语法解析树\n预处理:检查解析树是否合法,比如表和数据列是否存在,名字或者别名是否存在歧义\n优化执行计划:利有查询优化器优化查询\n查询优化器做的工作\n重新定义表的关联顺序\n将能转化为内连接的外连接转换为内连接如select * from a left join b on a.id=b.id where b.id=2;\n优化count()【myisam保存的行数】、max()、min()\n尝试将一个表达式转换为常数\n使用等价变换原则(索引覆盖)\n子查询优化(尝试将子查询转为关联查询)\n提前终止查询(发现一个必定不满足的条件,比如无符号类型小于0)\n对in()条件优化(对in中条件进行排序,再利用二分查找法查询)\n查询优化器优化错误的原因\n统计信息不准确(innodb是抽样统计)\n执行计划中的成本估算并不等于实际执行的成本\nmysql不会考虑其它并发查询(锁)\n有时也会基于一定规则来进行优化(存在全文索引就首先采用全文索引)\n不考虑不受其控制的成本(存储过程、用户自定义函数等)\n确定查询处理各个阶段消耗的时间 使用profile\n1 2 3 4 5 6 7 8 9 # 启动profile,这是一个session级的配置 set profiling= 1; # 执行查询。。。。 # 执行查询。。。。 # 执行查询。。。。 # 查看每一个查询消耗的总时间信息 show profiles; # 查看各个阶段所消耗的时间信息,n为上个命令返回的id值 show profile for query n; 产生警告的原因是mysql将在以后版本移除出profile,使用performance_schema\n使用performance_schema\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 #设置开启 update performance_schema.setup_instruments set enabled = \u0026#39;yes\u0026#39;, timed=\u0026#39;yes\u0026#39; where name like \u0026#39;stage%\u0026#39;; update performance_schema.setup_consumers set enabled = \u0026#39;yes\u0026#39; where name like \u0026#39;events%\u0026#39;; #进行查询 select events_statements_history_long.thread_id, sql_text, events_stages_history_long.event_name, ( events_stages_history_long.timer_end - events_stages_history_long.timer_start ) / 1000000000 as \u0026#39;duration(ms)\u0026#39; from events_statements_history_long join threads on events_statements_history_long.thread_id = threads.thread_id join events_stages_history_long on events_stages_history_long.thread_id = threads.thread_id and events_stages_history_long.event_id between events_statements_history_long.event_id and events_statements_history_long.end_event_id where threads.processlist_id = connection_id( ) and events_statements_history_long.event_name = \u0026#39;statement/sql/select\u0026#39; order by events_statements_history_long.thread_id, events_stages_history_long.event_id 修改大表结构 1 2 3 pt-online-schema-change --alter=\u0026#39;[modify filed varchar(32) not null ...]\u0026#39; \\ --user=[user] --password=[password] \\ d=\u0026#39;[dbname]\u0026#39;,t=\u0026#39;[tablename]\u0026#39; --charset=utf8 --execute 此工具的处理过程\n创建触发器(避免丢失新增和修改数据) 创建新的临时表 copy数据 旧表加排他锁 重命名表 接触锁 删除旧表 删除触发器 十二、分库分表 参见mycat部分\nmycat用于读写分离、分库分表等功能\n十三、部分概念 锁的概念 \t数据库锁定机制简单来说就是数据库为了保证数据的一致性而使各种共享资源在被并发访问访问变得有序所设计的一种规则。\n按照锁定级别分类可分为\n行级锁(row-level)【mysql存储引擎实现】\n行级锁是mysql中锁定粒度最细的一种锁,表示只针对当前操作的行进行加锁。行级锁能大大减少数据库操作的冲突。其加锁粒度最小,但加锁的开销也最大。行级锁分为共享锁和排他锁。\n开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高。\n表级锁(table-level)【mysql服务实现】\n表级锁是mysql中锁定粒度最大的一种锁,表示对当前操作的整张表加锁,它实现简单,资源消耗较少,被大部分mysql引擎支持。最常使用的myisam与memory以及innodb【默认行级锁】都支持表级锁。表级锁分为表共享读锁与表独占写锁。\n开销小,加锁快;不会出现死锁;锁定粒度大,发出锁冲突的概率最高,并发度最低。\n页级锁(page-level)【mysql存储引擎实现】\n页级锁是mysql中锁定粒度介于行级锁和表级锁中间的一种锁。表级锁速度快,但冲突多,行级冲突少,但速度慢。所以取了折衷的页级,一次锁定相邻的一组记录。bdb支持页级锁。\n开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般。\n手动共享表读锁\u0026amp;独占表写锁\n1 2 3 4 -- 加锁 lock table [表名称] read/write,[表名称] read/write, ... ; -- 解锁 unlock tables; innodb引擎的锁机制\n共享锁(s):允许一个事务去读一行,阻止其他事务获得相同数据集的排他锁\n排他锁(x):允许获得排他锁的事务更新数据,阻止其他事务取得相同数据集的共享读锁和排他写锁\n意向共享锁(is):事务打算给数据行加行共享锁,事务在给一个数据行加共享锁前必须先取得该表的is锁\n意向排他锁(ix):事务打算给数据行加行排他锁,事务在给一个数据行加排他锁前必须先取得该表的ix锁\n说明:\n1)共享锁和排他锁都是行锁,意向锁都是表锁,应用中我们只会使用到共享锁和排他锁,意向锁是mysql内部使用的,不需要用户干预\n2)对于update、delete和insert语句,innodb会自动给涉及数据集加排他锁(x)\n3)对于普通select语句,innodb不会加任何锁\n4)select可以通过以下语句显示给记录集加共享锁或排他锁\n1 2 select * from table_name where ... lock in share mode -- 共享锁(s) select * from table_name where ... for update -- 排他锁(x) 5)当两个事务进行,一个事务更新一条记录,另一事务可读取此记录(不变-从undo日志中读取的值),写入操作需要等更新操作提交事务\n6)innodb中的行锁都是间隙锁是在索引区间加锁\nb 树 \u0026amp; b+ 树 参考博客\nmysql处理sql请求的大致流程 客户端发送sql请求给服务器 服务器检查是否可以在查询缓存中命中改sql【缓存中包含的有这条sql的权限等信息,如果命中直接返回】 服务器端进行sql解析、权限校验、预处理、再由优化器生成对应的执行计划 根据执行计划,调用存储引擎api来查找数据 返回结果数据到客户端 mysql日志分类 mysql服务层:二进制日志、慢查日志、通用日志 mysql存储引擎层innodb日志:重做日志、回滚日志 sql的执行顺序(mysql为例) from(将最近的两张表,进行笛卡尔积) \u0026ndash;vt1\non(将vt1按照它的条件进行过滤) \u0026ndash;vt2\nleft join(保留左表的记录) \u0026ndash;vt3\nwhere(过滤vt3中的记录) \u0026ndash;vt4…vtn\ngroup by(对vt4的记录进行分组) \u0026ndash;vt5\nhaving(对vt5中的记录进行过滤) \u0026ndash;vt6\nselect(对vt6中的记录,投影选取指定的列)\u0026ndash;vt7\norder by(对vt7的记录进行排序) \u0026ndash;游标\nlimit(对排序之后的值进行分页)\nwhere条件执行顺序(影响性能)\nmysql:从左往右去执行where条件的。\noracle:从右往左去执行where条件的。\n结论:写where条件的时候,优先级高的部分要去编写过滤力度最大的条件语句\n十四、数据库数据恢复 数据恢复可以使用数据库备份的备份文件恢复,但是备份点到当前的数据不可恢复 使用延迟复制的方法,从延迟数据库进行恢复,如果延迟数据库也已经执行那条sql也不可恢复 使用日志闪回方式(日志必须row格式) 日志闪回 \tbinlog2sql日志闪回工具可以解析出执行的sql无法生成反向sql 。然后再清空业务表,重新执行sql即可完成数据恢复。\n前置条件:\n①停掉数据库读写操作\n②热备份现数据库(将备份文件在其它机器上实验通过)\n③清空需要恢复数据的业务表的全部记录,避免写入冲突\n第一步:安装,下载地址\n1 2 3 4 5 6 # 安装pip工具 yum install -y python-pip; cd binlog2sql-master; pip install -r requirements.txt; 第二步:查找日志文件\n1 show master logs; 第三步:解析出sql\n1 2 3 cd binlog2sql python binlog2sql.py -u[user] -p[password] -d[database] -t [table] --start-file=\u0026#39;[logfilename]\u0026#39; \u0026gt; [/path/tablename.sql] 第四步:删除解析出的sql中不要的语句\n第五步:直接执行sql\n十五、优化陷阱 mysql数据库设计常犯的错以及对性能的影响 1)过分的反范式化为表建立太多的列\n\tmysql的服务器层和存储引擎层是分离的,mysql的存储引擎api工作时需要把服务器层和存储引擎层之间通过缓冲格式来拷贝数据,然后在服务器层将缓冲层的数据解析成各个列,这个操作过程成本是非常高的,特别是对于myisam的变长结构,和innodb这种行结构在解析时还必须进行转换,这个转换的成本呢就依赖于列的数量,所以,如果一个表的列过多,在使用这个表时就会带来额外过多的cpu消耗 。\n2)过分的使用范式化设计造成了太多的表关联\n\t在进行数据库设计时候要进行适当的反范式化设计,把经常使用的两个小表合成一个大表,这样做对提升数据库的性能和sql查询的性能都是 有帮助的。\n3)在oltp环境中使用不恰当的分区表\n\t分区表可以帮助我们把一个大表在物理存储上按照分区键分成多个小表,但是在使用分区表时,分区键的选择非常关键,如果分区键的选择不恰当,就会造成查询时跨多个分区查询,这样不仅不会提升数据库的性能,而且还会降低数据库的查询性能。\n4)使用外键约束保证事务的完整性\n\t外键约束来保证数据的完整性,但是这样的效率是非常低的。\n","date":"2019-11-06","permalink":"https://hobocat.github.io/post/database/2019-11-06-mysql/","summary":"一、安装MySQL Yum源下载方式 预备工作 1 yum -y install yum-utils #安装yum-utils 第一步:下载yum源 在官网选择Downloads\u0026ndash;\u0026raquo;Comm","title":"mysql数据库性能及其架构优化"},]
[{"content":"一、oauth2的概念 \toauth(开放授权)是一个开放标准,允许用户授权第三方移动应用访问他们存储在另外的服务提供者上的信息,而不需要将用户名和密码提供给第三方移动应用或分享他们数据的所有内容,oauth2.0是oauth协议的延续版本,但不向后兼容oauth 1.0即完全废止了oauth1.0\n二、请求流程 三、名词定义 third-party application\n\t第三方应用程序,又称\u0026quot;客户端\u0026quot;(client),比如打开知乎,使用第三方登录,这时候知乎就是客户端\nhttp service\n\thttp服务提供商,简称\u0026quot;服务提供商\u0026quot;,即例子的qq\nresource owner\n\t资源所有者,又称\u0026quot;用户\u0026quot;(user)即登录用户\nuser agent\n\t用户代理,就是指浏览器\nauthorization server\n\t认证服务器,即服务提供商专门用来处理认证的服务器\nresource server\n\t资源服务器,即服务提供商存放用户生成的资源的服务器。它与认证服务器,可以是同一台服务器,也可以是不同的服务器\n四、运行流程 (a)用户打开客户端以后,客户端要求用户给予授权。\n(b)用户同意给予客户端授权。\n(c)客户端使用上一步获得的授权,向认证服务器申请令牌。\n(d)认证服务器对客户端进行认证以后,确认无误,同意发放令牌。\n(e)客户端使用令牌,向资源服务器申请获取资源。\n(f)资源服务器确认令牌无误,同意向客户端开放资源。\n五、四种授权模式 授权码模式(authorization code)\n简化模式(implicit)\n密码模式(resource owner password credentials)\n客户端模式(client credentials)\n六、授权码模式 授权码模式(authorization code)是功能最完整、流程最严密的授权模式。\n1)用户访问客户端,后者将前者导向认证服务器,假设用户给予授权,认证服务器将用户导向客户端事先指定的\u0026quot;重定向uri\u0026quot;(redirection uri),同时附上一个授权码\n2)客户端收到授权码,附上早先的\u0026quot;重定向uri\u0026quot;,向认证服务器申请令牌。请求成功返回code授权码\n3)认证服务器核对授权码和重定向uri,确认无误后向客户端发送访问令牌(access token)和更新令牌(refresh token)\n","date":"2019-10-09","permalink":"https://hobocat.github.io/post/application/2019-10-09-oauth2/","summary":"一、OAuth2的概念 OAuth(开放授权)是一个开放标准,允许用户授权第三方移动应用访问他们存储在另外的服务提供者上的信息,而不需要将用户名和密码提供给第三","title":"oauth2介绍"},]
[{"content":"一、基于游览器的安全 表单登陆 设置表单登陆【继承websecurityconfigureradapter进行适配】\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 /** * 游览器端安全配置,当访问非登陆请求时,会在filtersecurityinterceptor进行判断是否有权限 */ @configuration public class browsersecurityconfig extends websecurityconfigureradapter { // 密码的加密器,高版本必须使用 @bean public passwordencoder passwordencoder() { return new bcryptpasswordencoder(); } private authenticationsuccesshandler successhandler = new loginsuccesshandler(); private authenticationfailurehandler failurehandler = new loginfailurehandler(); /** * 登陆、安全拦截配置 */ @override protected void configure(httpsecurity http) throws exception { http.formlogin() // 设置为基于表带验证 // 当没有进行身份认证且访问需要权限的api时跳入到这个请求 .loginpage(\u0026#34;/authentication/require\u0026#34;) // 提交表单的地址,默认/login【查看usernamepasswordauthenticationfilter】 .loginprocessingurl(\u0026#34;/authentication/commit\u0026#34;) // 登陆成功的处理 .successhandler(successhandler) // 登陆失败的处理 .failurehandler(failurehandler) .and() .authorizerequests() //认证的请求 .antmatchers(httpmethod.get, \u0026#34;/authentication/require\u0026#34;,\t//先访问的请求 \u0026#34;/authentication/commit\u0026#34;,\t//提交表单的地址 \u0026#34;/login/user.html\u0026#34;)\t//登录页 .permitall() //允许所有 .anyrequest() //任何请求 .authenticated() //需要身份认证 .and().csrf().disable() //屏蔽csrf } } @restcontroller public class browsersecuritycontroller { private logger log = loggerfactory.getlogger(browsersecuritycontroller.class); private redirectstrategy redirectstrategy = new defaultredirectstrategy(); /** * 当没有进行身份认证且访问需要权限的api时跳入到这个请求 * 如果没权限根据请求的方式【ajax或者html】进行返回指定信息 */ @getmapping(\u0026#34;/authentication/require\u0026#34;) @responsestatus(httpstatus.unauthorized) public authenticationresponse requireauthentication( httpservletrequest request, httpservletresponse response) throws ioexception, servletexception { string requestedwith = request.getheader(\u0026#34;x-requested-with\u0026#34;); if (!\u0026#34;xmlhttprequest\u0026#34;.equals(requestedwith)) { log.debug(\u0026#34;未进行身份认证,游览器请求将跳转至登陆页面\u0026#34;); redirectstrategy.sendredirect(request, response, \u0026#34;/login/user.html\u0026#34;); return null; }else { log.debug(\u0026#34;未进行身份认证,ajax请求将返回状态码401\u0026#34;); return new authenticationresponse( request.getrequesturi(), \u0026#34;未登陆\u0026#34;, httpstatus.unauthorized.value()); } } } /** * 用户登陆成功 */ public class loginsuccesshandler implements authenticationsuccesshandler { private objectmapper objectmapper = new objectmapper(); private logger log = loggerfactory.getlogger(loginsuccesshandler.class); @override public void onauthenticationsuccess( httpservletrequest request, httpservletresponse response, authentication authentication) throws ioexception, servletexception { log.debug(\u0026#34;用户{}登陆成功\u0026#34;, authentication.getprincipal()); simpleresponse simpleresponse = new simpleresponse(string.valueof(httpstatus.ok.value()), \u0026#34;登陆成功\u0026#34;); response.setcontenttype(\u0026#34;application/json;charset=utf-8\u0026#34;); response.getwriter().write(objectmapper.writevalueasstring(simpleresponse)); response.flushbuffer(); } } /** * 用户登陆失败 */ public class loginfailurehandler implements authenticationfailurehandler { private logger log = loggerfactory.getlogger(loginfailurehandler.class); private objectmapper objectmapper = new objectmapper(); @override public void onauthenticationfailure( httpservletrequest request, httpservletresponse response, authenticationexception exception) throws ioexception, servletexception { log.info(\u0026#34;登录失败\u0026#34;); response.setstatus(httpstatus.ok.value()); response.setcontenttype(\u0026#34;application/json;charset=utf-8\u0026#34;); simpleresponse simpleresponse = new simpleresponse(string.valueof(httpstatus.internal_server_error.value()), exception.getmessage()); response.getwriter().write(objectmapper.writevalueasstring(simpleresponse)); } } /** * 实现 userdetailsservice 接口,用户获取用户登陆信息 */ @service public class securityuserdetailsserviceimpl implements userdetailsservice { private logger log = loggerfactory.getlogger(securityuserdetailsserviceimpl.class); @autowired private userservice userservice; // 过呢根据用户名进行登陆 @override public userdetails loaduserbyusername(string username) throws usernamenotfoundexception { log.debug(\u0026#34;根据用户名{}查找用户\u0026#34;, username); // 查询user user user = userservice.getuserbyusername(username); // 用户不存在 if (user== null) { throw new usernamenotfoundexception( \u0026#34;用户名\u0026#34; + username + \u0026#34;账户不存在\u0026#34;); } return user; } } /* * 实现userdetails满足userdetailsservice需要返回的类型 */ public class user implements userdetails { private integer id; private string username; private string password; // 权限信息 @override public collection\u0026lt;? extends grantedauthority\u0026gt; getauthorities() { return authorityutils.createauthoritylist(\u0026#34;admin\u0026#34;); } @override public string getpassword() { return this.password; } @override public string getusername() { return this.username; } // 账户没有过期 @override public boolean isaccountnonexpired() { return true; } // 账户没有锁定 @override public boolean isaccountnonlocked() { return true; } // 密码没有过期 @override public boolean iscredentialsnonexpired() { return true; } // 账户是否可用【注销?】 @override public boolean isenabled() { return true; } //=======================getter/setter======================= } 请求经过过滤器的流程图\n图片验证码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 /** * 验证码生成工具类 */ @configuration @conditionalonproperty(prefix = \u0026#34;login.verify.image\u0026#34;, name = \u0026#34;enable\u0026#34;) @enableconfigurationproperties(imagecodeproperties.class) public class imagecodeutil { private logger log = loggerfactory.getlogger(imagecodeutil.class); private imagecodeproperties imagecodeproperties; public imagecodeutil(imagecodeproperties imagecodeproperties) { this.imagecodeproperties = imagecodeproperties; } /** * code为生成的验证码 * codepic为生成的验证码bufferedimage对象 */ public imagevalidatecode generatecodeandpic() { long expiredate = imagecodeproperties.getexpiredate(); // 过期时间 int imagewidth = imagecodeproperties.getimagewidth(); // 定义图片的width int imageheight = imagecodeproperties.getfontheight(); // 定义图片的height int codecount = imagecodeproperties.getcodecount(); // 定义图片上显示验证码的个数 int fontheight = imagecodeproperties.getfontheight(); // 字体高度 int offsetx = imagecodeproperties.getoffsetx(); // 验证码生成x轴间隔 int offsety = imagecodeproperties.getoffsety(); // 验证码生成y轴间距 string fontname = imagecodeproperties.getfontname(); // 字体 char[] codesequence = imagecodeproperties.getcodesequence(); // 生成序列 // 定义图像buffer bufferedimage buffimg = new bufferedimage(imagewidth, imageheight, bufferedimage.type_int_rgb); graphics graphics = buffimg.getgraphics(); // 创建一个随机数生成器类 random random = new random(); // 将图像填充为白色 graphics.setcolor(color.white); graphics.fillrect(0, 0, imagewidth, imageheight); // 创建字体,字体的大小应该根据图片的高度来定。 font font = new font(fontname, font.bold, fontheight); // 设置字体。 graphics.setfont(font); // 画边框。 graphics.setcolor(color.black); graphics.drawrect(0, 0, imagewidth - 1, imageheight - 1); // 随机产生30条干扰线,使图象中的认证码不易被其它程序探测到。 graphics.setcolor(color.black); for (int i = 0; i \u0026lt; 0; i++) { int x1 = random.nextint(imagewidth); int y1 = random.nextint(imageheight); int x2 = random.nextint(imagewidth); int y2 = random.nextint(imageheight); graphics.drawline(x1, y1, x1 + x2, y1 + y2); } // randomcode用于保存随机产生的验证码,以便用户登录后进行验证。 stringbuffer randomcode = new stringbuffer(); int red = 0; int green = 0; int blue = 0; // 随机产生codecount数字的验证码。 for (int i = 0; i \u0026lt; codecount; i++) { // 得到随机产生的验证码数字。 string code = string.valueof(codesequence[random.nextint(codesequence.length)]); // 产生随机的颜色分量来构造颜色值,这样输出的每位数字的颜色值都将不同。设置为230避免使用纯白色 red = random.nextint(230); green = random.nextint(230); blue = random.nextint(230); // 用随机产生的颜色将验证码绘制到图像中。 graphics.setcolor(new color(red, green, blue)); graphics.drawstring(code, (i + 1) * offsetx, offsety); // 将产生的四个随机数组合在一起。 randomcode.append(code); } imagevalidatecode imagecode = new imagevalidatecode(randomcode.tostring(), buffimg); if (expiredate != null){ imagecode.setexpiredate(instant.now().getepochsecond() + expiredate); } log.debug(\u0026#34;生成图片验证码{}\u0026#34;, imagecode.getcode()); return imagecode ; } } @configurationproperties(prefix = \u0026#34;login.verify.image\u0026#34;, ignoreunknownfields = true) public class imagecodeproperties { private static final int default_image_width = 90; private static final int default_image_height = 90; private static final int default_code_count = 4; private static final int default_font_height = 18; private static final int default_image_offset_x = 15; private static final int default_image_offset_y = 16; private static final string default_font_name = \u0026#34;微软雅黑\u0026#34;; private static final char[] default_code_sequence = { \u0026#39;a\u0026#39;, \u0026#39;b\u0026#39;, \u0026#39;c\u0026#39;, \u0026#39;d\u0026#39;, \u0026#39;e\u0026#39;, \u0026#39;f\u0026#39;, \u0026#39;g\u0026#39;, \u0026#39;h\u0026#39;, \u0026#39;j\u0026#39;, \u0026#39;k\u0026#39;, \u0026#39;l\u0026#39;, \u0026#39;m\u0026#39;,\u0026#39;n\u0026#39;, \u0026#39;p\u0026#39;, \u0026#39;q\u0026#39;, \u0026#39;r\u0026#39;, \u0026#39;s\u0026#39;, \u0026#39;t\u0026#39;, \u0026#39;u\u0026#39;, \u0026#39;v\u0026#39;, \u0026#39;w\u0026#39;, \u0026#39;x\u0026#39;, \u0026#39;y\u0026#39;, \u0026#39;z\u0026#39;, \u0026#39;2\u0026#39;, \u0026#39;3\u0026#39;, \u0026#39;4\u0026#39;, \u0026#39;5\u0026#39;, \u0026#39;6\u0026#39;, \u0026#39;7\u0026#39;, \u0026#39;8\u0026#39;, \u0026#39;9\u0026#39; }; private long expiredate = 60l; // 过期时间 private int imagewidth = default_image_width; // 定义图片的width private int imageheight = default_image_height; // 定义图片的height private int codecount = default_code_count; // 定义图片上显示验证码的个数 private int fontheight = default_font_height; // 字体高度 private int offsetx = default_image_offset_x; // 验证码生成x轴间隔 private int offsety = default_image_offset_y; // 验证码生成y轴间距 private string fontname = default_font_name; // 字体 private char[] codesequence = default_code_sequence; // 生成序列 //=======================getter/setter======================= } /* * 获得验证码的controller */ @conditionalonproperty(prefix = \u0026#34;login.verify.image\u0026#34;, value = \u0026#34;enable\u0026#34;, havingvalue = \u0026#34;true\u0026#34;) @restcontroller public class imagecodecontroller { // spring工具类用于操作session private sessionstrategy sessionstrategy = new httpsessionsessionstrategy(); @autowired private imagecodeutil imagecodeutil; public static final string session_image_verify_code = \u0026#34;session_image_verify_code\u0026#34;; @getmapping(\u0026#34;/verify/image/code\u0026#34;) public void getverifycode(httpservletrequest request, httpservletresponse response) throws ioexception { imagevalidatecode imagecode = imagecodeutil.generatecodeandpic(); // 设置响应的类型格式为图片格式 response.setcontenttype(\u0026#34;image/jpeg\u0026#34;); // 禁止图像缓存。 response.setheader(\u0026#34;pragma\u0026#34;, \u0026#34;no-cache\u0026#34;); response.setheader(\u0026#34;cache-control\u0026#34;, \u0026#34;no-cache\u0026#34;); response.setdateheader(\u0026#34;expires\u0026#34;, 0); // 写入图片 imageio.write(imagecode.getcodepic(), \u0026#34;jpg\u0026#34;, response.getoutputstream()); response.getoutputstream().flush(); // code放入session imagecode.setcodepic(null); sessionstrategy.setattribute(new servletwebrequest(request),session_image_verify_code,imagecode); } } /** * 验证码校验filter,需要在browsersecurityconfig中在usernamepasswordauthenticationfilter * 前配置http.addfilterbefore(imagevalidatecodefilter, usernamepasswordauthenticationfilter.class) */ public class imagevalidatecodefilter extends onceperrequestfilter { @autowired private authenticationfailurehandler authenticationfailurehandler; private sessionstrategy sessionstrategy = new httpsessionsessionstrategy(); public imagevalidatecodefilter(authenticationfailurehandler authenticationfailurehandler) { this.authenticationfailurehandler = authenticationfailurehandler; } @override protected void dofilterinternal(httpservletrequest request, httpservletresponse response, filterchain filterchain) throws servletexception, ioexception { // 是登陆请求而且为post if(stringutils.equals(\u0026#34;/authentication/commit\u0026#34;, request.getrequesturi()) \u0026amp;\u0026amp; stringutils.equalsignorecase(request.getmethod(), \u0026#34;post\u0026#34;)) { try { validate(new servletwebrequest(request)); filterchain.dofilter(request, response); } catch (validatecodeexception e) { authenticationfailurehandler.onauthenticationfailure(request, response, e); } }else { filterchain.dofilter(request, response); } } private void validate(servletwebrequest servletwebrequest) throws servletrequestbindingexception{ imagevalidatecode codeinsession = (imagevalidatecode) sessionstrategy.getattribute(servletwebrequest, imagecodecontroller.session_image_verify_code); string codeinrequest = servletrequestutils.getstringparameter(servletwebrequest.getrequest(),\u0026#34;imagecode\u0026#34;); if(stringutils.isempty(codeinrequest)) { throw new validatecodeexception(\u0026#34;提交的验证码不能为空\u0026#34;); } if(codeinsession == null) { throw new validatecodeexception(\u0026#34;验证码不存在\u0026#34;); } if(codeinsession.compareexpired()) { sessionstrategy.removeattribute(servletwebrequest, imagecodecontroller.session_image_verify_code); throw new validatecodeexception(\u0026#34;验证码已过期\u0026#34;); } if(!stringutils.equalsignorecase(codeinrequest, codeinsession.getcode())) { throw new validatecodeexception(\u0026#34;验证码不匹配\u0026#34;); } // 匹配成功 sessionstrategy.removeattribute(servletwebrequest, imagecodecontroller.session_image_verify_code); } } 记住我 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 /** * security配置,部分信息省略 */ @configuration public class browsersecurityconfig extends websecurityconfigureradapter { // 创建表语句在jdbctokenrepositoryimpl包含 @bean public persistenttokenrepository persistenttokenrepository(datasource datasource) { jdbctokenrepositoryimpl jdbctokenrepository = new jdbctokenrepositoryimpl(); jdbctokenrepository.setdatasource(datasource); return jdbctokenrepository; } /** * 登陆、安全拦截配置 */ @override protected void configure(httpsecurity http) throws exception { http.addfilterbefore(imagevalidatecodefilter, usernamepasswordauthenticationfilter.class) //基于表带验证 .formlogin() //当没有进行身份认证且访问需要权限的api时跳入到这个请求 .loginpage(\u0026#34;/authentication/require\u0026#34;) .loginprocessingurl(\u0026#34;/authentication/commit\u0026#34;) .successhandler(successhandler) .failurehandler(failurehandler) .and() // 会加入remembermeauthenticationfilter .rememberme()\t//启用rememberme .tokenrepository(persistenttokenrepository()) .userdetailsservice(userdetailsservice) .tokenvalidityseconds(60 * 60 * 24 * 7)\t//记住我的有效时间 .remembermeparameter(\u0026#34;rememberme\u0026#34;)\t//rememberme参数名称 .and() .authorizerequests() //认证的请求 .antmatchers(httpmethod.get, \u0026#34;/authentication/require\u0026#34;,\t//先访问的请求 \u0026#34;/authentication/commit\u0026#34;,\t//提交表单的地址 \u0026#34;/login/user.html\u0026#34;)\t//登录页 .permitall() //允许所有 .anyrequest() //任何请求 .authenticated() //需要身份认证 .and().csrf().disable() //屏蔽csrf } } 手机验证码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 // 伪短信验证码生成 @configuration @conditionalonproperty(prefix = \u0026#34;login.verify.sms\u0026#34;, name = \u0026#34;enable\u0026#34;) @enableconfigurationproperties(smscodeproperties.class) public class smscodeutil { private logger log = loggerfactory.getlogger(smscodeutil.class); private smscodeproperties smscodeproperties; public smscodeutil(smscodeproperties smscodeproperties) { this.smscodeproperties = smscodeproperties; } /** * code为生成的验证码,此过程要发送短信 */ public smsvalidatecode generatecode(string mobile) { long expiredate = smscodeproperties.getexpiredate(); // 过期时间 int codecount = smscodeproperties.getcodecount(); // 定义短信验证码的个数 smsvalidatecode smscode = new smsvalidatecode(randomstringutils.randomnumeric(codecount), mobile); if (expiredate != null){ smscode.setexpiredate(instant.now().getepochsecond() + expiredate); } log.debug(\u0026#34;生成短信验证码{}\u0026#34;, smscode.getcode()); return smscode ; } } @configurationproperties(prefix = \u0026#34;login.verify.sms\u0026#34;, ignoreunknownfields = true) public class smscodeproperties { private static final int default_code_count = 4; private static final long default_expire_date = 300l; private long expiredate = default_expire_date; // 过期时间 private integer codecount = default_code_count; // 长度 //=======================getter/setter======================= } //短信验证码请求的url @restcontroller @conditionalonproperty(prefix=\u0026#34;login.verify.sms\u0026#34;, name = \u0026#34;enable\u0026#34;) public class smscodecontroller { private logger log = loggerfactory.getlogger(smscodecontroller.class); public static final string sms_code_mobile_prefix = \u0026#34;sms_code_mobile_\u0026#34;; @autowired private smscodeutil smscodeutil; // spring工具类用于操作session private sessionstrategy sessionstrategy = new httpsessionsessionstrategy(); @getmapping(\u0026#34;/verify/sms/code/{mobile}\u0026#34;, produces = mimetypeutils.application_json_value) public simpleresponse getverifycode(@pathvariable(\u0026#34;mobile\u0026#34;) string mobile, httpservletrequest request, httpservletresponse response) throws ioexception { smsvalidatecode smsvalidatecode = smscodeutil.generatecode(mobile); log.info(\u0026#34;给{}手机发送验证短信,验证码{}\u0026#34;, smsvalidatecode.getmobile(), smsvalidatecode.getcode()); sessionstrategy.setattribute(new servletwebrequest(request), sms_code_mobile_prefix + mobile, smsvalidatecode); simpleresponse simpleresponse = new simpleresponse(); simpleresponse.setcontent(\u0026#34;短信发送成功\u0026#34;); simpleresponse.setcode(\u0026#34;200\u0026#34;); return simpleresponse; } } // 短信验证码校验 public class smsvalidatecodefilter extends onceperrequestfilter { @autowired private authenticationfailurehandler authenticationfailurehandler; private sessionstrategy sessionstrategy = new httpsessionsessionstrategy(); public smsvalidatecodefilter(authenticationfailurehandler authenticationfailurehandler) { this.authenticationfailurehandler = authenticationfailurehandler; } @override protected void dofilterinternal(httpservletrequest request, httpservletresponse response, filterchain filterchain) throws servletexception, ioexception { // 是登陆请求而且为post if(stringutils.equals(\u0026#34;/authentication/sms/commit\u0026#34;, request.getrequesturi()) \u0026amp;\u0026amp; stringutils.equalsignorecase(request.getmethod(), \u0026#34;post\u0026#34;)) { try { validate(new servletwebrequest(request)); filterchain.dofilter(request, response); } catch (validatecodeexception e) { authenticationfailurehandler.onauthenticationfailure(request, response, e); } }else { filterchain.dofilter(request, response); } } private void validate(servletwebrequest servletwebrequest) { string questinmobile = null; string questincode = null; try { questinmobile = servletrequestutils.getrequiredstringparameter(servletwebrequest.getrequest(), \u0026#34;mobile\u0026#34;); questincode = servletrequestutils.getrequiredstringparameter(servletwebrequest.getrequest(), \u0026#34;code\u0026#34;); }catch (servletrequestbindingexception e) { throw new validatecodeexception(\u0026#34;提交的短信验证码不能为空\u0026#34;); } smsvalidatecode smsvalidatecode = (smsvalidatecode)sessionstrategy.getattribute(servletwebrequest, smscodecontroller.sms_code_mobile_prefix + questinmobile); if(stringutils.isempty(questinmobile)) { throw new validatecodeexception(\u0026#34;提交的手机号不能为空\u0026#34;); } if(stringutils.isempty(questincode)) { throw new validatecodeexception(\u0026#34;提交的短信验证码不能为空\u0026#34;); } if(smsvalidatecode == null) { throw new validatecodeexception(\u0026#34;手机号\u0026#34; + questinmobile + \u0026#34;短信验证码不存在\u0026#34;); } if(smsvalidatecode.compareexpired()) { throw new validatecodeexception(\u0026#34;短信验证码已过期\u0026#34;); } if(!stringutils.equalsignorecase(questincode, smsvalidatecode.getcode())) { throw new validatecodeexception(\u0026#34;验证码不匹配\u0026#34;); } } } // 校验通过时,providermanager挑选对应provider加载用户信息【权限】 public class smscodeauthenticationprovider implements authenticationprovider { private logger log = loggerfactory.getlogger(smscodeauthenticationprovider.class); private userservice userservice; @override public authentication authenticate(authentication authentication) throws authenticationexception { log.debug(\u0026#34;根据手机号{}查找用户\u0026#34;, authentication.getprincipal()); smscodeauthenticationtoken smscodeauthenticationtoken = (smscodeauthenticationtoken) authentication; user user = userservice.getuserbymobile((string) smscodeauthenticationtoken.getprincipal()); return new smscodeauthenticationtoken(user.getusername(),user.getpassword(),user.getauthorities()); } @override public boolean supports(class\u0026lt;?\u0026gt; authentication) { return smscodeauthenticationtoken.class.isassignablefrom(authentication); } public void setuserservice(userservice userservice) { this.userservice = userservice; } } /** * 短信认证的token */ public class smscodeauthenticationtoken extends abstractauthenticationtoken { private static final long serialversionuid = springsecuritycoreversion.serial_version_uid; private object principal; private object credentials; public smscodeauthenticationtoken(object principal, object credentials) { super(null); this.principal = principal; this.credentials = credentials; setauthenticated(false); } public smscodeauthenticationtoken(object principal, object credentials, collection\u0026lt;? extends grantedauthority\u0026gt; authorities) { super(authorities); this.principal = principal; this.credentials = credentials; super.setauthenticated(true); // must use super, as we override } public object getcredentials() { return this.credentials; } public object getprincipal() { return this.principal; } public void setauthenticated(boolean isauthenticated) throws illegalargumentexception { if (isauthenticated) { throw new illegalargumentexception( \u0026#34;cannot set this token to trusted - use constructor which takes a grantedauthority list instead\u0026#34;); } super.setauthenticated(false); } @override public void erasecredentials() { super.erasecredentials(); } } /** * security配置,部分信息省略 */ @configuration public class browsersecurityconfig extends websecurityconfigureradapter { /** * 登陆、安全拦截配置 */ @override protected void configure(httpsecurity http) throws exception { http.addfilterbefore(imagevalidatecodefilter, usernamepasswordauthenticationfilter.class) .addfilterbefore(smsvalidatecodefilter, usernamepasswordauthenticationfilter.class) //基于表带验证 .formlogin() //当没有进行身份认证且访问需要权限的api时跳入到这个请求 .loginpage(\u0026#34;/authentication/require\u0026#34;) .loginprocessingurl(\u0026#34;/authentication/commit\u0026#34;) .successhandler(successhandler) .failurehandler(failurehandler) .and() // 会加入remembermeauthenticationfilter .rememberme()\t//启用rememberme .tokenrepository(persistenttokenrepository()) .userdetailsservice(userdetailsservice) .tokenvalidityseconds(60 * 60 * 24 * 7)\t//记住我的有效时间 .remembermeparameter(\u0026#34;rememberme\u0026#34;)\t//rememberme参数名称 .and() .authorizerequests() //认证的请求 .antmatchers(httpmethod.get, \u0026#34;/authentication/require\u0026#34;,\t//先访问的请求 \u0026#34;/authentication/commit\u0026#34;,\t//提交表单的地址 \u0026#34;/login/user.html\u0026#34;)\t//登录页 .permitall() //允许所有 .anyrequest() //任何请求 .authenticated() //需要身份认证 .and().csrf().disable() //屏蔽csrf } } 第三方登陆【以qq为例】 qq登陆\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 public class qquserinfo { /** * 返回码 */ private string ret; /** * 如果ret\u0026lt;0,会有相应的错误信息提示,返回数据全部用utf-8编码。 */ private string msg; /** * */ private string openid; /** * 不知道什么东西,文档上没写,但是实际api返回里有。 */ private string is_lost; /** * 省(直辖市) */ private string province; /** * 市(直辖市区) */ private string city; /** * 出生年月 */ private string year; /** * 用户在qq空间的昵称。 */ private string nickname; /** * 星座 */ private string constellation; /** * 大小为30×30像素的qq空间头像url。 */ private string figureurl; /** * 大小为50×50像素的qq空间头像url。 */ private string figureurl_1; /** * 大小为100×100像素的qq空间头像url。 */ private string figureurl_2; /** * 大小为40×40像素的qq头像url。 */ private string figureurl_qq_1; /** * 大小为100×100像素的qq头像url。需要注意,不是所有的用户都拥有qq的100×100的头像,但40×40像素则是一定会有。 */ private string figureurl_qq_2; /** * 性别。 如果获取不到则默认返回”男” */ private string gender; /** * 标识用户是否为黄钻用户(0:不是;1:是)。 */ private string is_yellow_vip; /** * 标识用户是否为黄钻用户(0:不是;1:是) */ private string vip; /** * 黄钻等级 */ private string yellow_vip_level; /** * 黄钻等级 */ private string level; /** * 标识是否为年费黄钻用户(0:不是; 1:是) */ private string is_yellow_year_vip; //=======================getter/setter======================= } /** * 获取qq用户信息 */ public interface qq { qquserinfo getuserinfo(); } /** * 获取qq用户信息实现,继承abstractoauth2apibinding完成用户信息获取 */ public class qqimpl extends abstractoauth2apibinding implements qq{ // 获取openid【用户的唯一标识】的url private static final string get_openid_url = \u0026#34;https://graph.qq.com/oauth2.0/me?access_token={0}\u0026#34;; // 获取用户信息的url,accesstoken会因为tokenstrategy.access_token_parameter自动带上 private static final string get_user_info_url = \u0026#34;https://graph.qq.com/user/get_user_info?oauth_consumer_key={0}\u0026amp;openid={1}\u0026#34;; // 申请qq互联的app id private string oauthconsumerkey; // 用户openid【用户的唯一标识】 private string openid; public qqimpl(string accesstoken, string oauthconsumerkey) { super(accesstoken, tokenstrategy.access_token_parameter); this.oauthconsumerkey = oauthconsumerkey; // 获取openid string openidresult = getresttemplate().getforobject(messageformat.format(get_openid_url, accesstoken), string.class); if(stringutils.isempty(openidresult)) { throw new runtimeexception(\u0026#34;openid获取失败\u0026#34;); } this.openid = stringutils.substringbetween(openidresult, \u0026#34;\\\u0026#34;openid\\\u0026#34;:\\\u0026#34;\u0026#34;, \u0026#34;\\\u0026#34;}\u0026#34;); } @override public qquserinfo getuserinfo() { // 填充数据 string url = messageformat.format(get_user_info_url, oauthconsumerkey, openid); string userinfojson = getresttemplate().getforobject(url, string.class); qquserinfo qquserinfo = null; try { // 解析用户信息 objectmapper objectmapper = new objectmapper(); objectmapper.configure(deserializationfeature.fail_on_unknown_properties, false); qquserinfo = objectmapper.readvalue(userinfojson, qquserinfo.class); qquserinfo.setopenid(openid); } catch (ioexception e) { throw new runtimeexception(\u0026#34;json转换失败\u0026#34;); } return qquserinfo; } } /** * 将返回的qq用户信息转换为标准的用户信息用于存储 */ public class qqapiadapter implements apiadapter\u0026lt;qq\u0026gt; { /** * 不对网络进行检测 */ @override public boolean test(qq api) { return true; } /** * 获取用户信息 */ @override public void setconnectionvalues(qq api, connectionvalues values) { qquserinfo qquserinfo = api.getuserinfo(); // 显示的用户名(qq为昵称) values.setdisplayname(qquserinfo.getnickname()); // 头像(qq头像) values.setimageurl(qquserinfo.getfigureurl_qq_1()); // 个人主页(qq没有) values.setprofileurl(null); // 用户的唯一标识id values.setprovideruserid(qquserinfo.getopenid()); } /** * 解绑 */ @override public userprofile fetchuserprofile(qq api) { return null; } @override public void updatestatus(qq api, string message) { //发送消息等,qq没有个人主页,时间线不能更新 } } /** * 和服务提供商交换信息的类 */ public class qqserviceprovider extends abstractoauth2serviceprovider\u0026lt;qq\u0026gt; { // qq登录页url private static final string authorize_url = \u0026#34;https://graph.qq.com/oauth2.0/authorize\u0026#34;; // qq获取token的url private static final string access_token_url = \u0026#34;https://graph.qq.com/oauth2.0/token\u0026#34;; // qq互联申请的app id private string oauthconsumerkey; /** * clientid : qq互联申请的app id * clientsecret : qq互联申请的app key */ public qqserviceprovider(string clientid, string clientsecret) { super(new qqoauthtemplate(clientid, clientsecret, authorize_url, access_token_url)); this.oauthconsumerkey = clientid; } @override public qq getapi(string accesstoken) { return new qqimpl(accesstoken, oauthconsumerkey); } } /** * 发出请求的类 */ public class qqoauthtemplate extends oauth2template { public qqoauthtemplate(string clientid, string clientsecret, string authorizeurl, string accesstokenurl) { super(clientid, clientsecret, authorizeurl, accesstokenurl); // setuseparametersforclientauthentication设置为true才能将clientid、clientsecret以请求参数的方式带出去 setuseparametersforclientauthentication(true); } /** * qq返回的用户信息是text/html,所以需要处理返回类型 */ @override protected resttemplate createresttemplate() { resttemplate resttemplate = super.createresttemplate(); resttemplate.getmessageconverters().add(new stringhttpmessageconverter()); return resttemplate; } @override protected accessgrant postforaccessgrant(string accesstokenurl, multivaluemap\u0026lt;string, string\u0026gt; parameters) { string response = getresttemplate().postforobject(accesstokenurl, parameters, string.class); string[] items = response.split(\u0026#34;\u0026amp;\u0026#34;); string accesstoken = stringutils.substringafterlast(items[0], \u0026#34;=\u0026#34;); long expiresin = long.valueof(stringutils.substringafterlast(items[1], \u0026#34;=\u0026#34;)); string refreshtoken = stringutils.substringafterlast(items[2], \u0026#34;=\u0026#34;); return new accessgrant(accesstoken, null, refreshtoken, expiresin); } } /** * 获取连接信息的类 */ public class qqconnectfactory extends oauth2connectionfactory\u0026lt;qq\u0026gt; { /** * providerid:要与发出请求的路径最后结尾相同 * clientid:app id * clientsecret:app key */ public qqconnectfactory(string providerid, string clientid, string clientsecret ) { super(providerid, new qqserviceprovider(clientid, clientsecret), new qqapiadapter()); } } @configurationproperties(prefix = \u0026#34;qq.social\u0026#34;, ignoreunknownfields = true) public class qqsocialproperties { private string appid; private string appkey; private string callbackuri; private string providerid; //=======================getter/setter======================= } @configuration @conditionalonproperty(prefix = \u0026#34;qq.social\u0026#34;, name = \u0026#34;enable\u0026#34;) @enableconfigurationproperties(qqsocialproperties.class) @enablesocial public class qqsocialconfig extends socialconfigureradapter { private datasource datasource; private qqsocialproperties qqsocialproperties; @autowired private userservice userservice; public qqsocialconfig(qqsocialproperties qqsocialproperties, datasource datasource) { this.datasource = datasource; this.qqsocialproperties = qqsocialproperties; } @override public useridsource getuseridsource() { return new authenticationnameuseridsource(); } @override public usersconnectionrepository getusersconnectionrepository(connectionfactorylocator connectionfactorylocator) { jdbcusersconnectionrepository jdbcusersconnectionrepository = new jdbcusersconnectionrepository(datasource, connectionfactorylocator, encryptors.nooptext()); // 自注册,注意权限也要设置 jdbcusersconnectionrepository.setconnectionsignup(new connectionsignup() { @override public string execute(connection\u0026lt;?\u0026gt; connection) { user user = new user(); user.setusername(uuid.randomuuid().tostring()); userservice.save(user); return user.getuserid(); } }); return jdbcusersconnectionrepository; } @override public void addconnectionfactories(connectionfactoryconfigurer connectionfactoryconfigurer, environment environment) { connectionfactoryconfigurer.addconnectionfactory( new qqconnectfactory(qqsocialproperties.getproviderid(), qqsocialproperties.getappid(), qqsocialproperties.getappkey())); } } @configuration @conditionalonproperty(prefix = \u0026#34;qq.social\u0026#34;, name = \u0026#34;enable\u0026#34;) @enableconfigurationproperties(qqsocialproperties.class) public class qqspringsocialconfigurer extends springsocialconfigurer { private qqsocialproperties qqsocialproperties; // 如果是没设置setconnectionsignup则需要设置注册页 public qqspringsocialconfigurer(qqsocialproperties qqsocialproperties) { this.qqsocialproperties = qqsocialproperties; super.signupurl(\u0026#34;/register.html\u0026#34;); } @override protected \u0026lt;t\u0026gt; t postprocess(t object) { socialauthenticationfilter filter = (socialauthenticationfilter)super.postprocess(object); filter.setfilterprocessesurl(qqsocialproperties.getcallbackuri()); return (t) filter; } } @restcontroller public class usercontroller { private bcryptpasswordencoder passwordencoder = new bcryptpasswordencoder(); @autowired private userservice userservice; @autowired private providersigninutils providersigninutils; @postmapping(\u0026#34;/user/register\u0026#34;) public string register(user user, httpservletrequest request) { user.setpassword(passwordencoder.encode(user.getpassword())); userservice.save(user); // 调用再次尝试使用第三方账户登陆 providersigninutils.dopostsignup(user.getuserid(), new servletrequestattributes(request)); // 前台应该请求index页面 return \u0026#34;ok\u0026#34;; } } public class browsersecurityconfig extends websecurityconfigureradapter { /** * 获取社交账户信息 */ @bean public providersigninutils providersigninutils(connectionfactorylocator connectionfactorylocator, usersconnectionrepository connectionrepository){ return new providersigninutils(connectionfactorylocator, connectionrepository); } } 查看绑定状态\u0026amp;绑定\u0026amp;解绑\n前置需要手动@import(connectcontroller.class)并多配置一个回调接口为/connect/{providerid}\n查看绑定状态\n拿到已绑定的列表[/connect method=get] 配置视图 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 @component(\u0026#34;connect/status\u0026#34;) public class connectstatusview extends abstractview { private objectmapper objectmapper = new objectmapper(); @override protected void rendermergedoutputmodel(map\u0026lt;string, object\u0026gt; model, httpservletrequest request, httpservletresponse response) throws exception { map\u0026lt;string, list\u0026lt;connection\u0026lt;?\u0026gt;\u0026gt;\u0026gt; connectionmap = (map\u0026lt;string, list\u0026lt;connection\u0026lt;?\u0026gt;\u0026gt;\u0026gt;)model.get(\u0026#34;connectionmap\u0026#34;); map\u0026lt;string, boolean\u0026gt; connections = new hashmap\u0026lt;\u0026gt;(); for (map.entry\u0026lt;string, list\u0026lt;connection\u0026lt;?\u0026gt;\u0026gt;\u0026gt; entry : connectionmap.entryset()) { connections.put(entry.getkey(), !collectionutils.isempty(entry.getvalue())); } response.setcontenttype(mimetypeutils.application_json_value); response.setcharacterencoding(charencoding.utf_8); response.getwriter().write(objectmapper.writevalueasstring(connections)); } } 绑定\u0026amp;解绑\n绑定[/connect/qq method=post] 解绑[/connect/wechat method=delete] 绑定视图\u0026amp;解绑视图 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 @component({\u0026#34;connect/qqconnected\u0026#34;, \u0026#34;connect/qqconnect\u0026#34;}) public class connectview extends abstractview { @override protected void rendermergedoutputmodel( map\u0026lt;string, object\u0026gt; model, httpservletrequest request, httpservletresponse response) throws exception { response.setcharacterencoding(charencoding.utf_8); response.setcontenttype(mimetypeutils.text_html_value); if(model.get(\u0026#34;connections\u0026#34;) == null) { response.getwriter().write(\u0026#34;\u0026lt;h3\u0026gt;解绑成功\u0026lt;/h3\u0026gt;\u0026#34;); }else { response.getwriter().write(\u0026#34;\u0026lt;h3\u0026gt;绑定成功\u0026lt;/h3\u0026gt;\u0026#34;); } } } session管理 session超时设置\n1 server.servlet.session.timeout=pt30m session并发控制\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 /** * 登陆、安全拦截配置 */ @override protected void configure(httpsecurity http) throws exception { http //省略各项配置 .and() .sessionmanagement() .invalidsessionurl(\u0026#34;/session/invalid\u0026#34;)\t//session失效的处理url .maximumsessions(1)\t//只允许一个用户登陆,后登陆的把前登陆顶掉 //.maxsessionspreventslogin(true) //只允许一个用户登陆,不允许在在别的地方登陆 .expiredsessionstrategy(new browsersessioninformationexpiredstrategy()) //重复登陆提示 .and() //省略各项配置 } public class browsersessioninformationexpiredstrategy implements sessioninformationexpiredstrategy { @override public void onexpiredsessiondetected(sessioninformationexpiredevent event) throws ioexception, servletexception { event.getresponse().setcontenttype(mimetypeutils.application_json_value); event.getresponse().setcharacterencoding(charencoding.utf_8); event.getresponse().getwriter().write(\u0026#34;账号在别处登陆\u0026#34;); } } @restcontroller public class browsersecuritycontroller { @getmapping(\u0026#34;/session/invalid\u0026#34;) @responsestatus(httpstatus.unauthorized) public authenticationresponse invalidsession(httpservletrequest request, httpservletresponse response) throws ioexception, servletexception { string requestedwith = request.getheader(\u0026#34;x-requested-with\u0026#34;); if (!\u0026#34;xmlhttprequest\u0026#34;.equals(requestedwith)) { log.debug(\u0026#34;会话过期,游览器请求将跳转至登陆页面\u0026#34;); redirectstrategy.sendredirect(request, response, \u0026#34;/login/user.html\u0026#34;); } log.debug(\u0026#34;会话过期,ajax请求将返回状态码401\u0026#34;); return new authenticationresponse(request.getrequesturi(), \u0026#34;会话超时\u0026#34;, httpstatus.unauthorized.value()); } } 集群session管理\n1 2 3 4 #配置spring-session之后将redis存储到redis spring.session.store-type=redis spring.redis.host=192.168.1.158 spring.redis.port=6379 1 2 3 4 5 6 7 8 9 10 11 12 // 配置redistemplate序列化存储为json,否则前文验证码模块等需要实现java序列化接口才可使用 @bean public redistemplate\u0026lt;object, object\u0026gt; redistemplate(redisconnectionfactory redisconnectionfactory) { jackson2jsonredisserializer\u0026lt;object\u0026gt; jackson2jsonredisserializer = new jackson2jsonredisserializer\u0026lt;object\u0026gt;(object.class); redistemplate\u0026lt;object, object\u0026gt; template = new redistemplate\u0026lt;object, object\u0026gt;(); template.setconnectionfactory(redisconnectionfactory); template.setkeyserializer(jackson2jsonredisserializer); template.setvalueserializer(jackson2jsonredisserializer); template.sethashkeyserializer(jackson2jsonredisserializer); template.sethashvalueserializer(jackson2jsonredisserializer); return template; } 退出登陆 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 /** * 登陆、安全拦截配置 */ @override protected void configure(httpsecurity http) throws exception { http //省略各项配置 .and() .logout()\t// 会使session失效 //.logoutsuccesshandler()\t// 配置退出成功的处理器,进行扫尾工作,或者返回json .logouturl(\u0026#34;/authentication/out\u0026#34;) // 退出请求的url .logoutsuccessurl(\u0026#34;/logout.html\u0026#34;) // 退出成功请求的url,默认跳转到登录页,可不配置 //.deletecookies()\t// 删除cookie等操作 .and() //省略各项配置 } 二、基于app的安全 \n表单登陆 需要继承配置resourceserverconfigureradapter重载public void configure(httpsecurity http) 方法\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 @configuration public class appresourceserverconfigurer extends resourceserverconfigureradapter { @override public void configure(httpsecurity http) throws exception { // .... http.userdetailsservice(userdetailsservice); //表单登陆功能 formloginconfigurer\u0026lt;httpsecurity\u0026gt; formloginconfigurer = http.formlogin(); formloginconfigurer.loginpage(coresecurityproperties.getloginpageurl()); formloginconfigurer.loginprocessingurl(coresecurityproperties.getauthenticationurl()); formloginconfigurer.successhandler(successhandler); formloginconfigurer.failurehandler(failurehandler); // .... } /** * app默认的登陆失败处理器 */ public class defaultloginfailurehandler implements authenticationfailurehandler { private static logger log = loggerfactory.getlogger(defaultloginfailurehandler.class); private objectmapper objectmapper = new objectmapper(); @override public void onauthenticationfailure(httpservletrequest request, httpservletresponse response, authenticationexception exception) throws ioexception, servletexception { log.info(\u0026#34;登录失败\u0026#34;); response.setstatus(httpstatus.ok.value()); response.setcontenttype(mimetypeutils.application_json_value); response.setcharacterencoding(charencoding.utf_8); simpleresponse simpleresponse = new simpleresponse(string.valueof(httpstatus.internal_server_error.value()), exception.getmessage()); response.getwriter().write(objectmapper.writevalueasstring(simpleresponse)); } } /** * app登陆成功处理器,需要在登陆成功时发放oauth2令牌 */ public class defaultloginsuccesshandler implements authenticationsuccesshandler { private objectmapper objectmapper = new objectmapper(); private static logger log = loggerfactory.getlogger(defaultloginsuccesshandler.class); @autowired private clientdetailsservice clientdetailsservice; @autowired private authorizationservertokenservices authorizationservertokenservices; @autowired private passwordencoder passwordencoder; @override public void onauthenticationsuccess(httpservletrequest request, httpservletresponse response, authentication authentication) throws ioexception, servletexception { response.setcharacterencoding(charencoding.utf_8); response.setcontenttype(mimetypeutils.application_json_value); //用basic 认证传入clientid和secret string header = request.getheader(\u0026#34;authorization\u0026#34;); if (header == null || !header.tolowercase().startswith(\u0026#34;basic \u0026#34;)) { throw new authenticationexception(\u0026#34;没有oauth2需要的的认证信息\u0026#34;); } string[] tokens = extractanddecodeheader(header, request); string clientid = tokens[0]; string secret = tokens[1]; clientdetails clientdetails = clientdetailsservice.loadclientbyclientid(clientid); if(clientdetails == null) { response.getwriter().write(objectmapper.writevalueasstring(new authenticationexception(\u0026#34;clientid不正确\u0026#34;))); return; } if(!passwordencoder.matches(secret, clientdetails.getclientsecret())) { response.getwriter().write(objectmapper.writevalueasstring(new authenticationexception(\u0026#34;secret不正确\u0026#34;))); return; } tokenrequest tokenrequest = new tokenrequest(collections.empty_map, clientid, clientdetails.getscope(), \u0026#34;custom_login\u0026#34;); oauth2request oauth2request = tokenrequest.createoauth2request(clientdetails); oauth2authentication oauth2authentication = new oauth2authentication(oauth2request, authentication); oauth2accesstoken accesstoken = authorizationservertokenservices.createaccesstoken(oauth2authentication); log.debug(\u0026#34;用户{}登陆成功\u0026#34;, authentication.getprincipal()); response.getwriter().write(objectmapper.writevalueasstring(accesstoken)); } private string[] extractanddecodeheader(string header, httpservletrequest request) throws ioexception { byte[] base64token = header.substring(6).getbytes(\u0026#34;utf-8\u0026#34;); byte[] decoded; try { decoded = base64.getdecoder().decode(base64token); } catch (illegalargumentexception e) { throw new badcredentialsexception( \u0026#34;failed to decode basic authentication token\u0026#34;); } string token = new string(decoded, charencoding.utf_8); int delimiter = token.indexof(\u0026#34;:\u0026#34;); if (delimiter == -1) { throw new badcredentialsexception(\u0026#34;invalid basic authentication token\u0026#34;); } return new string[] { token.substring(0, delimiter), token.substring(delimiter + 1) }; } } 图片验证码 注意:不能使用session存储方式,需要将验证码存放如redis中\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 @conditionalonproperty(prefix = \u0026#34;login.verify.image\u0026#34;, value = \u0026#34;enable\u0026#34;, havingvalue = \u0026#34;true\u0026#34;) @controller public class imagecodecontroller { @autowired private imagecodeutil imagecodeutil; public static final string redis_image_verify_code = \u0026#34;verify_code:image_code:\u0026#34;; @autowired private redistemplate redistemplate; @getmapping(securitybrowserconstants.validate_image_url) @responsebody public void getverifycode(@requestparam(\u0026#34;device\u0026#34;) string device, httpservletresponse response) throws ioexception { imagevalidatecode imagecode = imagecodeutil.generatecodeandpic(); imagevalidatecode redisincode = new imagevalidatecode(); redisincode.setcode(imagecode.getcode()); redisincode.setexpiredate(imagecode.getexpiredate()); // 设置响应的类型格式为图片格式 response.setcontenttype(mimetypeutils.image_jpeg_value); // 禁止图像缓存。 response.setheader(\u0026#34;pragma\u0026#34;, \u0026#34;no-cache\u0026#34;); response.setheader(\u0026#34;cache-control\u0026#34;, \u0026#34;no-cache\u0026#34;); response.setdateheader(\u0026#34;expires\u0026#34;, 0); // 写入图片 imageio.write(imagecode.getcodepic(), \u0026#34;jpeg\u0026#34;, response.getoutputstream()); response.getoutputstream().flush(); if (imagecode.getexpiredate() == null) { redistemplate.boundvalueops(redis_image_verify_code + device).set(redisincode); }else { redistemplate.boundvalueops(redis_image_verify_code + device).set(redisincode, imagecode.getexpiredate(), timeunit.milliseconds); } } } /** * 图片验证码拦截匹配器 */ public class imagevalidatecodefilter extends onceperrequestfilter { @autowired private coresecurityproperties coresecurityproperties; private authenticationfailurehandler authenticationfailurehandler; @autowired private redistemplate redistemplate; public imagevalidatecodefilter(authenticationfailurehandler authenticationfailurehandler) { this.authenticationfailurehandler = authenticationfailurehandler; } @override protected void dofilterinternal(httpservletrequest request, httpservletresponse response, filterchain filterchain) throws servletexception, ioexception { // 是登陆请求而且为post if(stringutils.equals(coresecurityproperties.getauthenticationurl(), request.getrequesturi()) \u0026amp;\u0026amp; stringutils.equalsignorecase(request.getmethod(), \u0026#34;post\u0026#34;)) { try { validate(new servletwebrequest(request)); filterchain.dofilter(request, response); } catch (validatecodeexception e) { authenticationfailurehandler.onauthenticationfailure(request, response, e); } }else { filterchain.dofilter(request, response); } } private void validate(servletwebrequest servletwebrequest) throws servletrequestbindingexception{ string questindevice = null; string questincode = null; try { questindevice = servletrequestutils.getrequiredstringparameter(servletwebrequest.getrequest(), \u0026#34;device\u0026#34;); questincode = servletrequestutils.getstringparameter(servletwebrequest.getrequest(),\u0026#34;imagecode\u0026#34;); }catch (servletrequestbindingexception e) { throw new validatecodeexception(\u0026#34;提交的图片验证码参数缺失\u0026#34;); } string keyname = imagecodecontroller.redis_image_verify_code + questindevice; imagevalidatecode codeinredis = (imagevalidatecode)redistemplate.boundvalueops(keyname).get(); if(codeinredis == null) { // 过期判断由redis控制,redis设置了过期时间,程序不判断过期行为 throw new validatecodeexception(\u0026#34;验证码不存在,或已过期\u0026#34;); } if(!stringutils.equalsignorecase(questincode, codeinredis.getcode())) { throw new validatecodeexception(\u0026#34;验证码不匹配\u0026#34;); } // 匹配成功 redistemplate.delete(keyname); } } 手机验证码 注意:不能使用session存储方式,需要将验证码存放如redis中\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 @conditionalonproperty(prefix = \u0026#34;login.verify.sms\u0026#34;, value = \u0026#34;enable\u0026#34;, havingvalue = \u0026#34;true\u0026#34;) @controller public class smscodecontroller { private static logger log = loggerfactory.getlogger(smscodecontroller.class); public static final string sms_code_mobile_prefix = \u0026#34;verify_code:sms_code_mobile:\u0026#34;; @autowired private smscodeutil smscodeutil; @autowired private redistemplate redistemplate; @autowired private loginverifysmssender loginverifysmssender; @getmapping(value = \u0026#34;/verify/sms/code/{mobile}\u0026#34;, produces = mimetypeutils.application_json_value) @responsebody public simpleresponse getverifycode(@pathvariable(\u0026#34;mobile\u0026#34;) string mobile, @requestparam(\u0026#34;device\u0026#34;) string device, httpservletrequest request, httpservletresponse response) throws ioexception { smsvalidatecode smsvalidatecode = smscodeutil.generatecode(mobile); if(loginverifysmssender.sendverifycode(smsvalidatecode)) { //发送短信 log.debug(\u0026#34;给{}手机发送验证短信,验证码{}成功\u0026#34;, smsvalidatecode.getmobile(), smsvalidatecode.getcode()); }else { log.debug(\u0026#34;给{}手机发送验证短信,验证码{}失败\u0026#34;, smsvalidatecode.getmobile(), smsvalidatecode.getcode()); return new simpleresponse(string.valueof(httpstatus.ok.value()), \u0026#34;短信发送失败\u0026#34;); } redistemplate.boundvalueops(sms_code_mobile_prefix + device + \u0026#34;:\u0026#34; + mobile).set(smsvalidatecode, smsvalidatecode.getexpiredate(), timeunit.milliseconds); simpleresponse simpleresponse = new simpleresponse(string.valueof(httpstatus.ok.value()), \u0026#34;短信发送成功\u0026#34;); return simpleresponse; } } /** * 短信认证的token */ public class smscodeauthenticationtoken extends abstractauthenticationtoken { private static final long serialversionuid = springsecuritycoreversion.serial_version_uid; private object principal; private object credentials; public smscodeauthenticationtoken(object principal, object credentials) { super(null); this.principal = principal; this.credentials = credentials; setauthenticated(false); } public smscodeauthenticationtoken(object principal, object credentials, collection\u0026lt;? extends grantedauthority\u0026gt; authorities) { super(authorities); this.principal = principal; this.credentials = credentials; super.setauthenticated(true); // must use super, as we override } public object getcredentials() { return this.credentials; } public object getprincipal() { return this.principal; } public void setauthenticated(boolean isauthenticated) throws illegalargumentexception { if (isauthenticated) { throw new illegalargumentexception( \u0026#34;cannot set this token to trusted - use constructor which takes a grantedauthority list instead\u0026#34;); } super.setauthenticated(false); } @override public void erasecredentials() { super.erasecredentials(); } } /** * 短信认证登陆处理 */ public class smsauthenticationfilter extends abstractauthenticationprocessingfilter { public static final string security_form_mobile_key = \u0026#34;mobile\u0026#34;; private string mobileparameter = security_form_mobile_key; private boolean postonly = true; public smsauthenticationfilter() { super(new antpathrequestmatcher(\u0026#34;/authentication/sms/commit\u0026#34;, \u0026#34;post\u0026#34;)); } public authentication attemptauthentication(httpservletrequest request, httpservletresponse response) throws authenticationexception { if (postonly \u0026amp;\u0026amp; !request.getmethod().equals(\u0026#34;post\u0026#34;)) { throw new authenticationserviceexception( \u0026#34;authentication method not supported: \u0026#34; + request.getmethod()); } string mobile = obtainmobile(request); if (mobile == null) { mobile = \u0026#34;\u0026#34;; } mobile = mobile.trim(); smscodeauthenticationtoken authrequest = new smscodeauthenticationtoken(mobile, null); setdetails(request, authrequest); return this.getauthenticationmanager().authenticate(authrequest); } protected string obtainmobile(httpservletrequest request) { return request.getparameter(mobileparameter); } protected void setdetails(httpservletrequest request, smscodeauthenticationtoken authrequest) { authrequest.setdetails(authenticationdetailssource.builddetails(request)); } public void setmobileparameter(string mobileparameter) { assert.hastext(mobileparameter, \u0026#34;mobileparameter parameter must not be empty or null\u0026#34;); this.mobileparameter = mobileparameter; } } /** * 短信验证码拦截匹配器 */ public class smsvalidatecodefilter extends onceperrequestfilter { private authenticationfailurehandler authenticationfailurehandler; @autowired private coresecurityproperties coresecurityproperties; @autowired private redistemplate redistemplate; public smsvalidatecodefilter(authenticationfailurehandler authenticationfailurehandler) { this.authenticationfailurehandler = authenticationfailurehandler; } @override protected void dofilterinternal(httpservletrequest request, httpservletresponse response, filterchain filterchain) throws servletexception, ioexception { // 是登陆请求而且为post if(stringutils.equals(coresecurityproperties.getsmsauthenticationurl(), request.getrequesturi()) \u0026amp;\u0026amp; stringutils.equalsignorecase(request.getmethod(), \u0026#34;post\u0026#34;)) { try { validate(new servletwebrequest(request)); filterchain.dofilter(request, response); } catch (validatecodeexception e) { authenticationfailurehandler.onauthenticationfailure(request, response, e); } }else { filterchain.dofilter(request, response); } } private void validate(servletwebrequest servletwebrequest) { string questinmobile = null; string questincode = null; string questindevice = null; try { questinmobile = servletrequestutils.getrequiredstringparameter(servletwebrequest.getrequest(), \u0026#34;mobile\u0026#34;); questincode = servletrequestutils.getrequiredstringparameter(servletwebrequest.getrequest(), \u0026#34;code\u0026#34;); questindevice = servletrequestutils.getrequiredstringparameter(servletwebrequest.getrequest(), \u0026#34;device\u0026#34;); }catch (servletrequestbindingexception e) { throw new validatecodeexception(\u0026#34;提交的短信验证码参数缺失\u0026#34;); } string keyname = smscodecontroller.sms_code_mobile_prefix + questindevice + \u0026#34;:\u0026#34; +questinmobile; smsvalidatecode smsvalidatecode = (smsvalidatecode) redistemplate.boundvalueops(keyname).get(); if(stringutils.isempty(questinmobile)) { throw new validatecodeexception(\u0026#34;提交的手机号不能为空\u0026#34;); } if(stringutils.isempty(questincode)) { throw new validatecodeexception(\u0026#34;提交的短信验证码不能为空\u0026#34;); } if(smsvalidatecode == null) { // 过期判断由redis控制,redis设置了过期时间,程序不判断过期行为 throw new validatecodeexception(\u0026#34;手机号\u0026#34; + questinmobile + \u0026#34;短信验证码不存在或已过期\u0026#34;); } if(!stringutils.equalsignorecase(questincode, smsvalidatecode.getcode())) { throw new validatecodeexception(\u0026#34;验证码不匹配\u0026#34;); } // 匹配成功 redistemplate.delete(keyname); } } 第三方登陆 简化验证模式需要将openid服务器 授权码模式直接将请求转给服务器即可 三、权限设置 概览 请求经过的过滤器\n判断是否允许访问的过程\n简单的只区分是否登陆 1 2 3 4 5 6 7 8 9 10 http. //省略其它配置 .formlogin()//基于表带验证 .loginpage(\u0026#34;/authentication/require\u0026#34;) //设置先访问的请求 .loginprocessingurl(\u0026#34;/authentication/commit\u0026#34;) .authorizerequests() //认证的请求 .antmatchers(httpmethod.get,\u0026#34;/authentication/require\u0026#34;, \u0026#34;/me\u0026#34;)//匹配请求 .permitall() //允许所有 .anyrequest() //认证的请求 .authenticated() //需要进行登陆身份认证 //省略其它配置 区分简单、有限角色【硬编码】 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 http. .formlogin()//基于表带验证 .loginpage(\u0026#34;/authentication/require\u0026#34;) //设置先访问的请求 .loginprocessingurl(\u0026#34;/authentication/commit\u0026#34;) .and() .authorizerequests() //认证的请求 .antmatchers(httpmethod.get,\u0026#34;/authentication/require\u0026#34;)//匹配请求 .permitall() //允许所有 .antmatchers(\u0026#34;/user/**\u0026#34;)\t//匹配请求 .hasrole(\u0026#34;admin\u0026#34;)\t//需要管理员角色,匹配的是role_admin,会加前缀role .antmatchers(\u0026#34;/me\u0026#34;)\t//匹配请求 .hasrole(\u0026#34;anonymous\u0026#34;)\t//匿名角色可访问【访问此请求如果未登陆会创建一个匿名授权】 //.antmatchers(\u0026#34;/me\u0026#34;).anonymous() 也可使用这种方式,与上等价 .anyrequest() //认证的请求 .authenticated() //需要身份认证 如果访问的url不是指定的允许所有可访问,也不是指定角色为匿名用户可访问,那么访问时会抛出access is denied (user is anonymous)的异常\n复杂角色【一般用于后台管理】 security权限表达式\n表达式 说明 permitall 永远返回true denyall 永远返回false anonymous 当前用户是anonymous时返回true authenticated 当前用户不是anonymous时返回true rememberme 当前用户是rememberme时返回true fullauthenticated 当前用户即不是rememberme也不是anonymous时返回true hasrole(role) 当前用户拥有指定角色时返回true hasanyrole(role1,role2) 当前用户拥有任意指定角色时返回true hasauthority(authority) 当前用户拥有指定权限时返回true hasanyauthority(authority1,authority2) 当前用户拥有任意指定权限时返回true hasipaddress(ip) 请求匹配ip时返回true 使用方法\n1 2 3 4 5 6 7 8 9 10 11 12 13 //方法一:使用代码的方式指定条件,但是不能指定连续条件 expressionintercepturlregistry.antmatchers(\u0026#34;/user/add\u0026#34;).hasrole(\u0026#34;user_manager\u0026#34;); //方法二:使用表达式,可以指定连续条件 expressionintercepturlregistry.antmatchers(\u0026#34;/user/add\u0026#34;) .access(\u0026#34;hasrole(\u0026#39;user_manager\u0026#39;) and hasipaddress(\u0026#39;192.168.1.100\u0026#39;)\u0026#34;); //方法三:使用@preauthorize(express)注解 @getmapping(\u0026#34;/user/add\u0026#34;) @preauthorize(\u0026#34;hasrole(\u0026#39;admin\u0026#39;)\u0026#34;) public string useradd() { // dosomething } 四、代码 相关代码地址\n","date":"2019-10-09","permalink":"https://hobocat.github.io/post/spring/2019-10-09-spring-security/","summary":"一、基于游览器的安全 表单登陆 设置表单登陆【继承WebSecurityConfigurerAdapter进行适配】 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24","title":"spring security使用指南"},]
[{"content":"一、简介 单点登陆:在多系统中单一位置登录可以实现多系统同时登录的一种技术。常在互联网应用和企业级平台中使用。\n第三方登陆:在某系统中使用其他系统的用户实现本系统登录的方式。如,在京东中使用微信登录。解决信息孤岛和用户不对等的实现方案。\n单点登陆需要解决的问题:数据跨域、信息共享和安全。\n二、跨域解决方案 域的概念 \t在应用模型中一个完整的,有独立访问路径的功能集合称为一个域。如:百度称为一个应用或系统。百度有若干的域,如:搜索引擎【www.baidu.com】,百度贴吧【tie.baidu.com】,百度知道【zhidao.baidu.com】,百度地图【map.baidu.com】等。域信息,有时也称为多级域名。域的划分:以ip,端口,域名,主机名为标准,实现划分。\n跨域概念 客户端请求的时候,请求的服务器,不是同一个ip,端口,域名,主机名的时候,都称为跨域。\n如:localhost和127.0.0.1也属于跨域\nsession跨域 \t所谓session跨域就是摒弃了系统(web容器)提供的session,而使用自定义的类似session的机制来保存客户端数据的一种解决方案。如:通过设置cookie的domain来实现cookie的跨域传递。在cookie中传递一个自定义的session_id。这个session_id是客户端的唯一标记。将这个标记作为key,将客户端需要保存的数据作为value,在服务端进行保存。这种机制就是session的跨域解决。\n具体逻辑 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 \u0026lt;!-- 配置跨域请求 --\u0026gt; \u0026lt;filter\u0026gt; \u0026lt;filter-name\u0026gt;corsfilter\u0026lt;/filter-name\u0026gt; \u0026lt;filter-class\u0026gt;com.thetransactioncompany.cors.corsfilter\u0026lt;/filter-class\u0026gt; \u0026lt;init-param\u0026gt; \u0026lt;param-name\u0026gt;cors.alloworigin\u0026lt;/param-name\u0026gt; \u0026lt;param-value\u0026gt;*\u0026lt;/param-value\u0026gt; \u0026lt;/init-param\u0026gt; \u0026lt;init-param\u0026gt; \u0026lt;param-name\u0026gt;cors.supportedmethods\u0026lt;/param-name\u0026gt; \u0026lt;param-value\u0026gt;get, post, head, put, delete\u0026lt;/param-value\u0026gt; \u0026lt;/init-param\u0026gt; \u0026lt;init-param\u0026gt; \u0026lt;param-name\u0026gt;cors.supportedheaders\u0026lt;/param-name\u0026gt; \u0026lt;param-value\u0026gt;accept, origin, x-requested-with, content-type, last-modified\u0026lt;/param-value\u0026gt; \u0026lt;/init-param\u0026gt; \u0026lt;init-param\u0026gt; \u0026lt;param-name\u0026gt;cors.exposedheaders\u0026lt;/param-name\u0026gt; \u0026lt;param-value\u0026gt;set-cookie\u0026lt;/param-value\u0026gt; \u0026lt;/init-param\u0026gt; \u0026lt;init-param\u0026gt; \u0026lt;param-name\u0026gt;cors.supportscredentials\u0026lt;/param-name\u0026gt; \u0026lt;param-value\u0026gt;true\u0026lt;/param-value\u0026gt; \u0026lt;/init-param\u0026gt; \u0026lt;/filter\u0026gt; \u0026lt;filter-mapping\u0026gt; \u0026lt;filter-name\u0026gt;corsfilter\u0026lt;/filter-name\u0026gt; \u0026lt;url-pattern\u0026gt;/*\u0026lt;/url-pattern\u0026gt; \u0026lt;/filter-mapping\u0026gt; \u0026lt;!-- 设置token的servlet --\u0026gt; \u0026lt;servlet\u0026gt; \u0026lt;servlet-name\u0026gt;corssservlet\u0026lt;/servlet-name\u0026gt; \u0026lt;servlet-class\u0026gt;com.kun.corssservlet\u0026lt;/servlet-class\u0026gt; \u0026lt;/servlet\u0026gt; \u0026lt;servlet-mapping\u0026gt; \u0026lt;servlet-name\u0026gt;corssservlet\u0026lt;/servlet-name\u0026gt; \u0026lt;url-pattern\u0026gt;/corss\u0026lt;/url-pattern\u0026gt; \u0026lt;/servlet-mapping\u0026gt; 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 public class corssservlet extends httpservlet { @override protected void doget(httpservletrequest req, httpservletresponse resp) throws servletexception, ioexception { cookie[] cookies = req.getcookies(); printwriter writer = resp.getwriter(); //如果已经存在cookie则查看cookie值 boolean findauth = false; if(cookies != null) { for (cookie cookie : cookies) { if(cookie.getname().equals(\u0026#34;auth\u0026#34;)){ findauth = true; writer.println(cookie.getname()); writer.println(cookie.getvalue()); writer.println(cookie.getmaxage()); } } } //生成cookie,注意domain的域,应该用代码智能切分 //如www.baidu.com,tie.baidu.com均设置为.baidu.com if(!findauth) { string token = uuid.randomuuid().tostring().replace(\u0026#34;-\u0026#34;, \u0026#34;\u0026#34;); cookie authcookie = new cookie(\u0026#34;auth\u0026#34;, token); authcookie.setpath(\u0026#34;/\u0026#34;); authcookie.setdomain(\u0026#34;.kun.com\u0026#34;); resp.addcookie(authcookie); } } } 三、信息共享解决方案 spring-session \tspring-session技术是spring提供的用于处理集群会话共享的解决方案。spring-session技术是将用户session数据保存到三方存储容器中,如:mysql,redis等\n\tspring-session技术是解决同域名下的多服务器集群session共享问题的。不能直接解决跨域session共享问题。\n需要设置其它选项。\n第一步:导入依赖\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;redis.clients\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;jedis\u0026lt;/artifactid\u0026gt; \u0026lt;version\u0026gt;版本号\u0026lt;/version\u0026gt; \u0026lt;/dependency\u0026gt; \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;javax.servlet\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;javax.servlet-api\u0026lt;/artifactid\u0026gt; \u0026lt;version\u0026gt;版本号\u0026lt;/version\u0026gt; \u0026lt;scope\u0026gt;provided\u0026lt;/scope\u0026gt; \u0026lt;/dependency\u0026gt; \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;org.springframework.session\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;spring-session-data-redis\u0026lt;/artifactid\u0026gt; \u0026lt;version\u0026gt;版本号\u0026lt;/version\u0026gt; \u0026lt;/dependency\u0026gt; \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;org.springframework.session\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;spring-session\u0026lt;/artifactid\u0026gt; \u0026lt;version\u0026gt;版本号\u0026lt;/version\u0026gt; \u0026lt;/dependency\u0026gt; \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;org.springframework\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;spring-webmvc\u0026lt;/artifactid\u0026gt; \u0026lt;version\u0026gt;版本号\u0026lt;/version\u0026gt; \u0026lt;/dependency\u0026gt; 第二步:web.xml配置\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 \u0026lt;!-- session设置代理过滤器 --\u0026gt; \u0026lt;filter\u0026gt; \u0026lt;filter-name\u0026gt;springsessionrepositoryfilter\u0026lt;/filter-name\u0026gt; \u0026lt;filter-class\u0026gt;org.springframework.web.filter.delegatingfilterproxy\u0026lt;/filter-class\u0026gt; \u0026lt;/filter\u0026gt; \u0026lt;filter-mapping\u0026gt; \u0026lt;filter-name\u0026gt;springsessionrepositoryfilter\u0026lt;/filter-name\u0026gt; \u0026lt;url-pattern\u0026gt;/*\u0026lt;/url-pattern\u0026gt; \u0026lt;/filter-mapping\u0026gt; \u0026lt;listener\u0026gt; \u0026lt;listener-class\u0026gt;org.springframework.web.context.contextloaderlistener\u0026lt;/listener-class\u0026gt; \u0026lt;/listener\u0026gt; \u0026lt;context-param\u0026gt; \u0026lt;param-name\u0026gt;contextconfiglocation\u0026lt;/param-name\u0026gt; \u0026lt;param-value\u0026gt;classpath*:/spring-redis.xml\u0026lt;/param-value\u0026gt; \u0026lt;/context-param\u0026gt; \u0026lt;servlet\u0026gt; \u0026lt;servlet-name\u0026gt;dispatcher\u0026lt;/servlet-name\u0026gt; \u0026lt;servlet-class\u0026gt;org.springframework.web.servlet.dispatcherservlet\u0026lt;/servlet-class\u0026gt; \u0026lt;init-param\u0026gt; \u0026lt;param-name\u0026gt;contextconfiglocation\u0026lt;/param-name\u0026gt; \u0026lt;param-value\u0026gt;classpath*:/spring-mvc.xml\u0026lt;/param-value\u0026gt; \u0026lt;/init-param\u0026gt; \u0026lt;load-on-startup\u0026gt;1\u0026lt;/load-on-startup\u0026gt; \u0026lt;/servlet\u0026gt; \u0026lt;servlet-mapping\u0026gt; \u0026lt;servlet-name\u0026gt;dispatcher\u0026lt;/servlet-name\u0026gt; \u0026lt;url-pattern\u0026gt;/\u0026lt;/url-pattern\u0026gt; \u0026lt;/servlet-mapping\u0026gt; 第三步:spring-mvc,spring-redis配置\n1 2 3 4 5 6 \u0026lt;!-- spring-mvc配置 --\u0026gt; \u0026lt;context:component-scan base-package=\u0026#34;com.kun.controller\u0026#34; use-default-filters=\u0026#34;false\u0026#34; \u0026gt; \u0026lt;context:include-filter type=\u0026#34;annotation\u0026#34; expression=\u0026#34;org.springframework.stereotype.controller\u0026#34; /\u0026gt; \u0026lt;/context:component-scan\u0026gt; \u0026lt;mvc:annotation-driven/\u0026gt; \u0026lt;mvc:default-servlet-handler/\u0026gt; 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 \u0026lt;!-- spring-redis配置 --\u0026gt; \u0026lt;context:component-scan base-package=\u0026#34;com.kun\u0026#34; \u0026gt; \u0026lt;context:exclude-filter type=\u0026#34;annotation\u0026#34; expression=\u0026#34;org.springframework.stereotype.controller\u0026#34; /\u0026gt; \u0026lt;/context:component-scan\u0026gt; \u0026lt;bean id=\u0026#34;poolconfig\u0026#34; class=\u0026#34;redis.clients.jedis.jedispoolconfig\u0026#34;\u0026gt; \u0026lt;property name=\u0026#34;maxidle\u0026#34; value=\u0026#34;300\u0026#34;/\u0026gt; \u0026lt;property name=\u0026#34;maxwaitmillis\u0026#34; value=\u0026#34;1000\u0026#34;/\u0026gt; \u0026lt;property name=\u0026#34;testonborrow\u0026#34; value=\u0026#34;true\u0026#34;/\u0026gt; \u0026lt;/bean\u0026gt; \u0026lt;context:component-scan base-package=\u0026#34;org.springframework.web.filter\u0026#34;/\u0026gt; \u0026lt;!-- 添加redishttpsessionconfiguration用于session共享 --\u0026gt; \u0026lt;bean id=\u0026#34;redishttpsessionconfiguration\u0026#34; class=\u0026#34;org.springframework.session.data.redis.config.annotation.web.http.redishttpsessionconfiguration\u0026#34;\u0026gt; \u0026lt;property name=\u0026#34;maxinactiveintervalinseconds\u0026#34; value=\u0026#34;18000\u0026#34; /\u0026gt; \u0026lt;property name=\u0026#34;cookieserializer\u0026#34; ref=\u0026#34;defaultcookieserializer\u0026#34;/\u0026gt; \u0026lt;/bean\u0026gt; \u0026lt;!-- 设置cookie domain的名称,如果不设置将无法跨域 --\u0026gt; \u0026lt;bean id=\u0026#34;defaultcookieserializer\u0026#34; class=\u0026#34;org.springframework.session.web.http.defaultcookieserializer\u0026#34;\u0026gt; \u0026lt;property name=\u0026#34;domainname\u0026#34; value=\u0026#34;.kun.com\u0026#34;/\u0026gt; \u0026lt;property name=\u0026#34;cookiename\u0026#34; value=\u0026#34;session\u0026#34;/\u0026gt; \u0026lt;property name=\u0026#34;cookiepath\u0026#34; value=\u0026#34;/\u0026#34; /\u0026gt; \u0026lt;/bean\u0026gt; \u0026lt;bean id=\u0026#34;jedisconnectionfactory\u0026#34; class=\u0026#34;org.springframework.data.redis.connection.jedis.jedisconnectionfactory\u0026#34;\u0026gt; \u0026lt;property name=\u0026#34;hostname\u0026#34; value=\u0026#34;192.168.1.158\u0026#34;/\u0026gt; \u0026lt;property name=\u0026#34;port\u0026#34; value=\u0026#34;6379\u0026#34;/\u0026gt; \u0026lt;property name=\u0026#34;poolconfig\u0026#34; ref=\u0026#34;poolconfig\u0026#34;/\u0026gt; \u0026lt;property name=\u0026#34;usepool\u0026#34; value=\u0026#34;true\u0026#34;/\u0026gt; \u0026lt;property name=\u0026#34;timeout\u0026#34; value=\u0026#34;3000\u0026#34;/\u0026gt; \u0026lt;/bean\u0026gt; spring-session解决跨域修改web容器方案\n\t默认session存放在当前域下,如访问www.kun.com的session的domain为www.kun.com,访问pps.kun.com的session的domain为pps.kun.com。session因为domain不同所以session并不能跨域。\n\t解决方案:在web目录下,创建和web-inf同级的meta-inf目录,并创建context.xml文件,将以下内容写入即可改变session的domain实现跨域访问。\n1 2 3 \u0026lt;?xml version=\u0026#34;1.0\u0026#34; encoding=\u0026#34;utf-8\u0026#34;?\u0026gt; \u0026lt;!-- 设置主域名与子域名sessionid一致 --\u0026gt; \u0026lt;context sessioncookiepath=\u0026#34;/\u0026#34; sessioncookiedomain=\u0026#34;.kun.com\u0026#34;/\u0026gt; nginx session共享 \tnginx中的ip_hash技术能够将某个ip的请求定向到同一台后端,这样一来这个ip下的某个客户端和某个后端就能建立起稳固的session,ip_hash是在upstream配置中定义的,如下示例\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 # 设置为ip_hash策略,或者自定义hash策略【经过代理的不可设为ip_hash策略】 upstream nginx.app.com { server www.kun.com:8080; server pps.kun.com:8080; ip_hash; # hash $remote_add; 使用自定义hash策略 } server { listen 80; location / { proxy_pass http://nginx.app.com; proxy_set_header host $http_host; proxy_set_header cookie $http_cookie; proxy_set_header x-real-ip $remote_addr; proxy_set_header x-forwarded-for $proxy_add_x_forwarded_for; client_max_body_size 100m; } } 四、token单点登陆机制 传统身份认证【基于cookie】 客户端使用用户名还有密码通过了身份验证,不过下回这个客户端再发送请求时候因为http 是一种没有状态的协议,还得再验证一下。\n解决的方法是,当用户请求登录的时候,如果没有问题,我们在服务端生成一条记录,这个记录里存储了登录的用户信息,然后把这条记录的id号返给客户端。客户端收到以后把这个 id 号存储在 cookie 里,下次这个用户再向服务端发送请求的时候,可以带着这个 cookie ,这样服务端会验证一个这个 cookie 里的信息,看看能不能在服务端这里找到对应的记录,如果可以,说明用户已经通过了身份验证,就把用户请求的数据返回给客户端。\n这种认证中出现的问题是:\n会话存储:每次认证用户发起请求时,服务器需要去创建一个记录来存储信息。当越来越多的用户发请求时,内存的开销也会不断增加。\n可扩展性:如果在服务端的内存【不借助redis等】中存储登录信息,伴随而来的是可扩展性问题。如token需要同步。\ncors(跨域资源共享):如果让数据跨多台移动设备上使用时,跨域资源的共享是个问题。在使用ajax抓取另一个域的资源,就可以会出现禁止请求的情况。\ncsrf(跨站请求伪造):用户在访问银行网站时,可能被利用其访问其他的网站。\ntoken身份认证 使用基于 token 的身份验证方法,在服务端需要存储用户的登录记录。大致流程如下:\n客户端使用用户名、密码请求登录 服务端收到请求,验证用户名、密码 验证成功后,服务端会签发一个token,再把这个token发送给客户端 客户端收到 token 以后可以把它存储起来,比如放在cookie里或者local storage或session storage里 客户端每次向服务端请求资源时请求头需要带着服务端签发的token 服务端收到请求后验证客户端请求里面带着的token,如果验证成功,就向客户端返回请求的数据 使用token验证的优势:\n无状态、可扩展。在客户端存储的tokens是无状态的,并且能够被扩展。基于这种无状态和服务端不存储session信息,负载负载均衡器能够将用户信息从一个服务传到其他服务器上。\n安全性。请求中发送token而不再是发送cookie能够防止csrf(跨站请求伪造)。即使在客户端使用cookie存储token,cookie也仅仅是一个存储机制而不是用于认证。不将信息存储在session中,让我们少了对session操作。\n五、json web token(jwt)机制 \tjwt是一种紧凑且自包含的,用于在多方传递json对象的技术。传递的数据可以使用数字签名增加其安全行。可以使用hmac加密算法或rsa公钥/私钥加密方式。\n紧凑:数据小,可以通过url,post参数,请求头发送。且数据小代表传输速度快。\n自包含:使用payload数据块记录用户必要且不隐私的数据,可以有效的减少数据库访问次数,提高代码性能。\njwt一般用于处理用户身份验证或数据信息交换。\n用户身份验证:一旦用户登录,每个后续请求都将包含jwt,允许用户访问该令牌允许的路由,服务和资源。单点登录是当今广泛使用jwt的一项功能,因为它的开销很小,并且能够轻松地跨不同域使用。\n数据信息交换:jwt是一种非常方便的多方传递数据的载体,因为可以保证数据的有效性和安全性。\njwt数据结构 json web token由三部分组成,它们之间用圆点(.)连接。这三部分分别是:\nheader\nheader由两部分组成:token的类型(“jwt”)和算法名称(比如:hmac sha256或者rsa等等),如\n1 2 3 4 { \u0026#34;alg\u0026#34;: \u0026#34;hs256\u0026#34;, \u0026#34;type\u0026#34;: \u0026#34;jwt\u0026#34; } payload\n包含声明,声明有三种类型: registered, public 和 private。\nregistered claims : 这里有一组预定义的声明,它们不是强制的。如:iss (发行者), exp (过期时间), sub (主题), aud (受众)等。 public claims : 可以随意定义。一般都会在jwt注册表中增加定义。避免和已注册信息冲突。 private claims : 用于在同意使用它们的各方之间共享信息,并且不是注册的或公开的声明。 1 2 3 4 5 { \u0026#34;sub\u0026#34;: \u0026#34;user login\u0026#34;, \u0026#34;name\u0026#34;: \u0026#34;kun\u0026#34; \u0026#34;admin\u0026#34;: true } signature\n签名算法是header中指定的,用于将header和payload加密判断是否更改,具体操作步骤为:\n加密算法(base64urlencoder(header) + \u0026ldquo;.\u0026rdquo; + base64urlencoder(payload), secret)\n签名是用于验证消息在传递过程中有没有被更改,并且,对于使用私钥签名的token,它还可以验证jwt的发送方是否为它所称的发送方。\ntoken保存位置 webstorage\nwebstorage可保存的数据容量为5m分为localstorage和sessionstorage。且只能存储字符串数据。\nlocalstorage的生命周期是永久的,关闭页面或浏览器之后localstorage中的数据也不会消失。localstorage除非主动删除数据,否则数据永远不会消失。\nsessionstorage是会话相关的本地存储单元,生命周期是在仅在当前会话下有效。sessionstorage引入了一个“浏览器窗口”的概念,sessionstorage是在同源的窗口中始终存在的数据。只要这个浏览器窗口没有关闭,即使刷新页面或者进入同源另一个页面,数据依然存在。但是sessionstorage在关闭了浏览器窗口后就会被销毁。同时独立的打开同一个窗口同一个页面,sessionstorage也是不一样的。\ncookie\n使用cookie存储,使用请求头发送可以避免csrf(跨站请求伪造),且方便跨域请求。\njwt执行流程 jwt应用示例 jwt工具类,用于生成jwt和解析jwt\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 public class jwtutil { // 生成签名的时候使用的秘钥secret,这个方法本地封装了的,一般可以从本地配置文件中读取 // 切记这个秘钥不能外露哦。它就是你服务端的私钥,在任何场景都不应该流露出去。 // 一旦客户端得知这个secret, 那就意味着客户端是可以自我签发jwt了。 private static final string secret = \u0026#34;com.kun.secret\u0026#34;; /** * 用户登录成功后生成jwt * 使用hs256算法 私匙使用用户密码 */ public static string createjwt(long ttlmillis, user user) { // 指定签名的时候使用的签名算法,也就是header那部分,jjwt已经将这部分内容封装好了。 signaturealgorithm signaturealgorithm = signaturealgorithm.hs256; // 生成jwt的时间 long nowmillis = system.currenttimemillis(); // 创建payload的私有声明(根据特定的业务需要添加,如果要拿这个做验证,一般是需要和jwt的接收方提前沟通好验证方式的) map\u0026lt;string, object\u0026gt; claims = new hashmap\u0026lt;string, object\u0026gt;(); claims.put(\u0026#34;userid\u0026#34;, user.getid()); claims.put(\u0026#34;username\u0026#34;, user.getusername()); claims.put(\u0026#34;userage\u0026#34;, user.getuserage()); // 生成签发人 string subject = user.getusername(); // 下面就是在为payload添加各种标准声明和私有声明了 // 这里其实就是new一个jwtbuilder,设置jwt的body jwtbuilder builder = jwts.builder() // 如果有私有声明,一定要先设置这个自己创建的私有的声明,这个是给builder的claim赋值 // 一旦写在标准的声明赋值之后,就是覆盖了那些标准的声明的 .setclaims(claims) // 设置jti(jwt id):是jwt的唯一标识,根据业务需要,这个可以设置为一个不重复的值 // 主要用来作为一次性token,从而回避重放攻击。 .setid(uuid.randomuuid().tostring()) // iat: jwt的签发时间 .setissuedat(new date(nowmillis)) // 代表这个jwt的主体,即它的所有人 // 这个是一个json格式的字符串,可以存放什么userid,roldid之类的,作为什么用户的唯一标志。 .setsubject(subject) // 设置过期时间 .setexpiration(new date(nowmillis + ttlmillis)) // 设置签名使用的签名算法和签名使用的秘钥 .signwith(signaturealgorithm, secret); return builder.compact(); } /** * token的解密, parseclaimsjws步骤会校验 */ public static claims parsejwt(string token) { // 签名秘钥,和生成的签名的秘钥一模一样 // 得到defaultjwtparser claims claims = jwts.parser() //设置签名的秘钥 .setsigningkey(secret) //设置需要解析的jwt .parseclaimsjws(token).getbody(); return claims; } } jwt测试\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 public class jwttest { private static user user = new user(1001, \u0026#34;kun\u0026#34;, \u0026#34;123456\u0026#34;, 19); // 创建 @test public void create() { string token = jwtutil.createjwt(60000, user); system.out.println(token); } // 解析\u0026amp;校验 @test public void parse() { string token = \u0026#34;eyjhbgcioijiuzi1nij9.eyjzdwiioijrdw4ilcj1c2vytmftzsi6imt1biisimv4cci6mtu2mdmynzcxoswidxnlcklkijoxmdaxlcjpyxqioje1njazmjc2ntksinvzzxjbz2uioje5lcjqdgkioiiwnge1mdqxmi1jy2q5ltrhyzqtodywzc02nzcyytazmwvjmmeifq.t1q7jf6hyjra1r0xjd5qfpfbagpepjwpnnoeuffebux\u0026#34;; claims claims = jwtutil.parsejwt(token); system.out.println(claims.get(\u0026#34;userid\u0026#34;)); system.out.println(claims.get(\u0026#34;username\u0026#34;)); system.out.println(claims.get(\u0026#34;userage\u0026#34;)); } } jwt单点登陆使用注意点 使用cookie时需要解决跨域问题(设置domain),cookie只是存储手段,需要使用http请求头发送 服务器需要开启允许跨域请求,否则无法发起跨域请求 jwt的过期时间需要在每次请求之后进行修改 ","date":"2019-06-12","permalink":"https://hobocat.github.io/post/application/2019-06-12-single-sign-on/","summary":"一、简介 单点登陆:在多系统中单一位置登录可以实现多系统同时登录的一种技术。常在互联网应用和企业级平台中使用。 第三方登陆:在某系统中使用其他系统的用户实现本系统登","title":"单点登陆"},]
[{"content":"一、nginx概述 简介 \tnginx是一个开源且高效、可靠的http中间件、代理服务。\nnginx优势:\nio多路复用的epoll 轻量级【功能模块少、代码模块化】 cpu亲和【将一个进程\u0026quot;绑定\u0026quot; 到一个或一组cpu上,避免cacahe miss】 处理文件采用sendfile方式【mmap系统调用】 nginx版本选择\nmainline version\t开发版 stable version\t稳定版 legacy version\t历史版本 yum安装nginx 第一步:安装前准备\n1 2 3 4 5 6 #安装nginx必要库 yum -y install gcc-c++ gcc autoconf pcre-devel make automake #安装可选命令工具 yum -y install wget httpd-tools #官方要求执行 sudo yum install yum-utils 第二步:修改/etc/yum.repos.d/nginx.repo\n[nginx-stable] name=nginx stable repo baseurl=http://nginx.org/packages/centos/$releasever/$basearch/ gpgcheck=1 enabled=1 gpgkey=https://nginx.org/keys/nginx_signing.key [nginx-mainline] name=nginx mainline repo baseurl=http://nginx.org/packages/mainline/centos/$releasever/$basearch/ gpgcheck=1 enabled=0 gpgkey=https://nginx.org/keys/nginx_signing.key 第三步:执行安装\n1 sudo yum install nginx 安装文件\nrpm -ql nginx查看安装目录及文件\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 /etc/logrotate.d/nginx #nginx日志轮转,用于日志切割 /etc/nginx/nginx.conf #nginx主要配置文件 /etc/nginx/conf.d/default.conf #安装之后默认加载的文件 /etc/nginx/fastcgi_params #cgi配置 /etc/nginx/scgi_params #cgi配置 /etc/nginx/uwsgi_params #cgi配置 /etc/nginx/koi-utf #编码转换的映射文件 /etc/nginx/koi-win #编码转换的映射文件 /etc/nginx/win-utf #编码转换的映射文件 /etc/nginx/mime.types #设置http协议content-type与扩展名对应关系 /etc/nginx/modules #nginx模块目录指向/usr/lib64/nginx/modules /usr/lib64/nginx/modules #nginx模块目录 /etc/sysconfig/nginx #用于守护进程 /etc/sysconfig/nginx-debug #用于守护进程 /usr/lib/systemd/system/nginx-debug.service #用于守护进程\t/usr/lib/systemd/system/nginx.service #用于守护进程 /usr/sbin/nginx #nginx命令 /usr/sbin/nginx-debug #nginx-debug命令 /usr/share/doc/nginx-1.16.0 #nginx手册 /usr/share/doc/nginx-1.16.0/copyright #nginx手册 /usr/share/man/man8/nginx.8.gz #nginx帮助文件 /usr/share/nginx/html/50x.html #nginx默认50x界面 /usr/share/nginx/html/index.html #nginx默认index界面 /var/cache/nginx #nginx缓冲目录 /var/log/nginx #nginx日志目录 nginx源码安装 提前准备:\n下载并解压源码 安装必要库 1 yum -y install gcc-c++ gcc autoconf pcre-devel make automake zlib-devel openssl openssl-devel 第一步:设置编译参数\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 ./configure \\ --prefix=/etc/nginx \\ --sbin-path=/usr/sbin/nginx \\ --modules-path=/usr/lib64/nginx/modules \\ --conf-path=/etc/nginx/nginx.conf \\ --error-log-path=/var/log/nginx/error.log \\ --http-log-path=/var/log/nginx/access.log \\ --pid-path=/var/run/nginx.pid \\ --lock-path=/var/run/nginx.lock \\ --http-client-body-temp-path=/var/cache/nginx/client_temp \\ --http-proxy-temp-path=/var/cache/nginx/proxy_temp \\ --http-fastcgi-temp-path=/var/cache/nginx/fastcgi_temp \\ --http-uwsgi-temp-path=/var/cache/nginx/uwsgi_temp \\ --http-scgi-temp-path=/var/cache/nginx/scgi_temp \\ --user=nginx \\ --group=nginx \\ --with-compat \\ --with-file-aio \\ --with-threads \\ --with-http_addition_module \\ --with-http_auth_request_module \\ --with-http_dav_module \\ --with-http_flv_module \\ --with-http_gunzip_module \\ --with-http_gzip_static_module \\ --with-http_mp4_module \\ --with-http_random_index_module \\ --with-http_realip_module \\ --with-http_secure_link_module \\ --with-http_slice_module \\ --with-http_ssl_module \\ --with-http_stub_status_module \\ --with-http_sub_module \\ --with-http_v2_module \\ --with-mail \\ --with-mail_ssl_module \\ --with-stream \\ --with-stream_realip_module \\ --with-stream_ssl_module \\ --with-stream_ssl_preread_module \\ --with-cc-opt=\u0026#39;-o2 -g -pipe -wall -wp,-d_fortify_source=2 -fexceptions -fstack-protector-strong --param=ssp-buffer-size=4 -grecord-gcc-switches -m64 -mtune=generic -fpic\u0026#39; \\ --with-ld-opt=\u0026#39;-wl,-z,relro -wl,-z,now -pie\u0026#39; 第二步:编译\u0026amp;安装\n1 2 make make install 安装编译参数 使用nginx -v查看版本信息和安装编译参数\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 #安装目录或文件路径 --prefix=/etc/nginx --sbin-path=/usr/sbin/nginx --modules-path=/usr/lib64/nginx/modules --conf-path=/etc/nginx/nginx.conf --error-log-path=/var/log/nginx/error.log --http-log-path=/var/log/nginx/access.log --pid-path=/var/run/nginx.pid --lock-path=/var/run/nginx.lock #执行对应模块时,nginx所保留的临时文件 --http-client-body-temp-path=/var/cache/nginx/client_temp --http-proxy-temp-path=/var/cache/nginx/proxy_temp --http-fastcgi-temp-path=/var/cache/nginx/fastcgi_temp --http-uwsgi-temp-path=/var/cache/nginx/uwsgi_temp --http-scgi-temp-path=/var/cache/nginx/scgi_temp #nginx进程启动的用户和用户组 --user=nginx\t--group=nginx --with-compat --with-file-aio #使用aio传输文件,效率不一定比sendfile高 --with-threads --with-http_addition_module --with-http_auth_request_module --with-http_dav_module --with-http_flv_module --with-http_gunzip_module #支持gunzip的压缩方式。用于客户端不支持gzip压缩功能下 --with-http_gzip_static_module #预读gzip功能 --with-http_mp4_module --with-http_random_index_module #目录中随机选取主页模块 --with-http_realip_module --with-http_secure_link_module #安全下载链接模块 --with-http_slice_module #大文件拆分使用 --with-http_ssl_module #https的证书相关 --with-http_stub_status_module #查看nginx客户端状态模块 --with-http_sub_module #http内容替换模块 --with-http_v2_module --with-mail --with-mail_ssl_module --with-stream #编译ngx_stream_core_module --with-stream_realip_module --with-stream_ssl_module --with-stream_ssl_preread_module #定义要传递到c编译器命令行的其他选项 --with-cc-opt=\u0026#39;-o2 -g -pipe -wall -wp,-d_fortify_source=2 -fexceptions -fstack-protector-strong --param=ssp-buffer-size=4 -grecord-gcc-switches -m64 -mtune=generic -fpic\u0026#39; #定义要传递到c链接器命令行的其他选项 --with-ld-opt=\u0026#39;-wl,-z,relro -wl,-z,now -pie\u0026#39; 二、nginx基本命令 检查nginx配置文件语法是否正确\n1 nginx -t -c nginx.conf #t代表检查 c指定文件路径 重新加载配置文件\n1 nginx -s reload -c nginx.conf #s代表信号relaod参数表示重加载 c指定文件路径 查看安装模块\n1 nginx -v #查看编译时自己设置的参数包含模块信息 快速停止\n1 nginx -s stop 优雅停机(现有任务运行完成,其它请求拒绝)\n1 nginx -s quit 三、简单配置 配置文件位置 /etc/nginx/nginx.conf为主要配置文件,在此配置文件中默认配置了 include /etc/nginx/conf.d/*.conf即会加载conf.d下的配置文件\nnginx.conf配置 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 user nginx; #设置nginx服务的系统启动用户 worker_processes 1; #工作进程数,建议设置位cpu核心数 error_log /var/log/nginx/error.log warn; #nginx错误日志 pid /var/run/nginx.pid; #pid文件位置 events { worker_connections 1024; #每个进程允许的最大连接数,生成环境必须调整 } http { include /etc/nginx/mime.types; #content_type配置 default_type application/octet-stream; #日志格式定义 log_format main \u0026#39;$remote_addr - $remote_user [$time_local] \u0026#34;$request\u0026#34; \u0026#39; \u0026#39;$status $body_bytes_sent \u0026#34;$http_referer\u0026#34; \u0026#39; \u0026#39;\u0026#34;$http_user_agent\u0026#34; \u0026#34;$http_x_forwarded_for\u0026#34;\u0026#39;; #访问日志定义使用main格式打印 access_log /var/log/nginx/access.log main;\tsendfile on; #是否开启sendfile #tcp_nopush on; #是否不立即传输而是等待包大小或者时间到达条件,以提高效率 keepalive_timeout 65; #客户端和服务的keepalive超市时间 #gzip on; #压缩传输 include /etc/nginx/conf.d/*.conf; #引入辅助配置文件 } nginx配置结构 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 http { #...... server { listen 80; server_name localhost; location / { root /usr/share/nginx/html; index index.html index.htm; } error_page 500 502 503 504 /50x.html; location = /50x.html { root /usr/share/nginx/html; } } server { #...... } } nginx日志格式 nginx可用日志变量\nhttp请求变量:$arg_parameter、$http_header、$sent_http_header\n内置变量:\n名称 描述 $bytes_sent 发送到客户端的字节数 $connection 连接序列号 $connection_requests 通过连接发出的当前请求数 $msec 以秒为单位的时间 $pipe p代表pipelined方式请求,.代表其它方式 $request_length 请求长度(包括请求行,请求头和请求正文) $request_time 以毫秒为单位请求处理时间 $status 回应状态 $time_iso8601 iso 8601格式的当地时间 $time_local 本地时间格式 自定义变量\nnginx默认日志格式\n1 2 3 log_format main \u0026#39;$remote_addr $status - $remote_user [$time_local] \u0026#34;$request\u0026#34; \u0026#39; \u0026#39;$status $body_bytes_sent \u0026#34;$http_referer\u0026#34; \u0026#39; \u0026#39;\u0026#34;$http_user_agent\u0026#34; \u0026#34;$http_x_forwarded_for\u0026#34;\u0026#39;; 四、官方模块 http_stub_status_module 作用:监控nginx客户端状态\n1 2 3 syntax:\tstub_status; default: — context: server, location 配置示例\n1 2 3 4 5 6 7 8 location /stub_status { stub_status; } #-------------------------------访问/stub_status返回数据-------------------------------- #active connections: 2 当前连接数 #server accepts handled requests # 13 13 16 握手次数 连接次数 请求次数 #reading: 0 writing: 1 waiting: 1 读个数 写个数 等待个数 http_random_index_module 作用:访问随机主页\n1 2 3 syntax:\trandom_index on | off; default: random_index off; context: location 配置示例\n1 2 3 4 5 #只能配置在“/”下 location / {\troot /opt/nginx/app/randmon_page;\trandom_index on; } http_sub_module 作用:http内容替换\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 【替换指定字符串】 syntax:\tsub_filter string replacement; default: — context: http, server, location 【是否阻止response header中写入last-modified,防止缓存,默认是off,即防止缓存】 syntax:\tsub_filter_last_modified on | off; default: sub_filter_last_modified off; context: http, server, location 【是否只替换一次字符串】 syntax:\tsub_filter_once on | off; default: sub_filter_once on; context: http, server, location syntax:\tsub_filter_types mime-type ...; default: sub_filter_types text/html; context: http, server, location 配置示例\n1 2 3 4 5 6 location / { sub_filter \u0026#39;kun\u0026#39; \u0026#39;kun\u0026#39;; sub_filter_once off; root /opt/nginx/app/sub_module; index submodule.html; } http_limit_conn_module 作用:限制连接频率\n1 2 3 4 5 6 7 8 9 【开辟保存连接信息的空间 key:存储信息,name空间名称,size空间大小】 syntax:\tlimit_conn_zone key zone=name:size; default: — context: http 【限制同时连接的并发数量 zone:空间名称,number:限制个数】 syntax:\tlimit_conn zone number; default: — context: http, server, location 配置示例\n1 2 3 4 5 6 7 8 9 limit_conn_zone $binary_remote_addr zone=coon_addr:10m; #开辟10m空间 server { #...... location / { limit_conn addr 1; #每次一个ip只允许1次连接 root /usr/share/nginx/html; index index.html index.htm; } } http_limit_req_module 作用:限制请求频率\n1 2 3 4 5 6 7 8 9 【开辟保存请求信息的空间 key:存储信息,name空间名称,size空间大小,rate请求速率】 syntax: limit_req_zone key zone=name:size rate=rate [sync]; default: — context: http 【限制同时请求的并发数量 zone:空间名称,burst允许超过个数,nodelay是否延迟执行burst 】 syntax:\tlimit_req zone=name [burst=number] [nodelay | delay=number]; default:\t— context:\thttp, server, location 配置示例\n1 2 3 4 5 6 7 8 9 10 11 12 13 #开辟10m空间,每ip每秒只允许请求一次 limit_req_zone $binary_remote_addr zone=req_addr:10m rate=1r/s; server { #...... location / { limit_req zone=req_addr burst=3 nodelay;\t#允许突发连接数为3,不延迟 root /usr/share/nginx/html; index index.html index.htm; } } #------------------------------------使用ab工具压测#----------------------------------- #ab -n 20 -c 20 http://localhost/ #结果成功4个请求,失败16个请求 http_access_module 作用:控制访问的ip,如果多层代理此种方式有问题【基于remote_addr识别】\n1 2 3 4 5 6 7 8 9 【允许访问名单】 syntax: allow address | cidr | unix: | all; default: — context: http, server, location, limit_except 【拒绝访问名单】 syntax: deny address | cidr | unix: | all; default: — context: http, server, location, limit_except 配置示例\n1 2 3 4 5 6 location ~ ^/admin.html { root /opt/nginx/app/access_module; index admin.html; allow 192.168.1.0/24; #允许次网段访问 deny all; #不允许其它人访问,注意带all参数的放最后 } http_auth_basic_module 作用:用户登陆认证\n1 2 3 4 5 6 7 8 9 【需开启次模块进行认证,string代表页面上的登陆提示信息】 syntax: auth_basic string | off; default: auth_basic off; context: http, server, location, limit_excep 【存储用户名、密码信息的模块】 syntax: auth_basic_user_file file; default: — context: http, server, location, limit_except 配置示例\n1 2 3 4 5 6 7 location ~ ^/auth.html { root /opt/nginx/app/auth_module; auth_basic \u0026#34;manager site\u0026#34;; auth_basic_user_file /etc/nginx/auth_conf; } #------------------------------------------------------------------------------------- #使用【htpasswd -c /etc/nginx/auth_conf username 】制作存放密码文件 http_secure_link_module 作用:制定并允许检查请求的真实性以及保护资源免遭未授权的访问也可限制链接生效时长\n1 2 3 4 5 6 7 syntax: secure_link expression; default: — context: http, server, location syntax: secure_link_md5 expression; default: — context: http, server, location 配置示例\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #echo -n \u0026#39;$expire$uri kun\u0026#39;| openssl md5 -binary | openssl base64 | tr +/ -_ | tr -d = #即可等待md5值 location ~ ^/download { #定义md5和expire变量位置 secure_link $arg_md5,$arg_expire; #kun未混淆串 secure_link_md5 \u0026#34;$secure_link_expires$uri kun\u0026#34;; #如果md5不正确 if ($secure_link = \u0026#34;\u0026#34;) { return 403; } #如果expire已经失效 if ($secure_link = \u0026#34;0\u0026#34;) { return 410; } root /opt/nginx/app/secure_link; } http_geoip2_module 作用:基于ip地址匹配maxmind geoip二进制文件,读取ip所在地域信息。\n场景:区别国内国外作http访问规则,区别国内城市作http访问规则\n准备:下载城市信息 下载国家信息\n安装:\n安装libmaxminddb,详见地址 下载ngx_http_geoip2_module模块,详见地址 nginx重新编译安装,添加编译参数 1 2 #路径地址为解压的ngx_http_geoip2_module模块的路径 ./configure 【原参数】 --add-dynamic-module=/path/to/ngx_http_geoip2_module nginx.conf配置:\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 load_module modules/ngx_http_geoip2_module.so; #...... http { #...... geoip2 /etc/maxmind-country.mmdb { auto_reload 5m; $geoip2_metadata_country_build metadata build_epoch; #$variable_with_ip为用于辨别ip地址的变量,可设置为$remote_addr或自定义变量 $geoip2_data_country_code default=us source=$variable_with_ip country iso_code; $geoip2_data_country_name country names en; } geoip2 /etc/maxmind-city.mmdb { $geoip2_data_city_name default=london city names en; } } 五、nginx服务 nginx作为静态web服务 cdn服务简介\n用户请求域名,通过dns服务器解析之后,导向了最近的服务器以取得最快的访问服务。nginx作为静态资源缓存载体十分高效\n配置nginx文件读取相关\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 【采取epoll方式发送文件】 syntax: sendfile on | off; default: sendfile off; context: http, server, location, if in location 【不立即发送数据包,将多个包整体进行整合一次发送,提高传输效率,sendfile开启时才能使用】 syntax:\ttcp_nopush on | off; default: tcp_nopush off; context: http, server, location 【与tcp_nopush相反,立即发送数据包,keepalive开启时才能使用】 syntax: tcp_nodelay on | off; default: tcp_nodelay on; context: http, server, location --------------------------------ngx_http_gzip_module--------------------------------- 【允许传输gzip文件,在客户端解压,减少带宽压力】 syntax: gzip on | off; default: gzip off; context: http, server, location, if in location 【压缩级别(1-9)依次上升】 syntax: gzip_comp_level level; default: gzip_comp_level 1; context: http, server, location 【gzip的http协议版本】 syntax: gzip_http_version 1.0 | 1.1; default: gzip_http_version 1.1; context: http, server, location -------------------------------http_gzip_static_module------------------------------- 【预读gzip功能】 syntax: gzip_static on | off | always; default: gzip_static off; context: http, server, location 配置示例\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 location ~ .*\\.(jpg|gif|png)$ { gzip on;\t#开启压缩 gzip_http_version 1.1; #版本1.1 gzip_comp_level 2; #压缩等级2 gzip_types text/plain application/javascript application/x-javascript text/css application/xml text/javascript application/x-httpd-php image/jpeg image/gif image/png; root /opt/nginx/app/gzip/img; } location ~ .*\\.(txt|xml)$ { gzip on; #开启压缩 gzip_http_version 1.1; #版本1.1 gzip_comp_level 2; #压缩等级2 gzip_types text/plain application/javascript application/x-javascript text/css application/xml text/javascript application/x-httpd-php image/jpeg image/gif image/png; root /opt/nginx/app/gzip/doc; } location ~ ^/download { gzip_static on; #开启gzip预读取,必须要存在gzip压缩文件 tcp_nopush on; #开启tcp_nopush,累计包一起发送 root /opt/nginx/app/gzip; } 配置nginx浏览器缓存相关\n检验是否过期的方法:expires【http1.0】、cache-control(max-age)【http1.1】 相关语法\n1 2 3 4 5 ----------------------------------http_headers_module--------------------------------- 【设置缓存过期时间】 syntax: expires [modified] time; default: expires off; context: http, server, location, if in location 配置示例\n1 2 3 4 5 #响应头返回max-age=86400,但浏览器可能会发送max-age=0并不使用,目的是每次交互拿到最新数据 location ~ .*\\.html$ { expires 24h; root /opt/nginx/app/expires; } 跨域访问\n为避免csrf攻击,浏览器默认禁止跨域访问。但因为业务设计或者其它原因我们有时需要打开跨域访问\n1 2 3 4 5 ---------------------------------http_headers_module---------------------------------- 【添加access-control-allow-origin与access-control-allow-methods请求头】 syntax:\tadd_header name value [always]; default: — context: http, server, location, if in location 配置示例\n1 2 3 4 5 6 7 8 9 10 11 server {\tlisten 81; server_name www.kun.com; location ~ .*\\.html$ { root /opt/nginx/app/oringin; #被发起ajax请求的页面开启允许跨域访问,*代表允许所有ip跨域访问 add_header access-control-allow-origin http://192.168.1.155; add_header access-control-allow-methods get,post,put,delete,options; } } 基于http_refer防盗链\n1 2 3 4 5 ----------------------------------http_referer_module--------------------------------- 【有效的referers信息,none代表空,block代表允许不带协议信息的】 syntax:\tvalid_referers none | blocked | server_names | string ...; default: — context: server, location 配置示例\n1 2 3 4 5 6 7 8 9 10 11 12 location ~ .*\\.(jpg|gif|png)$ { #允许的referers信息,none代表空,block代表允许不带协议信息的 valid_referers none blocked 192.168.1.155; #当invalid_referer信息无效时$invalid_referer为1 if ($invalid_referer) { return 403; } root /opt/nginx/app/gzip/img; } #------------------------------------------------------------------------------------ #curl -i http://192.168.1.155/wei.png 返回200 #curl -i http://192.168.1.155/wei.png -e \u0026#34;http://www.baidu.com\u0026#34;\t返回403 nginx作为代理服务 正向代理\u0026amp;反向代理\n正向代理:客户端明确要到达的目的服务器,单无法自己去访问,借助正向代理访问目的服务器,如翻墙、通过一台能上网的主机代理上网\n正向代理:客户端知道要访问的服务器但是并不了解最终提供服务的服务器,如访问/admin和/merchant实际被代理到两条不同服务器\n正向代理区别和反向代理的区别在于代理的对象不一样\n正向代理代理的对象是客户端 反向代理代理的对象是服务器 配置代理\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 -----------------------------------http_proxy_module--------------------------------- 【设置代理的目的地址】 syntax: proxy_pass url; default: — context: location, if in location, limit_except 【缓存相关、是否尽可能多的缓存响应信息然后一次性发送给客户端】 syntax: proxy_buffering on | off; default: proxy_buffering on; context: http, server, location syntax: proxy_buffer_size size; default: proxy_buffer_size 4k|8k; context: http, server, location syntax:\tproxy_buffers number size; default: proxy_buffers 8 4k|8k; context: http, server, location syntax: proxy_busy_buffers_size size; default: proxy_busy_buffers_size 8k|16k; context: http, server, location 【重定向相关、对重定向的信息是否重写】 syntax:\tproxy_redirect default; proxy_redirect off; proxy_redirect redirect replacement; default: proxy_redirect default; context: http, server, location 【请求相关、更改请求信息】 syntax:\tproxy_set_header field value; default: proxy_set_header host $proxy_host; proxy_set_header connection close; context: http, server, location syntax: proxy_hide_header field; default: — context: http, server, location syntax: proxy_set_body value; default: — context: http, server, location 【超时相关】 syntax:\tproxy_connect_timeout time; default: proxy_connect_timeout 60s; context: http, server, location syntax:\tproxy_read_timeout time; default: proxy_read_timeout 60s; context: http, server, location syntax:\tproxy_send_timeout time; default: proxy_send_timeout 60s; context: http, server, location 配置示例\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 #---------------------------------------反向代理-------------------------------------- server { listen 81; server_name www.kun.com; location ~ / { root /opt/nginx/app/proxy; } } #设置反向代理 location ~ ^/proxy.html$ {\tproxy_pass http://192.168.1.155:81; } #--------------------------------------http正向代理------------------------------------ server { #配置dns解析ip地址,以及超时时间(5秒) resolver 8.8.8.8; # 必需 resolver_timeout 5s; #...... location / { #配置正向代理参数 proxy_pass http://$host$request_uri; #设置请求头信息 proxy_set_header host $http_host; proxy_set_header x-real-ip $remote_addr #重定向设置 proxy_redirect default; #设置超时时间 proxy_connect_timeout 30; proxy_send_timeout 60s; proxy_read_timeout 60s; #配置缓存大小 proxy_buffering on; proxy_buffer_size 32k; proxy_buffers 8 128k; proxy_busy_buffers_size 256k; #关闭磁盘缓存读写减少i/o proxy_max_temp_file_size 256k; } } #-------------------------------------https正向代理------------------------------------ server{ resolver 8.8.8.8; access_log /var/log/nginx/access_proxy-443.log main; listen 443; location / { root html; index index.html index.htm; proxy_pass https://$host$request_uri; proxy_buffers 8 128k; proxy_max_temp_file_size 0k; proxy_connect_timeout 30; proxy_send_timeout 60; proxy_read_timeout 60; proxy_next_upstream error timeout invalid_header http_502; } error_page 500 502 503 504 /50x.html; location = /50x.html { root html; } } #curl --proxy proxy.cn:443 http://www.alipay.com测试代理是否可用 nginx作为负载均衡服务 1 2 3 4 5 6 7 8 9 --------------------------------stream_upstream_module-------------------------------- syntax: upstream name { ... } default: — context: stream 【url_hash策略】 syntax:\thash key [consistent]; default: — context: upstream 后端服务器在负载均衡调度中的状态\n状态 解释 down 当前server暂时不参与负载均衡 backup 预留的备份服务器,当提供服务的server宕机顶上,恢复时隐退 max_fails 允许请求失败的次数 fail_timeout 经过max_fails失败后,服务暂停的时间 max_conns 限制最大的接收的连接数 调度算法\n算法 简介 轮询 默认算法,按时间顺序逐一分配到不同的后端服务器 weight 加权轮询weight值越大,分配访问几率越高 ip_hash 每个请求按访问ip的hash结果分配 least_conn 连接数最少的机器被连接 hash 关键数值 hash自定义的key 配置示例\n1 2 3 4 5 6 7 8 9 10 11 12 13 upstream app { #ip_hash; #策略配置 #hash $request_uri; #使用uri作为hash的key server 192.168.1.158:8001 backup; server 192.168.1.158:8002 down; server 192.168.1.158:8003 max_fails=3 fail_timeout=30s weight=3; } server { #...... location / { proxy_pass http://app; } } nginx作为缓存服务 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 ----------------------------------http_proxy_module---------------------------------- 【缓存文件定义】 syntax: proxy_cache_path path [levels=levels] [use_temp_path=on|off] keys_zone=name:size [inactive=time] [max_size=size] [manager_files=number] [manager_sleep=time] [manager_threshold=time] [loader_files=number] [loader_sleep=time] [loader_threshold=time] [purger=on|off] [purger_files=number] [purger_sleep=time] [purger_threshold=time]; default: — context: http 【是否开启缓存】 syntax:\tproxy_cache zone | off; default:\tproxy_cache off; context:\thttp, server, location 【缓存过期周期】 syntax: proxy_cache_valid [code ...] time; default: — context: http, server, location 【缓存的维度】 syntax: proxy_cache_key string; default: proxy_cache_key $scheme$proxy_host$request_uri; context: http, server, location 清除指定缓存的方式\nrm -rf 缓存目录 第三方扩展模块ngx_cache_purge 部分页面不缓存方式\n1 2 3 syntax: proxy_no_cache string ...; default: — context: http, server, location 配置示例\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 upstream app { server 192.168.1.158:8001; server 192.168.1.158:8002; server 192.168.1.158:8003; } #缓存文件配置 #参数位置1:路径【目录必须存在】 #参数位置2:目录结构,推荐1:2 #参数位置3:zone名称:zone空间大小【1m大约能存8千key信息】 #参数位置4:缓存文件最大占用空间 #参数位置5:某个缓存在inactive指定的时间内如果不访问,将会从缓存中删除 #参数位置6:是否使用临时路径存储,建议关闭 proxy_cache_path /var/cache/nginx/app levels=1:2 keys_zone=proxy_cache_zone:10m max_size=10g inactive=60m use_temp_path=off; server { #...... location / { proxy_cache proxy_cache_zone; proxy_cache_valid 200 304 12h; #200、304响应保存12小时 proxy_cache_valid any 10m; #任何响应保存10分钟 proxy_cache_key $host$uri$is_args$args; #缓存的key add_header nginx-cache \u0026#34;$upstream_cache_status\u0026#34;; #返回前端响应头 #当发生错误时重新请求 proxy_next_upstream error timeout invalid_header http_500 http_502 http_503 http_504;\tproxy_pass http://app; } } 大文件分片请求\n1 2 3 4 5 -----------------------------------http_slice_module---------------------------------- 【将请求的大文件进行拆分,分别向几台后端服务器发送读取请求】 syntax: slice size; default: slice 0; context: http, server, location 优势:每个子请求收到的数据都会形成一个独立的文件,一个请求断了,其它请求不受影响\n缺点:slice设置不合理时可能会导致文件描述符耗尽等情况\n六、动静分离 将动态资源和静态资源分离,提高程序效率,减少服务器压力而且当后台服务无法正常提供时静态服务依旧可用。策略是使用动态代理的方式转发请求到后台服务器。\n1 2 3 4 5 6 7 8 9 10 11 12 upstream api { server 192.168.1.117:8080; } server { #...... location / { root /opt/nginx/app/dynamic; } location ~ ^/api { proxy_pass http://api; } } 七、rewrite规则 应用场景:\nurl访问跳转,支持开发设计(页面跳转、兼容性支持、展示效果等) seo优化,便于排名靠前 维护(后台维护、流量转发) 安全 配置语法\n1 2 3 4 ---------------------------------http_rewrite_module--------------------------------- syntax: rewrite regex replacement [flag]; default: — context: server, location, if flag选项说明\n值 解释 last 停止后续rewrite指令集,利用修改后的uri在nginx中重新匹配 break 停止后续rewrite指令集,表示完成rewrite寻找结果文件 redirect 返回302临时重定向,地址栏会显示跳转后的地址,用户下次还访问此链接 permanent 返回301永久重定向,地址栏会显示跳转后的地址,浏览器会缓存,用户下次直接访问即使nginx关闭也会重定向链接 配置示例\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 #------------------------------------break\u0026amp;last-------------------------------------- #请求 http://hostname/last 会定位到/test返回200响应码,浏览器地址不变 #请求 http://hostname/break 回去寻找root下/test文件,找不到返回404响应码,浏览器地址不变 location ~ ^/break { rewrite ^/break /test break; } location ~ ^/last { rewrite ^/last /test last; } location /test { default_type application/json; return 200 \u0026#39;{\u0026#34;status\u0026#34;:\u0026#34;success\u0026#34;}\u0026#39;; } #---------------------------------redirect\u0026amp;permanent--------------------------------- #请求 http://hostname/redirect 会被临时重定向到www.baidu.com #请求 http://hostname/permanent 会被永久重定向到www.baidu.com,下次不会再请求次nginx location ~ /redirect { rewrite /redirect http://www.baidu.com redirect; } location ~ /permanent { rewrite /permanent http://www.baidu.com permanent; } rewirte加入控制流程\n1 2 3 syntax:\tif (condition) { ... } default: — context: server, location 符号 含义 =,!= 做是否完全匹配 ~,!~ 区分大小写是否匹配字符串 ~*,!~* 不区分大小写是否匹配字符串 -f,!-f 文件存在,文件是否存在 -d,!-d 目录存在,目录是否存在 -e ,!-e 文件、目录、符号链接是否存在 -x ,!-x 文件是否可执行 配置示例\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 #http://hostname/course-11-22-33.html会寻找/opt/nginx/app/course/11/22/course_33.html #如果页面存在则返回,如果不存在则返回404 # #如果访问路径有误则进入if判断 #如果是chrome则重定向到163 #如果文件不存在则重定向到baidu location ~ ^/course { rewrite /course-(\\d+)-(\\d+)-(\\d+).html /course/$1/$2/course_$3.html break; if ($http_user_agent ~* chrome) { rewrite ^/(.*)$ http://www.163.com redirect; } if (!-f $request_filename) { rewrite ^/(.*)$ http://www.baidu.com?wd=$1 redirect; } root /opt/nginx/app; } rewirte的优先级:http\u0026gt;server\u0026gt;location\n例:将请求全部定向到维护页 rewrite ^(.*)$ /pages/maintain.html break;\n八、https 对称加密原理 非对称加密原理 https加密原理 自建ca证书生成(非受信机构颁发) 步骤一:生成key密钥\n1 openssl genrsa -idea -out kun.key 1024 #idea为加密算法,过程中需要填写密码,需要记住 步骤二:生成证书签名请求文件(csr文件)\n1 openssl req -new -key kun.key -out kun.csr #如果给第三方机构需要按需填写 步骤三:生成证书签名文件(ca文件)\n1 openssl x509 -req -days 3650 -in kun.csr -signkey kun.key -out kun.crt #days有效期 附key脱密步骤\n1 2 #当key文件有密码时,每次启动nginx必须输入密码,造成不便 openssl rsa -in kun.key -out kun_nopass.key 根据苹果要求生成证书方式\n1 2 3 4 5 6 7 8 #1、openssl版本要求1.2以上 #2、https证书必须使用sha256以上哈希算法签名 #3、https证书必须使用rsa 2048位或ecc 256以上公钥算法 #4、使用前向加密技术 openssl genrsa -idea -out kun.key 1024 #-keyout 会重新生成不需要密码访问的key openssl req -days 3650 -x509 -sha256 -nodes -newkey rsa:2048 -keyout kun.key -out kun_apple.crt 配置应用 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 -----------------------------------http_ssl_module----------------------------------- 【开启ssl,此语法在1.15.0以后废弃,直接在监听端口后加ssl即可】 syntax:\tssl on | off; default: ssl off; context: http, server 【crt文件位置】 syntax: ssl_certificate file; default: — context: http, server 【key文件位置】 syntax: ssl_certificate_key file; default: — context: http, server 【ssl session缓存】 syntax:\tssl_session_cache off | none | [builtin[:size]] [shared:name:size]; default: ssl_session_cache none; context: http, server 【ssl session缓存时长】 syntax:\tssl_session_timeout time; default: ssl_session_timeout 5m; context: http, server 配置示例\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 #如果crt没有脱密,要使用nginx -c /etc/nginx/nginx.conf启动,不可使用服务重启 server{ #监听443 listen 443 ssl; server_name localhost; ssl_certificate /etc/nginx/ssl_key/kun.crt; #crt文件位置 ssl_certificate_key /etc/nginx/ssl_key/kun.key; #key文件位置 ssl_session_cache shared:ssl:10m; #10m贡献缓存大约可存储8k-10k会话 ssl_session_timeout 10m; #10分钟session过期 location / { root /usr/share/nginx/html; index index.html index.htm; } } 建议激活keepalive长连接【减少ssl握手网络的消耗】和设置ssl session缓存\n九、nginx与lua开发 nginx直接使用添加lua模块已经不建议使用,会带来效率损失,已经不稳定。建议使用openresty。\nopenresty是一个基于nginx与lua的高性能web平台,其内部集成了大量精良的lua库、第三方模块以及大多数的依赖项。用于方便地搭建能够处理超高并发、扩展性极高的动态 web 应用、web 服务和动态网关。\n源码安装步骤 第一步:安装pcre和openssl\n1 yum install -y pcre openssl 第二步:执行构建命令\n1 2 3 4 5 6 7 #配置安装模块,可更具环境自己挑选,使用./configure --help可查看可编译模块 ./configure --prefix=/opt/openresty \\ --with-luajit \\ --without-http_redis2_module \\ --with-http_iconv_module make make install 第三步:将命令加入path变量【可选】\n第四步:测试\n1 2 3 4 5 6 #将一下代码加入/opt/openresty/nginx/conf/nginx.conf location /hello_lua { default_type \u0026#39;text/plain\u0026#39;; content_by_lua \u0026#39;ngx.say(\u0026#34;hello, lua\u0026#34;)\u0026#39;; } #访问http://hostname/hello_lua查看是否打印出hello, lua nginx调用lua模块指令顺序 命令 时间 init_by_lua、init_by_lua_file 当nginx master进程在加载nginx配置文件时运行指定的lua脚本,通常用来注册 lua 的全局变量或在服务器启动时预加载lua模块和分配内存 init_worker_by_lua、init_worker_by_lua_file 在每个nginx worker进程启动时调用指定的lua代码 set_by_lua、set_by_lua_file 设置一个变量,常用与计算一个逻辑,然后返回结果 该阶段不能运行output api、control api、subrequest api、cosocket api rewrite_by_lua、rewrite_by_lua_file 作为rewrite阶段的处理,为每个请求执行指定的lua代码 access_by_lua,access_by_lua_file 每个请求在访问阶段的调用lua脚本进行处理 content_by_lua,content_by_lua_file 作为“content handler”为每个请求执行lua代码,为请求者输出响应内容 header_filter_by_lua,header_filter_by_lua_file 一般用来设置cookie和headers body_filter_by_lua,body_filter_by_lua_file 一般会在一次请求中被调用多次, 因为这是实现基于 http 1.1 chunked 编码的所谓“流式输出”的 log_by_lua,log_by_lua_file 在log阶段调用指定的lua脚本,并不会替换access log,而是在那之后进行调用 nginx lua api 名称 描述 ngx.cookie_time 设置cookie时间 ngx.ctx 当前请求的上下文 ngx.exec 内部重定向 ngx.var nginx变量 ngx.req.get_header 获取请求头 ngx.req.get_url_args 获取url请求参数 ngx.redirct 重定向 ngx.print 输出响应内容体 ngx.say 同ngx.print,单会加入换行符 十、常见问题 server_name多虚拟主机优先级访问 当出现同名同端口的虚拟主机时,nginx在加载配置时会报冲突警告,但是不会报错。\n1 2 3 4 5 6 7 8 9 10 server { listen 80; server_name www.test_server1.com www.kun.com #...... } server { listen 80; server_name www.test_server2.com www.kun.com #...... } 使用www.test_server1.com或者www.test_server2.com访问会定位到相应的虚拟主机 使用www.kun.com访问会定位到第一个匹配的虚拟主机,即和www.test_server1.com同台 使用ip地址访问会匹配第一个出现的虚拟主机,即和www.test_server1.com同台 location匹配优先级 1 2 3 4 syntax:\tlocation [ = | ~ | ~* | ^~ ] uri { ... } location @name { ... } default: — context: server, location ~ 和~* 前缀表示正则location\n=,^~ 、@ 和无任何前缀的都属于普通location\n匹配优先级\n普通location优先级大于正则location 普通location匹配时精确匹配=级别最高,^~如果同时匹配上多个,匹配长度最长的优先(最大前缀匹配) 正则location匹配时谁物理顺序先,谁最优先 当普通location中的前缀匹配和正则匹配均存在时。匹配到最大前缀匹配之后继续正则匹配,如果正则匹配上则覆盖前缀匹配结果 如果使用=或者^~时,会终止后续的正则匹配 try_files的使用 当资源文件未找到时的自定义处理\n1 2 3 4 syntax:\ttry_files file ... uri; try_files file ... =code; default: — context: server, location 配置示例\n1 2 3 4 5 6 7 8 9 location / { root /opt/nginx/app/try_files; try_files $uri @resource_not_ready; } #资源未找到,直接返回页面 location @resource_not_ready { return \u0026#34;200\u0026#34; \u0026#34;资源未准备好,请稍后再试\u0026#34;; } alias和root区别 1 2 3 4 5 6 7 8 9 10 11 12 13 #----------------------------------------root---------------------------------------- location /request_path/image/ { root /local_path/image/; } #访问 http:www.kun.com/request_path/image/cat.png #文件 /local_path/image/request_path/image/cat.png #----------------------------------------root---------------------------------------- location /request_path/image/ { alias /local_path/image/; } #访问 http:www.kun.com/request_path/image/cat.png #文件 /local_path/image/cat.png 如何获取用户的真实ip 在第一层代理设置x-real-ip,后续代理不可设置此头信息\n常见错误码 nginx:413 request entity too large\n原因:用户上传文件时大小受限(文件信息在request body内)\n解决方案:合理设置client_max_body_size大小\n1 2 3 syntax: client_max_body_size size; default: client_max_body_size 1m; context: http, server, location 502 bad gateway\n原因:后端服务未响应\n504 gateway time-out\n原因:后端服务执行超时\n十一、nginx性能优化 文件句柄设置 系统控制\n修改/etc/security/limits.conf配置,添加nginx用户限制\nnginx hard nproc 65535 nginx soft nproc 65535 nginx内部控制\n此设置值要设置比系统控制小\n1 worker_rlimit_core 65535; cpu亲和 使用cat /proc/cpuinfo | grep \u0026quot;processor\u0026quot;查看当前cpu核心数\n使用ps -eo pid,args,psr |grep nginx查看进程运行在哪些cpu核心\n1 2 3 worker_processes 4; #设置nginx进程数建议和cpu核心数一致 #worker_cpu_affinity 0001 0010 0100 1000 #指定绑定的cpu核心 #worker_cpu_affinity auto; #自动绑定 通用配置优化 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 user nginx; worker_processes 4; #建议和cpu核心数一致 worker_cpu_affinity auto; #自动绑定 error_log /var/log/nginx/error.log warn; pid /var/run/nginx.pid; events { use epoll; #使用epoll模式 worker_connections 10240; #调节连接数 } http { include /etc/nginx/mime.types; default_type application/octet-stream; charset utf-8; #设置字符集 log_format main \u0026#39;$remote_addr - $remote_user [$time_local] \u0026#34;$request\u0026#34; \u0026#39; \u0026#39;$status $body_bytes_sent \u0026#34;$http_referer\u0026#34; \u0026#39; \u0026#39;\u0026#34;$http_user_agent\u0026#34; \u0026#34;$http_x_forwarded_for\u0026#34;\u0026#39;; access_log /var/log/nginx/access.log main; sendfile on; #使用sendfile tcp_nopush on; #尽量多的合并包发送 #tcp_nodeny on; #实时性较高的场所可使用 keepalive_timeout 65; gzip on; #开启压缩 gzip_disable \u0026#34;mis [1-6]\\.\u0026#34;; #对ie关闭 gzip_http_version 1.1; #版本1.1 include /etc/nginx/conf.d/*.conf; } 十二、nginx_lua防火墙 ngx_lua_waf启动时会报错,但是可以使用,建议使用官方的waf模块\nnginx-lua开源防火墙下载地址\n安装步骤\n第一步:新建文件夹放置waf\n1 2 #存放nginx_lua mkdir /etc/nginx/waf 第二步:解压文件当waf目录下\n第三步:nginx.conf的http段加入配置\n1 2 3 4 lua_package_path \u0026#34;/etc/nginx/waf/?.lua\u0026#34;; lua_shared_dict limit 10m; init_by_lua_file /etc/nginx/waf/init.lua; access_by_lua_file /etc/nginx/waf/waf.lua; 第四步:修改/etc/nginx/waf/config.lua\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 rulepath = \u0026#34;/etc/nginx/waf/wafconf/\u0026#34; --wafconf规则目录文件 attacklog = \u0026#34;on\u0026#34; --是否开启日志 logdir = \u0026#34;/var/log/nginx/hack/\u0026#34; --hack文件夹需要新建 urldeny=\u0026#34;on\u0026#34; --是否拦截url访问 redirect=\u0026#34;on\u0026#34; --拦截后是否重定向 cookiematch=\u0026#34;on\u0026#34; --是否拦截cookie攻击 postmatch=\u0026#34;on\u0026#34; --是否拦截post攻击 whitemodule=\u0026#34;on\u0026#34; --是否开启url白名单 black_fileext={\u0026#34;php\u0026#34;,\u0026#34;jsp\u0026#34;} --填写不允许上传文件后缀类型 ipwhitelist={\u0026#34;127.0.0.1\u0026#34;} --ip白名单,多个ip用逗号分隔 ipblocklist={\u0026#34;1.0.0.1\u0026#34;} --ip黑名单,多个ip用逗号分隔 ccdeny=\u0026#34;on\u0026#34; --是否开启拦截cc攻击 ccrate=\u0026#34;100/60\u0026#34; --设置cc攻击频率,单位为秒.每分钟默认钟同一个ip只能请求同一个地址100次 --警告内容,可在中括号内自定义 html=[[ \u0026lt;html xmlns=\u0026#34;http://www.w3.org/1999/xhtml\u0026#34;\u0026gt;\u0026lt;head\u0026gt; \u0026lt;meta http-equiv=\u0026#34;content-type\u0026#34; content=\u0026#34;text/html; charset=utf-8\u0026#34;\u0026gt; \u0026lt;title\u0026gt;网站防火墙\u0026lt;/title\u0026gt; \u0026lt;style\u0026gt; p { line-height:20px; } ul{ list-style-type:none;} li{ list-style-type:none;} \u0026lt;/style\u0026gt; \u0026lt;/head\u0026gt; \u0026lt;body style=\u0026#34; padding:0; margin:0; font:14px/1.5 microsoft yahei, 宋体,sans-serif; color:#555;\u0026#34;\u0026gt; 重新加载nginx配置文件即可\n附录 curl命令 1 2 3 4 curl http://www.baidu.com #仅返回服务端的的响应报文 curl -v http://www.baidu.com \u0026gt;/dev/null #返回请求头和响应头信息并将响应报文重定向空设备 curl -i http://192.168.1.155/wei.png #i仅查看返回头信息 curl -i http://192.168.1.155/wei.png -e \u0026#34;http://www.baidu.com\u0026#34; #e设置referer值 ab命令 1 2 ab -n50 -c20 http://www.baidu.com/ #压测命令,n代表请求总个数,c代表同时并发个数 ab -n50 -c20 -k http://www.baidu.com/ #-k代表长连接 指标展示\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 server software: bws/1.1 server hostname: www.baidu.com server port: 80 document path: / document length: 153380 bytes concurrency level: 20 #并发级别 time taken for tests: 3.636 seconds #花费总时才 complete requests: 50 #完成请求个数 failed requests: 45 #失败个数 (connect: 0, receive: 0, length: 45, exceptions: 0) write errors: 0 keep-alive requests: 0 total transferred: 7728364 bytes html transferred: 7680157 bytes requests per second: 13.75 [#/sec] (mean) #qps【每秒请求量】 time per request: 1454.312 [ms] (mean) #一个请求消耗的时间 time per request: 72.716 [ms] (mean, across all concurrent requests) #服务端处理请求时间,不包含网络时间 transfer rate: 2075.82 [kbytes/sec] received #网络传输速率 connection times (ms) min mean[+/-sd] median max connect: 4 8 2.0 9 14 processing: 358 1288 716.1 1075 3609 waiting: 9 196 157.0 193 576 total: 366 1296 716.6 1086 3617 percentage of the requests served within a certain time (ms) 50% 1086\t66% 1408 75% 1570 80% 1932 90% 2421 95% 2853 98% 3617 99% 3617 100% 3617 (longest request) gzip命令 1 2 gzip –c filename \u0026gt; filename.gz #压缩为gzip格式,并保留源文件 gunzip filename #解压gzip文件haproxy ","date":"2019-06-04","permalink":"https://hobocat.github.io/post/nginx/2019-06-04-nginx/","summary":"一、Nginx概述 简介 Nginx是一个开源且高效、可靠的HTTP中间件、代理服务。 nginx优势: IO多路复用的epoll 轻量级【功能模块少、代码模块化】 CP","title":"nginx服务"},]
[{"content":"一、elasticsearch概念 \telasticsearch是一个基于lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于restful web接口。elasticsearch是用java开发的,并作为apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。\nelasticsearch的特点\n(1)可以作为一个大型分布式集群技术,处理pb级数据,服务大公司。也可以运行在单机上,服务小公司\n(2)对用户而言,是开箱即用的,非常简单\n(3)弥补数据库在全文检索,同义词处理,相关度排名,复杂数据分析,海量数据的近实时处理的不足\nelasticsearch的相关概念 cluster\n代表一个集群,集群中有多个节点,其中有一个为主节点,这个主节点是通过选举产生的,主从节点是对于集群内部来说的。elasticsearch的一个概念就是去中心化,字面上理解就是无中心节点,这是对于集群外部来说的,因为从外部来看elasticsearch集群,在逻辑上是个整体,与任何一个节点的通信和与整个elasticsearch集群通信是等价的。\nshards\n代表索引分片,elasticsearch可以把一个完整的索引分成多个分片,这样的好处是可以把一个大的索引拆分成多个,分布到不同的节点上。构成分布式搜索。分片的数量只能在索引创建前指定,并且索引创建后不能更改(primary shard)。\n水平扩容时,需要重新设置分片数量,重新导入数据\nreplicas\n代表索引副本(replica shard),elasticsearch可以设置多个索引副本,副本的作用一是提高系统的容错性,当某个节点某个分片损坏或丢失时可以从副本中恢复。二是提高elasticsearch的查询效率,elasticsearch会自动对搜索请求进行负载均衡。\nrecovery\n代表数据恢复或叫数据重新分布,elasticsearch在有节点加入或退出时会根据机器的负载对索引分片进行重新分配,挂掉的节点重新启动时也会进行数据恢复。\nriver\n代表elasticsearch的一个数据源,也是其它存储方式(如:数据库)同步数据elasticsearch的一个方法。它是以插件方式存在的一个elasticsearch服务,通过读取river中的数据并把它索引到elasticsearch中,官方的river有couchdb的,rabbitmq的,twitter的,wikipedia的\ngateway\n代表elasticsearch索引快照的存储方式,elasticsearch默认是先把索引存放到内存中,当内存满了时再持久化到本地硬盘。gateway对索引快照进行存储,当这个elasticsearch集群关闭再重新启动时就会从gateway中读取索引备份数据。elasticsearch支持多种类型的gateway,有本地文件系统(默认),分布式文件系统,hadoop的hdfs和amazon的s3云存储服务。\ndiscovery.zen\n代表elasticsearch的自动发现节点机制,elasticsearch是一个基于p2p的系统,它先通过广播寻找存在的节点,再通过多播协议来进行节点之间的通信,同时也支持点对点的交互。\ntransport\n代表elasticsearch内部节点或集群与客户端的交互方式,默认内部是使用tcp协议进行交互,同时它支持http协议(json格式)、thrift、servlet、memcached、zeromq等的传输协议(通过插件方式集成)。\nelasticsearch的核心概念 near realtime (nrt)\n从写入数据到可搜索数据有一个延迟(1秒左右,分析写入数据的过程)\ncluster\u0026amp;node\ncluster-集群,包含多个节点,每个节点通过配置来决定属于哪一个集群(默认集群命为“elasticsearch”)\nnode-节点,集群中的一个节点,节点的名字默认是随机分配的。节点名字在运维管理时很重要,节点默认会自动加入一个命名为“elasticsearch”的集群,如果直接启动多个节点,则自动组成一个名为“elasticsearch”的集群。单节点启动也是一个集群。\ndocument\nelasticsearch中的最小数据单元。一个document就是一条数据,一般使用json数据结构表示。每个index下的type中都可以存储多个document。一个document中有多个field,field就是数据字段。\n不要在document中描述java对象的双向关联关系。在转换为json字符串的时候会出现无限递归问题。\nindex\n索引,物理分类。包含若干相似结构的document数据。如:客户索引,订单索引,商品索引等。一个index包含多个document,也代表一类相似的或相同的document。\ntype\n类型。每个索引中都可以有若干type,type是index中的一个逻辑分类,同一个type中的document都有相同的field。\n6.x版本之后,type概念被弱化,一个index中只能有唯一的一个type。在7.x版本之后,会删除type。\n一个index默认10个shard,5个primary shard,5个replica shard\n一个index分配到多个shard上,primary shard和他对应的replica shard不能在同一个节点中存储\n二、linux环境下安装 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 elasticsearch | |--bin【可执行文件包】 | |--config【配置相关目录】 | |--lib【es需要依赖的jar包,es自开发的jar包】 | |--modules【组件包】 | |--plugins【插件目录包,三方插件或自主开发插件】 | |--logs【日志文件相关目录】 | |--data【在es启动后,会自动创建的目录,内部保存es运行过程中需要保存的数据】 安装elasticsearch 第一步、elasticsearch不允许root用户启动,所以需要先创建用户\n1 2 useradd -u es #添加用户和用户组为es chown -r es:es elasticsearch #修改elasticsearch所属主所属组 第二步、修改文件打开限制。至少需要65536的文件创建权限,修改限制信息/etc/security/limits.conf\nes hard nofile 65536 #number open file es soft nofile 65536 第三步、修改线程开启限制。linux默认用户进程有开启1024个线程权限,至少需要4096的线程池预备,修改/etc/security/limits.d/20-nproc.conf\nes soft nproc 4096 root soft nproc unlimited 第四步、修改系统虚拟内存权限。linux默认不允许任何用户和应用直接开辟虚拟内存,修改/etc/sysctl.conf\nvm.max_map_count=655360 第五步、修改客户端访问控制【可选】。修改config/elasticsearch.yml\n1 network.host: 0.0.0.0 第六步、切换用户并启动elasticsearch\n1 2 su es ./bin/elasticsearch 集群启动\n默认情况下一个网段的elasticsearch会自动组成集群。只需启动时指定集群名称和自身节点名称即可\n1 2 3 4 5 # 在不同的机器上执行即可自动组成集群 ./bin/elasticsearch -e cluster.name=my_cluster -e node.name=node_1 # 在同一台机器上启动集群测试 ./bin/elasticsearch -e cluster.name=my_cluster -e node.name=node_1 -epath.data=my_cluster_data_1 -e http.port=5200 配置集群参数discovery.zen.minimum_master_nodes:【投票通过数一般为 可投票机器数/2 + 1】避免集群脑裂\n安装kibana 第一步、修改客户端访问控制。修改config/kibana.yml\n1 2 3 #默认localhost,非本机不可访问 server.host: \u0026#34;0.0.0.0\u0026#34; #elasticsearch.hosts: [\u0026#34;http://localhost:9200\u0026#34;] 有必要时修改 第二步、切换用户并启动elasticsearch\nsu es ./bin/kibana 查看集群状态可安装cerebro软件\n三、kibana简单命令 查看健康状态 命令:get _cat/health?v\n返回:\n参数 含义 shards 分片总个数 pri primary shard个数 relo replica shard个数 unssign 未分配个数 status green【每个索引的primary shard和replica shard都是active的】\nyellow【每个索引的primary shard都是active的,但部分的replica shard不是active的】\nred【不是所有的索引都是primary shard都是active状态的】 检查分片信息 命令:get _cat/shards?v\n返回:\n显示了每个索引的分片信息\n查看索引信息 命令:get _cat/indices?v\n返回:\n索引相关 新增索引\n默认创建索引的时候,会分配5个primary shard,并为每个primary shard分配一个replica shard。\n默认限制:如果磁盘空间不足15%的时候,不分配replica shard。如果磁盘空间不足5%的时候,不再分配任何的primary shard。\n1 2 3 4 5 6 7 put /test_index { \u0026#34;settings\u0026#34;:{ \u0026#34;number_of_shards\u0026#34; : 2, //指定primary shard个数 \u0026#34;number_of_replicas\u0026#34; : 1 //指定每个primary shard的replica shard个数 } } 修改索引\n索引一旦创建,primary shard数量不可变化,可以改变replica shard数量\n1 2 3 4 put /test_index/_settings { \u0026#34;number_of_replicas\u0026#34; : 1 //设置replica shard个数 } 删除索引\n命令delete /test_index [, other_index]\nelasticsearch尽可能保证primary shard平均分布在多个节点上。replica shard会保证不和它自身备份的那个primary shard分配在同一个节点上\nprimary shared不可变的优缺点\n优点:不需要锁,提升并发能力,避免锁问题。数据不变,可以缓存在os cache中(前提是cache足够大)。filter cache始终在内存中,因为数据是不可变的。可以通过压缩技术来节省cpu和io的开销。\n缺点:只要index的结构发生任何变化,都必须重建索引。\n文档crud 创建文档\nput语法\n此操作为手工指定id的document新增方式【7以后必须使用post新增】\n1 2 3 4 5 6 put /test_index/my_type/1 { \u0026#34;name\u0026#34;:\u0026#34;test_doc_01\u0026#34;, \u0026#34;remark\u0026#34;:\u0026#34;first test elastic search\u0026#34;, \u0026#34;order_no\u0026#34;:1 } 返回内容:\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 { \u0026#34;_index\u0026#34; : \u0026#34;test_index\u0026#34;, #新增的document在什么index中 \u0026#34;_type\u0026#34; : \u0026#34;my_type\u0026#34;, #新增的document在什么type中 \u0026#34;_id\u0026#34; : \u0026#34;1\u0026#34;, #指定的id是多少 \u0026#34;_version\u0026#34; : 1, #document的版本是多少,版本从1开始递增,每次写操作都会+1 \u0026#34;result\u0026#34; : \u0026#34;created\u0026#34;, #created创建,updated修改,deleted删除 \u0026#34;_shards\u0026#34; : {\t\u0026#34;total\u0026#34; : 2, #分片数量只提示primary shard \u0026#34;successful\u0026#34; : 1, #成功几个 \u0026#34;failed\u0026#34; : 0 #失败几个 },\t\u0026#34;_seq_no\u0026#34; : 0, #执行的序列号 \u0026#34;_primary_term\u0026#34; : 1 #词条比对 } post语法\n此操作为elasticsearch自动生成id的新增document方式\n1 2 3 4 5 6 post /test_index/my_type { \u0026#34;name\u0026#34;:\u0026#34;test_doc_04\u0026#34;, \u0026#34;remark\u0026#34;:\u0026#34;forth test elastic search\u0026#34;, \u0026#34;order_no\u0026#34;:4 } 查询document\nget查询\n语法:get /index_name/type_name/id\n例如:get /test_index/my_type/1\nget /_mget查询\n1 2 3 4 get /test_index/my_type/_mget { \u0026#34;ids\u0026#34;:[1,2,3,4] } 修改document\n替换document(全量替换)\n语法:和新增put语法一致【put /index_name/type_name/id{field_name:new_field_value}】\n说明:如果有原文档此操作相当于删除原文档,并新增文档,和以前原文档没有任何关系\n1 2 3 4 5 6 put /test_index/my_type/1 { \u0026#34;name\u0026#34;:\u0026#34;new_test_doc_01\u0026#34;, \u0026#34;remark\u0026#34;:\u0026#34;first test elastic search\u0026#34;, \u0026#34;order_no\u0026#34;:1 } put语法强制新增\n语法:put /index_name/type_name/id/_create 或put /index_name/type_name/id?op_type=create\n说明:使用强制新增语法时,如果document的id已存在,则会报错。(version conflict, document already exists)\n1 2 3 4 5 6 put /test_index/my_type/1/_create { \u0026#34;name\u0026#34;:\u0026#34;new_test_doc_01\u0026#34;, \u0026#34;remark\u0026#34;:\u0026#34;first test elastic search\u0026#34;, \u0026#34;order_no\u0026#34;:1 } 更新document(部分更新)\n语法:post /index_name/type_name/id/_update{field_name:field_value_for_update}\n说明:只更新某document中的部分字段,文档必须存在。对比全量替换而言,只是操作上的方便,在底层执行上几乎没有区别\n1 2 3 4 5 6 post /test_index/my_type/1/_update { \u0026#34;doc\u0026#34;:{ \u0026#34;name\u0026#34;:\u0026#34; test_doc_01_for_update\u0026#34; } } 删除document\n语法:delete /index_name/type_name/id\n1 delete /test_index/my_type/1 bulk批量增删改\n语法:\n1 2 3 post /_bulk { \u0026#34;action_type\u0026#34; : { \u0026#34;metadata_name\u0026#34; : \u0026#34;metadata_value\u0026#34; } } { document datas | action datas } action_type可选值为:\n1)create : 强制创建,相当于put /index_name/type_name/id/_create\n2)index: 普通的put操作,相当于创建document或全量替换\n3)update: 更新操作(partial update),相当于 post /index_name/type_name/id/_update\n4)delete: 删除操作\n1 2 3 4 5 6 7 8 post /_bulk { \u0026#34;create\u0026#34; : { \u0026#34;_index\u0026#34; : \u0026#34;test_index\u0026#34; , \u0026#34;_type\u0026#34; : \u0026#34;my_type\u0026#34;, \u0026#34;_id\u0026#34; : \u0026#34;10\u0026#34; } } { \u0026#34;field_name\u0026#34; : \u0026#34;field value\u0026#34; } { \u0026#34;index\u0026#34; : { \u0026#34;_index\u0026#34; : \u0026#34;test_index\u0026#34;, \u0026#34;_type\u0026#34; : \u0026#34;my_type\u0026#34; , \u0026#34;_id\u0026#34; : \u0026#34;20\u0026#34; } } { \u0026#34;field_name\u0026#34; : \u0026#34;field value 2\u0026#34; } { \u0026#34;update\u0026#34; : { \u0026#34;_index\u0026#34; : \u0026#34;test_index\u0026#34;, \u0026#34;_type\u0026#34; : \u0026#34;my_type\u0026#34; , \u0026#34;_id\u0026#34; : 20 } } { \u0026#34;doc\u0026#34; : { \u0026#34;field_name\u0026#34; : \u0026#34;partial update field value\u0026#34; } } { \u0026#34;delete\u0026#34; : { \u0026#34;_index\u0026#34; : \u0026#34;test_index\u0026#34;, \u0026#34;_type\u0026#34; : \u0026#34;my_type\u0026#34;, \u0026#34;_id\u0026#34; : \u0026#34;2\u0026#34; } } 注意:bulk语法中要求一个完整的json串不能有换行\ndocument routing 机制\n\tdocument的路由算法决定了document存放在哪一个primary shard中。算法为:primary shard = hash(routing) % number_of_primary_shards,其中的routing默认为document中的元数据_id,也可以手工指定routing的值,指定方式为:put /index_name/type_name/id?routing=xxx\n1 2 3 4 5 put /test_index/my_type/5?routing=1001 { \u0026#34;detpno\u0026#34;:1001, \u0026#34;name\u0026#34;:\u0026#34;tom\u0026#34; } \t手工指定routing在海量数据中非常有用,通过手工指定的routing值,会将相关的document存储在同shard中,方便后期进行应用级别的负载均衡并可以提高数据检索的效率。如:存电商中的商品,使用商品类型的编号作为routing,elasticsearch会把同一个类型的商品document数据,存在同一个shard中。查询的时候,同一个类型的商品,在一个shard上查询,效率最高。\ndocument增删改原理简图\n\t执行步骤:\n\t1)客户端发起请求,执行增删改操作。所有的增删改操作都由primary shard直接处理,replica shard只被动的备份数据。此操作请求到节点2(请求发送到的节点随机),这个节点称为协调节点(coordinate node)\n\t2)协调节点通过路由算法,计算出本次操作的document所在的shard。假设本次操作的document所在shard为 primary shard 0。协调节点计算后,会将操作请求转发到节点1\n\t3)节点1中的primary shard 0在处理请求后,会将数据的变化同步到对应的replica shard 0中,也就是发送一个同步数据的请求到节点3中\n\t4)replica shard 0在同步数据后,会响应通知请求这同步成功,也就是响应给primary shard 0(节点1)\n\t5)primary shard 0(节点1)接收到replica shard 0的同步成功响应后,会响应请求者,本次操作完成。也就是响应给协调节点(节点2)\n\t6)协调节点返回响应给客户端,通知操作结果\ndocument查询简图 \t执行步骤:\n\t1)客户端发起请求,执行查询操作。查询操作都由所有shard共同处理。假设此操作请求到节点2(随机),这个节点称为协调节点(coordinate node)\n\t2)协调节点通过路由算法,计算出本次查询的document所在的shard。假设本次查询的document所在shard为 shard 0。协调节点计算后,会将操作请求转发到节点1或节点3。分配请求到节点1还是节点3通过随机算法计算\n\t3)节点1或节点3中在处理请求后,会将查询结果返回给协调节点(节点2)\n\t4)协调节点得到查询结果后,再将查询结果返回给客户端\n四、主要元数据 _index\n代表document存放在哪个index中,_index就是索引的名字。生成环境中,类似的document应该存放在一个index中。index名称必须是小写,且不能以【+,-,_】开头。\n_type\n代表document属于index中的哪个type(类别)。6.x版本中,一个index只能定义一个type。\n_id\n代表document的唯一标识。使用index、type和id可以定位唯一的一个document。id可以在新增document时手工指定,也可以由elasticsearch自动创建。\n_source元数据\n一个doc的原生的json数据,不会被索引,用于获取提取字段值 ,启动此字段,索引体积会变大。_source可以被关闭。\n_version\n代表的是document的版本。在elasticsearch中,为document定义了版本信息,document数据每次变化,代表一次版本的变更。版本变更可以避免数据错误问题(并发问题,乐观锁),同时提供es的搜索效率。第一次创建document时,_version版本号为1,默认情况下,后续每次对document执行修改或删除操作都会对_version数据自增1。\n删除document也会使_version自增。当使用put命令再次增加同id的document,_version会继续之前的版本继续自增。\n_seq_no\n一个整数,严格递增的,可用于乐观锁\n_primary_term\n_primary_term也是一个整数,每当primary shard发生重新分配时,比如重启,primary选举等,会自增1。\n元数据_all是指将一个doc中的所有field全部用空格分割合并成一个field,只能搜索,很少用。默认开启,建议禁用。\n五、mapping \tmapping决定了一个index中的field使用什么数据格式存储,使用什么分词器解析,是否有子字段,是否需要copy to其他字段等。mapping决定了index中的field的特征。\n查询当前索引mapping信息 1 get /book_index/_mapping mapping核心数据类型 类型名称 关键字 字符串 text(string) 整数 byte、short、integer、long 浮点型 float、double 布尔型 boolean 日期型 date 二进制类型 binary 半精度16位浮点数 half_float 支持固定的缩放因子的浮点数 scaled_float 5.x之后新增范围类型:integer_range、float_range、double_range、long_range、date_range\nscale_float:比如12.34,缩放因子(scaling_factor)为100,那么存储为1234。此时是一个整数,这大大有助于节省磁盘空间,因为整数比浮点更容易压缩。创建索引是要使用缩放因子scaling_factor。\n_all和_source 开启和关闭\n1 2 3 4 5 6 7 8 9 10 11 put /book_index { \u0026#34;mappings\u0026#34;: { //定义mapping \u0026#34;book_type\u0026#34;: { //类型名称 \u0026#34;properties\u0026#34;: { //mapping信息 } \u0026#34;_all\u0026#34; : { \u0026#34;enabled\u0026#34; : false }, \u0026#34;_source\u0026#34; : { \u0026#34;enabled\u0026#34; : false } } } } 字段的index\u0026amp;index_options\u0026amp;store\u0026amp;enable enable:仅存储不做查询和聚合分析\nstore:是否存储此字段,默认false,store设置和_source无关\nindex:代表字段是否建立倒排索引\nindex_options:用于控制倒排索引记录的内容\ndocs 只记录id freqs 记录id和词频(用于打分) positions 记录id、词频和词位置(第几个词,用于短语匹配) offsets 记录id、词频和词位置、词在文档中的偏移量(用于高亮显示) text默认为positions,其它默认为docs\nnull值处理 \u0026ldquo;null_value\u0026quot;可以把null值设置一个默认值,默认处理方式是忽略\n1 2 3 4 5 6 7 8 9 10 11 12 13 put my_index { \u0026#34;mappings\u0026#34;: { \u0026#34;_doc\u0026#34;: { \u0026#34;properties\u0026#34;: { \u0026#34;status_code\u0026#34;: { \u0026#34;type\u0026#34;:\u0026#34;keyword\u0026#34;, \u0026#34;null_value\u0026#34;: \u0026#34;null\u0026#34; } } } } } dynamic mapping mapping默认创建的数据类型\n数据 类型 true or false boolean 123 long 123.12 float 2018-01-01 date hello world text(string)【默认standard分词器,且会建立keyword字段】 日期的自动识别\n使用date_detection开启/关闭日期的自动识别,默认开启。\n使用dynamic_date_format设置日期格式,默认为yyyy/mm/dd hh:mm:ss z|yyyy/mm/dd z\n1 2 3 4 5 6 7 8 9 put /test_index { \u0026#34;mappings\u0026#34;: { \u0026#34;doc\u0026#34;: { \u0026#34;date_detection\u0026#34;: true, \u0026#34;dynamic_date_formats\u0026#34;: [\u0026#34;yyyy-mm-dd\u0026#34;] } } } 字符中数字的自动识别\n使用numeric_detection开启/关闭字符中数字的自动识别,默认关闭。\n1 2 3 4 5 6 7 8 put /test_index { \u0026#34;mappings\u0026#34;: { \u0026#34;doc\u0026#34;: { \u0026#34;numeric_detection\u0026#34;: true } } } 设置dynamic策略 设置dynamic mapping策略时,可选值有:\ntrue(默认值)遇到陌生字段自动进行dynamic mapping false 遇到陌生字段,不进行dynamic mapping(会保存数据,但是不做倒排索引,无法实现任何的搜索) strict 遇到陌生字段,直接报错。 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 put /dynamic_strategy { \u0026#34;mappings\u0026#34;: { \u0026#34;dynamic_type\u0026#34;: { \u0026#34;dynamic\u0026#34;: \u0026#34;strict\u0026#34;, \u0026#34;properties\u0026#34;: { \u0026#34;f1\u0026#34;: { \u0026#34;type\u0026#34;: \u0026#34;text\u0026#34;, \u0026#34;analyzer\u0026#34;: \u0026#34;standard\u0026#34; }, \u0026#34;f2\u0026#34;: { \u0026#34;type\u0026#34;: \u0026#34;object\u0026#34;, \u0026#34;dynamic\u0026#34; :false } } } } } =======================================插入测试======================================= put /dynamic_strategy/dynamic_type/1 { \u0026#34;f1\u0026#34;: \u0026#34;f1 field\u0026#34;, \u0026#34;f2\u0026#34;: { \u0026#34;f21\u0026#34;: \u0026#34;f21 field\u0026#34; //只会存储不会分词,不能索引 }, \u0026#34;f3\u0026#34;: \u0026#34;f3 field\u0026#34; //f3字段无法插入,会直接报错 } dynamic templates 设置默认的字段类型匹配规则,大大减少了索引创建需要的约束\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 put /test_index { \u0026#34;mappings\u0026#34;: { \u0026#34;doc\u0026#34;: { \u0026#34;dynamic_templates\u0026#34;: [ { \u0026#34;string_as_keyword\u0026#34;: { \u0026#34;match_mapping_type\u0026#34;: \u0026#34;string\u0026#34;, \u0026#34;mapping\u0026#34;: { \u0026#34;type\u0026#34;: \u0026#34;keyword\u0026#34; } } } ], \u0026#34;properties\u0026#34;:{ \u0026#34;price\u0026#34;: { \u0026#34;type\u0026#34;:\u0026#34;double\u0026#34; } } } } index template 设置index template可以根据各模板的优先级匹配字段\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 //==========================================创建模板=================================== put _template/template_1 { \u0026#34;order\u0026#34;: 0, \u0026#34;index_patterns\u0026#34;: [ \u0026#34;test*\u0026#34; ], \u0026#34;mappings\u0026#34;: { \u0026#34;_doc\u0026#34;: { \u0026#34;properties\u0026#34;: { \u0026#34;name\u0026#34;: { \u0026#34;type\u0026#34;: \u0026#34;text\u0026#34; } } } } } put _template/template_2 { \u0026#34;order\u0026#34;: 1, \u0026#34;index_patterns\u0026#34;: [ \u0026#34;test*\u0026#34; ], \u0026#34;mappings\u0026#34;: { \u0026#34;_doc\u0026#34;: { \u0026#34;properties\u0026#34;: { \u0026#34;name\u0026#34;: { \u0026#34;type\u0026#34;: \u0026#34;keyword\u0026#34; } } } } } //========================================创建索引======================================== # 如果未明确指定字段类型将根据索引模板的匹配的order优先级决定类型 post /test_index/_doc { \u0026#34;name\u0026#34;: \u0026#34;tom\u0026#34; } //======================================查看/删除索引模板=================================== delete /test_index get _template mapping的复杂定义 multi field\n数组类型和普通数据类型没有区别。只是要求字段中的多个数据的类型必须相同。\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 put /multi_index/multi_type/1 { \u0026#34;tags\u0026#34;: [\u0026#34;taga\u0026#34;, \u0026#34;tagb\u0026#34;, \u0026#34;tagc\u0026#34;] } =================================手工对应mapping================================= put /multi_index { \u0026#34;mappings\u0026#34;: { \u0026#34;multi_type\u0026#34;: { \u0026#34;properties\u0026#34;: { \u0026#34;tags\u0026#34;: { \u0026#34;analyzer\u0026#34;: \u0026#34;standard\u0026#34;, \u0026#34;type\u0026#34;: \u0026#34;text\u0026#34; } } } } } empty field\n空数据 :null,[],[null]\n空数据如果直接保存到index中,由es为index自动创建mapping,那么此空数据对应的field将不会创建mapping映射信息。而任意的mapping定义都可以保存空数据\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 put /empty_index/empty/1 { \u0026#34;filed_1\u0026#34;: null, \u0026#34;filed_2\u0026#34;: [], \u0026#34;filed_3\u0026#34;: [null] } ==================================mapping映射信息================================== get /empty_index/empty/_mapping //返回结果 { \u0026#34;empty_index\u0026#34; : { \u0026#34;mappings\u0026#34; : { \u0026#34;empty\u0026#34; : { }\t//无field_1、field_2、field_3信息 } } } object field\nes在底层存储对象数据时实际上使用对象.属性方式进行存储\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 put /object_index/object_type/1 { \u0026#34;name\u0026#34; : \u0026#34;张三\u0026#34; , \u0026#34;age\u0026#34; : 20, \u0026#34;address\u0026#34; : { \u0026#34;province\u0026#34; : \u0026#34;北京\u0026#34;, \u0026#34;city\u0026#34; : \u0026#34;北京\u0026#34;, \u0026#34;street\u0026#34; : \u0026#34;永泰庄东路\u0026#34; } } ===============================对应的手动mapping映射=============================== put /object_index { \u0026#34;mappings\u0026#34;: { \u0026#34;object_type\u0026#34;: { \u0026#34;properties\u0026#34;: { \u0026#34;name\u0026#34;: { \u0026#34;type\u0026#34;: \u0026#34;text\u0026#34;, \u0026#34;analyzer\u0026#34;: \u0026#34;ik_max_word\u0026#34; }, \u0026#34;age\u0026#34;: { \u0026#34;type\u0026#34;: \u0026#34;short\u0026#34; }, \u0026#34;address\u0026#34;: { \u0026#34;properties\u0026#34;: { \u0026#34;province\u0026#34;: { \u0026#34;type\u0026#34;: \u0026#34;text\u0026#34;, \u0026#34;analyzer\u0026#34;: \u0026#34;ik_max_word\u0026#34; }, \u0026#34;city\u0026#34;: { \u0026#34;type\u0026#34;: \u0026#34;text\u0026#34;, \u0026#34;analyzer\u0026#34;: \u0026#34;ik_max_word\u0026#34; }, \u0026#34;street\u0026#34;: { \u0026#34;type\u0026#34;: \u0026#34;text\u0026#34;, \u0026#34;analyzer\u0026#34;: \u0026#34;ik_max_word\u0026#34; } } } } } } } copy_to\n就是将多个字段,复制到一个字段中,实现一个多字段组合\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 =====================================创建索引====================================== put /products_index { \u0026#34;mappings\u0026#34;: { \u0026#34;doc\u0026#34;: { \u0026#34;properties\u0026#34;: { \u0026#34;name\u0026#34;: { \u0026#34;type\u0026#34;: \u0026#34;text\u0026#34;, \u0026#34;analyzer\u0026#34;: \u0026#34;standard\u0026#34;, \u0026#34;copy_to\u0026#34;: \u0026#34;search_key\u0026#34; }, \u0026#34;remark\u0026#34;: { \u0026#34;type\u0026#34;: \u0026#34;text\u0026#34;, \u0026#34;analyzer\u0026#34;: \u0026#34;standard\u0026#34;, \u0026#34;copy_to\u0026#34;: \u0026#34;search_key\u0026#34; }, \u0026#34;price\u0026#34;: { \u0026#34;type\u0026#34;: \u0026#34;integer\u0026#34; }, \u0026#34;producer\u0026#34;: { \u0026#34;type\u0026#34;: \u0026#34;text\u0026#34;, \u0026#34;analyzer\u0026#34;: \u0026#34;standard\u0026#34;, \u0026#34;copy_to\u0026#34;: \u0026#34;search_key\u0026#34; }, \u0026#34;tags\u0026#34;: { \u0026#34;type\u0026#34;: \u0026#34;text\u0026#34;, \u0026#34;analyzer\u0026#34;: \u0026#34;standard\u0026#34;, \u0026#34;copy_to\u0026#34;: \u0026#34;search_key\u0026#34; }, \u0026#34;search_key\u0026#34;: {\t//此字段需要和被copy类型分词器相同 \u0026#34;type\u0026#34;: \u0026#34;text\u0026#34;, \u0026#34;analyzer\u0026#34;: \u0026#34;standard\u0026#34; } } } } } =======================================搜索======================================= get /products_index/doc/_search { \u0026#34;query\u0026#34;: { \u0026#34;match\u0026#34;: { \u0026#34;search_key\u0026#34;: \u0026#34;iphone\u0026#34; } } } copy_to字段【上述的search_key】未必存储,但是在逻辑上是一定存在\n六、query string搜索 语法:get [/index_name/type_name/]_search[?parameter_name=parameter_value\u0026amp;...]\n1 get /current_index/_search?q=remark:test+and+name:doc\u0026amp;sort=order_no:desc 此搜索操作一般只用在快速检索数据使用,如果查询条件复杂,很难构建query string,生产环境中很少使用\n全数据查询 1 2 //查询所有索引下的数据,timeout为超时时长定义,不影响响应的正常返回,只影响返回条数 get _search?timeout=10ms 多索引搜索 所谓的multi-index就是指从多个index中搜索数据。相对使用较少,只有在复合数据搜索的时候,可能出现。\n如:搜索引擎中的无条件搜索。(现在的应用中都被屏蔽了。使用的是默认搜索条件,或不执行搜索)\n1 2 3 4 5 get /products_es,products_index/_search //在两个索引中搜索 get /products_*/_search //使用通配符匹配 get /_all/_search //_all代表所有索引 -,+符号条件 1 2 3 get /products_index/phone_type/_search?q=+name:plus\t//搜索的关键字必须包含plus get /products_index/phone_type/_search?q=-name:plus\t//搜索的关键字必须不能包含plus +:和不定义符号含义一样,就是搜索指定的字段中包含key words的数据\n- :与+符号含义相反,就是搜索指定的字段中不包含key words的数据\n七、query dsl搜索 query dsl【domain specified language】,所有查询均可开启\u0026quot;profile\u0026quot;: \u0026quot;true\u0026quot;查看执行的详细信息\n查询所有数据 1 2 3 4 get /current_index/_search { \u0026#34;query\u0026#34;: {\u0026#34;match_all\u0026#34;: {}} } 全文检索 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 get /es/doc/_search { \u0026#34;query\u0026#34;: { \u0026#34;match\u0026#34;: { //单字段模式 \u0026#34;note\u0026#34;: \u0026#34;only life\u0026#34; //会根据field对应的analyzer对搜索条件做分词 } } } get /es/doc/_search { \u0026#34;query\u0026#34;: { \u0026#34;match\u0026#34;: { \u0026#34;note\u0026#34;: { //查询的字段 \u0026#34;query\u0026#34;: \u0026#34;only life pick\u0026#34;, \u0026#34;operator\u0026#34;: \u0026#34;or\u0026#34;, //or,and \u0026#34;minimum_should_match\u0026#34;: 2 //必须匹配两个以上 } } }, \u0026#34;profile\u0026#34;: \u0026#34;true\u0026#34; } get /es/doc/_search { \u0026#34;query\u0026#34;: { \u0026#34;multi_match\u0026#34;: { //多字段模式 \u0026#34;query\u0026#34;: \u0026#34;only life\u0026#34;, //会根据field对应的analyzer对搜索条件做分词 \u0026#34;fields\u0026#34;: [\u0026#34;note\u0026#34;,\u0026#34;content\u0026#34;] //指定field } } } 词元搜索 搜索条件不分词,使用搜索条件进行精确匹配。如果搜索字段被分词,搜索条件是一段话则无法匹配这种情况下适合匹配不分词字段。\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 get /es/doc/_search { \u0026#34;query\u0026#34;: { \u0026#34;term\u0026#34;: { \u0026#34;note\u0026#34;: {\t//虽然note被分词,但是只匹配一个词元会匹配上 \u0026#34;value\u0026#34;: \u0026#34;people\u0026#34; } } } } ================================================================================== get /es/doc/_search { \u0026#34;query\u0026#34; : { \u0026#34;terms\u0026#34; : {\t//进行多个词元匹配 \u0026#34;note\u0026#34; : [ \u0026#34;people\u0026#34;, \u0026#34;necessarily\u0026#34; ] } } } 短语搜索 1 2 3 4 5 6 7 8 9 10 11 get /es/doc/_search { \u0026#34;query\u0026#34;: { \u0026#34;match_phrase\u0026#34;: { \u0026#34;note\u0026#34;: { \u0026#34;query\u0026#34;: \u0026#34;importance people\u0026#34;, //必须满足此短语,即顺序不可变 \u0026#34;slop\u0026#34;: 4 //可以移动4次实现短语匹配,移动次数越少分数越高 } } } } \tmatch phrase原理:在进行短语搜索的时候其实进行了分词操作,将短语进行分词之后在倒排索引中检索数据,检查匹配到的索引在同一个文档中是否连续(利用position判断)。【使用get _analyze可以查看分词信息】\n召回率和精准度平衡\n召回率:搜索结果比例\n精准度:搜索结果的准确率\n如果在搜索的时候,只使用match phrase语法,会导致召回率底下,因为搜索结果中必须包含短语(包括proximity search)。如果在搜索的时候,只使用match语法,会导致精准度底下,因为搜索结果排序是根据相关度分数算法计算得到。可将两者同时使用,平衡召回率和精准度。\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 get /es/doc/_search { \u0026#34;query\u0026#34;: { \u0026#34;bool\u0026#34;: { \u0026#34;must\u0026#34;: [ { \u0026#34;match\u0026#34;: { \u0026#34;note\u0026#34;: \u0026#34;importance people\u0026#34; } }, { \u0026#34;match_phrase\u0026#34;: { \u0026#34;note\u0026#34;: { \u0026#34;query\u0026#34;: \u0026#34;importance people\u0026#34;, \u0026#34;slop\u0026#34;: 50 } } } ] } } } 搜索的优化\nmatch一般来说,比match phrase效率高10倍左右,比proximity search高20倍左右\n优化的思路是:尽量减少proximity search搜索的document数量。即先用match来搜索出需要的数据,再用proximity search来提高term距离较近的document的相关度分数,从而影响结果排序,这个过程也叫rescore(重计分)。再rescore的时候,尽量使用分页,毕竟用户通常只会查看搜索数据的前几页。\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 get /es/doc/_search { \u0026#34;query\u0026#34;: { \u0026#34;match\u0026#34;: { \u0026#34;note\u0026#34;: \u0026#34;importance people\u0026#34; } }, \u0026#34;rescore\u0026#34;: { //开始重计分 \u0026#34;query\u0026#34;: { \u0026#34;rescore_query\u0026#34;: { //重新计分查询 \u0026#34;match_phrase\u0026#34;: { \u0026#34;note\u0026#34;: { \u0026#34;query\u0026#34;: \u0026#34;importance people\u0026#34;, \u0026#34;slop\u0026#34;: 50 } } } }, \u0026#34;window_size\u0026#34;: 50 //对match搜索结果的前多少条数据执行rescore操作 }, \u0026#34;from\u0026#34;: 0, \u0026#34;size\u0026#34;: 2 } 范围搜索 范围查询主要争对数值和日期类型\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 get /_search { \u0026#34;query\u0026#34; : { \u0026#34;range\u0026#34; : { \u0026#34;emps.age\u0026#34; : {\t//数字类型的范围搜索 \u0026#34;gt\u0026#34; : 21, \u0026#34;lte\u0026#34; : 45 } } } } ================================================================================== get /_search { \u0026#34;query\u0026#34;: { \u0026#34;range\u0026#34;: { \u0026#34;emps.join_date\u0026#34;: {\t//日期类型的范围搜索 \u0026#34;gte\u0026#34;: \u0026#34;2018-08-10||-40d\u0026#34; } } } } 组合搜索 bool - 用于组合多条件,相当于java中的布尔表达式。\nmust - 必须符合要求,相当于java中的逻辑运算符 ==或\u0026amp;\u0026amp;。\nmust_not - 必须不符合要求,相当于java中的逻辑运算符 !\nshould - 有任意条件符合要求即可,相当于java中的逻辑运算符 {%raw%}||{%endraw%}\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 get /emp_index/emp_type/_search { \u0026#34;query\u0026#34;: { \u0026#34;bool\u0026#34;: {\t//布尔条件开始 \u0026#34;must\u0026#34;: [\t//必须满足 { \u0026#34;match\u0026#34;: { \u0026#34;dept_name\u0026#34;: \u0026#34;sales department\u0026#34; } } ], \u0026#34;must_not\u0026#34;: [\t//不需不满足 { \u0026#34;range\u0026#34;: { \u0026#34;num_of_emps\u0026#34;: { \u0026#34;gt\u0026#34;: 10 } } } ], \u0026#34;should\u0026#34;: [\t//满足一个即可 { \u0026#34;match\u0026#34;: { \u0026#34;emps.name\u0026#34;: \u0026#34;wangwu\u0026#34; } }, { \u0026#34;range\u0026#34;: { \u0026#34;num_of_emps\u0026#34;: { \u0026#34;lt\u0026#34;: 20 } } } ] } } } scroll搜索 \t如果需要一次性搜索出大量数据,那么执行效率一定不会很高,这个时候可以使用scroll滚动搜索的方式实现搜索。scroll滚动搜索类似分页,是在搜索的时候,先查询一部分,之后再查询下一部分,分批查询总体数据。可以实现一个高效的响应。scroll搜索会在第一次搜索的时候保存一个快照,这个快照保存的时长由请求指定,后续的查询会依据这个快照执行再次查询。如果这个过程中,es中的document发生了变化,是不会影响到原搜索结果的。\nscroll搜索时,需要指定一个排序,可以使用_doc实现排序,这种排序性能更高一些。\nscroll搜索的2次以后请求,必须在指定的快照时长内发起,且每次请求都需要指定这个快照保存时长。\nscroll搜索的返回结果一定会包含一个特殊的结果数据_scroll_id。这个数据就是scroll搜索的快照id。scroll搜索的2次以后的请求,必须携带上这个id。\nscroll不是分页,不是用来替换分页技术。分页为用户提供数据的,scroll为系统内部处理分批提供数据的\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 =====================================第一次搜索===================================== get /es/doc/_search?scroll=1m { \u0026#34;size\u0026#34;: 1, \u0026#34;query\u0026#34;: { \u0026#34;match_all\u0026#34;: {} } } =====================================第二次搜索===================================== get /_search/scroll { \u0026#34;scroll\u0026#34;: \u0026#34;1m\u0026#34;, \u0026#34;scroll_id\u0026#34; : \u0026#34;【上次搜索返回的scroll_id】\u0026#34; } =====================================删除快照====================================== delete /_search/scroll/_all 搜索策略 基于dis_max实现best fields策略进行多字段搜索\nbest fields策略:如果某一个field中匹配到了尽可能多的关键词,那么就应被排在前面,即执行若干查询条件以若干分数中最高分为实际的得分进行排序\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 get /student/java/_search { \u0026#34;query\u0026#34;: { \u0026#34;dis_max\u0026#34;: { \u0026#34;queries\u0026#34;: [ { \u0026#34;match\u0026#34; : { \u0026#34;name\u0026#34;: \u0026#34;james gosling\u0026#34; } }, { \u0026#34;match\u0026#34;: { \u0026#34;remark\u0026#34;: \u0026#34;java developer\u0026#34; } } ] } } } 使用tie_breaker参数优化dis_max搜索效果\n\tdis_max是将多个搜索query条件中相关度分数最高的用于结果排序,忽略其他query分数。这时候可以使用tie_breaker参数来优化dis_max搜索。tie_breaker参数代表的含义是:将其他query搜索条件的相关度分数乘以参数值,再参与到结果排序中。如果不定义此参数,相当于参数值为0。所以其他query条件的相关度分数被忽略。\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 get /student/java/_search { \u0026#34;query\u0026#34;: { \u0026#34;dis_max\u0026#34;: { \u0026#34;tie_breaker\u0026#34;: 0.7, \u0026#34;queries\u0026#34;: [ { \u0026#34;match\u0026#34; : { \u0026#34;name\u0026#34;: \u0026#34;james gosling\u0026#34; } }, { \u0026#34;match\u0026#34;: { \u0026#34;remark\u0026#34;: \u0026#34;java developer\u0026#34; } } ] } } } 使用multi_match简化dis_max+tie_breaker\nmulti_match匹配多个字段,使用best_fields策略\n1 2 3 4 5 6 7 8 9 10 11 12 13 get /student/java/_search { \u0026#34;query\u0026#34;: { \u0026#34;multi_match\u0026#34;: { \u0026#34;query\u0026#34;: \u0026#34;james gosling java developer\u0026#34;, \u0026#34;fields\u0026#34;: [\u0026#34;name\u0026#34;, \u0026#34;remark^2\u0026#34;], //remark的boost为2 \u0026#34;type\u0026#34;: \u0026#34;best_fields\u0026#34;, \u0026#34;tie_breaker\u0026#34;: 0.7, \u0026#34;minimum_should_match\u0026#34;: 2, \u0026#34;analyzer\u0026#34;: \u0026#34;standard\u0026#34; } } } multi_match+most fields实现multi_field搜索\nmost fields策略:指搜索结果匹配了更多的字段的document分数高\n1 2 3 4 5 6 7 8 9 10 11 get /student/java/_search { \u0026#34;query\u0026#34;: { \u0026#34;multi_match\u0026#34;: { \u0026#34;query\u0026#34;: \u0026#34;james gosling java developer\u0026#34;, \u0026#34;fields\u0026#34;: [\u0026#34;name\u0026#34;, \u0026#34;remark\u0026#34;], \u0026#34;type\u0026#34;: \u0026#34;most_fields\u0026#34;, \u0026#34;analyzer\u0026#34;: \u0026#34;standard\u0026#34; } } } cross fields搜索\ncross-fields搜索,一个唯一标识,跨了多个field。比如是地址可以散落在province,city,street中。\n1 2 3 4 5 6 7 8 9 10 11 12 get student/java/_search { \u0026#34;query\u0026#34;: { \u0026#34;multi_match\u0026#34;: { \u0026#34;query\u0026#34;: \u0026#34;joshua developer\u0026#34;, \u0026#34;fields\u0026#34;: [\u0026#34;name\u0026#34;, \u0026#34;remark\u0026#34;], \u0026#34;type\u0026#34;: \u0026#34;cross_fields\u0026#34;, \u0026#34;analyzer\u0026#34;: \u0026#34;standard\u0026#34;, //注意要使用分词器 \u0026#34;operator\u0026#34; : \u0026#34;and\u0026#34; //(name必须包含joshua且remark必须包含developer)或者 } //(remark必须包含joshua且name必须包含developer) } } most fields策略是尽可能匹配更多的字段,所以会导致精确搜索结果排序问题。又因为cross fields搜索,不能使用minimum_should_match来去除长尾数据。所以在使用most fields和cross fields策略搜索数据的时候,都有不同的缺陷。所以商业项目开发中,都推荐使用best fields策略实现搜索。\nsuggest搜索建议 实现suggest的时,其构建的不是倒排索引,也不是正排索引,是纯的用于进行前缀搜索的一种特殊的数据结构,而且会全部放在内存中,所以suggest search进行的前缀搜索提示,性能非常高。\n需要使用suggest的时候,必须在定义index时,为其mapping指定开启suggest\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 ========================================建立索引======================================= put /suggest { \u0026#34;mappings\u0026#34;: { \u0026#34;doc\u0026#34;: { \u0026#34;properties\u0026#34;: { \u0026#34;title\u0026#34;: { \u0026#34;type\u0026#34;: \u0026#34;text\u0026#34;, \u0026#34;analyzer\u0026#34;: \u0026#34;ik_max_word\u0026#34;, \u0026#34;fields\u0026#34;: { \u0026#34;suggest\u0026#34;: { \u0026#34;type\u0026#34;: \u0026#34;completion\u0026#34;, \u0026#34;analyzer\u0026#34;: \u0026#34;ik_max_word\u0026#34; } } }, \u0026#34;content\u0026#34;: { \u0026#34;type\u0026#34;: \u0026#34;text\u0026#34;, \u0026#34;analyzer\u0026#34;: \u0026#34;ik_max_word\u0026#34; } } } } } ====================================应用suggest搜索==================================== get /suggest/doc/_search { \u0026#34;suggest\u0026#34;: { \u0026#34;suggest_by_title\u0026#34;: { \u0026#34;prefix\u0026#34;: \u0026#34;大话\u0026#34;, \u0026#34;completion\u0026#34;: { \u0026#34;field\u0026#34;: \u0026#34;title.suggest\u0026#34; } } } } 近似匹配 前缀匹配搜索\n针对前缀搜索,是对keyword类型字段而言。而keyword类型字段数据大小写敏感。前缀搜索效率比较低。前缀搜索不会计算相关度分数。前缀越短,效率越低。不推荐使用。\n1 2 3 4 5 6 7 8 9 10 get /es/doc/_search { \u0026#34;query\u0026#34;: { \u0026#34;prefix\u0026#34;: { \u0026#34;note.keyword\u0026#34;: { \u0026#34;value\u0026#34;: \u0026#34;may\u0026#34; } } } } 通配符搜索\n通配符可以在倒排索引中使用,也可以在keyword类型字段中使用。性能也很低,需要扫描完整的索引。不推荐使用。\n1 2 3 4 5 6 7 8 9 10 get /es/doc/_search { \u0026#34;query\u0026#34;: { \u0026#34;wildcard\u0026#34;: { \u0026#34;note\u0026#34;: { \u0026#34;value\u0026#34;: \u0026#34;*oug?\u0026#34; } } } } 正则搜索\nes支持正则表达式。可以在倒排索引或keyword类型字段中使用。性能也很低,需要扫描完整索引。不推荐使用。\n1 2 3 4 5 6 7 8 9 10 get /es/doc/_search { \u0026#34;query\u0026#34;: { \u0026#34;regexp\u0026#34;: { \u0026#34;note\u0026#34;: { \u0026#34;value\u0026#34;: \u0026#34;[a-z]noug.?\u0026#34; } } } } 搜索推荐\n其原理和match phrase类似,是先使用match匹配term数据,然后在指定的slop移动次数范围内,前缀匹配。\n1 2 3 4 5 6 7 8 9 10 11 12 get /es/doc/_search { \u0026#34;query\u0026#34;: { \u0026#34;match_phrase_prefix\u0026#34;: { \u0026#34;note\u0026#34;: { \u0026#34;query\u0026#34;: \u0026#34;happiest of peo\u0026#34;, \u0026#34;slop\u0026#34;: 3, \u0026#34;max_expansions\u0026#34;: 3\t//用于指定prefix最多匹配多少个term,超过这个数量就不再匹配了 } } } } 这种语法与的match phrase的区别只有最后一个term是执行前缀搜索的,因为效率较低,如果使用一定要使用max_expansions限定\nngram分词机制\nngram是在指定长度下,对一个单词再次实现拆分的机制,如单词hello。\n1 2 3 4 5 ngram length = 1 -- h e l l o ngram length = 2 -- he el ll lo ngram length = 3 -- hel ell llo ngram length = 4 -- hell ello ngram length = 5 -- hello 使用ngram搜索\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 =================================创建edge ngram索引==================================== put /engram { \u0026#34;settings\u0026#34;: { \u0026#34;analysis\u0026#34;: { \u0026#34;filter\u0026#34;: { \u0026#34;engram_analyzer_filter\u0026#34;: {\t//定义edge_ngram过滤器 \u0026#34;type\u0026#34;: \u0026#34;ngram\u0026#34;, \u0026#34;min_gram\u0026#34; : 1, \u0026#34;max_gram\u0026#34; : 30 } }, \u0026#34;analyzer\u0026#34;: { \u0026#34;engram_analyzer\u0026#34;: {\t//创建分词器 \u0026#34;type\u0026#34; : \u0026#34;custom\u0026#34;, \u0026#34;tokenizer\u0026#34; : \u0026#34;standard\u0026#34;, \u0026#34;filter\u0026#34; : [ \u0026#34;lowercase\u0026#34;, \u0026#34;engram_analyzer_filter\u0026#34; ] } } } }, \u0026#34;mappings\u0026#34;: { \u0026#34;doc\u0026#34; : { \u0026#34;properties\u0026#34;: { \u0026#34;note\u0026#34; : { \u0026#34;type\u0026#34;: \u0026#34;text\u0026#34;, \u0026#34;analyzer\u0026#34;: \u0026#34;engram_analyzer\u0026#34;\t//使用自定义的engram_analyzer } } } } } edge ngram是使用首字母向后实现单词内的逐字符拆分。如单词hello。可提高前缀搜索或搜索推荐效率\n1 2 3 4 5 h he hel hell hello 使用edge ngram搜索\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 =================================创建edge ngram索引==================================== put /engram { \u0026#34;settings\u0026#34;: { \u0026#34;analysis\u0026#34;: { \u0026#34;filter\u0026#34;: { \u0026#34;engram_analyzer_filter\u0026#34;: {\t//定义edge_ngram过滤器 \u0026#34;type\u0026#34;: \u0026#34;edge_ngram\u0026#34;, \u0026#34;min_gram\u0026#34; : 1, \u0026#34;max_gram\u0026#34; : 30 } }, \u0026#34;analyzer\u0026#34;: { \u0026#34;engram_analyzer\u0026#34;: {\t//创建分词器 \u0026#34;type\u0026#34; : \u0026#34;custom\u0026#34;, \u0026#34;tokenizer\u0026#34; : \u0026#34;standard\u0026#34;, \u0026#34;filter\u0026#34; : [ \u0026#34;lowercase\u0026#34;, \u0026#34;engram_analyzer_filter\u0026#34; ] } } } }, \u0026#34;mappings\u0026#34;: { \u0026#34;doc\u0026#34; : { \u0026#34;properties\u0026#34;: { \u0026#34;note\u0026#34; : { \u0026#34;type\u0026#34;: \u0026#34;text\u0026#34;, \u0026#34;analyzer\u0026#34;: \u0026#34;engram_analyzer\u0026#34;\t//使用自定义的engram_analyzer } } } } } 模糊搜索\nfuzzy技术就是用于解决错误拼写的(在英文中很有效,在中文中几乎无效)\n1 2 3 4 5 6 7 8 9 10 11 get /es/doc/_search { \u0026#34;query\u0026#34;: { \u0026#34;fuzzy\u0026#34;: { \u0026#34;note\u0026#34;: { \u0026#34;value\u0026#34;: \u0026#34;peple\u0026#34;, \u0026#34;fuzziness\u0026#34;: 2\t//允许错误的个数 } } } } 高亮显示 plain highlighting\n默认的高亮搜索模式,也是lucene底层实现的highlighting\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 get /es/doc/_search { \u0026#34;query\u0026#34;: { \u0026#34;match\u0026#34;: { \u0026#34;note\u0026#34;: \u0026#34;life\u0026#34; } }, \u0026#34;highlight\u0026#34;: { \u0026#34;pre_tags\u0026#34;: \u0026#34;\u0026lt;color=\u0026#39;red\u0026#39;\u0026gt;\u0026#34;, \u0026#34;post_tags\u0026#34;: \u0026#34;\u0026lt;/color\u0026gt;\u0026#34;, \u0026#34;fields\u0026#34;: { \u0026#34;note\u0026#34;: { \u0026#34;fragment_size\u0026#34;: 20, //返回每段的文本长度 \u0026#34;number_of_fragments\u0026#34;: 2 //最大片段数,影响返回的片段数 } } } } posting highlighting\nposting highlighting需要在创建索引的时候,在mapping中手工开启\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 put /posthightling { \u0026#34;mappings\u0026#34;: { \u0026#34;doc\u0026#34;: { \u0026#34;properties\u0026#34;: { \u0026#34;remark\u0026#34;: { \u0026#34;type\u0026#34;: \u0026#34;text\u0026#34;, \u0026#34;analyzer\u0026#34;: \u0026#34;standard\u0026#34;, \u0026#34;index_options\u0026#34;: \u0026#34;offsets\u0026#34; } } } } } 这种高亮搜索模式设定后,不会对高亮搜索语法有任何的影响。只是在底层实现逻辑不同。\n①性能比plain highlight要高,因为不需要重新对高亮文本进行分词。\n②对磁盘的消耗更少。\n如果索引常需要搜索且需要高亮显示建议使用posting highlighting\nfast vector highlighting\nfast vector highlighting模式和term vector有关,是借助index-time term vector来实现高亮显示。对于大field数据【大于1m】的高亮搜索性能更高。高亮搜索语法不变。\n1 2 3 4 5 6 7 8 9 10 11 12 put /posthightling { \u0026#34;mappings\u0026#34;: { \u0026#34;properties\u0026#34;: { \u0026#34;remark\u0026#34;: { \u0026#34;type\u0026#34;: \u0026#34;text\u0026#34;, \u0026#34;analyzer\u0026#34;: \u0026#34;standard\u0026#34;, \u0026#34;term_vector\u0026#34;: \u0026#34;with_positions_offsets\u0026#34; } } } } 地理位置搜索 定义geo point mapping 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 put /hotel_app { \u0026#34;mappings\u0026#34;: { \u0026#34;hotels\u0026#34;: { \u0026#34;properties\u0026#34;: { \u0026#34;name\u0026#34;: { \u0026#34;type\u0026#34;: \u0026#34;text\u0026#34;, \u0026#34;analyzer\u0026#34;: \u0026#34;ik_smart\u0026#34; }, \u0026#34;pin\u0026#34;: { \u0026#34;type\u0026#34;: \u0026#34;geo_point\u0026#34; } } } } } 搜索指定区域范围内的数据\n矩形范围搜索【遵循左上右下】 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 get /hotel_app/hotels/_search { \u0026#34;query\u0026#34;: { \u0026#34;bool\u0026#34;: { \u0026#34;filter\u0026#34;: { \u0026#34;geo_bounding_box\u0026#34;: { \u0026#34;pin\u0026#34;: { \u0026#34;top_left\u0026#34;: { \u0026#34;lat\u0026#34;: 40.73,\t#latitude纬度 \u0026#34;lon\u0026#34;: -74.1\t#longitude经度 }, \u0026#34;bottom_right\u0026#34;: { \u0026#34;lat\u0026#34;: 40.717, \u0026#34;lon\u0026#34;: -70.99 } } } } } } } 多边形搜索【不需要注意多边形点的顺序】 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 get /hotel_app/hotels/_search { \u0026#34;query\u0026#34;: { \u0026#34;bool\u0026#34;: { \u0026#34;filter\u0026#34;: { \u0026#34;geo_polygon\u0026#34;: { \u0026#34;pin\u0026#34;: { \u0026#34;points\u0026#34;: [ {\u0026#34;lat\u0026#34; : 40.73, \u0026#34;lon\u0026#34; : -74.1}, {\u0026#34;lat\u0026#34; : 40.01, \u0026#34;lon\u0026#34; : -71.12}, {\u0026#34;lat\u0026#34; : 50.56, \u0026#34;lon\u0026#34; : -90.58} ] } } } } } } 搜索某地点附近的数据\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 get /hotel_app/hotels/_search { \u0026#34;query\u0026#34;: { \u0026#34;bool\u0026#34;: { \u0026#34;filter\u0026#34;: { \u0026#34;geo_distance\u0026#34;: { \u0026#34;distance\u0026#34;: \u0026#34;100km\u0026#34;, \u0026#34;pin\u0026#34;: { \u0026#34;lat\u0026#34;: 40.73, \u0026#34;lon\u0026#34;: -71.1 } } } } } } span查询 \t跨度查询是low-level查询,可以对指定术语的顺序和接近度进行专业控制。这些通常用于对法律文件或专利实施非常具体的查询。跨度查询不能与非跨度查询混合(span_multi查询除外)。跨度查询是非常专业的查询方式,在一般的商业应用中并不多见。\nspan-term【只能作用在分词字段】\n如果单独使用,效果跟term查询差不多,但是一般还是用于其他的span查询的子查询。\n1 2 3 4 5 6 7 8 9 10 get cars/_search { \u0026#34;query\u0026#34;: { \u0026#34;span_term\u0026#34;: { \u0026#34;remark\u0026#34;: { \u0026#34;value\u0026#34;: \u0026#34;大众\u0026#34; } } } } span-multi\n可以嵌套的跨度查询,可以将其他的query搜索方案包装为一个span query跨度查询。如:通配符、前缀搜索、正则搜索、模糊搜索(fuzzy)等。\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 ========================================前缀搜索======================================= get cars/_search { \u0026#34;query\u0026#34;: { \u0026#34;span_multi\u0026#34;: { \u0026#34;match\u0026#34;: { \u0026#34;prefix\u0026#34;: { \u0026#34;remark\u0026#34;: { \u0026#34;value\u0026#34;: \u0026#34;大众\u0026#34; } } } } } } ========================================正则搜索======================================= get cars/_search { \u0026#34;query\u0026#34;: { \u0026#34;span_multi\u0026#34;: { \u0026#34;match\u0026#34;: { \u0026#34;regexp\u0026#34;: { \u0026#34;remark\u0026#34;: { \u0026#34;value\u0026#34;: \u0026#34;神*\u0026#34; } } } } } } =======================================通配符搜索====================================== get cars/_search { \u0026#34;query\u0026#34;: { \u0026#34;span_multi\u0026#34;: { \u0026#34;match\u0026#34;: { \u0026#34;wildcard\u0026#34;: { \u0026#34;remark\u0026#34;: { \u0026#34;value\u0026#34;: \u0026#34;大?\u0026#34; } } } } } } ========================================模糊搜索======================================= get cars/_search { \u0026#34;query\u0026#34;: { \u0026#34;span_multi\u0026#34;: { \u0026#34;match\u0026#34;: { \u0026#34;fuzzy\u0026#34;: { \u0026#34;remark\u0026#34;: { \u0026#34;value\u0026#34;: \u0026#34;高档车\u0026#34;, \u0026#34;fuzziness\u0026#34;: 1 } } } } } } span_first\n跨度查询中匹配字段开头数据,其中的match对应任意一个span query类型。end代表在这个span query匹配过程中,搜索条件数据在字段中最大的匹配范围。即(position\u0026lt;end)\n1 2 3 4 5 6 7 8 9 10 11 12 13 get cars/_search { \u0026#34;query\u0026#34;: { \u0026#34;span_first\u0026#34;: { \u0026#34;match\u0026#34;: { \u0026#34;span_term\u0026#34;: { \u0026#34;remark\u0026#34;: \u0026#34;中档车\u0026#34; } }, \u0026#34;end\u0026#34;: 3 } } } span_near\n跨度搜索中的近似匹配,类似match_phrase+slop组成的近似匹配。\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 get cars/_search { \u0026#34;query\u0026#34;: { \u0026#34;span_near\u0026#34;: { \u0026#34;clauses\u0026#34;: [ { \u0026#34;span_term\u0026#34;: { \u0026#34;remark\u0026#34;: { \u0026#34;value\u0026#34;: \u0026#34;大众\u0026#34; } } }, { \u0026#34;span_term\u0026#34;: { \u0026#34;remark\u0026#34;: { \u0026#34;value\u0026#34;: \u0026#34;中档\u0026#34; } } } ], \u0026#34;slop\u0026#34;: 2, //最大的跨度 \u0026#34;in_order\u0026#34;: false //顺序是否绝对 } } } span_or\n类似should逻辑。搜索span_or中的多个搜索条件的结果并集。\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 get cars/_search { \u0026#34;query\u0026#34;: { \u0026#34;span_or\u0026#34;: { \u0026#34;clauses\u0026#34;: [ { \u0026#34;span_term\u0026#34;: { \u0026#34;remark\u0026#34;: { \u0026#34;value\u0026#34;: \u0026#34;专用\u0026#34; } } }, { \u0026#34;span_term\u0026#34;: { \u0026#34;remark\u0026#34;: { \u0026#34;value\u0026#34;: \u0026#34;小资\u0026#34; } } } ] } } } span_not\n搜索条件的差集,不是搜索结果的差集。【大众中档车依旧会出现】\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 get cars/_search { \u0026#34;query\u0026#34;: { \u0026#34;span_not\u0026#34;: { \u0026#34;include\u0026#34;: { \u0026#34;span_term\u0026#34;: { \u0026#34;remark\u0026#34;: { \u0026#34;value\u0026#34;: \u0026#34;大众\u0026#34; } } }, \u0026#34;exclude\u0026#34;: { \u0026#34;span_term\u0026#34;: { \u0026#34;remark\u0026#34;: { \u0026#34;value\u0026#34;: \u0026#34;中档车\u0026#34; } } } } } } span_containing\n这个查询内部会有多个子查询,但是会设定某个子查询优先级更高,作用更大,通过关键字little和big来指定。big条件是一个更加精确的条件,little条件是一个相对宽泛条件。big条件必须包含little条件。\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 get cars/_search { \u0026#34;query\u0026#34;: { \u0026#34;span_containing\u0026#34;: { \u0026#34;little\u0026#34;: { \u0026#34;span_term\u0026#34;: { \u0026#34;remark\u0026#34;: { \u0026#34;value\u0026#34;: \u0026#34;大众\u0026#34; } } }, \u0026#34;big\u0026#34;: { \u0026#34;span_near\u0026#34;: { \u0026#34;clauses\u0026#34;: [ {get /_mget查询 \u0026#34;span_term\u0026#34;: { \u0026#34;remark\u0026#34;: { \u0026#34;value\u0026#34;: \u0026#34;肝疼\u0026#34; } } }, { \u0026#34;span_term\u0026#34;: { \u0026#34;remark\u0026#34;: { \u0026#34;value\u0026#34;: \u0026#34;大众\u0026#34; } } } ], \u0026#34;slop\u0026#34;: 12, \u0026#34;in_order\u0026#34;: false } } } } } span_within\n这个查询与span_containing查询作用差不多,不过span_containing是基于lucene中的spancontainingquery,而span_within则是基于spanwithinquery。\n搜索模板 一次性调用的template\n此方式没太大意义,只能调用一次的template是没有意义的\n{% raw %}\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 ===================================方式一【简单参数】=================================== get /cars/sales/_search/template { \u0026#34;source\u0026#34;: { \u0026#34;query\u0026#34;: { \u0026#34;match\u0026#34;: { \u0026#34;remark\u0026#34;: \u0026#34;{{kw}}\u0026#34; //使用双大括号表示变量 } }, \u0026#34;from\u0026#34;: \u0026#34;{{from}}{{\\^from}}100{{/from}}\u0026#34;, //默认值设置 \u0026#34;size\u0026#34;: \u0026#34;{{size}}\u0026#34; }, \u0026#34;params\u0026#34;: { //传入变量 \u0026#34;kw\u0026#34;: \u0026#34;大众\u0026#34;, \u0026#34;size\u0026#34;: 2 } } ===================================方式二【json方式】=================================== get /cars/sales/_search/template { \u0026#34;source\u0026#34;: \u0026#34;{ \\\u0026#34;query\\\u0026#34;: { \\\u0026#34;match\\\u0026#34;: {{#tojson}}parameter{{/tojson}} }}\u0026#34;,\t//字符串 \u0026#34;params\u0026#34;: { \u0026#34;parameter\u0026#34; : { \u0026#34;remark\u0026#34; : \u0026#34;大众\u0026#34; } } } ===================================方式三【join方式】=================================== get /cars/sales/_search/template { \u0026#34;source\u0026#34; : { \u0026#34;query\u0026#34; : { \u0026#34;match\u0026#34; : { \u0026#34;remark\u0026#34; : \u0026#34;{{#join delimiter=\u0026#39; \u0026#39;}}kw{{/join delimiter=\u0026#39; \u0026#39;}}\u0026#34; } } }, \u0026#34;params\u0026#34;: { \u0026#34;kw\u0026#34; : [\u0026#34;大众\u0026#34;, \u0026#34;标致\u0026#34;] } } {% endraw %}\n可重复调用的template\n{% raw %}\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 =====================================创建template===================================== post _scripts/test { \u0026#34;script\u0026#34;: { \u0026#34;lang\u0026#34;: \u0026#34;mustache\u0026#34;, \u0026#34;source\u0026#34;: { \u0026#34;query\u0026#34;: { \u0026#34;match\u0026#34; : { \u0026#34;remark\u0026#34; : \u0026#34;{{kw}}\u0026#34; } } } } } =====================================调用template===================================== get /cars/sales/_search/template { \u0026#34;id\u0026#34;: \u0026#34;test\u0026#34;, \u0026#34;params\u0026#34;: { \u0026#34;kw\u0026#34;: \u0026#34;大众\u0026#34; } } {% endraw %}\n查询已定义的template\n1 get _scripts/test 删除template\n1 delete _scripts/test 排序\u0026amp;分页\u0026amp;指定返回字段\u0026amp;仅获取数量 当字段类型为text时,使用字符串类型的字段作为排序依据会有问题【es对字段数据做分词,建立倒排索引。分词后,先使用哪一个单词做排序是不固定的】,此时需要在此字段上建立keyword类型的子字段,或者建立fielddata。\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 get /kibana_sample_data_ecommerce/_search { // 返回_source元数据的字段,如果_source被禁用则需在建立索引时指定是否store【默认false】,然后使用stored_fields获取 \u0026#34;_source\u0026#34;: [\u0026#34;customer_id\u0026#34;,\u0026#34;customer_first_name\u0026#34;,\u0026#34;customer_full_name\u0026#34;], \u0026#34;sort\u0026#34;: [ { \u0026#34;total_quantity\u0026#34;: \u0026#34;desc\u0026#34; }, { \u0026#34;_score\u0026#34;:\u0026#34;desc\u0026#34; // 如果没用有分数排序,es将不会进行打分操作 }, { \u0026#34;_doc\u0026#34;:\u0026#34;asc\u0026#34; // 使用lucene索引时的先后顺序,分布式下可能重复 }, { \u0026#34;_id\u0026#34;:\u0026#34;desc\u0026#34; // 使用id的顺序排序 } ], \u0026#34;from\u0026#34;: 100, \u0026#34;size\u0026#34;: 20 } get /es/doc/_count { \u0026#34;query\u0026#34;: { \u0026#34;match\u0026#34;: { \u0026#34;note\u0026#34;: { \u0026#34;query\u0026#34;: \u0026#34;only\u0026#34; } } } } 八、查询过滤 过滤语法 过滤的时候,不进行任何的匹配分数计算,且filter内置cache自动缓存常用的filter数据,有效提升过滤速度,相对于query来说,filter相对效率较高。query要计算搜索匹配相关度分数。query更加适合复杂的条件搜索。query和filter并行执行。\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 get /es/doc/_search { \u0026#34;query\u0026#34;: { \u0026#34;bool\u0026#34;: { \u0026#34;must\u0026#34;: [ { \u0026#34;match\u0026#34;: { \u0026#34;name\u0026#34;: \u0026#34;test_doc_2\u0026#34; } } ], \u0026#34;filter\u0026#34;: {\t//过滤,在已有的搜索结果中进行过滤。满足条件的返回。 \u0026#34;range\u0026#34;: { \u0026#34;qt\u0026#34;: { \u0026#34;gt\u0026#34;: 16 } } } } } } 如果单纯的过滤数据,不需要增加额外的搜索匹配,也可以使用下述语句:\n1 2 3 4 5 6 7 8 9 10 11 12 get /es/doc/_search { \u0026#34;query\u0026#34;: { \u0026#34;constant_score\u0026#34;: {\t//不进行分数判定 \u0026#34;filter\u0026#34;: { \u0026#34;match\u0026#34;: { \u0026#34;note\u0026#34;: \u0026#34;people\u0026#34; } } } } } filter 底层执行原理 构建bitset\nbitset是一个二进制的数组,数组下标对应的是当前index中document的搜索顺序。在bitset中,0代表不符合搜索条件,1代表符合搜索条件。es使用bitset来标记document是否符合搜索条件,也是为了用最简单的数据结构来描述搜索结果,来节省内存的开销。\n遍历bitset\n因为一个搜索中可以有多个filter条件,搜索在es执行后,filter对应的bitset可能有多个,es会遍历每个filter对应的bitset,且从最稀疏的开始遍历【1最少的】,以达到效率最佳。当所有的bitset遍历结束后,所有的filter条件过滤完成。得到过滤结果。\ncaching bitset\nes会缓存bitset数据到内存中,如果后续的搜索语法中,有相同的filter条件,那么从缓存中直接使用对应的bitset来过滤数据,效率最优。其缓存机制是:最近的256个filter中,如果某个filter执行次数达到一定的数量和一定条件,则缓存bitset。【如果数据少于1000则不缓存,如果索引分段数据不足索引整体数据的3%也不缓存】\n执行特性\nquery和filter的执行顺序\n一般情况,es会先执行filter,再执行query,因为filter效率高,能够过滤掉不符合搜索条件的数据。\nbitset cache 自动更新\n如果document的数据修改,或新增、删除了document,那么缓存的bitset会自动更新,保证缓存bitset的数据有效性。\nbitset cache的应用时机\n只要在执行query的时候包含filter过滤条件,会先检查cache中是否有这个filter的bitset cache,如果有,则直接使用,如果没有,则搜索过滤index中的document。\n九、搜索相关 分页搜索与deep paging问题 1 get /_search?from=0\u0026amp;size=10 // from从第几条开始查询,size返回的条数 \t执行搜索时请求发送到协调节点中,协调节点将搜索请求发送给所有的节点,而数据可能分部在多个节点中,所以会造成以下现象:集群有4个节点,每个节点有1个分片(primary shard),发起上述请求时,每个节点会返回150条数据,协调节点一共接收到600条数据,进行排序并取其中第100~150条数据,如果页数过深会造成效率低下问题。\nmatch底层转换 \telasticsearch执行match搜索时,通常都会对搜索条件进行底层转换,来实现最终的搜索结果。\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 ===================================================================================== get /student/java/_search { \u0026#34;query\u0026#34;: { \u0026#34;match\u0026#34;: { \u0026#34;remark\u0026#34;: \u0026#34;java developer\u0026#34; } } } //转换后为: get /student/java/_search { \u0026#34;query\u0026#34;: { \u0026#34;bool\u0026#34;: { \u0026#34;should\u0026#34;: [ { \u0026#34;term\u0026#34;: { \u0026#34;remark\u0026#34;: { \u0026#34;value\u0026#34;: \u0026#34;java\u0026#34; } } }, { \u0026#34;term\u0026#34;: { \u0026#34;remark\u0026#34;: { \u0026#34;value\u0026#34;: \u0026#34;developer\u0026#34; } } } ] } } } ==================================================================================== get /student/java/_search { \u0026#34;query\u0026#34;: { \u0026#34;match\u0026#34;: { \u0026#34;remark\u0026#34;: { \u0026#34;query\u0026#34;: \u0026#34;java developer\u0026#34;, \u0026#34;operator\u0026#34;: \u0026#34;and\u0026#34; } } } } //转换后为: get /student/java/_search { \u0026#34;query\u0026#34;: { \u0026#34;bool\u0026#34;: { \u0026#34;must\u0026#34;: [ { \u0026#34;term\u0026#34;: { \u0026#34;remark\u0026#34;: { \u0026#34;value\u0026#34;: \u0026#34;java\u0026#34; } } }, { \u0026#34;term\u0026#34;: { \u0026#34;remark\u0026#34;: { \u0026#34;value\u0026#34;: \u0026#34;developer\u0026#34; } } } ] } } } ==================================================================================== get /student/java/_search { \u0026#34;query\u0026#34;: { \u0026#34;match\u0026#34;: { \u0026#34;remark\u0026#34;: { \u0026#34;query\u0026#34;: \u0026#34;java developer architect\u0026#34;, \u0026#34;minimum_should_match\u0026#34;: \u0026#34;67%\u0026#34; } } } } //转换后为: get /student/java/_search { \u0026#34;query\u0026#34;: { \u0026#34;bool\u0026#34;: { \u0026#34;should\u0026#34;: [ { \u0026#34;term\u0026#34;: { \u0026#34;remark\u0026#34;: { \u0026#34;value\u0026#34;: \u0026#34;java\u0026#34; } } }, { \u0026#34;term\u0026#34;: { \u0026#34;remark\u0026#34;: { \u0026#34;value\u0026#34;: \u0026#34;developer\u0026#34; } } }, { \u0026#34;term\u0026#34;: { \u0026#34;remark\u0026#34;: { \u0026#34;value\u0026#34;: \u0026#34;architect\u0026#34; } } } ], \u0026#34;minimum_should_match\u0026#34;: 2 } } } 建议,如果不怕麻烦,尽量使用转换后的语法执行搜索,效率更高。\n十、聚合搜索 前序:分析,分组,聚合,字符串排序等操作需要设置正排索引【子字段keyword】或者字段的fielddata为true(建立正排索引)\n正排索引:类似数据库中的普通索引。依赖倒排索引中的数据,不做二次解析,将倒排索引内容重设一份正排索引,用于内存计算\n1 2 3 4 5 6 7 8 9 put /products_index/phone_type/_mapping { \u0026#34;properties\u0026#34;: { \u0026#34;tags\u0026#34;:{ //设置的字段 \u0026#34;type\u0026#34;: \u0026#34;text\u0026#34;, \u0026#34;fielddata\u0026#34;: true //fielddata开启\t} } } bucket[分桶类型] terms 在elasticsearch中默认为分组数据做排序使用的是_count[统计个数]执行降序排列。也可以使用_key[统计列的内容]元数据\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 get /cars/sales/_search { \u0026#34;size\u0026#34;: 0, //返回查询命中记录,如果为0则不返回 \u0026#34;aggs\u0026#34;: { \u0026#34;group_by_color\u0026#34;: { //聚合返回结果集的标签名 \u0026#34;terms\u0026#34;: { //词元统计 \u0026#34;field\u0026#34;: \u0026#34;color\u0026#34;, //统计color每个词元总数 \u0026#34;order\u0026#34;: { \u0026#34;_count\u0026#34;: \u0026#34;asc\u0026#34; } } } } } range 通过指定数值的范围来设定分桶规则\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 ======================================range划分======================================= get /products_index/phone_type/_search { \u0026#34;query\u0026#34;: { \u0026#34;match_all\u0026#34;: {} }, \u0026#34;_source\u0026#34;: \u0026#34;price\u0026#34;, \u0026#34;aggs\u0026#34;: { \u0026#34;rang_price\u0026#34;: {\t\u0026#34;range\u0026#34;: { //范围分组 \u0026#34;field\u0026#34;: \u0026#34;price\u0026#34;, //分组字段 \u0026#34;ranges\u0026#34;: [ //分组区间 { \u0026#34;from\u0026#34;: 500000, \u0026#34;to\u0026#34;: 700000 }, { \u0026#34;from\u0026#34;: 700000, \u0026#34;to\u0026#34;: 900000 } ] } } } } data_range 通过指定日期的范围来设定分桶规则\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 get /cars/sales/_search { \u0026#34;query\u0026#34;: { \u0026#34;match_all\u0026#34;: {} }, \u0026#34;_source\u0026#34;: \u0026#34;sold_date\u0026#34;, \u0026#34;aggs\u0026#34;: { \u0026#34;rang_price\u0026#34;: {\t\u0026#34;date_range\u0026#34;: { \u0026#34;field\u0026#34;: \u0026#34;sold_date\u0026#34;, \u0026#34;ranges\u0026#34;: [ { \u0026#34;from\u0026#34;: \u0026#34;2015-01-01\u0026#34;, \u0026#34;to\u0026#34;: \u0026#34;2017-01-01\u0026#34; }, { \u0026#34;from\u0026#34;: \u0026#34;2017-01-01\u0026#34;, \u0026#34;to\u0026#34;: \u0026#34;2019-01-01\u0026#34; } ] } } } } histogram 以固定间隔的策略来分割数据\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 ====================================histogram划分===================================== get /cars/_search { \u0026#34;size\u0026#34;: 0, \u0026#34;aggs\u0026#34;: { \u0026#34;histogarm_by_price\u0026#34;: { \u0026#34;histogram\u0026#34;: {\t\u0026#34;field\u0026#34;: \u0026#34;price\u0026#34;, \u0026#34;interval\u0026#34;: 10000, //以1w区间划分 \u0026#34;min_doc_count\u0026#34; : 0, //区间最小数量,0代表即使此区间无数据也返回 \u0026#34;extended_bounds\u0026#34;: { \u0026#34;min\u0026#34;: 100000, //仅min_doc_count为0时有效,为其实统计位置 \u0026#34;max\u0026#34;: 2000000 //当max指定的值超过实际最大值时有效,否则按照实际最大值统计 } } } } } data_histogram 针对日期,以固定间隔的策略来分割数据\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 ==================================date_histogram划分================================== get /cars/_search { \u0026#34;size\u0026#34;: 0, \u0026#34;aggs\u0026#34;: { \u0026#34;histogarm_by_date\u0026#34;: { \u0026#34;date_histogram\u0026#34;: { //时间区间划分 \u0026#34;field\u0026#34;: \u0026#34;sold_date\u0026#34;, \u0026#34;interval\u0026#34;: \u0026#34;month\u0026#34;, //划分规则\t\u0026#34;min_doc_count\u0026#34;: 1, \u0026#34;format\u0026#34;: \u0026#34;yyyy-mm-dd\u0026#34;, //最大、最小时间格式 \u0026#34;extended_bounds\u0026#34;: { //时间起始值和终止值 \u0026#34;min\u0026#34;: \u0026#34;2017-01-01\u0026#34;, \u0026#34;max\u0026#34;: \u0026#34;2018-12-31\u0026#34; } } } } } geo_distance 根据距离来分割数据\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 ===================================地理范围聚合划分===================================== get /hotel_app/hotels/_search { \u0026#34;size\u0026#34;: 0, \u0026#34;aggs\u0026#34;: { \u0026#34;agg_by_pin\u0026#34;: { \u0026#34;geo_distance\u0026#34;: { \u0026#34;field\u0026#34;: \u0026#34;pin\u0026#34;, \u0026#34;distance_type\u0026#34;: \u0026#34;arc\u0026#34;, #sloppy_arc默认算法、arc最高精度、plane最高效率 \u0026#34;origin\u0026#34;: { #原点 \u0026#34;lat\u0026#34;: 52.376, \u0026#34;lon\u0026#34;: 4.894 }, \u0026#34;unit\u0026#34;: \u0026#34;km\u0026#34;, #距离单位 \u0026#34;ranges\u0026#34;: [ #距离原点距离 { \u0026#34;to\u0026#34;: 100 }, { \u0026#34;from\u0026#34;: 100, \u0026#34;to\u0026#34;: 300 }, { \u0026#34;from\u0026#34;: 300, \u0026#34;to\u0026#34;: 3000 } ] } } } } metric[指标分析类型] 指标分析类型分为单值分析和多值分析两类\n单值 min,max,avg,sum cardinality 多值 stats,extended stats percentile,percentile rank top hits min,max,avg,sum 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 get /cars/sales/_search { \u0026#34;size\u0026#34;: 0, \u0026#34;aggs\u0026#34;: { \u0026#34;max_price\u0026#34;: { \u0026#34;max\u0026#34;: {\t//最大值 \u0026#34;field\u0026#34;: \u0026#34;price\u0026#34; } }, \u0026#34;min_price\u0026#34;: { \u0026#34;min\u0026#34;: {\t//最小值 \u0026#34;field\u0026#34;: \u0026#34;price\u0026#34; } }, \u0026#34;sum_price\u0026#34;: {\t//总计 \u0026#34;sum\u0026#34;: { \u0026#34;field\u0026#34;: \u0026#34;price\u0026#34; } }, \u0026#34;avg_price\u0026#34;: { //聚合返回结果集的标签名 \u0026#34;avg\u0026#34;: { //计算平均值 \u0026#34;field\u0026#34;: \u0026#34;price\u0026#34; //计算的字段 } } } } cardinality 使用cardinality语法去除重复数据后,统计数据量。这种语法的计算类似sql中的distinct count计算。\n1 2 3 4 5 6 7 8 9 10 11 12 get /cars/sales/_search { \u0026#34;size\u0026#34;: 0, \u0026#34;aggs\u0026#34;: { \u0026#34;count_of_province\u0026#34;: { \u0026#34;cardinality\u0026#34;: { \u0026#34;field\u0026#34;: \u0026#34;brand\u0026#34;, \u0026#34;precision_threshold\u0026#34;: 100 } } } } cardinality使用的是hyperloglog++算法,具有一定的错误率,可使用precision_threshold设置预估唯一值数量提高准确度(默认100)。\n优化cardinality\nhll算法的实现是:对所有cardinality指定字段取hash值,通过hash和bitset数据结构计算cardinality结果。可使用mapper-murmur3 plugin插件,在index_time时就计算hash值提高效率。【mapper-murmur3 plugin安装见官网】\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 put /cars { \u0026#34;mappings\u0026#34;: { \u0026#34;sales\u0026#34;: { \u0026#34;properties\u0026#34;: { \u0026#34;price\u0026#34;: { \u0026#34;type\u0026#34;: \u0026#34;long\u0026#34; }, \u0026#34;color\u0026#34;: { \u0026#34;type\u0026#34;: \u0026#34;keyword\u0026#34; }, \u0026#34;brand\u0026#34;: { \u0026#34;type\u0026#34;: \u0026#34;keyword\u0026#34;, \u0026#34;fields\u0026#34;: { \u0026#34;hash\u0026#34;: {\t//在创建索引时计算hash值,进行cardinality操作使用此字段 \u0026#34;type\u0026#34;: \u0026#34;murmur3\u0026#34; } } }, \u0026#34;model\u0026#34;: { \u0026#34;type\u0026#34;: \u0026#34;keyword\u0026#34; }, \u0026#34;sold_date\u0026#34;: { \u0026#34;type\u0026#34;: \u0026#34;date\u0026#34; }, \u0026#34;remark\u0026#34;: { \u0026#34;type\u0026#34;: \u0026#34;text\u0026#34;, \u0026#34;analyzer\u0026#34;: \u0026#34;ik_max_word\u0026#34; } } } } } 单个文档节省的时间是非常少的,但是如果聚合一亿数据,每个字段多花费10纳秒的时间,那么在每次查询时都会额外增加1秒,如果我们要在非常大量的数据里面使用 cardinality ,我们可以权衡使用。\nstats,extended stats stats会返回count、min、max、avg、sum统计信息\nextended stats会返回比stats多sum_of_squares[平方和]、variance[方差]、std_deviation[标准差]、std_deviation_bounds[标准差的上下值]\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 get /cars/sales/_search { \u0026#34;size\u0026#34;: 0, \u0026#34;aggs\u0026#34;: { \u0026#34;price_stats\u0026#34;: { \u0026#34;stats\u0026#34;: { \u0026#34;field\u0026#34;: \u0026#34;price\u0026#34; } }, \u0026#34;price_extended_stats\u0026#34;: { \u0026#34;extended_stats\u0026#34;: { \u0026#34;field\u0026#34;: \u0026#34;price\u0026#34; } } } } percentiles,percentile_rank percentiles:将数字字段从小到大排序,取百分比位置数据的值。用于计算百分比数据的。如:pt50、pt90、pt99等\npercentile_rank:给定一个值,查看它的排名\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 get /cars/sales/_search { \u0026#34;aggs\u0026#34;: { \u0026#34;price_percentiles\u0026#34;: { \u0026#34;percentiles\u0026#34;: { \u0026#34;field\u0026#34;: \u0026#34;price\u0026#34;, \u0026#34;percents\u0026#34;: [ 50,\t//取50%位置数据值 90,\t//取90%位置数据值 99\t//取99%位置数据值 ] } }, \u0026#34;price_percentiles_rank\u0026#34;: { \u0026#34;percentile_ranks\u0026#34;: { \u0026#34;field\u0026#34;: \u0026#34;price\u0026#34;, \u0026#34;values\u0026#34;: [ 1899000 //查询1899000能站多少名 ] } } } } 优化percentiles和percentile_ranks\npercentiles和percentile_ranks底层采用的都是tdigest算法,是用很多的节点来执行百分比计算,计算过程也是一种近似估计,有一定的错误率。节点越多,结果越精确(内存消耗越大)。\n参数compression用于限制节点的最大数目,限制为:20 * compression。这个参数的默认值为100。即默认提供2000个节点。一个节点大约使用 32 字节的内存,所以在最坏的情况下(例如,大量数据有序存入),默认设置会生成一个大小约为 64kb 的 tdigest算法空间。 在实际应用中,数据会更随机,所以 tdigest 使用的内存会更少。\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 get /cars/sales/_search { \u0026#34;aggs\u0026#34;: { \u0026#34;price_percentiles\u0026#34;: { \u0026#34;percentiles\u0026#34;: { \u0026#34;field\u0026#34;: \u0026#34;price\u0026#34;, \u0026#34;percents\u0026#34;: [ 50, 90, 99 ], \u0026#34;tdigest\u0026#34;: {\t\u0026#34;compression\u0026#34;: 200 } } } } } top_hits 对组内的数据进行排序,并选择其中排名高的数据,那么可以使用top_hits来实现。\ntop_hits中的属性size代表取组内多少条数据(默认为10)\nsort代表组内使用什么字段什么规则排序(默认使用_doc的asc规则排序)\nsource代表结果中包含document中的那些字段(默认包含全部字段)\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 get /cars/_search { \u0026#34;size\u0026#34;: 0, \u0026#34;aggs\u0026#34;: { \u0026#34;group_by_brank\u0026#34;: { //先根据brank分组 \u0026#34;terms\u0026#34;: { \u0026#34;field\u0026#34;: \u0026#34;brand\u0026#34; }, \u0026#34;aggs\u0026#34;: { \u0026#34;price_rank_two\u0026#34;: { //计算各分组类价钱最高的2个 \u0026#34;top_hits\u0026#34;: { \u0026#34;size\u0026#34;: 2, \u0026#34;sort\u0026#34;: [{\u0026#34;price\u0026#34;: \u0026#34;desc\u0026#34;}], //排序字段 \u0026#34;_source\u0026#34;: { //返回doc的信息 \u0026#34;includes\u0026#34;: [\u0026#34;model\u0026#34;, \u0026#34;price\u0026#34;] } } } } } } } pipeline[管道分析类型] 管道分析,根据输出位置的不同可以分为\nparent:结果内嵌到现有聚合结果集中 derivative【求导】 moving average【移动平均】 cumulative sum【累计求和】 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 get /cars/sales/_search { \u0026#34;size\u0026#34;: 0, \u0026#34;aggs\u0026#34;: { \u0026#34;sold_date_agg\u0026#34;: { \u0026#34;date_histogram\u0026#34;: { \u0026#34;field\u0026#34;: \u0026#34;sold_date\u0026#34;, \u0026#34;interval\u0026#34;: \u0026#34;month\u0026#34;, \u0026#34;min_doc_count\u0026#34;: 1 }, \u0026#34;aggs\u0026#34;: { \u0026#34;avg_price\u0026#34;: { \u0026#34;avg\u0026#34;: { \u0026#34;field\u0026#34;: \u0026#34;price\u0026#34; } }, \u0026#34;derivative_price\u0026#34;: { //按月分割,求每月平均值的导数 \u0026#34;derivative\u0026#34;: { \u0026#34;buckets_path\u0026#34;: \u0026#34;avg_price\u0026#34; } }, \u0026#34;moving_average_price\u0026#34;: { //按月分割,求每月移动平均值的导数 \u0026#34;moving_avg\u0026#34;: { \u0026#34;buckets_path\u0026#34;: \u0026#34;avg_price\u0026#34; } }, \u0026#34;cumulative_sum_price\u0026#34;: { //按月分割,求每月平均值的累计求和 \u0026#34;cumulative_sum\u0026#34;: { \u0026#34;buckets_path\u0026#34;: \u0026#34;avg_price\u0026#34; } } } } } } sibling:结果与现有聚合分析同级 max_bucket,min_bucket,avg_bucket,sum_bucket stats_bucket,extended_stats_bucket percentiles_bucket 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 get /cars/sales/_search { \u0026#34;size\u0026#34;: 0, \u0026#34;aggs\u0026#34;: { \u0026#34;brand_terms\u0026#34;: { \u0026#34;terms\u0026#34;: { \u0026#34;field\u0026#34;: \u0026#34;brand\u0026#34; }, \u0026#34;aggs\u0026#34;: { \u0026#34;avg_price\u0026#34;: { \u0026#34;avg\u0026#34;: { \u0026#34;field\u0026#34;: \u0026#34;price\u0026#34; } } } }, \u0026#34;min_price_car\u0026#34;: { //得到每个品牌价钱平均值的最小值 \u0026#34;min_bucket\u0026#34;: { \u0026#34;buckets_path\u0026#34;: \u0026#34;brand_terms\u0026gt;avg_price\u0026#34; } }, \u0026#34;max_price_car\u0026#34;: { //得到每个品牌价钱平均值的最大值 \u0026#34;max_bucket\u0026#34;: { \u0026#34;buckets_path\u0026#34;: \u0026#34;brand_terms\u0026gt;avg_price\u0026#34; } }, \u0026#34;sum_price_car\u0026#34;: { //得到每个品牌价钱平均值的总合 \u0026#34;sum_bucket\u0026#34;: { \u0026#34;buckets_path\u0026#34;: \u0026#34;brand_terms\u0026gt;avg_price\u0026#34; } }, \u0026#34;avg_price_car\u0026#34;: { //得到每个品牌价钱平均值的总合的平均值 \u0026#34;avg_bucket\u0026#34;: { \u0026#34;buckets_path\u0026#34;: \u0026#34;brand_terms\u0026gt;avg_price\u0026#34; } }, \u0026#34;stats_price_car\u0026#34; : { //得到每个品牌价钱平均值的state信息 \u0026#34;stats_bucket\u0026#34;: { \u0026#34;buckets_path\u0026#34;: \u0026#34;brand_terms\u0026gt;avg_price\u0026#34; } }, \u0026#34;extended_stats_price_car\u0026#34; : {//得到每个品牌价钱平均值的extended_stats_bucket信息 \u0026#34;extended_stats_bucket\u0026#34;: { \u0026#34;buckets_path\u0026#34;: \u0026#34;brand_terms\u0026gt;avg_price\u0026#34; } }, \u0026#34;percentiles_price_car\u0026#34; : { //得到每个品牌价钱平均值的percentiles信息 \u0026#34;percentiles_bucket\u0026#34;: { \u0026#34;buckets_path\u0026#34;: \u0026#34;brand_terms\u0026gt;avg_price\u0026#34;, \u0026#34;percents\u0026#34;: [ 10, 50, 90 ] } } } } 聚合嵌套 聚合是可以嵌套的,内层聚合是依托于外层聚合的结果之上实现聚合计算。\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 get /products_index/phone_type/_search { \u0026#34;query\u0026#34;: { \u0026#34;match\u0026#34;: { \u0026#34;name\u0026#34;: \u0026#34;plus\u0026#34; } }, \u0026#34;aggs\u0026#34;: { \u0026#34;count_term_tags\u0026#34;: { //聚合进行词元统计 \u0026#34;terms\u0026#34;: { \u0026#34;field\u0026#34;: \u0026#34;tags\u0026#34; }, \u0026#34;aggs\u0026#34;: { //在词元统计的结果之下进行求平均值 \u0026#34;avg_price\u0026#34;: { \u0026#34;avg\u0026#34;: { \u0026#34;field\u0026#34;: \u0026#34;price\u0026#34; } } } } } } 聚合平铺 聚合类嵌套的聚合条件是平级关系\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 get /cars/sales/_search { \u0026#34;size\u0026#34;: 0, \u0026#34;aggs\u0026#34;: { \u0026#34;group_by_color\u0026#34;: { \u0026#34;terms\u0026#34;: { \u0026#34;field\u0026#34;: \u0026#34;color\u0026#34; }, \u0026#34;aggs\u0026#34;: { \u0026#34;avg_by_price_color\u0026#34;: { //和group_by_brand平级 \u0026#34;avg\u0026#34;: { \u0026#34;field\u0026#34;: \u0026#34;price\u0026#34; } }, \u0026#34;group_by_brand\u0026#34;: { //和avg_by_price_color平级 \u0026#34;terms\u0026#34;: { \u0026#34;field\u0026#34;: \u0026#34;brand\u0026#34; } } } } } } 聚合排序 聚合中如果使用order排序的话,要求排序字段必须是一个聚合相关字段,可使用_count,_key这些元数据进行排序\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 //使用子聚合avg_price排序 //如果引用子聚合分析的子聚合分析需要使用\u0026gt;连接 //如果子聚合是用stats等多值指标分析,需用.属性的方式 get /products_index/phone_type/_search { \u0026#34;size\u0026#34;: 0, \u0026#34;aggs\u0026#34;: { \u0026#34;count_term_tags\u0026#34;: { \u0026#34;terms\u0026#34;: { \u0026#34;field\u0026#34;: \u0026#34;tags\u0026#34;, \u0026#34;order\u0026#34;: { \u0026#34;avg_price\u0026#34;: \u0026#34;asc\u0026#34; } }, \u0026#34;aggs\u0026#34;: { \u0026#34;avg_price\u0026#34;: { //子聚合avg_price \u0026#34;avg\u0026#34;: { \u0026#34;field\u0026#34;: \u0026#34;price\u0026#34; } } } } } } 改变聚合的作用范围 聚合内过滤 这个过滤器只对query搜索得到的结果执行filter过滤,即聚合的实际数据比查询数据少。\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 get /cars/_search { \u0026#34;size\u0026#34;: 0, \u0026#34;aggs\u0026#34;: { \u0026#34;group_by_brand_not_w\u0026#34;: { \u0026#34;filter\u0026#34;: { //过滤query之后的条件 \u0026#34;terms\u0026#34;: { \u0026#34;brand\u0026#34;: [\u0026#34;大众\u0026#34;,\u0026#34;奥迪\u0026#34;] } }, \u0026#34;aggs\u0026#34;: { \u0026#34;group_by_brand\u0026#34;: { \u0026#34;terms\u0026#34;: { \u0026#34;field\u0026#34;: \u0026#34;brand\u0026#34; } } } } } } global bucket 在聚合统计数据的时候,有些时候需要对比部分数据和总体数据。global是用于定义一个全局bucket,这个bucket会忽略query的条件,检索所有document进行对应的聚合统计。\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 get /cars/_search { \u0026#34;size\u0026#34;: 0, \u0026#34;query\u0026#34;: { \u0026#34;term\u0026#34;: { \u0026#34;brand\u0026#34;: \u0026#34;大众\u0026#34; } }, \u0026#34;aggs\u0026#34;: { \u0026#34;w_avg_by_price\u0026#34;: { \u0026#34;avg\u0026#34;: { \u0026#34;field\u0026#34;: \u0026#34;price\u0026#34; } }, \u0026#34;aggs\u0026#34;: { \u0026#34;global\u0026#34;: {}, //不会使用query搜索条件进行统计 \u0026#34;aggs\u0026#34;: { \u0026#34;all_avg_by_price\u0026#34;: { \u0026#34;avg\u0026#34;: { \u0026#34;field\u0026#34;: \u0026#34;price\u0026#34; } } } } } } post_filter 只过滤搜索结果,而不过滤聚合的过滤器。即聚合结果不会发生变化,而搜索显示的数据会发生变化。\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 // 聚合显示所有品牌,搜索结果只有大众 get /cars/sales/_search { \u0026#34;post_filter\u0026#34;: { \u0026#34;term\u0026#34;: { \u0026#34;brand\u0026#34;: \u0026#34;大众\u0026#34; } }, \u0026#34;size\u0026#34;: 10, \u0026#34;aggs\u0026#34;: { \u0026#34;brand_terms\u0026#34;: { \u0026#34;terms\u0026#34;: { \u0026#34;field\u0026#34;: \u0026#34;brand\u0026#34;, \u0026#34;size\u0026#34;: 10 } } } } 深度聚合和广度聚合 默认elasticsearch执行聚合分析时,是按照top_hits深度优先的方式去执行的。会计算出每一项结果。但是遇到计算销量前五的品牌中前十的车型这种问题时,使用深度优先计算不太合适,应该逐层聚合bucket,并过滤后,在当前层的结果基础上再次执行下一层的聚合(广度优先)。\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 get /cars/_search { \u0026#34;size\u0026#34;: 0, \u0026#34;aggs\u0026#34;: { \u0026#34;group_by_brand\u0026#34;: { \u0026#34;terms\u0026#34;: { \u0026#34;field\u0026#34;: \u0026#34;brand\u0026#34;, \u0026#34;size\u0026#34;: 5, \u0026#34;collect_mode\u0026#34;: \u0026#34;breadth_first\u0026#34; }, \u0026#34;aggs\u0026#34;: { \u0026#34;group_of_model\u0026#34;: { \u0026#34;terms\u0026#34;: { \u0026#34;field\u0026#34;: \u0026#34;model\u0026#34; } } } } } } 聚合算法精准度 大数据聚合时精准度概论 易并行聚合算法\n若干节点同时计算一个聚合结果,再返回给协调节点做最终计算,得到最终结果的方式。如聚合计算中的max,min等\n近似聚合算法\n有些聚合分析算法是很难使用易并行算法解决的,如:terms。这个时候es会采取近似聚合的方式来进行计算。近似聚合结果不完全准确,但是效率非常高,一般效率是精准算法的数十倍。\n近似聚合: 延时一般在100毫秒左右,有5%左右的错误率。\n精准算法: 延时一般在若干秒到若干小时之间,不会有任何错误。(批处理)\n三角选择原则\n精准度 + 实时性 :一定是数据量很小的时候,通常都在单机中执行,可以随时调用。\n精准度 + 大数据 : 这是非实时的计算,是在大数据存在的情况下,保证数据计算的精准度,一次计算可能需要若干小时才能完成,通常都是批处理程序。如:hadoop\n大数据 + 实时性 : 这是一种不精准的计算,近似估计,一般都会有一定错误率(一般5%以内)。如es中的近似聚合算法。\nes非精准聚合控制 设置shard数量为1,消除问题,但此时无法承载大量数据 聚合时合理设置shard_size大小,即每次从shard上获取额外数据,以提升精准度。默认为size * 1.5 + 10 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 get /cars/sales/_search { \u0026#34;size\u0026#34;: 0, \u0026#34;aggs\u0026#34;: { \u0026#34;brand_terms\u0026#34;: { \u0026#34;terms\u0026#34;: { \u0026#34;field\u0026#34;: \u0026#34;brand\u0026#34;, \u0026#34;size\u0026#34;: 10, \u0026#34;order\u0026#34;: { \u0026#34;_count\u0026#34;: \u0026#34;desc\u0026#34; }, \u0026#34;shard_size\u0026#34;: 50, //每个分片返回50个数据 \u0026#34;show_term_doc_count_error\u0026#34;: true //显示统计出错的最大值,如果为0则是精确计算 } } } } 十一、同义词与分词器 概念 同义词:\n为key_words提供更加完整的倒排索引。如:时态转化,单复数转化,全写简写,同义词等。\nnormalization是为了提升召回率(recall),提升搜索能力的。\nnormalization是配合分词器(analyzer)完成其功能\n分词器:\n分词器的功能是处理document中的field即创建倒排索引过程中用于切分field数据 默认提供的常见分词器 standard analyzer:是es中的默认分词器。标准分词器,处理英语语法的分词器。这种分词器也是es中默认的分词器。切分过程中会忽略停止词等。会进行单词的大小写转换。过滤连接符或括号等常见符号。\nsimple analyzer:简单分词器。就是将数据切分成一个个的单词。使用较少,经常会破坏英语语法。\nwhitespace analyzer:空白符分词器。就是根据空白符号切分数据。使用较少,经常会破坏英语语法。\nlanguage analyzer:对应语言的分词器,会忽略停止词、转换大小写、单复数转换、时态转换等。\n搜索条件中的key_words也需要经过分词,且搜索条件中的条件数据使用的分词器与对应的字段使用的分词器是统一的。否则会导致搜索结果丢失。\nik分词器 安装步骤\n第一步:下载源码包编译打包或者下载编译完成的代码包\n第二步:在elasticsearch的plugins目录下创建ik目录\n第三步:将编译完成的压缩包解压到plugins的ik目录下\nik分词器种类\nik_max_word:会将文本做最细粒度的拆分,会穷尽各种可能的组合,适合 term query\nik_smart:会做最粗粒度的拆分,适合 phrase 查询\nik分词器配置文件\nik的所有的dic词库文件,必须使用utf-8字符集\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 config | +- extra_main.dic【自定义词库,配置方式为相对于ikanalyzer.cfg.xml相对路径,非热更新】 |\t+- extra_single_word.dic【自定义单字词,配置相对于ikanalyzer.cfg.xml相对路径,非热更新】 | +- extra_single_word_full.dic【和extra_single_word.dic内容相同】 | +- extra_single_word_low_freq.dic【自定义单字低频词,非热更新】 | +- extra_stopword.dic【自定义停用词库,配置方式为相对于ikanalyzer.cfg.xml相对路径,非热更新】 | +- ikanalyzer.cfg.xml【配置加载外部扩展词文件】 | +- main.dic【内置词典,一行一词,未记录的单词无法实现分词,不建议修改】 | +- preposition.dic【内置的中文停用词】 | +- quantifier.dic【内置数据单位词典】 | +- stopword.dic【内置英文停用词】 | +- suffix.dic【内置后缀】 | +- surname.dic【内置姓氏词典】 ik词库热更新\n修改ikanalyzer.cfg.xml文件\n1 2 3 4 \u0026lt;!--这里配置远程扩展字典 --\u0026gt; \u0026lt;entry key=\u0026#34;remote_ext_dict\u0026#34;\u0026gt;location\u0026lt;/entry\u0026gt; \u0026lt;!--这里配置远程扩展停止词字典--\u0026gt; \u0026lt;entry key=\u0026#34;remote_ext_stopwords\u0026#34;\u0026gt;location\u0026lt;/entry\u0026gt; location 指url,比如 http://yoursite.com/getcustomdict,该请求需满足以下条件\n该 http 请求需要返回两个头部(header),一个是 last-modified,一个是 etag,这两者都是字符串类型,只要有一个发生变化,该插件就会去抓取新的分词进而更新词库。\n该 http 请求返回的内容格式是一行一个分词,换行符用 \\n\n测试ik分词器\n1 2 3 4 5 6 7 8 9 10 11 get /_analyze { \u0026#34;analyzer\u0026#34;: \u0026#34;ik_max_word\u0026#34;, \u0026#34;text\u0026#34;: [\u0026#34;中国人民共和国国歌\u0026#34;] } get /_analyze { \u0026#34;analyzer\u0026#34;: \u0026#34;ik_smart\u0026#34;, \u0026#34;text\u0026#34;: [\u0026#34;中国人民共和国国歌\u0026#34;] } 十二、es分布式架构分析 分布式机制的透明隐藏特性 \telasticsearch本身就是一个分布式系统,就是为了处理海量数据的应用。隐藏了复杂的分布式机制,简化了配置和操作的复杂度。elasticsearch在现在的互联网环境中,盛行的原因,主要的核心就是分布式的简化。\n\telasticsearch隐藏的分布式内容:分片机制、集群发现、负载均衡、路由请求、集群扩容、shard重分配等。\n节点变化时的数据重平衡 \t在节点发生变化时,es的cluster会自动调整每个节点中的数据,也就是shard的重新分配。这个过程叫做rebalance。rebalance目的是为了提高性能,理论上,当数据量达到一定级别的时候,每个shard分片上的数据量是均等的。那么每个节点管理的shard数量是均等的情况,es集群才能提供最好的服务性能。\nmaster节点作用 \t维护集群元数据的节点。如:索引的变更(创建和删除)对应的元数据保存在master节点中。\n\tmaster不是请求的唯一接收节点。只是维护元数据的特殊节点。不会导致单点瓶颈。\n\t集群在默认配置中,会自动的选举出master节点。元数据是一个收集管理的过程。不是一个必要的不可替代的数据。master如果宕机,集群会选举出新的master,新的master会在集群的所有节点中重新收集集群元数据并管理。\n节点平等的分布式架构 节点平等\n每个节点都能接收客户端请求。不会造成单点压力。\n自动请求路由\n节点在接收到客户端请求时,会自动的识别应该由哪个节点处理本次请求,并实现请求的转发。\n响应收集\n在自动请求路由后,接收客户端请求的节点会自动的收集其他节点的处理结果,并统一响应给客户端。\n1)客户端请求elasticsearch集群,搜索“张三”数据。请求发送到节点4。此操作代表节点的平等性。集群中每个节点的功能都是一致的。\n2)节点4将请求路由到节点1上。实现数据的搜索。这是自动请求路径的过程。\n3)节点1处理结束后,搜索结果会发送给节点4。这是响应收集的过程。\n4)节点4将最终结果响应给客户端,这种操作就屏蔽了集群对客户端的影响。\n并发冲突 使用内置_version【7.x版本以后废弃】\n全量替换(乐观锁):elasticsearch会检查请求中的version和存储中的version是否相等。如果不相等报错,如果相等则修改。\n1 2 3 4 put /test_index/my_type/1?version=4 { \u0026#34;name\u0026#34;:\u0026#34;doc_new_01\u0026#34; } 使用external version\nelasticsearch提供了一个特性,可以自定义version实现es内置的_version元数据版本管理功能。与元数据_version的区别是:元数据比对必须完全一致,且external version必须比元数据_version数据大。成功后_version修改为提供的external version数值。\n1 2 3 4 put /test_index/my_type/1?version=9\u0026amp;version_type=external { \u0026#34;name\u0026#34;:\u0026#34;doc_new_new_01\u0026#34; } 使用partial update乐观锁\n在elasticsearch中,使用partial update更新数据时,内部自动使用乐观锁控制数据的并发安全。如果出现版本不一致的时候,elasticsearch会提示更新失败。可以通过命令中的参数实现手工管理乐观锁。【retry_on_conflict和version参数不能同时使用】\n1 2 3 4 post /test_index/my_type/1/_update?retry_on_conflict=3 #retry_on_conflict尝试次数 { \u0026#34;name\u0026#34;:\u0026#34;doc_new_post_01\u0026#34; } 使用if_seq_no和if_primary_term替代内置_version\n1 2 3 4 put /test_index/my_type/1?if_seq_no=6\u0026amp;if_primary_term=3 { \u0026#34;name\u0026#34;:\u0026#34;doc_new_01\u0026#34; } 十三、document写入原理 elasticsearch为了实现搜索的近实时,结合了内存buffer、os cache、disk三种存储,尽可能的提升搜索能力。elasticsearch的底层使用lucene实现。在lucene中一个index是分为若干个segment(分段)的,每个segment都会存放index中的部分数据。在elasticsearch中,是将一个index先分解成若干shard,在shard中,使用若干segment来存储具体的数据。\ndocument写入过程 1)客户端发起增删改请求,请求发送到协调节点(任意节点都能成为协调节点)\n2)通过hash(routing)%number_of_primary_shards将请求转发到对应的主分片,主分片也会将请求转发到副本分片上【routing默认为id,也可指定routing】\n3)副本分片接收请求到并创建成功之后返回给主分片,主分片再结合自身情况发送创建成功或失败到协调节点,协调节点将结果返回给客户端\ndocument读取的实时性 倒排索引一旦生成是不可以更改的,有如下好处:\n不用考虑并发写文件问题,避免了加锁的开销 由于文件不能更改,可以充分利用文件系统缓存,只需要载入一次,内容直接从内容中读取 利于生成缓存数据,不用担心数据变化带来的缓存失效问题 elasticsearch区分新旧文档,查询时汇总新旧文档内容返回查询结果\ndocument写入细节 refresh\nsegment写入磁盘的过程依旧很耗时,可以借助文件系统缓存的特性,先将segment在缓存中创建并开放查询来提升实时性,改过程在称之为refresh。在refresh之前文档先存储在内存buffer中,此时还不能搜索,refresh时将buffer中所有文档都清空并生成segment。es默认每秒执行一次refresh,所以一秒之后文档即可查询。\ntranslog\nes将文档写入buffer时会同时将文档写入到translog文件中,默认每个文档都会在translog文件中即时落盘(fsync),避免丢失数据。es启动时会检查translog文件将文档载入buffer。\nflush\nflush负责将内存中的segment写入磁盘,主要做以下工作\n将translog写入磁盘 将index buffer清空,其中的文档生成一个新的segment相当于一个refresh操作 更新commit point并写入磁盘 执行fsync操作,将内存中的segment写入磁盘 删除旧的translog文件 删除与更新文档\nlucene专门维护一个.del的文件,记录所有已删除的文档【.del上记录的是lucene内部的id】,查询结果返回前会过滤掉.del中的所有文档。更新文档是首先删除文档,然后再创建新文档。\nsegment merging\n随着segment的增多,由于一次查询的segment数量增多,查询速度会变慢。所以es会定时在后台执行segment merge操作,以减少segment的数量。通过froce_merge也可手动强制执行segment merge的操作。\n十四、相关度评分算法 算法介绍 \tes中使用了term frequency / inverse document frequency算法,简称tf/idf算法。是elasticsearch相关度评分算法的一部分,也是最重要的部分。【es5.x之后使用的是bm25模型,是对tf/idf算法的优化】\ntf :计算搜索条件分词后,各词条在document的field中出现了多少次,出现次数越多,相关度越高。\nidf:计算搜索条件分词后,各词元在整个index中的所有document中出现的次数越多,相关度越低。\nfield-length norm:在匹配成功后,计算field字段数据的长度,长度越大,相关度越低。【tf算法的一部分】\nes中底层计算相关度的时候,不是简单的加减乘除,有其特有的算法。且与文档所存在的shard相关\n1 2 3 4 5 6 7 8 9 get /es/doc/_search { \u0026#34;query\u0026#34;: { \u0026#34;match\u0026#34;: { \u0026#34;note\u0026#34;: \u0026#34;people\u0026#34; } }, \u0026#34;explain\u0026#34;: true\t//使用explain查看评分的详细解释 } 相关度分数计算步骤 第一步:boolean model\n\telasticsearch搜索的时候,首先根据搜索条件,过滤符合条件的document。这个时候es是不做相关度分数计算的,只是记录true或false,标记document是否符合搜索要求。\n第二步:tf/idf\n\t用于计算单个term在document中的相关度分数\n第三步:\n\t向量空间模型算法。用于计算多个term对一个document的搜索相关度分数。\n\telasticsearch会根据一个term对于所有document的相关度分数,来计算得出一个query vector。在根据多个term对于一个document的相关度分数,来计算得出若干document vector。将这些计算结果放入一个向量空间,再通过一些数学算法来计算document vector相对于query vector的相似度,来得到最终相关度分数。\n多shard环境中相关度分数不准确问题 \t在elasticsearch的搜索结果中,相关度分数不是一定准确的。相同的数据,使用相同的搜索条件搜索,得到的相关度分数可能有误差。只要数据量达到一定程度,相关度分数误差就会逐渐趋近于0。\n\t在shard0中,有100个document中包含java词组。在shard1中,有10个document中包含java词组,在执行搜索的时候,es计算相关度分数时,就会出现计算不准确的问题。因为es计算相关度分数是在shard本地计算的。根据tf/idf算法,在shard0中的document相关度分数会低于shard1中的相关度分数。\n调节、优化相关对评分的方式 query-time boost\n指搜索的时候,提供boost,来影响相关度评分\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 get /student/java/_search { \u0026#34;query\u0026#34;: { \u0026#34;bool\u0026#34;: { \u0026#34;should\u0026#34;: [ { \u0026#34;term\u0026#34;: { \u0026#34;remark\u0026#34;: { \u0026#34;value\u0026#34;: \u0026#34;developer\u0026#34;, \u0026#34;boost\u0026#34;:2\t//默认值为1 } } }, { \u0026#34;term\u0026#34;: { \u0026#34;remark\u0026#34;: { \u0026#34;value\u0026#34;: \u0026#34;architect\u0026#34; } } } ] } } } negative boost\n用于降低一个term的相关度分数比例,使之往后排列\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 get /es/doc/_search { \u0026#34;query\u0026#34;: { \u0026#34;boosting\u0026#34;: { \u0026#34;positive\u0026#34;: { \u0026#34;match\u0026#34;: { \u0026#34;note\u0026#34;: \u0026#34;people\u0026#34; } }, \u0026#34;negative\u0026#34;: { \u0026#34;match\u0026#34;: { \u0026#34;note\u0026#34;: \u0026#34;enough\u0026#34; } }, \u0026#34;negative_boost\u0026#34;: 0.2 //降低negative下的得分 } } } constant_score\n\t不计算相关度评分,执行的时候会忽略相关度评分过程,所有的document的相关度分数都是1。在6.x中,constant_score内不能再使用query语法。只能通过filter来实现数据的过滤。所以这种影响相关度分数的方式已经没有太大的意义了。毕竟filter本来就不计算相关度分数。\n使用function score自定义相关分数算法\n\telasticsearch支持自定义相关度分数计算函数,这个自定义的相关度分数可以参与到es的相关度分数计算结果中,甚至可以替换相关度评分,但无法跳过相关度分数计算步骤。很少使用。\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 get /fscore/doc/_search { \u0026#34;query\u0026#34;: { \u0026#34;function_score\u0026#34;: {\t\u0026#34;query\u0026#34;: { \u0026#34;match\u0026#34;: { \u0026#34;f\u0026#34;: \u0026#34;hello spark\u0026#34; } }, \u0026#34;field_value_factor\u0026#34;: { //number_of_votes所在字段 \u0026#34;field\u0026#34;: \u0026#34;fc\u0026#34;, //field字段的计算公式log(1 + number_of_votes) \u0026#34;modifier\u0026#34;: \u0026#34;log1p\u0026#34;, //可以进一步影响分数,增加后,对fc字段的计算公式为log(1 + factor * number_of_votes) \u0026#34;factor\u0026#34;: 1.2\t}, //决定es计算的相关度分数与指定字段的值如何计算 \u0026#34;boost_mode\u0026#34;: \u0026#34;sum\u0026#34;, //限制字段fc最终计算出来的分数的最大值 \u0026#34;max_boost\u0026#34;: 0.3 } } } 十五、数据建模 一对一数据建模 一般对数据进行组合存储。将某一个数据结构作为一部分(对象类型属性)实现数据的存储。\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 put person_index { \u0026#34;mappings\u0026#34;: { \u0026#34;persons\u0026#34;: { \u0026#34;properties\u0026#34;: { \u0026#34;last_name\u0026#34;: { \u0026#34;type\u0026#34;: \u0026#34;keyword\u0026#34; }, \u0026#34;first_name\u0026#34;: { \u0026#34;type\u0026#34;: \u0026#34;keyword\u0026#34; }, \u0026#34;age\u0026#34;: { \u0026#34;type\u0026#34;: \u0026#34;byte\u0026#34; }, \u0026#34;identification_id\u0026#34;: { //身份证信息和个人是一对一关系 \u0026#34;properties\u0026#34;: { \u0026#34;id_no\u0026#34;: { \u0026#34;type\u0026#34;: \u0026#34;keyword\u0026#34; }, \u0026#34;address\u0026#34;: { \u0026#34;type\u0026#34;: \u0026#34;text\u0026#34;, \u0026#34;analyzer\u0026#34;: \u0026#34;ik_max_word\u0026#34;, \u0026#34;fields\u0026#34;: { \u0026#34;keyword\u0026#34;: { \u0026#34;type\u0026#34;: \u0026#34;keyword\u0026#34; } } } } } } } } } 一对多数据建模 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 ==================================一个用户对应多个地址================================== put /user { \u0026#34;mappings\u0026#34;: { \u0026#34;doc\u0026#34; : { \u0026#34;properties\u0026#34;: { \u0026#34;login_name\u0026#34; : { \u0026#34;type\u0026#34; : \u0026#34;keyword\u0026#34; }, \u0026#34;age \u0026#34; : { \u0026#34;type\u0026#34; : \u0026#34;short\u0026#34; }, \u0026#34;address\u0026#34; : { \u0026#34;properties\u0026#34;: { \u0026#34;province\u0026#34; : { \u0026#34;type\u0026#34; : \u0026#34;keyword\u0026#34; }, \u0026#34;city\u0026#34; : { \u0026#34;type\u0026#34; : \u0026#34;keyword\u0026#34; }, \u0026#34;street\u0026#34; : { \u0026#34;type\u0026#34; : \u0026#34;keyword\u0026#34; } } } } } } } 优点:思想简单,建模方便,查询方便\n缺点:数据大量冗余、耦合程度高、不易修改与维护\nnested object\n如果使用\u0026quot;一个用户对应多个地址\u0026quot;的存储方式,查询市和街道同时满足条件会返回大量不是我们想要的数据【返回中包含市匹配而街道不匹配的和街道匹配而市不匹配的】,原因是elasticsearch对底层对象做了扁平化处理。\n1 2 3 4 5 6 7 //查询北京、建材城西路上述数据也会返回但是并不是我们需要的 { \u0026#34;login_name\u0026#34; : \u0026#34;jack\u0026#34;, \u0026#34;address.province\u0026#34; : [ \u0026#34;北京\u0026#34;, \u0026#34;天津\u0026#34; ], \u0026#34;address.city\u0026#34; : [ \u0026#34;北京\u0026#34;, \u0026#34;天津\u0026#34; ] \u0026#34;address.street\u0026#34; : [ \u0026#34;西三旗东路\u0026#34;, \u0026#34;古文化街\u0026#34; ] } 建立nested索引使elasticsearch不进行扁平化处理\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 put /user { \u0026#34;mappings\u0026#34;: { \u0026#34;doc\u0026#34; : { \u0026#34;properties\u0026#34;: { \u0026#34;login_name\u0026#34; : { \u0026#34;type\u0026#34; : \u0026#34;keyword\u0026#34; }, \u0026#34;age \u0026#34; : { \u0026#34;type\u0026#34; : \u0026#34;short\u0026#34; }, \u0026#34;address\u0026#34; : { \u0026#34;type\u0026#34;: \u0026#34;nested\u0026#34;, \u0026#34;properties\u0026#34;: { \u0026#34;province\u0026#34; : { \u0026#34;type\u0026#34; : \u0026#34;keyword\u0026#34; }, \u0026#34;city\u0026#34; : { \u0026#34;type\u0026#34; : \u0026#34;keyword\u0026#34; }, \u0026#34;street\u0026#34; : { \u0026#34;type\u0026#34; : \u0026#34;keyword\u0026#34; } } } } } } } elasticsearch内部存储结构会变为\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 { { \u0026#34;login_name\u0026#34; : \u0026#34;jack\u0026#34; }, [ { \u0026#34;address.province\u0026#34; : \u0026#34;北京\u0026#34;, \u0026#34;address.city\u0026#34; : \u0026#34;北京\u0026#34;, \u0026#34;address.street\u0026#34; : \u0026#34;西三旗东路\u0026#34; }, { \u0026#34;address.province\u0026#34; : \u0026#34;北京\u0026#34;, \u0026#34;address.city\u0026#34; : \u0026#34;北京\u0026#34;, \u0026#34;address.street\u0026#34; : \u0026#34;西三旗东路\u0026#34;, } ] } nested查询\u0026amp;聚合语法\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 =========================================查询========================================= get /user_index/doc/_search { \u0026#34;query\u0026#34;: { \u0026#34;nested\u0026#34;: { //指定nested查询 \u0026#34;path\u0026#34;: \u0026#34;address\u0026#34;, //指定nested字段 \u0026#34;query\u0026#34;: { \u0026#34;bool\u0026#34;: { \u0026#34;must\u0026#34;: [ { \u0026#34;match\u0026#34;: { \u0026#34;address.province\u0026#34;: \u0026#34;北京\u0026#34; } }, { \u0026#34;match\u0026#34;: { \u0026#34;address.street\u0026#34;: \u0026#34;建材城西路\u0026#34; } } ] } } } } } ================================聚合条件只包含nested字段================================ get /user_index/user/_search { \u0026#34;size\u0026#34;: 0, \u0026#34;aggs\u0026#34;: { \u0026#34;group_by_address\u0026#34;: { \u0026#34;nested\u0026#34;: {\t//指定nested字段信息 \u0026#34;path\u0026#34;: \u0026#34;address\u0026#34; }, \u0026#34;aggs\u0026#34;: { \u0026#34;group_by_province\u0026#34;: { \u0026#34;terms\u0026#34;: { \u0026#34;field\u0026#34;: \u0026#34;address.province\u0026#34; }, \u0026#34;aggs\u0026#34;: { \u0026#34;group_by_city\u0026#34;: { \u0026#34;terms\u0026#34;: { \u0026#34;field\u0026#34;: \u0026#34;address.city\u0026#34; } } } } } } } } ================================聚合条件不仅包含nested字段=============================== get /user_index/user/_search { \u0026#34;size\u0026#34;: 0, \u0026#34;aggs\u0026#34;: { \u0026#34;group_by_address\u0026#34;: { \u0026#34;nested\u0026#34;: { \u0026#34;path\u0026#34;: \u0026#34;address\u0026#34; }, \u0026#34;aggs\u0026#34;: { \u0026#34;group_by_province\u0026#34;: { \u0026#34;terms\u0026#34;: { \u0026#34;field\u0026#34;: \u0026#34;address.province\u0026#34; }, \u0026#34;aggs\u0026#34;: { \u0026#34;reverse_aggs\u0026#34;: { \u0026#34;reverse_nested\u0026#34;: {},\t//标识子聚合不在nested字段中进行 \u0026#34;aggs\u0026#34;: { \u0026#34;avg_by_age\u0026#34;: { \u0026#34;avg\u0026#34;: { \u0026#34;field\u0026#34;: \u0026#34;age\u0026#34; } } } } } } } } } } 虽然语法变的复杂了,但是在数据的读写操作上都不会有错误发生,是推荐的设计方式。\n父子关系数据建模 父子关系数据建模是模拟关系型数据库的建模方式,用不同的索引保存各自的数据,通过底层提供的父子关系,让elasticsearch辅助实现类似关系型数据库的多表联合查询。这种建模方式,数据几乎没有冗余,且查询效率高。\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 ==================================建立父子关系mapping================================== put /ecommerce_products_index { \u0026#34;mappings\u0026#34;: { \u0026#34;ecommerce\u0026#34;: { \u0026#34;properties\u0026#34;: { \u0026#34;category_name\u0026#34;: { \u0026#34;type\u0026#34;: \u0026#34;text\u0026#34;, \u0026#34;analyzer\u0026#34;: \u0026#34;ik_max_word\u0026#34; }, \u0026#34;product_name\u0026#34;: { \u0026#34;type\u0026#34;: \u0026#34;text\u0026#34;, \u0026#34;analyzer\u0026#34;: \u0026#34;ik_max_word\u0026#34; }, \u0026#34;remark\u0026#34;: { \u0026#34;type\u0026#34;: \u0026#34;text\u0026#34;, \u0026#34;analyzer\u0026#34;: \u0026#34;ik_max_word\u0026#34; }, \u0026#34;price\u0026#34;: { \u0026#34;type\u0026#34;: \u0026#34;long\u0026#34; }, \u0026#34;sellpoint\u0026#34;: { \u0026#34;type\u0026#34;: \u0026#34;text\u0026#34;, \u0026#34;analyzer\u0026#34;: \u0026#34;ik_max_word\u0026#34; }, \u0026#34;ecommerce_join_field\u0026#34;: { //描述父子关系 \u0026#34;type\u0026#34;: \u0026#34;join\u0026#34;, //类型为join \u0026#34;relations\u0026#34;: { //关系描述,父在前,子在后 \u0026#34;category\u0026#34;: \u0026#34;product\u0026#34; } } } } } } =======================================插入数据======================================== post /ecommerce_products_index/ecommerce/_bulk {\u0026#34;index\u0026#34; : {\u0026#34;_id\u0026#34; : \u0026#34;1\u0026#34;}} {\u0026#34;category_name\u0026#34; : \u0026#34;电视\u0026#34;, \u0026#34;ecommerce_join_field\u0026#34; : { \u0026#34;name\u0026#34; : \u0026#34;category\u0026#34; }} {\u0026#34;index\u0026#34; : {\u0026#34;_id\u0026#34; : \u0026#34;2\u0026#34;}} {\u0026#34;category_name\u0026#34; : \u0026#34;电脑\u0026#34;, \u0026#34;ecommerce_join_field\u0026#34; : { \u0026#34;name\u0026#34; : \u0026#34;category\u0026#34; }} {\u0026#34;index\u0026#34; : {\u0026#34;_id\u0026#34; : \u0026#34;3\u0026#34;}} {\u0026#34;category_name\u0026#34; : \u0026#34;手机\u0026#34;, \u0026#34;ecommerce_join_field\u0026#34; : { \u0026#34;name\u0026#34; : \u0026#34;category\u0026#34; }} {\u0026#34;index\u0026#34; : {\u0026#34;_id\u0026#34; : \u0026#34;4\u0026#34;, \u0026#34;routing\u0026#34; : \u0026#34;1\u0026#34;}} {\u0026#34;product_name\u0026#34; : \u0026#34;长虹电视\u0026#34;, \u0026#34;remark\u0026#34; : \u0026#34;国产电视\u0026#34;, \u0026#34;price\u0026#34; : 199800, \u0026#34;sellpoint\u0026#34; : \u0026#34;便宜,个大\u0026#34;, \u0026#34;ecommerce_join_field\u0026#34; : { \u0026#34;name\u0026#34; : \u0026#34;product\u0026#34;, \u0026#34;parent\u0026#34; : \u0026#34;1\u0026#34; }} {\u0026#34;index\u0026#34; : {\u0026#34;_id\u0026#34; : \u0026#34;5\u0026#34;, \u0026#34;routing\u0026#34; : \u0026#34;1\u0026#34;}} {\u0026#34;product_name\u0026#34; : \u0026#34;西门子电视\u0026#34;, \u0026#34;remark\u0026#34; : \u0026#34;进口电视\u0026#34;, \u0026#34;price\u0026#34; : 599800, \u0026#34;sellpoint\u0026#34; : \u0026#34;就是贵\u0026#34;, \u0026#34;ecommerce_join_field\u0026#34; : { \u0026#34;name\u0026#34; : \u0026#34;product\u0026#34;, \u0026#34;parent\u0026#34; : \u0026#34;1\u0026#34; }} {\u0026#34;index\u0026#34; : {\u0026#34;_id\u0026#34; : \u0026#34;6\u0026#34;, \u0026#34;routing\u0026#34; : \u0026#34;2\u0026#34;}} {\u0026#34;product_name\u0026#34; : \u0026#34;thinkpad t99\u0026#34;, \u0026#34;remark\u0026#34; : \u0026#34;不知道啥时候生产\u0026#34;, \u0026#34;price\u0026#34; : 2999800, \u0026#34;sellpoint\u0026#34; : \u0026#34;可能会生产吧?\u0026#34;, \u0026#34;ecommerce_join_field\u0026#34; : { \u0026#34;name\u0026#34; : \u0026#34;product\u0026#34;, \u0026#34;parent\u0026#34; : \u0026#34;2\u0026#34; }} {\u0026#34;index\u0026#34; : {\u0026#34;_id\u0026#34; : \u0026#34;9\u0026#34;, \u0026#34;routing\u0026#34; : \u0026#34;3\u0026#34;}} {\u0026#34;product_name\u0026#34; : \u0026#34;iphone x\u0026#34;, \u0026#34;remark\u0026#34; : \u0026#34;齐刘海手机\u0026#34;, \u0026#34;price\u0026#34; : 899800, \u0026#34;sellpoint\u0026#34; : \u0026#34;卖肾买手机\u0026#34;, \u0026#34;ecommerce_join_field\u0026#34; : { \u0026#34;name\u0026#34; : \u0026#34;product\u0026#34;, \u0026#34;parent\u0026#34; : \u0026#34;3\u0026#34; }} 在父子关系数据模型中,要求有关系的父子数据必须在同一个shard中保存,否则es无法实现数据的关联管理,所以在保存子数据的时候,必须使用其对应的父数据在存储时使用的routing。默认情况下,es使用document的id作为routing值,所以子数据在保存的时候,必须使用父数据的id作为routing才可,否则无法建立父子关系。\n父子关系查询数据\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 =================================查询类型指定父类型的数据================================ get /ecommerce_products_index/ecommerce/_search { \u0026#34;query\u0026#34;: { \u0026#34;parent_id\u0026#34;: { \u0026#34;type\u0026#34;: \u0026#34;product\u0026#34;, \u0026#34;id\u0026#34;: 1 } } } ===============================查询满足条件的父类型的子类型=============================== get /ecommerce_products_index/ecommerce/_search { \u0026#34;query\u0026#34;: { \u0026#34;has_parent\u0026#34;: { \u0026#34;parent_type\u0026#34;: \u0026#34;category\u0026#34;, \u0026#34;query\u0026#34;: { \u0026#34;match\u0026#34;: { \u0026#34;category_name\u0026#34;: \u0026#34;电脑\u0026#34; } } } } } ===============================查询满足条件的子类型的父类型=============================== get /ecommerce_products_index/ecommerce/_search { \u0026#34;query\u0026#34;: { \u0026#34;has_child\u0026#34;: { \u0026#34;type\u0026#34;: \u0026#34;product\u0026#34;, \u0026#34;query\u0026#34;: { \u0026#34;range\u0026#34;: { \u0026#34;price\u0026#34;: { \u0026#34;gte\u0026#34;: 500000, \u0026#34;lte\u0026#34;: 1000000 } } } } } } 父子关系聚合数据\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 ==================================计算品类下产品的均价=================================== get /ecommerce_products_index/ecommerce/_search { \u0026#34;size\u0026#34;: 0, \u0026#34;aggs\u0026#34;: { \u0026#34;group_by_category\u0026#34;: { \u0026#34;terms\u0026#34;: { \u0026#34;field\u0026#34;: \u0026#34;category_name.keyword\u0026#34; }, \u0026#34;aggs\u0026#34;: { \u0026#34;products_bucket\u0026#34;: { \u0026#34;children\u0026#34;: { \u0026#34;type\u0026#34;: \u0026#34;product\u0026#34; }, \u0026#34;aggs\u0026#34;: { \u0026#34;avg_by_price\u0026#34;: { \u0026#34;avg\u0026#34;: { \u0026#34;field\u0026#34;: \u0026#34;price\u0026#34; } } } } } } } } nested与parent/child对比 对比 nested object parent/child 优点 文档存储在一起所以读性能高 父子文档可以独立更新,互不影响 缺点 更新父或子文档时需要更新整个文档 为了维护join关系,需要占用部分内存读取性能较差 场景 子文档偶尔更新,查询频繁 子文档更新频繁 文件系统数据建模 用于实现文件目录搜索\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 =======================================创建索引======================================== put /code { \u0026#34;settings\u0026#34;: { \u0026#34;analysis\u0026#34;: { \u0026#34;analyzer\u0026#34;: { \u0026#34;path_analyzer\u0026#34;: { //创建路径分析器 \u0026#34;tokenizer\u0026#34;: \u0026#34;path_hierarchy\u0026#34; } } } }, \u0026#34;mappings\u0026#34;: { \u0026#34;doc\u0026#34;: { \u0026#34;properties\u0026#34;: { \u0026#34;path\u0026#34;: { \u0026#34;type\u0026#34;: \u0026#34;text\u0026#34;, \u0026#34;analyzer\u0026#34;: \u0026#34;path_analyzer\u0026#34;, //使用路径分析器 \u0026#34;fields\u0026#34;: { \u0026#34;stand\u0026#34;: { \u0026#34;type\u0026#34;: \u0026#34;text\u0026#34;, \u0026#34;analyzer\u0026#34;: \u0026#34;standard\u0026#34; } } }, \u0026#34;author\u0026#34;: { \u0026#34;type\u0026#34;: \u0026#34;text\u0026#34;, \u0026#34;analyzer\u0026#34;: \u0026#34;standard\u0026#34; }, \u0026#34;content\u0026#34;: { \u0026#34;type\u0026#34;: \u0026#34;text\u0026#34;, \u0026#34;analyzer\u0026#34;: \u0026#34;standard\u0026#34; } } } } } =======================================查询数据======================================== get /code/doc/_search { \u0026#34;query\u0026#34;: { \u0026#34;match\u0026#34;: { \u0026#34;path\u0026#34;: \u0026#34;/com\u0026#34; //只能搜索出/com/kun路径开始的doc } } } get /code/doc/_search { \u0026#34;query\u0026#34;: { \u0026#34;match\u0026#34;: { \u0026#34;path.stand\u0026#34;: \u0026#34;/com/kun\u0026#34; //能搜索包含/com/kun的路径 } } } 十六、重建索引\u0026amp;零停机 重建索引-reindex 索引类型一旦建立便不可更改,如果要修改数据类型,只能重建索引:用新的设置创建新的索引并把文档从旧的索引复制到新的索引。\n方法一:用 scroll 从旧的索引检索批量文档 ,然后用 bulk api 把文档推送到新的索引中\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 //准备数据 put /old_index/test_type/1 { \u0026#34;field\u0026#34; : \u0026#34;2018-08-08\u0026#34; } put /old_index/test_type/2 { \u0026#34;field\u0026#34; : \u0026#34;2018-08-07\u0026#34; } put /old_index/test_type/3 { \u0026#34;field\u0026#34; : \u0026#34;2018-08-06\u0026#34; } //新建索引mapping put /new_index { \u0026#34;mappings\u0026#34;: { \u0026#34;test_type\u0026#34;:{ \u0026#34;properties\u0026#34;:{ \u0026#34;field\u0026#34;:{ \u0026#34;type\u0026#34;: \u0026#34;keyword\u0026#34; } } } } } //读取信息 get old_index/test_type/_search?scroll=1m { \u0026#34;query\u0026#34; : { \u0026#34;match_all\u0026#34; : {} }, \u0026#34;sort\u0026#34; : [ \u0026#34;_doc\u0026#34; ], \u0026#34;size\u0026#34; : 1 } get /_search/scroll { \u0026#34;scroll\u0026#34; : \u0026#34;1m\u0026#34;, \u0026#34;scroll_id\u0026#34; : \u0026#34;根据具体返回结果替换\u0026#34; } //bulk批量添加数据 post /_bulk {\u0026#34;index\u0026#34; : {\u0026#34;_index\u0026#34; : \u0026#34;new_index\u0026#34;, \u0026#34;_type\u0026#34; : \u0026#34;test_type\u0026#34;, \u0026#34;_id\u0026#34; : \u0026#34;1\u0026#34;}} {\u0026#34;field\u0026#34; : \u0026#34;2018-08-08\u0026#34;} 方法二:使用_reindex迁移索引数据\n1 2 3 4 5 6 7 8 9 10 11 12 //默认情况下一次批处理1000条记录,也可支持远程索引重建 //wait_for_completion=false 后台执行执行,返回任务id,通过id查看进度 get _tasks/[taskid] post _reindex?wait_for_completion=false { \u0026#34;conflicts\u0026#34;: \u0026#34;proceed\u0026#34;, //冲突时覆盖并继续 \u0026#34;source\u0026#34;: { \u0026#34;index\u0026#34;: \u0026#34;old_index\u0026#34; //还可以添加query条件 }, \u0026#34;dest\u0026#34;: { \u0026#34;index\u0026#34;: \u0026#34;new_index\u0026#34; } } 零停机 零停机问题:reindex索引,操作指向新的index,则必须停止后台服务,更改索引名称,这样会引起停机问题。\n解决方案:可以使用索引别名来解决reindex中的索引名变更问题。\n别名特性:在elasticsearch中一个别名可以指向多个索引,一个索引也可以被多个别名指向。\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 //定义索引别名 put index_name/_alias/alias_index //原子操作,移除就别名指向,添加新别名指向 post _aliases { \u0026#34;actions\u0026#34;: [ { \u0026#34;add\u0026#34;: { \u0026#34;index\u0026#34;: \u0026#34;new_index\u0026#34;, \u0026#34;alias\u0026#34;: \u0026#34;current_index\u0026#34; } }, { \u0026#34;remove\u0026#34;: { \u0026#34;index\u0026#34;: \u0026#34;old_index\u0026#34;, \u0026#34;alias\u0026#34;: \u0026#34;current_index\u0026#34; } } ] } 建议:在应用中使用别名而不是索引名。这样可以在任何时候重建索引,且别名的开销很小\n其它使用场景:如电商中有手机索引,座机索引,使用别名电话设备作为两个索引的别名。访问电话设备,则可以在两个索引中搜索数据。\n十七、正排索引 \telasticsearch在存储document时,会根据document中的field类型建立对应的索引。通常来说只创建倒排索引,倒排索引是为了搜索而存在的。但是如果对数据进行排序、聚合、过滤等操作的时候,就需要创建正排索引(doc values)。doc values会保存到磁盘中,如果os的内存足够会被缓存。\n\tdoc values只在不分词的字段中存在。倒排索引只在分词的字段中出现。正排索引和倒排索引不是在同一个字段同时存在的。但可以使用fielddata替代doc values正排索引和倒排索引在同一个字段出现。\n\t如果字段类型为text。那么默认是需要分词的,则只有倒排索引。\n\t如果真的需要同时使用倒排索引和正排索引,都是使用子字段的方式来实现。\ndoc values与聚合分析内部原理 假设倒排索引的内容如下【文档模型中只有一列body】\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 term doc_1 doc_2 doc_3 ------------------------------------------------------------------------------------- brown | x | x | dog | x | | x dogs | | x | x fox | x | | x foxes | | x | in | | x | jumped | x | | x lazy | x | x | leap | | x | over | x | x | x quick | x | x | x summer | | x | the | x | | x ------------------------------------------------------------------------------------- 1 2 3 4 5 6 7 8 9 10 get /my_index/_search { \u0026#34;aggs\u0026#34; : { \u0026#34;popular_terms\u0026#34;: { \u0026#34;terms\u0026#34; : { \u0026#34;field\u0026#34; : \u0026#34;body\u0026#34; } } } } 聚合部分,则无法使用正拍索引【不容易确定原doc内容】。doc values 通过转置两者间的关系来解决这个问题。倒排索引将词项映射到包含它们的文档,doc values(正排索引) 将文档映射到它们包含的词项\n1 2 3 4 5 6 doc terms -------------------------------------------------------------------------------------- doc_1 | brown, dog, fox, jumped, lazy, over, quick, the doc_2 | brown, dogs, foxes, in, lazy, leap, over, quick, summer doc_3 | dog, dogs, fox, jumped, over, quick, the -------------------------------------------------------------------------------------- 当数据被转置之后,收集到 doc中的token信息会非常容易。获得每个文档行,获取所有的词项即可。\ndoc values 不仅可以用于聚合。还包括排序,访问字段值的脚本,父子关系处理。doc values是在不可分词的类型field中创建的。如:keyword、int、date、long等\ndoc values特征总结 doc values也是索引创建时生成的,简单来说,就是数据录入索引时创建正排索引(index-time)\ndoc values也有缓存应用(内存级别, os cache等),如果内存不足时,doc values 会写入磁盘文件\nelasticsearch大部分操作都是基于系统缓存进行的,而不是jvm。官方建议不要给jvm分配太多的内存空间,这样会导致gc开销太大。通常来说,给jvm分配的内存不超过服务器物理内存的1/4。\nfielddata 如何没有建立doc value可设置fielddata=true,这样可以反转倒排索引并加载到内存中。大量消耗资源不推荐使用。默认fielddata在query time时产生。\n如果必须在text类型的field上,执行聚合分析。则由两种实现方案:\n为text类型的field增加一个子字段,子字段类型为keyword,执行聚合分析的时候,使用自字段(推荐方案)\n在text类型的field中,设置fielddata=true,辅助完成聚合分析。【以内存为代价】\nfielddata内存 fielddata对内存的开销极大,可以通过参数来设置内存限制。在配置文件config/elasticsearch.yml中增加 1 indices.fielddata.cache.size : 20% fielddata内存监控命令 1 2 3 get _stats/fielddata?fields=* get _nodes/stats/indices/fielddata?fields=* get _nodes/stats/indices/fielddata?level=indices\u0026amp;fields=* circuit breaker短路器 如果一次聚合操作时,加载的fielddata超过了总内存容量,则会抛出内存溢出错误(oom out of memory),这个时候可以增加短路器circuit breaker,circuit breaker会估算本次操作要加载的fielddata大小,如果超出了总内存容量,则请求短路,直接返回错误响应,不会产生oom错误导致es所在节点宕机或应用关闭。\n1 2 3 indices.breaker.fielddata.limit : 60% # fielddata的内存限制,默认60% indices.breaker.request.limit: 40% # 执行聚合的一次请求的内存限制,默认40% indices.breaker.total.limit: 70% # 综合上述两个限制,总计内存限制多少。默认无限制。 fielddata的filter过滤 在创建index时,为fielddata增加filter过滤器,实现一个更加细粒度的内存控制。\nmin:只有聚合分析的数据在大于min的document中出现过,才会加载fielddata到内存中。\nmax:只有聚合分析的数据在小于max的document中出现过,才会加载fielddata到内存中。\nmin_segment_size: 只有segment中的document数量大于min_segment_size时,才会加载到内存中。\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 put /fieddata_filter { \u0026#34;mappings\u0026#34;: { \u0026#34;doc\u0026#34;: { \u0026#34;properties\u0026#34;: { \u0026#34;note\u0026#34;: { \u0026#34;type\u0026#34;: \u0026#34;text\u0026#34;, \u0026#34;fielddata\u0026#34;: true, \u0026#34;fielddata_frequency_filter\u0026#34;: { \u0026#34;min\u0026#34;: 0.001, \u0026#34;max\u0026#34;: 0.1, \u0026#34;min_segment_size\u0026#34;: 500 } } } } } } fielddata的预加载 fielddata是一个query-time生成的正排索引,如果某index中必须使用fielddata,又希望可以提升其效率,则可以使用预加载的方式来实现性能的提升。预加载fielddata会提高query过程的效率,但是降低index写入数据的效率。且始终对内存有很高的压力。不建议使用。\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 put /fieddata_filter { \u0026#34;mappings\u0026#34;: { \u0026#34;doc\u0026#34;: { \u0026#34;properties\u0026#34;: { \u0026#34;note\u0026#34;: { \u0026#34;type\u0026#34;: \u0026#34;text\u0026#34;, \u0026#34;fielddata\u0026#34;: true, \u0026#34;fielddata_frequency_filter\u0026#34;: { \u0026#34;min\u0026#34;: 0.001, \u0026#34;max\u0026#34;: 0.1, \u0026#34;min_segment_size\u0026#34;: 500 }, \u0026#34;eager_global_ordinals\u0026#34;: true\t//开启预加载,默认false } } } } } ","date":"2019-05-22","permalink":"https://hobocat.github.io/post/searchengine/2019-05-22-elasticsearch/","summary":"一、ElasticSearch概念 ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful","title":"elasticsearch技术"},]
[{"content":"一、nosql简介 nosql分类 键值(key-value)存储数据库:这一类数据库主要会使用到一个hash表,如redis、oracle bdb 列存储数据库:通常是用来应对分布式存储的海量数据,键仍然存在但是他们指向了多个列,如hbase、riak 文档型数据库:该类型的数据模型是版本化的文档,比如json,允许之间进行嵌套,如mongodb 非关系型数据库特点 数据模型比较简单\n对于数据库性能要求较高\n不需要高度的数据一致性\n二、redis简介 以key-value形式存储,不一定遵循传统数据库的一些基本要求(非关系的、分布式的、开源的、水平可扩展的)\n优点:对数据高并发读写\n 对海量数据的高效率存储和访问\n 对数据的可扩展性和高可用性\n缺点:无法做太复杂的关系模型\nredis单线程:指处理我们的网络请求的时候只有一个线程来处理【文件刷盘等用的是多线程】\nredis单线程的好处:\nredis是基于内存的操作,cpu不是redis的瓶颈,redis的瓶颈最有可能是机器内存的大小或者网络带宽,单线程实现比较简单\n单线程避免了不必要的上下文切换和竞争条件以及加锁释放锁操作\n使用多路i/o复用模型,非阻塞io\n三、redis的安装 第一步:准备工作【解压tar包,创建redis相关目录】\n1 2 3 4 tar -zxvf redis-5.0.2.tar.gz mkdir /opt/redis mkdir /opt/redis/conf mkdir /opt/redis/data 第二步:编译redis\n1 2 3 4 5 #进入解压后的tar包执行 make #执行结束之后进入src目录 cd src make install prefix=/opt/redis 第三步:移动配置文件到conf目录\n1 cp redis.conf /opt/redis/conf 额外配置:\nredis开机自启 1 2 3 vim /etc/rc.local #加入 /opt/redis/bin/redis-server /opt/redis/conf/redis.conf 配置数据保存目录 1 2 3 vim /opt/redis/conf/redis.conf #修改 dir ./ ---\u0026gt; dir /opt/redis/data/ 四、redis基本通用命令 命令 说明 keys [pattern] 查找出匹配的key【生成环境禁止使用,数据量太大阻塞生成环境】 dbsize 统计key总数【使用的是redis的内部计数,并不是全部扫描,生产可用】 exists key [key \u0026hellip;] 检查key是否存在【存在返回1,不存在返回0】 del key [key\u0026hellip;] 删除key【成功删除返回1,不存在此key返回0】 expire key seconds 设置过期时间 ttl key 查看剩余的过期时间【-2代表已不存在,-1代表永不过期】 persist key 取消key的过期设置 type key 查询key的类型 五、redis数据类型及其使用 注意:redis操作下标都是闭区间的\n字符串【string】 string的值类型可以为字符类型、数字类型、bit类型\nstring类型是包含很多中类型的特殊类型,并且是二进制安全的。比如序列化的对象进行存储,比如一张图片进行二进制存储,比如一个简单地字符串,数值等等。\n使用场景:缓存、计数器、分布式锁等\n常用命令格式 描述 { get key },{ mget key [key \u0026hellip;] } 得到string { set key value },{ mset key value [key value \u0026hellip;] } 设置string { setnx key value },{ msetnx key value [key value \u0026hellip;] } 如果不存在则设置 set key value xx 如果存在则设置 setex key second value 设置过期时间 { incr key },{ incrby key increment } 自增操作 { decr key },{ decrby key decrement } 自减操作 getset key value 得到就值设置新值 append key value 追加字符串 strlen key 得到字符串长度,内部存有计数 getrange key start end 得到指定长度的value setrange key offset value 设置指定偏移量字符串内容 哈希【hash】 使用场景:存储具有一定结构化的数据\n常用命令格式 描述 hget key field 得到key对应field的value hset key field value 设置key对应field的value hdel key field 删除key对应field的value hexists key field 判断key的field是否存在 hlen key 获取指定key的filed数量【内部计数,生成环境可用】 hmget key field [field \u0026hellip;] 批量获得hash的field对应的value hmset key field value [field value \u0026hellip;] 批量设置hash的field和value hincrby key field increment 增加指定increment的对应key的field hgetall key 获取key对应所有field和value【生成环境慎用】 hvals key 返回key对应的所有value【生成环境慎用】 hkeys key 返回key对应的所有field【生成环境慎用】 hsetnx key field value 不存在此key对应的field则设置 列表【list】 列表为有序、可重复结构。可指定位置插入和删除、也可从左右插入和弹出(模拟栈结构)\n常用命令格式 描述 lpush|rpush key value [value \u0026hellip;] 从列表的左|右插入元素 linsert key before|after value newvalue 在list指定的值前|后插入新元素【时间复杂度o(n)】 lpop|rpop key 从列表左侧|右侧弹出一个元素 lrem key count value 根据count值,从列表删除所有等于value的值【时间复杂度o(n)】\n【count\u0026gt;0,从左到右删除count个】\n【count\u0026lt;0,从右到坐删除count个】\n【count=0,删除所有value相等的值】 ltrim key start end 按照索引范围保留list,删除大链表有用【时间复杂度o(n)】 lrangr key start end 获取列表指定索引范围内的值,数值为负则从右往左取值【时间复杂度o(n)】 lindex key index 获取列表指定索引的值,数值为负则从右取值【时间复杂度o(n)】 llen key 获取list长度【内部计数,生成环境可用】 lset key index newvalue 设置指定位置的值【时间复杂度o(n)】 blpop|rlpop key timeout lpop/rpop的阻塞版,timeout为0则表示永不阻塞 使用技巧:\nlpush + lpop = stack lpush + rpop = queue lpush + ltrim = capped collection【固定容量集合】 lpush + brpop = block queue 集合【set】 set无序、无重复、有集合间操作。\n常用命令格式 描述 sadd key element [member …] 向集合key添加元素 srem key element 删除集合key中的element元素 scard key 查询集合元素的个数【内部计数,生成环境可用】 sismember key element 集合中是否存在element元素 srandmember key 随机得到一个元素 smembers key 获取集合所有元素【慎用】 spop key 随机弹出一个元素 { sdiff key [key …] }、{ sdiffstore destination key [key …] } 返回/存储一个集合的全部成员,该集合是所有给定集合之间的差集 { sinter key [key …] }、{ sinterstore destination key [key …] } 返回/存储一个集合的全部成员,该集合是所有给定集合的交集 { sunion key [key …] }、{ sunionstore destination key [key …] } 返回/存储一个集合的全部成员,该集合是所有给定集合的并集 使用技巧\nsadd = tagging\nspop/srandmember = random item\nsadd + sinter = social graph【共同关注、有着相同兴趣等】\n有序集合【zset】 zset有序、无重复、包含分值与元素,有集合间操作。\n使用场景:排行榜\n常用命令格式 描述 zadd key score member [score member \u0026hellip;] 向集合添加元素 zrem key member [member …] 移除集合中的元素 zscore key member 得到元素的分数 zincrby key increment member 增长元素的分数 zcard key 获得集合中元素的个数 zrank key member 成员按分值递减(从小到大)排列的排名 zrange key start stop [withscores] 按score值递增(从小到大)排序,withscores返回分数 zrangebyscore key max min [withscores] 返回分数范围内数据,按score值递增(从小到大)排序,withscores返回分数 zcount key min max 统计得到分数在min和max之间的元素个数 { zremrangebyrank key start stop }、{ zremrangebyscore key min max} 按照排名/分数范围删除元素 zrevrank key member 成员按分值递减(从大到小)排列的排名 zrevrange key start stop [withscores] 按score值递增(从大到小)排序,withscores返回分数 zrevrangebyscore key max min [withscores] 返回分数范围内数据,按score值递增(从大到小)排序,withscores返回分数 六、redis高级功能 慢查询日志 慢查询发生在第三阶段 客户端超时不一定是慢查询导致,但慢查询可导致客户端超时 慢查询队列简介\n先进先出的队列 固定长度 长度不够时,丢弃最早记录 保存在内存中 慢查询设置\nslow-max-len【慢查询队列长度,默认128】\nslowlog-log-slower-than【慢查询的阙值(微秒,1000000 微秒=1 秒),默认10000(10毫秒),建议为1000(1毫秒)】\n更改慢查询参数建议使用config set parameter value方式,而不是更改redis.conf文件重启redis\n慢查询命令\n常用命令格式 描述 slowlog get n 获取慢查询队列一条记录 slowlog len 获取慢查询队列长度 slowlog reset 清空慢查询队列 查询结果示例\npipeline 一般情况下客户端发送一条命令到redis,redis处理结束返回结果,即 n条命令 = n次网络时间 + n次计算时间\npipeline将命令打包发送给客户端,redis处理完返回结果,pipline是一个异步处理方式,并不等待redis返回。\npipeline(n条命令) = 1次网络时间 + n次计算时间\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 /* * jest执行参考 */ long oldpipeline = instant.now().toepochmilli(); for (int i = 0; i \u0026lt; 100; i++) { pipeline pipeline = jedis.pipelined(); for (int j = 0; j \u0026lt; 100; j++) { pipeline.sadd(\u0026#34;s\u0026#34; + i * 100 + j, j + \u0026#34;\u0026#34;); } //pipeline.sync();异步不接受返回结果 pipeline.syncandreturnall(); //异步接受返回结果 } long nowpipeline = instant.now().toepochmilli(); system.out.println(nowpipeline - oldpipeline); /** * spring data redis参考 */ // 批量插入 redistemplate.executepipelined(new rediscallback\u0026lt;void\u0026gt;() { @override public void doinredis(redisconnection connection) throws dataaccessexception { string keyprefix = \u0026#34;pipeline-\u0026#34;; for (int i = 0; i \u0026lt; 10000; i++) { string key = keyprefix + i; connection.set(key.getbytes(), string.valueof(i).getbytes()); } } }); // 批量获取 list\u0026lt;object\u0026gt; data = redistemplate.executepipelined(new rediscallback\u0026lt;string\u0026gt;() { @override public string doinredis(redisconnection connection) throws dataaccessexception { string keyprefix = \u0026#34;pipeline-\u0026#34;; for (int i = 0; i \u0026lt; 10000; i++) { string key = keyprefix + i; connection.get(key.getbytes()); } } }); data.stream().foreach(system.out::println); 发布订阅 常用命令格式 描述 publish channel message 将信息 message 发送到指定的频道 channel subscribe channel [channel …] 订阅给定的一个或多个频道的信息 psubscribe pattern [pattern …] 订阅一个或多个符合给定pattern的频道 unsubscribe [channel [channel …]] 取消订阅 bitmap 常用命令格式 描述 setbit key offset value 对 key所储存的字符串值,设置或清除指定偏移量上的位(bit) getbit key offset 对 key所储存的字符串值,获取指定偏移量上的位(bit) bitcount key [start] [end] 计算给定字符串中,被设置为 1的比特位的数量 bitop operation destkey key [key …] 对一个或多个保存二进制位的字符串 key进行位元操作,并将结果保存到 destkey上\noperation 可以是 and 、 or 、 not 、 xor 这四种操作中的任意一种 bitpos key bit [start] [end] 返回位图中第一个值为 bit的二进制位的位置 hyperloglog 实质:用string类型实现,不能取出具体值,有错误率\n作用:极小的空间实现独立数量统计\n常用命令格式 描述 pfadd key element [element …] 将任意数量的元素添加到指定的hyperloglog pfcount key [key …] 计算hyperloglog有多少值 pfmerge destkey sourcekey [sourcekey …] 将多个hyperloglog合并为一个hyperloglog geo geo(地理信息定位):存储经纬度,计算两地距离,范围计算等\ngeo是使用zset实现\n常用命令格式 描述 geoadd key longitude latitude member [longitude latitude member …] longitude:经度,latitude:维度,member:标识 geopos key member [member …] 返回经纬度 geodist key member1 member2 [unit] 返回两个给定位置之间的距离 georadius key longitude latitude radius m|km|ft|mi [withcoord] [withdist] [withhash] [asc|desc] [count count] 返回指定范围内的数据 zrem key member 删除成员 七、redis持久化 rdb【redis database】 \trdb是redis用来进行持久化的一种方式,是把当前内存中的数据集快照写入磁盘,也就是 snapshot 快照(数据库中所有键值对数据)。恢复时是将快照文件直接读到内存里。\n触发机制\nsave\n手动触发,同步命令,会阻塞线程\nbgsave\n手动触发,fork出一个子进程,异步命令,不会阻塞线程【阻塞仅仅会发生在fork出子进程的阶段】\n自动\n1 2 3 save 900 1 #900秒改变1个就生成rdb文件 save 300 10 #300秒改变10个就生成rdb文件 save 60 10000 #60秒改变10000个就生成rdb文件 一般情况下建议关闭自动策略\n全量复制\n从节点执行全量复制操作的时候,主节点会自动触发bgsave命令生存rdb文件并发送给从节点\ndebug reload\n在执行debug reload重新加载redis的时候,也会自动触发bgsave\nshutdown\n默认情况下执行shutdown命令,如果没有开启aof持久化功能,就会自动执行bgsave\nrdb配置参数\n命令格式 描述 rdbcompression 压缩rdb文件,默认yes rdbchecksum rdb文件是否进行校验,默认yes dbfilename dump.rdb rdb文件名【可使用dump-端口号.rdb区分不同的redis实例】 dir ./ rdb文件存储的目录 stop-writes-on-bgsave-error bgsave出现错误时是否停止写入,默认yes aof【append-only file】 \taof是一个追加写入的日志文件从而实现持久化的方式,生成的aof文件是可识别的纯文本文件。redis默认使用rdb持久,开启aof持久化需要设置appendonly为yes\naof文件生成策略\nalways 不丢失数据,每次更新记录数据就进行io操作\neverysec\t可能会丢失1s数据,但io小\nno\t不启用aof\naof重写\n\taof支持aof文件重写(从内存中读取的数据,并非读取上次的aof文件进行重写)。aof重写可以减少硬盘占用、加速恢复速度。\naof配置参数\n命令格式 描述 appendonly 是否开启aof,默认no appendfilename 生成aof文件明【可使用appendonly-端口号.aof区分不同的redis实例】 appendfsync 刷盘策略,默认everysecond dir 保存文件的目录,默认./ no-appendfsync-on-rewrite aof重写过程中是否禁止append操作,默认no允许append auto-aof-rewrite-min-size 进行aof时文件最小尺寸,默认64mb auto-aof-rewrite-percentage 下次进行aof操作时的增量,默认100 aof-load-truncated aof文件结尾不完整,redis重启忽略不完整记录,默认yes 命令\nbgrewriteaof 手动进行aof重写操作 aof_current_size 查看aof当前尺寸 redis-cli info persistence可以查看统计信息aof_current_size【当前aof文件大小】和aof_base_size【上次重写aof文件大小】\nrdb与aof比较 命令 rdb aof 启动优先级 低 高 体积 小 大 恢复 快 慢 数据安全性 丢数据 根据策略决定 轻重 重 轻 混合持久化 redis 4.0 开始支持 rdb 和 aof 的混合持久化(默认开启),这样做的好处是可以结合 rdb 和 aof 的优点, 快速加载同时避免丢失过多的数据。缺点 aof 里面的 rdb 部分就是压缩格式不再是 aof 格式,可读性差。\n配置开启混合持久化aof-use-rdb-preamble yes\n命令开启混合持久化config set aof-use-rdb-preamble yes\n开启混合持久化时,aof rewrite 的时候就直接把 rdb 的内容写到 aof 文件开头。aof 文件内容会变成如下\n1 2 3 4 5 6 7 8 9 10 11 12 13 +------------------------+ | | | | | rdb | | format | | | | | | | +------------------------+ | | | aof | | format | +------------------------+ 持久化相关优化 fork操作优化\n控制redis实例最大可用内存:maxmemory\n合理配置linux内存分配策略:vm.overcommit_momory=1(默认0,当内存少时fork阻塞不进行)\n降低fork频率:例如放宽aof重写自动触发时机,不必要的全量复制\n子进程\ncpu\n开销:rdb和aof文件生成,属于cpu密集型\n优化:不做cpu绑定,不和cpu密集型服务部署\n内存\n开销:fork内存开销,使用了linux的copy-on-write【父进程未发生改变的内存页,不进行copy-write】\n优化:echo never \u0026gt; /sys/kernel/mm/transparent_hugepage/enabled【不分配大内存页】\n硬盘\n开销:aof和rdb文件写入,可以结合iostat,iotop分析\n优化:不和高硬盘负载服务部署一起,no-appendfsync-on-rewrite设置为yes\n八、redis主从复制原理和优化 一个master可以有多个slave 一个slave只能有一个master 数据流向是单向的,master到slave 主从实现两种方式 在从机上执行slaveof masterip masterport,此命令是异步。slaveof no one结束从属关系。\n修改redis配置文件\n1 2 slaveof masterip masterport #配置主从 slave-read-only yes #从节点只读 主从状态查看info replication\n全量复制和部分复制 redis4后使用psync2实现复制使redis重启也可使用部分同步,还为解决在主库故障时候从库切换为主库时候使用部分同步机制。redis从库默认开启复制积压缓冲区功能,以便从库故障切换变化master后,其他落后该从库可以从缓冲区中获取缺少的命令。该过程的实现通过两组replid、offset替换原来的master runid和offset变量实现:\n第一组:master_replid和master_repl_offset\n如果redis是主实例,则表示为自己的replid和复制偏移量; 如果redis是从实例,则表示为自己主实例的replid1和同步主实例的复制偏移量。\n第二组:master_replid2和second_repl_offset\n无论主从,都表示自己上次主实例repid1和复制偏移量;用于兄弟实例或级联复制,主库故障切换psync\n判断是否使用部分复制条件:如果从库提供的master_replid与master的replid不同,且与master的replid2不同,或同步速度快于master; 就必须进行全量复制,否则执行部分复制。\n以下常见的主从切换都可以使用部分复制:\n一主一从发生切换,a-\u0026gt;b 切换变成 b-\u0026gt;a 一主多从发生切换,兄弟节点变成父子节点时 级别复制发生切换, a-\u0026gt;b-\u0026gt;c 切换变成 b-\u0026gt;c-\u0026gt;a 全量复制开销 bgsave时间 rdb文件网络时间 从节点清空数据时间 从节点加载rdb时间 可能的aof重写时间 当从库与主库断开时间过长导致自己的偏移量不在master_repl_offset允许的范围之内,会触发全量复制\n主从相关参数配置 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 ##############从库############## slaveof \u0026lt;masterip\u0026gt; \u0026lt;masterport\u0026gt; #设置该数据库为其他数据库的从数据库 masterauth \u0026lt;master-password\u0026gt; #主从复制中,设置连接master服务器的密码(前提master启用了认证) slave-serve-stale-data yes # 当从库同主库失去连接或者复制正在进行,从库有两种运行方式: # 1) 如果slave-serve-stale-data设置为yes(默认设置),从库会继续相应客户端的请求 # 2) 如果slave-serve-stale-data设置为no,除了info和slavof命令之外的任何请求都会返回一个错误\u0026#34;sync with master in progress\u0026#34; slave-priority 100 #当主库发生宕机时候,哨兵会选择优先级最高的一个称为主库,从库优先级配置默认100,数值越小优先级越高 slave-read-only yes #从节点是否只读;默认yes只读,为了保持数据一致性,应保持默认 ##############主库############## repl-disable-tcp-nodelay no #在slave和master同步后(发送psync/sync),后续的同步是否设置成tcp_nodelay假如设置成yes,则redis会合并小的tcp包从而节省带宽,但会增加同步延迟(40ms),造成master与slave数据不一致假如设置成no,则redis master会立即发送同步数据,没有延迟 #前者关注性能,后者关注一致性 repl-ping-slave-period 10 #从库会按照一个时间间隔向主库发送ping命令来判断主服务器是否在线,默认是10秒 repl-backlog-size 1mb #复制积压缓冲区大小设置 repl-backlog-ttl 3600 #master没有slave一段时间会释放复制缓冲区的内存,repl-backlog-ttl用来设置该时间长度。单位为秒。 min-slaves-to-write 3 min-slaves-max-lag 10 #设置某个时间断内,如果从库数量小于该某个值则不允许主机进行写操作,以上参数表示10秒内如果主库的从节点小于3个,则主库不接受写请求,min-slaves-to-write 0代表关闭此功能。 主从配置问题\nmaxmomory不一致导致丢失数据\n数据结构参数优化只有优化了主机,从机未配置导致内存不一致,数据错误或丢失\n九、redis sentinel 主观下线:sentinel根据配置条件,发现redis节点达到故障标准,则此sentinel认为此redis节点下线 客观下线:当sentinel中认为此redis客观下线的总数达到配置阙值,则认为此节点客观下线 安装sentinel 配置sentinel.conf文件\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 #没有开启bind和密码的情况下,保护模式默认被开启。只接受来自环回ipv4和ipv6地址的连接。拒绝外部连接 bind 127.0.0.1 192.168.1.1 protected-mode no #端口 port 26379 #是否守护进程模式运行 daemonize no #pid以及日志文件位置 pidfile /var/run/redis-sentinel.pid logfile \u0026#34;\u0026#34; #工作目录 dir /tmp #监控的master #mymaster指此主从组的名称【sentinel可以监控多个主从组】 #最后一个数字代码多少个sentinel主观认为此master宕机为客观宕机事实 sentinel monitor mymaster 127.0.0.1 6379 2 #当多少毫秒master不返回ping结果即认为主观宕机 sentinel down-after-milliseconds mymaster 30000 #master重新选举之后slave并发复制master数据的并发量 sentinel parallel-syncs mymaster 1 #故障转移超时时间,默认为3分钟 sentinel failover-timeout mymaster 180000 #当sentinel有任何警告级别的事件发生时(比如说redis实例的主观失效和客观失效等等),将会调用这个脚本 #如果脚本以“1”退出,则稍后重试执行(最多可执行10次),脚本的最长运行时间为60秒 #sentinel notification-script mymaster /var/redis/notify.sh #当master因failover而发生改变,这个脚本将被调用,通知相关的客户端关于master地址已经发生改变的信息 #sentinel client-reconfig-script mymaster /var/redis/reconfig.sh #不允许使用sentinel set设置notification-script和client-reconfig-script sentinel deny-scripts-reconfig yes sentinel三个定时任务 每10秒每个sentinel对master和slave执行info 发现slave 确认主从关系 每2秒每个sentinel通过master节点的channel交换信息(pub/sub模式) 通过__sentinel__:hello频道交互 交互各节点的“看法”及自身信息 每1秒每个sentinel对其他sentinel和redis节点执行ping 心跳检查、失败依据 master选举过程 第一步:sentinel选举出leader\n原因:只需要一个sentinel完成故障转移\n选举:通过sentinel is-master-down-by-addr命令都希望自己成为领导者\n每个做主观下线的sentinel节点向其它sentinel节点发送命令,要求它给自己投票 收到命令的sentinel节点如果没有同意其它sentinel节点发送的命令,则同意投票否则拒绝 如果该sentinel节点发现自己的票数已经超过sentinel半数,那么它将成为leader 如果此过程未选出leader则等待一段时间继续选举 第二步:故障转移选举master\n从slave节点中选出一个“合适”的节点作为新的master节点\n选择slave-prority最高的slave节点,如果存在则返回【一般不修改】 选择复制偏移量最大的slave节点,如果存在则返回 选择runid最小的slave节点 对上面的slave节点执行slaveof no one命令让其成为master节点\n向剩余的slave节点发送slaveof命令,让它们成为master节点的slave节点,复制规则和paraller-sync参数有关\n更新对原来master节点配置为slave,并保存对其“关注”,当其恢复后命令它去复制新的master节点\n手动下线master机器sentinel failover \u0026lt;mastername\u0026gt;\n十、redis cluster 数据分布概论 分布方式 特点 典型产品 哈希分布 数据分散度高 memcache redis cluster 键值分布业务无关 无法顺序访问 支持批量操作 顺序分布 数据分散度易倾斜 bigtable hbase 键值分布业务相关 可顺序访问 支持批量操作 哈希分布方式 节点取余分区\n进行取模运算,将余数相等的放入同一节点,简单易操作,增加节点时数据偏移,导致数据的前移达到80%,翻倍扩容可以使数据迁移从80%降到50%\n一致性hash分区\n为系统中每个节点分配一个token,范围一般在0~2的32次方,这些token构成哈希环。数据读写执行节点查找操作时,先根据key计算hash值,然后顺时针找到第一个大于等于该哈希值的token节点,往往一个节点会对应多个token。加减节点会造成哈希环中部分数据无法命中,需要手动处理或者忽略这些数据,常用于缓存场景\n虚拟哈希分区\n虚拟分槽使用哈希函数把所有数据映射到一个固定范围的整数集合中,整数定义为槽(slot)。槽数范围远远大于节点数(rediscluster槽的范围是0~16383),每一个节点负责维护一部分槽以及所映射的键值数据\n基本架构 所有的redis节点彼此互联(ping-pong机制),内部使用二进制协议优化传输速度和带宽\n节点的fail是通过集群中超过半数的master节点检测失效时才生效\n客户端与redis节点直连,不需要中间proxy层.客户端连接集群中任何一个可用节点即可\nredis-cluster把所有的物理节点映射到[0-16383]slot上,cluster 负责维护node\u0026lt;-\u0026gt;slot\u0026lt;-\u0026gt;key\n安装cluster 修改redis配置文件\n1 2 cluster-enable yes cluster-config-file nodes-${port}.conf 原生安装\n启动所有节点\n执行redis-cli -p ${port} cluster meet ${ip} ${port}使节点相遇\n执行cluster addslots slot [slot...]分配槽\n1 2 3 4 5 6 7 8 start=$1 end=$2 port=$3 for slot in `seq ${start} ${end}` do echo \u0026#34;slot:${slot}\u0026#34; /opt/redis/bin/redis-cli -p ${port} cluster addslots ${slot} done 执行redis-cli -p ${port} cluster replicate ${nodeid}执行主从分配\n集群命令安装\nredis-cli --cluster create --cluster-replicas 1 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005\n\u0026ndash;cluster-replicas代表集群的每个主节点的从节点个数\nruby安装已废弃\ncluster配置参数\n1 2 3 4 cluster-enable yes cluster-config-file nodes-${port}.conf cluster-node-timeout 15000 cluster-require-full-coverage yes #必须集群所有节点能提供服务才提供服务 集群伸缩 扩展集群\n扩展步骤原理\n对目标节点发送cluster setslot {slot} importing {targetnodeid}命令,让目标节点准备导入槽的数据 对源节点发送cluster setslot {slot} migrating {sourcenodeid}命令,让源节点准备槽数据的导出 源节点上循环执行cluster getkeyinslot {slot} count 命令,每次获取属于这个槽中键的个数 在源节点上执行migrate {sourceip} {sourceport} key 0 {timeout}命令,迁移指定的key 重复执行步骤3~4直到槽下所有数据完成迁移 向集群内所有主节点发送cluster setslot {slot} node {targetnodeid}命令,通知槽分配给目标节点 扩展执行步骤\n加入集群\n执行redis-cli -p ${port} cluster meet ${ip} ${port}将节点加入集群\n设置主从关系\nredis-cli -p ${port} cluster replicate ${nodeid}设置主从关系\n任意节点执行迁移槽命令,后续过程根据提示进行\nredis-cli --cluster reshard {ip}:{port}\n查看节点分配情况\nredis-cli -p {prot} cluster nodes | grep master\n集群缩容\n迁移槽命令和扩展集群的迁移命令相同,迁移完成之后使用redis-cli cluster forget {downnodeid}下线节点\n迁移数据\nredis-cli --cluster reshard {ip}:{port} --cluster-from {sourcenodeid} --cluster-to {targetnodeid} --cluster-slots {slotsnum}\n下线节点\nredis-cli --cluster del-node {ip}:{port} {shutdownnodeid}\n客户端路由 使用cluster keyslot ${key}可查看key对应的hash值\nmoved重定向\nask重定向\nsmart客户端\n实现原理:追求性能\n从集群中选一个可运行节点,使用cluster slots初始化槽和节点映射 将cluster slots的结果映射到本地缓存,为每个节点创建jedispool 准备执行命令(使用crc16计算key对应的槽,找到映射节点执行) 1 2 3 4 5 6 7 8 9 10 11 12 13 public static void main(string[] args) { set\u0026lt;hostandport\u0026gt; nodes = new hashset\u0026lt;hostandport\u0026gt;(); nodes.add(new hostandport(\u0026#34;192.168.1.158\u0026#34;, 7000)); nodes.add(new hostandport(\u0026#34;192.168.1.158\u0026#34;, 7001)); nodes.add(new hostandport(\u0026#34;192.168.1.158\u0026#34;, 7002)); nodes.add(new hostandport(\u0026#34;192.168.1.158\u0026#34;, 7003)); nodes.add(new hostandport(\u0026#34;192.168.1.158\u0026#34;, 7004)); nodes.add(new hostandport(\u0026#34;192.168.1.158\u0026#34;, 7005)); jediscluster jediscluster = new jediscluster(nodes); jediscluster.set(\u0026#34;hello\u0026#34;, \u0026#34;cluster\u0026#34;); system.out.println(jediscluster.get(\u0026#34;hello\u0026#34;)); jediscluster.close(); } 批量操作 redis主要提供了以下几种批量操作方式:\n批量get/set(multi get/set) 管道(pipelining) 事务(transaction) 基于事务的管道(transaction in pipelining) 批量操作必须key在同一个槽,导致以上用法异常苛刻\n方案一:传统的串行io操作,也就说n个key,分n次串行操作来获取key,复杂度是o(n)\n方案二:将mget操作(n个key),利用已知的hash函数算出key对应的节点,这样就可以得到一个这样的关系:map\u0026lt;node, somekeys\u0026gt;,也就是每个节点对应的一些keys,这样将之前的o(n)的效率降低到o(node.size())\n方案三:在方案二的基础上将串行取数据改为并行取数据,进一步提高效率\n方案四:通过redis自带的hashtag功能,强制一批key分配到某台机器上【不建议,大量数据会造成数据倾斜】\n1 2 3 //使用{user}作为key,使key统一 jediscluster.mset(\u0026#34;{user}1001\u0026#34;,\u0026#34;zhangsan\u0026#34;,\u0026#34;{user}1002\u0026#34;,\u0026#34;lisi\u0026#34;,\u0026#34;{user}1003\u0026#34;,\u0026#34;wangwu\u0026#34;); list\u0026lt;string\u0026gt; users = jediscluster.mget(\u0026#34;{user}1001\u0026#34;,\u0026#34;{user}1002\u0026#34;,\u0026#34;{user}1003\u0026#34;); 故障转移 故障发现\n通过ping/pong信息实现故障发现,当半数以上持有槽的主节点都标记某节点主观下线则为客观下线【向集群广播下线节点的fail消息】 客观下线发送通知故障节点的从节点触发故障转义流程 故障恢复\n资格审查 每个从节点检查与故障主节点的断线时间 超过cluster-node-timeout * cluster-slave-validity-factor取消资格 cluster-slave-validity-factor默认是10 准备选举时间 最接近主节点的偏移量的从节点率先发起选举,稍后其他从节点发起选举 选举投票 收集票数大于n/2+1即为选举成功 替换主节点 当前从节点取消复制变为主节点(slave no one) 执行clusterdelslot撤销故障主节点负责的槽,并执行clusteraddslot把这些槽分配给自己 向集群广播自己的pong消息,表明已经替换了故障从节点 集群运维问题 集群完整性\ncluster-require-full-coverage yes默认为yes\n集群中16384个槽全部可用:保证集群完整性 节点故障或者正在故障转移,集群不可使用 大多数情况下业务无法容忍,建议cluster-require-full-coverage设置为no\npubsub广播\n任意节点发布消息所有节点都会订阅到消息,消耗带宽较多。jediscluster只会订阅任意一个节点\n数据倾斜\n造成的原因:\n节点槽分配不均 不同槽对应的键值数量差异较大【可能存在hashtag】 包含bigkey 内存相关配置不一致 使用redis-cli --cluster info {ip}:{port}可以查看key、slot分布情况\n使用redis-cli --cluster rebalance {ip}:{port}进行数据平衡【慎用】\n从机读写问题\n在集群模式下从节点不接受任何读写请求\n命令会重定向到负责槽的主节点 readonly命令可以读取【连接级别】 数据迁移\n官方工具不只能从单机向集群迁移,不支持断点续传,不支持在线迁移,单线程影响速度,不建议使用官方工具\n十一、缓存设计与优化 缓存使用的成本 数据不一致:缓存层和数据层有时间窗口不一致,和更新策略有关 代码维护成本:多了一层缓存逻辑 运维成本:例如redis cluster 缓存更新策略 redis里面存储的过期时间,都是绝对时间点,所以如果两台机器时钟不同步,那么超过的数据会全部删除。\nslaves不会独立删除数据,而是等待master给它发送删除指令的时候,再删除数据 如果slave当选为master的时候,会先淘汰keys,然后再成为master 设置maxmemory-policy值指定算法\n更新策略 解释 volatile-lru 过期的键使用lru策略剔除,没有可删除对象则退回到noeviction allkeys-lru 所有键均使用lru策略剔除,直到腾出足够空间 volatile-lfu 过期的键使用lfu策略剔除,没有可删除对象则退回到noeviction allkeys-lfu 所有键均使用lfu策略剔除,直到腾出足够空间 volatile-random 过期的键使用随机策略剔除,没有可删除对象则退回到noeviction allkeys-random 所有键均使用随机策略剔除,直到腾出足够空间 volatile-ttl 剔除ttl最小的键,没有可删除对象则退回到noeviction noeviction 默认策略,不做任何事,返回写错误 lru【least recently used】最近最少被使用\nlfu【least frequently used】最不常用\n被动更新\n当客户端方位key的时候,主动检测这些key是否过期,过期就删除\n主动更新\n每秒检测10次以下操作,测试随机的20个keys进行相关过期检测,删除所有的过期的keys,如果有多于25%的keys过期,重复此操作\n策略 一致性 维护成本 算法剔除 最差 低 被动更新 较差 低 主动更新 强 高 低一致性:最大内存和淘汰策略\n高一致性:超时剔除和主动更新结合,最大内存和淘汰策略兜底\n缓存穿透\u0026amp;缓存雪崩\u0026amp;无底洞 缓存穿透\n特点:\n当缓存和数据库中都没有数据的时候,当查询redis没有数据的时候,会继续查询数据库,数据库也没有数据,当大量查询请求发生或遭到恶意攻击时,这些访问全部透过redis,并且数据库也没有数据,这种现象称为“缓存穿透”。\n解决方案:\n缓存空对象,storage返回一个空对象,将键存储在缓存层,下次请求此键之间返回空对象 需要更多的键,建议设置过期时间 缓存层和存储层数据“短期”不一致 布隆过滤器 缓存击穿\n特点:\n当redis的热点数据key失效时,大量并发查询直接打到数据库,此时数据库负载压力骤增,这种现象称为“缓存击穿”\n解决方案:\n1.设置key值永不过期\n2.使用互斥锁,查到后就回填缓存\n缓存雪崩\n特点:\n缓存雪崩是指在短时间内,有大量缓存同时过期,导致大量的请求直接查询数据库,从而对数据库造成了巨大的压力,严重情况下可能会导致数据库宕机的情况叫做缓存雪崩。\n解决方案:\n随机设置key过期时间 随机延时,让一部分查询先将数据缓存起来 设置key值永不过期 无底洞问题\n现象:增加节点机器性能没提升反而下降\n解决方案参考批量操作\n热点key的重建优化 现象:热点key缓存重建过程过长导致浪费了不必要的资源\n解决方案:\n互斥锁【使用redis构建锁机制】\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 string get(string key) { string value = redis.get(key); if(value == null) { string mutexkey = \u0026#34;mutex:key:\u0026#34;+key; if(redis.setparams.setparams().ex(180).nx()) { value = db.get(key); redis.set(key,value); redis.delete(mutexkey); }else { thread.sleep(1000); get(key); } } return value; } 永不过期\n缓存层面:没有设置过期时间 功能层面:为每个value添加逻辑过期时间,但发现超过逻辑过期时间后,会使用单独的线程取构建缓存 方案 优点 缺点 互斥锁 思路简单 代码复杂度增加 保证一致性 存在死锁的风险 永不过期 基本杜绝热点key重建问题 不保证一致性 逻辑过期时间增加维护成本和内存成本 ## 十二、redis布隆过滤器 布隆过滤器的原理 首先需要k个hash函数,每个函数可以把key散列成为1个整数 初始化时,需要一个长度为n比特的数组,每个比特位初始化为0 某个key加入集合时,用k个hash函数计算出k个散列值,并把数组中对应的比特位置为1 判断某个key是否在集合时,用k个hash函数计算出k个散列值,并查询数组中对应的比特位,如果所有的比特位都是1,认为在集合中 优点:不需要存储key,节省空间\n缺点:算法判断key在集合中时,有一定的概率key其实不在集合中,且无法删除\ngoogle-guava库实现了java版的布隆过滤器\nredis布隆过滤器 使用插件的方式部署\nredis4.0之后支持使用插件的方式使用bloom filters和cuckoo filters,redis4.0之前需手动使用代码的方式编写布隆过滤器,安装步骤参考下列链接\ngithub地址 使用文档\n建议在conf配置文件中配置,不使用redis-server --loadmodule /path/to/rebloom.so启动\n1 loadmodule /path/to/rebloom.so 布隆过滤器命令\n命令 说明 bf.reserve {key} {error_rate} {size} 创建布隆过滤器,error_rate为错误率,size为预期数据大小 bf.add {key} {item} 添加item到指定布隆过滤器 bf.madd {key} {item} [item \u0026hellip;] 批量添加item到指定布隆过滤器 bf.exists {key} {item} 判断item是否存在与指定布隆过滤器 bf.mexists {key} {item} [item \u0026hellip;] 批量判断item是否存在与指定布隆过滤器 javaapi\n导入maven依赖\n1 2 3 4 5 \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;com.redislabs\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;jrebloom\u0026lt;/artifactid\u0026gt; \u0026lt;version\u0026gt;1.1.0\u0026lt;/version\u0026gt; \u0026lt;/dependency\u0026gt; api使用\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public static void main(string[] args) { jedispool jedispool = new jedispool(\u0026#34;192.168.1.158\u0026#34;, 6379); client client = new client(jedispool); client.createfilter(\u0026#34;main6\u0026#34;, 10000, 0.000001); //批量插入数据 for (int i = 0; i \u0026lt;100; i++) { string values[] = new string[100]; for (int j = 0; j \u0026lt; 100; j++) { string value = \u0026#34;item\u0026#34; + (i * 100 +j); values[j] = value; } client.addmulti(\u0026#34;main6\u0026#34;, values); } //判断是否存在 system.out.println(client.exists(\u0026#34;main6\u0026#34;, \u0026#34;item1\u0026#34;)); system.out.println(client.exists(\u0026#34;main6\u0026#34;, \u0026#34;a\u0026#34;)); jedispool.close(); } 十三、redis开发规范 bigkey处理 发现bigkey\ndebug object {key} 查看指定key的详细信息 redis-cli --bigkeys 扫描出bigkey【全表扫描,阻塞,建议从节点本地执行】 bigkey删除\n场景:当key非常大时,delete命令执行十分缓慢,会发生阻塞【过期bigkey也是进行删除操作也会阻塞】\nredis4.0之后:可以使用unlink命令进行后台删除,不阻塞前台\n生命周期管理 使用object idletime {key}查看key的闲置时间\n过期时间不易集中\n命令优化 有遍历需求可以使用hscan、sscan、zscan代替【这些扫描命令在field较少时count参数不会生效】\n必要情况下使用monitor命令监控,注意时间不要过长\njava客户端优化 参数名 含义 默认值 建议 testwhileidle 是否开启空闲资源检测 false true timebetweenevictionrunsmillis 空闲资源检测周期 -1 自选,也可使用jedispoolconfig中的默认值 minevictiableidletimemillis 资源池中资源最小空闲时间 30分钟 自选,也可使用jedispoolconfig中的默认值 numtestsperevictionrun 做空闲资源检测每次的采样数 3 自选,如果设置为-1则为全部做空闲检测 maxidle需要设置为接近maxtotal\n预估maxtotal方法的例子:\n一次命令时间平均耗时1ms,一个连接qps大约1000,业务期忘的qps时50000,理论上maxtotal=50000/1000=50\n十四、内存管理 内存消耗 内存统计\n执行info memory命令可以查看内存信息\n主要属性名 属性说明 used_memory 实际存储数据的内存总量 used_memory_rss redis进程占用的总物理内存 maxmemory 最大内存 maxmemory_policy 内存剔除策略 mem_fragmentation_ratio used_memory_rss/used_memory比值,表示内存碎片率 内存消耗划分\n客户端缓冲区设置规则\nclient-output-buffer-limit \u0026lt;class\u0026gt; \u0026lt;hard limit\u0026gt; \u0026lt;soft limit\u0026gt; \u0026lt;soft seconds\u0026gt;\n\u0026lt;class\u0026gt;:客户端类型,分为三种\n\t(a)normal:普通客户端\n\t(b)slave:用从节点用于复制,伪裝成客户端\n\t(c)pubsub:发布订阅客户端 \u0026lt;hardlimit\u0026gt;:如客户使用的输出冲区大于hardlimit客户端会被立即关闭\n\u0026lt;soft limit\u0026gt; 和\u0026lt;soft seconds\u0026gt;:如果客户端使用的输出缓冲区超过了 \u0026lt;soft limit\u0026gt;并且持续了\u0026lt;soft seconds\u0026gt;,客户会被立即关闭\n普通客户端默认:client-output-buffer-limit normal 0 0 0 salve客户端默认:client-output-buffer-limit slave 256mb 64mb 60 pubsub客户端默认:client-output-buffer-limit slave 32mb 8mb 60 复制缓冲区:用于slave和master断开重连时不进行全量复制保存偏移数据使用\n默认为repl-backlog-size 1mb\naof缓冲区:aof重写期间,aof缓冲区,没有容量限制\n内存回收策略 删除过期值\n惰性删除:访问key-\u0026gt;expired dict-\u0026gt;del key【先在过期表中找,发现过期删除key,返回null】 定时删除:每秒运行10次,采样删除 超过maxmemory使用maxmemory-policy进行控制,参见缓存更新策略\n十五、开发运维事项 linux内核优化 vm.overcommit_memory\nredis建议vm.overcommit_memory = 1(影响fork操作)\n立即生效:\n永久生效:vm.overcommit_memory = 1写入到/etc/sysctl.conf文件中\n值 含义 0 表示内核将检查是否有足够可用的内存。如果有足够可用的内存,内存申请通过,否则内存申请失败,并返回错误给进程 1 表示内核允许超量使用内存直到用完为止 2 表示内存绝不过量使用,即整个系统内存不能超过swap+50%的ram值 swappiness\n值 策略 0 linux3.5及以上:宁愿oom killer也不用swap linux3.5及以下:宁愿swap也不用oom killer 1 linux3.5及以上:宁愿swap也不用oom killer 60 默认值 100 操作系统会主动使用swap 建议:linux3.5以上vm.swappiness = 1,否则vm.swappiness = 0\n立即生效:echo {bestvalue} \u0026gt; /proc/sys/vm/swappiness\n永久生效:vm.swappiness = {bestvalue} 写入到/etc/sysctl.conf\nthp(transparent huge page)\n建议禁用,centos7在/sys/kernel/mm/transparent_hugepage/enabled下设置为never即可\nthp为大内存页时fork子线程时copy-on-write可能造成延迟\nulimit\n建议将redis启动用户的文件句柄限制调成10032,限制文件etc/security/limits\ntcp backlog\n建议将/proc/sys/net/core/somaxconn系统tcp backlog的限制设置为与redis一样默认511\nredis安全问题 在配置文件中配置\n1 2 #将命令更改为另一个字符串,原命令失效。如果字符串为空则表示禁用此命令 rename-command {cmd} {str} 附各种数据类型的内部编码:\n附redis云平台cachecloud【一键部署、监控、运维、数据迁移工具等】 github项目地址\n","date":"2019-03-21","permalink":"https://hobocat.github.io/post/nosql/2019-03-21-redis/","summary":"一、NoSQL简介 NoSQL分类 键值(Key-Value)存储数据库:这一类数据库主要会使用到一个hash表,如Redis、Oracle BDB 列存储数据库:通常是用","title":"redis使用详解"},]
[{"content":"一、基础知识 分布式系统 \t分布式系统是若干独立计算机的集合,这些计算机对于用户来说就像单个相关系统。\n架构发展演变 单一应用架构\n一个war包将所有功能都部署在一起搞定,减少部署节点和成本。此时,用于简化增删改查工作量的数据访问框架(orm)是关键。\n优点:适用与小型网站、简单易用\n缺点:性能扩展难、协同开发问题、不利于升级维护\n垂直应用架构\n当访问量逐渐增大,单一应用增加机器带来的加速度越来越小,将应用拆成互不相干的几个应用,以提升效率。此时,用于加速前端页面开发的web框架(mvc)是关键。\n优点:团队各司其职更易管理、性能扩展也更方便、更有针对性\n缺点:公用模块无法重复利用,开发性的浪费\n分布式服务架构\n当垂直应用越来越多,应用之间交互不可避免,将核心业务抽取出来,作为独立的服务,逐渐形成稳定的服务中心,使前端应用能更快速的响应多变的市场需求。此时,用于提高业务复用及整合的**分布式服务框架(rpc)[remote procedure call]**是关键。\n优点:增大系统容量、模块化高、开发及团队协作效率高\n缺点:系统设计、管理和运维难度增加\n流动计算架构\n当服务越来越多,容量的评估,小服务资源的浪费等问题逐渐显现,此时需增加一个调度中心基于访问压力实时管理集群容量,提高集群利用率。此时,用于提高机器利用率的**资源调度和治理中心(soa)[service oriented architecture]**是关键\n优点:增大系统容量、模块化高、动态协调资源、开发及团队协作效率高\n缺点:系统设计、管理和运维难度增加\nrpc rpc定义\n\trpc【remote procedure call】是指远程过程调用,是一种进程间通信方式,他是一种技术的思想,而不是规范。它允许程序调用另一个地址空间(通常是共享网络的另一台机器上)的过程或函数,而不用程序员显式编码这个远程调用的细节。即程序员无论是调用本地的还是远程的函数,本质上编写的调用代码基本相同。\nrpc基本原理\nrpc最核心两个模块:通讯、序列化\n二、dubbo核心概念 简介 \tdubbo是一款高性能、轻量级的开源java rpc框架,它提供了三大核心能力:面向接口的远程方法调用,智能容错和负载均衡,以及服务自动注册和发现。\n基本概念 服务提供者(provider):暴露服务的服务提供方,服务提供者在启动时,向注册中心注册自己提供的服务。\n服务消费者(consumer): 调用远程服务的服务消费方,服务消费者在启动时,向注册中心订阅自己所需的服务,服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。\n注册中心(registry):注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者\n监控中心(monitor):服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心\n调用关系说明\n服务容器负责启动,加载,运行服务提供者 服务提供者在启动时,向注册中心注册自己提供的服务 服务消费者在启动时,向注册中心订阅自己所需的服务 注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者。 服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用 服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心。 连通性说明\n注册中心负责服务地址的注册与查找,相当于目录服务,服务提供者和消费者只在启动时与注册中心交互,注册中心不转发请求,压力较小 监控中心负责统计各服务调用次数,调用时间等,统计先在内存汇总后每分钟一次发送到监控中心服务器,并以报表展示 服务提供者向注册中心注册其提供的服务,并汇报调用时间到监控中心,此时间不包含网络开销 服务消费者向注册中心获取服务提供者地址列表,并根据负载算法直接调用提供者,同时汇报调用时间到监控中心,此时间包含网络开销 注册中心,服务提供者,服务消费者三者之间均为长连接,监控中心除外 注册中心通过长连接感知服务提供者的存在,服务提供者宕机,注册中心将立即推送事件通知消费者 注册中心和监控中心全部宕机,不影响已运行的提供者和消费者,消费者在本地缓存了提供者列表 注册中心和监控中心都是可选的,服务消费者可以直连服务提供者 三、dubbbo入门 前提条件:配置zookeeper环境、incubator-dubbo-ops切换到master分支【dubbo-admin和dubbo-monitor】\nincubator-dubbo-ops下载地址\n搭建dubbo admin、搭建dubbo monitor方法详见github参考文档\n创建dubbo应用 创建maven项目公共项目抽取公共部分【bean、service接口等等】\n创建provider和consumer\n引入dubbo依赖,并引入curator依赖,并适配配置日志环境 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 \u0026lt;!-- 连接zookeeper使用的curator --\u0026gt; \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;org.apache.curator\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;curator-recipes\u0026lt;/artifactid\u0026gt; \u0026lt;version\u0026gt;2.13.0\u0026lt;/version\u0026gt; \u0026lt;exclusions\u0026gt; \u0026lt;exclusion\u0026gt; \u0026lt;groupid\u0026gt;log4j\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;log4j\u0026lt;/artifactid\u0026gt; \u0026lt;/exclusion\u0026gt; \u0026lt;exclusion\u0026gt; \u0026lt;groupid\u0026gt;org.slf4j\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;slf4j-api\u0026lt;/artifactid\u0026gt; \u0026lt;/exclusion\u0026gt; \u0026lt;/exclusions\u0026gt; \u0026lt;/dependency\u0026gt; \u0026lt;!-- 日志采用slfj+logback --\u0026gt; \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;org.slf4j\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;slf4j-api\u0026lt;/artifactid\u0026gt; \u0026lt;version\u0026gt;1.7.6\u0026lt;/version\u0026gt; \u0026lt;/dependency\u0026gt; \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;ch.qos.logback\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;logback-classic\u0026lt;/artifactid\u0026gt; \u0026lt;version\u0026gt;1.2.3\u0026lt;/version\u0026gt; \u0026lt;/dependency\u0026gt; \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;ch.qos.logback\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;logback-core\u0026lt;/artifactid\u0026gt; \u0026lt;version\u0026gt;1.2.3\u0026lt;/version\u0026gt; \u0026lt;/dependency\u0026gt; provider实现service并配置dubbo 1 2 3 4 5 6 7 8 9 10 11 12 13 14 \u0026lt;!-- 提供方应用信息,用于计算依赖关系 --\u0026gt; \u0026lt;dubbo:application name=\u0026#34;user-service-provider\u0026#34; /\u0026gt; \u0026lt;!-- 使用zookeeper广播注册中心暴露服务地址 --\u0026gt; \u0026lt;dubbo:registry protocol=\u0026#34;zookeeper\u0026#34; address=\u0026#34;192.168.1.155:2181,192.168.1.155:2182,192.168.1.155:2183\u0026#34;/\u0026gt; \u0026lt;!-- 用dubbo协议在20800端口暴露服务 --\u0026gt;\t\u0026lt;dubbo:protocol name=\u0026#34;dubbo\u0026#34; port=\u0026#34;20800\u0026#34;/\u0026gt; \u0026lt;!-- 声明需要暴露的服务接口 --\u0026gt; \u0026lt;dubbo:service interface=\u0026#34;com.kun.service.userservice\u0026#34; ref=\u0026#34;userservice\u0026#34;/\u0026gt; \u0026lt;!-- 和本地bean一样实现服务 --\u0026gt; \u0026lt;bean id=\u0026#34;userservice\u0026#34; class=\u0026#34;com.kun.service.impl.userserviceimpl\u0026#34;/\u0026gt; consumer调用service并配置dubbo 1 2 3 4 5 6 7 8 \u0026lt;!-- 消费方应用名,用于计算依赖关系,不是匹配条件,不要与提供方一样 --\u0026gt; \u0026lt;dubbo:application name=\u0026#34;user-service-consumer\u0026#34; /\u0026gt; \u0026lt;!-- 使用zookeeper注册中心暴露发现服务地址 --\u0026gt; \u0026lt;dubbo:registry protocol=\u0026#34;zookeeper\u0026#34; address=\u0026#34;192.168.1.155:2181,192.168.1.155:2182,192.168.1.155:2183\u0026#34; /\u0026gt; \u0026lt;!-- 生成远程服务代理,可以像本地bean一样使用userservice --\u0026gt; \u0026lt;dubbo:reference id=\u0026#34;userservice\u0026#34; interface=\u0026#34;com.kun.service.userservice\u0026#34; \u0026gt;\u0026lt;/dubbo:reference\u0026gt; 启动provider在dubbo admin可看相关信息,启动consumer进行消费在dubbo admin也可见相关信息\n四、dubbo常用详解 dubbo配置文件加载顺序\n覆盖关系的优先级:system properties【启动时的环境变量】\u0026gt; externlized configuration【使用控制台调节】 \u0026gt; spring/api【硬编码】 \u0026gt; local file【本地配置文件】\ndubbo配置的覆盖关系\n方法级优先,接口级次之,全局配置再次之【精确优先】 如果级别一样,则消费方优先,提供方次之【消费者优先】 dubbo启动检查\ndubbo:reference\u0026amp;dubbo:consumer设定了启动时是否检查,默认取dubbo:consumer的true\ndubbo超时设置\ntimeout为dubbo:method、dubbo:reference、dubbo:service、dubbo:consumer、dubbo:provider 属性 默认设置为1000。timeout为服务超时时间\ndubbo重试\nretries为dubbo:method、dubbo:reference、dubbo:service、dubbo:consumer、dubbo:provider 属性默认设置为2。retries为当服务未返回结果【由于网络、超时等原因】重试次数,不包含第一次请求\n幂等操作【查询、删除、修改】应当设置重试次数提高服务的可用性、非幂等操作【新增】为保证数据的正确性不应当设置重试次数\ndubbo多版本\nversion为dubbo:method、dubbo:reference、dubbo:service、dubbo:consumer、dubbo:provider 、dubbo:application属性。version用于实现灰度发布、测试版本区分等\ndubbo本地存根\nstub为dubbo:reference、dubbo:service属性。一般为dubbo:reference使用,为调用服务之前处理相关业务逻辑,一般情况下stub类存放在抽取的接口工程中\n1 \u0026lt;dubbo:reference id=\u0026#34;userservice\u0026#34; interface=\u0026#34;com.kun.service.userservice\u0026#34; stub=\u0026#34;com.kun.service.impl.userservicestub\u0026#34;\u0026gt;\u0026lt;/dubbo:reference\u0026gt; 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public class userservicestub implements userservice { private final userservice userservice; //必须有service作为参数的构造函数 public userservicestub(userservice userservice) { this.userservice = userservice; } @override public list\u0026lt;useraddress\u0026gt; getuseraddresslist(string userid) { system.out.println(\u0026#34;调用本地存根进行参数验证。。。\u0026#34;); if(userid != null \u0026amp;\u0026amp; !userid.trim().isempty()) { return userservice.getuseraddresslist(userid); } return null; } } 线程模型\n如果事件处理的逻辑能迅速完成,并且不会发起新的 io 请求,比如只是在内存中记个标识,则直接在 io 线程上处理更快,因为减少了线程池调度。\n但如果事件处理逻辑较慢,或者需要发起新的 io 请求,比如需要查询数据库,则必须派发到线程池,否则 io 线程阻塞,将导致不能接收其它请求。\n如果用 io 线程处理事件,又在事件处理过程中发起新的 io 请求,比如在连接事件中发起登录请求,会报“可能引发死锁”异常,但不会真死锁。\n因此,需要通过不同的派发策略和不同的线程池配置的组合来应对不同的场景,缺省设置如下\n1 \u0026lt;dubbo:protocol name=\u0026#34;dubbo\u0026#34; dispatcher=\u0026#34;all\u0026#34; threadpool=\u0026#34;fixed\u0026#34; threads=\u0026#34;200\u0026#34; /\u0026gt; dispatcher\nall 所有消息都派发到线程池,包括请求,响应,连接事件,断开事件,心跳等。 direct 所有消息都不派发到线程池,全部在 io 线程上直接执行。 message 只有请求响应消息派发到线程池,其它连接断开事件,心跳等消息,直接在 io 线程上执行。 execution 只请求消息派发到线程池,不含响应,响应和其它连接断开事件,心跳等消息,直接在 io 线程上执行。 connection 在 io 线程上,将连接断开事件放入队列,有序逐个执行,其它消息派发到线程池。 threadpool\nfixed 固定大小线程池,启动时建立线程,不关闭,一直持有。(缺省) cached 缓存线程池,空闲一分钟自动删除,需要时重建。 limited 可伸缩线程池,但池中的线程数只会增长不会收缩。只增长不收缩的目的是为了避免收缩时突然来了大流量引起的性能问题。 eager 优先创建worker线程池。在任务数量大于corepoolsize但是小于maximumpoolsize时,优先创建worker来处理任务。当任务数量大于maximumpoolsize时,将任务放入阻塞队列中。阻塞队列充满时抛出rejectedexecutionexception。(相比于cached:cached在任务数量超过maximumpoolsize时直接抛出异常而不是将任务放入阻塞队列) 属性 描述 threadpool 线程池类型,默认fixed threads 服务线程池大小(固定大小),默认200 iothreads io线程池,接收网络读写中断,以及序列化和反序列化,不处理业务,此线程池和cpu相关,不建议配置 accepts 服务提供者最大可接受连接数,默认0 dispatcher 协议的消息派发方式,用于指定线程模型,默认all queues 线程池队列大小,当线程池满时,排队等待执行的队列大小,建议不要设置,当线程程池时应立即失败,重试其它服务提供机器,而不是排队,除非有特殊需求 如果服务器抛出java.lang.outofmemoryerror: unable to create new native thread unable to create new native thread 异常可能是启动用户线程数限制导致的,需修改/etc/security/limits.d目录下的文件,最大限制数使用ulimit -u查看用户可创建线程的最大数,必须要小于这个数值否则线程占用完无法登陆主机导致死机现象\n直连提供者\n在开发及测试环境,绕过注册中心直连提供者,方便开发调试,线上勿用\n1 \u0026lt;dubbo:reference id=\u0026#34;xxxservice\u0026#34; interface=\u0026#34;com.kun.xxx.xxxservice\u0026#34; url=\u0026#34;dubbo://localhost:2090\u0026#34; /\u0026gt; 只订阅\n为方便开发测试,服务可能需要连接注册中心以依赖其他服务,而自己并不想注册在注册中心,可使用dubbo:registry中的registry属性控制是否只订阅\n只注册\n当有多个注册中心,需要只注册到一部分注册中心【依赖这部分注册中心的服务】,另一部分注册中心只提供服务【不依赖提供的服务】,使用dubbo:registry中的subscribe属性控制是否只注册\n五、服务启动与优雅停机 服务启动 使用com.alibaba.dubbo.container.main启动可实现服务启动和优雅停机\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 \u0026lt;!-- 打包jar文件时,配置manifest文件,加入lib包的jar依赖 --\u0026gt; \u0026lt;plugin\u0026gt; \u0026lt;groupid\u0026gt;org.apache.maven.plugins\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;maven-jar-plugin\u0026lt;/artifactid\u0026gt; \u0026lt;configuration\u0026gt; \u0026lt;classesdirectory\u0026gt;target/classes/\u0026lt;/classesdirectory\u0026gt; \u0026lt;archive\u0026gt; \u0026lt;manifest\u0026gt; \u0026lt;!-- 启动类 --\u0026gt; \u0026lt;mainclass\u0026gt;com.alibaba.dubbo.container.main\u0026lt;/mainclass\u0026gt; \u0026lt;!-- 打包时manifest.mf 文件不记录时间戳--\u0026gt; \u0026lt;useuniqueversions\u0026gt;false\u0026lt;/useuniqueversions\u0026gt; \u0026lt;addclasspath\u0026gt;true\u0026lt;/addclasspath\u0026gt; \u0026lt;classpathprefix\u0026gt;lib/\u0026lt;/classpathprefix\u0026gt; \u0026lt;/manifest\u0026gt; \u0026lt;/archive\u0026gt; \u0026lt;/configuration\u0026gt; \u0026lt;/plugin\u0026gt; 可使用dubbo包下的/meta-inf/assembly/bin/*.sh脚本管理程序的启动、停止、dump等\n注:dubbo.spring.config默认为meta-inf/spring,dubbo启动时会加载此路径下的文件为spring配置文件\n优雅停机 dubbo是通过jdk的shutdownhook完成优雅停机的,所以使用 kill -9 pid 等强制关闭指令只会强制关闭不会优雅停机,只有通过 kill pid 时,才会优雅停机\n六、高可用 zookeeper宕机\n现象:zookeeper注册中心宕机,还可以消费dubbo暴露的服务。\n监控中心宕掉不影响使用,只是丢失部分采样数据\n数据库宕掉后,注册中心仍能通过缓存提供服务列表查询,但不能注册新服务\n注册中心对等集群,任意一台宕掉后,将自动切换到另一台\n注册中心全部宕掉后,服务提供者和服务消费者仍能通过本地缓存通讯\n服务提供者无状态,任意一台宕掉后,不影响使用\n服务提供者全部宕掉后,服务消费者应用将无法使用,并无限次重连等待服务提供者恢复\ndubbo直连\nurl为dubbo:reference的属性。提供了dubbo直连方式【只需提供ip地址和端口号】,不经过注册中心\n七、负载均衡 random loadbalance 随机,按权重设置随机概率。 \nroundrobin loadbalance 轮询,按公约后的权重设置轮询比率。 \nleastactive loadbalance 最少活跃调用数,相同活跃数的随机,活跃数指调用前后计数差。\n\nconsistenthash loadbalance 一致性 hash,相同参数的请求总是发到同一提供者。\n\n默认dubbo采用random loadbalance负载均衡策略,可在dubbo:service、dubbo:reference、dubbo:method的loadbalance修改负载均衡策略\n八、服务降级 场景:当服务器压力剧增的情况下,根据实际业务情况及流量,对一些服务和页面有策略的不处理或换种简单的方式处理,从而释放服务器资源以保证核心交易正常运作或高效运作\n处理方式:可以通过服务降级功能临时屏蔽某个出错的非关键服务,并定义降级后的返回策略\nmock=force:return+null 表示消费方对该服务的方法调用都直接返回 null 值,不发起远程调用。用来屏蔽不重要服务不可用时对调用方的影响。【admin界面中点击【屏蔽】】 还可以改为 mock=fail:return+null 表示消费方对该服务的方法调用在失败后,再返回 null 值,不抛异常。用来容忍不重要服务不稳定时对调用方的影响【admin界面中点击【容错】】 九、集群容错 dubbo集群容错策略 在集群调用失败时,dubbo 提供了多种容错方案,缺省为 failover 重试\nfailover cluster\n失败自动切换,当出现失败,重试其它服务器 。通常用于读操作,但重试会带来更长延迟。可通过 retries=\u0026quot;2\u0026quot; 来设置重试次数(不含第一次)\nfailfast cluster\n快速失败,只发起一次调用,失败立即报错。通常用于非幂等性的写操作,比如新增记录\nfailsafe cluster\n失败安全,出现异常时,直接忽略。通常用于写入审计日志等操作\nfailback cluster\n失败自动恢复,后台记录失败请求,定时重发。通常用于消息通知操作\nforking cluster\n并行调用多个服务器,只要一个成功即返回。通常用于实时性要求较高的读操作,但需要浪费更多服务资源。可通过 forks=\u0026quot;2\u0026quot; 来设置最大并行数\nbroadcast cluster\n广播调用所有提供者,逐个调用,任意一台报错则报错 。通常用于通知所有提供者更新缓存或日志等本地资源信息\n可在dubbo:service和dubbo:reference中配置集群容错策略\n整合hystrix 配置spring-cloud-starter-netflix-hystrix\n1、导入依赖\n1 2 3 4 5 \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;org.springframework.cloud\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;spring-cloud-starter-netflix-hystrix\u0026lt;/artifactid\u0026gt; \u0026lt;version\u0026gt;1.4.4.release\u0026lt;/version\u0026gt; \u0026lt;/dependency\u0026gt; 2、在主配置类上添加@enablehystrix\n1 2 3 4 5 @springbootapplication @enablehystrix public class providerapplication { //...... } 3、配置provider端\n在dubbo的provider上增加@hystrixcommand配置,这样子调用就会经过hystrix代理\n1 2 3 4 5 6 7 8 9 10 @service(version = \u0026#34;1.0.0\u0026#34;) public class helloserviceimpl implements helloservice { @hystrixcommand(commandproperties = { @hystrixproperty(name = \u0026#34;circuitbreaker.requestvolumethreshold\u0026#34;, value = \u0026#34;10\u0026#34;), @hystrixproperty(name = \u0026#34;execution.isolation.thread.timeoutinmilliseconds\u0026#34;, value = \u0026#34;2000\u0026#34;) }) @override public string sayhello(string name) { throw new runtimeexception(\u0026#34;exception to show hystrix enabled.\u0026#34;); } } 4、配置consumer端\n对于consumer端,则可以增加一层method调用,并在method上配置@hystrixcommand。当调用出错时,会走到fallbackmethod = \u0026ldquo;reliable\u0026quot;的调用里\n1 2 3 4 5 6 7 8 9 10 @reference(version = \u0026#34;1.0.0\u0026#34;) private helloservice helloservice; @hystrixcommand(fallbackmethod = \u0026#34;reliable\u0026#34;) public string dosayhello(string name) { return helloservice.sayhello(name); } public string reliable(string name) { return \u0026#34;hystrix fallback value\u0026#34;; } 十、dubbo原理 框架设计 config 配置层:对外配置接口,以 serviceconfig, referenceconfig 为中心,可以直接初始化配置类,也可以通过 spring 解析配置生成配置类 proxy 服务代理层:服务接口透明代理,生成服务的客户端 stub 和服务器端 skeleton, 以 serviceproxy为中心,扩展接口为 proxyfactory registry 注册中心层:封装服务地址的注册与发现,以服务 url 为中心,扩展接口为 registryfactory, registry, registryservice cluster 路由层:封装多个提供者的路由及负载均衡,并桥接注册中心,以 invoker 为中心,扩展接口为 cluster, directory, router, loadbalance monitor 监控层:rpc 调用次数和调用时间监控,以 statistics 为中心,扩展接口为 monitorfactory, monitor, monitorservice protocol 远程调用层:封装 rpc 调用,以 invocation, result 为中心,扩展接口为 protocol, invoker, exporter exchange 信息交换层:封装请求响应模式,同步转异步,以 request, response 为中心,扩展接口为 exchanger, exchangechannel, exchangeclient, exchangeserver transport 网络传输层:抽象 mina 和 netty 为统一接口,以 message 为中心,扩展接口为 channel, transporter, client, server, codec serialize 数据序列化层:可复用的一些工具,扩展接口为 serialization, objectinput, objectoutput, threadpool 启动解析、加载配置信息 dubbo扩展了java 原生的 spi 机制会加载meta-inf/dubbo下的配置文件,加载到spring容器中\ndubbonamespacehandler集成了spring下的namespacehandlersupportj,用于解析dubbo名称空间标签\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public class dubbonamespacehandler extends namespacehandlersupport { //用于初始化各种解析器 @override public void init() { registerbeandefinitionparser(\u0026#34;application\u0026#34;, new dubbobeandefinitionparser(applicationconfig.class, true)); registerbeandefinitionparser(\u0026#34;module\u0026#34;, new dubbobeandefinitionparser(moduleconfig.class, true)); registerbeandefinitionparser(\u0026#34;registry\u0026#34;, new dubbobeandefinitionparser(registryconfig.class, true)); registerbeandefinitionparser(\u0026#34;config-center\u0026#34;, new dubbobeandefinitionparser(configcenterbean.class, true)); registerbeandefinitionparser(\u0026#34;metadata-report\u0026#34;, new dubbobeandefinitionparser(metadatareportconfig.class, true)); registerbeandefinitionparser(\u0026#34;monitor\u0026#34;, new dubbobeandefinitionparser(monitorconfig.class, true)); registerbeandefinitionparser(\u0026#34;provider\u0026#34;, new dubbobeandefinitionparser(providerconfig.class, true)); registerbeandefinitionparser(\u0026#34;consumer\u0026#34;, new dubbobeandefinitionparser(consumerconfig.class, true)); registerbeandefinitionparser(\u0026#34;protocol\u0026#34;, new dubbobeandefinitionparser(protocolconfig.class, true)); registerbeandefinitionparser(\u0026#34;service\u0026#34;, new dubbobeandefinitionparser(servicebean.class, true)); registerbeandefinitionparser(\u0026#34;reference\u0026#34;, new dubbobeandefinitionparser(referencebean.class, false)); registerbeandefinitionparser(\u0026#34;annotation\u0026#34;, new annotationbeandefinitionparser()); } } dubbobeandefinitionparser实现了spring下的beandefinitionparser,提供了标签解析功能\n服务暴露 服务导出的入口方法是servicebean的onapplicationevent,在spring容器上下文刷新后回调,执行暴露服务\n1 2 3 4 5 6 7 public void onapplicationevent(contextrefreshedevent event) { // 是否有延迟导出 \u0026amp;\u0026amp; 是否已导出 \u0026amp;\u0026amp; 是不是已被取消导出 if (isdelay() \u0026amp;\u0026amp; !isexported() \u0026amp;\u0026amp; !isunexported()) { // 导出服务 export(); } } 暴露过程中发现注册中心时zookeeper会将服务信息注册在zookeeper上\n暴露完成后会启动netty服务,持续提供服务\n服务引用 服务引用的入口方法为referencebean的实现factorybean中的getobject方法\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public object getobject() throws exception { return get(); } public synchronized t get() { if (destroyed) { throw new illegalstateexception(\u0026#34;already destroyed!\u0026#34;); } // 检测 ref 是否为空,为空则通过 init 方法创建 if (ref == null) { // init 方法主要用于处理配置,以及调用 createproxy 生成代理类 init(); } return ref; } init()方法中使用createproxy()方法实现创建代理对象\n服务调用流程 突破口是invokerinvocationhandler实现invocationhandler接口的invoke方法,得到调用结果,最后将结果转型并返回给调用方\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 public class invokerinvocationhandler implements invocationhandler { private final invoker\u0026lt;?\u0026gt; invoker; public invokerinvocationhandler(invoker\u0026lt;?\u0026gt; handler) { this.invoker = handler; } @override public object invoke(object proxy, method method, object[] args) throws throwable { string methodname = method.getname(); class\u0026lt;?\u0026gt;[] parametertypes = method.getparametertypes(); // 拦截定义在 object 类中的方法(未被子类重写),比如 wait/notify if (method.getdeclaringclass() == object.class) { return method.invoke(invoker, args); } // 如果 tostring、hashcode 和 equals 等方法被子类重写了,这里也直接调用 if (\u0026#34;tostring\u0026#34;.equals(methodname) \u0026amp;\u0026amp; parametertypes.length == 0) { return invoker.tostring(); } if (\u0026#34;hashcode\u0026#34;.equals(methodname) \u0026amp;\u0026amp; parametertypes.length == 0) { return invoker.hashcode(); } if (\u0026#34;equals\u0026#34;.equals(methodname) \u0026amp;\u0026amp; parametertypes.length == 1) { return invoker.equals(args[0]); } // 根据不同的invoker使用不同的集群容错策略,调用提供者的方法 return invoker.invoke(new rpcinvocation(method, args)).recreate(); } } ","date":"2019-03-01","permalink":"https://hobocat.github.io/post/dubbo/2019-03-01-dubbo/","summary":"一、基础知识 分布式系统 分布式系统是若干独立计算机的集合,这些计算机对于用户来说就像单个相关系统。 架构发展演变 单一应用架构 一个war包将所有功能都部署在一起搞定","title":"dubbo应用开发"},]
[{"content":"一、spring boot简单入门 spring boot简介 \t因为j2ee笨重的开发方式、繁琐的配置、低下的开发效率和复杂的部署流程、集成第三方插件难度大这些技术痛点的存在的存在,spring开发了一套易用的框架spring boot。\n\tspring boot目的是来简化spring应用开发,使用约定大于配置的规则,去繁从简单,just run就能创建一个独立的,产品级别的应用,spring勾画了一副企业级开发解决方案。\nspring boot具有以下优点:\n快速创建独立运行的spring 项目以及与主流框架集成 使用嵌入式的servlet容器,应用无需打成war包 starters自动依赖与版本控制 大量的自动配置,简化开发,也可修改默认值 无需配置xml,无代码生成,开箱即用 准生产环境的运行时应用监控 与云计算的天然集成 设计架构历史变化 单体架构 :一个归档包(例如war格式或者jar格式)包含了应用所有功能的应用程序,我们通常称之为单体应用。这种架构模式模块耦合度高、扩展能力受限,体积越来越大。\nsoa架构:面向服务的架构。这里的服务可以理解为service层业务服务。它们将整体构成一个彼此协作的套件。一般来说,每个组件会从始至终执行一块完整的业务逻辑,通常包括完成整体大action所需的各种具体任务与功能。\n微服务架构:在微服务架构中,业务逻辑被拆分成一系列小而松散耦合的分布式组件,共同构成了较大的应用。每个组件都被称为微服务,而每个微服务都在整体架构中执行着单独的任务,或负责单独的功能。每个微服务可能会被一个或多个其他微服务调用,以执行较大应用需要完成的具体任务\n功能 soa 微服务 组件大小 大块业务逻辑 单独任务或者小块业务逻辑 耦合 通常松耦合 总是松耦合 管理 着重中央管理 着重分散管理 目标 确保应用能够交互操作 执行新功能、快速拓展 spring boot 初探 第一步:创建maven工程,选在jar方式。在pom中添加\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 \u0026lt;!-- 指定父工程为spring-boot-starter-parent --\u0026gt; \u0026lt;parent\u0026gt; \u0026lt;groupid\u0026gt;org.springframework.boot\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;spring-boot-starter-parent\u0026lt;/artifactid\u0026gt; \u0026lt;version\u0026gt;2.1.1.release\u0026lt;/version\u0026gt; \u0026lt;/parent\u0026gt; \u0026lt;dependencies\u0026gt; \u0026lt;!-- 引入web模块 --\u0026gt; \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;org.springframework.boot\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;spring-boot-starter-web\u0026lt;/artifactid\u0026gt; \u0026lt;/dependency\u0026gt; \u0026lt;/dependencies\u0026gt; 第二步:创建主应用程序类\n1 2 3 4 5 6 7 8 9 10 11 /** * @springbootapplication标识这是一个主程序类,说明这是个spring boot应用 */ @springbootapplication public class helloworldmainapplication { //spring 应用启动起来 public static void main(string[] args) { springapplication.run(helloworldmainapplication.class, args); } } 第三步:创建controller,注意要在主程序类的子包下\n1 2 3 4 5 6 7 8 9 10 @controller public class helloworld { //直接run就可以通过游览器访问地址 @requestmapping(\u0026#34;/hello\u0026#34;) @responsebody public string hello() { return \u0026#34;hello world\u0026#34;; } } 第四步:打包部署,执行maven package即可生成jar包\n1 2 3 4 5 \u0026lt;!-- spring boot打包插件 --\u0026gt; \u0026lt;plugin\u0026gt; \u0026lt;groupid\u0026gt;org.springframework.boot\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;spring-boot-maven-plugin\u0026lt;/artifactid\u0026gt; \u0026lt;/plugin\u0026gt; 探究\npom文件\nspring-boot-starter-parent的重要信息:\n父项目是spring-boot-dependencies 管理了jdk版本 引入了各种打包、编译相关插件 spring-boot-dependencies的重要信息\n进行了版本仲裁 spring-boot-starter-web的重要信息\n映入了嵌入式tomcat、springmvc相关组件 springbootapplication注解梳理\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 /* * springbootapplication注解层级关系 * @springbootapplication * | * +- @springbootconfiguration * | | * | +- @configuration【标志自己是一个配置类用于加载配置】 * | * +- @enableautoconfiguration * | | * | +- @autoconfigurationpackage * | | | * | | +-@import(autoconfigurationpackages.registrar.class)【保存主配置包名,用于后续扫描】 * | | * | +- @import(autoconfigurationimportselector.class)【】 * | * +- @componentscan【设定包扫描过滤器,加载相应类】 */ @springbootconfiguration @enableautoconfiguration @componentscan(excludefilters = { @filter(type = filtertype.custom, classes = typeexcludefilter.class), @filter(type = filtertype.custom, classes = autoconfigurationexcludefilter.class) }) public @interface springbootapplication { @aliasfor(annotation = enableautoconfiguration.class) class\u0026lt;?\u0026gt;[] exclude() default {}; @aliasfor(annotation = enableautoconfiguration.class) string[] excludename() default {}; @aliasfor(annotation = componentscan.class, attribute = \u0026#34;basepackages\u0026#34;) string[] scanbasepackages() default {}; @aliasfor(annotation = componentscan.class, attribute = \u0026#34;basepackageclasses\u0026#34;) class\u0026lt;?\u0026gt;[] scanbasepackageclasses() default {}; } @import(autoconfigurationpackages.registrar.class)的作用\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 //autoconfigurationpackages是importbeandefinitionregistrar的实现类 static class registrar implements importbeandefinitionregistrar, determinableimports { @override public void registerbeandefinitions(annotationmetadata metadata, beandefinitionregistry registry) { register(registry, new packageimport(metadata).getpackagename()); } @override public set\u0026lt;object\u0026gt; determineimports(annotationmetadata metadata) { return collections.singleton(new packageimport(metadata)); } } public static void register(beandefinitionregistry registry, string... packagenames) { if (registry.containsbeandefinition(bean)) { beandefinition beandefinition = registry.getbeandefinition(bean); constructorargumentvalues constructorarguments = beandefinition.getconstructorargumentvalues(); constructorarguments.addindexedargumentvalue( 0,addbasepackages(constructorarguments, packagenames)); } else { //注册了basepackages,构造函数参数为@springbootapplication所在包的包名,为componentscan服务 genericbeandefinition beandefinition = new genericbeandefinition(); beandefinition.setbeanclass(basepackages.class); beandefinition.getconstructorargumentvalues() .addindexedargumentvalue(0, packagenames); beandefinition.setrole(beandefinition.role_infrastructure); registry.registerbeandefinition(bean, beandefinition); } } @import(autoconfigurationimportselector.class)的作用\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 //加载了meta-inf/spring.factories【properties】下类映射注入到容器 private static map\u0026lt;string, list\u0026lt;string\u0026gt;\u0026gt; loadspringfactories(@nullable classloader classloader) { multivaluemap\u0026lt;string, string\u0026gt; result = cache.get(classloader); if (result != null) { return result; } try { //spring-boot-autoconfigure/meta-inf/spring.factories //spring-boot/meta-inf/spring.factories enumeration\u0026lt;url\u0026gt; urls = (classloader != null ? classloader.getresources(factories_resource_location) : classloader.getsystemresources(factories_resource_location)); result = new linkedmultivaluemap\u0026lt;\u0026gt;(); while (urls.hasmoreelements()) { url url = urls.nextelement(); urlresource resource = new urlresource(url); properties properties = propertiesloaderutils.loadproperties(resource); for (map.entry\u0026lt;?, ?\u0026gt; entry : properties.entryset()) { string factoryclassname = ((string) entry.getkey()).trim(); for (string factoryname : stringutils.commadelimitedlisttostringarray((string) entry.getvalue())) { result.add(factoryclassname, factoryname.trim()); } } } cache.put(classloader, result); return result; } catch (ioexception ex) { throw new illegalargumentexception(\u0026#34;unable to load factories from location [\u0026#34; + factories_resource_location + \u0026#34;]\u0026#34;, ex); } } 二、spring boot工程结构 1 2 3 4 5 6 7 8 9 10 11 12 13 project | +- src/main/java 【java代码存放位置】 | +- src/main/resource 【资源文件】 | | | +- static 【静态资源文件存放位置】 | | | +- templates 【用于web开发的前端模板】 | | | +- application.yml【配置文件】 | +- src/test/java 【测试代码存放位置】 三、配置文件详解 yaml基本语法 k:(空格)v\t表示一对键值**【空格必须有】** 以空格缩进控制层级关系 属性值大小写敏感 值为双引号字符串特殊字符不会进行转义、值为单引号字符串特殊字符会进行转义 分为行外写法和行内写法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 #对象行外写法 xiaoming: age: 19 sex: f note: \u0026#39;i\\tlove\\tlili\u0026#39; #对象行内写法 xiaoming: {age: 19,sex: f,note: \u0026#39;i\\tlove\\tlili\u0026#39;} #对象行外写法 friends: - zhangsan - lisi - wangwu #对象行内写法 friends: [zhangsan,lisi,wangwu] yaml配置文件值获取 使用@configurationproperties指定前缀代表从yaml文件中读取对应属性,ide环境会自动提示加入pom依赖\n1 2 3 4 5 \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;org.springframework.boot\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;spring-boot-configuration-processor\u0026lt;/artifactid\u0026gt; \u0026lt;optional\u0026gt;true\u0026lt;/optional\u0026gt; \u0026lt;/dependency\u0026gt; 指定前缀要与yaml文件的前缀要匹配。如果属性是驼峰命令法【例如username】,yaml也可以使用-分割【user-name】\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 @component @configurationproperties(prefix=\u0026#34;person\u0026#34;) public class person { private integer id; private integer age; private string name; private boolean boss; private date\tbirth; private map\u0026lt;string,object\u0026gt; maps; private list\u0026lt;object\u0026gt; list; private dog\tdog; //=============getter/setter方法============= } public class dog { private string name; private string age; //=============getter/setter方法============= } 1 2 3 4 5 6 7 8 9 10 11 12 13 14 person: id: 1 name: 张三 age: 18 boss: false birth: 2019/01/01 maps: {k1: v1,k2: v2} list: - list1 - list2 - list3 dog: age: 10 name: tom @configurationproperties和@value对比 @configurationproperties @value 功能 批量注入配置文件中的属性 一项一项指定 松散绑定(松散语法) 支持 不支持 spel 不支持 支持 jsr303校验 支持 不支持 复杂类型封装 支持 不支持 适用范围:\n只是在某个业务逻辑中需要获取一下配置文件中的某项值,使用@value 专门编写了一个javabean来和配置文件进行映射,就直接使用@configurationproperties 配置文件属性校验 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 @component @configurationproperties(prefix=\u0026#34;person\u0026#34;)//支持jsr303 @validated//使用jsr303校验 public class person { private integer id; private integer age; @notempty private string name; private boolean boss; private date birth; private map\u0026lt;string,object\u0026gt; maps; private list\u0026lt;object\u0026gt; list; private dog\tdog; //=============getter/setter方法============= } @propertysource和@importresource导入配置文件 @propertysource:加载指定的配置文件,避免所有文件全配置在springboot全局配置文件中产生混淆\n1 2 3 4 5 6 7 8 9 10 //指定加载user.properties @propertysource(\u0026#34;classpath:user.properties\u0026#34;) @component @configurationproperties(prefix=\u0026#34;user\u0026#34;) public class user { private string username; private integer age; //=============getter/setter方法============= } @importresource:导入spring的xml配置文件,让配置文件里面的内容生效【不建议使用】\n配置文件占位符 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 person: id: 1 name: 张三 # 生成随机数 # ${random.uuid}、${random.int}、${random.long}、${random.10}、${random.[20,50]} age: ${random.uuid} boss: false birth: 2019/01/01 maps: {k1: v1,k2: v2} list: - list1 - list2 - list3 dog: age: 10 name: tom-${person.name:not-host} #使用占位符获取配置的值,如果没有使用:后值作为默认值 四、profile profile文件编写规则\n多profile文件\n主配置文件编写时可以是 application-{profile}.yml/properties,默认使用application.yml/properties\nyml多文档块\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 # 指定激活的profile spring: profiles: active: - dev --- server: port: 8081 # profile环境名称 spring: profiles: dev --- server: port: 8082 # profile环境名称 spring: profiles: prod 激活指定profile\n在配置文件中指定激活的profile【spring.profiles.active=dev】\n命令行参数【\u0026ndash;spring.profiles.active=dev】\n虚拟机参数【-dspring.profiles.active=dev】\n五、spring boot配置文件加载位置 spring boot 启动会扫描以下位置的application.properties或者application.yml文件作为spring boot的配置文件\nfile:./config/ file:./ classpath:/config/ classpath:/ 按照优先级从高到低的顺序加载,高优先级配置内容会覆盖低优先级配置内容。springboot会从这四个位置加载主配置文件,互补配置。也可以通过配置spring.config.location指定额外的配置文件来改变以上配置内容,一般在运维中使用\n六、自动配置原理 springboot启动的时候加载主配置类,开启了自动配置功能@enableautoconfiguration\n@enableautoconfiguration的作用\n类路径下 meta-inf/spring.factories 里面配置的所有enableautoconfiguration的值加入到了容器中\nspring.factories中每个xxxautoconfiguration都是容器中的组件,都加入到容器中,用做自动配置\n每个配置类会根据不同的判断条件决定是否生效,一但这个配置类生效,这个配置类就会给容器中添加各种组件。这些组件的属性是从对应的properties类中获取的,这些类里面的每一个属性又和配置文件绑定\n@conditional派生注解用于判断配置类是否生效\n@conditional扩展注解 判断是否满足当前指定条件 @conditionalonjava 系统的java版本是否符合要求 @conditionalonbean 容器中存在指定bean @conditionalonmissingbean 容器中不存在指定bean @conditionalonexpression 满足spel表达式指定 @conditionalonclass 系统中有指定的类 @conditionalonmissingclass 系统中没有指定的类 @conditionalonsinglecandidate 容器中只有一个指定的bean,或者这个bean是首选bean @conditionalonproperty 系统中指定的属性是否有指定的值 @conditionalonresource 类路径下是否存在指定资源文件 @conditionalonwebapplication 当前是web环境 @conditionalonnotwebapplication 当前不是web环境 @conditionalonjndi jndi存在指定项 注:可以通过启用【debug=true】属性来让控制台打印自动配置报告\n七、spring boot与日志 市场上主流日志框架分类\n日志门面 日志实现 jcl(jakarta commons logging)\nslf4j(simple logging facade for java)\njboss-logging log4j\njul(java.util.logging)\nlog4j2\nlogback springboot选用slf4j作为日志门面,logback作为日志实现\nslf4j的使用\n以后开发的时候,日志记录方法的调用,不应该来直接调用日志的实现类,而是调用日志抽象层里面的方法,给系统里面导入slf4j的jar和 logback的实现jar\n1 2 3 4 5 6 7 8 9 import org.slf4j.logger; import org.slf4j.loggerfactory; public class helloworld { public static void main(string[] args) { logger logger = loggerfactory.getlogger(helloworld.class); logger.info(\u0026#34;hello world\u0026#34;); } } slf4j与日志框架实现绑定图\n每个日志的实现框架都有自己的配置文件。使用slf4j以后,配置文件还是做成日志实现框架的配置文件\nslf4j统一日志实现框架\nspringboot能自动适配所有的日志,而且底层使用slf4j+logback的方式记录日志,引入其他框架的时候,只需要把这个框架依赖的日志框架排除掉即\n日志使用\nspringboot修改日志的默认配置\n1 2 3 4 5 6 7 8 9 10 11 12 #com.kun下的包日志级别是trace logging.level.com.kun=trace #logging.path=./\t不指定路径在当前项目下生成springboot.log日志,不能指定名字 #logging.file=g:/springboot.log 可以指定完整的路径 # 在当前磁盘的根路径下创建spring文件夹和里面的log文件夹;使用 spring.log 作为默认文件 logging.path=/spring/log # 在控制台输出的日志的格式 logging.pattern.console=%d{yyyy‐mm‐dd} [%thread] %‐5level %logger{50} ‐ %msg%n # 指定文件中日志输出的格式 logging.pattern.file=%d{yyyy‐mm‐dd} [%thread] %‐5level %logger{50} %msg%n logging.file logging.path example description (none) (none) 只在控制台输出 指定文件名 (none) my.log 输出日志到my.log文件 (none) 指定目录 /var/log 输出到指定目录的 spring.log 文件中 指定配置\n如果给类路径下放上每个日志框架自己的配置文件,springboot就不使用自身的默认配置\nlogging system customization logback logback-spring.xml logback-spring.groovy logback.xml or logback.groovy log4j2 log4j2-spring.xml or log4j2.xml jdk (java util logging) logging.properties logback.xml:直接就被日志框架识别了\nlogback-spring.xml:日志框架不直接加载日志的配置项,由springboot解析日志配置,可以使用springboot的高级profile功能 1 2 3 4 \u0026lt;!-- 可以指定某段配置只在某个环境下生效 --\u0026gt; \u0026lt;springprofile name=\u0026#34;dev\u0026#34;\u0026gt; \u0026lt;!-- 配置 --\u0026gt; \u0026lt;/springprofile\u0026gt; 例如\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 \u0026lt;appender name=\u0026#34;stdout\u0026#34; class=\u0026#34;ch.qos.logback.core.consoleappender\u0026#34;\u0026gt; \u0026lt;!-- 日志输出格式: %d\t表示日期时间 %thread\t表示线程名 %‐5level\t级别从左显示5个字符宽度 %logger{50} 表示logger名字最长50个字符,否则按照句点分割 %msg\t日志消息 %n\t换行符 --\u0026gt; \u0026lt;layout class=\u0026#34;ch.qos.logback.classic.patternlayout\u0026#34;\u0026gt; \u0026lt;springprofile name=\u0026#34;dev\u0026#34;\u0026gt; \u0026lt;pattern\u0026gt;%d{yyyy‐mm‐dd hh:mm:ss.sss} ‐‐‐‐\u0026gt; [%thread] ‐‐‐\u0026gt; %‐5level %logger{50} ‐ %msg%n \u0026lt;/pattern\u0026gt; \u0026lt;/springprofile\u0026gt; \u0026lt;springprofile name=\u0026#34;!dev\u0026#34;\u0026gt; \u0026lt;pattern\u0026gt;%d{yyyy‐mm‐dd hh:mm:ss.sss} ==== [%thread] ==== %‐5level %logger{50} ‐ %msg%n \u0026lt;/pattern\u0026gt; \u0026lt;/springprofile\u0026gt; \u0026lt;/layout\u0026gt; \u0026lt;/appender\u0026gt; 八、spring boot与web开发 静态资源的处理 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 @configuration @conditionalonwebapplication(type = type.servlet) @conditionalonclass({ servlet.class, dispatcherservlet.class, webmvcconfigurer.class }) @conditionalonmissingbean(webmvcconfigurationsupport.class) @autoconfigureorder(ordered.highest_precedence + 10) @autoconfigureafter({ dispatcherservletautoconfiguration.class, taskexecutionautoconfiguration.class, validationautoconfiguration.class }) public class webmvcautoconfiguration { //...... @configuration @import(enablewebmvcconfiguration.class) @enableconfigurationproperties({ webmvcproperties.class, resourceproperties.class }) @order(0) public static class webmvcautoconfigurationadapter implements webmvcconfigurer, resourceloaderaware { @override public void addresourcehandlers(resourcehandlerregistry registry) { if (!this.resourceproperties.isaddmappings()) { logger.debug(\u0026#34;default resource handling disabled\u0026#34;); return; } duration cacheperiod = this.resourceproperties.getcache().getperiod(); cachecontrol cachecontrol = this.resourceproperties.getcache() .getcachecontrol().tohttpcachecontrol(); // 所有/webjars/**,都去classpath:/meta-inf/resources/webjars/找资源 // webjars:以jar包的方式引入静态资源【参考http://www.webjars.org】 if (!registry.hasmappingforpattern(\u0026#34;/webjars/**\u0026#34;)) { customizeresourcehandlerregistration( registry.addresourcehandler(\u0026#34;/webjars/**\u0026#34;) .addresourcelocations(\u0026#34;classpath:/meta-inf/resources/webjars/\u0026#34;) .setcacheperiod(getseconds(cacheperiod)) .setcachecontrol(cachecontrol)); } /** * staticpathpattern = \u0026#34;/**\u0026#34; * staticlocations = \u0026#34;classpath:/meta-inf/resources/\u0026#34;, * \u0026#34;classpath:/resources/\u0026#34;, * \u0026#34;classpath:/static/\u0026#34;, * \u0026#34;classpath:/public/\u0026#34; */ string staticpathpattern = this.mvcproperties.getstaticpathpattern(); if (!registry.hasmappingforpattern(staticpathpattern)) { customizeresourcehandlerregistration( registry.addresourcehandler(staticpathpattern) .addresourcelocations(getresourcelocations(this.resourceproperties.getstaticlocations())) .setcacheperiod(getseconds(cacheperiod)) .setcachecontrol(cachecontrol)); } } //欢迎页请求映射处理 @bean public welcomepagehandlermapping welcomepagehandlermapping( applicationcontext applicationcontext) { return new welcomepagehandlermapping( new templateavailabilityproviders(applicationcontext), applicationcontext, getwelcomepage(), this.mvcproperties.getstaticpathpattern()); } //欢迎图标 @bean public resourcehttprequesthandler faviconrequesthandler() { resourcehttprequesthandler requesthandler = new resourcehttprequesthandler(); requesthandler.setlocations(resolvefaviconlocations()); return requesthandler; } } } 总结:\n所有 /webjars/** ,都去 classpath:/meta-inf/resources/webjars/ 找资源\n/** 访问当前项目的任何资源,都去(静态资源的文件夹)找映射\n1 2 3 4 \u0026#34;classpath:/meta‐inf/resources/\u0026#34;, \u0026#34;classpath:/resources/\u0026#34;, \u0026#34;classpath:/static/\u0026#34;, \u0026#34;classpath:/public/\u0026#34; 欢迎页,静态资源文件夹下的所有index.html页面被/**映射\n所有的 **/favicon.ico 都是在静态资源文件下找\n动态页面处理 使用thymeleaf模板引擎\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 \u0026lt;!-- 引入thymeleaf的starter --\u0026gt; \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;org.springframework.boot\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;spring-boot-starter-thymeleaf\u0026lt;/artifactid\u0026gt; \u0026lt;/dependency\u0026gt; \u0026lt;!-- 如果thymeleaf是2版本切换thymeleaf3版本方法 \u0026lt;properties\u0026gt; \u0026lt;thymeleaf.version\u0026gt;3.0.9.release\u0026lt;/thymeleaf.version\u0026gt; \u0026lt;!‐‐ 布局功能的支持程序 thymeleaf3主程序 layout2以上版本 ‐‐\u0026gt; \u0026lt;thymeleaf‐layout‐dialect.version\u0026gt;2.2.2\u0026lt;/thymeleaf‐layout‐dialect.version\u0026gt; \u0026lt;/properties\u0026gt; --\u0026gt; thymeleaf基本语法\n导入名称空间:\u0026lt;html lang=\u0026quot;en\u0026quot; xmlns:th=\u0026quot;http://www.thymeleaf.org\u0026quot;\u0026gt;\n详细语法参考\n内容协商 web客户端通过不同的请求策略,实现服务端响应对应视图内容输出\n视图解析器contentnegotiatingviewresolver:\n①关联viewresolver bean列表\n②关联contentnegotiationmanager\n③解析最佳匹配view\n常用的contentnegotiatingviewresolver:\ninternalresourceviewresolver beannameviewresolver thymeleafviewresolver 内容协商管理器contentnegotiationmanager:\n①由contentnegotitationconfigurer配置\n②由contnetnegotiationmanagerfactorybean创建\n③关联contentnegotiationstrategy集合\n内容协商策略contentnegotitationstragtegy\n常见的contentnegotitationstragtegy:\n固定mediatype:fixedcontentnegotitationstragtegy ”accept“请求头:headercontentnegotitationstragtegy 请求参数:parametercontentnegotitationstragtegy 路径扩展名:pathextensioncontentnegotitationstragtegy springmvc自动配置 spring boot 自动配了springmvc,以下是springboot对springmvc的默认配置:(webmvcautoconfiguration)\n包含了contentnegotiatingviewresolver和beannameviewresolver\n自动配置了viewresolver【视图解析器:根据方法的返回值得到视图对象(view),视图对象决定如何渲染(转发/重定向)】\ncontentnegotiatingviewresolver【用于组合所有的视图解析器】\n支持服务器静态资源,包括webjars\n静态首页访问\nfavicon.ico图标\n自动注册了converter ,genericconverter , formatter\nconverter:转换器【传入参数转换为对象】 formatter:格式化器【日期等格式格式化使用】 支持httpmessageconverters\nhttpmessageconverter:springmvc用来转换http请求和响应的 httpmessageconverters :从容器中获取所有的httpmessageconverter 自动注册messagecodesresolver【定义错误代码生成规则】\n自动使用configurablewebbindinginitializer【参数数据绑定使用】\n扩展springmvc 编写一个配置类(@configuration),实现webmvcconfigurer类,且不能标注@enablewebmvc\n1 2 3 4 5 6 7 8 9 10 11 @configuration public class appwebmvcconfigurer implements webmvcconfigurer{ @override public void addformatters(formatterregistry registry) { } @override public void addinterceptors(interceptorregistry registry) { } } 原理:\nwebmvcautoconfiguration是springmvc的自动配置类 webmvcautoconfiguration使用webmvcautoconfigurationadapter作为默认配置 webmvcautoconfigurationadapter使用了注解@import(enablewebmvcconfiguration.class) enablewebmvcconfiguration是delegatingwebmvcconfiguration子类 1 2 3 4 5 6 7 8 9 10 11 12 13 @configuration public class delegatingwebmvcconfiguration extends webmvcconfigurationsupport { private final webmvcconfigurercomposite configurers = new webmvcconfigurercomposite(); //从容器中获取所有webmvcconfigurer,将配置全部保存起来用于扩展 @autowired(required = false) public void setconfigurers(list\u0026lt;webmvcconfigurer\u0026gt; configurers) { if (!collectionutils.isempty(configurers)) { this.configurers.addwebmvcconfigurers(configurers); } } } 效果:springmvc的自动配置和我们的扩展配置都会起作用\n全面接管springmvc 只需要在配置类中添加@enablewebmvc\n1 2 3 4 5 6 7 8 9 10 11 12 @enablewebmvc @configuration public class appwebmvcconfigurer implements webmvcconfigurer{ @override public void addformatters(formatterregistry registry) { } @override public void addinterceptors(interceptorregistry registry) { } } 原理:\n@enablewebmvc使用了@import(delegatingwebmvcconfiguration.class)\n1 public class delegatingwebmvcconfiguration extends webmvcconfigurationsupport webmvcautoconfiguration使用了@conditionalonmissingbean(webmvcconfigurationsupport.class)\nwebmvcconfigurationsupport被@enablewebmvc已经导入故不再生效\n总结:在springboot中会有非常多的xxxconfigurer帮助我们进行扩展配置\n 在springboot中会有很多的xxxcustomizer帮助我们进行定制配置\n国际化 编写国际化配置文件\nmessage.properties【默认语言文件】\nmessage_en_us.properties【英语美国语言配置】\nmessage_zh_cn.properties【中文中国语言配置】\n注:编写国际化i18n文件可以再eclipse中安装resourcebundle插件\n配置springboot国际化文件读取路径\n1 2 3 4 #以下配置会读取【i18n/message】开头的properties文件 spring: messages: basename: i18n.message 在thymeleaf中使用国际化文件\n1 2 [[#{login.tip}]] \u0026lt;!-- 行外写法 --\u0026gt; \u0026lt;label th:text=\u0026#34;#{login.username}\u0026#34;\u0026gt;\u0026lt;/label\u0026gt; \u0026lt;!-- 行内写法 --\u0026gt; 错误处理机制 \tspringboot默认效果,游览器返回默认错误页面,其他工具返回json数据,springboot通过请求头的accept动态确定返回的信息类型\n原理:errormvcautoconfiguration【错误处理的自动配置类】给容器默认添加了如下组件\ndefaulterrorattributes 1 2 3 4 5 6 7 8 9 10 11 //存放页面展示需要使用错误的属性 @override public map\u0026lt;string, object\u0026gt; geterrorattributes(webrequest webrequest, boolean includestacktrace) { map\u0026lt;string, object\u0026gt; errorattributes = new linkedhashmap\u0026lt;\u0026gt;(); errorattributes.put(\u0026#34;timestamp\u0026#34;, new date()); addstatus(errorattributes, webrequest); adderrordetails(errorattributes, webrequest, includestacktrace); addpath(errorattributes, webrequest); return errorattributes; } basicerrorcontroller 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 @controller @requestmapping(\u0026#34;${server.error.path:${error.path:/error}}\u0026#34;) public class basicerrorcontroller extends abstracterrorcontroller { //...... //返回html需要的错误界面 @requestmapping(produces = mediatype.text_html_value) public modelandview errorhtml(httpservletrequest request, httpservletresponse response) { httpstatus status = getstatus(request); map\u0026lt;string, object\u0026gt; model = collections.unmodifiablemap( geterrorattributes(request, isincludestacktrace(request, mediatype.text_html))); response.setstatus(status.value()); modelandview modelandview = resolveerrorview(request, response, status, model); return (modelandview != null) ? modelandview : new modelandview(\u0026#34;error\u0026#34;, model); } //返回json错误数据 @requestmapping public responseentity\u0026lt;map\u0026lt;string, object\u0026gt;\u0026gt; error(httpservletrequest request) { map\u0026lt;string, object\u0026gt; body = geterrorattributes(request, isincludestacktrace(request, mediatype.all)); httpstatus status = getstatus(request); return new responseentity\u0026lt;\u0026gt;(body, status); } //...... } errorpagecustomizer 1 2 @value(\u0026#34;${error.path:/error}\u0026#34;) private string path = \u0026#34;/error\u0026#34;; //系统出现错误以后来到error请求进行处理相当于web.xml注册的错误页面规则 defaulterrorviewresolver 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 public class defaulterrorviewresolver implements errorviewresolver, ordered { private static final map\u0026lt;series, string\u0026gt; series_views; static { map\u0026lt;series, string\u0026gt; views = new enummap\u0026lt;\u0026gt;(series.class); views.put(series.client_error, \u0026#34;4xx\u0026#34;); views.put(series.server_error, \u0026#34;5xx\u0026#34;); series_views = collections.unmodifiablemap(views); } @override public modelandview resolveerrorview(httpservletrequest request, httpstatus status,map\u0026lt;string, object\u0026gt; model) { modelandview modelandview = resolve(string.valueof(status.value()), model); if (modelandview == null \u0026amp;\u0026amp; series_views.containskey(status.series())) { modelandview = resolve(series_views.get(status.series()), model); } return modelandview; } //寻找对应的错误视图 private modelandview resolve(string viewname, map\u0026lt;string, object\u0026gt; model) { //viewname是错误代码 string errorviewname = \u0026#34;error/\u0026#34; + viewname; //模板引擎可以解析这个页面地址就用模板引擎解析 templateavailabilityprovider provider = this.templateavailabilityproviders .getprovider(errorviewname, this.applicationcontext); if (provider != null) { return new modelandview(errorviewname, model); } //模板引擎不可用,就在静态资源文件夹下找errorviewname对应的页面 error/404.html return resolveresource(errorviewname, model); } private modelandview resolveresource(string viewname, map\u0026lt;string, object\u0026gt; model) { for (string location : this.resourceproperties.getstaticlocations()) { try { resource resource = this.applicationcontext.getresource(location); resource = resource.createrelative(viewname + \u0026#34;.html\u0026#34;); if (resource.exists()) { return new modelandview(new htmlresourceview(resource), model); } } catch (exception ex) { } } return null; } } 错误处理步骤:系统出现4xx或者5xx之类的错误,errorpagecustomizer就会生效(定制错误的响应规则)会来到/error请求,会被basicerrorcontroller处理\n定制错误页面\n有模板引擎的情况下,将错误页面命名为【错误状态码.html】放在模板引擎文件夹里面的 error文件夹下,发生此状态码的错误就会来到对应的页面。可以使用4xx和5xx作为错误页面的文件名来匹配这种类型的所有错误,精确优先(优先寻找精确的状态码.html)\n页面能获取的信息:\ntimestamp:时间戳 status:状态码 error:错误提示 exception:异常对象 message:异常消息 errors:jsr303数据校验的错误信息 没有模板引擎(模板引擎找不到这个错误页面),静态资源文件夹下找\n以上都没有错误页面,就是默认来到springboot默认的错误提示页面\n定制错误的json数据\n自定义异常处理或者返回定制json数据【失去自适应效果,需要自适应效果需要自己手动编写】\n1 2 3 4 5 6 7 8 9 10 11 12 13 @controlleradvice public class myexceptionhandler { @responsebody @exceptionhandler(usernotexistexception.class) public map\u0026lt;string,object\u0026gt; handleexception(exception e){ map\u0026lt;string,object\u0026gt; map = new hashmap\u0026lt;\u0026gt;(); map.put(\u0026#34;code\u0026#34;,\u0026#34;user.notexist\u0026#34;); map.put(\u0026#34;message\u0026#34;,e.getmessage()); return map; } } //没有自适应效果... 转发到/error进行自适应响应效果处理\n1 2 3 4 5 6 7 8 9 10 @exceptionhandler(usernotexistexception.class) public string handleexception(exception e, httpservletrequest request){ map\u0026lt;string,object\u0026gt; map = new hashmap\u0026lt;\u0026gt;(); //传入我们自己的错误状态码 4xx 5xx,否则就不会进入定制错误页面的解析流程 request.setattribute(\u0026#34;javax.servlet.error.status_code\u0026#34;,500); map.put(\u0026#34;code\u0026#34;,\u0026#34;user.notexist\u0026#34;); map.put(\u0026#34;message\u0026#34;,e.getmessage()); //转发到/error return \u0026#34;forward:/error\u0026#34;; } 定制数据携带出去\n\t出现错误以后,会来到/error请求,会被basicerrorcontroller处理,响应出去可以获取的数据是由父类的geterrorattributes得到的实现方式有两种:\n完全来编写一个errorcontroller的实现类【或者是编写abstracterrorcontroller的子类】,此方法较为麻烦 页面的数据或是json返回能用的数据都是通过errorattributes.geterrorattributes得到,所以自定义errorattributes就能完成功能,此方法比较简单。通常在自定义的exceptionhandler中把错误信息先存入。 1 2 3 4 5 6 7 8 9 10 11 12 13 //给容器中加入我们自己定义的errorattributes @component public class myerrorattributes extends defaulterrorattributes { @override public map\u0026lt;string, object\u0026gt; geterrorattributes(requestattributes requestattributes, boolean includestacktrace) { map\u0026lt;string, object\u0026gt; map = super.geterrorattributes(requestattributes, includestacktrace); string errorcode = requestattributes.getattribute(\u0026#34;code\u0026#34;); map.put(\u0026#34;errorcode\u0026#34;,errorcode); return map; } } 配置跨域访问 cross-origin resource sharing(cors)配置方式\n①注解驱动 :@corssorigin【也可以和@controller或@requestmapping同级更加精确】\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 public @interface crossorigin { @aliasfor(\u0026#34;origins\u0026#34;) string[] value() default {}; //允许可访问的域列表,*代表所有 @aliasfor(\u0026#34;value\u0026#34;) string[] origins() default {}; //运行的请求头 string[] allowedheaders() default {}; //配置获取响应的头信息, 在其中可以设置其他的头信息,不进行配置时, 默认可以获取到 //cache-control、content-language、content-type、expires、last-modified、pragma字段 string[] exposedheaders() default {}; //允许可访问的域发送请求的方法 requestmethod[] methods() default {}; //浏览器是否应该同时发送凭证(如cookie)。默认false,开启设置为true string allowcredentials() default \u0026#34;\u0026#34;; //准备响应前的缓存持续的最大时间(以秒为单位) long maxage() default -1l; } //---------------------------------------------------------------------------------- @springbootapplication @crossorigin(origins = {\u0026#34;*\u0026#34;}, maxage = 3600, methods = {requestmethod.get},allowcredentials = \u0026#34;true\u0026#34;) public class webapplication { public static void main(string[] args) { springapplication.run(webapplication.class, args); } } ②代码驱动:webmvcconfigurer#addcorsmappings\n1 2 3 4 5 6 7 8 9 10 11 12 @configuration public class appwebmvcconfigurer implements webmvcconfigurer { @override public void addcorsmappings(corsregistry registry) { registry.addmapping(\u0026#34;/**\u0026#34;) .allowedorigins(\u0026#34;*\u0026#34;) .allowcredentials(true) .allowedmethods(\u0026#34;get\u0026#34;, \u0026#34;post\u0026#34;, \u0026#34;delete\u0026#34;, \u0026#34;put\u0026#34;,\u0026#34;patch\u0026#34;) .maxage(3600); } } 九、spring webflux reactive概念 reactor【反应堆模式】是事件驱动的,有一个或多个并发输入源,有一个service handler,有多个request handlers。service handler会同步的将输入的请求(event)多路复用的分发给相应的request handler。\nreactive是异步非阻塞的,可以提高程序性能。\ncallback和future缺陷 callback和future均无法控制异步执行顺序,例如:加载资源和用户登陆同时进行而获取用户关注信息,需要等待用户登陆动作之后进行,callback和future在此情景下不容易控制。future可使用completablefuture解决问题。\nreactive编程定义 reactive具有的原则\n响应性的 适应性强的 弹性的 消息驱动的 效果:同步或异步非阻塞执行,数据传播被通知\nreactive的实现框架\njava9 flow api rxjava reactor webflux基本介绍 spring webflux是一套全新的reactive web栈技术,是springframework5.0添加的新功能。实现完全非阻塞,支持reactive streams背压等特性,并且运行环境不限于servlet容器。webflux实现了在资源有限的情况下,尽可能多的接收并处理请求【提升负载】而不是更快的响应。\nwebflux主要在如下两方面体现出独有的优势:\n在servlet3.1其实已经提供了非阻塞的api,webflux提供了一种比其更完美的解决方案。使用非阻塞的方式可以利用较小的线程或硬件资源来处理并发进而提高其可伸缩性\n函数式编程端点\nservlet模型\u0026amp;webflux servlet\nservlet由servlet container进行生命周期管理。container运行时接受请求,并为每个请求分配一个线程(一般从线程池中获取空闲线程)然后调用service()。\n弊端:servlet是一个简单的网络编程模型,当请求进入servlet container时,servlet container就会为其绑定一个线程,一旦并发上升,线程数量就会上涨,而线程资源代价是昂贵的(上线文切换,内存消耗大)严重影响请求的处理时间。在一些简单的业务场景下,不希望为每个request分配一个线程,只需要1个或几个线程就能应对极大并发的请求,这种业务场景下servlet模型没有优势。\nspring webmvc是基于servlet的一个路由模型,即实现了所有请求处理的一个servlet【dispatcherservlet】,并由该servlet进行路由。所以spring webmvc无法摆脱servlet模型的弊端。\nwebflux\nwebflux模式替换了旧的servlet线程模型。用少量的线程处理request和response的io操作,这些线程称为loop线程,而业务交给响应式编程框架处理,用户可以将业务中阻塞的操作提交到响应式框架的work线程中执行,而不阻塞的操作依然可以在loop线程中进行处理,大大提高了loop线程的利用率。\nspringmvc与springwebflux 它们都可以用注解式编程模型,都可以运行在tomcat,jetty,undertow等servlet容器当中。但是springmvc采用命令式编程方式,代码一句一句的执行,这样更有利于理解与调试,而webflux则是基于异步响应式编程,对于调试和理解增大了难度。两种框架官方给出的建议是:\n如果原先使用用springmvc好好的话,则没必要迁移。因为命令式编程是编写、理解和调试代码的最简单方法。因为老项目的类库与代码都是基于阻塞式的。 如果打算使用非阻塞式web框架,webflux确实是一个可考虑的技术路线,而且它支持类似于springmvc的annotation的方式实现编程模式,也可以在微服务架构中让webmvc与webflux共用controller,切换使用的成本相当小 在springmvc项目里如果需要调用远程服务的话,你不妨考虑一下使用webclient,而且方法的返回值可以考虑使用reactive type类型的,当每个调用的延迟时间越长,或者调用之间的相互依赖程度越高,其好处就越大 webhandler webflux已经脱离了servlet api,由webhandler实现类处理会话机制、请求过滤、静态资源等等。其实在httphandler的基本实现类通过适配器模式及装饰模式也间接的实现了webhandler接口。\nwebhandlerdecorator:webhandler的装饰器,利用装饰模式实现相关功能的扩展\nhttpwebhandleradapter: 进行http请求处理,同时也是httphandler的实现类\nfilteringwebhandler:通过webfilter进行过滤处理的类,类似于servlet中的filter\nexceptionhandlingwebhandler: 针对于异常的处理类\nresourcewebhandler:用于静态资源请求的处理类\ndispatcherhandler:请求的总控制器,类似于webmvc中的dispatcherservlet\n实现webflux示例 基于annotated controller方式实现和springmvc方式完全相同\n函数式编程方式\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 /** * 类似于controller,处理用户请求的真实逻辑 */ public class studenthandler { //这里采用mono模式类似于点对点,也可使用flux类似于发布、订阅 public static mono\u0026lt;serverresponse\u0026gt; selectstudent(serverrequest request) { student studentbody = new student(); request.bodytomono(student.class).subscribe( student -\u0026gt; beanutils.copyproperties(student, studentbody)); return ok().contenttype(application_json_utf8).body(fromobject(studentbody)); } public static mono\u0026lt;serverresponse\u0026gt; insertstudent(serverrequest request){ return ok().contenttype(text_plain).body(fromobject(\u0026#34;success\u0026#34;)); } private static class student { private integer id; private string name; public integer getid() { return id; } public void setid(integer id) { this.id = id; } public string getname() { return name; } public void setname(string name) { this.name = name; } } } //=================================================================================== //配置类 @configuration @enablewebflux public class webconfig implements webfluxconfigurer { @bean public routerfunction\u0026lt;?\u0026gt; routerfunctiona() { routerfunction\u0026lt;serverresponse\u0026gt; route = route() .get(\u0026#34;/student/{id}\u0026#34;, accept(application_json), studenthandler::selectstudent) .post(\u0026#34;/student\u0026#34;, studenthandler::insertstudent) .build(); return route; } } 十、配置嵌入式servlet容器 springboot默认使用tomcat作为嵌入式的servlet容器\n修改和嵌入式容器相关的配置参数方式 修改和server有关的配置(serverproperties)\n1 2 3 4 5 6 #修改通用配置 server:port: 8081 server:context-path: /crud #修改tomcat特定配置,如修改其他容器,更改容器名 server:tomcat:uri-encoding: utf-8 注册servlet三大组件【servlet、filter、listener】 springboot默认是以jar包的方式启动嵌入式的servlet容器来启动springboot的web应用,没有web.xml文件,注册三大组件用以下方式\nservletregistrationbean\n1 2 3 4 @bean public servletregistrationbean\u0026lt;helloservlet\u0026gt; helloservletbean() { return new servletregistrationbean\u0026lt;helloservlet\u0026gt;(new helloservlet(), \u0026#34;/hello\u0026#34;); } filterregistrationbean\n1 2 3 4 5 6 @bean public filterregistrationbean\u0026lt;hellofilter\u0026gt; hellofilterbean() { filterregistrationbean\u0026lt;hellofilter\u0026gt; hellofilterbean = new filterregistrationbean\u0026lt;hellofilter\u0026gt;(new hellofilter()); hellofilterbean.addurlpatterns(\u0026#34;/hello\u0026#34;); return hellofilterbean; } servletlistenerregistrationbean\n1 2 3 4 @bean public servletlistenerregistrationbean\u0026lt;hellolistener\u0026gt; hellolistenerbean() { return new servletlistenerregistrationbean\u0026lt;hellolistener\u0026gt;(new hellolistener()); } 替换为其他嵌入式servlet容器 tomcat(默认使用)\n1 2 3 4 5 \u0026lt;dependency\u0026gt; \u0026lt;!-- 引入web模块默认就是使用嵌入式的tomcat作为servlet容器 --\u0026gt; \u0026lt;groupid\u0026gt;org.springframework.boot\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;spring‐boot‐starter‐web\u0026lt;/artifactid\u0026gt; \u0026lt;/dependency\u0026gt; jetty\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 \u0026lt;!-- 引入web模块 --\u0026gt; \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;org.springframework.boot\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;spring‐boot‐starter‐web\u0026lt;/artifactid\u0026gt; \u0026lt;exclusions\u0026gt; \u0026lt;exclusion\u0026gt; \u0026lt;artifactid\u0026gt;spring‐boot‐starter‐tomcat\u0026lt;/artifactid\u0026gt; \u0026lt;groupid\u0026gt;org.springframework.boot\u0026lt;/groupid\u0026gt; \u0026lt;/exclusion\u0026gt; \u0026lt;/exclusions\u0026gt; \u0026lt;/dependency\u0026gt; \u0026lt;!-- 引入jetty --\u0026gt; \u0026lt;dependency\u0026gt; \u0026lt;artifactid\u0026gt;spring‐boot‐starter‐jetty\u0026lt;/artifactid\u0026gt; \u0026lt;groupid\u0026gt;org.springframework.boot\u0026lt;/groupid\u0026gt; \u0026lt;/dependency\u0026gt; undertow\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 \u0026lt;!-- 引入web模块 --\u0026gt; \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;org.springframework.boot\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;spring‐boot‐starter‐web\u0026lt;/artifactid\u0026gt; \u0026lt;exclusions\u0026gt; \u0026lt;exclusion\u0026gt; \u0026lt;artifactid\u0026gt;spring‐boot‐starter‐tomcat\u0026lt;/artifactid\u0026gt; \u0026lt;groupid\u0026gt;org.springframework.boot\u0026lt;/groupid\u0026gt; \u0026lt;/exclusion\u0026gt; \u0026lt;/exclusions\u0026gt; \u0026lt;/dependency\u0026gt; \u0026lt;!-- 引入undertow --\u0026gt; \u0026lt;dependency\u0026gt; \u0026lt;artifactid\u0026gt;spring‐boot‐starter‐undertow\u0026lt;\u0026lt;/artifactid\u0026gt; \u0026lt;groupid\u0026gt;org.springframework.boot\u0026lt;/groupid\u0026gt; \u0026lt;/dependency\u0026gt; 嵌入式servlet容器自动配置原理 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 @configuration @conditionalonwebapplication @enableconfigurationproperties(serverproperties.class) public class embeddedwebserverfactorycustomizerautoconfiguration { //配置tomcat的webserver @configuration @conditionalonclass({ tomcat.class, upgradeprotocol.class }) public static class tomcatwebserverfactorycustomizerconfiguration { @bean public tomcatwebserverfactorycustomizer tomcatwebserverfactorycustomizer( environment environment, serverproperties serverproperties) { return new tomcatwebserverfactorycustomizer(environment, serverproperties); } } //配置jetty的webserver @configuration @conditionalonclass({ server.class, loader.class, webappcontext.class }) public static class jettywebserverfactorycustomizerconfiguration { @bean public jettywebserverfactorycustomizer jettywebserverfactorycustomizer( environment environment, serverproperties serverproperties) { return new jettywebserverfactorycustomizer(environment, serverproperties); } } //配置undertow的webserver @configuration @conditionalonclass({ undertow.class, sslclientauthmode.class }) public static class undertowwebserverfactorycustomizerconfiguration { @bean public undertowwebserverfactorycustomizer undertowwebserverfactorycustomizer( environment environment, serverproperties serverproperties) { return new undertowwebserverfactorycustomizer(environment, serverproperties); } } //配置netty的webserver @configuration @conditionalonclass(httpserver.class) public static class nettywebserverfactorycustomizerconfiguration { @bean public nettywebserverfactorycustomizer nettywebserverfactorycustomizer( environment environment, serverproperties serverproperties) { return new nettywebserverfactorycustomizer(environment, serverproperties); } } } 步骤:\nspringboot启动时判断环境是,并根据环境不同创建不同的上下文\nservlet(annotationconfigservletwebserverapplicationcontext) reactive(annotationconfigreactivewebserverapplicationcontext) default(annotationconfigapplicationcontext) springboot根据导入的依赖情况,给容器中添加相应的xxxserverfactorycustomizer\n使用webserverfactorycustomizerbeanpostprocessor调用定制器的定制方法\n十一、使用外置的servlet容器 嵌入式servlet容器简单、便携,但是不支持jsp\n外置的servlet容器,外面安装tomcat应用war包的方式打包\n使用外置的servlet容器步骤\n必须创建一个war项目 将嵌入式的tomcat指定为provided 1 2 3 4 5 \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;org.springframework.boot\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;spring-boot-starter-tomcat\u0026lt;/artifactid\u0026gt; \u0026lt;scope\u0026gt;provided\u0026lt;/scope\u0026gt; \u0026lt;/dependency\u0026gt; 必须编写一个springbootservletinitializer的子类,并调用configure方法 1 2 3 4 5 6 public class servletinitializer extends springbootservletinitializer { @override protected springapplicationbuilder configure(springapplicationbuilder application) { return application.sources(springbootappwarapplication.class); } } 十二、启动配置原理 启动原理 创建springapplication对象\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 public springapplication(resourceloader resourceloader, class\u0026lt;?\u0026gt;... primarysources) { this.resourceloader = resourceloader; //传入run方法的配置类【配置类有多个】 this.primarysources = new linkedhashset\u0026lt;\u0026gt;(arrays.aslist(primarysources)); //根据加载的类判断当前环境【reactive、servlet、none】 this.webapplicationtype = webapplicationtype.deducefromclasspath(); //加载meta-inf/spring.factories的org.springframework.context.applicationcontextinitializer setinitializers((collection) getspringfactoriesinstances( applicationcontextinitializer.class)); //初始化器 //加载meta-inf/spring.factories的org.springframework.context.applicationlistener setlisteners((collection) getspringfactoriesinstances(applicationlistener.class)); //监听器 //确定主配置类【当前main方法的类】 this.mainapplicationclass = deducemainapplicationclass(); } 运行run方法启动程序\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 public configurableapplicationcontext run(string... args) { stopwatch stopwatch = new stopwatch(); stopwatch.start(); configurableapplicationcontext context = null; collection\u0026lt;springbootexceptionreporter\u0026gt; exceptionreporters = new arraylist\u0026lt;\u0026gt;(); configureheadlessproperty(); //获取springapplicationrunlisteners,在创建springapplication已加载 springapplicationrunlisteners listeners = getrunlisteners(args); //回调所有的获取springapplicationrunlistener.starting()方法 listeners.starting(); try { //封装命令行参数 applicationarguments applicationarguments = new defaultapplicationarguments( args); //准备环境,并在最后回调springapplicationrunlistener.environmentprepared();表示环境准备完成 configurableenvironment environment = prepareenvironment(listeners,applicationarguments); configureignorebeaninfo(environment); banner printedbanner = printbanner(environment); //创建applicationcontext【决定创建web的ioc还是普通的ioc】 context = createapplicationcontext(); //异常报告使用 exceptionreporters = getspringfactoriesinstances( springbootexceptionreporter.class, new class[] { configurableapplicationcontext.class }, context); //准备上下文环境【将environment保存到ioc中,并且applyinitializers()】 //applyinitializers():回调之前保存的所有的applicationcontextinitializer的initialize方法 //回调所有的springapplicationrunlistener的contextprepared() preparecontext(context, environment, listeners, applicationarguments, printedbanner); //刷新容器;ioc容器初始化(如果是web应用还会创建嵌入式的tomcat) refreshcontext(context); //留作子类扩展 afterrefresh(context, applicationarguments); stopwatch.stop(); if (this.logstartupinfo) { new startupinfologger(this.mainapplicationclass) .logstarted(getapplicationlog(), stopwatch); } //调用springapplicationrunlistener的started方法 listeners.started(context); //从ioc容器中获取所有的applicationrunner和commandlinerunner进行回调 //applicationrunner先回调,commandlinerunner再回调 callrunners(context, applicationarguments); } catch (throwable ex) { handlerunfailure(context, ex, exceptionreporters, listeners); throw new illegalstateexception(ex); } try { //调用springapplicationrunlistener的running方法 listeners.running(context); } catch (throwable ex) { handlerunfailure(context, ex, exceptionreporters, null); throw new illegalstateexception(ex); } return context; } 事件监听机制 applicationcontextinitializer的子类需要配置在meta-inf/spring.factories的org.springframework.context.applicationcontextinitializer属性中 springapplicationrunlistener的实现类直接放入ioc容器中会被加载 十三、自定义starter 编写自定义starter\n使用以下注解将编写自动配置类\n1 2 3 4 5 6 @configuration //指定这个类是一个配置类 @conditionalonxxx //在指定条件成立的情况下自动配置类生效 @autoconfigureafter //指定自动配置类的顺序 @bean //给容器中添加组件 @configurationproperties//结合相关xxxproperties类来绑定相关的配置 @enableconfigurationproperties //让xxxproperties生效加入到容器中 将自动配置类配置在meta‐inf/spring.factories文件中以org.springframework.boot.autoconfigure.enableautoconfiguration作为key\n约定\n启动器只用来做依赖导入,是一个空工程 非spring自身的启动器以自定义启动器名-spring-boot-starter命名 专起一个maven工程来写一个自动配置模块 启动器依赖自动配,别人只需要引入启动器(starter) ","date":"2019-01-30","permalink":"https://hobocat.github.io/post/spring/2019-01-30-spring-boot-%E5%9F%BA%E7%A1%80%E7%AF%87/","summary":"一、Spring Boot简单入门 Spring Boot简介 因为J2EE笨重的开发方式、繁琐的配置、低下的开发效率和复杂的部署流程、集成第三方插件难度大这些技术痛点的存在的","title":"spring boot基础篇"},]
[{"content":"一、简介 \tdocker是pass【platform as a service】提供商dotcloud开源的一个基于lxc【linux container】的高级容器引擎,源代码托管在github上。基于go语言并遵从apache2.0协议开源\n\tdocker的主要目标是“build and run any app, anywhere“,也就是通过对应用组件的封装、分发、部署、运行等生命周期的管理,使用户的app及其运行环境能够做到**“一次封装,到处运行”**。\n传统的开发部署协作方式\ndocker的开发部署协作方式\n二、虚拟化技术 虚拟机技术 \t虚拟机 (vm) 是一个物理硬件层抽象,用于将一台服务器变成多台服务器。管理程序允许多个 vm 在一台机器上运行。每个 vm 都包含一整套操作系统、一个或多个应用、必要的二进制文件和库资源,因此占用大量空间。而且 vm 启动也十分缓慢。\n容器虚拟化技术 \t容器是一个应用层抽象,用于将代码和依赖资源打包在一起。多个容器可以在同一台机器上运行,共享操作系统内核,但各自作为独立的进程在用户空间中运行。与虚拟机相比,容器占用的空间较少(容器镜像大小通常只有几十兆),瞬间就能完成启动。\n三、docker三要素 镜像(image)\n\t镜像就是一个只读模板。镜像可以用来创建docker容器,一个镜像可以创建多个容器。\n容器(container)\n\tdocker利用容器独立运行一个或一组应用。容器是镜像创建的运行示例。它可以被启动、停止、删除。每个容器都是相互隔离的、保证安全的平台。\n仓库(repository)\n\t仓库是集中存放镜像文件的场所。仓库和仓库注册服务器(registry)是有区别的。仓库注册服务器上往往存放着多个仓库,每个仓库又包含了多个镜像,每个镜像又不同的标签(tag)。\n注:docker 本身是一个容器运行载体或称之为管理引擎。我们把应用程序和配置依赖打包形成一个可交付的运行环境,这个打包好的运行环境就是镜像文件。只有通过这个镜像文件才能生成docker容器。镜像文件可以看作是容器的模板。docker根据镜像文件生成容器的实例。同一个镜像文件,可以生成多个同时运行的容器实例。\n四、yum安装docker 第一步:卸载原docker组件,确认安装了gcc、gcc-c++\n1 2 3 4 5 6 7 #卸载旧docker组件 yum remove docker docker-client docker-client-latest docker-common docker-latest \\ docker-latest-logrotate docker-logrotate docker-selinux \\ docker-engine-selinux docker-engine #安装依赖 yum -y install gcc gcc-c++ 第二步:安装docker仓库\n1 2 3 4 5 #安装必要的一些系统工具 yum install -y yum-utils device-mapper-persistent-data lvm2 #添加软件源信息,使用阿里云下载 yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo 第三步:更新、安装、开启docker服务\n1 2 3 4 5 6 #更新并安装docker-ce yum makecache fast yum -y install docker-ce #开启docker服务 systemctl start docker 第四步:配置镜像加速器\n1 2 3 4 5 6 7 8 sudo mkdir -p /etc/docker sudo tee /etc/docker/daemon.json \u0026lt;\u0026lt;-\u0026#39;eof\u0026#39; { \u0026#34;registry-mirrors\u0026#34;: [\u0026#34;自己的阿里云加速器地址\u0026#34;] } eof sudo systemctl daemon-reload sudo systemctl restart docker 第五步:运行hello-world镜像验证是否安装成功\n1 docker run hello-world 五、命令 帮助命令 查看版本信息\tdocker version 查看详细信息\tdocker info 查看命令帮助\tdocker \u0026ndash;help 镜像命令 列出镜像 docker images\n参数 描述 -a 列出本地主机上的镜像(包括中间层镜像) -q 列出本地主机上的镜像id 搜索镜像\ndocker search [镜像名]\n参数 描述 \u0026ndash;filter=stars=3 列出点赞数不小于指定值的镜像 \u0026ndash;no-trunc 显示完整镜像描述 拉取/删除镜像\ndocker pull/rmi [镜像名]:[tag]\n小技巧:docker rmi -f $(docker images -qa)\t删除所有镜像\n提交容器作为镜像\ndocker -a=\u0026ldquo;作者名\u0026rdquo; -m=\u0026ldquo;描述信息\u0026rdquo; commit [容器id] 名称:tag标签\n保存【导出】镜像\ndocker save [镜像名]:[tag] -o /path/[name].tar\n加载镜像\ndocker load -i [name].tar\n容器命令 运行容器命令\tdocker run [镜像名]:[tag]\n参数 描述 -i 以交互模式运行容器,通常与-t同时使用 -t 为容器重新分配一个伪输入终端,通常与-i同时使用 -p 指定映射端口,形式hostport:containerport -p 随机端口映射 -d 后台运行容器 \u0026ndash;name 为容器指定名称 \u0026ndash;restart=always docker服务启动容器就启动 -h name 设置主机名 \u0026ndash;add-host name:ip 注入hostname的ip解析 \u0026ndash;rm 容器停止时自动删除 \u0026ndash;link cname:hostname 向容器的/etc/hosts添加另一个ip地址的映射形式 退出容器方法\nexit\t容器停止退出 ctrl+p+q\t容器不停止退出 查看容器进程\tdocker ps\n参数 描述 -l 上次运行的容器 -a 所有运行过的容器 -q 静默只显示容器编号 启动/重启/停止容器\ndocker start/restart/stop [容器id]\n强制停止容器\ndocker kill [容器id]\n删除关闭的容器\ndocker rm [容器id]\n参数 描述 -f 强制删除 小技巧:docker rm -f $(docker ps -qa)\t删除所有容器\n查看容器日志\tdocker logs [容器id]\n参数 描述 -f 一直追加,显示最新日志 -t 显示每条日志时间戳 查看容器运行进程信息\ndocker top [容器id]\n查看容器内部细节\ndocker inspect [容器id]\n查看容器占用的系统资源\ndocker stats [容器id]\n不加容器id则查看所有容器的系统资源\n重新进入容器\ndocker attach [容器id]\n进入容器执行shell命令\ndocker exec -it [容器id shell命令]\n拷贝容器内文件\ndocker cp [容器id]:容器路径 本机路径\n容器运行机制\n\tdocker容器后台运行,就必须有一个前台进程,容器运行的命令如果不是会挂起的命令(比如top),会自动退出。最佳的解决方案是,将要运行的程序以前台进程的形式运行\n六、docker compose \tdocker compose是容器编排工具,允许用户在一个模板(yaml格式)中定义一组相关联的容器,对启动的优先级进行排序。\n命令 解释 -f 指定yaml文件位置 ps 显示容器所有信息 start/stop/restart 启动/停止/重启容器【已加载成为容器】 logs 查看日志信息 config -q 验证yaml是否正确 up -d 启动容器项目【未加载成为容器】 pause 暂停容器 unpause 恢复暂停 rm 删除容器 简单示例:\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 version: \u0026#39;3\u0026#39; services: db: image: \u0026#39;mysql:5.7\u0026#39; restart: \u0026#39;always\u0026#39; environment: mysql_root_password: \u0026#39;root\u0026#39; mysql_database: \u0026#39;wordpress\u0026#39; mysql_user: \u0026#39;wordpress\u0026#39; mysql_password: \u0026#39;wordpress\u0026#39; wordpress: depends_on: - db image: \u0026#39;wordpress:latest\u0026#39; restart: \u0026#39;always\u0026#39; ports: - \u0026#39;8080:80\u0026#39; environment: wordpress_db_host: \u0026#39;db:3306\u0026#39; wordpress_db_user: \u0026#39;wordpress\u0026#39; wordpress_db_password: \u0026#39;wordpress\u0026#39; 七、镜像加载原理 unionfs 联合文件系统 \t联合文件系统是一种分层、轻量级并且高性能的文件系统,他支持对文件系统的修改作为一次提交来一层一层的叠加,同时可以将不同目录挂载到同一个虚拟文件系统下。union文件系统是docker镜像的基础。镜像可以通过分成来进行继承,基于基础镜像(没有父镜像),可以制作各种具体的应用镜像。\n\t特征:一次同时加载多个文件系统,但从外面看起来,只能看到一个文件系统,联合加载会把各层文件系统叠加起来,这样最终的文件系统会包含所有底层的文件和目录。\ndocker镜像加载原理 \tdocker的镜像实际上由一层一层的文件系统组成即联合文件系统。\n\tbootfs(boot file system)主要包含bootloader和kernel, bootloader 主要是引导加载kernel, linux刚启动时会加载bootfs文件系统,在 docker镜像的最底层是bootfs.这一层与我们典型的linux/unix系统是一一样的,包含boot加载器和内核。当boot加载完成之后整个内核就都在内存中了,此时内存的使用权己由bootfs转交给内核,此时系统也会卸载bootfs。\n\trootfs (root file system),在bootfs之 上.包含的就是典型linux系统中的/dev, /proc, /bin, /etc等标准目录和文件。rootfs就是 各种不同的操作系统发行版,比如ubuntu, centos等等 。\n\t对于一个精简的os,rootfs 可以很小,只需要包括最基本的命令、工具和程序库就可以了,因为底层直接用宿主机的kernel,自己只需要提供rootfs就行了。由此可见对于不同的linux发行版,bootfs基本是一致的,rootfs会有差别,因此不同的发行版可以公用bootfs 。\n\t注意:docker在bootfs自检完毕之后并不会把rootfs的read-only改为read-write。而是利用union mount(unionfs的一种挂载机制)将一个或多个read-only的rootfs加载到之前的read-only的rootfs层之上。在加载了这么多层的rootfs之后,仍然让它看起来只像是一个文件系统,在docker的体系里把union mount的这些read-only的rootfs叫做docker的镜像。但是,此时的每一层rootfs都是read-only的,我们此时还不能对其进行操作。当我们创建一个容器,也就是将docker镜像进行实例化,系统会在一层或是多层read-only的rootfs之上分配一层空的read-write的rootfs。\n八、容器数据卷 简介 \t容器数据卷的作用是数据共享和数据持久化。卷就是目录或文件,存在于一个或多个容器中,由docker挂载到容器,但不属于联合文件系统,因此能够绕过联合文件系统,提供一些用于持续存储或共享数据的功能。\n\t卷的设计目的就是持久化,完全独立于容器的生命周期,因此docker不会在容器删除时删除其挂载的数据卷。如果没有指定映射卷位置(容器数据卷)将会在/var/lib/docker/volumes下创建默认容器管理数据卷\n容器卷具有以下特点:\n容器卷可在容器之间共享或重用数据 卷中的更改可以直接生效 数据卷中的更改不会包含在镜像的更新当中 数据卷的生命周期一直持续到没有容器使用它为止 使用容器数据卷 挂载完成可以使用docker inspect命令查看相关数据卷挂载信息\n使用命令\ndocker run [options] -v [宿主机绝对路径]:[docker容器绝对路径] 镜像id\t挂载容器数据卷\ndocker run [options] -v [宿主机绝对路径]:[docker容器绝对路径]:[ro] 镜像id\t只读模式挂载\n指定宿主机路径,目的时为了读写数据\n若不指定宿主机路径,则docker自动创建一个目录,这样使用是为了共享数据\n注意:当宿主机删除与容器挂载的目录时,容器的挂载目录变为只读。即使宿主机恢复容器的挂载目录也无效\n使用dockerfile文件的volume命令创建容器管理数据卷\nvolume [\u0026ldquo;docker容器绝对路径\u0026rdquo;,\u0026ldquo;docker容器绝对路径\u0026rdquo;]\n只会在容器内创建,宿主机目录由docker自行创建,目的时为了数据共享\n数据卷容器\n命名的容器挂载数据卷,其它容器通过挂在这个父容器实现数据共享,挂载的容器被称为数据卷容器\ndocker run [options] \u0026ndash;volumes-from 数据卷容器名称 镜像名称\n九、dockerfile 基础知识 每条保留字指令都必须为大写字母且后面至少跟随一个参数 指令按照从上到下,顺序执行 #表示注释 每条指令都会创建一个新的镜像层,并对镜像进行提交 最大不能超过128层 保留关键字 关键字 描述 from 基础镜像,当前新镜像时基于哪个镜像 label 镜像维护者的信息 run 执行的shell命令 expose 暴露服务的端口,只起显示作用 workdir 终端登陆之后的工作目录 env 设置环境变量 add 把文件拷贝到镜像并解压【必须和dockerfile在同一级目录下,不用加绝对路径】 copy 把文件拷贝到镜像【必须和dockerfile在同一级目录下,不用加绝对路径】 volume 创建数据容器卷 cmd 指定容器启动时要运行的命令,可以有多个cmd命令,但只有最后一个生效,cmd会被docker run 之后的参数替换 entrypoint 指定容器启动时要运行的命令,不会覆盖只会追加 onbuild 当构建一个被继承的dockerfile时运行的命令,父镜像在被子镜像继承时触发 示例 简单的使用 1 2 3 4 5 6 7 8 9 10 11 12 #在centos上架构 from centos #作者信息 label org.kun.vendor=\u0026#34;wangyukun\u0026#34; org.kun.build-date=\u0026#34;20181218\u0026#34; #设置环境变量,会存在于容器环境变量当中 env userlocal /usr/local #安装vim run yum install -y vim #设置登陆终端时的交互目录 workdir ${userlocal} #启动执行的命令 cmd [\u0026#34;/bin/bash\u0026#34;] cmd和entrypoint 1 2 3 4 5 6 7 8 9 #在centos上架构 from centos #安装curl run yum install -y curl #执行时可以在后追加参数,例如docker run [镜像名] -i 相当于 curl -s https://ip.cn entrypoint [\u0026#34;curl\u0026#34;,\u0026#34;-s\u0026#34;,\u0026#34;https://ip.cn\u0026#34;] #执行不可以追加参数相当于覆盖操作 #cmd [\u0026#34;curl\u0026#34;,\u0026#34;-s\u0026#34;,\u0026#34;https://ip.cn\u0026#34;] onbuild 1 2 3 4 from centos run yum install -y curl #在子类构建镜像时会触发,注意onbuild仅仅时触发器,后面需要跟保留关键字起作用,不能直接使用命令 onbuild run [\u0026#34;echo\u0026#34;,\u0026#34;onbuild tigger\u0026#34;] 自定义tomcat 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 from centos #拷贝jdk压缩包并解压 add jdk-8u191-linux-x64.tar.gz /opt/ run mv /opt/jdk1.8.0_191 /opt/jdk8 #配置java环境变量 env path=$path:/opt/jdk8/bin env java_home=/opt/jdk8 #拷贝tomcat压缩包并解压 add apache-tomcat-8.5.35.tar.gz /opt/ run mv /opt/apache-tomcat-8.5.35 /opt/tomcat env catalina_home=/opt/tomcat #设置工作目录 workdir $catalina_home #设置要暴露的端口 expose 8080 #启动tomcat并打印日志 cmd /opt/tomcat/bin/startup.sh start \u0026amp;\u0026amp; tail -f /opt/tomcat/logs/catalina.out 十、镜像仓库搭建 官方仓库搭建方式 仓库端\n启动仓库 1 docker run -d -v /data/registry:/var/lib/registry -p 5000:5000 --restart=always registry 修改【 /etc/docker/deamon.json】文件 1 2 3 { \u0026#34;insecure-registries\u0026#34;:[\u0026#34;仓库端ip:5000\u0026#34;] } 重启docker服务 1 systemctl restart docker 客户端\n修改【 /etc/docker/deamon.json】文件 1 2 3 { \u0026#34;insecure-registries\u0026#34;:[\u0026#34;仓库端ip:5000\u0026#34;] } 重启docker服务 1 systemctl restart docker 查看仓库镜像 1 2 3 4 # 查看镜像 curl -xget http://registrip:5000/v2/_catalog # 查看具体镜像版本 curl -xget http://registrip:5000/v2/image_name/tags/list 打包上传镜像 1 2 3 4 5 6 7 8 9 10 # 命令格式docker tag source_image[:tag] target_image[/libraryname][:tag] # 指定仓库需要加libraryname,官方搭建方式不能指定仓库,harbor可以创建仓库 # 例如:docker tag hello-world:latest 192.169.1.149:5000/hello-world:v1.0 docker tag source_image:[tag] registrip:5000[/username]/target_image:[tag] # 上传镜像到仓库 # 私有仓库登陆才能推送 # docker login ip/hostname # 例如:docker push 192.168.1.149:5000/hello-world:v1.0 docker push registrip:5000[/username]/target_image:[tag] harbor仓库搭建 harbor构建需要先安装python、compose。harborgithub地址\n构建ssl证书 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 # 构建证书 openssl genrsa -des3 -out server.key 2048 openssl req -new -key server.key -out server.csr # 脱密,证书退密钥 cp server.key server.key.org openssl rsa -in server.key.org -out server.key # 证书有效期 openssl x509 -req -days 365 -in server.csr -signkey server.key -out server.csr # 将证书移置指定目录 mkdir /data/cert chown -r 777 /data/cert cp server.* /data/cert 修改harbor.yml 1 2 3 4 5 6 7 8 9 10 11 12 # 修改hostname项 hostname: [hostname] # 屏蔽http协议 #http: # port: 80 # 开放https协议 https: port: 443 certificate: /data/cert/server.csr private_key: /data/cert/server.key 执行安装脚本 1 ./install.sh 访问harborhttps://ip/harbor/projects,默认账户:admin,密码:harbor12345 客户端配置(非进行公网认证过的ssl证书)\n修改【 /etc/docker/deamon.json】文件 1 2 3 { \u0026#34;insecure-registries\u0026#34;:[\u0026#34;registryip\u0026#34;] } 重启docker服务 1 systemctl restart docker 打包示例\ndocker tag hello-world:latest www.kun.com/library/hello-world:v1.0\n推送示例\n先登录:docker login www.kun.com\ndocker push www.kun.com/library/hello-world:v1.0\n十一、网络设置 网络通讯 容器与容器之间通讯使用docker的网桥(类似交换机作用)进行相互之间铜须\n容器访问外部网络使用snat转换\n外部网络访问容器使用dnat转换\n网络模式修改 进程网络修改【不常用】\n-b,\u0026ndash;bridge=”“:指定docker使用的网桥设备,默认情况下docker会自动创建和使用docker0网桥设备,通过此参数可以设置已经存在的设备\n\u0026ndash;bip:指定docker0的ip和掩码,使用标准的cidr格式如10.10.10.10/24\n\u0026ndash;dns:配置容器的dns,在启动docker进程时添加,所有容器全部生效\n容器网络修改\n\u0026ndash;dns:配置容器的dns \u0026ndash;net:指定容器的网络通讯方式 bridge:docker默认方式,网桥模式 none:容器没有网络栈 container:使用其它容器的网络栈,容器会加入其它容器的network namespace host:表示容器使用host的网络,没有自己独立的网络栈,容器可以完全访问host的网络,不安全 端口暴露方式\np/p 选项的使用格式\n-p : 将制定的容器端口映射至主机所有地址的一个动态端口 -p : 映射至指定的主机端口 -p :: 映射至指定的主机的ip的动态端口 -p :: 映射至指定的主机ip的主机端口 -p(大写) 暴露所需要的所有端口(expose端口)到随机端口 docker port [ontainername] 可以查看容器当前的映射关系\n容器间网络隔离 第一步:创建独立network namespace\n1 2 3 4 docker network create -d bridge \\ [--subnet \u0026#34;172.26.10.0/16\u0026#34;] \\ [--gateway \u0026#34;172.26.10.1\u0026#34;] \\ [netname] 第二步:运行镜像是指定network\n1 docker run -d --network=[netname] [imagename] 查看namespace: docker network ls\n十二、内存\u0026amp;cpu限制 \t默认情况下docker创建的容器会尽可能是用完操作系统内存,当服务异常时可能会导致崩溃,所以生产环境下cpu和内存必须加以限制。dockers底层使用cgroup进行资源限制。\nlinux内核有oome机制【out of memory exception】\n\t一旦发生oome,任何进程都有可能被杀死,包括docker daemon在内,为此docker调整了docker daemon的oom优先级,以免被内核关闭。\n内存相关设置 -m,\u0026ndash;memory 容器能使用的最大内存大小,单位m\n\u0026ndash;memory-swap 容器可使用的swap大小\n\u0026ndash;memory为正数m,\u0026ndash;memory-swap为正数s,swap空间为(s-m) \u0026ndash;memory为正数m,\u0026ndash;memory-swap为0或者unset,容器可用swap为2*m \u0026ndash;memory为正数m,\u0026ndash;memory-swap为-1,使用主机的swap限制 容器内使用free看到的swap空间不具有真实含义\n\u0026ndash;memory-swappiness swap出内存的比例。取值0-100,0代表不使用swap\n\u0026ndash;memory-resercation 内存软限制\n\u0026ndash;oom-kill-disable 发生oome时是否杀死容器,只有配置-m时使用才安全,否则会造成内存耗尽\ncpu相关设置 \tdocker提供的cpu资源限制选项可以在多核系统上限制容器能利用哪些vcpu,而对容器最多能使用的cpu时间 有两种限制方式:①设置各个容器能使用的cpu时间相对比例。②以绝对的方式设置容器在每个调度周期内最多能使用的时间\n\u0026ndash;cpuset-cpus=\u0026quot;\u0026quot; 使用的cpu集,例如:\u0026ldquo;0,1,1-3\u0026quot;分别表示使用第一块、第二和第一、第二、第三块cpu -c,\u0026ndash;cpu-shares=1024 cpu使用权重,默认1024 \u0026ndash;cpu-period=0 一个调度周期时间单位微秒(1000~1000000),和cpu-quota联用 \u0026ndash;cpu-quota=0 一个调度周期使用的cpu时间单位微妙,和cpu-period联用 docker run -it \u0026ndash;cpu-period=10000 \u0026ndash;cpu-quota=20000 centos /bin/bash #代表使用两块cpu\n十三、docker安装mysql、redis 安装mysql 1 2 3 4 5 6 7 8 9 10 #拉取mysql docker pull mysql:5.7 #注意外部访问需要修改root权限,docker mysql配置文件再/etc/mysql目录下,注意查看内容 docker run -p3306:3306 \\ -v /root/mysql/log/mysqld.log:/logs \\ -v /root/mysql/data:/var/lib/mysql \\ -v /root/mysql/conf/my.cnf:/etc/mysql/my.conf \\ -e mysql_root_password=123456 \\ -d mysql:5.7 安装redis 1 2 3 4 5 6 7 8 9 #拉取redis docker pull redis #启动redis,注意redis.conf中的dir要有权限,bind注释掉,protected-mode改为no docker run -p6379:6379 \\ -v /root/redis/conf/redis.conf:/usr/local/etc/redis.conf \\ -v /root/redis/data:/data \\ --privileged=true -it redis redis-server /usr/local/etc/redis.conf 附名词解释\u0026amp;容器状态转换图 iass\u0026amp;pass\u0026amp;sass lxc \tlinux的container技术在内核层面由两个独立的机制保证,一个保证资源的隔离性,名为namespace,一个进行资源的控制,名为cgroup。\nnamespace\n\tnamespace是对全局系统资源的一种封装隔离,使得处于不同namespace的进程拥有独立的全局系统资源,改变一个namespace中的系统资源只会影响当前namespace里的进程,对其他namespace中的进程没有影响。\n\tlinux现有的namespace有6种: uts[主机名], pid, ipc[进程通信], mnt[挂载点], net和user\ncgroup\n\tcgroup是linux下的一种将进程按组进行管理的机制,在用户层看来,cgroup技术就是把系统中的所有进程组织成一颗一颗独立的树,每棵树都包含系统的所有进程,树的每个节点是一个进程组,而每颗树又和一个或者多个subsystem关联,树的作用是将进程分组,而subsystem的作用就是对这些组进行操作。\nsubsystem\n\t一个subsystem就是一个内核模块,他被关联到一颗cgroup树之后,就会在树的每个节点(进程组)上做具体的操作。subsystem经常被称作\u0026quot;resource controller\u0026rdquo;,因为它主要被用来调度或者限制每个进程组的资源【比如限制cpu的使用时间,限制使用的内存,统计cpu的使用情况,冻结和恢复一组进程等】\nhierarchy\n\t一个hierarchy可以理解为一棵cgroup树,树的每个节点就是一个进程组,每棵树都会与零到多个subsystem关联。在一颗树里面,会包含linux系统中的所有进程,但每个进程只能属于一个节点(进程组)。系统中可以有很多颗cgroup树,每棵树都和不同的subsystem关联,一个进程可以属于多颗树,即一个进程可以属于多个进程组,只是这些进程组和不同的subsystem关联。\n容器状态转换图\n","date":"2018-12-20","permalink":"https://hobocat.github.io/post/docker/2018-12-20-docker-%E5%9F%BA%E7%A1%80%E7%AF%87/","summary":"一、简介 Docker是PASS【Platform As A Service】提供商dotCloud开源的一个基于LXC【Linux Container】的高级容器引擎,","title":"docker基础篇"},]
[{"content":"一、集成spring-data-solr 1 2 3 4 5 6 7 8 9 10 11 \u0026lt;!-- 单机连接 --\u0026gt; \u0026lt;solr:solr-client id=\u0026#34;solrclient\u0026#34; url=\u0026#34;http://192.168.1.155:8080/solr\u0026#34; /\u0026gt; \u0026lt;!-- 使用solrj的转换器,spring的转换器对于关联类型不友好 --\u0026gt; \u0026lt;bean id=\u0026#34;solrconverter\u0026#34; class=\u0026#34;org.springframework.data.solr.core.convert.solrjconverter\u0026#34; /\u0026gt; \u0026lt;!-- 配置solrtemplate,并配置转换器 --\u0026gt; \u0026lt;bean id=\u0026#34;solrtemplate\u0026#34; class=\u0026#34;org.springframework.data.solr.core.solrtemplate\u0026#34;\u0026gt; \u0026lt;constructor-arg ref=\u0026#34;solrclient\u0026#34;/\u0026gt; \u0026lt;property name=\u0026#34;solrconverter\u0026#34; ref=\u0026#34;solrconverter\u0026#34;/\u0026gt; \u0026lt;/bean\u0026gt; 二、功能的使用 1、前置准备 实体类的定义,和使用solrj一样,注意classify属性\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public class book { @field private string id; @field private string name; @field private string issn; @field private list\u0026lt;string\u0026gt; authors; @field private double price; private classify classify; @field private date pubshingtime; @field private boolean hasmarc; public string getclassifycode() { return this.classify == null ? null : this.classify.getcode(); } @field(\u0026#34;classifycode\u0026#34;) public void setclassifycode(string classifycode) { this.classify = (this.classify == null ? new classify() : this.classify); this.classify.setcode(classifycode); } //========================其他getter/setter======================== } 工具类【用于日期转换】\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 package com.kun.solr.springdata.util; import java.text.dateformat; import java.text.parseexception; import java.text.simpledateformat; import java.time.instant; import java.time.zoneid; import java.time.format.datetimeformatter; import java.util.date; public class dateutil { //字符串转换为date static public date parse(string datestr) { dateformat formart = new simpledateformat(\u0026#34;yyyy-mm-dd\u0026#34;); date date = null; try { date = formart.parse(datestr); } catch (parseexception e) { e.printstacktrace(); } return date; } //日期类型转换为utc字符串 static public string datetoutcstr(date date) { instant instant = date.toinstant(); zoneid zoneid = zoneid.systemdefault(); return instant.atzone(zoneid).format(datetimeformatter.iso_instant); } //utc格式字符串转换为date字符串 static public string utcstrtodatestr(string utc) { instant ins = instant.parse(utc); date date = date.from(ins); dateformat formart = new simpledateformat(\u0026#34;yyyy-mm-dd\u0026#34;); return formart.format(date); } //date格式日期转换为字符串 static public string todatestr(date date) { dateformat formart = new simpledateformat(\u0026#34;yyyy-mm-dd\u0026#34;); return formart.format(date); } //date字符串转utc格式字符串 static public string datestrtoutcstr(string date) { return datetoutcstr(parse(date)); } } 2、增加操作 1 2 3 4 5 6 7 8 9 10 11 12 13 public void testcreate() throws exception { book book = new book(); book.setid(\u0026#34;115373065864171877701\u0026#34;); book.setissn(\u0026#34;9787302341338\u0026#34;); book.setname(\u0026#34;青春梦想不是梦\u0026#34;); book.setprice(23); book.setpubshingtime(dateutil.parse(\u0026#34;2016-04-01\u0026#34;)); book.setauthors(arrays.aslist(\u0026#34;纪广洋\u0026#34;)); book.setclassifycode(\u0026#34;d\u0026#34;); book.sethasmarc(true); solrtemplate.savebean(\u0026#34;book\u0026#34;, book); solrtemplate.commit(\u0026#34;book\u0026#34;); } 3、删除操作 1 2 3 4 public void testdelete() throws exception { solrtemplate.deletebyids(\u0026#34;book\u0026#34;, \u0026#34;115373065864171877701\u0026#34;); solrtemplate.commit(\u0026#34;book\u0026#34;); } 4、查询操作 根据id查询\n1 2 3 4 public void testquerybyid() throws exception { optional\u0026lt;book\u0026gt; book = solrtemplate.getbyid(\u0026#34;book\u0026#34;,\u0026#34;115373065864171873622\u0026#34;,book.class); system.out.println(book.get()); } 普通语法查询\n1 2 3 4 5 6 7 8 9 10 11 12 public void testquerybysyntx() throws exception { query query = new simplequery(\u0026#34;*:*\u0026#34;); //设置分页信息,不设置getpageable中取值将会报错 query.setrows(3); query.setoffset(7l); page\u0026lt;book\u0026gt; bookpage = solrtemplate.query(\u0026#34;book\u0026#34;, query, book.class); system.out.println(\u0026#34;总页数:\u0026#34; + bookpage.gettotalpages());\t//总页数 system.out.println(\u0026#34;总数:\u0026#34; + bookpage.gettotalelements());\t//总元素数 system.out.println(\u0026#34;当前页:\u0026#34; + (bookpage.getpageable().getpagenumber()+1));\t//0为基数 system.out.println(\u0026#34;每页大小:\u0026#34; + bookpage.getpageable().getpagesize());\t//每页大小 bookpage.getcontent().foreach(system.out::println); } 范围查询\n时间范围查询 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public void testdaterangequery() throws exception { //不能直接设置date类型,需要utc时区字符串 string startstr = dateutil.datestrtoutcstr(\u0026#34;2013-09-01\u0026#34;); string endstr = dateutil.datestrtoutcstr(\u0026#34;2013-10-30\u0026#34;); criteria criteria = new criteria(\u0026#34;pubshingtime\u0026#34;).between(startstr, endstr); query query = new simplequery(criteria); //设置分页信息 query.setrows(5); query.setoffset(1l); page\u0026lt;book\u0026gt; bookpage = solrtemplate.query(\u0026#34;book\u0026#34;, query, book.class); system.out.println(\u0026#34;总页数:\u0026#34; + bookpage.gettotalpages()); system.out.println(\u0026#34;总数:\u0026#34; + bookpage.gettotalelements()); system.out.println(\u0026#34;当前页:\u0026#34; + (bookpage.getpageable().getpagenumber()+1)); system.out.println(\u0026#34;每页大小:\u0026#34; + bookpage.getpageable().getpagesize()); bookpage.getcontent().foreach(system.out::println); } 数字范围查询 1 2 3 4 5 6 7 8 9 10 11 12 13 public void testnumrangequery() throws exception { criteria criteria = new criteria(\u0026#34;price\u0026#34;).between(25, 35); query query = new simplequery(criteria); //设置分页信息 query.setrows(5); query.setoffset(0l); page\u0026lt;book\u0026gt; bookpage = solrtemplate.query(\u0026#34;book\u0026#34;, query, book.class); system.out.println(\u0026#34;总页数:\u0026#34; + bookpage.gettotalpages()); system.out.println(\u0026#34;总数:\u0026#34; + bookpage.gettotalelements()); system.out.println(\u0026#34;当前页:\u0026#34; + (bookpage.getpageable().getpagenumber()+1)); system.out.println(\u0026#34;每页大小:\u0026#34; + bookpage.getpageable().getpagesize()); bookpage.getcontent().foreach(system.out::println); } 过滤查询\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public void testfilterquery() throws exception { query query = new simplequery(\u0026#34;*:*\u0026#34;); //过滤条件 filterquery filterquery = new simplequery(\u0026#34;price:[45 to *]\u0026#34;); query.addfilterquery(filterquery); //设置分页信息 query.setrows(3); query.setoffset(0l); page\u0026lt;book\u0026gt; bookpage = solrtemplate.query(\u0026#34;book\u0026#34;, query, book.class); system.out.println(\u0026#34;总页数:\u0026#34; + bookpage.gettotalpages()); system.out.println(\u0026#34;总数:\u0026#34; + bookpage.gettotalelements()); system.out.println(\u0026#34;当前页:\u0026#34; + (bookpage.getpageable().getpagenumber()+1)); system.out.println(\u0026#34;每页大小:\u0026#34; + bookpage.getpageable().getpagesize());\tbookpage.getcontent().foreach(system.out::println); } 高亮查询\n普通高亮查询\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 @test public void testhighlighquery() throws exception { //设置查询语句 criteria criteria =new criteria(\u0026#34;name\u0026#34;).contains(\u0026#34;播音\u0026#34;); highlightquery query = new simplehighlightquery(criteria); //设置高亮参数 highlightoptions hoptions = new highlightoptions(); hoptions.addfield(\u0026#34;name\u0026#34;); hoptions.setsimpleprefix(\u0026#34;\u0026lt;span color=\u0026#39;read\u0026#39;\u0026gt;\u0026#34;); hoptions.setsimplepostfix(\u0026#34;\u0026lt;/span\u0026gt;\u0026#34;); //hoptions.setfragsize(10);\t//设置段 query.sethighlightoptions(hoptions); //设置分页参数 query.setrows(5); query.setoffset(0l); highlightpage\u0026lt;book\u0026gt; highlightpage = solrtemplate.queryforhighlightpage(\u0026#34;book\u0026#34;, query, book.class); //取出高亮信息 list\u0026lt;book\u0026gt; books = highlightpage.getcontent(); list\u0026lt;highlightentry\u0026lt;book\u0026gt;\u0026gt; hbookentrys = highlightpage.gethighlighted(); for (highlightentry\u0026lt;book\u0026gt; hbookentry : hbookentrys) { book book = hbookentry.getentity(); for (highlight hbook : hbookentry.gethighlights()) { string fieldname = hbook.getfield().getname(); if(fieldname.equals(\u0026#34;name\u0026#34;)) { book.setname(hbook.getsnipplets().get(0)); } } } system.out.println(books); } fastvectorhighlighter查询\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 @test public void testfastverctorhighlighquery() throws exception { //设置查询语句 criteria criteria =new criteria(\u0026#34;name\u0026#34;).contains(\u0026#34;播音\u0026#34;); highlightquery query = new simplehighlightquery(criteria); //设置高亮参数 highlightoptions hoptions = new highlightoptions(); hoptions.addfield(\u0026#34;name\u0026#34;); hoptions.addhighlightparameter(\u0026#34;hl.method\u0026#34;, \u0026#34;fastvector\u0026#34;); hoptions.addhighlightparameter(highlightparams.tag_pre, \u0026#34;\u0026lt;span color=\u0026#39;read\u0026#39;\u0026gt;\u0026#34;); hoptions.addhighlightparameter(highlightparams.tag_post, \u0026#34;\u0026lt;/span\u0026gt;\u0026#34;); //hoptions.setfragsize(10);\t//设置段 query.sethighlightoptions(hoptions); //设置分页参数 query.setrows(5); query.setoffset(0l); highlightpage\u0026lt;book\u0026gt; highlightpage = solrtemplate.queryforhighlightpage(\u0026#34;book\u0026#34;, query, book.class); //取出高亮信息 list\u0026lt;book\u0026gt; books = highlightpage.getcontent(); list\u0026lt;highlightentry\u0026lt;book\u0026gt;\u0026gt; hbookentrys = highlightpage.gethighlighted(); for (highlightentry\u0026lt;book\u0026gt; hbookentry : hbookentrys) { book book = hbookentry.getentity(); for (highlight hbook : hbookentry.gethighlights()) { string fieldname = hbook.getfield().getname(); if(fieldname.equals(\u0026#34;name\u0026#34;)) { book.setname(hbook.getsnipplets().get(0)); } } } system.out.println(books); } 分组查询\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 @test public void testgroupquery() throws exception { query query = new simplequery(\u0026#34;*:*\u0026#34;); //分组参数 groupoptions groupoptions = new groupoptions(); groupoptions.addgroupbyfield(new simplefield(\u0026#34;classifycode\u0026#34;)); groupoptions.setlimit(2);\t//每组最多匹配个数 groupoptions.setoffset(0);\t//每组数据偏移量 query.setgroupoptions(groupoptions); grouppage\u0026lt;book\u0026gt; bookgrouppage = solrtemplate.queryforgrouppage(\u0026#34;book\u0026#34;, query, book.class); //获取分组信息 groupresult\u0026lt;book\u0026gt; groupresult = bookgrouppage.getgroupresult(\u0026#34;classifycode\u0026#34;); system.out.println(\u0026#34;总组数:\u0026#34; + groupresult.getgroupscount()); system.out.println(\u0026#34;匹配个数:\u0026#34; + groupresult.getmatches()); for (groupentry\u0026lt;book\u0026gt; book : groupresult.getgroupentries()) { system.out.println(book.getgroupvalue()); book.getresult().foreach(system.out::println); } } 分面查询\n普通字段分片\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 @test public void testquerybyfacets() throws exception { criteria criteria = new criteria(); criteria.expression(\u0026#34;*:*\u0026#34;); facetquery query = new simplefacetquery(criteria); facetoptions facetoptions = new facetoptions(); facetoptions.addfacetonfield(\u0026#34;classifycode\u0026#34;); facetoptions.setfacetlimit(3);\t//取几个facet facetoptions.setfacetmincount(0);\t//每组facet最小有多少元素 query.setfacetoptions(facetoptions); //设置分页信息 query.setrows(0); query.setoffset(0l); facetpage\u0026lt;book\u0026gt; bookfacetpage = solrtemplate.queryforfacetpage(\u0026#34;book\u0026#34;, query, book.class); for (page\u0026lt;facetfieldentry\u0026gt; bookfieldpage : bookfacetpage.getfacetresultpages()) { system.out.println(\u0026#34;分类个数:\u0026#34;+bookfieldpage.gettotalelements()); list\u0026lt;facetfieldentry\u0026gt; content = bookfieldpage.getcontent(); for (facetfieldentry facetfieldentry : content) { system.out.println(facetfieldentry.getvalue()+\u0026#34;:\u0026#34;+facetfieldentry.getvaluecount()); } } } 日期分片\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public void testfacetsdaterange() throws exception { criteria criteria = new criteria(); criteria.expression(\u0026#34;*:*\u0026#34;); facetquery query = new simplefacetquery(criteria); //facets日期查询参数 facetoptions facetoptions = new facetoptions(); facetoptions.addfacetbyrange(new facetoptions.fieldwithdaterangeparameters( \u0026#34;pubshingtime\u0026#34;,dateutil.parse(\u0026#34;2013-09-01\u0026#34;),dateutil.parse(\u0026#34;2014-01-01\u0026#34;),\u0026#34;+1month\u0026#34;)); facetoptions.setfacetmincount(0);\t//每组facet最小有多少元素 facetoptions.setfacetsort(facetsort.count); query.setfacetoptions(facetoptions); //设置分页信息 query.setrows(0); query.setoffset(0l); facetpage\u0026lt;book\u0026gt; bookfacetpage = solrtemplate.queryforfacetpage(\u0026#34;book\u0026#34;, query, book.class); //取得信息 page\u0026lt;facetfieldentry\u0026gt; rangefacetresultpage = bookfacetpage.getrangefacetresultpage(\u0026#34;pubshingtime\u0026#34;); system.out.println(\u0026#34;总个数:\u0026#34; + rangefacetresultpage.gettotalelements()); for (facetfieldentry facetfieldentry : rangefacetresultpage) { system.out.println(facetfieldentry.getvalue() + \u0026#34;:\u0026#34; + facetfieldentry.getvaluecount()); } } 数字分片\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 @test public void testfacetsnumrange() throws exception { criteria criteria = new criteria(); criteria.expression(\u0026#34;*:*\u0026#34;); facetquery query = new simplefacetquery(criteria); facetoptions facetoptions = new facetoptions(); facetoptions.addfacetbyrange(new facetoptions.fieldwithnumericrangeparameters( \u0026#34;price\u0026#34;,20,50,10)); facetoptions.setfacetmincount(0);\t//每组facet最小有多少元素 query.setfacetoptions(facetoptions); //设置分页信息 query.setrows(0); query.setoffset(0l); //读取信息 facetpage\u0026lt;book\u0026gt; bookfacetpage = solrtemplate.queryforfacetpage(\u0026#34;book\u0026#34;, query, book.class); page\u0026lt;facetfieldentry\u0026gt; rangefacetresultpage = bookfacetpage.getrangefacetresultpage(\u0026#34;price\u0026#34;); system.out.println(\u0026#34;总格数:\u0026#34; + rangefacetresultpage.gettotalelements()); for (facetfieldentry facetfieldentry : rangefacetresultpage) { system.out.println(facetfieldentry.getvalue() +\u0026#34;:\u0026#34;+ facetfieldentry.getvaluecount()); } } suggest查询\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 @test public void testsuggestquery() throws exception { solrclient solrclient = solrtemplate.getsolrclient(); solrquery query = new solrquery(); //请求参数封装 query.setrequesthandler(\u0026#34;/suggest\u0026#34;);\t//handler query.add(\u0026#34;suggest\u0026#34;,\u0026#34;true\u0026#34;);\t//必须设置为true query.add(\u0026#34;suggest.dictionary\u0026#34;,\u0026#34;issnsuggester\u0026#34;);\t//词典 query.add(\u0026#34;suggest.q\u0026#34;,\u0026#34;9\u0026#34;);\t//查询参数 query.add(commonparams.wt,\u0026#34;json\u0026#34;);\t//返回格式 query.add(\u0026#34;suggest.build\u0026#34;,\u0026#34;true\u0026#34;); query.add(\u0026#34;suggest.cfq\u0026#34;,\u0026#34;d\u0026#34;);\t//根据上下文过滤 queryresponse response = solrclient.query(\u0026#34;book\u0026#34;,query); //获得建议的结果 suggesterresponse suggesterresponse = response.getsuggesterresponse(); map\u0026lt;string, list\u0026lt;string\u0026gt;\u0026gt; suggestedterms = suggesterresponse.getsuggestedterms(); list\u0026lt;string\u0026gt; termlist = suggestedterms.get(\u0026#34;issnsuggester\u0026#34;); system.out.println(termlist); } 详情参考链接\nmorelikethis查询\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 @test public void testmorelikethisquery() throws exception { solrclient solrclient = solrtemplate.getsolrclient(); solrquery query = new solrquery(\u0026#34;*:*\u0026#34;);\t//查询,返回的每个结果都会进行相似匹配 query.setfields(\u0026#34;id\u0026#34;);\t//返回的field query.addmorelikethisfield(\u0026#34;classifycode\u0026#34;);\t//判读相似的字段 query.setmorelikethiscount(2);\t//返回相似文档信息的个数 query.setmorelikethismindocfreq(1);\t//最小文档频率,所在文档的个数小于这个值的词将不用于相似判断 query.setmorelikethismintermfreq(1);\t//最小分词频率,在单个文档中出现频率小于这个值的词将不用于相似判断 queryresponse response = solrclient.query(\u0026#34;book\u0026#34;, query); namedlist\u0026lt;solrdocumentlist\u0026gt; morelikethislist = response.getmorelikethis(); for (entry\u0026lt;string, solrdocumentlist\u0026gt; entry : morelikethislist) { system.out.println(\u0026#34;id:\u0026#34; + entry.getkey()); solrdocumentlist documentlist = entry.getvalue(); system.out.println(\u0026#34;相似总个数:\u0026#34; + documentlist.getnumfound()); for (solrdocument solrdocument : documentlist) { system.out.println(solrdocument.get(\u0026#34;id\u0026#34;)); } } } 详情参考链接\n","date":"2018-12-06","permalink":"https://hobocat.github.io/post/spring/2018-12-06-spring-data-solr/","summary":"一、集成spring-data-solr 1 2 3 4 5 6 7 8 9 10 11 \u0026lt;!-- 单机连接 --\u0026gt; \u0026lt;solr:solr-client id=\u0026#34;solrClient\u0026#34; url=\u0026#34;http://192.168.1.155:8080/solr\u0026#34; /\u0026gt; \u0026lt;!-- 使用SolrJ的转换器,Spring的转换器对于关联类型不友好 --\u0026gt; \u0026lt;bean id=\u0026#34;solrConverter\u0026#34; class=\u0026#34;org.springframework.data.solr.core.convert.SolrJConverter\u0026#34; /\u0026gt; \u0026lt;!-- 配","title":"spring-data-solr的应用"},]
[{"content":"一、solr安装包主要目录布局 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 solr | +- bin |\t| |\t+- init.d【linux中制作solr服务的配置文件】 |\t| |\t+- solr和solr.cmd【solr在windows和linux下的启动脚本】 |\t| |\t+- post【与solr沟通的简单命令行窗口】 |\t| |\t+- solr.in.sh和solr.in.cmd【启动solr是配置的一些参数和检查项】 |\t| |\t+- install_solr_services.sh【linux下安装solr服务的脚本】 | +- contrib【插件目录】 | +- dist【solr的jar包】 | +- example【示例】 | +- server【服务目录】 | +- solr-webapp【ui界面】 | +- lib【jetty的lib包】 | +- logs和resources【日志和日志配置】 | +- solr【示例配置】 二、solr安装(tomcat) 前置条件:已安装tomcat、java\n第一步、解压solr\n\tunzip -q solr-7.5.0.zip\n第二步、拷贝文件到指定位置\n源(solr文件夹) 目标(tomcat文件夹) server/solr-webapp/webapp 文件夹 webapps/solr(复制并改名为solr) server/lib/ext*.jar 文件 webapps/solr/web-inf/lib*.jar 文件 server/lib/metrics*.jar 文件 webapps/solr/web-inf/lib*.jar 文件 dist/solr-dataimporthandler-*.jar 文件 webapps/solr/web-inf/lib*.jar 文件 server/resources/log4j2.xml webapps/solr/web-inf/classes(需创建classes文件夹) server/solr 文件夹 拷贝并命名为solr_home(不再tomcat文件夹下) 第三步、配置solr\n编辑web.xml文件,设置【solr/home】项,指向创建的solr_home文件夹\n1 2 3 4 5 \u0026lt;env-entry\u0026gt; \u0026lt;env-entry-name\u0026gt;solr/home\u0026lt;/env-entry-name\u0026gt; \u0026lt;env-entry-value\u0026gt;solr_home的目录位置\u0026lt;/env-entry-value\u0026gt; \u0026lt;env-entry-type\u0026gt;java.lang.string\u0026lt;/env-entry-type\u0026gt; \u0026lt;/env-entry\u0026gt; 配置安全性约束【security-constraint】项,注释相关内容。\n配置[【catalina.sh】,加入日志位置,例如\n1 java_opts=${java_opts}\u0026#34; -dsolr.log.dir=/opt/solr_home/log \u0026#34; 三、schema和solrconfig设计 field type主要属性\n属性名 作用 name fieldtype的名称,该值在字段定义中的type属性中使用 class 用于存储和索引此类型数据的类名,如果是第三方类名需要使用全限定名 positionincrementgap 对于多值字段,指定多个值之间的距离,以防止虚假短语匹配 autogeneratephrasequeries 对于文本字段。如果为true,solr自动为相邻术语生成短语查询。如果false,术语必须用双引号括起来作为短语。 synonymquerystyle 考虑使用查询时同义词搜索 docvaluesformat 定义docvaluesformat用于此类字段的自定义。这需要一个支持模式的编解码器 字段定义,field 默认属性\n属性 描述 默认值 indexed 是否索引 true stored 是否存储 true docvalues 字段的值是否将放在面向列的docvalues结构,用于排序操作 false sortmissingfirst sortmissinglast 没有该field的数据排在有该field的数据之后/前,不论请求时的排序规则 false multivalued 此字段是否存在多值行为 false omitnorms 字段的长度不影响得分和在索引时不做boost * omittermfreqandpositions 忽略匹配的term的位置和出现频率分数 * omitpositions 忽略匹配的term的位置分数 * termvectors termpositions termoffsets termpayloads fastvectorquery使用,存储trem向量信息用于快速查询,使用空间换得时间 false required 此字段必须存在 false usedocvaluesasstored 存储docvalues true large 大字段始终采用延迟加载,实际值\u0026lt;512kb只占用文档高速缓存空间。此选项需要stored=\u0026quot;true\u0026quot;和multivalued=\u0026quot;false\u0026quot;支持 false schema.xml文件含义及配置查看详情\nsolrconfig.xml文件含义及配置查看详情\n枚举类型的定义\n第一步:schema文件中定义枚举类型\n1 2 3 \u0026lt;field name=\u0026#34;sex\u0026#34; type=\u0026#34;sex_enum\u0026#34; indexed=\u0026#34;true\u0026#34; stored=\u0026#34;true\u0026#34; multivalued=\u0026#34;false\u0026#34; /\u0026gt; \u0026lt;fieldtype name=\u0026#34;sex_enum\u0026#34; class=\u0026#34;solr.enumfieldtype\u0026#34; docvalues=\u0026#34;true\u0026#34; enumsconfig=\u0026#34;enumsconfig.xml\u0026#34; enumname=\u0026#34;sex\u0026#34;/\u0026gt; 第二步:配置【enumsconfig.xml】文件,如果存储索引值不在文件中存在将会报错\n1 2 3 4 5 6 7 \u0026lt;?xml version=\u0026#34;1.0\u0026#34; ?\u0026gt; \u0026lt;enumsconfig\u0026gt; \u0026lt;enum name=\u0026#34;sex\u0026#34;\u0026gt; \u0026lt;value\u0026gt;m\u0026lt;/value\u0026gt; \u0026lt;value\u0026gt;f\u0026lt;/value\u0026gt; \u0026lt;/enum\u0026gt; \u0026lt;/enumsconfig\u0026gt; 四、ik分词器的应用 以下以ik7.5为例,ik分词器的链接地址\n将jar包放入solr服务的jetty或tomcat的webapp/web-inf/lib/目录下\n将resources目录下的5个配置文件放入solr服务的jetty或tomcat的webapp/web-inf/classes/目录下\n1 2 3 4 5 ikanalyzer.cfg.xml ext.dic stopword.dic ik.conf dynamicdic.txt 配置solr的schema.xml,添加ik分词器\n1 2 3 4 5 6 7 8 9 10 11 \u0026lt;!-- ik分词器 --\u0026gt; \u0026lt;fieldtype name=\u0026#34;text_ik\u0026#34; class=\u0026#34;solr.textfield\u0026#34;\u0026gt; \u0026lt;analyzer type=\u0026#34;index\u0026#34;\u0026gt; \u0026lt;tokenizer class=\u0026#34;org.wltea.analyzer.lucene.iktokenizerfactory\u0026#34; usesmart=\u0026#34;false\u0026#34; conf=\u0026#34;ik.conf\u0026#34;/\u0026gt; \u0026lt;filter class=\u0026#34;solr.lowercasefilterfactory\u0026#34;/\u0026gt; \u0026lt;/analyzer\u0026gt; \u0026lt;analyzer type=\u0026#34;query\u0026#34;\u0026gt; \u0026lt;tokenizer class=\u0026#34;org.wltea.analyzer.lucene.iktokenizerfactory\u0026#34; usesmart=\u0026#34;true\u0026#34; conf=\u0026#34;ik.conf\u0026#34;/\u0026gt; \u0026lt;filter class=\u0026#34;solr.lowercasefilterfactory\u0026#34;/\u0026gt; \u0026lt;/analyzer\u0026gt; \u0026lt;/fieldtype\u0026gt; ik.conf文件说明\n1 2 3 4 #动态字典列表,可以设置多个字典表,用逗号进行分隔,默认动态字典表为dynamicdic.txt files=dynamicdic.txt #默认值为0,每次对动态字典表修改后请+1,不然不会将字典表中新的词语添加到内存中 lastupdate=0 五、solrj功能的使用 schema.xml中定义的数据模型\n1 2 3 4 5 6 7 8 9 10 11 \u0026lt;field name=\u0026#34;id\u0026#34; type=\u0026#34;string\u0026#34; indexed=\u0026#34;true\u0026#34; stored=\u0026#34;true\u0026#34; required=\u0026#34;true\u0026#34; multivalued=\u0026#34;false\u0026#34; /\u0026gt; \u0026lt;field name=\u0026#34;_version_\u0026#34; type=\u0026#34;plong\u0026#34; indexed=\u0026#34;false\u0026#34; stored=\u0026#34;false\u0026#34;/\u0026gt; \u0026lt;field name=\u0026#34;_root_\u0026#34; type=\u0026#34;string\u0026#34; indexed=\u0026#34;true\u0026#34; stored=\u0026#34;false\u0026#34; docvalues=\u0026#34;false\u0026#34; /\u0026gt; \u0026lt;field name=\u0026#34;_text_\u0026#34; type=\u0026#34;text_general\u0026#34; indexed=\u0026#34;true\u0026#34; stored=\u0026#34;false\u0026#34; multivalued=\u0026#34;true\u0026#34;/\u0026gt; \u0026lt;field name=\u0026#34;issn\u0026#34; type=\u0026#34;string\u0026#34; indexed=\u0026#34;true\u0026#34; stored=\u0026#34;true\u0026#34; multivalued=\u0026#34;false\u0026#34; /\u0026gt; \u0026lt;field name=\u0026#34;name\u0026#34; type=\u0026#34;string\u0026#34; indexed=\u0026#34;true\u0026#34; stored=\u0026#34;true\u0026#34; multivalued=\u0026#34;false\u0026#34;/\u0026gt; \u0026lt;field name=\u0026#34;price\u0026#34; type=\u0026#34;pdouble\u0026#34; indexed=\u0026#34;true\u0026#34; stored=\u0026#34;true\u0026#34; multivalued=\u0026#34;false\u0026#34;/\u0026gt; \u0026lt;field name=\u0026#34;pubshingtime\u0026#34; type=\u0026#34;pdate\u0026#34; indexed=\u0026#34;true\u0026#34; stored=\u0026#34;true\u0026#34; multivalued=\u0026#34;false\u0026#34;/\u0026gt; \u0026lt;field name=\u0026#34;authors\u0026#34; type=\u0026#34;string\u0026#34; indexed=\u0026#34;true\u0026#34; stored=\u0026#34;true\u0026#34; multivalued=\u0026#34;true\u0026#34;/\u0026gt; \u0026lt;field name=\u0026#34;classifycode\u0026#34; type=\u0026#34;string\u0026#34; indexed=\u0026#34;true\u0026#34; stored=\u0026#34;true\u0026#34; multivalued=\u0026#34;false\u0026#34;/\u0026gt; \u0026lt;field name=\u0026#34;hasmarc\u0026#34; type=\u0026#34;boolean\u0026#34; indexed=\u0026#34;true\u0026#34; stored=\u0026#34;true\u0026#34; multivalued=\u0026#34;false\u0026#34;/\u0026gt; 1、创建/修改索引 方式一:使用字符串指定字段名\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 @test public void inputdoc () throws exception { solrclient sclient = getsolrclient(); for (book book : datautil.getbooklist()) { solrinputdocument doc = new solrinputdocument(); doc.addfield(\u0026#34;id\u0026#34;, book.getid()); doc.addfield(\u0026#34;issn\u0026#34;, book.getissn()); doc.addfield(\u0026#34;name\u0026#34;, book.getname()); doc.addfield(\u0026#34;price\u0026#34;, book.getprice()); doc.addfield(\u0026#34;pubshingtime\u0026#34;, book.getpubshingtime()); doc.addfield(\u0026#34;authors\u0026#34;, book.getauthors()); doc.addfield(\u0026#34;classifycode\u0026#34;, book.getclassify().getcode()); doc.addfield(\u0026#34;hasmarc\u0026#34;, book.gethasmarc()); sclient.add(doc); } sclient.commit(); sclient.close(); } 方式二:使用javabean\n创建模型\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 //使用@field注解标志solr对应的字段名 //classifycode属性需要额外注意,此种情况下只能在setter方法上标注,切记! public class book { @field private string id; @field private string name; @field private string issn; @field private list\u0026lt;string\u0026gt; authors; @field private double price; private classify classify; @field private date pubshingtime; @field private boolean hasmarc; public string getclassifycode() { return this.classify == null ? null : this.classify.getcode(); } @field public void setclassifycode(string classifycode) { this.classify = (this.classify == null ? new classify() : this.classify); this.classify.setcode(classifycode); } //其他的getter/setter } 创建索引\n1 2 3 4 5 6 7 @test public void inputdocbybean() throws exception { solrclient sclient = getsolrclient(); sclient.addbeans(datautil.getbooklist()); sclient.commit(); sclient.close(); } 2、删除索引 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 //通过查询删除 @test public void deletedocbyquery() throws exception { solrclient sclient = getsolrclient(); sclient.deletebyquery(\u0026#34;*:*\u0026#34;); sclient.commit(); sclient.close(); } //通过id删除 @test public void deletedocbyid() throws exception { solrclient sclient = getsolrclient(); sclient.deletebyid(\u0026#34;115373065864171873783\u0026#34;); sclient.commit(); sclient.close(); } 小技巧:在solr管控台界面可以在【documents】选项下选择“document type\u0026gt;xml”使用以下xml格式进行删除\n1 2 3 4 5 6 7 8 9 10 11 \u0026lt;!-- 方式一:通过查询删除 --\u0026gt; \u0026lt;delete\u0026gt; \u0026lt;query\u0026gt;*:*\u0026lt;/query\u0026gt; \u0026lt;/delete\u0026gt; \u0026lt;commit/\u0026gt; \u0026lt;!-- 方式二:指定id删除 --\u0026gt; \u0026lt;delete\u0026gt; \u0026lt;id\u0026gt;【id值】\u0026lt;/id\u0026gt; \u0026lt;/delete\u0026gt; \u0026lt;commit/\u0026gt; 3、主要查询功能 按照id查询\n1 2 3 4 5 6 7 8 9 10 11 @test public void testsearchbyid() throws exception { solrclient solrclient = getsolrclient(); //使用id查询 solrdocument solrdocument = solrclient.getbyid(\u0026#34;115373065864171873622\u0026#34;); //转换为bean documentobjectbinder documentobjectbinder = new documentobjectbinder(); book book = documentobjectbinder.getbean(book.class, solrdocument); system.out.println(book); solrclient.close(); } 按照查询语句查询\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 @test public void testsearchbyquery() throws exception { solrclient solrclient = getsolrclient(); solrquery query = new solrquery(\u0026#34;*:*\u0026#34;); query.setstart(2); //分页,开始索引。0为基数 query.setrows(2); //总共搜索条数 queryresponse response = solrclient.query(query); //response.getresults()返回solrdocumentlist对象,需要自己封装 list\u0026lt;book\u0026gt; books = response.getbeans(book.class); //直接拿到bean对象 long numfound = response.getresults().getnumfound(); long start = response.getresults().getstart(); system.out.println(\u0026#34;总记录数:\u0026#34;+numfound); system.out.println(\u0026#34;开始记录:\u0026#34;+start); books.foreach(system.out::println); } 数字范围查询\n1 2 3 4 5 6 7 8 9 10 11 12 @test public void testnumrangequery() throws exception { solrclient solrclient = getsolrclient(); solrquery query = new solrquery(\u0026#34; price:[35 to 45] \u0026#34; + simpleparams.and_operator +\u0026#34; classifycode:d \u0026#34;); queryresponse response = solrclient.query(query); list\u0026lt;book\u0026gt; books = response.getbeans(book.class); long numfound = response.getresults().getnumfound(); long start = response.getresults().getstart(); system.out.println(\u0026#34;总记录数:\u0026#34;+numfound); system.out.println(\u0026#34;开始记录:\u0026#34;+start); books.foreach(system.out::println); } 过滤查询【使用普通查询即and连接会影响评分,过滤查询不会影响评分】\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 @test public void testfilterquery() throws exception { solrclient solrclient = getsolrclient(); solrquery query = new solrquery(\u0026#34;*:*\u0026#34;); //过滤的条件 query.addfilterquery(\u0026#34;classifycode:d\u0026#34;); queryresponse response = solrclient.query(query); list\u0026lt;book\u0026gt; books = response.getbeans(book.class); long numfound = response.getresults().getnumfound(); long start = response.getresults().getstart(); system.out.println(\u0026#34;总记录数:\u0026#34;+numfound); system.out.println(\u0026#34;开始记录:\u0026#34;+start); books.foreach(system.out::println); } 高亮查询\n一般高亮查询 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 @test public void testhighlightquery() throws exception { solrclient solrclient = getsolrclient(); solrquery query = new solrquery(\u0026#34;name:*政府*\u0026#34;); //开启高亮 query.sethighlight(true); //设置高亮前缀与后缀 query.sethighlightsimplepre(\u0026#34;\u0026lt;front color=\u0026#39;read\u0026#39;\u0026gt;\u0026#34;); query.sethighlightsimplepost(\u0026#34;\u0026lt;/front\u0026gt;\u0026#34;); //设置高亮字段名 query.addhighlightfield(\u0026#34;name\u0026#34;); queryresponse response = solrclient.query(query); list\u0026lt;book\u0026gt; books = response.getbeans(book.class); //获取高亮属性 map\u0026lt;string, map\u0026lt;string, list\u0026lt;string\u0026gt;\u0026gt;\u0026gt; hmap = response.gethighlighting(); //将高亮属性设置到相对应属性 books.foreach((b) -\u0026gt; { map\u0026lt;string, list\u0026lt;string\u0026gt;\u0026gt; mapfield = hmap.get(b.getid()); string hname = mapfield.get(\u0026#34;name\u0026#34;) == null ? b.getname() : mapfield.get(\u0026#34;name\u0026#34;).get(0); b.setname(hname); }); long numfound = response.getresults().getnumfound(); long start = response.getresults().getstart(); system.out.println(\u0026#34;总记录数:\u0026#34;+numfound); system.out.println(\u0026#34;开始记录:\u0026#34;+start); books.foreach(system.out::println); } fastvectorhighlighter查询 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 @test public void testfasthighlightquery() throws exception { solrclient solrclient = getsolrclient(); solrquery query = new solrquery(\u0026#34;name:政府\u0026#34;); //开启高亮 query.sethighlight(true); query.add(\u0026#34;hl.method\u0026#34;,\u0026#34;fastvector\u0026#34;); //使用fastvector query.add(highlightparams.tag_pre,\u0026#34;\u0026lt;front color=\u0026#39;read\u0026#39;\u0026gt;\u0026#34;); //和普通的前缀不一样 query.add(highlightparams.tag_post,\u0026#34;\u0026lt;/front\u0026gt;\u0026#34;); //和普通的后缀不一样 query.addhighlightfield(\u0026#34;name\u0026#34;); queryresponse response = solrclient.query(query); list\u0026lt;book\u0026gt; books = response.getbeans(book.class); //获取高亮属性 map\u0026lt;string, map\u0026lt;string, list\u0026lt;string\u0026gt;\u0026gt;\u0026gt; hmap = response.gethighlighting(); //将高亮属性设置到相对应属性 books.foreach((b) -\u0026gt; { map\u0026lt;string, list\u0026lt;string\u0026gt;\u0026gt; mapfield = hmap.get(b.getid()); string hname = mapfield.get(\u0026#34;name\u0026#34;) == null ? b.getname() : mapfield.get(\u0026#34;name\u0026#34;).get(0); b.setname(hname); }); long numfound = response.getresults().getnumfound(); long start = response.getresults().getstart(); system.out.println(\u0026#34;总记录数:\u0026#34;+numfound); system.out.println(\u0026#34;开始记录:\u0026#34;+start); books.foreach(system.out::println); } 分组查询\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 @test public void testgroupquery() throws exception { solrclient solrclient = getsolrclient(); solrquery query = new solrquery(\u0026#34;*:*\u0026#34;); //分组参数 query.add(groupparams.group,\u0026#34;on\u0026#34;); query.add(groupparams.group_field,\u0026#34;classifycode\u0026#34;); query.add(groupparams.group_total_count,\u0026#34;on\u0026#34;); //开启总组数统计 query.add(groupparams.group_limit,\u0026#34;2\u0026#34;); //每个组返回的个数限制 query.add(groupparams.group_offset,\u0026#34;1\u0026#34;); //每个组的开始文档位置 //queryresponse无法获取总记录数和开始记录数 queryresponse response = solrclient.query(query); //获取分组响应信息 groupresponse groupresponse = response.getgroupresponse(); list\u0026lt;groupcommand\u0026gt; groupcommands = groupresponse.getvalues(); for (groupcommand groupcommand : groupcommands) { int matchnum = groupcommand.getmatches(); integer ngroups = groupcommand.getngroups(); system.out.println(\u0026#34;总组数:\u0026#34;+ngroups); system.out.println(\u0026#34;总个数:\u0026#34;+matchnum); groupcommand.getvalues().foreach(x -\u0026gt; { documentobjectbinder documentobjectbinder = new documentobjectbinder(); list\u0026lt;book\u0026gt; books = documentobjectbinder.getbeans(book.class, x.getresult()); system.out.println(\u0026#34;分组名\u0026#34;+x.getgroupvalue()); system.out.println(books); }); } } 分面查询\n普通字段分片 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 @test public void testfacetsquery() throws exception { solrclient solrclient = getsolrclient(); solrquery query = new solrquery(\u0026#34;*:*\u0026#34;); query.addfacetfield(\u0026#34;classifycode\u0026#34;); queryresponse response = solrclient.query(query); //获取分片信息 for (facetfield facetfield : response.getfacetfields()) { system.out.println(\u0026#34;分类字段名\u0026#34; + facetfield.getname()); //获取统计信息 for (facetfield.count count: facetfield.getvalues()) { system.out.println(count.getname() + \u0026#34;:\u0026#34; + count.getcount()); } } solrclient.close(); } 日期分片 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 //utc日期格式字符串转换为date类型字符串 static public string utcstrtodatestr(string utc) { instant ins = instant.parse(utc); date date = date.from(ins); dateformat formart = new simpledateformat(\u0026#34;yyyy-mm-dd\u0026#34;); return formart.format(date); } @test public void testdatefacetsquery() throws exception { solrclient solrclient = getsolrclient(); solrquery query = new solrquery(\u0026#34;*:*\u0026#34;); query.add(facetparams.facet_mincount,\u0026#34;1\u0026#34;); //最小统计数,小于此数不返回 date startdate = dateutil.parse(\u0026#34;2013-01-01\u0026#34;); date endtdate = dateutil.parse(\u0026#34;2015-01-01\u0026#34;);; string gap = \u0026#34;+1month\u0026#34;; query.adddaterangefacet(\u0026#34;pubshingtime\u0026#34;, startdate, endtdate, gap); queryresponse response = solrclient.query(query); //获取分片信息 for (rangefacet\u0026lt;date,date\u0026gt; rangefacet : response.getfacetranges()) { system.out.println(\u0026#34;分类字段名\u0026#34; + rangefacet.getname()); //获取统计信息 for (count count : rangefacet.getcounts()) { system.out.println(dateutil.utcstrtodatestr(count.getvalue())+\u0026#34; ~ \u0026#34; + gap + \u0026#34; count:\u0026#34;+count.getcount()); } } solrclient.close(); } 数字分片 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 @test public void testnumericfacetsquery() throws exception { solrclient solrclient = getsolrclient(); solrquery query = new solrquery(\u0026#34;*:*\u0026#34;); query.add(facetparams.facet_mincount,\u0026#34;1\u0026#34;); //最小统计数,小于此数不返回 number start = new double(\u0026#34;30.00\u0026#34;); number end = new double(\u0026#34;50.00\u0026#34;); number gap = new double(\u0026#34;5.00\u0026#34;);; query.addnumericrangefacet(\u0026#34;price\u0026#34;, start, end, gap); queryresponse response = solrclient.query(query); //获取分片数据区域列表 for (rangefacet\u0026lt;double,double\u0026gt; rangefacet : response.getfacetranges()) { system.out.println(\u0026#34;分类字段名\u0026#34; + rangefacet.getname()); //获取统计信息 for (count count : rangefacet.getcounts()) { system.out.println(count.getvalue()+\u0026#34; ~ \u0026#34; + gap + \u0026#34; count:\u0026#34;+count.getcount()); } } 注:从多个维度进行查询face.pivot\n日期范围查询\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 //将date类型转换为utc字符串形式,因为solr只认可utc格式的日期 static public string datetoutcstr(date date) { instant instant = date.toinstant(); zoneid zoneid = zoneid.systemdefault(); return instant.atzone(zoneid).format(datetimeformatter.iso_instant); } //时间查询 @test public void testdaterangquery() throws exception { solrclient solrclient = getsolrclient(); string datestart = dateutil.datetoutcstr(dateutil.parse(\u0026#34;2013-09-01\u0026#34;)); string dateend = dateutil.datetoutcstr(dateutil.parse(\u0026#34;2013-10-30\u0026#34;)); solrquery query = new solrquery(\u0026#34;pubshingtime:[\u0026#34;+datestart+\u0026#34; to \u0026#34;+dateend+ \u0026#34;]\u0026#34;); queryresponse response = solrclient.query(query); list\u0026lt;book\u0026gt; books = response.getbeans(book.class); long numfound = response.getresults().getnumfound(); long start = response.getresults().getstart(); system.out.println(\u0026#34;总记录数:\u0026#34;+numfound); system.out.println(\u0026#34;开始记录:\u0026#34;+start); books.foreach(system.out::println); solrclient.close(); } suggest查询\n使用suggest需要单独配置solrconfig.xml 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 \u0026lt;!-- 和requesthandler的components对应 --\u0026gt; \u0026lt;searchcomponent name=\u0026#34;suggest\u0026#34; class=\u0026#34;solr.suggestcomponent\u0026#34;\u0026gt; \u0026lt;lst name=\u0026#34;suggester\u0026#34;\u0026gt; \u0026lt;!-- 名称 --\u0026gt; \u0026lt;str name=\u0026#34;name\u0026#34;\u0026gt;issnsuggester\u0026lt;/str\u0026gt; \u0026lt;!-- analyzinginfixlookupfactory支持上下文过滤 analyzinglookupfactory不支持上下文过滤 --\u0026gt; \u0026lt;str name=\u0026#34;lookupimpl\u0026#34;\u0026gt;analyzinginfixlookupfactory\u0026lt;/str\u0026gt; \u0026lt;str name=\u0026#34;dictionaryimpl\u0026#34;\u0026gt;documentdictionaryfactory\u0026lt;/str\u0026gt; \u0026lt;!-- 建议应用的字段 --\u0026gt; \u0026lt;str name=\u0026#34;field\u0026#34;\u0026gt;issn\u0026lt;/str\u0026gt; \u0026lt;!-- 过滤的上下文字段 --\u0026gt; \u0026lt;str name=\u0026#34;contextfield\u0026#34;\u0026gt;classifycode\u0026lt;/str\u0026gt; \u0026lt;!-- 是否突出显示 --\u0026gt; \u0026lt;str name=\u0026#34;highlight\u0026#34;\u0026gt;false\u0026lt;/str\u0026gt; \u0026lt;!-- 权重字段不是必选字段 --\u0026gt; \u0026lt;!--\u0026lt;str name=\u0026#34;weightfield\u0026#34;\u0026gt;price\u0026lt;/str\u0026gt;--\u0026gt; \u0026lt;str name=\u0026#34;suggestanalyzerfieldtype\u0026#34;\u0026gt;text_general\u0026lt;/str\u0026gt; \u0026lt;!-- 何时建立索引,实时打开buildoncommit,也可手动提交参数suggest.build=true --\u0026gt; \u0026lt;str name=\u0026#34;buildonstartup\u0026#34;\u0026gt;false\u0026lt;/str\u0026gt; \u0026lt;str name=\u0026#34;buildoncommit\u0026#34;\u0026gt;true\u0026lt;/str\u0026gt; \u0026lt;str name=\u0026#34;buildonoptimize\u0026#34;\u0026gt;true\u0026lt;/str\u0026gt; \u0026lt;/lst\u0026gt; \u0026lt;/searchcomponent\u0026gt; \u0026lt;requesthandler name=\u0026#34;/suggest\u0026#34; class=\u0026#34;solr.searchhandler\u0026#34; startup=\u0026#34;lazy\u0026#34;\u0026gt; \u0026lt;lst name=\u0026#34;defaults\u0026#34;\u0026gt; \u0026lt;str name=\u0026#34;suggest\u0026#34;\u0026gt;true\u0026lt;/str\u0026gt; \u0026lt;!-- 查询建议的个数 --\u0026gt; \u0026lt;str name=\u0026#34;suggest.count\u0026#34;\u0026gt;5\u0026lt;/str\u0026gt; \u0026lt;/lst\u0026gt; \u0026lt;arr name=\u0026#34;components\u0026#34;\u0026gt; \u0026lt;str\u0026gt;suggest\u0026lt;/str\u0026gt; \u0026lt;/arr\u0026gt; \u0026lt;/requesthandler\u0026gt; 对应的java代码,注意setrequesthandler为【/suggest】 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 @test public void testsuggesterquery() throws exception { solrclient solrclient = getsolrclient(); solrquery query = new solrquery(); //请求参数封装 query.setrequesthandler(\u0026#34;/suggest\u0026#34;); //handler query.add(\u0026#34;suggest\u0026#34;,\u0026#34;true\u0026#34;); //必须设置为true query.add(\u0026#34;suggest.dictionary\u0026#34;,\u0026#34;issnsuggester\u0026#34;); //词典 query.add(\u0026#34;suggest.q\u0026#34;,\u0026#34;9\u0026#34;); //查询参数 query.add(commonparams.wt,\u0026#34;json\u0026#34;); //返回格式 query.add(\u0026#34;suggest.cfq\u0026#34;,\u0026#34;d\u0026#34;); //根据上下文过滤 //query.add(\u0026#34;suggest.build\u0026#34;,\u0026#34;true\u0026#34;); //是否立刻建立索引 queryresponse response = solrclient.query(query); //获得建议的结果 suggesterresponse suggesterresponse = response.getsuggesterresponse(); map\u0026lt;string, list\u0026lt;string\u0026gt;\u0026gt; suggestedterms = suggesterresponse.getsuggestedterms(); list\u0026lt;string\u0026gt; termlist = suggestedterms.get(\u0026#34;issnsuggester\u0026#34;); system.out.println(termlist); solrclient.close(); } morelikethis\n为了提高性能,判断相似的字段应该已经在 schema.xml 中存储了termvectors\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 //【classifycode ---\u0026gt; termvectors=\u0026#34;true\u0026#34;】 @test public void testmorelikethisquery() throws exception { solrclient solrclient = getsolrclient(); solrquery query = new solrquery(\u0026#34;*:*\u0026#34;); //查询,返回的每个结果都会进行相似匹配 query.setfields(\u0026#34;id\u0026#34;); //返回的field query.addmorelikethisfield(\u0026#34;classifycode\u0026#34;); //判读相似的字段 query.setmorelikethiscount(2); //返回相似文档信息的个数 query.setmorelikethismindocfreq(1); //最小文档频率,所在文档的个数小于这个值的词将不用于相似判断 query.setmorelikethismintermfreq(1); //最小分词频率,在单个文档中出现频率小于这个值的词将不用于相似判断 queryresponse response = solrclient.query(query); namedlist\u0026lt;solrdocumentlist\u0026gt; morelikethislist = response.getmorelikethis(); for (entry\u0026lt;string, solrdocumentlist\u0026gt; entry : morelikethislist) { system.out.println(\u0026#34;id:\u0026#34; + entry.getkey()); solrdocumentlist documentlist = entry.getvalue(); system.out.println(\u0026#34;相似总个数:\u0026#34; + documentlist.getnumfound()); for (solrdocument solrdocument : documentlist) { system.out.println(solrdocument.get(\u0026#34;id\u0026#34;)); } } solrclient.close(); } 六、从数据库导入数据 第一步:配置solrconfig.xml,添加dateimprt组件\n1 2 3 4 5 6 \u0026lt;!-- dateimprt component --\u0026gt; \u0026lt;requesthandler name=\u0026#34;/dataimport\u0026#34; class=\u0026#34;org.apache.solr.handler.dataimport.dataimporthandler\u0026#34;\u0026gt; \u0026lt;lst name=\u0026#34;defaults\u0026#34;\u0026gt; \u0026lt;str name=\u0026#34;config\u0026#34;\u0026gt;data-config.xml\u0026lt;/str\u0026gt; \u0026lt;/lst\u0026gt; \u0026lt;/requesthandler\u0026gt; 第二步:\t创建【data-config.xml】文件\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 \u0026lt;?xml version=\u0026#34;1.0\u0026#34; encoding=\u0026#34;utf-8\u0026#34;?\u0026gt; \u0026lt;dataconfig\u0026gt; \u0026lt;!-- 配置数据源 --\u0026gt; \u0026lt;datasource name=\u0026#34;booksource\u0026#34; type=\u0026#34;jdbcdatasource\u0026#34; driver=\u0026#34;com.mysql.jdbc.driver\u0026#34; url=\u0026#34;jdbc:mysql://192.168.1.107:3306/book?useunicode=true\u0026amp;amp;characterencoding=utf-8\u0026amp;amp;allowmultiqueries=true\u0026amp;amp;rewritebatchedstatements=true\u0026#34; user=\u0026#34;root\u0026#34; password=\u0026#34;123456\u0026#34; /\u0026gt; \u0026lt;document\u0026gt; \u0026lt;!-- 文档对象,可配置多个 --\u0026gt; \u0026lt;entity name=\u0026#34;book\u0026#34; datasource=\u0026#34;booksource\u0026#34; pk=\u0026#34;id\u0026#34; query=\u0026#34;select id,name,issn,authors,price,pubshingtime,hasmarc,classifycode from book \u0026#34;\u0026gt; \u0026lt;!-- 段名映射 --\u0026gt; \u0026lt;field column=\u0026#39;id\u0026#39; name=\u0026#39;id\u0026#39; /\u0026gt; \u0026lt;field column=\u0026#39;name\u0026#39; name=\u0026#39;name\u0026#39; /\u0026gt; \u0026lt;field column=\u0026#39;issn\u0026#39; name=\u0026#39;issn\u0026#39; /\u0026gt; \u0026lt;field column=\u0026#39;authors\u0026#39; name=\u0026#39;authors\u0026#39; /\u0026gt; \u0026lt;field column=\u0026#39;price\u0026#39; name=\u0026#39;price\u0026#39; /\u0026gt; \u0026lt;field column=\u0026#39;pubshingtime\u0026#39; name=\u0026#39;pubshingtime\u0026#39; /\u0026gt; \u0026lt;field column=\u0026#39;hasmarc\u0026#39; name=\u0026#39;hasmarc\u0026#39; /\u0026gt; \u0026lt;field column=\u0026#39;classifycode\u0026#39; name=\u0026#39;classifycode\u0026#39; /\u0026gt; \u0026lt;/entity\u0026gt; \u0026lt;/document\u0026gt; \u0026lt;/dataconfig\u0026gt; 第三步:在管控台界面执行\n【dataimport】下可以选择clean清空以前记录再导入,entity实体类型\n七、主从搭建 master配置 1 2 3 4 5 6 7 8 9 \u0026lt;requesthandler name=\u0026#34;/replication\u0026#34; class=\u0026#34;solr.replicationhandler\u0026#34; \u0026gt; \u0026lt;lst name=\u0026#34;master\u0026#34;\u0026gt; \u0026lt;!-- 何时触发复制 --\u0026gt; \u0026lt;str name=\u0026#34;replicateafter\u0026#34;\u0026gt;commit\u0026lt;/str\u0026gt; \u0026lt;str name=\u0026#34;replicateafter\u0026#34;\u0026gt;startup\u0026lt;/str\u0026gt; \u0026lt;!-- 要同步到slave的文件以,隔开[一定不能配 solrconfig.xml] --\u0026gt; \u0026lt;str name=\u0026#34;conffiles\u0026#34;\u0026gt;managed-schema\u0026lt;/str\u0026gt; \u0026lt;/lst\u0026gt; \u0026lt;/requesthandler\u0026gt; slave配置 1 2 3 4 5 6 7 8 9 10 11 12 \u0026lt;requesthandler name=\u0026#34;/replication\u0026#34; class=\u0026#34;solr.replicationhandler\u0026#34; \u0026gt; \u0026lt;lst name=\u0026#34;slave\u0026#34;\u0026gt; \u0026lt;!-- 主机位置,及其示例 --\u0026gt; \u0026lt;str name=\u0026#34;masterurl\u0026#34;\u0026gt;http://127.0.0.1:8080/solr/book\u0026lt;/str\u0026gt; \u0026lt;!-- 多少时间之后同步一次,设置为60秒 --\u0026gt; \u0026lt;str name=\u0026#34;pollinterval\u0026#34;\u0026gt;00:00:60\u0026lt;/str\u0026gt; \u0026lt;!-- 压缩机制,来传输索引, 可选internal|external, internal内网, external外网 --\u0026gt; \u0026lt;str name=\u0026#34;compression\u0026#34;\u0026gt;internal\u0026lt;/str\u0026gt; \u0026lt;str name=\u0026#34;httpconntimeout\u0026#34;\u0026gt;50000\u0026lt;/str\u0026gt; \u0026lt;str name=\u0026#34;httpreadtimeout\u0026#34;\u0026gt;500000\u0026lt;/str\u0026gt; \u0026lt;/lst\u0026gt; \u0026lt;/requesthandler\u0026gt; 八、集群搭建 第一步:配置zookeeper集群,并启动【修改zoo.cfg,注意修改datadir、端口、集群机器位置(使用ip)】\n1 2 3 4 5 6 synclimit=5 datadir=/opt/zookeeper_dir/zookeeper01/data clientport=2181 server.1=192.168.1.155:2888:3888 server.2=192.168.1.155:2889:3889 server.3=192.168.1.155:2890:3890 第二步:修改每个solr-tomcat的web.xml【修改solr_home】\n1 2 3 4 5 \u0026lt;env-entry\u0026gt; \u0026lt;env-entry-name\u0026gt;solr/home\u0026lt;/env-entry-name\u0026gt; \u0026lt;env-entry-value\u0026gt;/opt/solr_home_dir/solr_cluster_01\u0026lt;/env-entry-value\u0026gt; \u0026lt;env-entry-type\u0026gt;java.lang.string\u0026lt;/env-entry-type\u0026gt; \u0026lt;/env-entry\u0026gt; 第三步:修改tomcat的catalina.sh\n1 2 java_opts=\u0026#34;${java_opts} -dsolr.log.dir=/opt/solr_home_dir/solr_cluster_01/log \u0026#34; java_opts=\u0026#34;${java_opts} -dzkhost=192.168.1.155:2181,192.168.1.155:2182,192.168.1.155:2183 \u0026#34; 第四步:修改每个solr_home下的solr.xml【端口号与tomcat一致】\n1 2 3 4 5 6 7 8 \u0026lt;solr\u0026gt; \u0026lt;solrcloud\u0026gt; \u0026lt;!--......--\u0026gt; \u0026lt;str name=\u0026#34;host\u0026#34;\u0026gt;${host:192.168.1.155}\u0026lt;/str\u0026gt; \u0026lt;int name=\u0026#34;hostport\u0026#34;\u0026gt;${jetty.port:8080}\u0026lt;/int\u0026gt; \u0026lt;!--......--\u0026gt; \u0026lt;/solrcloud\u0026gt; \u0026lt;/solr\u0026gt; 第五步:上传solr配置文件到zookeeper【solr-7.5.0/server/scripts/cloud-scripts目录下】\n1 ./zkcli.sh -zkhost [ip:prot,ip:prot...] -cmd upconfig -confdir /opt/solr_home_dir/cluster_conf/conf -confname book 第六步:启动solr-tomcat,访问任意一个tomcat,在collections页面中添加core\n1 2 3 numshards:集群总分片数 -- 主节点数量 replicationfactor:每个节点有多少个从节点 -- 每个主节点从节点数量 maxshardspernode:单个服务器最大节点数 --每台服务器最大节点数 注:solrj连接solrcloud代码\n1 2 3 4 5 6 7 8 9 10 11 static solrclient getsolrclient(){ final list\u0026lt;string\u0026gt; zkservers = new arraylist\u0026lt;string\u0026gt;(); zkservers.add(\u0026#34;192.168.1.155:2181\u0026#34;); zkservers.add(\u0026#34;192.168.1.155:2182\u0026#34;); zkservers.add(\u0026#34;192.168.1.155:2183\u0026#34;); //第二个参数为上传到zookeeper的solr配置目录 cloudsolrclient cloudsolrclient = new cloudsolrclient.builder(zkservers, optional.of(\u0026#34;/\u0026#34;)).build(); //默认的collection cloudsolrclient.setdefaultcollection(\u0026#34;book\u0026#34;); return cloudsolrclient; } ","date":"2018-12-04","permalink":"https://hobocat.github.io/post/searchengine/2018-12-04-solr/","summary":"一、Solr安装包主要目录布局 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 solr | +- bin | | | +- init.d【linux中制作solr服务的配置文件】 |","title":"solr的应用"},]
[{"content":"一、术语\u0026amp;基础知识术语 结构化数据\n结构化数据:指具有固定格式或有限长度的数据,如数据库等 非结构化数据:指不定长或无固定格式的数据,如html等 数据查询方法\n顺序扫描法:从文件开始从扫描一直到文件结尾 全文检索:先建立索引,对索引进行匹配在进行取值(相当于从目录查找) 索引分类\n正向索引:\n\t“文档1”的id \u0026gt; 【 {单词1:次数,位置列表},{单词2:次数,位置列表}\u0026hellip;】\n\t“文档2”的id \u0026gt; 【 {单词1:次数,位置列表},{单词2:次数,位置列表}\u0026hellip;】\n倒排索引:\n\t“关键词1”:【{“文档1”的id,次数,位置列表},{“文档2”的id,次数,位置列表} …】\n\t“关键词2”:【{“文档1”的id,次数,位置列表},{“文档2”的id,次数,位置列表} …】\n二、lucene 实现全文检索的流程 概述 创建索引的步骤:原始文档 \u0026gt; 获取文档信息 \u0026gt; 构建文档对象 \u0026gt; lucene对文档对象进行分词 \u0026gt; 创建索引\n搜素文档的步骤:获得查询信息 \u0026gt; 创建查询 \u0026gt; 执行查询 \u0026gt; 渲染结果\n重要流程 文档对象的创建\n\t文档对象由多个域(field)组成,每个document 可以有多个field,不同的document 可以有不同的field。同一个document 可以有相同的field(域名和域值都相同)每个文档都有一个唯一的编号(id)。\n分词的过程\n\t对文档中的域进行分析:提取单词,将字母转为小写,去除标点,去除停用词生成最终的语汇单元。\n1 2 原始:lucene is a java full-text search engine 分词:lucene java full search engine \t每个单词叫做一个term ,不同的域中拆分出来的相同的单词是不同的term。term 中包含两部分一部分是文档的域名, 另一部分是单词的内容。\n三、lucene 创建索引库 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public void testcreateindex() throws exception { // 创建分词器,采用标准分词器对英文支持好,中文支持差 analyzer analyzer = new standardanalyzer(); // 索引库位置,fsdirectory会根据当前环境使用合适的方式打开例如niofsdirectory、mmapdirectory等 directory directory = fsdirectory.open(paths.get(\u0026#34;e:/luceneindex\u0026#34;)); // 配置indexwriter indexwriterconfig writerconfig = new indexwriterconfig(analyzer); // 创建indexwriter indexwriter indexwriter = new indexwriter(directory, writerconfig); // 创建文档对象 list\u0026lt;document\u0026gt; documents = new arraylist\u0026lt;\u0026gt;(); file files = new file(\u0026#34;e:/searchsource\u0026#34;); for (file file : files.listfiles()) { document document = new document(); document.add(new textfield(\u0026#34;filename\u0026#34;, file.getname(), store.yes)); document.add(new textfield(\u0026#34;filepath\u0026#34;, file.getpath(), store.yes)); document.add(new longpoint(\u0026#34;filesize\u0026#34;, file.length())); document.add(new storedfield(\u0026#34;filesize\u0026#34;,file.length())); document.add(new textfield(\u0026#34;filecontent\u0026#34;, fileutils.readfiletostring(file), store.no)); documents.add(document); } // 写入文档对象 indexwriter.adddocuments(documents); // 关闭indexwriter indexwriter.close(); } 注意:\nik分词器如今在github维护,下载地址ik-analyzer luke索引查看工具也在github维护,下载地址luke norm会更具文档长度自行计算(标准化因子,文档长度过长对重复次数评判有不公平性,使用norm使之较为公平。例如100w字重复11次比1w字重复10次多会被错误的排在前方) field类型 textfield:分词、索引、可选存储 stringfield:不分词、索引、可选存储 intpoint/longpoint/floatpoint/doublepoint:数字类型、索引、不存储(存储配合storedfield) sorteddocvaluesfield:按byte[]建立正排索引 sortedsetdocvaluesfield:按sortedset\u0026lt;byte[]\u0026gt;建立正排索引 numericdocvaluesfield:按long建立正排索引 sortednumericdocvaluesfield:按sortedset\u0026lt;long\u0026gt;建立正排索引 storedfield:不分词、不索引、存储 docvalues其实是lucene在构建倒排索引时,会额外建立一个有序的正排索引(基于document =\u0026gt; field value的映射列表)\n正排索引用于排序、聚合、分组、高亮等\ndocvalues只允许有一个相同域名的域【字段是非数组eg: price:80】,docvaluesset可以设置多个相同域名不同域值【字段是数组eg: price:[100, 80]】\n四、lucene 查询索引 term精确查询 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 @test public void testtermsearch() throws exception { directory directory = fsdirectory.open(paths.get(\u0026#34;e:/luceneindex\u0026#34;)); // 创建indexreader directoryreader indexreader = directoryreader.open(directory); indexsearcher indexserch = new indexsearcher(indexreader); // 精确查询条件 query query = new termquery(new term(\u0026#34;filecontent\u0026#34;, \u0026#34;apache\u0026#34;)); // 查询五条 topdocs topdocs = indexserch.search(query,5); // 查询的总数 system.out.println(\u0026#34;totalhits:\u0026#34;+topdocs.totalhits); for (scoredoc scoredoc : topdocs.scoredocs) { // 获得分数 system.out.println(\u0026#34;score:\u0026#34;+scoredoc.score); // 获得文档 document doc = indexserch.doc(scoredoc.doc); system.out.println(\u0026#34;filename:\u0026#34;+doc.get(\u0026#34;filename\u0026#34;)); system.out.println(\u0026#34;filepath:\u0026#34;+doc.get(\u0026#34;filepath\u0026#34;)); system.out.println(\u0026#34;filesize:\u0026#34;+doc.get(\u0026#34;filesize\u0026#34;)); system.out.println(\u0026#34;filecontent:\u0026#34;+doc.get(\u0026#34;filecontent\u0026#34;)); } indexreader.close(); } termquery范围查询 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 @test public void testtermrangesearch() throws exception { directory directory = fsdirectory.open(paths.get(\u0026#34;e:/luceneindex\u0026#34;)); // 创建indexreader directoryreader indexreader = directoryreader.open(directory); indexsearcher indexserch = new indexsearcher(indexreader); // 范围查询条件(单词开头大于\u0026#39;b\u0026#39;结束小于\u0026#39;e\u0026#39;),不可以用于数字类型 query query = new termrangequery(\u0026#34;filename\u0026#34;,new bytesref(\u0026#34;b\u0026#34;),new bytesref(\u0026#34;e\u0026#34;),true,true); // 查询二十条 topdocs topdocs = indexserch.search(query,20); // 查询的总数 system.out.println(\u0026#34;totalhits:\u0026#34;+topdocs.totalhits); for (scoredoc scoredoc : topdocs.scoredocs) { // 获得分数 system.out.println(\u0026#34;score:\u0026#34;+scoredoc.score); // 获得文档 document doc = indexserch.doc(scoredoc.doc); system.out.println(\u0026#34;filename:\u0026#34;+doc.get(\u0026#34;filename\u0026#34;)); system.out.println(\u0026#34;filepath:\u0026#34;+doc.get(\u0026#34;filepath\u0026#34;)); system.out.println(\u0026#34;filesize:\u0026#34;+doc.get(\u0026#34;filesize\u0026#34;)); system.out.println(\u0026#34;filecontent:\u0026#34;+doc.get(\u0026#34;filecontent\u0026#34;)); } indexreader.close(); } numericalrange数字范围查询 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 @test public void testnumericalrangesearch() throws exception { directory directory = fsdirectory.open(paths.get(\u0026#34;e:/luceneindex\u0026#34;)); // 创建indexreader directoryreader indexreader = directoryreader.open(directory); indexsearcher indexserch = new indexsearcher(indexreader); // 数字范围查询。newrangequery包含开头结尾 // 如果想不包含请使用 math.addexact(lowervalue[i], 1)或math.addexact(uppervalue[i], -1)处理 query query = longpoint.newrangequery(\u0026#34;filesize\u0026#34;, 100l, 800l); // 查询二十条 topdocs topdocs = indexserch.search(query,20); // 查询的总数 system.out.println(\u0026#34;totalhits:\u0026#34;+topdocs.totalhits); for (scoredoc scoredoc : topdocs.scoredocs) { // 获得分数 system.out.println(\u0026#34;score:\u0026#34;+scoredoc.score); // 获得文档 document doc = indexserch.doc(scoredoc.doc); system.out.println(\u0026#34;filename:\u0026#34;+doc.get(\u0026#34;filename\u0026#34;)); system.out.println(\u0026#34;filepath:\u0026#34;+doc.get(\u0026#34;filepath\u0026#34;)); system.out.println(\u0026#34;filesize:\u0026#34;+doc.get(\u0026#34;filesize\u0026#34;)); system.out.println(\u0026#34;filecontent:\u0026#34;+doc.get(\u0026#34;filecontent\u0026#34;)); } indexreader.close(); } prefixquery前缀查询 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 @test public void testprefixsearch() throws exception { directory directory = fsdirectory.open(paths.get(\u0026#34;e:/luceneindex\u0026#34;)); // 创建indexreader directoryreader indexreader = directoryreader.open(directory); indexsearcher indexserch = new indexsearcher(indexreader); // 前缀查询。含有前缀apa的关键词 query query = new prefixquery(new term(\u0026#34;filename\u0026#34;,\u0026#34;apa\u0026#34;)); // 查询二十条 topdocs topdocs = indexserch.search(query,20); // 查询的总数 system.out.println(\u0026#34;totalhits:\u0026#34;+topdocs.totalhits); for (scoredoc scoredoc : topdocs.scoredocs) { // 获得分数 system.out.println(\u0026#34;score:\u0026#34;+scoredoc.score); // 获得文档 document doc = indexserch.doc(scoredoc.doc); system.out.println(\u0026#34;filename:\u0026#34;+doc.get(\u0026#34;filename\u0026#34;)); system.out.println(\u0026#34;filepath:\u0026#34;+doc.get(\u0026#34;filepath\u0026#34;)); system.out.println(\u0026#34;filesize:\u0026#34;+doc.get(\u0026#34;filesize\u0026#34;)); system.out.println(\u0026#34;filecontent:\u0026#34;+doc.get(\u0026#34;filecontent\u0026#34;)); } indexreader.close(); } wildcardquery通配符查询 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 @test public void testwildcardsearch() throws exception { directory directory = fsdirectory.open(paths.get(\u0026#34;e:/luceneindex\u0026#34;)); // 创建indexreader directoryreader indexreader = directoryreader.open(directory); indexsearcher indexserch = new indexsearcher(indexreader); // 通配符查询,*代码任意个字符,?代表一位占位符 query query = new wildcardquery(new term(\u0026#34;filename\u0026#34;,\u0026#34;?a*\u0026#34;)); //查询二十条 topdocs topdocs = indexserch.search(query,20); // 查询的总数 system.out.println(\u0026#34;totalhits:\u0026#34;+topdocs.totalhits); for (scoredoc scoredoc : topdocs.scoredocs) { // 获得分数 system.out.println(\u0026#34;score:\u0026#34;+scoredoc.score); // 获得文档 document doc = indexserch.doc(scoredoc.doc); system.out.println(\u0026#34;filename:\u0026#34;+doc.get(\u0026#34;filename\u0026#34;)); system.out.println(\u0026#34;filepath:\u0026#34;+doc.get(\u0026#34;filepath\u0026#34;)); system.out.println(\u0026#34;filesize:\u0026#34;+doc.get(\u0026#34;filesize\u0026#34;)); system.out.println(\u0026#34;filecontent:\u0026#34;+doc.get(\u0026#34;filecontent\u0026#34;)); } indexreader.close(); } booleanquery多条件查询 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 @test public void testbooleansearch() throws exception { directory directory = fsdirectory.open(paths.get(\u0026#34;e:/luceneindex\u0026#34;)); // 创建indexreader directoryreader indexreader = directoryreader.open(directory); indexsearcher indexserch = new indexsearcher(indexreader); // occur.must 必须 相当于 and // occur.must_not 必须不 相当于 ! // occur.should 应该 相当于or // occur.filter 和must功能相同除了不参与计分,用于过滤替代了6.0之前的filter builder querybuilder = new booleanquery.builder(); query filenamequery = new termquery(new term(\u0026#34;filename\u0026#34;, \u0026#34;apache\u0026#34;)); query filecontentquery = new termquery(new term(\u0026#34;filecontent\u0026#34;, \u0026#34;java\u0026#34;)); querybuilder.add(filenamequery, occur.must); querybuilder.add(filecontentquery, occur.should); // 查询二十条 topdocs topdocs = indexserch.search(querybuilder.build(),20); // 查询的总数 system.out.println(\u0026#34;totalhits:\u0026#34;+topdocs.totalhits); for (scoredoc scoredoc : topdocs.scoredocs) { // 获得分数 system.out.println(\u0026#34;score:\u0026#34;+scoredoc.score); // 获得文档 document doc = indexserch.doc(scoredoc.doc); system.out.println(\u0026#34;filename:\u0026#34;+doc.get(\u0026#34;filename\u0026#34;)); system.out.println(\u0026#34;filepath:\u0026#34;+doc.get(\u0026#34;filepath\u0026#34;)); system.out.println(\u0026#34;filesize:\u0026#34;+doc.get(\u0026#34;filesize\u0026#34;)); system.out.println(\u0026#34;filecontent:\u0026#34;+doc.get(\u0026#34;filecontent\u0026#34;)); } indexreader.close(); } phrasequery短语查询 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 @test public void testphrasesearch() throws exception { directory directory = fsdirectory.open(paths.get(\u0026#34;e:/luceneindex\u0026#34;)); // 创建indexreader directoryreader indexreader = directoryreader.open(directory); indexsearcher indexserch = new indexsearcher(indexreader); // apache和solr相差十个单词以内 query query = new phrasequery(10,\u0026#34;filename\u0026#34;,\u0026#34;apache\u0026#34;,\u0026#34;solr\u0026#34;); // 查询二十条 topdocs topdocs = indexserch.search(query,20); // 查询的总数 system.out.println(\u0026#34;totalhits:\u0026#34;+topdocs.totalhits); for (scoredoc scoredoc : topdocs.scoredocs) { // 获得分数 system.out.println(\u0026#34;score:\u0026#34;+scoredoc.score); // 获得文档 document doc = indexserch.doc(scoredoc.doc); system.out.println(\u0026#34;filename:\u0026#34;+doc.get(\u0026#34;filename\u0026#34;)); system.out.println(\u0026#34;filepath:\u0026#34;+doc.get(\u0026#34;filepath\u0026#34;)); system.out.println(\u0026#34;filesize:\u0026#34;+doc.get(\u0026#34;filesize\u0026#34;)); system.out.println(\u0026#34;filecontent:\u0026#34;+doc.get(\u0026#34;filecontent\u0026#34;)); } indexreader.close(); } fuzzy模糊查询,允许匹配存在误差 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 @test public void testfuzzysearch() throws exception { directory directory = fsdirectory.open(paths.get(\u0026#34;e:/luceneindex\u0026#34;)); // 创建indexreader directoryreader indexreader = directoryreader.open(directory); indexsearcher indexserch = new indexsearcher(indexreader); // 允许aahe有两个字母不同(包括增加减少)例如可以匹配apache query query = new fuzzyquery(new term(\u0026#34;filename\u0026#34;,\u0026#34;aahe\u0026#34;),2); // 查询二十条 topdocs topdocs = indexserch.search(query,20); // 查询的总数 system.out.println(\u0026#34;totalhits:\u0026#34;+topdocs.totalhits); for (scoredoc scoredoc : topdocs.scoredocs) { // 获得分数 system.out.println(\u0026#34;score:\u0026#34;+scoredoc.score); // 获得文档 document doc = indexserch.doc(scoredoc.doc); system.out.println(\u0026#34;filename:\u0026#34;+doc.get(\u0026#34;filename\u0026#34;)); system.out.println(\u0026#34;filepath:\u0026#34;+doc.get(\u0026#34;filepath\u0026#34;)); system.out.println(\u0026#34;filesize:\u0026#34;+doc.get(\u0026#34;filesize\u0026#34;)); system.out.println(\u0026#34;filecontent:\u0026#34;+doc.get(\u0026#34;filecontent\u0026#34;)); } indexreader.close(); } queryparser分析语句查询 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 @test public void testqueryparsersearch() throws exception { directory directory = fsdirectory.open(paths.get(\u0026#34;e:/luceneindex\u0026#34;)); // 创建indexreader directoryreader indexreader = directoryreader.open(directory); indexsearcher indexserch = new indexsearcher(indexreader); // queryparser需要传入分词器 queryparser queryparser = new queryparser(\u0026#34;filename\u0026#34;,new standardanalyzer()); query query = queryparser.parse(\u0026#34;filename:apache and filecontent:java\u0026#34;); // 查询二十条 topdocs topdocs = indexserch.search(query,20); // 查询的总数 system.out.println(\u0026#34;totalhits:\u0026#34;+topdocs.totalhits); for (scoredoc scoredoc : topdocs.scoredocs) { // 获得分数 system.out.println(\u0026#34;score:\u0026#34;+scoredoc.score); // 获得文档 document doc = indexserch.doc(scoredoc.doc); system.out.println(\u0026#34;filename:\u0026#34;+doc.get(\u0026#34;filename\u0026#34;)); system.out.println(\u0026#34;filepath:\u0026#34;+doc.get(\u0026#34;filepath\u0026#34;)); system.out.println(\u0026#34;filesize:\u0026#34;+doc.get(\u0026#34;filesize\u0026#34;)); system.out.println(\u0026#34;filecontent:\u0026#34;+doc.get(\u0026#34;filecontent\u0026#34;)); } indexreader.close(); } 注意:queryparser.setallowleadingwildcard(false); 当为true时才可使用通配符和前缀查询\nqueryparser查询语法:\n符号 作用 例子 描述 + 相当于must 必须满足 +filename:apache and filename:solr 必须满足第一个条件,第二个可以不满足(第二个条件此种情况下无效,不论and\\or) # 相当于filter必须满足不计分 #filename:apache and filename:solr 必须满足第一个条件,第二个可以不满足(第二个条件此种情况下无效,不论and\\or) - 相当于must not 必须不满足 -filename:apache and filename:solr 必须不满足第一个条件,第二个必须不满足(第二个条件此种情况下必须满足不论and\\or) and 并且,左右两边条件必须满足 filename:apache and filename:solr 左右两个条件必须满足 or 或者,左右两边条件满足一个 filename:apache or filename:solr 可以使用空格达到同样的效果 “语句” 必须完全匹配语句 filename:\u0026ldquo;apache lucene.txt\u0026rdquo; 必须安全匹配apache lucene */? 通配符匹配 filename:apa* 文件名单词含有apa开头的 ~ 短语匹配 filename:\u0026ldquo;apache solr\u0026rdquo; ~10 apache和solr相差十个单词以内 ~ 模糊匹配 filename:apecha~0.4 模糊匹配,默认相似的0.5 [x to y] 字符串范围匹配 filename:[a to b] 使用的比较规则是字符串比较规则,先比较首字母然后依次类推,不包含使用{} ^ 改变提升因子 filename:apache^4 filename为apache的分数上升 字段:(+索引 +索引) 字段分组 filename:(+apache +solr) filename既包含apache又包含solr 注:directoryreader.open(directory directory)打开之后并不会跟随indexwriter的删除而感知到。directoryreader.openifchanged(directoryreader oldreader)如果索引文件发生变化返回一个新的indexreader,如果索引文件没有变化返回null可以进行感知;\n五、lucene 排序 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 @test public void testsortsearch() throws exception { directory directory = fsdirectory.open(paths.get(\u0026#34;e:/luceneindex\u0026#34;)); directoryreader indexreader = directoryreader.open(directory); indexsearcher indexsearcher = new indexsearcher(indexreader); queryparser queryparser = new queryparser(\u0026#34;filename\u0026#34;,new standardanalyzer()); query query = queryparser.parse(\u0026#34;*:* filename:apache\u0026#34;); // 按照分数排序,倒数第二个参数是是否计算分数,false不计算结果为nan // 最后一个参数为是否计算最高分 topdocs topdocs = indexsearcher.search(query,20,sort.relevance,true,false); // 查询的总数 system.out.println(\u0026#34;totalhits:\u0026#34;+topdocs.totalhits); for (scoredoc scoredoc : topdocs.scoredocs) { // 获得分数 system.out.println(\u0026#34;score:\u0026#34;+scoredoc.score); // 获得文档 document doc = indexsearcher.doc(scoredoc.doc); system.out.println(\u0026#34;id:\u0026#34;+doc.get(\u0026#34;id\u0026#34;)); system.out.println(\u0026#34;filename:\u0026#34;+doc.get(\u0026#34;filename\u0026#34;)); system.out.println(\u0026#34;filepath:\u0026#34;+doc.get(\u0026#34;filepath\u0026#34;)); system.out.println(\u0026#34;filesize:\u0026#34;+doc.get(\u0026#34;filesize\u0026#34;)); system.out.println(\u0026#34;filecontent:\u0026#34;+doc.get(\u0026#34;filecontent\u0026#34;)); } indexreader.close(); } sort的默认有两种\nsort.relevance\t按照分数排序 sort.indexorder\t按照序号排序,创建lucene的document顺序 sort的自定义实现\n使用自然比较 1 2 3 4 5 //使用long类型比较,第三个参数是否翻转排序结果 //自定义排序需要在field上存储对应的docvaluesfield才能排序,目的是提高效率 sortfield sortfield = new sortfield(\u0026#34;filesize\u0026#34;, type.long, false); sort sort = new sort(sortfield); topdocs topdocs = indexsearcher.search(query,20,sort,true,false); 使用自定义比较规则\n第一步创建自定义比较器 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 public class mycoustomfieldcomparatorsource extends fieldcomparatorsource { /** * 创建自定义比较器: * fieldname\t字段名 * numhits\t查出总记录数 * reversed\t是否翻转 */ @override public fieldcomparator\u0026lt;?\u0026gt; newcomparator(string fieldname, int numhits, int sortpos, boolean reversed) { return new mycoustomfieldcomparator(fieldname,numhits); } private class mycoustomfieldcomparator extends simplefieldcomparator\u0026lt;string\u0026gt; { private string values[]; private string fieldname; private string top; private string bottom; private leafreadercontext leafreadercontext; public mycoustomfieldcomparator(string fieldname,int numhits) { this.fieldname = fieldname; this.values = new string[numhits]; } // 设置leafreadercontext @override protected void dosetnextreader(leafreadercontext context) throws ioexception { this.leafreadercontext = context; } // 存储所有值slot当前下标,doc文档id @override public void copy(int slot, int doc) throws ioexception { values[slot] = leafreadercontext.reader().document(doc).getfield(fieldname).stringvalue(); } // 比较两个值,slot1,slot2下标 @override public int compare(int slot1, int slot2) { return integer.compare(values[slot1].length(), values[slot2].length()); } // 得到值,slot下标 @override public string value(int slot) { return values[slot]; } // 设置最小值,slot最小值下标 @override public void setbottom(int slot) throws ioexception { bottom = values[slot]; } // 设置最大值,value最大值 @override public void settopvalue(string value) { this.top = value; } // 和最小值比较,doc当前要比较的文档id @override public int comparebottom(int doc) throws ioexception { string currentfilename = leafreadercontext.reader().document(doc).getfield(fieldname).stringvalue(); return integer.compare(bottom.length(), currentfilename.length()); } // 和最大值比较,doc当前要比较的文档id @override public int comparetop(int doc) throws ioexception { string currentfilename = leafreadercontext.reader().document(doc).getfield(fieldname).stringvalue(); return integer.compare(top.length(), currentfilename.length()); } } } 第二步使用自定义比较器进行排序 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 @test public void testsortsearch2() throws exception { directory directory = fsdirectory.open(paths.get(\u0026#34;e:/luceneindex\u0026#34;)); directoryreader indexreader = directoryreader.open(directory); indexsearcher indexsearcher = new indexsearcher(indexreader); queryparser queryparser = new queryparser(\u0026#34;\u0026#34;,new standardanalyzer()); query query = queryparser.parse(\u0026#34;*:*\u0026#34;); // 创建自定义比较器 mycoustomfieldcomparatorsource mycoustomfieldcomparatorsource = new mycoustomfieldcomparatorsource(); // 创建sortfield使用自定义比较器 sortfield sortfield = new sortfield(\u0026#34;filename\u0026#34;, mycoustomfieldcomparatorsource); sort sort = new sort(sortfield); topdocs topdocs = indexsearcher.search(query,20,sort,true,false); // 查询的总数 system.out.println(\u0026#34;totalhits:\u0026#34;+topdocs.totalhits); for (scoredoc scoredoc : topdocs.scoredocs) { // 获得分数 system.out.println(\u0026#34;score:\u0026#34;+scoredoc.score); // 获得文档 document doc = indexsearcher.doc(scoredoc.doc); system.out.println(\u0026#34;id:\u0026#34;+doc.get(\u0026#34;id\u0026#34;)); system.out.println(\u0026#34;filename:\u0026#34;+doc.get(\u0026#34;filename\u0026#34;)); system.out.println(\u0026#34;filepath:\u0026#34;+doc.get(\u0026#34;filepath\u0026#34;)); system.out.println(\u0026#34;filesize:\u0026#34;+doc.get(\u0026#34;filesize\u0026#34;)); system.out.println(\u0026#34;filecontent:\u0026#34;+doc.get(\u0026#34;filecontent\u0026#34;)); } indexreader.close(); } 六、lucene 查询高亮 使用highlighter实现高亮 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 @test public void testhighlightersearch() throws exception { directory directory = fsdirectory.open(paths.get(\u0026#34;e:/luceneindex\u0026#34;)); directoryreader indexreader = directoryreader.open(directory); indexsearcher indexsearcher = new indexsearcher(indexreader); analyzer analyzer = new standardanalyzer(); queryparser queryparser = new queryparser(\u0026#34;filename\u0026#34;,analyzer); query query = queryparser.parse(\u0026#34;filename:apache\u0026#34;); // 高亮相关部分创建 queryscorer queryscorer = new queryscorer(query);\t// 简单的分段器 fragmenter fragmenter = new simplefragmenter(); // 格式 simplehtmlformatter simplehtmlformatter = new simplehtmlformatter(\u0026#34;\u0026lt;font color=\u0026#39;red\u0026#39;\u0026gt;\u0026#34;,\u0026#34;\u0026lt;/font\u0026gt;\u0026#34;); // 高亮查询器 highlighter highlighter = new highlighter(simplehtmlformatter, queryscorer); // 设置分段,会将长内容拿出含有关键字的部分 highlighter.settextfragmenter(fragmenter);\ttopdocs topdocs = indexsearcher.search(query, 20); // 查询的总数 system.out.println(\u0026#34;totalhits:\u0026#34;+topdocs.totalhits); for (scoredoc scoredoc : topdocs.scoredocs) { // 获得分数 system.out.println(\u0026#34;score:\u0026#34;+scoredoc.score); // 获得文档 document doc = indexsearcher.doc(scoredoc.doc); system.out.println(\u0026#34;id:\u0026#34;+doc.get(\u0026#34;id\u0026#34;)); string filename = doc.get(\u0026#34;filename\u0026#34;); system.out.println(\u0026#34;filename:\u0026#34;+ filename); if(filename != null) { // 得到对应的tokenstream tokenstream tokenstream = analyzer.tokenstream(\u0026#34;filename\u0026#34;, filename); // 拿出得分最高的段 string highlighttext = highlighter.getbestfragment(tokenstream,filename); system.out.println(highlighttext); } system.out.println(\u0026#34;filepath:\u0026#34;+doc.get(\u0026#34;filepath\u0026#34;)); system.out.println(\u0026#34;filesize:\u0026#34;+doc.get(\u0026#34;filesize\u0026#34;)); string filecontent = doc.get(\u0026#34;filecontent\u0026#34;); if(filecontent != null) { // 得到对应的tokenstream tokenstream tokenstream = analyzer.tokenstream(\u0026#34;filecontent\u0026#34;, filecontent); // 拿出得分最高的段 string highlighttext = highlighter.getbestfragment(tokenstream, filecontent); system.out.println(highlighttext); } } indexreader.close(); } 使用fastvectorhighlighter实现高亮,适合大文档 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 /** * 使用fastvectorhighlighter前置条件是字段创建时存储相关信息,牺牲存储换取时间 * fieldtype filenamefieldtype = new fieldtype(); * filenamefieldtype.setindexoptions(indexoptions.docs_and_freqs_and_positions); * filenamefieldtype.settokenized(true); * filenamefieldtype.setstored(true); * filenamefieldtype.setstoretermvectoroffsets(true); //记录相对增量 * filenamefieldtype.setstoretermvectorpositions(true); //记录位置信息 * filenamefieldtype.setstoretermvectors(true); //存储向量信息 * filenamefieldtype.freeze();\t//阻止改动信息 * field filenamefield = new field(\u0026#34;filename\u0026#34;, file.getname(), filenamefieldtype); * document.add(filenamefield); */ @test public void testfastvectorhighlightersearch() throws exception { directory directory = fsdirectory.open(paths.get(\u0026#34;e:/luceneindex\u0026#34;)); directoryreader indexreader = directoryreader.open(directory); indexsearcher indexsearcher = new indexsearcher(indexreader); analyzer analyzer = new standardanalyzer(); queryparser queryparser = new queryparser(\u0026#34;filename\u0026#34;,analyzer); query query = queryparser.parse(\u0026#34;filename:apache\u0026#34;); topdocs topdocs = indexsearcher.search(query, 20); // 高亮相关部分创建 fraglistbuilder fraglistbuilder = new simplefraglistbuilder(); fragmentsbuilder fragmentsbuilder = new simplefragmentsbuilder( basefragmentsbuilder.colored_pre_tags, basefragmentsbuilder.colored_post_tags); fastvectorhighlighter fastvectorhighlighter = new fastvectorhighlighter( true, true,fraglistbuilder,fragmentsbuilder); fieldquery fieldquery = fastvectorhighlighter.getfieldquery(query); // 查询的总数 system.out.println(\u0026#34;totalhits:\u0026#34;+topdocs.totalhits); for (scoredoc scoredoc : topdocs.scoredocs) { // 获得分数 system.out.println(\u0026#34;score:\u0026#34;+scoredoc.score); // 获得文档 document doc = indexsearcher.doc(scoredoc.doc); system.out.println(\u0026#34;id:\u0026#34;+doc.get(\u0026#34;id\u0026#34;)); string filename = doc.get(\u0026#34;filename\u0026#34;); system.out.println(\u0026#34;filename:\u0026#34;+ filename); if(filename != null) { string highlighttext = fastvectorhighlighter.getbestfragment( fieldquery, indexsearcher.getindexreader(), scoredoc.doc, \u0026#34;filename\u0026#34;,100); system.out.println(highlighttext); } system.out.println(\u0026#34;filepath:\u0026#34;+doc.get(\u0026#34;filepath\u0026#34;)); system.out.println(\u0026#34;filesize:\u0026#34;+doc.get(\u0026#34;filesize\u0026#34;)); string filecontent = doc.get(\u0026#34;filecontent\u0026#34;); if(filecontent != null) { string highlighttext = fastvectorhighlighter.getbestfragment( fieldquery, indexsearcher.getindexreader(), scoredoc.doc, \u0026#34;filecontent\u0026#34;, 100); system.out.println(highlighttext); } } indexreader.close(); } 七、lucene 分页 方式一,使用下标获取对象 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 topdocs topdocs = indexserch.search(query,200); // 获取第十条到第十五条记录 int startpos =10; int endpos =15; // 查询的总数 system.out.println(\u0026#34;totalhits:\u0026#34;+topdocs.totalhits); for (int i = startpos; i \u0026lt; endpos; i++) { scoredoc scoredoc = topdocs.scoredocs[i]; // 获得分数 system.out.println(\u0026#34;score:\u0026#34;+scoredoc.score); // 获得文档 document doc = indexserch.doc(scoredoc.doc); system.out.println(\u0026#34;filename:\u0026#34;+doc.get(\u0026#34;filename\u0026#34;)); system.out.println(\u0026#34;filepath:\u0026#34;+doc.get(\u0026#34;filepath\u0026#34;)); system.out.println(\u0026#34;filesize:\u0026#34;+doc.get(\u0026#34;filesize\u0026#34;)); system.out.println(\u0026#34;filecontent:\u0026#34;+doc.get(\u0026#34;filecontent\u0026#34;)); } 方式二,使用searchafter传入最后一个查询到的对象 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 scoredoc currentscoredoc = null; // 每页数量 int pagesize = 5; // 要查询第几页 int nextpage = 3; if(nextpage != 1) { // 获取上一页的最后是第多少条 int num = pagesize*(nextpage-1); topdocs td = indexserch.search(query, num); currentscoredoc = td.scoredocs[num-1]; } // 在最后一页的基础上在查几条 topdocs topdocs = indexserch.searchafter(currentscoredoc, query, pagesize); system.out.println(\u0026#34;totalhits:\u0026#34;+topdocs.totalhits); for (scoredoc scoredoc : topdocs.scoredocs) { // 获得分数 system.out.println(\u0026#34;score:\u0026#34;+scoredoc.score); // 获得文档 document doc = indexserch.doc(scoredoc.doc); system.out.println(\u0026#34;filename:\u0026#34;+doc.get(\u0026#34;filename\u0026#34;)); system.out.println(\u0026#34;filepath:\u0026#34;+doc.get(\u0026#34;filepath\u0026#34;)); system.out.println(\u0026#34;filesize:\u0026#34;+doc.get(\u0026#34;filesize\u0026#34;)); system.out.println(\u0026#34;filecontent:\u0026#34;+doc.get(\u0026#34;filecontent\u0026#34;)); } 八、lucene 删除索引 删除所有索引 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 @test public void testdeleteindex() throws exception { analyzer analyzer = new standardanalyzer();\t// 索引库位置 directory directory = niofsdirectory.open(paths.get(\u0026#34;e:/luceneindex\u0026#34;)); // 配置indexwriter indexwriterconfig writerconfig = new indexwriterconfig(analyzer); // 创建indexwriter indexwriter indexwriter = new indexwriter(directory, writerconfig); // 删除所有索引 indexwriter.deleteall(); // 提交删除,会清空所有 indexwriter.commit(); indexwriter.close(); } 删除查询出的索引 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 @test public void testrangedeleteindex() throws exception { analyzer analyzer = new standardanalyzer();\t// 索引库位置 directory directory = fsdirectory.open(paths.get(\u0026#34;e:/luceneindex\u0026#34;)); // 配置indexwriter indexwriterconfig writerconfig = new indexwriterconfig(analyzer); // 创建indexwriter indexwriter indexwriter = new indexwriter(directory, writerconfig); query query = longpoint.newrangequery(\u0026#34;filesize\u0026#34;, 1000, 100000); // 删除 indexwriter.deletedocuments(query); // 提交删除,会将删除的内容存放与“回收站中” indexwriter.commit(); // 在未关闭indexwriter的时间段,可以查询到总条数,总可查询条数,总删除条数 thread.sleep(100000l); indexwriter.close(); } 查询总记录数、可查询条数、回收站删除条数 1 2 3 system.out.println(\u0026#34;maxdoc:\u0026#34;+indexreader.maxdoc()); system.out.println(\u0026#34;numdocs:\u0026#34;+indexreader.numdocs()); system.out.println(\u0026#34;numdeleteddocs:\u0026#34;+indexreader.numdeleteddocs()); 九、lucene 修改索引 修改索引的本质是删除匹配的索引添加新的索引\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 @test public void testmodifyindex() throws exception { analyzer analyzer = new standardanalyzer();\t// 索引库位置 directory directory = fsdirectory.open(paths.get(\u0026#34;e:/luceneindex\u0026#34;)); // 配置indexwriter indexwriterconfig writerconfig = new indexwriterconfig(analyzer); // 创建indexwriter indexwriter indexwriter = new indexwriter(directory, writerconfig); // 要修改的term term termold = new term(\u0026#34;filename\u0026#34;,\u0026#34;apache\u0026#34;); // 要添加的document document newdoc = new document(); newdoc.add(new textfield(\u0026#34;filename\u0026#34;, \u0026#34;gogogo\u0026#34;, store.yes)); newdoc.add(new textfield(\u0026#34;filecontent\u0026#34;, \u0026#34;gogogo wowowo\u0026#34;, store.yes)); // 更新 indexwriter.updatedocument(termold, newdoc); // 提交 indexwriter.commit(); indexwriter.close(); } 十、lucene analyzer tokenizer:主要负责接收字符流reader,将reader进行分词操作 tokenfilter:将分好词的语汇单元进行各种过滤 tokenstream:分词器处理完成得到的一个流,这个流中存储了分词的各种信息,可以通过tokenstream有效的获取到分词单元 tokenstream主要存储的元素信息:\nchartermattribute\t存储每个语汇单元的信息,用于做filter offsetattribute\t每个语汇单元的偏移量 positionincrementattribute\t存储语汇单元之间的距离,可以做同义词 typeattribute\t使用的分词器的类型信息 十一、lucene 近实时搜索 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 @test public void testnearrealtimesearching() throws exception { directory directory = fsdirectory.open(paths.get(\u0026#34;e:/luceneindex\u0026#34;)); standardanalyzer standardanalyzer = new standardanalyzer(); indexwriterconfig indexwriterconfig = new indexwriterconfig(standardanalyzer); indexwriter indexwriter = new indexwriter(directory, indexwriterconfig); // 创建searchmanager实现近实时搜索 searchermanager searchermanager = new searchermanager(indexwriter,true,true,new searcherfactory()); // 将searchermanager给controlledrealtimereopenthread管理用于自动更新索引 controlledrealtimereopenthread\u0026lt;indexsearcher\u0026gt; crtreopenthread = new controlledrealtimereopenthread\u0026lt;indexsearcher\u0026gt;(indexwriter, searchermanager,5.0, 0.025) ; // 设置为后台进程 crtreopenthread.setdaemon(true); crtreopenthread.setname(\u0026#34;lucene后台刷新服务\u0026#34;); crtreopenthread.start(); //从searchmananger得到indexsearch indexsearcher indexsearcher = searchermanager.acquire(); } 其他 indexwriter下的,不要手动调用,lucene会在合适的时候自己调用优化结构\npublic void forcemerge(int maxnumsegments, boolean dowait) 将段文件合并 public void forcemergedeletes(boolean dowait) 删除”回收站“文件 读取各种各样的文档会使用对应的工具类例如,先可以使用tika来读取各种文档信息,tika实现了可视化界面用于查看信息官网提供了tika-app-版本号.jar的jar包下载\npdf使用pdfbox excel、word、ppt使用apache poi 读取txt使用apache common io tika使用方式一\n1 2 3 4 5 static private tika tika = new tika(); static public string filetotxt(file file,metadata metadata) throws ioexception, tikaexception { // metadata 元数据信息 return tika.parsetostring(new fileinputstream(file),metadata); } tika使用方式二\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 static private parser parser; static private contenthandler contenthandler; static private parsecontext parsecontext; static { // 自动解析器 parser = new autodetectparser(); // 创建contenthandler,解析结果为xml格式,只解析内容 contenthandler = new bodycontenthandler(); // 创建context parsecontext = new parsecontext(); parsecontext.set(parser.class,parser); } public static string filetotxt(file file,metadata metadata) throws ioexception, saxexception, tikaexception { parser.parse(new fileinputstream(file),contenthandler, metadata,parsecontext); return contenthandler.tostring(); } ","date":"2018-10-29","permalink":"https://hobocat.github.io/post/searchengine/2018-10-29-lucene/","summary":"一、术语\u0026amp;基础知识术语 结构化数据 结构化数据:指具有固定格式或有限长度的数据,如数据库等 非结构化数据:指不定长或无固定格式的数据,如HTML等 数据查询方法","title":"lucene基本应用"},]
[{"content":"一、map结构优化 \tjava8之前hashmap存储结构如下图,将map中的key进行哈希运算得到hashcode,当出现hashcode相同但equals不同时称此现象为碰撞,发生碰撞时会形成链表结构,取值时会遍历整个链表结构效率较低。\n\tjava8采用的hashmap存储结构如下图,当发生碰撞形成的链表上元素个数大于8时,总容量大于64会将链表转换为红黑树。此种情况下除了添加元素慢一些,其余操作(查询,删除)均高于链表结构。\n\tjava8之前concurrenthashmap为hashtable的组合达到线程安全的效果,默认并发级别为16即concurrenthashmap由16个hashtable组成。java8采用cas算法到达线程安全的效果,数据结构为java8的hashmap结构。\n注:hashmap起始默认容器大小为16,当容器元素个数到达75%(扩容因子)开始扩容,扩容一倍大小重新计算位置。\n二、jvm内存结构的改变 历史:之前很多公司生产的jvm早已没有永久代,只是sun的jvm还没有淘汰永久代\noracle-sun\thotspot oracle\throcket ibm\tj9 jvm alibaba\ttaobao jvm \tjava8将永久代变为元空间(metaspace)。之前永久代在jvm中分配,永久代基本不回收占用jvm内存空间。java8废弃永久代改为元空间,元空间在操作系统的内存上进行分配。\npremgensize和maxpremgenmaxsize被删除 metaspacesize和metaspcaemaxsiez被添加 三、lambda表达式 \t在函数式语言中,我们只需要给函数分配变量,并将这个函数作为参数传递给其它函数就可实现特定的功能。而java如前言中所述,不能直接将方法当作一个参数传递。同时匿名内部类又存在诸多不便:语法过于冗余,匿名类中的this和变量名容易使人产生误解,类型载入和实例创建语义不够灵活,无法捕获非final的局部变量等。 lambda 表达式的出现为 java 添加了缺失的函数式编程特点,使我们能将函数当做一等公民看待。\n概述 \tlambda 表达式在java 语言中引入了一个新的语法元素和操作符。这个操作符为-\u0026gt; ,该操作符被称为lambda 操作符或箭头操作符。它将lambda 分为两个部分: \t左侧:指定了lambda 表达式需要的所有参数 \t右侧:指定了lambda 体,即lambda 表达式要执行的功能\n\tlambda表达式实现的必须是函数式接口。\n\t只包含一个抽象方法的接口,称为函数式接口。可以通过lambda 表达式来创建该接口的对象。(若lambda 表达式抛出一个受检异常,那么该异常需要在目标接口的抽象方法上进行声明)。我们可以在任意函数式接口上使用@functionalinterface注解,这样做可以检查它是否是一个函数式接口,同时javadoc也会包含一条声明,说明这个接口是一个函数式接口。\n演示 1 2 3 4 5 6 7 8 /** * 情景一:无参数,无返回值,一条语句 */ @test public void test() throws exception { runnable r = () -\u0026gt; system.out.println(\u0026#34;hello lambda\u0026#34;); r.run(); } 1 2 3 4 5 6 7 8 /** * 情景二:有一个参数,并且无返回值,一条语句 */ @test public void test() throws exception { consumer\u0026lt;string\u0026gt; consumer = (x) -\u0026gt; system.out.println(\u0026#34;hello \u0026#34; + x); consumer.accept(\u0026#34;lambda\u0026#34;); } 1 2 3 4 5 6 7 8 9 10 /** * 情景三:有两个以上参数,多条语句 */ @test public void test() throws exception { comparator\u0026lt;integer\u0026gt; comparator = (x, y) -\u0026gt; { system.out.println(\u0026#34;多条语句\u0026#34;); return integer.compare(x, y); }; } 注:\n当参数只有一个时小括号可以不写,但一般情况下不省略。\n当只有lambda体中只有一条语句可以省略{}和return,一般情况下省略。\nlambda表达式的参数列表的数据类型可以省略不写,因为jvm编译器可以通过上下文进行类型推断。如果要写需要全部写上类型。\n内置核心函数式接口 ①消费型接口\n1 2 3 4 5 6 7 8 9 10 11 @functionalinterface public interface consumer\u0026lt;t\u0026gt; { void accept(t t); // 链式调用,之后继续调用消费型接口 default consumer\u0026lt;t\u0026gt; andthen(consumer\u0026lt;? super t\u0026gt; after) { objects.requirenonnull(after); return (t t) -\u0026gt; { accept(t); after.accept(t); }; } } ②供给型接口\n1 2 3 4 5 @functionalinterface public interface supplier\u0026lt;t\u0026gt; { t get(); } ③函数型接口\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 @functionalinterface public interface function\u0026lt;t, r\u0026gt; { r apply(t t); // 链式调用,在调用此方法之前调用传入的函数式接口 default \u0026lt;v\u0026gt; function\u0026lt;v, r\u0026gt; compose(function\u0026lt;? super v, ? extends t\u0026gt; before) { objects.requirenonnull(before); return (v v) -\u0026gt; apply(before.apply(v)); } // 链式调用,在调用此方法之后调用传入的函数式接口 default \u0026lt;v\u0026gt; function\u0026lt;t, v\u0026gt; andthen(function\u0026lt;? super r, ? extends v\u0026gt; after) { objects.requirenonnull(after); return (t t) -\u0026gt; after.apply(apply(t)); } // 返回输入的参数,function.identity().apply(\u0026#34;aaa\u0026#34;)返回aaa static \u0026lt;t\u0026gt; function\u0026lt;t, t\u0026gt; identity() { return t -\u0026gt; t; } } ④断言型接口\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 @functionalinterface public interface predicate\u0026lt;t\u0026gt; { boolean test(t t); // 链式调用,需要同时满足条件 default predicate\u0026lt;t\u0026gt; and(predicate\u0026lt;? super t\u0026gt; other) { objects.requirenonnull(other); return (t) -\u0026gt; test(t) \u0026amp;\u0026amp; other.test(t); } // 取相反值 default predicate\u0026lt;t\u0026gt; negate() { return (t) -\u0026gt; !test(t); } // 链式调用,只需要满足一个条件即可 default predicate\u0026lt;t\u0026gt; or(predicate\u0026lt;? super t\u0026gt; other) { objects.requirenonnull(other); return (t) -\u0026gt; test(t) || other.test(t); } static \u0026lt;t\u0026gt; predicate\u0026lt;t\u0026gt; isequal(object targetref) { return (null == targetref) ? objects::isnull : object -\u0026gt; targetref.equals(object); } } 四、方法引用与构造器引用 方法引用 \t当要传递给lambda体的操作,已经有实现的方法了,可以使用方法引用(实现抽象方法的参数列表和返回类型,必须与方法引用方法的参数列表和返回类型保持一致)\n\t方法引用:使用操作符:: 将方法名和对象或类的名字分隔开来。如下三种主要使用情况:\n对象::实例方法\n1 2 3 4 5 6 @test public void test() throws exception { printstream ps = system.out; consumer\u0026lt;string\u0026gt; consumer = ps::println; consumer.accept(\u0026#34;lambda\u0026#34;); } 类::静态方法\n1 2 3 4 @test public void test() throws exception { comparator\u0026lt;integer\u0026gt; comparator = integer::compare; } 类::实例方法,第一个参数是此方法的调用者,第二个参数是此方法的参数时可以使用classname::methodname\n1 2 3 4 @test public void test() throws exception { bipredicate\u0026lt;string, string\u0026gt; predicate = string::equals; } 构造器引用 普通对象的构造器引用 1 2 3 4 public void test() throws exception { supplier\u0026lt;employee\u0026gt; supplier = employee::new; // 与函数式接口参数列表匹配调用对应的构造方法 supplier.get(); } 数组对象的构造器引用 1 2 3 4 5 @test public void test() throws exception { // 传入的参数必须是integer,返回是一个数组 function\u0026lt;integer, employee[]\u0026gt; function = employee[]::new;//new employee[num] } 五、stream 简介 \tstream 是java8 中处理集合的关键抽象概念,它可以指定你希望对集合进行的操作,可以执行非常复杂的查找、过滤和映射数据等操作。使用stream api 对集合数据进行操作,就类似于使用sql 执行的数据库查询。也可以使用stream api 来并行执行操作。简而言之,stream api 提供了一种高效且易于使用的处理数据的方式。\n\t流是数据渠道,用于操作数据源(集合、数组等)所生成的元素序列。“集合讲的是数据,流讲的是计算”\nstream 自己不会存储元素 stream 不会改变源对象。相反,他们会返回一个持有结果的新stream stream 操作是延迟执行的。这意味着他们会等到需要结果的时候才执行 stream 的操作三个步骤 一、创建stream\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 @test public void test() throws exception { // 1、通过collection系列集合提供的stream()或parallelstream()获取 list\u0026lt;string\u0026gt; list = new arraylist\u0026lt;string\u0026gt;(); stream\u0026lt;string\u0026gt; stream1 = list.stream(); // 2、通过arrays中的静态方法stream()获取数组流 employee[] employees = new employee[10]; stream\u0026lt;employee\u0026gt; stream2 = arrays.stream(employees); // 3、通过stream类中的静态方法of() stream\u0026lt;string\u0026gt; stream3 = stream.of(\u0026#34;aaa\u0026#34;,\u0026#34;bbb\u0026#34;,\u0026#34;ccc\u0026#34;); // 4、迭代创建无限流 stream\u0026lt;integer\u0026gt; stream4 = stream.iterate(0, (x) -\u0026gt; x + 1); // 5、生成创建无限流 stream\u0026lt;double\u0026gt; stream5 = stream.generate(math::random); } 二、中间操作\n筛选\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 /** * filter——接受lambda,从流中排除某些元素 * limit——截断流,使其元素不超过给定数量 * skip(n)——跳过元素,返回一个扔掉了前n个元素的流。若流中元素不足n个,则返回一个空流。与limit互补 * distinct——去重,通过元素生成的hashcode和equals去重 */ @test public void test() throws exception { emps.stream().filter((e) -\u0026gt; e.getsalary() \u0026gt; 5000); emps.stream().limit(5); emps.stream().skip(5); emps.stream().distinct(); // 此操作会发生短路,取出工资大于5000的两个其余不再遍历 emps.stream().filter((e) -\u0026gt; e.getsalary() \u0026gt; 5000).limit(2); } 映射\n1 2 3 4 5 6 7 8 9 10 11 12 /** * map——接收lambda,将元素转换为其他形式。 * flatmap——接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个流 */ @test public void test() throws exception { emps.stream().map(employee::getname); // 会将【【a】,【b】,【c】】转换为【a,b,c】 list\u0026lt;list\u0026lt;string\u0026gt;\u0026gt; lls = arrays.aslist(arrays.aslist(\u0026#34;a\u0026#34;),arrays.aslist(\u0026#34;b\u0026#34;),arrays.aslist(\u0026#34;c\u0026#34;)); lls.stream().flatmap((ls) -\u0026gt; ls.stream()); } 排序\n1 2 3 4 5 6 7 8 9 10 /** * sorted():自然排序 * sorted(comparator com):定制排序 */ @test public void test() throws exception { list\u0026lt;string\u0026gt; arr = arrays.aslist(\u0026#34;aaa\u0026#34;,\u0026#34;bbb\u0026#34;,\u0026#34;ccc\u0026#34;); arr.stream().sorted(); // 自然排序 emps.stream().sorted((x, y) -\u0026gt; x.getage().compareto(y.getage())); // 定制排序 }\t三、终止操作(终端操作)\n查找与匹配\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 /** * allmatch:检查是否匹配所有元素 * anymatch:检查是否至少匹配一个元素 * nonematch:检查是否没有匹配所有元素 * findfirst:返回第一个元素 * findany:返回任意一个元素 * count:返回元素个数 * max:返回流中最大元素 * min:返回流中最小元素 */ @test public void test() throws exception { // employees是否年龄都大于18 boolean allmatch = emps.stream().allmatch((e) -\u0026gt; e.getage() \u0026gt; 18); // employees是否存在工资大于6k boolean anymatch = emps.stream().anymatch((e) -\u0026gt; e.getsalary() \u0026gt; 6000); // employees是否没有人叫小明 boolean nonematch = emps.stream().nonematch((e) -\u0026gt; e.getname().equals(\u0026#34;小明\u0026#34;)); // 返回第一个元素 optional\u0026lt;employee\u0026gt; findfirst = emps.stream().findfirst(); // 返回任意一个元素,stream()会一直返回第一个 optional\u0026lt;employee\u0026gt; findany = emps.parallelstream().findany(); // 返回元素个数 long count = emps.stream().count(); // 返回年龄最大的 optional\u0026lt;employee\u0026gt; max = emps.stream().max((x, y) -\u0026gt; integer.compare(x.getage(),y.getage())); // 返回年龄最小的 optional\u0026lt;employee\u0026gt; min = emps.stream().min((x, y) -\u0026gt; integer.compare(x.getage(),y.getage())); } 归约与收集\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 /** * 归约:reduce(t indetity, binaryoperator) / reduce(binaryoperator) * 可以将流中的元素反复结合起来得到一个新值,indetity-起始值 */ @test public void testreduce() throws exception { emps.stream().map(employee::getsalary).reduce(0.0, double::sum);\t//计算工资总和 } /** * 收集:collect - 将流转换为其他形式,接收一个collector接口实现,用于数据汇总【collectors工具类】 */ @test public void testcollect() throws exception { list\u0026lt;string\u0026gt; names = emps.stream().map(employee::getname).collect(collectors.tolist()); // 转换为自定义数据类型 hashset\u0026lt;double\u0026gt; salarys = emps.stream().map(employee::getsalary).collect(collectors.tocollection(hashset::new)); // 用收集器得到总个数 long count = emps.stream().collect(collectors.counting()); // 取平均值 double avg = emps.stream().collect(collectors.averagingdouble(employee::getsalary)); // 取总和 double sum = emps.stream().collect(collectors.summingdouble(employee::getsalary)); // 取最大值 optional\u0026lt;employee\u0026gt; max = emps.stream().collect(collectors.maxby( (x, y) -\u0026gt; double.compare(x.getsalary(), y.getsalary()))); // 拼接字符串 string joinnames = emps.stream().map(employee::getname).collect(collectors.joining(\u0026#34;,\u0026#34;)); // 通过summarystatistics获得值 doublesummarystatistics summarystatistics = emps.stream().collect(collectors.summarizingdouble(employee::getsalary)); summarystatistics.getaverage(); summarystatistics.getcount(); summarystatistics.getmax(); summarystatistics.getmin(); summarystatistics.getsum(); // 分组,也可以进行多级分组 map\u0026lt;double, list\u0026lt;employee\u0026gt;\u0026gt; groupsalary = emps.stream().collect(collectors.groupingby(employee::getsalary)); //以工资分组 map\u0026lt;string, list\u0026lt;employee\u0026gt;\u0026gt; groupage = emps.stream().collect(collectors.groupingby( (e) -\u0026gt; e.getage() \u0026gt; 35 ? \u0026#34;中年\u0026#34; : \u0026#34;青年\u0026#34;)); //以年龄分组 // 分区是一种特殊的分组,结果 map至少包含两个不同的分组一个true,一个false map\u0026lt;boolean, list\u0026lt;employee\u0026gt;\u0026gt; partitionsalary = emps.stream().collect(collectors.partitioningby((e) -\u0026gt; e.getsalary() \u0026gt; 5000)); } 遍历\n1 2 3 4 @test public void test() throws exception { emps.stream().foreach(system.out::println); } 并行流与串行流 传统线程池的缺陷 fork/join \tfork/join 框架:就是在必要的情况下,将一个大任务,进行拆分(fork)成若干个小任务(拆到不可再拆时),再将一个个的小任务运算的结果进行join 汇总。\n\t采用工作窃取模式(work-stealing): \t当执行新的任务时它可以将其拆分分成更小的任务执行,并将小任务加到线程队列中,然后再从一个随机线程的队列中偷一个并把它放在自己的队列中。相对于一般的线程池实现,fork/join框架的优势体现在对其中包含的任务的处理方式上。在一般的线程池中,如果一个线程正在执行的任务由于某些原因无法继续运行,那么该线程会处于等待状态。而在fork/join框架实现中,如果某个子问题由于等待另外一个子问题的完成而无法继续运行。那么处理该子问题的线程会主动寻找其他尚未运行的子问题来执行。这种方式减少了线程的等待时间,提高了性能。\nfork/join的好处\nfork/join示例\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 public class forkjoincalculate extends recursivetask\u0026lt;long\u0026gt; { private static final long serialversionuid = 1l; private long start; private long end; private static final long threshold = 10000; public forkjoincalculate(long start, long end) { this.start = start; this.end = end; } @override protected long compute() { long length = end - start; if(length \u0026lt;= threshold) { long sum = 0; for (long i = start; i \u0026lt;= end; i++) { sum += i; } return sum; }else { long middle = (start + end) / 2; forkjoincalculate left = new forkjoincalculate(start,middle); left.fork(); forkjoincalculate right = new forkjoincalculate(middle + 1,end); right.fork(); return left.join() + right.join(); } } public static void main(string[] args) { forkjoinpool pool = new forkjoinpool(); forkjoincalculate calculate = new forkjoincalculate(1, 1000000000l); long result = pool.invoke(calculate); system.out.println(result); } } 并行流 \t底层依旧使用的fork/join框架,使用的公共的forkjoinpool,大大简化了fork/join框架的使用难度\n1 2 3 4 5 @test public void test() throws exception { optionallong result = longstream.rangeclosed(1, 10000000l).parallel().reduce(long::sum); system.out.println(result.getaslong()); } 六、optional 类 \toptional 类(java.util.optional) 是一个容器类,代表一个值存在或不存在,原来用null 表示一个值不存在,现在optional 可以更好的表达这个概念。并且可以避免空指针异常。\n常用方法:\noptional.of(t t) : 创建一个optional 实例,t为null会抛出空指针异常 optional.get() : 如果没有值会抛出nosuchelementexception optional.empty() : 创建一个空的optional 实例 optional.ofnullable(t t):若t 不为null,创建optional 实例,否则创建空实例 ispresent() : 判断是否包含值 orelse(t t) : 如果调用对象包含值,返回该值,否则返回t orelseget(supplier s) :如果调用对象包含值,返回该值,否则返回s 获取的值 map(function f): 如果有值对其处理,并返回处理后的optional,否则返回optional.empty() flatmap(function mapper):与map 类似,要求返回值必须是optional 七、接口中方法 java 8中允许接口中包含具有具体实现的方法,该方法称为默认方法,使用default关键字修饰。\njava 8中允许接口中定义和实现静态方法。\n接口默认方法的”类优先”原则\n\t若一个接口中定义了一个默认方法,而另外一个父类或接口中又定义了一个同名的方法时选择父类中的方法。如果一个父类提供了具体的实现,那么接口中具有相同名称和参数的默认方法会被忽略。\n接口冲突\n\t如果一个父接口提供一个默认方法,而另一个接口也提供了一个具有相同名称和参数列表的方法(不管方法是否是默认方法),那么必须覆盖该方法来解决冲突。\n1 2 3 4 5 6 7 8 interface foo { default string getfoo() { // 默认方法 return \u0026#34;foo\u0026#34;; } static string showfoo() { // 静态方法 system.out.println(\u0026#34;foo\u0026#34;); } } 八、重复注解和类型注解 可重复注解 在可重复注解上使用@repeatable标注且提供容器类\n1 2 3 4 5 6 @retention(retentionpolicy.runtime) @target(elementtype.type) @repeatable(myannotations.class) public @interface myannotation { string value(); } 容器类必须提供可重复注解[] value()\n1 2 3 4 5 @retention(retentionpolicy.runtime) @target(elementtype.type) public @interface myannotations { myannotation[] value(); } 类型注解 elementtype.type_parameter(type parameter declaration) 用来标注类型参数\n1 2 3 4 5 6 7 8 9 10 11 12 @target(elementtype.type_parameter) @retention(retentionpolicy.runtime) public @interface typeparameterannotation { } // 如下是该注解的使用例子 public class typeparameterclass\u0026lt;@typeparameterannotation t\u0026gt; { public \u0026lt;@typeparameterannotation u\u0026gt; t foo(t t) { return null; } } elementtype.type_use(use of a type) 能标注任何类型名称\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 public class testtypeuse { @target(elementtype.type_use) @retention(retentionpolicy.runtime) public @interface typeuseannotation { } public static @typeuseannotation class typeuseclass\u0026lt;@typeuseannotation t\u0026gt; extends @typeuseannotation object { public void foo(@typeuseannotation t t) throws @typeuseannotation exception { } } // 如下注解的使用都是合法的 @suppresswarnings({ \u0026#34;rawtypes\u0026#34;, \u0026#34;unused\u0026#34;, \u0026#34;resource\u0026#34; }) public static void main(string[] args) throws exception { typeuseclass\u0026lt;@typeuseannotation string\u0026gt; typeuseclass = new @typeuseannotation typeuseclass\u0026lt;\u0026gt;(); typeuseclass.foo(\u0026#34;\u0026#34;); list\u0026lt;@typeuseannotation comparable\u0026gt; list1 = new arraylist\u0026lt;\u0026gt;(); list\u0026lt;? extends comparable\u0026gt; list2 = new arraylist\u0026lt;@typeuseannotation comparable\u0026gt;(); @typeuseannotation string text = (@typeuseannotation string)new object(); java.util. @typeuseannotation scanner console = new java.util.@typeuseannotation scanner(system.in); } } 九、新时间与日期 \tjava8提供的日期时间均是线程安全的,原始的data、dateformat、calendar等均线程不安全\njava.time.localdatetime 本地日期时间,包括本地时间的操作(增、减、所属星期、月份等) java.time.localdate\t本地日期,包括本地时间的操作(增、减所属星期、月份等) java.time.localtime 本地时间,包括本地时间的操作(增、减所属星期、月份等) java.time.instant\t时间戳,1970.01.01:00:00:00到现在的毫秒,可以增、减、得到所属星期、月份等【instant.toepochmilli()得到毫秒,纳秒、秒等用getxxx()】 java.time.duration\t计算时间间隔 java.time.period\t计算日期间隔 java.time.temporal.temporaladjusters\ttemporaladjuster【时间矫正器】的工具类,提供了下星期、明年的某天。。。 java.time.format.datetimeformatter\t格式化日期时间,使用ofpattern(string)自定义格式 java.time.zoneddatetime\t指定时区\t,在构造时间的时候会根据时区进行时间偏移,如果在后来设置,只是更改时区并不修改时间,可使用zoneid获得时区 ","date":"2018-10-17","permalink":"https://hobocat.github.io/post/java/2018-10-17-java8/","summary":"一、Map结构优化 java8之前HashMap存储结构如下图,将Map中的key进行哈希运算得到hashCode,当出现hashCode相同但equals不同","title":"java8新特性"},]
[{"content":"一、组件注册 \tspring注解驱动上下文环境类为annotationconfigapplicationcontext,避免使用application.xml进行配置。annotationconfigapplicationcontext(class\u0026lt;?\u0026gt;... annotatedclasses)传入配置类即可,相比xml配置更加便捷 。\n@configuration注解 configuration配置类,替代application.xml加载配置内容\n1 2 3 4 5 6 7 8 9 //配置类,作用相当于配置文件 @configuration public class mainconfig { @bean public person person() { return new person(\u0026#34;小牛\u0026#34;, 19); }\t} @componentscan注解 @componentscan包扫描类,加载指定包下的内容,为可重复注解,如果jdk小于1.7则可使用@componentscans配置多个@componentscan\n1 2 3 4 5 6 7 @configuration //配置包扫描,去除controller的加载 @componentscan(basepackages=\u0026#34;com.kun.componentscan\u0026#34;, excludefilters= {@filter(type=filtertype.annotation,classes=controller.class)}) public class mainconfig { } 1 2 3 4 5 6 7 8 @configuration //配置包扫描,只加载controlle,注意要设置usedefaultfilters=false @componentscan(basepackages=\u0026#34;com.kun.componentscan\u0026#34;, usedefaultfilters=false, includefilters= {@filter(type=filtertype.annotation,classes=controller.class)}) public class mainconfig { } filtertype的种类\nfiltertype.annotation\t根据注解类型过滤\nfiltertype.assignable_type\t更具指定类型加载类及其子类\nfiltertype.aspectj\t使用aspectj表达式过滤\nfiltertype.regex\t使用正则表达式过滤\nfiltertype.custom\t自定义规则\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public class mytypefilter implements typefilter{ /** * metadatareader:读取当前正在扫描类的信息 * metadatareaderfactory:可以获取到其他任何类的信息 */ @override public boolean match(metadatareader metadatareader, metadatareaderfactory metadatareaderfactory) throws ioexception { //获得当前扫描类的注解信息 annotationmetadata annotationmetadata = metadatareader.getannotationmetadata(); //获取当前扫描类的资源信息(类路径等) resource resource = metadatareader.getresource(); //获得当前扫描类的类信息 classmetadata classmetadata = metadatareader.getclassmetadata(); //获取类名 string classname = classmetadata.getclassname(); return true; } } @scope注解 @scope生命周期配置类\n@scope(configurablebeanfactory.scope_prototype)\t//原型,每次从容器获取均创建 @scope(configurablebeanfactory.scope_singleton) //单实例,每次从容器获取的都是同一个\n@lazy注解 @lazy懒加载,只对单实例bean有效。容器启动时并不创建对象,在第一次获取时才创建对象\n1 2 3 4 5 @bean @lazy public person person() { return new person(\u0026#34;小牛\u0026#34;, 19); } @condition注解 @condition按照条件进行动态创建,可标注在方法和类上。conditioncontext可以得到beanfactory、getenvironment、registry等重要信息。\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 public class linuxsystemcondition implements condition{ @override public boolean matches(conditioncontext context, annotatedtypemetadata metadata) { string osname = context.getenvironment().getproperty(\u0026#34;os.name\u0026#34;); return !osname.contains(\u0026#34;windows\u0026#34;); } } public class windowssystemcondition implements condition{ @override public boolean matches(conditioncontext context, annotatedtypemetadata metadata) { string osname = context.getenvironment().getproperty(\u0026#34;os.name\u0026#34;); return osname.contains(\u0026#34;windows\u0026#34;); } } @configuration public class mainconfig { @bean @conditional(windowssystemcondition.class) public person personwindows() { return new person(\u0026#34;bill gates\u0026#34;, 60); } @bean @conditional(linuxsystemcondition.class) public person personlinux() { return new person(\u0026#34;linus\u0026#34;,48); } } @import注解 @import容器会自动注册这个组件,id为全类名。@improt的value[]可配置以下类型:\n普通类,在容器中注册一个普通类型\nimportselector的实现类,实现string[] selectimports(annotationmetadata importingclassmetadata),返回需要类的全类名\nimportbeandefinitionregistrar,void registerbeandefinitions(annotationmetadata importingclassmetadata, beandefinitionregistry registry),使用registry注册类信息\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 @configuration @import(red.class) public class mainconfig { } public class myimportbeandefinitionregistrar implements importbeandefinitionregistrar{ @override public void registerbeandefinitions(annotationmetadata importingclassmetadata, beandefinitionregistry registry) { boolean registerred = registry.containsbeandefinition(\u0026#34;com.kun.model.red\u0026#34;); boolean registerblue = registry.containsbeandefinition(\u0026#34;com.kun.model.blue\u0026#34;); if(registerred \u0026amp;\u0026amp; registerblue) { registry.registerbeandefinition(\u0026#34;yellow\u0026#34;, new rootbeandefinition(yellow.class)); } } } public class myimportselector implements importselector{ @override public string[] selectimports(annotationmetadata importingclassmetadata) { return new string[]{\u0026#34;com.kun.model.blue\u0026#34;,\u0026#34;com.kun.model.pink\u0026#34;}; } } factorybean创建实例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public class colorfactorybean implements factorybean\u0026lt;color\u0026gt;{ @override public color getobject() throws exception { return new color(); } @override public class\u0026lt;?\u0026gt; getobjecttype() { return color.class; } } public class maintest { public static void main(string[] args) { applicationcontext applicationcontext = new annotationconfigapplicationcontext(mainconfig.class); //拿到colorfactorybean,factory_bean_prefix为前缀‘\u0026amp;’ object bean = applicationcontext.getbean(beanfactory.factory_bean_prefix+\u0026#34;color\u0026#34;); } } 总结:\n给容器中注册组件的方法\n包扫描+组件标注注解(@controller/@service/@repository/@component)[自己写的类]\n@bean[导入的第三方包里面的组件]\n@import(要导入到容器中的组件);容器中就会自动注册这个组件,id默认是全类名\n@bean配合spring提供的 factorybean(工厂bean)\n\t1)、默认获取到的是工厂bean调用getobject创建的对象\n\t2)、要获取工厂bean本身,我们需要给id前面加一个\u0026amp;\n二、生命周期 @bean设置初始化和销毁方法 单例对象时:在对象创建之后调用initmethod方法、在容器销毁时调用destroymethod\n非单例对象时:在对象创建之后调用initmethod方法,不会调用destroymethod\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public class car { public car() { system.out.println(\u0026#34;car.car()\u0026#34;); } public void init() { system.out.println(\u0026#34;car.init()\u0026#34;); } public void destory() { system.out.println(\u0026#34;car.destory()\u0026#34;); } } @configuration public class mainconfig { @bean(initmethod=\u0026#34;init\u0026#34;,destroymethod=\u0026#34;destory\u0026#34;) public car car() { return new car(); } } initializingbean和disposablebean 作用和在@bean中设置initmethod、destroymethod一样\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public class bus implements initializingbean, disposablebean { @override public void destroy() throws exception { system.out.println(\u0026#34;bus.destroy()\u0026#34;); } @override public void afterpropertiesset() throws exception { system.out.println(\u0026#34;bus.afterpropertiesset()\u0026#34;); } } @configuration public class mainconfig { @bean public bus bus() { return new bus(); } } jsr-250规范实现初始化和销毁方法 @postconstruct、@predestroy实现设置初始化和销毁\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public class dog { @postconstruct public void init() { system.out.println(\u0026#34;dog.init()\u0026#34;); } @predestroy public void destory() { system.out.println(\u0026#34;dog.destory()\u0026#34;); } } @configuration public class mainconfig {\t@bean public dog dog() { return new dog(); } } beanpostprocesser后置处理器控制初始化 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 @component public class mybeanpostprocesser implements beanpostprocessor { //在bean创建之后执行init方法之前调用 @override public object postprocessbeforeinitialization(object bean, string beanname) throws beansexception { if(beanname.equals(\u0026#34;car\u0026#34;)) { system.out.println(\u0026#34;car before initialization do something\u0026#34;); } return bean; } //在bean创建之后执行init方法之后调用 @override public object postprocessafterinitialization(object bean, string beanname) throws beansexception { if(beanname.equals(\u0026#34;car\u0026#34;)) { system.out.println(\u0026#34;car after initialization do something\u0026#34;); } return bean; } } 三、属性赋值 方式一:类比@value(\u0026ldquo;值\u0026rdquo;),将值直接注入\n方式二:类比@value(\u0026quot;#{20-2}\u0026quot;),使用spel计算\n方式三:配合@propertysource注解导入properties文件,类比@value(\u0026quot;${employee.name}\u0026quot;)方式取值\n@value实现属性\n四、自动装配 @autowired自动装配: 默认按照类型优先的方式去容器中找对应的组件 如果找到多个类型相同的组件,再使用属性名称取匹配(使用@qualifier可以指定查找的对象id名称) 自动装配如果找不到对应的bean会报错(可以使用@autowired(required=false)取消必须匹配) 再首选bean上指定@primary使之成为首选对象,如果此时找到多个类型相同的组件,使用首选bean注入,@primary优先级在@qualifier之下 标注在有参构造器上,如果此类只有一个有参构造器会使用自动装配实例化此类 @resource和@inject自动装配: @resource(jsr250):\n可以和@autowired一样实现自动装配功能,默认是按照组件名称进行装配的(可以使用name属性限定),匹配不到不会报错 不能支持@primary、@qualifier组合 @inject(jsr330):\n需要导入javax.inject的包,和autowired的功能一样,必须匹配到bean 不能支持@primary、@qualifier组合 @bean方法参数: 在@bean标注的方法中,创建对象时入参是通过spring注入的 1 2 3 4 5 6 7 //此person由spring注入 @bean public car car(person person) { car car = new car(); car.setperson(person); return car; } 使用aware接口 自定义组件如果要使用spring底层的一些组件(applicationcontext,beanfactory等等)自定义组件可以实现对应的aware接口,在创建对象时,spring会传入相关组件。 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 aware | +- applicationcontextaware | +- applicationeventpublisheraware | +- beanclassloaderaware | +- beanfactoryaware | +- beannameaware | +- embeddedvalueresolveraware | +- environmentaware | +- importaware | +- loadtimeweaveraware | +- messagesourceaware | +- notificationpublisheraware | +- resourceloaderaware | +- servletconfigaware | +- servletcontextaware @profile环境感知 @profile可以根据当前环境,动态的激活和切换一系列组件的功能\n默认@profile会激活值为default的配置 在jvm参数添加-dspring.profiles.active=值会激活对应的配置 使用java代码也可激活配置 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 /** * java代码激活 * annotationconfigapplicationcontext applicationcontext = new annotationconfigapplicationcontext(); * applicationcontext.getenvironment().setactiveprofiles(\u0026#34;test\u0026#34;); * applicationcontext.register(mainconfig3.class); * applicationcontext.refresh(); */ @configuration public class mainconfig3 { //默认激活 @profile(\u0026#34;default\u0026#34;) @bean(initmethod=\u0026#34;init\u0026#34;,destroymethod=\u0026#34;close\u0026#34;) public datasource datasourcedev() { druiddatasource datasource = new druiddatasource(); datasource.setusername(\u0026#34;root\u0026#34;); datasource.setpassword(\u0026#34;123\u0026#34;); datasource.seturl(\u0026#34;jdbc:mysql://localhost:3306/dev\u0026#34;); datasource.setdriverclassname(\u0026#34;com.mysql.jdbc.driver\u0026#34;); return datasource; } @profile(\u0026#34;test\u0026#34;) @bean(initmethod=\u0026#34;init\u0026#34;,destroymethod=\u0026#34;close\u0026#34;) public datasource datasourcetest() { druiddatasource datasource = new druiddatasource(); datasource.setusername(\u0026#34;root\u0026#34;); datasource.setpassword(\u0026#34;123\u0026#34;); datasource.seturl(\u0026#34;jdbc:mysql://localhost:3306/test\u0026#34;); datasource.setdriverclassname(\u0026#34;com.mysql.jdbc.driver\u0026#34;); return datasource; } @profile(\u0026#34;produ\u0026#34;) @bean(initmethod=\u0026#34;init\u0026#34;,destroymethod=\u0026#34;close\u0026#34;) public datasource datasourceprodu() { druiddatasource datasource = new druiddatasource(); datasource.setusername(\u0026#34;root\u0026#34;); datasource.setpassword(\u0026#34;123\u0026#34;); datasource.seturl(\u0026#34;jdbc:mysql://localhost:3306/produ\u0026#34;); datasource.setdriverclassname(\u0026#34;com.mysql.jdbc.driver\u0026#34;); return datasource; } } 五、aop aop【动态代理】:指在程序运行期间动态的将某段代码切入到指定方法指定位置进行运行的编程方式\naop的使用方法 导入aop模块【spring aop:(spring-aspects)】 定义一个业务逻辑类 定义一个切面类(并在切面类上加注解@aspect) 前置通知(@before)\t在目标方法运行之前运行 后置通知(@after)\t在目标方法运行结束之后运行(无论方法正常结束还是异常结束) 返回通知(@afterreturning)\t在目标方法正常返回之后运行 异常通知(@afterthrowing)\t在目标方法出现异常以后运行 环绕通知(@around)\t动态代理,手动推进目标方法运行(joinpoint.procced()) 给切面类的目标方法标注何时何地运行(通知注解) 将切面类和业务逻辑类(目标方法所在类)都加入到容器中 给配置类中加 @enableaspectjautoproxy 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 //业务逻辑类 public class mathcalculator { public int div(int i, int j) { return i / j; } } //切面类,@aspect标志自己是配置类 @aspect public class logaspects { //定义切面,本类引用直接写方法名,引用外部类的需要加上类全限定名 @pointcut(\u0026#34;execution(* com.kun.aop.mathcalculator.*(..))\u0026#34;) public void pointcut() {} @before(\u0026#34;pointcut()\u0026#34;) public void logstart(joinpoint joinpoint) { string methodname = joinpoint.getsignature().getname(); object[] args = joinpoint.getargs(); system.out.println(\u0026#34;方法名\u0026#34;+methodname); system.out.println(\u0026#34;参数\u0026#34;+arrays.tostring(args)); } @after(\u0026#34;pointcut()\u0026#34;) public void logend(joinpoint joinpoint) { system.out.println(joinpoint.getsignature().getname()+\u0026#34;调用结束\u0026#34;); } @afterreturning(pointcut=\u0026#34;pointcut()\u0026#34;,returning=\u0026#34;result\u0026#34;) public void logreturn(joinpoint joinpoint, object result) { system.out.println(joinpoint.getsignature().getname()+\u0026#34;正常返回,运行结果:\u0026#34;+result); } @afterthrowing(pointcut=\u0026#34;pointcut()\u0026#34;,throwing=\u0026#34;exception\u0026#34;) public void logexception(joinpoint joinpoint,exception exception){ system.out.println(joinpoint.getsignature().getname()+\u0026#34;异常,异常信息:\u0026#34;+exception); } } //配置类 @configuration @enableaspectjautoproxy\t//开启aop自动配置 public class mainconfig4 { //业务逻辑类加入容器中 @bean public mathcalculator calculator(){ return new mathcalculator(); } //切面类加入到容器中 @bean public logaspects logaspects(){ return new logaspects(); } } aop源码分析 1、enableaspectjautoproxy实际上导入了aspectjautoproxyregistrar.class\n1 2 3 4 5 @import(aspectjautoproxyregistrar.class) public @interface enableaspectjautoproxy { boolean proxytargetclass() default false; boolean exposeproxy() default false; } 2、aspectjautoproxyregistrar是importbeandefinitionregistrar的子类,实际注册了id为internalautoproxycreator的annotationawareaspectjautoproxycreator的类信息\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class aspectjautoproxyregistrar implements importbeandefinitionregistrar { @override public void registerbeandefinitions(annotationmetadata importingclassmetadata, beandefinitionregistry registry) { // 注册了id为org.springframework.aop.config.internalautoproxycreator的 // annotationawareaspectjautoproxycreator.class组件信息 aopconfigutils.registeraspectjannotationautoproxycreatorifnecessary(registry); //修改annotationawareaspectjautoproxycreator的信息 annotationattributes enableaspectjautoproxy = annotationconfigutils.attributesfor(importingclassmetadata, enableaspectjautoproxy.class); if (enableaspectjautoproxy != null) { if (enableaspectjautoproxy.getboolean(\u0026#34;proxytargetclass\u0026#34;)) { aopconfigutils.forceautoproxycreatortouseclassproxying(registry); } if (enableaspectjautoproxy.getboolean(\u0026#34;exposeproxy\u0026#34;)) { aopconfigutils.forceautoproxycreatortoexposeproxy(registry); } } } } 3、annotationawareaspectjautoproxycreator创建以及被代理类创建流程分析、\n传入配置类,创建ioc容器\n注册配置类,调用refresh()刷新容器\nregisterbeanpostprocessors(beanfactory),注册bean的后置处理器来方便拦截bean的创建\n先获取ioc容器已经定义了的需要创建对象的所有beanpostprocessor 给容器中加别的beanpostprocessor 优先注册实现了priorityordered接口的beanpostprocessor 再给容器中注册实现了ordered接口的beanpostprocessor 创建bean的实例 populatebean:给bean的各种属性赋值 initializebean:初始化bean invokeawaremethods():处理aware接口的方法回调 applybeanpostprocessorsbeforeinitialization():应用后置处理器的postprocessbeforeinitialization() invokeinitmethods():执行自定义的初始化方法 applybeanpostprocessorsafterinitialization():执行后置处理器的postprocessafterinitialization() beanpostprocessor(annotationawareaspectjautoproxycreator)创建成功\u0026ndash;\u0026gt;\taspectjadvisorsbuilde 注册没实现优先级接口的beanpostprocessor 把beanpostprocessor注册到beanfactory中 finishbeanfactoryinitialization(beanfactory)完成beanfactory初始化工作,创建剩下的单实例bean,与aop相关部分\n遍历获取容器中所有的bean,依次创建对象,在创建bean之前调用applybeanpostprocessorsbeforeinstantiation()\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 //识别保存@aspects注解类,保存相关注解信息和切面、切入点表达式 public object postprocessbeforeinstantiation(class\u0026lt;?\u0026gt; beanclass, string beanname) { object cachekey = getcachekey(beanclass, beanname); if (!stringutils.haslength(beanname) || !this.targetsourcedbeans.contains(beanname)) { if (this.advisedbeans.containskey(cachekey)) { return null; } if (isinfrastructureclass(beanclass) || shouldskip(beanclass, beanname)) { this.advisedbeans.put(cachekey, boolean.false); return null; } } targetsource targetsource = getcustomtargetsource(beanclass, beanname); if (targetsource != null) { if (stringutils.haslength(beanname)) { this.targetsourcedbeans.add(beanname); } object[] specificinterceptors = getadvicesandadvisorsforbean(beanclass, beanname, targetsource); object proxy = createproxy(beanclass, beanname, specificinterceptors, targetsource); this.proxytypes.put(cachekey, proxy.getclass()); return proxy; } return null; } \t2)运用applybeanpostprocessorsafterinitialization(),将对象进行动态代理\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public object postprocessafterinitialization(@nullable object bean, string beanname) { if (bean != null) { object cachekey = getcachekey(bean.getclass(), beanname); if (!this.earlyproxyreferences.contains(cachekey)) { //包装生成动态代理类, return wrapifnecessary(bean, beanname, cachekey); } } return bean; } /** wrapifnecessary(bean, beanname, cachekey); 1、获取当前bean的所有增强器(通知方法) object[] specificinterceptors 1、找到候选的所有的增强器(找哪些通知方法是需要切入当前bean方法的) 2、获取到能在bean使用的增强器 3、给增强器排序 2、保存当前bean在advisedbeans中 3、如果当前bean需要增强,创建当前bean的代理对象 1、获取所有增强器 2、保存到proxyfactory 3、创建代理对象:spring自动决定 **/ 4、目标方法的执行\ncglibaopproxy.intercept();拦截目标方法的执行\n根据proxyfactory对象获取将要执行的目标方法拦截器链\n1 2 3 4 5 6 7 8 9 10 11 12 //获取目标方法的过滤器链 list\u0026lt;object\u0026gt; chain = this.advised.getinterceptorsanddynamicinterceptionadvice(method, targetclass); object retval; //如果链为空,直接执行目标方法 if (chain.isempty() \u0026amp;\u0026amp; modifier.ispublic(method.getmodifiers())) { object[] argstouse = aopproxyutils.adaptargumentsifnecessary(method, args); retval = methodproxy.invoke(target, argstouse); } else { retval = new cglibmethodinvocation(proxy, target, method, args, targetclass, chain, methodproxy) .proceed(); } 如果有拦截器链,把需要执行的目标对象,目标方法,拦截器链等信息传入创建一个 cglibmethodinvocation 对象,并调用 object retval = mi.proceed()\n拦截器链的触发过程\n如果没有拦截器执行执行目标方法,或者拦截器的索引和拦截器数组-1大小一样(指定到了最后一个拦截器)执行目标方法 链式获取每一个拦截器,拦截器执行invoke方法,每一个拦截器等待下一个拦截器执行完成返回以后再来执行;拦截器链的机制,保证通知方法与目标方法的执行顺序 六、声明式事务 声明式事务使用方式 配置数据源和事务管理器 @enabletransactionmanagement 开启基于注解的事务管理功能 在service上需要事务的方法上注明@transactional 表示当前方法是一个事务方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 @enabletransactionmanagement @componentscan(\u0026#34;com.kun.transcation\u0026#34;) @configuration public class mainconfig { //配置事务管理器 @bean public datasourcetransactionmanager transactionmanagement() { return new datasourcetransactionmanager(datasource()); } //配置数据源 @bean(initmethod=\u0026#34;init\u0026#34;,destroymethod=\u0026#34;close\u0026#34;) public datasource datasource() { druiddatasource datasource = new druiddatasource(); datasource.seturl(\u0026#34;jdbc:mysql://localhost:3306/mapper\u0026#34;); datasource.setusername(\u0026#34;root\u0026#34;); datasource.setpassword(\u0026#34;123456\u0026#34;); datasource.setdriverclassname(\u0026#34;com.mysql.jdbc.driver\u0026#34;); return datasource; } //配置jdbctemplate @bean public jdbctemplate jdbctemplate() { return new jdbctemplate(datasource()); } } @repository public class testdao { @autowired private jdbctemplate jdbctemplate; public void insert() { jdbctemplate.update(\u0026#34;insert into person(name) values(?)\u0026#34;,\u0026#34;kun\u0026#34;); } } @service public class testservice { @autowired private testdao testdao; //声明事务 @transactional public void insert() { testdao.insert(); int i = 1/0; } } 声明式事务源码分析 @enabletransactionmanagement注解导入了transactionmanagementconfigurationselector.class 1 2 3 4 5 6 7 8 9 10 11 12 13 //transactionmanagementconfigurationselector实现了importselector接口 //使用默认配置会导入autoproxyregistrar和proxytransactionmanagementconfiguration protected string[] selectimports(advicemode advicemode) { switch (advicemode) { case proxy: return new string[] {autoproxyregistrar.class.getname(), proxytransactionmanagementconfiguration.class.getname()}; case aspectj: return new string[] {determinetransactionaspectclass()}; default: return null; } } autoproxyregistrar实现了importbeandefinitionregistrar接口导入了id为internalautoproxycreator的infrastructureadvisorautoproxycreator类实现了aop功能【使用postprocessafterinitialization()包装类实现动态代理】\nproxytransactionmanagementconfiguration\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 @configuration public class proxytransactionmanagementconfiguration extends abstracttransactionmanagementconfiguration { //实现切入点 @bean(name = transactionmanagementconfigutils.transaction_advisor_bean_name) @role(beandefinition.role_infrastructure) public beanfactorytransactionattributesourceadvisor transactionadvisor() { beanfactorytransactionattributesourceadvisor advisor = new beanfactorytransactionattributesourceadvisor(); advisor.settransactionattributesource(transactionattributesource()); advisor.setadvice(transactioninterceptor()); if (this.enabletx != null) { advisor.setorder(this.enabletx.\u0026lt;integer\u0026gt;getnumber(\u0026#34;order\u0026#34;)); } return advisor; } @bean @role(beandefinition.role_infrastructure) public transactionattributesource transactionattributesource() { return new annotationtransactionattributesource(); } //拦截器链 @bean @role(beandefinition.role_infrastructure) public transactioninterceptor transactioninterceptor() { transactioninterceptor interceptor = new transactioninterceptor(); interceptor.settransactionattributesource(transactionattributesource()); if (this.txmanager != null) { interceptor.settransactionmanager(this.txmanager); } return interceptor; } } 七、扩展原理 bean后置处理器 beanpostprocessor接口在容器内对象创建完成之后属性赋值前后调用\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public interface beanpostprocessor { //对象创建完成,在afterpropertiesset或自定义init方法执行之前 @nullable default object postprocessbeforeinitialization(object bean, string beanname) throws beansexception { return bean; } //对象创建完成,在afterpropertiesset或自定义init方法执行之后 @nullable default object postprocessafterinitialization(object bean, string beanname) throws beansexception { return bean; } } instantiationawarebeanpostprocessor接口在容器内对象创建前后调用\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public interface instantiationawarebeanpostprocessor extends beanpostprocessor { //对象实例化之前调用 @nullable default object postprocessbeforeinstantiation(class\u0026lt;?\u0026gt; beanclass, string beanname) throws beansexception { return null; } //对象实例化之后调用 default boolean postprocessafterinstantiation(object bean, string beanname) throws beansexception { return true; } //对象实例化之后属性赋值之前,@autowired、@resource等就是根据这个回调来实现最终注入依赖的 @nullable default propertyvalues postprocessproperties(propertyvalues pvs, object bean, string beanname) throws beansexception { return null; } } destructionawarebeanpostprocessor接口在对象销毁之前调用\n1 2 3 4 5 6 7 8 9 10 public interface destructionawarebeanpostprocessor extends beanpostprocessor { //对象销毁之前调用 void postprocessbeforedestruction(object bean, string beanname) throws beansexception; //判断是否需要处理这个对象的销毁 default boolean requiresdestruction(object bean) { return true; } } mergedbeandefinitionpostprocessor混合bean定义之后的处理器\n1 2 3 4 5 6 7 8 9 10 public interface mergedbeandefinitionpostprocessor extends beanpostprocessor { //合并bean定义后进行的处理 void postprocessmergedbeandefinition(rootbeandefinition beandefinition, class\u0026lt;?\u0026gt; beantype, string beanname); //通知指定名称的bean定义已被重置,这个后处理器应该清除受影响bean的任何元数据 default void resetbeandefinition(string beanname) {} } 执行时序\ninstantiationawarebeanpostprocessor.postprocessbeforeinstantiation(beanclass, beanname)在创建对象之前调用,如果有返回实例则,不会去走下面创建对象的逻辑但会调用postprocessafterinitialization() beanpostprocessor.postprocessafterinitialization(result, beanname)对象创建之后调用 smartinstantiationawarebeanpostprocessor.determinecandidateconstructors(beanclass, beanname)如果需要的话,会在实例化对象之前执行 mergedbeandefinitionpostprocessor.postprocessmergedbeandefinition(mbd, beantype, beanname)在对象实例化完毕 初始化之前执行 instantiationawarebeanpostprocessor.postprocessafterinstantiation(bw.getwrappedinstance(), beanname)在bean创建完毕初始化之前执行 instantiationawarebeanpostprocessor.postprocesspropertyvalues(pvs, filteredpds, bw.getwrappedinstance(), beanname)在bean的property属性注入完毕向bean中设置属性之前执行 beanpostprocessor.postprocessbeforeinitialization(result, beanname)在bean初始化(自定义init或者是实现了initializingbean.afterpropertiesset())之前执行 beanpostprocessor.postprocessafterinitialization(result, beanname)在bean初始化(自定义init或者是实现了initializingbean.afterpropertiesset())之后执行 其中destructionawarebeanpostprocessor方法的postprocessbeforedestruction(object bean, string beanname)会在销毁对象前执行 beanfactory后置处理器 beanfactorypostprocessor在beanfactory标准初始化之后调用,来定制和修改beanfactory的内容,此时所有的bean定义已经保存加载到beanfactory,但是bean的实例还未创建\n1 2 3 4 public interface beanfactorypostprocessor { //已有bean的定义 void postprocessbeanfactory(configurablelistablebeanfactory beanfactory) throws beansexception; } beandefinitionregistrypostprocessor,在beanfactorypostprocessor之后调用,用于注册bean信息\n1 2 3 4 5 public interface beandefinitionregistrypostprocessor extends beanfactorypostprocessor { void postprocessbeandefinitionregistry(beandefinitionregistry registry) throws beansexception; } 监听器 监听器的使用\n方式一:实现applicationlistener接口\n1 2 3 4 5 //event的类型有 public interface applicationlistener\u0026lt;e extends applicationevent\u0026gt; extends eventlistener { void onapplicationevent(e event); } 方式二:使用@eventlistener注解\n1 2 3 4 5 6 7 8 @service public class eventservice { @eventlistener public void playevent(applicationevent event) { system.out.println(event); } } 八、源码分析 spring容器的refresh()【创建刷新过程】\npreparerefresh()【刷新前的预处理】\ninitpropertysources()【初始化一些属性设置,交给子类自定义个性化的属性设置方法】 getenvironment().validaterequiredproperties()【检验属性的合法等】 this.earlyapplicationevents = new linkedhashset\u0026lt;\u0026gt;()【保存容器中的一些早期的事件的集合】 configurablelistablebeanfactory beanfactory = obtainfreshbeanfactory()【获得beanfactory】\nrefreshbeanfactory()【创建了一个this.beanfactory = new defaultlistablebeanfactory()并设置id】 getbeanfactory()【返回刚才genericapplicationcontext创建的beanfactory对象】 将创建的beanfactory【defaultlistablebeanfactory】返回 preparebeanfactory(beanfactory)【beanfactory的预准备工作】\n设置beanfactory的类加载器、支持表达式解析器等 添加部分beanpostprocessor【applicationcontextawareprocessor和applicationlistenerdetector】 设置忽略的自动装配的接口environmentaware、embeddedvalueresolveraware、resourceloaderaware、applicationeventpublisheraware、messagesourceaware和applicationcontextaware,即这些接口实现类无法通过autowired方式注入 注册可以解析的自动装配,我们能直接在任何组件中自动注入【beanfactory、resourceloader、applicationeventpublisher和applicationcontext】 添加编译时的aspectj相关组件 给beanfactory中注册一些能用的组件【environment、systemproperties和systemenvironment】 postprocessbeanfactory(beanfactory)【子类通过重写这个方法来在beanfactory创建并预准备完成以后做进一步的设置】\ninvokebeanfactorypostprocessors(beanfactory)【调用beanfactorypostprocessor的方法】\n执行beandefinitionregistrypostprocessor的实现类 获取所有的beandefinitionregistrypostprocessor 先执行实现了priorityordered优先级接口的beandefinitionregistrypostprocessor 调用postprocessor.postprocessbeandefinitionregistry(registry) 再执行实现了ordered顺序接口的beandefinitionregistrypostprocessor 调用postprocessor.postprocessbeandefinitionregistry(registry) 最后执行没有实现任何优先级或者是顺序接口的beandefinitionregistrypostprocessor 调用postprocessor.postprocessbeandefinitionregistry(registry) 执行beanfactorypostprocessor的实现类 获取所有的beanfactorypostprocessor 先执行实现了priorityordered优先级接口的beanfactorypostprocessor 调用postprocessor.postprocessbeanfactory(configurablelistablebeanfactory) 再执行实现了ordered顺序接口的beanfactorypostprocessor 调用postprocessor.postprocessbeanfactory(configurablelistablebeanfactory) 最后执行没有实现任何优先级或者是顺序接口的beanfactorypostprocessor 调用postprocessor.postprocessbeanfactory(configurablelistablebeanfactory) registerbeanpostprocessors(beanfactory)【注册beanpostprocessor并不执行】\n获取所有的 beanpostprocessor\n先注册priorityordered优先级接口的beanpostprocessor,把每一个beanpostprocessor添加到beanfactory\nsortpostprocessors(priorityorderedpostprocessors, beanfactory); registerbeanpostprocessors(beanfactory, priorityorderedpostprocessors);\n再注册ordered顺序接口的beanpostprocessor,把每一个beanpostprocessor添加到beanfactory\nsortpostprocessors(orderedpostprocessors, beanfactory); registerbeanpostprocessors(beanfactory, orderedpostprocessors);\n然后注册没有实现任何优先级或者是顺序接口的beanpostprocessorr\nregisterbeanpostprocessors(beanfactory, nonorderedpostprocessors);\n最终注册mergedbeandefinitionpostprocessor\nsortpostprocessors(internalpostprocessors, beanfactory); registerbeanpostprocessors(beanfactory, internalpostprocessors);\n注册一个applicationlistenerdetector【用于检查在bean创建完成后检查是否是applicationlistener】\ninitmessagesource()【初始化messagesource组件(做国际化功能;消息绑定,消息解析)】\n获取beanfactory 容器中是否有id为messagesource的,类型是messagesource的组件如果有赋值给messagesource,如果没有自己创建一个delegatingmessagesource 把创建好的messagesource注册在容器中,以后获取国际化配置文件的值的时候,可以自动注入messagesource initapplicationeventmulticaster()\n获取beanfactory 从beanfactory中获取applicationeventmulticaster的applicationeventmulticaster 如果上一步没有配置;创建一个simpleapplicationeventmulticaster 将创建的applicationeventmulticaster添加到beanfactory中,以后其他组件直接自动注入 onrefresh()【子类重写这个方法,在容器刷新的时候可以自定义逻辑】\nregisterlisteners()\n从容器中拿到所有的applicationlistener 将每个监听器添加到事件派发器中 派发之前步骤产生的事件【this.earlyapplicationevents保存的事件】 finishbeanfactoryinitialization(beanfactory)【初始化所有剩下的单实例bean,beanprocessor等的早已实例化】\nbeanfactory.preinstantiatesingletons()【获取容器中的所有bean,依次进行初始化和创建对象】\n取bean的定义信息【rootbeandefinition】\n如果bean不是抽象的,是单实例的,是懒加载\n判断是否是factorybean通过factorybean的规则获得bean\n不是工厂bean。利用getbean(beanname)创建对象\n先获取缓存中保存的单实例bean。如果能获取到说明这个bean之前被创建过,返回\n缓存中获取不到,开始bean的创建对象流程\n标记当前bean已经被创建【防止并发环境产生错误】\n获取bean的定义信息\n获取当前bean依赖的其他bean,如果有使用getbean(beanname)递归调用把依赖的bean先创建出来\n启动单实例bean的创建流程\nresolvebeforeinstantiation(beanname, mbdtouse)让beanpostprocessor先拦截返回代理信息对象【instantiationawarebeanpostprocessor提前执行】 先触发:postprocessbeforeinstantiation(); 如果有返回值:触发postprocessafterinitialization()\n如果前面的instantiationawarebeanpostprocessor没有返回代理对象调用下面步骤\nobject beaninstance = docreatebean(beanname, mbdtouse, args)【创建bean】\nobject beaninstance = docreatebean(beanname, mbdtouse, args)【利用工厂方法或者对象的构造器创建出bean实例】\npplymergedbeandefinitionpostprocessors(mbd, beantype, beanname)【调用mergedbeandefinitionpostprocessor的postprocessmergedbeandefinition(mbd, beantype, beanname)】\npopulatebean(beanname, mbd, instancewrapper)【bean属性赋值】\n拿到instantiationawarebeanpostprocessor后置处理器调用\npostprocessafterinstantiation()\npostprocesspropertyvalues()\n应用bean属性的值applypropertyvalues(beanname, mbd, bw, pvs)\ninitializebean(beanname, exposedobject, mbd)【bean初始化】\ninvokeawaremethods(beanname, bean)【执行aware接口方法】 applybeanpostprocessorsbeforeinitialization(wrappedbean, beanname)【init方法执行之前调用】 invokeinitmethods(beanname, wrappedbean, mbd)【执行初始化方法】 applybeanpostprocessorsafterinitialization(wrappedbean, beanname)【执行后置处理器初始化之后】 注册bean的销毁方法\nfinishrefresh()\ninitlifecycleprocessor()初始化和生命周期有关的后置处理器【默认从容器中找是否有lifecycleprocessor的组件,如果没有new defaultlifecycleprocessor()加入到容器用于处理生命周期回调】 getlifecycleprocessor().onrefresh()【拿到前面定义的生命周期处理器回调onrefresh()】 publishevent(new contextrefreshedevent(this));发布容器刷新完成事件 九、spring mvc纯注解 servlet3.0相关 前提:servlet3.0需要tomcat7以上版本\n实现servletcontainerinitializer接口完成容器启动配置功能,相当于web.xml 1 2 3 4 5 6 7 8 9 10 11 12 13 14 /** * 实现servletcontainerinitializer的接口需要在src目录下创建 * meta-inf/services/javax.servlet.servletcontainerinitializer文件 * 文件内容是实现其接口的实现类 */ @handlestypes(value= {iservice.class}) public class myservletcontainerinitializer implements servletcontainerinitializer{ //set\u0026lt;class\u0026lt;?\u0026gt;\u0026gt; c传入的是@handlestypes配置的类及其子类 @override public void onstartup(set\u0026lt;class\u0026lt;?\u0026gt;\u0026gt; c, servletcontext ctx) throws servletexception { //servletcontext可以添加servlet、fileter、listener、initparam等 } } 异步请求\n在servlet3.0之前,servlet采用thread-pre-request的方式处理请求,即每一次http请求都是由某一个线程从头到尾负责处理。如果一个请求需要进行io操作,那么其所对应的线程将同步地等待io操作完成,此时线程并不能及时的释放回线程池以供后续使用,在并发量越来越大的情况下这将带来严重的性能问题。 servlet3.0之后但是了异步处理机制,目的是解决大量低延迟、少量高延迟大并发情况下带来的性能瓶颈 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 @webservlet(value=\u0026#34;/async\u0026#34;,asyncsupported=true) public class helloasyncservlet extends httpservlet { @override protected void doget(httpservletrequest req, httpservletresponse resp) throws servletexception, ioexception { //1、支持异步处理asyncsupported=true //2、开启异步模式 system.out.println(\u0026#34;主线程开始。。。\u0026#34;+thread.currentthread()+\u0026#34;==\u0026gt;\u0026#34;+system.currenttimemillis()); asynccontext startasync = req.startasync(); //3、业务逻辑进行异步处理;开始异步处理 startasync.start(new runnable() { @override public void run() { try { system.out.println(\u0026#34;副线程开始。。。\u0026#34;+thread.currentthread()+\u0026#34;==\u0026gt;\u0026#34;+system.currenttimemillis()); sayhello(); //获取到异步上下文 asynccontext asynccontext = req.getasynccontext(); //4、获取响应 servletresponse response = asynccontext.getresponse(); response.getwriter().write(\u0026#34;hello async...\u0026#34;); system.out.println(\u0026#34;副线程结束。。。\u0026#34;+thread.currentthread()+\u0026#34;==\u0026gt;\u0026#34;+system.currenttimemillis()); } catch (exception e) { } } });\tsystem.out.println(\u0026#34;主线程结束。。。\u0026#34;+thread.currentthread()+\u0026#34;==\u0026gt;\u0026#34;+system.currenttimemillis()); } public void sayhello() throws exception{ system.out.println(thread.currentthread()+\u0026#34; processing...\u0026#34;); thread.sleep(3000); } } spring mvc纯注解 整合原理\n根据servlet3.0规范web容器在启动的时候,会扫描每个jar包下的meta-inf/services/javax.servlet.servletcontainerinitializer文件,而且spring web包下的此文件内容为org.springframework.web.springservletcontainerinitializer。 springservletcontainerinitializer会加载webapplicationinitializer子类及其实现类 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 @handlestypes(webapplicationinitializer.class) public class springservletcontainerinitializer implements servletcontainerinitializer { @override public void onstartup(@nullable set\u0026lt;class\u0026lt;?\u0026gt;\u0026gt; webappinitializerclasses, servletcontext servletcontext) throws servletexception { list\u0026lt;webapplicationinitializer\u0026gt; initializers = new linkedlist\u0026lt;\u0026gt;(); if (webappinitializerclasses != null) { for (class\u0026lt;?\u0026gt; waiclass : webappinitializerclasses) { //如果不是接口和抽象类会被实例化 if (!waiclass.isinterface() \u0026amp;\u0026amp; !modifier.isabstract(waiclass.getmodifiers()) \u0026amp;\u0026amp; webapplicationinitializer.class.isassignablefrom(waiclass)) { try { initializers.add( (webapplicationinitializer)reflectionutils.accessibleconstructor(waiclass).newinstance()); } catch (throwable ex) { throw new servletexception(\u0026#34;failed to instantiate webapplicationinitializer class\u0026#34;, ex); } } } } if (initializers.isempty()) { servletcontext.log(\u0026#34;no spring webapplicationinitializer types detected on classpath\u0026#34;); return; } servletcontext.log(initializers.size() + \u0026#34; spring webapplicationinitializers detected on classpath\u0026#34;); annotationawareordercomparator.sort(initializers); for (webapplicationinitializer initializer : initializers) { initializer.onstartup(servletcontext); } } } webapplicationinitializer子类有 1 2 3 4 5 6 7 8 9 10 webapplicationinitializer | +- abstractreactivewebinitializer | +- abstractcontextloaderinitializer【spring父容器初始化器】 | +- abstractdispatcherservletinitializer【创建了dispatcherservlet】 + | + abstractannotationconfigdispatcherservletinitializer【注解初始化器】 整合方法:以注解方式来启动springmvc,继承abstractannotationconfigdispatcherservletinitializer 实现抽象方法指定dispatcherservlet的配置信息 实现示例\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 public class mywebinitializer extends abstractannotationconfigdispatcherservletinitializer{ //获取根容器的配置类 @override protected class\u0026lt;?\u0026gt;[] getrootconfigclasses() { return new class\u0026lt;?\u0026gt;[] {rootconfig.class}; } //获取web容器的配置类 @override protected class\u0026lt;?\u0026gt;[] getservletconfigclasses() { return new class\u0026lt;?\u0026gt;[] {servletconfig.class}; } /** * 获取dispatcherservlet的映射信息 * /:拦截所有请求(包括静态资源(xx.js,xx.png)),但是不包括*.jsp; * /*:拦截所有请求;连*.jsp页面都拦截;jsp页面是tomcat的jsp引擎解析的; */ @override protected string[] getservletmappings() { return new string[] {\u0026#34;/\u0026#34;}; } //配置过滤器 override protected filter[] getservletfilters() { return new filter[] { new hiddenhttpmethodfilter(), new characterencodingfilter() }; } } @configuration @componentscan(basepackages= {\u0026#34;com.kun\u0026#34;},excludefilters= {@filter(type=filtertype.annotation,classes={controller.class})}) public class rootconfig { } @configuration @componentscan(basepackages= {\u0026#34;com.kun\u0026#34;},usedefaultfilters=false, includefilters= {@filter(type=filtertype.annotation,classes=controller.class)}) public class servletconfig { } 定制springmvc功能\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 @configuration @componentscan(basepackages= {\u0026#34;com.kun\u0026#34;},usedefaultfilters=false, includefilters= {@filter(type=filtertype.annotation,classes=controller.class)}) @enablewebmvc\t//定制spring mvc配置 public class servletconfig implements webmvcconfigurer{ @override public void configuredefaultservlethandling(defaultservlethandlerconfigurer configurer) { configurer.enable(); } @override public void configureviewresolvers(viewresolverregistry registry) { registry.jsp(\u0026#34;/web-inf/jsp\u0026#34;, \u0026#34;.jsp\u0026#34;); } } 异步请求\n控制器返回callable spring异步处理,将callable 提交到 taskexecutor 使用一个隔离的线程进行执行 dispatcherservlet和所有的filter退出web容器的线程,但是response 保持打开状态 callable返回结果,springmvc将请求重新派发给容器,恢复之前的处理 根据callable返回的结果。springmvc继续进行视图渲染流程等(从收请求-视图渲染) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 @controller public class asynccontroller { @responsebody @requestmapping(\u0026#34;/async\u0026#34;) public callable\u0026lt;string\u0026gt; async(){ system.out.println(\u0026#34;主线程开始...\u0026#34;+thread.currentthread()+\u0026#34;==\u0026gt;\u0026#34;+system.currenttimemillis()); callable\u0026lt;string\u0026gt; callable = new callable\u0026lt;string\u0026gt;() { @override public string call() throws exception { system.out.println(\u0026#34;副线程开始...\u0026#34;+thread.currentthread()+\u0026#34;==\u0026gt;\u0026#34;+system.currenttimemillis()); thread.sleep(2000); system.out.println(\u0026#34;副线程开始...\u0026#34;+thread.currentthread()+\u0026#34;==\u0026gt;\u0026#34;+system.currenttimemillis()); return \u0026#34;callable\u0026lt;string\u0026gt; async()\u0026#34;; } }; system.out.println(\u0026#34;主线程结束...\u0026#34;+thread.currentthread()+\u0026#34;==\u0026gt;\u0026#34;+system.currenttimemillis()); return callable; } } 运行结果\n1 2 3 4 5 6 7 8 prehandle.../springmvc-annotation/async 主线程开始...thread[http-bio-8081-exec-3,5,main]==\u0026gt;1513932494700 主线程结束...thread[http-bio-8081-exec-3,5,main]==\u0026gt;1513932494700 副线程开始...thread[mvcasync1,5,main]==\u0026gt;1513932494707 副线程开始...thread[mvcasync1,5,main]==\u0026gt;1513932496708 prehandle.../springmvc-annotation/async posthandle... aftercompletion... 运行结果解释\n拦截请求-\u0026gt;主线程执行-\u0026gt;主线程执行结束-\u0026gt;dispatcherservlet和所有的filter退出web容器的线程-\u0026gt;子线程开始-\u0026gt;子线程结束-\u0026gt;重新模拟请求-\u0026gt;前置拦截器-\u0026gt;返回子线程执行完成结果-\u0026gt;后置拦截器-\u0026gt;视图处理完成拦截器\n注意:spring mvc异步处理还可以使用返回deferredresult进行实现,拦截异步请求处理过程可以使用asynchandlerinterceptor进行拦截\n","date":"2018-10-08","permalink":"https://hobocat.github.io/post/spring/2018-10-08-spring-annotation/","summary":"一、组件注册 Spring注解驱动上下文环境类为AnnotationConfigApplicationContext,避免使用application.xml进行","title":"spring注解驱动及其源码分析"},]
[{"content":"一、概述 \t通用 mapper是一个可以实现任意 mybatis 通用方法的框架,项目提供了常规的增删改查操作以及查询相关的单表操作。通用 mapper 是为了解决 mybatis 使用中 90% 的基本操作,使用它可以很方便的进行开发,可以节省开发人员大量的时间。\n二、集成 spring集成 第一步:添加依赖\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;org.mybatis\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;mybatis\u0026lt;/artifactid\u0026gt; \u0026lt;version\u0026gt;版本号\u0026lt;/version\u0026gt; \u0026lt;/dependency\u0026gt; \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;org.mybatis\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;mybatis-spring\u0026lt;/artifactid\u0026gt; \u0026lt;version\u0026gt;版本号\u0026lt;/version\u0026gt; \u0026lt;/dependency\u0026gt; \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;org.springframework\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;spring-context\u0026lt;/artifactid\u0026gt; \u0026lt;version\u0026gt;版本号\u0026lt;/version\u0026gt; \u0026lt;/dependency\u0026gt; \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;org.springframework\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;spring-jdbc\u0026lt;/artifactid\u0026gt; \u0026lt;version\u0026gt;版本号\u0026lt;/version\u0026gt; \u0026lt;/dependency\u0026gt; \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;tk.mybatis\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;mapper\u0026lt;/artifactid\u0026gt; \u0026lt;version\u0026gt;版本号\u0026lt;/version\u0026gt; \u0026lt;/dependency\u0026gt; 第二步:开始集成\nxml配置有以下两种方式,选其一\n使用mapperscannerconfigurer\ntk.mybatis.spring.mapper.mapperscannerconfigurer代替org.mybatis.spring.mapper.mapperscannerconfigurer\n1 2 3 4 \u0026lt;bean class=\u0026#34;tk.mybatis.spring.mapper.mapperscannerconfigurer\u0026#34;\u0026gt; \u0026lt;property name=\u0026#34;basepackage\u0026#34; value=\u0026#34;扫描包名\u0026#34;/\u0026gt; ... \u0026lt;/bean\u0026gt; 使用configuration\n如果某些第三方也需要特殊的 mapperscannerconfigurer 时,就不能用上面的方式进行配置了,此时使用以下方法\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 \u0026lt;!--使用 configuration 方式进行配置--\u0026gt; \u0026lt;bean id=\u0026#34;mybatisconfig\u0026#34; class=\u0026#34;tk.mybatis.mapper.session.configuration\u0026#34;\u0026gt; \u0026lt;!-- 配置通用 mapper,有三种属性注入方式 --\u0026gt; \u0026lt;property name=\u0026#34;mapperproperties\u0026#34;\u0026gt; \u0026lt;value\u0026gt; notempty=true \u0026lt;/value\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;/bean\u0026gt; \u0026lt;bean id=\u0026#34;sqlsessionfactory\u0026#34; class=\u0026#34;org.mybatis.spring.sqlsessionfactorybean\u0026#34;\u0026gt; \u0026lt;property name=\u0026#34;datasource\u0026#34; ref=\u0026#34;datasource\u0026#34;/\u0026gt; \u0026lt;property name=\u0026#34;configuration\u0026#34; ref=\u0026#34;mybatisconfig\u0026#34;/\u0026gt; \u0026lt;/bean\u0026gt; \u0026lt;!-- 不需要考虑下面这个,注意这里是 org 的 --\u0026gt; \u0026lt;bean class=\u0026#34;org.mybatis.spring.mapper.mapperscannerconfigurer\u0026#34;\u0026gt; \u0026lt;property name=\u0026#34;basepackage\u0026#34; value=\u0026#34;tk.mybatis.mapper.configuration\u0026#34;/\u0026gt; \u0026lt;property name=\u0026#34;sqlsessionfactorybeanname\u0026#34; value=\u0026#34;sqlsessionfactory\u0026#34;/\u0026gt; \u0026lt;/bean\u0026gt; 这里使用了 tk.mybatis.mapper.session.configuration ,就是不能通过读取 mybatis-config.xml进行配置,直接使用 spring setter 配置属性\n使用java注解和代码集成方式有以下三种\n使用**@mapperscan的properties**属性\n1 2 3 4 5 6 7 8 9 10 @configuration @mapperscan(value = \u0026#34;tk.mybatis.mapper.annotation\u0026#34;, properties = { \u0026#34;mappers=tk.mybatis.mapper.common.mapper\u0026#34;, \u0026#34;notempty=true\u0026#34; } ) public class mybatisconfigproperties { } 使用**@mapperscan的mapperhelperref** 属性\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 @configuration @mapperscan(value = \u0026#34;tk.mybatis.mapper.annotation\u0026#34;, mapperhelperref = \u0026#34;mapperhelper\u0026#34;) public static class mybatisconfigref { //其他 @bean public mapperhelper mapperhelper() { config config = new config(); list\u0026lt;class\u0026gt; mappers = new arraylist\u0026lt;class\u0026gt;(); mappers.add(mapper.class); config.setmappers(mappers); mapperhelper mapperhelper = new mapperhelper(); mapperhelper.setconfig(config); return mapperhelper; } } 使用构造configuration的方式\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 @configuration @mapperscan(value = \u0026#34;tk.mybatis.mapper.annotation\u0026#34;) public static class mybatisconfig { @bean public sqlsessionfactory sqlsessionfactory() throws exception { sqlsessionfactorybean sessionfactory = new sqlsessionfactorybean(); sessionfactory.setdatasource(datasource()); //tk.mybatis.mapper.session.configuration configuration configuration = new configuration(); //可以对 mapperhelper 进行配置后 set configuration.setmapperhelper(new mapperhelper()); //设置为 tk 提供的 configuration sessionfactory.setconfiguration(configuration); return sessionfactory.getobject(); } } spring boot集成 基于 starter 的自动配置\n1 2 3 4 5 \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;tk.mybatis\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;mapper-spring-boot-starter\u0026lt;/artifactid\u0026gt; \u0026lt;version\u0026gt;版本号\u0026lt;/version\u0026gt; \u0026lt;/dependency\u0026gt; 在 starter 的逻辑中,如果你没有使用 @mapperscan 注解,你就需要在你的接口上增加 @mapper注解,否则 mybatis 无法判断扫描哪些接口。所以需要手动在所有接口上增加 @mapper 注解\n在yml中配置属性\n1 2 3 4 mapper: mappers: - tk.mybatis.mapper.common.mapper notempty: true 基于mapperscan注解\n1 2 3 4 5 @tk.mybatis.spring.annotation.mapperscan(basepackages = \u0026#34;扫描包\u0026#34;) @springbootapplication public class samplemapperapplication implements commandlinerunner { } 三、注解详解 @namestyle注解(mapper) 可以设置实体类字段与表字段的转换方式,可选值\n1 2 3 4 5 6 7 8 public enum style { normal, //原值 camelhump, //驼峰转下划线,默认值 uppercase, //转换为大写 lowercase, //转换为小写 camelhumpanduppercase, //驼峰转下划线大写形式 camelhumpandlowercase, //驼峰转下划线小写形式 } @table注解(jpa) 作用:建立实体类和数据库表之间的对应关系。 默认规则: 实体类类名首字母小写作为表名。 employee 类→employee 表 用法: 在@table注解的 name属性中指定目标数据库表的表名\n@column注解(jpa) 作用:建立实体类字段和数据库表字段之间的对应关系。\n默认规则:实体类字段:驼峰式命名。数据库表字段:使用“_”区分各个单词\n用法:在@column 注解的name 属性中指定目标字段的字段名\n@columntype注解(mapper) 主要用于枚举属性,其中column属性和 @column 中的 name 作用相同,但是 @column的优先级更高。除了 name 属性外,这个注解主要提供了 jdbctype 属性和 typehandler 属性。\njdbctype 用于设置特殊数据库类型时指定数据库中的 jdbctype。\ntypehandler 用于设置特殊类型处理器,常见的是枚举。\n@transient注解(jpa) 用于标记不与数据库表字段对应的实体类字段。对于类中的复杂对象,以及 map,list 等属性不需要配置这个注解。\n主键相关注解 主键策略\n自增类型的\n使用**@id配合@keysql**,偏向mybatis写法\n1 2 3 @id @keysql(usegeneratedkeys = true)//或者@generatedvalue(generator = \u0026#34;jdbc\u0026#34;) private integer id; 使用**@id配合@keysql**,偏向jpa写法\n1 2 3 @id @keysql(dialect = identitydialect.default)//或者直接指定数据库方言dialect = identitydialect.mysql private integer id; 使用**@generatedvalue**\n1 2 3 @id @generatedvalue(strategy = generationtype.identity) private integer id; 通过序列和任意 sql 获取主键值\n使用**@id配合@keysql**\n1 2 3 @id @keysql(sql = \u0026#34;select seq_id.nextval from dual\u0026#34;, order = order.before) private integer id; 使用**@generatedvalue**\n1 2 3 @id @generatedvalue( strategy = generationtype.sequence, generator = \u0026#34;select seq_id.nextval from dual\u0026#34;) private integer id; @verson注解(mapper) @verson注解已经不常用,以下只是简单说明:\n在使用乐观锁时,由于通用 mapper 是内置的实现,不是通过拦截器方式实现的,如果版本不一致可能执行影响数为0,但不会抛出异常,所以在 java6,7中使用时,你需要自己在调用方法后进行判断是否执行成功。\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 //java8+可以使用默认方法判断自动抛出异常 public interface mymapper\u0026lt;t\u0026gt; extends mapper\u0026lt;t\u0026gt; { default int deletewithversion(t t){ int result = delete(t); if(result == 0){ throw new runtimeexception(\u0026#34;删除失败!\u0026#34;); } return result; } default int updatebyprimarykeywithversion(object t){ int result = updatebyprimarykey(t); if(result == 0){ throw new runtimeexception(\u0026#34;更新失败!\u0026#34;); } return result; } } @registermapper 注解 作用: 通用 mapper 检测到该接口被继承时,会自动注册。否则需要配置扫描参数。\n四、全局主键 第一步:实现genid\u0026lt;t\u0026gt;接口,实现主键生成策略\n1 2 3 4 5 6 7 //用uuid实现主键生成策略 public class uuidgenid implements genid\u0026lt;string\u0026gt; { @override public string genid(string table, string column) { return uuid.randomuuid().tostring().replace(\u0026#34;-\u0026#34;,\u0026#34;\u0026#34;); } } 第二步:配置\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class user { @id @keysql(genid = uuidgenid.class) private string id; private string name; private string code; public user() { } public user(string name, string code) { this.name = name; this.code = code; } //省略 setter 和 getter } 如果你使用了**@keysql**提供的其他方式,genid就不会生效,genid 是所有方式中优先级最低的\n五、常用配置 指配置通用mapper的位置,以xml方式为例\n1 2 3 4 5 6 7 8 \u0026lt;bean class=\u0026#34;tk.mybatis.spring.mapper.mapperscannerconfigurer\u0026#34;\u0026gt; \u0026lt;property name=\u0026#34;basepackage\u0026#34; value=\u0026#34;com.kun.mapper.mapper\u0026#34;/\u0026gt; \u0026lt;property name=\u0026#34;properties\u0026#34;\u0026gt;\u0026lt;!--设置的是这个properties值--\u0026gt; \u0026lt;props\u0026gt; \u0026lt;prop key=\u0026#34;keyxxx\u0026#34;\u0026gt;valuexxx\u0026lt;/prop\u0026gt; \u0026lt;/props\u0026gt; \u0026lt;/property\u0026gt; \u0026lt;/bean\u0026gt; mappers \t4.0 之后,增加了一个 @registermapper 注解,通用 mapper 中提供的所有接口都有这个注解,有了该注解后,通用 mapper 会自动解析所有的接口,如果父接口(递归向上找到的最顶层)存在标记该注解的接口,就会自动注册上。因此 4.0 后使用通用 mapper 提供的方法时,不需要在配置这个参数。当自己扩展通用接口时,建议加上该注解,否则就要配置 mappers 参数。\nidentity \t取回主键的方式,可以配置的值为所列的数据库类型,例如mysql: select last_insert_id() ,配置为identity=mysql\norder \t用于配置何时获取主键\u0026lt;selectkey\u0026gt;中的order属性,可选值为before和after\ncatalog、schema \t数据库的catalog,如果设置该值,查询的时候表名会带catalog设置的前缀\n\tschema同catalog,catalog优先级高于schema\nenumassimpletype \t用于配置是否将枚举类型当成基本类型对待。默认 simpletype 会忽略枚举类型,使用 enumassimpletype 配置后会把枚举按简单类型处理,需要自己配置好 typehandler。\n\t配置方式如下:enumassimpletype=true\ncheckexampleentityclass \t用于校验通用 example 构造参数 entityclass 是否和当前调用的 mapper\u0026lt;entityclass\u0026gt;类型一致,默认 false 。配置该字段为 true 后就会对不匹配的情况进行校验。\nsafedelete、safeupdate \t配置为 true 后,delete 和 deletebyexample 都必须设置查询条件才能删除,否则会抛出异常\n\t配置为 true 后,updatebyexample 和 updatebyexampleselective 都必须设置查询条件才能更新,否则会抛出异常\n六、代码生成器 第一步:引入mbg依赖\n1 2 3 4 5 6 \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;org.mybatis.generator\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;mybatis-generator-core\u0026lt;/artifactid\u0026gt; \u0026lt;version\u0026gt;版本号\u0026lt;/version\u0026gt; \u0026lt;scope\u0026gt;test\u0026lt;/scope\u0026gt; \u0026lt;/dependency\u0026gt; 第二步:配置generatorconfig.xml\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 \u0026lt;?xml version=\u0026#34;1.0\u0026#34; encoding=\u0026#34;utf-8\u0026#34;?\u0026gt; \u0026lt;!doctype generatorconfiguration public \u0026#34;-//mybatis.org//dtd mybatis generator configuration 1.0//en\u0026#34; \u0026#34;http://mybatis.org/dtd/mybatis-generator-config_1_0.dtd\u0026#34;\u0026gt; \u0026lt;generatorconfiguration\u0026gt; \u0026lt;!-- mybatis3会生成xxxxexample --\u0026gt; \u0026lt;context id=\u0026#34;mysql\u0026#34; targetruntime=\u0026#34;mybatis3simple\u0026#34; defaultmodeltype=\u0026#34;flat\u0026#34;\u0026gt; \u0026lt;plugin type=\u0026#34;tk.mybatis.mapper.generator.mapperplugin\u0026#34;\u0026gt; \u0026lt;!-- 继承的mapper基类接口 --\u0026gt; \u0026lt;property name=\u0026#34;mappers\u0026#34; value=\u0026#34;tk.mybatis.mapper.common.mapper\u0026#34;/\u0026gt; \u0026lt;!-- casesensitive默认false,当数据库表名区分大小写时,可以将该属性设置为true --\u0026gt; \u0026lt;property name=\u0026#34;casesensitive\u0026#34; value=\u0026#34;true\u0026#34; /\u0026gt; \u0026lt;!-- 强制打上注解 --\u0026gt; \u0026lt;property name=\u0026#34;forceannotation\u0026#34; value=\u0026#34;true\u0026#34;/\u0026gt; \u0026lt;property name=\u0026#34;beginningdelimiter\u0026#34; value=\u0026#34;`\u0026#34;/\u0026gt; \u0026lt;property name=\u0026#34;endingdelimiter\u0026#34; value=\u0026#34;`\u0026#34;/\u0026gt; \u0026lt;!-- 是否使用lombok --\u0026gt; \u0026lt;property name=\u0026#34;lombok\u0026#34; value=\u0026#34;data\u0026#34;/\u0026gt; \u0026lt;/plugin\u0026gt; \u0026lt;!-- 数据库驱动配置 --\u0026gt; \u0026lt;jdbcconnection driverclass=\u0026#34;com.mysql.jdbc.driver\u0026#34; connectionurl=\u0026#34;jdbc:mysql://192.168.10.191:3306/test\u0026#34; userid=\u0026#34;root\u0026#34; password=\u0026#34;123456\u0026#34;\u0026gt; \u0026lt;!--解决读取别的数据库表问题--\u0026gt; \u0026lt;property name=\u0026#34;nullcatalogmeanscurrent\u0026#34; value=\u0026#34;true\u0026#34; /\u0026gt; \u0026lt;!--解决不生成delete、update等--\u0026gt; \u0026lt;property name=\u0026#34;useinformationschema\u0026#34; value=\u0026#34;true\u0026#34;/\u0026gt; \u0026lt;/jdbcconnection\u0026gt; \u0026lt;!-- java类型处理器 用于处理db中的类型到java中的类型,默认使用javatyperesolverdefaultimpl; 注意默认会先尝试使用integer,long,short等来对应decimal和 numeric数据类型; 如需配置类型对应关系应该继承它 --\u0026gt; \u0026lt;!-- \u0026lt;javatyperesolver type=\u0026#34;org.mybatis.generator.internal.types.javatyperesolverdefaultimpl\u0026#34;\u0026gt; true:使用bigdecimal对应decimal和 numeric数据类型 false:默认, scale\u0026gt;0;length\u0026gt;18:使用bigdecimal; scale=0;length[10,18]:使用long; scale=0;length[5,9]:使用integer; scale=0;length\u0026lt;5:使用short; \u0026lt;property name=\u0026#34;forcebigdecimals\u0026#34; value=\u0026#34;false\u0026#34;/\u0026gt; \u0026lt;/javatyperesolver\u0026gt; --\u0026gt; \u0026lt;!-- 生成pojo对象所在包 --\u0026gt; \u0026lt;javamodelgenerator targetpackage=\u0026#34;com.kun.model\u0026#34; targetproject=\u0026#34;src\\main\\java\u0026#34;\u0026gt; \u0026lt;!-- pojo类继承的基类,没有可以不写 --\u0026gt; \u0026lt;property name=\u0026#34;rootclass\u0026#34; value=\u0026#34;com.kun.model.basemodel\u0026#34;/\u0026gt; \u0026lt;/javamodelgenerator\u0026gt; \u0026lt;!-- 生成的mapper.xml所在文件夹 --\u0026gt; \u0026lt;sqlmapgenerator targetpackage=\u0026#34;mapper\u0026#34; targetproject=\u0026#34;src\\main\\resources\u0026#34; /\u0026gt; \u0026lt;!-- 生成的mapper接口所在包 --\u0026gt; \u0026lt;javaclientgenerator targetpackage=\u0026#34;com.kun.mapper\u0026#34; targetproject=\u0026#34;src\\main\\java\u0026#34; type=\u0026#34;xmlmapper\u0026#34; /\u0026gt; \u0026lt;!-- 表名,主键策略 --\u0026gt; \u0026lt;table tablename=\u0026#34;press_remi_express\u0026#34; enablecountbyexample=\u0026#34;false\u0026#34; enableupdatebyexample=\u0026#34;true\u0026#34; enabledeletebyexample=\u0026#34;true\u0026#34; enableselectbyexample=\u0026#34;true\u0026#34; selectbyexamplequeryid=\u0026#34;true\u0026#34;\u0026gt; \u0026lt;generatedkey column=\u0026#34;id\u0026#34; sqlstatement=\u0026#34;mysql\u0026#34; identity=\u0026#34;true\u0026#34; /\u0026gt; \u0026lt;/table\u0026gt; \u0026lt;/context\u0026gt; \u0026lt;/generatorconfiguration\u0026gt; 第三步:以java代码的方式运行mbg\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public class mybatisgenerator{ public static void main(string[] args) throws ioexception, xmlparserexception, invalidconfigurationexception, sqlexception, interruptedexception { inputstream configfile = mybatisgenerator.class.getresourceasstream(\u0026#34;/generatorconfig.xml\u0026#34;); system.out.println(configfile); list\u0026lt;string\u0026gt; warnings = new arraylist\u0026lt;string\u0026gt;(); boolean overwrite = true; configurationparser cp = new configurationparser(warnings); configuration config = cp.parseconfiguration(configfile); defaultshellcallback callback = new defaultshellcallback(overwrite); mybatisgenerator mybatisgenerator = new mybatisgenerator(config, callback, warnings); progresscallback progress = new verboseprogresscallback(); mybatisgenerator.generate(progress); } } 七、扩展通用接口 以自定义的selectall为例,演示创建通用接口步骤。\n第一步:创建接口,接口使用注解@registermapper使通用mapper扫描,使用注解@selectprovider指定驱动类,method = \u0026quot;dynamicsql\u0026quot;为固定写法。\n1 2 3 4 5 6 7 @registermapper public interface selectallmapper\u0026lt;t\u0026gt; { // 查询全部结果 @selectprovider(type = myselectprovider.class, method = \u0026#34;dynamicsql\u0026#34;) list\u0026lt;t\u0026gt; selectall(); } 第二步:实现驱动类,注意驱动类继承mappertemplate,创建的方法名需要与接口的方法名同名。\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public class myselectprovider extends mappertemplate { public baseselectprovider(class\u0026lt;?\u0026gt; mapperclass, mapperhelper mapperhelper) { super(mapperclass, mapperhelper); } // 查询全部结果 public string selectall(mappedstatement ms) { final class\u0026lt;?\u0026gt; entityclass = getentityclass(ms); //修改返回值类型为实体类型 setresulttype(ms, entityclass); stringbuilder sql = new stringbuilder(); sql.append(sqlhelper.selectallcolumns(entityclass)); sql.append(sqlhelper.fromtable(entityclass, tablename(entityclass))); sql.append(sqlhelper.orderbydefault(entityclass)); return sql.tostring(); } } 注:可映射驱动注解类型\n@selectprovider —— 查询驱动类型,返回值为其查询结果集合 @updateprovider —— 更新驱动类型,返回值为影响记录行数 @insertprovider —— 插入驱动类型,返回值为影响记录行数,主键填充在传入的参数中 @deleteprovider —— 删除驱动类型,返回值为影响记录行数 注:对开发自定义有帮助的类\nmappertemplate —— 通用mapper模板类,扩展通用mapper时需要继承该类 entityhelper —— 实体类工具类,处理实体和数据库表以及字段关键的一个类 fieldhelper —— 类字段工具类 sqlhelper —— 拼常用sql的工具类 mapperhelper —— 获取通用mapper的所有配置 自定义insert ignore插入\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 @registermapper public interface insertignoreselectivemapper\u0026lt;t\u0026gt; { @insertprovider(type = insertignoreselectiveprovider.class, method = \u0026#34;dynamicsql\u0026#34;) int insertignoreselective(t record); } public class insertignoreselectiveprovider extends mappertemplate { public insertignoreselectiveprovider(class\u0026lt;?\u0026gt; mapperclass, mapperhelper mapperhelper) { super(mapperclass, mapperhelper); } public string insertignoreselective(mappedstatement ms) { class\u0026lt;?\u0026gt; entityclass = getentityclass(ms); stringbuilder sql = new stringbuilder(); //获取全部列 set\u0026lt;entitycolumn\u0026gt; columnlist = entityhelper.getcolumns(entityclass); entitycolumn logicdeletecolumn = sqlhelper.getlogicdeletecolumn(entityclass); processkey(sql, entityclass, ms, columnlist); sql.append(\u0026#34;insert ignore into \u0026#34;); sql.append(sqlhelper.getdynamictablename(entityclass, tablename(entityclass))); sql.append(\u0026#34; \u0026#34;); sql.append(\u0026#34;\u0026lt;trim prefix=\\\u0026#34;(\\\u0026#34; suffix=\\\u0026#34;)\\\u0026#34; suffixoverrides=\\\u0026#34;,\\\u0026#34;\u0026gt;\u0026#34;); for (entitycolumn column : columnlist) { if (!column.isinsertable()) { continue; } if (column.isidentity()) { sql.append(column.getcolumn()).append(\u0026#34;,\u0026#34;); } else { if (logicdeletecolumn != null \u0026amp;\u0026amp; logicdeletecolumn == column) { sql.append(column.getcolumn()).append(\u0026#34;,\u0026#34;); continue; } sql.append(sqlhelper.getifnotnull(column, column.getcolumn() + \u0026#34;,\u0026#34;, isnotempty())); } } sql.append(\u0026#34;\u0026lt;/trim\u0026gt;\u0026#34;); sql.append(\u0026#34;\u0026lt;trim prefix=\\\u0026#34;values(\\\u0026#34; suffix=\\\u0026#34;)\\\u0026#34; suffixoverrides=\\\u0026#34;,\\\u0026#34;\u0026gt;\u0026#34;); for (entitycolumn column : columnlist) { if (!column.isinsertable()) { continue; } if (logicdeletecolumn != null \u0026amp;\u0026amp; logicdeletecolumn == column) { sql.append(sqlhelper.getlogicdeletedvalue(column, false)).append(\u0026#34;,\u0026#34;); continue; } //优先使用传入的属性值,当原属性property!=null时,用原属性 //自增的情况下,如果默认有值,就会备份到property_cache中,所以这里需要先判断备份的值是否存在 if (column.isidentity()) { sql.append(sqlhelper.getifcachenotnull(column, column.getcolumnholder(null, \u0026#34;_cache\u0026#34;, \u0026#34;,\u0026#34;))); } else { //其他情况值仍然存在原property中 sql.append(sqlhelper.getifnotnull(column, column.getcolumnholder(null, null, \u0026#34;,\u0026#34;), isnotempty())); } //当属性为null时,如果存在主键策略,会自动获取值,如果不存在,则使用null //序列的情况 if (column.isidentity()) { sql.append(sqlhelper.getifcacheisnull(column, column.getcolumnholder() + \u0026#34;,\u0026#34;)); } } sql.append(\u0026#34;\u0026lt;/trim\u0026gt;\u0026#34;); return sql.tostring(); } private void processkey(stringbuilder sql, class\u0026lt;?\u0026gt; entityclass, mappedstatement ms, set\u0026lt;entitycolumn\u0026gt; columnlist){ //identity列只能有一个 boolean hasidentitykey = false; //先处理cache或bind节点 for (entitycolumn column : columnlist) { if (column.isidentity()) { //这种情况下,如果原先的字段有值,需要先缓存起来,否则就一定会使用自动增长 //这是一个bind节点 sql.append(sqlhelper.getbindcache(column)); //如果是identity列,就需要插入selectkey //如果已经存在identity列,抛出异常 if (hasidentitykey) { //jdbc类型只需要添加一次 if (column.getgenerator() != null \u0026amp;\u0026amp; \u0026#34;jdbc\u0026#34;.equals(column.getgenerator())) { continue; } throw new mapperexception(ms.getid() + \u0026#34;对应的实体类\u0026#34; + entityclass.getcanonicalname() + \u0026#34;中包含多个mysql的自动增长列,最多只能有一个!\u0026#34;); } //插入selectkey selectkeyhelper.newselectkeymappedstatement(ms, column, entityclass, isbefore(), getidentity(column)); hasidentitykey = true; } else if(column.getgenidclass() != null){ sql.append(\u0026#34;\u0026lt;bind name=\\\u0026#34;\u0026#34;).append(column.getcolumn()).append(\u0026#34;genidbind\\\u0026#34; value=\\\u0026#34;@tk.mybatis.mapper.genid.genidutil@genid(\u0026#34;); sql.append(\u0026#34;_parameter\u0026#34;).append(\u0026#34;, \u0026#39;\u0026#34;).append(column.getproperty()).append(\u0026#34;\u0026#39;\u0026#34;); sql.append(\u0026#34;, @\u0026#34;).append(column.getgenidclass().getcanonicalname()).append(\u0026#34;@class\u0026#34;); sql.append(\u0026#34;, \u0026#39;\u0026#34;).append(tablename(entityclass)).append(\u0026#34;\u0026#39;\u0026#34;); sql.append(\u0026#34;, \u0026#39;\u0026#34;).append(column.getcolumn()).append(\u0026#34;\u0026#39;)\u0026#34;); sql.append(\u0026#34;\\\u0026#34;/\u0026gt;\u0026#34;); } } } } 八、example 用法 一、使用mbg生成的example子类\n1 2 3 4 5 countryexample example = new countryexample(); example.createcriteria().andcountrynamelike(\u0026#34;a%\u0026#34;); example.or().andidgreaterthan(100); example.setdistinct(true); int count = mapper.deletebyexample(example); 二、使用原始的example类\n1 2 3 4 5 example example = new example(country.class); example.setforupdate(true); example.createcriteria().andgreaterthan(\u0026#34;id\u0026#34;, 100).andlessthan(\u0026#34;id\u0026#34;,151); example.or().andlessthan(\u0026#34;id\u0026#34;, 41); list\u0026lt;country\u0026gt; countries = mapper.selectbyexample(example); 三、example.builder 方式\n1 2 3 4 5 6 7 example example = example.builder(country.class) .select(\u0026#34;countryname\u0026#34;) .where(sqls.custom().andgreaterthan(\u0026#34;id\u0026#34;, 100)) .orderbyasc(\u0026#34;countrycode\u0026#34;) .forupdate() .build(); list\u0026lt;country\u0026gt; countries = mapper.selectbyexample(example); 四、weekend 方式\n1 2 3 4 5 6 list\u0026lt;country\u0026gt; selectbyweekendsql = mapper.selectbyexample( example.builder(country.class) .where(weekendsqls.\u0026lt;country\u0026gt;custom() .andlike(country::getcountryname, \u0026#34;%a%\u0026#34;) .andgreaterthan(country::getcountrycode, \u0026#34;123\u0026#34;)) .build()); 九、typehandler用法 例如:数据库存放的用户地址信息为hebei/shijiazhuang、hebei/handan\n第一步:创建实体类\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public class address implements serializable { private static final long serialversionuid = 1l; private string province; private string city; // 省略getter、setter方法。。。 @override public string tostring() { stringbuilder builder = new stringbuilder(); if(province != null \u0026amp;\u0026amp; province.length() \u0026gt; 0){ builder.append(province); } if(city != null \u0026amp;\u0026amp; city.length() \u0026gt; 0){ builder.append(\u0026#34;/\u0026#34;).append(city); } return builder.tostring(); } } 1 2 3 4 5 6 7 8 public class user implements serializable { private static final long serialversionuid = 1l; @id private integer id; private string name; @columntype(typehandler = addresstypehandler.class)\t//指定typehandler private address address;\t//实体类对应的地址 } 第二步:创建对应的typehandler\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 public class addresstypehandler extends basetypehandler\u0026lt;address\u0026gt; { @override public void setnonnullparameter(preparedstatement ps, int i, address parameter, jdbctype jdbctype) throws sqlexception { ps.setstring(i, parameter.tostring()); } private address converttoaddress(string addressstr){ if(addressstr == null || addressstr.length() == 0){ return null; } string[] strings = addressstr.split(\u0026#34;/\u0026#34;); address address = new address(); if(strings.length \u0026gt; 0 \u0026amp;\u0026amp; strings[0].length() \u0026gt; 0){ address.setprovince(strings[0]); } if(strings.length \u0026gt; 1 \u0026amp;\u0026amp; strings[1].length() \u0026gt; 0){ address.setcity(strings[1]); } return address; } @override public address getnullableresult(resultset rs, string columnname) throws sqlexception { return converttoaddress(rs.getstring(columnname)); } @override public address getnullableresult(resultset rs, int columnindex) throws sqlexception { return converttoaddress(rs.getstring(columnindex)); } @override public address getnullableresult(callablestatement cs, int columnindex) throws sqlexception { return converttoaddress(cs.getstring(columnindex)); } } 注:上述为局部使用方法、也可以在mybatis-config.xml中配置全局的类型处理器\n1 2 3 \u0026lt;typehandlers\u0026gt; \u0026lt;typehandler handler=\u0026#34;tk.mybatis.mapper.typehandler.addresstypehandler\u0026#34;/\u0026gt; \u0026lt;/typehandlers\u0026gt; 并在实体类中配置@column使mybtais将复杂类型作为普通类型向数据库对应字段进行映射\n1 2 3 4 5 6 7 8 9 10 @table(name = \u0026#34;user\u0026#34;) public class user implements serializable { private static final long serialversionuid = 1l; @id private integer id; private string name; @column private address address; //省略 setter 和 getter } ","date":"2018-10-08","permalink":"https://hobocat.github.io/post/mybatis/2018-10-08-mapper/","summary":"一、概述 通用 Mapper是一个可以实现任意 MyBatis 通用方法的框架,项目提供了常规的增删改查操作以及查询相关的单表操作。通用 Mapper 是为了解决 MyBatis 使用中 90% 的基本操作,使用它可","title":"通用mapper使用指南"},]
[{"content":"一、简介 \tmybatis 是一款优秀的持久层框架,它支持定制化 sql、存储过程以及高级映射。mybatis 避免了几乎所有的 jdbc 代码和手动设置参数以及获取结果集。mybatis 可以使用简单的 xml 或注解来配置和映射原生信息,将接口和 java 的 pojos(plain old java objects,普通的 java对象)映射成数据库中的记录。\n二、启动 第一步、引入maven依赖\n1 2 3 4 5 \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;org.mybatis\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;mybatis\u0026lt;/artifactid\u0026gt; \u0026lt;version\u0026gt;x.x.x\u0026lt;/version\u0026gt; \u0026lt;/dependency\u0026gt; 第二步、构建 sqlsessionfactory\nmybatis 的应用都是以一个 sqlsessionfactory 的实例为核心的,sqlsessionfactory 的实例可以通过 sqlsessionfactorybuilder 获得。\n1 2 3 string resource = \u0026#34;mybatis-config.xml\u0026#34;; inputstream inputstream = resources.getresourceasstream(resource); sqlsessionfactory sqlsessionfactory = new sqlsessionfactorybuilder().build(inputstream); 简单的mybatis-config.xml\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 \u0026lt;?xml version=\u0026#34;1.0\u0026#34; encoding=\u0026#34;utf-8\u0026#34;?\u0026gt; \u0026lt;!doctype configuration public \u0026#34;-//mybatis.org//dtd config 3.0//en\u0026#34; \u0026#34;http://mybatis.org/dtd/mybatis-3-config.dtd\u0026#34;\u0026gt; \u0026lt;configuration\u0026gt; \u0026lt;environments default=\u0026#34;development\u0026#34;\u0026gt; \u0026lt;environment id=\u0026#34;development\u0026#34;\u0026gt; \u0026lt;transactionmanager type=\u0026#34;jdbc\u0026#34;/\u0026gt; \u0026lt;datasource type=\u0026#34;pooled\u0026#34;\u0026gt; \u0026lt;property name=\u0026#34;driver\u0026#34; value=\u0026#34;com.mysql.jdbc.driver\u0026#34;/\u0026gt; \u0026lt;property name=\u0026#34;url\u0026#34; value=\u0026#34;jdbc:mysql://127.0.0.1:3306/mybatis\u0026#34;/\u0026gt; \u0026lt;property name=\u0026#34;username\u0026#34; value=\u0026#34;root\u0026#34;/\u0026gt; \u0026lt;property name=\u0026#34;password\u0026#34; value=\u0026#34;123456\u0026#34;/\u0026gt; \u0026lt;/datasource\u0026gt; \u0026lt;/environment\u0026gt; \u0026lt;/environments\u0026gt; \u0026lt;mappers\u0026gt; \u0026lt;mapper resource=\u0026#34;mapper/personmapper.xml\u0026#34;/\u0026gt; \u0026lt;/mappers\u0026gt; \u0026lt;/configuration\u0026gt; 第三步、sqlsessionfactory 中获取 sqlsession\n1 2 3 4 5 6 sqlsession session = sqlsessionfactory.opensession(); //com.kun.start.mapper.personmapper是personmapper.xml的namespace,selectall具体sql的id list\u0026lt;object\u0026gt; persons = session.selectlist(\u0026#34;com.kun.start.mapper.personmapper.selectall\u0026#34;); for (object person : persons) { system.out.println(person); } 也可以使用接口的方式调用\n1 2 3 4 5 6 7 sqlsession session = sqlsessionfactory.opensession(); //会根据personmapper全限定命找到对应的personmapper.xml,动态代理此接口 personmapper mapper = session.getmapper(personmapper.class); list\u0026lt;person\u0026gt; persons = mapper.selectall(); for (person person : persons) { system.out.println(person); } 作用域(scope)和生命周期\nsqlsessionfactorybuilder:一旦创建了 sqlsessionfactory,就不再需要它,即会被丢弃。\nsqlsessionfactory:sqlsessionfactory 一旦被创建就应该在应用的运行期间一直存在,没有任何理由对它进行清除或重建,应用中应该只存在一个。\nsqlsession:每个线程都应该有它自己的 sqlsession 实例。sqlsession 的实例不是线程安全的,因此是不能被共享的,所以它的最佳的作用域是请求或方法作用域,不可以放在threadlocal当中\nmapper instances:用过之后即可废弃,并不需要显式地关闭映射器实例。\n三、xml 配置文件 常用的可能修改默认值的settings 参数 描述 默认值 lazyloadingenabled 懒加载的全局开关。当开启时,所有关联对象都会延迟加载。 特定关联关系中可通过设置fetchtype属性来覆盖该项的开关状态。 false aggressivelazyloading 当开启时,任何方法的调用都会加载该对象的所有属性。否则,每个属性会按需加载 false (true in ≤3.4.1) mapunderscoretocamelcase 否开启自动驼峰命名规则(camel case)映射 false lazyloadtriggermethods 指定对象的哪个方法触发延迟加载 equals,clone,hashcode,tostring defaultenumtypehandler 指定 enum 使用的默认 typehandler 。 (从3.4.5开始) org.apache.ibatis.type.enumtypehandler 详细的setting设置\ntypealiases设置 类型别名是为 java 类型设置一个短的名字,也可以在类上使用@alias(\u0026quot;xxx\u0026quot;)。它只和 xml 配置有关。例如:\n1 2 3 4 5 \u0026lt;typealiases\u0026gt; \u0026lt;typealias alias=\u0026#34;author\u0026#34; type=\u0026#34;domain.blog.author\u0026#34;/\u0026gt; \u0026lt;typealias alias=\u0026#34;blog\u0026#34; type=\u0026#34;domain.blog.blog\u0026#34;/\u0026gt; \u0026lt;typealias alias=\u0026#34;comment\u0026#34; type=\u0026#34;domain.blog.comment\u0026#34;/\u0026gt; \u0026lt;/typealiases\u0026gt; 可能需要更换的默认typehandlers 类型处理器 java 类型 jdbc 类型 enumtypehandler enumeration type varchar-任何兼容的字符串类型,存储枚举的名称(而不是索引) enumordinaltypehandler enumeration type 任何兼容的 numeric 或 double 类型,存储枚举的索引(而不是名称)。 自定义枚举处理器:\n枚举类接口,定义统一规范\n1 2 3 4 public interface baseenum\u0026lt;e extends enum\u0026lt;?\u0026gt;,t\u0026gt; { t getcode(); string getmessage(); } 自定义枚举类\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 public enum infoenum implements baseenum\u0026lt;infoenum,string\u0026gt;{ success(\u0026#34;200\u0026#34;,\u0026#34;成功\u0026#34;), faild(\u0026#34;500\u0026#34;,\u0026#34;错误\u0026#34;); private string code; private string message; static map\u0026lt;string,infoenum\u0026gt; enummap=new hashmap\u0026lt;string, infoenum\u0026gt;(); static{ (infoenum type:infoenum.values()){ enummap.put(type.getcode(), type); } } public static map\u0026lt;string,infoenum\u0026gt; getall() { return enummap; } private infoenum(string code, string message) { this.code = code; this.message = message; } @override public string getcode() { return this.code; } @override public string getmessage() { return this.message; } } 自定义枚举类型处理器\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public class infoenumtypehandler extends basetypehandler\u0026lt;infoenum\u0026gt;{ @override public void setnonnullparameter(preparedstatement ps, int i, infoenum parameter, jdbctype jdbctype) throws sqlexception { ps.setstring(i, parameter.getcode()); } @override public infoenum getnullableresult(resultset rs, string columnname) throws sqlexception { string columnvalue = rs.getstring(columnname); return infoenum.getall().get(columnvalue); } @override public infoenum getnullableresult(resultset rs, int columnindex) throws sqlexception { string columnvalue = rs.getstring(columnindex); return infoenum.getall().get(columnvalue); } @override public infoenum getnullableresult(callablestatement cs, int columnindex) throws sqlexception { string columnvalue = cs.getstring(columnindex); return infoenum.getall().get(columnvalue); } } 配置自定义类型处理器\n1 2 3 4 \u0026lt;!-- mybatis-config.xml --\u0026gt; \u0026lt;typehandlers\u0026gt; \u0026lt;typehandler handler=\u0026#34;com.kun.start.typehandler.infoenumtypehandler\u0026#34;/\u0026gt; \u0026lt;/typehandlers\u0026gt; 插件(plugins) mybatis 允许你在已映射语句执行过程中的某一点进行拦截调用。默认情况下,mybatis 允许使用插件来拦截的方法调用包括:\nexecutor (update, query, flushstatements, commit, rollback, gettransaction, close, isclosed) parameterhandler (getparameterobject, setparameters) resultsethandler (handleresultsets, handleoutputparameters) statementhandler (prepare, parameterize, batch, update, query) 例自定义插件:\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 @intercepts(value= {@signature(type=executor.class,method=\u0026#34;query\u0026#34;,args= {mappedstatement.class,object.class,rowbounds.class,resulthandler.class})}) public class exampleplugin implements interceptor{ @override public object intercept(invocation invocation) throws throwable { for (object arg : invocation.getargs()) { if(arg != null \u0026amp;\u0026amp; arg instanceof mappedstatement) { mappedstatement ms = (mappedstatement) arg; system.out.println(\u0026#34;id = \u0026#34; +ms.getid()); } } return invocation.proceed(); } @override public object plugin(object target) { return plugin.wrap(target, this); } @override public void setproperties(properties properties) { system.out.println(properties.get(\u0026#34;pro\u0026#34;)); } } 四、xml映射文件 sql 映射文件几个顶级元素\ncache – 给定命名空间的缓存配置。 cache-ref – 其他命名空间缓存配置的引用。 resultmap – 是最复杂也是最强大的元素,用来描述如何从数据库结果集中来加载对象。 sql – 可被其他语句引用的可重用语句块。 insert – 映射插入语句 update – 映射更新语句 delete – 映射删除语句 select – 映射查询语句 select 基本,#{id}会在预编译语中被替换为?,当只有一个参数时候,#{param}可以是任意名称,当参数个数大于1时,使用#{arg0},#{arg1},#{arg2}...或者#{param1},#{param2},#{param3}...,此时习惯使用@param(\u0026quot;[参数名称]\u0026quot;)来指定参数的名称。\n1 2 3 \u0026lt;select id=\u0026#34;selectperson\u0026#34; parametertype=\u0026#34;int\u0026#34; resulttype=\u0026#34;hashmap\u0026#34;\u0026gt; select * from person where id = #{id} \u0026lt;/select\u0026gt; 常用可选属性\n属性 描述 parametertype 将会传入这条语句的参数类的完全限定名或别名。这个属性是可选的,因为 mybatis 可以通过 typehandler 推断出具体传入语句的参数,默认值为 unset resulttype 从这条语句中返回的期望类型的类的完全限定名或别名。注意如果是集合情形,那应该是集合可以包含的类型,而不能是集合本身。使用 resulttype 或 resultmap,但不能同时使用 resultmap 外部 resultmap 的命名引用。结果集的映射是 mybatis 最强大的特性,对其有一个很好的理解的话,许多复杂映射的情形都能迎刃而解。使用 resultmap 或 resulttype,但不能同时使用 flushcache 将其设置为 true,任何时候只要语句被调用,都会导致本地缓存和二级缓存都会被清空,默认值:false usecache 将其设置为 true,将会导致本条语句的结果被二级缓存,默认值:对 select 元素为 true statementtype statement,prepared 或 callable 的一个。这会让 mybatis 分别使用 statement,preparedstatement 或 callablestatement,默认值:prepared insert, update 和 delete 常用可选属性(insert、update、delete)\n属性 描述 parametertype 将要传入语句的参数的完全限定类名或别名。这个属性是可选的,因为 mybatis 可以通过 typehandler 推断出具体传入语句的参数,默认值为 unset flushcache 将其设置为 true,任何时候只要语句被调用,都会导致本地缓存和二级缓存都会被清空,默认值:true statementtype statement,prepared 或 callable 的一个。这会让 mybatis 分别使用 statement,preparedstatement 或 callablestatement,默认值:prepared usegeneratedkeys (仅对 insert 和 update 有用)这会令 mybatis 使用 jdbc 的 getgeneratedkeys 方法来取出由数据库内部生成的主键(比如:像 mysql 和 sql server 这样的关系数据库管理系统的自动递增字段),默认值:false keyproperty (仅对 insert 和 update 有用)唯一标记一个属性,mybatis 会通过 getgeneratedkeys 的返回值或者通过 insert 语句的 selectkey 子元素设置它的键值,默认:unset。如果希望得到多个生成的列,也可以是逗号分隔的属性名称列表 keycolumn (仅对 insert 和 update 有用)通过生成的键值设置表中的列名,这个设置仅在某些数据库(像 postgresql)是必须的,当主键列不是表中的第一列的时候需要设置。如果希望得到多个生成的列,也可以是逗号分隔的属性名称列表 有些数据库(例如oracle)主键生成策略是序列化表,所以select引入子标签selectkey\n1 2 3 4 5 6 \u0026lt;insert id=\u0026#34;insertuser\u0026#34; \u0026gt; \u0026lt;selectkey resulttype=\u0026#34;int\u0026#34; keyproperty=\u0026#34;id\u0026#34; order=\u0026#34;before\u0026#34;\u0026gt; select seq_user_id.nextval as id from dual \u0026lt;/selectkey\u0026gt; insert into user (id,name,password) values (#{id},#{name},#{password}) \u0026lt;/insert\u0026gt; selectkey相关属性\n属性 描述 keyproperty selectkey 语句结果应该被设置的目标属性。如果希望得到多个生成的列,也可以是逗号分隔的属性名称列表 resulttype 结果的类型。mybatis 通常可以推算出来,但是为了更加确定写上也不会有什么问题。 order 这可以被设置为 before 或 after。如果设置为 before,那么它会首先选择主键,设置 keyproperty 然后执行插入语句。如果设置为 after,那么先执行插入语句,然后是 selectkey 元素 - 这和像 oracle 的数据库相似,在插入语句内部可能有嵌入索引调用 statementtype 与前面相同,mybatis 支持 statement,prepared 和 callable 语句的映射类型 sql 这个元素可以被用来定义可重用的 sql 代码段,可以包含在其他语句中。它可以被静态地(在加载参数) 参数化. 不同的属性值通过包含的实例变化. 比如:\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 \u0026lt;sql id=\u0026#34;sometable\u0026#34;\u0026gt; ${prefix}table \u0026lt;/sql\u0026gt; \u0026lt;sql id=\u0026#34;someinclude\u0026#34;\u0026gt; from \u0026lt;include refid=\u0026#34;${include_target}\u0026#34;/\u0026gt; \u0026lt;/sql\u0026gt; \u0026lt;select id=\u0026#34;select\u0026#34; resulttype=\u0026#34;map\u0026#34;\u0026gt; select field1, field2, field3 \u0026lt;include refid=\u0026#34;someinclude\u0026#34;\u0026gt; \u0026lt;property name=\u0026#34;prefix\u0026#34; value=\u0026#34;some\u0026#34;/\u0026gt; \u0026lt;property name=\u0026#34;include_target\u0026#34; value=\u0026#34;sometable\u0026#34;/\u0026gt; \u0026lt;/include\u0026gt; \u0026lt;/select\u0026gt; 参数 使用 #{} 格式的语法会导致 mybatis 创建 preparedstatement 参数并安全地设置参数(使用 ? )。不过有时需要在 sql 语句中插入一个不转义的字符串。比如 order by 就需要使用${}\n缓存 mybatis默认情况下是没有开启缓存的,除了局部的 session 缓存,可以增强处理循环。开启二级缓存需要加入cache标签\ncache的效果如下:\n映射语句文件中的所有 select 语句将会被缓存。 映射语句文件中的所有 insert,update 和 delete 语句会刷新缓存。 缓存会使用 least recently used(lru,最近最少使用的)算法来收回。 根据时间表(比如 no flush interval,没有刷新间隔), 缓存不会以任何时间顺序 来刷新。 缓存会存储列表集合或对象(无论查询方法返回什么)的 1024 个引用。 缓存会被视为是 read/write(可读/可写)的缓存,意味着对象检索不是共享的,而 且可以安全地被调用者修改,而不干扰其他调用者或线程所做的潜在修改。 1 2 \u0026lt;!--eviction:回收策略,flushinterval:刷新间隔,默认不设置,size:引用数目,默认1024,readonly:返回对象是否只读(保证安全性),默认false--\u0026gt; \u0026lt;cache eviction=\u0026#34;fifo\u0026#34; flushinterval=\u0026#34;60000\u0026#34; size=\u0026#34;512\u0026#34; readonly=\u0026#34;true\u0026#34;/\u0026gt; 收回策略有:\nlru – 最近最少使用的:移除最长时间不被使用的对象。 fifo – 先进先出:按对象进入缓存的顺序来移除它们。 soft – 软引用:移除基于垃圾回收器状态和软引用规则的对象。 weak – 弱引用:更积极地移除基于垃圾收集器状态和弱引用规则的对象。 使用cache-ref标签贡献缓存配置实例\n1 \u0026lt;cache-ref namespace=\u0026#34;com.someone.application.data.somemapper\u0026#34;/\u0026gt; 第三方缓存框架ehcache的使用 第一步:引入maven依赖\n1 2 3 4 5 6 7 8 9 10 \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;org.ehcache\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;ehcache\u0026lt;/artifactid\u0026gt; \u0026lt;version\u0026gt;版本号\u0026lt;/version\u0026gt; \u0026lt;/dependency\u0026gt; \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;org.mybatis.caches\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;mybatis-ehcache\u0026lt;/artifactid\u0026gt; \u0026lt;version\u0026gt;版本号\u0026lt;/version\u0026gt; \u0026lt;/dependency\u0026gt; 第二步:配置ehcache配置文件\n1 2 \u0026lt;!--name很重要,必须和mapper的命名空间对应--\u0026gt; \u0026lt;cache name=\u0026#34;com.kun.xxx.personmapper\u0026#34; maxelementsinmemory=\u0026#34;1024\u0026#34; external=\u0026#34;false\u0026#34; timetoidleseconds=\u0026#34;300\u0026#34; timetoliveseconds=\u0026#34;600\u0026#34; overflowtodisk=\u0026#34;true\u0026#34;/\u0026gt; 第三步:在mybatis配置文件中配置别名\n1 \u0026lt;typealias type=\u0026#34;org.mybatis.caches.ehcache.ehcachecache\u0026#34; alias=\u0026#34;ehcache\u0026#34; /\u0026gt; 第四步:在需要引用缓存的mapper文件中引用\n1 \u0026lt;cache type=\u0026#34;ehcache\u0026#34;/\u0026gt; 五、结果集 resultmap子元素\nconstructor - 用于在实例化类时,注入结果到构造方法中 idarg- id 参数;标记出作为 id 的结果可以帮助提高整体性能 arg - 将被注入到构造方法的一个普通结果 id – 标记出作为 id 的结果可以帮助提高整体性能 result – 注入到字段或 javabean 属性的普通结果 association – 一个复杂类型的关联;许多结果将包装成这种类型 collection – 一个复杂类型的集合 discriminator – 使用结果值来决定使用哪个 case – 基于某些值的结果映射 使用constructor子标签 ,注意多个参数,需要在pojo类构造函数上使用@param指定名称\n1 2 3 4 5 6 \u0026lt;resultmap type=\u0026#34;com.kun.start.model.person\u0026#34; id=\u0026#34;person\u0026#34;\u0026gt; \u0026lt;constructor\u0026gt; \u0026lt;idarg column=\u0026#34;id\u0026#34; name=\u0026#34;id\u0026#34;/\u0026gt;\t\u0026lt;!--指定主键提高效率--\u0026gt; \u0026lt;arg column=\u0026#34;name\u0026#34; name=\u0026#34;name\u0026#34;/\u0026gt; \u0026lt;/constructor\u0026gt; \u0026lt;/resultmap\u0026gt; 使用association 子标签,进行多对一或者一对一关联查询,直接映射结构\n1 2 3 4 \u0026lt;association property=\u0026#34;author\u0026#34; column=\u0026#34;blog_author_id\u0026#34; javatype=\u0026#34;author\u0026#34;\u0026gt; \u0026lt;id property=\u0026#34;id\u0026#34; column=\u0026#34;author_id\u0026#34;/\u0026gt; \u0026lt;result property=\u0026#34;username\u0026#34; column=\u0026#34;author_username\u0026#34;/\u0026gt; \u0026lt;/association\u0026gt; 使用association 子标签,进行多对一或者一对一关联的嵌套查询,这种写法可能引起“n+1”问题,可以使用懒加载或关联的嵌套结果查询\n1 2 3 4 \u0026lt;!--查询博客的作者--\u0026gt; \u0026lt;resultmap id=\u0026#34;blogresult\u0026#34; type=\u0026#34;blog\u0026#34;\u0026gt; \u0026lt;association property=\u0026#34;author\u0026#34; column=\u0026#34;author_id\u0026#34; javatype=\u0026#34;author\u0026#34; select=\u0026#34;selectauthor\u0026#34;/\u0026gt; \u0026lt;/resultmap\u0026gt; 使用association 子标签,进行多对一或者一对一关联的嵌套结果查询,避免了“n+1\u0026quot;问题\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 \u0026lt;!--查询博客的作者--\u0026gt; \u0026lt;resultmap id=\u0026#34;blogresult\u0026#34; type=\u0026#34;blog\u0026#34;\u0026gt; \u0026lt;id property=\u0026#34;id\u0026#34; column=\u0026#34;blog_id\u0026#34; /\u0026gt; \u0026lt;result property=\u0026#34;title\u0026#34; column=\u0026#34;blog_title\u0026#34;/\u0026gt; \u0026lt;association property=\u0026#34;author\u0026#34; column=\u0026#34;blog_author_id\u0026#34; javatype=\u0026#34;author\u0026#34; resultmap=\u0026#34;authorresult\u0026#34;/\u0026gt; \u0026lt;/resultmap\u0026gt; \u0026lt;resultmap id=\u0026#34;authorresult\u0026#34; type=\u0026#34;author\u0026#34;\u0026gt; \u0026lt;id property=\u0026#34;id\u0026#34; column=\u0026#34;author_id\u0026#34;/\u0026gt; \u0026lt;result property=\u0026#34;username\u0026#34; column=\u0026#34;author_username\u0026#34;/\u0026gt; \u0026lt;result property=\u0026#34;password\u0026#34; column=\u0026#34;author_password\u0026#34;/\u0026gt; \u0026lt;result property=\u0026#34;email\u0026#34; column=\u0026#34;author_email\u0026#34;/\u0026gt; \u0026lt;result property=\u0026#34;bio\u0026#34; column=\u0026#34;author_bio\u0026#34;/\u0026gt; \u0026lt;/resultmap\u0026gt; \u0026lt;select id=\u0026#34;selectblog\u0026#34; resultmap=\u0026#34;blogresult\u0026#34;\u0026gt; select b.id as blog_id, b.title as blog_title, b.author_id as blog_author_id, a.id as author_id, a.username as author_username, a.password as author_password, a.email as author_email, a.bio as author_bio from blog b left outer join author a on b.author_id = a.id where b.id = #{id} \u0026lt;/select\u0026gt; 使用collection子标签,进行集合的嵌套查询,注意oftype指的是元素类型,javatype能推测出来可以不写\n1 2 3 4 5 6 7 8 9 10 11 12 \u0026lt;!--查询博客下有多少文章--\u0026gt; \u0026lt;resultmap id=\u0026#34;blogresult\u0026#34; type=\u0026#34;blog\u0026#34;\u0026gt; \u0026lt;collection property=\u0026#34;posts\u0026#34; column=\u0026#34;id\u0026#34; oftype=\u0026#34;post\u0026#34; select=\u0026#34;selectpostsforblog\u0026#34;/\u0026gt; \u0026lt;/resultmap\u0026gt; \u0026lt;select id=\u0026#34;selectblog\u0026#34; resultmap=\u0026#34;blogresult\u0026#34;\u0026gt; select * from blog where id = #{id} \u0026lt;/select\u0026gt; \u0026lt;select id=\u0026#34;selectpostsforblog\u0026#34; resulttype=\u0026#34;post\u0026#34;\u0026gt; select * from post where blog_id = #{id} \u0026lt;/select\u0026gt; 使用collection子标签,进行集合的嵌套结果查询,避免多次发送sql,提高效率\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 \u0026lt;resultmap id=\u0026#34;blogresult\u0026#34; type=\u0026#34;blog\u0026#34;\u0026gt; \u0026lt;id property=\u0026#34;id\u0026#34; column=\u0026#34;blog_id\u0026#34; /\u0026gt; \u0026lt;result property=\u0026#34;title\u0026#34; column=\u0026#34;blog_title\u0026#34;/\u0026gt; \u0026lt;collection property=\u0026#34;posts\u0026#34; oftype=\u0026#34;post\u0026#34;\u0026gt; \u0026lt;id property=\u0026#34;id\u0026#34; column=\u0026#34;post_id\u0026#34;/\u0026gt; \u0026lt;result property=\u0026#34;subject\u0026#34; column=\u0026#34;post_subject\u0026#34;/\u0026gt; \u0026lt;result property=\u0026#34;body\u0026#34; column=\u0026#34;post_body\u0026#34;/\u0026gt; \u0026lt;/collection\u0026gt; \u0026lt;/resultmap\u0026gt; \u0026lt;select id=\u0026#34;selectblog\u0026#34; resultmap=\u0026#34;blogresult\u0026#34;\u0026gt; select b.id as blog_id, b.title as blog_title, b.author_id as blog_author_id, p.id as post_id, p.subject as post_subject, p.body as post_body, from blog b left outer join post p on b.id = p.blog_id where b.id = #{id} \u0026lt;/select\u0026gt; 使用discriminator 子标签完成鉴别器工作,相当于java中的switch语句。一般用于同表描述继承关系(不建议使用)\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 \u0026lt;!--根据鉴别字段的值自动映射成对应的子类--\u0026gt; \u0026lt;resultmap id=\u0026#34;vehicleresult\u0026#34; type=\u0026#34;vehicle\u0026#34;\u0026gt; \u0026lt;id property=\u0026#34;id\u0026#34; column=\u0026#34;id\u0026#34; /\u0026gt; \u0026lt;result property=\u0026#34;vin\u0026#34; column=\u0026#34;vin\u0026#34;/\u0026gt; \u0026lt;result property=\u0026#34;year\u0026#34; column=\u0026#34;year\u0026#34;/\u0026gt; \u0026lt;result property=\u0026#34;make\u0026#34; column=\u0026#34;make\u0026#34;/\u0026gt; \u0026lt;result property=\u0026#34;model\u0026#34; column=\u0026#34;model\u0026#34;/\u0026gt; \u0026lt;result property=\u0026#34;color\u0026#34; column=\u0026#34;color\u0026#34;/\u0026gt; \u0026lt;!-- javatype:返回的值类型(用于比较的列)--\u0026gt; \u0026lt;discriminator javatype=\u0026#34;int\u0026#34; column=\u0026#34;vehicle_type\u0026#34;\u0026gt; \u0026lt;!-- resulttype:对应哪个子类结果集,result子标签:子类特有属性 --\u0026gt; \u0026lt;case value=\u0026#34;1\u0026#34; resulttype=\u0026#34;carresult\u0026#34;\u0026gt; \u0026lt;result property=\u0026#34;doorcount\u0026#34; column=\u0026#34;door_count\u0026#34; /\u0026gt; \u0026lt;/case\u0026gt; \u0026lt;case value=\u0026#34;2\u0026#34; resulttype=\u0026#34;truckresult\u0026#34;\u0026gt; \u0026lt;result property=\u0026#34;boxsize\u0026#34; column=\u0026#34;box_size\u0026#34; /\u0026gt; \u0026lt;result property=\u0026#34;extendedcab\u0026#34; column=\u0026#34;extended_cab\u0026#34; /\u0026gt; \u0026lt;/case\u0026gt; \u0026lt;case value=\u0026#34;3\u0026#34; resulttype=\u0026#34;vanresult\u0026#34;\u0026gt; \u0026lt;result property=\u0026#34;powerslidingdoor\u0026#34; column=\u0026#34;power_sliding_door\u0026#34; /\u0026gt; \u0026lt;/case\u0026gt; \u0026lt;case value=\u0026#34;4\u0026#34; resulttype=\u0026#34;suvresult\u0026#34;\u0026gt; \u0026lt;result property=\u0026#34;allwheeldrive\u0026#34; column=\u0026#34;all_wheel_drive\u0026#34; /\u0026gt; \u0026lt;/case\u0026gt; \u0026lt;/discriminator\u0026gt; \u0026lt;/resultmap\u0026gt; 六、动态 sql if,用于条件判断 1 2 3 4 5 6 7 8 \u0026lt;select id=\u0026#34;findactiveblogwithtitlelike\u0026#34; resulttype=\u0026#34;blog\u0026#34;\u0026gt; select * from blog where state = ‘active’ \u0026lt;if test=\u0026#34;title != null\u0026#34;\u0026gt; and title like #{title} \u0026lt;/if\u0026gt; \u0026lt;/select\u0026gt; choose, choose-when, choose-otherwise 有时我们不想应用到所有的条件语句,而只想从中择其一项。针对这种情况,mybatis 提供了 choose 元素,它有点像 java 中的 switch 语句\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 \u0026lt;select id=\u0026#34;findactivebloglike\u0026#34; resulttype=\u0026#34;blog\u0026#34;\u0026gt; select * from blog where state = ‘active’ \u0026lt;choose\u0026gt; \u0026lt;when test=\u0026#34;title != null\u0026#34;\u0026gt; and title like #{title} \u0026lt;/when\u0026gt; \u0026lt;when test=\u0026#34;author != null and author.name != null\u0026#34;\u0026gt; and author_name like #{author.name} \u0026lt;/when\u0026gt; \u0026lt;otherwise\u0026gt; and featured = 1 \u0026lt;/otherwise\u0026gt; \u0026lt;/choose\u0026gt; \u0026lt;/select\u0026gt; trim, where, set 用于解决where后跟无意义条件例如where 1=1问题\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 \u0026lt;select id=\u0026#34;findactivebloglike\u0026#34; resulttype=\u0026#34;blog\u0026#34;\u0026gt; select * from blog \u0026lt;where\u0026gt; \u0026lt;if test=\u0026#34;state != null\u0026#34;\u0026gt; state = #{state} \u0026lt;/if\u0026gt; \u0026lt;if test=\u0026#34;title != null\u0026#34;\u0026gt; and title like #{title} \u0026lt;/if\u0026gt; \u0026lt;if test=\u0026#34;author != null and author.name != null\u0026#34;\u0026gt; and author_name like #{author.name} \u0026lt;/if\u0026gt; \u0026lt;/where\u0026gt; \u0026lt;/select\u0026gt; where 元素只会在至少有一个子元素的条件返回 sql 子句的情况下才去插入“where”子句。而且,若语句的开头为“and”或“or”,where 元素也会将它们去除\n类似于where解决select语句问题,set解决update语句问题\n1 2 3 4 5 6 7 8 9 10 \u0026lt;update id=\u0026#34;updateauthorifnecessary\u0026#34;\u0026gt; update author \u0026lt;set\u0026gt; \u0026lt;if test=\u0026#34;username != null\u0026#34;\u0026gt;username=#{username},\u0026lt;/if\u0026gt; \u0026lt;if test=\u0026#34;password != null\u0026#34;\u0026gt;password=#{password},\u0026lt;/if\u0026gt; \u0026lt;if test=\u0026#34;email != null\u0026#34;\u0026gt;email=#{email},\u0026lt;/if\u0026gt; \u0026lt;if test=\u0026#34;bio != null\u0026#34;\u0026gt;bio=#{bio}\u0026lt;/if\u0026gt; \u0026lt;/set\u0026gt; where id=#{id} \u0026lt;/update\u0026gt; 这里,set元素会动态前置 set 关键字,同时也会删掉无关的逗号,因为用了条件语句之后很可能就会在生成的 sql 语句的后面留下这些逗号\nwhere和set底层都是使用trim。prefix/suffix-加入的前(后)缀,prefixoverrides/suffixoverrides-前后覆盖的字符\n1 2 3 4 5 6 7 8 9 \u0026lt;!--相当于set标签--\u0026gt; \u0026lt;trim prefix=\u0026#34;set\u0026#34; prefixoverrides=\u0026#34;,\u0026#34; suffixoverrides=\u0026#34;,\u0026#34;\u0026gt; ...\t\u0026lt;/trim\u0026gt; \u0026lt;!--相当于where标签--\u0026gt; \u0026lt;trim prefix=\u0026#34;where\u0026#34; prefixoverrides=\u0026#34;and|or\u0026#34; suffixoverrides=\u0026#34;,\u0026#34;\u0026gt; ...\t\u0026lt;/trim\u0026gt; foreach 动态 sql 的另外一个常用的操作需求是对一个集合进行遍历,通常是在构建 in 条件语句的时候。比如:\n1 2 3 4 5 6 \u0026lt;select id=\u0026#34;selectpersonin\u0026#34; resulttype=\u0026#34;com.kun.person\u0026#34;\u0026gt; select * from person where id in \u0026lt;foreach item=\u0026#34;item\u0026#34; index=\u0026#34;index\u0026#34; collection=\u0026#34;ids\u0026#34; open=\u0026#34;(\u0026#34; separator=\u0026#34;,\u0026#34; close=\u0026#34;)\u0026#34;\u0026gt; #{item} \u0026lt;/foreach\u0026gt; \u0026lt;/select\u0026gt; item-变量集合去除的元素,index-元素的索引,collection-集合参数名称。\n集合类型可以是list、set、map的key、map的value。【index 作为map 的key。item为map的值】,例如:\n1 2 3 \u0026lt;foreach collection=\u0026#34;ent\u0026#34; item=\u0026#34;id\u0026#34; separator=\u0026#34;,\u0026#34; open=\u0026#34;(\u0026#34; close=\u0026#34;)\u0026#34;\u0026gt; #{id} \u0026lt;/foreach\u0026gt; bind 可以将ognl表达式的值绑定到一个变量中,方便后来引用这个变量的值。\n1 2 3 4 5 6 7 \u0026lt;select id=\u0026#34;getemps\u0026#34; resulttype=\u0026#34;com.hand.mybatis.bean.employee\u0026#34;\u0026gt; \u0026lt;bind name=\u0026#34;bindename\u0026#34; value=\u0026#34;\u0026#39;%\u0026#39;+ename+\u0026#39;%\u0026#39;\u0026#34;/\u0026gt; \u0026lt;!--ename是employee中一个属性值--\u0026gt; select * from emp \u0026lt;if test=\u0026#34;_parameter!=null\u0026#34;\u0026gt; where ename like #{bindename} \u0026lt;/if\u0026gt; \u0026lt;/select\u0026gt; ","date":"2018-09-27","permalink":"https://hobocat.github.io/post/mybatis/2018-09-27-mybatis/","summary":"一、简介 MyBatis 是一款优秀的持久层框架,它支持定制化 SQL、存储过程以及高级映射。MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集。MyBatis 可","title":"mybatis使用指南"},]
[{"content":"一、版本控制工具应具备的功能 协调修改 多人并行不悖的修改服务器端的同一个文件 数据备份 不仅保持目录和文件的当前状态,还能够保持每个提交过的历史状态 版本管理 在保存每一个版本的文件新鲜的时候要做到不保存重复数据以节省存储空间。【svn采用增量式管理方式,git使用文件系统快照管理方式】 权限控制 对团队中参与开发的人员进行权限控制 对团队外开发者贡献的代码进行审核——git独有 历史记录 查看修改人、修改时间、修改内容、日志信息 将本地文件恢复到某一个历史状态 分支管理 允许开发团队在工作过程中多条生产线同时推进任务,进一步提高效率 二、版本控制简介 版本控制 \t工程设计领域中使用版本控制管理工程蓝图的设计过程。在it 开发过程中也可以使用版本控制思想管理代码的版本迭代。\n版本控制工具 集中式版本控制工具:cvs、svn、vss……【当远程库损坏,重新上传代码,因为本地只保存了当前代码,所以以前记录将会丢失】 分布式版本控制工具:git、mercurial、bazaar、darcs……【当远程库损坏,重新上传代码,因为本地保存了所有记录,所以历史信息完好无损】 三、git 简介 git简史 git 的优势 大部分操作在本地完成,不需要联网 完整性保证 尽可能添加数据而不是删除或修改数据 分支操作非常快捷流畅 与 linux 命令全面兼容 git结构 四、git命令行操作 本地库初始化 命令:git init\n效果:生成.git目录,目录下有如下文件\n设置签名 注意:这里设置的签名和登陆远程库(代码托管中心)的账号、密码没有任何关系\n项目/仓库级别设置(优先)\n设置用户名:git config user.name hobocat 设置email:git config user.email hobocat@126.com 系统用户级别设置\n设置用户名:git config \u0026ndash;global user.name hobocat 设置email:git config \u0026ndash;global user.email hobocat@126.com 信息保存的位置,仓库级别存放于.git文件下的config,系统级别保存在用户家目录下的.gitconfig文件夹下\n基本操作 查看状态\ngit status\t查看当前所属分支以及工作区和暂存区状态\n添加文件到暂存区\ngit add [file name]\t将工作区的“新建/修改“添加到暂存区\n提交\ngit commit -m \u0026ldquo;commit message\u0026rdquo; [file name]\t将暂存区的内容提交到本地库\ngit commit -a -m “commit message”\t将暂存区的全部文件提交到本地库\n查看历史记录\ngit log\t多屏操作空格向下翻页、b 向上翻页、q 退出\ngit log \u0026ndash;pretty=oneline 简洁打印完整的hash值\ngit log \u0026ndash;oneline\t简洁打印部分hash值\n\tgit reflog\t以指针偏移值打印,head@{移动到当前版本需要多少步},可以显示回退之前版本\n前进后退【本质是头指针指向版本的改变】\ngit reset \u0026ndash;hard [index]\t基于索引值的操作【推荐】\ngit reset \u0026ndash;hard head^\t一个^表示后退一步,n 个表示后退n 步\ngit reset \u0026ndash;hard head~[n]\t表示后退n 步\nreset 命令的三个参数soft、mixed、hard对比\n\u0026ndash;soft 移动本地库\n\u0026ndash;mixed\t移动本地库、重置暂存区\n\u0026ndash;hard\t移动本地库、重置暂存区、重置工作区\n比较文件差异\ngit diff [文件名]\t比较指定文件与本地库区别\ngit diff 【本地库中历史版本】【文件名】\t比较指定文件与历史\ngit diff\t比较所有文件与本地库区别\n分支管理 分支定义:在版本控制过程中,使用多条线同时推进多个任务。\n分支的好处:\n同时并行推进多个功能开发,提高开发效率\n分支在开发过程中,如果某一个分支开发失败,不会对其他分支有任何影响。失败的分支删除重新开始即可\n分支操作\n创建分支\ngit branch [分支名]\n查看分支\ngit branch -v\n切换分支\ngit checkout\n合并分支\n第一步:切换到接受修改的分支(被合并,增加新内容) 第二步:执行merge 命令\tgit merge [有新内容分支名] 解决冲突\n冲突的表现 冲突的解决 第一步:编辑文件,删除特殊符号 第二步:把文件修改到满意的程度,保存退出 第三步:git add [文件名] 第四步:git commit -m \u0026ldquo;日志信息\u0026rdquo;,注意:此时commit 一定不能带具体文件名 五、git 基本原理 一致性保证 git 底层采用的是sha-1 算法校验文件是否相同\n保存版本的机制 集中式版本控制工具的文件管理机制\n以文件变更列表的方式存储信息。这类系统将原始文件作为基准文件,保存每次更改的差异信息。\ngit 的文件管理机制\ngit 把数据看作是小型文件系统的一组快照。每次提交更新时git 都会对当前的全部文件制作一个快照并保存这个快照的索引。为了高效,如果文件没有修改,git 不再重新存储该文件,而是只保留一个链接指向之前存储的文件。所以git 的工作方式可以称之为快照流。\n分支管理机制 分支的创建,仅仅是创建一个分支的指针指向当前分支\n切换分支,将head指针指向指定的分支即可\n六、git工作流 集中式工作流 \t像svn 一样,集中式工作流以中央仓库作为项目所有修改的单点实体。所有修改都提交到master 这个分支上。这种方式与svn 的主要区别就是开发人员有本地库。git 很多特性并没有用到。\ngitflow 工作流 \tgitflow 工作流通过为功能开发、发布准备和维护设立了独立的分支,让发布迭代过程更流畅。严格的分支模型也为大型项目提供了一些非常必要的结构。\nforking 工作流 \tforking 工作流是在gitflow 基础上,充分利用了git 的fork 和pull request 的功能以达到代码审核的目的。更适合安全可靠地管理大团队的开发者,而且能接受不信任贡献者的提交。\n\t主干分支master 主要负责管理正在运行的生产环境代码。永远保持与正在运行的生产环境完全一致。 开发分支develop 主要负责管理正在开发过程中的代码。一般情况下应该是最新的代码。 bug修理分支hotfix 主要负责管理生产环境下出现的紧急修复的代码。从主干分支分出,修理完毕并测试上线后,并回主干分支,并回后,视情况可以删除该分支。 准生产分支(预发布分支) release 较大的版本上线前,会从开发分支中分出准生产分支,进行最后阶段的集成测试。该版本上线后,会合并到主干分支。生产环境运行一段阶段较稳定后可以视情况删除。 功能分支feature 为了不影响较短周期的开发工作,一般把中长期开发模块,会从开发分支中独立出来。开发完成后会合并到开发分支。 七、gitlab安装 第一步:下载rpm包【gitlab过大在线安装不可靠】\nrpm包下载地址,社区版选择ce,注意版本没按照顺序排\n第二步:设置防火墙,防火墙已经被关闭则跳过此步骤\n1 2 3 4 5 sudo yum install -y curl policycoreutils-python openssh-server sudo systemctl enable sshd sudo systemctl start sshd sudo firewall-cmd --permanent --add-service=http sudo systemctl reload firewalld 第三步:安装邮件发送服务\n1 2 3 sudo yum install postfix sudo systemctl enable postfix sudo systemctl start postfix 第四步:安装gitlab\n1 2 3 4 5 6 sudo yum install -y curl policycoreutils-python openssh-server cronie sudo systemctl enable sshd sudo systemctl start sshd sudo rpm -ivh [rpm包] curl https://packages.gitlab.com/install/repositories/gitlab/gitlab-ce/script.rpm.sh | sudo bash sudo external_url=\u0026#34;http://gitlab.example.com\u0026#34; yum install -y gitlab-ce 第五步:gitlab初始化、启动、关闭\n1 2 3 gitlab-ctl reconfigure gitlab-ctl start gitlab-ctl stop 注意:\n机器内存大于2g 配置文件/etc/gitlab/gitlab.rb,修改之后使用gitlab-ctl reconfigure重新配置 ","date":"2018-09-20","permalink":"https://hobocat.github.io/post/tool/2018-09-20-git/","summary":"一、版本控制工具应具备的功能 协调修改 多人并行不悖的修改服务器端的同一个文件 数据备份 不仅保持目录和文件的当前状态,还能够保持每个提交过的历史状态 版本管理 在保存每一","title":"git使用指南"},]
[{"content":"spring 控制反转/依赖注入 ioc容器 ioc容器负责实例化,配置和组装对象。 ioc容器从xml文件获取信息并相应地工作。 ioc容器执行的主要任务是:\n实例化 应用程序类配置对象组装 对象之间的依赖关系 容器\nbeanfactory | 低级容器,负责加载bean,getbean xmlbeanfactory applicationcontext | 高级容器。依赖低级容器,同时具备别的功能 | 如fresh bean beanfactory等 classpathxmlapplicationcontext 什么是ioc\n控制反转,即把传统上有程序代码直接操作的对象的调用权交给容器,通过容器来实现对象组件的装配和管理。“控制反转”概念就是对组件对象控制权的转移,从程序代码转移到容器。\nioc有什么作用\n管理对象的创建和依赖关系的维护 解耦,有容器去维护具体的对象 托管了类的产生过程 ioc分类\n依赖注入:详见di 依赖查找 配置方式\n基于xml \u0026lt;bean id=\u0026quot;userservice\u0026quot; class=\u0026quot;xx.xxx.service.impl.xxximpl\u0026quot;\u0026gt;\u0026lt;/bean\u0026gt;\nbean标签详解\n1. bean标签作用:用于配置对象让spring创建;默认情况下它会调用类中的无参构造行数,如果没有无参构造行数则不能成功创建bean。 2. bean标签属性 ① id: 给对象在容器中提供唯一标识,用于获取对象。 ② class: 指定类的全限定类名。用于反射创建对象。 ③ scope: 指定对象的作用范围。 a. singleton: 默认值 单例的(在整个容器中只有一个对象) b. prototype: 多例 c. request:web项目中 基于注解 当一个类添加ioc注解,这个bean的id为这个类名的的首字母小写\n前提:包路径扫描\n\u0026lt;context:component-scan base-package=\u0026ldquo;xx.xxx.service,xx.xxx.dao\u0026rdquo;/\u0026gt;\n@componentscan 作用:定义扫描的路径,从中找出标识了需要装配的类自动装配到spring的bean容器中\n1. 自定扫描路径下带有@controller @service @repostitory @component注解加入到spring容器 2. 通过includefilter 加入扫描路径下没有以上几个注解的类加入spring容器 3. 通过excludefilter过滤出不用加入到spring容器的类 @component 相当于这个类当成bean,放到ioc容器中\n@controller 衍生 添加到web层\n@service 衍生 添加到service层\n@repository 衍生 添加到持久化层\ndi依赖注入 概念 依赖注入更加具体的实现了ioc的设计理念,是ioc的技术实现。\n实现原理 配置方式\n基于xml\n构造函数注入\nsetter注入\n集合类型 和引用类型 ref\n引用ref 集合\n基于注解\n@autowired\n默认按类型装配,可通过@qualifiler结合去指明bean中的id(按名称)\n@resource\n默认按名称装配,通过name属性进行指明bean中的id,若没有指名name,则默认按字段名找bean,若找不到匹配的bean,则按类型装配\n其他\n@value 给基本类型和string 注入值 一般情况下读取配置文件属性\n@scope 指定bean的作用范围,默认singleton\n@postconstruct 写在方法上,指定此方法为初始化回调方法\n@predestroy 写在方法上,指定此方法为销毁的回调方法\n注入方式\n构造方法 setter方法 接口注入 装配模式\nbyname\nbyname模式根据bean的名称注入对象依赖项。在这种情况下,属性名称和bean名称必须相同。它在内部调用setter方法。\nbytype\nbytype模式根据类型注入对象依赖项。因此属性名称和bean名称可以不同。它在内部调用setter方法。\nconstructor\n构造函数模式通过调用类的构造函数来注入依赖项。它会调用具有大量参数的构造函数。\ndi和ioc的区别\nioc 是 inversion of control 的缩写,翻译成中文是“控制反转”的意思,它不是一个具体的技术,而是一个实现对象解耦的思想。 di 是 dependency injection 的缩写,翻译成中文是“依赖注入”的意思。依赖注入不是一种设计实现,而是一种具体的技术,它是在 ioc 容器运行期间,动态地将某个依赖对象注入到当前对象的技术就叫做 di(依赖注入)。 优势\n使代码易于测试 使代码松散耦合,因此易于维护 spring aop 概念 aspect orient programming 面向切面编程,aop是一种编程思想。是面向对象编程(oop)的一种补充。实现在不修改源代码的情况下,给程序动态统一添加额外功能的一种技术。 拦截指定方法并进行增强,无需侵入业务代码\n作用 分离功能性需求和非功能性需求,可以集中处理某一个关注点,减少对业务代码的侵入,增强代码的可读性和可维护性。\n常用场景 事务 日志 权限 监测 核心 术语\njoinpoint 连接点\n指哪些被拦截到的点,在spring中只可以被动态代理拦截目标类的方法\npointcut 切入点\n指要对哪些joinpoint进行拦截,即被拦截的连接点\nadvice 通知\n指拦截到joinpoint之后要做的事情,即对切入点增强的内容\ntarget 目标\n指代理的目标对象\nweaving 植入\n指把增强代码应用到目标上,生成代理对象的过程\nproxy 代理\n指生成的代理对象\naspect 切面\n切入点和通知的结合\n通知分类\nbefore 前置通知\n通知方法在目标方法调用之前执行\nafter 后置通知\n通知方法在目标方法返回或异常后调用\nafter-returning 返回后通知\n通知方法在目标方法返回后调用\nafter-throwing 抛出异常通知\n通知方法在目标方法抛出异常后调用\naround 环绕通知\n通知方法会将目标方法封装起来\n织入时期\n编译期\n类加载期\n运行期\nspring aop使用方式 日常使用 基于aspectj\nxml\n注解\n@aspect 类上,声明当前类为切面\n@component 并交给spring容器管理\n自定义通知方法\n@pointcut 切入点\nexecution 表达式\n([方法修饰符] 返回类型 包名.类名.方法名(参与类型) [异常类型]) 方法修饰符 可省略 返回值类型、包名、类名、方法名 可以用通配符* 代表任意 包名与类名之间一个点 . 代表当前包下的类,两个点 .. 代表当前包下级子包下的类 参数列表可以使用两个点 .. 代表任意类型参数,任意个数 (* com.xx.xxx..*.*(..) ) xxx包及任意子包下所有方法 (* com.xx.xxx.*.*(..))xxx包下所有方法 (* com.xx.xxx.*.yyy.*.*(..)) xxx包下任意yyy包下的任意方法 within\nthis\ntarget\nargs\n@before 前置通知\n@after 后置通知\n@afterreturning 后置通知,有返回或有异常\n@arround 环绕通知\n@afterthrowing 异常通知\n配置自动代理\n\u0026lt;aop:aspectj-autoproxy/\u0026gt; @configuration + @enableaspectautoproxy spring 自带方式\n实现原理 动态代理实现\njdk动态代理 默认 基于接口的动态代理技术\ncglib代理 基于父类的动态代理技术\nspring 事务 概念 事务是逻辑上的一组操作,要么都执行,要么都不执行。\n注意 事务能否生效,主要看数据库引擎是否支持事务\nmysql 的innodb引擎支持事务,myisam引擎不支持事务 特性 acid 原子性 atomicity 一个事务中的所有操作,要么全部完成,要么全部不完成,不会结束在某个中间环节。若执行中发生错误,会被回滚到事务开始前的状态。\n一致性 consistency 事务开始之前和事务结束之后,数据路的完成性没有被破坏。即数据是预期和期望的样子\n隔离性 isolation 数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致的数据不一致。事务隔离分为不同级别\n持久性 durability 事务处理结束后,对数据的修改是永久的,即系统故障也不会丢失\n实现方式 编程式事务管理\n通过transactiontemplate或transactionmanager手动管理事务 声明式事务管理\n使用@transactional注解进行事务管理\n作用范围\n- 方法:推荐将注解用在方法上。另外要注意的是只有在public方法上才生效 - 类:放在类上,表示对类中所有的public方法都生效 - 接口:不推荐 常用参数配置\npropagation\n事务的传播行为,默认值为 required\nisolcation\n事务的隔离级别,默认值采用 default\ntimeout\n事务的超时时间,默认值为-1\nreadonly\n指定事务是否为只读事务,默认值为 false\nrollbackfor\n用于指定能够触发事务回滚的异常类型,并且可以指定多个异常类型\nnorollbackfor\n用于指定不触发事务回滚的异常类型,并且可以指定多个异常类型\n原理解释\n如果类或者类中public方法上被标注@transactional注解,spring容器会在启动时为其创建一个代理类,在调用被注解的public方法时,实际调用的是transactioninterceptor类中的invoke()方法。这个方法的作用就是在目标方法之前开启事务,方法执行过程中若遇到异常时回滚事务。方法调用完成之后提交事务。 transactioninterceptor 类中的 invoke()方法内部实际调用的是 transactionaspectsupport 类的 invokewithintransaction()方法\n推荐使用:代码侵入性小,基于aop实现\naop自调用问题\n同一类中其他没有@transactional注解的方法内部调用有@transactional注解的方法,有注解的方法事务会失效 只有当 @transactional 注解的方法在类以外被调用的时候,spring 事务管理才生效。 核心接口 platformtransactionmanager` 事务管理器,spring事务策略的核心。提供了不同平台的事务管理器如jdbc、hibernate、jpa等 主要方法\ntransactionstatus gettransaction(transactiondefinition var) 获取事务 void commit(transactionstatus var) 提交事务 void rollback(transactionstatus var) 回滚事务 transactiondefinition 事务定义信息\n隔离级别\ntransactiondefinition.isolation_default 使用后端数据库默认的隔离级别,mysql 默认采用的 repeatable_read 隔离级别 oracle 默认采用的 read_committed 隔离级别\ntransactiondefinition.isolation_read_uncommitted 最低的隔离级别,使用这个隔离级别很少,因为它允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读\ntransactiondefinition.isolation_read_committed 允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生\ntransactiondefinition.isolation_repeatable_read 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生\ntransactiondefinition.isolation_serializable 最高的隔离级别,完全服从 acid 的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。但是这将严重影响程序的性能。通常情况下也不会用到该级别。\n传播行为\ntransactiondefinition.propagation_required transactiondefinition.propagation_requires_new transactiondefinition.propagation_nested transactiondefinition.propagation_mandatory 超时\n指一个事务所允许执行的最长时间,若超过该时间限制事务还没有完成,则自动回滚事务。 单位秒,默认值-1\n只读\n只读数据查询的事务,不涉及数据的修改。适用于复杂业务,多条多次查询\n回滚规则\n定义遇到哪些异常才会事务回滚。默认runtimeexception及其子类回滚\n主要方法\nint getpropagationbehavior(); 返回事务的传播行为,默认值为 required。\nint getisolationlevel(); 返回事务的隔离级别,默认值是 default\nint gettimeout(); 返回事务的超时时间,默认值为-1。如果超过该时间限制但事务还没有完成,则自动回滚事务。\nboolean isreadonly(); 返回是否为只读事务,默认值为 false\ntransactionstatus 事务运行状态\n主要方法\nboolean isnewtransaction() 是否是新的事务\nboolean hassavepoint() 是否有恢复点\nvoid setrollbackonly() 设置为只回滚\nboolean isrollbackonly() 是否为只回滚\nboolean iscompleted 是否已完成\nspringframework 优点 预定义模板、松耦合、易于测试、轻巧、快速开发、声明式支持\nspring bean 生命周期流程图 springmvc 概念 基于spring的mvc框架 作用 解决页面代码与后台代码分离,解耦合 执行过程 or 原理 对servlet的封装,更易于使用\n流程\n用户发出请求被前端控制器dispatcherservlet拦截处理 dispatcherservlet收到请求调用handlermapping(处理器映射器) handlermapping找到具体的处理器(查找xml配置或注解配置),生成处理器对象及处理器拦截器(如果有),再一起返回给dispatcherservlet dispatcherservlet调用handleradapter(处理器适配器) handleradapter经过适配调用具体的处理器(handler/controller) controller执行完成返回modelandview对象 handleradapter将controller执行结果modelandview返回给dispatcherservlet dispatcherservlet将modelandview传给viewreslover(视图解析器) viewreslover解析modelandview后返回具体view(视图)给dispatcherservlet dispatcherservlet根据view进行渲染视图(即将模型数据填充至视图中) dispatcherservlet响应view给用户 组件\n1.dispatcherservlet 前端控制器 作用:接收请求,响应结果,相当于转发器,中央处理器。 由框架提供,在web.xml中配置 2.handlermapping 处理器映射器 作用:根据请求的url查找handler(处理器/controller) 通过xml或注解方式映射 3. handleradapter 处理器适配器 作用:按照特定规则(handleradapter要求的规则)执行handler中的方法 4.handler 处理器 作用:接收用户的请求信息,调用业务方法处理请求,也称为后端控制器 即controller 5.viewresolver 视图解析器 作用:视图解析,把逻辑视图解析成物理视图 springmvc提供多种技术 如 jstlview freemarkerview等 6. view 视图 作用:把数据展现给用户页面 view是个接口,实现类支持多种技术 如 jsp freemarker pdf等 使用\nweb.xml 中配置dispatcherservlet 编写controller 编写页面 springboot application创建过程 springapplication.run() 源码解析\n创建springapplication实例\n1. 新建实例 创建springapplication对象 2. 实例初始化 1. 设置resourceloader 2. 确定webapplicationtype类型 3. 设置applicationcontextinitializer。遍历执行所有通过springfactoriesloader 可以查找到的、并加载的applicationcontextinitializer, 4. 设置applicationlistener。 遍历执行所有通过springfactoriesloader 可以查找到的、并加载的applicationlistener 5. 设置mainapplicationclass 执行run方法\n设置系统环境变量 java.awt.headless 默认为true\n加载并执行springapplicationrunlistener 遍历执行所有通过springfactoriesloader 可以查找到的、并加载的springapplicationrunlistener\n遍历所有listeners,调用listener的starting方法 4.获取默认的applicationarguments new defaultapplicationarguments(args);\n创建并配置当前springboot应用将要使用的environment,包括配置要使用的projectysource及profile。configurableenvironment environment = prepareenvironment(listeners, applicationarguments); 2.根据webapplicationtype创建environment 3.配置environment的参数argumrnts(applicationarguments) 4. listeners遍历执行environmentprepared方法 表示springboot应用的environment准备好了 每个监听器将给application添加事件\n将environment绑到springapplication bindtospringapplication(environment); 获取是否配置了忽略的bean,设置环境变量spring.beaninfo.ignore。 configureignorebeaninfo(environment);\n若springapplication的showbanner属性被设置为true,则打印banner printbanner(environment)\n根据用户是否设置了applicationcontextclass类型以及初始化阶段的推断结果,决定该为springboot应用创建什么类型的applicationcontext并创建完成。 createapplicationcontext(); contextclass为空,则依据webapplicationtype创建不同类型的contextclass的类型。\n加载springbootexceptionreporter 遍历执行所有通过springfactoriesloader 可以查找到的、并加载的springbootexceptionreporter\nspringapplicationcontext进一步处理 preparecontext() 1. applicationcontext创建好之后,springapplication再次借助springfactoriesloader,查找并加载classpath中所有可用的application-initializer 2. 遍历调用这些applicationcontextinitializer的initalize方法来已经创建好的applicationcontext进行进一步处理 3. 遍历调用所有springapplicationrunlisteners的contextprepared方法 4. 加载特殊的单例bean 5. 将之前通过@enableautoconfiguration获取的所有配置的以及其他形式的ioc容器配置 (bean)加载到context上下文 6. 遍历调用springapplicationrunlisteners的contextloaded方法\n调用applicationcontext的refresh()方法 refresh方法 1. 准备对context进行刷新preparerefresh(); 2. 告诉子类刷新内部工厂obtainfreshbeanfactory(); 3. 预备工厂给context使用preparebeanfactory(beanfactory); 4. 允许在context子类中对beanfactory进行后续处理 postprocessbeanfactory(beanfactory); 5. 调用在context中注册bean的工厂处理器 invokebeanfactorypostprocessors(beanfactory); 6. 注册拦截bean创建的拦截处理器bean registerbeanpostprocessors(beanfactory); 7. 初始化context的消息源 initmessagesource(); 8. 初始化context的multicaster事件 initapplicationeventmulticaster(); 9. 初始化特殊的bean给特定的context onrefresh(); 10. 查找监听器bean并注册他们 registerlisteners(); 11. 实例化所有剩余的非懒加载的单例bean。 finishbeanfactoryinitialization(beanfactory); 12. 发布相应的事件finishrefresh();\n核心。工厂类 根据registershutdownhook判断是否需要添加shutdownhook 完成ioc容器可用的最后一道工序\n遍历调用所有springapplicationrunlisteners的started()方法\n查找当前applicationcontext中是否注册有commandlinerunner,若有,则遍历执行他们\n正常情况下,遍历调用执行springapplicationrunlistener的running方法\n若出现异常,则处理异常,遍历并调用springapplicationrunlistener的failed方法\nautoconfiguration 原理解析 @enableautoconfiguartion\n@autoconfigurationpackage 注册向指明了包路径的包。若未指明,则注册带注解的包 @import autoconfigurationimportselector 查找 meta-inf/spring.factories 获取到配置信息 获取到具体的xxxautoconfigurtaion类 @configuration 指明一个配置类 @conditionalonclass 指定类,只有当注解指定的类存在时,才加载 @autoconfigureafter 非必须 在该注解指定的自动配置类之后注册 @autoconfigurebefore 非必须在该注解指定的自动配置类之前注册 @autoconfigureorder 非必须指定自动配置类的注册顺序int。值越大级别越高 @enableconfigurationproperties 指定具体的配置类 xxxproperties类。如transactionproperties @configurationproperties 获取项目配置文件中对应的配置值 如 spring.redis 其实是一个pojo类,有默认值 @bean method注入对应的bean autoconfigure包已经集成常用的自动配置类。所以我们才能简单的使用组件 若自己集成的话,也是参照这个逻辑 ","date":"2018-09-18","permalink":"https://hobocat.github.io/post/spring/2018-09-18-spring-bean/","summary":"Spring 控制反转/依赖注入 IOC容器 IoC容器负责实例化,配置和组装对象。 IoC容器从XML文件获取信息并相应地工作。 IoC容器执行的主要任务是: 实例化 应用程序类配置","title":"spring基础"},]
[{"content":"前言 thymeleaf集成了spring framework的3.x和4.x版本,由两个名为thymeleaf-spring3和thymeleaf-spring4的独立库提供\n一、将thymeleaf与spring结合起来 thymeleaf提供了spring集成,允许将spring mvc中jsp的全方面替代\n@controller对象中的映射方法转发到由thymeleaf管理的模板,就像使用jsp一样 在模板中使用spring expression language(spring el)代替ognl 在模板中创建数据绑定,包括使用属性编辑器,转换服务和验证错误处理 显示由spring(通过常用messagesource对象)的国际化消息 使用spring自己的资源解析机制解析模板 二、springstandard方言 1 2 3 standarddialect | +- springstandarddialect springstandard引入了以下特定的功能\n使用spring expression language(spel)作为变量表达式语言,而不是ognl。因此,${...}和*{...}表达式都将由spring的表达式语言引擎进行解析。\n使用springel的语法访问application context中的任何bean: ${@mybean.dosomething()}\n于表格处理的新属性:th:field,th:errors和th:errorclass,除此还有一个th:object的新实现,允许它被用于形式命令选择\n一个新的表达式:#themes.code(...),相当于jsp自定义标签中的spring:theme\n在spring4.0集成中的一个新的表达式:#mvc.uri(...),相当于jsp自定义标签中的spring:mvcurl(...)\n一个bean配置示例\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 @bean public springresourcetemplateresolver templateresolver(){ springresourcetemplateresolver templateresolver = new springresourcetemplateresolver(); templateresolver.setapplicationcontext(this.applicationcontext); templateresolver.setprefix(\u0026#34;/web-inf/templates/\u0026#34;); templateresolver.setsuffix(\u0026#34;.html\u0026#34;); templateresolver.settemplatemode(templatemode.html); templateresolver.setcacheable(true); return templateresolver; } @bean public springtemplateengine templateengine(){ springtemplateengine templateengine = new springtemplateengine(); templateengine.settemplateresolver(templateresolver()); templateengine.setenablespringelcompiler(true); return templateengine; } 或者xml配置\n1 2 3 4 5 6 7 8 9 10 11 12 13 \u0026lt;bean id=\u0026#34;templateresolver\u0026#34; class=\u0026#34;org.thymeleaf.spring4.templateresolver.springresourcetemplateresolver\u0026#34;\u0026gt; \u0026lt;property name=\u0026#34;prefix\u0026#34; value=\u0026#34;/web-inf/templates/\u0026#34; /\u0026gt; \u0026lt;property name=\u0026#34;suffix\u0026#34; value=\u0026#34;.html\u0026#34; /\u0026gt; \u0026lt;property name=\u0026#34;templatemode\u0026#34; value=\u0026#34;html\u0026#34; /\u0026gt; \u0026lt;property name=\u0026#34;cacheable\u0026#34; value=\u0026#34;true\u0026#34; /\u0026gt; \u0026lt;/bean\u0026gt; \u0026lt;bean id=\u0026#34;templateengine\u0026#34; class=\u0026#34;org.thymeleaf.spring4.springtemplateengine\u0026#34;\u0026gt; \u0026lt;property name=\u0026#34;templateresolver\u0026#34; ref=\u0026#34;templateresolver\u0026#34; /\u0026gt; \u0026lt;property name=\u0026#34;enablespringelcompiler\u0026#34; value=\u0026#34;true\u0026#34; /\u0026gt; \u0026lt;/bean\u0026gt; 三、 视图和视图解析器 spring mvc中的视图和视图解析器 spring mvc中视图与视图解析器接口\norg.springframework.web.servlet.view org.springframework.web.servlet.viewresolver view是负责渲染实际的html,通常由一些模板引擎来负责,如jsp和thymeleaf\nviewresolvers根据controller返回的字符串数据,定位到资源位置并应用view合成界面\nspring视图解析器配置示例:\n1 2 3 4 5 6 7 \u0026lt;bean class=\u0026#34;org.springframework.web.servlet.view.internalresourceviewresolver\u0026#34;\u0026gt; \u0026lt;property name=\u0026#34;viewclass\u0026#34; value=\u0026#34;org.springframework.web.servlet.view.jstlview\u0026#34; /\u0026gt; \u0026lt;property name=\u0026#34;prefix\u0026#34; value=\u0026#34;/web-inf/jsps/\u0026#34; /\u0026gt; \u0026lt;property name=\u0026#34;suffix\u0026#34; value=\u0026#34;.jsp\u0026#34; /\u0026gt; \u0026lt;property name=\u0026#34;order\u0026#34; value=\u0026#34;2\u0026#34; /\u0026gt; \u0026lt;property name=\u0026#34;viewnames\u0026#34; value=\u0026#34;*jsp\u0026#34; /\u0026gt; \u0026lt;/bean\u0026gt; viewclass合成view实例的类 prefix并suffix视图前缀和后缀,用于定位模版 order 在链中查询viewresolver的顺序 viewnames viewresolver解析的视图名称 thymeleaf中的视图和视图解析器 thymeleaf为上面提到的两个接口提供了实现:\norg.thymeleaf.spring4.view.thymeleafview org.thymeleaf.spring4.view.thymeleafviewresolver thymeleaf view resolver的配置与jsp的配置非常相似:\n1 2 3 4 5 6 7 8 @bean public thymeleafviewresolver viewresolver(){ thymeleafviewresolver viewresolver = new thymeleafviewresolver(); viewresolver.settemplateengine(templateengine()); viewresolver.setorder(1); viewresolver.setviewnames(new string[] {\u0026#34;.html\u0026#34;}); return viewresolver; } 或者xml配置\n1 2 3 4 5 \u0026lt;bean class=\u0026#34;org.thymeleaf.spring4.view.thymeleafviewresolver\u0026#34;\u0026gt; \u0026lt;property name=\u0026#34;templateengine\u0026#34; ref=\u0026#34;templateengine\u0026#34; /\u0026gt; \u0026lt;property name=\u0026#34;order\u0026#34; value=\u0026#34;1\u0026#34; /\u0026gt; \u0026lt;property name=\u0026#34;viewnames\u0026#34; value=\u0026#34;*.html\u0026#34; /\u0026gt; \u0026lt;/bean\u0026gt; 解释:prefix和suffix在springresourcetemplateresolver指定传入到了springtemplateengine所以不用指定\n三、thymeleaf配置spring 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 @bean public springresourcetemplateresolver templateresolver(){ springresourcetemplateresolver templateresolver = new springresourcetemplateresolver(); templateresolver.setapplicationcontext(this.applicationcontext); templateresolver.setprefix(\u0026#34;/web-inf/templates/\u0026#34;); templateresolver.setsuffix(\u0026#34;.html\u0026#34;); templateresolver.settemplatemode(templatemode.html); templateresolver.setcacheable(true); return templateresolver; } @bean public springtemplateengine templateengine(){ springtemplateengine templateengine = new springtemplateengine(); templateengine.settemplateresolver(templateresolver()); templateengine.setenablespringelcompiler(true); return templateengine; } @bean public thymeleafviewresolver viewresolver(){ thymeleafviewresolver viewresolver = new thymeleafviewresolver(); viewresolver.settemplateengine(templateengine()); return viewresolver; } 或者xml配置\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 \u0026lt;bean id=\u0026#34;templateresolver\u0026#34; class=\u0026#34;org.thymeleaf.spring4.templateresolver.springresourcetemplateresolver\u0026#34;\u0026gt; \u0026lt;property name=\u0026#34;prefix\u0026#34; value=\u0026#34;/web-inf/templates/\u0026#34; /\u0026gt; \u0026lt;property name=\u0026#34;suffix\u0026#34; value=\u0026#34;.html\u0026#34; /\u0026gt; \u0026lt;property name=\u0026#34;templatemode\u0026#34; value=\u0026#34;html\u0026#34; /\u0026gt; \u0026lt;property name=\u0026#34;cacheable\u0026#34; value=\u0026#34;true\u0026#34; /\u0026gt; \u0026lt;/bean\u0026gt; \u0026lt;bean id=\u0026#34;templateengine\u0026#34; class=\u0026#34;org.thymeleaf.spring4.springtemplateengine\u0026#34;\u0026gt; \u0026lt;property name=\u0026#34;templateresolver\u0026#34; ref=\u0026#34;templateresolver\u0026#34; /\u0026gt; \u0026lt;property name=\u0026#34;enablespringelcompiler\u0026#34; value=\u0026#34;true\u0026#34; /\u0026gt; \u0026lt;/bean\u0026gt; \u0026lt;bean class=\u0026#34;org.thymeleaf.spring4.view.thymeleafviewresolver\u0026#34;\u0026gt; \u0026lt;property name=\u0026#34;templateengine\u0026#34; ref=\u0026#34;templateengine\u0026#34; /\u0026gt; \u0026lt;property name=\u0026#34;order\u0026#34; value=\u0026#34;1\u0026#34; /\u0026gt; \u0026lt;property name=\u0026#34;viewnames\u0026#34; value=\u0026#34;*.html\u0026#34; /\u0026gt; \u0026lt;/bean\u0026gt; 四、使用spring framework的配置 使用message解析 1 2 3 4 5 6 @bean public resourcebundlemessagesource messagesource() { resourcebundlemessagesource messagesource = new resourcebundlemessagesource(); messagesource.setbasename(\u0026#34;messages\u0026#34;); return messagesource; } 会加载类路径下的message_xx.properties文件作为国际化文件,#{...}使用国际化\n1 2 3 4 5 6 #{bool.true} #{date.format} #{foot.msg} 拼接字符串用法 \u0026lt;td th:text=\u0026#34;#{|bool.${sb.covered}|}\u0026#34;\u0026gt;yes\u0026lt;/td\u0026gt; 使用转换服务 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 public class dateformatter implements formatter\u0026lt;date\u0026gt; { @autowired private messagesource messagesource; public dateformatter() { super(); } @override public date parse(final string text, final locale locale) throws parseexception { final simpledateformat dateformat = createdateformat(locale); return dateformat.parse(text); } @override public string print(final date object, final locale locale) { final simpledateformat dateformat = createdateformat(locale); return dateformat.format(object); } private simpledateformat createdateformat(final locale locale) { //从spring message中获取日期格式 final string format = this.messagesource.getmessage(\u0026#34;date.format\u0026#34;, null, locale); final simpledateformat dateformat = new simpledateformat(format); dateformat.setlenient(false); return dateformat; } } 使用{{\u0026hellip;}}转换服务\n1 \u0026lt;td th:text=\u0026#34;${ { sb.dateplanted } }\u0026#34;\u0026gt;13/01/2011\u0026lt;/td\u0026gt; th:field标签 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 \u0026lt;form action=\u0026#34;@{/docommit}\u0026#34; method=\u0026#34;post\u0026#34; th:object=\u0026#34;${person}\u0026#34;\u0026gt; \u0026lt;p\u0026gt; \u0026lt;!-- th:field相当于同时设置id、name、value属性 --\u0026gt; \u0026lt;label for=\u0026#34;personname\u0026#34; th:text=\u0026#34;姓名\u0026#34;\u0026gt;姓名\u0026lt;/label\u0026gt;\t\u0026lt;input type=\u0026#34;text\u0026#34; th:field=\u0026#34;*{personname}\u0026#34;\u0026gt; \u0026lt;/p\u0026gt; \u0026lt;p\u0026gt; \u0026lt;!-- th:field和th:selected不可以同时使用。th:field会生成id、name但无法指定选定的值--\u0026gt; \u0026lt;label for=\u0026#34;city\u0026#34; th:text=\u0026#34;出生城市\u0026#34;\u0026gt;城市\u0026lt;/label\u0026gt; \u0026lt;select id=\u0026#34;city\u0026#34; name=\u0026#34;city\u0026#34;\u0026gt; \u0026lt;option th:each=\u0026#34;item:${citys}\u0026#34; th:value=\u0026#34;${item.id}\u0026#34; th:text=\u0026#34;${item.cityname}\u0026#34; th:selected=\u0026#34;${item.id} == *{city.id}\u0026#34;\u0026gt;\u0026lt;/option\u0026gt; \u0026lt;/select\u0026gt; \u0026lt;/p\u0026gt; \u0026lt;p\u0026gt; \u0026lt;label th:text=\u0026#34;想居住城市\u0026#34;\u0026gt;想居住城市\u0026lt;/label\u0026gt; \u0026lt;!-- 使用th:block th:each构造块,th:field会生成name和自增的id,th:field和th:checked不可以同时使用--\u0026gt; \u0026lt;!--/*/ \u0026lt;th:block th:each=\u0026#34;item:${citys}\u0026#34;\u0026gt; /*/--\u0026gt; \u0026lt;label th:for=\u0026#34;${#ids.next(\u0026#39;livecitys\u0026#39;)}\u0026#34; th:text=\u0026#34;${item.cityname}\u0026#34;\u0026gt;\u0026lt;/label\u0026gt; \u0026lt;input type=\u0026#34;checkbox\u0026#34; th:id=\u0026#34;${#ids.seq(\u0026#39;livecitys\u0026#39;)}\u0026#34; name=\u0026#34;livecitys\u0026#34; th:value=\u0026#34;${item.id}\u0026#34; th:checked=\u0026#34;${#lists.contains(person.livecitys,item)}\u0026#34; \u0026gt; \u0026lt;!--/*/ \u0026lt;/th:block\u0026gt; /*/--\u0026gt; \u0026lt;/p\u0026gt; \u0026lt;input type=\u0026#34;submit\u0026#34; value=\u0026#34;提交\u0026#34;\u0026gt; \u0026lt;/form\u0026gt; checkbox字段 1 2 3 4 5 6 7 8 9 10 11 12 13 14 \u0026lt;form action=\u0026#34;\u0026#34; th:object=\u0026#34;${user}\u0026#34;\u0026gt; \u0026lt;label th:for=\u0026#34;${#ids.next(\u0026#39;goodman\u0026#39;)}\u0026#34;\u0026gt;\u0026lt;/label\u0026gt;\t\u0026lt;!--需要使用next拿到最后的id--\u0026gt; \u0026lt;input type=\u0026#34;checkbox\u0026#34; th:field=\u0026#34;*{goodman}\u0026#34; /\u0026gt; \u0026lt;!--这个id先生成goodman1--\u0026gt; \u0026lt;/form\u0026gt; \u0026lt;!--数组类型的checkbox--\u0026gt; \u0026lt;ul\u0026gt; \u0026lt;li th:each=\u0026#34;feat : ${allfeatures}\u0026#34;\u0026gt; \u0026lt;input type=\u0026#34;checkbox\u0026#34; th:field=\u0026#34;*{features}\u0026#34; th:value=\u0026#34;${feat}\u0026#34; /\u0026gt; \u0026lt;!--需要使用prev拿到前面的id--\u0026gt; \u0026lt;label th:for=\u0026#34;${#ids.prev(\u0026#39;features\u0026#39;)}\u0026#34; th:text=\u0026#34;#{${\u0026#39;seedstarter.feature.\u0026#39; + feat}}\u0026#34;\u0026gt;heating\u0026lt;/label\u0026gt; \u0026lt;/li\u0026gt; \u0026lt;/ul\u0026gt; 对应生成html\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 \u0026lt;form action=\u0026#34;\u0026#34;\u0026gt; \u0026lt;label for=\u0026#34;goodman1\u0026#34;\u0026gt;\u0026lt;/label\u0026gt; \u0026lt;input type=\u0026#34;checkbox\u0026#34; id=\u0026#34;goodman1\u0026#34; name=\u0026#34;goodman\u0026#34; value=\u0026#34;true\u0026#34; /\u0026gt; \u0026lt;input type=\u0026#34;hidden\u0026#34; name=\u0026#34;_goodman\u0026#34; value=\u0026#34;on\u0026#34;/\u0026gt; \u0026lt;/form\u0026gt; \u0026lt;ul\u0026gt; \u0026lt;li\u0026gt; \u0026lt;input id=\u0026#34;features1\u0026#34; name=\u0026#34;features\u0026#34; type=\u0026#34;checkbox\u0026#34; value=\u0026#34;seedstarter_specific_substrate\u0026#34; /\u0026gt; \u0026lt;input name=\u0026#34;_features\u0026#34; type=\u0026#34;hidden\u0026#34; value=\u0026#34;on\u0026#34; /\u0026gt; \u0026lt;label for=\u0026#34;features1\u0026#34;\u0026gt;seed starter-specific substrate\u0026lt;/label\u0026gt; \u0026lt;/li\u0026gt; \u0026lt;li\u0026gt; \u0026lt;input id=\u0026#34;features2\u0026#34; name=\u0026#34;features\u0026#34; type=\u0026#34;checkbox\u0026#34; value=\u0026#34;fertilizer\u0026#34; /\u0026gt; \u0026lt;input name=\u0026#34;_features\u0026#34; type=\u0026#34;hidden\u0026#34; value=\u0026#34;on\u0026#34; /\u0026gt; \u0026lt;label for=\u0026#34;features2\u0026#34;\u0026gt;fertilizer used\u0026lt;/label\u0026gt; \u0026lt;/li\u0026gt; \u0026lt;li\u0026gt; \u0026lt;input id=\u0026#34;features3\u0026#34; name=\u0026#34;features\u0026#34; type=\u0026#34;checkbox\u0026#34; value=\u0026#34;ph_corrector\u0026#34; /\u0026gt; \u0026lt;input name=\u0026#34;_features\u0026#34; type=\u0026#34;hidden\u0026#34; value=\u0026#34;on\u0026#34; /\u0026gt; \u0026lt;label for=\u0026#34;features3\u0026#34;\u0026gt;ph corrector used\u0026lt;/label\u0026gt; \u0026lt;/li\u0026gt; \u0026lt;/ul\u0026gt; radio字段 1 2 3 4 5 6 7 \u0026lt;ul\u0026gt; \u0026lt;li th:each=\u0026#34;ele : ${hobbys}\u0026#34;\u0026gt; \u0026lt;input type=\u0026#34;radio\u0026#34; th:field=\u0026#34;${user.hobby}\u0026#34; th:value=\u0026#34;${ele}\u0026#34; /\u0026gt; \u0026lt;label th:for=\u0026#34;${#ids.prev(\u0026#39;hobby\u0026#39;)}\u0026#34; th:text=\u0026#34;#{|user.hobby.${ele}|}\u0026#34;\u0026gt;heating\u0026lt;/label\u0026gt; \u0026lt;/li\u0026gt; \u0026lt;/ul\u0026gt; 对应生成html\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 \u0026lt;ul\u0026gt; \u0026lt;li\u0026gt; \u0026lt;input type=\u0026#34;radio\u0026#34; value=\u0026#34;aaa\u0026#34; id=\u0026#34;hobby1\u0026#34; name=\u0026#34;hobby\u0026#34; checked=\u0026#34;checked\u0026#34; /\u0026gt; \u0026lt;label for=\u0026#34;hobby1\u0026#34; \u0026gt;篮球\u0026lt;/label\u0026gt; \u0026lt;/li\u0026gt; \u0026lt;li\u0026gt; \u0026lt;input type=\u0026#34;radio\u0026#34; value=\u0026#34;bbb\u0026#34; id=\u0026#34;hobby2\u0026#34; name=\u0026#34;hobby\u0026#34; /\u0026gt; \u0026lt;label for=\u0026#34;hobby2\u0026#34; \u0026gt;羽毛球\u0026lt;/label\u0026gt; \u0026lt;/li\u0026gt; \u0026lt;li\u0026gt; \u0026lt;input type=\u0026#34;radio\u0026#34; value=\u0026#34;ccc\u0026#34; id=\u0026#34;hobby3\u0026#34; name=\u0026#34;hobby\u0026#34; /\u0026gt; \u0026lt;label for=\u0026#34;hobby3\u0026#34; \u0026gt;排球\u0026lt;/label\u0026gt; \u0026lt;/li\u0026gt; \u0026lt;/ul\u0026gt; 下拉列表 1 2 3 4 5 \u0026lt;select\tth:field=\u0026#34;${user.hobby}\u0026#34;\u0026gt; \u0026lt;option th:each=\u0026#34;ele : ${hobbys}\u0026#34; th:text=\u0026#34;#{|user.hobby.${ele}|}\u0026#34; th:value=\u0026#34;${ele}\u0026#34;\u0026gt; \u0026lt;/select\u0026gt; 对应生成html\n1 2 3 4 5 \u0026lt;select id=\u0026#34;hobby\u0026#34; name=\u0026#34;hobby\u0026#34;\u0026gt; \u0026lt;option value=\u0026#34;aaa\u0026#34; \u0026gt;篮球 \u0026lt;option value=\u0026#34;bbb\u0026#34; selected=\u0026#34;selected\u0026#34;\u0026gt;羽毛球 \u0026lt;option value=\u0026#34;ccc\u0026#34;\u0026gt;排球 \u0026lt;/select\u0026gt; 五、校验和错误消息 错误必须使用jsr303规范校验,只能使用javax.validation.constraints.*注解标注,在java代码里需要校验的对象要加@validated注解\n字段错误 pom需要引入依赖\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 \u0026lt;!--jsr303标注--\u0026gt; \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;javax.validation\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;validation-api\u0026lt;/artifactid\u0026gt; \u0026lt;version\u0026gt;1.1.0.final\u0026lt;/version\u0026gt; \u0026lt;scope\u0026gt;compile\u0026lt;/scope\u0026gt; \u0026lt;/dependency\u0026gt; \u0026lt;!--hibernate对jsr303的实现--\u0026gt; \u0026lt;dependency\u0026gt; \u0026lt;groupid\u0026gt;org.hibernate\u0026lt;/groupid\u0026gt; \u0026lt;artifactid\u0026gt;hibernate-validator\u0026lt;/artifactid\u0026gt; \u0026lt;version\u0026gt;5.3.2.final\u0026lt;/version\u0026gt; \u0026lt;/dependency\u0026gt; java代码写法\n1 2 3 4 5 6 7 8 9 10 @requestmapping(\u0026#34;/add\u0026#34;) public string add(@validated user user,bindingresult result) { if(result.haserrors()){ for (objecterror error : result.getallerrors()) { system.out.println(error.getdefaultmessage()); } return \u0026#34;seedstartermng\u0026#34;; } return \u0026#34;seedstartermng\u0026#34;; } html代码写法\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 \u0026lt;form action=\u0026#34;\u0026#34; th:action=\u0026#34;@{/add}\u0026#34; method=\u0026#34;post\u0026#34; th:object=\u0026#34;${user}\u0026#34;\u0026gt; \u0026lt;!--遍历所有错误描述,进行打印--\u0026gt; \u0026lt;ul\u0026gt; \u0026lt;li th:each=\u0026#34;err : ${#fields.errors(\u0026#39;age\u0026#39;)}\u0026#34; th:text=\u0026#34;${err}\u0026#34; /\u0026gt; \u0026lt;/ul\u0026gt; \u0026lt;label th:for=\u0026#34;${#ids.next(\u0026#39;age\u0026#39;)}\u0026#34;\u0026gt;age\u0026lt;/label\u0026gt; \u0026lt;!--输入框会被标红--\u0026gt; \u0026lt;input type=\u0026#34;text\u0026#34; th:field=\u0026#34;*{age}\u0026#34; th:class=\u0026#34;${#fields.haserrors(\u0026#39;age\u0026#39;)}? fielderror\u0026#34; \u0026gt; \u0026lt;div\u0026gt; \u0026lt;!--显示此错误描述--\u0026gt; \u0026lt;span th:if=\u0026#34;${#fields.haserrors(\u0026#39;age\u0026#39;)}\u0026#34; th:errors=\u0026#34;*{age}\u0026#34;\u0026gt;\u0026lt;/span\u0026gt; \u0026lt;/div\u0026gt; \u0026lt;input type=\u0026#34;submit\u0026#34;\u0026gt; \u0026lt;/form\u0026gt; 简化css标签\n1 2 3 \u0026lt;input type=\u0026#34;text\u0026#34; th:field=\u0026#34;*{age}\u0026#34; th:class=\u0026#34;${#fields.haserrors(\u0026#39;age\u0026#39;)}? fielderror\u0026#34; \u0026gt; \u0026lt;!--可以简化为--\u0026gt; \u0026lt;input type=\u0026#34;text\u0026#34; th:field=\u0026#34;*{age}\u0026#34; th:errorclass=\u0026#34;fielderror\u0026#34; \u0026gt; 所有错误 *,all代表所有错误。\n#fields.haserrors('*')=#fields.hasanyerrors()=#fields.errors('*')=#fields.allerrors()\n1 2 3 \u0026lt;ul\u0026gt; \u0026lt;li th:each=\u0026#34;err : ${#fields.errors(\u0026#39;*\u0026#39;)}\u0026#34; th:text=\u0026#34;${err}\u0026#34; /\u0026gt; \u0026lt;/ul\u0026gt; 全局错误 1 2 3 4 5 6 7 8 9 10 \u0026lt;!-- 第一种遍历方式 --\u0026gt; \u0026lt;ul th:if=\u0026#34;${#fields.haserrors(\u0026#39;global\u0026#39;)}\u0026#34;\u0026gt; \u0026lt;li th:each=\u0026#34;err : ${#fields.errors(\u0026#39;global\u0026#39;)}\u0026#34; th:text=\u0026#34;${err}\u0026#34;\u0026gt;\u0026lt;/li\u0026gt; \u0026lt;/ul\u0026gt; \u0026lt;!-- 第二种遍历方式 --\u0026gt; \u0026lt;p th:if=\u0026#34;${#fields.haserrors(\u0026#39;global\u0026#39;)}\u0026#34; th:errors=\u0026#34;*{global}\u0026#34;\u0026gt;\u0026lt;/p\u0026gt; \u0026lt;!-- 第三种遍历方式 --\u0026gt; \u0026lt;div th:if=\u0026#34;${#fields.hasglobalerrors()}\u0026#34;\u0026gt; \u0026lt;p th:each=\u0026#34;err : ${#fields.globalerrors()}\u0026#34; th:text=\u0026#34;${err}\u0026#34;\u0026gt;...\u0026lt;/p\u0026gt; \u0026lt;/div\u0026gt; 六、转换服务 配置转换服务 通过扩展spring的webmvcconfigureradapter适配器,注册转换服务\n1 2 3 4 5 6 7 8 9 10 @override public void addformatters(final formatterregistry registry) { super.addformatters(registry); registry.addformatter(dateformatter());\t//实现formatter\u0026lt;date\u0026gt;接口 } @bean public dateformatter dateformatter() { return new dateformatter(); } 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public class dateformatter implements formatter\u0026lt;date\u0026gt; { @autowired private messagesource messagesource; @override public date parse(final string text, final locale locale) throws parseexception { final simpledateformat dateformat = createdateformat(locale); return dateformat.parse(text); } @override public string print(final date object, final locale locale) { final simpledateformat dateformat = createdateformat(locale); return dateformat.format(object); } private simpledateformat createdateformat(final locale locale) { final string format = this.messagesource.getmessage(\u0026#34;date.format\u0026#34;, null, locale); final simpledateformat dateformat = new simpledateformat(format); dateformat.setlenient(false); return dateformat; } } 使用转换服务 对于变量表达式: ${{...}} 对于选择表达式: *{{...}} #conversions对象 手动调用转换服务,#conversions.convert(object,classname):将对象转换为指定的类,例如${#conversions.convert(val,\u0026lsquo;string\u0026rsquo;)}\n","date":"2018-09-06","permalink":"https://hobocat.github.io/post/thymeleaf/2018-09-06-thymeleaf-spring/","summary":"前言 Thymeleaf集成了Spring Framework的3.x和4.x版本,由两个名为thymeleaf-spring3和thymeleaf-spring4","title":"thymeleaf与spring整合"},]
[{"content":"一、简介 thymeleaf是一个适用于web和独立环境的现代服务器端java模板引擎,能够处理html,xml,javascript,css甚至纯文本。\nthymeleaf具有以下几种模版模式\nhtml——标记模版模式 xml——标记模版模式 txt——文本模式 javascript——文本模式 css——文本模式 raw——无操作模式 html模式将允许任何类型的html的输入,不会执行验证或格式检查,并且尽可能尊重模板代码结构\nxml模式将允许xml输入,在这种情况下,会进行格式检查,不会执行任何代码检查(针对dtd或schema)\ntext模式将允许非标记性质的模板使用特殊的语法。此类模板的示例可能是文本电子邮件或模板文档。html或xml模板也可以被处理text,在这种情况下,它们不会被解析为标记,并且每个标记,doctype,注释等都将被视为纯文本\njavascript能够以与html文件相同的方式在javascript文件中使用模型数据,但是使用特定于javascript的集成,例如专门的转义或脚本。\ncss与javascript模式类似,css模板模式也是文本模式,并使用text模板模式中的特殊处理语法\nraw模式将不处理模板。它用于将未经处理的资源(文件,url响应等)插入到正在处理的模板中\n二、使用文本 多语言 thymeleaf国际化文本位置是可配置的,它取决于imessageresolver的具体实现。通常使用.properties文件实现。如果要从数据库获取消息,我们可以创建自己的实现。\n初始化期间没有为模板引擎指定消息解析器默认使用standardmessageresolver。\nstandardmessageresolver期望在html同目录下找到与此html文件名称对应的国际化文件。如/web-inf/templates/home.html下期望找到:\n/web-inf/templates/home_en.properties 英文文本 /web-inf/templates/home_zh.properties 中文文本 /web-inf/templates/home.properties 默认文本(如果区域设置不匹配) 使用#{..}从properties文件中取值\n上下文 thymeleaf上下文是实现org.thymeleaf.context.icontext接口的对象。上下文应包含变量映射中执行模板引擎所需的所有数据,并且还引用国际化消息的语言环境。\n1 2 3 4 5 6 public interface icontext { public locale getlocale(); public boolean containsvariable(final string name); public set\u0026lt;string\u0026gt; getvariablenames(); public object getvariable(final string name); } org.thymeleaf.context.iwebcontext扩展自icontext用于web应用程序(如springmvc)\n1 2 3 4 5 6 public interface iwebcontext extends icontext { public httpservletrequest getrequest(); public httpservletresponse getresponse(); public httpsession getsession(); public servletcontext getservletcontext(); } 可以使用指定的表达式从webcontext模板中获取请求参数以及request,session和applicationcontext属性。例如:\n${x}将返回x存储在thymeleaf上下文中的变量或作为request属性 ${param.x}将返回一个请求参数x(可能多值),例如**${param.userid}**取出请求参数userid ${session.x}将返回session会话属性x,例如**${session.user.name}**取出session中存放的用户名 ${application.x}将返回application属性x,例如**${application[\u0026lsquo;javax.servlet.context.tempdir\u0026rsquo;]}** 文字转义 th:utext:不转义,使用原样输出 th:text:转义 三、标准表达式语法 以下这些功能都可以组合和嵌套\n简单表达式 变量表达式:${\u0026hellip;} 选择变量表达式:*{\u0026hellip;} 消息表达式:#{\u0026hellip;} 链接网址表达式:@{\u0026hellip;} 片段表达式: ~{\u0026hellip;} 字面值 文本文字:\u0026lsquo;one text\u0026rsquo;,\u0026lsquo;another one!\u0026rsquo;,\u0026hellip; 号码文字:0,34,3.0,12.3,\u0026hellip; 布尔文字:true,false 空字面: null 文字标记:one,sometext,main,\u0026hellip; 文字操作 字符串连接:+ 文字替换:|the name is ${name}| 算术运算 二元运算符:+,-,*,/,% 负号(一元运算符):- 布尔运算 二元运算符:and,or 否定(一元运算符):!,not 比较运算 大小比较:\u0026gt;,\u0026lt;,\u0026gt;=,\u0026lt;=(gt,lt,ge,le) 相等比较:==,!=(eq,ne) 条件操作 if-then:(if)?(then) if-then-else:(if)?(then):(else) default:(value)?:(defaultvalue) 特殊操作 不操作:_ 消息 利用java.text.messageformat标准语法进行格式化输出\n1 home.welcome=welcome to our grocery store, {0} (from default messages)! 1 2 3 \u0026lt;p th:utext=\u0026#34;#{home.welcome(${session.user.name})}\u0026#34;\u0026gt; welcome to our grocery store, sebastian pepper! \u0026lt;/p\u0026gt; 消息密钥本身可以来自变量\n1 2 3 \u0026lt;p th:utext=\u0026#34;#{${welcomemsgkey}(${session.user.name})}\u0026#34;\u0026gt; welcome to our grocery store, sebastian pepper! \u0026lt;/p\u0026gt; 变量 ${\u0026hellip;}实际上是ognl表达式\n1 \u0026lt;p\u0026gt;today is: \u0026lt;span th:text=\u0026#34;${today}\u0026#34;\u0026gt;13 february 2011\u0026lt;/span\u0026gt;.\u0026lt;/p 相当于\n1 ctx.getvariable(\u0026#34;today\u0026#34;); 1 2 3 \u0026lt;p th:utext=\u0026#34;#{home.welcome(${session.user.name})}\u0026#34;\u0026gt; welcome to our grocery store, sebastian pepper! \u0026lt;/p\u0026gt; 相当于\n1 ((user) ctx.getvariable(\u0026#34;session\u0026#34;).get(\u0026#34;user\u0026#34;)).getname(); 表达式内置基本对象 #ctx:上下文对象 #vars: 上下文变量 #locale:上下文区域设置 #request:(仅限web contexts)httpservletrequest对象 #response:(仅限web contexts)httpservletresponse对象 #session:(仅限web contexts)httpsession对象 #servletcontext:(仅限web contexts)servletcontext对象 使用${#基本对象}取出值,例如${#locale`}\n表达式内置工具对象 #execinfo:有关正在处理的模板的信息 #messages:在变量表达式中获取外化消息的方法,与使用#{...}语法获取的方法相同 #uris:转义部分url / uri的方法 #conversions:用于执行已配置的转换服务的方法(如果有) #dates:java.util.date对象的方法:格式化,时间提取等 #calendars:java.util.calendar对象 #numbers:格式化数字对象的方法 #strings:string对象的方法:contains,startswith,prepending / appending等 #objects:一般的对象的方法 #bools:布尔方法 #arrays:数组方法 #lists:列表方法 #sets:集合方法 #maps:哈希方法 #aggregates:在数组或集合上创建聚合的方法。 #ids:处理可能重复的id属性的方法(例如,作为迭代的结果) 例如处理时间格式:\n1 2 3 4 \u0026lt;p\u0026gt; today is: \u0026lt;span th:text=\u0026#34;${#dates.format(today,\u0026#39;yyyy-mm-dd\u0026#39;)}\u0026#34;\u0026gt;2018-08-22\u0026lt;/span\u0026gt; \u0026lt;/p\u0026gt; 选择表达式 *{..}相当于从上层的th:object=\u0026quot;${..}\u0026quot;取值\n1 2 3 4 5 \u0026lt;div th:object=\u0026#34;${session.user}\u0026#34;\u0026gt; \u0026lt;p\u0026gt;name: \u0026lt;span th:text=\u0026#34;*{firstname}\u0026#34;\u0026gt;sebastian\u0026lt;/span\u0026gt;.\u0026lt;/p\u0026gt; \u0026lt;p\u0026gt;surname: \u0026lt;span th:text=\u0026#34;*{lastname}\u0026#34;\u0026gt;pepper\u0026lt;/span\u0026gt;.\u0026lt;/p\u0026gt; \u0026lt;p\u0026gt;nationality: \u0026lt;span th:text=\u0026#34;*{nationality}\u0026#34;\u0026gt;saturn\u0026lt;/span\u0026gt;.\u0026lt;/p\u0026gt; \u0026lt;/div\u0026gt; 相当于\n1 2 3 4 5 \u0026lt;div\u0026gt; \u0026lt;p\u0026gt;name: \u0026lt;span th:text=\u0026#34;${session.user.firstname}\u0026#34;\u0026gt;sebastian\u0026lt;/span\u0026gt;.\u0026lt;/p\u0026gt; \u0026lt;p\u0026gt;surname: \u0026lt;span th:text=\u0026#34;${session.user.lastname}\u0026#34;\u0026gt;pepper\u0026lt;/span\u0026gt;.\u0026lt;/p\u0026gt; \u0026lt;p\u0026gt;nationality: \u0026lt;span th:text=\u0026#34;${session.user.nationality}\u0026#34;\u0026gt;saturn\u0026lt;/span\u0026gt;.\u0026lt;/p\u0026gt; \u0026lt;/div\u0026gt; 链接表达式 使用@{...}处理链接\nhttp://localhost/thymeleaf/order/details?orderid=15 有以下几种写法\n1 2 \u0026lt;a href=\u0026#34;details.html\u0026#34; th:href=\u0026#34;@{http://localhost:8080/gtvg/order/details(orderid=${o.id})}\u0026#34;\u0026gt;view\u0026lt;/a\u0026gt; 相当于\n1 \u0026lt;a href=\u0026#34;details.html\u0026#34; th:href=\u0026#34;@{/order/details(orderid=${o.id})}\u0026#34;\u0026gt;view\u0026lt;/a\u0026gt; 相当于\n1 \u0026lt;a href=\u0026#34;details.html\u0026#34; th:href=\u0026#34;@{/order/details(orderid=${o.id})}\u0026#34;\u0026gt;view\u0026lt;/a\u0026gt; restfull风格写法:http://localhost/thymeleaf/order/15/details\n1 \u0026lt;a href=\u0026#34;details.html\u0026#34; th:href=\u0026#34;@{/order/{orderid}/details(orderid=${o.id})}\u0026#34;\u0026gt;view\u0026lt;/a\u0026gt; 注意restfull风格的@{...}可变orderid不加$\n段表达式 详见模版布局\n字面值 文本\n1 2 3 4 \u0026lt;p\u0026gt; now you are looking at a \u0026lt;span th:text=\u0026#34;\u0026#39;working web application\u0026#39;\u0026#34;\u0026gt;template file\u0026lt;/span\u0026gt;. \u0026lt;/p\u0026gt; 数字\n1 2 \u0026lt;p\u0026gt;the year is \u0026lt;span th:text=\u0026#34;2013\u0026#34;\u0026gt;1492\u0026lt;/span\u0026gt;.\u0026lt;/p\u0026gt; \u0026lt;p\u0026gt;in two years, it will be \u0026lt;span th:text=\u0026#34;2013 + 2\u0026#34;\u0026gt;1494\u0026lt;/span\u0026gt;.\u0026lt;/p\u0026gt; 布尔值判断\n==false在大括号后面有thymeleaf处理\n1 \u0026lt;div th:if=\u0026#34;${user.isadmin()} == false\u0026#34;\u0026gt; ... ==false在大括号里面由ongl/springel引擎负责\n1 \u0026lt;div th:if=\u0026#34;${user.isadmin() == false}\u0026#34;\u0026gt; ... null值判断\n1 \u0026lt;div th:if=\u0026#34;${variable.something} == null\u0026#34;\u0026gt; 文字替代\n1 2 3 \u0026lt;div th:class=\u0026#34;content\u0026#34;\u0026gt;...\u0026lt;/div\u0026gt; 相当于 \u0026lt;div th:class=\u0026#34;\u0026#39;content\u0026#39;\u0026#34;\u0026gt;...\u0026lt;/div\u0026gt; 拼接文本 使用+拼接\n1 \u0026lt;span th:text=\u0026#34;\u0026#39;the name of the user is \u0026#39; + ${user.name}\u0026#34;\u0026gt;\u0026lt;/span\u0026gt; 相当于\n1 \u0026lt;span th:text=\u0026#34;|welcome to our application, ${user.name}!|\u0026#34;\u0026gt;\u0026lt;/span\u0026gt; 算数运算 可以使用+, -,*, / , %进行运算\n1 2 \u0026lt;!-- thymeleaf处理 --\u0026gt; \u0026lt;div th:with=\u0026#34;iseven=(${prodstat.count} % 2 == 0)\u0026#34;\u0026gt; 结果相当于\n1 2 \u0026lt;!-- ongl、spel处理 --\u0026gt; \u0026lt;div th:with=\u0026#34;iseven=${prodstat.count % 2 == 0}\u0026#34;\u0026gt; 等于和大小判断 可以使用\u0026gt;,\u0026lt;,\u0026gt;=和\u0026lt;=符号,以及==和!=进行比较运算\n1 2 \u0026lt;div th:if=\u0026#34;${prodstat.count} \u0026gt; 1\u0026#34;\u0026gt; \u0026lt;span th:text=\u0026#34;((${execmode} == \u0026#39;dev\u0026#39;)? \u0026#39;development\u0026#39; : \u0026#39;production\u0026#39;)\u0026#34;\u0026gt; 可以使用\u0026amp;lt;(\u0026lt;)和\u0026amp;gt(\u0026gt;)\n或者使用别名gt (\u0026gt;), lt (\u0026lt;), ge (\u0026gt;=), le (\u0026lt;=)\n条件表达式 使用?:进行三元运算\n1 2 3 \u0026lt;tr th:class=\u0026#34;${row.even}? \u0026#39;even\u0026#39; : \u0026#39;odd\u0026#39;\u0026#34;\u0026gt; ... \u0026lt;/tr\u0026gt; 表达式也可以省略部分\n1 2 \u0026lt;!-- 返回值为false时,返回null,显示\u0026lt;span\u0026gt;\u0026lt;/span\u0026gt; --\u0026gt; \u0026lt;span th:text=\u0026#34;${row.even}? \u0026#39;alt\u0026#39;\u0026#34;\u0026gt;\u0026lt;/span\u0026gt; 1 2 \u0026lt;!-- 返回值为true时,返回\u0026#39;true\u0026#39;,显示\u0026lt;span\u0026gt;true\u0026lt;/span\u0026gt; --\u0026gt; \u0026lt;span th:text=\u0026#34;${row.even}? :\u0026#39;alt\u0026#39;\u0026#34;\u0026gt;\u0026lt;/span\u0026gt; 默认表达式(elvis运算符) 1 2 3 \u0026lt;div th:object=\u0026#34;${session.user}\u0026#34;\u0026gt; \u0026lt;p\u0026gt;age: \u0026lt;span th:text=\u0026#34;*{age}?: \u0026#39;(no age specified)\u0026#39;\u0026#34;\u0026gt;27\u0026lt;/span\u0026gt;.\u0026lt;/p\u0026gt; \u0026lt;/div\u0026gt; 上述代码相当于age为空时设置默认值,与下面代码作用相同\n1 \u0026lt;p\u0026gt;age: \u0026lt;span th:text=\u0026#34;*{age != null}? *{age} : \u0026#39;(no age specified)\u0026#39;\u0026#34;\u0026gt;27\u0026lt;/span\u0026gt;.\u0026lt;/p\u0026gt; 无操作表达式 1 \u0026lt;span th:text=\u0026#34;${user.name} ?: \u0026#39;no user authenticated\u0026#39;\u0026#34;\u0026gt;...\u0026lt;/span\u0026gt; 相当于\n1 \u0026lt;span th:text=\u0026#34;${user.name} ?: _\u0026#34;\u0026gt;no user authenticated\u0026lt;/span\u0026gt; 数据转换/格式化服务 见更多配置部分\n${{...}}和*{{...}}\n1 \u0026lt;td th:text=\u0026#34;${{user.lastaccessdate}}\u0026#34;\u0026gt;...\u0026lt;/td\u0026gt; 先获得user.lastaccessdate的值,在调用注册的转换服务,如果没有仅仅会调用tostring方法\nthymeleaf-spring3和thymeleaf-spring4集成软件包的集成了spring与thymeleaf的转换服务机制,所以在spring配置宣称,转换服务和格式化将进行自动获得${{...}}和*{{...}}表达\n预处理 预处理表达式与普通表达式完全相同,但显示为双下划线符号(如__${expression}__、__#{expression}__\u0026hellip;)\n例如\nmessages_zh.properties\n1 article.text=@myapp.translator.translator@translatetochinese({0}) messages_en.properties\n1 article.text=@myapp.translator.translator@translatetoenglish({0}) 使用预处理\n1 \u0026lt;p th:text=\u0026#34;${__#{article.text(\u0026#39;textvar\u0026#39;)}__}\u0026#34;\u0026gt;some text here...\u0026lt;/p\u0026gt; 更具语言环境会被替换为\n1 2 3 \u0026lt;p th:text=\u0026#34;${@myapp.translator.translator@translatetochinese(textvar)}\u0026#34;\u0026gt;\u0026lt;/p\u0026gt; 或者 \u0026lt;p th:text=\u0026#34;${@myapp.translator.translator@translatetoenglish(textvar)}\u0026#34;\u0026gt;\u0026lt;/p\u0026gt; 四、设置属性值 设置任何属性的值 使用th:attr设置任何属性\n1 2 \u0026lt;img src=\u0026#34;/images/gtvglogo.png\u0026#34; th:attr=\u0026#34;src=@{/images/gtvglogo.png},title=#{logo},alt=#{logo}\u0026#34; /\u0026gt; 处理之后的结果为\n1 2 3 \u0026lt;img src=\u0026#34;/gtgv/images/gtvglogo.png\u0026#34; title=\u0026#34;logo de good thymes\u0026#34; alt=\u0026#34;logo de good thymes\u0026#34; /\u0026gt; 为指定属性设置值 1 2 \u0026lt;img src=\u0026#34;/images/gtvglogo.png\u0026#34; th:attr=\u0026#34;src=@{/images/gtvglogo.png},title=#{logo},alt=#{logo}\u0026#34; /\u0026gt; 相当于\n1 2 3 4 \u0026lt;img src=\u0026#34;/images/gtvglogo.png\u0026#34; th:src=\u0026#34;@{/images/gtvglogo.png}\u0026#34; th:title=\u0026#34;#{logo}\u0026#34; th:alt=\u0026#34;#{logo}\u0026#34; /\u0026gt; 一次设置多个值 有两个比较特殊的属性th:alt-title和th:lang-xmllang可用于同时设置两个属性相同的值:\nth:alt-title将设置alt和title。 th:lang-xmllang将设置lang和xml:lang。 1 2 3 4 \u0026lt;img src=\u0026#34;/images/gtvglogo.png\u0026#34; th:src=\u0026#34;@{/images/gtvglogo.png}\u0026#34; th:title=\u0026#34;#{logo}\u0026#34; th:alt=\u0026#34;#{logo}\u0026#34; /\u0026gt; 相当于\n1 2 \u0026lt;img src=\u0026#34;/images/gtvglogo.png\u0026#34; th:src=\u0026#34;@{/images/gtvglogo.png}\u0026#34; th:alt-title=\u0026#34;#{logo}\u0026#34; /\u0026gt; 前后添加属性 1 \u0026lt;p class=\u0026#34;blockfont\u0026#34; th:attrappend=\u0026#34;class=${\u0026#39; \u0026#39; + cssstyle}\u0026#34;\u0026gt;hello\u0026lt;/p\u0026gt; 拼接结果\n1 \u0026lt;p class=\u0026#34;blockfont redfont\u0026#34;\u0026gt;hello\u0026lt;/p\u0026gt; 1 \u0026lt;p class=\u0026#34;blockfont\u0026#34; th:attrprepend=\u0026#34;class=${cssstyle + \u0026#39; \u0026#39;}\u0026#34;\u0026gt;hello\u0026lt;/p\u0026gt; 拼接结果\n1 \u0026lt;p class=\u0026#34;redfont blockfont\u0026#34;\u0026gt;hello\u0026lt;/p\u0026gt; 标准方言中还有两个属性:th:classappend和th:styleappend,用于向元素添加css类或style片段而不覆盖现有元素\n固定值布尔属性 标准方言将计算表达式的值,如果为true,则将属性设置为其固定值,如果计算为false,则不会设置该属性\n1 \u0026lt;input type=\u0026#34;checkbox\u0026#34; name=\u0026#34;active\u0026#34; th:checked=\u0026#34;${user.active}\u0026#34; /\u0026gt; 设置任何属性的值 thymeleaf提供了一个默认属性处理器,允许设置任何属性的值,即使th:*,在标准方言中没有为它定义特定的处理器\n1 \u0026lt;span th:whatever=\u0026#34;${user.name}\u0026#34;\u0026gt;...\u0026lt;/span\u0026gt; 结果为\n1 \u0026lt;span whatever=\u0026#34;john apricot\u0026#34;\u0026gt;...\u0026lt;/span\u0026gt; html5友好的属性和元素名称 也可以使用html5规定的用户自定义属性写法data-{prefix}-{name},此做法无需开使用任何命名空间的名称\n例如\u0026lt;span data-th-text=\u0026quot;${user.login}\u0026quot;\u0026gt;...\u0026lt;/span\u0026gt;\n五、循环 基础 使用th:each实现遍历\nlist遍历\n1 2 3 \u0026lt;ul th:each=\u0026#34;user : ${users}\u0026#34;\u0026gt; \u0026lt;li th:text=\u0026#34;${user.firstname}\u0026#34;\u0026gt;\u0026lt;/li\u0026gt; \u0026lt;/ul\u0026gt; map遍历\n1 2 3 \u0026lt;ul th:each=\u0026#34;user : ${usermaps}\u0026#34;\u0026gt; \u0026lt;li th:text=\u0026#34;|${user.key} - ${user.value.firstname}\u0026#34;\u0026gt;\u0026lt;/li\u0026gt; \u0026lt;/ul\u0026gt; 迭代状态 状态变量在th:each属性中定义,包含以下属性:\n属性 描述 index 当前迭代索引,从0开始 count 当前迭代索引,从1开始 size 集合中元素的总量 current 当前遍历的元素 even/odd 当前迭代是偶数还是奇数 first 当前迭代是否是第一个 last 当前迭代是否是最后一个 使用迭代变量,迭代状态变量:集合的方式进行迭代,如果没有显示指定迭代变量,则thymeleaf创建以迭代变量名+stat命令的迭代状态变量,例如\n1 2 3 4 5 6 7 8 9 10 11 \u0026lt;ul th:each=\u0026#34;user,iterstat : ${users}\u0026#34;\u0026gt; \u0026lt;li th:text=\u0026#34;${user.firstname}\u0026#34;\u0026gt;\u0026lt;/li\u0026gt; \u0026lt;li th:text=\u0026#34;${iterstat.first}\u0026#34;\u0026gt;\u0026lt;/li\u0026gt; \u0026lt;li th:text=\u0026#34;${iterstat.last}\u0026#34;\u0026gt;\u0026lt;/li\u0026gt; \u0026lt;li th:text=\u0026#34;${iterstat.index}\u0026#34;\u0026gt;\u0026lt;/li\u0026gt; \u0026lt;li th:text=\u0026#34;${iterstat.count}\u0026#34;\u0026gt;\u0026lt;/li\u0026gt; \u0026lt;li th:text=\u0026#34;${iterstat.size}\u0026#34;\u0026gt;\u0026lt;/li\u0026gt; \u0026lt;li th:text=\u0026#34;${iterstat.current}\u0026#34;\u0026gt;\u0026lt;/li\u0026gt; \u0026lt;li th:text=\u0026#34;${iterstat.even}\u0026#34;\u0026gt;\u0026lt;/li\u0026gt; \u0026lt;li th:text=\u0026#34;${iterstat.odd}\u0026#34;\u0026gt;\u0026lt;/li\u0026gt; \u0026lt;/ul\u0026gt; 相当于\n1 2 3 4 5 6 7 8 9 10 11 \u0026lt;ul th:each=\u0026#34;user : ${users}\u0026#34;\u0026gt; \u0026lt;li th:text=\u0026#34;${user.firstname}\u0026#34;\u0026gt;\u0026lt;/li\u0026gt; \u0026lt;li th:text=\u0026#34;${userstat.first}\u0026#34;\u0026gt;\u0026lt;/li\u0026gt; \u0026lt;li th:text=\u0026#34;${userstat.last}\u0026#34;\u0026gt;\u0026lt;/li\u0026gt; \u0026lt;li th:text=\u0026#34;${userstat.index}\u0026#34;\u0026gt;\u0026lt;/li\u0026gt; \u0026lt;li th:text=\u0026#34;${userstat.count}\u0026#34;\u0026gt;\u0026lt;/li\u0026gt; \u0026lt;li th:text=\u0026#34;${userstat.size}\u0026#34;\u0026gt;\u0026lt;/li\u0026gt; \u0026lt;li th:text=\u0026#34;${userstat.current}\u0026#34;\u0026gt;\u0026lt;/li\u0026gt; \u0026lt;li th:text=\u0026#34;${userstat.even}\u0026#34;\u0026gt;\u0026lt;/li\u0026gt; \u0026lt;li th:text=\u0026#34;${userstat.odd}\u0026#34;\u0026gt;\u0026lt;/li\u0026gt; \u0026lt;/ul\u0026gt; 懒加载 设置变量时public void setvariable(final string name, final object value),被放入上下文环境中的类实现lazycontextvariable接口即可实现懒加载,如果加载的条件不满足,则不会触发loadvalue方法。注意每次加载都会触发loadvalue\n1 2 3 4 5 6 7 8 ctx.setvariable( \u0026#34;users\u0026#34;, new lazycontextvariable\u0026lt;list\u0026lt;user\u0026gt;\u0026gt;() { @override protected list\u0026lt;user\u0026gt; loadvalue() { return users.findallusers(); } }) 六、条件评估 th:if属性按照true以下规则评估指定的表达式:\n如果value不为null: 如果value是布尔值,则为true。 如果value是数字且不为零 如果value是一个字符且不为零 如果value是string并且不是“false”,“off”或“no” 如果value不是布尔值,数字,字符或字符串。 如果value为null,则为false unless相当于\u0026quot;if not\u0026quot;\nswitch语句,默认值为*\n1 2 3 4 5 \u0026lt;div th:switch=\u0026#34;${user.role}\u0026#34;\u0026gt; \u0026lt;p th:case=\u0026#34;\u0026#39;admin\u0026#39;\u0026#34;\u0026gt;user is an administrator\u0026lt;/p\u0026gt; \u0026lt;p th:case=\u0026#34;#{roles.manager}\u0026#34;\u0026gt;user is a manager\u0026lt;/p\u0026gt; \u0026lt;p th:case=\u0026#34;*\u0026#34;\u0026gt;user is some other thing\u0026lt;/p\u0026gt; \u0026lt;/div\u0026gt; 七、模版布局 定义模版片段 使用th:fragment定义片段,例如:\n1 2 3 4 5 6 7 8 \u0026lt;!doctype html\u0026gt; \u0026lt;html xmlns:th=\u0026#34;http://www.thymeleaf.org\u0026#34;\u0026gt; \u0026lt;body\u0026gt; \u0026lt;div th:fragment=\u0026#34;copy\u0026#34;\u0026gt; \u0026amp;copy; 2011 the good thymes virtual grocery \u0026lt;/div\u0026gt; \u0026lt;/body\u0026gt; \u0026lt;/html\u0026gt; 引用片段 使用th:insert插入引用片段\n1 2 3 \u0026lt;body\u0026gt; \u0026lt;div th:insert=\u0026#34;~{footer :: copy}\u0026#34;\u0026gt;\u0026lt;/div\u0026gt; \u0026lt;/body\u0026gt; 结果\n1 2 3 4 5 6 7 \u0026lt;body\u0026gt; \u0026lt;div\u0026gt; \u0026lt;div\u0026gt; \u0026amp;copy; 2011 the good thymes virtual grocery \u0026lt;/div\u0026gt; \u0026lt;/div\u0026gt; \u0026lt;body\u0026gt; 使用th:replace插入引用片段\n1 2 3 \u0026lt;body\u0026gt; \u0026lt;div th:insert=\u0026#34;~{footer :: copy}\u0026#34;\u0026gt;\u0026lt;/div\u0026gt; \u0026lt;/body\u0026gt; 结果\n1 2 3 4 5 \u0026lt;body\u0026gt; \u0026lt;div\u0026gt; \u0026amp;copy; 2011 the good thymes virtual grocery \u0026lt;/div\u0026gt; \u0026lt;/body\u0026gt; 片段规范语法 使用th:insert=\u0026quot;~{文件名::片段名}\u0026quot;或者th:insert=\u0026quot;文件名::片段名\u0026quot; \u0026quot;~{templatename}\u0026quot;包含名为templatename的完整模板,会将把指定元素替换为templatename整个网页 ~{::selector}\u0026quot;或\u0026quot;~{this::selector}\u0026quot;插入来自当前模板的片段,进行匹配selector。如果在表达式出现的模板上找不到,则模板调用(插入)的堆栈将遍历最初处理的模板(根),直到selector在某个级别匹配 不标记th:fragment 1 2 3 \u0026lt;div id=\u0026#34;copy-section\u0026#34;\u0026gt; \u0026amp;copy; 2011 the good thymes virtual grocery \u0026lt;/div\u0026gt; 引用此片段(使用id选择器)\n1 2 3 \u0026lt;body\u0026gt; \u0026lt;div th:insert=\u0026#34;~{footer :: #copy-section}\u0026#34;\u0026gt;\u0026lt;/div\u0026gt; \u0026lt;/body\u0026gt; 可参数化的片段签名 声明片段\n1 2 3 \u0026lt;div th:fragment=\u0026#34;frag (onevar,twovar)\u0026#34;\u0026gt; \u0026lt;p th:text=\u0026#34;${onevar} + \u0026#39; - \u0026#39; + ${twovar}\u0026#34;\u0026gt;...\u0026lt;/p\u0026gt; \u0026lt;/div\u0026gt; 调用此片段\n1 2 \u0026lt;div th:replace=\u0026#34;::frag (${value1},${value2})\u0026#34;\u0026gt;...\u0026lt;/div\u0026gt; \u0026lt;div th:replace=\u0026#34;::frag (onevar=${value1},twovar=${value2})\u0026#34;\u0026gt;...\u0026lt;/div 灵活布局 1 2 3 4 5 6 7 8 9 10 11 12 \u0026lt;head th:fragment=\u0026#34;common_header(title,links)\u0026#34;\u0026gt; \u0026lt;!--/* 替换title */--\u0026gt; \u0026lt;title th:replace=\u0026#34;${title}\u0026#34;\u0026gt;the awesome application\u0026lt;/title\u0026gt; \u0026lt;!-- 不是重点 --\u0026gt; \u0026lt;link rel=\u0026#34;shortcut icon\u0026#34; th:href=\u0026#34;@{/images/favicon.ico}\u0026#34;\u0026gt; \u0026lt;script type=\u0026#34;text/javascript\u0026#34; th:src=\u0026#34;@{/sh/scripts/codebase.js}\u0026#34;\u0026gt;\u0026lt;/script\u0026gt; \u0026lt;!--/* 会将传入的links全部替换在此 */--\u0026gt; \u0026lt;th:block th:replace=\u0026#34;${links}\u0026#34; /\u0026gt; \u0026lt;/head\u0026gt; 调用此片段\n1 2 3 4 5 6 7 \u0026lt;head th:replace=\u0026#34;base :: common_header(~{::title},~{::link})\u0026#34;\u0026gt; \u0026lt;title\u0026gt;awesome - main\u0026lt;/title\u0026gt; \u0026lt;link rel=\u0026#34;stylesheet\u0026#34; th:href=\u0026#34;@{/css/bootstrap.min.css}\u0026#34;\u0026gt; \u0026lt;link rel=\u0026#34;stylesheet\u0026#34; th:href=\u0026#34;@{/themes/smoothness/jquery-ui.css}\u0026#34;\u0026gt; \u0026lt;/head\u0026gt; 结果,使用的调用者本身的title,加上调用者本身的链接\n1 2 3 4 5 6 7 8 9 10 11 \u0026lt;head\u0026gt; \u0026lt;title\u0026gt;awesome - main\u0026lt;/title\u0026gt; \u0026lt;!-- 不是重点 --\u0026gt; \u0026lt;link rel=\u0026#34;shortcut icon\u0026#34; href=\u0026#34;/awe/images/favicon.ico\u0026#34;\u0026gt; \u0026lt;script type=\u0026#34;text/javascript\u0026#34; src=\u0026#34;/awe/sh/scripts/codebase.js\u0026#34;\u0026gt;\u0026lt;/script\u0026gt; \u0026lt;link rel=\u0026#34;stylesheet\u0026#34; href=\u0026#34;/awe/css/bootstrap.min.css\u0026#34;\u0026gt; \u0026lt;link rel=\u0026#34;stylesheet\u0026#34; href=\u0026#34;/awe/themes/smoothness/jquery-ui.css\u0026#34;\u0026gt; \u0026lt;/head\u0026gt; 无标记传入\n1 2 3 4 5 \u0026lt;head th:replace=\u0026#34;base :: common_header(~{::title},~{})\u0026#34;\u0026gt; \u0026lt;title\u0026gt;awesome - main\u0026lt;/title\u0026gt; \u0026lt;/head\u0026gt; 结果为\n1 2 3 4 5 6 7 8 9 \u0026lt;head\u0026gt; \u0026lt;title\u0026gt;awesome - main\u0026lt;/title\u0026gt; \u0026lt;!-- 不是重点 --\u0026gt; \u0026lt;link rel=\u0026#34;shortcut icon\u0026#34; href=\u0026#34;/awe/images/favicon.ico\u0026#34;\u0026gt; \u0026lt;script type=\u0026#34;text/javascript\u0026#34; src=\u0026#34;/awe/sh/scripts/codebase.js\u0026#34;\u0026gt;\u0026lt;/script\u0026gt; \u0026lt;/head\u0026gt; 无操作_标记传入\n1 2 3 4 5 6 7 8 \u0026lt;head th:replace=\u0026#34;base :: common_header(_,~{::link})\u0026#34;\u0026gt; \u0026lt;title\u0026gt;awesome - main\u0026lt;/title\u0026gt; \u0026lt;link rel=\u0026#34;stylesheet\u0026#34; th:href=\u0026#34;@{/css/bootstrap.min.css}\u0026#34;\u0026gt; \u0026lt;link rel=\u0026#34;stylesheet\u0026#34; th:href=\u0026#34;@{/themes/smoothness/jquery-ui.css}\u0026#34;\u0026gt; \u0026lt;/head\u0026gt; 结果为\n1 2 3 4 5 6 7 8 9 10 11 12 \u0026lt;head\u0026gt; \u0026lt;title\u0026gt;the awesome application\u0026lt;/title\u0026gt; \u0026lt;!-- 不是重点 --\u0026gt; \u0026lt;link rel=\u0026#34;shortcut icon\u0026#34; href=\u0026#34;/awe/images/favicon.ico\u0026#34;\u0026gt; \u0026lt;script type=\u0026#34;text/javascript\u0026#34; src=\u0026#34;/awe/sh/scripts/codebase.js\u0026#34;\u0026gt;\u0026lt;/script\u0026gt; \u0026lt;link rel=\u0026#34;stylesheet\u0026#34; href=\u0026#34;/awe/css/bootstrap.min.css\u0026#34;\u0026gt; \u0026lt;link rel=\u0026#34;stylesheet\u0026#34; href=\u0026#34;/awe/themes/smoothness/jquery-ui.css\u0026#34;\u0026gt; \u0026lt;/head\u0026gt; 删除模板片段 模拟数据的时候会模拟很多行,那么循环遍历是就需要删除不需要的数据例如\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 \u0026lt;table\u0026gt; \u0026lt;thead\u0026gt; \u0026lt;tr\u0026gt; \u0026lt;th\u0026gt;姓名\u0026lt;/th\u0026gt; \u0026lt;th\u0026gt;年龄\u0026lt;/th\u0026gt; \u0026lt;/tr\u0026gt; \u0026lt;tr\u0026gt; \u0026lt;td\u0026gt;小明\u0026lt;/td\u0026gt; \u0026lt;td\u0026gt;18\u0026lt;/td\u0026gt; \u0026lt;/tr\u0026gt; \u0026lt;tr\u0026gt; \u0026lt;td\u0026gt;小红\u0026lt;/td\u0026gt; \u0026lt;td\u0026gt;16\u0026lt;/td\u0026gt; \u0026lt;/tr\u0026gt; \u0026lt;tr\u0026gt; \u0026lt;td\u0026gt;小白\u0026lt;/td\u0026gt; \u0026lt;td\u0026gt;20\u0026lt;/td\u0026gt; \u0026lt;/tr\u0026gt; \u0026lt;/thead\u0026gt; \u0026lt;/table\u0026gt; 使用th:remove处理\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 \u0026lt;table\u0026gt; \u0026lt;thead\u0026gt; \u0026lt;tr\u0026gt; \u0026lt;th\u0026gt;姓名\u0026lt;/th\u0026gt; \u0026lt;th\u0026gt;年龄\u0026lt;/th\u0026gt; \u0026lt;/tr\u0026gt; \u0026lt;tr th:each=\u0026#34;user : ${users}\u0026#34; th:remove=\u0026#34;all-but-first\u0026#34;\u0026gt; \u0026lt;td\u0026gt;[[user.name]]\u0026lt;/td\u0026gt; \u0026lt;td\u0026gt;[[user.age]]\u0026lt;/td\u0026gt; \u0026lt;/tr\u0026gt; \u0026lt;tr\u0026gt; \u0026lt;td\u0026gt;小明\u0026lt;/td\u0026gt; \u0026lt;td\u0026gt;18\u0026lt;/td\u0026gt; \u0026lt;/tr\u0026gt; \u0026lt;tr\u0026gt; \u0026lt;td\u0026gt;小红\u0026lt;/td\u0026gt; \u0026lt;td\u0026gt;16\u0026lt;/td\u0026gt; \u0026lt;/tr\u0026gt; \u0026lt;tr\u0026gt; \u0026lt;td\u0026gt;小白\u0026lt;/td\u0026gt; \u0026lt;td\u0026gt;20\u0026lt;/td\u0026gt; \u0026lt;/tr\u0026gt; \u0026lt;/thead\u0026gt; \u0026lt;/table\u0026gt; th:remove可选属性\nall:删除包含标记及其所有子标记。 body:不要删除包含标记,但删除其所有子标记。 tag:删除包含标记,但不删除其子标记。 all-but-first:除第一个子项外,删除包含标记的所有子项。 none: 没做什么。 八、局部变量 hymeleaf提供了一种使用th:with属性声明局部变量方法,可以使用,定义多个,其语法类似于属性值赋值:\n1 2 3 4 5 6 \u0026lt;!-- firstper只在声明的div块内可见 --\u0026gt; \u0026lt;div th:with=\u0026#34;firstper=${persons[0]}\u0026#34;\u0026gt; \u0026lt;p\u0026gt; \u0026lt;span th:text=\u0026#34;${firstper.name}\u0026#34;\u0026gt;\u0026lt;/span\u0026gt; \u0026lt;/p\u0026gt; \u0026lt;/div\u0026gt; 场景:如果根据地区不同显示不同的日期格式,可以使用下述方法\nhome_en.properties:\n1 date.format=mm dd yyyy home_zh.properties:\n1 date.format=yyyy-mm-dd th:with使用\n1 2 3 \u0026lt;p th:with=\u0026#34;df=#{date.format}\u0026#34;\u0026gt; today is: \u0026lt;span th:text=\u0026#34;${#date.format(today,df)}\u0026#34;\u0026gt;\u0026lt;/span\u0026gt; \u0026lt;/p 或者\n1 2 3 4 \u0026lt;p\u0026gt; today is: \u0026lt;span th:with=\u0026#34;df=#{date.format}\u0026#34; th:text=\u0026#34;${#date.format(today,df)}\u0026#34;\u0026gt;\u0026lt;/span\u0026gt; \u0026lt;/p\u0026gt; 九、属性优先级 优先级别 描述 属性 1 片段包含 th:insert th:replace 2 迭代 th:each 3 条件判断 th:if th:unless th:switch th:case 4 局部变量定义 th:object th:with 5 一般属性修改 th:attr th:attrprepend th:attrappend 6 具体属性修改 th:value th:href th:src \u0026hellip; 7 文字 th:text th:utext 8 片段定义 th:fragment 9 片段删除 th:remove 十、注释和块 标准html/xml注释\n标准html / xml注释\u0026lt;!-- ... --\u0026gt;可以在thymeleaf模板中的任何位置使用。thymeleaf不会处理这些注释,并将逐字复制到结果中\nthymeleaf解析器级别注释\nthymeleaf将简单删除一切与\u0026lt;!--/*和*/--\u0026gt;之间的注释,不会解析和显示\n1 \u0026lt;!--/* 单行注释掉! */--\u0026gt; 1 2 3 4 5 \u0026lt;!--/* ... 整块注释掉 ... */--\u0026gt; 原型的注释\n\u0026lt;!--/*/ /*/--\u0026gt;,thymeleaf会解析但是不会显示\n搭配th:block标签\nth:block和\u0026lt;!--/*/ /*/--\u0026gt;搭配使用,th:block下的变量可见,不需要再写上级标签\n1 2 3 4 5 6 7 8 \u0026lt;table\u0026gt; \u0026lt;!--/*/ \u0026lt;th:block th:each=\u0026#34;user : ${users}\u0026#34;\u0026gt; /*/--\u0026gt; \u0026lt;tr\u0026gt; \u0026lt;td th:text=\u0026#34;${user.login}\u0026#34;\u0026gt;...\u0026lt;/td\u0026gt; \u0026lt;td th:text=\u0026#34;${user.name}\u0026#34;\u0026gt;...\u0026lt;/td\u0026gt; \u0026lt;/tr\u0026gt; \u0026lt;!--/*/ \u0026lt;/th:block\u0026gt; /*/--\u0026gt; \u0026lt;/table\u0026gt; 十一、内联 内联表达式 内联表达式th:inline=\u0026quot;text\u0026quot;默认是开启的,th:inline=\u0026quot;javascript\u0026quot;和th:inline=\u0026quot;css\u0026quot;需要显示开启\n[[...]]相当于th:text\n[(...)]相当于th:utext\nth:inline=\u0026quot;none\u0026quot;禁用内联表达式\n1 \u0026lt;p th:inline=\u0026#34;none\u0026#34;\u0026gt;a double array looks like this: [[1, 2, 3], [4, 5]]!\u0026lt;/p\u0026gt; 结果为\n1 \u0026lt;p\u0026gt;a double array looks like this: [[1, 2, 3], [4, 5]]!\u0026lt;/p\u0026gt; 文字内联 详见文本模版\njavascript内联 详见文本模版\ncss内联 1 2 3 \u0026lt;style th:inline=\u0026#34;css\u0026#34;\u0026gt; ... \u0026lt;/style\u0026gt; 例如\nclassname = \u0026lsquo;main elems\u0026rsquo; align = \u0026lsquo;center\u0026rsquo;\n1 2 3 4 5 6 7 8 9 10 \u0026lt;style th:inline=\u0026#34;css\u0026#34;\u0026gt; .[[${classname}]] { text-align: [[${align}]]; } \u0026lt;/style\u0026gt; \u0026lt;style th:inline=\u0026#34;css\u0026#34;\u0026gt; .[(${classname})] { text-align: [[${align}]]; } \u0026lt;/style\u0026gt; 结果将是\n1 2 3 4 5 6 7 8 9 10 \u0026lt;style th:inline=\u0026#34;css\u0026#34;\u0026gt; .main\\ elems { text-align: center; } \u0026lt;/style\u0026gt; \u0026lt;style th:inline=\u0026#34;css\u0026#34;\u0026gt; .main elems { text-align: center; } \u0026lt;/style\u0026gt; 高级自然模版写法,后面声明的元素会被替换\n1 2 3 4 5 \u0026lt;style th:inline=\u0026#34;css\u0026#34;\u0026gt; .main elems { text-align: /*[[${align}]]*/ left; } \u0026lt;/style\u0026gt; 十二、文本模板模式 text,javascript和css均属于文本模板,html和xml属于标记模板。\n文本语法 文本模板模式与标记模式之间的关键区别在于,文本模板中没有标签可以以属性的形式插入逻辑,因此我们必须依赖其他机制。\n可以在文本模版中使用[[${...}]]或者[(...)]进行取值操作\n文本模版中遍历\n1 2 3 [#th:block th:each=\u0026#34;item : ${items}\u0026#34;] - [#th:block th:utext=\u0026#34;${item}\u0026#34; /] [/th:block] 可以使用[# ...] ... [/] 替代[#th:block ...]... [/th:block]\n1 2 3 [# th:each=\u0026#34;item : ${items}\u0026#34;] - [# th:utext=\u0026#34;${item}\u0026#34; /] [/] [# th:utext=\u0026quot;${...}\u0026quot; /]等效于内联非转义表达式,所以可以使用如下替代\n1 2 3 [# th:each=\u0026#34;item : ${items}\u0026#34;] - [(${item})] [/] 文本模版中判断\n1 2 3 4 5 6 [# th:if=\u0026#34;${oid}\u0026gt;0\u0026#34; ] 大于0 [/] [# th:if=\u0026#34;${session.user.firstname}==\u0026#39;小明\u0026#39;\u0026#34; ] 他叫小明 [/] 原型注代码块 在javascript和css模板模式(不适用于text),允许包括一个特殊的注释语法之间的代码/*[+...+]*/,这样thymeleaf处理模板时会自动取消注释,将其输出\n1 2 3 4 5 6 7 var x = 23; /*[+ var msg = \u0026#34;hello, \u0026#34; + [[${session.user.name}]]; +]*/ 将被执行为\n1 2 3 var x = 23; var msg = \u0026#34;hello,小明\u0026#34;; 原型注释块 1 2 3 4 5 6 7 8 var x = 23; /*[+ /*[- 我是注释 -]*/ var msg = \u0026#34;hello, \u0026#34; + [[${session.user.name}]]; +]*/ javascript和css自然模版 javascript和css内联提供了在javascript / css注释中包含内联表达式的方式\n1 2 3 ... var username = /*[[${session.user.name}]]*/ \u0026#34;sebastian lychee\u0026#34;; ... 1 2 3 /*[# th:if=\u0026#34;${user.admin}\u0026#34;]*/ alert(\u0026#39;welcome admin\u0026#39;); /*[/]*/ 上述方式javascript可以正常打开\n十三、有关配置信息 模板解析器 thymeleaf 自身模板解析器\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 itemplateresolver | +- abstracttemplateresolver | +- defaulttemplateresolver【默认模版解析器】 | +- stringtemplateresolver【可以直接解析模板】 | +- abstractconfigurabletemplateresolver | +- classloadertemplateresolver【将模板解析为类加载器资源】 | +- filetemplateresolver【将模板解析为文件系统中的文件】 | +- servletcontexttemplateresolver【从servlet context获取模板作为资源】 | +- urltemplateresolver【将模板解析为url】 设置相关属性\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 //前缀和后缀 templateresolver.setprefix(\u0026#34;/web-inf/templates/\u0026#34;); templateresolver.setsuffix(\u0026#34;.html\u0026#34;); //设置编码 templateresolver.setencoding(\u0026#34;utf-8\u0026#34;); //要使用的模板模式,默认html templateresolver.settemplatemode(\u0026#34;xml\u0026#34;); //模板缓存,默认开启 templateresolver.setcacheable(false); templateresolver.getcacheablepatternspec().addpattern(\u0026#34;/users/*\u0026#34;); //缓存条目的ttl,如果未设置,从缓存中删除条目的唯一方法是超过缓存最大大小(将删除最旧的条目) templateresolver.setcachettlms(60000l); 链接模板解析器 模板引擎可以指定多个模板解析器,在这种情况下,可以在它们之间建立用于模板解析的顺序(通过setorder方法),这样,如果第一个无法解析模板,则会询问第二个,依此类推,例如:\n1 2 3 4 5 6 7 8 9 classloadertemplateresolver classloadertemplateresolver = new classloadertemplateresolver(); classloadertemplateresolver.setorder(integer.valueof(1)); servletcontexttemplateresolver servletcontexttemplateresolver = new servletcontexttemplateresolver(servletcontext); servletcontexttemplateresolver.setorder(integer.valueof(2)); templateengine.addtemplateresolver(classloadertemplateresolver); templateengine.addtemplateresolver(servletcontexttemplateresolver) 当应用多个模板解析器时,建议为每个模板解析器指定模式,以便thymeleaf可以快速丢弃那些不打算解析模板的模板解析器,从而提高性能,例如:\n1 2 3 4 5 6 7 8 9 classloadertemplateresolver classloadertemplateresolver = new classloadertemplateresolver(); classloadertemplateresolver.setorder(integer.valueof(1)); //如果路径不匹配则直接不使用此解析器 classloadertemplateresolver.getresolvablepatternspec().addpattern(\u0026#34;/layout/*.html\u0026#34;); classloadertemplateresolver.getresolvablepatternspec().addpattern(\u0026#34;/menu/*.html\u0026#34;); servletcontexttemplateresolver servletcontexttemplateresolver = new servletcontexttemplateresolver(servletcontext); servletcontexttemplateresolver.setorder(integer.valueof(2)); 如果未指定这些pattern,我们将依赖于itemplateresolver每个实现的特定功能【可能不是我们想要的结果】\n消息解析器 standardmessageresolver在定位当解析资源时,会在同级目录下寻找properties文件\n1 2 3 4 5 imessageresolver | +- abstractmessageresolver | +- standardmessageresolver【默认使用】 链接消息解析器 1 2 3 4 5 6 //设置唯一一个 templateengine.setmessageresolver(messageresolver); //添加一个,如果第一个消息解析器无法解析特定消息,则会询问第二个,然后是第三个... templateengine.addmessageresolver(messageresolver); ... 转换服务 使用${{...}}调用转换服务,配置转换服务的方法:\n1 2 3 4 5 6 istandardconversionservice customconversionservice = ... standarddialect dialect = new standarddialect(); dialect.setconversionservice(customconversionservice); templateengine.setdialect(dialect); 日志 thymeleaf使用的日志门面是slf4j,配置示例:\n1 2 3 4 log4j.logger.org.thymeleaf=debug log4j.logger.org.thymeleaf.templateengine.config=trace log4j.logger.org.thymeleaf.templateengine.timer=trace log4j.logger.org.thymeleaf.templateengine.cache.template_cache=trace 十四、模板缓存 启用缓存代码\n1 2 3 4 5 6 //默认true templateresolver.setcacheable(true); //设置指定的缓存模版,默认全部 templateresolver.getcacheablepatternspec().addpattern(\u0026#34;/users/*\u0026#34;); //默认200 cachemanager.settemplatecachemaxsize(100); 缓存管理器接口icachemanager,默认实现类standardcachemanager\n十五、模版逻辑解耦 配置解耦模版 thymeleaf可以彻底与模板逻辑脱钩,将逻辑创建在xml文件当中。\n例如home.html文件可以完全无逻辑:\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 \u0026lt;!doctype html\u0026gt; \u0026lt;html\u0026gt; \u0026lt;body\u0026gt; \u0026lt;table id=\u0026#34;userstable\u0026#34;\u0026gt; \u0026lt;tr\u0026gt; \u0026lt;td class=\u0026#34;username\u0026#34;\u0026gt;jeremy grapefruit\u0026lt;/td\u0026gt; \u0026lt;td class=\u0026#34;usertype\u0026#34;\u0026gt;normal user\u0026lt;/td\u0026gt; \u0026lt;/tr\u0026gt; \u0026lt;tr\u0026gt; \u0026lt;td class=\u0026#34;username\u0026#34;\u0026gt;alice watermelon\u0026lt;/td\u0026gt; \u0026lt;td class=\u0026#34;usertype\u0026#34;\u0026gt;administrator\u0026lt;/td\u0026gt; \u0026lt;/tr\u0026gt; \u0026lt;/table\u0026gt; \u0026lt;/body\u0026gt; \u0026lt;/html\u0026gt; 创建逻辑附加文件home.th.xml\n1 2 3 4 5 6 7 8 9 \u0026lt;?xml version=\u0026#34;1.0\u0026#34;?\u0026gt; \u0026lt;thlogic\u0026gt; \u0026lt;attr sel=\u0026#34;#userstable\u0026#34; th:remove=\u0026#34;all-but-first\u0026#34;\u0026gt; \u0026lt;attr sel=\u0026#34;/tr[0]\u0026#34; th:each=\u0026#34;user : ${users}\u0026#34;\u0026gt; \u0026lt;attr sel=\u0026#34;td.username\u0026#34; th:text=\u0026#34;${user.name}\u0026#34; /\u0026gt; \u0026lt;attr sel=\u0026#34;td.usertype\u0026#34; th:text=\u0026#34;#{|user.type.${user.type}|}\u0026#34; /\u0026gt; \u0026lt;/attr\u0026gt; \u0026lt;/attr\u0026gt; \u0026lt;/thlogic\u0026gt; 相当于\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 \u0026lt;!doctype html\u0026gt; \u0026lt;html\u0026gt; \u0026lt;body\u0026gt; \u0026lt;table id=\u0026#34;userstable\u0026#34; th:remove=\u0026#34;all-but-first\u0026#34;\u0026gt; \u0026lt;tr th:each=\u0026#34;user : ${users}\u0026#34;\u0026gt; \u0026lt;td class=\u0026#34;username\u0026#34; th:text=\u0026#34;${user.name}\u0026#34;\u0026gt;jeremy grapefruit\u0026lt;/td\u0026gt; \u0026lt;td class=\u0026#34;usertype\u0026#34; th:text=\u0026#34;#{|user.type.${user.type}|}\u0026#34;\u0026gt;normal user\u0026lt;/td\u0026gt; \u0026lt;/tr\u0026gt; \u0026lt;tr\u0026gt; \u0026lt;td class=\u0026#34;username\u0026#34;\u0026gt;alice watermelon\u0026lt;/td\u0026gt; \u0026lt;td class=\u0026#34;usertype\u0026#34;\u0026gt;administrator\u0026lt;/td\u0026gt; \u0026lt;/tr\u0026gt; \u0026lt;/table\u0026gt; \u0026lt;/body\u0026gt; \u0026lt;/html\u0026gt; 启动解耦模版 1 2 3 servletcontexttemplateresolver templateresolver = new servletcontexttemplateresolver(servletcontext); templateresolver.setusedecoupledlogic(true); th:ref属性 th:ref只是一个标记属性,避免将html中加入大量id(锚点作用)污染文件\nth:ref属性的适用性不仅适用于解耦的逻辑模板文件,它还可以用于片段表达式(~{...})。\nidecoupledtemplatelogicresolver接口 org.thymeleaf.templateparser.markup.decoupled.idecoupledtemplatelogicresolver的默认实现是standarddecoupledtemplatelogicresolver,它具有以下默认标准\n默认情况下,前缀为空,后缀为.th.xml。\n模板资源与原本资源具有相同名称的相对路径itemplateresource#relative(string relativelocation)\n1 2 3 4 standarddecoupledtemplatelogicresolver decoupledresolver = new standarddecoupledtemplatelogicresolver(); decoupledresolver.setprefix(\u0026#34;../viewlogic/\u0026#34;); templateengine.setdecoupledtemplatelogicresolver(decoupledresolver); 附录 表达式基本对象 基础对象\n1 2 3 4 5 6 7 8 9 10 11 12 13 //vars并且#root是同一对象的同义词,但#ctx建议使用 //icontext接口的基本对象 ${#ctx.locale} ${#ctx.variablenames} //iwebcontext接口的基本对象 ${#ctx.request} ${#ctx.response} ${#ctx.session} ${#ctx.servletcontext} //之间访问locale ${#locale} 请求/会话属性\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 /* * ================================================================================= * param相关 * ================================================================================= */ ${param.foo} //取出foo参数 ${param.size()} ${param.isempty()} ${param.containskey(\u0026#39;foo\u0026#39;)} /* * ================================================================================= * session相关 * ================================================================================= */ ${session.foo} //取出session属性foo ${session.size()} ${session.isempty()} ${session.containskey(\u0026#39;foo\u0026#39;)} /* * ================================================================================= * application * ================================================================================= */ ${application.foo} //application ${application.size()} ${application.isempty()} ${application.containskey(\u0026#39;foo\u0026#39;)} web上下文对象\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 /* * ================================================================================= * httpservletrequest * ================================================================================= */ ${#request.getattribute(\u0026#39;foo\u0026#39;)} ${#request.getparameter(\u0026#39;foo\u0026#39;)} ${#request.getcontextpath()} ${#request.getrequestname()} ... /* * ================================================================================= * httpsession * ================================================================================= */ ${#session.getattribute(\u0026#39;foo\u0026#39;)} ${#session.id} ${#session.lastaccessedtime} ... /* * ================================================================================= * servletcontext * ================================================================================= */ ${#servletcontext.getattribute(\u0026#39;foo\u0026#39;)} ${#servletcontext.contextpath} ... 表达式内置对象 执行信息\n#execinfo:表达式对象,提供有关在thymeleaf标准表达式中处理的模板的有用信息\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 //当前模版名、模版模式 ${#execinfo.templatename} ${#execinfo.templatemode} //根模版名、模版模式 ${#execinfo.processedtemplatename} ${#execinfo.processedtemplatemode} //返回堆栈上模版信息 ${#execinfo.templatenames} ${#execinfo.templatemodes} //返回模版栈 ${#execinfo.templatestack} 消息\n#messages:用于在变量表达式中获取国际化消息,与使用#{...}语法获取它们的方式相同\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 /* * ================================================================================= * message,返回默认值用法${#messages.msg(\u0026#39;msgkey\u0026#39;)}?:defaultvalue * ================================================================================= */ ${#messages.msg(\u0026#39;msgkey\u0026#39;)} ${#messages.msg(\u0026#39;msgkey\u0026#39;, param1)} ${#messages.msg(\u0026#39;msgkey\u0026#39;, param1, param2)} ${#messages.msg(\u0026#39;msgkey\u0026#39;, param1, param2, param3)} ${#messages.msgwithparams(\u0026#39;msgkey\u0026#39;, new object[] {param1, param2, param3, param4})} ${#messages.arraymsg(messagekeyarray)} ${#messages.listmsg(messagekeylist)} ${#messages.setmsg(messagekeyset)} /* * ================================================================================= * message,返回null用法 * ================================================================================= */ ${#messages.msgornull(\u0026#39;msgkey\u0026#39;)} ${#messages.msgornull(\u0026#39;msgkey\u0026#39;, param1)} ${#messages.msgornull(\u0026#39;msgkey\u0026#39;, param1, param2)} ${#messages.msgornull(\u0026#39;msgkey\u0026#39;, param1, param2, param3)} ${#messages.msgornullwithparams(\u0026#39;msgkey\u0026#39;, new object[] {param1, param2, param3, param4})} ${#messages.arraymsgornull(messagekeyarray)} ${#messages.listmsgornull(messagekeylist)} ${#messages.setmsgornull(messagekeyset)} uri\n#uris:用于在thymeleaf标准表达式中执行uri / url操作的对象\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 //转义/不转义作为uri/url ${#uris.escapepath(uri)} ${#uris.escapepath(uri, encoding)} ${#uris.unescapepath(uri)} ${#uris.unescapepath(uri, encoding)} //转义/不转义作为uri/url路径段(在\u0026#39;/\u0026#39;符号之间) ${#uris.escapepathsegment(uri)} ${#uris.escapepathsegment(uri, encoding)} ${#uris.unescapepathsegment(uri)} ${#uris.unescapepathsegment(uri, encoding)} //转义/不转义作为段标识 ${#uris.escapefragmentid(uri)} ${#uris.escapefragmentid(uri, encoding)} ${#uris.unescapefragmentid(uri)} ${#uris.unescapefragmentid(uri, encoding)} //转义/不转义作为查询参数 ${#uris.escapequeryparam(uri)} ${#uris.escapequeryparam(uri, encoding)} ${#uris.unescapequeryparam(uri)} ${#uris.unescapequeryparam(uri, encoding)} 转换\n1 2 3 //转换对象为java.util.timezone ${#conversions.convert(object, \u0026#39;java.util.timezone\u0026#39;)} ${#conversions.convert(object, targetclass)} 日期\n#dates:java.util.date对象\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 //转换为本地日期格式 ${#dates.format(date)} ${#dates.arrayformat(datesarray)} ${#dates.listformat(dateslist)} ${#dates.setformat(datesset)} //格式日期采用iso8601格式 ${#dates.formatiso(date)} ${#dates.arrayformatiso(datesarray)} ${#dates.listformatiso(dateslist)} ${#dates.setformatiso(datesset)} //格式日期使用指定的模式 ${#dates.format(date, \u0026#39;dd/mmm/yyyy hh:mm\u0026#39;)} ${#dates.arrayformat(datesarray, \u0026#39;dd/mmm/yyyy hh:mm\u0026#39;)} ${#dates.listformat(dateslist, \u0026#39;dd/mmm/yyyy hh:mm\u0026#39;)} ${#dates.setformat(datesset, \u0026#39;dd/mmm/yyyy hh:mm\u0026#39;)} //获取日期属性 ${#dates.day(date)} //arrayday(...), listday(...), etc. ${#dates.month(date)} //arraymonth(...), listmonth(...), etc. ${#dates.monthname(date)} //arraymonthname(...), listmonthname(...), etc. ${#dates.monthnameshort(date)}\t//arraymonthnameshort(...), listmonthnameshort(...), etc. ${#dates.year(date)}\t//arrayyear(...), listyear(...), etc. ${#dates.dayofweek(date)}\t//arraydayofweek(...), listdayofweek(...), etc. ${#dates.dayofweekname(date)}//arraydayofweekname(...), listdayofweekname(...), etc. ${#dates.dayofweeknameshort(date)}//arraydayofweeknameshort(...), listdayofweeknameshort(...), etc. ${#dates.hour(date)}\t//arrayhour(...), listhour(...), etc. ${#dates.minute(date)}\t//arrayminute(...), listminute(...), etc. ${#dates.second(date)} //arraysecond(...), listsecond(...), etc. ${#dates.millisecond(date)} //arraymillisecond(...), listmillisecond(...), etc. //创建日期 ${#dates.create(year,month,day)} ${#dates.create(year,month,day,hour,minute)} ${#dates.create(year,month,day,hour,minute,second)} ${#dates.create(year,month,day,hour,minute,second,millisecond) ${#dates.createnow()} ${#dates.createnowfortimezone()} ${#dates.createtoday()}\t//time设置为00:00 ${#dates.createtodayfortimezone()} 日历\n#calendars:java.util.calendar对象:\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 //转换为本地日期格式 ${#calendars.format(cal)} ${#calendars.arrayformat(calarray)} ${#calendars.listformat(callist)} ${#calendars.setformat(calset)} //格式日期采用iso8601格式 ${#calendars.formatiso(cal)} ${#calendars.arrayformatiso(calarray)} ${#calendars.listformatiso(callist)} ${#calendars.setformatiso(calset)} //格式日期使用指定的模式 ${#calendars.format(cal, \u0026#39;dd/mmm/yyyy hh:mm\u0026#39;)} ${#calendars.arrayformat(calarray, \u0026#39;dd/mmm/yyyy hh:mm\u0026#39;)} ${#calendars.listformat(callist, \u0026#39;dd/mmm/yyyy hh:mm\u0026#39;)} ${#calendars.setformat(calset, \u0026#39;dd/mmm/yyyy hh:mm\u0026#39;)} //获取日期属性 ${#calendars.day(date)} //arrayday(...), listday(...), etc. ${#calendars.month(date)} //arraymonth(...), listmonth(...), etc. ${#calendars.monthname(date)}\t//arraymonthname(...), listmonthname(...), etc. ${#calendars.monthnameshort(date)} //arraymonthnameshort(...), listmonthnameshort(...), etc. ${#calendars.year(date)} //arrayyear(...), listyear(...), etc. ${#calendars.dayofweek(date)} //arraydayofweek(...), listdayofweek(...), etc. ${#calendars.dayofweekname(date)} //arraydayofweekname(...), listdayofweekname(...), etc. ${#calendars.dayofweeknameshort(date)} //arraydayofweeknameshort(...), listdayofweeknameshort(...), etc. ${#calendars.hour(date)} //arrayhour(...), listhour(...), etc. ${#calendars.minute(date)} //arrayminute(...), listminute(...), etc. ${#calendars.second(date)} //arraysecond(...), listsecond(...), etc. ${#calendars.millisecond(date)} //arraymillisecond(...), listmillisecond(...), etc. //创建日期 ${#calendars.create(year,month,day)} ${#calendars.create(year,month,day,hour,minute)} ${#calendars.create(year,month,day,hour,minute,second)} ${#calendars.create(year,month,day,hour,minute,second,millisecond)} ${#calendars.createfortimezone(year,month,day,timezone)} ${#calendars.createfortimezone(year,month,day,hour,minute,timezone)} ${#calendars.createfortimezone(year,month,day,hour,minute,second,timezone)} ${#calendars.createfortimezone(year,month,day,hour,minute,second,millisecond,timezone)} ${#calendars.createnow()} ${#calendars.createnowfortimezone()} ${#calendars.createtoday()} ${#calendars.createtodayfortimezone()} 数字\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 //设置数值的整数部分允许的最小位数,例如33 =》 033 ${#numbers.formatinteger(num,3)} ${#numbers.arrayformatinteger(numarray,3)} ${#numbers.listformatinteger(numlist,3)} ${#numbers.setformatinteger(numset,3)} //设置数值的整数部分允许的最小位数和千分位分割符 ${#numbers.formatinteger(num,3,\u0026#39;point\u0026#39;)} ${#numbers.arrayformatinteger(numarray,3,\u0026#39;point\u0026#39;)} ${#numbers.listformatinteger(numlist,3,\u0026#39;point\u0026#39;)} ${#numbers.setformatinteger(numset,3,\u0026#39;point\u0026#39;)} //设置数值的整数部分允许的最小位数和(精确的)小数位数 ${#numbers.formatdecimal(num,3,2)} ${#numbers.arrayformatdecimal(numarray,3,2)} ${#numbers.listformatdecimal(numlist,3,2)} ${#numbers.setformatdecimal(numset,3,2)} //设置数值的整数部分允许的最小位数和(精确的)小数位数以及小数位分割符 ${#numbers.formatdecimal(num,3,2,\u0026#39;comma\u0026#39;)} ${#numbers.arrayformatdecimal(numarray,3,2,\u0026#39;comma\u0026#39;)} ${#numbers.listformatdecimal(numlist,3,2,\u0026#39;comma\u0026#39;)} ${#numbers.setformatdecimal(numset,3,2,\u0026#39;comma\u0026#39;)} //设置数值的整数部分允许的最小位数和(精确的)小数位数以及千分位、小数位分割符 ${#numbers.formatdecimal(num,3,\u0026#39;point\u0026#39;,2,\u0026#39;comma\u0026#39;)} ${#numbers.arrayformatdecimal(numarray,3,\u0026#39;point\u0026#39;,2,\u0026#39;comma\u0026#39;)} ${#numbers.listformatdecimal(numlist,3,\u0026#39;point\u0026#39;,2,\u0026#39;comma\u0026#39;)} ${#numbers.setformatdecimal(numset,3,\u0026#39;point\u0026#39;,2,\u0026#39;comma\u0026#39;)} //货币格式加¥ ${#numbers.formatcurrency(num)} ${#numbers.arrayformatcurrency(numarray)} ${#numbers.listformatcurrency(numlist)} ${#numbers.setformatcurrency(numset)} //设置数值的整数部分允许的最小位数和小数精确位 ${#numbers.formatpercent(num, 3, 2)} ${#numbers.arrayformatpercent(numarray, 3, 2)} ${#numbers.listformatpercent(numlist, 3, 2)} ${#numbers.setformatpercent(numset, 3, 2)} //创建序列从x到y ${#numbers.sequence(from,to)} ${#numbers.sequence(from,to,step)} 字符串\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 //null值安全 ${#strings.tostring(obj)} // array*, list* and set* //检查字符串是否为空(或空)。检查前执行trim()操作 ${#strings.isempty(name)} ${#strings.arrayisempty(namearr)} ${#strings.listisempty(namelist)} ${#strings.setisempty(nameset)} //对字符串执行\u0026#39;isempty()\u0026#39;检查,如果为false,则返回。如果为真,返回另一个指定的字符串 ${#strings.defaultstring(text,default)} ${#strings.arraydefaultstring(textarr,default)} ${#strings.listdefaultstring(textlist,default)} ${#strings.setdefaultstring(textset,default)} //检查字符串是否包含指定子串 ${#strings.contains(name,\u0026#39;ez\u0026#39;)} // array*, list* and set* ${#strings.containsignorecase(name,\u0026#39;ez\u0026#39;)} // array*, list* and set* //检查字符串是否以此开头或者结尾 ${#strings.startswith(name,\u0026#39;don\u0026#39;)} // array*, list* and set* ${#strings.endswith(name,endingfragment)} // array*, list* and set* //取出指定范围子串 ${#strings.indexof(name,frag)} // array*, list* and set* ${#strings.substring(name,3,5)} // array*, list* and set* ${#strings.substringafter(name,prefix)} // array*, list* and set* ${#strings.substringbefore(name,suffix)} // array*, list* and set* ${#strings.replace(name,\u0026#39;las\u0026#39;,\u0026#39;ler\u0026#39;)} // array*, list* and set* //追加内容 ${#strings.prepend(str,prefix)} // also array*, list* and set* ${#strings.append(str,suffix)} // also array*, list* and set* //大小写转换 ${#strings.touppercase(name)} // array*, list* and set* ${#strings.tolowercase(name)} // array*, list* and set* //split 和 join ${#strings.arrayjoin(namesarray,\u0026#39;,\u0026#39;)} ${#strings.listjoin(nameslist,\u0026#39;,\u0026#39;)} ${#strings.setjoin(namesset,\u0026#39;,\u0026#39;)} ${#strings.arraysplit(namesstr,\u0026#39;,\u0026#39;)} // returns string[] ${#strings.listsplit(namesstr,\u0026#39;,\u0026#39;)} // returns list\u0026lt;string\u0026gt; ${#strings.setsplit(namesstr,\u0026#39;,\u0026#39;)} // returns set\u0026lt;string\u0026gt; //trim操作 ${#strings.trim(str)} // array*, list* and set* //获取长度 ${#strings.length(str)} // array*, list* and set* //当str的长度小于maxwidth的,则返回str //当str的长度大于maxwidth的,显示maxwidth位(最后三位用...代替) //当maxwidth小于4时,抛出illegalargumentexception异常 ${#strings.abbreviate(str,10)} // also array*, list* and set* //将第一个字符转换为大写或者小写 ${#strings.capitalize(str)} // array*, list* and set* ${#strings.uncapitalize(str)} // array*, list* and set* //将第一个单词转换为大写或者小写 ${#strings.capitalizewords(str)} // array*, list* and set* ${#strings.capitalizewords(str,delimiters)} // array*, list* and set* //转义/不转义操作 ${#strings.escapexml(str)} // array*, list* and set* ${#strings.escapejava(str)} // array*, list* and set* ${#strings.escapejavascript(str)} // array*, list* and set* ${#strings.unescapejava(str)} // array*, list* and set* ${#strings.unescapejavascript(str)} // array*, list* and set* //null安全的比较,连接,替换 ${#strings.equals(first, second)} ${#strings.equalsignorecase(first, second)} ${#strings.concat(values...)} ${#strings.concatreplacenulls(nullvalue, values...)} //生成指定长度的字母和数字的随机组合字符串 ${#strings.randomalphanumeric(count)} 对象\n1 2 3 4 5 //如果对象是null返回default ${#objects.nullsafe(obj,default)} ${#objects.arraynullsafe(objarray,default)} ${#objects.listnullsafe(objlist,default)} ${#objects.setnullsafe(objset,default)} 布尔\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 //像th:if一样判断是否为true ${#bools.istrue(obj)} ${#bools.arrayistrue(objarray)} ${#bools.lististrue(objlist)} ${#bools.setistrue(objset)} //像th:unless一样判断是否为true ${#bools.isfalse(cond)} ${#bools.arrayisfalse(condarray)} ${#bools.listisfalse(condlist)} ${#bools.setisfalse(condset)} //判断具有and操作 ${#bools.arrayand(condarray)} ${#bools.listand(condlist)} ${#bools.setand(condset)} //判断就有or操作 ${#bools.arrayor(condarray)} ${#bools.listor(condlist)} ${#bools.setor(condset)} 数组\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 //转换为数组 ${#arrays.toarray(object)} //转换为指定组件类的数组 ${#arrays.tostringarray(object)} ${#arrays.tointegerarray(object)} ${#arrays.tolongarray(object)} ${#arrays.todoublearray(object)} ${#arrays.tofloatarray(object)} ${#arrays.tobooleanarray(object)} //返回数组长度 ${#arrays.length(array)} //判断数组是否为空 ${#arrays.isempty(array)} //判断数组是否包含此元素 ${#arrays.contains(array, element)} ${#arrays.containsall(array, elements)} list\n1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 //转换为list ${#lists.tolist(object)} //返回list大小 ${#lists.size(list)} //检查list是否为空 ${#lists.isempty(list)} //判断list中是否含有指定元素 ${#lists.contains(list, element)} ${#lists.containsall(list, elements)} //排序list ${#lists.sort(list)} ${#lists.sort(list, comparator)} set\n1 2 3 4 5 6 7 8 9 10 11 12 //转换为set ${#sets.toset(object)} //返回set大小 ${#sets.size(set)} //检查set是否为空 ${#sets.isempty(set)} //判断set中是否含有指定元素 ${#sets.contains(set, element)} ${#sets.containsall(set, elements)} map\n1 2 3 4 5 6 7 8 9 10 11 //返回map大小 ${#maps.size(map)} //检查map是否为空 ${#maps.isempty(map)} //判断map中是否含有指定元素 ${#maps.containskey(map, key)} ${#maps.containsallkeys(map, keys)} ${#maps.containsvalue(map, value)} ${#maps.containsallvalues(map, value)} aggregates\n1 2 3 4 5 6 7 //对集合求和 ${#aggregates.sum(array)} ${#aggregates.sum(collection)} //对集合求平局值 ${#aggregates.avg(array)} ${#aggregates.avg(collection)} ids\n用于处理id可能重复的方法\n1 2 3 4 //通常用于th:id属性,用于向id属性值追加计数器 ${#ids.seq(\u0026#39;someid\u0026#39;)} ${#ids.next(\u0026#39;someid\u0026#39;)} ${#ids.prev(\u0026#39;someid\u0026#39;)} 例如\n1 2 3 4 5 6 7 8 [[${#ids.seq(\u0026#39;someid\u0026#39;)}]] ==\u0026gt;someid1 [[${#ids.seq(\u0026#39;someid\u0026#39;)}]]\t==\u0026gt;someid2 [[${#ids.next(\u0026#39;someid\u0026#39;)}]]\t==\u0026gt;someid3 [[${#ids.next(\u0026#39;someid\u0026#39;)}]]\t==\u0026gt;someid3 [[${#ids.prev(\u0026#39;someid\u0026#39;)}]]\t==\u0026gt;someid2 [[${#ids.prev(\u0026#39;someid\u0026#39;)}]]\t==\u0026gt;someid2 ","date":"2018-08-29","permalink":"https://hobocat.github.io/post/thymeleaf/2018-08-29-thymeleaf/","summary":"一、简介 Thymeleaf是一个适用于Web和独立环境的现代服务器端Java模板引擎,能够处理HTML,XML,JavaScript,CSS甚至纯文本。 Thym","title":"thymeleaf的基本使用"},]
[{"content":"🌞 我的 \u0026gt; github \u0026gt; gitee 阿里云ram 华为云 stackedit中文版 微信公众平台 蓝湖 processon 知乎 小红书 抖音 博客园 简书 🗎 文档 docker nacos spring spring中文文档 layui elastic redis 微信开放平台 支付宝开放平台 银联开放平台 德衫支付开方平台 vue ant-design-vue vben-admin elementui 🔨 工具 arthas json工具 maven codeif 文心一言 chatgpt copilot 图片压缩 \u0026gt; 图床-wallhaven tinypng miru 洛雪music 万城vpn chrome扩展组件 地理小工具 新浪短网址 emoji 🍺 博客 \u0026gt; 小林coding 廖雪峰 芋道源码 菜鸟教程 hugo-virgo 知了 hugo ☕️ 休闲娱乐 bt1027 比思 \u0026gt; 樱花动漫 \u0026gt; bilibili 京东 淘宝 👮 遵纪守法 违法举报 🔞 vpn 命令行参数 · project v 官方网站 vmess 协议 · v2ray 配置指南|v2ray 白话文教程 图文教程搭建一个vpn翻墙 v2ray-vpn搭建 ✍ 富文本 summernote ckeditor mavon-editor tinymce tinymce\u0026ndash;一款非常好用的富文本编辑器 vue集成tinymce编辑器 🔖 标签 mysql索引背后的数据结构及算法原理 天物大宗 手机网站支付快速接入-支付宝文档中心 wap支付-中国银联开放平台 详解安装ubuntu linux系统时硬盘分区最合理的方法 logback的使用和logback.xml详解 mysql千万级大表优化解决方案 springboot中各类成员的初始化顺序及静态成员的依赖注入 ","date":"0001-01-01","permalink":"https://hobocat.github.io/nav/","summary":"🌞 我的 \u0026gt; Github \u0026gt; Gitee 阿里云RAM 华为云 StackEdit中文版 微信公众平台 蓝湖 processOn 知乎 小红书 抖音 博客园 简书 🗎 文档 Docker Nacos Spring Spring中文文档 layui ElaStic Redis 微信开放平台 支付宝开放平","title":"♾️ 导航 ♍"},]
